Drupal Website Development, Drupal website Design, Drupal, Drupal developer
Upload
truongdangCategory
view
233download
3
Presented 2009-05-30 by David Strauss
Designing, Scoping, and Configuring Scalable Drupal Infrastructure

UnderstandingLoad Distribution

Predicting peak trafficTraffic over the day can be highly irregular. To plan for peak loads, design as if all traffic were as heavy as the peak hour of load in a typical month -- and then plan for some growth.

3%
10%
40%
50%
30%
100%
70%
20%
Analyzing hit distribution
Anonymous
Authenticated
Dynam
ic Pages
Static Content
Human
Web Craw
lerNo Special Treatment
7%
“Pay Wall” Bypass

Throughput vs. Delivery MethodsGreen
(Static)Yellow
(Dynamic, Cacheable)Red
(Dynamic)
Content Delivery Network
Reverse Proxy Cache
Drupal + Page Cache+ memcached
Drupal + Page Cache
Drupal
●●●●●●●●●● ✖ ✖
●●●●●●● ●●●●●●● ✖
●●● ●●● ✖
●●● ●● ✖
●●● ● ●
1
Delivered by Apache without Drupal
1
1
1
More dots = More throughput Some actually can do this.2
2
10 req/s
1000 req/s

Objective
Deliver hits using the fastest, most scalable
method available.
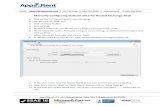
Layering: Less Traffic at Each Step
CDN
Load Balancer
Reverse Proxy Cache
Application Server
Database
Traffic
Your Datacenter
DNS Round Robin

Offload from the master database
Application Server
Search
Memory Cache
SlaveDatabase
Your master database is the single greatest limitation on scalability.
MasterDatabase

