
MP3 - dis.um.esdis.um.es/~jfernand/0607/smig/puzzle-audio.pdf · demuestran que la distorsión...
22
MP3 MPEG-1 Audio Layer 3, más conocido como MP3, conocido también por su grafía emepetrés, es un formato de audio digital comprimido con pérdida desarrollado por el Moving Picture Experts Group (MPEG) para formar parte de la versión 1 (y posteriormente ampliado en la versión 2) del formato de video MPEG. Su nombre es el acrónimo de MPEG-1 Audio Layer 3. Dentro de los estándares de vídeo MPEG (de los que hablaremos en temas posteriores) hay también creados estándares de compresión de audio. Como se permiten distintas calidades existen tres "capas" con distintos esquemas de compresión: la capa 1, la 2 y la 3 (de forma que la complejidad es progresiva y un decodificador funciona también con las capas anteriores), y esta última se conoce por MP3 o MPEG Audio Layer-3. El MP3 permite comprimir en un factor aproximado de 12 la información original muestreada (unos 120 Kbits por segundo, es decir, más o menos 1 Mb por minuto) sin perder calidad de sonido de forma apreciable (por un oído no entrenado... y de hecho los estudios de percepción de calidad de mp3 se han hecho con oyentes humanos opinando sobre las diferencias). Para hacernos una idea aproximada de la compresión obtenida, en un CD-ROM podemos almacenar unos 700 minutos de música, es decir, más de ¡11 horas! (unas 175 canciones de 4 minutos cada una). Formato Compresión Kb/seg Layer1 4 a 1 384 Layer2 6 a 1 8 a 1 256 192 Layer3 10 a 1 12 a 1 128 112 Este formato fue desarrollado principalmente por Karlheinz Brandenburg, director de tecnologías de medios electrónicos del Instituto Fraunhofer IIS, perteneciente a una red de 47 centros de investigación alemanes que junto con Thomson Multimedia controla el grueso de las patentes relacionadas con el MP3. La primera de ellas fue registrada en 1986 y varias más en 1991. Pero no fue hasta julio de 1995 cuando Brandenburg usó por primera vez la extensión .mp3 para los archivos relacionados con el MP3 que guardaba en su ordenador. Un año después su instituto ingresaba en concepto de patentes 1,2 millones de euros . Diez años más tarde esta cantidad ha alcanzado los 26,1 millones. El formato MP3 se convirtió en el estándar utilizado para streaming de audio y compresión de audio de alta calidad (con pérdida en equipos de alta fidelidad) gracias a la posibilidad de ajustar la calidad de la compresión, proporcional al tamaño por segundo (bitrate ), y por tanto el tamaño final del archivo, que podía llegar a ocupar 12 e incluso 15 veces menos que el archivo original sin comprimir. Fue el primer formato de compresión de audio popularizado gracias a Internet , ya que hizo posible el intercambio de ficheros musicales. Esto derivó en procesos judiciales contra empresas como Napster y AudioGalaxy .
Transcript of MP3 - dis.um.esdis.um.es/~jfernand/0607/smig/puzzle-audio.pdf · demuestran que la distorsión...

MP3 MPEG-1 Audio Layer 3, más conocido como MP3, conocido también por su grafía emepetrés, es un formato de audio digital comprimido con pérdida desarrollado por el Moving Picture Experts Group (MPEG) para formar parte de la versión 1 (y posteriormente ampliado en la versión 2) del formato de video MPEG. Su nombre es el acrónimo de MPEG-1 Audio Layer 3.
Dentro de los estándares de vídeo MPEG (de los que hablaremos en temas posteriores) hay también creados estándares de compresión de audio. Como se permiten distintas calidades existen tres "capas" con distintos esquemas de compresión: la capa 1, la 2 y la 3 (de forma que la complejidad es progresiva y un decodificador funciona también con las capas anteriores), y esta última se conoce por MP3 o MPEG Audio Layer-3.
El MP3 permite comprimir en un factor aproximado de 12 la información original muestreada (unos 120 Kbits por segundo, es decir, más o menos 1 Mb por minuto) sin perder calidad de sonido de forma apreciable (por un oído no entrenado... y de hecho los estudios de percepción de calidad de mp3 se han hecho con oyentes humanos opinando sobre las diferencias). Para hacernos una idea aproximada de la compresión obtenida, en un CD-ROM podemos almacenar unos 700 minutos de música, es decir, más de ¡11 horas! (unas 175 canciones de 4 minutos cada una).
Formato
Compresión Kb/seg
Layer1 4 a 1 384
Layer2 6 a 1 8 a 1
256 192
Layer3 10 a 1 12 a 1
128 112
Este formato fue desarrollado principalmente por Karlheinz Brandenburg, director de tecnologías de medios electrónicos del Instituto Fraunhofer IIS, perteneciente a una red de 47 centros de investigación alemanes que junto con Thomson Multimedia controla el grueso de las patentes relacionadas con el MP3. La primera de ellas fue registrada en 1986 y varias más en 1991. Pero no fue hasta julio de 1995 cuando Brandenburg usó por primera vez la extensión .mp3 para los archivos relacionados con el MP3 que guardaba en su ordenador. Un año después su instituto ingresaba en concepto de patentes 1,2 millones de euros. Diez años más tarde esta cantidad ha alcanzado los 26,1 millones.
El formato MP3 se convirtió en el estándar utilizado para streaming de audio y compresión de audio de alta calidad (con pérdida en equipos de alta fidelidad) gracias a la posibilidad de ajustar la calidad de la compresión, proporcional al tamaño por segundo (bitrate), y por tanto el tamaño final del archivo, que podía llegar a ocupar 12 e incluso 15 veces menos que el archivo original sin comprimir.
Fue el primer formato de compresión de audio popularizado gracias a Internet, ya que hizo posible el intercambio de ficheros musicales. Esto derivó en procesos judiciales contra empresas como Napster y AudioGalaxy.

