
This chart represents all revenue for speech related ecosystem activity.
25
IBM Research © 2006 IBM Corporation Superhuman Speech Recognition: Technology Challenges & Market Adoption David Nahamoo IBM Fellow Speech CTO, IBM Research July 2, 2008
description
Superhuman Speech Recognition: Technology Challenges & Market Adoption David Nahamoo IBM Fellow Speech CTO, IBM Research July 2, 2008. Overall Speech Market Opportunity. WW Voice-Driven Conversation Access Technology Forecast. - PowerPoint PPT Presentation
Transcript of This chart represents all revenue for speech related ecosystem activity.

IBM Research
© 2006 IBM Corporation
Superhuman Speech Recognition:Technology Challenges & Market Adoption
David NahamooIBM FellowSpeech CTO, IBM Research
July 2, 2008

IBM Research
© 2006 IBM Corporation2
•This chart represents all revenue for speech related ecosystem activity.
•Revenue exceeded $1B for the 1st time in 2006
•Note also that hosted services will represent ½ of speech related revenue in 2011
WW Voice-Driven Conversation Access Technology Forecast
*Opus Research 02_2007
Overall Speech Market Opportunity

IBM Research
© 2006 IBM Corporation3
Speech Segments Need-based Segmentation Market Usage
Speech Self Service Transaction/Problem Solving Contact Centers
Speech Analytics Intelligence Contact Centers, Media, Government
Speech Biometrics Security Contact Centers, Government
Speech Transcription Information Access and provision Media, Medical, Legal, Education, Government, Unified Messaging
Speech Translation Multilingual Communication Contact Centers, Tourism, Global Digital Communities, Media (XCast)
Speech Control Command & Control Embedded - Automotive, Mobile Devices, Appliances, Entertainment
Speech Search & Messaging Information Search & Retrieval Mobile Internet, Yellow Pages SMS, IM, email
Speech Market Segments
• Improved accuracy• Much larger vocabulary speech recognition system