Tools to use
‣ Apache Solr for search.(Acquia offers hosting of this now.)
‣ Squid or Varnish for reverse proxy caching.
‣ Any third-party service for CDN.
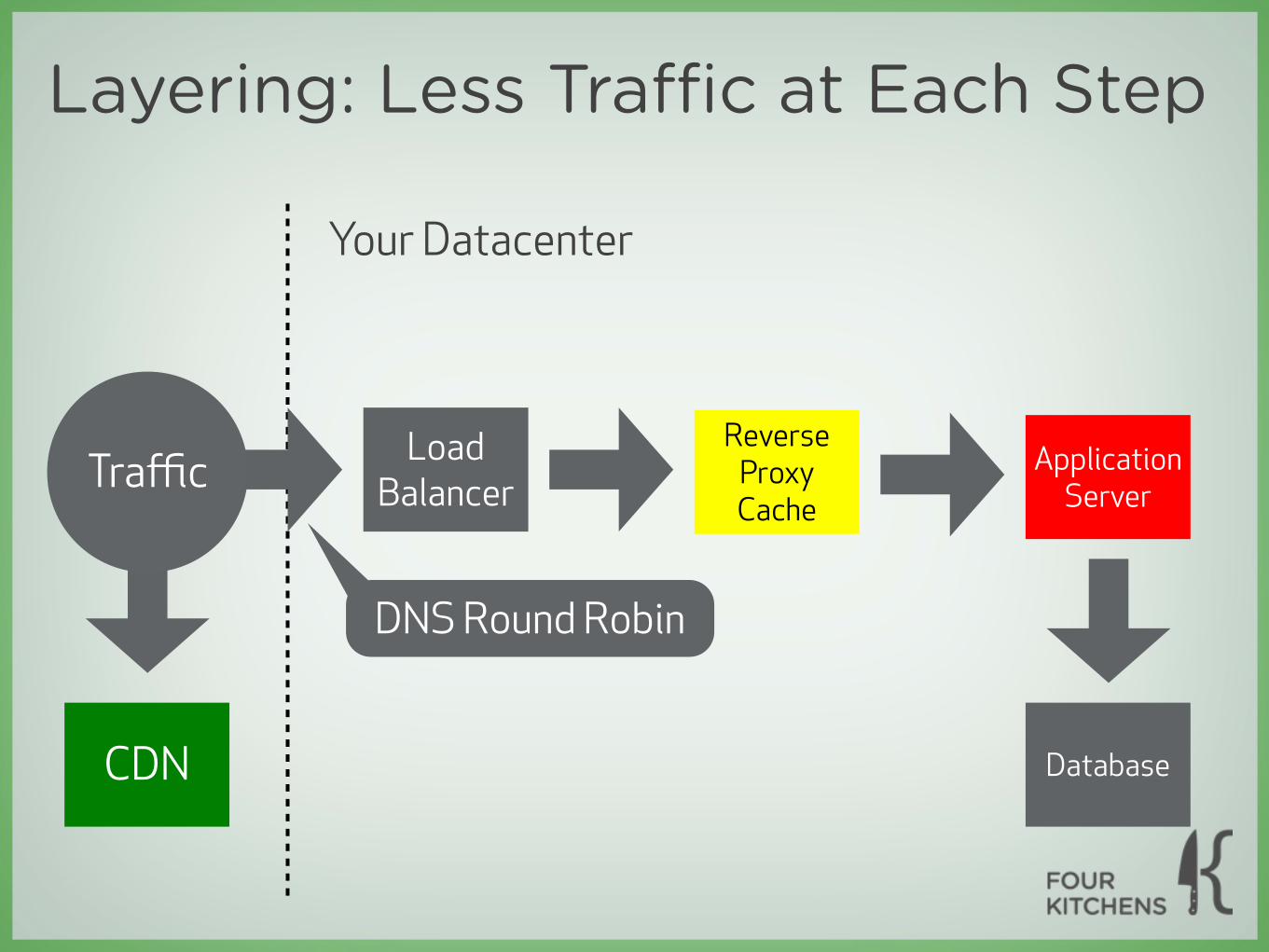
Do the math‣ All non-CDN traffic travels through your load
balancers and reverse proxy caches. Even traffic passed through to application servers must run through the initial layers.
Load Balancer
Reverse Proxy Cache
Application Server
Traffic
What hit rate is each layer geing?How many servers share the load?
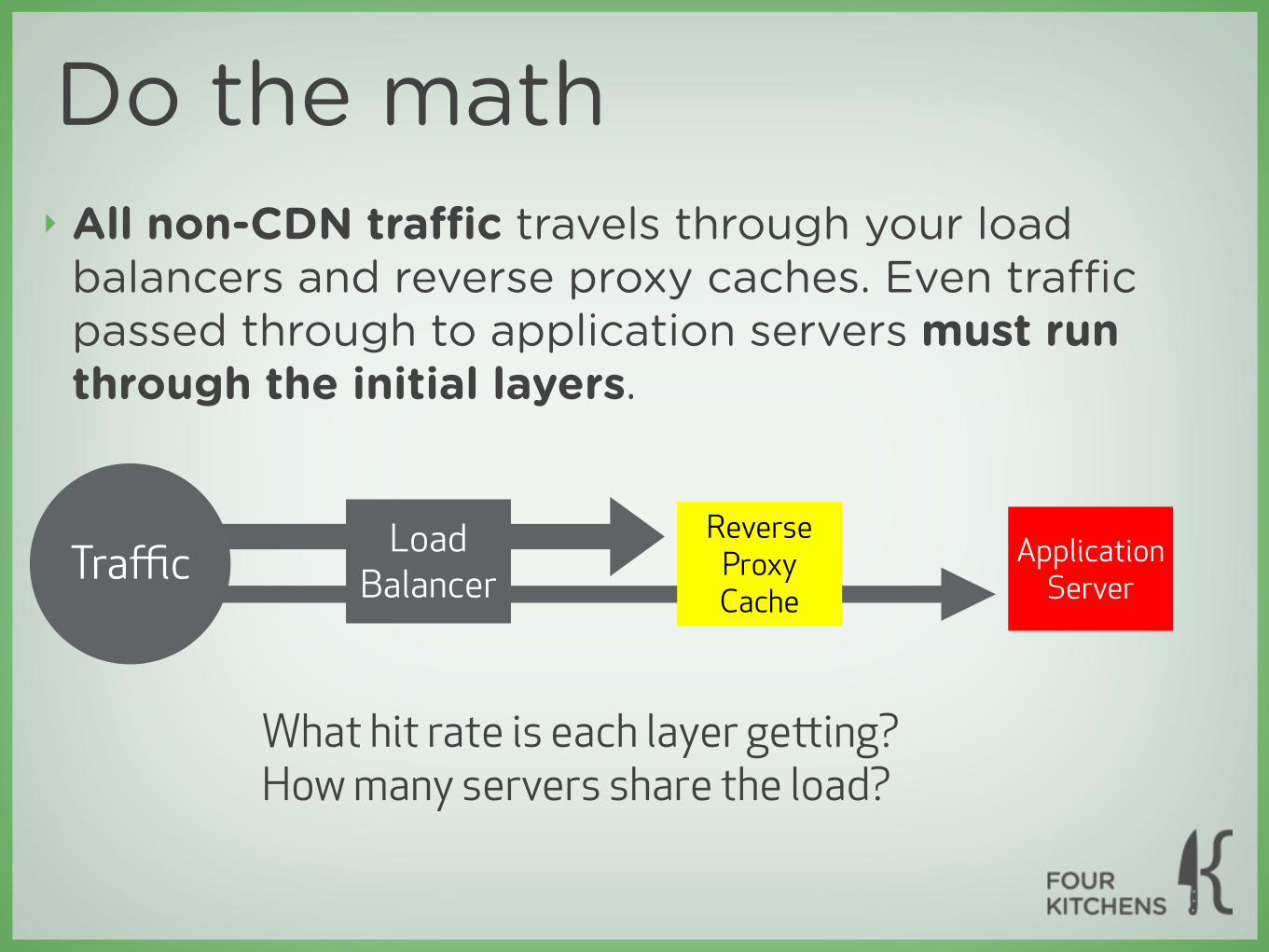
Get a management/monitoring box
ManagementApplication
Server
Reverse Proxy Cache
Database
Load Balancer
(maybe two or three and have them specialized or
redundant)