Tras el desarrollo de reproductores autónomos, portátiles o integrados en cadenas musicales (estéreos), el formato MP3 llega más allá del mundo de la informática.
A principios de 2002 otros formatos de audio comprimido como Windows Media Audio y Ogg Vorbis empiezan a ser masivamente incluidos en programas, sistemas operativos y reproductores autónomos, lo que hizo prever que el MP3 fuera paulatinamente cayendo en desuso, en favor de otros formatos, como los mencionados, de mucha mejor calidad. Uno de los factores que influye en el declive del MP3 es que tiene patente. Técnicamente no significa que su calidad sea inferior ni superior, pero impide que la comunidad pueda seguir mejorándolo y puede obligar a pagar por la utilización de algún códec, esto es lo que ocurre con los reproductores de MP3. Aún así, a inicios del 2007, el formato mp3 continua siendo el más usado y el que goza de más éxito.
El formato mp3 utiliza unos cuantos trucos para comprimir el sonido, fundamentalmente técnicas de codificación de percepción que aprovechan la manera en la que el oído humano percibe el sonido. Veamos algunas de las claves:
Umbral mínimo de audición.
El umbral mínimo de audición humano (minimal audition threshold) no es lineal. De acuerdo a la ley de Fletcher y Munsen, se representa por una curva entre 2 y 5 KHz. Cualquier sonido situado fuera de este margen puede no codificarse, ya que no será percibido de cualquier modo.
Efecto máscara.
Hay una serie de propiedades de ocultación (masking effect) del oído humano. De la misma forma que al mirar a un objeto muy brillante se anula la percepción de otros objetos que puedan cruzarlo, en audio los sonidos fuertes no dejan oir a los débiles. Para conseguir aprovechar esta característica mp3 usa un modelo psicoacústico del comportamiento del oído humano, que filtra los sonidos más débiles cuando hay sonidos muy fuertes a la vez.
Reserva de bytes.
Partes de una obra pueden no ser codificados por debajo de un número de bytes por segundo para mantener la calidad. En estos casos, mp3 usa partes que sí pueden codificarse en un tamaño inferior para almacenar parte de los otros, de modo que actúa como una especie de buffer de las partes más exigentes.
Fusión de estéreo.
En muchas músicas, en frecuencias determinadas, el oído humano no puede distinguir el origen espacial de los sonidos de un canal u otro del estéreo. En este caso mp3 puede fusionar las dos señales en una única (mono) añadiendo quizás alguna información de diferenciación de canales para disminuir al mínimo la información determinada por la diferencia entre uno y otro canal.

Codificación de Huffman.
El código Huffman se aplica al final de la compresión. En cierto modo complementa a las otras partes de la codificación mp3: en algunas partes polifónicas se puede reducir mucha información enmascarada o de estéreo, y en ese caso habrá poca redundancia (y por ello poca reducción por codificación Huffman); mientras que en partes de solos se podrán aplicar pocos efectos de máscara pero habrá muchos bytes redundantes (mucha reducción por Huffman).
Detalles técnicos
En esta capa existen varias diferencias respecto a los estándares MPEG-1 y MPEG-2, entre las que se encuentra el llamado banco de filtros híbrido que hace que su diseño tenga mayor complejidad. Esta mejora de la resolución frecuencial empeora la resolución temporal introduciendo problemas de pre-eco que son predecidos y corregidos. Además, permite calidad de audio en tasas tan bajas como 64Kbps.
Banco de filtros
El banco de filtros utilizado en esta capa es el llamado banco de filtros híbrido polifase/MDCT. Se encarga de realizar el mapeado del dominio del tiempo al de la frecuencia tanto para el codificador como para los filtros de reconstrucción del decodificador. Las muestras de salida del banco están cuantizadas y proporcionan una resolución en frecuencia variable, 6x32 o 18x32 subbandas, ajustándose mucho mejor a las bandas críticas de las diferentes frecuencias. Usando 18 puntos, el número máximo de componentes frecuenciales es: 32 x 18 = 576. Dando lugar a una resolución frecuencial de: 24000/576 = 41,67 Hz (si fs = 48 Khz.). Si se usan 6 líneas de frecuencia la resolución frecuencial es menor, pero la temporal es mayor, y se aplica en aquellas zonas en las que se espera efectos de preeco (transiciones bruscas de silencio a altos niveles energéticos).
La Capa III tiene tres modos de bloque de funcionamiento: dos modos donde las 32 salidas del banco de filtros pueden pasar a través de las ventanas y las transformadas MDCT y un modo de bloque mixto donde las dos bandas de frecuencia más baja usan bloques largos y las 30 bandas superiores usan bloques cortos. Para el caso concreto del MPEG-1 Audio Layer 3 (que concretamente significa la tercera capa de audio para el estandar MPEG-1) especifica cuatro tipos de ventanas: (a) NORMAL, (b) transición de ventana larga a corta (START), (c) 3 ventanas cortas (SHORT), y (d) transición de ventana corta a larga (STOP).
El modelo psicoacústico
La compresión se basa en la eliminación de información perceptualmente irrelevante, es decir, en la incapacidad del sistema auditivo para detectar los errores de cuantificación en condiciones de enmascaramiento. Este estándar divide la señal en bandas de frecuencia que se aproximan a las bandas críticas, y luego cuantifica cada subbanda en función del umbral de detección del ruido dentro de esa banda. El modelo psicoacústico es una modificación del empleado en el esquema II, y utiliza un método denominado predicción polinómica. Analiza la señal de audio y calcula la cantidad de ruido que se puede introducir en función de la frecuencia, es decir, calcula la “cantidad de enmascaramiento” o umbral de enmascaramiento en función de la frecuencia.

