
7 - Prokaryotic Transcription and Translation
93
Prokaryotic transcription and translation 5BBB0230 Gene Cloning and Expression A 5BBB0231 Gene Cloning and Expression A/B Harris Lecture Theatre (Hodgkin) Ken Bruce [email protected]
-
Upload
natalia-ronatowicz -
Category
Documents
-
view
242 -
download
0
description
.
Transcript of 7 - Prokaryotic Transcription and Translation

Prokaryotic transcription and translation
5BBB0230 G
ene Cloning and E
xpression A
5BBB0231 G
ene Cloning and E
xpression A/B
H
arris Lecture Theatre (Hodgkin)
Ken B
ruce kenneth.bruce@
kcl.ac.uk

These sessions are on prokaryotic gene expression • They wont cover RNA chemistry or RNA synthesis
chemistry – refresh from common year one lectures
Focus today is to extend detail on processes of transcription and translation
We benefit from understanding gene expression We’ll see how • Information on expressed genes can show how
bacterial species cause infections • Stages of transcription and more so translation
are antibiotic targets
First though, to recap on these processes.
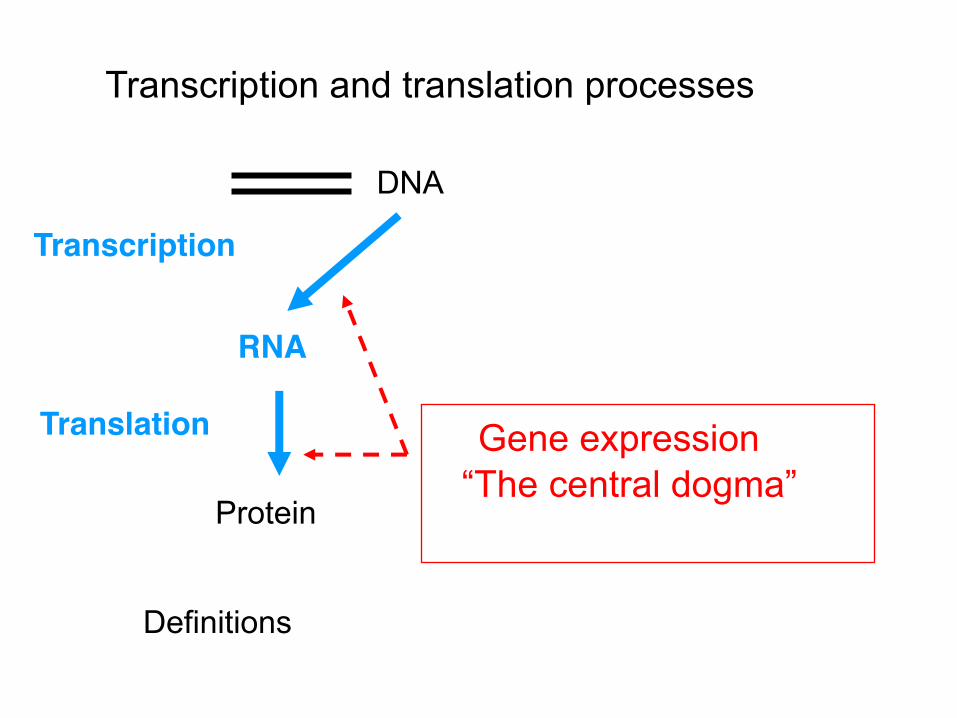
RNA
Transcription
Protein
Translation
DNA
Gene expression “The central dogma”
Transcription and translation processes
Definitions
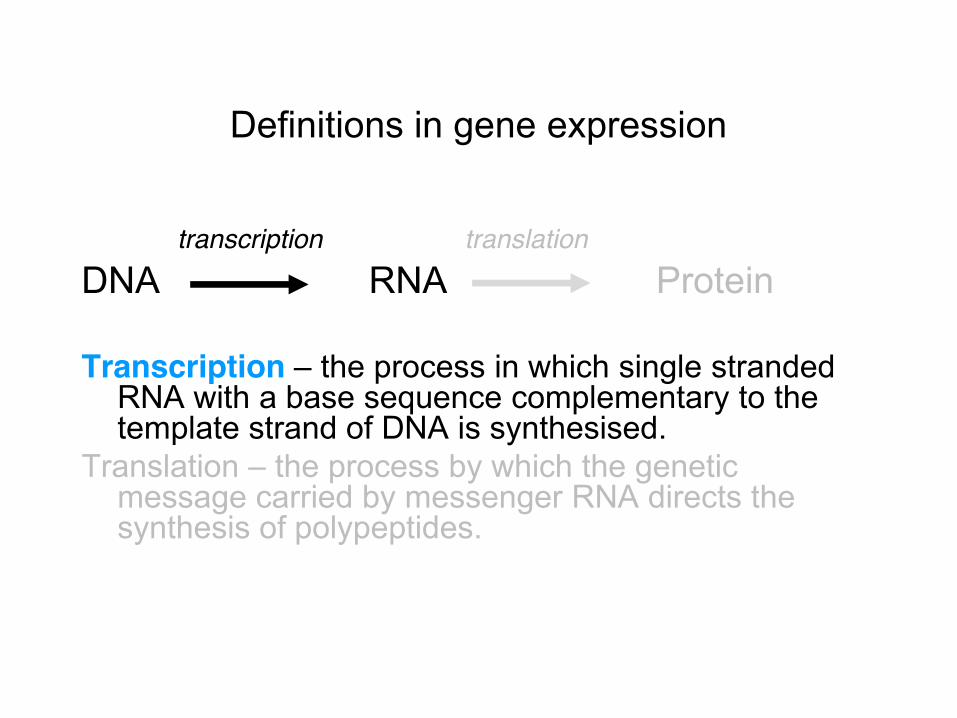
Definitions in gene expression
transcription translation DNA RNA Protein Transcription – the process in which single stranded
RNA with a base sequence complementary to the template strand of DNA is synthesised.
Translation – the process by which the genetic message carried by messenger RNA directs the synthesis of polypeptides.

Definitions in gene expression
transcription translation DNA RNA Protein Transcription – the process in which single stranded
RNA with a base sequence complementary to the template strand of DNA is synthesised.
Translation – the process by which the genetic message carried by messenger RNA directs the synthesis of polypeptides.
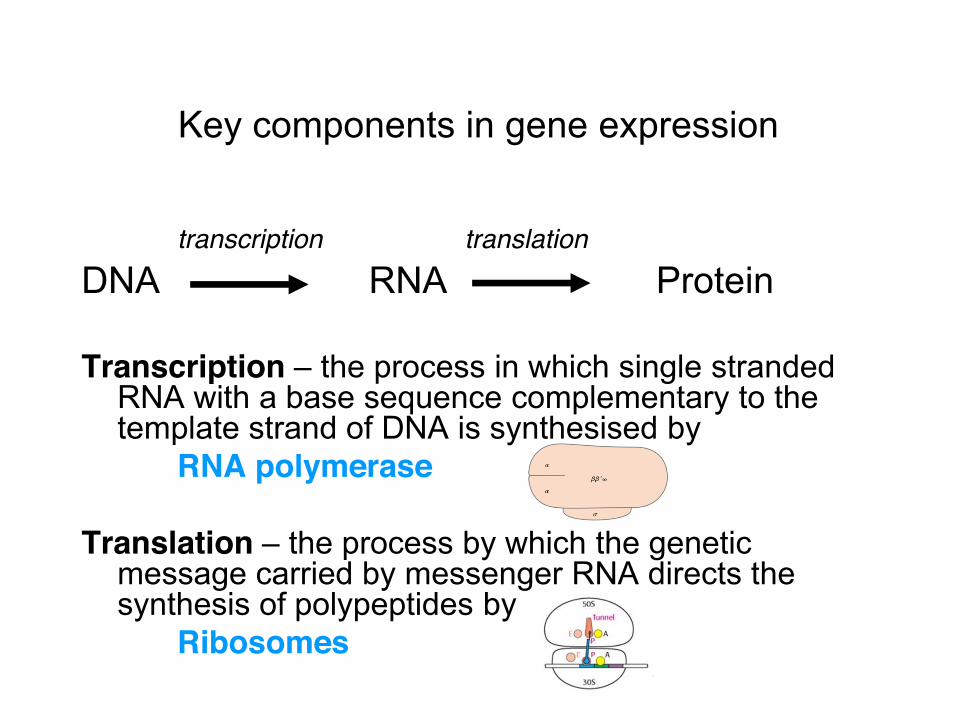
Key components in gene expression
transcription translation DNA RNA Protein Transcription – the process in which single stranded
RNA with a base sequence complementary to the template strand of DNA is synthesised by
RNA polymerase Translation – the process by which the genetic
message carried by messenger RNA directs the synthesis of polypeptides by
Ribosomes

