Ringkasan UTS Data Mining
23
Timothy Orvin Edwardo – LE01 – 1901456205 Ringkasan UTS Data Mining 1. Data mining ekstraksi / pemahaman pattern yang menarik pada data. Memiliki sifat non – trivial, implisit, sebelumnya tidak diketahui, dan berpotensi berguna. 2. Istilah lain dalam data mining : Knowledge Discovery on Database (KDD). Data / pattern analysis. Data dredging. Data archeology. Knowledge extraction. Business intelligence. Information harvesting. 3. Interesting point diukur dari : Objective measure Subjective measure 4. Proses pada data mining :
Transcript of Ringkasan UTS Data Mining

Timothy Orvin Edwardo – LE01 – 1901456205
Ringkasan UTS Data Mining
1. Data mining ekstraksi / pemahaman pattern yang menarik
pada data. Memiliki sifat non – trivial, implisit, sebelumnya tidak
diketahui, dan berpotensi berguna.
2. Istilah lain dalam data mining :
Knowledge Discovery on Database (KDD).
Data / pattern analysis.
Data dredging.
Data archeology.
Knowledge extraction.
Business intelligence.
Information harvesting.
3. Interesting point diukur dari :
Objective measure
Subjective measure
4. Proses pada data mining :

Timothy Orvin Edwardo – LE01 – 1901456205
5. Data mining pada business intelligence :
6. Contoh aplikasi data mining :
Sistem database dan data warehouse web mining,
business intelligence.
Machine learning + statistik healthcare + medical data
mining.
7. Data bisa berasal dari :
Structured :
Database
Data warehouse
Flat file transaction record
Advanced :

Timothy Orvin Edwardo – LE01 – 1901456205
Data online
Sequence data / temporal
Object relational database
Database heterogen
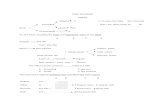
Data spasial
8. Fungsi data mining :
Generalisasi :
Karakterisasi mendeskripsikan suatu class dari ciri –
ciri atau atributnya.
Diskriminasi karakteristik yang membedakan antar
class.
Asosiasi dan korelasi / mining frequent pattern
mendeskripsikan hubungan antar atribut.
Classification dan reggression :
Classification dari ciri – ciri akan menghasilkan label.
Reggression lebih ke ciri – cirinya, dan yang dicari
adalah nominal value.
Cluster analysis data untuk melatih mesin tidak ada label.
Digunakan untuk preposition classification. Termasuk
unsupervised learning.
Outlier analysis transaksi normal jumlahnya banyak
sekali, mendeteksi terjadinya keanehan atau terjadi masalah
pada transaksi (mendeteksi anomali / kejadian tidak biasa).
9. Teknik yang digunakan data intensive, data warehouse, OLAP,
statistik, pattern recognition.
10. Evaluasi knowledge coverage, accuracy, timeliness
11. Isu major pada data mining :

Timothy Orvin Edwardo – LE01 – 1901456205
Mining methodology harus semakin canggih (akurat dan
cepat).
User interaction bisa dipahami secara interaktif.
Efisiensi dan scalability berkaitan dengan sumber daya,
semakin cepat maka semakin efisien.
Keberagaman data type
Data mining dan society berkaitan dengan data privasi.
12. Karakteristik data set :
Dimensionality banyak atribut, belum tentu baik.
Sparsity titik jarang pada dimensi besar.
Resolution skala data.
Distribution dispersion / penyebaran data.
13. Dataset dibuat dari data object (sampel atau 1 row). Data
object dideskripsikan oleh attribute.
14. Jenis attribute jenis nilai dari kolom :
Nominal kategori / jenis class dan tidak ada ranking atau
perbedaan nilai. Contoh pekerjaan (PNS, guru).
Binary atribut yang hanya 2 states dan tidak ada
perbedaan nilai. Contoh jenis kelamin (laki – laki,
perempuan).
Ordinal atribut yang ada nilai rankingnya. Contoh :
jenjang pendidikan, jabatan di perusahaan.
Numeric kuantitas, ada ukuran nilai dimana jarak antar
nilai jelas. Contoh : umur. Ada 2 jenis numeric :
Interval tidak ada true zero point. Contoh : Celsius.
Rasio ada true zero point (kosong). Contoh : Kelvin,
ruang kelas yang kosong.

