
Sanjay Chatterji Dev shri Roy Sudeshna Sarkar Anupam Basu CSE, IIT Kharagpur A Hybrid Approach for...
23
Sanjay Chatterji Dev shri Roy Sudeshna Sarkar Anupam Basu CSE, IIT Kharagpur A Hybrid Approach for Bengali to Hindi Machine Translation
-
Upload
dennis-casey -
Category
Documents
-
view
224 -
download
0
Transcript of Sanjay Chatterji Dev shri Roy Sudeshna Sarkar Anupam Basu CSE, IIT Kharagpur A Hybrid Approach for...

Sanjay ChatterjiDev shri Roy
Sudeshna SarkarAnupam Basu
CSE, IIT Kharagpur
A Hybrid Approach for Bengali to Hindi Machine
Translation

ContentsAbstract and MotivationRule Based and Statistical Machine TranslationHybrid SystemSystem ArchitecturePhrase table enhancement using lexical
resourcesSuffix, Infix and Pattern based postprocessingExperiments with Example SentenceEvaluationConclusionReferences

Abstract and Previous workMT translate a text from one natural language(such as
Bengali) to another (such as Hindi) – Meaning must be restored
Current MT software allows for customization by domain – Improving output by limiting scope
History: 1946: A.D. Booth proposed using digital computers for translation of
natural languages. 1954: Georgetown experiment involved MT of 60 Russian languages
into English. Claimed 3-5 Years MT would be a solved problem. 1966: ALPAI report 10 years long research has failed to fulfill
expectations
Translation Challenges:Decoding the meaning of the source textRe-encoding the meaning in the target language

Rule Based and Statistical MT
Statistical MT• Uses statistical model with bilingual corpora• Provides good quality when large and qualified
corpora are available• Poor for other domains• Fluent and cheaper• Bengali-Hindi: 2 month 2 person effort – BLEU Score
0.1745
Rule Based MT• Relies on countless built-in linguistic rules and
dictionary• Good out-of-domain quality and is predictable• Lack of fluency, long and costly• Bengali-Hindi: 2 years 5 person effort – BLEU
Score 0.0424

Hybrid SystemThere is a clear need for a third approach
through which• Users would reach better translation quality
and high performance(Rule based)• Less investment – cost and time (Statistical)• Bengali-Hindi: BLEU Score 0.2318
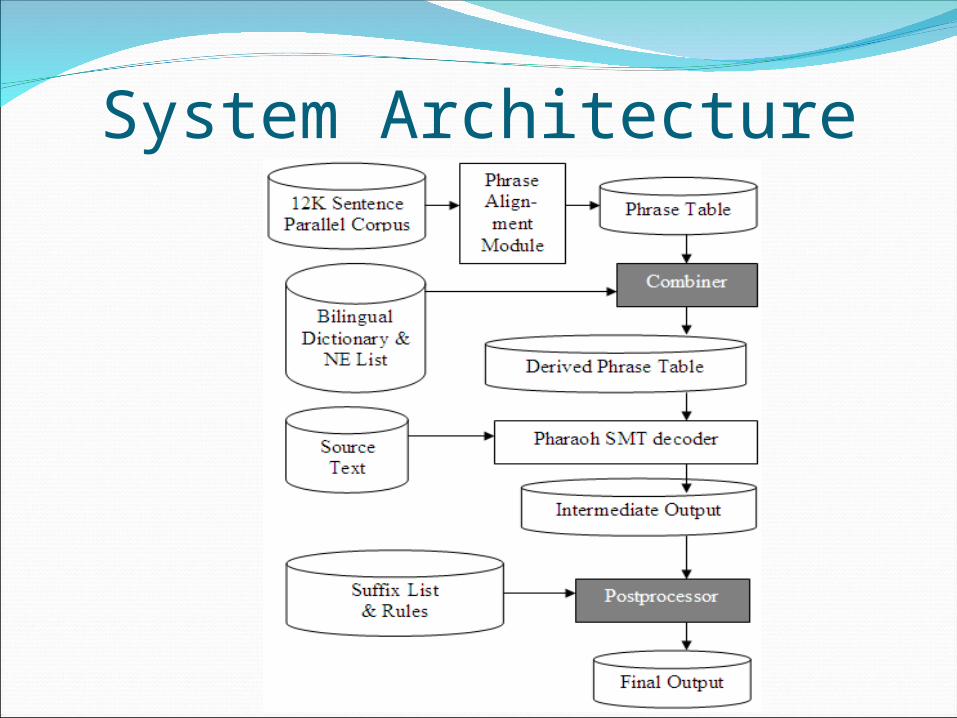
System Architecture