Gene expression in eukaryotes
Two cellular compartments: • Transcription in nucleus • Translation in cytoplasm
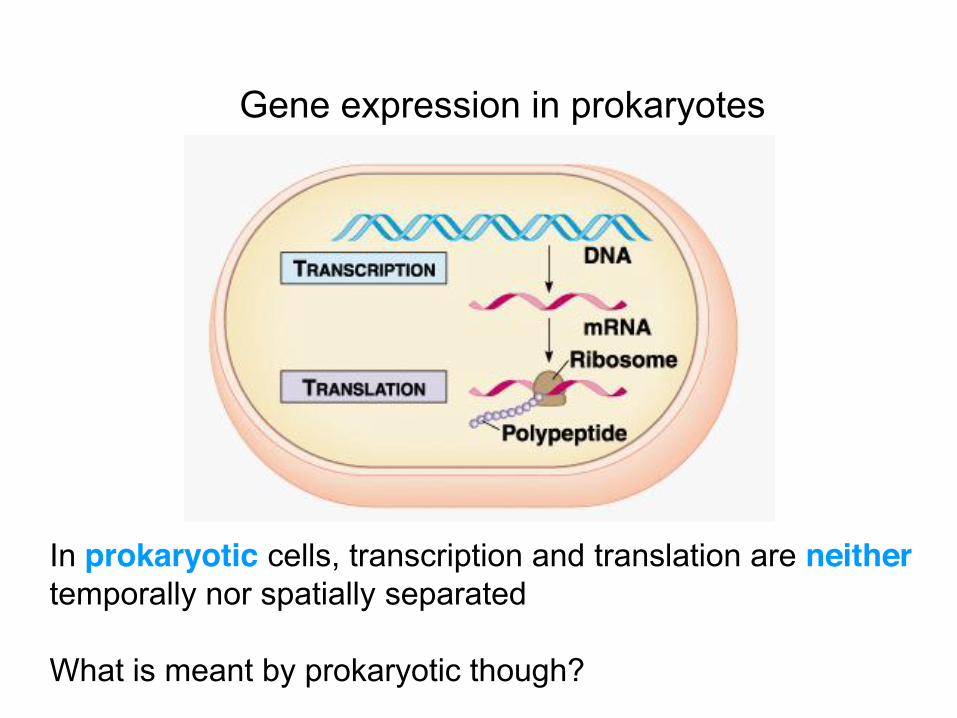
Gene expression in prokaryotes
In prokaryotic cells, transcription and translation are neither temporally nor spatially separated What is meant by prokaryotic though?

Prokaryotes are cells whose genetic material is not enclosed by a membrane
• Two Domains are prokaryotes – Bacteria and Archaea
No time to cover this in detail, but this tree is based on ribosomal gene sequences – see www.ncbi.nlm.nih.gov/ pmc/articles/PMC2786576/

In practice, prokaryotes often means bacteria – with less known about archaeal cells
Bacteria too often means a single bacterial species Escherichia coli
• E. coli acts here as a “model” – and is the most studied bacterial species

There are however many thousands of different bacterial species – maybe millions of species (see Gans et al., 2005 Science vol 309 p 1387)
• By focusing on E. coli, we therefore miss differences in transcription and translation processes in other prokaryotes
Even for E. coli, these processes are complex • We also still lack the full story of these processes for
this species
Before considering these processes though, we’ll next focus on E. coli and then its genome.

Escherichia coli
A bacterial species “normal” in the human intestine (c. 0.1% of the total # of cells)
This is E. coli growing in the lab on selective agar in a Petri dish • Colonies form over time from initially individual cells Individual cells can only be seen microscopically (1x3um)
Certain strains can cause infection – 40,000 cases in
England last year.

Like other bacterial species, E. coli has a complex genome
• E. coli has c. 4,300 genes per cell www.ncbi.nlm.nih.gov/pubmed/9278503
Implications? • From evolutionary fitness arguments, each gene
would be lost from the genome if it was never used • This infers that these 4,300 genes are not just
carried, but are also needed at some time point • We also know that some genes need to be
expressed at different time points
Combining these points, it also suggests that the process of gene expression must be controlled.

“Correct”, rapid and controlled gene expression is important
For bacterial cell survival • Expressing the correct genes at the right time is critical
for the survival of a single “exposed” cell • This means the timing of gene expression must be well
coordinated (e.g. to avoid wasting resource etc)
For bacterial cell division • More than survival though, the “goal” for any bacterial
cell is to grow and divide into daughter cells • Process must also be accurate and rapid (... can be
every 20 minutes) to exploit the nutrients surrounding a single bacterial cell
One scenario where this is important is in infection.

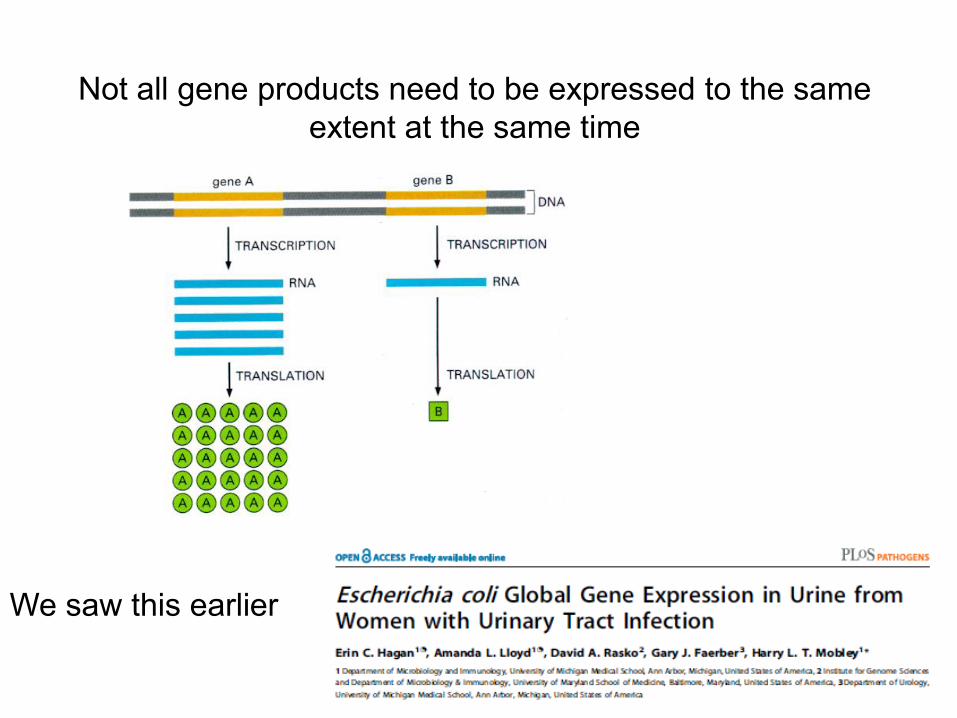
We can determine what genes E. coli is expressing in infections e.g. here in urinary tract infections (UTI)
this article from 2010 found that
iron acquisition and peptide transport
By knowing this information, we may develop strategies on

Transcription is a multistep process
These steps are – Initiation – Elongation – Termination
The key to transcription is RNA polymerase (RNAP) So, we’ll look into RNAP now in more detail.

