
A Conceptual Modeling Approach for the Rapid Development ...the design of chatbot interfaces for...
130
POLITECNICO DI MILANO Master of Science in Computer Science and Engineering Dipartimento di Elettronica, Informazione e Bioingegneria A Conceptual Modeling Approach for the Rapid Development of Chatbots for Conversational Data Exploration Supervisor: Prof. Maristella Matera Co-supervisors: Prof. Florian Daniel, Prof. Vittorio Zaccaria M.Sc. Thesis by: Nicola Castaldo - 875019 Academic Year 2018-2019
Transcript of A Conceptual Modeling Approach for the Rapid Development ...the design of chatbot interfaces for...

POLITECNICO DI MILANOMaster of Science in Computer Science and Engineering
Dipartimento di Elettronica, Informazione e Bioingegneria
A Conceptual Modeling Approach for
the Rapid Development of Chatbots
for Conversational Data Exploration
Supervisor: Prof. Maristella Matera
Co-supervisors:
Prof. Florian Daniel,
Prof. Vittorio Zaccaria
M.Sc. Thesis by:
Nicola Castaldo - 875019
Academic Year 2018-2019


Ai miei genitori.


Abstract
A chatbot is a a conversational software agent able to interact with user
through natural language, using voice or text channels and trying to emulate
human-to-human communication. This Thesis presents a framework for the
design of Chatbots for Data Exploration. With respect to conversational vir-
tual assistants (such as Amazon Alexa or Apple Siri), this class of chatbots
exploits structured input to retrieve data from known data sources. The ap-
proach is based on a conceptual representation of the available data sources,
and on a set of modeling abstractions that allow designers to characterize the
role that key data elements play in the user requests to be handled. Starting
from the resulting specifications, the framework then generates a conversa-
tion for exploring the content exposed by the considered data sources. The
contributes of this Thesis are:
• A characterization of Chatbots for Data Exploration, in terms of re-
quirements and goals that must be satisfied when designing these agents;
• A methodology to design chatbots which poses the attention on some
notable data elements, along with a technique to generate conversa-
tional agents based on annotations made directly on the schema of the
data source;
• An architecture for a framework supporting the design, generation and
execution of these chatbots exploiting state-of-art technologies;
• A prototype of the framework integrating different technologies for
chatbot deployment.
The Thesis also reports on some lessons learned that we derived from
a user study that compared the user performance and satisfaction with a
chatbot generated with our framework to the performance and satisfaction
of the same users when interacting the basic SQL command line.
I


Sommario
Il chatbot e un agente informatico capace di interagire con l’utente attraver-
so il linguaggio naturale, utilizzando canali vocali o testuali, nel tentativo
di emulare la comunicazione tipica dell’uomo. Questa Tesi descrive un fra-
mework per il design di Chatbot per l’Esplorazione di Dati. Rispetto agli as-
sistenti virtuali (come per esempio Alexa di Amazon o Siri di Apple), questa
classe di chatbot sfrutta richieste strutturate per estrarre dati da specifiche
sorgenti dati. L’approccio e basato su un insieme di astrazioni concettuali che
permettono ai progettisti di specificare il ruolo che alcuni elementi della base
di dati assumeranno nelle future richieste dell’utente. Sulla base di queste
specifiche, il framework genera dunque una conversazione per l’esplorazione
di tali dati. I contributi di questa Tesi sono:
• Una caratterizzazione dei Chatbot per l’Esplorazione di Dati, con par-
ticolare attenzione ai requisiti e agli obiettivi da considerare durante la
loro progettazione;
• Una metodologia per progettare tali chatbot che privilegia la tipologia
e il ruolo degli elementi che i dati rappresentano, oltre a una tecnica per
la generazione di agenti conversazionali basata su annotazioni effettuate
direttamente sullo schema dell base di dati;
• L’architettura di un framework in grado di supportare la progettazione,
la generazione e l’esecuzione di questi chatbot usando tecnologie allo
stato dell’arte;
• Un prototipo di questo sistema che integra tecnologie innovative.
La Tesi inoltre discute alcune implicazioni sul design di Chatbot per l’Esplo-
razione dei Dati che derivano da quanto osservato in uno studio con gli utenti.
Lo studio ha confrontato le prestazioni e la soddisfazione di un campione di
utenti che ha interrogato un database di esempio usando un chatbot generato
con il nostro framework e la linea di comando SQL.
III


Ringraziamenti
Ringrazio mia madre Cristina, mio padre Roberto e mia sorella Martina, per
esserci sempre stati e non aver mai smesso di credere in me. Grazie per aver-
mi insegnato valori come l’onesta e la cortesia e per avermi mostrato che con
l’impegno, la tenacia e la passione si possono raggiungere gli obiettivi piu
difficili. Ringrazio anche i miei zii, i miei cugini e le mie nonne, per l’affetto
che mi avete sempre dimostrato.
Un ringraziamento speciale, poi, va a Monica, per aver avuto cura di me
nei momenti felici e anche in quelli piu ardui, scegliendo sempre di viverli e
affrontarli assieme.
Vorrei inoltre ringraziare i miei amici, per i divertimenti e le difficolta che
abbiamo condiviso e per avermi sempre rispettato, apprezzato e voluto bene.
Ringrazio inoltre i professori Florian Daniel e Vittorio Zaccaria per il sup-
porto e i consigli che mi hanno dato durante tutta la stesura della Tesi. Un
grazie sincero va anche ai ragazzi del “TIS Lab”, che hanno accettato di par-
tecipare ai test di valutazione del sistema oggetto di questa Tesi.
Infine, un ringraziamento particolare va alla mia relatrice, la professoressa
Maristella Matera, per il tempo, l’energia e la fiducia che ha scelto di dedicare
a me e a questa Tesi.
V


Contents
Abstract I
Sommario III
Ringraziamenti V
1 Introduction 1
1.1 Scenario and Problem Statement . . . . . . . . . . . . . . . . 2
1.2 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Structure of Thesis . . . . . . . . . . . . . . . . . . . . . . . . 5
2 State of the Art 7
2.1 The (R)evolution of Chatbots . . . . . . . . . . . . . . . . . . 7
2.1.1 The Loebner Prize . . . . . . . . . . . . . . . . . . . . 7
2.1.2 Virtual assistants . . . . . . . . . . . . . . . . . . . . . 8
2.1.3 A chatbot for everything . . . . . . . . . . . . . . . . . 8
2.2 Design Approach . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Development Choices . . . . . . . . . . . . . . . . . . . . . . . 9
2.3.1 Local or remote . . . . . . . . . . . . . . . . . . . . . . 9
2.3.2 The chat interface . . . . . . . . . . . . . . . . . . . . . 10
2.4 Different Chatbot Frameworks . . . . . . . . . . . . . . . . . . 11
2.5 Related Research Approaches . . . . . . . . . . . . . . . . . . 13
3 Chatbots for Data Exploration 15
3.1 Concepts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 Main Requirements . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2.1 Connect to the database to obtain the schema . . . . . 17
VII

3.2.2 Extract and learn database-specific vocabulary and ac-
tions from schema . . . . . . . . . . . . . . . . . . . . . 17
3.2.3 Automatic intent and entities generation and extraction 18
3.2.4 Proper communication and data visualization . . . . . 19
3.2.5 Allow the user to manipulate query results . . . . . . . 19
3.2.6 Support context and conversation history management 20
4 Approach 21
4.1 Design Process . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.2 Schema Annotation . . . . . . . . . . . . . . . . . . . . . . . . 22
4.2.1 Conversational Objects . . . . . . . . . . . . . . . . . . 22
4.2.2 Display Attributes . . . . . . . . . . . . . . . . . . . . 24
4.2.3 Conversational Qualifiers . . . . . . . . . . . . . . . . . 25
4.2.4 Conversational Types, Values and Operators . . . . . . 26
4.2.5 Conversational Relationships . . . . . . . . . . . . . . . 28
4.3 Conversation Modeling . . . . . . . . . . . . . . . . . . . . . . 28
4.3.1 Intents . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.3.2 Entities . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.4 From the Conversation Model
to the Interaction . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.4.1 Interaction paradigm . . . . . . . . . . . . . . . . . . . 34
4.4.2 Automatic query generation . . . . . . . . . . . . . . . 35
4.4.3 Chatbot responses . . . . . . . . . . . . . . . . . . . . 42
4.4.4 History navigation . . . . . . . . . . . . . . . . . . . . 45
5 System Architecture and Implementation 47
5.1 Technologies . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.1.1 RASA . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.1.2 Chatito . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.1.3 Telegram . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2 Framework Architecture . . . . . . . . . . . . . . . . . . . . . 53
5.3 Chatbot Architecture . . . . . . . . . . . . . . . . . . . . . . . 55
5.4 Implementation Tools . . . . . . . . . . . . . . . . . . . . . . . 58
6 User Study 61
6.1 Comparative Study: General Setting and Research Questions . 61
6.2 Participants and Design . . . . . . . . . . . . . . . . . . . . . 63
6.3 Tasks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
VIII

6.4 Procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6.5 Data Collection . . . . . . . . . . . . . . . . . . . . . . . . . . 66
6.6 Usability Analysis . . . . . . . . . . . . . . . . . . . . . . . . . 67
6.6.1 Efficiency . . . . . . . . . . . . . . . . . . . . . . . . . 68
6.6.2 Effectiveness . . . . . . . . . . . . . . . . . . . . . . . . 68
6.7 Satisfaction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
6.7.1 Usability . . . . . . . . . . . . . . . . . . . . . . . . . . 70
6.7.2 Workload . . . . . . . . . . . . . . . . . . . . . . . . . 71
6.7.3 Easiness of exploring DB/retrieving data/using com-
mands and quality of presentation . . . . . . . . . . . . 72
6.7.4 User ranking of systems along completeness, easiness
and usefulness . . . . . . . . . . . . . . . . . . . . . . . 73
6.8 Qualitative Data Analysis . . . . . . . . . . . . . . . . . . . . 74
6.9 Lesson Learned . . . . . . . . . . . . . . . . . . . . . . . . . . 75
7 Conclusions 79
7.1 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
7.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
7.3 Publications . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
References 83
A Parsed Database Schema 87
B Database Schema Annotation 91
C User Study Questionnaires 103
C.1 Demographic Questionnaire . . . . . . . . . . . . . . . . . . . 103
C.2 System Questionnaire . . . . . . . . . . . . . . . . . . . . . . . 104
C.2.1 Ease of use . . . . . . . . . . . . . . . . . . . . . . . . 104
C.2.2 Cognitive load . . . . . . . . . . . . . . . . . . . . . . . 106
C.2.3 General questions . . . . . . . . . . . . . . . . . . . . . 107
C.3 Final Questionnaire . . . . . . . . . . . . . . . . . . . . . . . . 108
IX

X

List of Figures
3.1 A Conversation example between a user and the chatbot. . . . 16
4.1 The relational schema of the database. . . . . . . . . . . . . . 23
4.2 The Conversational Objects annotation. . . . . . . . . . . . . 24
4.3 The Display Attributes annotation. . . . . . . . . . . . . . . . 25
4.4 The Conversational Qualifiers annotation, focus on customer. . 27
4.5 The Conversational Relationships annotation. . . . . . . . . . 29
4.6 An example of the entity extraction phase. . . . . . . . . . . . 32
4.7 The typo resolution procedure. . . . . . . . . . . . . . . . . . 42
4.8 The response of the chatbot to display a single result. . . . . . 44
4.9 The response of the chatbot to display multiple results. . . . . 44
4.10 An example of conversation history visualization. . . . . . . . 45
5.1 An overview of the Framework Architecture, based on the
three-tier model. . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.2 The Chatbot Architecture in details. . . . . . . . . . . . . . . 55
6.1 The classicmodels database schema used in the evaluation tests. 62
6.2 Comparison for the two systems of the number of successes . . 71
6.3 NASA-TLX dimensions: means and standard deviation com-
parison. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
XI

XII

List of Tables
4.1 Phrase structure for find intents. . . . . . . . . . . . . . . . . 32
4.2 Phrase structure for filter intents. . . . . . . . . . . . . . . . . 33
4.3 Phrase structure for help intents. . . . . . . . . . . . . . . . . 33
6.1 Paired Sample t-test results related to the time the users spent
on each task. . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
6.2 Detail on the completion of each task: Failures, Partial suc-
cess, Success . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
6.3 NASA-TLX dimensions values. . . . . . . . . . . . . . . . . . 72
XIII

XIV

List of Algorithms
1 Find Query Builder . . . . . . . . . . . . . . . . . . . . . . . . 36
2 Join Query Builder . . . . . . . . . . . . . . . . . . . . . . . . . 40
Listings
5.1 A json extract of the training data. . . . . . . . . . . . . . . . 49
5.2 An example of input document for Chatito. . . . . . . . . . . 51
5.3 A json extract of the simplified database. . . . . . . . . . . . . 58
5.4 A json extract of the database Schema Annotation. . . . . . . 59
XV

XVI

Chapter 1
Introduction
Chatbots are growing fast in number and pervade in a broad range of activ-
ities. Their natural language paradigm simplifies the interaction with appli-
cations to the point that experts consider chatbots one of the most promising
technologies to transform instant messaging systems into software delivery
platforms [15, 18]. The major messaging platforms have thus opened their
APIs to third-party developers, to expose high-level services (e.g., messag-
ing, payments, bot directory) and User Interface (UI) elements (e.g., buttons
and icons), to facilitate and promote the development of innovative services
based on conversational UIs [21].
Despite the huge emphasis on these new applications, it is still not clear
what implications their rapid uptake will have on the design of interactive
systems for data access and exploration. The applications proposed so far
mainly support the retrieval of very specific data from online services. It
is still unclear how this paradigm can be applied for the interaction with
large bodies of information and machine agents. A critical challenge lies
in understanding how to make the development of bots for data exploration
scalable and sustainable, in terms of both software infrastructures and design
models and methodologies [2, 27].
To fill this gap, in this Thesis we propose a methodology to support
the design of chatbot interfaces for accessing extensive collections of data by
means of a conversational interaction; in particular, we propose a data-driven
paradigm that, starting from the annotation of a database schema, leads to
the generation of a conversation that enables the exploration of the database
content.

1.1 Scenario and Problem Statement
Let us consider the situation in which a person enters in a library and asks
some information about a novel at the helping desk. Usually librarians are
able to identify books quite well, but this time the task has some unexpected
difficulties: the client does not know either the title or the author and just
wants something to read. The employee cannot do very much without in-
vestigating the client’s preferences or giving personal advices, because the
searches on the online catalog of the library are possible only using keywords
that are somehow related to a book, in terms of title, author or publishing
house.
In this example the attitude of the client is not to simply find something
in particular, based on some known properties of the object being researched,
but is rather to explore the library resources without a fixed target and not
knowing what will be the result of the inspection. What if the librarian
could fulfill the customer’s needs with a tool able to support this kind of
exploration? How could this device be designed?
The key point of this appliance would be the ease to use: its users should
not need to learn how the system works, but they should understand its
features and possibilities while using it. So, a possible approach is to cre-
ate a tool able to emulate human-to-human interaction, by communicating
through the natural language, using text or vocal channels. This technology
is also known as chatbot and its implementation may fit the needs of our
purpose. The chatbot, also known as conversational agent, should allow the
user to navigate across the catalog, exploiting all the relations between the
different entities in it. For example it could support the input phrase “find
the books written by Dante” and execute the search against the catalog, by
automatically understanding that “Dante” is the keyword for the name of
the author. Then it could display the titles of the books in the forms of
buttons and, upon clicking on “La Divina Commedia - Inferno”, it could
present the details of the volume as well as its basic relations, i.e. author,
publishing house, etc.
Up to now, it seems that our imaginary chatbot would be able to act
as a special search engine, that understands and translates sentences into
commands, but still distant from offering the above mentioned explorative
feature. What if, then, the user could navigate from the “La Divina Comme-
dia - Inferno” to the collections of volumes that include the masterpiece and
2

were borrowed by someone else? Then, after clicking on the details of one of
these, the navigation could proceed towards its publishing house, then to its
publishers, then maybe to one of these authors and then again to the books
given to the library by someone that once borrowed a volume from this last
writer. The chatbot could offer all of these features and more, by presenting
to the user different relations and paths to be taken from the various entities
under observation.
The term exploration can be finally applied to this type of navigation,
since the user can navigate among entities and relations of the library catalog
without really having a destination in mind.
There are many real world application where such a conversational agent
could be used and each one of them might have different modalities, with
respect to the users it is supposed to embrace, the quantity of relations among
the data and the values to be displayed. For example, this feature could be
supported by a data storage for investigative research, enabling detectives to
easily and freely navigate across the data describing past cases. This system
could be also applied to a medical database, allowing doctors to explore
attributes and possible relations of clinical past situations. Moreover, this
kind of chatbot may be used within a business company, in order to explore
the data its database contains, with different levels of granularity, in terms
of searches and relations among the various elements.
1.2 Contributions
In this Thesis we define a data-driven design paradigm that, starting
from the structure of a typical data system, enables the generation of con-
versation paths for its exploration.
In particular, we provide:
• An explanation of the concept of Chatbots for Data Exploration, with
reference to the requirements and goals that must be satisfied when
designing these type of systems;
• An architecture for a framework able to support the creation of these
conversational agents, also exploiting state-of-art technologies;
• A methodology to design chatbots which poses the attention on the
data characteristics, rather than the technologies involved;
3

• A technique to generate conversational agents based on annotations
made directly on the schema of the data source;
• A prototype of this framework integrating different technologies to de-
ploy it;
• Some design implications derived from a comparative study that we
conducted to test the performance of the chatbot generated through
our framework with respect to the basic SQL command line interaction.
From the qualitative and quantitative analysis of the data gathered through
the user study we can state that the resulting applications, as well as the
framework for their development, can be considered as a first valid step
towards the generation of Chatbots for Data Exploration.
1.3 Definitions
We provide below the definitions of the main concepts related to our work.
• Chatbot: a conversational software agent able to interact with user
through natural language, using voice or text channels and trying to
emulate human-to-human communication.
• Chatbot Framework: is a cloud based chatbot’s development platform
that enable on line development and testing of chatbots; usually, it also
provides Natural Language Processing (NLP), Artificial Intelligence
and Machine Learning services with Platform as a Service paradigm
(PaaS).
• Chat Interface: with this term, we refer to any system that supports
text-based input from the users.
• Schema Annotation: abbreviation for Database Schema Annotation,
it refers to the procedure (and its outcome) of characterizing tables,
relations and attributes of a database conceptual model, in order to
produce a mapping between the data source and the conversation in-
teraction basis.
• NLU: it stands for Natural Language Understanding, and it is a branch
of Artificial Intelligence that uses computer software to understand
input made in the form of sentences in text or speech format [26].
4

