







Languages
Pages
Legal


1
ALEKSANDRA SIMONOVIKJ
Trabajo Fin de Master (TFM) / MA Dissertation
Máster oficial en literatura y lingüística inglesas
SECOND LANGUAGE ACQUISITION OF
UNACCUSATIVE SYNTAX:
MACEDONIAN AND SPANISH LEARNERS
OF L2 ENGLISH
Departamento de Filologías Inglesa y Alemana
Universidad de Granada
Octubre 2011
Supervisor: Dr. Cristóbal Lozano

2
TABLE OF CONTENTS
TABLE OF CONTENTS .......................................................................................................................... 2
OVERVIEW ......................................................................................................................................... 7
1 INTRODUCTION......................................................................................................................... 10
1.1 THE PHENOMENON UNDER INVESTIGATION ........................................................................................ 11
1.2 AN OVERVIEW OF L2 ACQUISITION ................................................................................................... 13
1.2.1 Linguistic theories of second language acquisition .............................................................. 14
1.2.2 Individual differences in second language acquisition ......................................................... 26
1.2.3 Sources of interlanguage (IL) knowledge .............................................................................. 27
2 LINGUISTIC BACKGROUND: UNACCUSATIVITY AND POSTVERBAL SUBJECTS ............................... 31
2.1 PRELIMINARY THEORETICAL FOUNDATIONS ........................................................................................ 31
2.1.1 L2 acquisition and Universal Grammar ................................................................................ 31
2.1.2 The pro-drop parameter ....................................................................................................... 33
2.1.3 The architecture of language and the interfaces .................................................................. 39
2.2 THE PHENOMENON UNDER INVESTIGATION: SUBJECT-VERB INVERSION (SV/VS ORDERS) .......................... 41
2.2.1 The Unaccusative Hypothesis (UH) ....................................................................................... 47
2.2.2 Cross-linguistic evidence for the UH ..................................................................................... 51
2.2.3 Unaccusativity in the languages under consideration .......................................................... 56
2.2.3.1 Unaccusativity and word order in native English ....................................................................... 56
2.2.3.1.1 Existential inversion............................................................................................................... 58
2.2.3.1.2 Locative inversion .................................................................................................................. 60
2.2.3.2 Unaccusativity and word order in native Spanish ...................................................................... 64
2.2.3.3 Unaccusativity and word order in native Macedonian ............................................................... 67

3
2.2.3.3.1 Description of unaccusativity ................................................................................................ 71
2.2.3.3.2 Pilot study: Macedonian native speakers’ intuitions on unaccusativity ................................ 72
3 THE L2 ACQUISITION OF UNACCUSATIVITY ................................................................................ 77
3.1 PRELIMINARY BACKGROUND: L2 ACQUISITION AND THE INTERFACES ......................................................... 77
3.2 UNACCUSATIVES IN L2 ACQUISITION .................................................................................................. 78
3.2.1 Introduction: some examples of learners’ production on unaccusativity ............................. 78
3.2.2 Passivized unaccusatives ...................................................................................................... 80
3.2.3 Unaccusative auxiliary selection ........................................................................................... 84
3.2.4 Unaccusative postverbal subjects ......................................................................................... 85
3.3 CONCLUSION: THE PSYCHOLOGICAL REALITY OF UH .............................................................................. 93
4 HYPOTHESES ............................................................................................................................. 94
5 METHOD ................................................................................................................................... 96
5.1 SUBJECTS ..................................................................................................................................... 96
5.2 INSTRUMENTS ............................................................................................................................... 98
5.2.1 Main experimental test: the acceptability judgement test ................................................... 98
5.2.2 Proficiency test: The Oxford Placement Test ...................................................................... 101
5.3 VARIABLES AND EXPERIMENTAL DESIGN ............................................................................................ 102
5.4 PROCEDURE ................................................................................................................................ 104
5.5 DESIGN ...................................................................................................................................... 107
5.6 DATA CODING AND DATA ANALYSIS .................................................................................................. 107
6 RESULTS .................................................................................................................................. 109
6.1 QUANTITATIVE RESULTS ................................................................................................................ 109
6.1.1 Results for H1: L2 knowledge of unaccusativity (lexicon-syntax interface) ........................ 109
6.1.2 Results for H2: At initial stages all unaccusative XP-V-S structures will be treated as
grammatical. ................................................................................................................................... 113

4
6.1.3 Results for H3: No transfer hypothesis: Learners’ behavour cannot simply be accounted for
by L1 transfer ................................................................................................................................... 119
6.1.4 Results for H4: Learners will follow the developmental stages proposed by the Unaccusative
Trap (Oshita 2000). .......................................................................................................................... 121
6.2 QUALITATIVE COMMENTS MADE BY THE LEARNERS.............................................................................. 122
6.3 CONTRASTING RESULTS: BY OPT AND BY SELF-PROFICIENCY .................................................................. 125
7 DISCUSSION ............................................................................................................................ 128
7.1 L2 LEARNERS’ KNOWLEDGE OF UH .................................................................................................. 128
7.1.1 Discussion of H1: L2 knowledge of unaccusativity (lexicon-syntax interface) .................... 128
7.1.2 Discussion of H2: L2 knowledge of the different preverbal structures: .............................. 129
7.1.3 Discussion of H3: the No-transfer hypothesis and other possible sources of L2 learners’
knowledge........................................................................................................................................ 132
7.1.3.1 Input ......................................................................................................................................... 132
7.1.3.2 Instruction ................................................................................................................................ 133
7.1.3.3 L1 transfer ................................................................................................................................ 133
7.1.3.4 Reasons for lack of L1 transfer ................................................................................................. 134
7.1.4 Discussion of H4: Developmental stages and Oshita’s (2001) Unaccusative Trap hypoThesis
135
7.2 POSSIBLE PEDAGOGICAL IMPLICATIONS: TEACHING POSTVERBAL SUBJECTS IN L2 ENGLISH ........................... 137
7.3 RECOMMENDATIONS FOR FUTURE RESEARCH ..................................................................................... 138
7.3.1 Postverbal subjects with ‘be’ (expl + be + NP-subject) ........................................................ 138
7.3.2 The effects of weight and focus on postverbal subjects ..................................................... 139
8 CONCLUSION .......................................................................................................................... 140
9 ACKNOWLEDGEMENTS ........................................................................................................... 142
10 REFERENCES ............................................................................................................................ 144
11 APPENDICES ............................................................................................................................ 152
11.1 MAIN EXPERIMENTAL TEST: CONTEXTUALISED ACCEPTABILITY JUDGEMENT TEST (ONLINE VERSION) .............. 152

5
11.1.1 Main experimental test for English natives (SAES) ......................................................... 152
11.1.2 Main experimental test for L1 Spa-L2 Eng learners (EASI) ............................................. 164
11.1.3 Main experimental tests for l1 maced-L2 Eng (IUSAJ) .................................................... 177
11.1.4 Randomization of sentences in the main experimental test .......................................... 191
11.2 OPT (OXFORD PLACEMENT TEST) ................................................................................................... 192
11.3 PILOT STUDY ON MACEDONIAN NATIVES’ INTUITIONS ON UNACCUSATIVITY ............................................. 197
11.3.1 Pilot study on Macedonian natives: the test .................................................................. 198
11.3.2 Pilot study on Macedonian natives: raw data ................................................................ 207
11.3.3 Pilot study on Macedonian natives: outputs (charts) ..................................................... 210
11.4 RAW DATA FOR THE MAIN EXPERIMENTAL TEST (FULL TABLES) ............................................................... 210
11.4.1 Raw data for English natives .......................................................................................... 211
11.4.2 Raw data for L1 Spa – L2 Eng learners ........................................................................... 212
11.4.3 Raw data for L1 Maced – L2 English learners ................................................................ 213
11.5 CHARTS FOR THE MAIN EXPERIMENT (CHART OUTPUTS) ....................................................................... 214
11.5.1 Charts for the main experiment: L1 Spa – L2 Eng learners ............................................. 214
11.5.2 Charts for the main experiment: L1 Maced – L2 English learners .................................. 215
11.6 EMAIL: INVITATION TO PARTICIPATE ................................................................................................. 215
11.6.1 Participate in SAES (invitation for English natives) ......................................................... 216
11.6.2 Participate in EASI (invitation for L1 Spanish-L2 English leaners) .................................. 217
11.6.3 Participate in IUSAJ (invitation for L1 MaceDonian-L2 English leaners) ........................ 218
11.7 EMAIL: SEE YOUR RESULTS ............................................................................................................. 219
11.7.1 Email sent to L1 Spa-L2 Eng learners: see your results ................................................... 220
11.7.2 Email sent to L1 Maced-L2 Eng learners: see your results ............................................. 220
11.8 EMAIL: PLEASE COMPLETE THE OPT ................................................................................................ 220
11.8.1 Email sent to L1 Spa-L2 Eng learners: Please complete the OPT .................................... 221

6
11.8.2 Email sent to L1 Maced-L2 Eng learners: Please complete the OPT ............................... 222
11.9 CERTIFICATE OF PARTICIPATION ....................................................................................................... 222
11.9.1 Certificate of participation for L1 Spa-L2 Eng learners ................................................... 223
11.9.2 Certificate of participation for L1 Maced-L2 Eng learners .............................................. 225

7
OVERVIEW
The Unaccusative Hypothesis (Perlmutter 1978, Levin & Rappaport-Hovav 1995 is a
proposed linguistic principle that divides intransitive verbs into two types: unergatives,
whose only argument (subject) typically denotes activities controlled by an agent, and
unaccusatives whose argument is generated postverbally in object position and is a
theme. One of the surface syntactic manifestations of UH is that, while Subject-Verb
order is allowed with both verb types, Verb-Subject order is allowed under certain
conditions: (i) the verb is unaccusative; (ii) the subject introduces new information
(focus); and (iii) the subject is long (heavy).
Previous research has shown that L2 learners are sensitive to the Unaccusative
Hypothesis (UH), irrespective of instruction, input and their L1. One of the aims of this
study is to support previous findings claiming that different L1 background learners of
L2 English are sensitive to the syntactic constraints of the UH by investigating the
acceptance of postverbal subjects by Spanish and Macedonian learners of L2 English. In
particular, the study focuses on the acquisition of postverbal subject structures of the
type (XP)-V-S (1-4), where a preverbal element is realized either as an ungrammatical
overt expletive “it”, an ungrammatical null element (Ø), a grammatical “there”
expletive (existential inversion) and a grammatical PP (locative inversion). These
structures have been widely reported in the L2 literature to be produced by learners of
English with different L1 backgrounds (Spanish, Italian, Chinese, Japanese, Arabic)
with unaccusative verbs, but never with unergatives.
(1) *it-V-S
a) *…it happened a tragic event…. (L1 Italian)
b) *…it arrived the day of his departure. (L1 Spanish)
c) *…it will happen something exciting. (L1 Spanish)

8
(2) there-V-S
a) …there often arise the problem of political indifference.(L1 Japanese)
b) …there exist two kind of jobs… (L1 Italian)
c) …there exist many kind of prejudice. (L1 Korean)
(3) *Ø -V-S
…it is difficult that [exist volunteers with such a feeling against it]…
(L1 Spanish)
…like a mirage [appeared the large expanse of the sea]… (L1 Italian)
(4) PP-V-S
…in the town lived a small Indian. (L1 Spanish)
…on this particular place happened a story which now appears on all
Mexican history books. (L1 Spanish)
… on her face appeared those two red cheeks and above them beautiful
deep eyes. (L1 Arabic)
This study differs from previous studies in several respects: (i) the participants are
native Macedonian learners of L2 English (who will be compared against L1 Spanish –
L2 English learners); (ii) the study is developmental, measuring the development of XP-
V-S through all proficiency levels (from A1 to C2), which will then be compared
against the English native speakers‟ norm; and (iii) the nature of the preverbal element
(XP) in XP-V-S structures will be analyzed in detail.
Data were collected online via a contextualized acceptability judgment test. 91
Macedonian and 91 Spanish learners of L2 English classified in groups of six
proficiency levels (A1-C2) and 24 native English participants took part in this study.
The overall results indicate that Macedonian and Spanish learners of L2 English are
sensitive to the universal constraints of the UH by allowing the occurrence of postverbal
subjects with unaccusative verbs more than with unergative verbs. In accordance with
the theory of Universal Grammar (UG) it has also been noticed that L1 Macedonian and

9
L1 Spanish learners follow similar developmental stages in the L2 acquisition of
postverbal subjects which converge with the grammars of the control English native
group, suggesting that the acceptance of the structures cannot be accounted for solely by
L1 transfer. Finally, this study will discuss the nature of the preverbal phrase (XP) in
learners‟ grammars, i.e., structural cases like *it-V-S (e.g...it happened a tragic event..)
and *Ø-V-S (e.g. …like a mirage [appeared the large expanse of the sea]… ) will be
discussed, as they will shed some light on, learners‟ processing difficulties and/or
crosslinguistic influence, which will also be discussed in detail.
This study concludes with some pedagogical recommendations for the teaching of
postverbal subjects in L2 English and some suggestions for future research on the nature
of unaccusativity in L2 acquisition.

10
1 INTRODUCTION
The main focus of this study supports the claims that second language (L2) learners are
sensitive to the properties of the Unaccusative Hypothesis (UH) as a proposed invariant
principle of Universal Grammar (UG). The intuition of language learners to the UH
confirms the claims that language acquisition cannot be accounted for only L1 transfer
but it is rather a complex process developing through predetermined stages. We are
interested in exploring the L2 acquisition of postverbal subject structures in L2 English
which is a widely attested phenomenon. Our study analyzes the acquisition of
postverbal subject structures of the type XP-V-S by L1 Macedonian – L2 English
learners compared to L1 Spanish – L2 English learners.
Before we start explaining the phenomenon under investigation we will briefly describe
the organization of this dissertation.
The introductory part of the paper (Section 1) discusses the linguistic phenomenon of
interest and presents an outline of second language acquisition (SLA) theories and some
of the key factors involved in the L2 acquisition process. The following part (Section 2)
discusses the influence of UH on the word order of the three languages under
investigation (English, Spanish, Macedonian). Then there follows (Section 3) the part
explaining the L2 acquisition of unaccusative structures, with particular reference to
postverbal subjects. The following parts (Sections 4, 5 and 6) elaborate the hypothesis,
the method and the results of the study which are later discussed (Section 7).
Conclusions are presented at the end of the dissertation (Section 8).

11
1.1 THE PHENOMENON UNDER INVESTIGATION
In order to describe the phenomenon under investigation we will present examples of
XP-V-S structures (5-9) produced by different L1 learners of L2 English taken from
several empirical studies (Zobl 1989; Rutherford 1989; Oshita 2000; Oshita 2004;
Lozano and Mendikoetxea 2008, 2010) analyzing the acquisition of postverbal subjects
in English. For notation purposes, the preverbal element (XP) is presented in italics, the
verb is underlined and the postverbal subject is marked in bold. All examples provide
information about the L1 of the learner who produced it and the study this structure was
obtained from. Some of the structures are grammatically (i.e., structurally) possible in
native English (PPloc-V-S and there-V-S) and some ungrammatical (*it-V-S; *Ø-V-S;
*PPtemp-V-S) 1.
(5) PP (locative) - V - S
a) … on her face appeared those two red cheeks …
(L1 Arabic; Rutherford, 1989, p. 179).
b) … because in our century have appeared the car and the plane.
(L1 Spanish; Oshita, 2004, p. 120).
c) …on the earth lived people which were born criminal.
(L1 Spanish; Lozano & Mendikoetxea, 2008, p. 106).
d) In some places still exist popularly supported death penalty.
(L1 Spanish; Lozano & Mendikoetxea, 2010, p. 486).
(6) there-insertion – V - S
a) .… there often arise the problem of political indifference …
1 “Ungrammatical” structures are marked by an asterisk (*). The term “ungrammatical” means that a
particular sentence is not possible in native English. “Ungrammaticality” here does not refer to SV
agreement or wrong tense use. For example, the sentence In some places still exist popularly supported
death penalty (5d) may be considered ungrammatical because there is a subject–verb agreement mismatch
but it is considered grammatical because PP (locative)-V-S is possible in native English.

12
(L1 Japanese; Oshita, 2000, p. 315).
b) … there exist two kinds of jobs.
(L1 Italian; Oshita, 2000, p. 315).
c) … there exist many kinds of prejudice.
(L1 Korean; Oshita, 2000, p. 315).
d) …there still remains a predominance of men over women.
(L1 Spanish; Lozano & Mendikoetxea,2008, p. 106).
(7) *it-insertion - V - S
a) *… it happened a tragic event …
(L1 Italian; Oshita, 2004, p. 119).
b) *…it existed a lot of restrictions.
(L1 Italian; Oshita, 2000, p. 315).
c) *…it will not exist a machine or something able to imitate the
human imagination.
(L1 Spanish; Lozano & Mendikoetxea ,2008, p. 106.).
d) *In the name of religion it had occured many important events…
(L1 Spanish; Lozano & Mendikoetxea, 2010, p. 486).
(8) *Ø -insertion - V - S2
a) *… like a mirage [ appeared the large expanse of the sea ]…
(L1 Italian; Oshita, 2004, p. 120).
b) *There is no doubt that [ does exist a big difference between…
(L1 Italian; Oshita, 2000, p. 316).
2 The existence of null expletives in Ø -insertion - V - S structures is argued by Oshita (2004) who claims
that null expletives are psychologically real to speakers of pro-drop languages and they occupy the
sentence subject position.

13
c) *…because [ exist science technology and the industrialization. ]
(L1 Spanish; Lozano & Mendikoetxea,2010, p. 487).
d) *It is difficult that [ exist volunteers with such a feeling against it.]
(L1 Spanish; Lozano & Mendikoetxea,2010, p. 487).
(9) *PP (temporal) - V - S 3
a) * after a few minutes arrive the girlfriend with his family too.
(L1 Spanish; Rutherford, 1989, p. 178).
b) *One day happened a revolution.
(L1 Italian; Oshita, 2004, p. 120).
c) *In 1760 occurs the restoration of Charles II in England.
(L1 Spanish; Lozano & Mendikoetxea,2010, p. 486).
The interesting fact is that learners of L2 English with typologically different L1s
produce the same type of errors, which is a phenomenon that needs to be accounted for.
This study examines the acceptance of all XP-V-S structures listed in (5-8). PPtemp-V-
S (9), which has been widely reported in the literature, will be further referred to in
order to support the Unaccusative Hypothesis but will not be examined in this empirical
study, as we will use PPloc (i.e., locative inversion) instead, in the experimental section.
1.2 AN OVERVIEW OF L2 ACQUISITION
In this section we will present a brief overview of some of the main linguistic theories
that aim to account for second language acquisition (SLA), as well as the main
individual factors involved in SLA. The purpose here is not to show an exhaustive
description of the different theories and constructs of SLA, which would be out of the
3 As shown by the examples PP locative produced by learners is typically structurally possible in English
as will be discussed further on this dissertation, while PP temporal is not. Learners however consider
*PPtemp-V-S structures to be grammatical probably due to the grammaticality of PPloc-V-S hence it can
be said that they use use a loco/temporal PP preverbal element as a general device.

14
scope of this study, but rather a preliminary background that will help contextualize this
dissertation.
Mitchell and Myles (2004) define second language acquisition (SLA) as the learning
of another language (other than the mother tongue) spoken in the community or the
learning of any foreign language. There is not yet a general overarching theory that can
fully account for all aspects of SLA, though different approaches and theories try to
explain how the L2 learner acquires linguistic knowledge, each approach showing a
different focus.
1.2.1 LINGUISTIC THEORIES OF SECOND LANGUAGE ACQUISITION
An early theory trying to account for SLA was Contrastive Analysis (CA). It was a
very influential SLA theory in the 60s which studied the interference of L1 on L2,
known as transfer or cross-linguistic influence. It was proposed by Lado (1957) who
claimed the following:
the student who comes into contact with a foreign language will find some features of it
quite easy and others extremely difficult. Those elements that are similar to his native
language will be simple for him, and those elements that are different will be difficult.
(Lado, 1957:2)
This theory contrasted different linguistic levels of L1 and L2 (morphology, phonology,
syntax, semantics) in order to determine the differences and similarities between two
languages and to predict the possible problematic areas for the L2 learner. If a certain
structure is different in L1 from L2, CA predicted that an error or negative transfer will
occur.
(10) Syntactic structure
a) English Adj-N (white house).
b) Spanish N-Adj (casa blanca) transfer * house white
c) Macedonian Adj-N (Bela kukja)
White house

15
„A white house‟
Noun phrases with adjectives in Spanish have the N-Adj order (casa blanca) while in
English the order is Adj-N (10a) (white house). CA would predict that Spanish learners
of L2 English will produce the ungrammatical *house white (10b) due to negative
transfer. Macedonian learners of L2 English will not produce *house white as
Macedonian has the same Adj-N order as English. They will produce the correct white
house (10c), example of positive transfer which does not cause errors and occurs when
a certain structure is similar in L1 and L2.
The CA is based on the psychological theory of behavourism, which considers SLA to
be a habit formation process during which learners repeat and imitate the stimuli from
the input they are exposed to. Correct imitation should be encouraged and incorrect
imitation should be immediately corrected.
Even though this theory was widely accepted by linguists in the 60s, it started losing
support when it could not answer why learners did not make L1 transfer when it was
expected. An example is the order of object pronouns. In English the object pronoun
occurs postverbally as shown in (11a). In Spanish the object pronoun is placed
preverbally between the subject and the verb, as in (11b). It would be expected for L1
Spanish L2 English learners to make negative transfer (11c) but they produce the
correct „I see them‟ (Hawkins 2001).
(11)
a) I see them
b) Yo los veo
c) I them see [not produced by L1 Spa-L2 Eng]
English learners of L2 Spanish, on the other hand, produce the incorrect “*Yo veo los”
or even “*Yo veo ellos”, which may be considered to be negative transfer from their L1
English. Nevertheless, as we will see in this dissertation, what may seem as clear cases
of transfer, on closer inspection (if we use a fine-grained linguistic analysis) prove to be
cases due to universal developmental patterns, which are well attested in SLA. For
example, adult beginners use simple sentences in the SLA the same as children do when
they learn their mother tongue as shown in (12). These structures are produced by
learners of various L1 backgrounds where they are (morpho) syntactically different
from each other. This clearly indicates that not all L2 errors are due to transfer.

16
(12) No understand
Yesterday I meet my teacher
(Lightbown and Spada 2001, p. 36)
In short, these basic examples indicate that L1 is not the only source of errors in the
SLA process.
The failure of CA to predict all errors produced by L2 learners brought the study of the
origin of errors called Error Analysis (EA) which supports Chomsky‟s (1965) claim
that humans have innate language learning abilities. EA proposes that errors are not bad
habits, as was proposed by the CA. They may occur due to L1 transfer, but they may
also be a product of the innate or cognitive capacities of the learner. Corder (1967)
defined the difference between error and mistake, the former being systematic
referring to learners‟ current knowledge of the language and the latter being
unsystematic errors of performance occurring due to tiredness, anxiety or other external
factors. Even though this theory, which was widely accepted, meant an important leap
forward in our understanding of SLA, it has certain limitations:
i. The origin of errors may be difficult to classify. The no+verb constructions (I no
have a bike) might be considered a transfer error for Spanish L2 learners of
English, but the same error is produced by other L1 learners of L2 English
whose negative structure is not no+V and, additionally, has also been noticed in
L1 English acquisition. It may be the case that „no+verb constructions reflect
transfer and developmental processes working in conjuction (Ellis 2008:311), or
perhaps simply a universal developmental process.
ii. Since EA focuses on the origin of errors, it may not be able to indicate what
exactly has been acquired by the learner.
iii. Learners may avoid L2 structures which do not exist in their L1, which may lead
to lack of data necessary to provide insights about the acquisition of a particular
structure. Schachter (1974) discovered that Chinese and Japanese L2 learners of
English make fewer errors in using relative clauses than Arabic or Persian
learners because these structures are absent in their L1s.
EA stated that learners base their linguistic knowledge on different sources and make
errors which are not always caused by L1 transfer. They may be part of the

17
developmental stages of learners‟ interim grammar defined as Interlanguage by
Selinker (1972). The theory of Interlanguage, which has had a tremendous impact on
our understanding of SLA, studies the development of learner‟s mental grammar, which
is constantly changing as the learner advances towards native-like competence. The
development of the interlanguage is influenced by L1, input and cognitive mechanisms.
All Interlanguage grammars have the following properties:
i. Systematic: Governed by abstract rules at any stage of L2 development.
ii. Transitional: It changes frequently and the progression may be discontinuous (U
shaped learning). At initial stage learners use the correct grammatical form of an
L2 structure (came, ate, went) but they do not understand the rules of the
structure. They only learn the form. At the next stage the learner starts
understanding the rules of the structure and it seems that instead of advancing
their knowledge they go backwards by overgeneralizing and using an incorrect
form of the structure (comed, eated, goed). The last stage shows that learners
have acquired the rules of the structure and use the correct irregular (came, ate,
went) and regular forms of the structure (stayed, played).
iii. Learning strategies: These cognitive mechanisms are used by learners when
building their interlanguage grammar e.g. overregularization (Tanya comed
yesterday).
iv. Fossilization: Interlanguage often fossilizes at a certain stage (according to
Selinker 95% of L2 learners) and does not advance even though learners are
exposed to sufficient input.
v. Variability: Even though it is systematic, the interlanguage grammar shows
variability. The examples in (13) are taken from L1 Spanish – L2 English
learners. This is in fact the type of structures we will analyze in this study.
(13) a) Optional production of passive and active sentences due to the type
of intransitive verb:
Last year my mother died/Last year my mother was died.
b) Production of preverbal/postverbal subjects due to the type of verb
(unaccusative) and the type of subject (light/heavy and topic/focus).
It exist many problems in Spain

18
Many problems exist in Spain
There exist many problems in Spain
The theory of Interlanguage has been largely influential in SLA research in the 70s. The
studies based on the Theory of Interlanguage claim that SLA is governed by a
computational model or innate language acquisition device (LAD), later known as
Universal Grammar (see discussion below).
The morpheme order studies in the 70‟s focused on the acquisition of morphology in
L1 and L2 acquisition and investigated the developmental stages of learners‟
interlanguage. Brown (1973) conducted a longitudinal study on the acquisition of 14
grammatical morphemes in the L1 English of three children. The major finding showed
that all three children followed the same order of acquisition of the morphemes, which
is shown in Table 1 (illustrating the first ten morphemes). Brown‟s study found that the
frequency of input is not crucial for the order of acquisition of morphemes. The definite
article the or 3rd person singular – s are widely present in the input but they are
acquired quite late. Similar orders to Brown‟s have been confirmed by later research
studies examining L2 acquisition of morphemes by children (Dulay and Burt 1974a).
Table 1: Development of morphology in L1 English (Brown 1973)
AGE MORPHEME EXAMPLE
1 2 present progressive -ing Mommy running.
2 prepositions (in, on) in the box
3 plural - s two books
4 2,6 irregular past baby went
5 possessive - s daddy’s hat.
6 uncontractible copula – be Annie is a nice girl.
7 3 article - a, an, the a cat, the cats
8 3,6 regular past - ed She walked
9 3rd person singular -s He lives in the USA.
10 irregular 3rd person - s She has a dog.
Bailey, Madden and Krashen (1974) studied the order of acquisition of morphemes of
L2 English by 33 adults with various L1s. They discovered that adults, irrespective of

19
their L1, follow similar pattern as children acquiring their L1 morphology and they
named it „the natural order‟ of acquisition of morphemes shown in Table 2 below.
Table 2: Development of morphology in L2 English (Bailey, Madden and Krashen 1974)
If we compare Table 1 and Table 2, it can be seen that the acquisition order of L1 and
L2 morphology is similar, indicating that L1 influence in the SLA process for
morphology is not as large as originally proposed by the CA proponents. Other studies
have been conducted and have confirmed the natural order for the acquisition of syntax,
e.g., negation, questions (Bloom and Lahey 1978, inter alia).
The idea proposed by the Morpheme Order Studies states that interlanguage grammar
develops systematically and independently of the influence of the input or L1, in
contrast to the previous proposals of the CA.
The Monitor Model was developed by Stephen Krashen (1982), who was one of the
researchers conducting the Morpheme Order Studies in the 70s. This model, consisting
of five hypotheses, became very influential in SLA research and pedagogy in the 80s.
i. The Acquisition-Learning Hypothesis states that there are two independent
systems for developing second language ability. ACQUISITION is the
unconscious learning process (similar to what occurs with children acquiring
their mother tongue) and LEARNING employs the conscious language learning
process, i.e., explicit knowledge about the language. Some of the features of
both systems are presented in Figure 1.

20
Figure 1: Features of Acquisition and Learning Systems according to Krashen’s Acquistion-Learning Hypothesis.
ii. The Monitor Hypothesis explains how the separate systems of ACQUISITION
and LEARNING are used in second language performance. Acquisition
"initiates" L2 utterances and provides the fluency of communication. Learning
functions as a MONITOR of the produced utterances and is responsible for their
editing or changing (self-correction) after they have been produced by the
acquisition. This is possible when certain necessary but insufficient conditions
are met (sufficient time to think, knowledge of the rules and focus on form).
This process is shown in Figure 2 below.
Figure 2: Krashen’s Monitor Model of Language Acquisition
iii. The Natural Order Hypothesis is based on the morpheme order studies
claiming that there is a natural order for the L2 acquisition of English
morphology, which is similar to the order followed by children acquiring their
L1 English. Krashen made a summary of the morpheme order obtained by
several studies, as shown in Figure 3. Morphemes are acquired according to a
predictable natural order which is independent of what is taught in class.
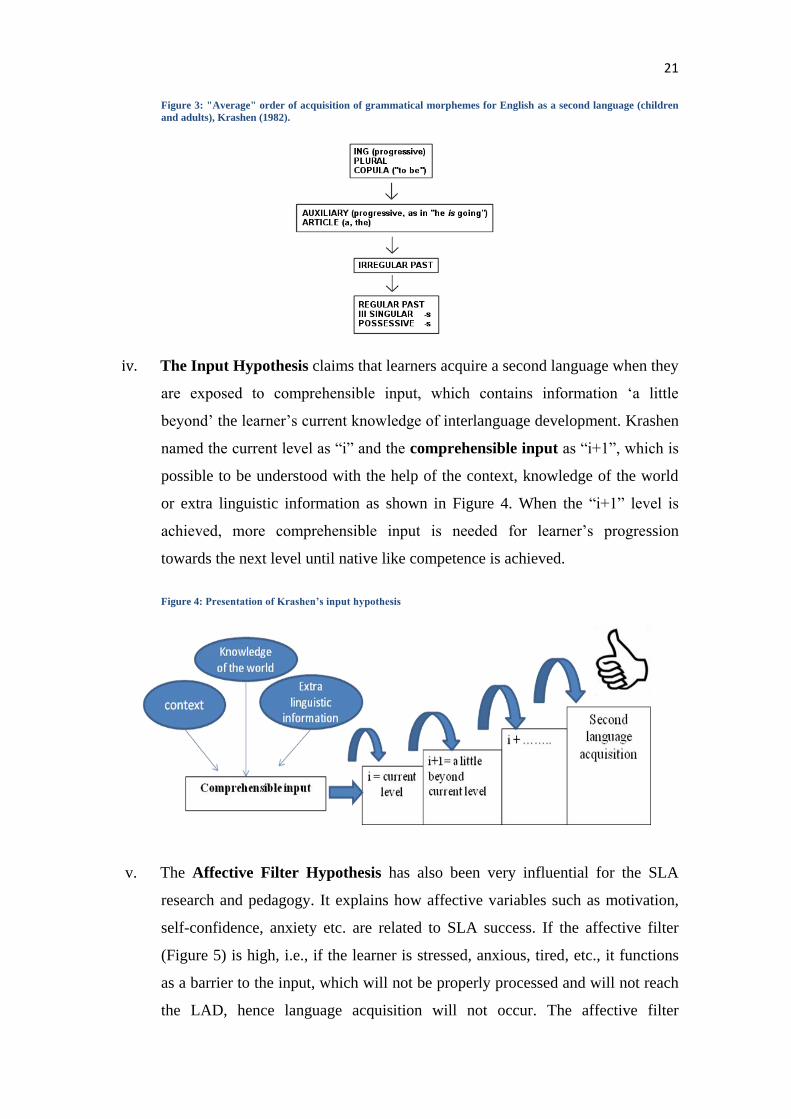
21
Figure 3: "Average" order of acquisition of grammatical morphemes for English as a second language (children
and adults), Krashen (1982).
iv. The Input Hypothesis claims that learners acquire a second language when they
are exposed to comprehensible input, which contains information „a little
beyond‟ the learner‟s current knowledge of interlanguage development. Krashen
named the current level as “i” and the comprehensible input as “i+1”, which is
possible to be understood with the help of the context, knowledge of the world
or extra linguistic information as shown in Figure 4. When the “i+1” level is
achieved, more comprehensible input is needed for learner‟s progression
towards the next level until native like competence is achieved.
Figure 4: Presentation of Krashen’s input hypothesis
v. The Affective Filter Hypothesis has also been very influential for the SLA
research and pedagogy. It explains how affective variables such as motivation,
self-confidence, anxiety etc. are related to SLA success. If the affective filter
(Figure 5) is high, i.e., if the learner is stressed, anxious, tired, etc., it functions
as a barrier to the input, which will not be properly processed and will not reach
the LAD, hence language acquisition will not occur. The affective filter

22
hypothesis explains that when L2 learners fossilize at a certain developmental
stage in spite of the abundant comprehensible input, it is probably due to the
affective filter.
Figure 5: Presentation of Krashen’s Affective Filter Hypothesis
Krashen‟s monitor model has been very influential in the 80s and the 90s for the SLA
acquisition theory, even though it has been criticized for being descriptive without
explaining in detail how the L2 input is converted into L2 knowledge. It also neglects
the role of L1, even though it mentions that L1 does not have a great influence over the
natural order of acquisition.
The Theory of the Universal Grammar (UG) claims that human beings have an innate
capacity to acquire their native language (L1). It states that acquisition of L1occurs
through the inborn language learning mechanism which allows the acquisition of any
language in a native-like form. The presence of the UG in the L1 acquisition process is
evident in the following occurrences (Lightbown and Spada 2001; White 2003; Mitchell
and Myles 2004; Hawkins 2001):
i. Lack of negative evidence: It is a known fact that parents do not correct their
children every time they make mistakes when they learn their mother tongue.
Even when they do provide correction, children do not seem to benefit from it
and continue using the form they have acquired up until that moment. They start
using the correct form when they become „ready‟ to use the structure,
independently of whether a correction has been provided or not. Such example
is shown in (14)
(14) Child: I putted the plates on the table

23
Mother: You mean, I put the plates on the table
Child: No, I putted them on all by myself.
(Lightbown and Spada 2001 p.16).
ii. Poverty of stimulus: This is also known as „the logical problem of L1
acquisition‟. It states that UG is responsible for the acquisition of L1 because
children acquire complex and abstract L1 structures which are underdetermined
in the input. White (2003:5) gives an example of abstract knowledge which is
successfully acquired by children. She explains the complexity of the
distribution of overt or null subject pronouns in embedded sentences in non-pro
drop and pro-drop languages, regarding the type of antecedent in the main clause
they refer to. Namely, in non-pro drop languages like English the embedded
overt pronoun can have a referential (15a), a quantified (15b) and a discourse
antecedent (15c).
(15)
a) referential antecedent [Maryi thinks [(that) shei will win]]
b) quantified antecedent [Everyonei thinks [(that) shei will
win]]
c) discourse antecedent [Whoi thinks [(that) shei will win?]]
White argues that quantified antecedents allow the pronoun to be ambiguous, as
shown in (15b), and explains the ambiguity as follows: if one imagines a room
full of women and everybody thinks of herself as a possible winner or everybody
thinks that one specific woman is a winner.
In pro-drop languages like Spanish and Macedonian, the null subject will take
either a referential or quantified expression in the main clause (see example
from Spanish in (16a,b) and Macedonian (16 c,d)) although it is not
ungrammatical if the overt pronoun is used with the referential antecedent (yet
it is pragmatically redundant). The use of an overt pronoun with a quantified
antecedent is ungrammatical.
(16)
a) referential antecedent [Juani cree [que proi es inteligente]]

24
Johni believes that (hei) is intelligent
[Juani cree [que éli es inteligente]]
Johni believes that hei is intelligent
b) quantified antecedent [Nadiei cree [que proi es inteligente]]
Nobodyi believes that (hei) is intelligent
*Nadiei cree [que eli es inteligente]]
Nobodyi believes that (hei) is intelligent
c) referential antecedent [Juani veruva [ deka proi e inteligenten]]
Johni believes that (hei) is intelligent
[Juani veruva [ deka toji e inteligenten]]
Johni believes that hei is intelligent
d) quantified antecedent [Nikoji ne veruva [deka proi e inteligenten]]
Nobodyi believes that (hei) is intelligent
*Nikoji ne veruva [deka tojli e inteligenten]]
Nobodyi believes that (hei) is intelligent
White (2003) presented an abstract and complex rule which is not possible to be
learnt or acquired from mere exposure to the input. It has to be inferred
somehow from the innate faculty which provides the possibilities for the
formation of mental language representations.
Our study also deals with a poverty of stimulus structure governed by complex
rules which is underdetermined in the input, namely, the unaccusative/unergative
distinction.

