
The SAMGrid Data Handling System Outline: What Is SAMGrid? Use Cases for SAMGrid in Run II...
26
The SAMGrid Data Handling System Outline: What Is SAMGrid? Use Cases for SAMGrid in Run II Experiments Current Operational Load Stress Testing Future Project Plans Wyatt Merritt (FNAL/CD/DØ) for the SAMGrid Team (Talk created by Adam Lyon)
-
Upload
margaret-oneal -
Category
Documents
-
view
216 -
download
1
Transcript of The SAMGrid Data Handling System Outline: What Is SAMGrid? Use Cases for SAMGrid in Run II...

The SAMGrid Data Handling System
Outline: What Is SAMGrid? Use Cases for SAMGrid in Run II Experiments Current Operational Load Stress Testing Future Project Plans
Wyatt Merritt (FNAL/CD/DØ) for the SAMGrid Team(Talk created by Adam Lyon)

2
What is SAMGrid? Data handling system for Run II DØ and CDF
SAMGrid manages file storage (replica catalogs) Data files are stored in tape systems at FNAL and elsewhere (most
use ENSTORE at FNAL) Files are cached around the world for fast access
SAMGrid manages file delivery Users at FNAL and remote sites retrieve files out of file storage.
SAMGrid handles caching for efficiency You don't care about file locations
SAMGrid manages file meta-data cataloging SAMGrid DB holds meta-data for each file. You don't need to know
the file names to get data
SAMGrid manages analysis bookkeeping SAMGrid remembers what files you ran over, what files you
processed successfully, what applications you ran, when you ran them and wher

3
SAMGrid Terms and Concepts A project runs on a station and requests delivery of a
dataset to one or more consumers on that station.
Station: Processing power + disk cache + (connection to tape storage) + network access to SAMGrid catalog and other station cachesExample: a linux analysis cluster at D0
Dataset: metadata description which is resolved through a catalog query to a list of files. Datasets are named.Examples: (syntax not exact) data_type physics and run_number 78904 and data_tier raw request_id 5879 and data_tier thumbnail
Consumer: User application (one or many exe instances)Examples: script to copy files; reconstruction job

4
Physics Analysis Use Cases
I. Process Simulated Data
II. Process Unskimmed Collider Data
III. Process Skimmed Collider Data
IV. Process Missed/New Data
V. Analyze Sets of Individual Events ("Pick Events")
Note that there are more use cases for production of simulated data and reconstruction not covered here

5
I. Process Simulated Data Look up simulation request with parameters of
interest e.g. Request 5874 has using Pythia
with mt = 174 GeV/c2
Define dataset (via command-line or GUI): request_id 5874 and data_tier thumbnail
Submit project to SAMGrid station and submit executable instance(s) to batch system (our tools to make that easy) Consumer is started Station delivers files to executable instance(s) Station marks which files were delivered and consumed
successfully and which had errors
Xt

6
II. Process Unskimmed Collider Data Define dataset by describing files of interest
(not listing file names) using command-line or GUI data_tier thumbnail and version p14.06.01 and run_type
physics and run_qual_group MUO and run_quality GOOD
Submit project to SAMGrid station and submit executable instance(s) to batch system (our tools to make that easy) Consumer is started Station delivers files to executable instance(s) Station marks which files were delivered and
consumed successfully and which had errors

7
III. Process Skimmed Collider Data
Someone (a Physics group, the Common Skimming Group, or an individual) has produced skimmed files
They created a dataset that describes these files
You can...Submit project/jobs using their dataset name ORCreate a new dataset based on theirs and adding
additional constraints__set__ DiElectronSkim and run_number 168339
Submission is same as before

8
IV. Process Missed/New Data
The set of files that satisfy the dataset query at a given time is a snapshot and is remembered with the SAMGrid project information
One can make new datasets with:Files that satisfy a dataset but are newer than
the snapshot (new since the project ran)Files that should have been processed by the
original project but were not delivered or not consumed
__set__ myDataSet minus (project_name myProject and
consumed_status consumed and consumer lyon)