• Intent: it represents the purpose of the user’s interaction with a chat-
bot; for instance, from the phrase “What time is it?” the intent, if
defined, could be to know the current time.
• Intent-matching: it is the NLU process of understanding the intent
from a given input phrase.
• Entity: it is a word or a set of words that represent a concept in a
given utterance; for instance, in the phrase “I live in Milan” the word
“Milan” may be an entity related to the concept of location.
• Entity-extraction: it is the NLU procedure of identifying entities inside
input phrases provided to the chatbot.
• Context: it represents the current background of a user’s request;[12] in
a chatbot, it is needed to correct handle subsequent inputs which may
refer to previous outcomes; for instance, in the consecutive interactions
[User: “What is the weather like in Milan?”] → [Chatbot: “Sunny”]
and [User: “And in Rome?”]→ [Chatbot: “Cloudy”], the second ques-
tion would not make sense without the previous request, which creates
the context (in this case, related to the weather) of the whole dialog.
1.4 Structure of Thesis
• Chapter 2 is an overview of the history of chatbots, the state of art
and the most popular available frameworks that support the deploy-
ment of such applications. In this Chapter we highlight the differences
among the various technologies, highlighting pros and cons of each one,
considering implementation and design choices.
• Chapter 3 provides a definition of Chatbots for Data Exploration and
defines the main goals and requirements that must be treated to design
them.
• In Chapter 4 we provide a conceptual modeling approach for the de-
sign of these kinds of chatbots. We offer a solution to the requirements
defined in the previous Chapter, splitting the design process in three
parts: the Schema Annotation, the Conversation modeling and the In-
teraction modeling.
5

• Chapter 5 describes the architectural and implementation choices that
we made when developing the prototype of a Chatbot for Data Explo-
ration.
• In Chapter 6 we provide an evaluation of our framework, by means
of a comparative study between our conversational agent and the SQL
command line, regarding the execution of some information retrieval
tasks on the same data source. We discuss the details of our tests and
the collected data, making quantitative and qualitative analysis.
• In Chapter 7 we conclude the Thesis with a summary of the overall
study, considering limitations, future works and possible improvements
of our framework.
• The Appendices report:
(i) a JSON-based specification of the database schema of the example
database used throughout the Thesis (Appendix A),
(ii) the annotated database schema, which is the input of the process
leading to the generation of a conversation for the exploration of
the example database content (Appendix B),
(iii) the questionnaires administered during the user study
(Appendix C).
6

Chapter 2
State of the Art
2.1 The (R)evolution of Chatbots
In this Section we will discuss how chatbots grew from past to present, in
terms of technologies and capabilities, and how nowadays there are more and
more domains in which they are applied.
2.1.1 The Loebner Prize
Nowadays, chatbots technologies are growing faster than ever [9], but their
story started in in the second half of 1900s. The Turing Test, also known as
the Imitation Game, was proposed by Alan Turing in 1950 as a replacement
for the question “Can machines think?” [1, 25]. It consists in a quiz to be
held with a computer able to answer questions, requiring the judge to be
uncapable to distinguish whether the interlocutor is a human or not.
This idea was taken by Hugh Loebner, which in 1991 decided to create
an annual competition for evaluating computer programs ability to emulate
a human, just like the original Turing Test required. The contest survived
all of these years and different chatbots won the first place over time.
The first winning machine was ELIZA, a computer program created in
1966 whose conversation structure was then associated to the ones pursued
by certain psychotherapists, known as Rogerians [32]; the program won three
consequent Loebner prizes (’91, ’92, ’93).
Other examples of more recent winning chatbots are A.L.I.C.E (2000,
2001, 2004) and Mitsuku (2013, 2016, 2017, 2018) [1, 29]. Both programs
were created using a AIML knowledge base, that is a derivative of XML, and

performed pattern matching on each input to elaborate a response.
2.1.2 Virtual assistants
The Loebner prize, as introduced in the Subsection 2.1.1, is assigned by
evaluating ability of the chatbot to mock human behavior. However, in the
last few years, another type of chatbot come up: the Virtual Assistant, a
software agent that can interpret human speech and respond via synthesized
voices. The most popular examples of such systems are Apple’s Siri, Ama-
zon’s Alexa, Microsoft’s Cortana, and Google’s Assistant. According to [17],
“these kinds of chatbots are always connected to the Internet and each in-
teraction is sent back to a central computing system that analyzes the user’s
voice commands and provides the assistant with the proper response.”
They offer generic one-size-fits-all services [11], by enabling their users
to access different functionalities like setting reminders, performing inter-
net searches, communicate with remote home automation systems and other
simple tasks that would require longer interactions to be completed manually.
2.1.3 A chatbot for everything
Besides the systems described in the previous subsections, chatbots start to
be created and used in an increasing number of specific domains, each with
its own requirements. For example, a 19-year-old student designed a chatbot
to help drivers that received parking tickets, in London and New York, to
contest the fine; the results of 2016 show that the system had a success rate
of 64%, in less than two years from its launch, by overturning 160,000 tickets
[23]. In 2017, at the Manipal University, a conversational agent was designed
to answer FAQs related to that educational institute [30]. Another more
recent example, dated 2018, consists in the development of a chatbot for
meal recommendation [13].
2.2 Design Approach
From a high perspective, chatbots can be distinguished in two different mod-
els by the way they generate responses: Retrieval-based and Generative-
based [31, 28].
8

The first approach allow to assemble the answer by selecting from a set of
predefined responses according to the input, the context and some heuristic.
The latter may be as simple as a rule-based expression match, or i could
include Machine Learning classifiers trained to predict the matching score.
Their main advantage is that the answers provided are always grammatically
correct, but since they are picked from a finite set of choices, they may lack
originality.
Chatbots designed following the second model, instead, build new re-
sponses from scratch, treating generation of conversational dialogue as a
statistical machine translation problem. In fact, depending on the current
context of the conversation, they are able to autonomously create the answer
word by word, based on a given vocabulary.
2.3 Development Choices
As we have seen in Section 2.1, there are multiple applications of the chatbot
concept, each one with different purposes. It is important to highlight how,
over the years and starting from the first conversational agent ELIZA, these
systems increasingly exploited technologies belonging to the Web and, more
specifically, those related to the APIs.
A common example is the case of the chatbot for weather forecasting, that
is able to help getting information about present and future climate changes
based on the location of the users. This is possible thanks to the availability
of some external Web based APIs which the system can make request to, in
order to transform their response into an utterance that includes the wanted
data about weather.
Let us discuss now which development choices must be taken when start-
ing to developing a chatbot like the one just described.
2.3.1 Local or remote
To begin with, we can distinguish three development choices related to the
possibility of taking advantage of existing Web resources. Thus, let us pose
our attention on where to place the internal modules of the chatbot, i.e. the
Natural Language Understanding service and the application unit.
A first approach considers relying completely on existing development
frameworks available online. These systems usually offer a user friendly in-
9

terface and tools to develop a fully functioning chatbot easily. Their main
drawback is represented by their rigidity and lack of customization features,
along with their strict dependence on the Web platform they stand upon.
Another option, instead, is to rely on a Web based system to develop the
Natural Language Understanding unit, while deploying the application mod-
ule independently. This gives both the opportunity to completely manage
all the logic behind the conversation, while delegating the problem of intent
matching and entity translation to the remote service. In this case, the latter
acts as an on demand translator of input phrases, properly sent by means of
a dedicated API. It is important to remind that this choice does not prevent
the developer from instructing the Web service on how utterances should be
managed: the necessity to define which intents the chatbot can recognize,
as well as the entities, is still present and bound to the remote architecture
specifications.
The last approach is related to the development of a standalone system,
in which the developer has to create an ad-hoc model which includes both the
utterance parsing and the dialogue management part. This development di-
rection allows not to be dependent to Web services, on the Natural Language
Understanding side, but it could still require a stable Internet connection in
case information retrieval is related to some APIs. The main advantage of
this development approach is the possibility to completely craft a system
able to respond to the developers needs, both in terms of how the chatbot
can interpret utterances and how the conversation must continue once this
procedure is completed.
2.3.2 The chat interface
Another aspect that must be considered, during the development of a chat-
bot, is the communication channel that will support the input of the users
that will interact with the system.
A first solution may include the creation of a custom chat interface in-
tegrated to the system and accessible through a dedicated application; it
could be deployed locally or as a remote service, i.e. accessible by means of
a Web page. In this situation an additional effort is required to the devel-
oper, bearing in mind that the conversation quality may be enhanced by the
introduction of dedicated buttons, for instance.
Instead, a more convenient way is to take advantage of existing chat
10

platforms that already offer a solution to these kind of problems. In fact,
they allow the developer to create an account belonging to their system and
provide an API to control the messages sent and received by this online
profile. The main advantage derived by the usage of these online interfaces
is that they are always available and already provide advanced user friendly
communication features, e.g. buttons, images exchange, document sharing,
etc. Moreover, the developer may use more than one of these systems at
a time just enabling the system to understand and communicate with the
APIs, without changing the logic of the application. The main drawback of
such development choice is the dependence on an always available Internet
connection. Examples of these systems are Telegram1, Slack2, Messenger3,
Twitter4, Kik5, Line6, Viber7, etc.
2.4 Different Chatbot Frameworks
In the previous section we analyzed the choices that must be made when
developing a chatbot, in terms of where the various modules could be allo-
cated, if locally or remotely, and whether it is better to use an existing chat
interface or to build a new one from scratch.
Now let us consider in details the most popular frameworks that allow
to develop a chatbot, considering the services they offer with respect to the
development decisions described so far. Thus, during this analysis we will
concentrate both on NLU and dialogue management features, along with the
ease of set up and interoperability with existing chat interfaces.
Dialogflow8, as first example, is an online framework that require a
manual configuration of intents, entities and contexts management and dec-
laration capabilities. Besides the NLU feature, it integrates a dialogue man-
agement system able to perform customizable API calls and to maintain in
memory some parameters with settable lifespans. Moreover, it integrates well
with the majority of chat interfaces available online, it offers SDKs for multi-
1https://telegram.org/2https://slack.com/3https://www.messenger.com/4https://twitter.com/5https://www.kik.com/6https://line.me7https://www.viber.com/8https://dialogflow.com/
11

ple programming language and integrates a Machine Learning procedure to
increase the chatbot comprehension of the user’s input.
Wit.ai9 is a very similar online tool and provides almost the same func-
tionalities. The definition of custom actions is common to both, along with
their ease of integration with external application programming and chat in-
terfaces. Both the systems present an HTTP API to limit the interaction to
create and use the chatbot; moreover, the two present an internal system for
speech recognition.
PandoraBots10, instead, limits its features to the NLU tool, which is
accessible via its API. It is based on the AIML language, a derivation of
XML, which allow the definition of input pattern and related templates for
the answer. Its definition is not as intuitive as the other framework a analyzed
so far, but it allows the total control of the bot’s knowledge based. In any
case there is a limitation in terms of max number interactions with the free
license.
Another online framework is FlowXO11, which allow the definition of the
chatbot conversation by means of an online graphical editor. While being
highly integrated with various chat interfaces and existing APIs, it allows
the connection with a custom Webhook as well. It also present an internal
NLU system for message parsing.
Watson12 is another online tool that provides the development of chat-
bots. As DialogFlow and Wit.ai, it allows the definition of intents and entities
and provides a dialogue management system, as well as a NLU interface. The
developer can also connect a custom webhook and/or communicate with a
dedicated API. The main disadvantages, besides requiring a continue Inter-
net connection since it can only be hosted in cloud, include the necessity to
define sequences of intents for context management.
Chatscript13, instead, is “a rule based engine, where rules are created by
human through a process called dialog flow scripting”. This chatbot tool can
run locally and offer services like: a pattern matching algorithm aimed at
detecting the phrase meanings, an extensive and extensible ontology of nouns,
verbs, adjectives and adverbs, the ability of remembering user interactions
9https://wit.ai/10https://www.pandorabots.com/11https://flowxo.com/12https://www.ibm.com/watson13https://github.com/ChatScript/ChatScript
12

across conversations and the rules capabilities to dynamically alter engine
and script behavior [12].
Another framework is represented by RASA14, which is “a set of open
source machine learning tools for developers to create contextual AI assis-
tants and chatbots”. It offers two different technologies: RASA Core and
RASA NLU.
The first one is a chatbot framework with Machine Learning-based dia-
logue management, which allows the definition of the conversation structure,
by means of a dedicated markup language. During the design phase, the
developer may describe some wanted conversation paths, in terms of likely
future sequences of intents. Then, after the dialogue engine is trained ac-
cording to this model, the chatbot is able to match the received phrases
against these intents while maintaining the context in a previously created
target sequence. Moreover, the developer can specify custom actions which
will be called when a specific intent is matched, as well as direct utterances
to respond to user messages or custom variables to extract, persist and reuse
during the conversation.
RASA NLU, instead, is a library for Natural Language Understanding
which offers intent classification and entity extraction features. Its main
advantages are that it can run locally and it is highly customizable, while
being lightweight from a programming point of view. In fact, the developer
does not have to learn and apply a new language, like in the case of AIML,
since RASA NLU allows the definition of free-text training phrases; these
examples, then, are used to train an Artificial Intelligence model that will be
used during the conversation phase. Moreover, although it is an open-source
solution, it easily competes with the other commercial products analyzed so
far [5].
2.5 Related Research Approaches
As we said, in the last years we have assisted to the creation and spread
of new frameworks for the development of chatbots, as well as the opening
of the APIs conducted by the major messaging platforms towards third-
party developers. However, what seems to be still missing is a common
methodology that guide the creation of a conversational agent, i.e., a model
14https://rasa.com/
13

that define the design procedure in terms of requirements, objectives and
dialogue characteristics.
Some commercial frameworks developed their own dialogue management
system, exploiting the concepts coming from the NLU field and each defining
a dedicated engine based on popular Knowledge Bases, Machine Learning
technologies or Artificial Intelligence concepts. However, besides offering
state-of-the-art technologies and a user-friendly interface for their integration,
they are limited to the creation of specific chatbots; in other words, when
using these systems, the design process is limited to the offered model and,
above all, has to be conducted differently with respect to the requirements
of each conversational agent.
The lack of a models for a design methodology can be traced back to
the complexities that the development of a chatbot involves. A scientific
investigation conducted in 2018 describes “the lack of research about how to
effectively workout a Return-Of-Investment (ROI) plan” when dealing with
the design of a chatbot [27]. In particular, it introduces a few important
dimensions that need to be considered, like the interaction of the user with the
agent, in terms of information retrieval and presentation, or the integration
aspect with databases or external APIs. Moreover, the conversation quality
assurance, maintainability and dialogue analysis are also fundamental aspects
that need to be considered when designing these conversational agents.
A research approach similar to the one we discuss in this Thesis proposes
a data-driven model for the design of a chatbot dedicated to educational sup-
port [2]. Although the project aimed at the creation of a learning assistant,
the first step for its development started from a definition of a paradigm to
annotate the dataset involved. The introduction of a procedure that acts on
the data system enabled the overall study not to be bound to the content of
the data, rather to be extended to all the information systems built with the
same technology.
This is also the aim of our research, i.e., the definition of a model that,
starting from the characterization of the data, enables its exploration by
means of a conversational support.
14

Chapter 3
Chatbots for Data Exploration
3.1 Concepts
Let us introduce the idea of a Chatbot for Data Exploration with the help of
a conversation example between an user and the chatbot itself, as shown in
Figure 3.1.
At first, the user does not know how the system works, but after a few
messages the capabilities of the chatbot are made clear. It is easy to see how
all the interactions have a common thread, that is the dynamic visualization
of some data. What is remarkable is that knowing the structure of data is
not a precondition for their visualization, since the system helps the user
by showing examples and buttons, which can be considered as hints for the
continuation of the conversation. This mechanism of interplay between user
requests and application responses, represents what can be defined as an
exploration of a set of data, by means of a conversational approach.
These three keywords, indicated in bold above, are the concepts that will
guide the definition of the objectives and the characterization of the field of
action to develop our system.
3.2 Main Requirements
The goal of the system that is the object of this work is to offer a tool
capable of navigating among some data. To achieve our objective, there are
a number of requirements to be fulfilled by the environment for the chatbot
generation and execution.
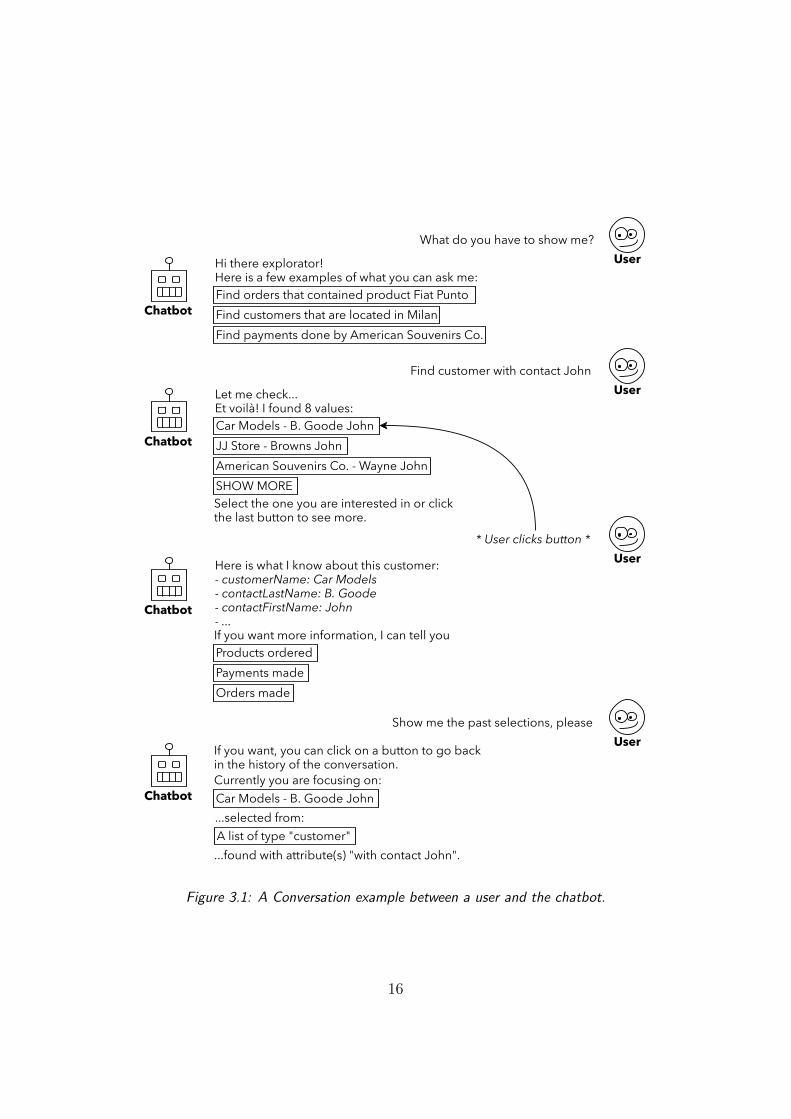
What do you have to show me?
Hi there explorator!Here is a few examples of what you can ask me:Find orders that contained product Fiat PuntoFind customers that are located in MilanFind payments done by American Souvenirs Co.
Find customer with contact John
Let me check...Et voilà! I found 8 values:Car Models - B. Goode JohnJJ Store - Browns JohnAmerican Souvenirs Co. - Wayne John
Select the one you are interested in or clickthe last button to see more.
* User clicks button *
Here is what I know about this customer:- customerName: Car Models- contactLastName: B. Goode- contactFirstName: John - ...If you want more information, I can tell youProducts ordered Payments madeOrders made
Show me the past selections, please
If you want, you can click on a button to go backin the history of the conversation.
Car Models - B. Goode John Currently you are focusing on:
...selected from:A list of type "customer" ...found with attribute(s) "with contact John".
Chatbot
Chatbot
Chatbot
Chatbot
User
User
User
User
SHOW MORE
Figure 3.1: A Conversation example between a user and the chatbot.
16