IBM Research
© 2006 IBM Corporation4
New Opportunity Areas Contact Centers Analytics
– Quality Assurance, Real Time Alerts, Compliance
Media Transcription– Closed captioning
Accessibility– Government, Lectures
Content Analytics– Audio-indexing, cross-lingual information retrieval, multi-media mining
Dictation– Medical, Legal, Insurance, Education
Unified Communication– Voicemail, Conference calls, email and SMS on hand held
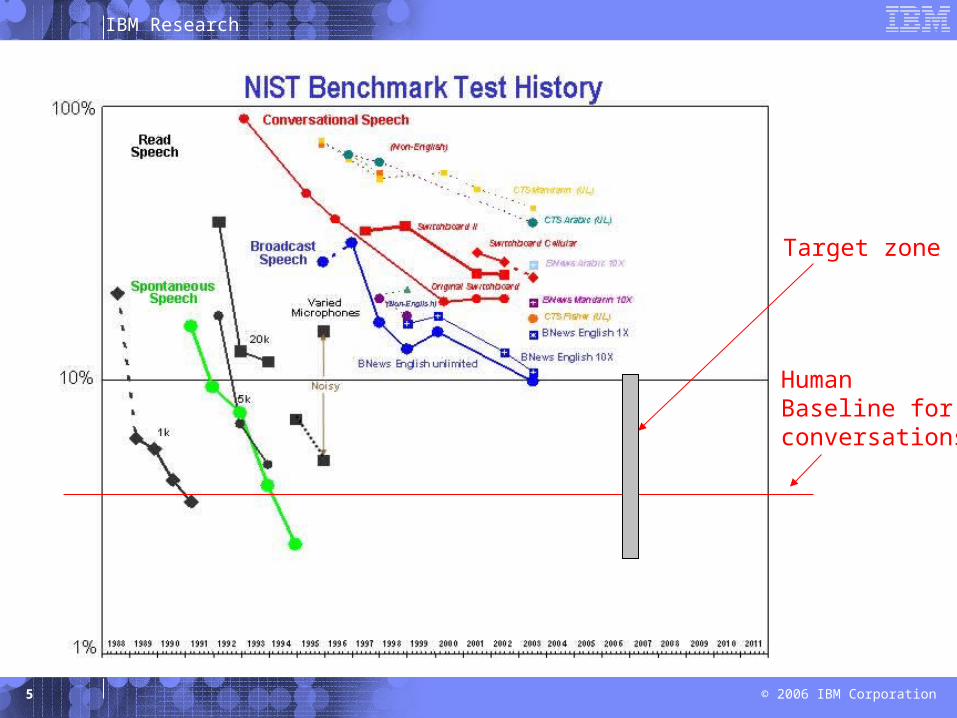
IBM Research
© 2006 IBM Corporation5
HumanBaseline forconversations
Target zone
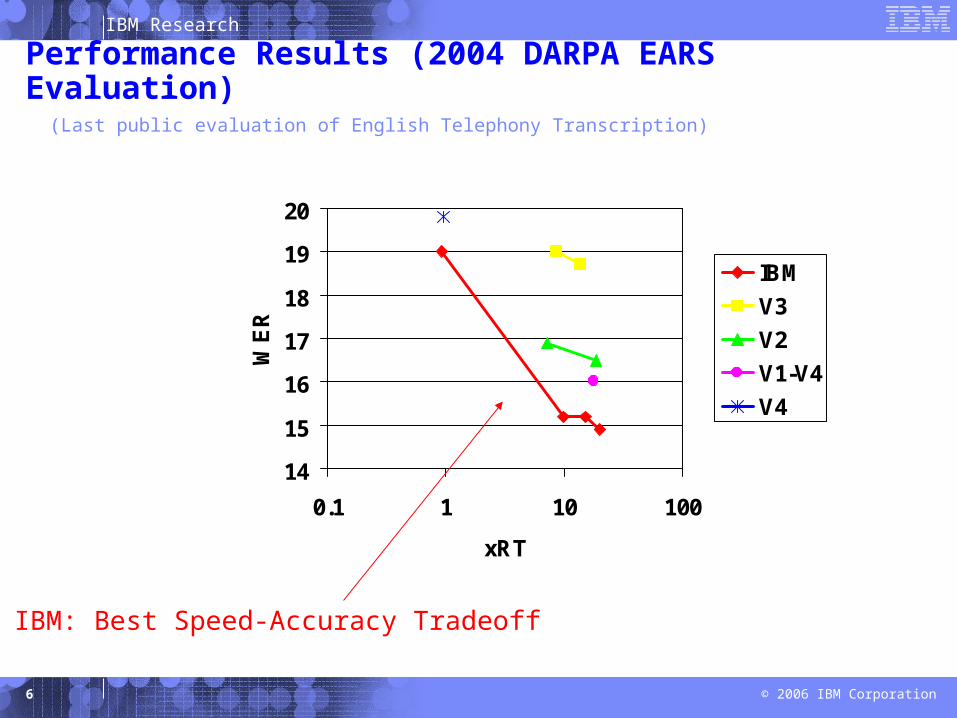
IBM Research
© 2006 IBM Corporation6
Performance Results (2004 DARPA EARS Evaluation)
14
15
16
17
18
19
20
0.1 1 10 100
xRT
WE
RIBM
V3
V2
V1-V4
V4
IBM: Best Speed-Accuracy Tradeoff
(Last public evaluation of English Telephony Transcription)