9
V. Analyze Individual Events (Pick Events) Users want to analyze individual events
with lower level data tiers (e.g. raw)Event displaysSpecial investigations
The SAMGrid catalog keeps information on each raw event (run#, event#, trigger bits, file)
Users run a pick events tool that creates a dataset and submits an executable to extract and process these events

10
Current SAMGrid Production Configurations Large SMP
A 10 TB central cache with 128 attached processors Mostly used for Pick Events Local job submission (not Grid)
Linux production farms Reconstruction, Monte Carlo Production, Reprocessing Various cache arrangements: distributed on worker nodes,
NFS-mounted from a central head node, routed through a central head node and then distributed
Local or Grid (Condor) job submission
Linux analysis clusters Analysis jobs Various cache arrangements: distributed on worker nodes,
routed through a central head node and then distributed; cached on central node only
Local job submission or remote submission (with experiment-specific tools, not Condor)
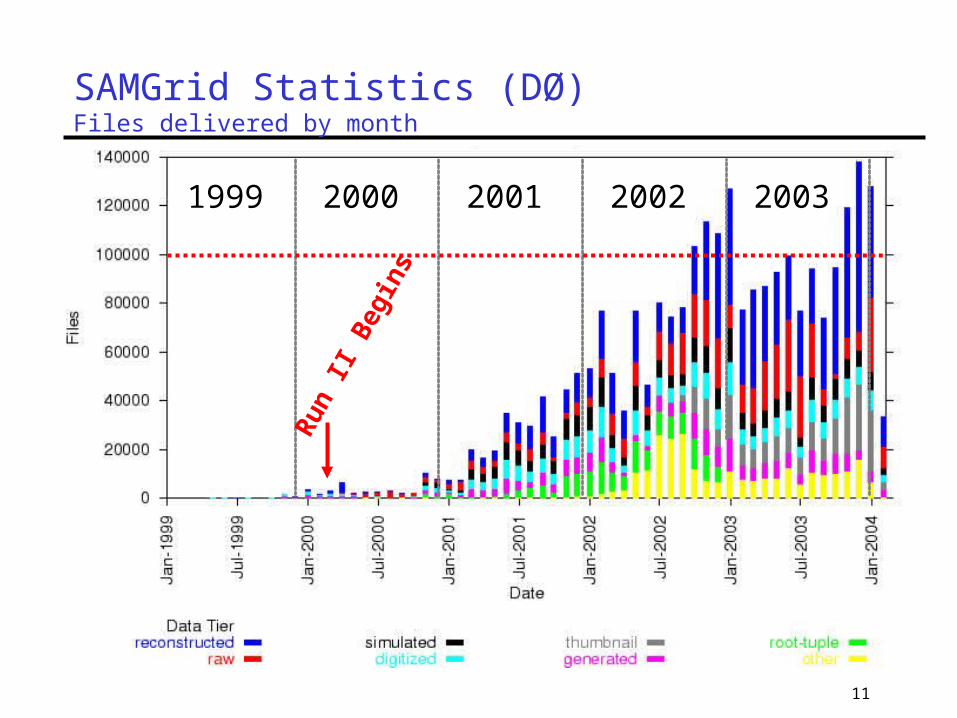
11
SAMGrid Statistics (DØ) Files delivered by month
1999 2000 2001 2002 2003
Run II Begin
s
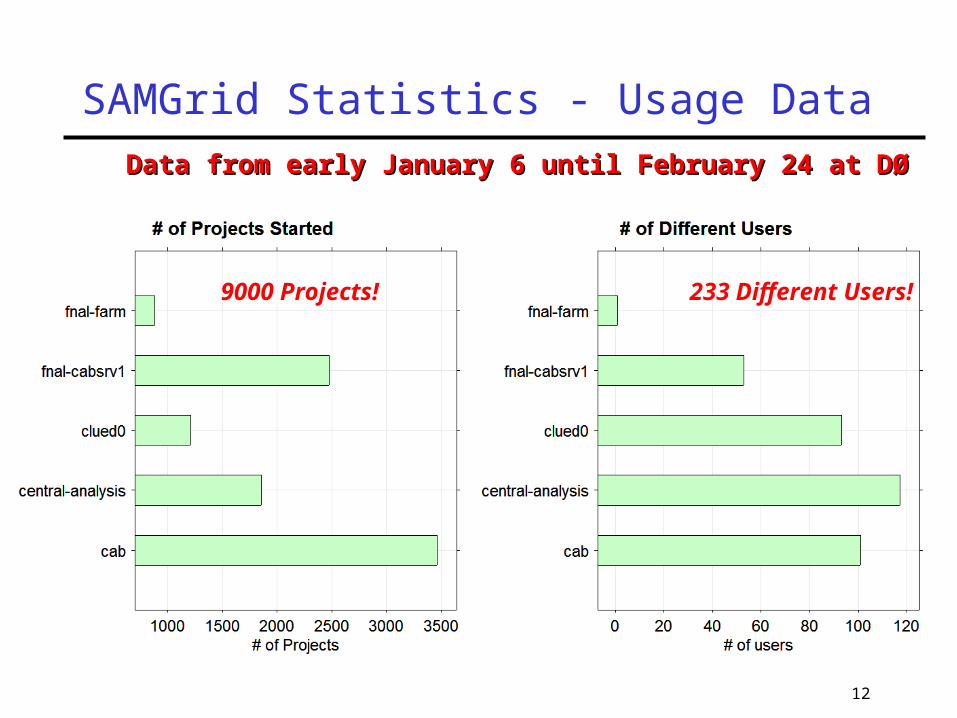
12
SAMGrid Statistics - Usage Data
9000 Projects! 233 Different Users!
Data from early January 6 until February 24 at DØData from early January 6 until February 24 at DØ