3.2.1 Connect to the database to obtain the schema
As a first requirement, the chatbot must be able to connect to with a
database. In this Thesis we focus on relational databases, but in princi-
ple this requirement is to be considered for any data model. However, in the
following, we will make reference to the relational model, which is the one
our prototype has been defined for. In any case, the information retrieval
can take place only when both the right query language and the internal
structure of the data system are known to the chatbot.
While the first problem can be solved with the help of the right connec-
tor, which is capable of connecting to a database and performing queries,
the second issue may be more difficult to solve: the system must be able
to correctly identify the relations among the different tables and create an
abstraction of the schema suitable for the type of navigation at the basis of
the chatbot.
3.2.2 Extract and learn database-specific vocabulary
and actions from schema
Not only the conceptual model of a database is unique in terms of tables,
attributes and relations, but also the information it stores varies depending
on the elements its tables represent and the characteristics more valuable
in the context of its usage. A system able to support this conceptual and
logical heterogeneity is not likely to fit the need of a proper conversation by
simply relying on the structure of the database, since there is no guarantee
that the information it represents becomes relevant when visualized as it is.
For example, if we consider a Cross-Reference Table in a relational database,
we clearly see how its rows become human-readable only when analyzed with
the tables it relates to. One possible approach to tackle this problem could
be the automated limitation of the visualization of some tables based on
their structure, but this might lead to the unintentional removal of possible
valuable information.
A better perspective could be to consider the complexity of the database
as a starting point towards the definition of a suitable abstraction in the con-
text of a conversation. The result of such a procedure would be a data-driven
model that represents the database as a network of connected elements that
could fit the necessities of the final user. Specific vocabulary, for example,
17

might be used to refer to the different entities of the data system, as well as
custom actions to take when focusing on each of them, by exploiting existing
relations and defining new ones, in a user-oriented viewpoint.
This customization is more likely to be carried out manually, by a De-
signer that knows how information is organized in the database and what
could be the interests of visualization and navigation of the final users. This
process can be considered as the design of the conversation and may allow the
definition of multiple conversation models for the same data system, depend-
ing on the most relevant interests of the ultimate consumers, as identified by
the Designer.
3.2.3 Automatic intent and entities generation and ex-
traction
Since the key feature of a chatbot is the ability to interpret natural lan-
guage input, one requirement that our system must meet is the capability to
automatically train a natural language model which permits to understand
phrases related to the context of the data it handles. In the previous Sub-
section we discussed how the schema of the database may be abstracted in
a conversation-oriented perspective, but we did not define how this resulting
model might be used to guarantee the specifications just declared.
A possible approach, following along these design choices, could take ad-
vantage of the concepts of intents and entities belonging to the Natural Lan-
guage Processing (NLP) area. While intents, which can be considered as the
intention of the user, could be mapped to specific actions to be performed
on the database (e.g. filter, select, join, etc.), entities represent the
elements that the chatbot can extract from an input phrase and that could
be associated with the elements structuring the data system, i.e., its tables,
relations and values.
Relying on these assumptions, when the chatbot receives a phrase, it
could perform what is called intent matching : the process of understanding
what the objective of the input utterance is and its consequent translation
into a database query. Entity extraction, instead, could be used to correctly
parametrize the request, in terms of table and attribute references.
It is important to consider the fact that the phrases the chatbot receives
don’t have to be formulated in a metalanguage which only relax the syntax
requirements of the SQL language; rather the system should rather accept
18

and correctly understand utterances belonging to the natural language. In
order to reach this objective, the bot might train its NLP model using some
sets of example phrases for each intent to recognize, labelled in accordance
to the entities each pattern contains.
3.2.4 Proper communication and data visualization
Once the system interprets a user utterance and executes the correspond-
ing command, the problem of presenting the results arises. While the chat
environment can be considered a user-oriented communication channel as it
simplifies the way requests can be done by relying on the natural language
format, it is also true that it may represent an issue from the system per-
spective. In fact, the user experience must be designed on the basis of a
conversation, thus with a number of limits that a graphic tool, for instance,
would not have.
Since the object of the navigation are the data, the first issue to solve
is how to present them in a readable way. Let us consider the Figure 3.1:
after the user asks the bot to find some elements and the system performs
the related search, the results are displayed as a list of buttons, identified
with some words representing the elements they link to. This simple example
already highlights how the chatbot should be able to:
• Respond to the user using natural language, in order to present its
results;
• List the results in a readable way, taking into account their quantity
and short messages to identify them;
• Take advantage of buttons, to simplify selections and the overall navi-
gation.
Besides these requirements, the system may handle cases of typos, wrong
insertions/selections, help requests and so on, which are conditions in which
the communication flow skews from its expected path.
3.2.5 Allow the user to manipulate query results
A possible request by the user may involve the visualization of a high number
of elements and, because of this, the chat environment might represent the
19

bottleneck of their readable visualization. Thus, the user may have the need
not to view them all, but to filter them according to some attribute.
3.2.6 Support context and conversation history man-
agement
Other important aspects that may be part of the system refer to the man-
agement of context memory. This represents the capability to interpret each
user request not just as an independent single command, but as the out-
come of an evolution of connected intentions over time. While from a human
perspective this condition represents the basis of a conversation, in which
every interaction is guided directly or indirectly by the progression of the
past ones, this aspect has to be considered carefully in the computer systems
dimension.
For what concerns the system we aim to define, we should consider the
context management as a key functionality, since navigation is only possible
when the steps that shape the chosen path among data are known to the
chatbot. In other words, the the system must remember previous user’s
requests to enable the refinement of the results by some filtering, or the
exploration of elements related to the past ones displayed.
Besides this critical requirement, the chatbot could also offer the possibil-
ity to go back in conversation, by restoring its context to a precise moment
and allowing the navigation through a different dimension from the previ-
ously chosen one. This is the case of the last interaction represented in
Figure 3.1, where the chatbot displays the history of its conversation with
some buttons linking to the elements they refer to.
20

Chapter 4
Approach
Now that the requirements and goals have been made explicit, it is important
to define what are the steps that have to be taken when designing the chatbot
according to our methodology. Since entities of various types are necessary
and each of them play different roles in the system, we need to take particular
care of their heterogeneity during the design phase and we must consider what
is our purpose at each step. Therefore, our modeling choices are directed
towards our objectives, while being feasible with respect to the architectures
they rely upon.
4.1 Design Process
We can consider the creation of the chatbot for the exploration of a database
as a semi-automatic procedure. In fact, the process of designing the system
includes both automatic and manual phases. The manual phases have to
be performed by a Designer, who knows the database, the goals and the
requirements of the bot to be developed.
Parsing of the database schema. This is the first phase of the chatbot
design process and it is automatically executed by the system. In this step,
the schema of the target database is parsed and interpreted, in order to obtain
a simplified version which highlights its structure, in terms of table attributes
and relations among entities, not considering additional details about data
types, nullable or default values, etc. Moreover, this representation is needed
to support the annotation activity described in the next paragraph.

Schema Annotation. This can be considered as the core part of the whole
design process and must be performed manually by the Designer. In this
phase the simplified database schema is annotated with special tags that will
be used in next step to generate the conversation itself.
NLU model extraction This last phase is done automatically by the
system and consists in the training of the Natural Language Understanding
(NLU) model. This process is carried out in two separate steps:
1) The generation of the training phrases, based on the annotation of the
schema.
2) The training of the NLU model, starting from the utterances just cre-
ated.
It is important to say that this phase is quite delicate even if it is completely
performed by the system. In Section 4.3 we explain in details what are the
key points to generate the NLU model, while in Chapter 5 we describe a
possible solution that supports this procedure.
4.2 Schema Annotation
To translate an input phrase into a specific query on the database, we propose
the definition of a mapping between what can be understood by the chatbot
(intents and entities) and the elements of the database (tables, attributes,
relations) by means of a Schema Annotation. This section is devoted to
illustrate the main ingredients for this mapping procedure and the recipe of
the approach; to make the description easier to follow, we will refer to an
example database shown in Figure 4.1.
4.2.1 Conversational Objects
The first step is to characterize the database tables to express the role that
the elements they represent play in the exploration of data:
1) Primary - tag [P]
2) Secondary - tag [S]
3) Crossable Relationship - tag [X]
22

customers
customerNumberPK
customerNameNN
contactLastNameNN
contactFirstNameNN
phoneNN
addressLine1NN
cityNN
state
countryNNpayments
customerNumberPK, FK
checkNumberPK
paymentDateNN
amountNN
orderdetails
orderNumberPK,FK1
productCodePK,FK2
orders
orderNumberPK
orderDateNN
statusNN
customerNumberFK, NN
products
productCodePK
productNameNN
productScaleNN
productDescriptNN
quantityInStockNN
Figure 4.1: The relational schema of the database.
The distinction between the first two types is that while values belonging
to a Primary table may represent useful information without the need of
a context, Secondary tables contain data strongly related to other entities,
which become clear only when that specific relationship is considered. For
example, tagging as Secondary the table payments means that the access
to its values depends on another table, customers. In other words, with
this characterization the Designer defines that instances of payments can be
retrieved only by passing first through instances of customers, for example
because payments data would not be meaningful otherwise. Labeling ta-
bles as Primary, in contrast, relaxes this dependence constraint and enables
direct queries on tables. Finally, Crossable Relationship characterization is
dedicated to bridge tables, i.e., the ones that represent many-to-many re-
lationships between entities. Their rows may have a meaning only when a
join operation across them is executed; thus no direct or deferred search is
allowed on them.
Some tables might have names not suitable in the context of a conver-
sation. Thus, as reported in Figure 4.2, each Primary and Secondary table
has to be labeled with a keyword, i.e., the name that will represent it during
the conversation, that from now on we will call Conversational Object.
23

For example, in the request “find customer with contact John” in Figure
3.1, the chatbot understands that customer is the placeholder for the table
customers. As represented in Figure 4.2, multiple words can be associated
to a table, acting as aliases for the same element; this will allow the users
to refer to them in multiple ways. As a result, the chatbot will be able to
understand customer, client and both their plural form as keywords for the
same, enabling the user to prefer different utterances, like “find client with
contact John”.
customers
payments
orderdetails
orders
products
[X]
[P] product
[P] order [P] customer
[S] payment
customersclient clients
orders
products
item
items payments
Figure 4.2: The Conversational Objects annotation.
4.2.2 Display Attributes
If we pay attention to Figure 3.1, we can see how the chatbot, after the
first interaction, displays a list of customers. What is remarkable is that the
values shown seems to be representative of the objects they refer to. In other
words, the chatbot does not show all the information related to each element
when displaying them in a list and it does not even limits the visualization
to their primary key, which is unique but maybe not informative; it rather
shows the name of the customer, as well as its contact.
This is possible because the Designer, when dealing with the Schema An-
notation, tagged the table attributes customerName and the pair (contact-
24

LastName, contactFirstName) as Display Attributes. In fact, this pro-
cedure enables the chatbot to refer to the values there contained to display
the results in lists as we described before and it can be applied to Primary
and Secondary tables. In Subsection 4.4.3 the problem of results visualiza-
tion is described in details. In Figure 4.3 there is a graphic representation of
the Display Attributes annotation performed on the example database.
By looking at the Figure, we can appreciate how some of these columns
may be aggregated into a single list, like in the case of (contactLastName,
contactFirstName), as we already considered in the example just described.
Some others, instead, present a word or a short phrase linked to them. This
annotation, visible in correspondence to the table payments in which the
label for amount is Euros and the one for paymentDate is in date, will
allow the chatbot to display lists of payments with this example format:
“[Euros: 12345 - in date: 16-04-2019]”
customers
customerName
contactLastName
contactFirstName
payments
paymentDate
amount
orderdetails
orders
orderNumber
orderDate
products
productName
_
_
Euros
in date
_
_
in date
Figure 4.3: The Display Attributes annotation.
4.2.3 Conversational Qualifiers
Defining the role of tables and their related placeholders enables the system
to translate phrases like “find customers”, which aim to select all the in-
stances of the corresponding table. Other elements are needed to interpret
conditions for filtering subsets of instances, for example queries like “find
customers that are located in Milan”. In order to support this granularity in
25

the results, the Designer can define a set of Conversational Qualifiers for
each data element, as shown in Figure 4.4 where the treated entity refers to
the customers.
This annotation procedure considers what are the attributes that will be
used to filter the results and how the final user will refer to them, i.e., through
which expressions. For example, in Figure 4.4, the attributes city, state
and country are labeled with the expression located in: this gives the chat-
bot the capability to understand input phrases like “find customer located
in Milan”, and process it as a query that selects the customers having city
= Milan, or state = Milan, or country = Milan. These Conversational
Qualifiers may belong to other tables, rather than the one directly addressed
by the user request. This is for example the case of the Conversational Qual-
ifier that bought, that, even if it was defined for the field productName of
table products, can be used also in queries like “find customer that bought
Fiat Punto”. The table customers is indeed reachable through the tables
orders and orderdetails. This is graphically represented in Figure 4.4 by
means of dotted arrows.
In some cases the user may also ask: “find customer Car Models”, without
including in the utterance any Conversational Qualifier, i.e., without speci-
fying what the Car Models value stands for. The system, then, will search
for related instances in the table customers by the attribute customerName;
for this attribute, indeed, there is not any specific expression specified as
Conversational Qualifiers (graphically denoted by “ ”).
4.2.4 Conversational Types, Values and Operators
In order to help the chatbot process and interpret correctly the utterance, for
each Conversational Qualifier it is important to specify its Conversational
Type:
• WORD: any information without a particular structure or syntax;
• NUM: numerical values;
• DATE: datetime/date values;
• Custom ENUM: entities that can assume enumerable values.
The last one may be useful when an attribute can assume only a fixed set
of values. An example, not present in our database, could be the attribute
26

customers
customerName
contactLastName
contactFirstName
city
state
countrypayments
amount
orderdetails
orders
products
productName
[P] customer
with contact : WORD
_ : WORD
located in : WORD
that paid : NUM
that bought : WORD
Figure 4.4: The Conversational Qualifiers annotation, focus on customer.
businessName for the table customers and with enumerable values Public
Administration and Private Company.
It is important to clarify how the Conversational Type format is used by
the Designer during the Schema Annotation phase and it will be recovered by
the framework during the Conversation Modeling phase, as we will describe
in Section 4.3. However, from now on when dealing with example phrases, we
will use the term Conversational Value to refer to the real value, always
remembering that its identity is strictly related to the concept of Conversa-
tional Type, as already described. Thus, according to this notation, in the
phrase “find customer Car Models” the bold words will be identified as the
Conversational Value.
The utterances received may include some more complexity, apart from
the examples analyzed so far. For instance, the user may type a phrase like
“find the customer that paid more than 42000 Euros”, and the system should
identify the correct references for what concerns the Conversational Object
“customer”, Conversational Qualifier “that paid” and Conversational Type
NUM, with Conversational Value “42000 ”. The problem here is that the
chatbot may not consider the expression “more than”, leading to a malformed
search with likely wrong results.
This issue can be solved by introducing the concepts of Conversational
Operators and enabling their usage with respect to the defined Conversa-
tional Types.
27

A possible trace could be the following:
• WORD → “like”, “different from”;
• NUM → “more than”, “less than”;
• DATE → “before”, “after”;
4.2.5 Conversational Relationships
Always referring at the the conversation example in Figure 3.1, after the
user has successfully selected a customer, its data and a few buttons are dis-
played. These last represent the relationships that can be navigated starting
from the instance being examined; we will refer to them as Conversational
Relationships. These relationships have to be specified in the annotated
database schema (see labeled arcs in Figure 4.5) so that user utterances can
also imply navigation in the database through join operations. The arcs
in Figure 4.5 are not bidirectional, since during conversation the user may
refer differently to relationships depending on the direction in which they
are traversed. Note that the relation between product and order needs to
be supported by a Crossable Relationship table, being it a many-to-many
relationship.
This kind of support is needed also in the relation named as products
bought, that links the customer entity to product. Here we can appreciate
how enabling the definition of this kind of connection relaxes the constraints
imposed by the structure of the database. In fact, the Conversational Rela-
tionship just analyzed is oriented to what the final user may be interested in,
rather than on how data is physically organized: customers and products,
in this case, are connected with a direct link, while the underlying relational
model needs multiple subsequent relations to obtain the same functionality.
4.3 Conversation Modeling
In the previous section we analyzed how Schema Annotation opens the design
process. In this section, instead, we will consider how that procedure can be
used to obtain a chatbot able to understand phrases related to the considered
data system, by taking advantage of the concepts already defined in the
previous Section.
28

[X]
[P] product
[P] order [P] customer
[S] payment
contained products
in orders
made by customer
orders made
payments made
made by
products bought
Figure 4.5: The Conversational Relationships annotation.
Designing a Natural Language Understanding model means to define the
intents and the entities that the chatbot will be able to match and extract,
respectively. However, we are in the situation in which the target database
of the system is not fixed, so it is not possible to define an end-to-end con-
nectivity between these NLU concepts and the query they refer to when they
appear in a utterance.
This limit becomes evident if we consider that the chatbot may be in-
terfaced with a very large database, with dozens of complex tables and even
more relations: defining, for example, an intent for each possible query struc-
ture and an entity related to each value of the tables could lead to a NLU
model exponentially bigger than the data system.
In order to avoid this situation, we came up with a solution that auto-
matically generates intents and entities starting from the database Schema
Annotation. However, we also needed a procedure to generate the example
phrases to train the chatbot, each with labelled entities and related to an
intent.
29

4.3.1 Intents
With respect to the tools our chatbot should provide, we decided to define
four types of intents related to the following concepts: find, filter, naviga-
tion and help. A description of each one of them follows.
• Find intents. They are related to the action of searching into the
data source specific elements that will represent the starting point for
the consequent conversational exploration.
• Filter intents. They are associated to methods that allow to further
filter a list of elements already presented in the chat.
• History intents. They allow the user to access the history of the
conversation or undoing operations.
• Help intents. They provide general or specific advice and hints during
the navigation.
In order to enable the correct match of these concepts, the NLU model
must be trained with phrases featuring a structure similar to the one of
possible user utterances. In particular, we decided to take advantage of some
words that were more likely to be found in phrases related to some intents
with respect to the others. This way, we could automatize the whole phrase
generation process.
For example, all the training utterances for the find intents start with
a word that can be either “find”, “are there” or “show me”, followed by
a sequence of other words related to the particular elements they refer to.
We will discuss about this pattern composition in the next Subsection, when
talking about the entities, since the majority of phrases cannot be generated
without them.
The only intent category that does not depend on the target database for
which the chatbot is generated refers to the history intents, whose training
phrases are fixed since no entity is used. We provide here an extract of their
possible definition:
• show history → “show me the history”, “the history, please”, “where
are we?”, etc.
• go back → “go back”, “undo, please”, “back”, “undo”, etc.
30

4.3.2 Entities
They are related to the database that the chatbot is going to interface and,
because of this, they depend on the specific outcome of the Schema Anno-
tation phase, as well as on the real values that compose the data system.
While intents are used to understand what is the general purpose of the
received utterance, entities become arguments of the methods that will be
called. Therefore, they cannot be extracted without a previous successful
intent-matching step.
In this context, we used and applied all the modeling primitives con-
cepts described in Section 4.2, in order to define the type of entities that the
chatbot should be able to support. The only exception refers to the Con-
versational relationships introduced in Subsection 4.2.5, which do not have
a corresponding entity to be identified in the utterance, since their usage is
limited to the interaction via buttons and thus they do not pass through the
NLU unit. We will discuss this aspect in the following section, when treating
the issues related to the chat environment.
Let us now describe in details the structure of the training phrases related
to the intents with dynamic content.
Entities for find intents. The intents of this type must contain the Con-
versational Object for which the search is intended and at least one Conver-
sational Value that will be used to filter the results. By looking at Table 4.1
we clearly see that there is a pattern to define and generate these phrases,
whose structure depends on the types and number of the utterance compo-
nents to include. Even if the table only shows generated utterances related
to the customer, we see how the Conversational Qualifiers are coherent with
the related Type:
• “located in” is followed by a WORD whose Value is “Milan”
• “that paid” is linked to a NUM, with Value “20000 ”
What is remarkable is that the phrases have a meaning because the Con-
versational Values are consistent with the rest of the utterance. In fact, while
Conversational Objects and Qualifiers are defined by the Designer, the values
are extracted automatically by the system. This can be made possible by
defining an ad-hoc procedure that connects to the database and executes a
31

