
Universidad Nacional de La Plata - Aula Virtual -...
29
1 DISE DISEÑO EXPERIMENTAL O EXPERIMENTAL (Modelos Multivariados) (Modelos Multivariados) Universidad Nacional de La Plata Universidad Nacional de La Plata Facultad de Ciencias Agrarias y Forestales Facultad de Ciencias Agrarias y Forestales CONTENIDOS CONTENIDOS Repaso. Concepto de muestra y población. Estimadores. Pruebas de hipótesis. Concepto de factor y de niveles de un factor. Modelo ANOVA de un solo factor. Comparación de medias. Contrastes ortogonales. Conceptos generales del diseño de experimentos. Conducción de ensayos. Diseño completamente aleatorizado (DCA). Modelos de clasificación según dos factores con una única observación por casilla. Diseño en bloques completos aleatorizados (DBCA). Medidas de eficiencia relativa entre cada diseño.Técnicas experimentales.
Transcript of Universidad Nacional de La Plata - Aula Virtual -...

1
DISEDISEÑÑO EXPERIMENTALO EXPERIMENTAL(Modelos Multivariados)(Modelos Multivariados)
Universidad Nacional de La PlataUniversidad Nacional de La PlataFacultad de Ciencias Agrarias y ForestalesFacultad de Ciencias Agrarias y Forestales
CONTENIDOSCONTENIDOS
Repaso. Concepto de muestra y población. Estimadores. Pruebas de
hipótesis. Concepto de factor y de niveles de un factor. Modelo
ANOVA de un solo factor. Comparación de medias. Contrastes
ortogonales. Conceptos generales del diseño de experimentos.
Conducción de ensayos. Diseño completamente aleatorizado (DCA).
Modelos de clasificación según dos factores con una única
observación por casilla. Diseño en bloques completos aleatorizados
(DBCA). Medidas de eficiencia relativa entre cada diseño.Técnicas
experimentales.

2
� MONTGOMERY D. (1991). Diseño y Análisis de experimentos.
México: Grupo Ed.Iberoamérica.
� MONTGOMERY D.; RUNGER, G. (1996). Probabilidad y
estadística aplicadas a la ingeniería. México: Mc Graw Hill.
� KUEHL, R. (2001). Diseño de Experimentos. México: Ed.
Thomson Learning.
� PEÑA, D. (1989). Estadística: Modelos y Métodos -Tomo II: Modelos Lineales. Madrid: Alianza Universidad Textos.
Bibliografía de Referencia