13
SAMGrid Statistics - Usage Data
~500K Files! ~1%

14
SAMGrid Statistics - Usage Data
Raw
Thumbnails + …
256 TB!
8.3 Billion Events!
Data from early January 6 until February 24 at DØData from early January 6 until February 24 at DØ

15
SAMGrid Statistics - Operations Data
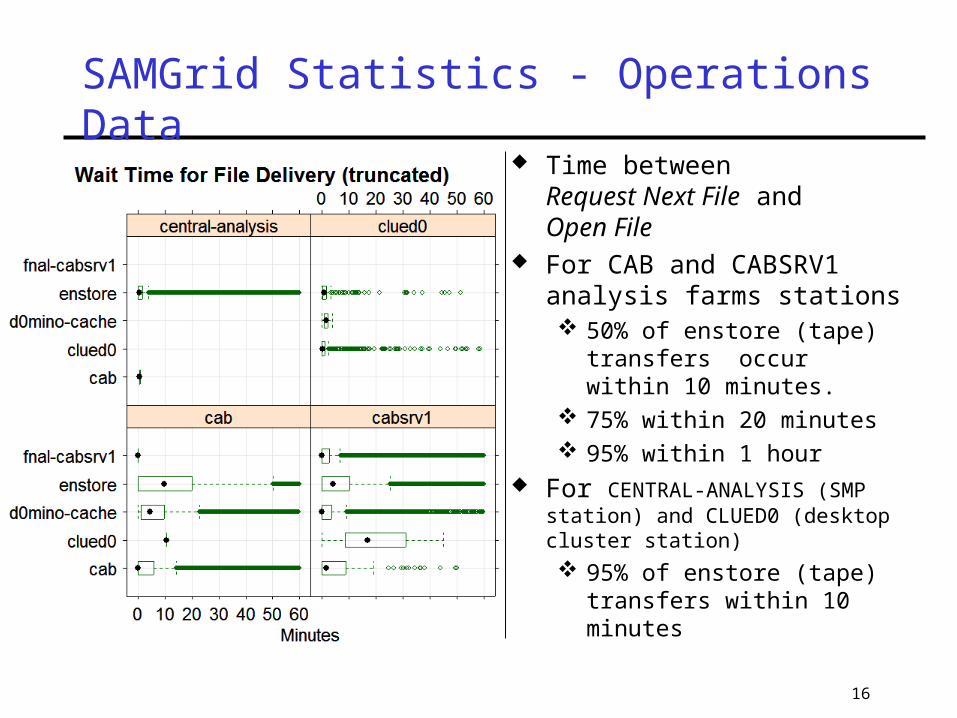
16
SAMGrid Statistics - Operations Data Time between
Request Next File andOpen File
For CAB and CABSRV1 analysis farms stations 50% of enstore (tape)
transfers occur within 10 minutes.
75% within 20 minutes 95% within 1 hour
For CENTRAL-ANALYSIS (SMP station) and CLUED0 (desktop cluster station) 95% of enstore (tape)
transfers within 10 minutes
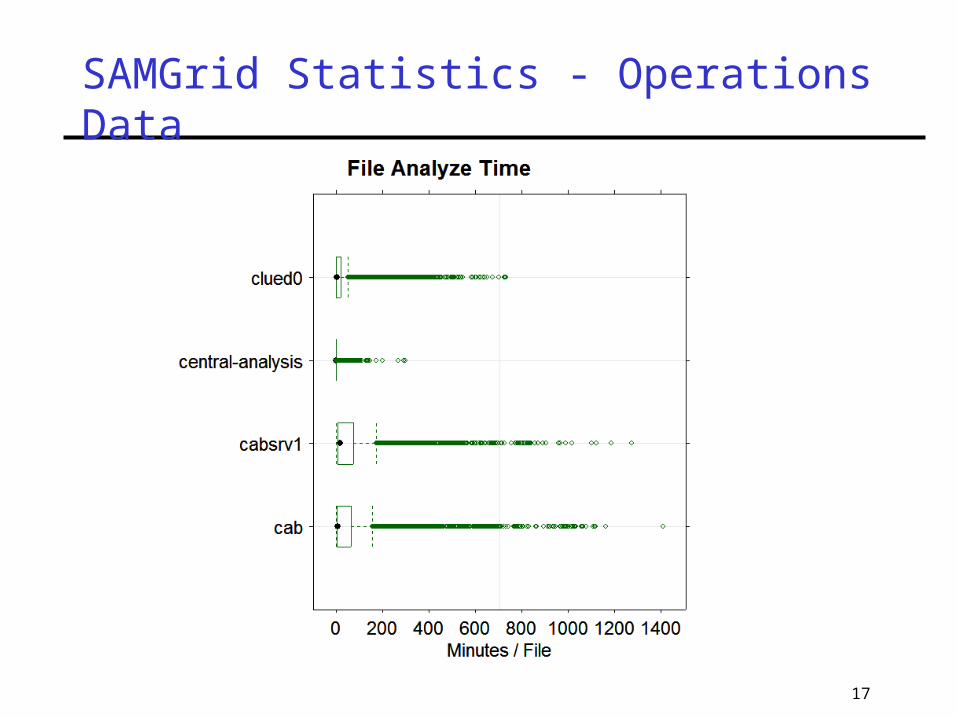
17
SAMGrid Statistics - Operations Data