Keyword Entities Example
Find* Obj Val Find - customer - Car Models
Find* Obj Qual Val Are there - customers - located in - Milan
Find* Obj Qual Op Val Search - customers - that paid - more than - 20000
Find* Val* Obj Find - Private Company - customers
Find* → Find, Are there, Search
Val* → Values related to ENUM Conversational Types
Table 4.1: Phrase structure for find intents.
series of short queries to extract example Values for each referenced Con-
versational Type. These values will be used in the training phrases, thus
enabling the definition of utterances very similar to the one the chatbot will
receive.
The entity extraction phase, during the conversation, will be able to per-
form the extraction based on the NLU model trained according to these
training phrases. A simple graphical example of how this procedure works
can be seen in Figure 4.6. We can see how in the received utterance the
word “Euros” is present, but this does not limit at all the capabilities of the
system to correctly understand the overall meaning, thanks to an accurate
definition of the training phrases. In fact, since “Euros” is not present in the
examples, it will not be extracted as an entity, but this will not prevent the
correct mapping of the other utterance components.
Find customer that paid 20,000more than
Find customer that paid more than 20,000 Euros
Euros
Object Qualifier
Operator Value
> NUM
PHRASE RECEIVED:
NLU ENTITY EXTRACTION:
Type
Figure 4.6: An example of the entity extraction phase.
32

Entities for filter intents. In case of these types of intents, all the consid-
erations made in the previous paragraph are valid, except for the constraint
on the presence of the Conversational Objects in the phrase. Here that may
be missing, since the filter action can be applied only to a previously re-
trieved list of elements. Thus, including the keyword for the element is not
necessary because the system will be able to extract it from the Context. In
any case, we will analyze these concepts in Subsection 4.4.2.
Table 4.3 graphically summarizes these ideas, providing examples for each
considered pattern.
Keyword Entities Example
Filter* Obj Val Filter - customer - Australian Souvenirs
Filter* Val Show only - Car Models
Filter* Obj Qual Val Filter - customers - that bought - Harley Davidson
Filter* Qual Val Only show - those - located in - Spain
Filter* Obj Qual Op Val Filter - customer - that paid - more than - 40 Euros
Filter* Qual Op Val Filter the ones - different from - Shopping
Filter* Val* Obj Filter - Public Administration - customers
Filter* Val* Show only - Private Companies
Filter* → Filter, Filter the ones, Show only, Only show
Val* → Values related to ENUM Conversational Types
Table 4.2: Phrase structure for filter intents.
Entities for help intents. These intents are quite simple, with respect to
the others analyzed in this Subsection, but still very important. The related
phrases may include the presence of Conversational Objects or not, enabling
the system to give advice on its functionalities and capabilities in general,
or to concentrate into the properties of a particular element; this can be
graphically seen in Table 4.3.
Keyword Entities Example
Help* I need help
Help* Obj Help on - customers
Help* → Help, I need help, Help on
Table 4.3: Phrase structure for help intents.
33

4.4 From the Conversation Model
to the Interaction
Once the conversation model just described in the previous Section is applied
to a given database, the result is a system that can understand natural
language queries on the data source. Let us analyze how this communication
can take place, by solving the problems that arise when trying to enrich the
message exchanges with the final user.
We have to remember that the chat represents a fast and user-friendly
form of communication, but the same does not hold from the system per-
spective: there are a lot of issues that must be considered and solved, which
we discuss in the following.
4.4.1 Interaction paradigm
In order to define how the system supports data exploration, a very important
problem is related to its capabilities to receive requests from the user. Our
system enables the generation of chatbots providing two types of input, here
described.
• Textual input. It consists in the most basic form of communication
and it requires the users to type manually a phrase into the chat sys-
tem. Then, the utterance is received by the chatbot and the natural
language processing unit extracts the corresponding intent and entities,
as described in Section 4.3. The user should always be able to access
this form of interaction and it is fundamental to start the conversation.
• Button based input. As the name suggests, the chat system also
supports the possibility to display buttons among the messages pre-
sented. These items might be labelled with the element or action they
refer to and they may send a customized message to the system when
clicked. Buttons are intended to facilitate the communication, by giv-
ing the user some pre-defined options to navigate among data or quick
hints that remind the possibility to use some commands; we analyze
these features in details in Subsection 4.4.3.
34

4.4.2 Automatic query generation
Once the user makes a request, in form of textual input or by means of a
callback message of a clicked button, the translation procedure takes place.
Select and join. As introduced in Subsection 4.2.3, the system allows
the definition of Conversational Qualifiers for each Primary Conversational
Object, but it does not constraint them to be related to the real attributes
of the database table that element refers to.
Let us take, for instance, the Object customer and the Qualifier that
bought, both visible in Figure 4.4: while the first is the placeholder for
the table customers, the second one refers to the field productName, which
belongs to the table products. Considering this, once the system successfully
recognize the phrase “Find customers that bought an Harley Davidson”, the
corresponding query must be created and executed. The algorithm governing
this translation is shown in Algorithm 1.
We can see from the algorithm how the query is created and step by step
modified according to the inputs, from the basic SELECT and FROM commands,
to the more complex WHERE statement which needs two different phases. The
first part (lines 1-12) is devoted to the composition of the SELECT-FROM clause.
Then, the following part (lines 13-17) refers to the generation of the JOIN
section, in which the various conditions are composed by means of the AND
operator. Then, the last part (lines 18-24) present phrases connected with
the OR conjunction and is related to the value and the operand received.
Now let us spend few words on the methods that appear in the proce-
dure, in order to clarify their utility; besides the “getters”, whose behavior is
intuitive, the “extractor” functions need some clarifications, provided below:
• line 3, extractObjectRelatedQualifiers(Map, obj): it analyzes the Schema
Annotation Map and retrieves all the Conversational Qualifiers that
where defined for the Conversational Object obj ;
• line 5, extractObjectTable(Map, obj): it retrieves the database Table
linked to the Conversational Object obj, by looking at Map;
• line 6, extractTableColumns(DS, t): it analyzes the simplified database
schema DS, in order to extract the column fields composing the Table
t ;
35

Algorithm 1: Find Query Builder
in : the simplified database schema DS, the Schema Annotation
Map, the Conversational Object to find obj, the extracted
Conversational Qualifier qual, the Conversational Value v, the
Conversational Operator op
out: the final query q
1 begin
2 q ← an empty String
3 OQ← extractObjectRelatedQualifiers(Map, obj)
4 if qual ∈ OQ then
5 t← extractObjectTable(Map, obj)
6 TC ← extractTableColumns(DS, t)
7 q ← q + “SELECT” + getColumnNames(TC)
8 q ← q + “FROM” + getTableName(t)
9 ST ← extractSupportTables(Map, qual)
10 foreach st ∈ ST do
11 q ← q + “,” + getTableName(st)
12 end
13 q ← q + “WHERE”
14 JST ← extractJoinSupportTables(Map, qual)
15 foreach (fromTable, toTable) ∈ JST do
16 q ← q +
extractJoinStatement(DS, fromTable, toTable) + “AND”
17 end
18 QC ← extractQualifierColumns(DS, qual)
19 foreach qc ∈ QC do
20 q ← q + extractV alueStatement(DS, qc, v, op)
21 if ac 6= last element of QC then
22 q ← q + “OR”
23 end
24 end
25 end
26 return q
27 end
36

• line 9, extractSupportTables(Map, qual): it checks and extract from the
Mappings Map the tables that supports the Conversational Qualifier
qual ; if qual belongs to the same table the Conversational Object refers
to, then the method returns an empty set;
• line 14, extractJoinSupportTables(Map, qual): it analyzes the Map by
looking at the Conversational Qualifier qual like the previous function,
but it returns a set of pairs (fromTable, toTable) which represent how
the different Tables are related to each other; it may give no result in
case qual belongs to the Conversational Object and no further Table
has to be queried;
• line 16, extractJoinStatement(DS, fromTable, toTable): this function
generate the SQL condition which links the origin Table fromTable to
the destination one toTable, using the correct foreign keys and refer-
ences;
• line 18, extractQualifierColumns(DS, qual): it scans the simplified data-
base schema DS and extracts the column fields of the Table the Con-
versational Qualifier refers to;
• line 20, extractValueStatement(DS, qc, v, op): this function returns the
SQL statement which links the value v to the column qc by means of
the operand op.
If we recap the previous example message “Find customers that bought an
Harley Davidson”, after the execution of the procedure the resulting query
will be:
SELECT C.customerNumber, C.customerName, C.contactLastName,
C.contactFirstName, ...
FROM customer AS C, orders AS O, orderdetails AS X,
products AS P
WHERE C.customerNumber=O.customerNumber AND
O.orderNumber=X.orderNumber AND X.productCode=P.productCode
AND P.productName LIKE ‘%Harley Davidson%’
As we can see, the input phrase gets translated into a complex query by
the system, that autonomously connects the tables that “stands” between
customers and products, which are orders and orderdetails. This is
37

possible thanks to the fact that the Designer tagged these two tables while
defining the Conversational Qualifier that bought, action represented by the
dotted arrows in Figure 4.4. What is remarkable here is that the chatbot
was able to identify autonomously what were the table attributes needed
to perform the join among the different tables.
Moreover, if we pay attention at the last WHERE condition of the query
above, we can see how the Conversational Value “Harley Davidson” is pre-
ceded by the SQL operator LIKE. This is due to the fact that in the entity-
extraction phase the motorcycle name was associated to the Conversational
Type WORD. Again, the system independently creates the query according
to the mapping described in Section 4.2.
Maintaining the Context Previously we analyzed a possible case of Find
intent matching and execution; that was made possible thanks to the dis-
tinction made by the Designer while describing the Conversation Modeling,
as described in Section 4.3. However, what would have happened in case of
a Filter intent?
Let us imagine that the above query had given more than one result and
now the user wanted to filter them based on some other attributes. Again this
is possible thanks to the same Schema Annotation, but from a system point-
of-view accomplishing this may be difficult without a proper strategy. Let us
explain the solution, thanks to another example: once three customers that
bought an Harley Davidson are displayed, according to the previous search,
now the user types “Filter those that paid more than 40,000 Euros”.
In order to interpret this utterance, the system must perform two subse-
quent actions:
1) record the last interaction with the database, with particular attention
to its results and the query that was executed;
2) modify the last interpreted query, updating the last recorded interac-
tion.
If we apply these two operations to an example and update it by adding
the filter condition, the resulting query will be:
38

SELECT C.customerNumber, C.customerName, C.contactLastName,
C.contactFirstName, ...
FROM customer AS C, orders AS O, orderdetails AS X,
products AS P, payments as PAY
WHERE C.customerNumber=O.customerNumber AND
O.orderNumber=X.orderNumber AND X.productCode=P.procuctCode
AND P.productName LIKE ‘%HarleyDavidson%’ AND
P.customerNumber=PAY.customerNumber AND PAY.amount>40000
We can clearly see how the SQL command has been modified to limit the
results even more, thanks to another JOIN and value-condition. Here the
Conversational Type was NUM and this enabled the extraction and usage
of the operator ‘>’.
The procedure that is invoked here is very similar to Algorithm 1, but in
addition to the already identified Conversational Qualifier, it also includes
the ones present in the Context and related to the last Conversational Object.
Repeating all the for-loops related to the Qualifier leads to the creation of the
correct query, but some more attention must be paid in order not to include
repetitions.
In this last example we have seen how recording the last interaction be-
comes useful, if not fundamental; this is actually the Context of the con-
versation and it does not limit to the latest SQL operation and results, but
it can be extended to a list of subsequent previous actions. This may have a
max length after which previous interactions are removed from the records,
and/or a limit in time before it gets deleted if not updated.
It is important to say that the Context is crucial in case the user ac-
cesses a given Conversational Relationship when focusing on a single element.
Again, an example may help the reader to clarify this concept.
If the user has just retrieved a customer, maybe from the previous ana-
lyzed query, and now wants to see the customer’s orders, the system might
display the button “[orders made]” as a possible relation to cross, according
to the annotation in Figure 4.4.
Once the button is clicked a translation procedure starts, which follows
the rules described in Algorithm 2.
This program creates the final query following the same steps of Algo-
rithm 1, but has four main differences with respect to the former:
39

Algorithm 2: Join Query Builder
in : the simplified database schema DS, the Schema Annotation of
the database Map, the Context C, the Conversational
Relationship r
out: the final query q
1 begin
2 q ← an empty String
3 obj ← extractContextObject(Map,C)
4 OR← extractObjectRelationships(Map, obj)
5 if r ∈ OR then
6 t← extractRelationTable(Map, r)
7 TC ← extractTableColumns(DS, t)
8 q ← q + “SELECT” + getColumnNames(TC)
9 q ← q + “FROM” + getTableName(t)
10 ST ← extractSupportTables(Map, r)
11 foreach st ∈ ST do
12 q ← q + “,” + getTableName(st)
13 end
14 q ← q + “WHERE”
15 JST ← extractJoinSupportTables(Map, r)
16 foreach (fromTable, toTable) ∈ JST do
17 q ← q +
extractJoinStatement(DS, fromTable, toTable) + “AND”
18 end
19 PC ← extractPrimaryColumns(DS, c)
20 foreach pc ∈ PC do
21 v ← extractPrimaryV alue(pc, obj)
22 q ← q + extractV alueStatement(DS, pc, v,=′)
23 if r 6= last element of PC then
24 q ← q + “AND”
25 end
26 end
27 end
28 return q
29 end
40

1) the Conversational Object is not an input, but is dynamically extracted
from the Context with the function extractContextObject(Map, C) - line
3;
2) the target Table is not related to the Conversational Object, but it
is the destination Table of the Conversational Relationship r ; this is
possible thanks to the method extractRelationTable(Map, r) - line 6;
3) the Conversational Value is not given as input, but is extracted for each
primary column related to the Conversational Object; this is done by
the method extractPrimaryValue(pc, obj) - line 21;
4) all the conditions in the WHERE statement are combined by the AND
conjunction and present the only possible operator ‘=’.
If we recall the previous example and assume that the customer in the
Context has customerNumber equal to 123, the system translates the request
into the following query:
SELECT O.orderNumber, O.orderDate, O.status, O.customerNumber
FROM orders AS O, customers AS C
WHERE O.customerNumber=C.customerNumber AND
C.customerNumber=123
Here, as before, the program autonomously understands what are the
JOIN attributes and that customerNumber is the identifier for the table
customers. Moreover, the SELECT is not executed on the customers, but
on the table orders, as the relation specified.
Error handling. Once there is an algorithm to convert phrases into queries,
the problems are not all completely solved. In fact SQL, like all program-
ming languages, is constrained to a strict syntax, which admits no typos
and is bound to a specific punctuaction. When dealing with a chatbot, it is
not possible to require such a precision from the user, since one of the main
strength of this kind of system is the ability to accept and understand natural
language inputs. Moreover, besides the likely probability of typo errors and
the consequent user frustration derived from their system refusals, words can
be abbreviated, nouns may be different when their plural is expressed, verbs
may be irregular in their different conjugations, etc.
41

It may be unfeasible to store, inside the chatbot, all these possibilities for
each saved lemma; then, a possible solution may be to include some algo-
rithms able to associate the given word or set of words to the understandable
correspondence. In the next Chapter, which is related to the Architecture
of the system, we will present a procedure that can be used to tackle this
problem; however, for the moment, let us consider an intuitive representation
of problem and solution by looking at Figure 4.7.
Find csstamer Car Models
Object?
Value
WORD
NLU ENTITY EXTRACTION: COMPARISON:
Objects
customer
order
client
product
TYPO RESOLUTION:
csstamer
csstamer VS
customer
Type
Figure 4.7: The typo resolution procedure.
Here we can see how the word csstamer is correctly extracted as a Con-
versational Object by the NLU unit, but it needs to be checked against the
possible objects that the system supports. If the word is “similar enough”
to an existing one, customer in this case, than the conversion is performed
and the related query can be then executed.
4.4.3 Chatbot responses
We have described the process undertaken to govern the conversation, from
the utterances receipt to their transformation into queries. We have also
introduced the idea that stands behind the Context and why it becomes so
important in our system.
Now, let us describe in details how the chatbot may answer to the requests
it receives, after the above translation phase.
Natural language utterances. A possible approach to make the chatbot
give human-like feedback is to have a set of pre-defined utterances available
for any occasion. This allows the system to communicate with its users in a
richer form, guaranteeing complete explanation to the results found.
42

Of course, these phrases do not need to be static, but they may need to
be preceded by a slot-filling phase, based on their execution Context. For
example, after the completion of a search on a database over the customers,
the system may introduce the values found by a simple but effective phrase:
“Hey, I found 12 elements of type customer in the data system!” The struc-
ture of the utterance may be applied to each type of results (i.e., customers,
products, orders, ...) and the feedback is quick and easily understandable.
The example phrase just described may be extracted by the system from
the string: I found [] elements of type [] in the data system!.
This procedure can be applied easily to a variety of different utterances,
leading to the design a more descriptive chatbot.
Result visualization. In Section 4.4.2 we analyzed how input phrases
can be transformed into queries, let us now consider how the results of these
database interactions can be prompted to the user. We can distinguish two
possible cases: Single result and Multiple results.
When we are in the first condition, the extracted element can be shown as
is in the database, after a proper introduction, i.e., “Here is what I know about
this customer:”. In Figure 4.8 there is a visualization example that shows how
a possible customer can be displayed in the chat. Moreover, we can see how
the bot presents the buttons, as introduced in Subsection 4.4.1, which permit
the navigation across the database along the Conversational Relationships
they stand for; in the Figure they are Products bought, Payments made and
Orders made.
If we are in the situation in which multiple results have to be displayed,
instead, we have to guarantee their readability. This can be achieved by the
application of two ideas:
1) displaying only key values for each result;
2) controlling the layout of the outcomes.
In order to apply the first concept, the system needs to know for each ta-
ble in the database what are its main attributes, i.e., those that summarize
and somehow differentiate the various rows. Thus, the Designer can tag the
desired columns during the Schema Annotation phase, as described in Sub-
section 4.2.2; for example the table customers can have as Display Attributes
only the keys customerName, contactLastName and contactFirstName.
43

Here is what I know about this customer:- customerName: Car Models- contactLastName: B. Goode- contactFirstName: John - phone: 1234567890- addressLine1: Via Roma, 1- city: Milan- state: None- country: ItalyIf you want more information, I can tell you:Products bought Payments madeOrders made
Figure 4.8: The response of the chatbot to display a single result.
Layout control, instead, is intended to limit the size of the results dis-
played at a time, giving the user the possibility to explore further elements
only if requested. In case of many results, in fact, a single response which
shows them all may be counterproductive, since it may represent a huge and
unmanageable quantity of information.
To facilitate the user interaction, moreover, multiple results may be dis-
played as buttons linking to the elements they refer to. In Figure 4.9 we can
see how these ideas can be applied, thanks to a simple use case over elements
of type customer.
Let me check...Et voilà! I found 8 values:
Car Models - B. Goode JohnJJ Store - Browns JohnAmerican Souvenirs Co. - Wayne John
Select the one you are interested in or clickthe last button to see more.
SHOW MORE
Shown results from 1 to 3 of 12
Figure 4.9: The response of the chatbot to display multiple results.
44