Planning + Scoping

Infrastructure goals
‣ Redundancy
‣ Scalability
‣ Performance
‣ Manageability

Redundancy
‣ When one server fails, the website shouldbe able to recover without taking too long.
‣ This requires N+1, putting a flooron system requirements.
‣ How long can your site be down?
‣ Automatic versus manual failover

Performance
‣ Find the “sweet spot” for hardware. This is the best price/performance point.
‣ Avoid overspending on any type of component
‣ Yet, avoid creating bottlenecks
‣ Swapping memory to disk is very dangerous

Relative importance
Processors/Cores Memory Disk Speed
Reverse Proxy Cache
Web Server
Database Server
Monitoring
● ●●● ●●
●●●●● ●● ●
●● ●●●● ●●●●
● ● ●

Reverse proxy caches‣ Squid makes poor use of multiple cores. Focus on
getting the highest per-core performance. The best per-core performance is often on dual-core processors with high clock rates and lots of cache.
‣ Varnish is much more multithreaded.
‣ 4-8 GB memory, total
‣ Expect 1000 requests per second, per Squid
‣ 64-bit operating system if more than 2 GB RAM

Web servers‣ Apache 2.2 + mod_php + memcached
‣ Many processors + many cores is best
‣ 25 Apache threads per core
‣ 50 MB memory per thread, system-wide
‣ 1 GB memory for system
‣ 1 GB memory for memcached
‣ Configure MaxClients in Apache to maximum system-wide thread count
‣ Expect 1 request per thread, per second

Database servers‣ MySQL 5.0 cannot use more than eight cores
effectively but gets good gains from at least quad-core processors.
‣ Depend on each Apache thread needing one connection, and add another 50.
‣ Each MySQL connection needs around 6 MB.
‣ MySQL with InnoDB needs a buffer pool large enough to cache all indexes. Start by giving the pool most remaining database server memory and working from there.
‣ 64-bit operating system if more than 2 GB RAM

Monitoring server
‣ Very low hardware requirements
‣ Choose hardware that is inexpensive but essentially similar to the rest of the cluster to reduce management overhead
‣ Reliability and fast failover are typically low priorities for monitoring services

Assembling the numbers‣ Start with an architecture providing redundancy.
‣ Two servers, each running the whole stack
‣ Increase the number of proxy caches based on anonymous and search engine traffic.
‣ Increase the number of web servers based on authenticated traffic.
‣ Databases are harder to predict, but large sites should run them on at least two separate boxes with replication.

PressflowMake Drupal sites scale by upgrading corewith a compatible, powerful replacement.

Common large-site issues‣ Drupal core requires patching to effectively
support the advanced scalability techniques discussed here.
‣ Patches often conflict and have to be reapplied with each Drupal upgrade.
‣ The original patches are often unmaintained.
‣ Sites stagnate, running old, insecure versions of Drupal core because updating is too difficult.