3
5to año
1
2

4
¿ Qué es la estadística ?
Es la disciplina que se ocupa de la recopilación, presentación, análisis e interpretación de datos para la toma de decisiones y resolución de problemas.
La importancia que la Estadística ha alcanzado en nuestros días, tanto en el trabajo profesional como en la investigación, es innegable.
La tendencia positivista de las ciencias modernas, ha hecho que la legitimación y comprobación de resultados o garantías de su validez dependan cada vez más de la utilización de herramientas o métodos estadísticos.
5
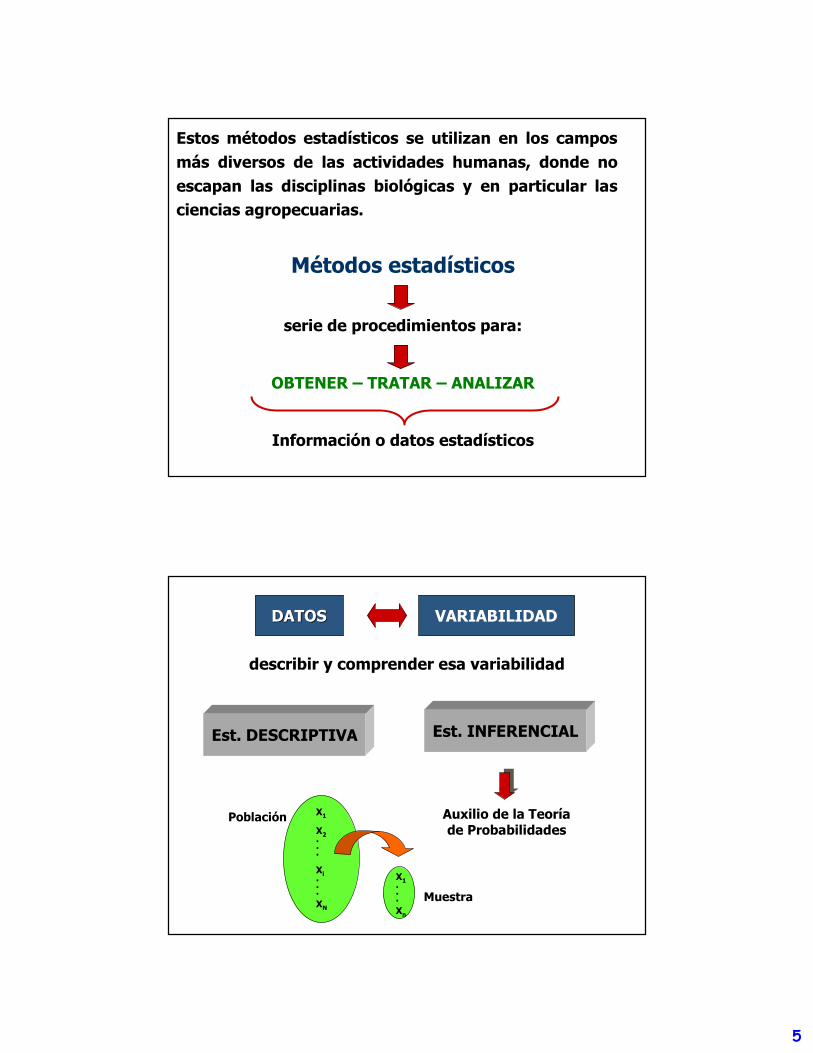
Estos métodos estadísticos se utilizan en los campos más diversos de las actividades humanas, donde no escapan las disciplinas biológicas y en particular las ciencias agropecuarias.
Métodos estadísticos
serie de procedimientos para:
OBTENER – TRATAR – ANALIZAR
Información o datos estadísticos
describir y comprender esa variabilidad
Est. DESCRIPTIVA Est. INFERENCIAL
DATOSDATOS VARIABILIDAD
X1
X2...
Xi...XN
X1...Xn
Auxilio de la Teoría de Probabilidades
Muestra
Población

6
MUESTRO
COMO CUANTO
Muestreo simple al azar
Muestreo estratificado al azar
Variabilidad de los datos
Error admisible
Confianza
Estimación de Parámetros
Estimador: es un estadístico o función obtenido de los datos de una muestra y que pretendemos que represente lo más fielmente posible a un parámetro poblacional desconocido, que es el objeto de nuestro estudio.
Muestra
Población
θθθθ
θθθθ̂

