

Seo camp2017 Marguerite Leenhardt
51
by
-
Upload
seo-camp-association -
Category
Internet
-
view
1.404 -
download
2
Transcript of Seo camp2017 Marguerite Leenhardt

by

CEO, XIKO / PRÉSIDENTE, AFTAL
Formation
• PhD. Linguistique Appliquée, Traitement Automatique des Langues (TAL a.k.a NLP)
• MSc. TAL + MSc. Ingénierie Linguistique Multilingue
CEO, XiKO (www.xiko.fr)
• KOVERI : IA sémantique pour l’analyse de tous les textes dans toutes les langues
• Applications : marketing programmatique, enrichissement sémantique
Présidente, AFTAL (@AssoForTAL)
• Anciens des Formations en Traitement Automatique des Langues
• Association inter-universitaire (Paris, Toulouse, Lille, Tours, …)
Avant ça/et aussi…
• Expériences en agence et en freelance, R&D Project Manager
• Charges d’enseignement (niveau Licence & Master)

CEO, XIKO / PRÉSIDENTE, AFTAL
Formation
• PhD. Linguistique Appliquée, Traitement Automatique des Langues (TAL a.k.a NLP)
• MSc. TAL + MSc. Ingénierie Linguistique Multilingue
CEO, XiKO (www.xiko.fr)
• KOVERI : IA sémantique pour l’analyse de tous les textes dans toutes les langues
• Marketing programmatique, enrichissement sémantique, Insight-as-a-Service
Présidente, AFTAL (@AssoForTAL)
• Anciens des Formations en Traitement Automatique des Langues
• Association inter-universitaire (Paris, Toulouse, Lille, Tours, …)
Avant ça/et aussi…
• Expériences en agence et en freelance, R&D Project Manager
• Charges d’enseignement (niveau Licence & Master)

CEO, XIKO / PRÉSIDENTE, AFTAL
Formation
• PhD. Linguistique Appliquée, Traitement Automatique des Langues (TAL a.k.a NLP)
• MSc. TAL + MSc. Ingénierie Linguistique Multilingue
CEO, XiKO (www.xiko.fr)
• KOVERI : IA sémantique pour l’analyse de tous les textes dans toutes les langues
• Marketing programmatique, enrichissement sémantique, Insight-as-a-Service
Présidente, AFTAL (@AssoForTAL)
• Anciens des Formations en Traitement Automatique des Langues
• Association inter-universitaire (Paris, Toulouse, Lille, Tours, …)
Avant ça/et aussi…
• Expériences en agence et en freelance, R&D Project Manager
• Charges d’enseignement (niveau Licence & Master)

CEO, XIKO / PRÉSIDENTE, AFTAL
Formation
• PhD. Linguistique Appliquée, Traitement Automatique des Langues (TAL a.k.a NLP)
• MSc. TAL + MSc. Ingénierie Linguistique Multilingue
CEO, XiKO (www.xiko.fr)
• KOVERI : IA sémantique pour l’analyse de tous les textes dans toutes les langues
• Marketing programmatique, enrichissement sémantique, Insight-as-a-Service
Présidente, AFTAL (@AssoForTAL)
• Anciens des Formations en Traitement Automatique des Langues
• Association inter-universitaire (Paris, Toulouse, Lille, Tours, …)
Avant ça/et aussi…
• Expériences en agence et en freelance, R&D Project Manager
• Charges d’enseignement (niveau Licence & Master)linkedin.com/in/margueriteleenhardt/


AU CŒUR DES RECHERCHES EN TRAITEMENT AUTOMATIQUE DES LANGUES
Traitements automatiques de corpus
Contenus textuels
Expression écrite en langage naturelA
NA
LYS
E D
E C
OR
PU
S
ANALYSE DE CONTENUS
ACQUISITION DE CONNAISSANCES
FOUILLE DE TEXTES
EXTRACTION D’INFORMATION
RECHERCHE DOCUMENTAIRE
EXTENSION DES INDEX DE RECHERCHE & DE REQUÊTES
CATÉGORISATION DE DOCUMENTS
CLASSIFICATION DE DOCUMENTS