Help and Fallback. Exhaustive responses are essential for the correct ex-
ploration of data, but we must consider also the case when the user may lack
some information to exploit the different features of the chatbots. This can
be achieved by providing help messages and buttons which briefly describe
these characteristics. For instance, at the beginning, the user may write Help,
leading to a response which describes the chatbot capabilities.
Another case may be to give support on a specific element; upon re-
ceipt of the message Tell me more about customer, for instance, the system
may present a list of examples that the user can use to access that element,
describing its Conversational Qualifiers, e.g. “find customer located in ...”.
Another help, instead, may give the user some hints to filter multiple results,
as an additional advice to shrink their size.
Moreover, even though in the previous Subsection we have seen how the
chatbot handles typos and writing inaccuracies, somehow that procedure
does not solve the problem. In these situations the system may provide an
exhaustive answer based on which concepts it was able to understand and
what is, instead, the missing information. However, in case no intent is
matched, the system may just say something like “I did not get that :( ”
4.4.4 History navigation
If you want, you can click on a button to go backin the history of the conversation.
Car Models - B. Goode John Currently you are focusing on:
...selected from:A list of type "customer" ...found with attribute(s) "with contact John".
Figure 4.10: An example of conversation history visualization.
In Subsection 4.4.2 we introduced the concept of Context and we under-
lined its fundamental role when dealing with query refinement and execution
of queries. Maintaining a record of previous actions, however, can be ex-
ploited in a different way: allowing the user to navigate backwards and reset
the Context to a past moment. This becomes very useful after the execution
of an unwanted action or when resuming a previously crossed object can be
45

more useful than repeating the requests needed to reach those items.
In order to have a descriptive history navigation, we may use buttons that
link to the objects they refer to, as well as some messages which summarize
the actions that were taken to get to them. An example of application is
described in Figure 4.10, where we can see how, in a 2-step conversation,
and how the system helps the user go back.
Another tool that could be made available is the option to move back-
wards to the previously seen objects. This is corresponds to the undo com-
mand and it could be accessed by an ad-hoc Help intent, related, for instance,
to the utterances “go back” or “undo”.
46

Chapter 5
System Architecture and
Implementation
This Chapter describes our prototype of Chatbot for Data Exploration, in
terms of architecture and implementation decisions. We will also discuss
about some tools that helped us during the development of the system.
5.1 Technologies
This Section is dedicated to the choices that we made, in terms of the adopted
technologies, to create a system able to fulfill the requirements described in
Chapter 3 and consistent with the design decisions illustrated in Chapter 4.
5.1.1 RASA
As we said in Section 2.4, there is a great variety of libraries online that
help developers create a conversational agent, each one with strengths and
disadvantages. In particular, for our system, we decided to use the tools
provided by RASA.
During the first phases of the design of our system, RASA Core was the
best choice for what concerns the dialogue management, as it offers high
customizable options and it is deployable in a local machine. However, after
the first initial tests, we decided not to use this framework and we preferred
to create an ad-hoc system and thus handle all the logic upon which the
chatbot should have based. This was due to the fact that, besides all the
features offered by this open source tool, in order to completely control the

Context of the conversation, we would have used only a small part of the
framework, unnecessarily overloading the dependencies of the system.
Instead, we took advantage and widely applied the second technology
above mentioned, i.e., RASA NLU. As explained in Section 2.4, the main
reasons to prefer this framework include the possibility to run the tool locally
and the high customizability of the training model.
Let us discuss in details, then, all the tools belonging to this framework
that we decided to apply in our system.
Training phrases in a markup language. In order to make the chatbot
understand the received messages, RASA NLU supports the definition of the
so called training data. It is a file, or a collection of files, in a markdown
or json format, in which the developer can define the intents the system
will be able to match and provide a set of example phrases related to each
one. These utterances may also contain the entities, marked according to the
format specifications, which will be used in the entity extraction phase.
The json extract in Listing 5.1 is an example of what the training data
file may contain. There, the target intent is find object by qualifier for
which an example utterance is provided: “are there customers located in
France?”. We can also see how the entities are listed in the corresponding
json field, each related to the represented value.
Define and train the Machine Learning NLU model. The training
data described above is used as input to train the NLU model, i.e., the
structure that will guide the intent matching and entity extraction procedures
during the conversation. RASA NLU gives the possibility to choose these
components in order to find the best solution for each problem, or even to
define an ad-hoc one if some additional property is needed.
These components are executed one after another at each incoming mes-
sage, in a so-called processing pipeline, and they may be needed for entity ex-
traction, for intent classification, pre-processing, and other purposes. RASA
NLU also provides some templates, that are pre-configured lists of compo-
nents, among which two of them are the most used:
• spacy sklearn1, which uses pre-trained word vectors from either GloVe2
1https://rasa.com/docs/nlu/components/#intent-classifier-sklearn2https://nlp.stanford.edu/projects/glove/
48

{
"text": "are there customers located in France?",
"intent ": "find_object_by_qualifier",
"entities ": [
{
"end": 19,
"entity ": "object",
"start ": 10,
"value ": "customers"
},
{
"end": 30,
"entity ": "qualifier",
"start ": 20,
"value ": "located in"
},
{
"end": 37,
"entity ": "word",
"start ": 31,
"value ": "France"
}
]
}
Listing 5.1: A json extract of the training data.
49

or fastText3 and it is specific for each language chosen for the chatbot;
• tensorflow embedding4, that does not use any pre-trained word vec-
tors, but instead fits these specifically for the dataset in input.
Since the objective of our investigation is to create a system able to
interact with a domain-specific dataset, designed for the information stored
in the target database, we preferred to use the tensorflow embedding
pipeline. Its components are:
1) tokenizer whitespace, which creates a token for every whitespace
separated character sequence;
2) ner crf, that implements conditional random fields to do named entity
recognition;
3) ner synonyms, which maps synonymous entity values to the same
value;
4) intent featurizer count vectors, that creates bag-of-words repre-
sentation of intent features, needed for the next component;
5) intent classifier tensorflow embedding, needed to embed user in-
puts and intent labels into the same space.
Dynamic intent matching and entity extraction. As we discussed
in the previous chapter, defining and training an NLU model is needed to
perform intent matching and entity extraction. When the system receives
an input message, this one traverses all the components of the pipeline and
a particular object is returned, which specifies what the NLU unit actually
understood of the received message.
Let us consider a trained NLU model in which the input training data in-
cludes the json excerpt described in Listing 5.1. If the model is well defined,
after receiving the phrase “Find customers located in Italy”, for instance,
it should be able to output an object having find object by qualifier as
intent and a correct mapping of the entities, i.e. object→ customers, qual-
ifier → located in, word → Italy.
3https://fasttext.cc/4https://rasa.com/docs/nlu/components/#intent-classifier-tensorflow-embedding
50

%[ find_object_by_qualifier ](’training ’: ’5’)
~[find] @[object] @[qualifier] @[word]
~[find]
find
search
look for
@[object]
customer
client
@[qualifier]
located in
@[word]
France
Italy
England
Listing 5.2: An example of input document for Chatito.
5.1.2 Chatito
Chatito5 is an open-source tool which helps generating datasets for training
and validating chatbot models using a minimalistic Domain-Specific Lan-
guage. It allows the definition of a document in which the developer can
specify grammar rules for each intent, as well as the entity keywords with
the related possible examples.
Listing 5.2 shows an example of the content of this file, in which the target
intent is find element by qualifier.
Giving this document as input to the Chatito framework, the latter gen-
erates five utterances, as requested in the training field, by following the
requested specifications. For example, it may output the following phrases
(here represented without the entities notation, which instead is present):
• look for customer located in Italy
• find customer located in France
• find customer located in England
• search client located in Italy
• find customer located in France
5https://github.com/rodrigopivi/Chatito
51

We decided to include Chatito in the design process of our chatbot, in
order to generate the training data starting from the Schema Annotation.
Besides the fundamental feature of creating large datasets of domain specific
utterances, it was convenient to use the framework for two reasons:
1) It gives the possibility to get the output in a format compatible with
RASA NLU training data specifications;
2) It can be installed and run locally.
5.1.3 Telegram
For what concerns the chat interface, we decided not to create an ad-hoc
system, but we preferred to take advantage of the Telegram Bot API6. In
particular, we logged in the Telegram messaging platform and we contacted
the BotFather7 account, which guided us throughout the few steps towards
the creation of our chatbot interface, that we named DataExplorerBot.
After receiving the authorization key, we managed to connect with our
Bot through the dedicated API; this way, we could receive and send mes-
sages to the users that were interacting with DataExplorerBot directly over
Telegram.
We decided to use this messaging platform, among the others introduced
in Subsection 2.3.2, because of its ease of use and set up. Moreover, Telegram
enables the developers to create custom buttons, besides the possibility to
completely manage the textual conversation with its user, so we decided to
take advantage also of this functionality.
However, as we will discuss in the next Sections, we chose not to bound
the internal management of the conversation to the Telegram API format
specifications, but we preferred to implement an adapter module in charge
of translating the messages for the messaging platform. This way, we could
achieve a good level of scalability, in terms of integration with other chat
interfaces.
6https://core.telegram.org/bots/api7https://telegram.me/botfather
52

5.2 Framework Architecture
Our architecture is based on the three-tier model, which ensures high scal-
ability and provides modularization of the different technologies based on
their application in the system. The tiers, or layers, include: a Data tier, an
Application tier and a Presentation tier. In order to describe their role
and their interactions within the global the architecture, we will refer to the
Figure 5.1 which presents an overview of the system.
Chatbot Architecture
Conversationmanagers
Resources
Applicationmanagers
Databaseconnectors
Chatinterface
Chatinterface
Chatinterface
NLU managers
Database
Presentation Tier Application Tier Data Tier
Figure 5.1: An overview of the Framework Architecture, based on the three-tier model.
Data tier. This layer includes the database where the information is stored
and retrieved, according to the requests made through the system. It may
contain any kind of data, completely unrelated with the chatbot foundations.
However, the structure and hierarchy of these records will be used by the
Designer to create the Schema Annotation and by the system itself to present
their values, as described in Section 4.2 and Section 4.4, respectively.
Our solution does not rely on the database to store the internal resources
of the system, because of the small size of such elements in our applications,
but the system may take advantage of another persistent data storage for
this usage. This option may help to reduce the computational load on the
application side, but might introduce unwanted latencies to use these infor-
mation during the conversation. A feasible alternative could be to place some
of these files in the data system, while maintaining the most used ones at the
application side, but we will discuss about this in the next Subsection.
53

One final comment: the database server may be placed in the same ma-
chine of the logic environment of the system or it could stay on a remote
computing apparatus. Again, this choice impacts on the scalability, on one
side, and on the performance of the overall architecture on the other. In any
case, this hardware based decision must be made considering the maximum
size of the target data storage as well as the number of final users.
Application tier. This layer represents the core of the system and includes
the modules needed in both the design process and the conversation execu-
tion. As Figure 5.1 shows, it includes five interconnected modules in it. We
will describe their internals in details in the next Subsection. For the moment
let us pose our attention on the arrows that exit from the external module:
they represent the communication channels with the modules of the other
two layers. Inside the system, the modules that handle these connections
are the Database connectors and the Conversation managers, which
are responsible for the interaction with the data and the presentation layer,
respectively. These two components must be designed with the purpose of al-
lowing both remote and local connections, in accordance to the architectural
choices regarding the setting of the three tiers.
Moreover, always referring to the same Figure, we can appreciate the het-
erogeneous shape of the different modules. In the next Subsection, we will
describe in details their properties and roles inside the architecture, high-
lighting their differences and justifying the choice to represent them in a
varied graphical format.
Presentation tier. In our system, we decided to take advantage of exist-
ing external interfaces for what concerns the front-end of our architecture. In
fact, as we already mentioned in Chapter 2, there is a great number of online
messaging platforms which already integrate the possibility to create a chat-
bot in their framework and then control its logical behavior by means of an
API. This is exactly the direction that guided our design choices when dealing
with this part of the architecture and it enabled to have a nice-looking and
easy-to-use interface just by setting up the right connector to communicate
with the external API.
However, creating an ad-hoc chat environment, for example in a Website
or even locally where the application runs, remains possible but it may need
the introduction of another connector inside the system or a definition of a
54

dedicated API.
Moreover, we can see from the same Figure 5.1 that the geometric shapes
representing these chat interfaces have a logo sticked on them, each different.
They stand for Facebook Messenger, Slack and Telegram, and suggest how
the system may support different technologies belonging to the presentation
tier, contributing to the scalability and extensibility of the overall architec-
ture.
5.3 Chatbot Architecture
In this section we discuss about the architectural choices that lead to the
definition of the actual internal structure of the chatbot. In order to make
the description as clear as possible, we will refer to Figure 5.2 which shows
how each module is organized inside.
Chatbot Architecture
Conversation managers
Application managers
Database connectors
NLU managers ResourcesNLU managers
Patterns
NLU model
NLU data - element+attr+attr
- attr+element
## intent
Schema
Annotation
element
Schema
NLU library
Trainer
Writer
Extractor
Phrasegenerator
library
Resolver Broker Parser
Database connector libraryCaller Actions Utils
Messages Buttons
Connectors library
Contextmanager
Connectors
Figure 5.2: The Chatbot Architecture in details.
Conversation managers. This module is responsible for the receipt and
dispatch of the messages sent by the end-user. Here, we can distinguish the
55

Connectors component, in charge of communicating with the external chat
interfaces and the Patterns block. The latter is composed by the Messages
and the Buttons elements, which provide the responses as simple text or as
dynamic buttons.
Application managers. It is the core module of the system, as it contains
all the logical components needed to compute a response upon the receipt
of a message. Here we can find the Caller unit, which retrieves the Context
by interacting with the Context manager and calls the right method of the
Actions module. The relation between the message received and the action
to call is made clear thanks to the Extractor, a component belonging to the
NLU managers, which translates the utterances into an intent and a set of
entities. These two elements, as well as the Context, represent the arguments
of the method that gets finally invoked.
Moreover, the Caller is responsible of concurrency, as it creates a new
thread in charge of handling the new request until the response is sent. This
allows the system to manage more connections at a time, each with its own
Context and session state.
Inside the Actions module, instead, the engine of the chatbot lies: here
the actions define different execution paths, based on: the entities extracted,
the actual conversation Context, the query results and in general all the
parameters defined during the design process. The Utils unit is then needed
to leverage the load and complexity of the Actions module, as it contains
simple helper methods.
NLU managers. This unit contains all the needed components of the
chatbot Natural Language Understanding sections, as well as the libraries
to support these technologies. Since the system supports both the design
and the usage of the conversation, the items in this group play different roles
depending on two execution moments.
The Writer module is needed to translate the Schema Annotation made
by the Designer into the NLU data, both contained in the Resources group,
as can be seen by Figure 5.2; this is done by means of the Phrase generator
library, whose implementation details are described in Section 4.3.
Instead, the Trainer unit is needed to create a model able to support the
intent matching and entity extraction phases of the final conversation and it
uses the features provided by the NLU library. The input of this procedure
56

are the generated phrases contained in the NLU data component, while the
output is the NLU model ; they are both visible in the Resources section.
The Extractor component is used during the conversation phase and it
is needed to analyze the utterances received and execute the procedures of
intent matching and entity-extraction.
Database connectors. As the name suggests, this unit includes the com-
ponents needed to interact with the database system. This justifies the pres-
ence of the Database connector library, which provides all the methods and
drivers to communicate with the DBMS.
The Parser component plays a fundamental, but relatively “short”, role
in the design process of the chatbot, as it is needed only in the first part:
it analyzes the database and extracts a simplified version of its structure,
creating the Schema resource.
The Resolver functions, instead, are invoked by the Actions component
in order to execute the queries on the database starting from the intent
and the entities. However, this module does not interact directly with the
database, but it is needed to extract from the Schema Annotation resource
the information about the tables upon which the final query will be executed.
The task of building the query is left to the third unit, that is the Bro-
ker. This construction phase is made based on the Schema Annotation and
the Schema files, needed to correctly parametrize the resulting command
prototype. The query, then, is directly executed on the database system.
Resources. We already described how the elements inside this group are
used and we discussed the alternatives to place some or all of them in a
persistent storage.
The NLU model and NLU data are files used by the Natural Language
Understanding control part, while the Schema document is a simplified rep-
resentation of the database.
The Schema Annotation resource, instead, represents the output of the
modeling phase and it is the main supporting document of both the genera-
tion and execution phases of the chatbot.
The files are both saved in a json format, for which an extract of their
content can be seen in Listing 5.3 and Listing 5.4, respectively.
57

{
"customers ": {
"column_list ": [
"customerNumber",
"customerName",
"contactLastName", "contactFirstName",
"phone",
"addressLine1", "addressLine2",
"city",
"state", "postalCode", "country",
"salesRepEmployeeNumber",
"creditLimit"
],
"primary_key_list ": [" customerNumber "],
"references ": {
"employees ": {
"foreign_key_list ": [" salesRepEmployeeNumber "],
"reference_key_list ": [" employeeNumber "]
}
}
},
...
}
Listing 5.3: A json extract of the simplified database.
5.4 Implementation Tools
The majority of the scripts to design the logic of the application are in Python
and we used Python 3.7 as Interpreter, taking advantage of some modules
belonging to the Python standard library.
To parse the database we used the sqlparse module, along with mysql-
connector to execute queries on the database which we decided to run locally
in a MySQL v5.7.16 server.
We used the rasa nlu Python module along with the tensorflow and
sklearn crfsuite libraries, for the Natural Language Understanding tools.
The Python unit nltk is used for the computation of the edit distance to
perform typo resolution. For the phrase generation part we used Chatito8
which freely available online and needs Node.js.
To interface the system with the Telegram API we used telepot, a
Python library which helps simplifies the execution of the remote requests to
the messaging platform.
8https://github.com/rodrigopivi/Chatito
58

As we already mentioned, the resources are saved in a json format. The
Appendix B reports an example of the Schema Annotation for the classic-
models9 database. The parsed schema of the same database is reported in
Appendix A.
[
{
"object_name ":" customer",
"aliases ": [" customers", "client", "clients"],
"type": "primary",
"table_name ": "customers",
"display_attributes ":[
{
"keyword ": "",
"columns ": [" customerName "]
}
],
"qualifiers ": [
{
"keyword ": "located in",
"type": "word",
"columns ": ["city", "state", "country "]
},
...
]
"relations ": [
{
"keyword ": "payments made",
"object_name ": "payment",
"by": [
{
"from_table_name ": "customers",
"from_columns ": [" customerNumber "],
"to_table_name ": "payments",
"to_columns ": [" customerNumber "]
}
]
},
...
]
},
...
]
Listing 5.4: A json extract of the database Schema Annotation.
9http://www.mysqltutorial.org/mysql-sample-database.aspx
59