25
iii. Rapid development: Children acquire most of the grammatical structures until
the third year. By the fifth year, children are able to produce abstract and
complex grammar which could not be happening due to their ability to analyze
complex structures because they are very young. This phenomenon is possible if
the innate mental language capacity (UG) is at work. Note that learning such
subtle rules takes learners many years and, in most cases, they never achieve
native-like competence.
.
iv. Uniformity: All children learn their mother tongue following the same route in a
uniform manner. Note, by contrast, that L2 learners show variability in success,
which is a trademark of SLA.
v. Grammatical success: All normally developed children achieve native
knowledge of their mother tongue grammar irrespective of their intelligence,
culture, race etc. contrary to L2 learners, which rarely attain native-like L2
competence.
vi. No effort: Children acquire their mother tongue4 without employing any
conscious effort, contrary to L2 acquisition, which is achieved consciously and
with effort (as was previously discussed for the Krashen‟s Monitor Model).
Universal Grammar consists of Priniciples and Parameters (Chomsky, 1981) which
form the design of natural languages. The principles are equal for all languages hence
they are universal and they consist of parameters which cause variation between
languages, i.e., certain parameters are „on‟ for some languages and „off‟ for other
languages. A single parameter setting possesses a cluster of syntactic properties,
although in current version of the models parametric variation is located in the abstract
linguistic features of functional categories. All natural language grammars may be
explained with this syntactic model, which has given opportunities to language
researchers to provide a viable account for the acquisition of L1 and L2 in terms of the
4 The acquisition of L1 is argued to have a critical period (CP) beyond which it will be impossible to
develop native like language features (the cases of Victor and Genie described in Singleton and Ryan,
2004).

26
learners‟ interlanguage linguistic competence only (since the model is silent about
other learner-related characteristics such as motivation, aptitude, etc).
Hawkins (2001) explains the null subject parameter. The universal principle i.e.
Extended Projection Principle (EPP) (Chomsky, 1981) says that all languages have a
grammatical subject, while the parameter provides the possibility for the subject to be
overt (phonetically represented) or null (phonetically empty). In English there are
expletive and referential subjects which are phonetically represented in subject position,
while in Spanish and Macedonian subject position may be occupied by the empty (null)
subject, as shown in (17).
(17)
English It rains I believe that she speaks English.
Spanish Ø Llueve Ø creo que Ø habla Ingles
Macedonian Ø Vrne Ø veruvam deka Ø zboruva angliski
Hence, according to the Principles and Parameters model, the input provides the
design of the mother tongue for the child. The child acquires a certain form of a
proposed parameter (overt or null subjects) with the help of the innate capacity which
allows natural language acquisition.
Therefore, UG provides a “template” of options for the child (e.g., overt/null) and then
the child will set the parameter to its correct value according to the input he/she hears.
The various language acquisition theories we have mentioned so far attempt to
formulate understandable explanations on how language is learnt. It is obvious that
these theories offer acceptable clarifications of the language acquisition process,
although none of them can account for every aspect of language development or even
for other learner-related characteristics not having to do with language itself. The
impossibility for the theories to arrive at a universal acceptance by linguists leads to the
fact that there are other factors affecting second language learning, such as individual
differences.
1.2.2 INDIVIDUAL DIFFERENCES IN SECOND LANGUAGE ACQUISITION
UG mentions the creative ability of the learner to use inner mental mechanisms and
arrive to conclusions. Researchers have agreed that every learner has unique

27
characteristics (Krashen 1995; Lightbown and Spada 2001; Mitchell and Myles 2004)
which influence the outcome of the SLA, in spite of the fact that it is difficult to
measure or directly observe these qualities. Cognitive factors (intelligence, language
aptitude, language learning strategies), affective factors (language attitude, motivation,
language anxiety) and age are the unique features of every individual learner
influencing the SLA success. These factors are claimed to be responsible for the wide
variability in L2 attainment, i.e., the fact that, unlike L1 acquisition, some L2 learners
achieve relatively high levels of native-like competence, while most fall short of it to
varying degrees, as discussed above.
The group of cognitive factors consists of (i) intelligence, which has been claimed to
lead to better language learning results (at least in formal settings); (ii) aptitude, which
stands for the special „feeling‟ for languages possessed by some learners and which
appears to help some learners acquire language more easily and rapidly; (iii) the use of
language learning strategies (LLS) as “behaviors and thought processes that learners
use in the process of learning.” (Rubin 1987:19), which is considered to be very helpful
in SLA, as proven by the great number of studies dedicated to LLS.
The affective factors encompass: (i) anxiety, which is inhibitory for language learning
success; (ii) attitude of the learner towards the second language and the culture of its
native speakers, which influences SLA success; (iii) motivation, which governs the
pushing force for undertaking language learning activities.
The age factor, which most researchers consider a biological factor, has caused many
controversies among researchers who have argued the possibility for the existence of a
critical period (CP) for language learning, as proposed by Lenneberg (1967). Beyond
this critical period (supposedly the age around 12), the learner will not be able to
achieve native like competence of the second language. Some researchers support the
existence of a critical period in the SLA process (Singleton 1995; Singleton and Ryan
2004; Scovel 2000) and others have attempted to prove the opposite, that native like
competence can be achieved at an older age as well (Ioup 1995; Bialystok 2001).
1.2.3 SOURCES OF INTERLANGUAGE (IL) KNOWLEDGE
As was previously underlined, interlanguage (IL) stands for the variable and dynamic
learner language system which follows developmental stages over the course of

28
language learning. The variability of the IL performance leads to the question of the
sources influencing the development of the learners‟ interlanguage grammar.
Ritchie and Bhatia (2009) present the „sequence of interlanguage systems’ as follows:
ILS1, ILS2 …. ILSi, ILSi+1…. ILSu‟ (p.26), out of which the final one presents the last
stage of a particular case of SLA. The middle stages of the interlanguage do not
coincide with the grammar of L1 or L2, but they refer to a proper and systematic
grammar internalized by the learner and which is developing under the influence of
various sources.
There are many cases when learner‟s grammar differs systematically from the grammar
of the native speaker, as indicated in (18) (Reynolds 1995), coming from a study
conducted with native Japanese, Chinese, Korean and Indonesian and showing the
difference in the distribution of expletive pronominal subjects which are semantically
empty. This example may be an indication that L1 transfer influences learner‟s
grammar.
(18) I prefer the weekend because is my free time ... I don't have to think
what hour is necessary to wake up ... I consider is necessary to have weekend
because in this case people always will be more relaxed and will work in the
rest of the days better.
The influence of L1 transfer on learner‟s grammar has been proved by other studies as
well. Fathman (1975) studied Korean and Spanish children learning English and
showed that Korean children acquired articles later than Spanish children, which was
accounted for by the absence of this structure in their L1 Korean. Hakuta (1976)
conducted a longitudinal study examining the acquisition of morphemes of a child
Japanese learner of English and noted that structures such as plurals or articles, which
are absent in Japanese, were acquired quite late. Therefore, he claims that innateness
cannot account for all aspects of language development. But recall from our discussion
about Contrastive Analysis earlier that L1 transfer is not the only source of learners‟
errors.
Input alone is necessary but not sufficient for SLA (White 2003). It was previously
mentioned that various linguistic theories gave input different significance for the SLA
process. Brown (1973) and Krashen (1982) were among the first researchers to confirm

29
that learners do not necessarily acquire first what is taught first or what is frequently
present in the input, e.g. the definite article the is acquired quite late both by children
acquiring their L1 and adult learners of L2 English. Hawkins (2001) explains that even
though input may be different in naturalistic and classroom environments, learner
development is similar in the two settings, which suggests that input has a minor
influence on the course of learner development.
White (1991) studied the role of input in the classroom studying the acquisition of the
position of adverbs by L1 French L2 English learners. She was interested whether
learners would benefit more if the instruction was based on the form, i.e., teaching
explicitly the grammatical structure or if learners were exposed to input flooding, i.e,.
input which contains frequent use of adverbs. In English, adverbs of frequency occur
preverbally (Mary often plays the piano – SAVO) while in French they occur
postverbally (*Mary plays often the piano – SVAO). White concluded that formal
instruction influences the acquired knowledge on a short term basis, but it does not have
a significant long-term influence. Hence it could be assumed that formal instruction
does not necessarily mean that learners will acquire a certain structure.
On the other hand Long (1983) reviewed 11 studies which examined classroom,
naturalistic and mixed exposure to L2 and concluded that formal instruction helps in the
achievement of a rapid and better language acquisition without influencing the course of
development,i.e., teaching may change the rate (speed) of acquisition, but not the route
(course) of acquisition). Hence input and instruction play an important role in achieving
better or rapid SLA results but they do not change the course of acquisition of linguistic
structures.
There are cases when learners acquire structures which are not frequent in the input,
even though they are not taught how to construct them. Learners demonstrate
unconscious knowledge of complex structures which are unlikely to be derived from L2
input or instruction.
Learners somehow acquire certain structural grammatical rules, e.g., the production of
postverbal subjects in English with a subtype of intransitive verbs called unaccusatives
(come, appear, exist, happen) as indicated in (19a), and which are the focus of this
dissertation. Sometimes they introduce some elements which may be an indication of
transfer from their L1 (if they are natives of a pro-drop language such as Spanish) as
shown in (19b), which is an ungrammatical structure with a null expletive in English. In

30
other cases, learners produce structures as a result of their grammatical development,
including an overt subject “it”, which is ungrammatical, as shown in (19c), but indicates
that learners have started understanding the function of the structure i.e. they are
following certain developmental stages to acquire the structure.
(19) a. There existed social ills as serious as the ones that exist today.
b. It is difficult that exist volunteers with such a feeling against it.
c. In the name of religion it had occurred many important events.
(L1 Spanish; Lozano & Mendikoetxea, 2010, p. 486-487).
These examples show that interlanguage knowledge is influenced by various sources:
L1 transfer, innateness, developmental mechanisms, input etc.
As we will see in the following sections, the acquisition of an abstract syntactic
structure, namely, postverbal subjects in L2 English, as in (19), will be discussed. It will
be shown that learners‟ knowledge of postverbal subjects is too subtle to be accounted
for only by L1 transfer or by input alone.

31
2 LINGUISTIC BACKGROUND: UNACCUSATIVITY
AND POSTVERBAL SUBJECTS
In this section we will briefly discuss the preliminary theoretical foundations relevant
for our study. We will also introduce the unaccusative syntax and how it is represented
in the languages under consideration with the focus on word order.
2.1 PRELIMINARY THEORETICAL FOUNDATIONS
In the following subsections, brief introduction to the role of Universal Grammar (UG)
in SLA will be presented. We will then move on to the pro-drop parameter, which is
central for our discussion, since both Macedonian and Spanish are pro-drop languages.
In particular, we will focus on the second property of the pro-drop parameter, namely,
subject-verb inversion (i.e. postverbal subjects). Finally, we will present a brief
overview of the architecture of the language faculty, which is essential to understand
some of the later findings in the empirical section.
2.1.1 L2 ACQUISITION AND UNIVERSAL GRAMMAR
As discussed in the preceding chapter, UG is a system of principles and parameters
which constrains L1 grammars. L2 learners have the similar task as L1 learners i.e. to
arrive at a native-like knowledge of the linguistic system in order to acquire a certain
language. If, according to UG, languages are acquired through the operations of the
inborn language acquisition device (LAD), which is active for L1, it could presumably
be active for L2 acquisition. Then it is understandable that similar language learning
processes will be followed, i.e., the setting of language parameters in L2 has to take
place, though this has been a very controversial issue over the past three decades (see
Hawkins 2001 and White 2003 for overviews).
The role of UG is obvious in cases where poverty of stimulus occurs. These are cases
when L2 learners cannot infer some abstract grammatical knowledge from the input,
formal instruction or transfer due to rare usage of the structure, yet they manage to
acquire it (Hertel 2003; Lozano 2006a, 2006b; Lozano 2008; Lozano and Mendikoetxea
2008, 2010, Oshita 2000, 2001, Zobl 1989; see also the earlier discussion in the

32
preceding chapter). The explanation for these phenomena is typically attributed to the
fact that learners know more than what is present in the input due to the presence of the
inborn language learning ability.
White (2003) discusses whether UG is accessible in SLA. There are several options:
i. No access is the first hypothesis, claiming that UG is accessible only for L1
acquisition and not for L2 acquisition.
ii. Full Access is the second hypothesis, according to which second languages are
constrained by UG. Mitchell and Myles (2004) further elaborate that this access
has three positions:
a. Full access/no transfer: UG is completely accessible in L2 acquisition,
the same as in L1 acquisition
b. Full access/full transfer: UG is completely accessible in L2 acquisition,
but learners transfer the parameters of their first language in initial
stages, which are then reset in further stages when L2 ceases to conform
to the first language parameters
c. Full access/early impaired representations: UG is partially accessible in
a way that L2 parameters can be reset, but initially they lack functional
categories.
iii. Indirect Access: proposes that learners have access to UG, but only through
their L1 grammar. L1 developed parameters form the basis for second language
development.
Zobl (1983) discusses the default stages of parameters and supports the idea that the
initial state of the learner is his/her L1 setting, which may have marked and unmarked
structures. If the L1 has an unmarked form of a certain structure and the second
language uses a marked form of the same structure, the parameters for this structure
have to be reset, meaning that the learner has to be exposed to more input to acquire this
particular structure. This may be an indicator that a particular parameter is marked. If
the second language also uses the unmarked form of the structure, then the parameters
will not be reset and the structure will be acquired more easily compared to a marked
one. This point of view may explain the possible developmental L2 acquisition stages.

33
An example of a marked /unmarked setting is presented by Hawkins (2001). Namely,
English learners of L2 French find it more difficult to acquire the preverbal pronominal
object described in (20a) and they often produce the ungrammatical (20b), which is the
same as English (20c). Therefore, we might assume that they are making transfer from
L1. French learners of English, on the other hand, do not have any issues acquiring the
final position of object pronouns in English (20c) and never produce (20d), which is
unattested, as marked by the symbol “@”.
(20)
a. Le chien les a mange
b. *Le chien a mange les.
c. The dog has eaten them.
d. @The dog them has eaten
This might be an implication that the unmarked setting for the pronominal direct object
places it in postverbal position, which in French undergoes movement of the NP to
preverbal position whenever a pronominal subject is used.
White (2003) explains that the main idea of the Principles and Parameters theory is that
one parameter setting encompasses a whole cluster of related syntactic properties. The
learner only needs to discover one feature of a single parameter and the whole cluster of
syntactic properties will be automatically elicited. This can be indicated by the
elaboration of the settings of the pro-drop parameter which is relevant for our study.
Current generative L2 theory however, does not focus on the assumption whether
parameters encompass a cluster of properties. The trend nowadays is to explore whether
learners can acquire features and, in particular, whether learners show deficits at the
interfaces (which is one of the topics we will mention later).
2.1.2 THE PRO-DROP PARAMETER
Cook (1983) refers to the Extended Principle Parameter (EPP) (Chomsky, 1981), and
states that every sentence has a subject, exemplifying that some languages like English
require subjects to appear in their surface structure (21a) and languages like Spanish
(21b), Macedonian (21c) or Italian, (21d) may omit the subject in the sentence:

34
(21)
a) He speaks English
b) Habla Spanish
c) Zboruva Macedonian
d) Parla Italian
The pro-drop parameter encompasses a cluster of properties which characterize all pro–
drop languages (Spanish, Macedonian, Italian, Greek, Arabic etc.), as discussed by
numerous researchers (e.g., Haegeman and Gueron 1999; Hawkins 2001; Phinney 1987;
Cook 1993, Lozano 2002, 2008):
i. Null subject (pro): regarding the pro–drop parameter, two groups of languages
can be distinguished. The ones that allow the null or pro subject (Spanish,
Macedonian, Italian, etc.) called pro-drop or null subject languages and the ones
that require overt subjects (English, German, French etc.) called non pro-drop or
non null subject languages (22a). It is considered that even though the subject
may not appear overtly in the surface structure in pro–drop languages like
Spanish, Macedonian and Italian, it exists in sentence initial position (as it is
understood semantically) in the form of a phonetically empty null subject or pro
(22 b,c,d).
(22)
a) He speaks English
b) pro habla Spanish
c) pro zboruva Macedonian
d) pro parla Italian

35
ii. Free5 subject–verb inversion (postverbal subjects)
Tres chicas llegaron. SV (Spanish)
Three girls came
pro llegaron tres chicas VS
pro came three girls
„Three girls came‟.
(L1 Spanish; Lozano & Mendikoetxea,2010, p. 477).
Tri devojki dojdoa SV (Macedonian)
Three girls came
pro dojdoa tri devojki VS
pro came three girls
„Three girls came‟.
iii. ‘That’-trace effects; Pro-drop languages (Spanish, Macedonian) allow „that
trace‟ which means that the complementiser “que” (Spanish), “deka”
(Macedonian), „remains in trace position after Wh-movement from subject
position‟(Cook 1993:161). Non pro-drop languages like English have a trace t in
the surface structure. The overt use of the complementiser „that‟ is
ungrammatical in English.
Spanish - ¿Quién dijiste que vino? (Who did you say that came?)
Macedonian - Koj rece deka dojde ? (Who did you say that came?)
5 At this stage we are just using a traditional approach to the pro-drop parameter and simply state that
Subject-Verb inversion is „free‟. However, as we will see later, such apparently free inversion is
constrained by several interfaces: lexicon-syntax interface (Unaccusative Hypothesis), syntax-discourse
interface (End-Focus Principle) and syntax-phonology interface (End-Weight Principle).

36
English - Who did you say t came? vs. *Who did you say that came?
(Cook, 1993, p. 162).
iv. Expletives it and there: The expletives serve as empty (dummy) subjects for the
requirements of non pro-drop English to have its subject position filled and case
features checked in non pro-drop languages which require an overt subject. They
are usually used in some „existential‟ sentences such as:
There 6are good teachers and bad teachers.
There is plenty of ice cream.
(Ward, G., Birner, B. J., & Huddleston, R, 2002, p.1393)
or “weather” sentences such as.
It’s raining.
It’s snowing.
Expletive „it‟ is the most unmarked personal pronoun used as empty expletive in
expressions referring also to time and distance: e.g. It‟s long way from here to Cairo
(Quirk 1985:349).
Pro – drop languages do not require overt expletives due to the fact that they allow their
subject position to be occupied by the null proexpl subject which can also check case
features. The null proexpl is the silent counterpart of the dummy it and there. They have
the same syntactic function with the difference that proexpl is not phonetically
represented. The structures containing the empty proexpl subject are presented as
follows
proexpl hay muchos estudiantes en la clase (Spanish)
is a lot of students in the classroom
„There are a lot of students in the classroom‟
(Lozano 2002, p.73)
6 Expletive there will be explained in detail in 2.2.3.1.1.

37
proexpl ima dobri lugje (Macedonian)
have good people
„There are good people‟
(Minova-Gjurkova, 2000, p.176)
proexpl Llueve (Spanish)
rains
„It‟s raining‟
(Lozano 2002, p.73)
proexpl Vrne (Macedonian)
rains
„It‟s raining‟
(Minova-Gjurkova, 2000, p.176)
v. Rich agreement structure: Pro-drop languages (Spanish, Macedonian) show
rich agreement or inflectional morphology of verbs. The verb itself conveys
information about the person and the number of the subject. It contains the
necessary data about the subject which does not have to be overt, but is often
replaced by the null pro. Hence agreement governs pro. Non pro-drop languages
(English) have to have their subject in the surface position because they lack
inflections of the verb thus they have to provide sufficient information about the
doer of the action in the sentence. The difference between the pro-drop and non
pro- drop languages is the choice regarding the nature of agreement. We present
below examples from the verbal paradigm in English (23), Spanish (24) and
Macedonian (25), showing the difference in agreement between non pro-drop
English and pro-drop Macedonian and Spanish.

38
(23) English
1sg I speak 1pl We speak
2sg You speak 2pl You speak
3sg She speak-s 3pl They speak
(Haegman and Gueron, 1999, p.398)
As Haegman and Gueron (1999) state English has only one verbal inflection (3rd
person
singular – s). Subjects are obligatory to be used overtly in order to provide the necessary
information about the utterance. We cannot retrieve any information from the verbal
morphology about the subject. In other words, subjects cannot be identified by the poor
verbal morphology.
The example with the Spanish verb hablar (to speak) illustrates the rich agreement via
the six different agreement inflections for person (first, second and third) and number
(singular and plural) of the same verb. Hawkins (2001) explains that the inflections
define the person and number of the subject which does not need to be overt, but
remains empty in the form of the null pro.
(24) Spanish
1sg habl-o (I speak) 1pl habl-amos (We speak)
2sg habl-as (You speak) 2pl habl-ais (You speak)
3sg habl-a (She speaks) 3pl habl-an (They speak)
(Hawkins, 2001, p.198)
The same situation accounts for Macedonian which is another pro-drop language.
(25) Macedonian
1sg zboruva-m (I speak) 1pl zboruva-me (We speak)
2sg zboruva-sh (You speak) 2pl zboruva-te (You speak)
3sg zboruva-ø (She speaks) 3pl zboruva-at (They speak)

39
(See details for the morphological inflections in Macedonian in Friedman (1993, p.274))
As elaborated by Friedman (1993) and Minova-Gjurkova (2000) subject–verb
agreement in Macedonian expresses person (first, second and third) and number
(singular and plural). The infinitive verb forms can be predicted from the third person
singular in present tense which occurs without any inflections. Due to the fact that we
can elicit information about the subject from the rich morphology of the verb, in
Macedonian the verb may occur without the overt subject, similarly to what occurs in
Spanish.
Our study involves two pro-drop languages, Spanish and Macedonian compared to
English, a non pro-drop language. It focuses on subject-verb inversion i.e. postverbal
subjects as the 2nd
property of the pro-drop parameter.
2.1.3 THE ARCHITECTURE OF LANGUAGE AND THE INTERFACES
SLA research has been dealing with problematic areas even when UG access is obvious.
These areas are called interfaces, referring to „how different modules of the
interlanguage grammar relate to each other‟ as defined by White (2009). There has been
a shift of emphasis in SLA. Namely in the 80s and 90s there was a debate about access
to UG, but now the issue is related to the role of the interfaces in SLA. It has been
investigated whether failure to achieve native like competence in L2 acquisition can be
accounted for problems at the interfaces as an area where cross-linguistic influence
possibly occurs.
The Minimalist program of Chomsky (1995) explains that grammar consists of modules
such as syntax, semantics, morphology and phonology, mapping between each other at
different levels of representation (Figure 6). These interactions are called grammar
internal interfaces. The internal interface relevant for our study is the one between the
lexicon, containing the lexical items (and their corresponding linguistic features) to be
processed, and the syntax, functioning as a computational system or a processor
generating utterances made of the elements of the lexicon. These utterances are
produced by the grammar interfacing with external systems including the articulatory
perceptual (sensory motor (S-M)) at phonetic form (PF) and conceptual-intentional (C-
I) at logical form (LF). The PF deals with sounds while the LF deals with meanings of
linguistic elements.

40
Figure 6: The architecture of language
Sorace and Filiaci (2006) proposed the Interface Hypothesis stating that external
interfaces are more difficult to be acquired than internal interfaces. Figure 6 shows the
interaction between syntax and the knowledge of the external systems in L2 grammar.
The Conceptual-Intentional system encompasses discourse, pragmatics and information
structure which strongly influence language use even though they are external to the
computational system. Casielles-Suarez (2009) states that discourse determines new
information to be placed towards the end of the sentence. This is known as the End-
Focus Principle. The relation between focus and sentence-final position is evident for
pro-drop or null subject languages which allow subject pronouns to be null or overt. As
explained by White (2009), this choice is not optional i.e., it is discourse constrained:
null subjects are used in topic context while overt pronouns are required when focus
information is introduced. Additionally, any focused element, even the subject, may be
placed at sentence final position. English is a non pro-drop language using overt
pronouns to refer to old and new information which may not affect the syntax, even
though in certain occasions the topic-focus structure is followed.The acceptance of
postverbal subjects (VS) where the subject is focus is the target of this study which is
related to the 2nd
property of the null-subject parameter, something that will be
explained in the methodology section.
Wasow and Arnold (2003) indicate the possible reason for placing old information
before new information. Old information is more feasible to be produced early in
structures because it is more accessible than new information. It links the structure to

41
previous sentences and introduces the context for the new information which facilitates
comprehension and production.
Articulatory-Perceptual (or sensory motor (S-M)) system is another external interface
considered to be problematic for L2 learners. According to Wasow (1997), many
languages place light constituents at the beginning and heavy elements at the end of the
sentence, which is known as the End-Weight Principle. Due to the fact that language
use is a communicative activity, we have to analyze it from the point of view of the
involved participants. From the speakers‟ perspective, this may be due to facilitation of
planning and production of utterances. From the listeners‟ perspective, if complex
elements are placed at the end of the sentence, it will be more comprehensible. Lozano
and Mendikoetxea (2010) emphasize that „processing constraints in the performance
systems like the End-Weight Principle, influence syntax, leading to non-canonical word
order structures‟ (pp.480). This is, once again, related to the target of this study which
analyzes postverbal subject structures where the subject is focus and heavy.
White (2011) suggests that problems at the interfaces may not occur due to
representational differences between L2 and native speaker grammars. They may reflect
the processing problems of L2 learners who are not always able to use their underlying
knowledge to access the needed linguistic representation. She also adds that if L2
learners produce certain utterances in a different way than native speakers, it may
suggest that learners face not only production but comprehension problems, referring as
well to the possibility for interfaces to have several sources of difficulty. We will return
to these issues in the final discussion of this dissertation.
2.2 THE PHENOMENON UNDER INVESTIGATION: SUBJECT-
VERB INVERSION (SV/VS ORDERS)
This section shows examples of preverbal and postverbal subjects in the three languages
of interest for our study: English, Spanish and Macedonian, in order to present the
possibilities for the occurrence of subject-verb inversion (i.e., the second property of the
pro-drop parameter) and to emphasize the structures of interest for our study.
English language has a canonical SVO word order (Biber et. al. (1999); Ward, Birner &
Huddleston, (2002)) which regulates the principal elements in the sentence to have a
strictly determined position in the clause. The sentences in (26) show the fixed word

42
order of the English language, which places the subject (in bold) in sentence initial
position followed by the verb (underlined) and other sentence elements.
(26) SV
a) Kim wrote the letter.
(Ward, G., Birner, B. J., & Huddleston, R., 2002, p.1365).
b) Sharon plays bingo on Sunday night.
(Biber et al., 1999, p. 957).
c) Prime Minister John Major was opposite him on one of the
three tables set out for the lavish dinner.
d) A row of Van Goghs hung on one long wall.
e) A silver urn bursting with branches of red berries stood next
to it.
f) A bear is sitting in the corner.
g) Three girls arrived.
The unmarked canonical word order in English may be changed in order to meet certain
conditions of information flow (End-Focus Principle) or weight distribution (End-
Weight Principle) and to achieve emphasis, cohesion or stylistic effect.
As explained by Biber et al. (1999), besides fronting of postverbal elements, subject
verb inversion is one of the marked choices of English word order. There are two types
of inversion allowing variation of the position of the sentence elements: subject-
operator inversion (partial inversion) as in (27), which will not be of further interest
for our study, and subject-verb (full inversion), which is the focus of our study.
Subject-verb inversion is possible to occur in native English if (i) the clause-initial
position is occupied by an opening adverbial element (PPlocative, PPtemporal etc) (in
italics), (ii) the verb is intransitive or copula be denoting existence or appearance
(underlined) and (iii) the subject occurring at clause-final position is heavy and
introduces new information (in bold) as shown in (28).

43
(27) subject-operator inversion
At no time did he indicate he couldn‟t cope.
(Biber et al., 1999, p., 916).
(28) subject-verb inversion (PP-be-S) / (PP-V-S)
a) Opposite him on one of the three tables set out for the lavish
dinner was Prime Minister John Major.
b) On one long wall hung a row of Van Goghs.
c) Next to it stood a silver urn bursting with branches of red
berries.
(Biber et al., 1999, p., 916).
The sentences shown in (28) are the inverted sentences (26c,d,e). They open
with a locative adverbial, the verb is intransitive of existence and appearance or
copula be and the subject is new information (focus) and long (heavy).
Sentences (26a,b,) do not contain intransitive verbs of existence and appearance
or copula be and do not have a focus or heavy subject, hence they do not allow
inversion as shown in (29).
(29)
a) *The letter wrote Kim.
b) *On Sunday night plays Sharon bingo.
Existential there construction is another structure licensing postverbal subjects
with intransitives of existence and appearance and be (Biber et.al 1999; Ward,
G., Birner, B. J., & Huddleston, R., 2002). Sentences (26f,g) also contain
intransitive verb of existence and appearance or copula be and allow postverbal
subjects in existential constructions, as shown in (30).
(30) Existential there constructions (There-be-S) / (There-V-S)
a) There is a bear sitting in the corner.

44
(Biber et al., 1999, p. 912).
b) There arrived three girls.
(Biber et al., 1999, p. 912).
As we are able to see from the examples in (28) and (30), inversion (VS) constructions
in English are mostly possible with intransitive verbs of existence and appearance and
the copula be.
It extraposition is another structure licencing postverbal subjects. Several examples of
this structure are shown in (31).
(31) It extraposition - V - S
a) It is unclear why she told him.
b) It worries me that he hasn’t phoned.
c) It would be pointless to resist.
d) It is a miracle that he did it at all.
(Ward, G., Birner, B. J., & Huddleston, R, 2002, p.1403)
It extraposition is a different phenomenon i.e. its postverbal subject is a subordinate
clause which is why it is not going to be dealt with further on in this study. We are
interested in postverbal subject structures where the postverbal subject is a noun phrase.
Spanish is the second language of interest for our study. Due to the fact that Spanish is
a pro-drop language, there is an apparently “free” word order with all verb classes, as
explained by Lozano (2006a,b); (2008). The input available to learners of L2 Spanish
implies that canonical word order (SV) and inversion (VS) are optional alternations, as
indicated in (32) and (33).
(32)
a) Una mujer gritó. (SV)
A woman shouted
‘A woman shouted‟

45
b) Gritó una mujer. (VS)
Shouted a woman
„Awoman shouted‟
c) Un vecino vino. (SV)
A neighbour arrived
„A neighbor arrived‟
d) Vino un vecino. (VS)
Arrived a neighbor
„A neighbor arrived‟.
(Lozano, 2008, p. 137).
(33)
a) Maria ha comprado un libro (SVO)
Maria has bought a book
„Maria has bought a book‟.
b) Ha comprado un libro Maria (VOS)
has bought a book Maria
„Maria has bought a book‟
(Lozano and Mendikoetxea, 2010, p. 476).
c) Un libro ha comprado Maria (OVS)
a book has bought Maria
„Maria has bought a book‟
d) Ha comprado Maria un libro (VSO)
has bought Maria a book

46
„Maria has bought a book‟
Macedonian is a Slavic language which belongs to the group of pro-drop languages,
sharing similarities with Romance languages such as Spanish. Being a pro-drop
language, Macedonian allows various free inversion structures of the sentence elements,
as indicated in (34) and (35), even though SV word order is considered to be the
unmarked order (Friedman 1993; Venovska-Antevska 1995).
(34)
a) Poshtar dojde (SV)
Postman came
„A postman came‟
b) Dojde poshtar (VS)
Came a postman
„A postman came‟
(Topolinska, 1995, p. 51)
c) Edna devojka vleze (SV)
A girl entered
„A girl entered‟
d) Vleze edna devojka (VS)
Entered a girl
„A girl entered‟
(Minova-Gjurkova, 2000, p. 226)
(35)
a. Jana saka sladoled. (SVO)
Jana likes ice-cream
„Jana likes ice-cream.‟

47
b) Saka Jana sladoled. (VSO)
likes Jana ice-cream
„Jana likes ice-cream.‟
c) Sladoled saka Jana. (OVS)
ice-cream likes Jana
„Jana likes ice-cream.‟
d) Saka sladoled Jana., etc. (VOS)
likes ice-cream Jana
Jana likes ice-cream.‟
(Lazarova-Nikovska, 2003, p. 130).
As the data above show, SV/VS alternations are apparently free in Spanish and
Macedonian. Word order alternations are highly constrained in English. Let us explore
these facts below.
2.2.1 THE UNACCUSATIVE HYPOTHESIS (UH)
In relation to the number of arguments required by the verb, two types of verbs are
distinguished: transitive and intransitive. Transitive verbs require at least two arguments
while intransitive verbs occur only with one argument in the structure. Perlmutter
(1978) noted that the surface subject of one group of intransitive verbs is generated in
object position, i.e., postverbally. Burzio (1986) supported this view and proposed the
Unaccusative Hypothesis (UH), which claims that there are two classes of intransitive
verbs which differ in the position occupied by their only argument in the deep structure
(D-structure): unergatives, generating their argument in the external subject position of
the VP (36a) and unaccusatives (also known as ergatives), which generate their only
argument in the internal object position of the VP, as shown in (36b). The label
unaccusatives derives from the fact that, even though these verbs generate their subjects
in object position, they do not assign accusative case.