AU CŒUR DES RECHERCHES EN TRAITEMENT AUTOMATIQUE DES LANGUES
Traitements automatiques de corpus
Contenus textuels
Expression écrite en langage naturelA
NA
LYS
E D
E C
OR
PU
S
ANALYSE DE CONTENUS
ACQUISITION DE CONNAISSANCES
FOUILLE DE TEXTES
EXTRACTION D’INFORMATION
RECHERCHE DOCUMENTAIRE
EXTENSION DES INDEX DE RECHERCHE & DE REQUÊTES
CATÉGORISATION DE DOCUMENTS
CLASSIFICATION DE DOCUMENTS

AU CŒUR DES RECHERCHES EN TRAITEMENT AUTOMATIQUE DES LANGUES
Traitements automatiques de corpus
Contenus textuels
Expression écrite en langage naturelA
NA
LYS
E D
E C
OR
PU
S
ANALYSE DE CONTENUS
ACQUISITION DE CONNAISSANCES
FOUILLE DE TEXTES
EXTRACTION D’INFORMATION
RECHERCHE DOCUMENTAIRE
EXTENSION DES INDEX DE RECHERCHE & DE REQUÊTES
CATÉGORISATION DE DOCUMENTS
CLASSIFICATION DE DOCUMENTS
LINGUISTIQUE DE CORPUS

AU CŒUR DES RECHERCHES EN TRAITEMENT AUTOMATIQUE DES LANGUES
Traitements automatiques de corpus
Contenus textuels
Expression écrite en langage naturelA
NA
LYS
E D
E C
OR
PU
S
ANALYSE DE CONTENUS
ACQUISITION DE CONNAISSANCES
FOUILLE DE TEXTES
EXTRACTION D’INFORMATION
RECHERCHE DOCUMENTAIRE
EXTENSION DES INDEX DE RECHERCHE & DE REQUÊTES
CATÉGORISATION DE DOCUMENTS
CLASSIFICATION DE DOCUMENTS
TRAITEMENT AUTOMATIQUE DES
LANGUES
LINGUISTIQUE DE CORPUS

QUI INTÈGRE DES TECHNIQUES DE TRAITEMENT AUTOMATIQUE DES LANGUES
Dédiées à la recherche documentaire
Collections de documents
Techniques d’indexation et de rechercheA
NA
LYS
E D
E C
OR
PU
S
ANALYSE DE CONTENUS
ACQUISITION DE CONNAISSANCES
FOUILLE DE TEXTES
EXTRACTION D’INFORMATION
RECHERCHE DOCUMENTAIRE
EXTENSION DES INDEX DE RECHERCHE & DE REQUÊTES
CATÉGORISATION DE DOCUMENTS
CLASSIFICATION DE DOCUMENTS

AN
ALY
SE
DE
CO
RP
US
ANALYSE DE CONTENUS
ACQUISITION DE CONNAISSANCES
FOUILLE DE TEXTES
EXTRACTION D’INFORMATION
RECHERCHE DOCUMENTAIRE
EXTENSION DES INDEX DE RECHERCHE & DE REQUÊTES
CATÉGORISATION DE DOCUMENTS
CLASSIFICATION DE DOCUMENTS
QUI INTÈGRE DES TECHNIQUES DE TRAITEMENT AUTOMATIQUE DES LANGUES
Dédiées à la recherche documentaire
Collections de documents
Techniques d’indexation et de recherche

