Update Rules for CNN Backpropagation
15
Update rules for CNN Backpropagation Algorithm Thomas Epelbaum March 29, 2017 Abstract In this note, we derive step by step the update rules for a Convolutional Neural Network (CNN) similar to the LeNet CNN Contents 1 Forward propagation 3 1.1 Input layer ............................ 3 1.2 First hidden layer ......................... 3 1.3 Second hidden layer ....................... 5 1.4 Third hidden layer ........................ 6 1.5 Fourth hidden layer ....................... 7 1.6 Output layer ........................... 8 1.7 Summary ............................. 9 2 Backward propagation 9 2.1 Derivation ............................. 9 2.2 Summary ............................. 15 Update rules for CNN Backpropagation Algorithm Page 1/15
-
Upload
thomas-epelbaum -
Category
Science
-
view
387 -
download
0
Transcript of Update Rules for CNN Backpropagation

Update rules for CNN BackpropagationAlgorithm
Thomas Epelbaum
March 29, 2017
Abstract
In this note, we derive step by step the update rules for a ConvolutionalNeural Network (CNN) similar to the LeNet CNN
Contents
1 Forward propagation 31.1 Input layer . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 First hidden layer . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Second hidden layer . . . . . . . . . . . . . . . . . . . . . . . 51.4 Third hidden layer . . . . . . . . . . . . . . . . . . . . . . . . 61.5 Fourth hidden layer . . . . . . . . . . . . . . . . . . . . . . . 71.6 Output layer . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2 Backward propagation 92.1 Derivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
Update rules for CNN Backpropagation Algorithm Page 1/15

Inpu
tLa
yer
...
N0
T0F
0 R0
R0
S0
Wei
ghts
1
. ......F
1
. .
Firs
tco
nvol
utio
nla
yer
. . .S
1
R1
R1
N1
T1F
1
Firs
tPo
olin
gla
yer
. . .S
2
R2
R2 N
2
T2
F2
Wei
ghts
2
. ......F
3
. .
Seco
ndC
onvo
lutio
nla
yer
. . . . . .T
3
N3
F3
Seco
ndPo
olin
gla
yer
bias
. . . . . .F
4
Wei
ghts
3 . . . . . . ....F
5
. . . . . .
Out
put . . . . . .
F5
h(t
)(0)
ijk
=X
(t)
ijk
Θ(0
)fij
k
Θ(0
)f
a(t
)(0)
flm
=F
0−
1 ∑ i=0
R0−
1 ∑ j=0
R0−
1 ∑ k=
0Θ
(0)f
ij
kh
(t)(
0)iS
0l+
jS
0m
+k
h(t
)(1)
flm
=Θ
(0)f
g( a
(t)(
0)f
lm
)a
(t)(
1)f
lm
=R
1−
1m
axj,
k=
0
∣ ∣ ∣h(t)(
1)f
S1l+
jS
1m
+k
∣ ∣ ∣
h(t
)(2)
flm
=a
(t)(
1)f
lm
Θ(1
)fij
k
Θ(1
)f
a(t
)(2)
flm
=F3−
1 ∑ i=0
R2−
1 ∑ j=0
R2−
1 ∑ k=
0Θ
(1)f
ij
kh
(t)(
2)iS
2l+
jS
2m
+k
h(t
)(3)
flm
=Θ
(1)f
g( a
(t)(
2)f
lm
)a(t
)(3)
f=
T3−
1m
axj=
0
N3−
1m
axk
=0
∣ ∣ ∣h(t)(
3)f
jk
∣ ∣ ∣h
(t)(
4)f
=a
(t)(
3)f
Θ(2
)f
f′
a(t
)(4)
f=
F4 ∑ f
′ =0Θ
(2)
ff
′h(t
)(4)
f′
h(t
)(5)
f=
o( a
(t)(
4)f
)
i∈
J0,F
0−
1Kch
anne
ls
j∈
J0,T
0−
1Khe
ight
k∈
J0,N
0−
1Kw
idth
Rec
eptiv
efie
ldR
0
Strid
eS
0
t∈
J0,T
trai
n−
1Ktr
aini
ngse
tf∈
J0,F
1−
1K
F1
wha
twe
want
i∈
J0,F
0−
1K
j∈
J0,T
0−
1K
k∈
J0,N
0−
1K
f∈
J0,F
1−
1K
T1
=T
0−
R0
S0
+1
N1
=N
0−
R0
S0
+1
Rec
eptiv
efie
ldR
1
Strid
eS
1
l∈
J0,T
1−
1K
m∈
J0,N
1−
1K
f∈
J0,F
2−
1K
T2
=T
1−
R1
S1
+1
N2
=N
1−
R1
S1
+1
F2
=F
1
Rec
eptiv
efie
ldR
2
Strid
eS
1
l∈
J0,T
2−
1K
m∈
J0,N
2−
1K
f∈
J0,F
3−
1K
F3
wha
twe
want
i∈
J0,F
2−
1K
j∈
J0,T
2−
1K
k∈
J0,N
2−
1K
f∈
J0,F
3−
1K
T3
=T
2−
R2
S2
+1
N3
=N
2−
R2
S2
+1
Rec
eptiv
efie
ldN
3×
T3
Strid
e1
l∈
J0,T
3−
1K
m∈
J0,N
3−
1K
f∈
J0,F
4−
1K
F4
=F
3
f∈
J0,F
5−
1K
f′∈
J0,F
4K
f∈
J0,F
5−
1K
F5
wha
twe
want
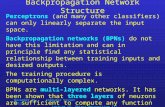
Figure 1: The CNN described in the present note
Update rules for CNN Backpropagation Algorithm Page 2/15