48
(36)
a. unergative b. unaccusative
“John spoke” “Three girls arrived”
(Lozano & Mendikoetxea,2010, p. 486)
The argument of unergatives (e.g., speak, cry, shout, sing) is associated with the volition
of the agent and takes only a subject, while the argument of unaccusatives (e.g., arrive,
come, exist, happen) is related to the theme and takes an object position even though it
is a subject.
Baker (1988) proposed the Uniformity of Theta Assigned Hypothesis (UTAH)
underlying that syntactic positions in the D-structure are assigned a particular thematic
role before spell-out. It means that agents are assigned to a subject position and themes
take object position before spell-out. As is also indicated in (36), the surface position of
English sentences requires either the external or the internal argument of the VP to
move to the surface subject position in the sentence, i.e., to Spec IP, in order to check its
nominative case features. Although generated in object position, the argument of
unaccusative verbs moves from its base position to surface subject position in order to
acquire nominative case, because the verb lacks an external subject and does not assign
accusative case to its object element. Hence the canonical word order in English for
both verb types, unergatives (36a) and unaccusatives (36b), is SV.
White (2003) explains the distinction between unaccusatives and unergatives to be
related to universal mapping principles by which the argument structure of the two
different classes of intransitives is built in a different way in the mental representation
of the interlanguage grammar. If these two classes of intransitives are compared to
transitive causative verbs, it will become clear that the sole argument of unaccusatives

49
performs the role of the object of transitive causatives and the argument of unergatives
behaves like the transitive causative subject.
(37)
a) Causative argument structure: ( x <y>)
b) Unaccusative argument structure: (ø <y>)
c) Unergative argument: ( x <ø> )
In (37), (x) represents the external and <y> the internal argument of transitives
corresponding to the initial syntactic subject and object respectively. Both arguments
(external x and internal <y>) occur in identical syntactic environments with preverbal
subjects when they move to surface subject (Spec IP), which is why the distinction
between unergatives and unaccusatives is not immediately obvious in English (38).
(38)
a) Unaccusative: The guest arrived
b) Unergative: The boy jumped
In (38a) the surface subject guest which can be represented by <y> has moved from its
D structure object position to surface subject position, while in (38b) the subject boy (x)
has remained in its base subject position. These different behaviours are shown in (39a)
and (39b):
(39)
a) Unaccusative: the guesti [VP arrived ti]
b) Unergative: the boy [VP jumped]
(Oshita, 2001, p. 280-281)
Additionally, there are some alternating unaccusatives (break, melt, increase) (40)
which can have both transitive (37a) and intransitive (37b) argument structure which
opposes the monadic unaccusatives which do not behave like causative verbs.

50
(40)
The sun melted the ice (transitive)
The ice melted (instransitive)
Crucially, the internal argument of unaccusatives in English may remain postverbally in
its base generated position (in situ) in there (existential) constructions, as shown in
(30b), here repeated as (41a), in which the expletive there occupies the subject position
according to the requirements of English to have an overt element in the Spec IP
position for case checking purposes (EPP).
(41)
a) There arrived three girls.
b) On one long wall hung a row of Van Goghs.
c) Next to it stood a silver urn bursting with branches of red
berries.
(Biber et al., 1999, p. 912).
Importantly, this construction is not possible with all unaccusative verbs. Levin &
Rappaport–Hovav (1995) proposed an approach stating that unccusativity is
semantically determined and syntactically represented. They distinguish three different
classes of unaccusative verbs: (i) externally caused or verbs of change of state (e.g.,
open, break); (ii) inherently directed motion unaccusatives (e.g., arrive, come, fall)
and (iii) unaccusatives of appearance or existence (e.g., exist, appear, remain). Only
the second and the third group of unaccusative verbs allow postverbal subjects with
there constructions (41a) and (42b). The same classes of verbs allow PP-V-S
constructions or subject-verb inversion in English as shown in (28b,c), here repeated as
(41b,c) above.
Levin (1993) and Levin & Rappaport-Hovav (1995) created an inventory of
intransitives, including the semantic classes and subclasses of both unaccusatives and
unergatives. This inventory is presented in Table 3 below which is relevant for our
empirical study.

51
Table 3: Inventory of unaccusatives and unergatives (based on Levin 1993; Levin & Rappaport-Hovav 1995)
2.2.2 CROSS-LINGUISTIC EVIDENCE FOR THE UH
Different languages employ different mechanisms to mark unaccusativity: syntax,
morphology, auxiliary selection etc. There are several syntactic diagnostics showing the
difference between unaccusatives and unergatives shown by various languages. One of
them is subject-verb inversion (SV and VS orders). As was shown in 2.2.1, some
subclasses of unaccusative verbs (of existence and appearance and inherently directed
motion) allow their sole argument to remain in situ if surface subject position (Spec IP)
is occupied by the semantically empty expletive there, licensing the occurrence of a
postverbal subject (42). If there does not occupy the subject position, the argument
moves from its base object position in the D-structure to surface subject position (43).
As opposed to unaccusatives, unergative verbs cannot appear in there existential
constructions (44).
(42)
a) There arrived [three girls]

52
b) There appeared [a grotesque figure]
c) There stands [a man] by the bus stop
(Lozano & Mendikoetxea, 2010, p. 478)
(Lozano, 2008, p.150)
(43)
a) [Three girls]i arrived ti
b) [A grotesque figure]i appeared ti
c) [A man]i stands ti by the bus stop
(44)
a) *There opened the door.
b) *There broke the window.
c) *There melted the butter.
(Lozano & Mendikoetxea,2010, p. 478)
The same subclasses of unaccusative verbs allow inversion of the type PP-V-S (45). In
English it is possible for some unergatives to license locative inversion, which will be
explained in detail in 2.2.3.1.2.
(45)
a) Next to it stood a silver urn bursting with branches of red berries.
(Biber et al., 1999, p. 912).
UH determines word order in pro-drop languages which have an apparently free word
order alternation. In Spanish, SV word order sounds more natural with unergatives (46
a) and VS with unaccusatives (46b) (Hertel 2003; Lozano 2006a,b; 2008, Lozano and
Mendikoetxea 2008). It is important to note that this happens at the lexicon-syntax
interface, i.e., when the verb determines the syntax, in contexts where the whole
sentence is focus (neutral context answering questions like What happened?).

53
(46)
a) Juan ha hablado *Ha hablado Juan
Juan has spoken has spoken Juan
b) *Juan ha llegado Ha llegado Juan
Juan has arrived has arrived Juan
(Lozano & Mendikoetxea 2008, p. 92)
Italian is another pro-drop language which prefers VS order with unaccusatives, as
indicated by Sorace (1993) shown in (47).
(47)
Subject-verb inversion (base-generated)
Sono arivati tre studenti.
Are arrived three students.
‟Three students have arrived‟.
(Sorace 1993, p. 26)
Auxiliary selection is another syntactic marking regulated by the UH. Languages
which alternate auxiliaries (Italian, French) select have with unergatives and be with
unaccusatives in perfective tenses. In Italian unergatives select avere and unaccusatives
(change of state, inherently directed motion and existence and appearance) select essere,
also explained by Sorace (1993) shown in (48a). Also, modal verbs in Italian usually
take avere but they can co-occur with essere when they take unaccusative verbs as
complements (48b). Such constructions allow clitic climbing (48c), i.e., raising of
unstressed preverbal object pronoun. When the clitic (-ci) raises, it is the auxiliary
essere that occurs obligatorily with the modal dovere (have to) (48d).
(48)
a) Mario è/*ha andato a casa.
Mario is/has gone home.

54
„Mario went home‟.
b) Mario ha/è dovuto andare a casa.
Mario has had to-go home
c) (A casa) Mario ha/è dovuto andar-ci.
(Home), Mario there has had to go.
d) (A casa) Mario ci è/*ha dovuto andaré.
(Home), Mario there has had to-go.
(Sorace 1993, pp. 25, 26, 27)
Sorace also explains that in French ètre (be) occurs only with unaccusatives which
denotes change of location (49), while the other two subtypes take avoir (have).
(49)
a) Jim est/a* arrive
Jim arrived
Japanese also recognizes unaccusativity. Hirakawa (1999) elaborates the different
semantic interpretation of Japanese sentences with unaccusatives and unergatives, as
shown in (50). He gives an example with the adverb takusan (a lot) which may modify
both the subject S and the object O of the verb. Japanese has SOV word order and,
whenever the subject and the object are topic, they may be omitted. In such case, it
would be difficult to ascertain whether the subject or the object is quantified by the
adverb takusan (a lot). Native Japanese would know that takusan (a lot) can only
modify the object i.e. the internal argument, but not the subject.
(50)
a) Takusan kaita.
A lot write-PAST
„Somebody wrote a lot.‟
b) Takusan oti-masi-ta.

55
a lot fall-POL-PAST
„A lot (of things) fell.
c) Takusan hashitta.
a lot run-PAST
„Somebody ran a lot.
(Hirakawa, 1999, p. 91)
In (50a), the verb is transitive and the subject and the object are omitted. The meaning
of the sentence cannot be confused: some person wrote a lot of things. When takusan is
used with unaccusatives it can modify its subject which is actually the underlying
object. Therefore, in (50b) takusan refers to the underlying object (things) of the
unaccusative fell and the sentence has the meaning „A lot of things fell‟. In (50c)
takusan cannot modify the subject of the unergative verb because this is the underlying
subject and it cannot mean “A lot of people ran” but the meaning is “Somebody ran a
lot”. This indicates that the adverb takusan modifies the constituent generated in
postverbal position, i.e., the object of a transitive verb and also the subject of an
unaccusative verb, but never the subject of an unergative verb.
Unaccusativity is also evident in Chinese, which is an SVO language, such as English.
As explained by Yuan (1999), the internal argument of Chinese unaccusative verbs may
occur preverbally, as in English, as shown in (51a), or it may display surface
unaccusativity by occuring postverbally, as shown in (51b). The internal argument
appears postverbally only if it is an indenfinite noun phrase. If the argument is a definite
NP, its postverbal position is ungrammatical, as indicated in (51c). The argument of
unergative verbs in Chinese may only appear in preverbal subject position, similar to
English and Japanese. Hence the so called “definiteness effect” is observed in Chinese.
It means that the postverbal subject of unaccusatives has to be an indefinite NP. If it
occurs in preverbal position it is a definite NP. This is similar to English where
postverbal subjects are usually indefinite NPs (focus) even though the rule is not as
strict as in Chinese.

56
(51)
a) shang ge yue, san sou chuan zai zhe ge hai yu chen le.
last CL month three CL ship in this CL sea area sink PFV
„Last month, three ships sank in this sea area.‟
b) shang ge yue, zai zhe ge hai yu chen le san sou chuan.
last CL month in this CL sea area sink PFV three CL ship
„Last month, three ships sank in this sea area.‟
c) *shang ge yue, zai zhe ge hai yu chen le na sou chuan.
last CL month in this CL sea area sink PFV that CL ship
„Last month, that ship sank in this sea area.‟
(Yuan, 1999, p. 279)
2.2.3 UNACCUSATIVITY IN THE LANGUAGES UNDER CONSIDERATION
In the following sections we will focus on the syntactic representation of unaccusativity
in the languages under consideration: English, Spanish and Macedonian. Some of these
syntactic details were shortly explained for English and Spanish in section 2.2.2.
2.2.3.1 Unaccusativity and word order in native English
As explained in 2.2., English is a canonical word order language (SVO) always
requiring its subject position to be occupied by an overt element for feature checking
purposes (EPP). As already explained, the subject of unergatives base generates in
subject position of the VP but the subject of unaccusatives generates in object position
of the VP. It moves to Spec IP to check its nominative case features. The canonical
word order in English is SV, both with unergatives (52) and unaccusatives (53), where
the preceding question (What happened…?) requires an all-focus answer where all
constituents are new information (focus). These contexts are labeled all focus contexts,
as will be explained below.
(52) What happened last night in the street?
a) [A woman shouted] Foc SV
b) *[Shouted a woman] Foc VS

57
(Lozano, 2008, p.144)
(53) What happened last night at the party?
a) [The police arrived] Foc SV
b) *[Arrived the police] Foc VS
(Lozano, 2008, p.145)
Here we can discuss the influence of discourse on word order, which is relevant for our
study. As was mentioned in 2.1.3. (Casielles-Suarez (2009)), discourse may go beyond
syntax and influence the order of sentence elements. For our purposes it is necessary to
distinguish two contexts: (i) Neutral focus context is produced as a reply to an all-
focus question like „What happened?. In neutral context we let the lexicon determine
the syntax, i.e., we are dealing with the lexicon-syntax interface. In English the word
order in neutral context is SV, both with unergatives and unaccusatives, indicating that
verb type (unaccusative or unergative) does not seem to play a role in the word order.
Non-canonical word order is ungrammatical (52b) and (53b).
(ii) Presentational focus context requires a focused subject as an answer to a question
like „Who shouted?.‟ Examples (54) and (55) show the word order in English in
presentational context which is determined by the discourse.
(54) Who shouted last night in the street?
[A WOMAN] Foc shouted SV
*Shouted [A WOMAN] Foc VS
(Lozano, 2008, p.161)
(55) Who arrived last night at the party?
[THE POLICE] Foc arrived SV
*Arrived [THE POLICE] Foc VS
(Lozano, 2008, p.161)
The presentationally focused subject of unergative verbs raises from its base position
Spec VP to Spec IP for case and focus checking purposes and the word order is SV. The
subject of unaccusatives moved from the VP object position to the surface subject

58
position Spec IP to acquire nominative case, as English language requires the subject
position to be occupied by an overt element, as mentioned several times in this
dissertation. Hence it can be concluded that English word order is SV for both neutral
and presentational contexts with unergative and unaccusative verbs. Additionally, in
presentationally focused contexts, the subject occurs postverbally with unaccusatives
when it is heavy and focus (Biber et.al (1999)) (as they are in our empirical study). This
fact will be elaborated and explained in detail in the following sections.
2.2.3.1.1 EXISTENTIAL INVERSION
Existential there is defined by Biber et al., (1999) as a:
„formal device used together with an intransitive verb to predicate the existence
or occurrence of something (including the non-existence or non-occurrence of
something) „ (p.943).
According to Ward, Birner and Huddleston (2002), existential inversion may have the
structure there+be+indefinite NP, known as existential clauses, as in (56), and also
there+V(intransitive)+indefinite NP, known as presentational clauses or existential
clauses with verbs other than be, as in (57).
(56) There are around 6000 accidents in the kitchen of Northern Ireland
homes every year.
(Biber et al., 1999, p. 943).
(57) Somewhere deep inside there arose a desperate hope that he would
embrace her.
(Biber et al., 1999, p. 943)
Before we continue describing the structure we will refer to the difference between
existential there and locative there.
Existential there is derived from the locative adverb there (thereloc), but has lost its
original locative meaning and functions as a semantically empty expletive (therepro).
The difference between expletive there and locative there is shown in (58).

59
(58)
a) Therepro is nothing thereloc.
b) What is therepro thereloc. ?
(Ward, G., Birner, B. J., & Huddleston, R, 2002, pp.1391)
Syntactically, existential there functions as an empty grammatical subject in existential
and presentational constructions which satisfies the requirements of English language to
have an overt element in surface subject position (according to the Extended Projection
Principle (EPP) which was mentioned several times in this dissertation).
Biber et. al. (1999:945) explain that existential constructions with verbs other than be
(presentational constructions) are rare and occupy only a small part of all existential
clauses: in fiction and academic prose less than 5% and in news and conversation less
than 1%. This is a very important factor for this study since we are investigating these
sentences and it is unlikely that L2 learners picked up the structure from the input (due
to its extremely low frequency in the input).
The focus of this study will be existential clauses with verbs other than be
(presentational clauses), where the postverbal subject co-occurs with intransitive verbs
(namely, a subset of unaccusative verbs, though in the descriptive literature (grammars
by Biber et al. 1999, Huddleston & Pullum 2002, Quirk et al. 1985) there is no
discussion about which type these intransitive verbs belong to, though in the generative
literature they have been well studied and have been classified as a subset of
unaccusatives, as we have explained earlier. We will therefore not discuss structures of
the type there-be-NP any further.
Unaccusative verbs of existence and appearance and inherently directed motion (as
explained in 2.2.1), are the intransitive verbs other than be, allowing there
constructions, as shown in (59), where the preverbal element (expletive there in this
case) is in italics, the unaccusative verb is underlined and the postverbal subject is in
bold.
(59)
a) There came a roar of pure delight as it closed around him and
carried him on.

60
b) There seems no likelihood of a settlement.
c) In all such relations there exists a set of mutual obligations in the
instrumental and economic fields.
(Biber et al., 1999, p. 943)
d) There remain only two further issues to discuss.
e) After they had travelled for many weeks, there came the moonlit
night when the air was still and cold.
(Ward, G., Birner, B. J., & Huddleston, R, 2002, p.1402)
The subject remains in its base generated object position (in situ) and the surface subject
position is occupied by the expletive there. Existential constructions are often used in
conjunction with adverbials of time or place (59c,e), because things happen in the
context of time and place. Biber et.al (1999) additionally explain that existential there
presents new information into the discourse, because it typically occurs with an
indefinite subject which carries focus (new) information. This fact is important for this
study as it deals with postverbal subjects which are focus. Even though it does not occur
often, presentational constructions allow postverbal subjects with definite noun phrases
as shown in (59e) (see details in Biber et.al 1999, section 11.4.3.).
2.2.3.1.2 LOCATIVE INVERSION
Sometimes, subject – verb inversion opens with place adverbials. This structure is often
referred to as locative inversion. Levin and Rappaport-Hovav (1995) explain that
locative inversion has a non-canonical word order „PP-V-S‟ which is a result of the
change of place between the subject (S) and the locative adverbial (PP). The verb in the
locative inversion must be intransitive, considered to belong mostly to the subclass of
unaccusative verbs of appearance (60a,b) and existence (60c). Sometimes
unaccusatives of inherently directed motion appear in locative inversion constructions
(60d). The preverbal element (now a PP) is shown in italics, the unaccusative verb is
underlined and the postverbal subject is in bold.
(60)
a) Over her shoulder appeared the head of Jenny’s mother.

61
b) From such optical tricks arise all the varieties of romantic
hallucination…
c) .. in the corners and the corridors and the bus debarkation point
existed that stricken awareness..
d) Here and there flourish groves of aged live oaks.
(Levin and Rappaport-Hovav 1995, pp. 220-221)
Unaccusative verbs of change of state do not typically occur in locative inversion
constructions as shown in (61a,b) or existential constructions (61c) due to the fact that
they are usually alternating unaccusatives which alternate in transitivity.
(61)
a) *On the top of the skyscraper broke many windows.
b) *On the streets of Chicago melted a lot of snow.
(Levin and Rappaport-Hovav 1995, pp. 224)
c) * There melted a lot of snow.
As Levin and Rappaport-Hovav (1995) further explain, even though locative inversion
is mostly related to unaccusative verbs of existence and appearance, there are several
subclasses of unergative verbs which are found in this construction. The unergative
verbs entering into this construction behave as unaccusatives by being used with
directional adverbials (62a) or activity verbs with animate subjects (62b). Also, verbs of
light emission (62c) and of body internal motion (62d) may appear in locative inversion
constructions.
(62)
a) Inside swam fish from an iridescent spectrum of colours …
b) On the third floor worked two young women called Maryanne
Thomson and Ava Brent.
c) On one hand flashes a 14-carat round diamond…
d) Black across the clouds flapped the cormorant.

62
(Levin and Rappaport-Hovav 1995, pp. 224-225)
Levin and Rappaport-Hovav (1995) explain that the subject in these constructions has to
be less familiar than the preverbal element (focus). This is also the reason why verbs
which are informationally heavy (rush, walk) are not found in locative inversion with
locative adverbials. It is possible for the heaviness of the verb to become lighter if
directional adverbial is used instead. They also propose that this phenomenon can be
taken into account from discourse considerations. Mendikoetxea (2006) elaborates that
unergative verbs of manner of motion become unaccusatives if the construction opens
with a directional PP.
(63)
a) Down the dusty Crisholm Trail into Abilene rode taciturn Spit
Weaver, his lean brown face an enigma…
b) Into this scene walked Corky’s sister, Vera, eight years old…
(Mendikoetxea 2006 p. 137 taken from Levin and Rappaport-Hovav 1995, p. 221)
The flexibility of locative inversion to accept different subclasses of verbs
(unaccusatives and unergatives) may be related to the origin of Modern English i.e. the
verb second (V2) structure of Old and Middle English. The verb second (V2) structure
has been “lost” in present day English, throughout the Middle English period, although
it has remained to persist as a feature of all other Germanic languages. Namely, this
property places the finite verb in the second constituent position in the clause after the
initial element, regardless of its clause function, usually a pronominal, negative and
temporal or locative adverb (Burrow and Turville-Petre, 2001; Haeberli 2007; Heycock
and Kroch 1993). More precisely, when the subject was long (which definitely means
that it was new), it was postverbal, i.e., the V2 mechanism basically worked as
presentational/locative inversion: the preverbal element is informationally light and
typically relates the info to the preceding discourse, and then the postverbal subject is
long and focus.
This is very similar to Modern English. Casiellez-Suarez (2009) explains that focus is
the stressed and informative part of the utterance which tends to occur towards the end
of the sentence (syntax-discourse interface). She claims that in English utterances
follow the Topic-Focus structure and that there is a tendency for accented focus to be

63
placed towards the end of the sentence. Basically, it is a general psycholinguistic
mechanism used to alleviate the speaker and listener‟s processing of the information. As
mentioned in 2.1.3. Additionally, Wasow (1997) explains that many languages put light
constituents at the beginning of the sentence and heavy elements towards the end of the
sentence (syntax-phonology interface) in order to make the utterances more
comprehensible for both the listener and the speaker involved in the communicative
activity. In English, this phenomenon is shown most clearly in the postverbal elements
(64).
(64)
a) There's a sentence in the letter assuring to the extent legally
possible confidentiality.
(Wasow 1997, p. 87)
b) With this competitiveness comes the desire to stand out from
the crowd and be the best.
c) Thus began the campaign to educate to public on how one
contracts aids.
(Lozano and Mendikoetxea 2010 pp. 486,490)
In English SV is the word order used with all types of verbs (unergatives and
unaccusatives) but if the subject is focus and heavy it tends to be placed postverbally
with unaccusative verbs in XP-V-S constructions. Unergative verbs, as it was already
mentioned, allow postverbal subjects in locative constructions only (PPloc-V-S). Hence
it can be concluded that inversion in English is not constrained only at the lexicon-
syntax interface but it is also constrained at the syntax-discourse (focus) and the syntax-
phonology interface (heavy).
It has been proposed that the interfaces of syntax with other parts of grammar are more
problematic to be acquired and they show L1 influence even though narrow syntax has
been acquired. Rankin (2011) studied this issue with German and Dutch (V2 languages)
learners of L2 English and focused on the transfer possibilities of V2 structure. The
results confirmed the predictions that even though syntax was mastered, transfer
happened at discourse syntax interface, where L1 preference of topicalization structures

64
continued to occur. Further on, Rankin proposed that „it is discourse-pragmatic patterns
that transfer as opposed to syntactic interference‟ p.16., i.e. that V2 transfer may be
happening due to transfer of discourse-pragmatic patterns from the L1 rather than
syntactic deficits. This is relevant for our study which will also discuss the possible
transfer of PP-V-S from L1 Macedonian and Spanish which is in fact a V2 structure.
(see sections 7.1.3.3. and 7.1.3.4.)
2.2.3.2 Unaccusativity and word order in native Spanish
Recall from our previous discussion in 2.1.2 that the second property of the pro-drop
parameter relates to the possibility of inverting the subject and the verb. But the
apparently flexible word order in Spanish is actually constrained by syntactic rules
stemming from the type of verb involved in the structure (lexicon-syntax interface),
and discourse rules depending on the type of information encoded in the sentence
(syntax-discourse interface) (Hertel 2003; Dominguez and Arche 2008; Lozano
2006a,b; Lozano 2008; Lozano and Mendikoetxea 2008, 2010). Spanish is a topic first
focus last language, meaning that the focused element in a sentence is expected to
appear in sentence-final position, even if the canonical word order is to be changed.
Example (65a) shows the word order in neutral context, providing an all-focus reply to
the question „What happened‟ (¿Que pasó?) and (65b) shows the word order in a
presentational context, where the subject has been focused and, therefore, needs to
appear in sentence-final position.
(65)
a) What happened?
[Juan ha traído el perro]Foc SVO
Juan has-brought the dog
„Juan has brought the dog‟
b) Who has brought the dog?
Ha traído el perro [Juan] Foc VOS
has brought the dog Juan
„Juan has brought the dog‟

65
*[Juan] ha traído el perroFoc *SVO
Juan has-brought the dog
„Juan has brought the dog‟
(Arche and Dominguez 2008, p. 2)
As has been shown earlier, the verb type also influences the word order in Spanish.
Namely, the subject of unaccusatives always appears postverbally irrespective of the
information status of the sentence (neutral or presentational focus), as explained by
Hertel (2003), Lozano (2006a, 2006b) and Arche and Domiguez (2008). Examples (66)
and (67) show the word order with unergatives and unaccusatives in neutral context and
(68) and (69) show the word order in presentational context.
(66) neutral focus / unergatives
¿Qué pasó anoche en la calle?
What happened last night in the street?
[Una mujer grito] Foc SV
A woman shouted
„A woman shouted‟
*[Grito una mujer] Foc VS
Shouted a woman
„A woman shouted‟
(Lozano, 2008, p.144)
(67) neutral focus / unaccusatives
¿Qué pasó anoche en la fiesta?
What happened last night at the party?
*[La policia vino] Foc SV
The police arrived
„The police arrived‟
[Vino la policia] Foc VS

66
Arrived the police
„The police arrived‟
(Lozano, 2008, p.145)
Examples (66) and (67) show that the canonical word order is used in neutral context
with unergatives, but VS is pragmatically more acceptable with unaccusatives. As
explained by Lozano (2006a), Spanish marks the presentational focus syntactically by
placing the subject in sentence final position.
(68) presentational focus / unergatives
Quien grito anoche en la calle?
Who shouted last night in the street?
*[UNA MUJER] Foc grito SV
A woman shouted
„A woman shouted‟
Grito [UNA MUJER] Foc VS
Shouted a woman
„A woman shouted‟
(69) presentational focus / unaccusatives
Quien vino anoche a la fiesta?
Who came last night to the party?
*[LA POLICIA] Foc vino SV
The police arrived
„The pólice arrived‟
Vino [LA POLICIA]Foc VS
Arrived the police
„The police arrived‟
(Lozano, 2008, p.161)

67
Therefore, in presentational context VS is pragmatically more acceptable both with
unergatives and unaccusatives, proving that word order in Spanish is also determined at
syntax-discourse level. This is clearly shown in the bar chart below, Figure 7 (source:
experimental data from Spanish native speakers reported by Lozano (2006a) and
adapted here for expository purposes).
Figure 7: Word order in neutral and presentational contexs in Spanish
Therefore it can be summed up that in Spanish word order is constrained by the lexicon
at the lexicon-syntax interface (all focus contexts) where unergatives require SV and
unaccusatives VS. At the syntax-discourse interface word order is constrained by focus
requiring VS both with unergatives and unaccusatives when the subject is new
information.
2.2.3.3 Unaccusativity and word order in native Macedonian
The Macedonian language has not been largely studied from a generative point of view.
We are not aware of any previous studies on unaccusativity in Macedonian. There are
some theoretical studies about the word order in Macedonian, governed by discourse
(topic and focus information), which we will refer to further on, but none of these
studies elaborate in detail the focus of our interest or mention the
unaccusative/unergative distinction.
Sussex and Cubberley (2006) studied in detail the Slavic languages and state that these
languages (Macedonian, Serbian, Bulgarian, Russian etc.) place old or topic information
at the beginning of the sentence and new information goes towards the end i.e., they are

68
topic first focus last (which, as we have seen in the preceding section, is what happens
in native Spanish).
As mentioned in 2.2., the unmarked word order in Macedonian is SVO. Due to its pro-
drop features, Macedonian shows word order flexibility, as in (34a,b) here repeated as
(70).
(70)
a) Poshtar dojde (SV)
postman came
„A postman came‟
b) Dojde poshtar (VS)
Came a postman
„A postman came‟
(Topolinska, 1995, p. 51)
Topolinska (1995) describes that (70b) is unmarked by definiteness. The subject
„poshtar-postman‟ is an indefinite NP (focus) and is placed after the verb. The subject is
placed before the verb when it is marked by definiteness (topic), such as in (71), thus it
may be assumed that topic information is placed at the beginning of the sentence and
focus usually after the verb.
(71) Poshtarot dojde (SV)
Postman-the came
„The postman came‟
In relation to the above, Minova-Gjurkova (2000) discusses word order in Macedonian
from a functional point of view (discourse), elaborating that the natural order is to place
the theme (topic) before the rheme (focus) information (34c) here repeated as (72a).
This word order in Macedonian is called objective word order. The rheme (focus) can
be placed at the beginning of the sentence if emotional emphasis is involved. The
speaker starts with the most important element, even if it would be pragmatically more

69
logical to place it in sentence final position (34d) here repeated as (72b). This is the
subjective word order. Both statements are acceptable and the information will be
suitably transmitted.
(72)
a) Vleze edna devojka (VS)
Entered a girl
„A girl enetered‟.
b) Edna devojka vleze (SV)
A girl entered
„A girl entered‟
(Minova-Gjurkova, 2000, p. 226)
The topic-focus word order with locative inversion is common in Macedonian. As
explained by Milenkovska (2002a), when the locative or temporal adverbial refers to the
previous context it is usually placed in sentence initial position and semantically
motivates inversion, as in (73).
(73)
Vo kukjata od samoto moste vleguva Rusanka.
In house-the from itself-the bridge enters Rusanka.
„In the house, from the bridge itself enters Rusanka‟
(Milenkovska (2002), p.124)
Milenkovska (2002) also mentions that the subject NP occur postverbally (marked
realization of the word order) when it carries new information (focus). She provides
several examples taken from novels written by renowned Macedonian authors as in
(74). Even though nothing was mentioned about the heaviness of the subject it is
obvious from the below examples that, besides being focus, the subject is also heavy.

70
(74)
a) Od chistinata nagore se protegashe padina so sitni
grmushki i so mnogu kamenja.
from clearing-the above spreaded slope with small bushes
and a lot of stones.
„Above the clearing spreaded a slope with small bushes and a lot of
stones.‟
b) Se izvivaat goli vetrovi fateni vo mrezhata na ulicata.
Blew sharp winds caught in the web of the street.
„Sharp winds were blowing caught in the street web.‟
c) No zad niv stoeja drugi vojnici, nahraneti i obleceni
i so pushki ili stapovi vo racete.
But behind them stood other soldiers, fed, and dressed up
and with guns or sticks in arms-the.
„But behind them stood other soldiers, fed and dressed up carrying
guns or sticks in their arms‟.
(Milenkovska 2002a,b, pp.126/127, 249)
As was previously mentioned, unaccusativity in Macedonian has not been studied.
Word order is flexible but it is unclear whether it is governed by the lexicon-syntax
interface due to the fact that SV/VS is allowed with all verb types (neutral context). As
far as the presentational focus context is concerned, we could only refer to the above
studies and examples, which suggest that focus and heavy subjects tend to occur
postverbally in Macedonian. Hence we could assume that syntax-discourse and
syntax-phonology interface influence word order in Macedonian by placing focus and
heavy subjects towards the end of the sentence.