Feeding dictionary into SMTLexical entries from Transfer Based
system(tourism) is used to increase word alignments in SMT(news)
Dictionary is from another domain
Dictionary contains only words, not phrases

Postprocessing by suffix listSuffix list (1000)
Monolingual corpuses of same size for source and target languages (500K each)
Some of the suffices which occur more than 1000 times in Bengali corpus and Zero times in Hindi corpus
Some other suffixes which occur more than 5000 times in Bengali corpus and more than 99% of total occurrences in combined corpus occur in Bengali corpus
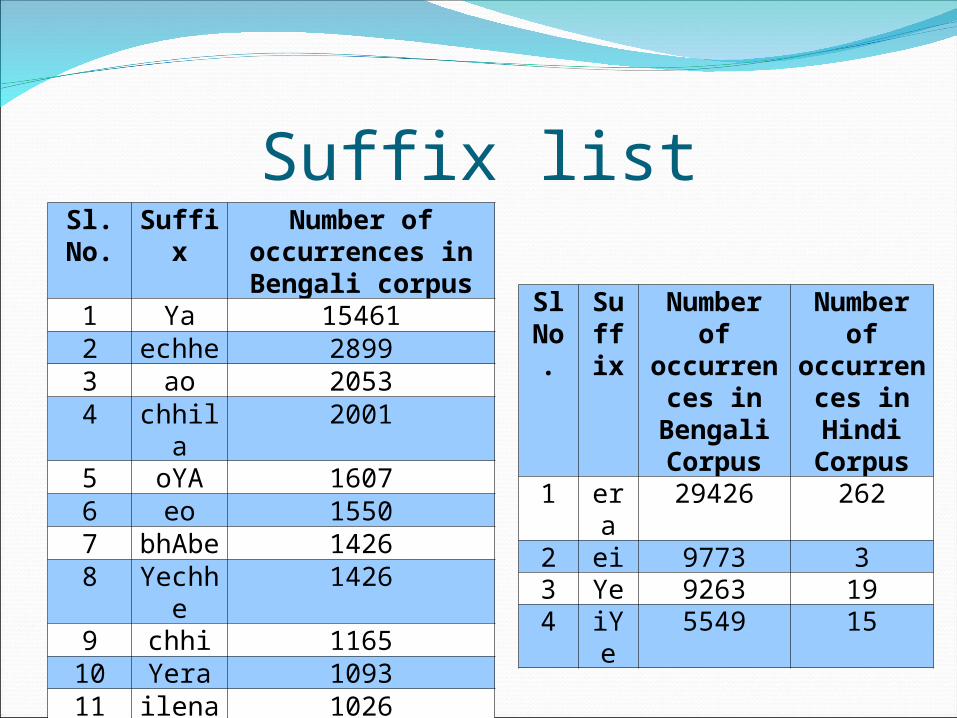
Suffix listSl. No.
Suffix Number of occurrences in Bengali corpus
1 Ya 154612 echhe 28993 ao 20534 chhila 20015 oYA 16076 eo 15507 bhAbe 14268 Yechh
e1426
9 chhi 116510 Yera 109311 ilena 102612 achhe 1004
Sl No.
Suffix
Number of occurrences in Bengali
Corpus
Number of occurrences in Hindi Corpus
1 era 29426 2622 ei 9773 33 Ye 9263 194 iYe 5549 15

