
Closing the loop by using adaptive capacity workshops - Kerry Bridle
Upload
danielle-penaCategory
view
35download
5description

A Multi-Level Adaptive Loop Scheduler for Power 5 Architecture
Yun Zhang, Michael J. Voss
University of Toronto
Guansong Zhang, Raul Silvera
IBM Toronto Lab
Apr 20, 2023

2
Agenda
Background Motivation Previous Work Adaptive Schedulers IBM Power 5 Architecture A Multi-Level Hierarchical Scheduler Evaluation Future Work

3
Simultaneous Multi-Threading
Architecture
Several threads per physical processor
Threads share Caches Registers Functional Units

4
Power 5 SMT Execution Resource
Resource 0
Resource 1
Resource n
……
……
…
Thread 0 Thread 1
Clock Cycles
Execution Resource
Resource 0
Resource 1
Resource n
……
……
…
Thread 0 Thread 1
Clock CyclesExecution Resource
Resource 0
Resource 1
Resource n
……
……
…
Thread 0 Thread 1
Clock Cycles

5
OpenMP
OpenMPA standard API for shared memory
programmingAdd directives for parallel regions
Standard Loop SchedulersStaticDynamicGuidedRuntime

6
OpenMP API#pragma omp parallel for shared(a, b) private(i, j) schedule(runtime)for ( i = 0; i < 100; i ++ ) {
for ( j = 0; j < 100; j ++) {a[i , j] = a[i , j] + b[i , j];
}}
An example of a parallel loop in C code. (Similar in Fortran)
……..
……..
……..…
.
….
….
….
….
j
i
T0 Tn

7
Motivation OpenMP Applications
Designed for SMP systems Not aware of HT technology Understanding and controlling performance of
OpenMP applications on SMT processors is not trivial
Important performance issues on SMP system with SMT nodes Inter-thread data locality Instruction Mix SMT-related Load Balance

8
Scaling (Spec & NAS)
0.00
0.50
1.00
1.50
2.00
2.50
3.00
3.50
4.00
1 2 3 4 5 6 7 8
Number of Threads
Sp
eed
up
ammp
apsi
art
equake
mgrid
swim
wupwise
BT
CG
EP
FT
MG
SP1 Thread per Processor 1-2 Threads per Processor
4 Intel Xeon Processors with Hyperthre
ading

9
Why do they scale poorly? Inter-thread data locality
cache misses Instruction Mix
functional units sharing benefit gained this way may outweigh cache
misses SMT-related Load Balance
We should balance work loads well among: processors threads running on the same physical processor.

10
Previous Work:Runtime Adaptive Scheduler
Hierarchical SchedulingUpper level schedulerLower level scheduler
Select scheduler and the number of threads to run at runtimeOne thread per physical processorTwo threads per physical processor

11
Two-Level Hierarchical Scheduler

12
Traditional Scheduling
……..……..
……..
…. …. …. …. ….
Static Scheduling
……..……..
……..
…. …. …. …. ….
TnT0T0 Tn Ti Tk
Dynamic Scheduling
jj
i i
13
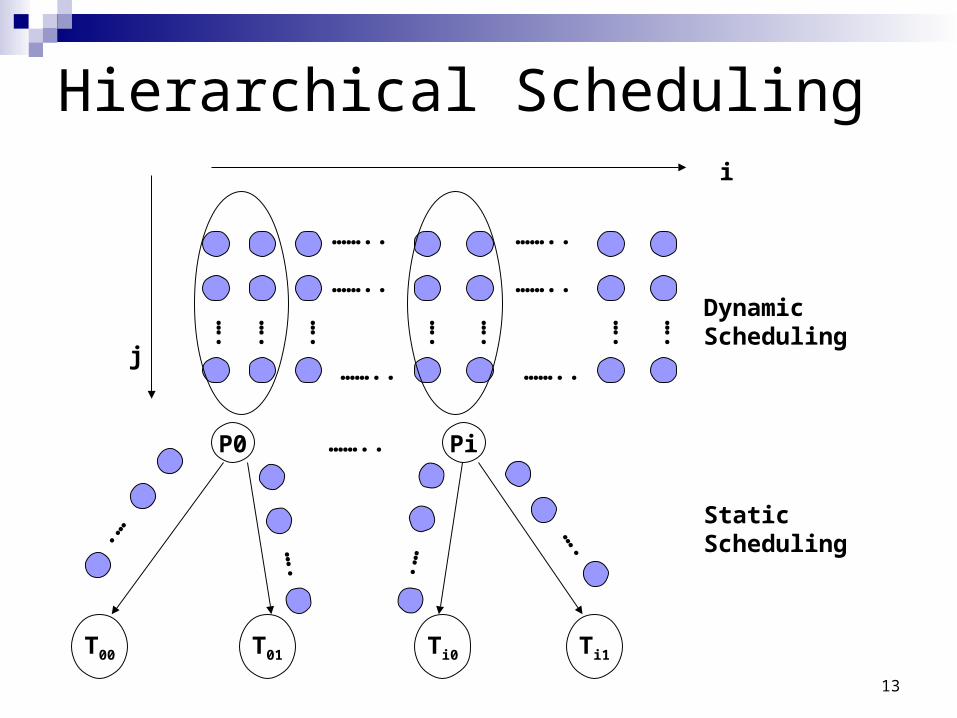
Hierarchical Scheduling
Dynamic Scheduling
T01T00 Ti0 Ti1
……..
….
….…. ….
Static Scheduling
i
j
……..
……..
……..
…. …. …. …. ….
P0 Pi
……..
……..
……..
…. ….