71
2.2.3.3.1 DESCRIPTION OF UNACCUSATIVITY
In the previous section, we were able to see the preference of SV / VS with unergatives
and unaccusatives in neutral and presentational contexts by English and Spanish
natives. Table 4 summarizes the word order for different contexts for English and Table
5 for Spanish. Given that there are no experimental studies on native Macedonian, we
will discuss the SV/VS alternation in native Macedonian in the section below, where we
report on a short experimental study testing Macedonian natives‟ preferences.
Table 4: Word order in neutral and presentational contexs in English
English
neutral context unergatives SV
unaccusatives SV
presentational context unergatives SV
unaccusatives SV
presentational context
(if the subject is focus
and heavy)
unergatives
existential
constructions
SV
locative
inversion VS
unaccusatives
existential
constructions VS
locative
inversion VS
It is obvious that unaccusativity is not represented at a surface level in neutral and
presentational contexts in English due to the fixed word order and the requirements of
English to have an overt subject in the sentence (EPP). If, however, the subject is focus
(new information) AND heavy (long) postverbal subject constructions are allowed with
unaccusative verbs in existential constructions and locative inversion constructions
which are presentational context constructions. Postverbal subject constructions are
possible with some subclasses of unergatives (see description in 2.2.3.1.2. above) with
long and heavy subjects in locative inversion constructions only.
Table 5: Word order in neutral and presentational contexs in Spanish
Spanish
neutral context unergatives SV
unaccusatives VS
presentational context unergatives VS
unaccusatives VS

72
Unaccusativity in Spanish is more obvious at surface level showing SV only with
unergatives in neutral context. Unaccusatives in neutral context and both types of verbs
in presentational context prefer VS.
As just mentioned, we did not come across any Macedonian studies or descriptive
papers on unaccusativity and word order in different contexts. Due to the fact that these
data are crucial for our study, investigating whether acquisition of postverbal subjects in
L2 English is a result of transfer or rather a developmental issue, we conducted a pilot
study to examine the intuitions on SV/VS with unergatives and unaccusatives in neutral
and presentational context in Macedonian, which is described in the next section.
2.2.3.3.2 PILOT STUDY: MACEDONIAN NATIVE SPEAKERS’ INTUITIONS ON
UNACCUSATIVITY
A contextualized grammaticality judgment test was developed (see appendix 11.3, p.
197). We used 4 unergatives (work, play, speak, cry) and 4 unaccusatives (come, exist,
begin, appear) and developed 16 sentences with unergatives (8 neutral context and 8
presentational context) and 16 with unaccusatives (8 neutral context and 8
presentational context). The test consisted of 32 contexualized situations which ended
with a question referring either to neutral context „Shto se sluchi?‟ (What happened?) or
presentational context “Koj dojde/zboruvashe/raboteshe?(Who came/spoke/worked..?)
The participants could accept either SV or VS orders for each contextualized question.
In (75) we have shown one example of the pilot test showing the neutral context
question (75a) with the unaccusative APPEAR and the presentational context question
(75b) with the unaccusative COME, provided in Macedonian (Cyrillic alphabet) and
followed by an English translation.
(75)
a) Гледаш хорор филм со Весна и заѕвонува нејзиниот телефон.
Таа излегува од собата и се враќа по завршувањето на
разговорот. Во меѓувреме испушти еден дел од филмот и
прашува: “Што се случи“? Ти одговараш:
1) се појави дух (VS)

73
2) дух се појави (SV)
You are watching a horror film with Vesna when her telephone starts
ringing. She goes out of the room and comes back after she has finished
the conversation. She missed one part of the film and asks: “What
happened”? You answer:
1) appeared a ghost (VS)
2) a ghost appeared (SV)
b) Ти си на забава со твојата пријателка Тања. Таа оди да си земе
пијалок а во меѓувреме на забавата доаѓа некој непознат човек.
Тања се враќа, забележува дека некој дошол и прашува: “Кој
дојде“? Ти одговараш:
1) еден човек дојде (SV)
2) дојде еден човек (VS)
You are at a party with your friend Tanya. She goes to get a drink
and in the meantime there comes an unknown man. Tanya returns,
notices that someone has come and asks: “Who came”? You answer:
1) a man came (SV)
2) came a man (VS)
We randomized the order of the questions in terms of context and type of verb. Also,
the order of SV/VS options was randomized for different sentences in order to avoid an
order-of-presentation effect.
The test was developed in Google Docs, which is a data storage service which provides
a possibility for its users to create and edit documents online which was convenient for
our purpose. The test was distributed online to potential participants over the internet.
The participants were explained that we needed their opinion on the acceptability of the
sentence without explaining any linguistic details regarding the experimental aims, and
that they had to choose one option only. 62 native speakers of Macedonian took part in
the testing. After we received and analyzed the results we took out two verbs from the

74
Macedonian results (1 unergative-SPEAK and 1 unaccusative-APPEAR)7 and we
compared them with the overall Spanish results (Figure 8a and 8b respectively).
Figure 8a: Word order in neutral and presentational contexs in Macedonian
10,8
43,5
30,1
66,1
89,2
56,5
69,9
33,9
0
10
20
30
40
50
60
70
80
90
100
neutral_unac(%) neutral_unerg(%) presentational_unac(%) presentational_unerg(%)
% o
f accep
tan
ce [fo
rced
ch
oic
e S
V/V
S]
Macedonian natives (N=62)
SV
VS
Macedonians prefer VS with unaccusatives, both in neutral and presentational context
which is the same as in native Spanish. These results indicate that Macedonians are
sensitive to the UH knowing that the internal argument of unaccusative verbs generates
in its object position in the VP. Surprisingly enough, Macedonians prefer VS in neutral
context with unergatives as well (even though the difference compared with
unaccusatives is minor, i.e., we could be dealing here with a case of native optionality,
since both SV and VS are preferred with unergatives in neutral contexts) but SV with
unergatives in presentational context, which is completely opposite to the Spanish
results.
7 SPEAK (unergative) and APPEAR (unaccusative) were eliminated because they were the weakest
candidates in their condition.
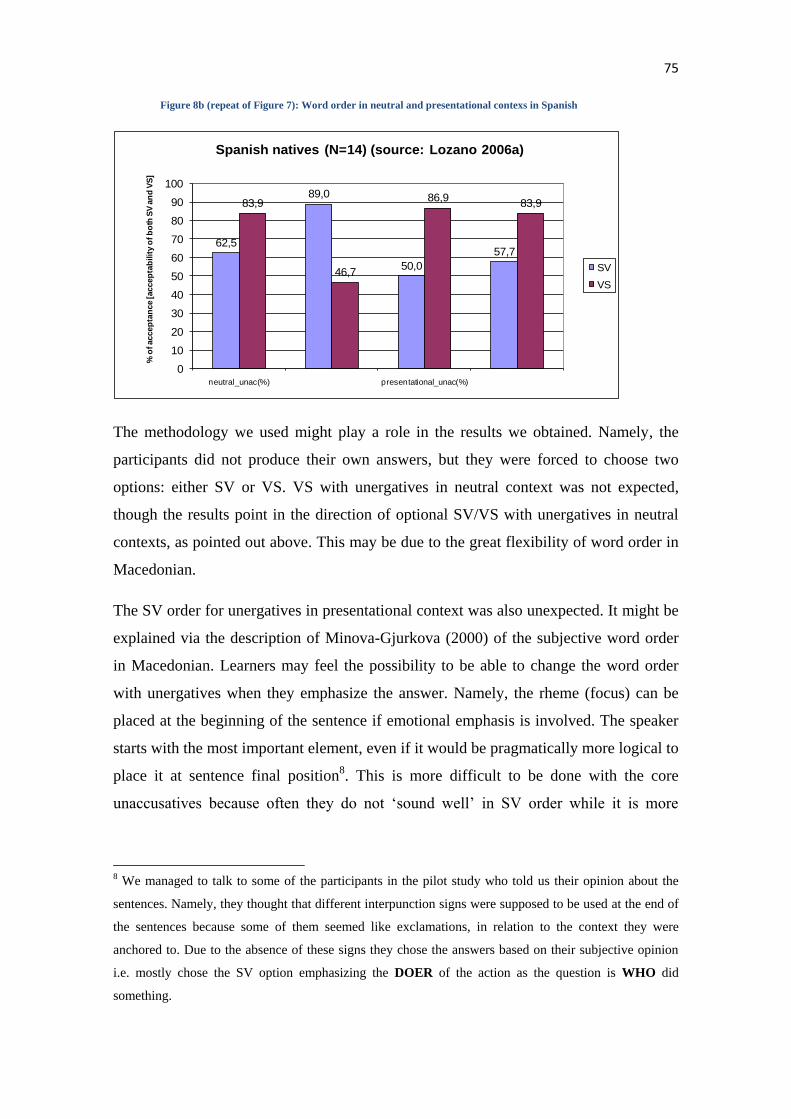
75
Figure 8b (repeat of Figure 7): Word order in neutral and presentational contexs in Spanish
62,5
89,0
50,0
57,7
83,9
46,7
86,983,9
0
10
20
30
40
50
60
70
80
90
100
neutral_unac(%) presentational_unac(%)
% o
f accep
tan
ce [accep
tab
ilit
y o
f b
oth
SV
an
d V
S]
Spanish natives (N=14) (source: Lozano 2006a)
SV
VS
The methodology we used might play a role in the results we obtained. Namely, the
participants did not produce their own answers, but they were forced to choose two
options: either SV or VS. VS with unergatives in neutral context was not expected,
though the results point in the direction of optional SV/VS with unergatives in neutral
contexts, as pointed out above. This may be due to the great flexibility of word order in
Macedonian.
The SV order for unergatives in presentational context was also unexpected. It might be
explained via the description of Minova-Gjurkova (2000) of the subjective word order
in Macedonian. Learners may feel the possibility to be able to change the word order
with unergatives when they emphasize the answer. Namely, the rheme (focus) can be
placed at the beginning of the sentence if emotional emphasis is involved. The speaker
starts with the most important element, even if it would be pragmatically more logical to
place it at sentence final position8. This is more difficult to be done with the core
unaccusatives because often they do not „sound well‟ in SV order while it is more
8 We managed to talk to some of the participants in the pilot study who told us their opinion about the
sentences. Namely, they thought that different interpunction signs were supposed to be used at the end of
the sentences because some of them seemed like exclamations, in relation to the context they were
anchored to. Due to the absence of these signs they chose the answers based on their subjective opinion
i.e. mostly chose the SV option emphasizing the DOER of the action as the question is WHO did
something.
76
possible to be done with unergatives. The obtained word order in different contexts in
Macedonian is shown in Table 6.
Table 6: Word order in neutral and presentational contexts in Macedonian
As we will see in the experimental section, the distribution of SV/VS with
unaccusatives and unergatives that we have just reported for English, Spanish and
Macedonian will be crucial to interpret the results of this dissertation.
Macedonian
neutral context unergatives VS/(SV)
unaccusatives VS
presentational context unergatives SV
unaccusatives VS

77
3 THE L2 ACQUISITION OF UNACCUSATIVITY
The main outline of this chapter is to present unaccusativity in L2 acquisition by
providing preliminary background on L2 acquisition and the interfaces and describing
unaccusatives in L2 acquisition with reference to postverbal subjects supported by
examples of learners‟ production on unccusativity taken from various empirical studies.
3.1 PRELIMINARY BACKGROUND: L2 ACQUISITION AND THE
INTERFACES
In the 80s SLA research focused on the issue of access to UG and parameter resetting
(Chomsky 1981). In the mid 90s research moved on from studying these rather global
issues to the development of the Minimalist program (Chomsky 1995), which considers
the human language ability to consist of a computational system (syntax) which is fed
by the lexicon (features). Such system interacts with external interfaces (phonology and
semantics, or, technically speaking, the sensi-motor system and the conceptual-
intentional system). In particular, advances in linguistic theory have been interested in
studying interface conditions, which has has also been a topic of interest in recent SLA,
which in the 2000s has focused on how the computational system interacts with the
interfaces. Researchers examine whether failure to acquire fully native-like L2
competence occurs due to learners‟ inability to integrate material at the interfaces and
whether interfaces encompass cross-linguistic influence. These issues are relevant for
this empirical study.
Therefore SLA can be explored from three levels: (i) lexicon-syntax interface, referring
to the lexicon-semantic features of the structures to be acquired and their interaction
with the grammar, (ii) syntax-discourse interface, which refers to the interaction of the
discourse with the syntactic properties of the structure and (iii) syntax-phonology
interface dealing with the interaction of syntax and the phonological properties of the
structure. The Unaccusative Hypothesis is instantiated at the lexicon–syntax level. But
interface conditions are crucial for our study. It shows that unaccusativity (lexicon-
syntax interface) is a necessary but not sufficient condition for the production of
postverbal subjects (which are the focus of this study), because other interfaces are

78
involved in their production and acceptance: syntax-discourse (end-focus principle) and
syntax-phonology (end-weight principle), as will be seen below.
3.2 UNACCUSATIVES IN L2 ACQUISITION
The theory of the Unaccusative Hypothesis (see chapter 2) has shown various
diagnostics on unaccusativity (semantic, syntactic etc.) The sensitivity to the
unaccusative hypothesis in SLA is observed in the behavior of various L1 learners
producing ungrammatical and contextually inappropriate passive unaccusatives e.g., An
accident was happened for “An accident happened” (Balcom, 1997; Hirakawa, 1999; Ju
2000; Oshita, 2000; Zobl, 1989). It was already mentioned in 2.2.2. that unaccusatives
determine the selection of auxiliaries in languages choosing different auxiliaries in
perfective tenses. Learner‟s sensitivity to follow the native norm of auxiliary selection
depending on the verb type is part of the phenomena described by Sorace (1993). One
of the factors allowing postverbal subjects in L2 English is the UH which has been
largely studied by several authors (Zobl 1989; Rutherford 1989; Yuan 1998; Oshita
2001, 2004; Lozano & Mendikoetxea 2008, 2010).
In the following subsections we will review studies on unaccusativity in L2 acquisition,
which will serve as a background for the experimental study. The last subsection on
unaccusative postverbal subjects in L2 acquisition, which is the focus of this study, is
crucial to understand the experimental section and the results.
3.2.1 INTRODUCTION: SOME EXAMPLES OF LEARNERS’ PRODUCTION ON
UNACCUSATIVITY
This section provides examples produced by learners of L2 English of various L1
backgrounds to indicate the universal sensitivity to the UH. Learners produce similar
structures (grammatical and ungrammatical) regardless of their L1, (76-78).
(76) PASSIVE UNACCUSATIVES
a) *Most of the people are fallen in love and marry with somebody.
b) *My mother was died when I was just a baby.
(Zobl 1989, p. 204).

79
(77) AUXILIARY SELECTION
a) *Non ha potuto venire
b) Non e potuta venire
(Sorace 1993, p. 41).
(78) POSTVERBAL SUBJECTS
a) PP (locative) - V (unaccusative) - S
. … on her face appeared those two red cheeks …
(L1 Arabic; Rutherford, 1989, p. 179).
b) *PP (temporal) - V (unaccusative) - S
*One day happened a revolution.
(L1 Spanish; Oshita, 2004, p. 120).
c) there-insertion - V (unaccusative) - S
… there often arise the problem of political indifference …
(L1 Japanese; Oshita, 2000, p. 315).
d) *it-insertion - V (unaccusative) - S
*… it arrived the day of his departure …
(L1 Japanese; Oshita, 2004, p. 119).
e) Ø-insertion - V (unaccusative) - S
It is difficult that exist volunteers with such a feeling against it.
(L1 Spanish; Lozano & Mendikoetxea,2010, p. 487).
We will review the acquisition of these linguistic data (76-78) in the following
subsections.

80
3.2.2 PASSIVIZED UNACCUSATIVES
Zobl (1989) was one of the first researchers showing that learners produce certain
errors, as indicated in (76), here repeated as (79), due to unaccusativity.
(79)
a) *Most of the people are fallen in love and marry with somebody.
(L1 Japanese, Zobl 1989, p. 204).
b) *My mother was died when I was just a baby.
(L1 Thai, Zobl 1989, p. 204).
L2 learners of English with different L1 languages (Thai, Arabic – Zobl (1989);
Chinese-Balcom (1997); Korean-Ju (2000), Oshita (2000,2004); Italian, Spanish-Oshita
(2000, 2004); Japanese-Oshita (2004), Zobl (1989)) passivize intransitive unaccusative
verbs (are fallen in love, was died), even though native English speakers passivize only
transitive verbs. This behavior may indicate that learners are somehow able to notice the
parallel between the passivized errors they produce and the real transitive passives. In
English passives, the theme argument NP moves from object (80a) to subject (80b)
position for case checking purposes, which is realised by passive morphology (80c).
(80)
a) [proexpl INFL [ vp V NP]]
b) [NPi INFL [vp V ti]]
(Zobl 1989, p. 207).
c) The candiesi were bought ti by the children.
The argument structure of unaccusatives has its theme argument in base object position,
which in English has to be moved in the surface subject position due to case checking
purposes, as was explained in 2.2.1. Even though this movement is not marked in
English, learners passivize only unaccusatives which indicates that they are somehow
sensitive to their underlying argument structure which undergoes similar movement to

81
that of transitive passives. The result is the erroneous use of passive morphology with
unaccusatives, even though passivization has not occurred. By using passive
morphology with unaccusatives, they discard the doer of the action, i.e., the agent,
which does not exist with unaccusatives, hence the ungrammaticality of the structure.
Oshita (2000) studied written production of passivization errors. A total of 941 tokens
were produced with unaccusatives, out of which 38 were passivization errors (81). Also,
640 tokens involved unergative verbs, but learners produced only one passivization
error (82), which indicates that unergatives are not passivized. This is another proof that
learners are sensitive to the fact that the argument of unaccusatives is VP
internal/theme.
(81)
a) *They were happened a few days ago.
(L1 Italian; Oshita 2000, p. 314).
b) *..suddenly pale face was appeared out of the window.
(L1 Korean; Oshita 2000, p. 312).
c) *After that we were arrived at the station.
(L1 Japanese; Oshita 2000, p. 314).
(82)
*He has been walked since last month.
(L1 Spanish; Oshita 2000, p. 310).
Balcom (1997) explains the passivization process with different types of unaccusatives.
She distinguishes two types of unaccusatives in the formation of passive morphology.
The first one are the unaccusatives with a transitive counterpart (e.g. break, open) which
have an external and internal argument (Agent and Theme) and which allow transitive /
unaccusative alternation. They are „derived from causatives by binding the external
argument in the lexical semantic representation so the agent is not projected to the
argument structure‟ (p.7), the pattern being shown in (83).

82
(83)
Unaccusative with Transitive Counterpart
[[ x DO-SOMETHING] CAUSE [ y BECOME STATE]]
ø <y>
The other subtype are the unaccusatives without a transitive counterpart (e.g. happen,
fall) which may have two internal arguments (Theme and Location), out of which the
latter is possible to be implicit, and no external argument. They follow the pattern in
(84).
(84)
Unaccusative without transitive counterparts
[ y BE/BECOME AT z]
<y> Ploc<z>
In order to be passivized, unaccusatives without a transitive counterpart have to add an
external argument via causativization before passivization occurs. Both subtypes of
unaccusatives with „be‟+en are derived by passivization, which occurs when the
external argument is bound at argument structure. In such cases, learners would produce
incorrect structures with unaccusatives without a transitive counterpart, as presented in
(85), thus following the passivization pattern (86).
(85)
a) *Jane was fallen down by Mary.
b) *The accident was happened to collect the insurance.
These examples are obtained by Hirakawa (1994) and were presented in Balcom (1997, p.8).

83
(86)
[[ xDO-SOMETHING] CAUSE [ y BECOME STATE]]
x ø <y>
Oshita (2000) analyzed Balcom‟s claim that causativization is one of the reasons for the
occurrence of passive unaccusatives. His study provided only one example (87) of
possible causativization of the verb before having been passivized.
(87)
* It [i.e., a wall] was falled down in order to get a bigger green house.
(L1Spanish; Oshita 2000, p. 313).
According to Oshita, causativization is unlikely to happen in situations which denote
events beyond the control of a volitional subject (88a) or when the doer of the action is
the subject NP (88b), which does not require causativization and then passivization of
the verb.
(88)
a) *… the word, „the role of women‟ is appeared just several years
ago.
(L1Korean; Oshita 2000, p. 314).
b) *I was nearly arrived to my office.
(L1Italian; Oshita 2000, p. 314).
Ju (2000) proposes that a cognitive factor influences the overpassivization phenomenon.
Whenever there is a context which implies a possible external causer (89) of an event
(available for a by phrase passive interpretation), learners perceive an agent and they
tend to passivize the unaccusatives appearing in such contexts more than unaccusatives
which do not. In this case, the fan is perceived as an external doer of the action
motivating learners to produce the incorrect structure due to the non-agentive verb.

84
(89)
Tom switched on the fan.
*Shortly after, the smoke in the room was disappeared by the fan.
(Ju 2000, p. 93).
The conclusion is that passivization of unaccusatives should be viewed as an overt
marker of NP movement, more precisely, an overgeneralization of the passive
morphosyntax of L2 English i.e., overpassivization.
3.2.3 UNACCUSATIVE AUXILIARY SELECTION
Recall that one of the diagnostics for the unaccusatives/unergative opposition is
auxiliary selection (section 2.2.2). Sorace (1993) studied the sensitivity to the UH of
English and French learners of L2 Italian. In Italian (as explained in 2.2.2),
unaccusatives (i) occur with the auxiliary essere (be), (ii) optionally occur with essere
(be) when taken as complements with modals and (iii) take essere as the co-occuring
auxiliary with dovere when clitic climbing occurs, as presented in (48) above. The study
involved native French speakers (French uses only unaccusatives of change of location
with etrè (be) and other unaccusatives with avoir (have)) and English natives (which
use only have in perfective constructions). Sorace conducted a grammaticality
judgement test including various types of unaccusatives used with essere in the
constructions mentioned above. Avere (have) was also used in the same constructions
and participants had to select the correct auxiliary.
Table 7 Mean acceptability judgments on five categories of unaccusative verbs, Essere and Avere versions. (Sorace 1993)

85
The results showed (Table 7) that both French and English speakers are sensitive to the
fact that unaccusatives normally occur with essere in Italian. L1 showed to be
influential for the auxiliary choice because French and English speakers accepted at a
greater degree avere (have) with unaccusatives describing a state than native Italians.
3.2.4 UNACCUSATIVE POSTVERBAL SUBJECTS
The study of Zobl (1989) mentioned in 3.2.2., also noticed that speakers from various
L1 backgrounds produced ungrammatical VS orders mostly with unaccusative verbs
(90)
(90)
a) Sometimes comes a good regular wave.
b) I was just patient until dried my clothes
c) I think it continue of today condition forever.
(L1Japanese; Zobl 1989, p. 204).
Learners seem to be sensitive to the fact that the internal argument of unaccusatives
appears in object position (in situ) and they do not move it to surface subject position
(Spec IP) to get nominative case. In these cases, learners either do not fulfill the surface
subject position i.e., do not provide the necessary expletive there required in English as
in (90a,b) or they provide the expletive „it‟ (90c) and form ungrammatical structures
(which, as we will see, are crucial to understand the experimental section in this
dissertation). Zobl emphasizes that these structures are produced by intermediate, upper
intermediate and advanced level students. Additionally he explains that it is unlikely
that transfer occurs due to the fact that participants‟ L1 is Japanese, which is a SOV
language.
Postverbal subjects were also produced only with unaccusatives in the studies
conducted by Oshita (2000; 2004). The structures there-V-S (91a), *it-V-S (91b) and
*Ø -V-S (91c) were produced by Spanish, Italian , Korean and Japanese L1 speakers.
(91)
a) ..there exist many kind of prejudice.

86
(L1Korean; Oshita 2000, p. 316).
b) ..*it arrived the day of his departure.
(L1 Spanish; Oshita, 2004, p. 119).
c) ..*like a mirage appeared the large expanse of the sea.
(L1 Italian; Oshita, 2004, p. 120)
There-V-S was the rarest produced structure, even though it is grammatical. Spanish
and Italian speakers produced more VS structures than Japanese and Korean who
produced more passive unacccusatives. Oshita claims that null expletives are transferred
from the L1 Spanish and Italian, hence the production of *Ø -V-S mostly among Italian
and Spanish speakers (a fact that will be relevant for the experimental study in this
dissertation). The production of *it-V-S is due to the fact learners prefer it in subject
position instead of the grammatical there due to its nominal features. On the other hand,
the low production of postverbal subjects among Japanese and Korean speakers
indicates that null expletives do not exist in their native languages.
Yuan (1999) studied whether English learners of L2 Chinese will be sensitive to the
unaccusative/unergative distinction in Chinese in the acquisition of VS structures.
English and Chinese have different mapping of the semantics and the syntax as
explained in 2.2.2. The internal argument of Chinese unaccusative verbs may occur
preverbally, as in English, as shown in (51a), here repeated as (92a), or it may display
surface unaccusativity by occuring postverbally as shown in (51b), here (92b). The
internal argument in Chinese appears postverbally only if it is an indefinite noun phrase
as in (92b). Definite noun phrase cannot occur postverbally as in (51c), here (92c).
(92)
a) shang ge yue, san sou chuan zai zhe ge hai yu chen le.
last CL month three CL ship in this CL sea area sink PFV
„Last month, three ships sank in this sea area.‟
b) shang ge yue, zai zhe ge hai yu chen le san sou chuan.
last CL month in this CL sea area sink PFV three CL ship
„Last month, three ships sank in this sea area.‟
c) *shang ge yue, zai zhe ge hai yu chen le na sou chuan.
last CL month in this CL sea area sink PFV that CL ship

87
„Last month, that ship sank in this sea area.‟
(Yuan, 1999, pp. 279)
The subjects were 48 native English learners of L2 Chinese divided into 4 proficiency
levels and a native Chinese control group. They described pictures which required the
use of unaccusative verbs allowing both preverbal and postverbal occurrence of the
subject, and unergative verbs which do not allow postverbal subjects. Additionally, they
were tested by a grammaticality judgment test including the same type of sentences. The
verbs used for the test, which allow VS with indefinite noun phrase, were (i) externally
caused unaccusatives (ii) unaccusatives of directed motion (iii) unergatives which
behave as unaccusatives when used with a directional phrase9 (PP jump + direction
+NP) as explained in 2.2.3.1.2. Unergative subjects do not appear in postverbal
position. The results indicated that the unaccusative/unergative distinction is acquired
very late or it is never acquired at a native-like competence by English learners of L2
Chinese and that the acquisition follows certain developmental stages which are not
linear.
Oshita (2001) studied the results obtained by Yuan (1999) and proposed his
Unaccusative Trap Hypothesis which explains the developmental stages of the
acquisition of the unaccusative / unergative distinction. Figures 9, 10 and 11 show the
results obtained by Yuan, represented in column charts by Oshita (pp. 296-297). Figure
9 shows the results of the picture descriptions requiring use of unaccusative verbs.
Learners produced postverbal structures correctly with externally caused (break) and
directed motion (fall) unaccusatives and incorrectly with some internally caused
unergatives (run). The lowest proficiency level group hardly produced any VS
structures. Groups 2 and 3 produced them with an increasing tendency, while the most
proficient group tended to decrease the VS production. Natives produced VS with all
the verbs allowing the VS occurrence. Simultaneously all learners preferred SV to VS
order for all verbs.
9 For additional explanation see“Unergatives that „become‟ unaccusatives in English locative inversion
structures: A lexical syntactic approach by Amaya Mendikoetxea (2006).
88
Figure 9. Percentage of V-NP production on the picture description task (based on Table 3 in Yuan, 1999, p. 285)
Figure 10 shows the acceptability of VS on a scale ranging from -2 (completely
unacceptable) to 2 (completely acceptable) from the grammaticality judgment test. It is
obvious that group 1 rejects VS completely. Groups 2 and 3 accept VS with all verbs.
At intermediate stages learners seem to overextend the structure to all verb types. Group
4 distinguishes the verbs allowing VS from the ones that do not allow the structure, but
not as sharply as the native speakers.
Figure 10: V-NP Acceptance on the grammaticality judgment task (based on Tables 4, 5, and 6 in Yuan, 1999, p. 286).
Yuan divided the fourth group into 3 subgroups (Figure 11), according to the results
from the picture description data and the grammaticality judgment test. Namely, 4A
accepted and 4B rejected all VS sentences. 4C distinguished correctly the grammatical
and ungrammatical structures. It means that 4A behaves like groups 2 and 3 and 4B like
group 1. Based on these results, Oshita proposes the three developmental stages for the
acquisition of the unaccusative / unergative distinction named the Unaccusative Trap
(UT), as shown below.

89
Figure 11. V-NP Acceptance on the grammaticality judgment task (based on Tables 4, 5, and 6 in Yuan, 1999, p. 286).
The first stage (unergative stage): The interlanguage grammar perceives both
unaccusatives and unergatives as being unergatives and only SV is produced and
accepted. Learners do not possess the knowledge of the underlying structure of both
unergatives and unaccusatives at this level. They misanalyze unaccusatives as
unergatives and do not „correctly‟ use SV with all verb types.
The second stage: The second stage recognizes acceptance of VS structures
irrespective of their ungrammaticality. The learner probably becomes aware of the
syntactically relevant semantic features of unaccusative verbs, hence the use of passive
unaccusatives, use of (it)-V-S structures and reluctance to use SV, indicating that
learners have progressed to the second stage. Oshita explains that at this stage learners
probably become aware of the mapping of the internal argument in object position but
they are not clear about how to produce the structure without the required subject in
English, hence the production of the ungrammatical structures (*it-V-S and passive
unaccusatives My mother was died). Even though SV is mostly used in the input,
learners somehow become sensitive to the fact that the subject of unaccusatives is
generated in object position.
In Yuan‟s data, nothing suggests that groups 2 and 3 are sensitive to the
unaccusative/unergative distinction but they somehow start accepting VS and
overgeneralize it with all types of verbs. Oshita compares this measure to the locative
construction in English, which allows unergatives in VS structures, as explained in
2.2.3.1.2.

90
The third stage: Learners achieve native-like competence when they start using the
object to subject movement without producing ungrammatical structures (*it insertion,
passive unaccusatives). At this stage learners may start using grammatical there
constructions. In Yuan‟s data, only the 4C group reached near-native competence while
the 4A and 4B remained at the first and second developmental stage in spite of their
high proficiency level.
It is clear from the previous studies that the production of VS structures is a result of
unaccusativity (Unaccusative Hypothesis, UH). But unaccusativity is a necessary but
insufficient condition for the occurrence of postverbal subjects in English (Lozano and
Mendikoetxea 2008; 2010). Namely, L1 Spanish learners of L2 English produced
postverbal subject constructions (both grammatical PP-V-S and there–V-S and
ungrammatical *it-V-S and * Ø -V-S) only with unaccusatives which shows the
constraints of the lexicon-syntax interface. Additionally, the subjects have to be focus
i.e., introduce new information (End Focus Principle), and heavy or long (End Weight
Principle), involving the influence of the syntax-discourse and syntax-phonology
interfaces respectively in the production of VS as shown in (93).
(93)
a) PP (locative) - V - S
In some places still exist popularly supported death penalty.
b) there-insertion – V - S
Furthermore there also exists a wide variety of optional
channels which have to be paid.
c) *it-insertion - V - S
*In the name of religion it had occured many important events
d) * Ø -insertion - V - S
*It is difficult that exist volunteers with such a feeling against it.
e) *PP (temporal) - V - S

91
*In 1760 occurs the restoration of Charles II in England.
(L1 Spanish; Lozano & Mendikoetxea, 2010, pp. 486,487).
In short, three interface constraints are needed for the production of postverbal subjects
in L2 English. This is a crucial fact for the setting up of hypotheses and for the
experimental design of the stimuli in the following chapters.
Examples taken from the Main Experimental Test for L1 Macedonian-L2 English
(IUSAJ) (See Appendix 11.1.3) are shown in (94) in order to illustrate the design of the
examples about to be studied in the experimental section. Importantly, the experimental
sentences follow the structural pattern of the sentences in (93) from the corpus studies.
The experimental constructions contain unaccusative and unergative verbs in order to
test whether learners would accept the correct XP-V-S constructions with unaccusatives
and unergatives.
(94)
a) PP (locative) - V - S
… in my dictionary appears a very interesting definition for this
word. (UNACCUSATIVE)
… but in room 4 spoke a very important doctor from Oxford
University (UNERGATIVE)
b) there-insertion – V - S
…so there came a dramatic increase of 45% of unemployment
(UNACCUSATIVE)
*…so there talked the president of the United States
(UNERGATIVE)
c) *it-insertion - V - S
*…some politicians think that it began a new period in Spanish
history. (UNACCUSATIVE)

92
*…I think that it played only the children of the people who were
rich (UNERGATIVE)
d) Ø -insertion - V - S
*…some experts say that exist some students who support it.
(UNACCUSATIVE)
*…that work only the people who have stable job.
(UNERGATIVE)
In order to support the point that postverbal subjects are produced when the 3 interface
conditions (unaccusativity, focus, and heaviness) are met and that otherwise the subject
is produced in preverbal position, we show examples of preverbal subjects with
unaccusatives which are light and topic (95).
(95)
a) The feminism begun with the French Revolution and the
Industrial Revolution
b) These debates began over two decades ago.
c) Hugo came from a burgoisie background.
(Lozano and Mendikoetxea 2010, pp.489,490)
The difference between the production of postverbal subjects between L2 learners and
English natives is not in the interface conditions that allow VS order (simply because
learners obey the same interface constraints as native English speakers do), but rather
lies in the grammaticality of the preverbal structures they produce. Learners produced
mostly ungrammatical sentences with an ungrammatical it - insertion and grammatical
locative, while natives produced grammatical PP-insertion and there-insertion. Namely,
the ungrammatical postverbal subjects are not the source of grammatical deficits:
as learners have no difficulties in identifying topic/focus and heavy/light
postverbal subjects, but rather they belong to the computational system and/or
the failure to map this information into appropriate syntactic structures: learners
cannot encode End-Weight and End-Focus Principles onto the correct

93
grammatical constructions and overuse the construction (it-insertion and Ø-
insertion), possibly due to processing difficulties and crosslinguistic influence.
(Lozano and Mendikoetxea 2010, p. 494).
3.3 CONCLUSION: THE PSYCHOLOGICAL REALITY OF UH
The studies mentioned in 3.2. state that L2 learners treat unaccusatives differently from
unergatives from a (morpho)syntactic point of view. Oshita (2004) claims that the UH is
psychologically real in L2 acquisition. This was shown in the studies explaining
passivized unaccusatives (Zobl 1989, Balcom 1997, Oshita 2000, Ju 2000), auxiliary
selection (Sorace 1993), and the production of postverbal subjects (Oshita 2000, Yuan
1999, Zobl 1989, Lozano and Mendikoetxea 2008; 2010). In English, unaccusatives are
mostly produced in SV constructions, and such word order does not indicate the
unaccusative/unergative distinction overtly. Inversion in native English is mostly
possible with unaccusatives but the constructions are very rare, as indicated in 2.2.3.1.1.
(See Biber et.al (1999, p. 945)), therefore, it is unlikely that learners acquire these
structures as a result of positive evidence from the input. All the studies mentioned so
far refer to the fact that learners are sensitive to the unaccusative/unergative distinction
which is what our study will focus on.