60

Chapter 6
User Study
6.1 Comparative Study: General Setting and
Research Questions
We carried out an experimental study to understand to which extent the
chatbots generated through our design framework would support users in
accessing and exploring the content of a database. We considered a sample
database referring to a company’s customers (very similar to the example
database used throughout the previous chapters). The database schema is
reported in Figure 6.1.
On top of the customer database we developed a chatbot following the
modeling methodology described in Chapter 4. This means that through
the chatbot some tables were directly (primary tables) or indirectly (sec-
ondary tables) accessible by means of natural language requests. Other tables
(crossing relationships) would not be “visible” but they would be anyway ex-
ploited to provide links to navigate across the tables they put in relationship.
Through the study we then compared the performance and the satisfaction
of database experts when querying the database with two paradigms: the
DataExplorer chatbot, enabling natural language queries, and the SQL com-
mand line supporting SQL queries on top of the same database. Through
the comparison we wanted to identify pros and cons of using the DataEx-
plorer chatbot for exploring and retrieving data. More in general, we aimed
to identify guidelines for the design of chatbots for data exploration.
The choice to involve database experts is due to our intention to assess
whether, despite some intrinsic limitations and simplifications (e.g., making

customers
customerNumberPK
customerNameNN
contactLastNameNN
contactFirstNameNN
phoneNN
addressLine1NN
addressLine2
cityNN
state
postalCode
countryNN
salesRepEmployeeNumberFK
creditLimit
payments
customerNumberPK, FK
checkNumberPK
paymentDateNN
amountNN
orderdetails
orderNumberPK,FK1
productCodePK,FK2
quantityOrderedNN
priceEachNN
orderLineNumberNN
orders
orderNumberPK
orderDateNN
requiredDateNN
shippedDate
statusNN
comments
customerNumberFK, NN
products
productCodePK
productNameNN
productLineFK, NN
productScaleNN
productVendorNN
productDescriptionNN
quantityInStockNN
buyPriceNN
MSRPNN
employees
employeeNumberPK
lastNameNN
firstNameNN
extensionNN
emailNN
officeCodeFK, NN
reportsToFK
jobTitleNNoffices
officeCodePK
cityNN
phoneNN
addressLine1NN
addressLine2
cityNN
state
countryNN
postalCodeNN
territoryNN
productlines
productLinePK, FK
textDescription
htmlDescription
image
Figure 6.1: The classicmodels database schema used in the evaluation tests.
62

some tables not visible) deriving from the conversation design, the chatbot
query paradigm would enable users to explore data with performance and
satisfaction comparable to the ones achieved through the SQL language. We
also wanted to understand to which extent experts in database would find
the conversational paradigm interesting and useful.
It is worth remarking that the goal of our research is not to define a new
query language with the same expressive power as SQL; rather, we aim to
identify abstractions for the generation of conversations for data exploration.
For its nature, the SQL language is much more expressive of the chatbot
language. We anyway selected the SQL command line as a rich baseline
that would allow us to gather indications on how to improve the conversa-
tion design and make the resulting conversation paradigm useful for data
exploration.
We identified some tasks that could be tackled with both the systems.
To accomplish them, the participants would be allowed to access and query
directly all the database tables when using the SQL command line; when
using the chatbot they would have a direct visibility on primary and sec-
ondary tables, while they would exploit crossing relationships tables only in
an indirect way, i.e., in form of links to navigate to the tables they put in
relationship.
The research question driving the study was:
What is the difference between the considered systems in terms of the us-
ability of the paradigm for exploring the database content and retrieving
specific information?
6.2 Participants and Design
We recruited 15 participants (2 females, 13 males) among the students of
the Master Degree in Computer Engineering at Politecnico di Milano. Their
mean age was 24.86 years (SD = 2.28, min = 23, max = 32). As resulting
from the demographic questionnaire that they filled in at the beginning of
the study, participants had an excellent experience in IT ( x = 8.07, SD =
0.61, min = 7, max = 9), a good experience in using chatbots (x = 5.92,
SD = 0.99, min = 5, max = 8), and an excellent experience in using SQL
language (x = 7.42, SD = 0.94, min = 5, max = 9). The Likert scales used
63

to assess such skills ranged from 1 to 10 (1 very low - 10 very high).
The controlled experiment adopted a within-subject design, with the sys-
tem as an independent variable and two within-subject factors, i.e., chatbot
and SQL. Each participant used the two systems in sequence. In order to
minimize learning effects [14], based on the Latin-Square design they used the
system in a different order by considering permutations of the two systems
and of the experimental tasks.
6.3 Tasks
With each system, the participants performed 6 tasks that can be classified
in three types:
• Type 1 consisted in understanding the structure of the database and
the content it stores. It included 2 tasks, purposely defined to verify
to which extent users were able to understand which information could
be accessed.
• Type 2 included 2 tasks to verify if the participants were able to identify
specific data items through selection and filtering.
• Type 3 asked the participants to retrieve specific data items by means
of joins. It included 2 tasks asking the users to navigate the database
through the available relationships.
Some tasks were split in 2 or 3 parts, in order to make clearer the objective
of the user activity. With reference to the database reported in Figure 6.1,
the final task list was:
• Task 1 (Type 1 ):
a) Try to understand what are the tables that
compose the database
b) Try to understand what are the attributes
more relevant for each one of the previous
tables
• Task 2 (Type 1 ): Try to understand how the different tables are related
to each other.
• Task 3 (Type 2 ): Select the customers (the name) that have, as con-
tact, a person whose name is Diego.
64

• Task 4 (Type 2 ):
a) Try to select the customers (the name) that
are placed in Australia.
b) How many of them did you find?
c) Now find (the name) the one whose contact
person is named after Peter.
• Task 5 (Type 3 ):
a) Try to find in which city the sales represen-
tative of the client Euro+ Shopping Channel
has the office
b) Is it the same of the one where this customer
is located?
• Task 6 (Type 3 ): Find the payments (for each, the amount of money)
of the clients that paid more than 110000 Euro.
For each task, users had a maximum time of 4 minutes (240 seconds). In
accordance with the within-subjects design, each participant performed 12
tasks that required executing a total of 170 queries.
6.4 Procedure
The study took place in a quiet university room where the study apparatus
was installed. Two HCI researchers were involved: one acted as an observer,
the other as a facilitator. Two laptops with a 15-inch display provided with
an external mouse were available. The study lasted 1 day. Each study session
involved two participants and followed the same procedure. First, a 5-minute
presentation was given by the facilitator to introduce the participants to the
goal of the study and what they had to do. Then, participants were asked to
sign a consent form for video-audio recordings and photo shoots, and to fill
in the questionnaire for collecting demographic data and their competences
on IT in general and on chatbot and database in particular. The facilitator
introduced the systems to be used demonstrating how to perform queries on
a sample database different from the one the participants should refer to.
Then every single participant was invited to perform the experimental tasks.
The participant read aloud the task text and then started it.
At the end of all the experimental tasks with each system, the participant
filled in an online questionnaire about the system used. Then, another online
65

questionnaire was administered at the end of the session. It asked to rank
the two systems on the basis of their usefulness, completeness, and ease
of use, and to choose which system the participants would like to use in
their activities. The procedure was preliminarily assessed by a pilot study
involving two further participants.
6.5 Data Collection
The ISO 9241-11 [19] standard defines usability as “the extent to which a
product can be used by specified users to achieve specified goals with effective-
ness, efficiency and satisfaction in a specified context of use”. The ISO/IEC
9126-4 [20] recommends that usability metrics should focus on:
• Effectiveness : The accuracy and completeness with which users achieve
specified goals.
• Efficiency : The resources expended in relation to the accuracy and
completeness with which users achieve goals.
• Satisfaction: The comfort and acceptability of use.
Both qualitative and quantitative data were collected to analyze these
metrics on two systems. We considered the set of notes taken by the ob-
server during the task execution, the video recorded during the different
study sessions, the questionnaire answers, the free comments participants
provided during the study. Regarding qualitative analysis, two researchers
transcribed the audio/video recordings, the observer’s notes, and the ques-
tionnaire open questions. A thematic analysis was carried out on these data.
Then, the two researchers independently double-checked the results. The ini-
tial reliability value was 91%, thus the researchers discussed the differences
and reached a full agreement [6]. The researchers built an excel file reporting
for each query performed by each user the following data: user ID (from 1
to 15), type of system (SQL, Chatbot) task ID (T1 - T6), time (in seconds),
task success (success - partial success - failure), and significant comments.
Time has been considered to analyze efficiency, while task success was used
to analyze effectiveness.
Regarding user satisfaction, two online questionnaires were administered
during the study. The first questionnaire, organized in 4 sections, was used
to evaluate each system. The first section included the System Usability
66

Score (SUS) [7], which gives an overview of the user’s subjective usability
evaluation of a given system. It is a closed-ended questionnaire encompassing
10 statements on an ordinal 5-point Likert scale from “strongly disagree” to
“strongly agree”. This questionnaire was chosen for its reliability, brevity
and wide adoption [4].
The second section included the NASA-TLX questionnaire, used as “Raw
TLX” (Hart, 2006). It is a 6-item survey that rates perceived workload in
using a system through 6 subjective dimensions, i.e., mental demand, physical
demand, temporal demand, performance, effort, and frustration, which are
rated within a 100-points range with 5-point steps (lower is better). These
ratings were combined to calculate the overall NASA-TLX workload index
[16].
The third section had four questions about:
1) The easiness of exploring and understand the database content, related
to Type 1 tasks,
2) The easiness of retrieving specific data items, related to Type 2 and
Type 3 tasks,
3) The easiness of the commands to be used, and
4) The quality of the presentation of query results.
Likert scales ranging from 1 to 10 (1 very low - 10 very high) were used
for these questions. This section ended with three open questions on the
advantages and disadvantages of the system and on possible suggestions to
improve the systems.
The second questionnaire was administered at the end of each partici-
pant’s session. It asked to rank the systems based on their utility, complete-
ness and ease of use (from 1 to 2, 1 is the best), and to explain the reasons
for the expressed order. Paired-samples t-test was adopted to analyses SUS,
NASA-TLX results and task time. Wilcoxon signed-rank test was used to
analyze task success rate and system ranking.
6.6 Usability Analysis
In order to answer the research question, namely, if there is any difference
in terms of usability in exploring information, we analyzed the user’s per-
formances following the three usability metrics, i.e., effectiveness, efficiency
67

and satisfaction. In the following, we report details about how we measured,
analyzed and compared these metrics.
6.6.1 Efficiency
System efficiency was analyzed by considering the time participants spent
in executing tasks with the two systems (Chatbot x = 107.48, SD = 79.31;
SQL x = 117.57, SD = 78.93). The paired-samples t-test test does not
highlighted any significant difference among these systems (t(1110) = −.968,
p = .335).
A deeper analysis was carried out focusing on the time the users spent
on each task. Table 6.1 summarizes the user performances for each task and
the results of the paired sample t-test. It is clear that no tasks revealed
significant differences since their p-value is always greater than 0.05.
For Task 2, the table does not report the results of the t-test as all the
users took the maximum time (240 seconds), thus the comparison was not
significant. Task 2 indeed did not require the users to output some detailed
answers; rather it required an extensive exploration of the database aimed to
identify the relationships among the different tables. When using the SQL
command line, 3 out of 15 users were able to identify all the relationships,
11 users partially identified the relationships (x ≥ 2) and only 1 completely
failed. With the chatbot, 9 users partially identified the relationships that
were visible, while the other 6 failed. The task, however, was useful to observe
the strategies adopted by the users to explore the database content through
the available commands (see Section 6.2).
6.6.2 Effectiveness
System effectiveness was analyzed by calculating the success rate. This mea-
sure is typically adopted to evaluate how the systems support the completion
of a task. In our study, each query executed by the participants was coded as
“Success” if the task was completely executed, “Partial” if the participant
was able to come out with partial results, and “Failure” if the participant
task execution was wrong. The success rate can be calculated as the per-
centage of users who were able to successfully complete the tasks. The task
success rate for each user has been calculated as:
68

Chatbot SQL Paired sample t-test
Task x SD x SD df t Sig. (2-tailed)
1a 91.78 70.33 68.28 25.02 13 1.378 .192
1b 178.10 27.20 169.40 21.16 9 .687 .509
2 240 0 240 0
3 107.07 57.70 86.71 50.40 13 .971 .349
4a 94.93 42.11 112.06 46.41 14 -1.704 .111
4b 4.73 1.16 11.60 13.64 14 -1.916 .076
4c 82.12 30.05 62.12 26.67 7 1.639 .145
5a 201.00 20.08 216.60 25.65 4 -.807 .465
5b 30.50 14.84 24.50 28.99 1 .194 .878
6 155.70 68.78 165.40 49.55 9 -.285 .782
Table 6.1: Paired Sample t-test results related to the time the users spent on each
task.
successRate =#successfulTasks + (#partialSuccessfulTasks/2)
#tasks× 100
The global success rate for each system is then calculated as the average
success rate of all the users. According to this formula, the systems success
rates are:
successRatechatbot =65 + (46/2)
150= 58.6%
successRateSQL =80 + (34/2)
150= 64.66%
Success rates resulted quite balanced between Chatbot and the SQL com-
mand line, also the Wilcoxon signed-rank test did not reveal any significant
difference (Z = −1.257, p = .209). Table 6.2 reports the detail on the com-
pletion of each task; Figure 6.2 shows the comparison for the two systems of
the number of successes for each task.
6.7 Satisfaction
Users satisfaction was analyzed by considering different dimensions measured
through SUS and NASA-TLX questionnaires, as well as specific Likert-based
questions. In the following, we report on the results of all the satisfaction
dimensions.
69

Chatbot SQL
Partial Partial
Task Failure Success Success Failure Success Success
1a 1 13 1 0 1 14
1b 5 8 2 2 7 6
2 6 9 0 1 11 3
3 1 4 10 0 0 15
4a 0 0 15 0 0 15
4b 0 0 15 0 0 15
4c 3 0 12 7 1 7
5a 9 3 3 10 2 3
5b 9 0 6 13 0 2
6 5 9 1 3 12 0
Table 6.2: Detail on the completion of each task: Failures, Partial success, Success
6.7.1 Usability
SUS analysis revealed different scores about the perceived usability of the two
systems (Chatbot x = 66.3, SD = 14.4; SQL x = 55.7, SD = 16.7). The
Chatbot result is in line with the average SUS scores (69.5) of one thousand
studies reported in [3], while the SQL score was quite lower. However, t-test
highlighted that the SUS scores difference between the two systems is not
statistically significant (t(14) = 1.994, p = .066).
In addition, according to [24], we split the overall SUS score into two
factors, i.e., System Learnability (considering statements #4 and #10) and
System Usability (all the other statements). The Chatbot Learnability score
was 63.0 (SD = 22.8) while SQL Learnability score was 62.5 (SD = 32.1).
However, t-test highlighted that the Learnability score difference is not sta-
tistically significant (t(14) = .280, p = .783). Regarding SUS Usabil-
ity, the Chatbot score was 65.10 (SD = 16.7) while SQL score was 51.25
(SD = 19.8). Even in this case, t-test highlighted that the difference be-
tween these scores is not statistically significant (t(14) = 1.968, p = .069).
Besides providing an objective indication about the usability and learn-
ability of the tested systems, SUS results can be used as benchmarks in the
comparison of further approaches to explore databases.
70
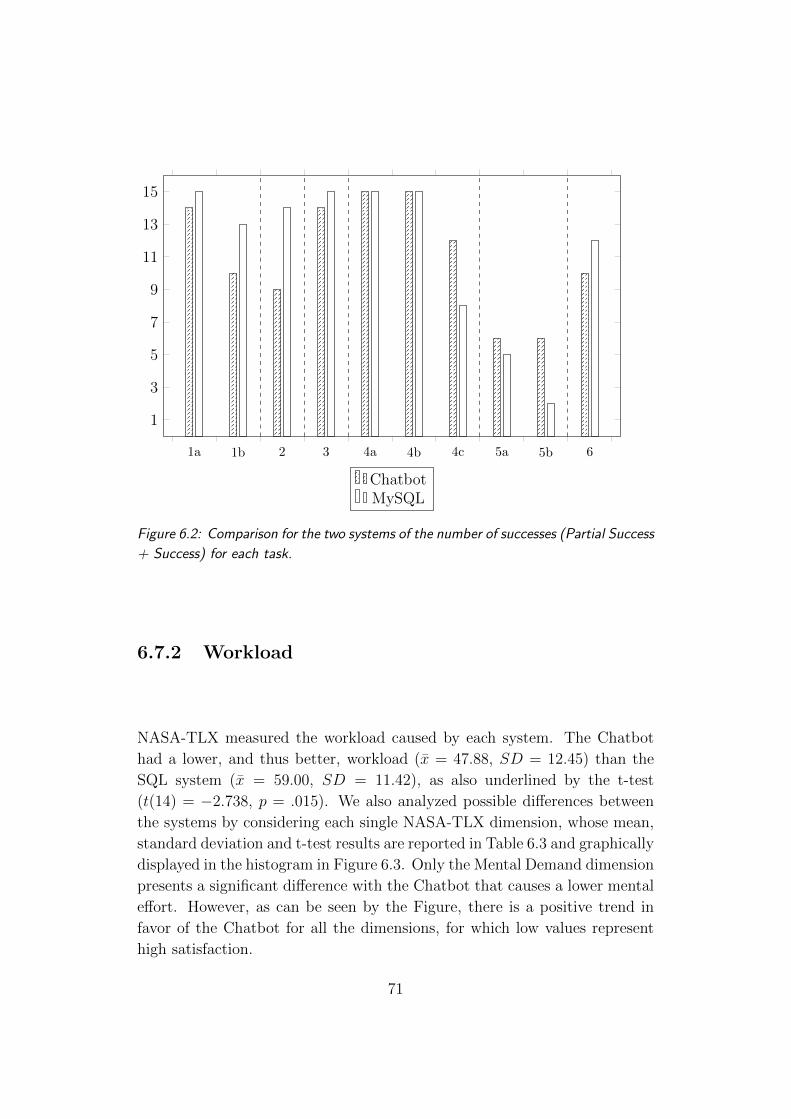
1a 1b 2 3 4a 4b 4c 5a 5b 6
1
3
5
7
9
11
13
15
ChatbotMySQL
Figure 6.2: Comparison for the two systems of the number of successes (Partial Success
+ Success) for each task.
6.7.2 Workload
NASA-TLX measured the workload caused by each system. The Chatbot
had a lower, and thus better, workload (x = 47.88, SD = 12.45) than the
SQL system (x = 59.00, SD = 11.42), as also underlined by the t-test
(t(14) = −2.738, p = .015). We also analyzed possible differences between
the systems by considering each single NASA-TLX dimension, whose mean,
standard deviation and t-test results are reported in Table 6.3 and graphically
displayed in the histogram in Figure 6.3. Only the Mental Demand dimension
presents a significant difference with the Chatbot that causes a lower mental
effort. However, as can be seen by the Figure, there is a positive trend in
favor of the Chatbot for all the dimensions, for which low values represent
high satisfaction.
71