14
Why can we benefit fromruntime scheduler selection?
Many parallel loops in OpenMP applications are executed again and again.
Example
# of calls vs. Execution time
< 10 times
10 – 40 times
> 40 times
ammp 0% 0% 84.20%
apsi 0% 0% 82.55%
art 100% 0% 0%
equake 0.05% 0% 98.23%
mgrid 0% 0.11% 95.95%
swim 0.09% 0% 99.25%
wupwise 0.12% 0% 99.49%
BT 0% 0% 100%
CG 0.92% 3.5% 92.57%
EP 100% 0% 0%
MG 12.73% 12.87% 71.91%
SP 1.02% 0% 92.71%
for (k = 1; k<100; k++) { …………. calculate(); ………….}
void calculate () {#pragma omp parallel for schedule(runtime) for (i = 1; i<100; i++) {
……………; // calculation }}

15
Adaptive Schedulers Region Based Scheduler
Select loop schedulers at runtime Parallel loops in one parallel region have to use the
same scheduler which may not be the best
Loop Based Scheduler Higher runtime overhead More accurate loop scheduler for each parallel loop

16
Sample from NAS2004!$omp parallel default(shared) private(i,j,k)!$omp do schedule(runtime) do j=1,lastrow-firstrow+1
do k=rowstr(j),rowstr(j+1)-1 colidx(k) = colidx(k) - firstcol + 1enddo
enddo!$omp end do nowait!$omp do schedule(runtime) do i = 1, na+1
x(i) = 1.0D0 enddo!$omp end do nowait!$omp do schedule(runtime) do j=1, lastcol-firstcol+1
q(j) = 0.0d0z(j) = 0.0d0r(j) = 0.0d0p(j) = 0.0d0
enddo!$omp end do nowait!$omp end parallel
loop based scheduler picks a scheduler
region based scheduler picks one scheduler that applies to all three loops
loop based scheduler picks a scheduler
loop based scheduler picks a scheduler

17
Runtime Loop Scheduler SelectionPhase 1: try upper level scheduler, run with 4 threads…………
M1
P1P0
T1T0
P3P2
T3T2
Static Scheduler

18
Runtime Loop Scheduler SelectionPhase 1: try upper level scheduler, run with 4 threads…………
M1
P1P0
T1T0
P3P2
T3T2
Dynamic Scheduler

19
Runtime Loop Scheduler SelectionPhase 1: try upper level scheduler, run with 4 threads…………
M1
P1P0
T1T0
P3P2
T3T2
Affinity Scheduler

20
Runtime Loop Scheduler SelectionPhase 1: Made a decision on upper level scheduler, try lower level scheduler, run with 8 threads…………
T0
M1
P1P0
T3T2T1
P1P0
T7T6T5T4
Affinity Scheduler
Static

21
Sample from NAS2004!$omp parallel default(shared) private(i,j,k)!$omp do schedule(runtime) do j=1,lastrow-firstrow+1
do k=rowstr(j),rowstr(j+1)-1 colidx(k) = colidx(k) - firstcol + 1enddo
enddo!$omp end do nowait!$omp do schedule(runtime) do i = 1, na+1
x(i) = 1.0D0 enddo!$omp end do nowait!$omp do schedule(runtime) do j=1, lastcol-firstcol+1
q(j) = 0.0d0z(j) = 0.0d0r(j) = 0.0d0p(j) = 0.0d0
enddo!$omp end do nowait!$omp end parallel
Static-Static, 8 threads
TSS, 4 threads
TSS, 4 threads