7
Distribución de la media muestral
x es una V.A. con parámetros distribucionales:
xxx µµµµ====µµµµ====)E(n
x xx
22222222 σσσσ
====σσσσ====)V(
Teorema Central del Límite : Si x1 , x2 , ... , xn es una muestra aleatoria de
tamaño n de una población con media µx y variancia σx2 y si es la media
muestral, entonces la forma límite de la distribución de
cuando n → ∞ es la distribución normal estándar
x
Tenemos una distribución del alejamiento de un estimador
al parámetro que estima
n
xZ
x
x
σσσσ
µµµµ−−−−====
Conociendo establecer x1 y x2 tal que:x
P(x1< µµµµx <x2) = 1-αααα
Operando:
nzxi
σσσσ±±±±==== 2222αααα−−−−1111µµµµ )/()(l
Tamaño de muestra óptimo: 2222
σσσσ====
EA.z
n
Intervalo de confianza para µµµµ con σσσσ2 conocida
8
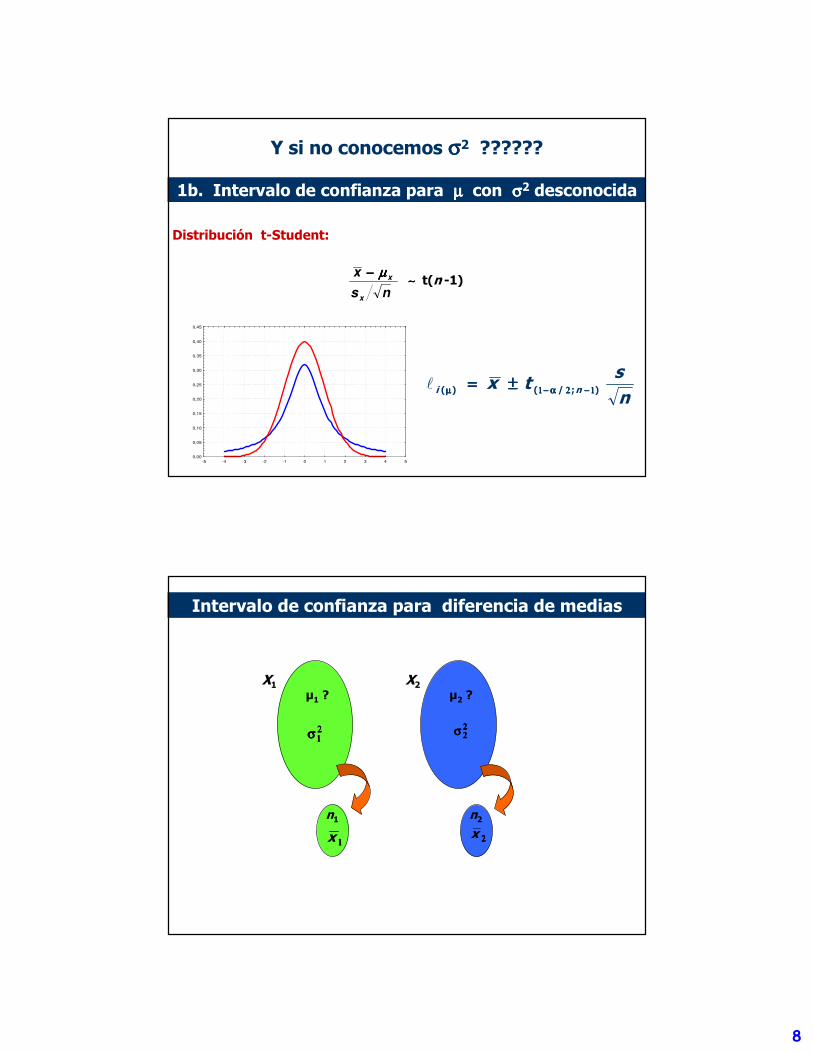
Y si no conocemos σσσσ2 ??????
Distribución t-Student:
∼∼∼∼ t(n -1)
-5 -4 -3 -2 -1 0 1 2 3 4 50,00
0,05
0,10
0,15
0,20
0,25
0,30
0,35
0,40
0,45
ns
tx ni );/()( 1111−−−−2222αααα−−−−1111µµµµ ±±±±====l
1b. Intervalo de confianza para µµµµ con σσσσ2 desconocida
ns
x
x
xµµµµ−−−−
µ1 ?
22221111σσσσ
X1µ2 ?
X2
22222222σσσσ
n1 n2
1111x 2222x
Intervalo de confianza para diferencia de medias

9
Con varianzas poblacionales conocidas
(iguales o distintas)
y
y
x
xi nn
zyxyx
22222222
2222αααα−−−−1111µµµµ−−−−µµµµ
σσσσ++++
σσσσ±±±±−−−−==== )/()( )(l
222222222222
22221111 σσσσ====σσσσ====σσσσ 2222−−−−++++
⋅⋅⋅⋅1111−−−−++++⋅⋅⋅⋅1111−−−−====
22221111
222222222222
2222111111112222
nnsnsn
s p)()(
Situación 1:
Con varianzas poblacionales desconocidas
y
p
x
pnni n
sns
tyxyxyx
22222222
2222−−−−++++2222αααα−−−−1111µµµµ−−−−µµµµ++++±±±±−−−−==== );/()( )(l
Pruebas de Hipótesis
Estimación de Parámetros Pruebas de Hipótesis
INFERENCIA ESTADÍSTICA
¿¿ QuQuéé es una hipes una hipóótesis estadtesis estadíística ?stica ?
Es una proposición o afirmación sobre la distribución de probabilidad de una variable aleatoria.