IBM Research
© 2006 IBM Corporation7
MALACHMultilingual Access to Large Spoken ArCHives
• Funded by NSF, 5-year project (Started in Oct. 2001)
Project Participants
– IBM, Visual History Foundation, Johns Hopkins University, University of Maryland, Charles University and University of West Bohemia
Objective
– Improve access to large multilingual collections of spontaneous speech by advancing the state-of-the-art in technologies that work together to achieve this objective: Automatic Speech Recognition, Computer-Assisted Translation , Natural Language Processing and Information Retrieval
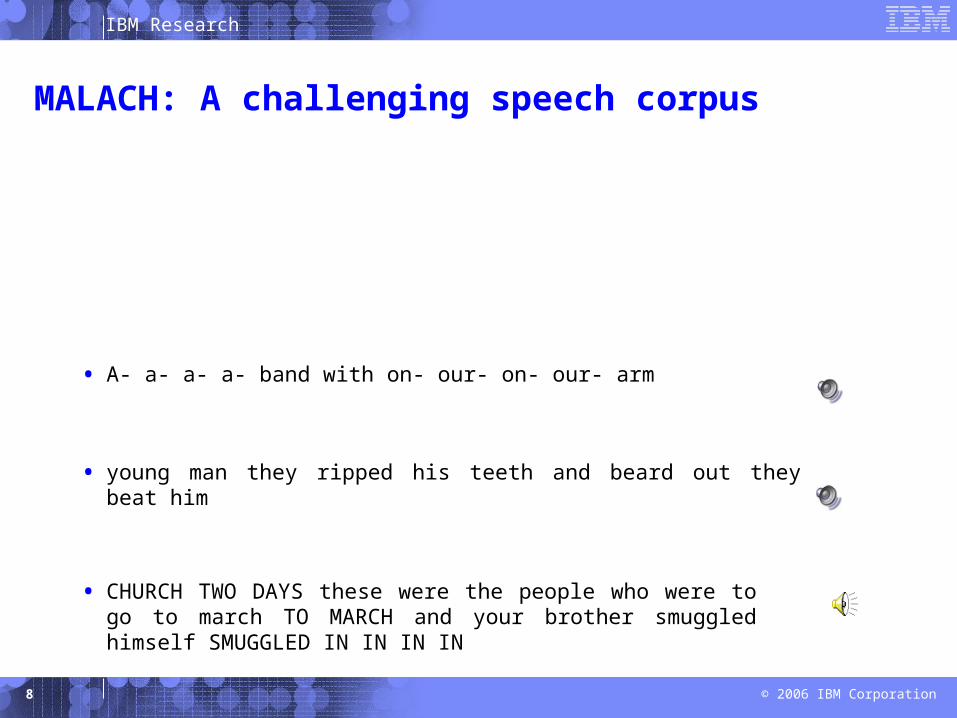
IBM Research
© 2006 IBM Corporation8
MALACH: A challenging speech corpus
Emotional speech• young man they ripped his teeth and beard out they beat him
Disfluencies• A- a- a- a- band with on- our- on- our- arm
Multimedia digital archive: 116,000 hours of interviews with over 52,000 survivors, liberators, rescuers and witnesses of the Nazi Holocaust, recorded in 32 languages.
Goal: improved access to large multilingual spoken archives
Challenges:
Frequent interruptions:
• CHURCH TWO DAYS these were the people who were to go to march TO MARCH and your brother smuggled himself SMUGGLED IN IN IN IN

IBM Research
© 2006 IBM Corporation9
Word Error Rates
20
30
40
50
60
70
80
90
Jan. '02 Oct. '02 Oct. '03 June '04 Nov. '04
Effects of Customization (MALACH Data)
State-of-the-art ASR systemtrained on SWB data (8KHz)
MALACH Training data seenby AM and LM
fMPE, MPE, Consensus decoding

IBM Research
© 2006 IBM Corporation10
Improvement in Word Error Rate for IBM embedded ViaVoice
0
1
2
3
4
5
6
WER across 3 car speeds and 4 grammars

IBM Research
© 2006 IBM Corporation11
Progress in Word Error Rate – IBM WebSphere Voice Server
Grammar Tasks over Telephone2001 - 2006
0
1
2
3
4
5
6
WVS
Word Error Rate %
45% relative improvement in WER the last 2.5 years20% relative improvement in speed in the last 1.5 years

