
Version 1.0, mars 2015 CLASSIFICATION INITIALE DE...
26
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 28 Version 1.0, mars 2015 CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE Classificaon iniale de la végétaon par analyse d’image Chapitre 3 P29: Introducon P30: Sélecon d’images satellite P31: Prétraitement et amélioraon radiométrique d’images satellite P33: Indices de végétaon P34: Analyse en composante principale P35: Sélecon d’une combinaison de bandes pour la classificaon P36: Déterminer le nombre et le type de classes P38: Méthodes de classificaon P39: Classificaon non-supervisée P40: Classificaon supervisée P43: Classificaon visuelle P44: Évaluaon de l’exactude de l’image classée P46: Test stasque de l’indice K hat P47: Contrôle qualité, finaliser la classificaon iniale de l’occupaon des sols, et étapes suivantes P48: Appendice A : Revue des opons d’images satellite P53: Appendice B : Espace indiciel transformé (Tasseled Cap Transformaon) Par Sapta Ananda Proklamasi, Greenpeace Indonésie ; Moe Myint, Mapping and Natural Resources Informaon Integraon ; Ihwan Rafina, TFT ; et Tri A. Sugiyanto, PT SMART/TFT. Les auteurs ennent à remercier Ario Bhriowo, TFT ; Yves Laumonier, CIFOR ; Arturo Sanchez-Asofeifa, Université d’Alberta ; Chue Poh Tan, ETH-Zurich et leurs collègues du World Resources Instute pour leurs précieux commentaires sur les versions précédentes de ce chapitre. SOMMAIRE
Transcript of Version 1.0, mars 2015 CLASSIFICATION INITIALE DE...

GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 28
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Classification initiale de la végétation par analyse d’image
Chapitre 3
P29: Introduction
P30: Sélection d’images satellite
P31: Prétraitement et amélioration radiométrique d’images satellite
P33: Indices de végétation
P34: Analyse en composante principale
P35: Sélection d’une combinaison de bandes pour la classification
P36: Déterminer le nombre et le type de classes
P38: Méthodes de classification
P39: Classification non-supervisée
P40: Classification supervisée
P43: Classification visuelle
P44: Évaluation de l’exactitude de l’image classée
P46: Test statistique de l’indice Khat
P47: Contrôle qualité, finaliser la classification initiale de l’occupation des sols, et étapes suivantes
P48: Appendice A : Revue des options d’images satellite
P53: Appendice B : Espace indiciel transformé (Tasseled Cap Transformation)
Par Sapta Ananda Proklamasi, Greenpeace Indonésie ; Moe Myint, Mapping and Natural Resources Information Integration ; Ihwan Rafina, TFT ; et Tri A. Sugiyanto, PT SMART/TFT.
Les auteurs tiennent à remercier Ario Bhriowo, TFT ; Yves Laumonier, CIFOR ; Arturo Sanchez-Asofeifa, Université d’Alberta ; Chue Poh Tan, ETH-Zurich et leurs collègues du World Resources Institute pour leurs précieux commentaires sur les versions précédentes de ce chapitre.
SOMMAIRE

GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 29
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Introduction
« La méthodologie a été conçue pour être applicable à toute forêt tropicale humide établie sur sol minéral »
Le but de la première phase d’une évaluation HCS est de créer une carte indicative des zones de forêts HCS potentielles dans une concession et le paysage environnant, en utilisant une combinaison d’images satellite et de données de terrain. Ce chapitre se concentre sur la première étape de la Phase 1 : utiliser des images et des données pour une classification de la végétation en catégories uniformes. Nous guiderons le lecteur à travers la méthodologie pour cette première étape, y compris la sélection d’une banque d’images, comment déterminer le nombre de classes d’occupation des sols, et comment mener la classification elle-même.
La méthodologie présentée dans ce chapitre a été testée et affinée lors de tests de terrain dans des concessions en Indonésie, au Libéria et en Papouasie Nouvelle Guinée. Elle a été conçue pour être applicable à toute forêt tropicale humide établie sur un sol minéral. Par conséquent nous avons inclus des détails de variantes méthodologiques. Celles-ci pourront s’avérer nécessaires afin de résoudre tout problème éventuel lié à la qualité des images disponibles et aux types d’occupation et d’utilisation des sols dans différentes régions.
Les personnes ciblées par ce chapitre sont des experts techniques possédant une expérience en télédétection, qui peuvent utiliser ce document comme guide dans leur travail et créer une carte indicative des zones de forêts HCS potentielles sans aide supplémentaire. Bien que nous ayons fourni les références de guides plus détaillés lorsque cela semblait utile, nous supposons donc que le lecteur a un niveau de connaissances avancé des techniques d’analyse et de normalisation.
PHASE 1: ETAPES DU PROCESSUS
Stra�fica�on des images satellites en classes de végéta�on
Es�ma�on du carbone pour chaque classe
Mesures et collecte des données
Localisa�on des place�es
d’échan�llonnage
Analyse de parcelle HCS
(Arbre de décision)
RESULTATS: Forêts HCS
poten�elles iden�fiées
Conserva�on de la forêt HCS
PHASE 1: CLASSIFICATION DE
LA VÉGÉTATION POUR IDENTIFIER LES
ZONES DE FORÊTS
PHASE 2 : ANALYSE ET CONSERVATION DES PARCELLES DE FORÊT HCS

En-haut: USGS ©À gauche: Corozal Sustainable Future Initiative, Belize ©
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 30
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Sélection d’images satellite
La sélection des images satellite qui seront utilisées dans le processus de classification de la végétation devra assurer que celles-ci fournissent une couverture suffisante de la zone concernée, tout en favorisant les résolutions spatiales et temporelles les plus pertinentes à l’évaluation. En particulier:• Les images ne devraient pas dater de plus de 12 mois, et devraient avoir
une résolution minimum de 30 mètres.
• Les données devraient être d’une qualité suffisante pour permettre l’analyse, avec une couverture nuageuse de moins de 5% dans la zone d’intérêt (AOI), sans ou avec une présence très localisée et minimale de brumes.
• En considérant la disponibilité des bandes spectrales verte, rouge, proche infrarouge et infrarouge moyen, qui aident à déterminer le couvert végétal, ainsi que la vigueur et la densité de la végétation au sol.
L’utilisateur devra télécharger et évaluer plusieurs aperçus d’images géoréférencées avec leurs métadonnées provenant de plusieurs chemins et lignes satellites. Ceci aidera à définir la stratégie de sélection d’un échantillon d’images sans nuages. Dans ce but, l’utilisateur devra se procurer une ou plusieurs images satellite et créer un catalogue d’images multi-temporelles afin d’obtenir un sous-ensemble d’images de bonne qualité pour l’analyse dans l’AOI. L’acquisition d’images Landsat-8 multi-temporelles proches dans le temps (la prochaine visite ou deux visites suivantes du satellite au-dessus de la même zone) est recommandée. Pour éviter l’influence de l’angle solaire et des conditions atmosphériques d’images prises à différentes dates, chaque sous-ensemble d’images devrait être analysé et classé séparément.
Il existe plusieurs types d’images et de fournisseurs d’images présentant les informations visibles, infrarouges et micro-ondes appropriées. Le tableau en Appendice A présente différentes options de bases de données, leurs coûts et avantages respectifs, ainsi que de nouvelles technologies émergentes, telles que les drones. Noter qu’il n’est pas recommandé d’utiliser le satellite Landsat-7 pour l’analyse et la classification d’images après mai 2003, du fait des bandes résultant de l’erreur Scan Line Corrector Off depuis cette date. Bien que les bandes Landsat-7 SLC-off puissent être remplies, ceci ne devrait être utilisé que pour améliorer la visualisation et l’interprétation visuelle.
Une fois les images les plus appropriées sélectionnées, elles sont alors redimensionnées pour inclure seulement la zone d’intérêt (AOI). Puisque la classification est faite en utilisant des taux relatifs de couvert végétal et des calculs de stock de carbone dans un contexte paysager donné, l’AOI devrait inclure autant du paysage plus large autour de la concession que possible afin de classifier au mieux la forêt à l’intérieur de la concession. Par exemple, les parcelles de forêt présentes dans une concession très dégradée avec une présence minimale de zones HCS potentielles devront être comparées avec d’autres paysages forestiers plus larges en dehors de la concession afin de pouvoir les placer dans un contexte.
Au minimum une zone d’un kilomètre au-delà des limites de la concession est nécessaire afin de s’assurer que le couvert forestier dans le paysage est pris en compte. En pratique, le mieux serait d’inclure une proportion plus grande du paysage environnant, par exemple considérer l’ensemble du bassin hydrographique correspondant au bassin versant ou aux rivières de la zone d’intérêt.
Le rectangle contenant l’AOI pourra être créé et affiché sur USGS Earth Explorer afin de sélectionner les images à télécharger.

GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 31
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Réduction du bruit: Réduit la quantité de « bruits » dans une couche raster. La technique permet de préserver les détails subtils d’une image, tels que des lignes fines, tout en supprimant le bruit le long des contours et dans les zones planes.
Suppression du bruit périodique: Si un bruit périodique n’est pas dû à un problème lié au détecteur, mais plutôt à des conditions atmosphériques temporaires par exemple, le bruit peut être supprimé de l’image en procédant à une amélioration automatique de sa transformation de Fourier.
L’image de base est d’abord divisée en blocs de 128 par 128 pixels qui se chevauchent. La transformation de Fourier est alors calculée pour chaque bloc, et la moyenne des amplitudes logarithmiques de la Transformée de Fourier Rapide (TFR) pour chaque bloc calculée. Le calcul de la moyenne supprime toutes valeurs dans le domaine fréquentiel, à part celles présentes dans chaque bloc (par exemple, toute interférence périodique). Le spectre de puissance moyen est alors utilisé comme filtre pour ajuster la TFR de l’image entière. Lorsque la Transformation de Fourier inverse est calculée, l’image résultante devrait avoir tout bruit périodique supprimé ou considérablement réduit. La méthode ci-dessus est basée sur les algorithmes présentés dans Cannon, Lehar, et Preston (1983) et dans Srinivasan, Cannon et White (1988).
Le niveau de Fréquence minimum affectée devrait être réglé au plus haut possible afin d’obtenir le meilleur résultat. Une valeur faible aura un effet sur les fréquences plus basses de la transformée de Fourier qui représentent les caractéristiques globales de l’image telles que brillance et contraste, tandis qu’une valeur élevée affectera les fréquences correspondant au détail de l’image.
Remplacement de mauvaises lignes: Suppression de mauvaises lignes ou de colonnes dans l’image raster.
Histogrammes correspondants: Une fonction mathématique qui détermine une LUT afin de convertir l’histogramme d’une image donnée pour ressembler à l’histogramme d’une autre.
Conversion de brillance: Inverse la gamme d’intensité linéaire et non-linéaire, pour produire une image en négatif de l’image d’origine. Les détails sombres deviennent clairs et les détails clairs deviennent sombres.
Égalisation d’histogrammes: Applique un étirement de contraste non-linéaire qui redistribue la valeur des pixels pour avoir approximativement le même nombre de pixels de chaque valeur dans une plage donnée.
Normalisation topographique (Modèle de Lambert): Utilise la loi de Lambert pour réduire l’effet topographique dans une image numérique. L’effet topographique correspond à la différence d’illumination du fait uniquement de l’orientation de pente et d’aspects de terrain par rapport à l’altitude et l’angle d’azimut du soleil. Le résultat net est une image avec un niveau d’illumination plus uniforme. Les informations sur l’élévation et l’azimut du soleil nécessaire au processus de normalisation topographique sont disponibles au moment du téléchargement des métadonnées de l’image. L’analyste devrait choisir un modèle numérique de terrain (MNT) de bonne qualité comme donnée de base pour la normalisation topographique.
Prétraitement et amélioration radiométrique d’images satellite
Le processus de standardisation, mené avant l’analyse, est une étape ardue mais cruciale afin de garantir des résultats satisfaisants lors d’une classification de l’occupation des sols. La standardisation convertit des images provenant de sources multiples, prises à des dates différentes et sous des conditions atmosphériques variées, en un ensemble d’images aux propriétés similaires pouvant être utilisées conjointement. Ce processus peut aussi être désigné sous le terme de Correction Radiométrique avant traitement des données. Il est à noter que même après standardisation, certaines images sources peuvent garder certaines limitations, telles que les bandes dans les images Landsat post-2003 mentionnées précédemment.
Le processus de standardisation peut inclure plusieurs étapes de prétraitement des images. Quelques-unes des fonctions standard de prétraitement, basées sur le Système de traitement d’image Erdas Imagine sont décrites ci-dessous ; les autres systèmes standards de traitement d’image contiennent des fonctions similaires. Il n’est pas nécessaire de compléter toutes les procédures de prétraitement, correction radiométrique ou standardisation d’images décrites ici. L’analyste devrait évaluer la qualité des images et suivre un processus de prétraitement seulement si ceci est nécessaire pour améliorer la classification.
Extension de la dynamique : Transforme les valeurs des nombres numériques (DN) des pixels de l’image en utilisant une LUT (Look up table) d’étalement existante.
Remise à échelle: Remet à échelle les données de tout format bit d’entrée et de sortie. Le processus ajuste l’échelle de valeur en bit afin d’inclure l’ensemble du jeu de données, en préservant les valeurs relatives et en maintenant la forme de l’histogramme correspondant.
Réduction des brumes: Les effets atmosphériques peuvent être la cause d’une plage dynamique restreinte, qui se traduit par une apparence brumeuse ou un niveau de contraste faible. La réduction des brumes permet de rendre une image plus nette, en utilisant une transformation de l’espace indiciel (Tasseled Cap transformation) ou une convolution par dispersion des points. Le processus se base sur une transformation de l’espace indiciel pour les images multi spectres, car la transformation comporte un élément de corrélation avec les brumes d’une image. Cet élément de corrélation est alors supprimé pour retransformer l’image en un espace RGB. Pour les images panchromatiques, une rétro-convolution par dispersion des points est utilisée.

GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 32
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Indices de végétation
Les indices de végétation sont des mesures radiométriques sans unité, qui traduisent l’abondance et l’activité photosynthétique relatives de la végétation. Ils comprennent l’indice de surface foliaire (ISF), le pourcentage de couvert végétal, la biomasse verte chlorophyllienne et la radiation photosynthétiquement active absorbée (RPAA). D’après Running et al. (1994) et Huete et Justice (1999), un indice de végétation devrait :
• Maximiser la sensibilité des paramètres biophysiques des plantes, de préférence sur base d’une réponse linéaire, pour que cette sensibilité soit disponible pour une gamme variée de conditions de végétation, et pour faciliter la validation et le calibrage de l’indice ;
• Être normalisé sur des effets externes tels que l’angle solaire, l’angle de vue, et l’atmosphère pour une comparaison spatiale et temporelle cohérente ;
• Normaliser les effets internes tels que les variations de fond de la canopée, y compris la topographie (pente et orientation terrain), les variations pédologiques et de végétations âgée ou boisée (composantes non photosynthétiques de la canopée) ; et
• Être couplé à un paramètre biophysique mesurable spécifique tel que la biomasse, l’ISF ou la RPAA dans le cadre du processus de validation et de contrôle qualité.
De nombreux indices de végétation pourraient être utilisés pour une analyse HCS ; ce guide pratique HCS se concentre sur les indices NDVI et l’espace indiciel transformé de Kauth-Thomas, qui sont les indices recommandés pour l’approche HCS.
« Les indices de végétation sont des mesures radiométriques sans unité, qui traduisent l’abondance et l’activité photosynthétique relatives de la végétation »
Indice de végétation par différence normalisé (Normalised Difference Vegetation Index NDVI)
L’indice Simple Ratio (SR) fut le premier vrai indice de végétation ; comme l’ont décrit Birth et McVey (1968) il représente le ratio du flux radiant réfléchi rouge (Prouge) sur le flux de réflectance proche infrarouge (Ppir):
SR = Pred / Pnir
Le Simple Ratio fournit des informations importantes sur la biomasse végétale ou l’indice de surface foliaire (ISF) (Schlerf et al., 2005). Il est particulièrement sensible aux variations de biomasse et/ou de l’ISF dans les zones de végétation à haute biomasse telles que les forêts (Huete et al., 2002).
Rouse et al. (1974) ont développé l’indice NDVI générique comme un indicateur graphique qui peut être utilisé pour analyser le couvert végétal. L’indice NDVI est obtenu en calculant le ratio de (bande proche infrarouge- bande rouge) sur (bande proche infrarouge + bande rouge) :
NDVI = (Pnir – Pred) / (Pnir + Pred)Le résultat du calcul de l’indice NDVI est compris entre-1 et +1.
L’indice NDVI est équivalent en pratique au Simple Ratio : il en représente simplement une transformation non linéaire. Il n’y a pas de dispersion dans la représentation graphique du SR par rapport à celle de l’indice NDVI, et chaque valeur SR a une valeur NDVI correspondante fixe.
L’indice NDVI est un indice de végétation important car :
• Les variations de croissance et d’activité de la végétation d’une saison ou d’une année à l’autre peuvent être suivies.
• Il réduit plusieurs types de bruits (différences de luminosité solaire, ombres nuageuses, atténuation atmosphérique, et variations topographiques) présents dans l’imagerie multi temporelle à plusieurs bandes.
Cependant, l’indice NDVI a plusieurs désavantages que l’analyste devra considérer, y compris :
• Il est calculé sur base d’un ratio, il est non-linéaire et peut être influencé par des effets de bruit tels que la radiance du cheminement atmosphérique.
• Il est fortement corrélé avec l’ISF. Cependant cette corrélation serait plus faible lorsque l’ISF est à son maximum, du fait apparemment d’un effet de saturation de l’indice NDVI lorsque l’ISF est très élevé (Wang et al. 2005). La plage dynamique NDVI est donc plus étirée en conditions de biomasse faible et plus comprimée pour des régions forestières où la biomasse est plus élevée. Les forêts de forte et moyenne densité sont par conséquent difficiles à différencier sur base de l’indice NDVI. Le raisonnement contraire s’applique au Simple Ratio, dont la plus grande partie de la plage dynamique couvre les forêts de forte biomasse, avec très peu de variations dans les régions où la biomasse est plus faible (par ex. dans les prairies et les biomes arides et semi-arides).
• Il est très sensible aux variations en arrière-plan de la canopée, comme par exemple lorsque le sol est visible. Les valeurs du NDVI sont très élevées pour un arrière-plan plus sombre.

Photos: En-haut, Corozal Sustainable Future Initiative, Belize ©. Autres: TFT ©
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 33
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
L’espace indiciel transformé (Tasseled Cap Transformation) Kauth-Thomas
L’espace indiciel transformé (TC) est un indice de végétation global qui considère séparément la luminance du sol, la végétation et le taux d’humidité pour chaque pixel. Avec cette méthode, chaque image est transformée à l’aide de coefficients TC spécifiques au satellite utilisé pour obtenir un indice de végétation. Les valeurs TC sont générées en convertissant les bandes de départ d’une image en de nouvelles bandes dont l’interprétation est prédéfinie pour être utile à des fins de cartographie de la végétation. La première bande TC correspond au niveau de luminance général de l’image. Cette bande met particulièrement en évidence les zones urbaines. La seconde bande représente le niveau de « verdure » et est généralement utilisée comme indicateur d’une végétation photosynthétique active : plus il y a de biomasse dans un pixel donné, et plus ce pixel sera lumineux dans la représentation de la verdure.
La troisième bande TC est souvent interprétée comme un indice d’humidité (par exemple représentant le taux d’humidité dans le sol ou en surface) ou de jaunissement (par ex. quantité de végétation morte/sèche). Le quatrième paramètre TC correspond à la brume. Il est possible de calculer les coefficients TC selon les conditions locales, en utilisant l’algorithme et les méthodes mathématiques de Jackson (1983). L’Appendice B fournit les équations et coefficients nécessaires pour dériver les indices de Luminance, Verdure et Jaunissement à partir d’images Landsat MSS, Landsat TM, Landsat 7 ETM + et Landsat 8.
« L’espace indiciel transformé (TC) est un indice de végétation global qui considère séparément la luminance du sol, la végétation et le taux d’humidité pour chaque pixel. »