El codificador usa esta información para decidir la mejor manera de gastar los bits disponibles. Este estándar provee dos modelos psicoacústicos de diferente complejidad: el modelo I es menos complejo que el modelo psicoacústico II y simplifica mucho los cálculos. Estudios demuestran que la distorsión generada es imperceptible para el oído experimentado en un ambiente óptimo desde los 256 kbps y en condiciones normales y para el oído no experimentado 128 kbps es suficiente. Para el oído no experimentado, o común, con 128 kbps o hasta 96 kbps basta para que se oiga "bien" (a menos que se posea un equipo de audio de alta calidad donde se nota excesivamente la falta de graves y se destaca el sonido de "fritura" en los agudos), sin embargo, en las personas que escuchan mucha música o que tienen experiencia en la parte auditiva, desde 192 o 256 kbps basta para oír bien, lamentablemente en internet circula música a 128 kbps en su gran mayoría.
Codificación y cuantificación
La solución que propone este estándar en cuanto a la repartición de bits o ruido se hace en un ciclo de iteración que consiste de un ciclo interno y uno externo. Examina tanto las muestras de salida del banco de filtros como el SMR (signal-to-mask ratio) proporcionado por el modelo psicoacústico, y ajusta la asignación de bits o ruido, según el esquema utilizado, para satisfacer simultáneamente los requisitos de tasa de bits y de enmascaramiento. Dichos ciclos consisten en:
(i)Ciclo interno. El ciclo interno realiza la cuantización no-uniforme de acuerdo con el sistema de punto flotante (cada valor espectral MDCT se eleva a la potencia 3/4). El ciclo escoge un determinado intervalo de cuantización y, a los datos cuantizados, se les aplica codificación de Huffman en el siguiente bloque. El ciclo termina cuando los valores cuantizados que han sido codificados con Huffman usan menor o igual número de bits que la máxima cantidad de bits permitida.
(ii)Ciclo externo. Ahora el ciclo externo se encarga de verificar si el factor de escala para cada subbanda tiene más distorsión de la permitida (ruido en la señal codificada), comparando cada banda del factor de escala con los datos previamente calculados en el análisis psicoacústico. El ciclo externo termina cuando una de las siguientes condiciones se cumple:
Ninguna de las bandas del factor de escala tiene mucho ruido.
Si la siguiente iteración amplifica una de las bandas más de lo permitido.
Todas las bandas han sido amplificadas al menos una vez.
Empaquetado o formateador de bitstream
Este bloque toma las muestras cuantificadas del banco de filtros, junto a los datos de asignación de bits/ruido y almacena el audio codificado y algunos datos adicionales en las tramas. Cada trama contiene información de 1152 muestras de audio y consiste de un encabezado, de los datos de audio junto con el chequeo de errores mediante CRC y de los datos auxiliares (estos dos últimos opcionales). El encabezado nos describe cuál capa, tasa de bits y frecuencia de muestreo se están usando para el audio codificado. Las tramas empiezan con la misma cabecera de sincronización y diferenciación y su longitud puede variar. Además de tratar con esta información, también incluye la codificación Huffman de longitud variable, un método de codificación entrópica que sin pérdida de información elimina redundancia. Actúa al final de la compresión para codificar la información. Los métodos de longitud variable se caracterizan, en

general, por asignar palabras cortas a los eventos más frecuentes, dejando las largas para los más infrecuentes.
Estructura de un fichero MP3
Un fichero Mp3 se constituye de diferentes frames MP3 que a su vez se componen de una cabecera Mp3 y los datos MP3. Esta secuencia de datos es la denominada stream elemental. Cada uno de los Frames son independientes, es decir, una persona puede cortar los frames de un fichero MP3 y después reproducirlos en cualquier reproductor MP3 del Mercado. El grafico muestra que la cabecera consta de una palabra de sincronismo que es utilizada para indicar el principio de un frame valido. A continuación siguen una serie de bits que indican que el fichero analizado es un fichero Standard MPEG y si usa o no la capa 3. Después de todo esto los valores difieren dependiendo del tipo de archivo MP3. Los rangos de valores quedan definidos en la ISO/IEC 11172-3.
Señal Longitud (bits)
Posición (bits)
Descripción
A 11 (31-21) Sincronización (todos los bits a 1)
B 2 (20,19) Versión MPEG Audio
00 - MPEG Versión 2.5
01 - reserved 10 - MPEG Versión 2 (ISO/IEC 13818-3) 11 - MPEG Versión 1 (ISO/IEC 11172-3)
Nota: MPEG Versión 2.5 fue añadida al estándar MPEG 2, usada para bitrates muy bajos. Para decodificadores que no soporten esta extensión se recomienda el uso de 12 bits para sincronización en vez de 11.
C 2 (18,17) Descripción de nivel 00 - reserved 01 - Layer III 10 - Layer II 11 - Layer I
D 1 (16) Bit de Protección
0 – Protegido por CRC 1 - No protegido
E 4 (15,12) Bitrate en kbps
bits V1,L1 V1,L2 V1,L3 V2,L1 V2, L2 & L3
0000 Libre Libre Libre Libre Libre