94
4 HYPOTHESES
After having presented the theoretical background on unaccusativity (chapter 2) and
reviewed the relevant studies on the L2 acquisition of unaccusative/unergative contrasts
(chapter 3), we are now in a position to set up some hypotheses about the acquisition of
unaccusatives vs unergatives in L1 Macedonian – L2 English and L1 Spanish – L2
English..
It is expected that Macedonian learners of L2 English will be sensitive to the constraints
of the Unaccusative Hypothesis (UH) by allowing postverbal subjects with
unaccusatives (more than with unergatives) in L2 English, as English natives do.
Considering the fact that Macedonian data will be compared against Spanish data, it is
also expected that both groups of learners will show similar behavior throughout
different proficiency levels, approaching native-like competence as they approach the
final developmental stage. In short, L2 learners obey the Unaccusativity Hypothesis at
the lexicon-syntax interface. Recall from chapter 2 that all three languages in question
(English, Macedonian and Spanish) treat postverbal subjects as new (focus)
information, whereas preverbal subjects represent old (topic) information (End-Focus
Principle). Additionally, postverbal subjects are usually considered to be heavier than
preverbal subjects (End-Weight Principle). Hence it is expected that both groups
(Macedonian and Spanish) will accept postverbal subjects in the same contexts in which
they are allowed in native English. Therefore, based on numerous theoretical studies
and previous empirical findings we formulate four hypotheses, which are presented here
in a general format, though we will examine their different nuances as we present the
data.
H1: L2 knowledge of Unaccusativity at the lexicon-syntax interface: As was
stated in previous research, L2 English learners will obey the principles of the
Unaccusative Hypothesis (UH) right from the early stages of acquisition and
independently of their L1 (Macedonian/Spanish), thus accepting VS with
unaccusatives more than with unergatives, as English natives do. L2 learners
therefore obey the UH constraints at the lexicon-syntax interface.

95
H2: L2 knowledge of the different preverbal structures: Even though the UH is
observed through all developmental stages, at initial levels all unaccusative
structures will be treated as grammatical by both groups of learners,
independently of their grammatical status in native English (there/PP/*Ø/*it-V-
S). Ungrammatical unaccusative structures (*it-V-S; *Ø-V-S) will be rejected as
proficiency increases, showing a clear developmental pattern. The overuse of
ungrammatical expletive *it and *Ø will be accounted for in terms of (i) the
universal EPP principle (chapter 2), (ii) the selection of a default expletive from
the mental lexicon, and (iii) some possible L1 transfer effects.
H3: No transfer hypothesis: the observed behavior cannot be simply accounted for
by L1 transfer alone10
, since the observed developmental pattern is a general
result of learners‟ sensitivity to UH.
H4: Learners will follow the developmental stages proposed by the Unaccusative
Trap of Oshita (2001): (i) The first stage (unergative stage): learners perceive
both unaccusatives and unergatives as being unergatives and only SV is
produced and accepted (ii) The second stage: The second stage recognizes
acceptance of VS structures irrespective of their ungrammaticality with all verb
types (unaccusatives and unergatives). Learners start acquiring the rules of the
structure hence the production of ungrammatical passive unaccusatives or it-V-S
structures. (iii) The third stage: Learners achieve native-like competence when
they start using the object to subject movement without producing
ungrammatical structures (*it insertion, passive unaccusatives).
10 Note that we are highlighting the fact that the results cannot be due to L1 transfer only, though some L1
influence/advantage on group of learners over the other (Macedonian vs Spanish) cannot be discarded, as
will be discussed later.

96
5 METHOD
In this chapter we will describe the method used to conduct our empirical study by
providing detailed information about the participants, the instrument used to collect
data, the procedure followed to collect and analyze the data and the design of the study.
5.1 SUBJECTS
The subjects who participated in this empirical study can be divided into three groups.
The first group consisted of native Macedonian learners of L2 English. A larger group
of participants belonged to a foreign language teaching school and two student service
centres in Kavadarci and Skopje (Macedonia) and another small group of participants
belonged to the postgraduate program at FON University in Skopje Macedonia. The rest
of the subjects volunteered to participate after receiving an email containing the test (see
appendix 11.6.3. for details). This study reached an overall number of 314 participants,
out of which 215 completed the acceptability judgment test but only 95 completed both
the acceptability judgment test and the proficiency placement test necessary for the data
to be concluded. Four cases were removed from the final data due to invalid results,
thus the final number was 91 (28-male and 63 female). The proficiency test divided the
participants into six levels: A1-26; A2-14; B1-10; B2-15; C1-13; C2-13. The age of the
participants ranged from 13 to 39. The L1 Macedonian-L2 English learners biodata can
be seen in appendix 11.4.3. Table 8a11
presents a brief summary of the main biodata
characteristics (mean values presented) of the Macedonian group.
11 AGE and YEARS STUDYING ENGLISH for B1 level was calculated for 8 cases, 1 case did not
provide info.
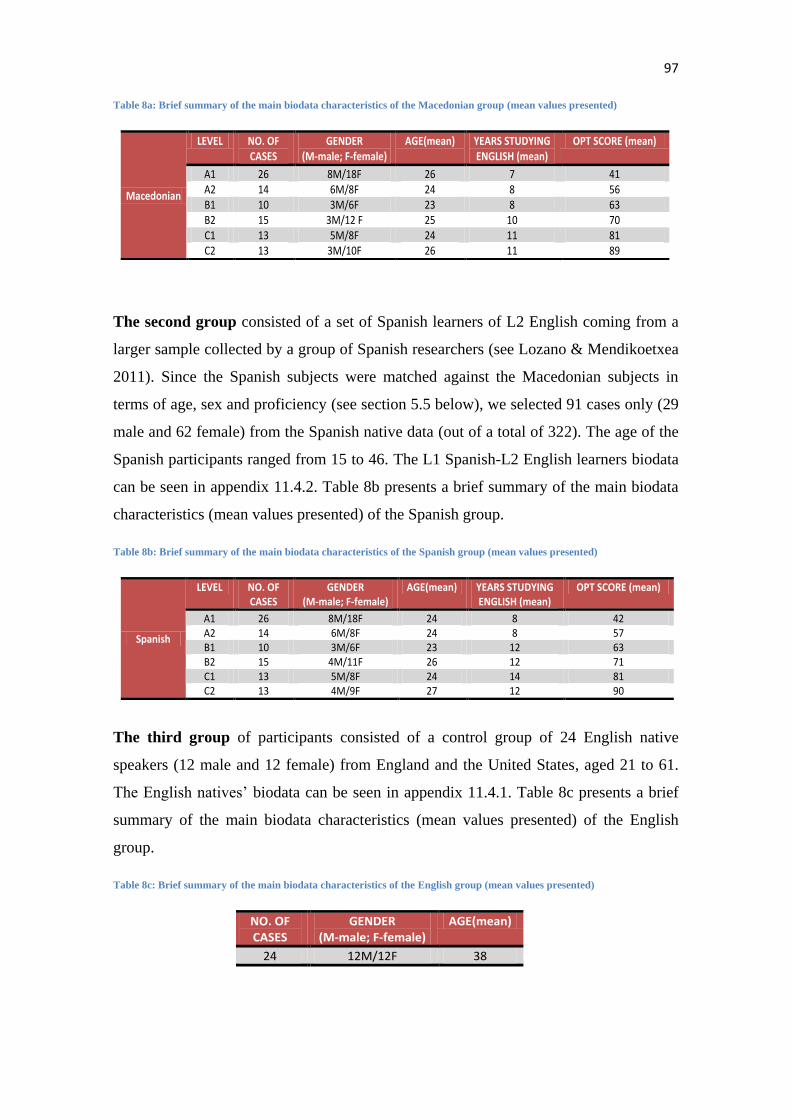
97
Table 8a: Brief summary of the main biodata characteristics of the Macedonian group (mean values presented)
Macedonian
LEVEL NO. OF CASES
GENDER (M-male; F-female)
AGE(mean) YEARS STUDYING ENGLISH (mean)
OPT SCORE (mean)
A1 26 8M/18F 26 7 41 A2 14 6M/8F 24 8 56 B1 10 3M/6F 23 8 63 B2 15 3M/12 F 25 10 70 C1 13 5M/8F 24 11 81 C2 13 3M/10F 26 11 89
The second group consisted of a set of Spanish learners of L2 English coming from a
larger sample collected by a group of Spanish researchers (see Lozano & Mendikoetxea
2011). Since the Spanish subjects were matched against the Macedonian subjects in
terms of age, sex and proficiency (see section 5.5 below), we selected 91 cases only (29
male and 62 female) from the Spanish native data (out of a total of 322). The age of the
Spanish participants ranged from 15 to 46. The L1 Spanish-L2 English learners biodata
can be seen in appendix 11.4.2. Table 8b presents a brief summary of the main biodata
characteristics (mean values presented) of the Spanish group.
Table 8b: Brief summary of the main biodata characteristics of the Spanish group (mean values presented)
Spanish
LEVEL NO. OF CASES
GENDER (M-male; F-female)
AGE(mean) YEARS STUDYING ENGLISH (mean)
OPT SCORE (mean)
A1 26 8M/18F 24 8 42 A2 14 6M/8F 24 8 57 B1 10 3M/6F 23 12 63 B2 15 4M/11F 26 12 71 C1 13 5M/8F 24 14 81 C2 13 4M/9F 27 12 90
The third group of participants consisted of a control group of 24 English native
speakers (12 male and 12 female) from England and the United States, aged 21 to 61.
The English natives‟ biodata can be seen in appendix 11.4.1. Table 8c presents a brief
summary of the main biodata characteristics (mean values presented) of the English
group.
Table 8c: Brief summary of the main biodata characteristics of the English group (mean values presented)
English
NO. OF CASES
GENDER (M-male; F-female)
AGE(mean)
24 12M/12F 38

98
5.2 INSTRUMENTS
A set of two tests was used for the purpose of this study: (i) a contextualized
acceptability judgment test (see appendix 11.1) to measure the phenomenon under
investigation, which is the main experimental test of this dissertation, and (ii) a
proficiency test (see appendix 11.2) in order to examine the variations in learners‟
behavior per proficiency level. The set of tests was created in a form of an online test
via the LimeSurvey12
platform for web based research.
5.2.1 MAIN EXPERIMENTAL TEST: THE ACCEPTABILITY JUDGEMENT TEST
We considered that an acceptability judgment test would be a suitable tool for
measuring the phenomenon under investigation due to the fact that judgment tasks
provide a means of establishing whether learners know that certain forms are impossible
or ungrammatical in the L2. Thus, an acceptability judgment task can be used to find
out whether sentences which are ruled out by principles of UG are also disallowed in
the interlanguage grammar (White 2003:18).
The acceptability judgment test was developed by a group of researchers at the
University of Granada and Universidad Autónoma de Madrid for the purpose of an
ongoing study called EASI (Estudio sobre Adquisiciòn de la Syntaxis del Inglés) to
measure native Spanish learners‟ sensitivity for the conditions allowing VS in English.
Due to the fact that we are measuring the same phenomenon with native Macedonians,
we decided that this test was the most suitable instrument for our study. In this way, by
using the same instrument, comparisons between the Macedonian vs. Spanish learners
of L2 English could be made and, therefore, issues such as L1 transfer and universal
12 The LimeSurvey web platform for distribution of online questionnaires has been hosted by CSIRC
(Centro de Servicios de Informática y Redes de Comunicaciones – Centre for Information Services and
Communication Networks) for the research needs of the University of Granada. LimeSurvey is an open-
source software which is being developed world-wide by computer scientists.This platform provides
online distribution of tests in a way that after completion results are automatically sent back to a
designated email address. It also provides numerous data presentation options such as extrapolation of
data in different formats (Excel, PDF, CSV) or programs (SPSS).

99
developmental patterns could be contrasted. The Macedonian version of the study
received the name IUSAJ (Istrazuvanje za Usvojuvanje na Sintaksata na Makedonskiot
Jazik), translated in English as (SAES) Study on the Acquisition of English Syntax,
which was the name used for the online test distributed in English to the English native
control group.
The actual experimental design and variables of the main empirical test is described in
the section below (section 5.3), though we will present here a description of the
instrument. The opening part of the test (see appendix 11.1.3) contained instructions on
how to do the test. Then there followed a background information section in which the
subjects were supposed to provide information about their sex, mother tongue, mother
tongue of their parents, spoken language at home, age, educational background,
language learning background, stay abroad and self- proficiency rate (note that this self-
proficiency rating is a subjective measure given by the learners, but we also used an
objective placement test to determine learners‟ proficiency: The Oxford Placement Test,
to be described below). The acceptability judgment test consists of 32 postverbal
subjects stimuli which can be represented by the XP-V-S structure.
Four unaccusatives (exist/appear/begin/come) and four unergatives
(talk/work/play/speak) were selected for the creation of the stimuli. The choice of these
verbs was based on their most frequent occurrence in postverbal subject structures in the
Spanish subcorpora of the International Corpus of Learner English (ICLE), and
(WriCLE) Written Corpus of Learner English, which consists of eleven subcorpora of
academic essays written by lower advanced L2 English learners of eleven different L1s.
These verbs are also part of Levin (1993) and Levin and Rappaport-Hovav (1995)
inventory of unaccusative and unergative lemmas represented as core unaccusatives and
unergatives (see discussion in section 2.2.1). Each verb appears in four different stimuli
having one of the four XPs (ungrammatical *it insertion and *Ø expletive and
grammatical there insertion and locative adverbial PPloc) at clause-initial position as
indicated in (96), an example with the unaccusative EXIST.
(96)
a) *it EXIST

100
Nowadays, if you work as a policeman in Spain, you can easily
get into difficult situations. But…
…I think that it exist many more risky and dangerous jobs.
b) there EXIST
Even though we live in a democratic country with plenty of
opportunities…
…I believe that there exist unlucky people who are extremely
poor.
c) Ø EXIST
A lot of university students have recently complained about the
„Bologna process‟, but…
…some experts say that exist some students who support it.
d) PPloc EXIST
Nowadays, it is very dangerous to walk alone at night in a big
city...
...because in those cities exist many dangerous criminals who
could kill you.
The introductory sentence, which sets the scene and introduces a certain context, does
not contain postverbal subjects. This preceding discourse was included due to the fact
that (i) it sets the scene for the target sentence and is needed because we are dealing
with discursive factors here and (ii) it biases for a postverbal focus and heavy subject in
the target sentence. So, the preceding discourse in a way biases towards such type of
postverbal subject.
The final position of the target sentence is occupied by a focus and heavy subject
containing 6 to 8 words13
hence these are presentational structures of the type discussed
in section 2.2. The participants provided their opinion on whether the target sentence is
grammatical or ungrammatical, on a 5-point Likert scale, ranging from 1 (totally
ungrammatical) to 5 (totally grammatical), as indicated in (97) (see appendix 11.3.1. for
a full detail of the test). If participants consider a given structure to be completely
13 Previous studies (Lozano & Mendikoetxea 2008, 2010) have found in corpus data that 6 to 8 words
make a long (heavy) subject. Lower than that, the subject was considered short (light).

101
ungrammatical they are expected to choose 1 and if the sentence is viewed to be
completely grammatical, they are expected to choose 5. Intermediate values (2–4) are
given if the participants consider the sentence structure to be partially acceptable.
(97)
The house was very dirty. All the windows were closed, the rooms were dark...
... and from the kitchen came a horrible smell of burning oil .
1 2 3 4 5
Odberete:
The sentences were ordered in a scrambled randomized sequence in which the same XP
(ungrammatical *it insertion / *Ø insertion / grammatical there insertion / locative
adverbial PPloc) or verb (unaccusative / unergative) does not appear in two consequent
sentences (see section 11.1.4 on the procedure on how sentences were randomized). At
the end, participants were given the option to provide their opinion about the test. The
complete version of the test is attached under the Appendix number (11.1).
5.2.2 PROFICIENCY TEST: THE OXFORD PLACEMENT TEST
The second instrument used for the study was the online version of the Oxford
Placement Test (see Appendix 11.2), which was the second part of the LimeSurvey set
of two tests. The placement test appeared immediately after the first (acceptability
judgement) test was completed.
After the learners completed the two tests, they received an email with their proficiency
test results and a short description of the grammar parts which should be improved
based on the test performance.
The web-based type of research proved to be feasible for our study. To support this
claim some previous studies, examining some aspects related to the use of this type of
research, will be mentioned. Wilson and Dewaele (2011) list the pros and cons of
conducting web based research. They underlined five advantages and two disadvantages
of conducting a study of this kind. Namely, they claim that conducting a web based

102
research is more economic than conducting a traditional research. Another advantage is
that the administration of the test is faster and easily distributable which provides a
large sample of participants. The collection of data is automatically imported into a
spreadsheet software where it can be easily processed. It is also probable that the
anonymity of the web research increases the level of honesty because the participants do
not feel threatened when providing their answers. Web research is also convenient to
access large and varied samples worldwide as well as small and specialized populations
otherwise difficult to be reached. The disadvantages are related to the self-selection of
participants and the increased heterogeneity in the sample.
The sample of our study is not entirely homogeneous. Even though all our subjects have
learnt English and possess certain knowledge of the language, they have different
background features. Our participants are „self-selected‟ due to the fact that they have
been contacted at random and invited to participate if they have any knowledge of
English. They were also invited to further distribute the test. Considering the fact that
we are examining a universal phenomenon, we assumed that similar background
features of the subjects would not strongly influence the outcome of the results should
they all have certain knowledge of English. In order to ensure more homogeneity in the
sample and to conduct a more reliable study we did a matched-pair design of our study
(see section 5.4. below).
The largest problem we faced with our web based research is related to the lack of
possibilities to control the completion of the questionnaires due to the absence of the
researcher (even though the absence of the researcher can have positive effects if
participants feel anxious if they are observed when tested). Namely, participants were
properly instructed to include the same email address twice, i.e., before doing both tests
and that they had to complete both tests for their results to be valid and processed. We
had many incomplete tests or completed ones without having the same email address for
the second test, which made it impossible for these cases to be traced and used for the
study. Despite this, the number of volunteers exceded our expectations since a sizeable
sample for each of the proficiency levels was obtained.
5.3 VARIABLES AND EXPERIMENTAL DESIGN

103
In this section we will present in detail the scheme about the variables upon which the
acceptability judgement test was developed in order to present a visual idea of the test
for the readers.
Two independent variables were used in the test: the verb type
(unergative/unaccusative) and the preverbal element XP (*it / there /*Ø / PPloc). As was
previously mentioned in 5.2.1., the verbs were taken from the Spanish corpora
International Corpus of Learner English (ICLE) and (WriCLE) Written Corpus of
Learner English based on their most frequent occurrence in postverbal structures (see
percentage of concordances for each verb below). The most frequent unaccusatives used
in XP-V-S constructions were EXIST, APPEAR, BEGIN and COME and the most
inverted unergatives were TALK, WORK, PLAY and SPEAK. The four types of
preverbal XP were also taken from the corpus data. For each verb there are 4 stimuli
(one for each preverbal XP), as summarized below.
INDEPENDENT VARIABLES
■Var1: Verb (unac / unerg)
■Unacc: n=4, high inversion (inv/totalinv in ICLE+WRICLE)
Exist (41.4%)
Appear (24%)
Begin (8.6%)
Come (6.9%)
■Unerg: n=4, most frequent (conc/totalconcs in ICLE+WRICLE)
Talk (35.7%)
Work (30.2%)
Play (7.7%)
Speak (4.4%)
■Var2: pre-verbal XP
■*it (n=4)
■there (n=4)
■*Ø (n=4)
■PPloc (n=4)
Three constants were observed in the development of the test: (i) each stimuli contains
postverbal subject which is focus, (ii) the postverbal subject of the stimuli is also heavy
(containing 6 to 8 words), and (iii) the word order of all stimuli is VS.

104
CONSTANTS
■C1: Info status (focus) of subject
■C2: Weight (heavy), between 6 words (median) and 8 words (mean)
■C3: Word order (VS)
SV orders were not included in this version of the test for the simple reason that, since
participation is on a volunteer basis, a long test containing the same amount of SV as of
VS sentences would mean that it would be too long and too tedious, hence the risk of
not getting enough volunteers for this study.
The stimuli design of the acceptability judgement test is shown below. There are 32 VS
stimuli, 16 unaccusatives and 16 unergatives. Each verb was used in four stimuli
opening with a different preverbal element (*it / there /*Ø / PPloc).
STIMULI DESIGN
■32 stimuli (VS order):
►4 XP (*it / there / *Ø / PPloc ) x 4 Vunac (exist/appear/begin/come): 1. *it EXIST
2. there EXIST
3. *ø EXIST
4. PPloc EXIST
5. *it APPEAR
6. there APPEAR
7. *ø APPEAR
8. PPloc APPEAR
9. *it BEGIN
10. there BEGIN
11. *ø BEGIN
12. PPloc BEGIN
13. *it COME
14. there COME
15. *ø COME
16. PPloc COME
►4 XP (*it / *there / *Ø / *PPloc ) x 4 Vunerg (talk/work/play/speak): 17. *it TALK
18. *there TALK
19. *ø TALK
20. PPloc TALK
21. *it WORK
22. *there WORK
23. *ø WORK
24. *PPloc WORK
25. *it PLAY
26. *there PLAY
27. *ø PLAY
28. *PPloc PLAY
29. *it SPEAK
30. *there SPEAK
31. *ø SPEAK
32. *PPloc SPEAK
5.4 PROCEDURE
As was already mentioned in 5.2., the online version of the acceptability judgement test
and the OPT were already used for the purpose of EASI (Estudio sobre Adquisición de

105
la Sintaxis del Inglés), which examined the same phenomenon with native Spanish
learners of L2 English. Due to the fact that the existing instructions were in Spanish, we
had to activate another questionnaire in the LimeSurvey platform as another part of the
same study under the name IUSAJ (Istrazuvanje za Usvojuvanje na Sintaksata na
Angliskiot Jazik) (see appendix in section 11.1.3). All the instructions were translated
into Macedonian, but the content of the acceptability judgement test obviously remained
intact (i.e., in English).
After the questionnaire was adapted to be used by native Macedonian learners of L2
English, we created an invitation email in Macedonian asking the potential participants
to take part in this study. This message contained the following: brief information about
the study; information how to participate indicating that only native Macedonians who
have knowledge of English can take part; information that participants will learn about
their proficiency level and which grammar aspects should be improved; note that they
will be sent a thank you certificate after we receive their complete results. Next there
followed the link for participation in the study. (see appendix in section 11.6.3).
Then we continued with the distribution of the test. The message was sent to a large
number of foreign language schools in Macedonia, student service companies, public
and private institutions and personal contacts. They were all kindly asked to further
distribute the message. We also contacted several Macedonian Universities and invited
them to participate in this study and include their students as well. We received many
individual submissions of the test, but except for the two positive reactions mentioned
in the acknowledgements we did not receive any interest for a group testing to be
conducted in a certain educational institution. The final test results from the
LimeSurvey platform showed the number of 314 tests out of which 95 were complete.
Four participants of this 95 were eliminated due to invalid results thus the final number
of useful participants was 91.
As was explained in 5.3., web based data collected from LimeSurvey are automatically
imported into a spreadsheet software, where they can be easily processed. Whenever a
participant completed the acceptability judgement test, we received an email at a
previously designated email address. Raw data were coded into an excel spreadsheet
containing four sheets (Appendix 11.4 shows the final version of the raw data). The first
sheet contained the copied raw data and the OPT score and OPT level (A2-C2) for

106
every participant. The second sheet contained the completed results grouped per
proficiency level and the values and sums of the unaccusative/unergative preference per
level and per structure (ungrammatical *it insertion and *Ø expletive / grammatical
there insertion and locative adverbial PPloc). The third sheet contained the bar charts
and trend charts showing the obtained results (see appendix 11.5). The fourth sheet
contained the full OPT results. These results were accessible at the following web page
http://www.wagsoft.com/testResults-gr.txt and provided the email addresses of the
participants who properly completed the two tests. Due to the fact that we needed to
track these participants separately in order to thank them for their participation and to
ask them whether they would be interested in receiving a printed certificate of
participation, we used the following link http://www.wagsoft.com/cgi-
bin/showDiagnostics-gr.cgi? and added [+email%40domain.country] and obtained the
individual results for each particular participant and the information explaining which
grammar parts should be improved. This link contained an electronically generated
form with information about precise placement results, which was suitably emailed
to each participant separately in order for them to be able to refer to it and examine their
results in detail (Appendix 11.7).
Throughout the data extraction procedure, we became aware that many tests could not
be used as final data because they were either incomplete or the necessary email address
was not included in the two tests. The number of incomplete tests was increasing and
we decided to resend a reminder email to the participants to complete the unfinished
parts (Appendix 11.8). The response to these emails was not very high. We consider
that this is due to the length of the two tests together. Namely, one participant would
need at least 30 minutes to complete the tests and we think they were unwilling to
repeat the completion of the missing parts. The final number of valid cases was 91. All
valid cases received a specially designed electronic certificate of participation in the
IUSAJ study (Appendix 11.9).
After obtaining the Macedonian data, we made another version of the online
questionnaire designed for the control English natives group. The introductory part was
translated in English, some of the background questions (mother tongue of the parents;
language instruction) were removed and we created another email message explaining
that we needed a group of English natives to give us their opinion on whether a certain

107
structure seems grammatical or not (Appendix 11.1.1). Understandably, the OPT was
not included for the English natives. After distributing the test we obtained 24
completed results. As we already had the Spanish data available, we started designing
the comparison of collected data.
5.5 DESIGN
Due to the fact that we are examining a universal phenomenon, we decided to match the
91 Macedonian case with cases from the Spanish native data, collected under the same
method, i.e., to conduct a matched-pair design of the study by comparing IUSAJ data
and EASI data. The Spanish data were larger than the completed Macedonian data
which provided the possibility for each Macedonian case to be paired with a very
similar Spanish case. The cases were matched by gender, age and proficiency score
(OPT). Each of the 91 Macedonian cases, 28 male and 63 female, was compared to the
most similar Spanish case and we obtained 29 male and 62 female Spanish cases. The
ID number of each Macedonian case was paired with the ID number of the most similar
Spanish case.
In order to make it more convenient, we combined the two excel sheets containing the
final Macedonian and Spanish data with the paired ID numbers into one document,
containing only the paired cases, divided by proficiency and the bar and trend charts for
Macedonian and Spanish data. At the end, we added the results of the 24 native English
controls.
It was decided that the matched pair design of the study should be used in order to
obtain a more homogeneous sample and to minimize the variability between the
learners, hence to increase the reliability of the study.
5.6 DATA CODING AND DATA ANALYSIS
First the data coding process will be explained and at the end of the section we will
explain the statistical data analysis.
As was mentioned in 5.2 in the Instruments section, the participants evaluated the
grammaticality of each of the 32 postverbal subject structures on a Likert scale from 1
to 5. Data were collected online in the LimeSurvey platform, as explained earlier, which
generated excel spreadsheets containing the raw data with the values selected by

108
each case for every sentence and the mean values for each case both for unaccusative
and for unergative structures (see the raw data spreadsheet in appendix 11.4.)
The spreadsheet with the raw data was then manipulated in order to make sense of the
raw data, since the output generated by LimeSurvey was randomized, as the sentences
were in the experiment.
The spreadsheet also contains mean values for unaccusative and unergative structures
per proficiency level and for the native English group as well. This representation of the
data gives a clear indication for the learners‟ behavior regarding the
unaccusative/unergative preference from initial stages. .
The spreadsheets also contain mean values per case and per level for every structure
regarding the clause initial XP element (*it-V-S/there-V-S/*Ø-V-S/PP-V-S) for both
unaccusatives and for unergatives. It can also be observed whether, even if considered
grammatical at initial stages, these structures are preferred more with unaccusatives than
with unergatives. The stability or instability of the grammatical and ungrammatical
structures will also become evident and possible developmental stages will be observed.
The values will show whether Macedonian and Spanish learners behave in a similar
way regarding the evaluation of the structures, even though the two languages differ in
the presentationally focused context.
The best explanatory analysis of the data will be provided by the bar charts and trend
charts visually showing the unaccusative vs. unergative distinction; the acceptance of
the different initial XP per proficiency level; the acceptance of postverbal subjects
examined separately for every unaccusative or unergative verb; the tendency to accept
or reject certain structures with proficiency; the sensitivity to the grammaticality or
ungrammaticality of structures per proficiency level and the comparison of learners‟
behavior with the behavior of the English native controls.
Data were analyzed quantitatively (mainly by looking at the means) since there are too
many variables at stake, as shown earlier. We have not done any inferential statistics (t-
tests) because there are too many variables (not only the linguistic ones: XP (*it/*Ø
/there/PP), verb type (unac/unerg), verb lexeme (work, play, exist…), but also the
developmental ones: proficiency (A1-C2). Hence, it is impossible to perform an
ANOVA, since there would be too many interactions between the variables to
understand what they mean.