QUI INTÈGRE DES TECHNIQUES DE TRAITEMENT AUTOMATIQUE DES LANGUES
Dédiées à la recherche documentaire
Collections de documents
Techniques d’indexation et de rechercheA
NA
LYS
E D
E C
OR
PU
S
ANALYSE DE CONTENUS
ACQUISITION DE CONNAISSANCES
FOUILLE DE TEXTES
EXTRACTION D’INFORMATION
RECHERCHE DOCUMENTAIRE
EXTENSION DES INDEX DE RECHERCHE & DE REQUÊTES
CATÉGORISATION DE DOCUMENTS
CLASSIFICATION DE DOCUMENTS


L’USAGE ET L’ATTENTE DES UTILISATEURS FINAUX A CHANGÉ
L’avènement du Natural Language Search
Évolution des algorithmes des moteurs de recherche
Évolution des tactiques SEO
Système de Questions-Réponses Système de mots-clés Système hybrides + techniques TAL & IA

L’USAGE ET L’ATTENTE DES UTILISATEURS FINAUX A CHANGÉ
L’avènement du Natural Language Search
Évolution des algorithmes des moteurs de recherche
Évolution des tactiques SEO
1996 1998 2017
Questions-Réponses mots-clés hybrides + techniques TAL & IA
…

L’USAGE ET L’ATTENTE DES UTILISATEURS FINAUX A CHANGÉ
L’avènement du Natural Language Search
Évolution des algorithmes des moteurs de recherche
Évolution des tactiques SEO
1996 1998 2017
Questions-Réponses mots-clés hybrides + techniques TAL & IA
…

L’USAGE ET L’ATTENTE DES UTILISATEURS FINAUX A CHANGÉ
L’avènement du Natural Language Search
Évolution des algorithmes des moteurs de recherche
Évolution des tactiques SEO
1996 1998 2017
Questions-Réponses mots-clés hybrides + techniques TAL & IA
…

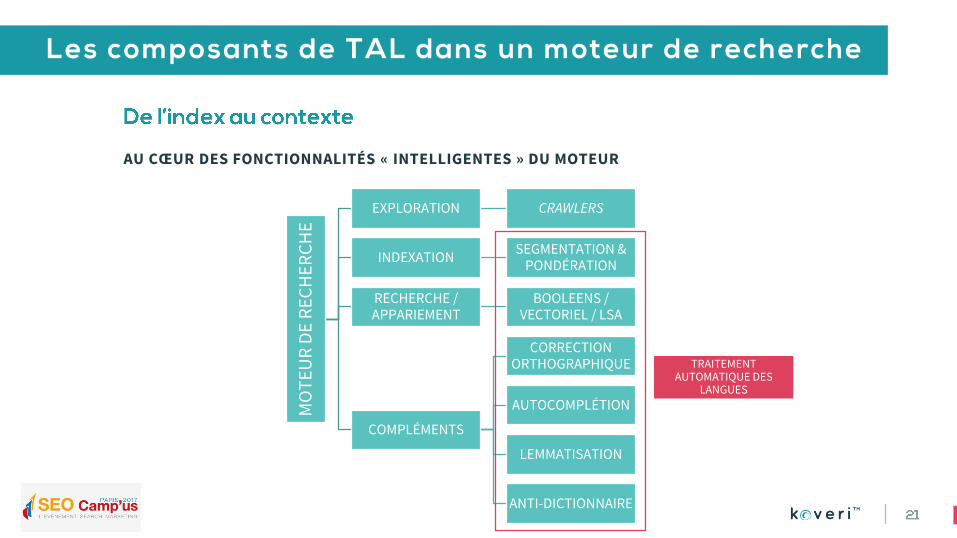
AU CŒUR DES FONCTIONNALITÉS « INTELLIGENTES » DU MOTEUR
MO
TE
UR
DE
RE
CH
ER
CH
E
EXPLORATION CRAWLERS
INDEXATIONSEGMENTATION &
PONDÉRATION
RECHERCHE / APPARIEMENT
BOOLEENS / VECTORIEL / LSA
COMPLÉMENTS
CORRECTION ORTHOGRAPHIQUE
AUTOCOMPLÉTION
LEMMATISATION
ANTI-DICTIONNAIRE

