
Solid Day - Machine learning para organizaciones
36
Ya eres parte de la evolución Solid Day #MachineLearning para Organizaciones Jesus Ramos @xuxoramos [email protected] linkedin.com/in/xuxoramos #sgnext
-
Upload
software-guru -
Category
Data & Analytics
-
view
86 -
download
2
Transcript of Solid Day - Machine learning para organizaciones

Ya eres partedelaevolución
SolidDay
#MachineLearning paraOrganizaciones
Jesus Ramos@xuxoramos
[email protected]/in/xuxoramos
#sgnext

Y éste qué?- Ingeniero de Software de nacimiento (ITESM).- Econometrista Financiero por azar (Unottingham +
UWashington).- Estadístico Computacional por convicción (Coursera, a mucha
honra).- Consultado con 6 firmas (BMV, GBM, ConCredito, Movistar, etc)
para levantar sus capacidades analíticas.- Co fundador de @TheDataPub, comunidad dedicada a reventar
la burbuja y detener el tren del m*** del ML y del Pig Data.- Gamer los sábados (PSN: xuxoramos).- Foodie los domingos.

En qué ando?

Lo feo del#MachineLearning…

#MachineLearning BubbleMachineLearning

Montaña rusa sin freno…
$232mmdd
Gran Inversión
4%Stats/Maths/Prog
Poco skill Mala cultura
Governance:Datos rehenesde cabal de IT

…y sin cinturón!

El freno para esta montaña rusa…

Roadmap+Riesgos para la banda
SkillSi eres dev,
métele a stats+maths.Si eres de maths+stats,
métele a dev.
Biz IntimacyOlvídate de laHerramienta.Enfócate en el
lenguaje de negocio.
OperationalNo entregues reportes,
entrega APIs.
Sin contexto==
Hacer la preguntaequivocada
No hayescalamiento
Mala predicción + Alto sesgo
==Perder dinero/
lastimar personas
Etapa
Riesgo

Roadmap+Riesgos para orgs
Etapa
Riesgo
DWHTodos los datosen 1 solo lugar.
Gov’nanceTotal apertura ycon conexiones
SelfServ-BIQue gente de negociose sirva reportes sola.
Mayor sesgo +
sinobserver
effect
DataScience==
Reporteo/BICorrelación
==Causalidad

Lo básico para volver a acelerar…
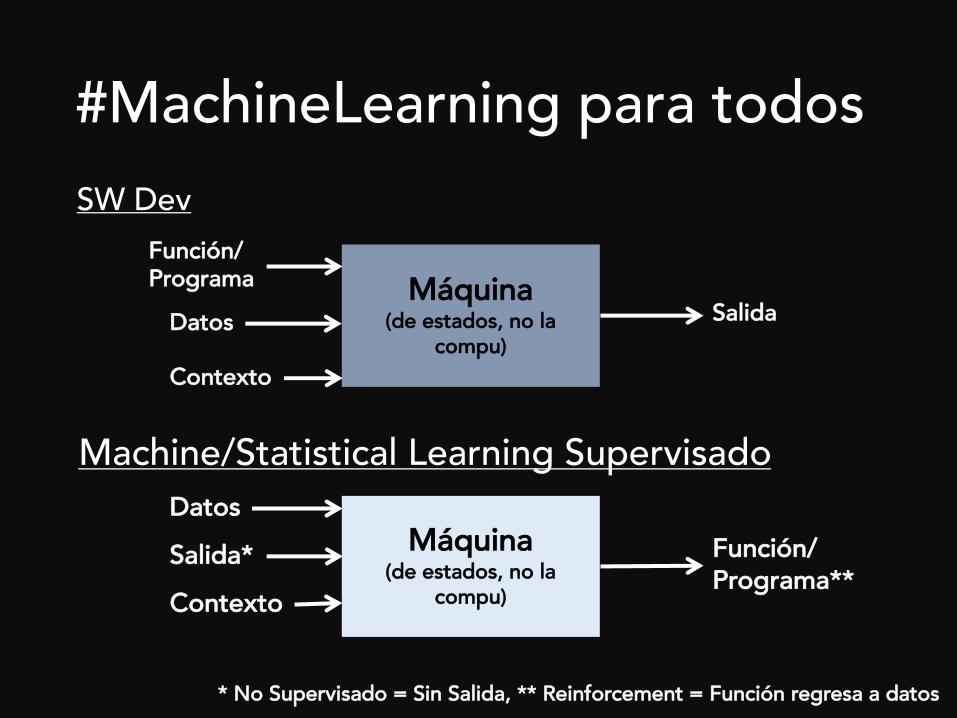
#MachineLearning para todosSW Dev
Máquina(de estados, no la
compu)Datos
Función/Programa
Salida
Machine/Statistical Learning Supervisado
Máquina(de estados, no la
compu)Salida*Datos
Función/Programa**
Contexto
Contexto
* No Supervisado = Sin Salida, ** Reinforcement = Función regresa a datos

#MachineLearning para todosObjetivo 1: identificar patrones

Error Total
#MachineLearning para todosObjetivo 2: reducir el error de la función
Error de Predicción Error del Fenómeno(Varianza) Sesgo/Bias
Reducción: modelomás/menos complejo
Reducción: más datos+más variables.
Reducción:CONTEXTO!