DNA dependent RNA Polymerase (RNAP) Function – RNAP synthesises RNA In bacteria, one RNAP makes all RNA – mRNA, ncRNA • except primer RNA Okazaki fragments which are made
by primase at DNA replication • contrasts to eukaryote cells that have three nuclear RNA
polymerases and a mitochondrial RNA polymerase • each bacterial cell has c. 2,000 RNAP molecules
Each complete bacterial RNAP has six subunits • two identical (alpha) subunits • one (beta) subunit • one ’ (beta prime) subunit • one w (omega) subunit • one (sigma) subunit.

When fully assembled, the bacterial RNA polymerase (RNAP) multisubunit structure is called the holoenzyme
• This has a molecular weight of >400,000 kDa • one of the biggest enzymes in the bacterial cell. With no (sigma) subunit, the structure is known as the
core polymerase
A lot of effort has been put into characterising the 3D structure of these two forms of RNAP
• Structure then links to models of function of RNAP first the core polymerase.


RNA Polymerase (RNAP) holoenzyme
This now shows the positioning of the sigma subunit that we’ll use in a few slides time
So, what’s known about the functions of the different subunits?

Functions of RNAP subunits – part I The identical alpha subunits are 329 amino acids (aa) in
size and are encoded by the rpoA gene • The alpha subunits are thought to be needed for
assembly of the enzyme and transcriptional regulation – may have roles in catalysis (polymerase activity) too
• The beta subunit is 1342 aa in size (rpoB) has roles in catalysis
• The beta' subunit 1407 aa (rpoC) can bind to DNA and also has roles in catalysis
Alpha subunit I interacts with the beta subunit, and alpha subunit II interacts with 15-45Pand

Promoter regions typically have two common features • One feature, called the -35 sequence, is six bases in
size and occurs 35 bases upstream of the transcription starting point.
• A second feature, the -10 sequence (or TATA or Pribnow box), is analogously 10 bases before the transcription starting point. Transcription starts at a base shortly downstream of this Pribnow box
Promoter DNA also binds to different domains of sigma factor
• Sigma factor domain 4 (tied to the beta subunit) binds to the -35 promoter sequence
• Sigma factor domain 2 (tied to the beta’ pincer) binds to the -10 promoter sequence
How variable are these sequences though?

The short answer is that sequence content at the “-10 sequence” and the “-35 sequence” has some similarity but are not identical
• Also the spacing between the -35 and -10 sequence features can differ too
The following is an example of this for five of the 4,300
genes (rrnB, trp, lac, recA and araB) in the E. coli genome.

Consensus rrnB trp lac recA araB
Promoter regions of different genes Transcription
starts here
Note the sequence differences at the -35 and -10 regions and also variations in the gap sizes.

Despite this variation, “consensus sequences” as we’ve seen have been defined for sigma factors
• For sigma 70 for example, the -35 sequence has been defined as TTGACA and the -10 sequence has been defined as TATAAT
Sigma 70 binding to both sequence regions is necessary for transcription of the vast majority of housekeeping genes – for “routine” cell growth
Other sigma subunit types are however present in the same bacterial cell
Depending on which of these sigma factors is attached, the holoenzyme RNAP recognises different promoters
So, why is this important?

Specialist sigma factors control subsets of genes required for growth under “non-routine” conditions
Different sets of genes have promoters with recognition sequence features that allow specific sigma factors to bind This specificity importantly allows a bacterial cell to respond to a specific situation at a given time • For example, in periods of stress, some e.g. σS can to a degree “take over” from the usual vegetative σ70

There can be extra complexity This complexity includes an additional binding site for the
alpha subunit at - 57 to – 38 upstream of the start site. This enhances how strong the binding of RNAP is.
• Other upstream promoter elements contact RNAP and can influence transcription too
Also, transcription factors can bind directly to RNAP and/ or promoter DNA and as such regulate mRNA output from specific promoters
• For example, anti-sigma factors are proteins that “cover” sigma subunit surfaces so affecting transcription
Clearly complex – see this article for detail if interested http://www.nature.com/nrmicro/journal/v6/n7/full/nrmicro1912.html#f1

So far, we’ve concentrated on the components that are needed for this process to occur
This process is dynamic though and has as before three
phases • Initiation • Elongation • Termination
We can now start with initiation.
Process of transcription

Initiation – the process Sigma factor binds to the core polymerase with the
holoenzyme RNAP recognising and binding to DS DNA at promoter sites
• As before, sigma factor domain 2 binds to the -10 sequence • sigma factor domain 4 recognises the -35 sequence As this binding occurs with the DNA still double stranded and
as such “closed”, this is known as a closed complex
The beta’ pincer then closes around the DNA & forms a channel and active site around the template strand of the DNA
This allows the sigma factor domain 2 to separate the strands of DNA at the −10 region
• Note the DNA strands separate without needing additional helicases.

As the strands of DNA at the −10 region of the promoter are “open”, this is now called an open complex
• The +1 nucleotide of the template strand is held in the active-site channel, where mRNA will form
Ribonucleoside triphosphates then enter • A complementary ribonucleoside triphosphate
(normally ATP or GTP) to the exposed base (usually T or C) enters
• A second ribonucleoside triphosphate enters – if this can base pair with the next (+2) nucleotide of the template strand, a phosphodiester bond forms between it and the first nucleotide
This is called the initiation complex

When the RNA chain grows to around 10 nucleotides, it meets a physical block preventing the newly made mRNA leaving through the exit channel
• This is a loop (the 3.2 loop) of the sigma subunit This steric block typically causes transcription to stop
often with the release of the 10 nucleotide chain of mRNA.
• This is called abortive initiation
For some unclear reason, a growing mRNA chain will make it past the sigma 3.2 loop however
• This causes the release of the sigma factor – termed promoter escape
• The transcription bubble now enlarges to 17 bases and the enzyme moves along the DNA template.

We can cover this dynamic process again
Starts then with the binding of the holoenzyme as we’ve just seen
An RNA polymerase-promoter intermediate complex is formed, with the beta’ subunit closed around DS DNA to form a channel

The DNA double helix is opened by the RNA polymerase at positions −11 to +3 (relative to transcription start)
This forms a RNA Polymerase-promoter open complex – this is often called the transcription “bubble”

As before, there is a transient unwinding of the DS DNA. This exposes bases which are then copied into the RNA complement by the RNA polymerase

It was thought that after a short stretch of RNA (8-12 bases) has been generated, the sigma subunit dissociates
True, but the detail is more complex with a series of short transcripts generated (abortive initiation)
The sigma factor will only release from the RNAP once a growing 12nt transcript has moved a specific feature on it (the sigma 3.2 loop) aside; mRNA then enters the exit channel.