22
Hardware Counter Scheduler Motivation
The RBS and LBS has runtime overhead. They will work even better if we can reduce the overhead as much as possible
Algorithm Try different schedulers on parallel loops on a subset of the
benchmarks using training data Use the characteristic: cache miss, number of floating point
operations, number of micro-ops, load imbalance and the best scheduler for that loop as input
Feed the above data to classification software (we use C4.5) to build a decision tree
Apply this decision tree to a loop at runtime. Feed the runtime collected hardware counter data as input, and get the result – scheduler – as output.

23
Speedup on 4 Threads
1.00
1.50
2.00
2.50
3.00
3.50
4.00
4.50
amm
pap
si art
equa
ke
mgr
idsw
im
wupwise
BT(W)
CG EP MG
SP(W)
Avera
ge
Benchmarks
Sp
eed
up
static
dynamic
guided
afs
tss
original
RBS
LBS
HCS
4 Intel Xeon Processors with Hyperthre
ading

24
Speedup on 8 Threads
1.00
1.50
2.00
2.50
3.00
3.50
4.00
amm
pap
si art
equa
ke
mgr
idsw
im
wupwise
BT(W)
CG EP MG
SP(W)
Avera
ge
Benchmarks
Sp
eed
up
static
dynamic
guided
afs
tss
original
RBS
LBS
HCS
4 Intel Xeon Processors with Hyperthre
ading

25
IBM Power 5
Technology: 130nm Dual processor core 8-way superscalar Simultaneous Multi-
Threaded (SMT) core Up to 2 virtual processors 24% area growth per core
for SMT Natural extension to Power
4 design

26
Single Thread
Single Thread has advantage when executing unit limited applications Floating or fixed point intensive workloads
Extra resources necessary for SMT provide higher performance benefit when dedicated to a single thread
Data locality on one SMT core is better with single thread for some applications

27
Power 5 Multi-Chip Module (MCM)
Or Multi-Chipped Monster 4 processor chips
2 processors per chip
4 L3 cache chips

28
Power5 64-way Plane Topology
Each MCM has 4 inter-connected processor chips
Each processor chip has two processors on chip
Each processor has SMT technology therefore two threads can be executed on it simultaneously

29
Multi-Level Scheduler Loop Iterations
Iterations for Module 1
1st LevelScheduler
Iterations for Module i
Iterations for Module n
2nd LevelScheduler
2nd LevelScheduler
Iterations for Processor m
Iterations for Processor 1
Iterations for Processor m
Iterations for Processor 1
3rd LevelScheduler
3rd LevelScheduler
Iterations for Thread k
Iterations for Thread 1
Iterations for Thread k
Iterations for Thread 1
……………….
…….…….
……………….
………………. ……………….

30
OpenMP Implementation
Outline Technique New subroutines
created with body of each parallel construct
Runtime routines receives as a parameter the address of the outlined procedure

31
long main {_xlsmpParallelDoSetup_TPO(…)}
1. Initialize Work Itemsand work shares2. Call _xlsmp_DynamicChunkCall(…)
void main@OL@1 ( … ) { do { loop body; } while (loop end condition meets); return;}
while (still iterations left, go to get some iterations for this thread) { ………… call main@OL@1(...); …………. }
Outlined Functions
Source Code:#pragma omp parallel for shared(a,b) private(i)for ( i = 0; i < 100; i ++ ) { a = a + b;}
Runtime Library