AU CŒUR DES FONCTIONNALITÉS « INTELLIGENTES » DU MOTEUR
MO
TE
UR
DE
RE
CH
ER
CH
E
EXPLORATION CRAWLERS
INDEXATIONSEGMENTATION &
PONDÉRATION
RECHERCHE / APPARIEMENT
BOOLEENS / VECTORIEL / LSA
COMPLÉMENTS
CORRECTION ORTHOGRAPHIQUE
AUTOCOMPLÉTION
LEMMATISATION
ANTI-DICTIONNAIRE
AU CŒUR DES FONCTIONNALITÉS « INTELLIGENTES » DU MOTEUR
MO
TE
UR
DE
RE
CH
ER
CH
E
EXPLORATION CRAWLERS
INDEXATIONSEGMENTATION &
PONDÉRATION
RECHERCHE / APPARIEMENT
BOOLEENS / VECTORIEL / LSA
COMPLÉMENTS
CORRECTION ORTHOGRAPHIQUE
AUTOCOMPLÉTION
LEMMATISATION
ANTI-DICTIONNAIRE
TRAITEMENT AUTOMATIQUE DES
LANGUES

AU CŒUR DES FONCTIONNALITÉS « INTELLIGENTES » DU MOTEUR
MO
TE
UR
DE
RE
CH
ER
CH
E
EXPLORATION CRAWLERS
INDEXATIONSEGMENTATION &
PONDÉRATION
RECHERCHE / APPARIEMENT
BOOLEENS / VECTORIEL / LSA
COMPLÉMENTS
CORRECTION ORTHOGRAPHIQUE
AUTOCOMPLÉTION
LEMMATISATION
ANTI-DICTIONNAIRE

AU CŒUR DES FONCTIONNALITÉS « INTELLIGENTES » DU MOTEUR
MO
TE
UR
DE
RE
CH
ER
CH
E
EXPLORATION CRAWLERS
INDEXATIONSEGMENTATION &
PONDÉRATION
RECHERCHE / APPARIEMENT
BOOLEENS / VECTORIEL / LSA
COMPLÉMENTS
CORRECTION ORTHOGRAPHIQUE
AUTOCOMPLÉTION
LEMMATISATION
ANTI-DICTIONNAIRE
REPRÉSENTATION DU CONTENU
DESCRIPTION DU SENS

LA FORME DES MOTS
La segmentation en mots
Quelle définition du mot ?
• Naïve / a-linguistique : chaîne de caractères entre deux séparateurs
• Pas si simple en français... complexe dans d’autres langues (ex : pas de « mot graphique » en chinois)
Apostrophe Trait d’union
Aujourd’hui
L’eau
Demi-sel
Savez-vous
UN OU DEUX MOTS ?
Flexions Sens
Avions
Vis
Glace
Caisse
AMBIGUÏTÉS !

LA FORME DES MOTS
La segmentation en mots
Quelle définition du mot ?
• Naïve / a-linguistique : chaîne de caractères entre deux séparateurs
• Pas si simple en français... complexe dans d’autres langues (ex : pas de « mot graphique » en chinois)
Apostrophe Trait d’union
Aujourd’hui
L’eau
Demi-sel
Savez-vous
UN OU DEUX MOTS ?
Flexions Sens
Avions
Vis
Glace
Caisse
AMBIGUÏTÉS !

LA FORME DES MOTS
La segmentation en mots
Quelle définition du mot ?
• Naïve / a-linguistique : chaîne de caractères entre deux séparateurs
• Pas si simple en français... complexe dans d’autres langues (ex : pas de « mot graphique » en chinois)
Apostrophe Trait d’union
Aujourd’hui
L’eau
Demi-sel
Savez-vous
UN OU DEUX MOTS ?
Flexions Sens
Avions
Vis
Glace
Caisse
AMBIGUÏTÉS !