What is Pressflow?‣ Pressflow is a derivative of Drupal core that
integrates the most popular performance and scalability enhancements.
‣ Pressflow is completely compatible with existing Drupal 5 and 6 modules, both standard and custom.
‣ Pressflow installs as a drop-in replacement for standard Drupal.
‣ Pressflow is free as long as the matching version of Drupal is also supported by the community.

What are the enhancements?‣ Reverse proxy support
‣ Database replication support
‣ Lower database and session management load
‣ More efficient queries
‣ Testing and optimization by Four Kitchenswith standard high-performance softwareand hardware configuration
‣ Industry-leading scalability supportby Four Kitchens and Tag1 Consulting

Four Kitchens + Tag1
‣ Provide the development, support, scalability, and performance services behind Pressflow
‣ Comprise most members of the Drupal.org infrastructure team
‣ Have the most experience scaling Drupal sitesof all sizes and all types

Ready to scale?‣ Learn more about Pressflow:
‣ Pick up pamphlets in the lobby
‣ Request Pressflow releases at fourkitchens.com
‣ Get the help you need to make it happen:
‣ Talk to me (David) or Todd here at DrupalCamp
‣ Email [email protected]

Managing the Cluster

The problem
Application Server
Application Server
Application Server
Application Server
Application Server
Soware and Configuration
Objectives:Fast, atomic deployment and rollbackMinimize single points of failure and contentionRestart servicesIntegrate with version control systems
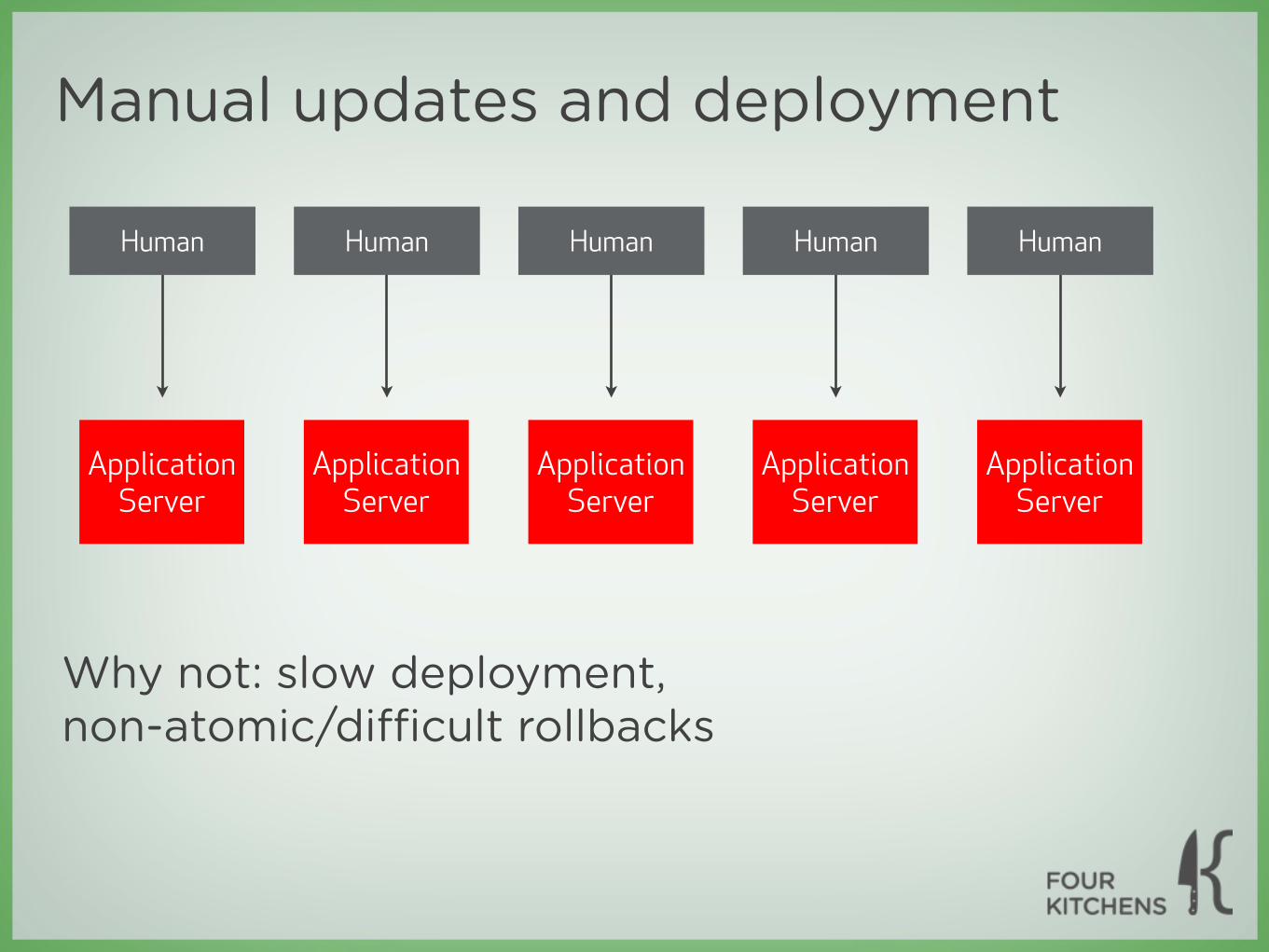
Manual updates and deployment
Application Server
Application Server
Application Server
Application Server
Application Server
Human Human Human Human Human
Why not: slow deployment,non-atomic/difficult rollbacks