When this happens, the sigma factor leaves the core polymerase to finish the process. 42
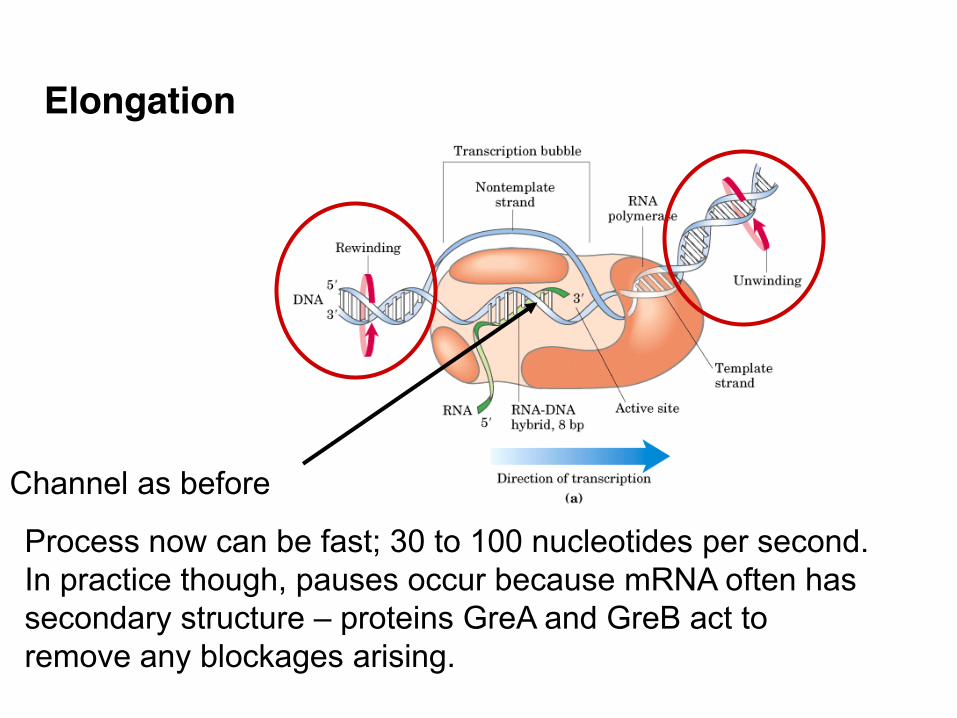
Elongation
Channel as before
Process now can be fast; 30 to 100 nucleotides per second. In practice though, pauses occur because mRNA often has secondary structure – proteins GreA and GreB act to remove any blockages arising.

Elongation uses the same basic chemistry as DNA synthesis • RNAn + NTP RNAn+1 + PPi
Existing chain New nucleotide Extended chain Pyrophosphate Overall

Termination Once RNA polymerase has initiated transcription,
polymerisation occurs, often with pauses, until it finds a termination site in the DNA
Two forms of termination have been recognised. • Factor independent termination • Factor dependent termination
The difference here is whether they operate with just RNAP and DNA or need additional factors
Both termination forms need the newly transcribed mRNA to promote termination
• This means that RNA polymerase must transcribe the terminator region before termination can occur.
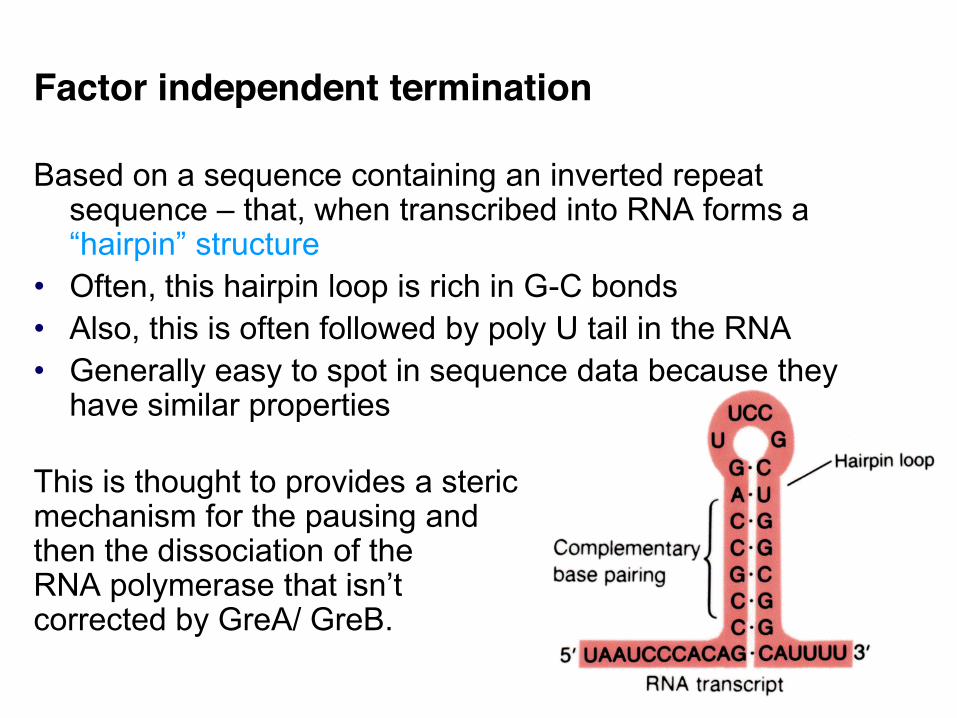
Factor independent termination Based on a sequence containing an inverted repeat
sequence – that, when transcribed into RNA forms a “hairpin” structure
• Often, this hairpin loop is rich in G-C bonds • Also, this is often followed by poly U tail in the RNA • Generally easy to spot in sequence data because they
have similar properties This is thought to provides a steric mechanism for the pausing and then the dissociation of the RNA polymerase that isn’t corrected by GreA/ GreB.

Factor dependent termination There is little or no similar features in terms of termination sequence in factor dependent termination • this makes generalisation hard
E. coli has at least three transcription termination factors called Tau, NusA and Rho. • Of these, most is known about the Rho protein which seems to be present in many bacterial species • This is thought to bind to a Rho utilising site in the RNA • Through RNA:DNA helicase activity and at the cost of ATP, it causes dissociation of RNA from DNA.

Transcriptional process control “Control over gene expression is exerted mainly at the
level of transcription. RNAP is the vital enzyme in transcription and therefore the main target of transcriptional regulation”. Finn et al. (2000)
Control of this process is critical for the cell to both survive and grow effectively.
This makes sense as we know that there is a lack of separation of transcriptional and translational processes in bacteria

In the “real” context of bacterial gene expression, there are other factors that need to be considered however
• Bacterial genes are expressed depending on the environment of the cell
As such, not all genes are expressed at the same time
This Gene Chip shows the expression level of different bacterial genes within the E. coli genome, with each spot representing one gene of the 4,300 in the cell.
An enlarged section shows some genes but not others expressed
Affymetrix E. coli Gene Chip Global RNA expression
50
Not all gene products need to be expressed to the same extent at the same time
We saw this earlier

So far, we’ve assumed that each bacterial gene is effectively independent
• That is, that one promoter controls one gene • However, as before, there are thousands more genes
present within a bacterial genome than promoters
How does this work? • Need now to introduce briefly operons
An operon can be defined as a cluster of coordinately regulated genes transcribed from one promoter.
An operon contains: • Structural genes: encoding e.g. enzymes • Regulatory genes: encode transcriptional repressors or
activators of expression • Regulatory sites: e.g. promoter regions, operators.

The E. coli genome has approximately 600 operons containing two or more structural genes • Typically, one operon generates a single mRNA
transcript for the structural genes (polycistronic – more than one protein).
The traditional view is that the structural genes within an operon were functionally related • Recent evidence challenges this to some extent, but for most operons there is a link between the expression of their structural genes and a task the cell needs
With the mRNA formed, now need to move to translation.

Translation
Four parts to cover; 1 Amino acid activation
2 Translation initiation
3 Translation elongation 4 Translation termination

We’ve seen how mRNA, the template code, is made Now need to return to the two other forms of RNA in the
bacterial cell; rRNA and tRNA • Transfer RNA – the adaptor molecule • Ribosomal RNA – which has positional and catalytic
roles rRNA and tRNA make up c. 95% of all bacterial cellular
RNA • Bacterial rRNA and tRNA is also relatively stable
though bacterial mRNA half life is on average is 1 to 3 minutes
First focus then is on tRNA in relation to translating this
newly synthesised mRNA.