LE POIDS DES MOTS
La pondération
Quels moyens pour savoir combien « pèse » le mot afin d’indexer une page ?
• Les mots « importants » doivent avoir un poids fort
• TF-IDF : approche la plus répandue
Évaluer le poids d’un terme dans un document vs. un corpus / une collection de
documents
TF-IDF
Ordonner les documents potentiellement pertinents pour répondre à une requête
Utilisation du TF-IDF en RI :
- décrire les documents dans un modèle vectoriel
Mesure de similarité en fonction de la distance
entre le vecteur « requête » et les vecteurs « documents »
RECHERCHE / APPARIEMENT

LE POIDS DES MOTS
La pondération
Quels moyens pour savoir combien « pèse » le mot afin d’indexer une page ?
• Les mots « importants » doivent avoir un poids fort
• TF-IDF : approche la plus répandue
Évaluer le poids d’un terme dans un document vs. un corpus / une collection de
documents
TF-IDF
Ordonner les documents potentiellement pertinents pour répondre à une requête
Utilisation du TF-IDF en RI :
- décrire les documents dans un modèle vectoriel
Mesure de similarité en fonction de la distance
entre le vecteur « requête » et les vecteurs « documents »
RECHERCHE / APPARIEMENT

LE POIDS DES MOTS
La pondération
Quels moyens pour savoir combien « pèse » le mot afin d’indexer une page ?
• Les mots « importants » doivent avoir un poids fort
• TF-IDF : approche la plus répandue
Évaluer le poids d’un terme dans un document vs. un corpus / une collection de
documents
TF-IDF
Ordonner les documents potentiellement pertinents pour répondre à une requête
Utilisation du TF-IDF en RI :
- décrire les documents dans un modèle vectoriel
Mesure de similarité en fonction de la distance
entre le vecteur « requête » et les vecteurs « documents »
RECHERCHE / APPARIEMENT

LE POIDS DES MOTS
La pondération
Quels moyens pour savoir combien « pèse » le mot afin d’indexer une page ?
• Les mots « importants » doivent avoir un poids fort
• TF-IDF : approche la plus répandue
Évaluer le poids d’un terme dans un document vs. un corpus / une collection de
documents
TF-IDF
Ordonner les documents potentiellement pertinents pour répondre à une requête
Utilisation du TF-IDF en RI :
- décrire les documents dans un modèle vectoriel
Mesure de similarité en fonction de la distance
entre le vecteur « requête » et les vecteurs « documents »
RECHERCHE / APPARIEMENT

LE SENS DES MOTS
Décrire le sens des documents
Comment « donner du sens » à l’appariement ?
• Intégrer des données sémantiques à la représentation des documents
• Défi : flexibilité & capacité d’adaptation de la technologie sémantique
Défi de robustesse face à la grande variabilité des textes libres sur le web multilingue
GESTION DES TEXTES LIBRES (UGC)

LE SENS DES MOTS
Décrire le sens des documents
Comment « donner du sens » à l’appariement ?
• Intégrer des données sémantiques à la représentation des documents
• Défi : flexibilité & capacité d’adaptation de la technologie sémantique
Défi de robustesse face à la grande variabilité des textes libres sur le web multilingue
GESTION DES TEXTES LIBRES (UGC)
Entités de recherche
Entités Nommées
Requête
Liens
Document
Moment
…
Personne
Date
Lieu
Organisation
…
Relations
Rachat
Cause
Appartenance
…
Signaux complexes
Perception
Conseil
Intention d’achat
…
RECHERCHE / APPARIEMENT

