
Traitement d'événements
45
Traitement d’évènements en temps réel Michael Garcia – Architecte Solutions – [email protected] @aws_actus
-
Upload
amazon-web-services -
Category
Technology
-
view
168 -
download
0
Transcript of Traitement d'événements

Traitement d’évènements en
temps réelMichael Garcia – Architecte Solutions –
@aws_actus
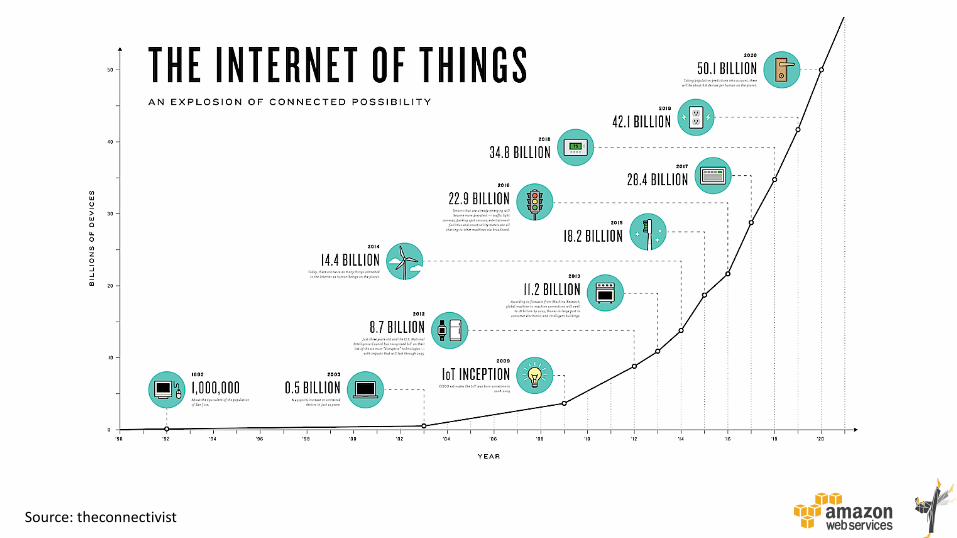
Source: theconnectivist

Big Data
3VVolume - Variety - Velocity

Big Data Real-time Big Data
Customers Want Fast Answers

Decision
impact(also proportional
to risk)
Decision rate
2000’s – “How often can we run a permission-based email mktg. campaign?” Rules-based alerts
2010’s – Millions of decisions and actions taken, all in less than a blink of an eye
1
2
3
1990’s – “Should we advertise on the Superbowl? Should we run direct mail this qtr.?” Batch mode1
2
3
Evolution of real time decisions
Business
Impact

Plethora of Tools
Glacier
S3 DynamoDB
RDS
EMR
Redshift
Data PipelineKinesis
Cassandra CloudSearch
Kinesis-
enabled
app

Tools anti-pattern
App/Web Tier
Client Tier
Database & Storage Tier

Use the right tool for the right job
App/Web Tier
Client Tier
Database & Storage Tier
Amazon RDSAmazon DynamoDB
Amazon ElastiCache
Amazon S3
Amazon Glacier
Amazon EMR
Amazon Redshift

Histoire d’une migration vers
Amazon RedshiftNicolas Baron – CTO, FollowAnalytics
@nico_b
www.linkedin.com/in/nicolasbaron

FollowAnalyticsEn quelques mots
Mobile Marketing AutomationSaaS Platform
Startup créée à ParisHQ à San Francisco
Positionnement Fortune 1000 / SBF 120 SAP & Hummer Winblad

User Analyt ics
1
CRMIntegrat ion
AlertsUserProf i le
Engagement
In App Message
Push Noti f icat ion
23 4
5

Architecture Big Picture

Contexte
Croissance importante PerformanceMongoDB

Les challenges
6 mois Changer de paradigme Améliorer la productivitéDes développements