Transfer RNA tRNA is the adaptor molecule that allows the genetic
code to be translated into an amino acid sequence tRNA molecules are important for two main reasons: • Firstly, they have an anticodon region that base
pairs with the codon of the mRNA • Secondly, they also are specific for the corresponding
amino acid
In structural terms • They are short – between 73 and 93 nucleotides in
length and have conserved and variable regions • tRNA molecules are a single strand, however they
as RNA have regions of secondary and tertiary structure as follows.

tRNA – secondary structure
Variable loop
“Cloverleaf” structure with two most important regions
These names emerge from either the bases there or the functions
DHU or D loop
Acceptor arm
TyC loop with unusual bases e.g. pseudo-uracil

Alexander Rich and Aaron Klug determined the 3-D structure of yeast Phe-tRNA by X-Ray crystallography in 1974
tRNA – tertiary structure
In bacterial cells, this forms a 3D “L shape”.
is actually

Background to tRNA function 3’ end of tRNA has conserved CCA sequence • Attachment site of amino acid Aminoacyl-tRNA synthetase specific for each tRNA • First step is formation of aminoacyl-AMP intermediate
(activated) via ATP The formation of aminoacyl-tRNA – tRNA is “charged” • Aminoactyl-tRNA synthetase have ability to “edit” the
amino acid – checking that correct one has been added
• This is important as chemically similar amino acids can become mis-incorporated
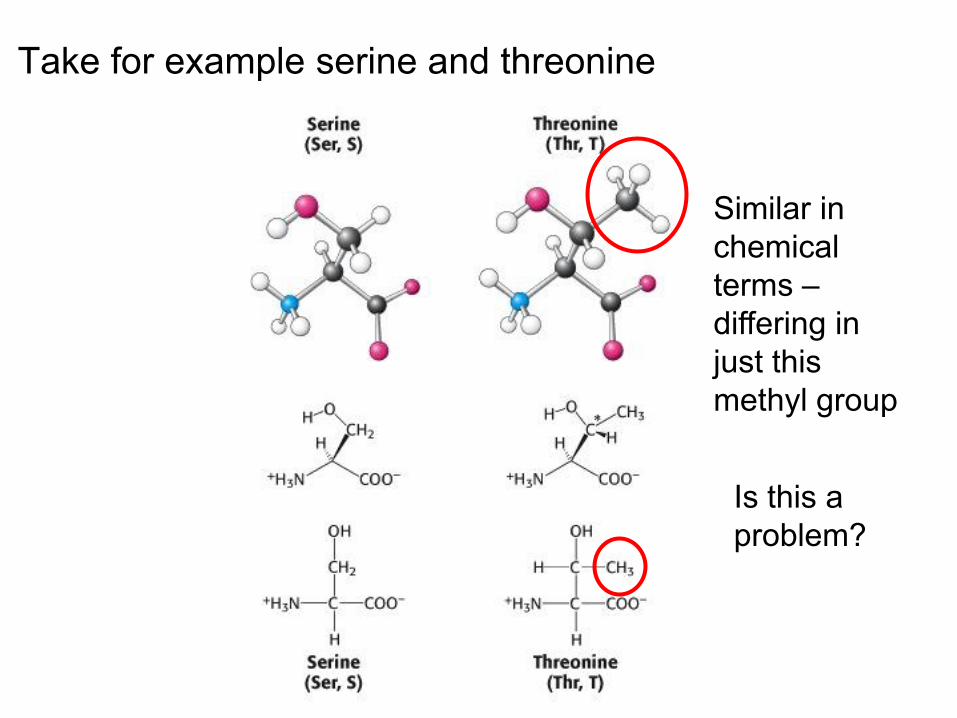
Take for example serine and threonine
Similar in chemical terms – differing in just this methyl group
Is this a problem?

rapid hydrolysis solves this problem
threonine + tRNAthr threonine-tRNAthr serine + tRNAthr serine-tRNAthr serine + tRNAthr
threonine activating enzyme
... Yes, but if misincorporated, this can be edited
Here, assume serine insertion is “wrong”; there are two options

Most synthetases have an ability to edit and so increase specificity
• This increased specificity is important as the next step – protein synthesis – only recognises the anticodon only of the charged tRNA and cannot tell whether it is adding the correct amino acid to the peptide chain
• As such, only tRNA molecules truly “know” the genetic code as they see the codon and have a bound amino acid
So, by now, we’ve got mRNA and aminoacyltRNAs

ribosomes Aminoacyl-tRNAs + mRNA proteins (lots of energy, etc..) E. coli has between 3,000-20,000 ribosomes/ cell with
this number highly regulated 20,000 ribosomes represents c. 25% of the mass of an individual bacterial cell This makes bacterial cells very efficient at making proteins (E. coli and certain bacterial species can double in number every 20 minutes) So what are ribosomes?
The next key requirement is for ribosomes

Ribosomes Ribosomes are the site of protein synthesis • Ribosomes are again complex in structure In bacteria, the ribosome is formed from two subunits – the
30S and 50S subunits which come together to form the overall 70S subunit
• These “S” values refer to the unit named after Svedberg who led the way in how to measure these subunits originally
Post initiation, the primary role of the 30S subunit is to select the correct aa-tRNA for each codon while the 50S subunit forms peptide bonds and translocates the tRNAs from one site to another
The following slide shows the RNAs and proteins that form a ribosome and its subunits.

The Prokaryotic Ribosome
Even here, in this well known system, there could well be other more transiently associated proteins

RNA forms most of the ribosome and provides the catalytic function of joining new amino acids to a growing chain • This peptidyltransferase function is carried out by the 23S rRNA and not a ribosomal protein The next slide shows the secondary structure of one of the rRNAs in the ribosome – the 16S rRNA.
X-ray crystalography – complex structures
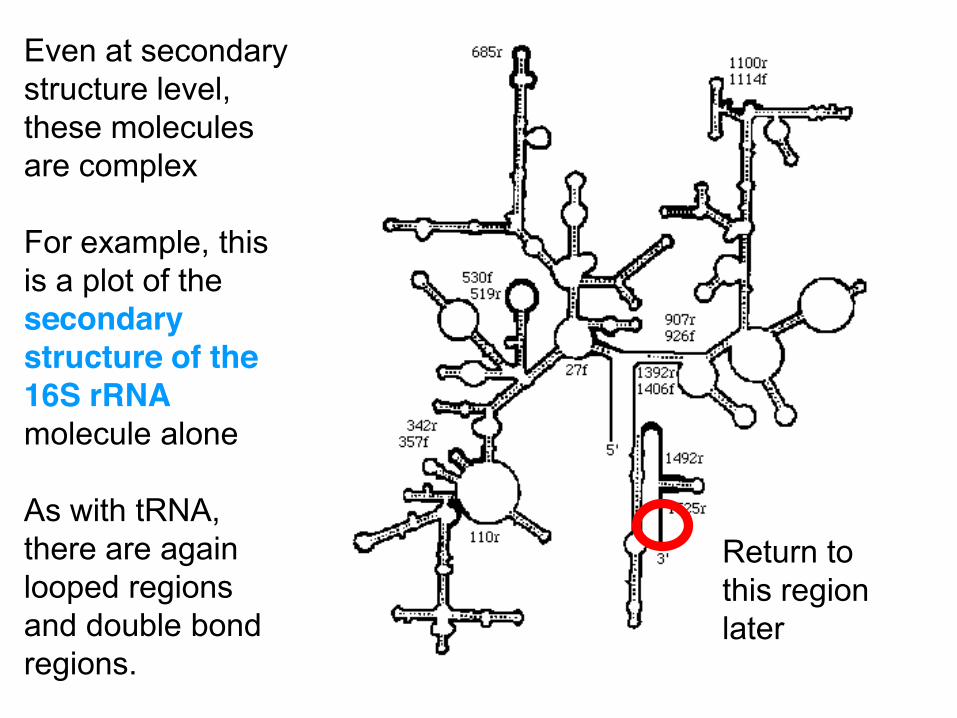
Even at secondary structure level, these molecules are complex For example, this is a plot of the secondary structure of the 16S rRNA molecule alone As with tRNA, there are again looped regions and double bond regions.
Return to this region later

Protein Synthesis/Translation Overview
• Amino acid activation • Translation initiation • Translation elongation • Translation termination Before these steps, two slides with a simple but
important overview of the process.