IBM Research
© 2006 IBM Corporation12
Multi-Talker Speech Separation Task
male and female speaker at 0dB
Lay white at X 8 soon
Bin Green with F 7 now

IBM Research
© 2006 IBM Corporation13
Two Talker Speech Separation Challenge ResultsR
ecog
nitio
n E
rror
Examples:
Mixture
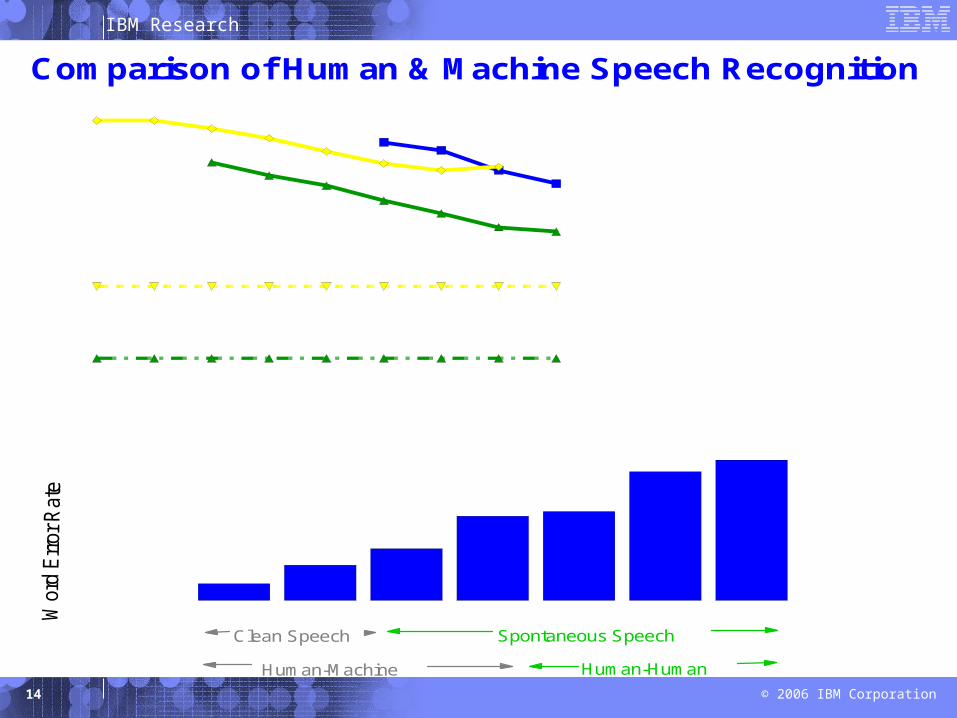
IBM Research
© 2006 IBM Corporation14
1992 1993 1994 1995 1996 1997 1998 1999 20001
10
100
Voicemail
SWITCHBOARD
BROADCAST NEWS
BROADCAST-HUMAN
SWITCHBOARD-HUMAN
Comparison of Human & Machine Speech Recognition
WSJ Broadcast Conv Tel Vmail SWB Call center Meeting 0
10
20
30
40
50
60
70
Clean Speech Spontaneous Speech
Human-Machine Human-Human

IBM Research
© 2006 IBM Corporation15
IBM’s Superhuman Speech Recognition
Universal Recognizer• Any accent
• Any topic
• Any noise conditions
• Broadcast, phone, in car, or live
• Multiple languages
• Conversational

IBM Research
© 2006 IBM Corporation16
Human Experiments Question:
– Can post-processing of recognizer hypotheses by humans improve accuracy?– What is the relative contribution of linguistic vs. acoustic information (in this post-processing
operation?)
Experiment– Produce recognizer hypotheses in form of “sausages”– Allow human to correct output either with linguistic information alone or with short segments of
acoustic information
Results– Human performance still far from maximum possible, given information in “sausages”– Recognizer hypothesized linguistic context information not useful by itself– Acoustic information in limited span (1 sec. average) marginally useful
What we learned
– Hard-to-design
– Expensive to conduct
– Hard to decide if not valuableand
that
it
I
they
could
cuts
comes
cut
stem
down
stay
them
on
I’m