18
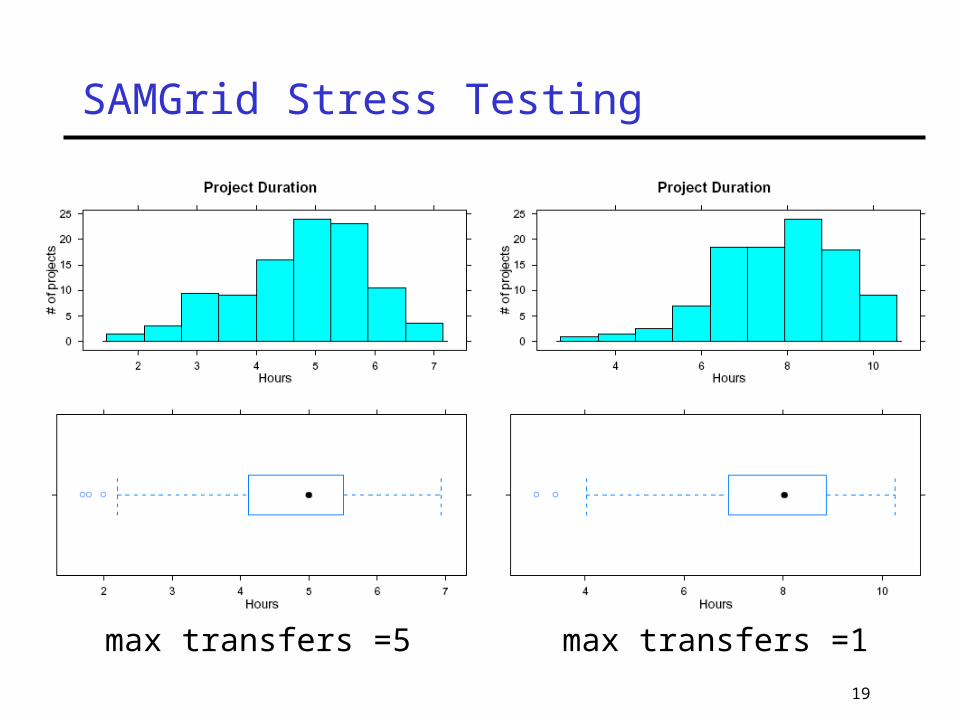
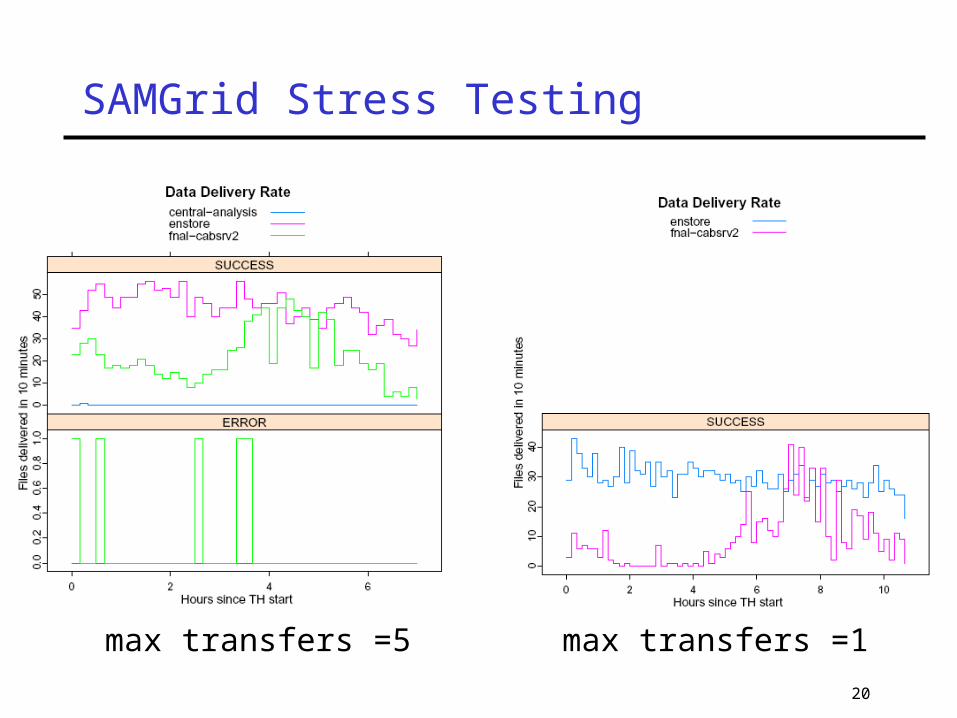
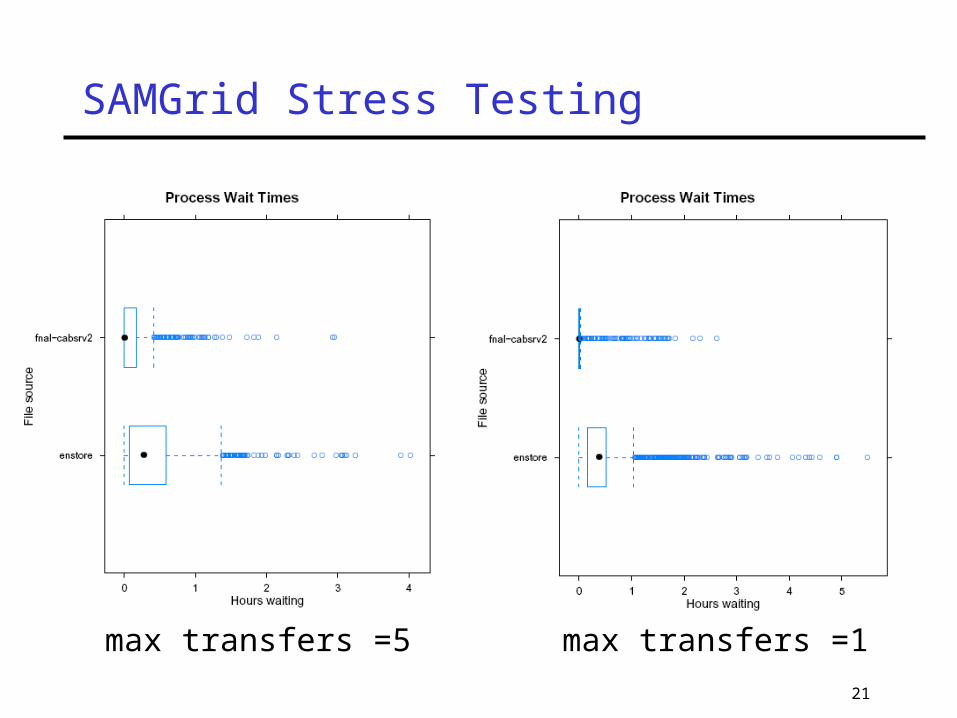
Stress Testing There are many station parameters to tune
Maximum parallel transfersMaximum concurrent enstore requestsConfiguration of cache disks…
We're moving away from d0mino to LinuxHow robust are these linux machines?How many projects can they run?How many concurrent file transfers can they
handle? Running test harness on a small cluster to
explore SAMGrid parameter space
19
SAMGrid Stress Testing
max transfers =5 max transfers =1
20
SAMGrid Stress Testing
max transfers =5 max transfers =1
21
SAMGrid Stress Testing
max transfers =5 max transfers =1