Timothy Orvin Edwardo – LE01 – 1901456205
Discrete nilai diantaranya ada finite value. Contoh : zip
code.
Continuous antara 2 nilai tidak dapat dihitung. Contoh :
panjang.
15. Mendeskripsikan data dengan basic statistic :
Central tendecy :
Mean rata – rata nilai
Median nilai tengah
Modus frekuensi yang paling sering muncul
MidRange rata – rata value terbesar dan terkecil
data.
Dispersion :
Range max – min
Quartiles membagi menjadi 4 bagian.
Inter – quartiles range Q3 – Q1.
5 number summary min, q1, median, q3, max.
Boxplot mendeskripsikan 5 number summary.
Quantile to quantile plot

Timothy Orvin Edwardo – LE01 – 1901456205
Scatter plot
Standar deviasi
Varian
Outlier
16. Visualisasi data mempermudah melihat data di dimensi
tinggi pada 2 dimensi atau 3 dimensi. Jenisnya :
Pixel – oriented warna pixel merefleksikan nilai yang
berkorespondensi.

Timothy Orvin Edwardo – LE01 – 1901456205
Geomterical projection visualisasi melalui transformasi
dan proyeksi geometri.
Icon – based visualisasi nilai data sebagai icon.
Hierarchical visualisasi data menggunakan partisi hirarki
ke subspace.
Visualisasi complex data visualisasi data non numerik
seperti text atau sosial media.
17. Proximity measure cara mengukur perbedaan 2 titik
(jarak antar 2 row) bisa persamaan atau perbedaannya.
18. Ukuran kualitas data :
Akurasi berkaitan dengan error rate dan alat ukur.
Interpretability
Completeness
Konsistensi
Timeliness data update harus sesuai dengan jadwalnya.
Believability
19. Task yang dilakukan pada data preprocessing :
Data cleaning incomplete (value yang hilang), noisy (data
yang diluar expected value), inconsistent (berhubungan
dengan format data), intentional (data yang disembunyikan
karena tidak relevan).
Data integration menggabungkan data dari sumber
berbeda ke coherent store.
Data reduction menghapus atribut tidak penting. Contoh
: data compression

Timothy Orvin Edwardo – LE01 – 1901456205
Data transformation fungsi yang memetakan seluruh
value ke himpunan baru yang valuenya digantikan (value
lama bisa diidentifikasi dengan value baru). Tekniknya :
Smoothing menghilangkan noise dari data.
Attribut / feature construction atribut baru dibuat
dari yang diberikan.
Aggregation summarization, data cube
construction.
Normalization discale menjadi range yang lebih
kecil. (contoh : min – max, z – score, decimal scaling)
Discretization konsep hierarchy climbing (contoh
binning equal – width dan equal – depth).
20. Cara handle data yang hilang / tidak lengkap :
Mengabaikan tuple
Mengisi missing value :
Manual
Global constant
Ukuran central tendecy
Mean / median yang dari kelas yang sama
Value yang memungkinkan
21. Cara handle noisy data :
Binning smoothing bin means, median, boundaries.
Regresion smooth ke fungsi regresi.
Clustering deteksi dan menghilangkan outlier.
Gabungan inspeksi manusia dan komputer deteksi value
yang mencurigakan dan diperiksa oleh manusia.
22. Proses data cleaning :

Timothy Orvin Edwardo – LE01 – 1901456205
Data discrepancy detection menggunakan metadata,
check field overloading, menggunakan data scrubing dan
auditing.
Data scrubing menggunakan simple domain
knowledge untuk cek error dan membuat koreksi.
Data auditing dengan analisa data untuk
menemukan rules dan relationship untuk deteksi
violator.
Data migration dan integration ETL untuk mengizinkan
user specify transformasi ke GUI.
23. Data integration proses mengombinasikan data dari
source berbeda ke coherent store. Harus memperhatikan schema,
entity, dan resolve data conflict. Ini dilakukan agar meminimalkan
redundancy.
24. Schema integration mengintegrasikan metadata dari
source berbeda contoh : A.custID = B.custNo.
25. Indentifikasi masalah entitas identifikasi entitas real
world, attribute value dari source berbeda.
26. Deteksi dan menyelesaikan konflik data value :
Untuk entitas yang sama, value attribute dari source
berbeda adalah berbeda.
Possible reasons : representasi berbeda, skala yang berbeda
(contoh : metric vs british unit).
27. Data redundancy terjadi ketika integrasi dengan database
berbeda :