1 Forward propagationWe will adopt C convention for the indices : they will thus start from 0.
In parenthesis one can find numerical values for the different network sizesin one particular network design.
1.1 Input layer
Input Layer
...
N0
T0
F0
Figure 2: The Input layer
We will be considering a input of F0 channels ( F0 ∈ J1, 4K for instance).Each image in each channel will be of size N0 × T0. To fix ideas, a typicalimage might be of size 60 × 60. The input will be denoted X
(t)i j k, with
t ∈ J0, Ttrain−1K (size of the training set), j ∈ J0, T0−1K and k ∈ J0, N0−1K.
1.2 First hidden layerThe first hidden layer will be obtained after a convolution operation,
where there is F1 (80) feature maps, a receptive field of size R0×R0 (9× 9)and a stride of size S0 (1). This gives
(N0−R0S0
+ 1)×(T0−R0S0
+ 1)
(52× 52)hidden units in each feature maps, but only F0×R0×R0 +1 (the +1 comingfrom the bias terms : the prefactors of the sigmoid function) parameters ofeach feature map . These weights will be denoted Θ(0)f
i j k , with f ∈ J0, F1−1K,i ∈ J0, F0 − 1K and j, k ∈ J0, R0 − 1K. We will write
h(t)(0)i j k = X
(t)i j k , a
(t)(0)f lm =
F0−1∑i=0
R0−1∑j=0
R0−1∑k=0
Θ(0)fi j k h
(t)(0)i S0l+j S0m+k . (1)
Update rules for CNN Backpropagation Algorithm Page 3/15

Input Layer
...
N0
T0
F0
R0
R0
S0
Weights 1
.......
F1
..
First convolution layer
...
N1
T1
F1
Figure 3: The first covolution operation
Here a(0) is obtained via a so called convolution operation, hence thename of the layer
a(t)(0)f lm =
F0−1∑i=0
(Θ(0)fi • • ? h
(t)(0)i • •
)lm
, (2)
where
(Θ(0)fi • • ? h
(t)(0)i • •
)lm
=R0−1∑j=0
R0−1∑k=0
Θ(0)fi j k h
(t)(0)i S0l+j S0m+k . (3)
One obtains the hidden units via a sigmoid function application
h(t)(1)f lm = Θ(0)fg
(a
(t)(0)f lm
). (4)
For the following, we will denote
N1 = N0 −R0S0
+ 1 , T1 = T0 −R0S0
+ 1 . (5)
In practice N1 = T1 = 52.
Update rules for CNN Backpropagation Algorithm Page 4/15