LE SENS DES MOTS
Décrire le sens des documents
Comment « donner du sens » à l’appariement ?
• Intégrer des données sémantiques à la représentation des documents
• Défi : flexibilité & capacité d’adaptation de la technologie sémantique
Défi de robustesse face à la grande variabilité des textes libres sur le web multilingue
GESTION DES TEXTES LIBRES (UGC)
Entités de recherche
Entités Nommées
Requête
Liens
Document
Moment
…
Personne
Date
Lieu
Organisation
…
Relations
Rachat
Cause
Appartenance
…
Signaux complexes
Perception
Conseil
Intention d’achat
…
RECHERCHE / APPARIEMENT

LE SENS DES MOTS
Décrire le sens des documents
Comment « donner du sens » à l’appariement ?
• Intégrer des données sémantiques à la représentation des documents
• Défi : flexibilité & capacité d’adaptation de la technologie sémantique
Défi de robustesse face à la grande variabilité des textes libres sur le web multilingue
GESTION DES TEXTES LIBRES (UGC)
Entités de recherche
Entités Nommées
Requête
Liens
Document
Moment
…
Personne
Date
Lieu
Organisation
…
Relations
Rachat
Cause
Appartenance
…
Signaux complexes
Perception
Conseil
Intention d’achat
…
RECHERCHE / APPARIEMENT


DES BÉNÉFICES POTENTIELS
Amélioration de l’expérience de recherche
Confort de l’utilisateur et performance du système
Contextualisation des résultats
(donnée sémantique + historique cross-devices +
géolocalisation + …)
CONFORT
Allègement de la charge des calculs sur les centres de
données
PERFORMANCE

DES BÉNÉFICES POTENTIELS
Amélioration de l’expérience de recherche
Confort de l’utilisateur et performance du système
Contextualisation des résultats
(donnée sémantique + historique cross-devices +
géolocalisation + …)
CONFORT
Allègement de la charge des calculs sur les centres de
données
PERFORMANCE

DES BÉNÉFICES POTENTIELS
Amélioration de l’expérience de recherche
Confort de l’utilisateur et performance du système
Contextualisation des résultats
(donnée sémantique + historique cross-devices +
géolocalisation + …)
CONFORT
Allègement de la charge des calculs sur les centres de
données
PERFORMANCE

UN COÛT RÉEL
Adaptation aux nouveaux standards
Des efforts pour intégrer le Web Sémantique
Adaptation côté éditeurs & référenceurs
ROI pas forcémentimmédiat
EFFORTS
Indexation sémantique des données non structurées
COMPLEXITÉ

UN COÛT RÉEL
Adaptation aux nouveaux standards
Des efforts pour intégrer le Web Sémantique
Adaptation côté éditeurs & référenceurs
ROI pas forcémentimmédiat
EFFORTS
Indexation sémantique des données non structurées
COMPLEXITÉ

UN COÛT RÉEL
Adaptation aux nouveaux standards
Des efforts pour intégrer le Web Sémantique
Adaptation côté éditeurs & référenceurs
ROI pas forcémentimmédiat
EFFORTS
Indexation sémantique des données non structurées
COMPLEXITÉ

POUR RÉPONDRE AUX BESOINS MÉTIER
Avec robustesse et flexibilité
Enrichissement sémantique du contenu en minimisant les coûts / les efforts
Même sur les sites qui n’intègrent pas de descripteurs structurés pour le Web Sémantique
En complément des descripteurs existants pour le Web Sémantique
Gestion des signaux sémantiques complexes
Robustesse face à la grande variabilité des textes libres sur le web multilingue

POUR RÉPONDRE AUX BESOINS MÉTIER
Quelques applications utiles au SEO
SÉLECTION & CATÉGORISATION DE MOTS-CLÉS
MAPPING SEGMENTS IAB
ENRICHISSEMENT DU CONTENU ÉDITORIALAUDIT SÉMANTIQUE
ENRICHISSEMENT TAGGING
CATÉGORISATION DE SITES
DÉTECTION DES CONTENUS DUPLIQUÉSMAPPING ONTOLOGIES / TAXONOMIES
NOUVEAUX ANGLES ÉDITORIAUXENRICHISSEMENT SÉMANTIQUE
SEGMENTATION CONTEXTUELLE