Timothy Orvin Edwardo – LE01 – 1901456205
Object identification atribut yang sama / objek mungkin
memiliki nama berbeda di database lain.
Derivable data satu atribut bisa saja diturunkan menjadi
derived attribute di tabel lain.
Bisa dideteksi dengan correlation analysis dan covariance
analysis.
Integrasi yang teliti dari source berbeda mungkin membantu
menghindari redundancy dan ketidak konsisten-an dan
meningkatkan kecepatan dan kualitas mining.
28. Correlation analysis :
Untuk data nominal menggunakan chi square test.
Untuk numeric data menggunakan correlation
coefficient.
29. Data reduction :
Bertujuan untuk mendapat reduced representation dari
dataset yang lebih kecil secara volume tetapi menghasilkan
hasil analisis yang sama / mendekati.
Dilakukan ketika : dimensi tinggi sehingga diturunkan agar
lebih mudah dianalisis.
Strategi :
Dimensionality reduction menghapus atribut tidak
penting.
Numerosity reduction.
Data compression.
30. Akibat dimensionality :
Ketika dimensionality meningkat, sparsity data meningkat.

Timothy Orvin Edwardo – LE01 – 1901456205
Density dan distance antar point yang kritis terhadap
clustering, outlier detection menjadi kurang meaningful.
Possible combinations of subspace meningkat secara
eksponensial.
31. Dimensionality reduction :
Menghindari akibat dari dimensionality.
Membantu eliminasi fitur yang tidak relevan dan
mengurangi noise.
Mengurangi waktu dan space yang dibutuhkan pada data
mining.
Mengizinkan visualisasi yang lebih mudah.
32. Teknik untuk mengurangi dimensionality :
Wavelet transforms.
Principal Component Analysis (PCA) mencari proyeksi
yang merekam variasi terbesar dari data. Caranya, data asli
di proyeksikan ke space yang kecil, menghasilkan
dimensionality reduction, kemudian menemukan
eigenvector dari covariance matrix. Eigenvektor ini
mendefinisikan space baru.
Supervised dan teknik nonlinear (contoh feature selection).
33. Numerosity reduction mengurangi data volume dengan
memilih alternatif, bentuk kecil dari representasi data.
Metodenya :
Parametric asumsikan data fit model, estimasikan model
parameter, store hanya parameter, dan discard data.
Contoh regresi, log – linear model.
Regresi

Timothy Orvin Edwardo – LE01 – 1901456205
o Linear data dimodelkan untuk fit garis lurus.
Rumus : y = wx+b
o Multiple mengizinkan respon variabel Y untuk
dimodelkan sebagai fungsi linear dari
multidimensional feature vector. Rumus : y = b0 +
b1x1 + b2x2.
Log – linear model memperkirakan discrete
multidimensional distributions.
Non – parametric jangan asumsikan model. Contoh :
histogram, clustering, sampling.
Histogram membagi data ke bucket dan store
average (sum) untuk setiap bucket. Partition rules :
o Equal width equal bucket range.
o Equal frequency equal depth.
Clustering partisi dataset ke cluster berdasarkan
kesamaan kemudian store representasi cluster
(centroid dan diameter).
o Lebih efektif jika data di cluster tapi tidak efektif
jika data smeared.
o Bisa mempunyai hierarchical clustering dan
distore ke multidimensional index tree structure.
o Banyak pilihan clustering definitions dan
algoritma.
34. Data cube aggregation :
Lowest level (base cuboid)
o Aggregated data untuk entitas interest individual.
o Contoh : customer memanggil data warehouse.
Multiple level lebih jauh mengurangi ukuran data.