First convolution layer
...
N1
T1
F1
Figure 4: The first hidden layer
1.3 Second hidden layerThe second hidden layer will be the result of a max pooling operation.
Calling S1 the stride of the pooling layer and R1 the size of the receptivefield, we have
a(t)(1)f lm = R1−1max
j,k=0
∣∣∣h(t)(1)f S1l+j S1m+k
∣∣∣ , (6)
where we have used the rectification procedure.
First convolution layer
...S1
R1
R1
N1
T1
F1
First Pooling layer
...
N2
T2
F2
Figure 5: The first pool operation
denoting j?flm, k?
flmthe indices at which the f, l,m maximum is reached
We then define the second hidden layer as
h(t)(2)f lm = a
(t)(1)f lm =
∣∣∣∣h(t)(1)f S1l+j?
flmS1m+k?
flm
∣∣∣∣ . (7)
Here we have F2 = F1 feature maps, each of dimension
N2 = N1 −R1S1
+ 1 , T2 = T1 −R1S1
+ 1 . (8)
Update rules for CNN Backpropagation Algorithm Page 5/15

In practice we will take R1 = 8, S1 = 4, so that T2 = N2 = 12.
First Pooling layer
...
N2
T2
F2
Figure 6: The second hidden layer
1.4 Third hidden layerThe third hidden layer is again a convolution layer. Historically (for time
consumption issues), one did not sample from the full F2 feature maps, butonly from a random subset F2
δ2(with δ2 = 4 being a standard choice), which
gave feature maps F3 = δ2F2. Here We will sample from the full F2 featuremap
a(t)(2)f lm =
F2−1∑i=0
R2−1∑j=0
R2−1∑k=0
Θ(1)fi j k h
(t)(2)i S2l+j S2m+k . (9)
First Pooling layer
...S2
R2
R2
N2
T2
F2
Weights 2
..
..
..
.F3
..
Second Convolution layer
......T3
N3
F3
Figure 7: The second covolution operation
Each new feature maps is of size(N2−R2S2
+ 1)×(T2−R2S2
+ 1), that we
respectively call N3 and T3. The hidden units are then obtained via asigmoid function application
h(t)(3)f lm = Θ(1)fg
(a
(t)(2)f lm
). (10)
Update rules for CNN Backpropagation Algorithm Page 6/15

We will take F3 = 480, R2 = 8 and S2 = 1, so that N3 = T3 = 5.
Second Convolution layer
......T3
N3
F3
Figure 8: The third hidden layer
1.5 Fourth hidden layerThe fourth hidden layer is again the result of a pooling operation. Calling
S3 the stride of the pooling layer and R3 the size of the receptive field, wehave
a(t)(3)f lm = R3−1max
j,k=0
∣∣∣h(t)(3)f S3l+j S3m+k
∣∣∣ . (11)
Second Convolution layer
......T3
N3
F3
Second Pooling layer
......F4
Figure 9: The second pool operation
We then define the forth hidden layer as
h(t)(4)f lm = a
(t)(3)f lm . (12)
Here we have F4 = F3 feature maps, each of dimension
N4 = N3 −R3S3
+ 1 , T4 = T3 −R3S3
+ 1 . (13)
At this point it is standard to have N4 = T4 = 1. In our case this impliesR3 = 5 and S3 = 1.
Update rules for CNN Backpropagation Algorithm Page 7/15