Chatbot SQL Paired sample t-test
Dimension x SD x SD df t Sig. (2-tailed)
Effort 58.66 25.31 69.33 14.86 14 1.621 .127
Frustration 46.66 22.88 57.33 24.92 14 1.204 .249
Mental Demand 49.33 14.86 60.66 13.87 14 3.238 .006
Physical Demand 30.00 15.58 47.33 24.92 14 1.992 .066
Temporal Demand 58.00 23.36 73.33 16.32 14 1.982 .068
Performance 44.66 15.97 46.00 15.94 14 .235 .818
Table 6.3: NASA-TLX dimensions values. Only the Mental Demand dimension
presents a significant difference with the Chatbot that causes a lower mental effort.
6.7.3 Easiness of exploring DB/retrieving data/using
commands and quality of presentation
Participants were asked to answer ad-hoc questions about the: (i) easiness of
exploring and understanding the database content, related to Type 1 tasks,
(ii) easiness of retrieving specific data items, related to Type 2 and Type 3
tasks, (iii) the easiness of the commands to be used, and (iv) the quality of
the presentation of query results.
Regarding the easiness of exploring and understand the database content,
related to Type 1 tasks, Chatbot obtained an average score of 6.13 (SD = 2.5),
while SQL obtained 5.33 (SD = 2.46). However, the t-test does not reveal a
significant difference (t(14) = .893, p = .387).
About the easiness of retrieving specific data items, related to Type 2 and
Type 3 tasks, Chatbot obtained an average score of 7.26 (SD = 2.3), while
SQL obtained 5.53 (SD = 1.72). This difference is statistically significant in
favor of Chatbot, as shown by the t-test (t(14) = 2.179, p = .047).
Concerning the easiness of the commands to be used, Chatbot obtained
an average score of 7.60 (SD = 1.29), while SQL obtained 6.27 (SD = 1.90).
Even in this case, this difference is statistically significant in favor of Chatbot,
as shown by the t-test (t(14) = 2.467, p = .027).
Lastly, about the quality of the presentation of query results, Chatbot
obtained an average score of 6.93 (SD = 1.79), while SQL obtained 5.53
(SD = 2.23). T-test has shown that this difference is statistically significant
in favor of Chatbot (t(14) = 2.365, p = .033).
72

Effort Frustration Mental
Demand
Physical
Demand
Temporal
Demand
Performance0
20
40
60
80
100
ChatbotMySQL
Figure 6.3: NASA-TLX dimensions: means and standard deviation comparison. Low
values represent high satisfaction.
6.7.4 User ranking of systems along completeness, eas-
iness and usefulness
The questionnaire administered at the end of each participant’s session asked
to rank the two systems based on their utility, completeness and ease of use
(from 1 to 2, 1 is the best). Regarding utility, Chatbot obtained an average
rank of 1.35 (SD = .49) while SQL a rank of 1.64 (SD = .49), but Wilcoxon
test highlights that this difference is not statistically significant (Z = −1.069,
p = .285).
In case of completeness, Chatbot obtained an average rank of 1.85 (SD =
.36) while SQL a rank of 1.14 (SD = .36), which was significantly better, as
demonstrated by the Wilcoxon test (Z = −2.673, p = .008).
Finally, about usefulness, Chatbot obtained an average rank of 1.28 (SD =
.47) while SQL a rank of 1.71 (SD = .47), but no significant difference was
found by the Wilcoxon test (Z = −1.604, p = .109).
73

6.8 Qualitative Data Analysis
The participants appreciated the chatbot because it is simple to use and
allow them to use “natural terms” that are “intuitive” and “easy to remem-
ber” without needing to know a specific language. This was also confirmed
by the quantitative analysis of the usability score and of the Mental Demand
dimension of the NASA-TLX questionnaire. Some of them appreciated the
possibility to navigate through the history of commands - this is a very pos-
itive aspect that recognizes one of the main advantages that the interactive
paradigm of chatbots can have with respect to using formal query languages
[22]. As a further advantage they recognized the possibility to “rapidly find
information without knowing the database structure”.
The most severe problem of the chatbot relates to the difficulty to specify
complex queries, for example the ones based on multiple joins. This is specif-
ically due to the explorative nature of the chatbot, which mainly provides
commands to discover the available data progressively navigating through
the available tables. However, apparently they were not able to identify this
peculiarity, as with the chatbot they tried to formulate SQL-like queries.
One participant said that “it was difficult to translate SQL commands into
messages for the chatbot”. However, the same participant highlighted that
“perhaps this difficulty arises only for database experts”.
In general, the majority of participants felt constrained by the chatbot
commands, as they could not specify the same queries they would execute
with the SQL command line. This is in line with what emerged from the
quantitative analysis of the completeness, as reported in Subsection 6.7.4.
They however pointed out that the chatbot conversational paradigm could
be very useful in situations where “one would need to execute simple queries
(for which knowing in details the structure of the database is not needed),
that must be executed rapidly, frequently, with few variations”.
In the comparison between the two systems, the majority of participants
found that the chatbot is more useful than SQL, as it can be easily used also
by people without any experience with databases. Regarding its utility some
of them observed that it can be useful for people with technical expertise,
who however do not work with databases frequently. In this situation, they
would not be required to struggle with the SQL syntax, as the bot can be
queried with intuitive command, and they would be productive in the short
time. With similar motivations, thy also expressed that the chatbot is easier
74

to use, although some of them also recognized that for people who know SQL
the SQL command line is easy as well.
Overall the majority of participants said that they would use SQL more
than the chatbot. The main motivation behind this choice relates to the
completeness of the SQL language, which gives them a greater awareness of
the available data and of the operations that they can perform (“It is easy
to have an overview of the available tables and of their content”; “I can find
any information I need with one unique query”).
6.9 Lesson Learned
This experimental study allowed us to find out whether the Chatbot could
represent a valid alternative to the basic SQL command line, which is a
typical form of interaction with a database system. In relation to our re-
search question, we did not find any significant difference in the effectiveness
and efficiency of the two systems, while the analysis highlighted significant
differences in favor of the Chatbot system for some satisfaction dimensions.
These results are positive: the lack of significant differences for the two
systems for almost all the considered dimensions shows that the users appre-
ciated the Chatbot even though, as database experts, they found the SQL
command line more complete. Moreover, the analysis highlighted a clear
preference for some aspects of the Chatbot:
• The easiness of retrieving specific data items ;
• The easiness of the commands to be used ;
• The quality of the presentation of query results.
We believe these aspects are the ones that more characterize the chatbot
paradigm; therefore, these results are encouraging in relation to our idea to
promote Chatbot for Data Exploration.
In the following we report some conclusions that we drew by considering
the qualitative analysis of the gathered data and what we observed during
the task execution by users.
More significant help messages. By observing the message exchanges,
we saw that the first user messages were mainly intended to receive help
on the capabilities of the chatbot. As we have discussed in Section 4.3,
75

our framework generates a conversational agent able to support assistance
requests, which correspond to general or more element-specific answers to
the user.
A possible improvement of the application may include the extension of
these kind of help responses, by giving extended explanations related to the
system functionalities and the data involved. Moreover, the Chatbot may
provide a sort of tutorial that could be activated through dedicated message
patterns like “tutorial” or “guide me”; the tutorial might be composed of
a sequence of pre-defined interactions that the application would suggest to
the user, while explaining the information displayed.
Feedback on wrong user requests. Some users got stuck after receiving
multiple times the fallback message “I did not get that :( ”, i.e., the default
message that the Chatbot sends in case no intent is matched. These sit-
uations derive, for instance, from: messages that present too many typos,
requests not supported by the Chatbot (such as complex queries, orderings
or searches based on unmapped attributes), or because users tried to click
buttons shown in past interactions and thus inactive.
The problems related to textual inputs could be solved by extending the
conversation model to support the identification of some common (but not
supported) messages and providing appropriate feedbacks. In case of invalid
button clicks, instead, the Chatbot could just respond with: “You can not
click on previously displayed buttons!”.
Complex queries. In the future, the Chatbot may support complex quer-
ies, i.e., requests that use more than one attribute at a time, or the ability
to cross relations also when considering more than one element. We derived
this conclusion by noticing that the majority of the messages sent by the
users aimed to reach the elements required by the tasks in a single request,
without following a step-by-step exploration.
In any case, we believe that this attitude was due to the participants
expertise in database systems, in the sense that often they tried to formulate
long and articulated requests, which corresponds to the a typical approach
followed when writing SQL commands.
Order by clause. Some users reported the absence of the SQL command
ORDER BY, which enables the ordering of the results based on some values.
76

As a future improvement, this feature could be added to support the related
command.
Enable chit-chat. Finally, we noticed that some users tried to chit-chat
with the Chatbot, by sending messages like “Hello, how are you?” or “I am
Nicola, who are you?”. Even though these requests are not related to any
explorative intentions, they may help the users to feel more comfortable and
even enjoy the conversation with the application.
For example, the Chatbot may save personal information of its users,
along with the Context of the conversation, in order to use it in chit-chat
interactions and emulate a real human-to-human conversation by recalling
the user name or age.
We believe that almost all the features reported above can be considered
valid in general for Chatbots for Data Exploration, not only for the specific
conversations that can be generated through our framework. One of the goals
of our research is indeed to identify guidelines for the design of such class of
applications, which is a research field not yet exhaustively explored.
77

78

Chapter 7
Conclusions
In this Thesis we proposed a novel conceptual modeling approach for the
definition and development of conversational agents for data exploration.
We began our journey by analyzing the state-of-the-art technologies nowa-
days available, with particular attention to the existing frameworks that offer
their usages; they allow developers to create a complete functioning chatbot,
integrated with messaging platforms and third-party API. However, we dis-
cuss the lack of a common methodology that define a general guideline that,
starting from the structure of the data involved, describes the steps to be
considered towards the definition of the final conversational agent. These
steps include dimensions relatable to the capabilities of the chatbot, such as
interaction paradigm, data visualization, context handling, integration.
On this basis, we aim to provide a data-driven paradigm that enables
the development of a conversational agent considering all the phases of its
design. However, we concentrated our analysis on modeling a specific type
of chatbots, i.e., chatbots for data exploration. We provided a definition
of these systems, outlining requirements and objectives of their creation; in
particular, these specifications include the capability to autonomously extract
the schema from a database endpoint, the support of schema annotation by
a Designer and, most importantly, the generation of a dialogue management
system that can be reached by the most popular chat interfaces to access the
data involved.
Afterwards, we provided a solution that could satisfy the requirements de-
fined, describing accurately each step of the design process. In particular, we
started from accurately explaining the above mentioned schema annotation
procedure; then, we illustrated how the chatbot could use these information

to generate an NLU model to support conversations related to the target
data. After that, we defined an execution paradigm, describing all the issues
that arise when dealing with the actual request handling, their translation
into queries, the results visualization and the context management.
Subsequently we described the prototype of our system, with particular
attention on the architecture components and the adopted technologies to
provide the wanted functionalities. We also posed our attention to a few
available tools that helped us in the various development steps.
Finally, we conducted a comparative study between a conversational
agent generated through our framework and the SQL command line, in terms
of the execution of some information retrieval tasks on the same data system.
We provided a quantitative and qualitative analysis based on the interaction
differences with our application and the SQL command line, which allowed
us to draw some positive conclusions about our chatbot prototype, as well
as many considerations about future improvements of our system.
7.1 Limitations
During the definition of our framework, we operated some structural choices
that influenced the design and the characteristics of the overall system.
First of all, our model introduces an abstraction of the target data system:
the translation between the information taken as is and its representation in
a conversational environment leads to the inevitable reformatting and hiding
of less significant data. While this procedure helps the end user easily retrieve
what can be considered as the “most important” elements in the data system,
it introduces difficulties or even limits for what concerns visualization of
“secondary” properties.
Secondly, as we have understood from the qualitative analysis of the user
study, the chatbot generated with our system was expected to understand
complex commands for data manipulation. However, the model provides
the support of a predefined set of actions for each object to retrieve, to be
executed individually and according to the required format. This means that
the ability of the chatbot to express its capabilities is still limited. Strategies
for better guiding the user conversation are needed.
Another limitation of the framework is the necessity of the Designer par-
ticipation, whose task is to annotate the database schema according to the
knowledge of the data system and the ideas for the future conversational ex-
80

ploration. Although this procedure enables the generation of chatbots with
different characteristics and objectives, it limits the autonomy of the overall
generative phase.
7.2 Future Work
The introduction of chatbots for data exploration and our definition of a
possible methodology for their development lead the way towards future im-
provements on this subject.
First of all, future improvements on NLP and Machine Learning tech-
nologies may lead to a better and more complex understanding of the input
phrases. Moreover, the possibility to introduce and use a dedicated Knowl-
edge Base next to the target database may lead to the definition and exploita-
tion of NLU models able to manage requests based also on their semantics,
rather than their only syntax.
Secondly, we developed our system on the basis of a relational database
(OLTP), but as a future work it could support the integration with other data
models, such as NoSQL data storages, Graph-based databases or even Data
Warehouses (OLAP). For what concerns the latter systems, the introduction
of a chatbot for the exploration of data might represent an additional, com-
plementary tool for the data analysis features these data structures already
provide.
Besides the integration with various data models, a Chatbot for Data Ex-
ploration could be also extended to interact with heterogeneous data sources.
In this case, the Context of the conversation might not be limited to influ-
ence the dialogue state, but it could become an active part for the dynamic
selection of resources by means of dedicated on-the-fly Mashups [10].
Furthermore, among the integration of the chatbot with external inter-
faces, the support of voice-based requests along with the introduction of
dedicated libraries for their transcription could lead to a better and easiest
user experience. Also, the results visualization format could be more interac-
tive or include, besides textual and button-based messages, also figures and
graphic content.
For what concerns the Schema Annotation, the procedure may be con-
ducted graphically, with the help of a dedicated software and it might in-
clude some heuristics or even integrate AI units for the automatic detection
of connections among tables and attributes priority. Otherwise, the complete
81

activity may be conducted with the help of the very same chat interface that
later will be used for the data retrieval: this way, a kind of “Conversational”
Schema Annotation could be accomplished.
Another option, deriving from the previous point, is to substitute the
Designer and assign the role directly to the end user, enabling the dynamic
definition of the exploration limits and characteristics with respect to the
will and preferences of the user. In this situation, the architecture should be
able to keep track, along with the conversation Context for each user, also
of the complete NLU model for data access by each single user. This would
lead to the notion of “Personal” Chatbot for Data Exploration.
Finally, as future work, we would like to take into account an observation
we received from a review for a paper accepted to the International Web En-
gineering Conference 2019 [8]. The suggestion described the idea to give the
Designer the possibility to manage “a holistic Conceptual Model that should
be the blueprint of the physical database”. In this scenario, the possibility
to navigate across a data system, that is the goal of a Chatbot for Data
Exploration, would not be seen only as an additional feature for an existing
database, but it could influence the definition from scratch of the model of
new data sources.
7.3 Publications
The main idea of the methodology proposed in this thesis, i.e., the conceptual
modeling of conversational elements by annotation of the database schema,
has been published in the following article:
“Nicola Castaldo, Florian Daniel, Maristella Matera, and Vittorio Zaccaria.
Conversational Data Exploration. In Web Engineering - 19h International
Conference, ICWE 2019, Daejeon, Korea, June 11-14, 2019, Proceedings.
Springer, 2019.”
The full methodology, the framework and the results of the evaluation study
will be the object of a journal paper that we are already authoring.
82

Bibliography
[1] Sameera A. Abdul-Kader and Dr. John Woods. Survey on chatbot de-
sign techniques in speech conversation systems. International Journal
of Advanced Computer Science and Applications, 6(7), 2015.
[2] Damla Ezgi Akcora, Andrea Belli, Marina Berardi, Stella Casola,
Nicoletta Di Blas, Stefano Falletta, Alessandro Faraotti, Luca Lodi,
Daniela Nossa Diaz, Paolo Paolini, Fabrizio Renzi, and Filippo Van-
nella. Conversational support for education. In Artificial Intelligence in
Education - 19th International Conference, AIED 2018, London, UK,
June 27-30, 2018, Proceedings, Part II, pages 14–19, 2018.
[3] Aaron Bangor, Philip Kortum, and James Miller. Determining what
individual sus scores mean: Adding an adjective rating scale. J. Usability
Studies, 4(3):114–123, May 2009.
[4] Simone Borsci, Stefano Federici, and Marco Lauriola. On the dimension-
ality of the system usability scale: A test of alternative measurement
models. Cognitive processing, 10:193–7, 07 2009.
[5] Daniel Braun, Adrian Hernandez-Mendez, Florian Matthes, and Man-
fred Langen. Evaluating natural language understanding services for
conversational question answering systems. In SIGDIAL Conference,
2017.
[6] Virginia Braun and Victoria Clarke. Using thematic analysis in psychol-
ogy. Qualitative research in psychology, 3:77–101, 01 2006.
[7] John Brooke. Sus: A quick and dirty usability scale. Usability Eval.
Ind., 189, 11 1995.
83

[8] Nicola Castaldo, Florian Daniel, Maristella Matera, and Vittorio Zac-
caria. Conversational data exploration. In Web Engineering - 19h Inter-
national Conference, ICWE 2019, Daejeon, Korea, June 11-14, 2019,
Proceedings. Springer, 2019.
[9] Robert Dale. The return of the chatbots. Natural Language Engineering,
22(5):811–817, 2016.
[10] Florian Daniel, Maristella Matera, Elisa Quintarelli, Letizia Tanca, and
Vittorio Zaccaria. Context-aware access to heterogeneous resources
through on-the-fly mashups. In Advanced Information Systems Engi-
neering - 30th International Conference, CAiSE 2018, Tallinn, Estonia,
June 11-15, 2018, Proceedings, pages 119–134, 2018.
[11] Florian Daniel, Maristella Matera, Vittorio Zaccaria, and Alessandro
Dell’Orto. Toward truly personal chatbots: On the development of
custom conversational assistants. In Proceedings of the 1st International
Workshop on Software Engineering for Cognitive Services, SE4COG ’18,
pages 31–36, New York, NY, USA, 2018. ACM.
[12] Alessandro Dell’Orto. Interactive development of personal chatbots: To-
ward enabling non-programmers. Master’s thesis, Politecnico di Milano,
2018. Supervisor: Prof. Florian Daniel.
[13] Ahmed Fadhil. Can a chatbot determine my diet?: Addressing
challenges of chatbot application for meal recommendation. CoRR,
abs/1802.09100, 2018.
[14] A.M. Graziano and M.L. Raulin. Research Methods: A Process of In-
quiry. Prentice Hall PTR, 2012.
[15] Matt Grech. The current state of chatbots in 2017. GetVoIP.com, April
2017.
[16] Sandra G. Hart and Lowell E. Staveland. Development of nasa-tlx (task
load index): Results of empirical and theoretical research. In Peter A.
Hancock and Najmedin Meshkati, editors, Human Mental Workload,
volume 52 of Advances in Psychology, pages 139 – 183. North-Holland,
1988.
84

[17] Matthew B. Hoy. Alexa, siri, cortana, and more: An introduction
to voice assistants. Medical Reference Services Quarterly, 37(1):81–88,
2018. PMID: 29327988.
[18] Inbenta Technologies Inc. The ultimate guide to chatbots for businesses.
Technical report, www.inbenta.com, 2016.
[19] ISO. ISO 9241-11:1998 Ergonomic requirements for office work with vi-
sual display terminals (VDTs) – Part 11: Guidance on usability. Tech-
nical report, International Organization for Standardization, 1998.
[20] ISO/IEC. ISO/IEC 9126. Software engineering – Product quality.
ISO/IEC, 2001.
[21] Lorenz Cuno Klopfenstein, Saverio Delpriori, Silvia Malatini, and
Alessandro Bogliolo. The rise of bots: A survey of conversational in-
terfaces, patterns, and paradigms. In Proc. of the 2017 Conference on
Designing Interactive Systems, DIS ’17, Edinburgh, United Kingdom,
June 10-14, 2017, pages 555–565, 2017.
[22] Lorenz Cuno Klopfenstein, Saverio Delpriori, Silvia Malatini, and
Alessandro Bogliolo. The rise of bots: A survey of conversational inter-
faces, patterns, and paradigms. In Proceedings of the 2017 Conference
on Designing Interactive Systems, DIS ’17, pages 555–565, New York,
NY, USA, 2017. ACM.
[23] Chatbot lawyer overturns 160000 parking tickets in London and New
York. https://www.theguardian.com/technology/2016/jun/28/chatbot-
ai-lawyer-donotpay-parking-tickets-london-new-york. Accessed: 2019-
03-13.
[24] James R. Lewis and Jeff Sauro. The factor structure of the system us-
ability scale. In Masaaki Kurosu, editor, Human Centered Design, First
International Conference, HCD 2009, Held as Part of HCI International
2009, San Diego, CA, USA, July 19-24, 2009, Proceedings, volume 5619
of Lecture Notes in Computer Science, pages 94–103. Springer, 2009.
[25] Michael L Mauldin. Chatterbots, tinymuds, and the turing test: Enter-
ing the loebner prize competition. In AAAI, volume 94, pages 16–21,
1994.
85