Prise de décision
MPP databases Hadoop
Amazon Redshift

Prise de décision
Amazon Redshift

Adoption d’Amazon Redshift
Amazon S3Amazon
Redshift

Adoption d’Amazon Redshift
16 Noeuds – dw2.Large
– 2.5 To (SSD)
• Test sur plusieurs milliards de lignes de logs
• 90% des requêtes en moins de 10 secondes
Pro tip: design du schéma !
Avant (MongoDB) Après (Amazon Redshift)
Millions Milliards
Pré-calcul systématique < 10 secondes

Quels bénéfices ?
“Right tool forthe right job”
Pas de nouvellescompétences
Service AWS managé

Big Data Lifecycle

Ingest Store Process Visualize
Stages of Big Data Processing
Batch analysis – one set of tools
Real time analysis – another set of tools
Minutes/Hours
Seconds


Types of Data Ingest• Transactional
– Database reads/writes (structured
data)
• File
– Logs (unstructured data)
Database
Cloud Storage
Data has to be extracted from multiple source to be processed periodically

Types of Data Ingest
• Stream
– Click-stream logs
– Mobile analytics
– IoT
– Telemetry
– Any real-time data from any producer
StreamStorage
Data is streamed and can be processed continuously

What is a good ingest tool?
• Sequential streams are easier to process
• Need to scale
• Need to persist
• Architectural flexibility
• Real time! Processing
Kafka
Or
Kinesis
ProcessingIngest To
ol

Introducing Amazon Kinesis

Amazon Kinesis

Amazon Kinesis• Streams contain Shards. Each Shard
ingests data up to 1MB/sec, and up to
1000 TPS
• Each Shard emits up to 2 MB/sec
• All data is stored for 24 hours
• Scale Kinesis streams by adding or
removing Shards
• Replay data inside of 24Hr. Window
• Fully managed & low cost

13.4 Mo/s
500 Millions tweet a day @2.4 Ko per tweetHypothesis:
577 $ / monthSource: dioncosales. Pricing example is for Amazon Kinesis Only

“Amazon Kinesis also offloads a lot of developer burden in building a real-time, streaming data ingestion platform, and enables Supercell to focus on delivering games that delight players worldwide."
Sami Yliharju, Services Lead

Database
Cloud Storage

Which Stream Store Should I Use?• Amazon Kinesis and Kafka have many similarities
– Multiple consumers
– Ordering of records
– Streaming MapReduce
– Low latency. Highly durable, available, and scalable
• Differences
– Record lifetime: 24 hours in Amazon Kinesis, configurable in Kafka
– Record size: 50 KB in Amazon Kinesis, configurable in Kafka
– Amazon Kinesis is a fully managed service – easier to provision, manage,
and scale


What Database and Storage Should I Use?
• Data structure
• Query complexity
• Use case
• Workload
• Data characteristics: hot, warm, cold


Process
• Answering questions about data
• Questions
– Analytics: Think SQL/data warehouse
– Classification: Think sentiment analysis
• Who is asking them
– Data scientist
– Business owners
• When do you need them
– In seconds
– Weekly/Monthly

Processing Tools
• Batch/Interactive
– Amazon Redshift
– Amazon EMR
• Hive/Tez, Pig, Impala, Spark, Presto, ….
• Stream/Real-time processing
– Apache Spark streaming
– Apache Storm (+ Trident)
– Amazon Kinesis client and
connector library
– AWS Lambda

Spark Streaming,
Storm, Kinesis App
Amazon Redshift
Spark, Impala, Presto
Hive
Amazon Redshift
Hive
Spark, Presto
Amazon Kinesis/
Kafka
Amazon DynamoDB
Amazon S3Data
Hot ColdData TemperatureQ
ue
ry L
ate
nc
y
Low
HighAnswers
HDFS
Hive
Native Client
Data Temperature vs Query Latency


AWS Marketplace


Demo
Amazon S3
Amazon
DynamoDB
Amazon Kinesis
Site internetUtilisateurs
Dashboard
(Démonstration)

Real-TimeAnalysis
Amazon Kinesis

Thank you !!
@aws_actus

Inscrivez-vous gratuitement à l’adresse :
aws.amazon.com/summits/paris


