10
Parámetros de la distribución
Asociadas a una o más poblaciones
Forma de la distribución
EjemplosEjemplos::
La edad media de los alumnos del curso es de 22 años.
Con la aplicación de un determinado nutriente se obtendrán rendimientos
medios superiores a 2.000 kg/ha, que es la producción usual de la zona.
El peso promedio al nacimiento de ovejas hembras es menor al de los
machos
La altura de alámos sigue una distribución normal
El número de semillas germinadas por placa responde a una distribución
binomial
HipHipóótesis acerca de los partesis acerca de los paráámetros de una poblacimetros de una poblacióón:n:
Caso 1
H0: θ = θ1
H1: θ = θ2
Caso 3
H0: θ = θ0
H1: θ < θ0
Caso 4
H0: θ = θ0
H1: θ > θ0
Hipótesis nula
Hipótesis alternativa
Hipótesis puntuales o simples
Caso 2
H0: θ = θ0
H1: θ ≠ θ0Hipótesis compuestas

11
Consideraciones importantes:Consideraciones importantes:
� Las hipótesis son siempre afirmaciones relativas a la población o distribución bajo estudio, no en torno a la muestra
� La hipótesis nula siempre ‘contiene’ a la hipótesis θ = θ0
� Hay una estrecha relación entre la prueba de hipótesis en torno a un parámetro θ y el intervalo de confianza de θ
Puedan combinarse otros casos de Hipótesis nulas e Hipótesis alternativas
Caso 5
H0: θ ≥≥≥≥ θ0
H1: θ < θ0
Hipótesis compuestas
Caso 6
H0: θ ≤≤≤≤ θ0
H1: θ > θ0
EstadEstadíístico de prueba y Regla de Decisistico de prueba y Regla de Decisióónn
Ho: µ = 15
H1: µ ≠ 15X1
X2...
Xi...XN
Población
Muestra
X1...Xn
Prueba de hipPrueba de hipóótesis:tesis:
Es un procedimiento (o experiencia) que conduce a una toma de decisión en cuanto a optar por una u otra hipótesis, a la luz de la información proporcionada por una muestra aleatoria extraída de la población bajo estudio

12
7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
Variableµµµµ
10 11 12 13 14 15 16 17 18 19 20µµµµ x
NO RECHAZORECHAZO RECHAZO
obsx obsxobsx
Conclusión sujeta a error
PruebasPruebas
Bilaterales
Unilaterales
Ho es Verdadera Ho es Falsa
Error Decisión correcta
Tipos de error:Tipos de error:
DECISIÓ
N Rechazo H0
No Rechazo H0 Decisión correcta Error
Error de Tipo I
Error de Tipo II
P(Error Tipo I) = P(Rechazar H0 | H0 es Verdadera) = α
P(Error Tipo II) = P(No Rechazar H0 | H0 es Falsa) = β
Potencia = 1 - β = P(Rechazar H0 | H0 es Falsa)

13
ProcedimienoProcedimieno general para una prueba de hipgeneral para una prueba de hipóótesis:tesis:
Del contexto del problema identificar el parámetro de interés
Plantear H0 y H1
Planificar una experiencia para la extracción de la muestra
Establecer el nivel de significación de la prueba
Seleccionar un estadístico de prueba e identificar su distribución bajo H0
Establecer regiones de rechazo y no rechazo para el estadístico de prueba
Calcular de la muestra el valor del estadístico
Decidir si debe o no rechazarse H0 e interpretar esto en el contexto del problema
Prueba t : comparación de 2 medias
H0: µµµµ1 = µµµµ2 µµµµ1 - µµµµ2 = 0
H0: µµµµ1 ≠≠≠≠ µµµµ2 µµµµ1 - µµµµ2 ≠≠≠≠ 0
2
22
1
21
2121 )()(
ns
ns
xxtobs
++++
−−−−−−−−−−−−====
µµµµµµµµ
ANANÁÁLISIS DE LA VARIANCIALISIS DE LA VARIANCIA