Shared storageApplication
ServerApplication
ServerApplication
ServerApplication
ServerApplication
Server
NFS
Why not: single point of contention and failure
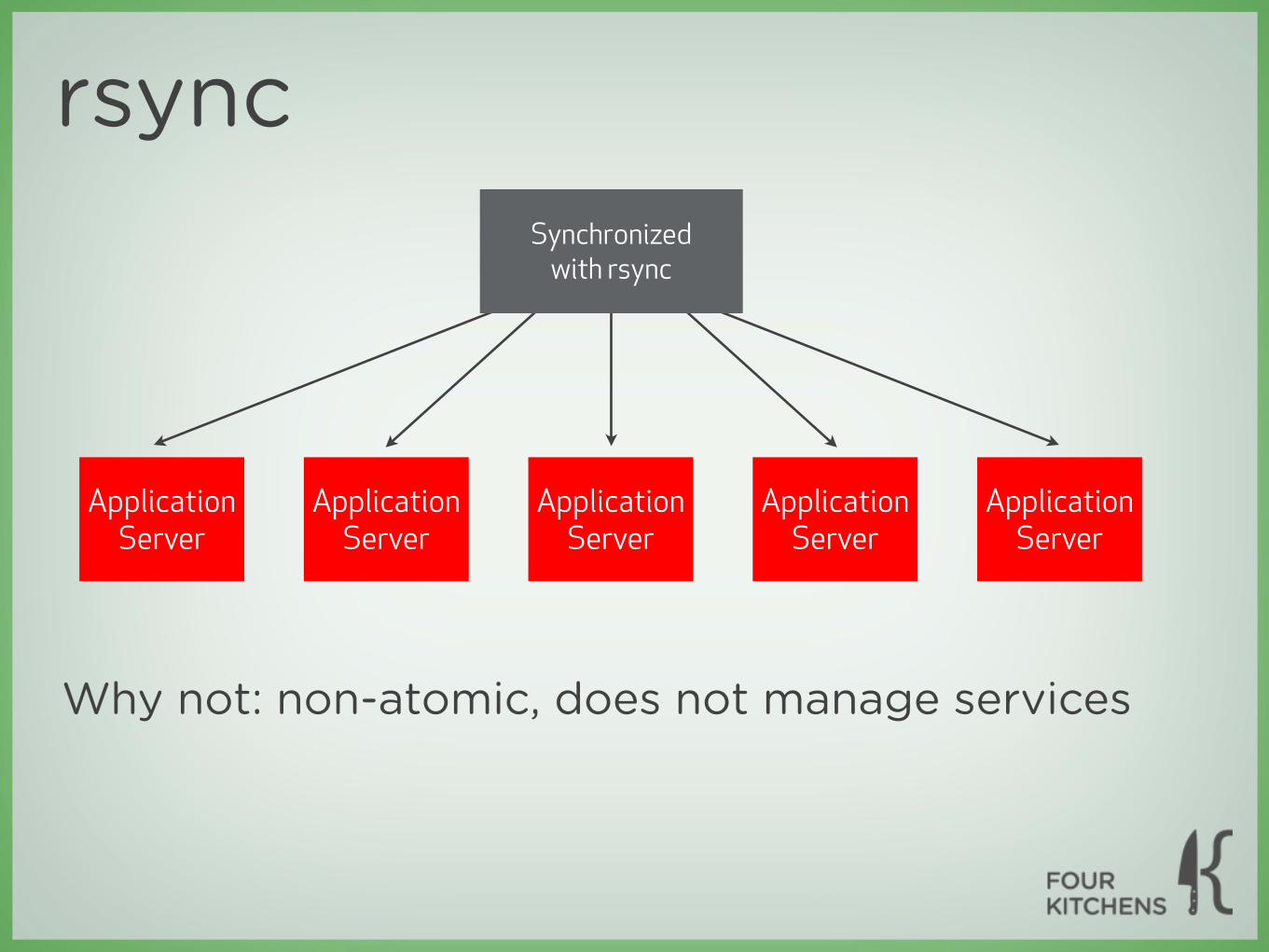
rsync
Application Server
Application Server
Application Server
Application Server
Application Server
Synchronizedwith rsync
Why not: non-atomic, does not manage services