22
SAMGrid Projects Recently Completed:
Python & C++ Client APIImproved DB SchemaBatch system adapters1st generation monitoring
Active & Future: DB-Middleware improvements2nd generation monitoringImproved query languageGrid submissionConversion to SRM interface for cache functions

23
Summary
SAMGrid has been successfully used at DØ for all data handling Over the past year 44 stations consumed (remote = outside
fermilab)
3.6 million files (0.46 million files remote) 40 billion events (3 billion events remote)
1.6 Petabytes of data (137 TB of data remote) ~25 million MC events produced remotely with SAMGrid ~90 million events reprocessed remotely with SAMGrid
SAMGrid will soon become the data handling system for CDF and later MINOS
SAMGrid deployment on grids is contributing improvements to Grid tools & interfaces

24
EXTRA SLIDES FOLLOW

25
ENSTORE Statistics 0.6 Petabytes in tape
storage!Data sizes
0 100 200 300
9940B
9940A
LTO
Terabytes
Tape usage
0 2000 4000 6000
9940B
9940A
LTO
# of tapes
Only 5 files unrecoverable (5 GB total; 8ppm loss) !!!One of them was RAW file

26
Some SAMGrid buzzwords Dataset Definition
A set of requirements to obtain a particular set of files e.g. data_tier thumbnail and run_number 181933 Datasets can change over time
• More files that satisfy the dataset may be added to SAMGrid
Snapshot The files that satisfy a dataset at a particular time (e.g. when
you start an analysis job) Snapshots are static
Project The running of an executable over files in SAMGrid Consists of the dataset definition, the snapshot from that
dataset definition, and application information Bookkeeping data is kept - how many files did you
successfully process, where did your job run, how long did it take











![COMPUTING NEEDS OF LHC EXPERIMENTS AND ...models' performance (throughputs, latencies) and verify the resource requirement baselines (computing, data handling, networks) [11]. As a](https://static.fdocuments.in/doc/165x107/5f5b0dcfd02eaa166479d3e5/computing-needs-of-lhc-experiments-and-models-performance-throughputs-latencies.jpg)






