
10-601 Machine Learning
12
Problem Set 2 10-601 Machine Learning
Transcript of 10-601 Machine Learning

Problem Set 2
10-601
Machine Learning

MATLAB tips
• Conventional wisdom: MATLAB hates loops
– May be less of an issue with most recent versions
– Ideally use matrix operations whenever possible
• Examples:

MATLAB tips
• Conventional wisdom: MATLAB hates loops
– May be less of an issue with most recent versions
– Ideally use matrix operations whenever possible
• Examples:

MATLAB tips
• Conventional wisdom: MATLAB hates loops
– May be less of an issue with most recent versions
– Ideally use matrix operations whenever possible
• Examples:

MATLAB tips
• Conventional wisdom: MATLAB hates loops
– May be less of an issue with most recent versions
– Ideally use matrix operations whenever possible
• Examples:

MATLAB tips
• Conventional wisdom: MATLAB hates loops
– May be less of an issue with most recent versions
– Ideally use matrix operations whenever possible
• Examples:

Logistic regression implementation
• In my code that solves for w, the only loop is the one that iterates until the weight vector has converged
• My code converges in ~40k iterations (35.6s) when
– lambda = 0
– w and v initialized to 1
– k = 0.5
• Can use ‘tic’ and ‘toc’ to time your code

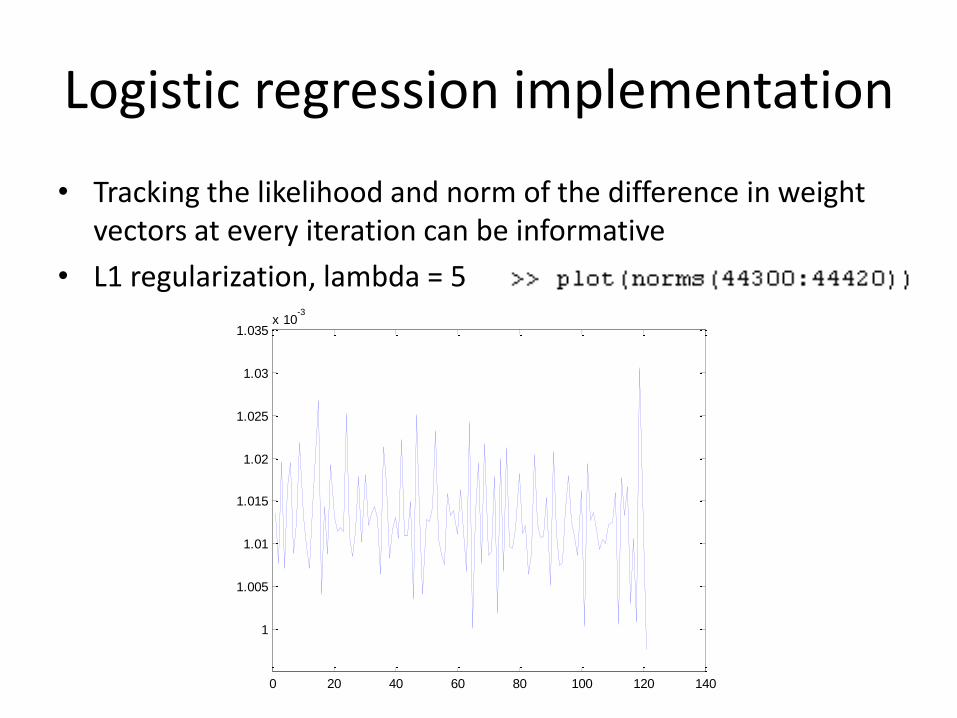
Logistic regression implementation
• Tracking the likelihood and norm of the difference in weight vectors at every iteration can be informative
• L1 regularization, lambda = 5
0 500 1000 1500 2000 2500 3000 3500 4000 45000.98
1
1.02
1.04
1.06
1.08
1.1
1.12
1.14
1.16
1.18x 10
-3
Logistic regression implementation
• Tracking the likelihood and norm of the difference in weight vectors at every iteration can be informative
• L1 regularization, lambda = 5
0 20 40 60 80 100 120 140
1
1.005
1.01
1.015
1.02
1.025
1.03
1.035x 10
-3

Logistic regression implementation
• To test your code, observe what happens to the weight vector as you increase lambda
-100 -80 -60 -40 -20 0 20 40 60 800
5
10
15
20
25
30
35
40
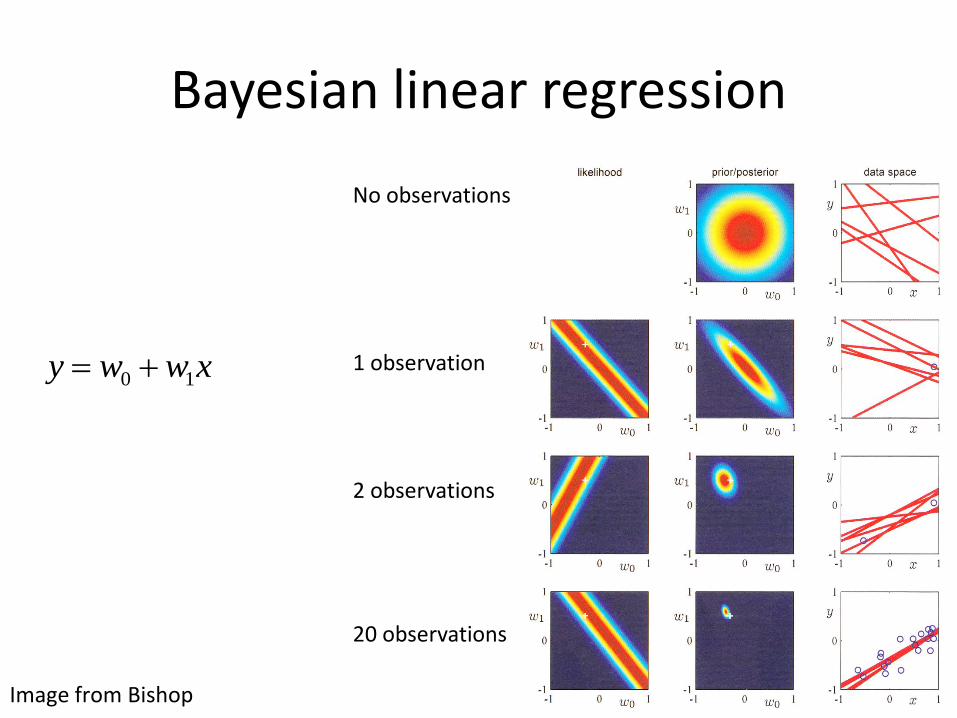
Bayesian linear regression
Image from Bishop
xwwy 10
No observations
1 observation
2 observations
20 observations

We also discussed…
• Why the Gaussian prior on w in Bayesian linear regression is a conjugate prior, as well as how to compute the posterior
• How to compute information gain in a decision tree with continuous attributes


