Capistrano
Application Server
Application Server
Application Server
Application Server
Application Server
Deployed withCapistrano
Capistrano provides near-atomic deployment,service restarts, automated rollback, test automation, and version control integration (tagged releases).
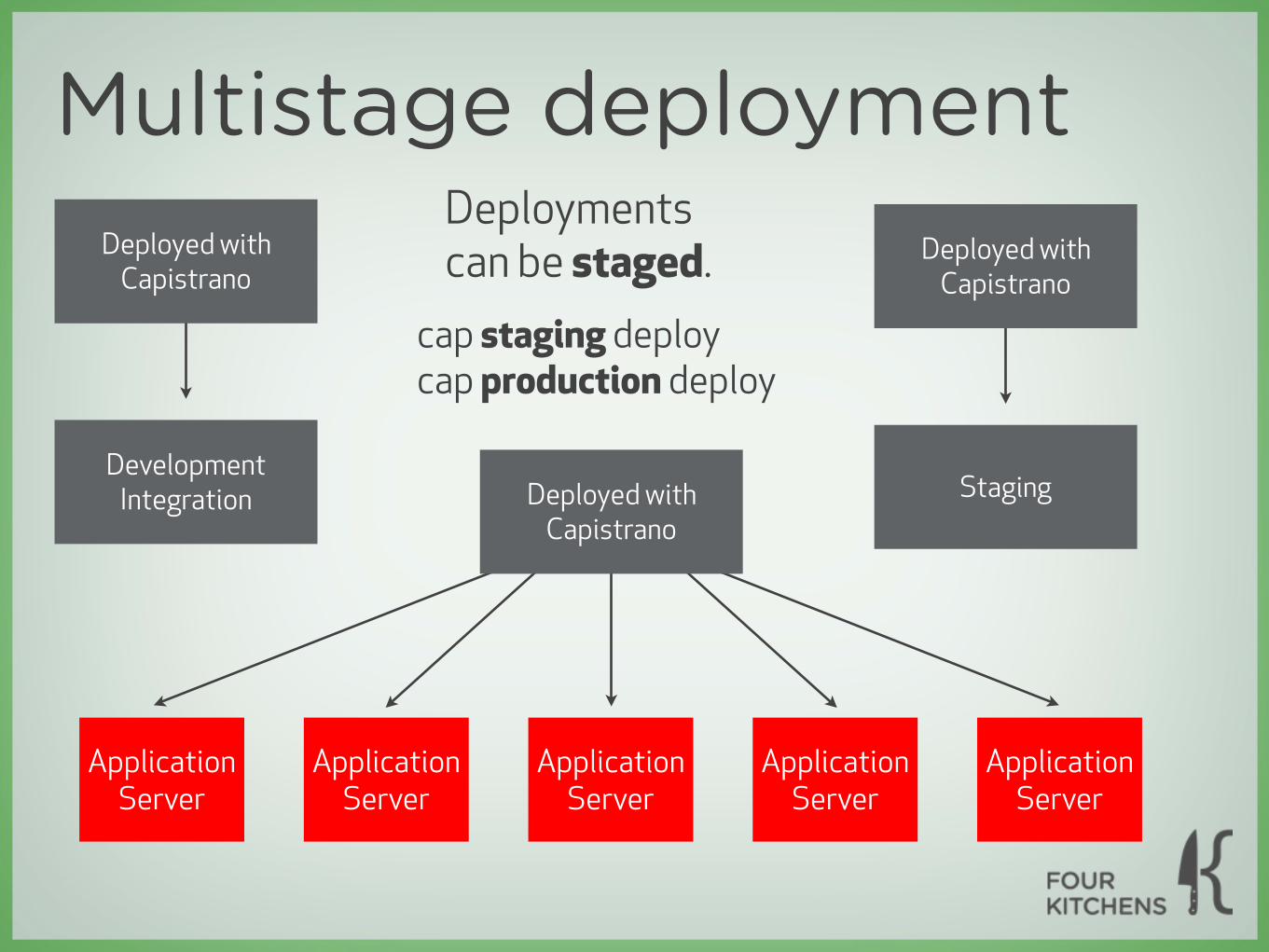
Multistage deployment
Application Server
Application Server
Application Server
Application Server
Application Server
Deployed withCapistrano
Development Integration
Deployed withCapistrano
Staging
Deployed withCapistrano
Deploymentscan be staged.
cap staging deploycap production deploy