14
Si H0 : σσσσ12 = σσσσ2
2 tobs ∼∼∼∼ t(n1+n2 –2)
221
222
2112
−−−−++++
⋅⋅⋅⋅++++⋅⋅⋅⋅====
nnsnsn
s pond
ns
xxt
pondobs 2
21
.2
)( −−−−====
Si H0 : σσσσ12 ≠≠≠≠ σσσσ2
2 tobs ∼∼∼∼ t(νννν )
(((( ))))(((( )))) (((( ))))
1/
1/
//
2
2
22
2
1
2
12
1
2
22
212
1
−−−−++++
−−−−
++++====
nns
nns
nsnsυυυυ
Contrastar 3 o más medias comparación de a pares
Inconvenientes:
Engorroso y poco práctico
Aumento de error tipo I
Ejemplo: comparación 5 medias = 10 pruebas
P(no rechazar H0/H0 es verdadero) = 0,9510 = 0,5987
ααααGlobal = 0,40
2
5
∼∼∼∼

15
Regla de Bonferroni:
Error Tipo I cada prueba:
donde:
Forma aproximada:
en nuestro caso: αααα = 0,05/10 = 0,005 (0,00511)
entonces ααααglobal = 1 - (1-αααα)10 = 1-0,995 10 = 0,0488
cglobalαααα
αααα ====
====
2
Nro.mediasc
cglobal )1(1 αααααααα −−−−−−−−====
≤≤≤≤ cglobal )1(1 αααα−−−−−−−−
MODELO DE CLASIFICACIMODELO DE CLASIFICACIÓÓN N
SEGSEGÚÚN UN SOLO FACTORN UN SOLO FACTOR
OBJETIVO: Determinar si existen diferencias significativas entre
medias correspondientes a distintos niveles de un factor
Factor: variable controlada que clasifica los individuos, también llamada
‘tratamiento’ (fertilizante, temperatura, color, estado civil)
Nivel: diversas categorías o valores que puede tomar un factor
Variable de respuesta: variable objeto de estudio (cuantitativa)
Repeticiones: conjunto de individuos que reciben igual nivel del factor

16
SUPUESTOS:
Existen k poblaciones de medias µµµµ1 , µµµµ2 , ... , µµµµk asociadas a los
distintos niveles del factor, donde las observaciones o datos están
distribuidos de manera normal e independiente, con la misma
varianza para cada población.
µµµµ1 µµµµ2 µµµµi µµµµkYijµµµµ
i = 1, 2, ... , k
j = 1, 2, ... , nj
yij = µ µ µ µ + (µµµµi - µµµµ) + (yij - µµµµi)
EFECTO TRATAMIENTO
ERROR ALEATORIO
Modelo Poblacional
yij = µ µ µ µ + ττττi + ξξξξij con ττττi = 0 y ξξξξij ∼∼∼∼ N(0,σσσσ2)∑∑∑∑====
k
i 1
Hipótesis
H0: µµµµ1 = µµµµ2 = µµµµi = ... = µµµµk = µµµµ
H1: al menos una µµµµi ≠≠≠≠
H0: ττττi = 0 ∀∀∀∀ i
H1: ττττi ≠≠≠≠ 0 para algún i
Modelo Muestral
)()( iijiij yyyyyy −−−−++++−−−−++++====

17
Descomposición de la Variablidad
)()()( iijiij yyyyyy −−−−++++−−−−====−−−−
∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑==== ======== ======== ====
−−−−++++−−−−====−−−−k
i
n
jiij
k
i
n
ji
k
ii
n
ijij yyyyyy
1 1
2
1 1
22 )()()(
SCTotal (SCY) SCTrat (SCEntre Grupos) SCError (SCDentro Grupos)
glTotal = n.k – 1 glTrat = k - 1 glError = nk - k
Fórmulas de Cálculo
∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑
∑∑∑∑∑∑∑∑∑∑∑∑==== ========
==== ====
======== ====
−−−−====
−−−−====−−−−====k
i
n
jij
k
i
k
i
n
jijn
jij
k
i
n
jij kn
yy
kn
y
yyy1
2..
1
2
1
2
1 1
1
2
1 1
2Total ..
)(SC
FC)(SC 1
2.
1 1
2Trat −−−−====−−−−====
∑∑∑∑∑∑∑∑∑∑∑∑ ====
==== ==== n
yyy
k
iik
i
n
ji
FC
∑∑∑∑∑∑∑∑
∑∑∑∑∑∑∑∑∑∑∑∑====
====
======== ====
−−−−====−−−−====k
i
k
iin
jij
k
i
n
jiij n
yyyy
1
1
2.
1
2
1 1
2Error )(SC Por diferencia