Photos: En-haut et à gauche, Corozal Sustainable Future Initiative, Belize ©. À droite, TFT ©.
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 34
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Une caractéristique importante des images composantes ACP provient du fait que la première composante image (PC1) comprend le plus grand pourcentage de la variance totale, qui va alors décroissant dans les images composantes suivantes (PC2, PC3, PC4….PCn). De plus, comme les composantes successives sont choisies orthogonales à toutes celles qui précèdent, les données qu’elles contiennent sont décorrélées.
Dans le cas du Landsat MSS, les deux premières composantes principales (PC1 et PC2) expliquent pratiquement toute la variance de l’image. On fait alors référence à la dimensionnalité intrinsèque du Landsat MSS comme étant 2. De la même manière, les trois premières composantes (PC1, PC2 et PC3) expliquent pratiquement l’entièreté de la variance des images Landsat TM, dont la dimensionnalité intrinsèque est 3. Ceci veut dire qu’à des fins de classification, les données provenant de Landsat TM, ETM+, Landsat 8 ou tout autre satellite similaire peuvent souvent se réduire en trois images composantes principales.
Le détail de la méthode statistique utilisée pour dériver la transformation en composante principale ne fait pas l’objet de ce guide pratique ; celle-ci est bien décrite en pages 60 à 65 du livre Classification Methods for Remotely Sensed Data (2001) par Brandt Tso et Paul M. Mather. Il est important de noter en conclusion que l’ACP devrait être menée à partir de bandes bleue, verte, rouge, proche infrarouge, infrarouge ondes courtes I et II de résolution spatiale similaire (par exemple Landsat 8), car toutes ces bandes contiennent des informations similaires redondantes sur la végétation et l’occupation des sols.
L’analyse en composante principales (ACP) est un autre outil général qui identifie les données redondantes et génère un nouvel ensemble d’informations qui regroupe les données corrélées. La taille des données résultant du regroupement en composantes principales est généralement réduite, ce qui a comme avantage d’accélérer le temps de traitement. Cependant, comme pour l’espace indiciel, les nouveaux axes définis par l’ACP ne sont pas spécifiés par l’analyste avant la définition de la matrice de transformation, mais plutôt dérivés de la matrice de variance-covariance ou de corrélation calculée à partir de l’analyse des données.
Une corrélation trop importante entre les bandes est un problème fréquent lors de l’analyse d’images multibandes ; en d’autres termes, les images générées à partir de données numériques tirées de bandes de différentes longueurs d’onde sont souvent similaires et comportent essentiellement la même information. Les transformations en composante principale et en composante canonique sont deux techniques qui permettent de réduire cette redondance dans les données multibandes. Ces transformations peuvent servir à améliorer les données avant une interprétation à l’œil nu, ou bien être mises en application comme technique de prétraitement avant une classification numérique des données. Dans le deuxième cas, ces transformations améliorent généralement l’efficacité des calculs et du processus de classification grâce à la réduction de la taille des données de départ. Le but de ces procédures est de comprimer toutes les informations contenues dans les données de la bande n de départ en de nouvelles bandes n moins nombreuses. Les nouvelles bandes sont alors utilisées à la place des données de départ.
Le processus général de l’ACP peut être divisé en trois étapes :
1. Calcul de la matrice de variance-covariance (ou matrice de corrélation) des images multibandes (par ex. dans le cas d’une image à six bandes, la matrice de variance-covariance est une matrice de dimension 6x6),
2. Extraction des valeurs et vecteurs propres de la matrice, et
3. Transformation des coordonnées de l’espace considéré sur base de ces vecteurs propres.
En résumé, la valeur des données en composante principale de l’image sont simplement une combinaison linéaire des valeurs de départ multipliées par la transformation appropriée de coefficients appelés vecteurs propres. Donc une image en composante principale est le résultat d’une combinaison linéaire des données de départ et des vecteurs propres, calculée pixel par pixel sur l’ensemble de l’image.
Analyse en composante principale

Photos: USGS ©
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 35
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Sélection d’une combinaison de bandes pour la classification
Plusieurs combinaisons de bandes peuvent maintenant être sélectionnées à partir des bandes de départ, en utilisant différents résultats de transformations (NDVI, ACP ou espace indiciel transformé) pour créer un nouvel ensemble de données. L’analyste devra choisir ou modifier une combinaison appropriée de bandes selon la zone étudiée, les caractéristiques d’occupation des sols et ses propriétés spectrales. Par exemple, un modèle numérique de terrain pourrait éventuellement être inclus au nouvel ensemble de bandes afin de fournir une information topographique. Ceci pourrait éviter une mauvaise classification de terres agricoles au sommet de montagnes. Les processeurs informatiques modernes (à multi-cœur) peuvent traiter des données multi spectre sans trop de temps de traitement additionnel, même si des bandes supplémentaires sont incluses dans la classification.
Les options suivantes présentent aux analystes une idée générale des combinaisons possibles de sélection de bandes à des fins de classification.
Option 1
Bande 1 = Bande spectrale bleue
Bande 2 = Bande spectrale verte
Bande 3 = Bande spectrale rouge
Bande 4 = Bande spectrale proche infrarouge
Bande 5 = Bande spectrale infrarouge moyen I
Bande 6 = Bande spectrale infrarouge moyen II
Bande 7 = Brillance de l’espace indiciel
Bande 8 = Verdure de l’espace indiciel
Bande 9 = Humidité de l’espace indiciel
Bande 10 = NDVI (Redimensionné à l’échelle des données des bandes ci-dessus)
Bande 11 = SR (Redimensionné à l’échelle des données des bandes ci-dessus – optionnel)
Bande 12 = Modèle numérique de terrain (optionnel)
Option 2
Bande 1 = Composante Principale 1 (PC1)
Bande 2 = Composante Principale 2 (PC2)
Bande 3 = Composante Principale 3 (PC3)
Bande 4 = Brillance de l’espace indiciel
Bande 5 = Verdure de l’espace indiciel
Bande 6 = Humidité de l’espace indiciel
Bande 7 = NDVI (Redimensionné à l’échelle des données des bandes ci-dessus)
Bande 8 = SR (Redimensionné à l’échelle des données des bandes ci-dessus – optionnel)
Bande 9 = Modèle numérique de terrain (optionnel)
Option 3
Des données micro-ondes comme celles de Sentinel-1 peuvent être incluses comme bandes supplémentaires aux options 1 et 2. Bien que les options 1 et 2 soient excellentes pour une détection utilisant les caractéristiques chimiques d’objets spatiaux, des données micro-ondes peuvent fournir des informations physiques telles qu’un degré de rugosité des surfaces (structure de la végétation), une constante diélectrique (teneur en eau) et l’orientation des objets dans l’espace par rapport à la direction de l’équipement de détection. Les données de Sentinel-1 peuvent être téléchargées gratuitement à toutes fins de recherche scientifique et non lucratives.

GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 36
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
HCS CLASSIFICATION
Determining the number and type of classes
« Le processus final de négociation et le renoncement éventuel des communautés à leurs droits d’utiliser des forêts HCS n’a lieu qu’une fois le processus de classification HCS complété »
Une fois les images sélectionnées et standardisées, l’étape suivante est de grouper l’occupation des sols en classes homogènes afin d’obtenir les éventuelles zones de forêts HCS. L’objectif principal de cet exercice est de mettre en évidence:
• Les forêts à basse, moyenne et haute densité (LDF, MDF, HDF) ;
• Les jeunes forêts en régénération (YRF) ;
• Les forêts défrichées ou zones anciennement boisées, y compris les friches (S) et les zones ouvertes (OL) ; et
• Les zones non-HCS telles que routes, plans d’eau et habitations.
Comme l’indique le schéma ci-dessous, la limite pour les éventuelles forêts à considérer comme HCS se trouve entre les catégories zone de friche (S) et jeune forêt en régénération (YRF). Les catégories YRF, LDF, MDF et HDF sont alors considérées des forêts potentiellement HCS, tandis que S et OS ne sont pas considérées HCS. Dans la deuxième partie de la méthodologie, les zones YRF et S seront ajustées après une étude suivant l’arbre de décision par analyse de parcelles HCS et une planification de la conservation.
Au cours de l’exercice de classification d’image satellite, d’autres zones de forêts non-HCS mais avec une couverture forestière importante, telles que des zones d’agroforesterie communautaire avec un mélange de végétation naturelle, de plantations d’arbres fruitiers, de cultures de rente (hévéa, café, cacao, palmier à huile) et de cultures maraîchères, pourraient être identifiées. Ces zones devraient normalement déjà avoir été relevées au cours de la cartographie participative et des processus de CLIP décrits dans le Chapitre 2. Si de telles zones sont repérées sur les images satellite mais ne figurent pas sur les cartes des zones communautaires, la qualité de la cartographie participative de l’utilisation des terres devrait être mise en doute, et cette étape pourrait être à refaire.
Les classes d’occupation des sols définies par ce processus varient selon le paysage et les types d’occupation des sols présents dans la concession. Le tableau sur la page suivante présente une description des classifications les plus communément utilisées. Les catégories comprises dans les catégories HCS sont marquées en vert : il est à noter que le tableau comprend des facteurs qualitatifs qui ne deviendront évidents qu’une fois les relevés de terrain complétés. Il est aussi important de se souvenir qu’il est possible que les forêts HCS et les zones communautaires se chevauchent, par exemple les forêts utilisées pour la collecte de PFNL ou pour la chasse. Le processus final de négociation et le renoncement éventuel des communautés à leurs droits d’utiliser des forêts HCS n’a lieu qu’une fois le processus de classification HCS complété.
FORET A HAUT STOCK DE CARBONE (HCS) TERRES DEGRADEES (ANTÉRIEUREMENT FORÊTS)
LIMITE HCSu
FORET A HAUTE DENSITE (HDF)
FORET A MOYENNE DENSITE (MDF)
JEUNE FORET EN REGENERATION (YRF)
FORET A BASSE DENSITE (LDF)
FRICHE (S, DE L’ANGLAIS SCRUB)
ZONE OUVERTE (OL, DE L’ANGLAIS OPEN LAND)

Photos: Corozal Sustainable Future Initiative, Belize ©.
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 37
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Lorsque des forêts monospécifiques ou presque monospécifiques peuvent être identifiées et cartographiées, comme par exemple les forêts de Gelam (Melaleuca spp.) en Indonésie, il faudra se poser la question de savoir si les zones correspondantes peuvent être traitées comme une classe de végétation séparée (non-standard). Si la décision est de considérer une zone monospécifique séparément, l’approche HCS standard de stratification de la végétation en zones à stock de carbone plus ou moins élevé est toujours valide.
Il est à noter que puisque la majeure partie de la plage dynamique de l’indice Simple Ratio (SR) correspond à des conditions de biomasse élevée, telles que des zones forestières, avec très peu de variations dans les régions où la biomasse est plus faible, les zones de régénération naturelle et de forêts naturelles pourraient être détectées avec cette méthode. De plus, les données micro-ondes de Sentinel-1 pourraient aussi être incluses pour détecter les forêts naturelles et les régions de régénération naturelle, puisque la structure dynamique des individus est différente et peut être inférée à partir du degré de rugosité des surfaces.
TABLEAU: CATÉGORIES D’OCCUPATION DES SOLS GÉNÉRIQUES
VEGETATION COVER DESCRIPTION CATEGORIES
HDF, MDF, LDF Forêt à haute, moyenne et basse densité Forêt à la canopée fermée variant de très dense à peu dense.
Les données d’inventaire indiquent la présence d’arbres de
diamètre > 30 cm, et la dominance d’espèces culminantes.
YRF Jeune forêt en régénération Forêt très dégradée ou zones forestières en cours de
régénération vers leur structure d’origine. Le profil de diamètres
est dominé par des arbres de 10 à 30 cm et une plus haute
fréquence d’espèces pionnières que dans les forêts LDF. Cette
catégorie d’utilisation des sols peut présenter de petites zones
d’agriculture paysanne.
Remarque : Des plantations abandonnées dont moins de 50%
de la superficie consiste d’arbres plantés peuvent être
considérées dans cette catégorie, ou une catégorie supérieure.
Une superficie représentant plus de 50% de la surface terrière
devra être considérée comme une plantation plutôt qu’une
forêt HCS et être classée séparément.
S Friche Zone anciennement forestière récemment défrichée. Dominée
par des broussailles basses avec une fermeture limitée de la
canopée. Comprend des zones où la couverture herbacée est
haute avec des fougères et des espèces pionnières parsemées.
Des parcelles de forêts plus matures peuvent éventuellement
se trouver dans cette catégorie.
OL Zone ouverte Terres défrichées récemment, principalement prairies ou
cultures. Peu d’espèces ligneuses.
EXEMPLES D’AUTRES CATÉGORIES D’OCCUPATION DES SOLS NON-HCS
FP Plantation forestière Vaste zone d’arbres plantés (par exemple hévéa, acacia).
AGRI Domaine agricole Par exemple des plantations de palmiers à huile à grande
échelle chevauchant la concession.
MINE Zone minière Ces zones peuvent être subdivisées entre zones de mines
réglementées et zones de mines illégales/non-réglementées.
SH Agriculture et utilisation paysanne à petite échelle Ces zones peuvent être subdivisées entre jardins forestiers
mixtes/systèmes agroforestiers qui peuvent potentiellement
servir de corridors biologiques, systèmes d’agriculture avec
rotation des cultures/swidden pour la production de
cultures maraîchères de subsistance, etc.
(Autre) Plans d’eau tels que rivières et lacs, zones développées,
habitations, routes, etc.