Process restarts
“Ribosome cycling” Process ends
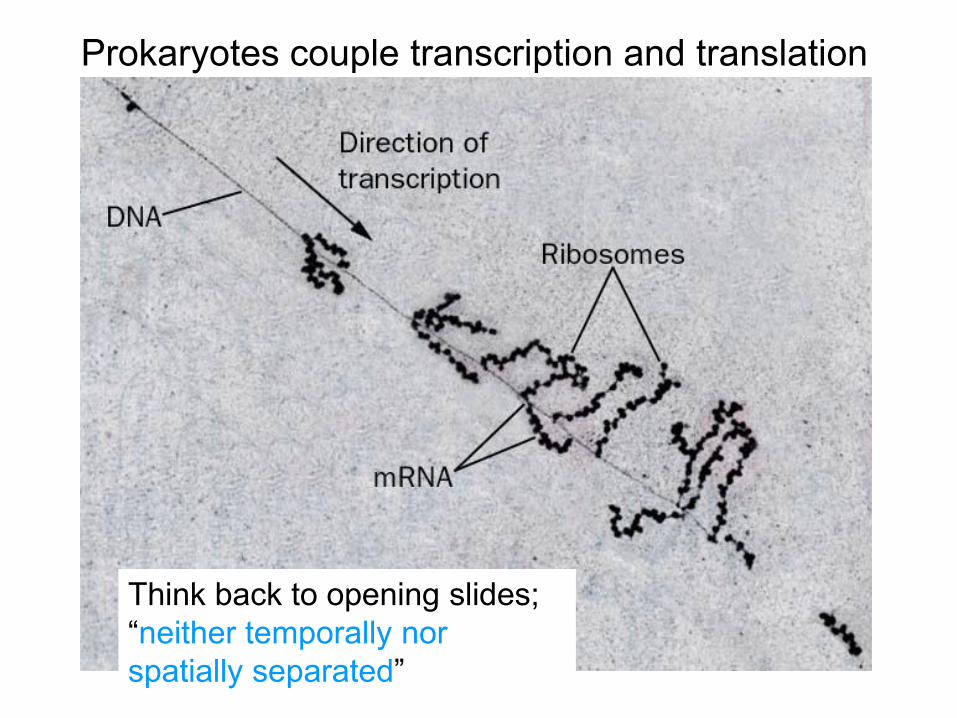
Prokaryotes couple transcription and translation
Think back to opening slides; “neither temporally nor spatially separated”

Protein Synthesis/Translation
• Translation initiation • Translation elongation • Translation termination In translation, the ribosome moves along the mRNA and
has three important sites A (aminoacyl) site – this is where after initiation each
“new” aminoacyl-tRNA attaches P (peptidyl) site – where the peptide bonds are formed E (exit) site – where tRNA leaves the ribosome.
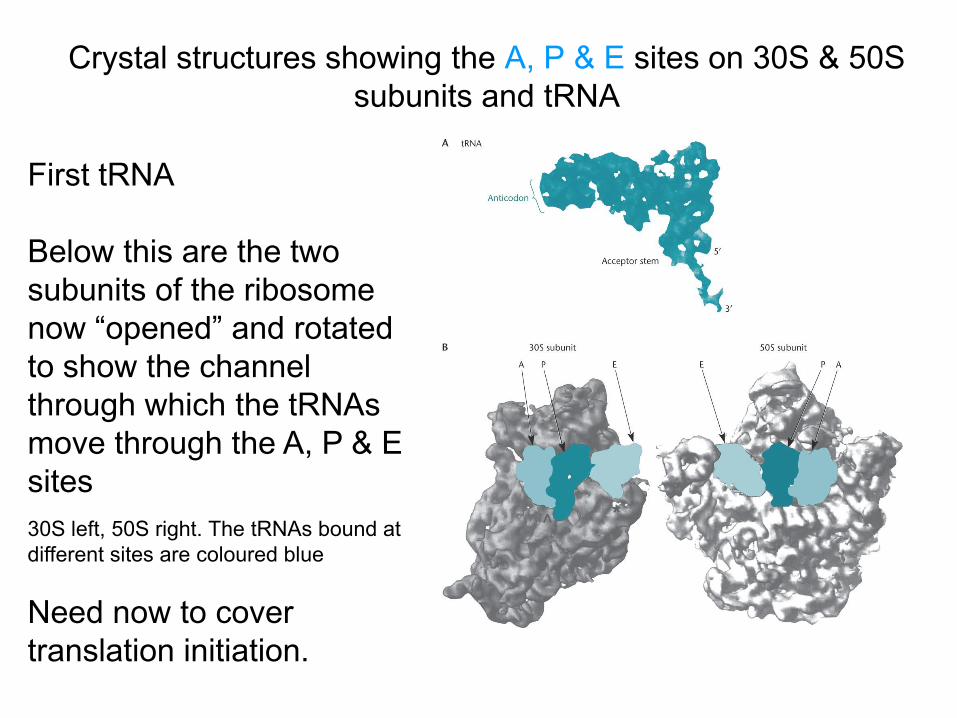
Crystal structures showing the A, P & E sites on 30S & 50S subunits and tRNA
First tRNA Below this are the two subunits of the ribosome now “opened” and rotated to show the channel through which the tRNAs move through the A, P & E sites
30S left, 50S right. The tRNAs bound at different sites are coloured blue
Need now to cover translation initiation.

Translation Initiation For translation, a pre-initiation complex is formed
involving a 30S subunit, the mRNA, formylmethionine tRNA, initiation factors (IF1-3) and GTP
Initially, IF3 binds to the 30S subunit to prevent it associating with the 50S subunit
Initiation always begins with formylmethionine tRNA binding to the initiation codon, usually AUG, of the mRNA strand
• Upstream of this AUG is a stretch of 3-10 nucleotides at the 5’ end of the mRNA that bind it to the ribosome (ribosome binding site or Shine–Dalgarno sequence)
• The reason this “works” is that these 3-10 nucleotides on the mRNA are complementary to a conserved 3’ end of the 16S rRNA molecule in the 30S subunit – as in the red region highlighted before
This Shine Dalgarno sequence now in more detail.