[26] Definition: natural language understanding (NLU).
https://searchenterpriseai.techtarget.com/definition/natural-language-
understanding-nlu. Accessed: 2019-03-31.
[27] Juanan Pereira and Oscar Dıaz. Chatbot dimensions that matter:
Lessons from the trenches. In Web Engineering - 18th International
Conference, ICWE 2018, Caceres, Spain, June 5-8, 2018, Proceedings,
pages 129–135, 2018.
[28] Alberto Mario Pirovano. State of art and best practices in generative
conversational ai. Master’s thesis, Politecnico di Milano, 2018. Super-
visor: Prof. Matteo Matteucci.
[29] Loebner Prize. https://www.aisb.org.uk/events/loebner-prize. Ac-
cessed: 2019-03-12.
[30] B. R. Ranoliya, N. Raghuwanshi, and S. Singh. Chatbot for university
related faqs. In 2017 International Conference on Advances in Com-
puting, Communications and Informatics (ICACCI), pages 1525–1530,
Sep. 2017.
[31] Aniruddha Tammewar, Monik Pamecha, Chirag Jain, Apurva
Nagvenkar, and Krupal Modi. Production ready chatbots: Generate
if not retrieve, 2018.
[32] Joseph Weizenbaum et al. Eliza—a computer program for the study of
natural language communication between man and machine. Commu-
nications of the ACM, 9(1):36–45, 1966.
86

Appendix A
Parsed Database Schema
{
"customers ": {
"column_list ": [
"customerNumber",
"customerName",
"contactLastName",
"contactFirstName",
"phone",
"addressLine1",
"addressLine2",
"city",
"state",
"postalCode",
"country",
"salesRepEmployeeNumber",
"creditLimit"
],
"primary_key_list ": [
"customerNumber"
],
"references ": {
"employees ": {
"foreign_key_list ": [
"salesRepEmployeeNumber"
],
"reference_key_list ": [
"employeeNumber"
]
}
}
},
"employees ": {
"column_list ": [
"employeeNumber",
"lastName",
"firstName",

"extension",
"email",
"officeCode",
"reportsTo",
"jobTitle"
],
"primary_key_list ": [
"employeeNumber"
],
"references ": {
"employees ": {
"foreign_key_list ": [
"reportsTo"
],
"reference_key_list ": [
"employeeNumber"
]
},
"offices ": {
"foreign_key_list ": [
"officeCode"
],
"reference_key_list ": [
"officeCode"
]
}
}
},
"offices ": {
"column_list ": [
"officeCode",
"city",
"phone",
"addressLine1",
"addressLine2",
"state",
"country",
"postalCode",
"territory"
],
"primary_key_list ": [
"officeCode"
]
},
"orderdetails ": {
"column_list ": [
"orderNumber",
"productCode",
"quantityOrdered",
"priceEach",
"orderLineNumber"
],
"primary_key_list ": [
88

"orderNumber",
"productCode"
],
"references ": {
"orders ": {
"foreign_key_list ": [
"orderNumber"
],
"reference_key_list ": [
"orderNumber"
]
},
"products ": {
"foreign_key_list ": [
"productCode"
],
"reference_key_list ": [
"productCode"
]
}
}
},
"orders ": {
"column_list ": [
"orderNumber",
"orderDate",
"requiredDate",
"shippedDate",
"status",
"comments",
"customerNumber"
],
"primary_key_list ": [
"orderNumber"
],
"references ": {
"customers ": {
"foreign_key_list ": [
"customerNumber"
],
"reference_key_list ": [
"customerNumber"
]
}
}
},
"payments ": {
"column_list ": [
"customerNumber",
"checkNumber",
"paymentDate",
"amount"
],
89

"primary_key_list ": [
"customerNumber",
"checkNumber"
],
"references ": {
"customers ": {
"foreign_key_list ": [
"customerNumber"
],
"reference_key_list ": [
"customerNumber"
]
}
}
},
"productlines ": {
"column_list ": [
"productLine",
"textDescription",
"htmlDescription",
"image"
],
"primary_key_list ": [
"productLine"
]
},
"products ": {
"column_list ": [
"productCode",
"productName",
"productLine",
"productScale",
"productVendor",
"productDescription",
"quantityInStock",
"buyPrice",
"MSRP"
],
"primary_key_list ": [
"productCode"
],
"references ": {
"productlines ": {
"foreign_key_list ": [
"productLine"
],
"reference_key_list ": [
"productLine"
]
}
}
}
}
90

Appendix B
Database Schema Annotation
[
{
"object_name ":" customer",
"aliases ": [" customers", "client", "clients"],
"type": "primary",
"table_name ": "customers",
"display_attributes ":[
{
"keyword ": "",
"columns ": [" customerName "]
}
],
"qualifiers ": [
{
"keyword ": "",
"type": "word",
"columns ": [" customerName "]
},
{
"keyword ": "with contact",
"type": "word",
"columns ": [" contactLastName", "contactFirstName "]
},
{
"keyword ": "located in",
"type": "word",
"columns ": ["city", "state", "country "]
},
{
"keyword ": "that paid",
"type": "num",
"columns ": [" amount"],
"by": [
{
"from_table_name ": "customers",
"from_columns ": [" customerNumber "],

"to_table_name ": "payments",
"to_columns ": [" customerNumber "]
}
]
},
{
"keyword ": "that bought",
"type": "word",
"columns ": [" productName "],
"by": [
{
"from_table_name ": "customers",
"from_columns ": [" customerNumber "],
"to_table_name ": "orders",
"to_columns ": [" customerNumber "]
},
{
"from_table_name ": "orders",
"from_columns ": [" orderNumber "],
"to_table_name ": "orderdetails",
"to_columns ": [" orderNumber "]
},
{
"from_table_name ": "orderdetails",
"from_columns ": [" productCode "],
"to_table_name ": "products",
"to_columns ": [" productCode "]
}
]
},
{
"keyword ": "that reported to",
"type": "word",
"columns ": [" lastName", "firstName"],
"by": [
{
"from_table_name ": "customers",
"from_columns ": [" salesRepEmployeeNumber "],
"to_table_name ": "employees",
"to_columns ": [" employeeNumber "]
}
]
}
],
"relations ": [
{
"keyword ": "payments made",
"object_name ": "payment",
"by": [
{
"from_table_name ": "customers",
"from_columns ": [" customerNumber "],
"to_table_name ": "payments",
92

"to_columns ": [" customerNumber "]
}
]
},
{
"keyword ": "related sales representative",
"object_name ": "employee",
"by": [
{
"from_table_name ": "customers",
"from_columns ": [" salesRepEmployeeNumber "],
"to_table_name ": "employees",
"to_columns ": [" employeeNumber "]
}
]
},
{
"keyword ": "orders made",
"object_name ": "order",
"by": [
{
"from_table_name ": "customers",
"from_columns ": [" customerNumber "],
"to_table_name ": "orders",
"to_columns ": [" customerNumber "]
}
]
},
{
"keyword ": "products bought",
"object_name ": "product",
"by": [
{
"from_table_name ": "customers",
"from_columns ": [" customerNumber "],
"to_table_name ": "orders",
"to_columns ": [" customerNumber "]
},
{
"from_table_name ": "orders",
"from_columns ": [" orderNumber "],
"to_table_name ": "orderdetails",
"to_columns ": [" orderNumber "]
},
{
"from_table_name ": "orderdetails",
"from_columns ": [" productCode "],
"to_table_name ": "products",
"to_columns ": [" productCode "]
}
]
}
]
93

},
{
"object_name ":" employee",
"aliases ": [" employees", "worker", "workers"],
"type": "primary",
"table_name ": "employees",
"display_attributes ":[
{
"keyword ": "",
"columns ": [" lastName", "firstName "]
}
],
"qualifiers ": [
{
"keyword ": "",
"type": "word",
"columns ": [" lastName", "firstName "]
},
{
"keyword ": "with first name",
"type": "word",
"columns ": [" firstName "]
},
{
"keyword ": "with last name",
"type": "word",
"columns ": [" lastName "]
},
{
"keyword ": "that work in",
"type": "word",
"columns ": ["city", "country"],
"by": [
{
"from_table_name ": "employees",
"from_columns ": [" officeCode "],
"to_table_name ": "offices",
"to_columns ": [" officeCode "]
}
]
}
],
"relations ": [
{
"keyword ": "works in office",
"object_name ": "office",
"by": [
{
"from_table_name ": "employees",
"from_columns ": [" officeCode "],
"to_table_name ": "offices",
"to_columns ": [" officeCode "]
}
94

]
},
{
"keyword ": "related customers",
"object_name ": "customer",
"by": [
{
"from_table_name ": "employees",
"from_columns ": [" employeeNumber "],
"to_table_name ": "customers",
"to_columns ": [" salesRepEmployeeNumber "]
}
]
},
{
"keyword ": "reports to",
"object_name ": "employee",
"by": [
{
"from_table_name ": "employees",
"from_columns ": [" reportsTo"],
"to_table_name ": "employees",
"to_columns ": [" employeeNumber "]
}
]
}
]
},
{
"object_name ":" office",
"aliases ": [" offices"],
"type": "primary",
"table_name ": "offices",
"display_attributes ":[
{
"keyword ": "address",
"columns ": ["city", "addressLine1 "]
}
],
"qualifiers ": [
{
"keyword ": "with address",
"type": "word",
"columns ": ["city", "addressLine1 "]
},
{
"keyword ": "located in",
"type": "word",
"columns ": ["city", "country "]
},
{
"keyword ": "of",
"type": "word",
95

"columns ": [" lastName", "firstName"],
"by": [
{
"from_table_name ": "offices",
"from_columns ": [" officeCode "],
"to_table_name ": "employees",
"to_columns ": [" officeCode "]
}
]
}
],
"relations ": [
{
"keyword ": "employees working here",
"object_name ": "employee",
"by": [
{
"from_table_name ": "offices",
"from_columns ": [" officeCode "],
"to_table_name ": "employees",
"to_columns ": [" officeCode "]
}
]
}
]
},
{
"object_name ":" order",
"aliases ": [" orders"],
"type": "primary",
"table_name ": "orders",
"display_attributes ":[
{
"keyword ": "ordered",
"columns ": [" orderDate "]
},
{
"keyword ": "shipped",
"columns ": [" shippedDate "]
}
],
"qualifiers ": [
{
"keyword ": "made by",
"type": "word",
"columns ": [" customerName "],
"by": [
{
"from_table_name ": "orders",
"from_columns ": [" customerNumber "],
"to_table_name ": "customers",
"to_columns ": [" customerNumber "]
96

}
]
},
{
"keyword ": "with product",
"type": "word",
"columns ": [" productName "],
"by": [
{
"from_table_name ": "orders",
"from_columns ": [" orderNumber "],
"to_table_name ": "orderdetails",
"to_columns ": [" orderNumber "]
},
{
"from_table_name ": "orderdetails",
"from_columns ": [" productCode "],
"to_table_name ": "products",
"to_columns ": [" productCode "]
}
]
}
],
"relations ": [
{
"keyword ": "made by",
"object_name ": "customer",
"by": [
{
"from_table_name ": "orders",
"from_columns ": [" customerNumber "],
"to_table_name ": "customers",
"to_columns ": [" customerNumber "]
}
]
},
{
"keyword ": "contained products",
"object_name ": "product",
"by": [
{
"from_table_name ": "orders",
"from_columns ": [" orderNumber "],
"to_table_name ": "orderdetails",
"to_columns ": [" orderNumber "]
},
{
"from_table_name ": "orderdetails",
"from_columns ": [" productCode "],
"to_table_name ": "products",
"to_columns ": [" productCode "]
}
]
97

}
]
},
{
"object_name ":" payment",
"aliases ": [" payments"],
"type": "secondary",
"table_name ": "payments",
"display_attributes ":[
{
"keyword ": "quantity",
"columns ": [" amount "]
},
{
"keyword ": "date",
"columns ": [" paymentDate "]
}
],
"qualifiers ": [
],
"relations ": [
{
"keyword ": "made by",
"object_name ": "customer",
"by": [
{
"from_table_name ": "payments",
"from_columns ": [" customerNumber "],
"to_table_name ": "customers",
"to_columns ": [" customerNumber "]
}
]
}
]
},
{
"object_name ": "product line",
"aliases ": [" brand", "brands"],
"type": "primary",
"table_name ": "productlines",
"display_attributes ":[
{
"keyword ": "",
"columns ": [" productLine "]
}
],
"qualifiers ": [
{
"keyword ": "",
"type": "word",
"columns ": [" productLine "]
},
98

{
"keyword ": "of product",
"type": "word",
"columns ": [" productName "],
"by": [
{
"from_table_name ": "productlines",
"from_columns ": [" productLine "],
"to_table_name ": "products",
"to_columns ": [" productLine "]
}
]
}
],
"relations ": [
{
"keyword ": "related products",
"object_name ": "product",
"by": [
{
"from_table_name ": "productlines",
"from_columns ": [" productLine "],
"to_table_name ": "products",
"to_columns ": [" productLine "]
}
]
}
]
},
{
"object_name ": "product",
"aliases ": [" products"],
"type": "primary",
"table_name ": "products",
"display_attributes ":[
{
"keyword ": "",
"columns ": [" productName "]
},
{
"keyword ": "of product line",
"columns ": [" productLine "]
}
],
"qualifiers ": [
{
"keyword ": "",
"type": "word",
"columns ": [" productName "]
},
{
"keyword ": "of product line",
99

"type": "word",
"columns ": [" productLine "],
"by": [
{
"from_table_name ": "products",
"from_columns ": [" productLine "],
"to_table_name ": "productlines",
"to_columns ": [" productLine "]
}
]
},
{
"keyword ": "bought by",
"type": "word",
"columns ": [" customerName "],
"by": [
{
"from_table_name ": "products",
"from_columns ": [" productCode "],
"to_table_name ": "orderdetails",
"to_columns ": [" productCode "]
},
{
"from_table_name ": "orderdetails",
"from_columns ": [" orderNumber "],
"to_table_name ": "orders",
"to_columns ": [" orderNumber "]
},
{
"from_table_name ": "orders",
"from_columns ": [" customerNumber "],
"to_table_name ": "customers",
"to_columns ": [" customerNumber "]
}
]
}
],
"relations ": [
{
"keyword ": "related product line",
"object_name ": "product line",
"by": [
{
"from_table_name ": "products",
"from_columns ": [" productLine "],
"to_table_name ": "productlines",
"to_columns ": [" productLine "]
}
]
},
{
"keyword ": "in orders",
100

"object_name ": "order",
"by": [
{
"from_table_name ": "products",
"from_columns ": [" productCode "],
"to_table_name ": "orderdetails",
"to_columns ": [" productCode "]
},
{
"from_table_name ": "orderdetails",
"from_columns ": [" orderNumber "],
"to_table_name ": "orders",
"to_columns ": [" orderNumber "]
}
]
},
{
"keyword ": "bought by",
"object_name ": "customer",
"by": [
{
"from_table_name ": "products",
"from_columns ": [" productCode "],
"to_table_name ": "orderdetails",
"to_columns ": [" productCode "]
},
{
"from_table_name ": "orderdetails",
"from_columns ": [" orderNumber "],
"to_table_name ": "orders",
"to_columns ": [" orderNumber "]
},
{
"from_table_name ": "orders",
"from_columns ": [" customerNumber "],
"to_table_name ": "customers",
"to_columns ": [" customerNumber "]
}
]
}
]
},
{
"object_name ": "orderdetails",
"type": "crossable",
"table_name ": "orderdetails"
}
]
101

102

Appendix C
User Study Questionnaires
This Appendix reports the English translation (from Italian) of the question-
naires administered during the User Study.
C.1 Demographic Questionnaire
Insert the “participant code” you received:
Insert your age:
Gender:Man Woman Other
� � �
Education:High. S. Bachelor Master PhD Other
� � � � �
How do you evaluate your expertise with information technology?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �

How do you rate your expertise with the use of chatbots?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
How do you rate your expertise with querying databases?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
C.2 System Questionnaire
Insert the “participant code” you received:
System used:Chatbot SQL
� �
C.2.1 Ease of use
I think I would like to use this system frequently.
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
I found the system unnecessarily complex.
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
I thought the system was easy to use.
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
104

I think that I would need the support of a technical person to be able to
use this system.
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
I found the various functions in this system were well integrated.
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
I thought there was too much inconsistency in this system.
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
I would imagine that most people would learn to use this system very quickly.
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
I found the system very cumbersome to use.
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
I felt very confident using the system.
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
I needed to learn a lot of things before I could get going with this system.
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
105

How likely are you to recommend this system to a friend or colleague?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
C.2.2 Cognitive load
How mentally demanding were the tasks?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
How physically demanding were the tasks?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
How hurried or rushed was the pace of the tasks?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
How successful were you in accomplishing what you were asked to do?
Perfect 1 2 3 4 5 6 7 8 9 10 Failure
� � � � � � � � � �
How hard did you have to work to accomplish your level of performance?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
106

How insecure, discouraged, irritated, stressed and annoyed were you?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
C.2.3 General questions
How easy was it to explore the database with this system, for example to
identify the information contained in it or to navigate among the various
tables?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
How easy was it to find the requested information, for example the detailed
information on customers?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
How easy was it to understand or remember the commands to use in or-
der to find the requested information?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
How do you consider the way in which the commands and information found
are presented?
Low 1 2 3 4 5 6 7 8 9 10 High
� � � � � � � � � �
107

Which scenarios of use do you think are the most appropriate for the system
you used?
Do you have any ideas on how to improve the presentation of results (for
example through graphics)?
Main advantages of the system used.
Main disadvantages of the system used.
C.3 Final Questionnaire
Insert the “participant code” you received:
With respect to their UTILITY, order the systems you used
(1 = the one you consider most useful, 2 = the one you think is least useful):
Chatbot: 1 2
� �SQL: 1 2
� �
108

Explain the reasons for your ranking:
With respect to their COMPLETENESS, order the systems you used
(1 = the one you consider most useful, 2 = the one you think is least useful):
Chatbot: 1 2
� �SQL: 1 2
� �
Explain the reasons for your ranking:
With respect to their EASE OF USE, order the systems you used
(1 = the one you consider most useful, 2 = the one you think is least useful):
Chatbot: 1 2
� �SQL: 1 2
� �
Explain the reasons for your ranking:
109

Overall, which system would you adopt in your activities?
Chatbot SQL
� �
Additional comments and / or suggestions (advantages, disadvantages, ad-
ditional features, etc.):
110


