Photos: USGS ©
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 38
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Méthodes de classification
« Le choix de la méthode utilisée pour interpréter les images est généralement déterminé par le niveau d’expertise de l’interprète et sa connaissance du paysage »
Une fois les images sélectionnées et affinées, l’occupation des sols est regroupée en classes relativement homogènes telles que celles décrites ci-avant afin de distinguer les forêts HCS des forêts non-HCS. Ce processus consiste principalement en une analyse des images satellite avec des logiciels de télédétection et de Systèmes d’Information Géographique (SIG), qui fournissent des outils d’interprétation de l’occupation des sols. Plusieurs logiciels peuvent être utilisés pour la classification, y compris Erdas Imagine, ENVI, ESRI Image Analysis et des logiciels en OpenSource (Quantum GIS).
La classification de l’occupation des sols est réalisée pour plusieurs raisons :
1. Elle permet l’identification de différentes classes d’occupation des sols avec des caractéristiques forestières et non-forestières variées qui peuvent être repérées par analyse d’image (par ex. couleur, degré de fermeture et de rugosité de la canopée).
2. La condition d’une forêt est souvent (bien que pas toujours) corrélée avec son stock de carbone et sa biodiversité. Par exemple, une forêt dense et bien fournie est généralement associée avec un stock de carbone (ainsi qu’une biodiversité) plus élevé que des forêts dégradées, moins bien fournies.
3. Diviser l’occupation des sols en classes permet de développer des plans plus efficaces pour les relevés de terrain (voir aussi le Chapitre 4), et simplifie la révision des résultats d’inventaire forestier et de relevés aériens.
Les études HCS combinent généralement plusieurs étapes méthodologiques pour assurer une représentation exacte de l’occupation des sols, c’est-à-dire une analyse pixel à pixel suivant une méthode supervisée et non-supervisée, ainsi que des méthodes visuelles au cours d’autres étapes. Quelles que soient les techniques de classification utilisées, une connaissance locale de l’utilisation et de l’occupation des sols, des types de forêts et de leurs compositions en espèces, des types de cultures agricoles, et de la phénologie de la végétation par rapport à sa signature spectrale dans la banque d’images sélectionnées est essentielle.
Le choix de la méthode utilisée pour interpréter les images est généralement déterminé par le niveau d’expertise de l’interprète et sa connaissance du paysage et l’occupation des sols de la zone en question. Par exemple, si l’interprète a un niveau de compréhension suffisant des techniques sophistiquées de télédétection et une bonne connaissance de la zone, l’utilisation de méthodes de classification supervisée et/ou d’arbre de décision de classification, avec des outils tels que Knowledge Engineer et Knowledge Classifier, est recommandée. Dans le cas d’une zone pour laquelle il n’existe aucune information préalable sur l’occupation des sols, l’interprète ou l’analyste peut commencer l’analyse par une technique de classification non-supervisée afin de repérer les objets et phénomènes de spectre comparables ou contigus dans l’espace.
En général, les techniques de classification non-supervisée, classification supervisée, et arbres de décision hiérarchique pour la classification sont des outils complémentaires pour déterminer les différentes classes d’occupation des sols dans la zone étudiée.

Photos: En-bas: TFT ©. Autres: Corozal Sustainable Future Initiative, Belize ©
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 39
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Classification non-supervisée
La classification non-supervisée utilise un logiciel de traitement d’image qui groupe les pixels selon leurs caractéristiques génériques sans utiliser de classes prédéterminées. Ce type de classification utilise un algorithme de segmentation d’images par la méthode des K-means, ou sa variante ISODATA (Iterative Self-Organising Data Analysis), afin de repérer les pixels dont le spectre est similaire et les grouper en classes homogènes. L’utilisateur/trice peut spécifier quel algorithme le logiciel devrait utiliser et le nombre de classes désirées, mais n’intervient pas autrement avec le processus de classification. L’utilisateur/trice devra quand même avoir un certain niveau de connaissance de la zone étudiée car il/elle devra faire correspondre les groupements de pixels, produits par la classification non-supervisée sur base de caractéristiques communes, à la réalité sur le terrain (par ex. zones humides, zones urbanisées, forêts de conifères, etc.)
Les classes produites par une classification non-supervisée sont des classes spectrales. Parce qu’elles sont basées uniquement sur les valeurs d’une image, ces classes spectrales ne sont initialement pas identifiables. L’analyste devra comparer les classes obtenues avec des données de référence telles que des cartes existantes, ou des données de terrain afin d’identifier les classes spectrales, ou déterminer leur valeur informative ou classe d’information.
Une fois les classes distinctes sur le plan spectral identifiées, l’analyste pourra les fusionner en un nombre de catégories plus restreint voulu. Il se peut que plusieurs classes spectrales soient liées à plus d’une classe d’information. Par exemple, la classe spectrale 3 peut correspondre à une Jeune forêt en régénération dans certains endroits, ou à une Forêt à basse densité dans d’autres. De même, la classe spectrale 6 peut inclure des forêts à moyenne ou haute densité. Ceci implique que ces classes d’information sont similaires sur le plan spectral et ne peuvent pas être distinguées pour certaines données. Dans ce cas, l’analyste devra considérer ajouter d’autres bandes aux données analysées, comme on en a discuté précédemment.
Au final, la qualité d’une classification non-supervisée dépendra du niveau de compréhension qu’a l’analyste des concepts sur base desquels fonctionne le logiciel de classification disponible, ainsi que de sa connaissance des types d’occupation des sols étudiés. Pour une classification non-supervisée dans le cadre d’un processus HCS, 16 classes sont normalement suffisantes pour déterminer les classes forestières et non-forestières qui seront alors combinées avec la couverture végétale et pourront être utilisées comme référence pour localiser les points d’échantillonnage sur le terrain (cf. Chapitre 4).

Photos: En-haut: TFT ©. En bas: Corozal Sustainable Future Initiative, Belize ©
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 40
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Classification supervisée
« La classification supervisée se base sur le concept qu’un(e) utilisateur/trice peut sélectionner un échantillon des pixels représentatifs de classes spécifiques au sein d’une image, qui peuvent alors devenir les points de référence pour la classification de tous les autres pixels de l’image »
La classification supervisée se base sur le concept qu’un(e) utilisateur/trice peut sélectionner un échantillon des pixels représentatifs de classes spécifiques au sein d’une image, et instruire le logiciel de classification d’utiliser ces zones d’entraînement comme référence pour la classification de tous les autres pixels de l’image. Les zones d’entraînement (ou données test) sont sélectionnées sur base de connaissances préexistantes de l’utilisateur/trice, qui définit aussi le degré de similarité requis entre pixels afin de pouvoir les regrouper. Ce degré de similarité est souvent défini sur base des caractéristiques spectrales de la zone d’entraînement, plus ou moins une valeur donnée (souvent basée sur la « brillance » ou le degré de réflexion de bandes spectrales spécifiques). L’utilisateur/trice impose aussi le nombre de classes à utiliser pour classer l’image.
Une procédure de classification supervisée typique comprend trois étapes de base :
1. Au cours de l’étape d’entraînement, l’analyste identifie des zones d’entraînement représentatives et développe une description numérique des attributs spectraux de chaque type d’occupation des sols dans la zone.
2. Au cours de l’étape de classification, chaque pixel de l’image est trié dans la catégorie d’utilisation des sols qui lui correspond le mieux. Si le pixel n’est suffisamment similaire à aucune des données d’entraînement, il sera généralement classé comme inconnu.
3. Une fois l’entièreté des données catégorisée, les résultats sont produits lors de l’étape de présentation des résultats. Les données classées deviennent les données de base du SIG.
Chacune de ces étapes est décrite en détails dans les pages suivantes.
Étape d’entraînement
L’objectif général de l’étape d’entraînement est de rassembler un ensemble de statistiques qui décrivent la réponse spectrale pour chacun des types d’utilisation des sols à classer dans une image. Il est important de remarquer que toutes les classes spectrales comprises dans chaque classe d’information doivent être représentées de façon adéquate par les statistiques d’entraînement utilisées pour classer l’image correspondante. Il est rare d’acquérir plus de 100 zones d’entraînement afin de représenter toute les variabilités spectrales présentes dans une image. Produire un histogramme pour chaque zone d’entraînement devient alors particulièrement important lorsqu’un outil de classification par maximum de vraisemblance est utilisé, car il permet une vérification visuelle d’une distribution normale de la réponse spectrale. Dans Remote Sensing and Image Interpretation (Cinquième Édition, 2004), Liliesand et Kiefer présentent des informations détaillées et des exemples d’identifications de zones d’entraînement statistiquement valides.
La sélection d’un échantillon de parcelles d’entraînement et l’évaluation des statistiques de l’échantillon d’entraînement prend du temps, mais sont des étapes importantes pour une classification de bonne qualité. L’analyste devrait prendre son temps pour créer un échantillon de parcelles d’entraînement représentatif et statistiquement distinct qui correspond aux classes d’information. Une matrice de confusion (ou matrice d’erreur - présentée plus loin dans ce chapitre) peut être créée pour l’échantillon de pixels d’entraînement et les résultats de la classification supervisée.