0001 32 32 32 32 8
0010 64 48 40 48 16
0011 96 56 48 56 24
0100 128 64 56 64 32
0101 160 80 64 80 40
0110 192 96 80 96 48
0111 224 112 96 112 56
1000 256 128 112 128 64
1001 288 160 128 144 80
1010 320 192 160 160 96
1011 352 224 192 176 112
1100 384 256 224 192 128
1101 416 320 256 224 144
1110 448 384 320 256 160
1111 Mal Mal Mal Mal Mal
V1 - MPEG Versión 1 V2 - MPEG Versión 2 y Versión 2.5 L1 - Layer I
L2 - Layer II
L3 - Layer III "libre": formato libre. Debe ser constante y por debajo del máximo permitido. No tiene por qué ser aceptado por un decodificador. "mal": valor no permitido.
Algunos ficheros MPEG usan bitrate variable (VBR). Cada frame puede poseer un bitare diferente. Esta característica es soportada por los decodificadores Layer III, no por todos los de Layer I y II

F 2 (11,10) Frecuencia de muestreo
bits MPEG1 MPEG2 MPEG2.5
00 44100 Hz 22050 Hz 11025 Hz
01 48000 Hz 24000 Hz 12000 Hz
10 32000 Hz 16000 Hz 8000 Hz
11 reserv. reserv. reserv.
G 1 (9) Bit de ajuste
0 - frame no ajustado
1 - frame ajustado con un slot extra
Sirve para asegurarnos que cada frame cumple los requisitos del bitrate.
H 1 (8) Bit Privado, informativo. Si no existe, se pone un checksum de 16 bits antes de los datos de audio
I 2 (7,6) Modo 00 - Stereo 01 - Joint stereo (Stereo) 10 - Dual channel (2 mono channels) 11 - Single channel (Mono) Nota: Los archivos de canal dual se construyen a partir de dos mono independientes, cada uno usa la mitad del bitrate.
J 2 (5,4) Extensión de Modo (para Joint stereo)
Determinados directa y dinámicamente por un codificador. Se divide el rango de frecuencias en 32 subbandas. Para Layer I y II los bits determinan las bandas donde se aplica el estéreo intenso. Para Layer III determinan qué tipo de estéreo se usa (intenso o MS)
Layer I y II Layer III
valor Layer I & II
00 bandas 4 a 31
01 bandas 8 a 31
Intenso MS
off off
on off

10 bandas 12 a 31
11 bandas 16 a 31
off on
on on
K 1 (3) Copyright 0 - Audio sin copyright
1 - Audio con copyright
L 1 (2) Originalidad 0 - Copia 1 - Original
M 2 (1,0) Énfasis 00 - no 01 - 50/15 ms 10 – reservado
11 - CCIT J.17
Indica al decodificador si el fichero ha de ser re-ecualizado. No se suele usar
Transformada de Fourier discreta
En matemáticas, la transformada de Fourier discreta, designada con frecuencia por la abreviatura DFT (del inglés discrete Fourier transform), y a la que en ocasiones se denomina transformada de Fourier finita, es una transformada de Fourier ampliamente empleada en tratamiento de señales y en campos afines para analizar las frecuencias presentes en una señal muestreada, resolver ecuaciones diferenciales parciales y realizar otras operaciones, como convoluciones. Es utilizada en el proceso de elaboracion de un fichero MP3.
La transformada de Fourier discreta puede calcularse de modo muy eficiente mediante el algoritmo FFT.

WAV WAV (o WAVE), apócope de WAVEform audio format, es un formato de audio digital normalmente sin compresión de datos desarrollado y propiedad de Microsoft y de IBM que se utiliza para almacenar sonidos en el PC , admite archivos mono y estéreo a diversas resoluciones y velocidades de muestreo, su extensión es .wav.
Es una variante del formato RIFF (Resource Interchange File Format, formato de fichero para intercambio de recursos), método para almacenamiento en "paquetes", y relativamente parecido al IFF y al formato AIFF usado por Macintosh. El formato toma en cuenta algunas peculiaridades de la CPU Intel, y es el formato principal usado por Windows.
A pesar de que el formato WAV puede soportar casi cualquier códec de audio, se utiliza principalmente con el formato PCM (no comprimido) y al no tener pérdida de calidad puede ser usado por profesionales, Para tener calidad Disco compacto se necesita que el sonido se grabe a 44100 Hz y a 16 bits, por cada minuto de grabación de sonido se consumen unos 5 megabytes de disco duro. Una de sus grandes limitaciones, debida realmente al sistema operativo MS Windows, es que solo se puede grabar un archivo de hasta 4 gigabites, que equivale aproximadamente a 6,6 horas en calidad disco compacto.
En Internet no es popular, fundamentalmente porque los archivos sin compresión son muy grandes. Son más frecuentes los formatos comprimidos con pérdida, como el MP3 o el Ogg Vorbis. Como éstos son más pequeños la transferencia a través de Internet es mucho más rápida. Además existen códecs de compresión sin pérdida más eficaces como Apple Lossless o FLAC.
El formato de los ficheros .WAV es el siguiente:
Bytes Contenido Usual Propósito/Descripción
00 - 03 "RIFF" Bloque de identificación (sin comillas).
04 - 07 ??? Entero largo. Tamaño del fichero en bytes, incluyendo cabecera.
08 - 11 "WAVE" Otro identificador.
12 - 15 "fmt " Otro identificador
16 -19 16, 0, 0, 0 Tamaño de la cabecera hasta este punto.
20 - 21 1, 0 Etiqueta de formato. (Algo así como la versión del tipo de formato utilizado).
22 - 23 1, 0 (mono) ; 2,0 (estéreo)
Número de canales (2 si es estéreo).