Infix based postprocessingMultiple suffixes can be attached and
they are stackedchhelegulike = chhele + guli + keInfix in Bengali is translated to infix in
HindiSl. No. Infix
1 dera
2 gulo + guli
3 na
4 iYechha + iYechhe + iYechhi + iYechho
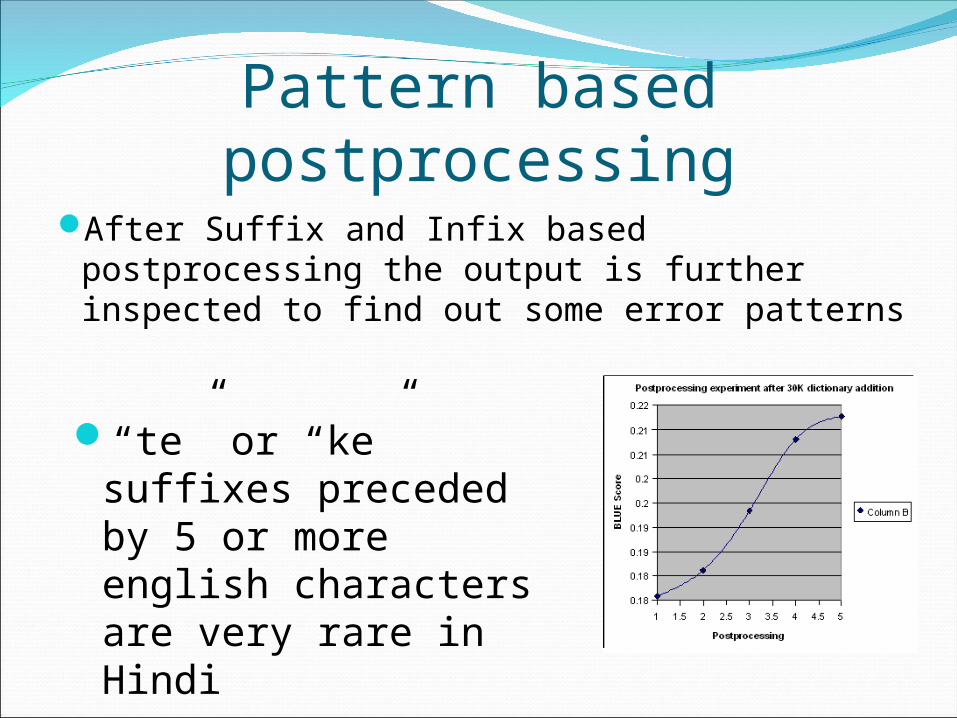
Pattern based postprocessingAfter Suffix and Infix based
postprocessing the output is further inspected to find out some error patterns
“te” or “ke” suffixes preceded by 5 or more english characters are very rare in Hindi

ExperimentResources:
Training corpus (12K sentences) of EMILLE-CIILDevelopment corpus(1K Sentences) of EMILLE-
CIILTest Corpus(100 Sentences) of EMILLE-CIILSuffix List: 1000 Bengali linguistic suffixesDictionary: 15,000 parallel synsets of ILMT-DITGazetteer list: 50K parallel names of ILMT-DITMonolingual Corpus: 500K words from SL and
TL
Systems: Giza++; Moses; Mart; Pharaoh.

Example SentenceBengali: AmarA saba skulagulike pariskArabhAbe
bale diYechhi ye mAtApitAderake ekaTA likhita nathipatra dena.
English: We have told every school clearly that give the parents a written document.
SMT (with enhanced phrase table) output: hama sabhI skulagulike pariskArabhAbe batA diYA hai kI mAtApitAderake eka likhita dalila de.N.
Postprocessing output: hama sabhI skulao.N ko sApha tarahA se batA diYA hai kI mAtApitAo.N ko eka likhita dalila de.N.