Timothy Orvin Edwardo – LE01 – 1901456205
Reference appropriate menggunakan representasi
terkecil yang cukup untuk menyelesaikan tugas.
Query berkaitan informasi aggregate dijawab menggunakan
data cube.
35. Transformasi data :
Fungsi yang mapping semua nilai attribute ke set baru
dimana value lama bisa diidentifikasi dengan value baru.
Metode :
Smoothing menghilangkan noise data.
Attribute / feature construction atribut baru dibuat
dari data yang diberikan.
Aggregation summarization, data cube
construction.
Normalization discale ke range yang lebih kecil dan
specified.
Discretization konsep hierarchy climbing.
36. Data warehouse decision support database yang
dimaintain terpisah dari database operasional. Sifatnya : subject
oriented, integrated, time – variant, non – volatile. Proses
membuat data warehouse disebut data warehousing.
37. Sifat data warehouse :
Subject oriented fokus modelling dan analisis data untuk
decision makers, dan diatur berdasarkan subject (customer,
product, sales), serta mengeluarkan data yang tidak
dibutuhkan.
Integrated dibuat dengan integrasi dari source data yang
berbeda. Disini diapply data cleaning dan data integration.

Timothy Orvin Edwardo – LE01 – 1901456205
Time – variant berisi data historical dan mengandung
elemen waktu baik eksplisit maupun implisit.
Non – volatile update dari operational database tidak
terjadi di data warehouse environment. Tidak butuh proses
transaksi, recovery, dan control concurrency.
38. Data warehouse dipisahkan dengan database operasional
karena :
Lebih khusus di tune untuk analisis (OLAP) complex OLAP
queries, multidimensional view, consolidation.
Fungsi berbeda dan data berbeda :
Data yang hilang membutuhkan historical data yang
tidak biasa dimaintain operational DB.
Data consolidation membutuhkan agregation dan
summarization data dari source yang berbeda.
Data quality source yang berbeda biasa datanya
tidak konsisten dan harus di reconciled.
39. Arsitektur data warehouse :

Timothy Orvin Edwardo – LE01 – 1901456205
40. Data warehouse model :
Enterprise warehouse mengumpulkan semua informasi
tentang subject spanning keseluruhan organisasi.
Data mart subset dari coorporate – wide data yang
valuenya hanya digunakan untuk specified user.
Virtual warehouse kumpulan view operational database
dan hanya beberapa summary view yang bisa di
materialized.
41. Extraction, Transformation, Loading (ETL) :
Data extraction data didapat dari beragam source.
Data cleaning deteksi error di data dan membenarkannya
ketika memungkinkan.
Data transformation konversi data dari format asal ke
format warehouse.
Load sort, summarize, consolidate, menghitung views,
cek integrity, membuat indicies dan partisi.
Refresh menjalankan update dari data source ke
warehouse.
42. Metadata repository :
Metadata adalah data yang mendefinisikan warehouse
object.
Deskripsi struktur data warehouse skema, view, dimensi,
hirarki, derived data, data mart location, konten.
Operational metadata history data yang dimigrasi dan
path transformasi, monitor informasi, keadaan data (aktif /
archived / purged).
Algoritma summarization.
Mapping dari operational ke warehouse.

Timothy Orvin Edwardo – LE01 – 1901456205
Data terkait performa sistem warehouse skema, view,
derived data definition.
Business data business terms dan definisi, kepemilikkan
data, charging policies.
43. Data cube dilihat dari berbagai dimensi :
Dimension table contoh item, waktu.
Fact table mengandung measure dan key dari dimension
table yang terkait.
44. Modelling data warehouse :
Star schema fact table terhubung dengan kumpulan
dimension table.
Snowflake schema beberapa dimensi ternormalisasi ke
set yang lebih kecil.
Fact constellations beberapa fact table share dimension
table. Dilihat sebagai kumpulan star schema. Disebut juga
galaxy schema.
45. Data cube measure :
Distributive jika hasil derive dengan apply fungsi ke n
aggregate values SAMA dengan derived dengan apply fungsi
ke semua data tanpa partisi. Contoh : COUNT, SUM, MIN,
MAX.
Algebraic jika bisa dikomputasi dengan fungsi aljabar
dengan M argumen, tiap argumen di apply dengan
distributive aggregate function. Contoh : AVG, MIN_N,
STDEV.