18
Cuadrados Medios
glSC
CM ====
2ERROR σ)E(CM ====
∑∑∑∑==== −−−−
++++====k
i
i
kn
1
22
TRAT 1.)E(CM
ττττσσσσ
ERROR
TRATOBS CM
CMF ====
TABLA ANOVA MODELO DE CLASIFICACITABLA ANOVA MODELO DE CLASIFICACIÓÓN N
SEGSEGÚÚN UN SOLO FACTORN UN SOLO FACTOR
F.V. gl SC CM E(CM) Fobs Fcrit
Trat. k-1 FC1
2.
−−−−∑∑∑∑
====
n
yk
ii
1SCTRAT
−−−−k ∑∑∑∑
==== −−−−++++
k
i
i
kn
1
22
1.
ττττσσσσ
ERROR
TRAT
CMCM
Fcrit 5%
Fcrit 1%
Error k(n-1) Diferencia )1(
SCError
−−−−nk 2σσσσ
Total nk-1 ∑∑∑∑∑∑∑∑==== ====
−−−−k
ii
n
ijijy FC2

19
Estructura Tabla de Datos
Ejemplo
TRAT Repeticiones Totales
1 2 . . . i . . k
y11 y12 ... y1j ... y1n y21 y22 ... y2j ... y2n ……....................... ……....................... ……....................... yi1 yi2 ... yij ... yin ……....................... ……....................... yk1 yk2 ... ykj ... ykn
y1. Y2. . . .
yi. . .
yk.
y..
TRAT Repeticiones Tot. Medias S2
T1
T2
T3
3 5 2 3 2 4 5 4 6 7 5 7 9 8 6
15 26 35
3 5,2 7
1,5 1,7 2,5
76
Comparaciones IndividualesComparaciones Individuales
1. Pruebas a Posteriori H0: µµµµi = µµµµj ∀∀∀∀ i ≠≠≠≠ j
1a. Prueba LSD
nt
gl
ERROR
)2
1;CM.(crit
CM.2.
ERRORαααα
−−−−====∆∆∆∆
Rechazo H0 si | µµµµi - µµµµj | > ∆∆∆∆crit

20
1b. Prueba de Tukey (1953): más conservador
nq
kgl
ERROR
)2
1;;CM.(crit
CM.
ERRORαααα
−−−−====∆∆∆∆
1c. Prueba de Dunnett (1964): sólo k-1 comparaciones con testigo
H0: µµµµ0 = µµµµi ∀∀∀∀ i
1d. Pruebas de Newman-Keuls (1952) y Duncan (1955):
El valor de diferencia crítica tiene en cuenta en número de
medias p que pertenecen al rango determinado por las dos
medias analizadas
2. Pruebas a Priori
2a. Contrastes ortogonales: se plantean comparaciones de dos
grupos de medias por algún interés experimental antes de conocer
los resultados de la prueba F. Descomposición de SC y gl de
Tratamiento.
Ejemplo: H0: µµµµ1 vs { µµµµ2 ; µµµµ3 } H0: 2µµµµ1 - µµµµ2 - µµµµ3 = 0
FC2
)(SC
2.3.2
2.1
c1 −−−−++++
++++====nyy
ny
glc1 = 1
OJO !!!!! con FC cuando no intervienen
todas las medias en un contraste

21
Expresión vectorial de un contraste:
c1 : [ 2 -1 -1 ]
c2 : [ 0 1 -1 ]
Fórmula general SC de un contraste:
k’ = niveles que intervienen en el contraste
c = coeficientes del contraste∑∑∑∑
∑∑∑∑
====
====
==== '
1
2
2'
1.
c
.
.SC k
i
k
ii
cn
yc
2b. Polinomios ortogonales: cuando variable clasificatoria carácter
ordinal tendencia
Para 2 gl Tendencia lineal: [1 0 -1]
Tendencia cuadrática: [1 -2 1]
Para 3 gl Tendencia lineal: [-3 -1 1 3]
Tendencia cuadrática: [ 1 -1 -1 1]
Tendencia cúbica: [-1 3 -3 1]