But your application isn’t the only thing to manage.

Beneath the application
Application Server
Application Server
Application Server
Application Server
Application Server
cfengine and bcfg2 are popularcluster-level system configuration tools.
Reverse Proxy Cache
DatabaseCluster-level configuration
Cluster management applies to package management, updates, and soware configuration.

System configuration management‣ Deploys and updates packages, cluster-wide or
selectively.
‣ Manages arbitrary text configuration files
‣ Analyzes inconsistent configurations (and converges them)
‣ Manages device classes (app. servers, database servers, etc.)
‣ Allows confident configuration testing on a staging server.

All on the management box
Management {Development
Integration
Staging
Deployment Tools
Monitoring

Monitoring

Types of monitoringFailure Capacity/Load
Analyzing Downtime
Viewing Failover
Troubleshooting
Notification
Analyzing Trends
Predicting Load
Checking Results of Configuration and Soware Changes

Everyone needs both.

What to use
Failure/Uptime Capacity/Load
Nagios
Hyperic
Cacti
Munin

Nagios‣ Highly recommended.
‣ Used by Four Kitchens and Tag1 Consulting for client work, Drupal.org, Wikipedia, etc.
‣ Easy to install on CentOS 5 using EPEL packages.
‣ Easy to install nrpe agents to monitor diverse services.
‣ Can notify administrators on failure.
‣ We use this on Drupal.org

Hyperic
‣ I haven’t used this much, but it’s fairly popular.
‣ More difficult to set up than Nagios.

Cacti‣ Highly annoying to set up.
‣ One instance generally collects all statistics.(No “agents” on the systems being monitored.)
‣ Provides flexible graphs that can be customized on demand.
‣ Optimized database for perpetual statistics collection.
‣ We use this on Drupal.org and for client sites.

Munin‣ Fairly easy to set up.
‣ One instance generally collects all statistics.(No “agents” on the systems being monitored.)
‣ Provides static graphs that cannot be customized.