Second Pooling layerbias
......F4
Figure 10: The fourth hidden layer
Thus, denoting j??f, k??
fthe indices at which the f maximum is reached
h(t)(4)f = a
(t)(3)f = T3−1max
j=0
N3−1maxk=0
∣∣∣h(t)(3)f j k
∣∣∣ =∣∣∣∣h(t)(3)f j??
fk??
f
∣∣∣∣ . (14)
1.6 Output layerThe output layer is finally obtained via a full connection to the last
hidden layer (assuming N4 = T4 = 1)
a(t)(4)f =
F4∑f ′=0
Θ(2)f f ′h
(t)(4)f ′ , (15)
where a bias term have been added. F5 can be taken freely.
Second Pooling layer
bias
......F4
Weights 3
......
..
..F5
......
Output
......F5
Figure 11: The fully connected operation
The ouput is then
h(t)(5)f = o(a(t)(4)
f ) , (16)
and in the case of the Euclidean loss function, the output function is justthe identity.
Update rules for CNN Backpropagation Algorithm Page 8/15

Output
......F5
Figure 12: The output layer
1.7 SummaryForward propagation amounts to apply all the steps described in the
previous sections
h(t)(0)f lm = X
(t)f lm , a
(t)(0)f lm =
F0−1∑i=0
(Θ(0)fi • • ? h
(t)(0)i • •
)lm
, (17)
h(t)(1)f lm = Θ(0)fg
(a
(t)(0)f lm
), a
(t)(1)f lm =
∣∣∣∣h(t)(1)f S1l+j?
flmS1m+k?
flm
∣∣∣∣ , (18)
h(t)(2)f lm = a
(t)(1)f lm , a
(t)(2)f lm =
F2−1∑i=0
(Θ(1)fi • • ? h
(t)(2)i • •
)lm
, (19)
h(t)(3)f lm = Θ(1)fg
(a
(t)(2)f lm
), a
(t)(3)f =
∣∣∣∣h(t)(3)f j??
fk??
f
∣∣∣∣ , (20)
h(t)(4)f = a
(t)(3)f , a
(t)(4)f =
F4∑f ′=0
Θ(2)f f ′h
(t)(4)f ′ , (21)
h(t)(5)f = o(a(t)(4)
f ) . (22)
2 Backward propagation
2.1 DerivationDefining the loss function (forgetting for the time being the regularizing
terms)
J(Θ) = 12Ttrain
Ttrain−1∑t=0
F5−1∑f=0
(y
(t)f − h
(t)(5)f
)2
= 12Ttrain
Ttrain−1∑t=0
F5−1∑f=0
(y
(t)f − a
(t)(4)f
)2= 1Ttrain
Ttrain−1∑t=0
J (t)(Θ) , (23)
Update rules for CNN Backpropagation Algorithm Page 9/15

we are interested in finding (i ∈ J0, F5 − 1K, j ∈ J0, F4K)
∆(2)ij = ∂
∂Θ(2)ij
J (t)(Θ) , (24)
as well as (f ∈ J0, F3 − 1K, i ∈ J0, F2 − 1K, i, j ∈ J0, R2 − 1K)
∆(1)fijk = ∂
∂Θ(1)fi j k
J (t)(Θ) , ∆(1)f = ∂
∂Θ(1)f J(t)(Θ) , (25)
and (f ∈ J0, F1 − 1K, i ∈ J0, F0 − 1K, i, j ∈ J0, R0 − 1K)
∆(0)fijk = ∂
∂Θ(0)fi j k
J (t)(Θ) , ∆(0)f = ∂
∂Θ(0)f J(t)(Θ) . (26)
First, we have
∆(2)ij =
F5−1∑f=0
∂a(t)(4)f
∂Θ(2)ij
∂
∂a(t)(4)f
J (t)(Θ) , (27)
and calling
δ(t)(4)f = ∂
∂a(t)(4)f
J (t)(Θ) =(h
(t)(5)f − y(t)
f
), (28)
we get
∆(2)ij =
F5−1∑f=0
F4∑f ′=0
∂Θ(2)f f ′
∂Θ(2)ij
h(t)(4)f ′
(h
(t)(5)f − y(t)
f
)= δ
(t)(4)i h
(t)(4)j . (29)
To go further we need
δ(t)(3)f = ∂
∂a(t)(3)f
J (t)(Θ) =F5−1∑f ′=0
∂a(t)(4)f ′
∂a(t)(3)f
δ(t)(4)f ′ =
F5−1∑f ′=0
F4∑f ′′=0
Θ(2)f ′ f ′′
∂h(t)(4)f ′′
∂h(t)(4)f
δ(t)(4)f ′
=F5−1∑f ′=0
Θ(2)f ′ fδ
(t)(4)f ′ , (30)
so that (calling ε the function returning the sign of its argument)
∆(1)f =F3−1∑f ′=0
∂a(t)(3)f ′
∂Θ(1)f δ(t)(3)f ′ =
F3−1∑f ′=0
ε
(h
(t)(3)f ′ j??
f ′k??
f ′
) ∂h(t)(3)f ′ j??
f ′k??
f ′
∂Θ(1)f δ(t)(3)f ′
= ε
(h
(t)(3)f j??
fk??
f
)g
(a
(t)(2)f j??
fk??
f
)δ
(t)(3)f . (31)
Update rules for CNN Backpropagation Algorithm Page 10/15