Shine-Dalgarno sequences position the ribosome at the correct start site • Note the variation here in the Shine Dalgarno regions (and also in one example at the start codon).
Start
Shine-Dalgarno sequences in four E. coli mRNA
and initiation codon
30S ribosomal subunit
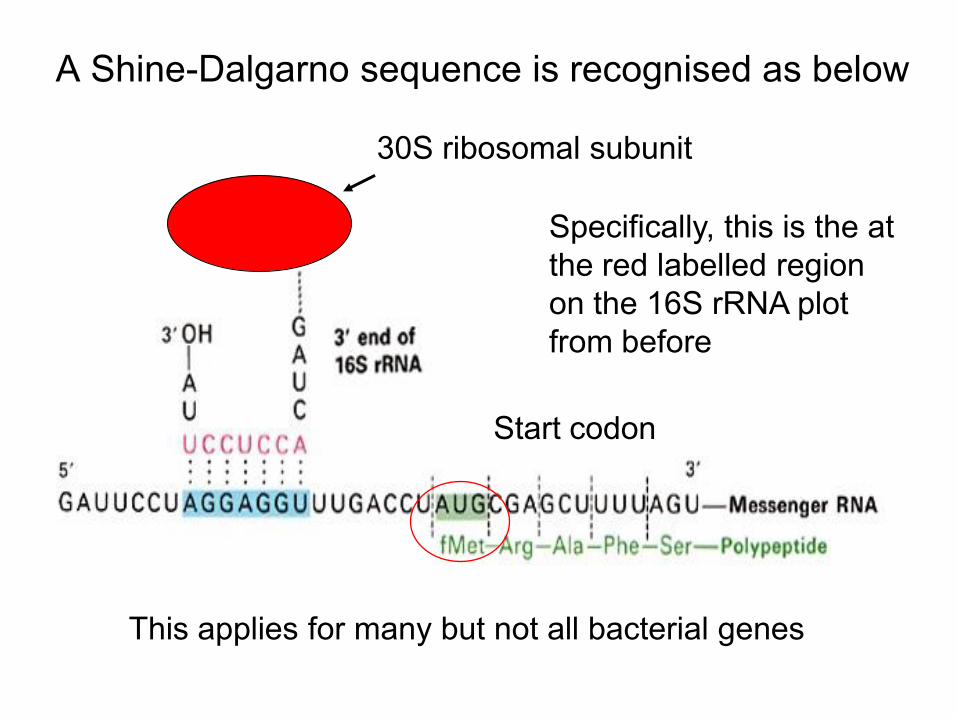
A Shine-Dalgarno sequence is recognised as below
This applies for many but not all bacterial genes
Specifically, this is the at the red labelled region on the 16S rRNA plot from before
Start codon

Translation Initiation 2 From before, we had a pre-initiation complex formed
involving a 30S subunit, the mRNA, formylmethionine tRNA, initiation factors (IF1-3) and GTP
Normally, the A (aminoacyl) site is where each new aminoacyl-tRNA attaches
At initiation though, the fMet tRNA binds to the P (peptidyl) site with initiation factor 1 so blocking the A site
All this is done in the context of correctly positioning the mRNA (e.g. Shine Dalgarno), with the mRNA, the fMet and Initiation factor 2 also bound to the P site
We can put this together in the following diagram.

IF3 keeps 30S from binding a 50S subunit IF1 blocks the A site fMettRNA and mRNA bind with IF2
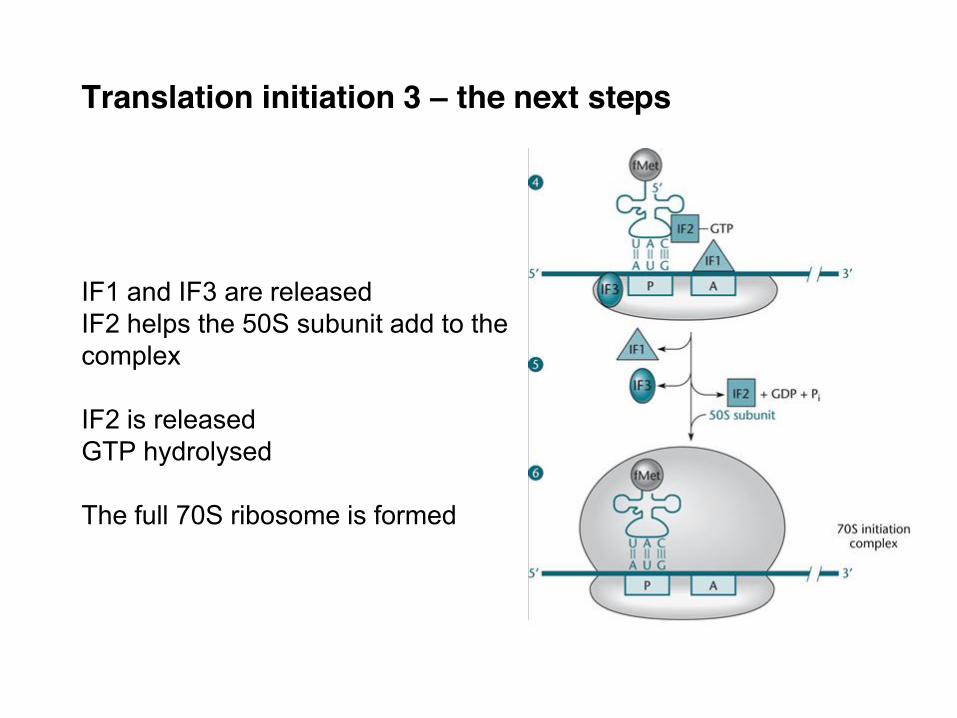
Translation initiation 3 – the next steps IF1 and IF3 are released IF2 helps the 50S subunit add to the complex IF2 is released GTP hydrolysed The full 70S ribosome is formed

mRNA added
fMet tRNA bound
50S added
This less detailed view of initiation is also helpful.
Important to note that the exit channel for the growing amino acid chain is not the E site

Translation elongation After initiation, the normal roles of the different sites are
as follows At the A (aminoacyl) site – this is where each “new”
aminoacyl-tRNA attaches • This is assisted by EF-Tu (Elongation Factor Thermo
unstable) • The aa-tRNA anticodon is checked for
complementarity to the mRNA codon with only those that are correct retained
At the P (peptidyl) site –peptide bonds are formed • Translocation occurs to push the now tRNA (n.b. not
aminoacyl-tRNA) to the E site
With that, the “empty” tRNA leaves through the E (exit) site
We can see this now schematically.
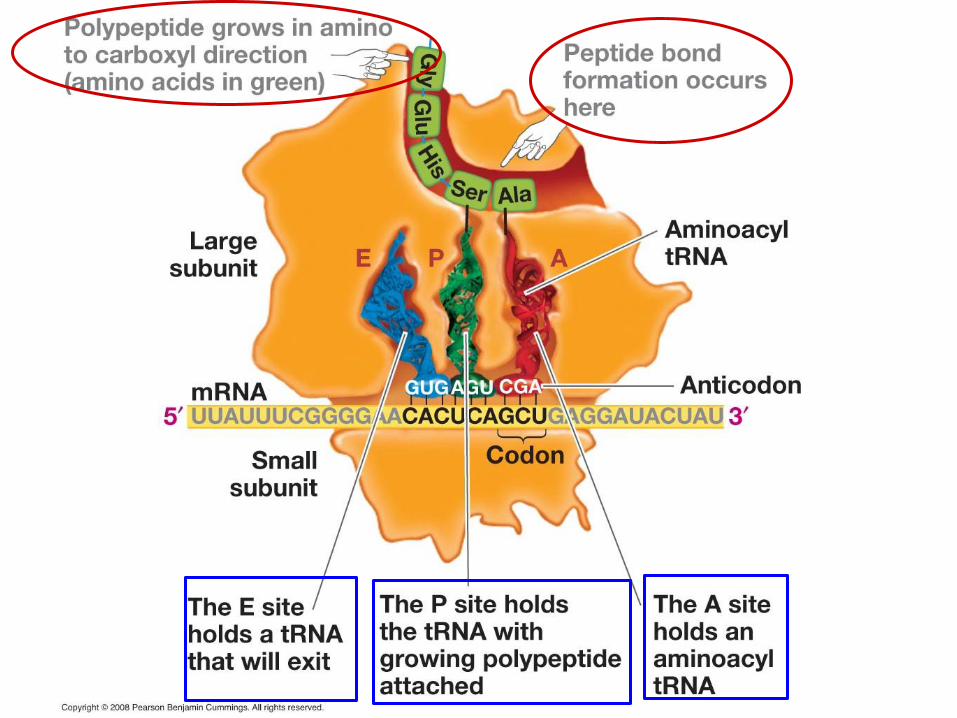

The polypeptide chain being synthesised passes out through a channel running through the 50S subunit
This channel is long enough to hold a chain of about 70 amino acids • most bacterial genes are 1kb DNA so 333 amino acids
So a polypeptide of this length must be synthesised before the N-terminal end of a protein first emerges from the ribosome.