Example SentenceBengali: AmarA saba skulagulike pariskArabhAbe
bale diYechhi ye mAtApitAderake ekaTA likhita nathipatra dena.
English: We have told every school clearly that give the parents a written document.
SMT (with enhanced phrase table) output: hama sabhI skulagulike pariskArabhAbe batA diYA hai kI mAtApitAderake eka likhita dalila de.N.
Postprocessing output: hama sabhI skulao.N ko sApha tarahA se batA diYA hai kI mAtApitAo.N ko eka likhita dalila de.N.

Example SentenceBengali: AmarA saba skulagulike pariskArabhAbe
bale diYechhi ye mAtApitAderake ekaTA likhita nathipatra dena.
English: We have told every school clearly that give the parents a written document.
SMT (with enhanced phrase table) output: hama sabhI skulagulike sApha tarahA se batA diYA hai kI mAtApitAderake eka likhita dalila de.N.
Postprocessing output: hama sabhI skulao.N ko sApha tarahA se batA diYA hai kI mAtApitAo.N ko eka likhita dalila de.N.

Example SentenceBengali: AmarA saba skulagulike pariskArabhAbe
bale diYechhi ye mAtApitAderake ekaTA likhita nathipatra dena.
English: We have told every school clearly that give the parents a written document.
SMT (with enhanced phrase table) output: hama sabhI skulao.Nke sApha tarahA se batA diYA hai kI mAtApitAo.Nke eka likhita dalila de.N.
Postprocessing output: hama sabhI skulao.N ko sApha tarahA se batA diYA hai kI mAtApitAo.N ko eka likhita dalila de.N.

Example SentenceBengali: AmarA saba skulagulike pariskArabhAbe
bale diYechhi ye mAtApitAderake ekaTA likhita nathipatra dena.
English: We have told every school clearly that give the parents a written document.
SMT (with enhanced phrase table) output: hama sabhI skulao.N ko sApha tarahA se batA diYA hai kI mAtApitAo.N ko eka likhita dalila de.N.
Postprocessing output: hama sabhI skulao.N ko sApha tarahA se batA diYA hai kI mAtApitAo.N ko eka likhita dalila de.N.

EvaluationExperiments BLEU NISTSMT baseline 0.1745 4.2072
30K dictionary 0.1759 4.2267
50K dictionary 0.1712 4.1631Suffix based
postprocessing 0.1933 4.5062Infix based
postprocessing 0.2128 4.6865Pattern based
postprocessing 0.2275 4.8405