This corresponds to the following backward pooling
Second Convolution layer
......j??
f
k??f
F3
Second Pooling layer
......F4
Figure 13: Backward pooling through the second Conv-Pool layers. j??f
and k??f
correspond to the indices at which the maximum of T3−1maxj=0
N3−1maxk=0
∣∣∣h(t)(3)f j k
∣∣∣ is reached
Calling
δ(t)(i)flm = ∂
∂a(t)(i)f lm
J (t)(Θ) , (32)
to go further we need
δ(t)(2)flm =
F4−1∑f ′=0
∂a(t)(3)f ′
∂a(t)(2)f lm
∂
∂a(t)(3)f ′
J (t)(Θ) =F4−1∑f ′=0
∂a(t)(3)f ′
∂a(t)(2)f lm
δ(t)(3)f ′
=F4−1∑f ′=0
∂
∣∣∣∣h(t)(3)f ′ j??
f ′k??
f ′
∣∣∣∣∂a
(t)(2)f lm
δ(t)(3)f ′ =
F4−1∑f ′=0
ε(h(t)(3)f ′ j??
f ′k??
f ′)∂h
(t)(3)f ′ j??
f ′k??
f ′
∂a(t)(2)f lm
δ(t)(3)f ′
=F4−1∑f ′=0
ε(h(t)(3)f ′ j??
f ′k??
f ′)Θ(1)f ′
∂g
(a
(t)(2)f ′ j??
f ′k??
f ′
)∂a
(t)(2)f lm
δ(t)(3)f ′
= ε(h(t)(3)f j??
fk??
f)Θ(1)fg′
(a
(t)(2)f j??
fk??
f
)δ
(t)(3)f δ
j??f
l δk??
fm . (33)
Thus
∆(1)fijk =
F3−1∑f ′=0
T3−1∑l=0
N3−1∑m=0
∂a(t)(2)f ′ l m
∂Θ(1)fi j k
∂
∂a(t)(2)f ′ l m
J (t)(Θ)
=F3−1∑f ′=0
T3−1∑l=0
N3−1∑m=0
F3−1∑i′=0
R2−1∑j′=0
R2−1∑k′=0
∂Θ(1)f ′i′ j′ k′
∂Θ(1)fi j k
h(t)(2)i′ S2l+j′ S2m+k′
∂
∂a(t)(2)f ′ l m
J (t)(Θ)
=T3−1∑l=0
N3−1∑m=0
h(t)(2)i S2l+j S2m+kδ
(t)(2)f lm . (34)
Update rules for CNN Backpropagation Algorithm Page 11/15