32
long main {_xlsmpParallelDoSetup_TPO(…)}
1. Initialize Work Itemsand work shares2. Call _xlsmp_DynamicChunkCall(…)
void main@OL@1 ( … ) { do { loop body; } while (loop end condition meets); return;}
while (hier_sched(…))) { ………… call main@OL@1(...); …………. }
Outlined Functions
Source Code:#pragma omp parallel for shared(a,b) private(i)for ( i = 0; i < 100; i ++ ) { a = a + b;}
Runtime Library
33
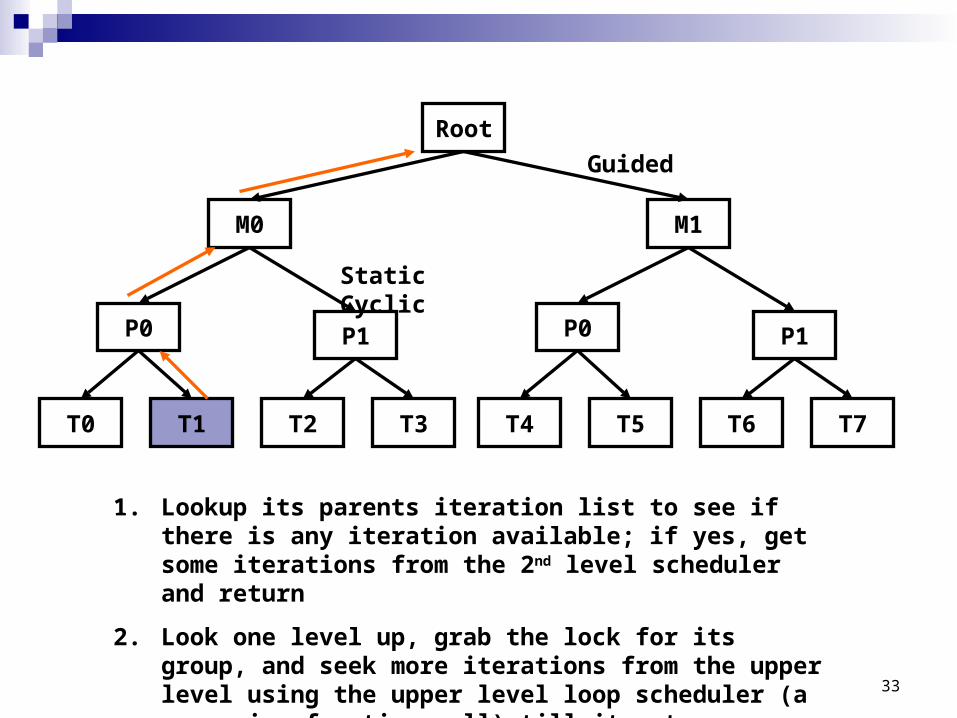
1. Lookup its parents iteration list to see if there is any iteration available; if yes, get some iterations from the 2nd level scheduler and return
2. Look one level up, grab the lock for its group, and seek more iterations from the upper level using the upper level loop scheduler (a recursive function call) till it gets some iteration or the whole loop ends
M0
P1P0
T3T2T1T0
M1
P1P0
T7T6T5T4
Root
Guided
Static Cyclic

34
Hierarchical Scheduler
Guided as the 1st level scheduler Balance work loads among processors Reduce runtime overhead
Static Cyclic as the 2nd level scheduler Improve cache locality Reduce runtime overhead
….
T0 T1
Iteration space dividing using standard static scheduling
….
T0 T1
Iteration space dividing using static cyclic scheduling
T1 T1 T1T0 T0 T0

35
Evaluation
IBM Power 5 System 4 Power 5 1904 MHz SMT processors 31872 M memory
Operating System AIX 5.3
Compiler: IBM XL C/C++, XL Fortran compiler
Benchmark SpecOMP2001
36
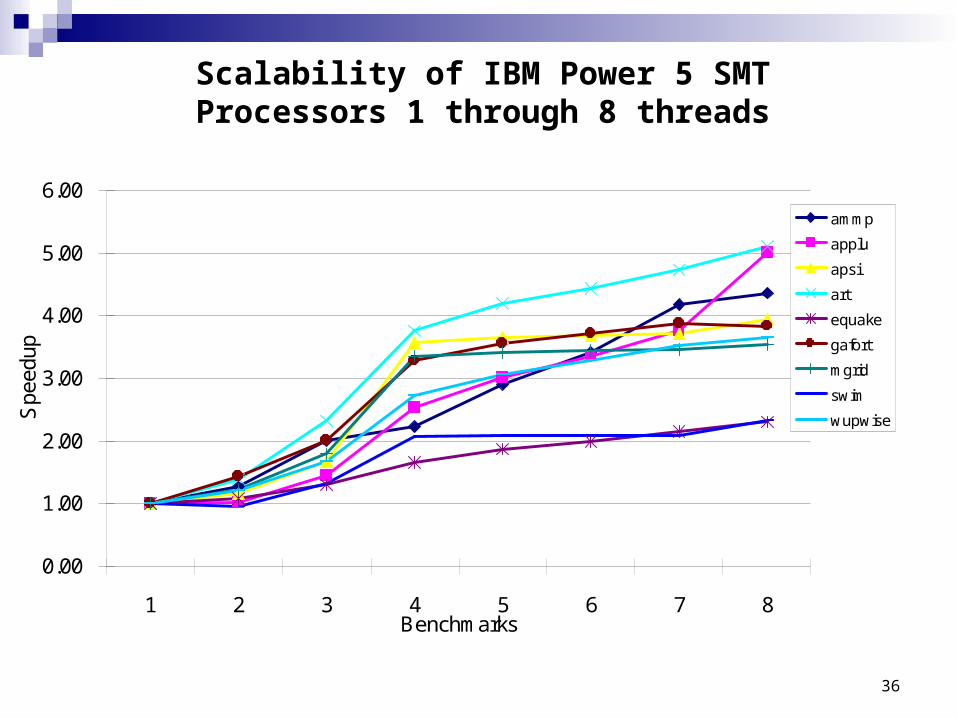
Scalability of IBM Power 5 SMT Processors 1 through 8 threads
0.00
1.00
2.00
3.00
4.00
5.00
6.00
1 2 3 4 5 6 7 8Benchmarks
Speedup
ammp
applu
apsi
art
equake
gafort
mgrid
swim
wupwise