Timothy Orvin Edwardo – LE01 – 1901456205
Holistic jika tidak ada bound konstan di storage size yang
butuh dijelaskan subaggregate. Contoh : MEDIAN, MODE,
RANK.
46. Operasi OLAP :
Roll – up / drill – up menaikkan hirarki (dimensi
reduction).
Roll – down / drill – down dari high level ke low level
summary (data lebih detail).
Slice dan dice proyeksi dan select.
Pivot visualisasi, reorient cube, 3D ke 2D.
Drill across melibatkan lebih dari 1 fact table.
Drill through melalui bottom level cube ke back end
relational table (menggunakan SQL).
47. 4 views mengenai design data warehouse :
Top – down mengizinkan selection informasi relevan yang
diperlukan untuk data warehouse.
Data source ekspos informasi yang akan dicapture,
stored, dan manage oleh operational system.
Data warehouse mengandung dimension tabel dan fact
tabel.
Business query view melihat perspektif data di
warehouse dari view end user.
48. Data warehouse process design :
Top – down dimulai oleh desain keseluruhan dan
perencanaan matang.
Bottom up dimulai dari eksperimen dan prototype
(rapid).

Timothy Orvin Edwardo – LE01 – 1901456205
Waterfall analisis sistematis dan terstruktur pada tiap
step sebelum proses ke step berikutnya.
Spiral rapid generation dari functional system, short
turnaround time, quick turnaround.
49. Proses desain data warehouse yang dilakukan :
Memilih bisnis proses ke model.
Memilih grain (atomic level pada data) dari business
process.
Memilih dimensi yang diapply ke tiap record tabel fact.
Memilih measure yang mempopulasikan tiap record tabel
fact.
50. Kegunaan data warehouse :
Pemrosesan informasi support query, analisis statistik
dasar, reporting menggunakan crosstabs, tabel, chart, graph.
Pemrosesan analytical :
Analisis multidimensional dari data data warehouse.
Support basic operasi OLAP, slice – dice, drill, pivot.
Data mining :
Knowledge discovery dari pattern tersembunyi.
Support asosiasi, membangun model analitikal,
menjalankan prediksi dan klasifikasi,
mempresentasikan hasil mining menggunakan tools
visualisasi.
51. Online analytical mining (OLAM) :
Kualitas data yang tinggi di data warehouse karena
mengandung data yang integrated, konsisten, dan telah
dibersihkan.

Timothy Orvin Edwardo – LE01 – 1901456205
Menyediakan struktur pemrosesan informasi seputar data
warehouse ODBC, OLEDB, web accessing, service faclities.
OLAP based exploratory data analysis mining dengan
OLAP operation (drilling, dicing, pivoting).
On-line selection fungsi data mining integrasi dan
swapping dengan berbagai fungsi mining, algoritma, dan
tugas.
52. Data cube bisa dilihat sebagai lattice of cuboid :
Paling bawah base cuboid
Paling atas hanya mengandung 1 cell.
Berapa cuboid dalam n – dimensional cube dengan L level.
53. Indexing data OLAP :
Join index map value ke list record => mematerialkan
relational join dan mempercepat relational join.
Pada data warehouse, join index berkaitan dengan value
dimensi start schema ke baris di tabel fact.
54. Pemrosesan secara efisien query OLAP :
Menentukan operasi mana yang harus dijalankan di cuboid
yang tersedia transform, drill, roll ke OLAP operasi
(contoh : dice = selection + projection).
Menentukan materialized cuboid mana yang harus dipilih
OLAP.
55. Arsitektur server OLAP :
Relational OLAP :