Alternatively, it could be more convenient to compute
∆(1)fijk = Θ(1)fh
(t)(2)i S2j??
f+j S2k??
f+kε(h
(t)(3)f j??
fk??
f) g′
(a
(t)(2)f j??
fk??
f
)δ
(t)(3)f . (35)
First Pooling layer
...S2j
??f + j
S2k??f + k
N2
T2
F2
Weights 2
..
..
..
.F3
..
Second Convolution layer
......j??
f
k??f
F3
Figure 14: Backward pooling through the second Conv first pool layers. j??f
andk??
fcorrespond to the indices at which the maximum of T3−1max
j=0
N3−1maxk=0
∣∣∣h(t)(3)f j k
∣∣∣ is reached
This corresponds to the backward pooling of the previous figure. Now,to go further we will need
δ(t)(1)flm =
F3−1∑f ′=0
T3−1∑l′=0
N3−1∑m′=0
∂a(t)(2)f ′ l′m′
∂a(t)(1)f lm
δ(t)(2)f ′l′m′ . (36)
First
∂a(t)(2)f ′ l′m′
∂a(t)(1)f lm
=F3−1∑i=0
R2−1∑j=0
R2−1∑k=0
Θ(1)f ′i j k
∂h(t)(2)i S2l′+j S2m′+k
∂a(t)(1)f lm
(37)
In practice, we will take S2 = 1 that will greatly simplifies our life. Thus
∂a(t)(2)f ′ l′m′
∂a(t)(1)f lm
=F3−1∑i=0
R2−1∑j=0
R2−1∑k=0
Θ(1)f ′i j k
∂a(t)(1)i l′+j m′+k
∂a(t)(1)f lm
=R2−1∑j=0
R2−1∑k=0
Θ(1)f ′f j k δ
l′+jl δm
′+km , (38)
so that
δ(t)(1)flm =
F3−1∑f ′=0
R2−1∑j=0
R2−1∑k=0
Θ(1)f ′f j k δ
(t)(2)f ′l−jm−j . (39)
Update rules for CNN Backpropagation Algorithm Page 12/15

This expression only make sense for l,m ≥ R2−1. To complete it and obtainsome kind of convolution product, we do ”padding”, this means adding 0rows and columns in the upper left part of δ(t)(2)
f ′lm . Now
∆(0)f = ∂
∂Θ(0)f J(t)(Θ) =
F2−1∑f ′=0
T2−1∑l=0
N2−1∑m=0
∂a(t)(1)f ′ l m
∂Θ(0)f δ(t)(1)f ′ l m
=T2−1∑l=0
N2−1∑m=0
ε
(h
(t)(1)f S1l+j?
flmS1m+k?
flm
)g
(a
(t)(0)f S1l+j?
flmS1m+k?
flm
)δ
(t)(1)f lm .
(40)
This corresponds to the backward pooling of the following figure
First convolution layer
...S1m + k?
flm
S1l + j?flm
N1
T1
F1
First Pooling layer
...m
l
N2
T2
F2
Figure 15: Backward pooling through the first Conv-Pool layers. j?flm
and k?flm
correspond to the indices at which the maximum of R1−1maxj,k=0
∣∣∣h(t)(1)f S1l+j S1m+k
∣∣∣ is reached
To conclude, we need
δ(t)(0)flm =
F2−1∑f ′=0
T2−1∑l′=0
N2−1∑m′=0
∂a(t)(1)f ′ l′m′
∂a(t)(0)f lm
δ(t)(1)f ′ l′m′
=F4−1∑f ′=0
T2−1∑l′=0
N2−1∑m′=0
ε
(h
(t)(1)f ′ S1l′+j?
f ′l′m′S1m′+k?
f ′l′m′
)
×∂h
(t)(1)f ′ S1l′+j?
f ′l′m′S1m′+k?
f ′l′m′
∂a(t)(0)f lm
δ(t)(1)f ′ l′m′
= Θ(0)fε(h
(t)(1)f lm
)g′(a
(t)(0)f lm
)δ
(t)(1)
fl−j?
flmS1
m−k?flm
S1
. (41)
Update rules for CNN Backpropagation Algorithm Page 13/15