IBM Research
© 2006 IBM Corporation17
Acoustic Modeling Today Approach: Hidden Markov Models
– Observation densities (GMM) for P( feature | class )
• Mature mathematical framework, easy to combine with linguistic information• However, does not directly model what we want i.e., P( words | acoustics )
Training: Use transcribed speech data– Maximum Likelihood – Various discriminative criteria
Handling Training/Test Mismatches:– Avoid mismatches by collecting “custom” data– Adaptation & adaptive training algorithms
Significantly worse than humans for tasks with little or no linguistic information - e.g., digits/letters recognition
Human performance extremely robust to acoustic variations – due to speaker, speaking style, microphone, channel, noise, accent, & dialect variations
Steady progress over the yearsContinued progress using current methodology very likely in the future

IBM Research
© 2006 IBM Corporation18
Towards a Non-Parametric Approach to Acoustics General Idea: Back to pattern recognition basics!
– Break test utterance into sequence of larger segments (phone, syllable, word, phrase)
– Match segments to closest ones in training corpus using some metric (possibly using long distance models)
– Helps to get it right if you’ve heard it before Why prefer this approach over HMMs?
– HMMs compress training by x1000; too many modeling assumptions• 1000hrs ~ 30Gb; State-of-the-art acoustic models ~ 30Mb• Relaxing assumptions have been key to all recent improvements in acoustic modeling
How can we accomplish this?– Store & index training data for rapid access of training segments close to test segments– Develop a metric D( train_seq, test_seq): obvious candidate is DTW with appropriate metric and warping rules
Back to the Future?
– Reminiscent of DTW & Segmental models from late 80’s – ME was missing
– Limited by computational resources (storage/cpu/data) then & so HMMs won Implications:
– Need 100x more data for handling larger units (hence 100x more computing resources)
– Better performance with more data – likely to have “heard it before”

IBM Research
© 2006 IBM Corporation19
Utilizing Linguistic Information in ASRUtilizing Linguistic Information in ASR Today’s standard ASR does not explicitly use linguistic information
– But recent work at JHU, SRI and IBM all show promise– Semantic structured LM improves ASR significantly for limited domains
Reduces WER by 25% across many tasks (Air Travel, Medical)
A large amount of linguistic knowledge sources now available, but not used for ASR Inside IBM
WWW text: Raw text: 50 million pages ~25 billion words, ~10% useful after cleanup News text: 3-4 billion words, broadcast or newswires Name entity annotated text: 2 million words tagged Ontologies Linguistic knowledge used in rule-based MT system
External WordNet, FrameNet, Cyc ontologies PennTreeBank, Brown corpus (syntactic & semantic annotated) Online dictionaries and thesaurus Google
IBM Research
© 2006 IBM Corporation20
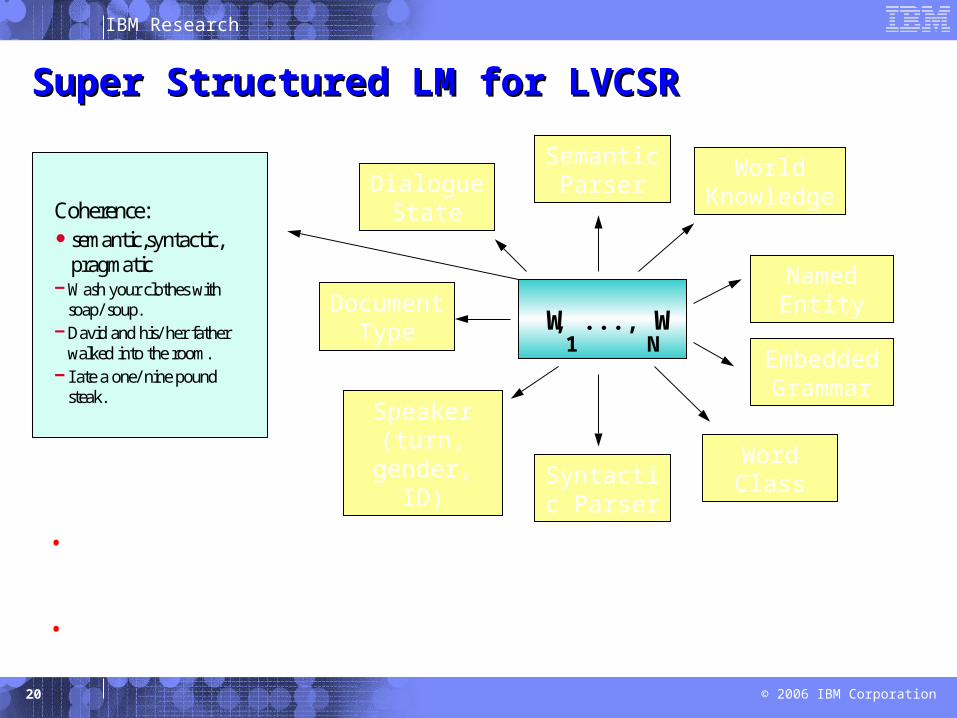
•Acoustic Confusability: LM should be optimized to distinguish between acoustic confusablesets, rather than based on N-gram counts•Automatic LM adaptation at different levels: discourse, semantic structure, and phrase
levels
Coherence:semantic,syntactic, pragmaticWash your clothes with soap/ soup.David and his/ her father walked into the room.I ate a one/ nine pound steak.
Semantic ParserDialogue
State
Document Type
Speaker (turn,
gender, ID) Syntactic Parser
Word Class
Embedded
Grammar
Named Entity
World Knowledge
W1, ..., W
N
Super Structured LM for LVCSRSuper Structured LM for LVCSR