109
6 RESULTS
This chapter contains description of the resuls obtained in this empirical study. The
results corresponding to each hypothesis will be presented with bar and trend charts and
will be explained in detail. Additionally the qualitative comments of the participants
will be included in order to obtain a clear idea whether learners were aware of the
structures they were evaluating.
6.1 QUANTITATIVE RESULTS
Data will first be analyzed quantitatively and then qualitatively. The quantitative
analysis encompasses presentation of the mean values obtained for each XP-V-S
structure and for each proficiency level for both groups (Spanish and Macedonian). The
qualitative analysis encompasses the qualitative comments of the participants about the
test and the structures they had to evaluate.
6.1.1 RESULTS FOR H1: L2 KNOWLEDGE OF UNACCUSATIVITY (LEXICON-
SYNTAX INTERFACE)
The Macedonian group of L2 English learners prefers postverbal subjects (VS) more
with unaccusatives than with unergatives at all proficiency levels (Figure 12). Even
though unaccusatives are accepted more than unergatives at all levels, the distinction
between the two types of verbs is different per level. The acceptance of VS order
decreases as proficiency increases. A1 level shows the highest VS preference with all
unaccusatives (3,9), but also rates high VS with unergatives (3,4). A2 level shows larger
difference between unaccusatives (3,8) and unergatives (3,0). B1 level is the best
discriminator of the unaccusative (3,7) unergative (2,8) distinction. B2 level shows
similar behavior to B1 slightly decreasing the difference between unaccusatives (3,5)
and unergatives (2,7). C1 and C2 levels show decrease of the difference and the same
values for unaccusatives (3,0) and unergatives (2,5). English natives show greater
unaccusative (2,9) / unergative (2,1) distinction than A and C levels but similar to B
levels.
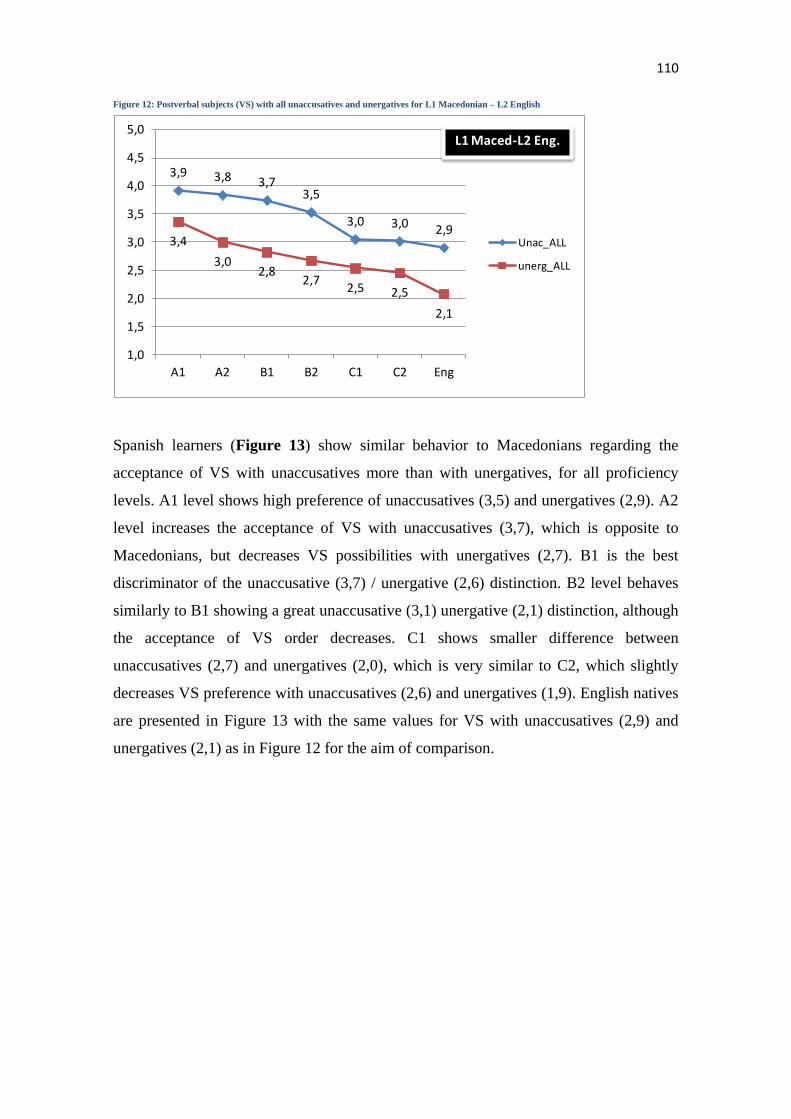
110
Figure 12: Postverbal subjects (VS) with all unaccusatives and unergatives for L1 Macedonian – L2 English
3,9 3,8 3,73,5
3,0 3,0 2,93,4
3,02,8
2,72,5 2,5
2,1
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
A1 A2 B1 B2 C1 C2 Eng
Unac_ALL
unerg_ALL
L1 Maced-L2 Eng.
Spanish learners (Figure 13) show similar behavior to Macedonians regarding the
acceptance of VS with unaccusatives more than with unergatives, for all proficiency
levels. A1 level shows high preference of unaccusatives (3,5) and unergatives (2,9). A2
level increases the acceptance of VS with unaccusatives (3,7), which is opposite to
Macedonians, but decreases VS possibilities with unergatives (2,7). B1 is the best
discriminator of the unaccusative (3,7) / unergative (2,6) distinction. B2 level behaves
similarly to B1 showing a great unaccusative (3,1) unergative (2,1) distinction, although
the acceptance of VS order decreases. C1 shows smaller difference between
unaccusatives (2,7) and unergatives (2,0), which is very similar to C2, which slightly
decreases VS preference with unaccusatives (2,6) and unergatives (1,9). English natives
are presented in Figure 13 with the same values for VS with unaccusatives (2,9) and
unergatives (2,1) as in Figure 12 for the aim of comparison.
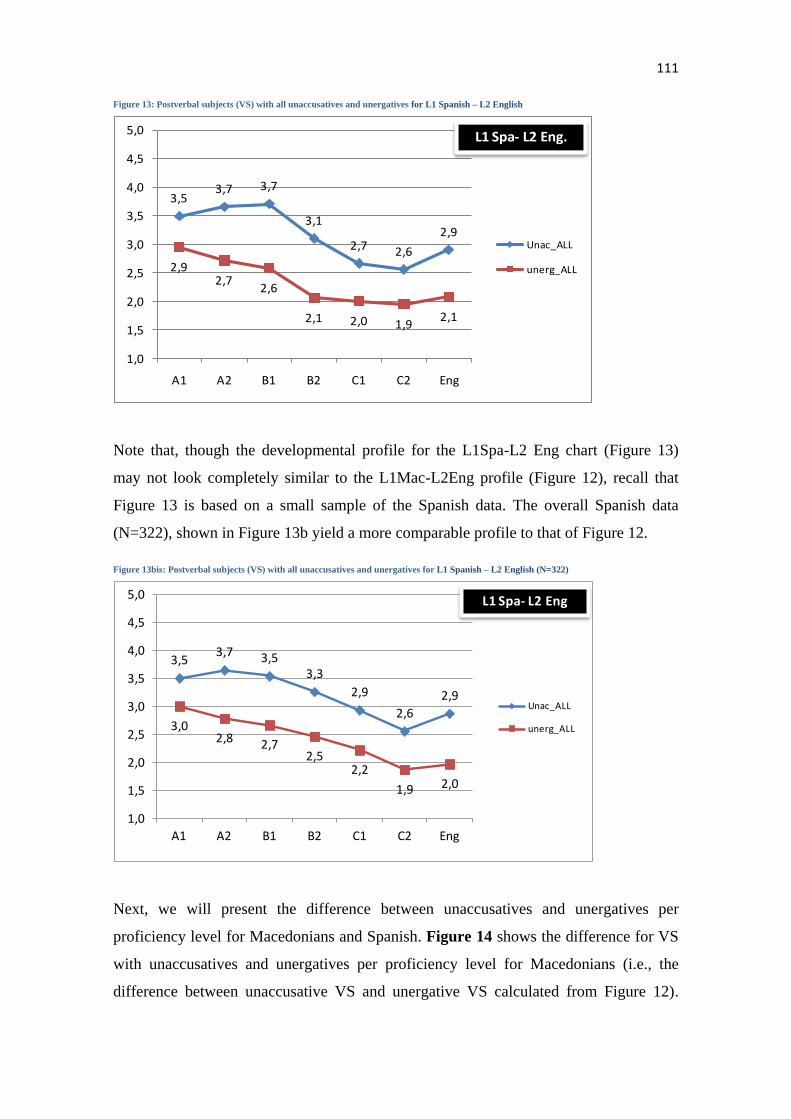
111
Figure 13: Postverbal subjects (VS) with all unaccusatives and unergatives for L1 Spanish – L2 English
3,53,7 3,7
3,1
2,7 2,6
2,9
2,92,7
2,6
2,1 2,0 1,92,1
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
A1 A2 B1 B2 C1 C2 Eng
Unac_ALL
unerg_ALL
L1 Spa- L2 Eng.
Note that, though the developmental profile for the L1Spa-L2 Eng chart (Figure 13)
may not look completely similar to the L1Mac-L2Eng profile (Figure 12), recall that
Figure 13 is based on a small sample of the Spanish data. The overall Spanish data
(N=322), shown in Figure 13b yield a more comparable profile to that of Figure 12.
Figure 13bis: Postverbal subjects (VS) with all unaccusatives and unergatives for L1 Spanish – L2 English (N=322)
3,53,7 3,5
3,3
2,9
2,6
2,9
3,02,8 2,7
2,52,2
1,9 2,0
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
A1 A2 B1 B2 C1 C2 Eng
Unac_ALL
unerg_ALL
L1 Spa- L2 Eng
Next, we will present the difference between unaccusatives and unergatives per
proficiency level for Macedonians and Spanish. Figure 14 shows the difference for VS
with unaccusatives and unergatives per proficiency level for Macedonians (i.e., the
difference between unaccusative VS and unergative VS calculated from Figure 12).
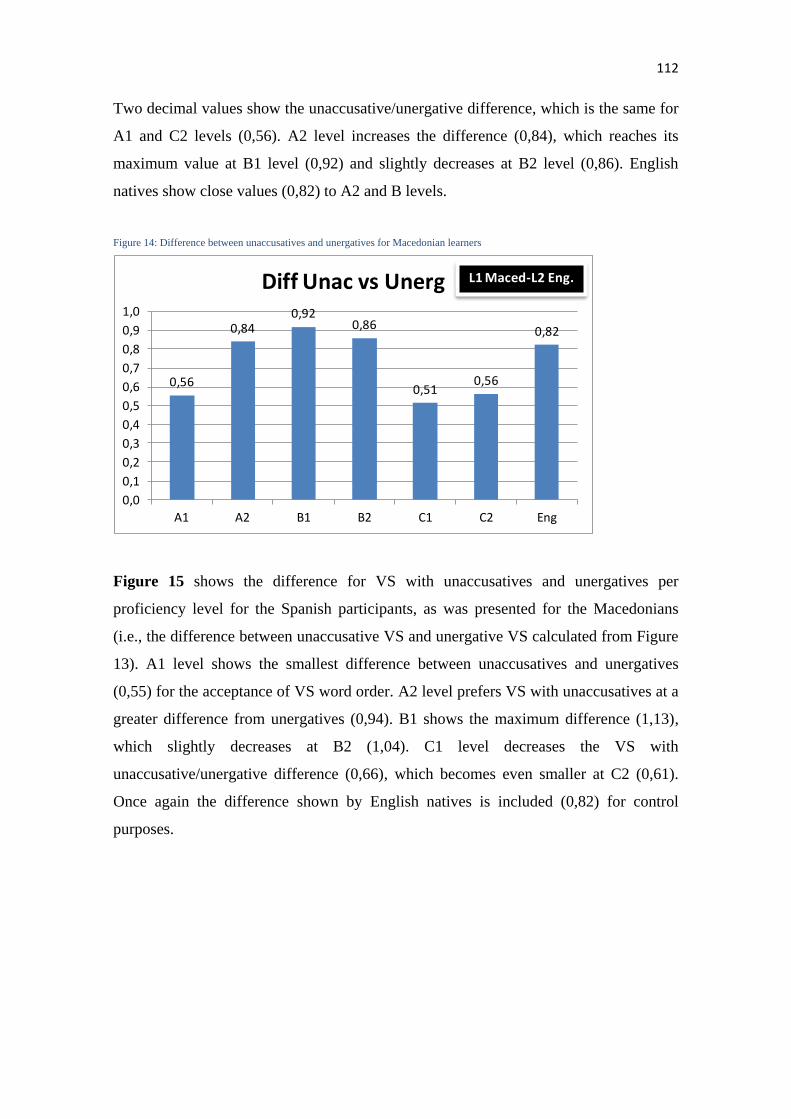
112
Two decimal values show the unaccusative/unergative difference, which is the same for
A1 and C2 levels (0,56). A2 level increases the difference (0,84), which reaches its
maximum value at B1 level (0,92) and slightly decreases at B2 level (0,86). English
natives show close values (0,82) to A2 and B levels.
Figure 14: Difference between unaccusatives and unergatives for Macedonian learners
0,56
0,840,92
0,86
0,510,56
0,82
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
A1 A2 B1 B2 C1 C2 Eng
Diff Unac vs Unerg L1 Maced-L2 Eng.
Figure 15 shows the difference for VS with unaccusatives and unergatives per
proficiency level for the Spanish participants, as was presented for the Macedonians
(i.e., the difference between unaccusative VS and unergative VS calculated from Figure
13). A1 level shows the smallest difference between unaccusatives and unergatives
(0,55) for the acceptance of VS word order. A2 level prefers VS with unaccusatives at a
greater difference from unergatives (0,94). B1 shows the maximum difference (1,13),
which slightly decreases at B2 (1,04). C1 level decreases the VS with
unaccusative/unergative difference (0,66), which becomes even smaller at C2 (0,61).
Once again the difference shown by English natives is included (0,82) for control
purposes.
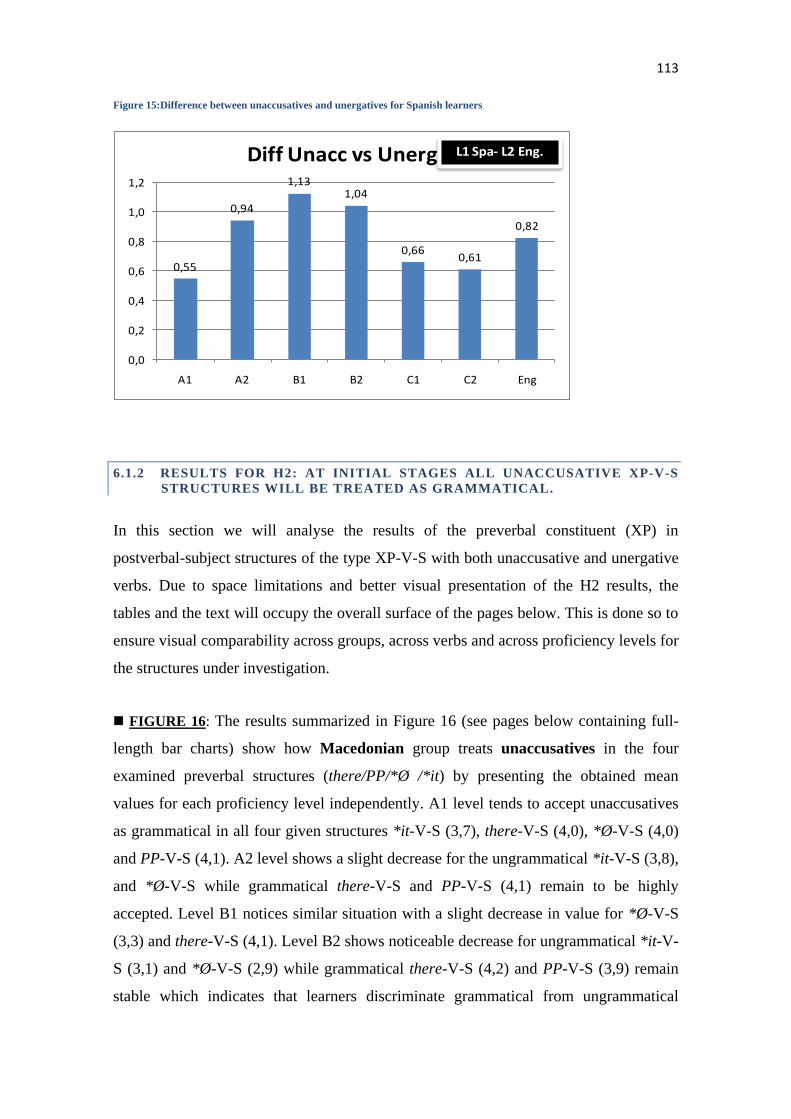
113
Figure 15:Difference between unaccusatives and unergatives for Spanish learners
0,55
0,94
1,131,04
0,660,61
0,82
0,0
0,2
0,4
0,6
0,8
1,0
1,2
A1 A2 B1 B2 C1 C2 Eng
Diff Unacc vs Unerg L1 Spa- L2 Eng.
6.1.2 RESULTS FOR H2: AT INITIAL STAGES ALL UNACCUSATIVE XP-V-S
STRUCTURES WILL BE TREATED AS GRAMMATICAL.
In this section we will analyse the results of the preverbal constituent (XP) in
postverbal-subject structures of the type XP-V-S with both unaccusative and unergative
verbs. Due to space limitations and better visual presentation of the H2 results, the
tables and the text will occupy the overall surface of the pages below. This is done so to
ensure visual comparability across groups, across verbs and across proficiency levels for
the structures under investigation.
FIGURE 16: The results summarized in Figure 16 (see pages below containing full-
length bar charts) show how Macedonian group treats unaccusatives in the four
examined preverbal structures (there/PP/*Ø /*it) by presenting the obtained mean
values for each proficiency level independently. A1 level tends to accept unaccusatives
as grammatical in all four given structures *it-V-S (3,7), there-V-S (4,0), *Ø-V-S (4,0)
and PP-V-S (4,1). A2 level shows a slight decrease for the ungrammatical *it-V-S (3,8),
and *Ø-V-S while grammatical there-V-S and PP-V-S (4,1) remain to be highly
accepted. Level B1 notices similar situation with a slight decrease in value for *Ø-V-S
(3,3) and there-V-S (4,1). Level B2 shows noticeable decrease for ungrammatical *it-V-
S (3,1) and *Ø-V-S (2,9) while grammatical there-V-S (4,2) and PP-V-S (3,9) remain
stable which indicates that learners discriminate grammatical from ungrammatical

114
structures. At C1 level there is a decrease in the acceptance of all VS structures. The
lowest acceptance is obtained for *it-V-S (2,5) and *Ø-V-S (2,6) while grammatical
there-V-S (3,5) and PP-V-S (3,6) are accepted at a higher rate. At level C2
ungrammatical *it-V-S (2,1) and *Ø-V-S (2,5) are even less accepted. There-V-S
notices increase (3,8) while PP-V-S notices only a slight decrease (3,5). English natives
also accept ungrammatical *it-V-S (2,1) and *Ø-V-S (2,5) at a very low rate. These
results imply that, at initial stages, Macedonians treat all unaccusatives rather equally,
regardless of the (un)grammaticality of the structure they appear in (there/PP vs *Ø
/*it). As proficiency increases learners distinguish between the grammatical (there/PP:
remain rather stable) vs. ungrammatical (*Ø /*it: decrease constantly) structures. This
will be discussed in detail in the Discussion section.
FIGURE 17 (see pages below) shows the treatment of Macedonians of VS with
unergatives in the same four preverbal structures. Compared to unaccusatives in Figure
16, unergatives are less accepted with all VS structures in accordance with the UH.
They are not completely rejected due to the fact that in native English locative inversion
with unergatives is possible (see discussion in section 2.2.3.1.2.) A1 level allows all
structures out of which PP-V-S has the highest value (4,0), while *Ø-V-S and *there-V-
S shows the same value (3,3) and *it-V-S is the least accepted (2,8). At level A2 only
*there-V-S (3,4) notices slightly increased value while the other three structures PP-V-
S (3,5), *Ø-V-S (2,9) and *it-V-S (2,2) notice decreased values. B1 notices decrease of
VS with unergatives for all structures except for PP-V-S (3,6). *it-V-S shows the
lowest value (2,1). *Ø-V-S (2,6) is also less accepted than *there-V-S (3,0). At B2
level only PP-V-S (3,8) shows slightly increased values while all other structures, *it-
V-S (1,8), *Ø-V-S (2,4) and *there-V-S (2,7) decrease. C levels notice a decrease of
VS with unergatives for all structures. At C1 *it-V-S (1,9) slightly increases while *Ø
-V-S (2,3), *there-V-S (2,6) and PP-V-S (3,4) decrease. The VS decreasing tendency
with ungrammatical structures *it-V-S (1,7) and *Ø-V-S (2,0) continues at C2 level and
*there-V-S (2,7) and PP-V-S (3,5) slightly increase. English natives results show low
rates of VS with unergatives for all structures. PP-V-S (3,1) is the most accepted, as
expected (due to its grammaticality), while *it-V-S (1,4), *Ø-V-S (1,8) *there-V-S (2,0)
show very low values.
The same as with unaccusatives, we can notice that learners initially discriminate
between grammatical PP-V-S vs. the rest of ungrammatical unergatives (*there/*it/*

115
Ø), therefore they are aware that there-V-S is possible only with unaccusatives which is
again in accordance with the UH. This will also be discussed in detail in the Discussion
section.
FIGURE 18 (see pages below): The acceptance of the Spanish group of VS with
unaccusatives in all four structures is presented in Figure 18. At A1 level we can notice
very similar values for all structures: *it-V-S (3,4), there-V-S (3,5), *Ø-V-S (3,3) and
PP-V-S (3,8) which is an implication that the Spanish group treats all structures as
grammatical at initial stages, similar to the Macedonians. At level A2 learners behave
in a similar way as A1 showing the high mean values for all structures: *it-V-S (3,4),
there-V-S (3,5), *Ø-V-S (3,6) and PP-V-S (4,1). Level B1 also notices acceptance of all
structures as grammatical: *it-V-S (3,7), there-V-S (3,8), *Ø-V-S (3,6) and PP-V-S
(3,8). B2 level shows large decrease in the acceptance of VS with unaccusatives for *it-
V-S (2,9), there-V-S (2,8), *Ø-V-S (2,8) while PP-V-S (3,8) remains the same. At C1
there is a decrease of the VS acceptance for *it-V-S (2,6), *Ø-V-S (2,0) while PP-V-S
(2,9) except for there-V-S (3,2) which notices a higher value. C2 level shows a further
decrease of ungrammatical VS in *it-V-S (2,0) and *Ø-V-S (1,9) structures and
acceptance of grammatical VS in there-V-S (3,4) and PP-V-S (2,9). English natives
accept, at very low rates, ungrammatical VS structures *it-V-S (2,1) and *Ø-V-S (2,1)
while grammatical structures notice a significantly higher acceptance: there-V-S (3,6)
and PP-V-S (3,8). This behavior implies that, at higher stages, the Spanish group
discriminates between grammatical and ungrammatical structures, which is different
from the behavior of the Macedonians, who start distinguishing between them at lower
stages. The tendency to accept grammatical structures and reject ungrammatical as
proficiency level increases is the same among Macedonians and Spanish. The difference
is that Macedonians are more sensitive at lower levels. We will discuss this in detail in
the Discussion section.
FIGURE 19 (see pages below): The acceptance of VS structures with unergatives
by the Spanish group is presented in Figure 19. A1 level shows the highest acceptance
for grammatical PP-V-S (3,5) and lower acceptance for the other ungrammatical
structures *it-V-S (2,7), *there-V-S (2,8), *Ø-V-S (2,9), which is an indication that
learners discriminate between grammatical PP-V-S vs. the ungrammatical unergative

116
structures (*there/*it/*Ø). At A2 level PP-V-S (3,4) remains rather stable, while *it-V-
S (2,2), *there-V-S (2,4) and *Ø-V-S (2,8) notice decreased values. Level B1 allows
VS with unergatives with PP-V-S (3,1) at the highest rate. *It-V-S (2,5) and *there-V-S
(2,4) behave similarly to A2 and *Ø-V-S (2,3) is accepted at a lower rate. B2 level
shows large decrease of the ungrammatical *it-V-S (1,8), *there-V-S (2,1) and *Ø-V-S
(1,6), while PP-V-S (2,8) remains as the most accepted VS structure with unergatives.
At C1 there is a very similar situation having lower values for *it-V-S (1,6), *there-V-S
(2,3), *Ø-V-S (1,4) and a higher value for PP-V-S (2,7). Surprisingly enough, C2
notices the highest value for *there-V-S (2,5), while *it-V-S (1,6), *Ø-V-S (1,7) and
PP-V-S (2,0) show lower acceptance rates (though PP-V-S remains as the highest of
ungrammatical *it and *Ø). English natives also accept at very low rates
ungrammatical structures *it-V-S (1,4) *there-V-S (2,0) and *Ø-V-S (1,8), while
grammatical PP-V-S (3,8) is accepted at a higher rate. Therefore, the Spanish group
also discriminates the grammatical PP-V-S vs the ungrammatical structures from the
outset (a discrimination that increases as proficiency level increases), with the exception
of C2 level which seem to overgeneralize there-V-S with unaccusatives and accept it as
grammatical with unergatives. We will discuss in detail the implications of all these
findings in the Discussion section.
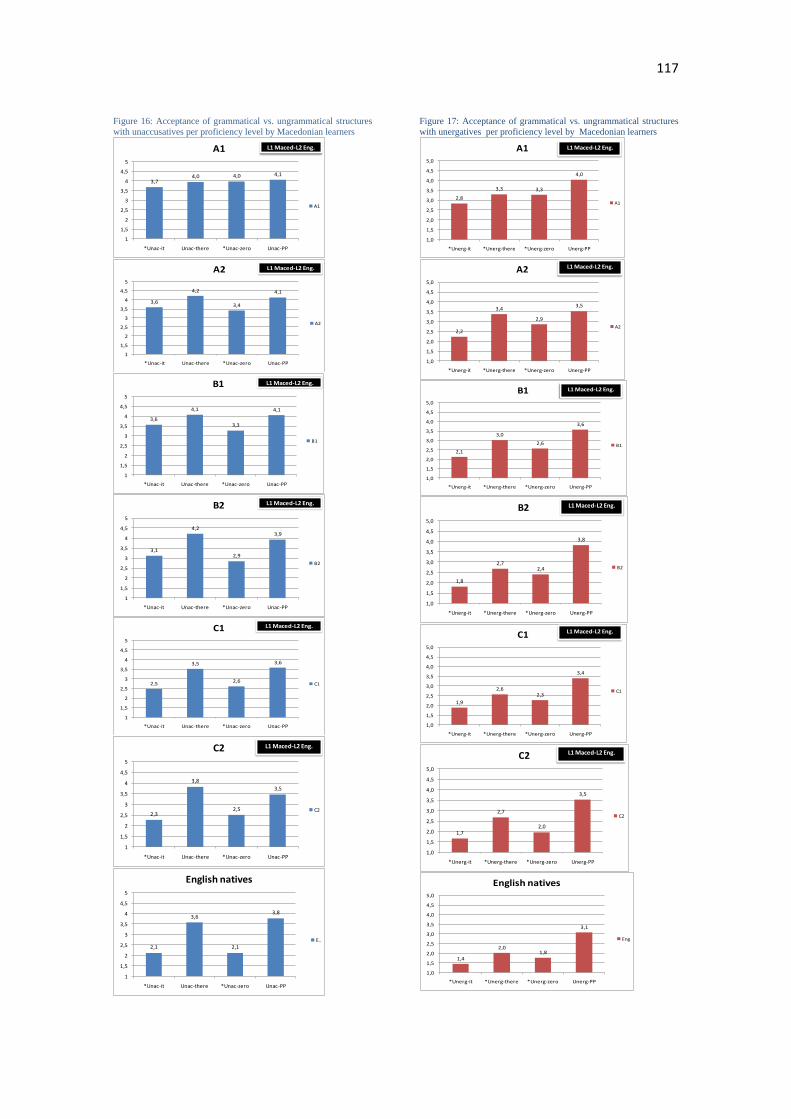
117
Figure 16: Acceptance of grammatical vs. ungrammatical structures
with unaccusatives per proficiency level by Macedonian learners
3,74,0 4,0 4,1
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
A1
A1
L1 Maced-L2 Eng.
3,6
4,2
3,4
4,1
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
A2
A2
L1 Maced-L2 Eng.
3,6
4,1
3,3
4,1
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
B1
B1
L1 Maced-L2 Eng.
3,1
4,2
2,9
3,9
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
B2
B2
L1 Maced-L2 Eng.
2,5
3,5
2,6
3,6
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
C1
C1
L1 Maced-L2 Eng.
2,3
3,8
2,5
3,5
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
C2
C2
L1 Maced-L2 Eng.
2,1
3,6
2,1
3,8
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
English natives
E…
Figure 17: Acceptance of grammatical vs. ungrammatical structures
with unergatives per proficiency level by Macedonian learners
2,8
3,3 3,3
4,0
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
A1
A1
L1 Maced-L2 Eng.
2,2
3,4
2,9
3,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
A2
A2
L1 Maced-L2 Eng.
2,1
3,0
2,6
3,6
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
B1
B1
L1 Maced-L2 Eng.
1,8
2,72,4
3,8
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
B2
B2
L1 Maced-L2 Eng.
1,9
2,62,3
3,4
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
C1
C1
L1 Maced-L2 Eng.
1,7
2,7
2,0
3,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
C2
C2
L1 Maced-L2 Eng.
1,4
2,01,8
3,1
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
English natives
Eng
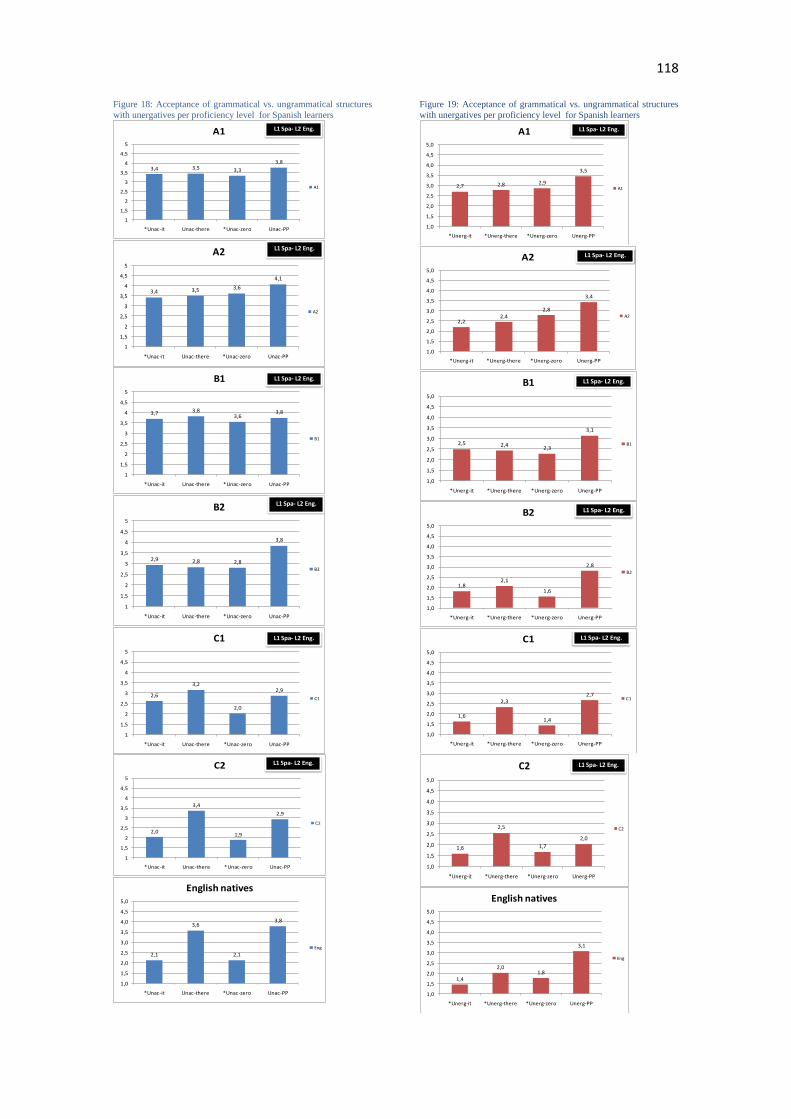
118
Figure 18: Acceptance of grammatical vs. ungrammatical structures
with unergatives per proficiency level for Spanish learners
3,4 3,5 3,3
3,8
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
A1
A1
L1 Spa- L2 Eng.
3,4 3,5 3,6
4,1
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
A2
A2
L1 Spa- L2 Eng.
3,7 3,83,6
3,8
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
B1
B1
L1 Spa- L2 Eng.
2,9 2,8 2,8
3,8
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
B2
B2
L1 Spa- L2 Eng.
2,6
3,2
2,0
2,9
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
C1
C1
L1 Spa- L2 Eng.
2,0
3,4
1,9
2,9
1
1,5
2
2,5
3
3,5
4
4,5
5
*Unac-it Unac-there *Unac-zero Unac-PP
C2
C2
L1 Spa- L2 Eng.
2,1
3,6
2,1
3,8
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unac-it Unac-there *Unac-zero Unac-PP
English natives
Eng
Figure 19: Acceptance of grammatical vs. ungrammatical structures
with unergatives per proficiency level for Spanish learners
2,7 2,8 2,9
3,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
A1
A1
L1 Spa- L2 Eng.
2,22,4
2,8
3,4
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
A2
A2
L1 Spa- L2 Eng.
2,5 2,42,3
3,1
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
B1
B1
L1 Spa- L2 Eng.
1,82,1
1,6
2,8
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
B2
B2
L1 Spa- L2 Eng.
1,6
2,3
1,4
2,7
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
C1
C1
L1 Spa- L2 Eng.
1,6
2,5
1,7
2,0
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
C2
C2
L1 Spa- L2 Eng.
1,4
2,01,8
3,1
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
*Unerg-it *Unerg-there *Unerg-zero Unerg-PP
English natives
Eng

119
6.1.3 RESULTS FOR H3: NO TRANSFER HYPOTHESIS: LEARNERS’
BEHAVOUR CANNOT SIMPLY BE ACCOUNTED FOR BY L1 TRANSFER
The results presented for H2 are also relevant for H3. In this section we will present the
same results as trend charts in order to provide a better developmental visual insight of
the no-transfer account.
Figure 20 shows the acceptance of unaccusative VS in all structures by the Macedonian
group. Considering the fact that Macedonian and Spanish are pro-drop languages
allowing null subjects, *Ø-V-S would be expected to be highly accepted if learners were
making L1 transfer. At A1 level, *Ø-V-S (marked with the green line) is treated as
grammatical and is accepted at high rates, together with the other structures (recall that
this is in line with H2: at initial stages all preverbal structures are treated similarly,
independently of their (un)grammaticality). At A2 level, *Ø-V-S becomes the least
accepted, showing the early discrimination of *Ø-V-S as ungrammatical, which is
unexpected if L1 transfer occurs. As proficiency increases, the acceptance of *Ø-V-S
gradually decreases. The Spanish group behaves in a similar way, as shown in Figure
21. At initial stages they accept all structures as grammatical. The rate for *Ø-V-S
becomes the lowest at B1 level, and narrowly decreases at B2 indicating that transfer
cannot be the only source of learners‟ interlanguage knowledge. The rates continue to
decrease at C levels. As can be seen from Figure 20 and Figure 21, both Macedonian
and Spanish groups start distinguishing grammatical from ungrammatical structures
from early stages. Macedonians become sensitive even at A2 level while Spanish
distinguish at intermediate levels.
Figure 20: Acceptance of grammatical vs. ungrammatical structures with unaccusatives per proficiency level for Macedonian learners
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
5
A1 A2 B1 B2 C1 C2 Eng
*Unac-it
Unac-there
*Unac-zero
Unac-PP
L1 Maced-L2 Eng.
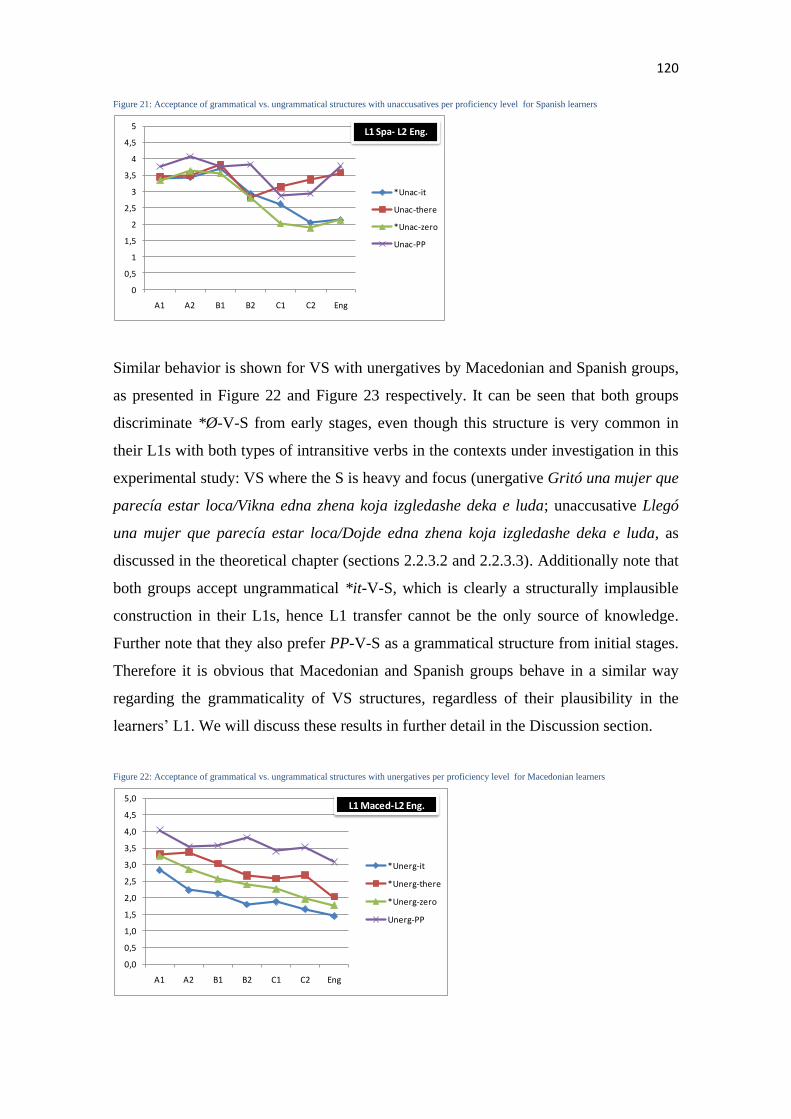
120
Figure 21: Acceptance of grammatical vs. ungrammatical structures with unaccusatives per proficiency level for Spanish learners
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
5
A1 A2 B1 B2 C1 C2 Eng
*Unac-it
Unac-there
*Unac-zero
Unac-PP
L1 Spa- L2 Eng.
Similar behavior is shown for VS with unergatives by Macedonian and Spanish groups,
as presented in Figure 22 and Figure 23 respectively. It can be seen that both groups
discriminate *Ø-V-S from early stages, even though this structure is very common in
their L1s with both types of intransitive verbs in the contexts under investigation in this
experimental study: VS where the S is heavy and focus (unergative Gritó una mujer que
parecía estar loca/Vikna edna zhena koja izgledashe deka e luda; unaccusative Llegó
una mujer que parecía estar loca/Dojde edna zhena koja izgledashe deka e luda, as
discussed in the theoretical chapter (sections 2.2.3.2 and 2.2.3.3). Additionally note that
both groups accept ungrammatical *it-V-S, which is clearly a structurally implausible
construction in their L1s, hence L1 transfer cannot be the only source of knowledge.
Further note that they also prefer PP-V-S as a grammatical structure from initial stages.
Therefore it is obvious that Macedonian and Spanish groups behave in a similar way
regarding the grammaticality of VS structures, regardless of their plausibility in the
learners‟ L1. We will discuss these results in further detail in the Discussion section.
Figure 22: Acceptance of grammatical vs. ungrammatical structures with unergatives per proficiency level for Macedonian learners
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
A1 A2 B1 B2 C1 C2 Eng
*Unerg-it
*Unerg-there
*Unerg-zero
Unerg-PP
L1 Maced-L2 Eng.