#MachineLearning para todosVarianza vs Sesgo

#MachineLearning para todosVarianza vs Sesgo

#MachineLearning para todosTipos: Clasificación

#MachineLearning para todosTipos: Regresión

#MachineLearning para todosTipos: Clustering == Clasificación Sin Output

#MachineLearning para todosTipos: Dimensionality Redux/Feature Engineering

#MachineLearning para todosY cuál uso?
(Los que me den menos varianza y menos bias)

#MachineLearning para todosMetodología
DescribirQué me pareceinteresante demi dataset?
ExplorarQué researchquestion quieroHacerle a midataset?
InferirLa respuestapuedegeneralizarse?
PredecirLa respuestaaplica a nuevasobservaciones?
- Distribuciones- Media- Moda- Kurtosis
- Clustering- Kohonen- DBSCAN- MultidimScaling
- Hypo Test- GLM- ANOVA- MSE
- RandomForest
- Boosting- Bagging- DeepLearning
ML ML

Ya le quitamos el m*me al tren. Ahora...?
Aplicaciones!

B*n*m*x• Conversión de cliente de nómina a TC en
29%.• $2.7mmdp en revenue al año desde 2010.• Cómo lo hizo?• Clasificación!
f(edad, género, monto, antigüedad, …) = tiene TC
Predictores / variables independientes variable respuesta / dependiente

UPS• Ahorro de combustible haciendo que
camiones sólo den vuelta a la derecha.• Ahorro de $47mdd al año.• Cómo lo hicieron?• Diseño de experimentos!
Exploratorio -> Recolección de datos -> Hypothesis Testing -> GLMs -> Clasificación

T*lc*l• Identificación de usrs consumiendo $7K MXN
semanales de tiempo aire en prepago.• Creación de producto de crédito de tiempo
aire de hasta $2K.• $4mmdp al año de revenue.• Cómo lo hicieron?• Clustering!
Multidimensional Scaling + K-means/DBSCAN

Western Union• Prevención de fraude en remesas en
automático y personalizado.• $32mdd en ahorro operativo en 2012.
$21mdd son de transacciones detenidas al momento.• Cómo le hicieron?• Clasificación!• Similar a algoritmos de spam/ham.

Gr*p* *xp*ns**n• Bajar bounce rate y mantener al visitante en
sitios de las marcas del grupo.• Aumentar ad impressions.• Cómo lo están haciendo?• Recommender Systems!
Clasif 1 + Clasif 2 + … + Clasif N
Quémúsica prefiere?
Quécomidaprefiere?
Quépelisha visto?

Y las startups?

En la delantera!• Konfio, Kueski, Prestadero + ensemble
learning = credit scoring.• Piggo + multidimensional scaling + DBSCAN
= recomendación de inversiones.• Klustera + Filtros Kalman (un tipo de
regresión) = ubicación de gente en centros comerciales.• HolaGus + deep convolutional neural
networks = clasificación de texto.

Qué puede salir mal?
Todo!

#MachineLearning Flops• Google Flu Trends – Contexto = predicción
fallida de AH1N1 en Francia.• Google Image Classifier – Contexto = 2
afroamericanos taggeados como ‘gorilas’.• Walmart + Modelo complejo de alta varianza
= productos en mal estado vendidos a clientes.• Wall Street + Model simple de alto bias =
crisis hipotecaria de 2008• T*lc*l – Contexto = Préstamos a sospechosos.

Concluyendo…

Cómo le entro al ML?• Comienza por prepararte en mates y estadística. Leete
“Think Stats” de Allen Downey.• Acércate al depto de mates de tu universidad. Seguro
encuentras diplomados en mates.• MOOCs: “Data Science Specialization” de Coursera es la
opción.• Síguele con el de Andrew Ng de Stanford.• No te cases ni con Python ni con R. Usa ambos.• No te cases con ningún algoritmo. Primero pregunta “qué
quiero lograr?”• Context is KING!

¿Preguntas?

[email protected]@gmail.comlinkedin.com/in/xuxoramos


