24 – 27 ??? Frecuencia de muestreo (muestras/segundo).
28 – 31 ??? Número medio de bytes/segundo.
32 – 33 1, 0 Bytes por muestra
34 – 35 8, 0 Número de Bits por muestra (normalmente 8, 16 ó 32).
36 – 39 "data" Marcador que indica el comienzo de los datos de las muestras.
40 – 43 ??? Número de bytes muestreados.
Resto ??? Muestras (cuantificación uniforme)
Cabecera RIFF
El fichero RIFF lleva siempre una cabecera de 8 bytes, que identifica al fichero y especifica la longitud de los datos a partir de la cabecera (esto es, la longitud total menos 8).
Esta cabecera se compone de 4 bytes con el contenido "RIFF" y los otros 4 indican la longitud. Después de la cabecera RIFF siempre hay 4 bytes que identifican el tipo de los datos que contiene; para el caso .WAV estos 4 bytes contienen "WAVE".
Chunks RIFF
Los datos de un fichero RIFF se componen de una secuencia de chunks, cada uno de los cuales consta de un campo de identificación de 4 bytes, una longitud de datos de 4 bytes y el conjunto de los datos. Al procesar un fichero RIFF, se deben ignorar los segmentos desconocidos, para asegurar compatibilidad con futuras definiciones de los formatos de fichero.
Generalidades del formato WAVE
Del conjunto de segmentos que se definen para el formato WAVE existen dos que son obligatorios: el segmento de formato y el segmento de datos. Además el segmento de formato debe aparecer antes que el segmento de datos.
El resto de segmentos son opcionales, aunque como se verá más adelante el segmento FACT es obligatorio en algunos casos.
Segmento de formato (Format Chunk)
El segmento de formato identifica por "fmt " y se compone de dos elementos: un conjunto de campos comunes y un conjunto de campos específicos.
Este último puede no aparecer, en función del formato concreto elegido. Los campos comunes pueden representarse en la siguiente estructura:

Categorías del formato WAVE
La categoría se especifica a través del campo wFormatTag. Los campos específicos del segmento de formato y la representación de los datos en el segmento de datos dependen de este valor.
Actualmente se han definido los siguientes formatos no propietarios:
Formato WAVE_FORMAT_PCM
Este formato define un único campo específico que indica el número de bits por muestra de cada canal.Si este campo está comprendido entre 1 y 8 bits, el valor que se almacena en una muestra es un entero sin signo. Si su valor supera los 8 bits entonces el valor almacenado en las muestras es un entero con signo.
Este campo, dividido entre ocho y redondeado al entero mayor más próximo indica el número de bytes por muestra, y permite estimar el campo wAvgBytesPerSec como:
wChannels � wSamplesPerSecond � BytesPerSample
Del mismo modo se puede calcular el valor de wBloackAlign de la siguiente forma:
wChannels � BytesPerSample
La ordenación de los bytes de datos es la siguiente: los datos se organizan en bloques de wBlockAlign bytes. Estos bloques son una secuencia de las muestras para cada canal (en estéreo 0 es izquierdo y 1 es derecho), dentro de cada canal el byte menos significativo va primero.
Segmento de datos (Data Chunk)
El segmento de datos puede ser de dos tipos: tipo data o tipo data-list.

El primero es una secuencia de datos sin más elementos. El segundo en una secuencia de dos tipo de segmentos: de datos o de silencio.
Un segmento tipo data se identifica por "data", mientras que un segmento tipo data-list se identifica por "wavl". Los segmentos de silencio ("slnt") sólo contienen un campo que es una doble palabra con el número de muestras a mantener el silencio.
NOTA: El valor de las muestras de silencio no deben ser asignadas a cero, sino al valor de la última muestra reproducida. De lo contrario, puede oírse un 'click' debido al salto que recibe el conversor D/A de salida. Es responsabilidad de la aplicación evitar este 'click' al igual que el que se puede producir al final del silencio.
Segmento FACT
El segmento FACT tiene como objetivo almacenar información importante sobre los datos del fichero. Es un segmento obligatorio en caso de que el campo de datos sea de tipo data-list y con cualquier tipo de compresión.
La definición básica de este segmento contiene un único campo (dwFileSize) pero en futuras definiciones del formato WAVE ampliará su contenido por lo que se debe usar el campo longitud de la cabecera del segmento para determinar los campos que están presentes.
Segmento Cue-Points
Este segmento ("cue") tiene como objetivo marcar determinadas posiciones dentro de la forma de onda que contiene el fichero. El segmento consta de un campo dwCuePoints indicando el número de puntos a posicionar y una secuencia de estructuras como la siguiente:
Segmento Playlist
Especifica un orden de reproducción a partir de diferentes posiciones en el fichero. Se identifica por "plst" y contiene un campo dwSegments, que indica el número de segmentos que se reproducen y a continuación una lista de estructuras que describen el segmento a reproducir:

Segmento de datos asociados
Este segmento se identifica por "adtl" y permite asociar información a secciones de la forma de onda del fichero. Se define como una lista de otros segmentos que son:
• Etiqueta ("labl")
• Nota ("note")
• Texto con información de longitud de datos ("ltxt")
• Información de fichero embebido ("file")
Segmentos "labl" y "note"
Su formato es similar, "labl" contiene una etiqueta o título asociado a una determinada posición de la forma de onda y "note" aporta un comentario sobre esa posición. Los dos segmentos constan de dos campos: un campo dwName que identifica el punto de la forma de onda considerado y un campo data que es una cadena terminada con un carácter nula que especifica el contenido de la etiqueta o la nota.
Segmento "ltxt"
Este segmento contiene información asociada a una porción de datos de una longitud determinada. Los campos de los que se compone son los siguientes:
Segmento "file"
Este segmento contiene información descrita en otros formatos de fichero. Su formato es el siguiente:



Ogg Vorbis
Vorbis es un códec de audio libre de compresión con pérdida. Forma parte del proyecto Ogg y entonces es llamado Ogg Vorbis y también (incorrectamente) sólo ogg por ser más corto de escribir (y decir) y por ser el códec más comúnmente encontrado en el contenedor Ogg.
Introducción
Vorbis es un códec de audio perceptivo de fines generales previsto para permitir flexibilidad máxima del codificador y así permitiéndole escalar competitivamente sobre una gama excepcionalmente amplia de bitrates. En la escala de nivel de calidad/bitrate (CD audio o DAT-rate estéreo, 16/24 bits) se encuentra en la misma liga que MPEG-2 y Musepack (MPC) y comparable con AAC en la mayoría de bitrates. Similarmente, el codificador 1.0 puede codificar niveles de calidad desde CD audio y DAT-rate estéreo hasta 48kbps sin bajar la frecuencia de muestreo. Vorbis también está pensado para frecuencias de muestreo bajas desde telefonía de 8kHz y hasta alta definición de 192kHz, y una gama de representaciones de canales (monoaural, polifónico, estéreo, quadrafónico, 5.1, ambisónico o hasta 255 canales discretos).
Ogg Vorbis es totalmente abierto, libre de patentes y de regalías; la biblioteca de referencia (libvorbis) se distribuye bajo una licencia tipo BSD por lo que cualquiera puede implementarlo ya sea tanto para propósitos comerciales como no comerciales.
Historia
Vorbis es el primer códec desarrollado como parte de los proyectos multimedia de la Fundación Xiph.org. Comenzó inmediatamente después que Fraunhofer IIS (creadores del MP3) enviaran una "carta de infracción" a varios proyectos pequeños que desarrollan MPEG Audio Layer 3, mencionando que debido a las patentes que poseen sobre el MP3 tienen el derecho de cobrar regalías por cualquier reproductor comercial, todos los codificadores (ya sea vendidos o gratuitos) y también trabajos de arte vendidos en formato MP3. Por este motivo fue creado el Ogg Vorbis y la Fundación Xiph.org: para proteger la multimedia en Internet del control de intereses privados.
El formato del bitstream para Vorbis I fue congelado el 8 de Mayo de 2000; todos los archivos creados desde esa fecha seguirán siendo compatibles con futuros lanzamientos de Vorbis.
La versión 1.0 fue anunciada en Julio 2002, con una «Carta de anuncio de Ogg-Vorbis 1.0» agradeciendo el apoyo recibido y explicando el porqué es necesario el desarrollo de códecs libres.
Vorbis recibe este nombre de un personaje del libro Dioses menores de Terry Pratchett.