121
Figure 23: Acceptance of grammatical vs. ungrammatical structures with unergatives perproficiency level for Spanish learners
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
A1 A2 B1 B2 C1 C2 Eng
*Unerg-it
*Unerg-there
*Unerg-zero
Unerg-PP
L1 Spa- L2 Eng.
6.1.4 RESULTS FOR H4: LEARNERS WILL FOLLOW THE DEVELOPMENTAL
STAGES PROPOSED BY THE UNACCUSATIVE TRAP (OSHITA 2001).
Figure 24 and Figure 25 show that Macedonian and Spanish learners prefer VS with
unaccusatives more than with unergatives at all levels (i.e., from A1 level to B2 level),
which is in accordance with the behavior of the native English control group and
contrary to Oshita‟s (2001) claim that learners treat unaccusatives as unergatives and do
not allow VS at initial stages (see discussion in the L2 literature review chapter, section
3.2.4). Therefore, our fourth hypothesis (H4) is rejected.
Figure 24: Acceptance of VS wih unaccusatives more than with Figure 25: Acceptance of VS wih unaccusatives more than with unergatives
unergatives by Macedonian learners by Spanish learners
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
Unac_ALL unerg_ALL
A1
A2
B1
B2
C1
C2
Eng
L1 Maced-L2 Eng.
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
Unac_ALL unerg_ALL
A1
A2
B1
B2
C1
C2
Eng
L1 Spa- L2 Eng.
Despite the fact that our data seem to reject Oshita‟s proposal, it is worth remembering
that learners do show their best discrimination between unaccusative VS and unergative
VS at intermediate levels, which may be in accordance with Oshita‟s UT, according to
which learners accept VS with all intransitive verbs (both unergatives and
unaccusatives) at intermediate stages, indicating that they become sensitive to rules
allowing the structure. The discrimination at intermediate levels was presented in Figure
14, here repeated as Figure 26 for the Macedonian group, and Figure 15, here repeated

122
as Figure 27 for the Spanish group. Even though VS is preferred with unaccusatives at
all levels, it is also accepted with unergatives, especially at initial stages. Surprisingly
enough, the English natives control group does not completely reject VS with
unergatives in ungrammatical structures (*it-V-S, *there-V-S and *Ø-V-S), a fact that
will be discussed later. To summarise, learners are apparently „better‟ at intermediate
stages simply because they are unaccusativising intransitive verbs, i.e., they treat as
unaccusatives all intransitives (this will be discussed in detail in the Discussion section).
Figure 26: Difference between unaccusatives and unergatives for Figure 27: Difference between unaccusatives and unergatives for Spanish
Macedonian learners learners
0,56
0,840,92
0,86
0,510,56
0,82
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
A1 A2 B1 B2 C1 C2 Eng
Diff Unac vs Unerg L1 Maced-L2 Eng.
0,55
0,94
1,131,04
0,660,61
0,82
0,0
0,2
0,4
0,6
0,8
1,0
1,2
A1 A2 B1 B2 C1 C2 Eng
Diff Unacc vs Unerg L1 Spa- L2 Eng.
6.2 QUALITATIVE COMMENTS MADE BY THE LEARNERS
Our subjects were given the option to type in their personal opinion about the sentences
they were evaluating in the acceptability judgment test. We selected a couple of phrases
provided by the Macedonian group, several from the Spanish group and a few from the
English natives in order to present how they understood the structure they were
evaluating. The sentences will be given in their original form followed by an English
translation and information about the level of the learner.
MACEDONIAN LEARNERS’ QUALITATIVE COMMENTS
1. za nekoi recenici neznaev dali da stavam nekoja sredna ocena iako mislam deka samo eden zbor ne
bese tocen, drugoto bese vo red, no i pokraj toa staviv 1, dali e vo red? mislam deka bi mozelo
samo da ima dali e tocna ili ne, da ne postojat i srednite vrednosti
[Translation] I was not sure whether I was supposed to mark a medium value even though I think
that only one word was incorrect in spite of which I chose 1, is this ok? I think it would be
sufficient to choose only correct or incorrect options without having to choose values in between. –
level A1
2. nejasnosti imav mnogu

123
[Translation] I had many doubts - level A1
3. Smetam deka trebase pod sekoe prasanje da dademe primer kako smetam deka treba da izgleda
recenicata. Mi bese mnogu tesko da gi ocenam.
[Translation] I think that we were supposed to be given the option to provide our version of each
sentence. I found it very difficult to evaluate the sentences. – level B1
4. 90% od recenicite dobija 2 bidejki bea gramaticki nelogicni.
[Translation] 90% of the sentences were evaluated with 2 because they were grammatically
illogical. – level C1
5. Dali navistina treba samo da se zema vo predvid redosledot na zborovite vo recenicata ili i
pravilnata, odnosno nepravilnata upotreba na odredeni zborovi i upotreba na drugi zborovi namesto
niv?
[Translation] Do we really have to take into consideration only the word order or we should also
pay attention to the correct or incorrect use of certain words and use other words instead? – level
C2
As we are able to see from the comments above, Macedonian learners of L2 English are
not aware of the conditions allowing VS structures, thus it can be said that they behave
according to their intuitions about the correctness of the sentences. They clearly indicate
that they were not certain about the correctness of the structures which shows that they
do not have the conscious knowledge about the conditions allowing VS structures. They
do not indicate any knowledge about different types of intransitive verbs or different VS
structures (*it-V-S, there-V-S and *Ø-V-S, PP-V-S) due to the lack of formal
instructions teaching the unique behavior of intransitive verbs or the specific structures
allowing VS with certain types of verbs.
Similar comments were obtained by the Spanish participants in this study.
SPANISH LEARNERS’ QUALITATIVE COMMENTS
1. Hay algunas preguntas en las que dudo... sobre todo con las expresiones "there + verbo", pero
porque creo que no lo he visto en mi vida.
[Translation] There are some questions I doubt … mostly the ones containing the expression "there
+ verb" because I have never seen this structure before. – level A1
2. Un test largo, y muchas preguntas con errores del mismo tipo.
[Translation] A very long test and a lot of questions containing the same type of errors- level B1

124
3. El error que mas se repite creo que es el de estructura sintáctica, el orden en de las oraciones de
indicativo en inglés deben tener la estructura SVO. Luego hay construcciones con "there" + un
verbo que no es "to be", y creo que es incorrecto aunque no estoy seguro al 100%. Saludos.
[Translation] I think that the most repeating error is related to the syntactic structure, the sentence
order of the indicative in English should be SVO. Also, there are structures such as "there" + verb
which is not “to be” and I think this is incorrect although I am not 100% sure. Regards. – level
B2
4. He empezado el test viendo que todas las oraciones estaban mal debido al sujeto, pero luego me ha
parecido que algunas si que son gramaticalmente correctas, y me ha despertado dudas sobre este
tipo de oraciones que ahora tengo que repasar porque no me acuerdo bien!!
[Translation] I started doing the test and I realized that all sentences were wrong due to the
subject, but later I realized that some sentences are grammatically correct and I started having
doubts about this type of sentences which I have to revise because I do not remember them well!! –
level C1
5. Opino que se ha repetido excesivamente un mismo tipo de error. El test se alarga con preguntas
que tienden a ser iguales las unas a las otras, y dudo que esto aporte nuevos datos.
[Translation] I think that the same type of error was excessively repeating. The test is prolonged
with questions which are similar to one another, and I doubt that it can bring new knowledge –
level C2
The A1 level student clearly indicates that he/she has never come across the there+verb
expression, which indicates the rarity of the structure in the input. Even at higher levels
(B2), there+verb is considered to be uncommon, supporting the fact that students are
not instructed to learn this structure in class or do not find it often in the input. The C1
student states his/her instructed knowledge about the grammaticality of SVO word
order, but is confused by his/her approval of the grammaticality of “some” VS
structures showing the sensitivity for VS under certain conditions. This learner believes
that these structures were learnt in class, even though this is probably not the case,
which clearly indicates that knowledge of the Unaccusative Hypothesis is independent
from instructed knowledge.
And these are some comments made by the English native speakers:
ENGLISH NATIVES’ QUALITATIVE COMMENTS
1. I think that most of the issues here were to do with tenses and phrasing. Some meaning was lost
due to spelling error.
2. In the directions, it may be better to inform us that we are to judge the second half of the
sentence or the last phrase or add space between the given and the judged sentence. Some of the
sentences were hard to read anyway because the grammar was incorrect, which is the point of the

125
assignment, so by making the directions as clear and direct as possible is best. Thank you.
Even though English natives clearly distinguish grammatical from ungrammatical
structures and make all the relevant contrasts that we have discussed throughout this
dissertation, they do not show conscious awareness of the unaccusative/unergative
distinction, but they rely on their native sensitivity for the correctness of the structures.
In spite of the ungrammaticality of *it-V-S, *there-V-S and *Ø-V-S with unergatives,
English natives do not fully reject these structures. We were advised by some of the
English natives14
that these structures are not completely rejected in everyday speech,
where various structures become possible. In particular, informal talks with English
natives revealed that the postverbal subject did not sound “that bad”, particularly in *it-
V-S structures (it appeared a new social class called „the climbers‟), because English
allows superficially similar constructions, namely, it-extraposition (it appears that John
is ill). Obviously, inversion is not structurally identical to extraposition, since in the
former the postverbal subject is an NP, while in the latter it is a full clause. This
linguistically naive assumption that both structures are the same, might have led English
natives not to reject drastically the ungrammatical constructions under investigation.
The crucial fact that can be drawn from the qualitative comments made by the
participants is that, despite their beliefs and opinions, they all follow a clear
developmental pattern and show clear contrasts between verbs
(unaccusatives/unergatives) and between preverbal material (*it/*Ø/there/PP), which
indicates that the observed behavior is not random, but is rather constrained by the
Unaccusative Hypothesis, as argued throughout this dissertation.
6.3 CONTRASTING RESULTS: BY OPT AND BY SELF-PROFICIENCY
This section is an aside on the quantitative data which was worth exploring briefly. As
was explained in 5.3., after we collected the Macedonian data, we had many incomplete
tests and we could not trace the proficiency level of more than 200 Macedonian cases.
In order to obtain some idea about the acceptability judgment test results of the whole
lot (complete and incomplete tests), we decided to divide the subjects in proficiency
14 A special gratitude to Prof. Cristobal Lozano for discussing the acceptance of ungrammatical VS , especially *it-V-S structures
with native English speakers.

126
levels according to the self-rated proficiency they provided in the background
information section. These results are shown in Figure 28 and are compared with the
completed Macedonian results divided by the objective Oxford Placement Test (OPT)
in Figure 12 above, here repeated as Figure 29.
Figure 28: Acceptance of VS wih unaccusatives more than with unergatives by Macedonian learners rated by self-proficiency
3,8
3,43,6
3,8
3,53,2
3,5
3,03,2 3,1
2,72,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
A1 A2 B1 B2 C1 C2
Unac_ALL
unerg_ALL
L1 Maced-L2 Eng
(self-proficiency)
Figure 29: Subject-verb inversion (VS) with all unaccusatives and unergatives for Macedonian learners [Fig. 12 above]
3,9 3,8 3,73,5
3,0 3,0 2,93,4
3,02,8
2,72,5 2,5
2,1
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
A1 A2 B1 B2 C1 C2 Eng
Unac_ALL
unerg_ALL
L1 Maced-L2 Eng.
As can be appreciated by contrasting both figures, even though the learners‟ self-
proficiency classification cannot be taken for granted (since it represents the proficiency
level they believe they are in [Figure 28], and not the actual one they are in [Figure
29]15
), both charts are presented only for the purpose of general comparison and
15 Figure 29 contains the English natives‟ results which denote that learners follow certain developmental
stages in SLA acquisition of VS structures and approach the native-like norm
(by OPT))

127
verification of learners‟ awareness of the possibilities allowing VS in English. All self-
rated proficiency levels observe the UH and prefer VS more with unaccusatives than
with unergatives. This is the expected behavior, which is in accordance with the valid
Macedonian cases, as measured by the OPT. As can be seen in Figure 28 A1 level
shows high acceptance of VS both with unaccusatives and unergatives. A2 level accepts
VS less than B1 and B2, which is similar to the previous matched-pair results, showing
that B levels are the best discriminators of the unaccusative / unergative difference. C1
and C2 levels of the self-proficiency results show decrease in the overall acceptance of
VS word order which is the same as the results obtained by the OPT levels. The
difference between unaccusatives and unergatives is observed at high rates among the
self-proficiency results while OPT results indicate smaller unaccusative / unergative
distinction. Even though these two figures show differences, it is obvious that all
learners prefer VS more with unaccusatives than with unergatives, which, once again,
indicates their sensitivity to the principles of the UH.

128
7 DISCUSSION
In this chapter we will discuss the results obtained in the study and we will attempt to
explain the implications of the findings in relation to whether they support the proposed
four hypotheses. We will include possible ideas for future research.
7.1 L2 LEARNERS‟ KNOWLEDGE OF UH
In this section we will discuss whether the results (chapter 6) confirm or reject the four
proposed hypotheses (chapter 4).
7.1.1 DISCUSSION OF H1: L2 KNOWLEDGE OF UNACCUSATIVITY
(LEXICON-SYNTAX INTERFACE)
The main result of our study confirms previous research that L2 learners obey the
principles of the Unaccusative Hypothesis. Both Macedonian and Spanish groups
accept postverbal subjects as grammatical with unaccusatives more than with
unergatives, as native speakers do, (Figures 12 and 13). VS is preferred more with
unaccusatives for all XP-V-S structures, even at initial stages, showing that learners are
sensitive to the UH from the very outset.
The early stages showed interesting results. Even though VS structures are accepted
more with unaccusatives than with unergatives, there is a high acceptance rate for both
types of verbs. It is possible that learners are either “experimenting/restructuring” or
perhaps “L1 influence” is taking place (This will be discussed later on). At initial stages
(A1, A2) there is a high acceptance of postverbal subjects (Macedonian and Spanish),
both with unaccusatives and unergatives (although UH is obeyed) and learners initially
treat all structures as grammatical. It may be considered that, learners start restructuring
at initial levels hence the high acceptance for both unaccusative/unergative postverbal
subjects. If this was not the case, learners would not have accepted VS (the non
canonical word order of sentences), which is not present in the input they are exposed
to.
Learners may be influenced by their first language word order flexibility, showing
acceptance rates of postverbal subjects for both types of verbs (unaccusatives and
unergatives), though we will discuss this issue later.

129
Intermediate levels are the best discriminators of the unaccusative/unergative
distinction. It seems that learners overgeneralize the VS rule at intermediate levels,
experiment with and overgeneralise the VunacS structure, start understanding it and at C
levels they go back to the canonical SV order, which is the most frequent in the input
and it is the preferred word order of native English speakers as well.
At advanced levels learners become more severe with VS order and tend to reject it
while accepting the canonical SV order in their ILG. They are not experimenting with
the data, but have decided to accept the canonical word order which is present in the
input.
To summarise, at the lexicon-syntax interface learners are sensitive to the Unaccusative
Hypothesis in L2 English, as they prefer XP-V-S more with unaccusatives than with
unergatives. This confirms the first hypothesis (H1).
7.1.2 DISCUSSION OF H2: L2 KNOWLEDGE OF THE DIFFERENT PREVERBAL
STRUCTURES:
As was shown by the results (Figures 20 and 21), at early stages all unaccusative
structures (there/PP, vs *it/*Ø) are treated as identically grammatical, while
ungrammatical ones are constantly rejected as proficiency increases, thus showing a
clear developmental pattern, which confirms our H2. It is important to state that even
though the ungrammaticality of the different preverbal structures is not distinguished
from the outset, the UH is recognized at all levels.
Importantly, the grammaticality of structures is observed at initial stages for
unergatives. PPloc-V-S is discriminated as grammatical vs. the rest of the
ungrammatical structures (*there/*it/*Ø) at the outset, both by Macedonian and Spanish
learners (Figures 22 and 23).
The crucial finding for our study is the fact that, as proficiency increases, Macedonian
and Spanish groups discriminate more between grammatical unaccusative there/PP vs.
ungrammatical *it/*Ø. Figures 16 for Macedonians and 18 for Spanish show a clear
developmental pattern in the acquisition of the grammaticality of this structure. The
final pattern for the grammaticality of structures for unaccusatives is as follows: PPloc
≥ There > *it ≥ *Ø and for unergatives : PP loc >> *There > *Ø ≥ *it, as shown below
(where the wide gaps indicate a large difference „>>‟ and a small gap a minimal
difference „≥‟), indicating that learners acquire the grammaticality of the structure by
following certain linear developmental stages across proficiency levels.

130
UNACCUSATIVE pattern of XP acceptance in XP-V-S structures:
UNERGATIVE pattern of XP acceptance in XP-V-S structures:
Let us examine each of these preverbal XPs in detail:
*it-V-S is high at initial and interim stages. This corresponds to the second and third
stage of Oshita‟s UT claiming that learners become sensitive to the rules of the
structure. They exploit the rules in the interim stage and acquire the correct structure in
the final stage. While they are in the interim stage learners become aware of the
postverbal position of the argument of unaccusatives by allowing the subject in
postverbal position, but they are also aware that in English the subject position has to be
occupied by an overt element by inserting expletive it in subject position. The
ungrammatical it*-V-S is one of the structures occurring as a possible solution of
learners‟ search for an answer for this syntactic encoding problem. As proficiency
increases, the ungrammatical *it-V-S decreases for both unaccusatives and unergatives.
Macedonians, however, are more sensitive to the ungrammaticality of *it-V-S and they
reject it at lower levels.
there-V-S remains stable with unaccusatives across proficiency for both groups
(Figures 20 and 21), which is expected due to its grammaticality, but decreases with
unergatives, showing that L2 learners of English are sensitive to the fact that there-V-S
is possible only with unaccusatives.
This knowledge cannot be derived from instruction/teaching alone, since textbooks do
not contain information specifying that there-V-S is allowed with a subset of
unaccusatives and never with unergatives (and English teachers are not aware about the
unaccusative hypothesis and its complex rules). A plausible explanation is that learners
are sensitive to positive evidence from the input, but, as was argued in chapter 2,

131
English native corpus data illustrate that this structures show an extremely low
frequency (2.2.3.1.1). A more likely explanation is that learners are sensitive to the UH.
They do not get negative evidence that “there-Vunerg-S” is ungrammatical, i.e., they are
not overgeneralizing the there-V-S structure to unergatives, which also supports H1.
According to Oshita (2001) there-V-S is acquired in the final stage, when learners
acquire the correct pleonastic element (i.e., expletive) placed in the sentence subject
position.
PP-V-S is the most preferred structure both with unaccusatives and unergatives, since
locative inversion is possible in native English with both types of verbs (Levin and
Rappaport-Hovav (1995); Biber et al. (1999); Mendikoetxea (2006); Oshita (2001); and
see also the discussion in section 2.2.). This is also confirmed by the preference of PP-
V-S among English natives in our results. Thus, it may be considered that learners are
sensitive to the structure and behave as English natives do.
As for PP-V-S with unergatives (Figures 11 and 12), learners discriminate grammatical
PP (locative inversion) from the beginning vs. the rest of the ungrammatical structures
(*there *it and *Ø). The structural configuration of PP-V-S is similar to the verb second
(V2) structure (see discussion in section 2.2.3.1.2), which relates the opening element to
the previous context. The use of PP-V-S both with unaccusatives and unergatives may
indicate that syntax-discourse interface overrides lexicon-syntax interface. Namely, in
V2 languages VS is possible with all verbs which is probably why, as a consequence of
the historical features of English being a V2 language, unergatives are also allowed with
PP in this structure, since the structure has historically served a discursive function, i.e.,
introducing onto the scene a new element (postverbal subject) by linking the sentence to
the prior discourse with an opening element (preverbal PP).
*Ø-V-S shows low acceptance rates, which indicates that learners do not make
transfer or, at least, that the structure is not the priviledged target for transfer because, if
transfer was taking place, then higher rates of Ø would be expected in both groups, as
their L1 is pro-drop and contains an identical structure. This matter merits further
analysis, so it will be discussed in the following section.

132
7.1.3 DISCUSSION OF H3: THE NO-TRANSFER HYPOTHESIS AND OTHER
POSSIBLE SOURCES OF L2 LEARNERS’ KNOWLEDGE
In the preceding sections we have argued that learners‟ knowledge is constrained by a
universal constraint at the lexicon-syntax interface, namely, the UH. In the next
subsections we will explore the possibility of there being other sources or learners‟
knowledge of unaccusativity.
7.1.3.1 Input
There-V-S remains rather stable for unaccusatives not only for both the Macedonian &
Spanish matched groups, but also for the entire sample of the Spanish group for all
proficiency levels, but decreases with unergatives, hence it may be assumed that
learners are sensitive to the fact that there-V-S is possible only with unaccusative verbs
(as a result of the UH) or they may have picked it up from the input.
In order to check previous claims about the rarity of this construction and to see whether
learners can derive them from the input, we checked several popular L2 English
textbooks (LifeLines Pre-Intermediate; New English File-Intermediate; Upstream-
Advanced level) and tried to find XP-V-S instances. Throughout the three mentioned
textbooks, we did not come across any examples of these constructions. They are not
mentioned in the grammar syllabus and the texts included in the books do not contain
such constructions.
The fact that this structure is not found in any textbooks and is not part of classroom
instruction (since, typically, teachers do not know the subtleties of there-V-S being
possible only with a subset of unaccusatives but never with unergatives), indicates that
learners are sensitive to the UH. They do not get negative evidence (i.e., correction)
that there-V-S is ungrammatical with unergatives, then their knowledge derives from
the UH. Such knowledge cannot be accounted by overgeneralization because learners
do not overgeneralize there-Vunacc-S to there-Vunerg-S. This lends support to H1.
Another indication that input alone cannot account for the acquisition of this structure is
the fact that it is rarely produced by natives and learners cannot encounter it often in the
input. We are dealing with a poverty of stimulus construction which has been recorded
to be „rare and make up a very small proportion of all existential clauses: less than 5%
in fiction and academic prose and less than 1% in news and conversation (Biber et.

133
al.1999:945) (already mentioned in section 2.2.3.1.1.). In accordance to this, results
from empirical studies (Lozano & Mendikoetxea (2010)) have reported that native
English produce less VS structures than learners of L2 English. These claims imply that
it is unlikely that XP-V-S structures can be inferred from input.
7.1.3.2 Instruction
As was mentioned above (7.1.3.1) we checked several popular L2 English textbooks
(LifeLines Pre-Intermediate; New English File-Intermediate; Upstream-Advanced level)
and tried to find XP-V-S instances. These constructions were not included in any of
these textbooks which means that XP-V-S structures are not part of the formal
instruction of L2 English. Thus, it is unlikely that teachers are aware of the
unaccusative/unergative distinction and the constraints allowing XP-V-S occurrence.
Additionally, the qualitative comments of the Macedonian and Spanish group (see
section 6.2.) show that learners are not aware of the conditions allowing VS structures
because they have probably not been instructed about the unique behavior of intransitive
verbs or the specific structures allowing VS with certain types of verbs.
To sum up, learners cannot „learn‟ XP-V-S constructions because they are not included
in the formal instruction of L2 English.
7.1.3.3 L1 transfer
In the following paragraphs we will discuss the possibility that learners might be
transferring the structures under investigation (XP-V-S) from their L1 Macedonian or
L1 Spanish. While this seems a logical and obvious conclusion, we will see in the
following subsection how such an assumption is simplistic, since not all the data can be
accounted for by mere L1 transfer. A closer and fine-grained inspection of the results
reveals that there are important universal and developmental constraints in the
acquisition of the unaccusative/unergative syntactic structures in L2 English.
The initial high acceptance of VS both with unaccusatives and unergatives by
Macedonian and Spanish learners (Figures 12 and 13) may be argued to be due to
learners (according to the full/access full transfer account) being influenced by their first
language word order flexibility, showing high acceptance rates of postverbal subjects
for both types of verbs (unaccusatives and unergatives).

134
The high acceptance of PP-V-S from the initial stages with both types of verbs might
also indicate that learners are transferring from their L1. Even though this structure is
grammatical in English, it is also grammatical in the learners L1 (Macedonian and
Spanish) with all verbs, which may trigger the overacceptance of the locative inversion
structure in L2 English.
The data however show that both groups accept not only PP-V-S but also there-V-S as
grammatical structures (there/PP-V-S) and reject ungrammatical structures (*Ø/*it-V-S)
with unaccusatives from relatively early stages of acquisition which may not support the
transfer account but shows that learners are sensitive to the grammaticality of the
structures.
High acceptance of *Ø-V-S at initial levels may be considered again a result of L1
transfer, but the fact that all structures are treated similarly at the outset, does not
provide a solid ground for the transfer account (see section 7.1.3.4 below).
7.1.3.4 Reasons for lack of L1 transfer
There is subtle evidence in the results which indicates that learners are not transferring
wholesale from their L1. Such evidence, which is about to be discussed, supports H3.
Let us examine several pieces of evidence.
PIECE OF EVIDENCE #1. Spanish and Macedonian are pro-drop languages having
Ø-V-S as a very common structure, as discussed extensively in chapter 2. The fact that
*Ø-V-S is accepted in L2 English (by native speakers of L1 Spanish and L1
Macedonian) at low rates is a possible indication that transfer is not taking place. If
transfer occurred, higher acceptance of *Ø-V-S would have been expected for both
groups of learners. According to the results (Figures 20-23) this structure is
discriminated as ungrammatical (both with unaccusatives and unergatives) from
relatively early stages of development, even though it is completely plausible in
learners‟ L1s (Macedonian and Spanish). Additionally, if transfer occurred, *Ø-V-S
would have been more accepted than *it-V-S, given the fact that *it-V-S is not a
possible syntactic structure in either Spanish or Macedonian. The results show that this
is not the case and that both structures decrease simultaneously as proficiency increases,
hence the lack of L1 transfer effects, which supports H3.

135
PIECE OF EVIDENCE #2. Another indication against transfer is the fact that Spanish
learners discriminate between unaccusative VS order vs. unergative VS order, even
though this is unexpected, as heavy and focused subjects in native Spanish are sentence
final (VS), independently of the verb type. Thus, the Unaccusative Hypothesis (lexicon-
syntax interface) is overridden when discursive factors like focus and topic are involved
(syntax-discourse interface). This finding goes against the transfer hypothesis, thus
supporting H3.
PIECE OF EVIDENCE #3. Experimental data show that Macedonians, on the other
hand, appear to prefer in their mother tongue VS with unaccusatives and SV (with
unergatives) in presentational focused context (see 2.2.3.3.2.), while Spanish natives
prefer VS both with unaccusatives and unergatives in such contexts, as stated in the
preceding paragraph. If transfer occurred, we would expect (i) Macedonians to prefer
VS with unaccusatives more than with unergatives but (ii) Spanish to treat them
similarly. Contrary to this expectation, both groups of learners behave alike, thus
confirming that this behavior cannot be accounted for L1 transfer alone, which supports
H3.
PIECE OF EVIDENCE #4. An additional piece of evidence against the no-transfer
position comes from the different acceptance of the preverbal element. Data show
that both groups discriminate grammatical structures (there/PP-V-S) vs. ungrammatical
structures (*Ø/*it-V-S) with unaccusatives from relatively early stages of acquisition,
but all these structures are possible in their L1s (Macedonian and Spanish). Hence, if
transfer was taking place, we would expect learners not to show such an early
sensitivity to the grammatical vs. ungrammatical constructions, which is contrary to
fact. This supports the no-transfer account, thus supporting H3.
7.1.4 DISCUSSION OF H4: DEVELOPMENTAL STAGES AND OSHITA’S (2001)
UNACCUSATIVE TRAP HYPOTHESIS
Our H4 is related to the developmental stages proposed by Oshita (2001) and his
Unaccusative Trap. We predicted that our learners will follow the three stages of the UT
(see section 3.2.4). The obtained results have shown features both rejecting and
supporting these claims.

136
The behavior of our subjects at initial levels is not in accordance with the predictions of
the UT. Oshita claimed that in the first stage all intransitive verbs (unaccusatives and
unergatives) are perceived as unergatives and learners produce only SV, irrespective of
the verb type. Our results show that learners (Macedonian and Spanish) discriminate VS
from the very outset. They seem to be doing the opposite of the UT: VS is accepted
highly with unergatives from initial stages, indicating that learners are somehow
unaccusativizing unergatives, even though they correctly prefer VunacS to VunergS. This
behavior may be due to the nature of the methodology we used. It might have misled
the participants to accept structures which they would not produce if they had to provide
their own utterances. This idea is supported by corpus data which shows that learners
invert only with unaccusatives, never with unergatives (Lozano & Mendikoetxea 2008,
2010, Zobl 1989, Oshita 2004). Another possible interpretation of this kind of behavior
is related to L1 transfer effects. VS structures are very common both in Spanish and
Macedonian and learners may transfer this L1 structure to their L2, accepting VS at the
outset with all types of verbs and in all VS structures. But note that transfer has been
discarded as the privileged source of knowledge in L2 (see preceding section).
The second stage of Oshita states that learners become aware of the syntactically
relevant semantic features of unaccusative verbs, which is in accordance with our data.
Our learners distinguish unaccusatives from unergatives, which is shown in the fact that
learners start accepting grammatical structures (PP/there) and rejecting ungrammatical
ones (*it/*Ø). Both Macedonian and Spanish learners follow similar patterns. They
show their highest sensitivity to UH in intermediate stages, showing the highest
unaccusatives vs unergatives difference (even higher than natives‟). This means that
they have picked up the Unaccusativity rules and, therefore, they are overaccepting the
rule. Later, in advanced stages, such a difference diminishes towards the native norm.
Oshita claims that at the second stage learners understand the internal lexico-syntactic
structure of unaccusatives vs unergatives, hence the acceptance and production of
ungrammatical unaccusative passives and/or *it-V-S. They are trying to find solutions
and to produce VS structures. This is in accordance with our data, which shows that
learners exploit the structures and they start distinguishing the grammatical structures
from the ungrammatical ones.

137
The final stage of Oshita states that unaccusative syntactic structures will be acquired
when unaccusatives will be correctly differentiated from unergatives. Our data support
these claims with the acceptance of the grammatical structures and the rejection of the
ungrammatical ones at higher proficiency levels.
7.2 POSSIBLE PEDAGOGICAL IMPLICATIONS: TEACHING POSTVERBAL
SUBJECTS IN L2 ENGLISH
Palacios-Martínez and Martínez-Insua (2006) studied native and learner use of
existential there-be-NP of the type shown in (98)
(98)
a) ..think that there are more disadvantages than there are advantages
thus they are likely to reject..
b) Throughout the first scenes, especially, there is a repetition of
“rien” perhaps reflecting..
Its usage was studied among Spanish learners of English and a native group of English
speakers and it was hypothesized that these two groups will differ in the frequency of
use, complexity, polarity concord and pragmatic value. The results showed that Spanish
learners use there-be-NP constructions more frequently than natives, which may be
related to its early introduction in the language learning process and the ability of
learners to memorize them as formulaic chunks. They recommended that pedagogical
instruction about these constructions might help their proper acquisition. This is a study
examining inversion with be and our empirical study studies inversion with
unaccusatives.
Considering the fact that postverbal subject constructions of the type XP-V-S are not
part of any L2 English course book, as we have shown in 7.1.3.2, it is understandable
that learners are prone to producing *it/*Ø-V-S ungrammatical structures (passive
unaccusatives or ungrammatical postverbal structures), which are so common in
learners‟ written and spoken production. Positive evidence (i.e., input) about different
subtypes of intransitive verbs and the specific syntactic structures allowed by
unaccusative verbs should be explained in formal instruction settings, that is, in the
classroom. Teachers might introduce a group of presentational verbs apart from be and

138
explain their specific meaning. The pragmatic meaning of existential and presentational
constructions should also be explained. Additionally, the most common mistakes
produced in XP-V-S constructions should be described so that learners will be able to
understand and properly acquire the structure. However, as was indicated throughout
the dissertation there seems to be a developmental pattern. Therefore, it is unclear
whether learners would acquire these structures if they were taught. According to the
Teachability Hypothesis (Pienemann, 1988) learners should be taught grammatical
structures they are ready to acquire. If the learner is at the second developmental stage
of acquisition of a certain structure and the teacher teaches a structure corresponding to
a fourth developmental stage the learner may go forward to the third stage but will not
jump directly to the fourth stage. Therefore learners should be taught structures they are
ready to acquire. Instruction cannot change the natural order of acquisition. It may
change the speed of acquisition (to provoke faster acquisition of L2 structures) but not
the course.
7.3 RECOMMENDATIONS FOR FUTURE RESEARCH
In the next subsections we will discuss some potential avenues of future research on the
L2 acquisition of unaccusativity.
7.3.1 POSTVERBAL SUBJECTS WITH ‘BE’ (EXPL + BE + NP-SUBJECT)
A research on the production of postverbal subjects with the verb be is one suggestion
for future study. In native English be is a more common verb for the production of
there-V-S and locative inversion constructions than the intransitive unaccusative verbs
of existence and appearance, which have been the focus of this dissertation. As
explained by Biber et. al. (1999), the verb be forms 95% of existential there
constructions and half of the locative inversion constructions, while unaccusative verbs
of existence and appearance represent only a small fraction of inverted structures. We
suggest that the acquisition of expletive+be+NP-subject should be studied in order to
observe the possible developmental stages for the acquisition of this structure and
understand under which interface conditions (lexicon-syntax, syntax-discourse, syntax-
phonology) they are produced and accepted in L2 English.

139
7.3.2 THE EFFECTS OF WEIGHT AND FOCUS ON POSTVERBAL SUBJECTS
Another possible suggestion for future research would be to study the influence of
weight and focus on the postverbal subject. Our study dealt with the lexicon-syntax
interface and the UH, since weight and information status were controlled for in the
experiment (i.e., the postverbal subject was always long and focus). Further on we could
focus on the influence of the End Weight and End Focus principle on the acquisition of
postverbal subjects by Macedonian L2 learners of English.