22
VerificaciVerificacióón de supuestosn de supuestos
1. Aleatoriedad de residuales
2. Normalidad de residuales
3. Homocedasticidad Test de Levene
|eij| = µ µ µ µ + ττττi + ξξξξij
H0: µµµµ1 = µµµµ2 = µµµµi = ... = µµµµk = µµµµ
H1: al menos una µµµµi ≠≠≠≠
Conclusiones de un ANOVAConclusiones de un ANOVA
1. Agrupamiento niveles de tratamiento: uso de letras o líneas
2. Intervalos de confianza para medias
3. Intervalos de confianza para diferencias de medias
4. Representaciones gráficas
Current effect: F(2, 12)=10,561, p=,00226
Effective hypothesis decomposition
Vertical bars denote 0,95 confidence intervals
T1 T2 T3
Tratamiento
0
1
2
3
4
5
6
7
8
9
10
Y

23
DISEDISEÑÑO ASOCIADOO ASOCIADO
DISEÑO COMPLETAMENTE ALEATORIZADO
DCA
T1
T1
T1
T1
T1 T2 T2
T2
T2 T2 T3
T3T3
T3T3
Modelo Poblacional
yij = µ µ µ µ + ααααi + ββββj + ξξξξij
Con: ααααi = 0 , ββββj = 0
ξξξξij ∼∼∼∼ N(0,σσσσ2) σσσσ2 = cte ∀∀∀∀ i,j
ααααi y ββββj aditivos
∑∑∑∑====
a
i 1∑∑∑∑
====
b
j 1
iid
i = 1,2, ... , a
j = 1,2, ... , b
MODELO DE CLASIFICACIMODELO DE CLASIFICACIÓÓN N
SEGSEGÚÚN DOS FACTORES SIN INTERACCIN DOS FACTORES SIN INTERACCIÓÓNN

24
Hipótesis
H01: µµµµ1 = µµµµ2 = µµµµi = ... = µµµµa = µµµµαααα
H11: al menos una µµµµi ≠≠≠≠
H01: ααααi = 0 ∀∀∀∀ i
H11: ααααi ≠≠≠≠ 0 para algún i
Modelo Muestral
H02: µµµµ1 = µµµµ2 = µµµµj = ... = µµµµb = µµµµββββ
H12: al menos una µµµµj ≠≠≠≠
H02: ββββj = 0 ∀∀∀∀ j
H12: ββββj ≠≠≠≠ 0 para algún j
)()()( ............ yyyyyyyyyy jiijjiij ++++−−−−−−−−++++−−−−++++−−−−++++====
Diseño asociado: DBCA (aleatorización restringuida)
C A
N A
L
R I E G O
BI BII BIII BIV BV
T1
T2 T1
T2 T1
T3
T2
T1
T2
T3 T1
T2
T3T3 T3
Técnicas en Fábricas
Nivel Social en Escuelas

25
B1 B2 ... Bj ... Bb
A1 A2 . . .
Ai . .
Aa
y11 y12 ... y1j ... y1b y21 y22 ... y2j ... y2b yi1 yi2 ... yij ... yib ya1 ya2 ... yaj ... yab
y1.
Y2. . . .
yi. . .
ya.
y.1 y.2 ... y.j ... y.b y..
Estructura Tabla de Datos
Factor B
Fac
tor
A
Sumas de Cuadrados y Grados de Libertad
bay
ba
ya
i
b
jij
..FC
2..
2
====
====
∑∑∑∑∑∑∑∑
∑∑∑∑∑∑∑∑ −−−−====a
i
b
jijy FCSC 2
TOTAL
FCSC
2.
A −−−−====∑∑∑∑
b
ya
ii
FCSC
2.
B −−−−====
∑∑∑∑
a
yb
jj
gl = a.b - 1
gl = b - 1
gl = a - 1