We could alternatively write
δ(t)(0)flm = Θ(0)f
T2−1∑l′=0
N2−1∑m′=0
ε
(h
(t)(1)f S1l′+j?
flmS1m′+k?
flm
)
× g′(a
(t)(0)f S1l′+j?
flmS1m′+k?
flm
)δ
(t)(1)f l′m′δ
S1l′+j?flm
l δS1m′+k?
flmm (42)
so that
∆(0)fijk =
F1−1∑f ′=0
T1−1∑l=0
N1−1∑m=0
∂a(t)(0)f ′ l m
∂Θ(0)fi j k
δ(t)(0)f ′lm
=T1−1∑l=0
N1−1∑m=0
h(t)(0)i S0l+j S0m+kδ
(t)(0)flm , (43)
This corresponds to the backward conv of the following figure
Input Layer
...
N0
T0
F0
S0(S1m + k?flm) + k)
S0(S1l + j?flm) + j)
..
..
.F1
..
First convolution layer
...S1m + k?
flm
S1l + j?flm
N1
T1
F1
Weights 1
..
Figure 16: Backward pooling through the first Conv - Input layers. j?flm
and k?flm
correspond to the indices at which the maximum of R1−1maxj,k=0
∣∣∣h(t)(1)f S1l+j S1m+k
∣∣∣ is reached
and it could be more convenient to compute
∆(0)fijk = Θ(0)f
T2−1∑l=0
N2−1∑m=0
h(t)(0)i S0(S1l+j?
flm)+j S0(S1m+k?
flm)+k
× ε(h
(t)(1)f S1l+j?
flmS1m+k?
flm
)g′(a
(t)(0)f S1l+j?
flmS1m+k?
flm
)δ
(t)(1)f lm , (44)
Update rules for CNN Backpropagation Algorithm Page 14/15

2.2 SummaryWe can re-write things as (the star number corresponds to the number
of the convolutional layer)
δ(t)(4)f = h
(t)(5)f − y(t)
f , (45)
δ(t)(3)f =
F5−1∑f ′=0
Θ(2)f ′ fδ
(t)(4)f ′ , (46)
δ(t)(2)flm = Θ(1)fε(h(t)(3)
f j??fk??
f)g′(a
(t)(2)f j??
fk??
f
)δ
(t)(3)f δ
j??f
l δk??
fm , (47)
δ(t)(1)flm =
F3−1∑f ′=0
R2−1∑j=0
R2−1∑k=0
Θ(1)f ′f j k δ
(t)(2)f ′l−jm−j , (48)
where the indices l,m of δ(t)(2)flm should run from 1−R2 to N3, T3. With
these quantities we have
∆(2)ij = δ
(t)(4)i h
(t)(4)j , (49)
∆(1)fijk = Θ(1)fh
(t)(2)i S2j??
f+j S2k??
f+kε(h
(t)(3)f j??
fk??
f) g′
(a
(t)(2)f j??
fk??
f
)δ
(t)(3)f , (50)
∆(0)fijk = Θ(0)f
T2−1∑l=0
N2−1∑m=0
h(t)(0)i S0(S1l+j?
flm)+j S0(S1m+k?
flm)+k
× ε(h
(t)(1)f S1l+j?
flmS1m+k?
flm
)g′(a
(t)(0)f S1l+j?
flmS1m+k?
flm
)δ
(t)(1)f lm , (51)
and
∆(1)f = ε
(h
(t)(3)f j??
fk??
f
)g
(a
(t)(2)f j??
fk??
f
)δ
(t)(3)f , (52)
∆(0)f =T2−1∑l=0
N2−1∑m=0
ε
(h
(t)(1)f S1l+j?
flmS1m+k?
flm
)g
(a
(t)(0)f S1l+j?
flmS1m+k?
flm
)δ
(t)(1)f lm .
(53)
Update rules for CNN Backpropagation Algorithm Page 15/15


