Photo: USGS ©
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 41
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Étape de classification
Bien que beaucoup de techniques puissent être utilisées pour l’étape de classification supervisée, ce guide pratique se concentre sur la méthode de classification Gaussienne par maximum de vraisemblance1 et présente aussi brièvement comment utiliser un arbre de décision pour une classification supervisée hiérarchique.
La classification Gaussienne par maximum de vraisemblance évalue de manière quantitative la variance et la covariance de la réponse de chaque catégorie (à partir des statistiques des échantillons d’entraînement) au moment de la classification d’un pixel inconnu. L’hypothèse étant que la distribution du nuage de points représentant les données d’entraînement de chaque catégorie est Gaussienne (c-à-d. distribution normale), alors la distribution de la réponse d’une catégorie donnée devrait pouvoir être entièrement décrite par le vecteur moyen et la matrice de covariance. Sur base de ces paramètres, l’outil de classification calcule la probabilité statistique qu’un pixel donné puisse faire partie d’une classe d’occupation des sols, ou d’une classe HCS, donnée. Une fois cette probabilité calculée pour chaque catégorie, le pixel est assigné à la classe la plus probable (avec la valeur de probabilité la plus élevée), ou classé comme « inconnu » si les valeurs de probabilité sont en-deçà de la valeur limite imposée par l’analyste.
« De nombreux analystes utilisent les méthodes de classification supervisées et non-supervisées de façon combinée et complémentaire pour conduire l’analyse et produire la classification finale des cartes indicatives »
1. Voir pages 271 à 277 du livre Resource Management Information Systems: Remote Sensing, GIS and Modelling (deuxième édition) par Keith R. McCloy pour plus de détails sur la classification par maximum de vraisemblance.
La classification de Bayes est une extension de l’approche par maximum de vraisemblance qui applique deux facteurs pondérés aux estimations de probabilité. L’analyste détermine d’abord une probabilité « a priori », ou vraisemblance anticipée, de l’occurrence de chaque classe dans une image donnée. Dans un deuxième temps, un coefficient associé au coût d’une mauvaise classification est alors appliqué à chaque classe. Ensemble, ces facteurs ont pour but de minimiser le coût de mauvaises classifications, ayant pour résultat en théorie une classification optimale. En pratique, la plupart des classifications par vraisemblance maximum est faite en supposant que la probabilité d’occurrence et le coût d’une mauvaise classification sont les mêmes pour toutes les classes.
La classification par maximum de vraisemblance requiert des ressources informatiques de calcul importantes afin de classer chaque pixel, en particulier si plusieurs bandes spectrales doivent être traitées ou si un grand nombre de classes spectrales doivent être différentiées, cependant les microprocesseurs multi-cœur d’ordinateurs modernes peuvent faire ce genre de classification relativement rapidement. Pour optimiser la classification par maximum de vraisemblance, une autre méthode est d’utiliser les composantes principales (CP1, CP2 et CP3) au lieu des bandes d’origine comme données de base pour la classification.
Une autre alternative à la classification par maximum de vraisemblance est l’utilisation d’arbres de décision qui stratifient la classification ou la traitent par couches successives afin de simplifier les calculs tout en maintenant leur exactitude. Ces outils de classification sont appliqués en une série d’étapes au cours desquels certaines classes seront séparées de la façon la plus simple possible. Par exemple, l’eau pourrait être distinguée à partir de la bande proche infrarouge à l’aide d’une simple valeur limite. La catégorisation d’autres classes peut requérir la combinaison de deux ou trois bandes à l’aide d’algorithmes de classification simples tels que la méthode par minimisation de distance à la moyenne ou la méthode du parallélépipède. L’utilisation de plusieurs bandes ou de la méthode par maximum de vraisemblance serait alors restreinte aux catégories d’occupation des sols pour lesquelles une ambiguïté résiduelle existe entre les classes se chevauchant au cours du calcul des espaces. En dernier lieu, au lieu d’appliquer la méthode de classification par maximum de vraisemblance, une régression logique multinomiale pourrait utiliser les statistiques sur les échantillons d’entraînement pour dériver la probabilité d’appartenance de chaque pixel aux classes d’information.
De nombreux analystes utilisent les méthodes de classification supervisées et non-supervisées de façon combinée et complémentaire pour conduire l’analyse et produire la classification finale des cartes indicatives.

Étude de cas: Kalimantan Occidental
Dans cet exemple, pris au Kalimantan Occidental en Indonésie, des images satellite Landsat 8 traitées avec l’extension Image Analysis d’ArcGIS 10.1 ont été utilisées pour classer l’occupation des sols. Les images satellite ont d’abord été prétraitées pour produire l’image de l’AOI ci-contre.
Avec les outils disponibles dans le logiciel de traitement d’image, six zones d’entraînement ont été sélectionnées pour représenter les six classes d’occupation des sols HCS (voir l’image du milieu).
Une fois les échantillons d’entraînement considérés suffisants et représentatifs, le logiciel de traitement est utilisé pour faire une classification supervisée en utilisant la méthode de classification par maximum de vraisemblance. La photo en bas de page montre la carte intérimaire de la végétation résultant de l’analyse de l’image.
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 42
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE

ÉTAPES DE LA STRATIFICATION VISUELLE DE LA VÉGÉTATION
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 43
Un(e) analyste possédant un niveau de connaissances excellent des conditions d’occupation des sols dans la zone peut mener une classification visuelle avancée ou un processus de numérisation manuelle. Il/elle doit alors déterminer chaque classe d’occupation des sols grâce à une analyse d’images satellite à l’écran. Dans ce cas, les images sont généralement améliorées pour faciliter l’identification des classes. L’interprète doit connaître les données d’interprétation pour l’occupation des sols dans la zone, être d’une intégrité absolue, professionnel(le), et avoir une expérience physique de la zone étudiée.
La classification visuelle est menée une fois l’image calibrée, et standardisée si une mosaïque de plusieurs images a été utilisée. Appliquée de façon indépendante, celle-ci peut typiquement être la méthode de classification la plus exacte si l’utilisateur/trice connaît bien la zone. Cependant, ceci a un coût car c’est une technique qui requiert beaucoup de temps de numérisation. Elle peut aussi être biaisée, et devrait donc seulement être utilisée de façon complètement indépendante si des images de haute résolution sont disponibles, et seulement lorsque l’utilisateur/trice a un bon niveau de connaissance de la zone.
Sinon, une classification visuelle peut aussi être utilisée en complément de classifications supervisées et non-supervisées, car ces processus peuvent générer des erreurs, en particulier lorsque brume, fumée, ombres topographiques, ombres nuageuses ou nuages amoindrissent la qualité de l’image. Ces erreurs, ou tout biais, peuvent alors être minimisés grâce à un contrôle qualité visuel par l’interprète. Dans les zones où l’interprétation est incorrecte, des corrections peuvent alors être faites pour correspondre aux conditions connues. Au cours de cette étape, les résultats d’interprétation supervisée ou non-supervisée (s’ils existent) peuvent être combinés à d’autres informations, telles que des données de précipitation, ou de type de sol. Une bonne compréhension des conditions de terrain est cruciale pour produire une classification juste et précise. Plus l’interprète aura à disposition des données spécifiques à la zone d’étude, plus le risque d’erreur sera réduit. Les différentes étapes d’une stratification visuelle de la végétation sont présentées sur le schéma de droite.
Toute information numérique supplémentaire telle que température, précipitation, humidité, rayonnement solaire, grille de vitesse des vents, modèles numériques de terrain et topographiques, peut être considérée comme bande additionnelle dans la classification seulement si ces données fournissent effectivement des informations supplémentaires permettant une meilleure différentiation des classes spectrales. Toute information catégorique supplémentaire telle que types de sol, géologie, géomorphologie et emplacements de types de végétation peut être appliquée pour affiner l’interprétation et éliminer tout biaisement.
Pour les études HCS, les auteurs recommandent que la classification visuelle ne soit pas utilisée avant d’avoir acquis une expérience considérable de la méthodologie à l’aide des approches de classification supervisée et non-supervisée utilisées en parallèle avec les études de terrain décrites dans le chapitre suivant.
Classification visuelle
Numérisa�on à l’écran pour délimiter les
classes de végéta�on (six classes de végéta�ons)
Contrôle qualité et re-classifica�on
Classifica�on supervisée ou non-supervisée
Évalua�on de l’exac�tude
Prétraitement et transforma-�on des images
Images satellite
Données physiques• Type de sol
• Climat• Écosystème
Informa on sur le site• Emplacement de la végéta�on
• Condi�on de la végéta�on • Structure de la végéta�on, etc
« Une bonne compréhension des conditions de terrain est cruciale pour produire une classification juste et précise. Plus l’interprète aura à disposition des données spécifiques à la zone d’étude, plus le risque d’erreur sera réduit »
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE

MATRICE D’ERREUR SUR BASE D’ÉCHANTILLONS D’ENTRAÎNEMENT
44 GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Évaluation de l’exactitude de l’image classée
Cette section présente l’évaluation à mener pour vérifier l’exactitude de la classification. Pour de plus amples informations, Remote Sensing Thematic Accuracy Assessment: A Compendium (1994 par ASPRS et Assessing the Accuracy of Remotely Sensed Data: Principle and Practices(Congalton et Green, 1999) sont d’excellentes références.
Matrice d’erreur sur base des données de l’échantillon d’entraînement
Préparer une matrice d’erreur (matrice de confusion ou tableau de contingence) de la classification est une méthode communément utilisée pour représenter l’exactitude de la classification. Les matrices d’erreur comparent catégorie par catégorie la relation entre les données de référence (vérification de terrain) et les résultats de l’image classée correspondants.
Le tableau ci-dessous présente un exemple de matrice d’erreur extraite de Liliesand et Kiefer (2004), calculée sur base d’échantillons d’entraînement et des résultats d’une classification. Cette classification a fait une bonne catégorisation d’un échantillon de pixel représentatifs utilisés pour l’entraînement d’un processus de classification supervisée. La matrice représente la manière dont l’échantillon classé a été trié entre les bonnes catégories d’occupation des sols en les positionnant le long de sa diagonale principale (en jaune). Tous les éléments ne se trouvant pas sur la diagonale correspondent à une erreur d’omission (exclusion) ou une erreur de commission (inclusion).
L’erreur d’omission est représentée par les éléments COLONNE non-diagonaux, par exemple les 16 pixels qui ont été classés « S » pour sable ont été omis de la catégorie. Les résultats d’exactitude producteur sont calculés en divisant le nombre de pixels correctement classés par catégorie (sur la diagonale
principale) par le nombre de pixels d’entraînement utilisés pour cette même catégorie (le total colonne). Dans le cas présenté, le niveau d’exactitude producteur est compris entre 51% et 100% ; ceci est une mesure de l’erreur d’omission et donne une indication de la manière dont les pixels de l’échantillon d’entraînement pour un type d’occupation des sols donné ont été classés.
Les erreurs de commission sont représentées par les éléments LIGNE non-diagonaux, par exemple 38 pixels de développement urbain (U) et 79 de foin (H) ont été inclus de manière erronée dans la catégorie Maïs (C). Les résultats d’exactitude utilisateur sont obtenus en divisant le nombre de pixels correctement classés par catégorie (sur la diagonale principale) par le nombre de pixels d’entraînement utilisés pour cette même catégorie (le total ligne). Le niveau d’exactitude utilisateur est une mesure de l’erreur de commission et indique la probabilité qu’un pixel classé dans une catégorie donnée représente bien cette catégorie en réalité. Dans le cas présenté, elle est comprise entre 72% et 99%.
L’exactitude totale est calculée en divisant le nombre total de pixels correctement classés (la somme des éléments situés le long de la diagonale principale) par le nombre total de pixels de référence. Dans le tableau de contingence présenté en exemple, l’exactitude totale est 84%.
Il est important de noter que la matrice d’erreur utilise comme données de base les données d’entraînement, et ces procédures n’indiquent par conséquent que la manière dont les statistiques extraites de zones données ont pu être utilisées pour catégoriser ces mêmes zones. De bons résultats ne sont donc qu’une indication du fait que les zones d’entraînement sont homogènes, que les classes d’entraînement sont distinctes, et que la stratégie de classification utilisée fonctionne bien pour les zones d’entraînement. Ils ne donnent que très peu d’information sur la performance de l’outil de classification dans d’autres endroits de l’image. Les résultats d’exactitude des zones d’entraînement ne devraient donc pas être utilisés comme témoin de l’exactitude globale.
Données d’entraînement (Types d’occupation des sols connus) W S F U C H Total (ligne)Données de classificationW 480 0 5 0 0 0 485S 0 52 0 20 0 0 72F 0 0 313 40 0 0 353 U 0 16 0 126 0 0 142C 0 0 0 38 342 79 459H 0 0 38 246 60 359 481Colonne 480 68 356 248 402 438 1992
Exactitude totale = (480 + 52 + 313 +126 + 342 +359) / 1992 = 84%
Exactitude producteur:W = 480/480 = 100%S = 52/68 = 76%F = 313/356 = 88%U = 126/248 = 51%C = 342/402 = 85%H = 359/438 = 82%
Exactitude utilisateur: W = 480/485 = 99%S = 52/72 = 72% F = 313/353 = 87% U = 126/142 = 89% C = 342/459 = 74% H = 359/481 = 75%