37
0.80
0.85
0.90
0.95
1.00
1.05
1.10
ammp applu apsi art equake gafort mgrid swim wupwise
Benchmarks
Nor
mal
ized
Tim
e ov
er S
tatic
static
dynamic
guided
Hier
Evaluation on Power 5Execution Time Normalized to Default (Static) Scheduler

38
Conclusion Standard schedulers are not aware of SMT technology Adaptive hierarchical schedulers take SMT specific char
acteristics into account, which could make OpenMP API (software) and SMT technology (hardware) work better together.
OpenMP parallel applications running on Power 5 architecture with SMT has the same problem
Multi-level hierarchical scheduler designed for IBM Power 5 achieves an average improvement over the default loop scheduler of 3% on SPEC OMP2001 Large improvements of 7% and 11% on some benchmarks Improves on average over all other standard OpenMP loop sche
dulers by at least 2%

39
Future Work
Evaluate multi-level hierarchical scheduler on a larger system with 32 SMT processors (with MCM)
Explore performance on auto-parallelized benchmarks (SPEC CPU FP)
Examine mechanisms for determining best scheduler configuration at compile-time
Explore the use of helper threads on Power 5 Cache prefetching

Thank You~

41
(A cache miss comparison chart will be shown here)
If find a way to calculate the overall L2 load/store miss generally.
If not, will show the overhead of this optimization from the tprof data.

42
Schedulers’ Speedup on 4 threads
1.00
1.50
2.00
2.50
3.00
3.50
4.00
Benchmarks
Sp
eed
up
static
dynamic
guided
afs
tss
original

43
Scheduler’s Speedup on 8 Threads
1.00
1.50
2.00
2.50
3.00
3.50
4.00
ammp apsi art equake mgrid swim wupwise BT(W) CG EP MG SP(W) Average
Sp
ee
du
p
static
dynamic
guided
afs
tss
original

44
Decision Tree Only one decision tree is
built offline, before executing the program
Apply that decision tree to loops at runtime without changing the tree
Make a decision on which scheduler we should use with only one run of each loop, which greatly reduces runtime scheduling overhead
uops <= 3.62885e+08 :| cachemiss <= 111979 :| | uops > 748339 : static-4 | | uops <= 748339 :| | | l/s <= 167693 : static-4 (| | | l/s > 167693 : static-static | cachemiss > 111979 :| | floatpoint <= 1.52397e+07 :| | | cachemiss <= 384690 :| | | | uops <= 2.06431e+07 : static-static | | | | uops > 2.06431e+07 :| | | | | imbalance <= 1330 : afs-static | | | | | imbalance > 1330 :| | | | | | cachemiss <= 301582 : afs-4 | | | | | | cachemiss > 301582 : guided-static ……………………………. uops > 3.62885e+08 :| l/s > 7.22489e+08 : static-4 | l/s <= 7.22489e+08 :| | imbalance <= 32236 : static-4 | | imbalance > 32236 :| | | floatpoint <= 5.34465e+07 : static-4 | | | floatpoint > 5.34465e+07 :| | | | floatpoint <= 1.20539e+08 : tss-4 | | | | floatpoint > 1.20539e+08 :| | | | | floatpoint <= 1.45588e+08 : static-4 | | | | | floatpoint > 1.45588e+08 : tss-4 END hardwar
e-counter schedulingEND hardware-counter scheduling

45
(Load imbalance comparison chart will be shown here)
Generating……..

