EXEMPLES
Case : enrichissement sémantique sur 100 domaines / FR / Régie premium
Enrichissement de la taxonomie sur l’ensemble des domaines
• Focus : exemple sur la catégorie « AUTO »
FAMILIALES INTERMEDIAIRES
FORDAMERICAINES
BMWDIESEL
GASOLINE
Quelques catégories découvertes pour enrichir « Auto »

EXEMPLES
Case : enrichissement sémantique sur 100 domaines / FR / Régie premium
Enrichissement de la taxonomie sur l’ensemble des domaines
• Focus : exemple sur la catégorie « AUTO »
Exemple de page qualifiéehttp://bourse.lefigaro.fr/indices-actions/actu-conseils/renault-annonce-des-tarifs-pour-le-nouvel-espace-3992015
QUALIFICATION
ECONOMIE - FINANCE AUTO
RENAULT
GRANDS MONOSPACES
FRANÇAISES
Taxonomie de base (client) Enrichissements

EXEMPLES
Case : enrichissement sémantique sur 100 domaines / FR / Régie premium
Enrichissement de la taxonomie sur l’ensemble des domaines
• Focus : exemple sur la catégorie « AUTO »
QUALIFICATIONExemple de page qualifiée
http://www.leparisien.fr/espace-premium/actu/dans-le-retro-la-longue-route-des-vehicules-electriques-21-10-2015-5205945.php
Taxonomie de base (client) Enrichissements
ACTU HYBRIDE
ELECTRIQUE
JAPONAISES
NISSAN
FRANÇAISES
COMPACTES
RENAULT

EXEMPLES
Case : enrichissement sémantique sur 100 domaines / FR / Régie premium
Enrichissement de la taxonomie sur l’ensemble des domaines
• Focus : exemple sur la catégorie « AUTO »
QUALIFICATION
Taxonomie de base (client) Enrichissements
Exemple de page qualifiéehttp://forum.doctissimo.fr/viepratique/automobile/67000km-garantie-atlantique-sujet_6086_1.htm
N/A AUTO
FRANÇAISES
RENAULT
CITROËN
COMPACTES

EXEMPLES
Case : identification des centres d’intérêt édito vs. segments d’audience participative / FR / Éditeur
Enrichissement des drivers d’intérêt / nouveaux angles éditoriaux (données éditeur)
• Focus : exemple sur quelques segments d’audience ciblés
Beauty Addict
• Focus on health and body in general ; Refine the angles of certain subjects, hairfor example
Mam’s
• Good targeting capabilities for subjectsas pregnancy, childlife, educationalenvironment ; refine and focus on Leisure

EXEMPLES
Case : identification des centres d’intérêt édito vs. segments d’audience participative / FR / Éditeur
Enrichissement des drivers d’intérêt / nouveaux angles éditoriaux (données éditeur)
• Focus : exemple sur quelques segments d’audience ciblés
Trendista
• Good targeting capabilities for clothing, fashion. More focus on brands is needed. This profile is rare in [editors’] forum
Working Girl
• Focus on Professional life subjects ; takein account women who uses the websitefor promoting their activity or searchingfor a job

EXEMPLES
Case : détection de brand safety triggers / EN / Démo publique
Affiner un ciblage trop large sur la catégorie « ALCOOL »
• Améliorer l’adéquation entre le contenu et son environnement
KOVERI_health-fitnessKOVERI_culture_entertainmentKOVERI_content-editoKOVERI_health-fitness_substance-abuseKOVERI_culture_entertainment-television
Source: http://www.huffingtonpost.fr/2016/04/04/recettes-pompettes-alcool-anpaa-prevention_n_9609504.html?utm_hp_ref=france#Test realized with our public demo: http://www.xiko.fr/koveri-context-demo/


