MATRICE D’ERREUR SUR BASE DE PIXELS TEST
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 45
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Considérations pour l’échantillonnage de zones test
Afin d’évaluer l’exactitude de la classification pour l’image, des zones test représentatives avec une occupation des sols homogène devront être sélectionnées. Ces zones test peuvent être choisies pour correspondre à un modèle d’échantillonnage aléatoire, aléatoire stratifié ou systématique. Elles peuvent aussi être sélectionnées au même moment que les zones d’entraînement, en mettant de côté certaines d’entre celles-ci comme zones test qui ne devront alors pas être utilisées pour l’étape d’entraînement. Des pixels individuels, des groupements de pixels ou des polygones sont tous des unités d’échantillonnage appropriées, bien qu’un échantillonnage de polygones soit la méthode la plus communément utilisée.
En règle générale, un minimum de 50 échantillons devrait être inclus dans la matrice d’erreur comme zones test pour chaque catégorie d’occupation des sols afin d’évaluer la exactitude de la classification de l’image entière. Si la zone est large (par ex. plus de 400,000 ha) ou bien si la classification comporte un grand nombre de catégories de végétation ou d’occupation des sols (plus de 12 catégories), le nombre minimum d’échantillons devrait être augmenté à 75 ou 100 par catégorie (Congalton et Green, 1999, p.18). Un nombre plus important d’échantillons devrait aussi être sélectionné pour les catégories plus importantes ou plus variables.
« En règle générale, un minimum de 50 échantillons devrait être inclus dans la matrice d’erreur comme zones test pour chaque catégorie d’occupation des sols afin d’évaluer l’exactitude de la classification de l’image entière »
Évaluation de la matrice d’erreur de la classification à l’aide des zones ou pixels testUne fois les données d’exactitude collectées avec les zones test (soit sous forme de pixels, groupes de pixels, ou polygones) et regroupées dans la matrice d’erreur, elles sont normalement soumises à une interprétation détaillée et des analyses statistiques supplémentaires. La matrice d’erreur ci-dessous a été calculée sur base de pixels test sélectionnés de façon aléatoire ; elle est aussi extraite de Liliesand et Kiefer (2004).
L’exactitude totale est seulement de 65%. Si le but de l’exercice de cartographie est de localiser les forêts (F), alors l’exactitude producteur est relativement bonne à 84%. La conclusion pourrait alors être que bien que l’exactitude globale de la classification soit faible (65%), la carte est appropriée à des fins de cartographie des forêts. Un des problèmes qui se pose alors est le fait que l’exactitude utilisateur est seulement de 60% : ceci veut dire que bien que 84% des zones de forêts ont été correctement identifiées comme forêts, seulement 60% des zones identifiées comme forêts dans la classification appartiennent réellement à cette catégorie. C’est-à-dire qu’un utilisateur de cette classification trouverait qu’une zone marquée comme forêt sur l’image classée ne serait en réalité une forêt que dans 60% des cas.
Une inspection plus soignée de la matrice d’erreur indique une confusion importante entre les catégories forêt (F) et développement urbain (U). Dans cet exemple, la seule catégorie fiable pour le producteur comme pour l’utilisateur est l’eau (W).
Données de référence pour des pixels test sélectionnés de façon aléatoire W S F U C H Total (ligne)Données de classificationW 226 0 0 12 0 1 239S 0 216 0 92 1 0 309F 3 0 360 228 3 5 599 U 2 108 2 397 8 4 521C 1 4 48 132 190 78 453H 1 0 19 84 36 219 359Total colonne 233 238 429 945 238 307 2480
Exactitude totale = (226 + 216 + 360 + 397 + 190 + 219) / 2480 = 65%
Erreur d’omission:W = 226/233 = 97%S = 216/328 = 66%F = 360/429 = 84%U = 397/945 = 42%C = 190/238 = 80%H = 219/307 = 71%
Erreur de commission: W = 226/239 = 94%S = 216/309 = 70% F = 360/599 = 60% U = 397/521 = 76% C = 190/453 = 42% H = 219/359 = 75%

GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 46
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Test statistique de l’indice Khat
L’indice Khat est une mesure de la différence entre l’accord réel entre des données de référence et un outil de classification automatisé, et l’accord aléatoire entre ces données de référence et une classification aléatoire. Il est conceptualisé de la façon suivante :
Khat = ( fréquence observée – accord aléatoire) / (1 – accord aléatoire)
Cette statistique donne une indication de la mesure dans laquelle les pourcentages d’exactitude calculés dans une matrice de confusion sont dus à des accords « réels » plutôt qu’à des accords « aléatoires ». Au plus l’accord réel (observé) tend vers 1 et l’accord aléatoire vers 0, au plus Khat tend vers 1. Khat est en réalité compris entre 0 et 1. Par exemple une valeur de Khat de 0.67 peut être interprétée comme une indication que la classification observée est 67% meilleure qu’une classification qui résulterait d’un processus aléatoire. Un Khat d’une valeur 0 suggère au contraire que la classification correspondante ne vaut pas mieux qu’une affectation aléatoire des pixels. Si l’accord aléatoire est supérieur à la fréquence observée, il peut arriver que Khat prenne une valeur négative, ce qui indiquerait une classification très pauvre.
La valeur de Khat est calculée comme suit :
Khat =
Où :
r = nombre de colonnes dans la matrice d’erreur
xii = nombre d’observations dans la ligne i et la colonne i (sur la diagonale principale)
xi+ = total des observations dans la ligne i (total indiqué en marge de la matrice sur la droite)
x+i = total des observations dans la colonne i (total indiqué au bas de la matrice)
N = nombre total d’observations dans la matrice
Pour les matrices d’erreur présentées ci-dessus, le calcul de Khat est :
∑i=1xii = 226 + 216 + 360 + 397 +190 + 219 = 1608
∑i=1(xi+*x+i) = (239 * 233) + (309 * 328) + (599 * 429) + (521 * 945) + (453 * 238) + (359 * 307) = 1,124, 382
Khat = (2480 (1608) - 1124382) 24802 - 1124382)
Khat = 0.57
L’indice Khat (0.57) est inférieur à l’exactitude globale (0.67) calculée précédemment. En effet l’exactitude globale ne prend en compte que les données sur la diagonale principale et exclut les erreurs d’omission et de commission. L’indice Khat inclut les éléments sur la diagonale principale ainsi que les éléments non-diagonaux de la matrice d’erreur comme produit des marges de ligne et de colonne. L’un des avantages de calculer les statistiques de l’indice Khat est de pouvoir utiliser cette valeur comme base pour déterminer l’importance statistique de n’importe quelle matrice ou des différences entre matrices.
Il est normalement préférable de calculer et d’analyser l’exactitude globale ainsi que l’indice de Khat. Pour l’assurance qualité des classifications HCS, l’analyste devrait présenter une matrice d’erreur calculée sur base de l’échantillon d’entraînement, une matrice d’erreur des zones test ou des pixels test, l’exactitude globale, l’exactitude producteur, l’exactitude utilisateur, et les statistiques de l’indice Khat pour les matrices d’erreur fournies.
Photo: USGS © Photo: TFT ©

GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 47
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Contrôle qualité, finaliser la classification initiale de l’occupation des sols, et étapes suivantes
Les étapes nécessaires afin de finaliser la classification initiale de l’occupation des sols sont présentées ci-dessous.
Conversion raster vers vecteur
Convertir l’image raster en un fichier vecteur pour faciliter la correction des limites des classes d’occupation des sols.
Élimination des petites parcelles
Éliminer les petits polygones (de 4 pixels ou moins) en les fusionnant avec des polygones plus larges aux propriétés similaires ; éliminer les polygones fins (allongés) en appliquant le ratio superficie/périmètre. La zone ou les unités minimum pour la cartographie devraient être spécifiés afin de pouvoir éliminer les polygones de parcelles.
Intégration d’autres informations sur l’utilisation des sols
Au moment de la finalisation de la carte préliminaire, incorporer à l’analyse toute information relative à l’utilisation actuelle des sols. Par exemple, les zones déjà développées devraient être retirées des zones de forêts HCS potentielles.
Correction des classes de végétation à l’aide d’une image composite Landsat 8-654 bandes (LDCM)
Au cours de cette étape, superposer les données vecteur représentant les classes d’occupation des sols à une image composite Landsat (654 bandes), faire une comparaison visuelle et apporter les corrections nécessaires.
Contrôle qualité reclassification des résultats vecteur corrigés en classes HCS
Reclasser les couches d’occupation des sols entre les six classes de végétation HCS standard : OL, S, YRF, LDF, MDF, et HDF.
Appariement des contours vecteur
Si plus d’une image Landsat est utilisée, joindre la classification finale en utilisant un processus d’appariement des données.
Relevé aérien (si possible)
Si possible, réaliser un relevé aérien des zones de forêts naturelles contiguës. Une base de données géographique pourra être créée pour permettre la visualisation des photos dans un SIG, et ainsi faciliter la vérification de la classification de l’occupation des sols.
Préparation de la carte initiale d’occupation des sols
Préparer une carte initiale d’occupation des sols, classée selon les catégories identifiées au cours du processus décrit ci-dessus, afin de planifier et de réaliser le travail de terrain, y compris le relevé aérien et l’inventaire forestier.
« Au cours de l’étape suivante les résultats d’interprétation de l’image seront comparés avec des relevés de terrain, pour permettre d’estimer le stock de carbone de chaque classe »
Étapes suivantes
L’étape suivante de la classification HCS est de tester l’exactitude des résultats d’interprétation ; celle-ci sera importante pour guider le niveau de confiance qu’un utilisateur peut avoir pour les données et méthodes d’analyse. On a présenté le rapport initial d’exactitude de classification pour la classification d’une image satellite en vue d’une stratification de végétation HCS, avec tableau de contingence (matrice d’erreur ou de confusion), exactitude producteur, exactitude utilisateur, exactitude globale, et statistiques de l’indice Khat. On a aussi discuté de l’interprétation du rapport d’évaluation d’exactitude. L’étape suivante sera de comparer les résultats d’interprétation de l’image avec des relevés de terrain, ce qui permettra aussi d’estimer le stock de carbone pour chaque classe.
Le chapitre suivant explique comment recueillir les données de terrain nécessaires afin d’estimer la biomasse aérienne ligneuse et le stock de carbone, attribuer un niveau moyen de carbone à chaque catégorie (en notant bien que le but n’est pas de calculer une quantité de carbone exacte mais plutôt de différencier les types d’occupation des sols par l’intermédiaire de valeurs estimées), et finalement affiner la classification afin de produire une carte d’occupation des sols dans laquelle les zones potentielles de forêts à haut stock de carbone sont délimitées.

GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 48
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Appendices
Nom
du
sate
llite
Prés
enta
tion
Réso
lutio
n sp
atial
e (m
)
Réso
lutio
n te
mpo
relle
Date
s de
capt
ure
d’im
ages
Coût
par
imag
e (U
SD)
Band
es d
ispo
nibl
es
Taill
e de
s im
ages
Not
es
Landsat 8
ALOS (AVNIR-2, PRISM)
IKONOS
http://landsat.usgs.gov/landsat8.php
http://www.alos-restec.jp/en/
http://geofuse.geoeye.com/landing/
http://glcf.umd.edu/data/
30m
10m
4m
16 jours
46 jours
14 jours
Février
2013 –
Présent
Jan 2006
– Mai
2011
2000 –
Gratuit
$16-56/
Km2
11 Bandes:
1. 0.433–0.453
30 m
2. 0.450–0.515
30 m
3. 0.525–0.600
30 m
4. 0.630–0.680
30 m
5. 0.845–0.885
30 m
6. 1.560–1.660
30 m
1270 MHz (L-band),
Polarization HH+VV
1 (Bleu)
2 (Vert)
3 (Rouge)
4 (proche IR)
185km
par
180km
14km
par
14km
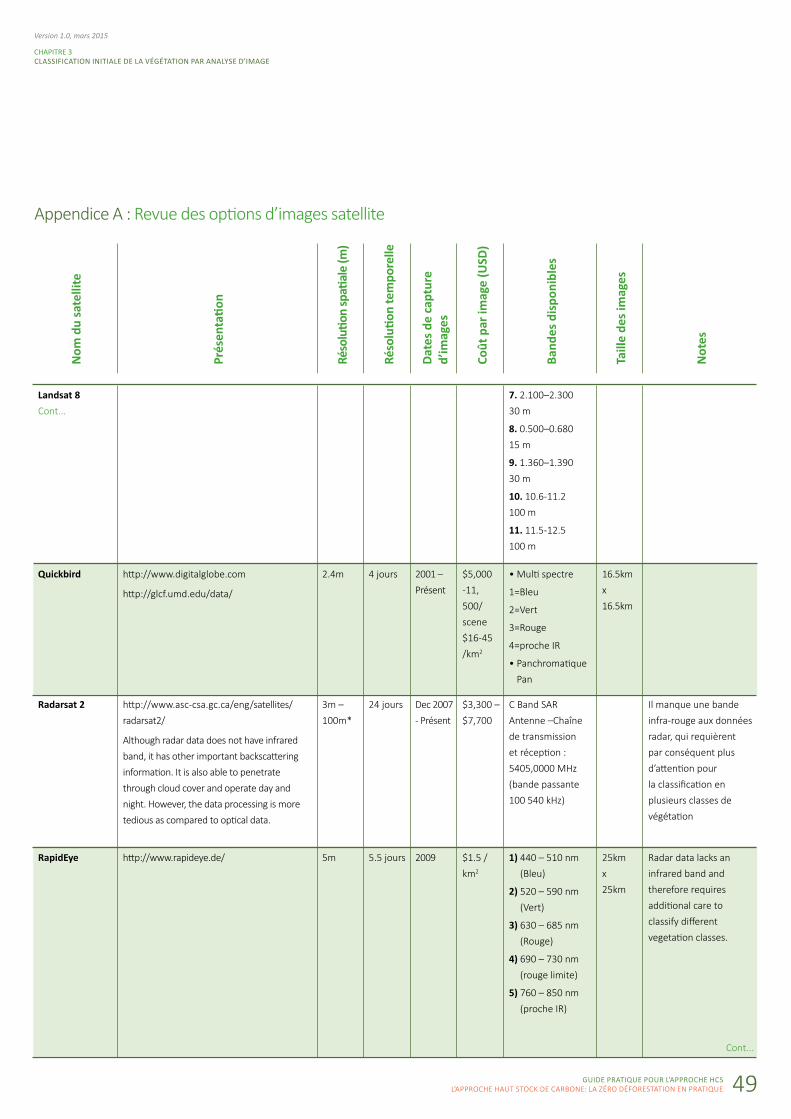
Appendice A : Revue des options d’images satellite
Landsat 7 Missions satellite d’observation de la Terre
du Gouvernement des États Unis, gérées
conjointement par la NASA et l’USGS. Les
bandes comprennent :
• Multi-spectrum Scanner (MSS)
• Thematic Mapper (TM)
• Enhanced Thematic Mapper Plus (ETM+)
http://landsat.gsfc.nasa.gov/
http://glcf.umd.edu/data/
Depuis 2003, les données image de Landsat
7 ont été marquées par un problème dit de
stripping, qui a réduit la qualité des images
produites.
30m 16 jours Avril
1999 –
Présent
Gratuit 8 Bandes :
1. 0.45 - 0.515 30m
2. 0.525 - 0.605 30m
3. 0.63 - 0.69 30m
4. 0.75 - 0.90 30m
5. 1.55 - 1.75 30m
6. 10.40 - 12.5 60m
7. 2.09 - 2.35 30m
Pan Band. 0.52 - 0.90
15m
170km
par
183km
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 49
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Nom
du
sate
llite
Prés
enta
tion
Réso
lutio
n sp
atial
e (m
)
Réso
lutio
n te
mpo
relle
Date
s de
capt
ure
d’im
ages
Coût
par
imag
e (U
SD)
Band
es d
ispo
nibl
es
Taill
e de
s im
ages
Not
es
Landsat 8 Cont...
Quickbird
Radarsat 2
http://www.digitalglobe.com
http://glcf.umd.edu/data/
http://www.asc-csa.gc.ca/eng/satellites/
radarsat2/
Although radar data does not have infrared
band, it has other important backscattering
information. It is also able to penetrate
through cloud cover and operate day and
night. However, the data processing is more
tedious as compared to optical data.
2.4m
3m –
100m*
4 jours
24 jours
2001 –
Présent
Dec 2007
- Présent
$5,000
-11,
500/
scene
$16-45
/km2
$3,300 –
$7,700
7. 2.100–2.300
30 m
8. 0.500–0.680
15 m
9. 1.360–1.390
30 m
10. 10.6-11.2
100 m
11. 11.5-12.5
100 m
• Multi spectre
1=Bleu
2=Vert
3=Rouge
4=proche IR
• Panchromatique
Pan
C Band SAR
Antenne –Chaîne
de transmission
et réception :
5405,0000 MHz
(bande passante
100 540 kHz)
16.5km
x
16.5km
Il manque une bande
infra-rouge aux données
radar, qui requièrent
par conséquent plus
d’attention pour
la classification en
plusieurs classes de
végétation
Appendice A : Revue des options d’images satellite
RapidEye http://www.rapideye.de/ 5m 5.5 jours 2009 $1.5 /
km2
1) 440 – 510 nm
(Bleu)
2) 520 – 590 nm
(Vert)
3) 630 – 685 nm
(Rouge)
4) 690 – 730 nm
(rouge limite)
5) 760 – 850 nm
(proche IR)
25km
x
25km
Radar data lacks an
infrared band and
therefore requires
additional care to
classify different
vegetation classes.
Cont...
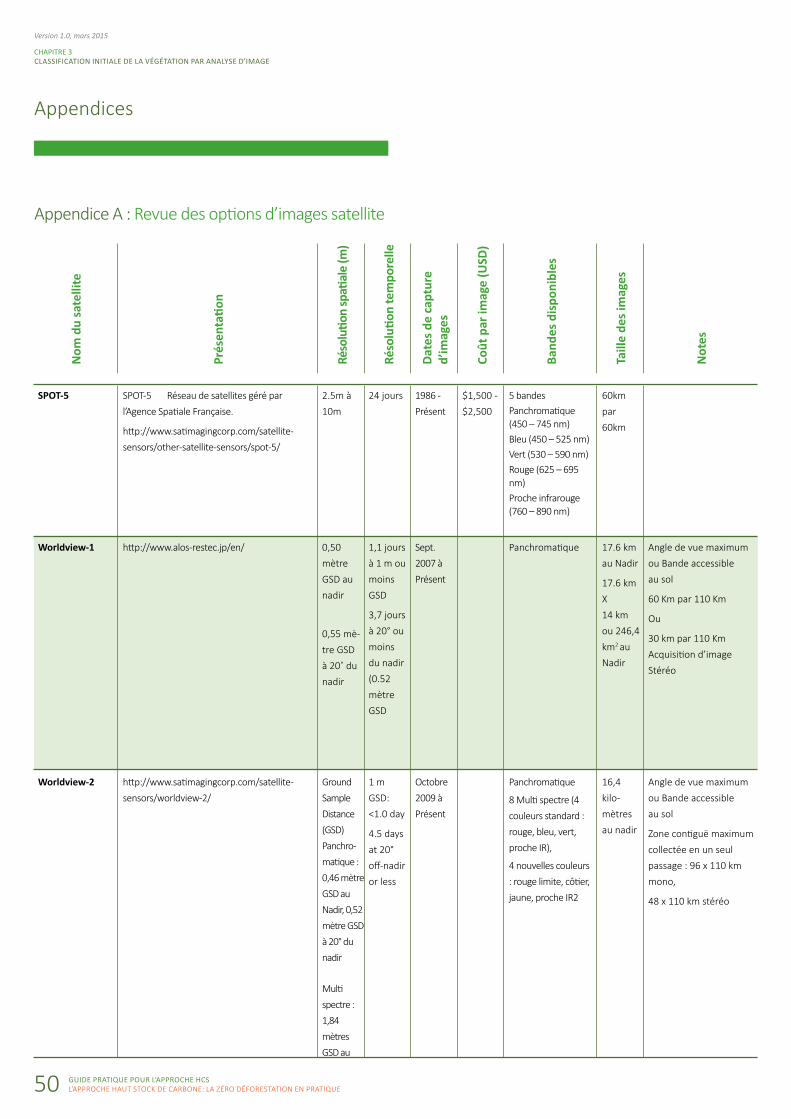
GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 50
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Appendices
Appendice A : Revue des options d’images satellite
Worldview-1
Worldview-2
http://www.alos-restec.jp/en/
http://www.satimagingcorp.com/satellite-
sensors/worldview-2/
0,50
mètre
GSD au
nadir
0,55 mè-
tre GSD
à 20˚ du
nadir
Ground
Sample
Distance
(GSD)
Panchro-
matique :
0,46 mètre
GSD au
Nadir, 0,52
mètre GSD
à 20° du
nadir
Multi
spectre :
1,84
mètres
GSD au
1,1 jours
à 1 m ou
moins
GSD
3,7 jours
à 20° ou
moins
du nadir
(0.52
mètre
GSD
1 m
GSD:
<1.0 day
4.5 days
at 20°
off-nadir
or less
Sept.
2007 à
Présent
Octobre
2009 à
Présent
Panchromatique
Panchromatique
8 Multi spectre (4
couleurs standard :
rouge, bleu, vert,
proche IR),
4 nouvelles couleurs
: rouge limite, côtier,
jaune, proche IR2
17.6 km
au Nadir
17.6 km
X
14 km
ou 246,4
km2 au
Nadir
16,4
kilo-
mètres
au nadir
Angle de vue maximum
ou Bande accessible
au sol
60 Km par 110 Km
Ou
30 km par 110 Km
Acquisition d’image
Stéréo
Angle de vue maximum
ou Bande accessible
au sol
Zone contiguë maximum
collectée en un seul
passage : 96 x 110 km
mono,
48 x 110 km stéréo
SPOT-5 SPOT-5 Réseau de satellites géré par
l’Agence Spatiale Française.
http://www.satimagingcorp.com/satellite-
sensors/other-satellite-sensors/spot-5/
2.5m à
10m
24 jours 1986 -
Présent
$1,500 -
$2,500
5 bandesPanchromatique (450 – 745 nm)Bleu (450 – 525 nm)Vert (530 – 590 nm)Rouge (625 – 695 nm)Proche infrarouge (760 – 890 nm)
60km
par
60km
Nom
du
sate
llite
Prés
enta
tion
Réso
lutio
n sp
atial
e (m
)
Réso
lutio
n te
mpo
relle
Date
s de
capt
ure
d’im
ages
Coût
par
imag
e (U
SD)
Band
es d
ispo
nibl
es
Taill
e de
s im
ages
Not
es

GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 51
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Appendice A : Revue des options d’images satellite
Worldview-2 Cont...
Worldview-3 http://www.satimagingcorp.com/satellite-
sensors/worldview-3/
nadir, 2,4
mètres
GSD à 20°
du nadir
Panchro-
matique
nadir :
0,31 m
GSD au
Nadir
0,34 m
à 20° du
nadir
Multi
spectre
nadir :
1,24 m
au nadir,
1,38 m
à 20° du
nadir
SWIR
nadir :
3,70 m
au nadir,
4,10 m
à 20° du
nadir
CAVIS
nadir :
30,00 m
11 m
GSD : <
1,0 jour
4,5 jours
à 20° ou
moins
du nadir
Août
2014 à
Présent
Panchromatique @
450-800 nm
8 bandes Multi
spectre @ 400
– 1040 nm
8 bandes SWIR @
1195 – 2365 nm
12 bandes CAVIS
@405 – 2245 nm
Au nadir:
13,1 km
Zone contiguë maximum
collectée en un seul
passage (à un angle de
30° du nadir)
Mono : 66,5 km x 112
km (5 bandes)
Stéréo : 26,6 km x 112
km (2 pairs)
Nom
du
sate
llite
Prés
enta
tion
Réso
lutio
n sp
atial
e (m
)
Réso
lutio
n te
mpo
relle
Date
s de
capt
ure
d’im
ages
Coût
par
imag
e (U
SD)
Band
es d
ispo
nibl
es
Taill
e de
s im
ages
Not
es

GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 52
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Appendices
Capt
eur
Site
Inte
rnet
/Not
es
Réso
lutio
n sp
atial
e
Réso
lutio
n te
mpo
relle
Date
de
capt
ure
d’im
age
Coût
de
l’im
age
Band
es d
ispo
nibl
es
Band
e
Appendice A : Revue des options d’images satellite: Nouvelles technologies
Drone (ou UAV -unmanned aerial vehicles) Ebee
Données LiDAR
LiDAR par avion
Radar micro-onde ou à synthèse d’ouverture (SAR) ERS, ENVISAT (mis hors service) et Sentinel-1, lancé en avril 2014
www.sensefly.com
Pour cartographier en très haute résolution la
topographie, l’occupation des sols, la couverture
terrestre et ses changements.
C’est un très bon outil pour contrôler les
changements pouvant survenir dans une zone
donnée.
Dans certaines zones, seuls des pilotes accrédités
sont autorisés à utiliser cette technologie.
Plusieurs drones multirotor et à ailes fixes
devraient être considérés par des experts car ces
technologies évoluent rapidement.
http://www.lidarbasemaps.org/
Pour cartographier la topographie, créer MNT
et lignes de contours, et relever l’occupation
des sols et la couverture terrestre. Ce n’est pas
l’outil idéal pour surveiller les changements
d’occupation des sols et couverture terrestre,
du fait du coût élevé en temps et en argent de
survols fréquents.
https://earth.esa.int/web/guest/missions/
esa-future-missions
https://earth.esa.int/web/guest/missions/
esa-future-missions/sentinel-1
https://sentinel.esa.int/web/sentinel/
sentinel-data-access
Les archives de ERS et ENVISATS datant d’avant
2012 sont disponibles.
De
moins
d’un
mètre
à plus
de 5 m
Cf. site
internet
30 000
points
par
second
à une
précision
de 15
mètres
Senti-
nel-1
Résolu-
tion
de 20m
N’importe
quel jour ou
heure dans
de bonnes
conditions
météorolo-
giques
Cf. site
internet
N’importe
quand dans
de bonnes
conditions
météoro-
logiques
Sentinel-1
Visite tous
les 12 jours
N’importe
quelle date
à laquelle
l’équipe a
fixé le vol
Cf. site
internet
Choix des
analystes
Sentinel-1:
Since April
2014
35 USD par km2 pour une
acquisition d’images
stéréo
700 images par vol
10 km2 par vol de 45
minutes
Le temps de traitement
est de 12 heures par 100
images @ ~800 USD par
jour de travail
Cf. site internet
Sentinel-1
Depuis avril 2014
Visible (bleu, vert et
rouge) avec un
appareil photo
visible
Proche infrarouge
avec un appareil
proche infrarouge
Cf. site internet
Sentinel-1
C-Band SAR
10 km
par 10
km
Cf. site
internet
Sentinel-1
bande
de
250 km

GUIDE PRATIQUE POUR L’APPROCHE HCS L’APPROCHE HAUT STOCK DE CARBONE: LA ZÉRO DÉFORESTATION EN PRATIQUE 53
Version 1.0, mars 2015
CHAPITRE 3 CLASSIFICATION INITIALE DE LA VÉGÉTATION PAR ANALYSE D’IMAGE
Kauth et Thomas (1976) ont développé une transformation orthogonale de l’espace d’origine des données Landsat MSS en un nouvel espace à quatre dimensions. Cette transformation a été nommée l’espace indiciel transformé (« Tasselled Cap » en anglais) ou transformation Kauth-Thomas. Le nom « Tasselled Cap » provient de la forme en chapeau de la projection de la verdure (en Y) en fonction de la brillance (en X). Quatre nouveaux axes ont été créés : l’indice de brillance du sol (B), l’indice de verdure de la végétation (G), l’indice de jaunissement (Y) et rien de la sorte (N). Les noms associés aux nouveaux axes indiquent les caractéristiques que ceux-ci décrivent.
Les coefficients pour Landsat MSS sont (Kauth et al., 1979) :
B = 0.322*MSS1 + 0.603*MSS2 + 0.675*MSS3 + 0.262*MSS4
G= - 0.283*MSS1 -0.660*MSS2 + 0.577*MSS3 + 0.388*MSS4
Y = - 0.899*MSS1 + 0.428*MSS2 + 0.076*MSS3 – 0.041*MSS4
N = - 0.061*MSS1 +0.131*MSS2 - 0.452 * MSS3 + 0.882 * MSS4
Crist et Kauth (1986) ont dérivé les coefficients pour transformer les bandes visible, proche infrarouge et infrarouge moyen des images Landsat Thematic Mapper (TM) en variables de brillance (B), verdure (G) et humidité (W).
B = 0.2909*TM1 + 0.2493*TM2 + 0.4806*TM3 + 0.5568*TM4 + 0.4438*TM5 + 0.1706*TM7
G = - 0.2728*TM1 – 0.2174*TM2 – 0.5508*TM3 +0.7221*TM4 + 0.0733*TM5 – 0.1648*TM7
W = 0.1446 * TM1 + 0.1761*TM2 +0.3322*TM3 +0.3396*TM4 – 0.6210*TM5 – 0.4186*TM7
Les coefficients de l’espace indiciel transformé pour Landsat 7 Enhanced Thematic Mapper Plus (ETM+) sont (Huang et al., 2002) :)
B = 0.3561*TM1 + 0.3972*TM2 + 0.3904*TM3 + 0.6966*TM4 + 0.2286*TM5 + 0.1596*TM7
G = -0.334*TM1 – 0.354*TM2 -0.456*TM3 + 0.6966*TM4 – 0.24*TM5 – 0.263* TM7
W = 0.2626*TM1 + 0.2141*TM2 + 0.0926*TM3 + 0.0656*TM4 – 0.763*TM5 – 0.539*TM7
Quatrièm= 0.0805*TM1 – 0.050*TM2 + 0.1950*TM3 – 0.133*TM4 + 0.5752*TM5 – 0.777*TM7
Cinquième = -0.725*TM1 – 0.020*TM2 + 0.6683*TM3 + 0.0631*TM4 - 0.149*TM5 – 0.027*TM7
Sixième = -0.400*TM1 – 0.817*TM2 + 0.3832*TM3 + 0.0602*TM4 – 0.109*TM5 + 0.0985*TM7
Les coefficients de l’espace indiciel transformé pour les images Landsat 8 sont (Baig et al., 2014)
B = 0.3029*TM2 + 0.2786*TM3 + 0.4733*TM4 + 0.5599*TM5 + 0.508*TM6 + 0.1872*TM7
G = -0.2941*TM2 – 0.243*TM3 – 0.5424*TM4 + 0.7276*TM5 + 0.0713*TM6 – 0.1608*TM7
W = 0.1511*TM2 + 0.1973*TM3 + 0.3283*TM4 + 0.3407*TM5 - 0.7117*TM6 - 0.4559*TM7
Quatrièm = - 0.8239*TM2 + 0.0849*TM3 + 0.4396*TM4 - 0.058*TM5 + 0.2013*TM6 - 0.2773*TM7
Cinquième = -0.3294*TM2 + 0.0557*TM3 + 0.1056*TM4 + 0.1855*TM5 - 0.4349*TM6 + 0.8085*TM7
Sixième = 0.1079*TM2 - 0.9023*TM3 + 0.4119*TM4 + 0.0575*TM5 - 0.0259*TM6 + 0.0252*TM7
Appendice B : Espace indiciel transformé (Tasseled Cap Transformation)


