26
TABLA ANOVA MODELO DE CLASIFICACITABLA ANOVA MODELO DE CLASIFICACIÓÓN N
SEGSEGÚÚN DOS FACTORES ADITIVOSN DOS FACTORES ADITIVOS
F.V. gl SC CM E(CM) Fobs Fcrit
Factor A a-1 FC
2.
−−−−∑∑∑∑
b
ya
ii
1
SCA
−−−−a
11
2
2
−−−−
⋅⋅⋅⋅
++++∑∑∑∑
====
a
ba
iiαααα
σσσσ ERROR
A
CM
CM====AF Fcrit 5%
Fcrit 1%
Factor B b-1 FC
2.
−−−−
∑∑∑∑
a
yb
jj
1
SC
−−−−bb
1
1
2
2
−−−−
⋅⋅⋅⋅
++++
∑∑∑∑====
b
ab
jjββββ
σσσσ ERROR
B
CM
CM====BF
Fcrit 5%
Fcrit 1%
Error (a-1).(b-1) Diferencia )1).(1(
SCError
−−−−−−−− ba 2σσσσ
Total a.b-1 ∑∑∑∑ ∑∑∑∑ −−−−a
i
b
jijy FC2
Ejemplo
Ho1: No hay efecto factor A
Ho2: No hay efecto factor B
1
A
2
B
3
Y
1
2
3
4
5
6
7
8
9
10
11
12
A1 B1 6,00
A1 B2 2,00
A1 B3 9,00
A1 B4 3,00
A2 B1 8,00
A2 B2 9,00
A2 B3 11,00
A2 B4 12,00
A3 B1 4,00
A3 B2 4,00
A3 B3 10,00
A3 B4 6,00
B1 B2 B3 B4
A1
A2
A3
6 2 9 3
8 9 11 12
4 4 10 6
20
40
24
18 15 30 21 84

27
Univariate Results for Each DV (NLIN)
Sigma-restricted parameterization
Effective hypothesis decomposition
GENERAL
EffectDegr. of
Freedom
Y
SS
Y
MS
Y
F
Y
p
Intercept
A
B
Error
Total
1 588,00 588,00 160,3636 0,000015
2 56,00 28,00 7,6364 0,022438
3 42,00 14,00 3,8182 0,076473
6 22,00 3,67
11 120,00
FC
Salidas Statistica
5,14 10,94,76 9,98
Tukey HSD test; variable Y (NLIN)
Probabilities for Post Hoc Tests
Error: Between MS = 3,6667, df = 6,0000
Cell No.A {1}
5,0000
{2}
10,000
{3}
6,0000
1
2
3
A1 0,0238 0,7512
A2 0,0238 0,0577
A3 0,7512 0,0577
A; LS Means
Current effect: F(2, 6)=7,6364, p=,02244
Effective hypothesis decomposition
Vertical bars denote 0,95 confidence intervals
A1 A2 A3
A
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Y
B; LS Means
Current effect: F(3, 6)=3,8182, p=,07647
Effective hypothesis decomposition
Vertical bars denote 0,95 confidence intervals
B1 B2 B3 B4
B
0
2
4
6
8
10
12
14
Y
A1 A3 A2
B1 B2 B3 B4

28
Eficiencia de un DBCA respecto a un DCA
SCERROR DBCA < SCERROR DCA SIEMPRE !!!!
CMERROR DBCA significativamente < CMERROR DCA cuando efecto bloque**
)()(
EfDBCACMDCACM
error
error====
Cómo obtener CMerror(DCA)
F.V. gl SC CM F P-value
A 2 56,00 28,00 7,63 0,0224
B 3 42,00 14,00 3,81 0,0764
Error 6 22,00 3,67
Total 11 120,00
F.V. gl SC CM F P-value
A 2 56,00 28,00 7,63 0,0224
Error 9 64,00 7,11
Total 11 120,00
94,167,311,7
Ef ======== DBCA 94% más eficiente

29
Si DBCA más eficiente y deseara trabajar con un DCA
necesitaría mayor número de repeticiones para neutralizar la
heterogeneidad del material experimental que no se tiene en
cuenta al no bloquear
Existen otras expresiones de eficiencia
con correcciones por gl


