IBM Research
© 2006 IBM Corporation21
Combination Decoders “ROVER” is used in all current systems
– NIST tool that combines multiple system outputs through voting
Individual systems currently designed in an ad-hoc manner
Only 5 or so systems possible
“I feel shine today”
“I veal fine today”
“I feel fine toady”
“I feel fine today”
An army (“Million”) of simple decoders• Each makes uncorrelated errors

IBM Research
© 2006 IBM Corporation22
• Feature definition is key challenge• Maximum entropy model used to compute word probabilities.• Information sources combined in unified theoretical framework.• Long-span segmental analysis inherently robust to both stationary and transient noise
Million Feature Paradigm: Acoustic information for ASR
Discard transient noise;Global adaptation forstationary noise
Segmental analysisBroadband featuresNarrowband features Onset features
Trajectory features
Information Sources Noise Sources

IBM Research
© 2006 IBM Corporation23
Implications of the data-driven learning paradigm
ASR systems give the best results when test data is similar to the training data
Performance degrades as the test data diverges from the training data
– Differences can occur both at the acoustic and linguistic levels, e.g.
1. A system designed to transcribe standard telephone audio (8kHz) cannot transcribe compressed telephony archives (6kHz)
2. A system designed for a given domain (e.g. broadcast news) will perform worse on a different domain (e.g. dictation)
Hence the training and test sets have to be carefully chosen if the task at hand expects a variety of acoustic sources

IBM Research
© 2006 IBM Corporation24
Generalization DilemmaP
erfo
rman
ce
In-Domain Out-of-Domain
Test Conditions
Complex model: brute force learning
Simple model
Want to get here:
Model combination: Can we at least get best of both worlds?
Correct complex model
(simple model on the right manifold)
The Gutter of Data Addiction

IBM Research
© 2006 IBM Corporation25
Summary Continue the current tried-and-true technical approach
Continue the yearly milestones and evaluations
Continue the focus on accuracy, robustness, & efficiency
Increase the focus on quantum leap innovation
Increase the focus on language modeling
Plan for 2 orders of magnitude increase in
– Access to annotated speech and text data
– Computing resources
Improve cross-fertilization among different projects


