Ogg es el nombre que recibe un proyecto que tenía como objetivo diseñar un nuevo sistema multimedia de código abierto. La segunda parte del nombre viene de la denominación que se dio al esquema de compresión de audio usado para crear archivos con este formato. De ahí que el nombre de este nuevo formato sea Ogg Vorbis. Como es lógico, la extensión que toman los ficheros bajo este formato es .ogg. Ogg Vorbis es un nuevo formato de compresión de audio con calidad digital tanto para grabar como para reproducir música. Es comparable a los formatos mencionados anteriormente, aunque cuenta con una característica que le diferencia de los demás y que además es bastante importante, y es que es completamente gratuito y no está sujeto a ninguna patente. A partir de este momento comenzaron a aparecer diferentes componentes de software, de los que luego hablaremos, entre los que no solo encontramos reproductores del formato, sino que además podremos tener acceso al código del formato mediante herramientas de desarrollo que los programadores podrán usar para comenzar a trabajar universalmente con Ogg vorbis.
Ogg Vorbis está basado en la licencia pública general de GNU. GNU es el nombre que recibe un proyecto que data del año 1984 cuyo objetivo era el desarrollo de un sistema operativo basado en Unix y con la calificación de software libre. Estos sistemas son hoy en día muy usados bajo el nombre de Linux. El término de Software Libre está asociado íntimamente con el proyecto GNU, y por tanto a Ogg Vorbis, y se basa en la libertad que según los miembros de este proyecto debería existir sobre el software. Para quienes configuran el GNU el hecho de no poseer software libre, supone una privación de la tecnología a cierto sector de la sociedad, algo que no debería estar permitido y que seguirá siendo así mientras exista el copyright. Ogg Vorbis se rige en su totalidad por las normas del proyecto GNU, por lo que se considera un sistema libre que podrá circular, copiarse, mejorarse de manera libre. El código de desarrollo de este formato, está a disposición de los programadores para ir puliendo los pequeños defectos que pueda tener, al tiempo que se mejora su implementación. El objetivo se sitúa en que algún día, todo el software que requiera de contenido de audio, sea desarrollado y distribuido con código de Ogg Vorbis. Por tanto, no está sujeto a patentes como lo está MP3, y su uso no implica la obligación de abonar una cantidad al grupo de desarrollo de Ogg Vorbis. Tenemos un formato de calidad futurible, que no nos dará una sorpresa dentro de un mes, haciéndose de pago. Esto implica un posible soporte para otras empresas, que pueden añadir música de calidad a sus creaciones sin tener que pensar en el presupuesto necesario para poder usar la tecnología actual.
La intención de Ogg Vorbis es conseguir una mayor aceptación que el resto de formatos destinados al mismo fin. Pero para lograrlo, el mejor argumento siempre es poseer la mejor calidad, por ello, y aunque las comparaciones son odiosas, el mp3 es el punto de referencia sobre el que fijarnos a la hora de evaluar este formato. En una hipotética situación de compresión de una misma canción, tanto en formato mp3 a 128 kbps como en formato ogg, el espacio que ambos ficheros ocuparían en disco es el mismo aproximadamente, aunque en el segundo caso, la calidad auditiva sería superior. La explicación se debe fundamentalmente a los valores de muestreo en los que es capaz de trabajar este formato, llegando desde los 16 kbps hasta los 128 kbps por canal, aunque en las especificaciones del formato no se detalla específicamente que no se pueda codificar un archivo a 8 kbps o 512 kbps. Ogg Vorbis tiene una muy bien definida cabecera para comentarios en los archivos, que es extensible y fácil de usar, sin tener que usar etiquetas de ID3. Posee además una escala de muestreo, es decir, una función que permite cambiar la cantidad de muestra de un archivo o transmisión sin tener que recodificar el archivo entero, con el tiempo que ello conlleva, simplemente se acortan los paquetes al tamaño deseado. Los archivos Vorbis pueden ser troceados y luego editados con
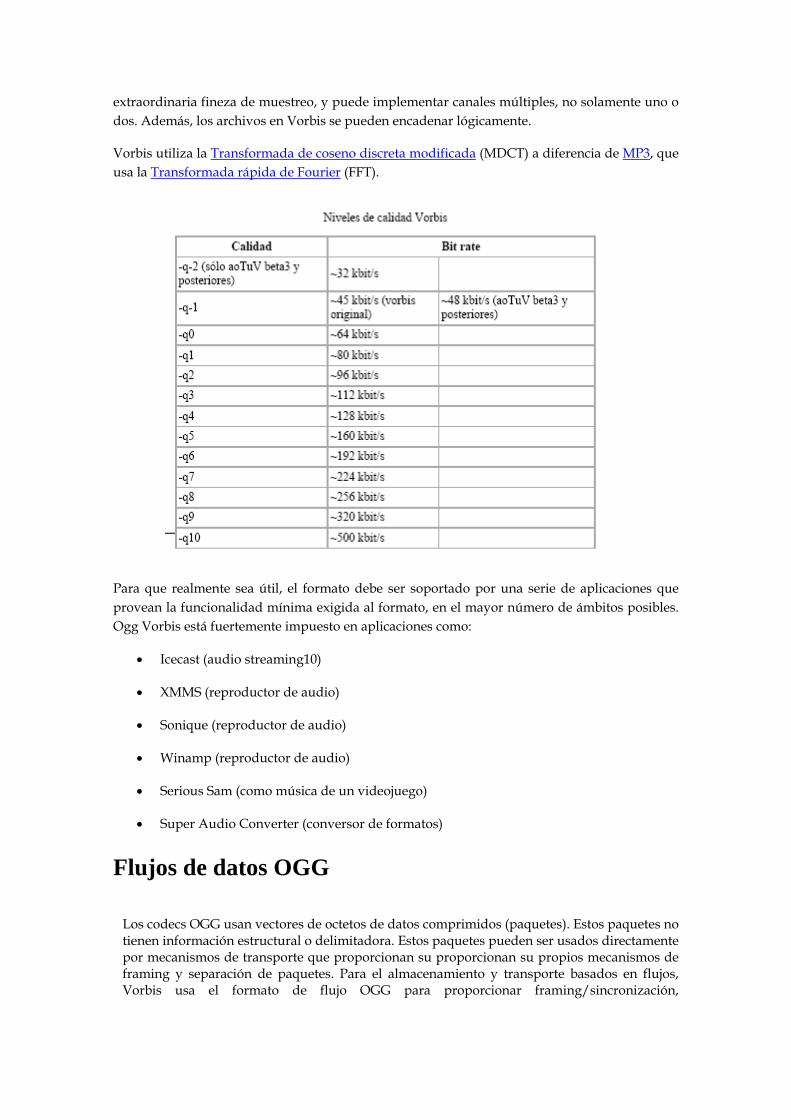
extraordinaria fineza de muestreo, y puede implementar canales múltiples, no solamente uno o dos. Además, los archivos en Vorbis se pueden encadenar lógicamente.
Vorbis utiliza la Transformada de coseno discreta modificada (MDCT) a diferencia de MP3, que usa la Transformada rápida de Fourier (FFT).
Para que realmente sea útil, el formato debe ser soportado por una serie de aplicaciones que provean la funcionalidad mínima exigida al formato, en el mayor número de ámbitos posibles. Ogg Vorbis está fuertemente impuesto en aplicaciones como:
• Icecast (audio streaming10)
• XMMS (reproductor de audio)
• Sonique (reproductor de audio)
• Winamp (reproductor de audio)
• Serious Sam (como música de un videojuego)
• Super Audio Converter (conversor de formatos)
Flujos de datos OGG
Los codecs OGG usan vectores de octetos de datos comprimidos (paquetes). Estos paquetes no tienen información estructural o delimitadora. Estos paquetes pueden ser usados directamente por mecanismos de transporte que proporcionan su proporcionan su propios mecanismos de framing y separación de paquetes. Para el almacenamiento y transporte basados en flujos, Vorbis usa el formato de flujo OGG para proporcionar framing/sincronización,

resincronización tras errores, marcas durante la búsqueda, y suficiente información para separar los datos en los paquetes.
Los paquetes raw se agrupan y codifican en páginas contiguas de flujos de bits estructurados llamados flujos lógicos. Un flujo lógico contiene páginas pertenecientes a un único códec. Cada página es una entidad autocontenida, esto es, el mecanismo que decodifica la página está diseñado para reconocer, verificar y gestionar individualmente páginas del flujo. Se pueden combinar (con restricciones) varios flujos lógicos en un flujo físico. Un flujo físico consiste en múltiples flujos lógicos multiplexados al nivel de página y puede incluir una meta cabecera al principio del flujo lógico multiplexado que sirve como identificador. Se toman ordenadamente páginas completas de los flujos lógicos y se combinan en un único flujo físico de páginas. El decodificador reconstruye los flujos lógicos originales a partir del físico tomando las páginas en orden y redireccionándolas en la entidad lógica apropiada. El flujo físico más simple está compuesto de un único flujo lógico sin multiplexar, sin cabecera, al que se le llama “flujo degenerado”.
El flujo de transporte OGG está diseñado para proporcionar framing, protección ante errores y estructuras de búsqueda para flujos de códecs de nivel superior que consisten en paquetes de datos sin encapsular como el códec de audio Vorbis o el de vídeo Theora.