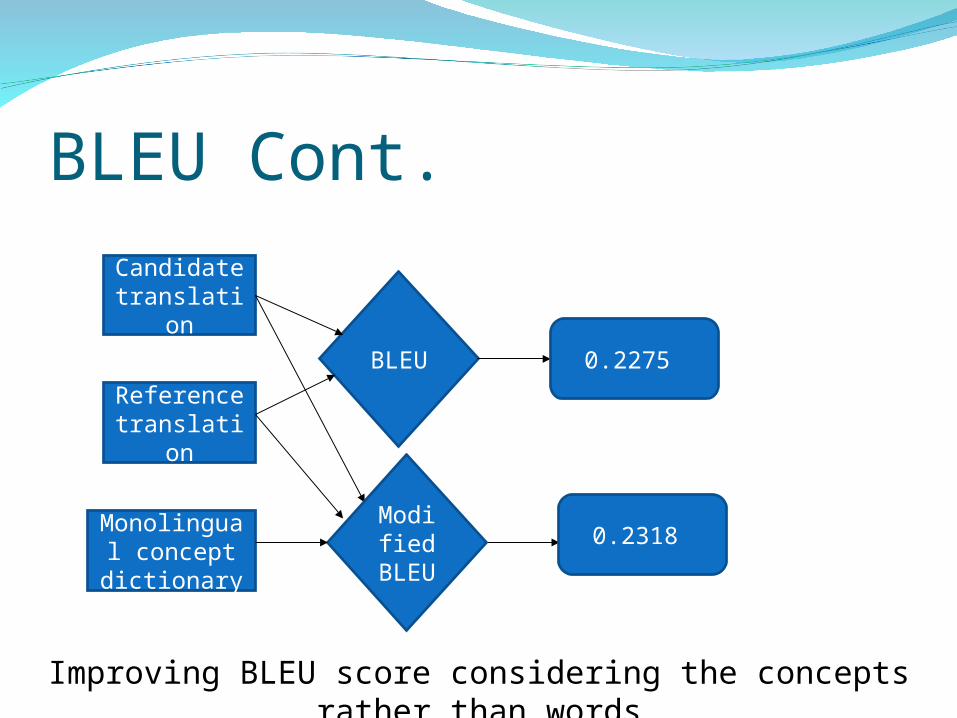
BLEUAutomatic, inexpensive, quick and language
independent evaluation system
The closer a machine translation output to a professional human reference translation, the better is the BLEU score
Source word can be translated to different word choices
Candidate translation will select one of them
may not match with the reference translation word choice
BLEU Cont.
Candidate translation
Reference translation
BLEU
0.2275
Monolingual concept dictionary
Modified BLE
U
0.2318
Improving BLEU score considering the concepts rather than words

ConclusionTargeted to postprocess the inflected words which
remain unchanged after translation
The words which are wrongly translated are not considered
A morphological analyzer/generator may be useful
By considering the dictionary fluency level is decreased

ReferencesW. S. Bennett, J. Slocum. 1985. The Irc Machine Translation System. In Comp. Linguist.,
pp. 11(2-3): 111-121.P. F. Brown, S. D. Pietra, V. J. D. Pietra, R. L. Mercer. 1993. The mathematics of
statistical machine translation: Parameter estimation. In Comp. Linguist., pp. 19(2) 263-312.
A. Eisele, C. Federmann, H. Uszkoreit, H. Saint-Amand, M. Kay, M. Jellinghaus, S. Hunsicker, T. Herrmann, Y. Chen. 2008. Hybrid Machine Translation Architectures within and beyond the EuroMatrix project. In Proceedings of the European Machine Translation Conference, pp. 27-34.
Ethnologue: Languages of the World, 16th edition, Edited by M. Paul Lewis, 2009. P. Isabelle, C. Goutte, M. Simard. 2007. Domain adaptation of MT systems through
automatic post-editing. In Proceedings Of MTSummit XI, pp. 255-261, Copenhagen, Denmark.
P. Koehn, F. J. Och, D. Marcu. 2003. Statistical phrase-based translation. In Proceedings Of NAACL-HLT, pp. 48-54, Edmonton, Canada.
P. Koehn. 2004. Pharaoh: A beam search decoder for phrase-based statistical machine translation models. In Proceedings of Association of Machine Translation in the Americas (AMTA-2004).
F. J. Och, H. Ney. 2000. Improved Statistical Alignment Models. In proceedings of the 38th Annual Meeting of the ACL, pp. 440-447.
F. J. Och, H. Ney. 2004. The Alignment Template Approach to Statistical Machine Translation. In Computational Linguistics Vol. 30 Num. 4, pp. 417-449.
K. Papineni, S. Roukos, T. Ward, W. Zhu. 2002. BLEU: a Method for Automatic Evaluation of Machine Translation. In 40th Annual meeting of the ACL, Philadelphia, pp. 311-318.
A. Ushioda. 2007. Phrase Alignment for Integration of SMT and RBMT Resources. In MT Summit XI Workshop on Patent Translation Programme.
H. Wu, H. Wang. 2004. Improving Statistical Word Alignment with a Rule-Based Machine Translation System, In Proceedings of Coling, pp. 29-35.

Thank You


