Schematically, we had at the start of elongation
This is a dynamic process though

This is repeated until termination occurs
Entry of aa-tRNA Bond formation
EF-G catalyzes translocation of the A site tRNA to the P site, freeing the A site for another aa-tRNA
Exit of tRNA

Termination and Peptide Release
• Occurs when one of three stop codons: UAG, UAA, UGA is reached
• Release factors (RF1, RF2, RF3) bind to stop codons in the “A” site – RF1 responds to UAA and UAG – RF2 responds to UAA and UGA – RF3 releases RF1 and RF2 from the ribosome
• These factors cleave the last aa-tRNA bond • This causes the release of tRNA, mRNA, protein and
dissociation of the ribosome back to 30S and 50S subunits
This allows the process to begin again.

1. Amino acid activation aminoacyl-tRNA synthetase 1-20 amino acids1-20 + transfer RNA 1-20 ----------> aminoacyl-tRNA 1-20 ATP 2. Translation initiation ribosomes mRNA + formylmethionine-tRNAfmet --------> initiation complex Initiation Factors (IF), GTP 3. Translation elongation ribosomes, mRNA aminoacyl-tRNA1-20 -----------> growing polypeptide chain Elongation Factors (EF), GTP 4. Translation termination mRNA (stop codon) -------------> release completed polypeptide Release Factors (RF)
Protein synthesis/translation summary
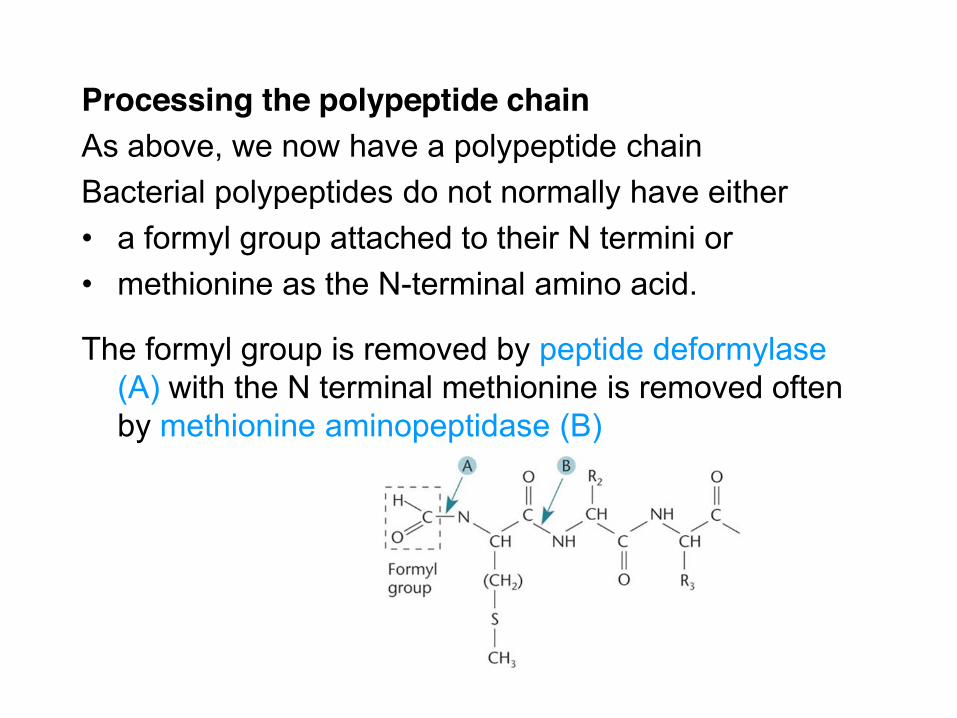
Processing the polypeptide chain As above, we now have a polypeptide chain Bacterial polypeptides do not normally have either • a formyl group attached to their N termini or • methionine as the N-terminal amino acid.
The formyl group is removed by peptide deformylase (A) with the N terminal methionine is removed often by methionine aminopeptidase (B)

Protein folding
So far, a chain of polypeptides has been created.
To be an active protein, this needs to be folded into its final confirmation – this is typically the most stable state
This would happen “eventually”, but special proteins called chaperones are important in the protein achieving this state quickly • Remember the importance for the bacterial cell to respond quickly to different environments Of these, the Hsp70 family of chaperones is the most important.

Active proteins
The last stages in the process include the correct positioning of the proteins This is primarily important for membrane proteins and those proteins that are to be secreted Again, there is a series of helper proteins e.g. the Sec system proteins that are involved in these processes The end point is a fully active protein located where needed by the bacterial cell.

Thus, the transcription elongation rate remains under
tight translational control throughout bacterial growth. This shows that its more than just no separation of
processes but in fact a cooperation between the processes of transcription and translation.
Some recent work shows just how linked the processes outlined today are We’ve said there is no separation of transcription and translation This paper had the following quote

For interest, both transcription and translation are important targets for antibacterial activity
More known on the latter as the following slide shows.
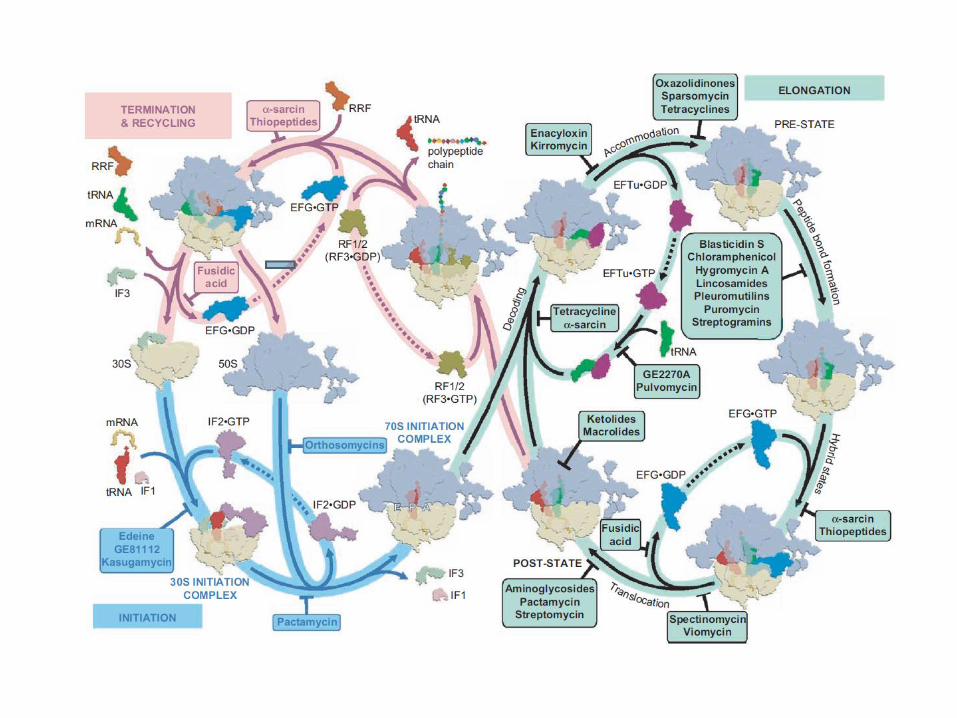

Knowing more about both processes may give new targets that are needed now http://antibiotic-action.com/
Information sources Many sources used – most from “Molecular Genetics of
Bacteria” (Snyder et al. 4th edition American Society for Microbiology Press 2013)
This updated as relevant from more recent sources This information together with the slides used here will be
on the course web pages soon Finally, today’s learning objectives are as follows.

Objectives
The main aim was to consider the processes of transcription and translation for prokaryotes
To be able to discuss 1. The context/ importance of transcription and
translation 2. The use of the species Escherichia coli as a model
system 3. The requirements and process for transcription 4. Points related to transcription and operons 5. The requirements and process for translation 6. The process of turning a chain of polypeptides into a
protein.
