MP3 Surround MP3 Surround es un tipo de archivo MP3 que soporta canales 5.1 de audio. Fue desarrollado por Fraunhofer IIS en colaboración con Agere Systems. El codificador actual tiene licencia de uso personal y no comercial. Un archivo MP3 surround puede ser creado a partir de canales 5 o 6 de audio WAV.
MP3 ha sido sinónimo de almacenamiento y transmisión estéreo en los últimos 15 años. Sin embargo, cada vez es más común que los hogares dispongan de un entorno de sonido multicanal. Una consecuencia de esta tendencia será un aumento en la demanda de material audio multicanal frente al estéreo. Por ello se vio la necesidad de ofrecer un formato multicanal a la comunidad de usuarios de MP3 para la representación eficiente de sonido surround. Naturalmente, es importante mantener cierto grado de compatibilidad con los sistemas MP3 existentes y facilitar una suave migración hacia tecnologías de transmisión y reproducción multicanal.
La siguiente figura ilustra la estructura general de un codificador MP3 surround para el caso de una señal multicanal 3/2 (L, R, C, Ls, Rs). Como primer paso, un canal doble compatible con estéreo (Lc, Rc) es generado a partir de la información multicanal. Esta señal estéreo se codifica con un codificador MP3 convencional, al tiempo que se extrae un conjunto de parámetros espaciales (ICLD, ICRD, ICC) de la señal multicanal. Estos parámetros se codifican e incluyen como datos de mejora surround en el flujo MP3 para aquellos decodificadores con capacidad para tratarla.
La siguiente figura muestra la parte de decodificación. El flujo MP3 surround se decodifica en una señal compatible estéreo que se puede reproducir directamente en unos altavoces estéreo. Debido a que este paso se basa en Audio MPEG-1, cualquier decodificador MP3 puede realizarlo. Los decodificadores MP3 surround podrían detectar las mejoras surround embebidas y, en su caso, transformar la señal de dos canales en multicanal usando un decodificador BCC (Binaural Cue Coding).

El proceso MP3 surround implica información tanto de una versión multicanal como una versión estéreo de la señal. Por lo tanto, es necesario proporcionar ambas versiones simultáneamente. El enfoque más común es obtener una señal estéreo de una señal multicanal (downmixing) . Esto implica una combinación lineal de ciertas señales de los canales para obtener las señales estéreo. En esta conversión se tiene que tener en cuenta una serie de factores psicoacústicos y prácticas de producción. Por un lado, se desea presentar todas las partes del sonido multicanal al oyente estéreo. Por otro lado, se sabe que la capacidad del oyente para separar las componentes de sonido disminuye entre fuentes de sonido delanteras y traseras. En consecuencia, las fuentes de sonido traseras son generalmente atenuadas con un mixdown estéreo para garantizar la audibilidad de las fuentes delanteras importantes. En la práctica, hay diferentes formas de producir material estéreo a partir de audio multicanal:
• Mix manual: En muchos casos, el ingeniero de sonido produce un downmix manual de las fuentes de sonido multicanal usando parámetros optimizado manualmente con el fin de preservar al máximo la libertad artística
• Downmixing automático simple: El enfoque más básico es usar una ecuación fija (como pueden ser las recomendadas por la ITU-R para reproducción estéreo de señales multicanal). Aunque es un método subóptimo respecto al procedimiento manual, puede ser en la práctica suficiente para la mayoría de aplicaciones.
• Downmixing automático avanzado/dinámico: Con el paso del tiempo, métodos más avanzados se han ido desarrollando teniendo en cuenta factores tales como posicionamiento absoluto de las fuentes, la forma en que las fuentes de sonido se mezclan en señales multicanal y relaciones de fase entrecanales. Estos algoritmos adaptan su comportamiento al material procesado y pueden conseguir calidad similar al procedimiento manual.
El enfoque básico del MP3 Surround no impone restricción alguna sobre qué método debe usarse. De hecho, esta parte puede considerarse como un componente del sistema externo al esquema general de codificación, lo que se muestra en la figura siguiente.

Considerando la tendencia general en el marco doméstico y profesional del sonido surround, comentaremos diversas aplicaciones para la tecnología MP3 surround, haciendo hincapié en las mejoras de los servicios existentes debidos a la compatibilidad multicanal. La característica clave de MP3 surround en este contexto es su capacidad para distribuir audio multicanal a bitrates comparables a los estéreo.
• Descarga de música: Actualmente existe una gran cantidad de servicios comerciales de descarga de música. Estos servicios podrían proporcionar servicios multicanal al mismo tiempo que mantener el servicio estéreo. En ordenadores con configuración 5.1 los archivos MP3 surround se decodifican en sonido surround, mientras que en reproductores MP3 portátiles se reproducen en estéreo.
• Servicio de streaming de música/ radio por Internet: Muchos servicios de radio por Internet funcionan actualmente con restricciones de ancho de banda y, por ello, solo pueden ofrecer contenidos mono o estéreo. El sonido MP3 surround podría extender el servicio mono o estéreo a un servicio multicanal con un rango variable de bitrates. Puesto que la eficiencia es un factor importante en esta aplicación, el aspecto de compresión MP3 surround entra en juego. Como muestra, la representación de los 5 canales a partir de los dos canales ahorra un 60% comparado con la codificación multicanal completa.
• Audio para juegos: Muchos ordenadores se han convertido en máquina de juegos y están equipados con sistemas de altavoces 5.1. La sintetización del sonido 5.1 a partir de una base de sonido compatible estéreo permite un almacenamiento eficiente de la música de fondo multicanal.


