Cluster Problems

Cache/session coherency‣ Systems that run properly on single boxes may
lose coherency when run on a networked cluster.
‣ Some caches, like APC’s object cache, have no ability to handle network-level coherency. (APC’s opcode cache is safe to use on clusters.)
‣ memcached, if misconfigured, can hash values inconsistently across the cluster, resulting in different servers using different memcached instances for the same keys.
‣ Session coherency can be helped with load balancer affinity.
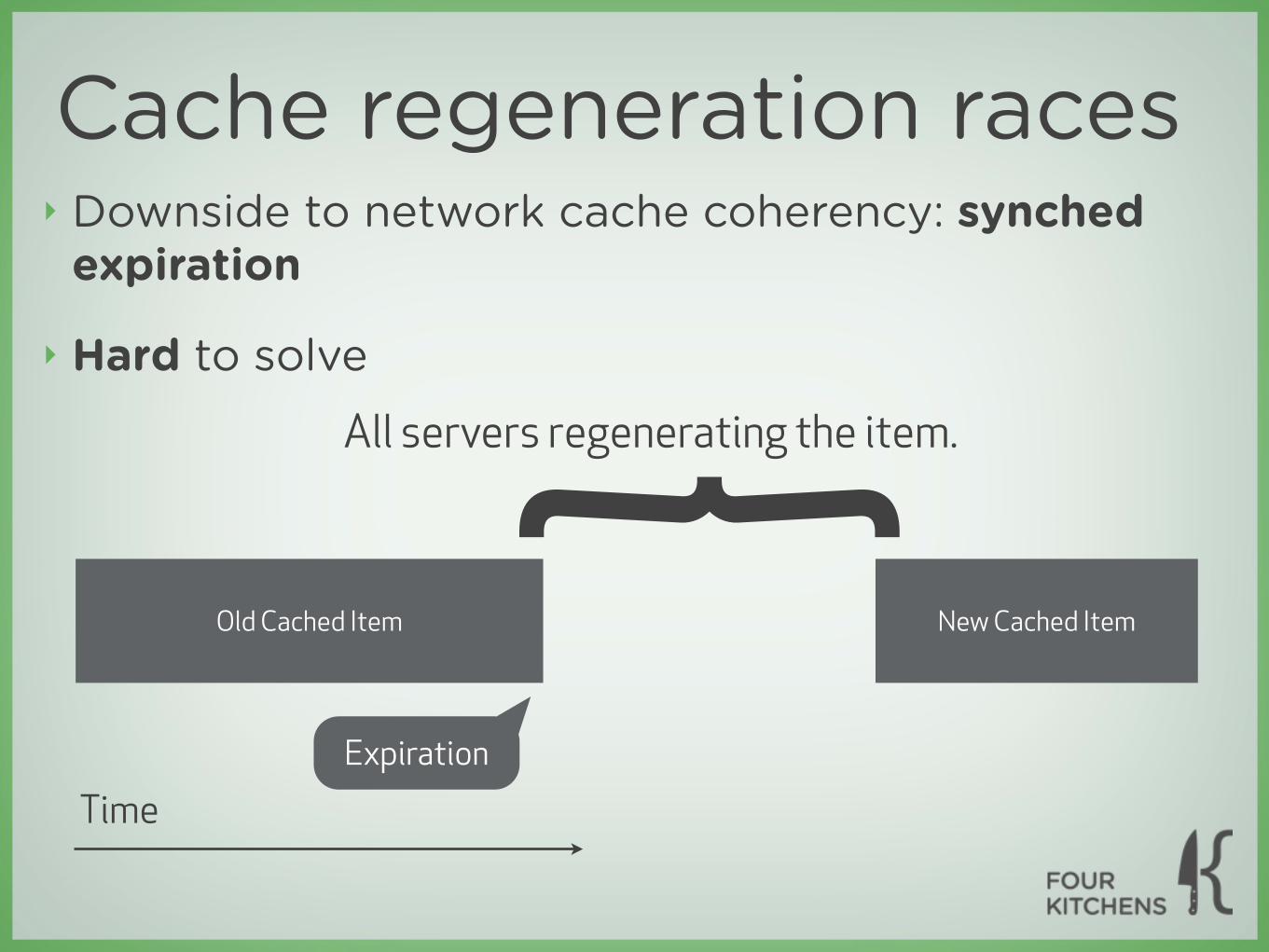
Cache regeneration races‣ Downside to network cache coherency: synched
expiration
‣ Hard to solve
Old Cached Item
Time
Expiration
New Cached Item
{All servers regenerating the item.

Broken replication
‣ MySQL slave servers get out of synch, fall further behind
‣ No means of automated recovery
‣ Only solvable with good monitoring and recovery procedures
‣ Can automate removal from use, but requires cluster management tools

Server failure‣ Load balancers can remove broken or overloaded
application reverse proxy caches.
‣ Reverse proxy caches like Varnish can automatically use only functional application servers.
‣ Cluster management tools like heartbeat2 can manage service IPs on MySQL servers to automate failover.
‣ Conclusion: Each layer intelligently monitors and uses the servers beneath it.

All content in this presentation, except where noted otherwise, is Creative Commons Attribution-ShareAlike 3.0 licensed and copyright 2009 Four Kitchen Studios, LLC.