Timothy Orvin Edwardo – LE01 – 1901456205
Menggunakan relational atau extended-relational
DBMS untuk store dan manage warehouse data dan
OLAP middleware.
Menyertakan optimisasi DBMS backend, implementasi
aggregation logic navigasi, tools dan service tambahan.
Scalability yang lebih baik.
Multidimensional OLAP :
Sparse array – based multidimensional storage engine.
Indexing cepat untuk prekomputasi data yang
diringkas.
Hybrid OLAP :
Fleksibilitas, contoh : low level (relational), high level
(array).
Specialized SQL Server :
Dukungan spesialisasi untuk query SQL diatas star /
snowflake schema.
56. Attribute oriented induction :
Mengumpulkan task – relevant data menggunakan database
query.
Menjalankan generalisasi dengan penghapusan atribut atau
generalisasi atribut.
Mengaplikasikan aggregation dengan merging tuple yang
identik dan tergeneralisasi, kemudian menghitung count
nya.
Interaksi dengan user untuk presentasi knowledge.
57. Prinsip dasar attribute orientation :
Data focusing task – relevant data termasuk dimensi,
hasilnya adalah initial relation.

Timothy Orvin Edwardo – LE01 – 1901456205
Penghapusan atribut menghapus atribut jika ada banyak
distinct value tetapi tidak ada operator generalisasi atau
diekspresikan sebagai atribut lain.
Generalisasi atribut jika ada banyak distinct value dan ada
operasi generalisasi, kemudian select operator dan
generalisasi atribut.
Attribute threshold control biasanya 2 – 8, bisa
ditentukan sendiri / default.
Generalized relation threshold control control relasi akhir
/ rule size.
58. Algoritma dasar attribute oriented induction :
InitialRel query processing task – relevant data,
menurunkan initial relation.
PreGen berdasarkan analisis banyaknya distinct value di
tiap atribut, menentukan rencana generalisasi untuk
penghapusan atribut atau cara generalisasi.
PrimeGen berdasarkan PreGen plan, menjalankan
generalisasi ke right level untuk menurunkan “prime
generalized relation”, mengakumulasi count nya.
Presentation interaksi user : mengatur level dengan
drilling, pivoting, map ke rules / crosstabs / visualisasi.
59. Presentasi hasil yang telah digeneralisasi :
Generalized relation :
Relasi dimana beberapa atau semua atribut
digeneralisasi dengan count atau aggregation.
Cross tabulation :
Memetakan hasil ke cross tabulation.

Timothy Orvin Edwardo – LE01 – 1901456205
Teknik visualisasi diagram pie, diagram batang,
kurva, cubes.
Quantitative characteristic rule :
Memetakan hasil yang telah digeneralisasi ke aturan
karakteristik dengan informasi kuantitatif yang terkait.
60. Perbandingan kelas mining :
Metode :
Partisi kumpulan data relevan ke target class dan
contrasting class.
Generalisasi kedua class ke konsep high level yang
sama.
Membandingkan baris dengan high level description
yang sama.
Mempresentasikan setiap tuple description dan 2
measure : support dan comparison.
Highlight tuple dengan fitur diskriminan yang kuat.
Analisis relevan menemukan atribut / fitur yang
membedakan class.
61. Persamaan dan perbedaan concept description dengan cube
– based OLAP :
Persamaan :
Generalisasi data.
Presentasi data summarization di berbagai level
abstraksi.
Drilling, pivot, slice, dice secara interaktif.
Perbedaan :
OLAP memiliki preprocessing yang sistematis, query
independent, dan bisa drill down ke low level.

Timothy Orvin Edwardo – LE01 – 1901456205
AOI memiliki alokasi level otomatis dan bisa
menjalankan analisis relevansi dimensi ketika ada
beberapa dimensi relevan.
AOI bekerja di data yang tidak berada di relational
forms.
62. Frequent pattern :
Pattern yang dicari bisa berupa item set.
Mencati sekelompok item yang muncul frequently.
Tujuan : mengetahui pola frequent item set.
63. Apriori prior knowledge tentang pattern sehingga
menemukan frequent pattern.
64. Prior knowledge suatu item set yang frequent pattern,
pasti subsetnya frequent juga. Jika salah 1 subset tidak frequent
pattern, maka itemset tersebut tidak frequent.
65. Pattern growth mengubah bentuk transaksi ke frequent
pattern tree.
66. Suatu itemset disebut frequent jika support nya lebih besar
sama dengan minimum support.
67. Suatu association rules dianggap interesting jika :
Support >= minimum support.
Confidence >= minimum confidence.