140
8 CONCLUSION
Previous research has shown that learners are sensitive to the Unaccusative Hypothesis
(UH) and produce postverbal subjects with a subtype of intransitive verbs, namely,
unaccusative verbs of existence and appearance but not with another type of
intransitives (unergatives). Unaccusativity (which is contrained at the lexicon-syntax
interface) is one of the three conditions allowing the production of postverbal-subject
constructions of the type XP-V-S in English (locative inversion like PP-V-S and
existential there constructions like there-V-S), which are the focus of this empirical
study. The other two conditions necessary for subject inversion in English require the
subject to be new information (focus) (syntax-discourse interface) and long (heavy)
(syntax-phonology interface).
Two groups of learners of L2 English (one with L1 Macedonian and the other with L1
Spanish) participated in a contextualized acceptability judgement test to measure their
knowledge of postverbal-subject structures of the type XP-V-S. Results indicate that the
Macedonian and Spanish participants in our study observed the conditions for the
acceptance of postverbal subjects in English. Namely, they accepted VS with
unaccusatives more than with unergatives when the subject is focus and heavy, thus
observing the UH at the lexicon-syntax interface and the constraints at the other two
interfaces (syntax-discourse and syntax-phonology).
These results imply that Macedonian and Spanish learners of L2 English accept VS
under the same conditions as English natives do. But, in spite of this, learners produce
(as attested in previous empirical studies) and accept (as reported in this study)
structurally impossible VS constructions with a preverbal element of the type *it-V-S
and *Ø-V-S, which are a very common type of error found in L2 English. Hence,
acceptance of both grammatical (PP-V-S / there-V-S) and ungrammatical structures
(*it-V-S / *Ø-V-S) were examined in this study in order to check the possibilities for L1
transfer or developmental factors in the course of acquisition of XP-V-S structure in L2
English. It was shown that learners reject the *Ø-V-S structure at initial levels, which
implies that L1 transfer alone cannot account for the data because this structure is very
common in L1 Macedonian and Spanish. Additionally, the L1 transfer

141
hypothesis was also rejected for PP-V-S (locative inversion), which is possible with
both types of verbs (unacusatives and unergatives) in English, the same as in L1
Macedonian and Spanish, due to the fact that learners distinguish grammatical PP-V-S
and there-V-S from ungrammatical *it-V-S and *Ø-V-S from early stages. They also
accept grammatical PP-V-S both with unaccusatives and unergatives, while there-V-S is
accepted only with unaccusatives, which implies that learners are aware of the
grammaticality of the structures in L2 English. The structure *it-V-S was rejected at
higher levels, which indicates that learners follow certain developmental stages in the
acquisition of VS order throughout which they become aware of the postverbal position
of the subject of unaccusatives. Due to the fact that in English the subject position has to
be occupied by an overt element learners insert expletive it in subject position. They
produce the ungrammatical it*-V-S as a possible solution for this syntactic encoding
problem.
The rarity of the XP-V-S construction in native English implies that its knowledge in L2
English cannot be derived from the input alone. Additionally, this construction is not
included in any formal instruction of L2 English, hence instruction canot be accounted
for its acquisition.
To sum up, it can be concluded that the syntactic knowledge of Macedonian and
Spanish learners of L2 English for the production of XP-V-S structures is universally
constrained at the three interfaces (i) the verb is unaccusative - UH (lexicon syntax
interface); (ii) the subject is focus (syntax discourse interface) and, (iii) the subject is
heavy (syntax phonology interface). The acceptance of ungrammatical structures (it-V-S
and *Ø-V-S), which is developmentally temporary, may be due to failure to properly
map the UH knowledge onto the suitable syntactic structure.

142
9 ACKNOWLEDGEMENTS
First and foremost I would like to express my enormous gratitude to Prof.
Cristobal Lozano, my thesis supervisor, who selflessly shared with me his
knowledge, expertise and research experience. Prof. Lozano has been greatly
interested and prepared to patiently explain and clarify all the questions I had
regarding the topic throughout the whole MA thesis preparation period. I thank
Prof. Lozano for all the time he dedicated to help me complete successfully this
MA project, for all the useful pieces of advice regarding the study I received, for
all the instructions on how to conduct the study successfully, for all the support
and encouragement, for the professional and friendly manner of communication
which gives confidence that the research can be completed successfully; for his
preparedness to help me whenever I was not certain about things, for his
excellent guidance through the conduct of research and the whole dissertation
writing procedure.
Prof. Lozano immediately became the role model for me of a successful
researcher in the field. He should serve an example of an excellent professor
and supervisor. I consider myself lucky to have had Prof. Lozano to be my
supervisor. THANK YOU
I would also like to thank my supervisor, Prof. Cristobal Lozano for allowing me
to use the Spanish natives L2 English data obtained in the EASI research study
and the method and instrument used for this study, conducted by Prof. Cristobal
Lozano himself and Prof. Amaya Mendikoetxea from Universidad Autonoma de
Madrid.
I thank Prof. Sonja Kitanovska from the FON University in Skopje, Macedonia
for helping us gather more participants for the IUSAJ research by distributing
the online test among her group of postgraduate students.
I thank Prof. Ana–Lazarova Nikovska from the FON University in Skopje for
giving us useful information about references on related topics.

143
I would like to thank the foreign language teaching school “Next Level” and the
Student Service Centres “Traveo” in Kavadarci, Macedonia and “Kouzon
Student Service Centre” in Skopje for helping us gather more participants by
distributing the test among their L2 English students.
I thank all the volunteer participants who took part in this study for their time
and willingness to help us gather the necessary data for this research. The
contribution of every single participant was of utmost importance for us and was
considered extremely valuable. This research was conducted successfully due to
the volunteer participation of every single case which is greatly appreciated.
My enormous thank you goes to all of my friends who showed their unselfish
willingness to help me gather as many cases as possible by participating in the
study and by distributing the online test to their friends and acquaintances. I
could not be more grateful for that.
Last but definitely not least, my wholehearted thank you to my family for being
always supportive and giving me the strength and encouragement to do my best
throughout the research and dissertation writing period.

144
10 REFERENCES
Andersen, R. W. (1978). An implicational model for second language research.
Language Learning, 28, (pp.221-282).
Baker, M. (1988): Incorporation: A Theory of Grammatical Function Changing.
Chicago: Chicago University Press.
Balcom, P. (1997). Why is this happened? Passive morphology and
unaccusativity. Second Language Research, 13(1), (pp.1-9).
Bailey, N., Madden, C., & Krashen, S. D. (1974). Is there a “natural sequence” in adult
second language learning? Language Learning, 24, (pp.235-243).
Bialystok, E. (2001). On the Reliability of Robustness, A Reply to DeKeyser. SSLA, 24,
(pp.481–488).
Biber, D., Johansson, S., Leech, G., Conrad, S., & Finegan, E. (1999). Word order and
related syntactic choices (chapter 9). In Longman Grammar of Spoken and
Written English (pp. 896-964). Harlow: Pearson Education Limited.
Bloom, L. and Lahey, M. (1978). Language Development and Language Disorders,
New York: John Wiley.
Brown, R. (1973). A first language. Cambridge, MA: Harvard University Press.
Burrow, J.A. and Turville-Petre, T. (2001). A Book of Middle English, second edition:
Oxford: Blackwell Publishers Ltd.
Burzio, L. (1986). Italian Syntax: A Government-Binding Approach. Dordrecht: Reidel.
Casielles-Suarez, E. (2009). The Syntax-Information Structure Interface: New York:
Routhledge.
Chomsky, N. (1965). Aspects of the Theory of Syntax. Cambridge MASS: MIT Press.
Chomsky, N. (1981). Lectures on Government and Binding. Dordrecht: Foris.
Chomsky, N. (1995). The Minimalist Program. Cambridge, MASS.: MIT Press.

145
Cook, V. (1993). Linguistics and Second Language Acquisition. London: Macmillan
Corder, S. P. (1967). The significance of learners'errors. IRAL, V(4), (pp.161-170).
Domínguez, L., & Arche, M. J. (2008). Optionality in L2 grammars: The acquisition of
SV/VS contrast in Spanish. In H. Chan, H. Jacob, & E. Kapia (Eds.), BUCLD
32: Proceddings of the 32nd Annual Boston University Conference on Language
Development (pp. 96-107). Somerville, MA: Cascadilla Press.
Dulay, H. C., & Burt, M. K. (1974b). Natural sequences in child second language
acquisition. Language Learning, 24, (pp. 37-53).
Ellis, R. (2008). The Study of Second Language Acquisition (2nd Ed.). Oxford: Oxford
University Press.
Fathman, A. (1975). Language background, age and the order of acquisition of English
structures. In M. K. Burt & H. C. Dulay (Eds.), On TESOL ‟75: New directions
in second language learning, teaching and bilingual education (pp. 33-43).
Washington, DC: TESOL.
Friedman, V. A. (1993). Macedonian. In: Comrie B. & Corbett, G. C. (eds.),The
Slavonic Languages. London: Routledge. (pp. 249-305).
Haeberli, E. (2007). The development of subject-verb inversion in middle English and
the role of language contact. GG@G (Generative Grammar in Geneva) 5 (pp.
15-33).
Hawkins, R. (2001). Second Language Syntax: A Generative Introduction. Oxford:
Blackwell Publishers
Haegman, L., & Gueron, J. English Grammar: A Generative Perspective. Oxford:
Blackwell Publishers
Hakuta, K. (1976). A case study of a Japanese child learning English as a second language.
Language Learning, 26, (pp.321-351).
Hertel, T. J. (2003). Lexical and discourse factors in the second language acquisition of
Spanish word order. Second Language Research, 19(4), (pp.273-304).

146
Heycock, C. and Kroch, A. (1993). Verb Movement and the Status of Subjects:
Implications for the Theory of Licencing. Groninger Arbeiten zur
Germanistischen Linguistik Nr. 36, (pp.75-102).
Hirakawa, M. (1999). L2 acquisition of Japanese unaccusative verbs by speakers of
English and Chinese. In K. Kanno (Ed.), The Acquisition of Japanese as a
Second Language (pp. 89-114). Amsterdam: John Benjamins.
Huddleston, R. and Pullum, G.K. (2002). The Cambridge Grammar of the English
Language. Cambridge: Cambridge University Press.
Ioup, G. (1995). Evaluating the Need for Input Enhancement in Post-Critical Period
Language Acquisition. In D. Singleton and Z. Lengyel (Eds.), The Age Factor in
Second Language Acquisition. Clevedon: Multilingual Matters (pp. 95-123)
Ju, M. K. (2000). Overpassivization errors by second language learners: The effect of
conceptualizable agents in discourse. Studies in Second Language Acquisition,
22, (pp. 85-111).
Krashen, S. (1982). Principles and Practice in Second Language Acquisition. New
York : Pergamon Press.
Krashen, D.S (1995). The Natural Approach: Language Acquisition in the classroom.
London: Prentice Hall International.
Lado, R. (1957). Linguistics Across Cultures: Ann Harbor, Michigan: University of
Michingan Press.
Lazarova-Nikovska, A. (2003). „On Interrogative Sentences in Macedonian: A
Generative Perspective.‟2003. RCEAL Working Papers in English and Applied
Linguistics 9, (pp.129-59).
Lenneberg, E. (1967). Biological Foundations of Language. New York: John Wiley &
Sons Inc.
Lightbown, M.P., & Spada, N. (2001). How Languages are Learned. Oxford: Oxford
University Press.
Levin, B., & Rappaport-Hovav, M. (1995). Unaccusativity at the Syntax-Lexical
Semantics Interface. Cambridge, MASS: MIT Press.

147
Levin, B. (1993). English Verb Classes and Alternations: A Preliminary Investigation.
Chicago: University of Chicago Press.
Long, M. H. (1983). Native speaker/non-native speaker conversation and the
negotiation of comprehensible input. Applied Linguistics, 4(2), (pp.126-141).
Lozano, C. (2002). Knowledge of expletive and pronominal subjects by learners of
Spanish. ITL Review of Applied Linguistics, 135/6, (pp.37-60).
Lozano, C. (2006a). Focus and split-intransitivity: The acquisition of word-order
alternations in non-native Spanish. Second Language Research 22(2) (pp.145-
187).
Lozano, C. (2006b). The development of the syntax-discourse interface: Greek learners
of Spanish. In V. Torrens & L. Escobar (Eds.), The Acquisition of Syntax in
Romance Languages (pp. 371-399). Amsterdam: John Benjamins.
Lozano, C. (2008). The Acquisition of Syntax and Discourse: Saarbrüken: VDM Verlag.
Lozano, C. & Mendikoetxea, A. (2008). Postverbal subjects at the interfaces in Spanish
and Italian learners of L2 English: a corpus analysis. In G. Gilquin, S. Papp, &
M. B. Díez-Bedmar (Eds.), Linking up Contrastive and Learner Corpus
Research (pp. 85-125). Amsterdam: Rodopi
Lozano, C., & Mendikoetxea, A. (2010). Postverbal subjects in L2 English: A corpus-
based study. Bilingualism: Language and Cognition, 13(4), (pp. 475-497).
Lozano, C. & Mendikoetxea, A. (2011): Acquisition at the interfaces in L1 Spanish –
L2 English: From corpus data to experimental data. Paper presented in EUROSLA 21,
University of Stockholm.
Mendikoetxea, A. (2006). Unergatives that „become‟ unaccusatives in English
locative inversion: a lexical-syntactic approach. In C. Copy y L-Gournay (eds.)
Points de Vue sur l‟Inversion. Cahiers de Recherche en Grammaire Anglaise de
l‟Énonciation. Tome 9. Paris: Editions Orphys. (pp. 133-155).
Milenkovska, S. (2002a) Linearizacija i referencijalna karakteristika na nominativnite
(subjektnite) imenski sintagmi (Linearization and referential characteristics of

148
the nominative/subject noun phrases). Makedonski Jazik: Institut za Makedonski
Jazik Krste Misirkov (Macedonian Language: Institute for Macedonian
Language), (pp.123-129)
Milenkovska, S. (2002b) Linearizacija i referencijalna karakteristika na imenskata
sintagma vo akuzativen odnos (Linearization and referential characteristics of
the noun phrases in acusative position). Slavic Studies (Magazine published by
the Slavic studies department at the Faculty of Philology ”Blazhe Koneski”, 10,
(pp. 247-256).
Minova-Gjurkova, L. (2000). Sintaksa na Makedoskiot Standarden Jazik (Syntax of
Standard Macedonian Language). Skopje: Magor
Mitchell, R., & Myles, F. (2004). Second Language Learning Theories. London:Hodder
Arnold
Oshita, H. (2000). What is happened may not be what appears to be happening: a corpus
study of 'passive' unaccusatives in L2 English. Second Language Research,
16(4), (pp. 293-324).
Oshita, H. (2001). The unaccusative trap in second language acquisition. Studies in
Second Language Acquisition, 23, (pp. 279-304).
Oshita, H. (2004). Is there anything there when there is not there? Null expletives and
second language data. Second Language Research, 20(2), (pp.95-130).
Palacios-Martínez, I., & Martínez-Insua, A. (2006). Connecting linguistic description
and language teaching: native and learner use of existential there. International
Journal of Applied Linguistics, 16(2), (pp.213-231).
Perlmutter, D. (1978). Impersonal passives and the Unaccusative Hypothesis. In
Berkeley Linguistics Society, 4, (pp.157-189).
Phinney, M. (1987). The pro-drop parameter in second language acquisition. In T
Roeper & E. Williams (eds.), Parameter setting, (pp.221–238). Dordrecht:
Reidel.
Pienemann, M. (1988). Determining the influence of instruction on L2 speech
processing. AILA Review, 5(1), (pp.40-72).

149
Quirk, R., Greenbaum, S., Leech, G., & Svartvik, J. (1985). A comprehensive grammar
of the English language. London: Longman.
Rankin, T. (2011). The transfer of V2: Inversion and negation in German and Dutch
learners of English. International Journal of Bilingualism, (pp.1-20).
Reynolds, D. (1995). Repetition in non-native speaker writing. Studies in Second
Language Acquisition, 17 (pp.185-209).
Rubin, J. (1987). "Learner Strategies: Theoretical Assumptions. Research History and
Typology." In A.Wenden and J. (eds.). Learner Strategies in Language
Learning. (pp.15-30).
Rutherford, W. (1989). Interlanguage and pragmatic word order. In S. M. Gass & J.
Schachter (Eds.), Linguistic Perspectives on Second Language Acquisition (pp.
163-182). Cambridge: Cambridge University Press.
Schachter, J. (1974). An error in error analysis. Language Learning, 24, (pp.205-214).
Scovel, T. (2000). A Critical Review of the Critical Period Research. Annual Review of
Applied Linguistics 20, (pp.213-223).
Selinker, L. (1972). Interlanguage. International Review of Applied Linguistics, X(3),
(pp.209-231)
Singleton, D. (1995). Introduction: A Critical Look at the Critical Period Hypothesis in
Second Language Acquisition Research. In D. Singleton and Z. Lengyel (Eds.),
The Age Factor in Second Language Acquisition. Clevedon: Multilingual
Matters. (pp.1-29).
Singleton, D., and Ryan, L. (2004). Language Acquisition: The Age Factor. Clevedon:
Multilingual Matters.
Sorace, A. (1993). Incomplete vs. divergent representations of unaccusativity in non-
native grammars of Italian. Second Language Research, 9(1), (pp.22-47).
Sorace, A.,& Filiaci, F., (2006). Anaphora resolution in near-native speakers of Italian.
Second Language Research 22, (pp.339–368).

150
Sussex, R & Cubberley, P. (2006). The Slavic Languages. Cambridge: Cambridge
University Press.
Topolinska Z. (1995). Makedonskite dijalekti vo Egejska Makedonija: Sintaksa I del.
(Macedonian Dialects in Aegean Macedonia: Syntax I part.): Skopje:
Makedonska Akademija na Naukite i Umetnostite (Skopje: Macedonian
Academy of Science and Arts).
Yuan, B. (1999). Acquiring the unaccusative/unergative distinction in a second
language: evidence from English-speaking learners of L2 Chinese. Linguistics,
37(2), (pp.275-296).
Venovska-Antevska, S. (1995). Zborored na Makedonskiot Standarden Jazik (Word
Order in Standard Macedonian Language), Literaturen Zbor (Literary Word)5-6,
(pp.63-69).
Ward, G., Birner, B. J., & Huddleston, R. (2002). Information Packaging. In R.
Huddleston & G. K. Pullum (Eds.), The Cambridge Grammar of the English
Language (pp. 1365-1444). Cambridge: Cambridge University Press.
Wasow, T. (1997). Remarks on Grammatical Weight. Language Variation and Change,
9 (pp.81-105).
Wasow, T. (1997). End Weight from the Speaker‟s Perspective. Journal of
Psycholinguistic Research, 26/3 (pp.347-361).
Wasow, T., & Arnold, J. (2003). Post-verbal constituent ordering in English. In G.
Rohdenburg & B. Mondorf (Eds.), Determinants of Grammatical Variation
(pp.119-154). Cambridge: Cambridge University Press.
White, L. (1991). Positive evidence and preemption in the second language classroom.
Studies in Second Language Acquisition, 7, (pp.133-161).
White, L. (2003). Second Language Acquisition and Universal Grammar. Cambridge:
Cambridge University Press.
White, L. (2009). Grammatical Theory: Interface and L2. In W. C. Ritchie and T.
Bhatia (Eds.), The New Handbook of Second Language Acquisition. (pp.49-65)
Bingley (United Kingdom): Emerald.

151
White, L. (2011). Second Language Acquisition at the Interfaces, Lingua 121. (pp.577-
590).
Wilson, R., & Dewaele, J.M. (2011) The use of web questionnaires in second language
acquisition and bilingualism research. Second Language Research 26,1 (pp.103–
123).
Zobl, H. (1989). Canonical typological structures and ergativity in English L2
acquisition. In S. M. Gass & J. Shachter (Eds.), Linguistic Perspectives on
Second Language Acquisition (pp.203-221). Cambridge: Cambridge University
Press.

152
11 APPENDICES
In the appendices we will present all the experimental material used in the data
collection, as well as the statistical outputs and tables.
11.1 MAIN EXPERIMENTAL TEST: CONTEXTUALISED ACCEPTABILITY
JUDGEMENT TEST (ONLINE VERSION)
In this section we present the experimental tests (online version) that we used to collect
data online about the acceptability of VS with unaccusatives and unergatives. This is the
key test of this dissertation and will be presented according to the L1 of the participants:
English natives (Study on the Acquisition of English Syntax - SAES), L1 Spanish-L2
English learners (Estudio sobre la Adquisición de la Sintaxis del Inglés - EASI) and L1
Macedonian –L2 English learners (Istrazuvanje za Usvojuvanje na Sintaksata na
Angliskiot Jazik - IUSAJ).
The software used to administer the main experimental test was LimeSurvey, which is a
computer application for the design of online questionnaires and experiments. This
software is hosted in the servers at the Universidad de Granada and has been extensively
used worldwide to collect data. See further details in footnote 12, page 96.
11.1.1 MAIN EXPERIMENTAL TEST FOR ENGLISH NATIVES (SAES)
Study on the Acquisition of English Syntax (SAES) English version
Welcome:
We are investigating how Spanish speakers learn English grammar. For comparative purposes, we also need English native speakers like you to participate in this study. This

153
study is part of a larger research project on the acquisition of English grammar, conducted at the Universidad de Granada and the Universidad Autónoma de Madrid (for more info
click here).
Participating is very simple. All you need to do is to decide whether some English sentences seem grammatically acceptable to you.
Your data will be anonymous and will be treated confidentially.
There are 37 questions in this survey.
A note on privacy This survey is anonymous.
The record kept of your survey responses does not contain any identifying information about you unless a specific question in the survey has asked for this. If you have responded
to a survey that used an identifying token to allow you to access the survey, you can rest assured that the identifying token is not kept with your responses. It is managed in a
separate database, and will only be updated to indicate that you have (or haven't) completed this survey. There is no way of matching identification tokens with survey
responses in this survey.
Study on the Acquisition of English Syntax (SAES) English version
You have completed 0% of this survey
0%
100%
PREGUNTAS INICIALES SOBRE EL APRENDIZAJE Por favor, conteste a las siguientes preguntas sobre su historial de aprendizaje en inglés.
*Please state your sex (male/female):
Female
Male

154
Please state your age (years):
Only numbers may be entered in this field
*Please state your mother tongue: Choose one of the following answers
English
Another language
Study on the Acquisition of English Syntax (SAES) English version
You have completed 33% of this survey
0%
100%
INSTRUCTIONS On the next page you will see some English sentences.
The first part of the sentence provides a bit of a context. The second sentence is the one you have
to judge.
Judging is very simple: 1 if you think that the sentence is totally ungrammatical and 5 if you think it is totally grammatical. You can choose intermediate values, depending on your judgement.
Remember: we are interested in your first reaction.
*For example: Consider the following sentence :
Many students in Spain study only before the exam... ...because they like don't to study during the year.
1 2 3 4 5

155
Choose:
HELP: You have to judge the second sentence "because they like
don't to study during the year" on the 1 to 5 scale.
Study on the Acquisition of English Syntax (SAES) English version
You have completed 66% of this survey
0%
100%
ENGLISH SENTENCES This is the beginning of the test. Please rate the following sentences:
* Nowadays, if you work as a policeman in Spain, you can easily
get into difficult situations, but... ... I think that it exist many more risky and dangerous jobs.
1 2 3 4 5
Choose:
* In a very important meeting about the world crisis, the world
leaders were waiting for somebody to give a solution… …so there talked the president of the United States.
1 2 3 4 5
Choose:

156
* Winter finishes around February or March and then the spring
begins because the birds start singing... …and appear the first flowers that grow in the gardens.
1 2 3 4 5
Choose:
* The new building has a shopping centre and some offices. You
can find the shopping centre on the ground floor, … ... but on the top floor work the bosses of important
companies like Microsoft.
1 2 3 4 5
Choose:
* In 2004 there were some terrible terrorist attacks in Madrid.
So, … … some politicians think that it began a new period in
Spanish history.
1 2 3 4 5
Choose:
* The manager of Real Madrid decided that the football match
with Real Valladolid was not important… …so there played only those football players who were very
young.
1 2 3 4 5

157
Choose:
* The Industrial Revolution was a period between the 18th and
the 19th century. Almost every aspect of human life was influenced …
...and came many important changes in the life of people.
1 2 3 4 5
Choose:
* It was a very big conference about medicine. Most talks were
in rooms 1, 2 and 3, … … but in room 4 spoke a very important doctor from Oxford
University.
1 2 3 4 5
Choose:
* Even though we live in a democratic country with plenty of
opportunities,... ... I believe that there exist unlucky people who are
extremely poor.
1 2 3 4 5
Choose:
* The economic crisis is affecting everybody. A lot of workers
are unemployed. The result is… … that work only the people who have a stable job.

158
1 2 3 4 5
Choose:
* In 1666 a small bakery burned in the centre of London by
accident… …and from this place began a great fire that destroyed the
city.
1 2 3 4 5
Choose:
* Yesterday we were at school doing an exam. The teacher told
us to be silent… …but it talked a boy who complained about the exam
questions.
1 2 3 4 5
Choose:
* For a while, it seemed that nobody in the meeting was going
to say anything about the corruption in the British Government…
...However, there spoke a woman with a very strong Irish accent.
1 2 3 4 5
Choose:
*

159
Dictionaries often give an unusual definition of some words. For example, think about the word “cool”.
... In my dictionary appears a very interesting definition for this word.
1 2 3 4 5
Choose:
* I was at a funeral yesterday. Everybody got very emotional …
…because talked the wife of the man who had died.
1 2 3 4 5
Choose:
* The house was very dirty. All the windows were closed, the
rooms were dark.... …and from the kitchen came a horrible smell of burning oil.
1 2 3 4 5
Choose:
* There was a basketball competition at school, but John could
not participate… …because played only the children who were 10 years old.
1 2 3 4 5
Choose:
* In 1789 France was a country with a lot of poor people who

160
were unhappy, … …so there began a new revolution called “The French
Revolution”.
1 2 3 4 5
Choose:
* My American friend, Paul, thinks that in Spain people are very
lazy and… …that it work only the people who are very ambitious.
1 2 3 4 5
Choose:
* Nowadays, it is very dangerous to walk alone at night in a big
city... ...because in those cities exist many dangerous criminals
who could kill you.
1 2 3 4 5
Choose:
* Spain was not a democratic country for many years, but when
democracy arrived… …there appeared a great variety of new social problems.
1 2 3 4 5
Choose:
*

161
After the Spanish civil war, the country was so poor that there were no toys for children, so...
…I think that it played only the children of people who were rich.
1 2 3 4 5
Choose:
* In the conference several speakers talked about the economic
crisis. They all met later for dinner … …and spoke the president of the Economic Society of
America.
1 2 3 4 5
Choose:
* Some historians believe that 1940 is a very important year …
…because began a terrible war called the 'Second World War'.
1 2 3 4 5
Choose:
* In the 1970’s AIDS was an unknown illness. At the end of the
1980’s it was better known... …but it came discrimination against people infected by the
illness.
1 2 3 4 5
Choose:

162
*A lot of university students have recently complained about the 'Bologna process', but...
...some experts say that exist some students who support it.
1 2 3 4 5
Choose:
* When I was at school, there was a special playing area, …
…but in this area played only the boys and girls who behaved well.
1 2 3 4 5
Choose:
* After several hours of discussion about work conditions,
everybody thought the meeting had finished... ...but it spoke a very angry man who started shouting.
1 2 3 4 5
Choose:
* Nowadays, people think that teachers do not work too much,
but the fact is that... ... there work only those teachers who are motivated.
1 2 3 4 5
Choose:
* Tourists are always interested in visiting the Houses of

163
Parliament in London … … because in that place talk the most important politicians
of the United Kingdom.
1 2 3 4 5
Choose:
* The economic crisis in the 1970’s affected the financial markets first. Then it affected a lot of companies and
business, … ... so there came a dramatic increase of 45% in
unemployment.
1 2 3 4 5
Choose:
* Malaria is one of the most common infectious diseases. In the
1980s people were optimistic… …because it appeared a new medicine that was effective
against malaria.
1 2 3 4 5
Choose:
Please, if you wish, write any final comment or remark on the test (doutbs, opinions, problematic areas, etc.)
(This is an optional question)

164
11.1.2 MAIN EXPERIMENTAL TEST FOR L1 SPA-L2 ENG LEARNERS (EASI)
EASI (Estudio sobre Adquisición de la Sintaxis del Inglés)
Bienvenido/a.
Dentro del proyecto de investigación OPOGRAM (Opcionalidad y Pseudo-
Opcionalidad en Gramáticas nativas y no nativas), financiado por el Ministerio de Innovación y Ciencia, estamos estudiando cómo aprenden inglés los hablantes
nativos de español.
Participar en el estudio es muy sencillo. El estudio es anónimo, está disponible "online" y solo tienes que decidir si unas oraciones te suenan mejor que otras (unos 15 minutos aprox.). Sólo pueden participar hablantes de español
que sepan inglés (cualquier nivel).
Al finalizar, recibirás un certificado de participación en el experimento.
Posteriormente publicaremos los resultados globales del experimento en esta página web. Si quieres saber más sobre nosotros y nuestro trabajo de
investigación, consulta la página web (WOSLAC).
En primer lugar, te haremos algunas preguntas sencillas sobre su historial de
aprendizaje del inglés.
Hay 45 preguntas en esta encuesta.
Nota sobre la privacidad Esta encuesta es anónima.
Los registros que contienen sus respuestas a la encuesta no contienen ninguna
identificación suya a menos que una pregunta específicamente así lo haga. Si responde a
esta encuesta utilizando una contraseña que le da acceso al cuestionario, puede estar
seguro que la misma no se asocia a ninguna de sus respuestas. Ésto se administra en una
tabla de datos separada, que sólo se actualiza para indicar que ha completado o no la
encuesta, pero sin establecer vínculo alguno con la tabla donde se almacenan sus

165
respuestas, por lo que no hay manera de asociar una respuesta con la persona que la hizo.
EASI (Estudio sobre Adquisición de la Sintaxis del Inglés)
Usted ha completado 0% de esta encuesta
0%
100%
PREGUNTAS INICIALES SOBRE EL APRENDIZAJE Por favor, conteste a las siguientes preguntas sobre su historial de aprendizaje en inglés.
*Por favor, escriba su DNI para verificar que usted ya ha hecho el Oxford Placement Test:
*Indique su sexo:
Femenino
Masculino
Indique su edad (años):
Sólo se aceptan números en este campo
Indique el nombre de su universidad o colegio (si actualmente no está estudiando, ponga "ninguno").

166
¿Cuánto tiempo lleva aprendiendo inglés? (aproximadamente en años)
Sólo se aceptan números en este campo
Si usted ha estado alguna vez en un país de habla inglesa, indique los paises y la duración de la estancia. (Si nunca lo ha estado, ignore esta pregunta)
*Indique su lengua materna:
Seleccione una de las siguientes opciones
Español
Otra lengua
*¿Cuál es la lengua materna de su padre? Seleccione una de las siguientes opciones
Español
Inglés
Otra lengua
*¿Cuál es la lengua materna de su madre? Seleccione una de las siguientes opciones
Español
Inglés
Otra lengua

167
*¿Qué idiomas habla usted en casa? Seleccione una de las siguientes opciones
Español
Español y otra(s) lengua(s)
*Indique cuál cree usted que es su dominio aproximado del inglés:
Seleccione una de las siguientes opciones
Avanzado alto (C2)
Avanzado bajo (C1)
Intermedio alto (B2)
Intermedio bajo (B1)
Principiante alto (A2)
Principiante bajo (A1)
EASI (Estudio sobre Adquisición de la Sintaxis del Inglés) UAM
Usted ha completado 33% de esta encuesta
0%
100%
INSTRUCCIONES En la página siguiente, usted verá una serie de oraciones en inglés.
La primera parte de la oración proporciona algo de contexto. La segunda parte es la que usted
tiene que valorar.
La valoración es muy sencilla: 1 si cree que la estructura de la oración no está bien, y 5 si cree que su estructura está bien. Usted puede elegir valores intermedios, dependiendo de lo que usted
piense sobre su estructura. O sea, a mayor puntuación, mejor estructuralidad oracional, según su opinión.

168
RECUERDE: esto no es un examen. Nos interesan todas sus respuestas y también su primera
reacción.
*Por ejemplo: Considere la siguiente oración a modo de prueba:
Many students in Spain study only before the exam... ...because they like don't to study during the year.
1 2 3 4 5
Elija:
Ayuda: usted tiene que valorar la segunda oración "because they like don't to study during the year" en la
escala del 1 al 5.
EASI (Estudio sobre Adquisición de la Sintaxis del Inglés)
Usted ha completado 66% de esta encuesta
0%
100%
ORACIONES EN INGLÉS Aquí comienza el test. Por favor, juzgue las siguientes oraciones:
* Nowadays, if you work as a policeman in Spain, you can
easily get into difficult situations, but... ... I think that it exist many more risky and dangerous jobs.
1 2 3 4 5
Elija:

169
* In a very important meeting about the world crisis, the
world leaders were waiting for somebody to give a solution…
…so there talked the president of the United States.
1 2 3 4 5
Elija:
* Winter finishes around February or March and then the
spring begins because the birds start singing... …and appear the first flowers that grow in the gardens.
1 2 3 4 5
Elija:
* The new building has a shopping centre and some offices. You can find the shopping centre on the ground floor, …
... but on the top floor work the bosses of important companies like Microsoft.
1 2 3 4 5
Elija:
* In 2004 there were some terrible terrorist attacks in Madrid.
So, … … some politicians think that it began a new period in
Spanish history.
1 2 3 4 5
Elija:

170
* The manager of Real Madrid decided that the football
match with Real Valladolid was not important… …so there played only those football players who were
very young.
1 2 3 4 5
Elija:
* The Industrial Revolution was a period between the 18th and the 19th century. Almost every aspect of human life
was influenced … ...and came many important changes in the life of people.
1 2 3 4 5
Elija:
* It was a very big conference about medicine. Most talks
were in rooms 1, 2 and 3, … … but in room 4 spoke a very important doctor from
Oxford University.
1 2 3 4 5
Elija:
* Even though we live in a democratic country with plenty of
opportunities,... ... I believe that there exist unlucky people who are
extremely poor.
1 2 3 4 5

171
Elija:
* The economic crisis is affecting everybody. A lot of workers
are unemployed. The result is… … that work only the people who have a stable job.
1 2 3 4 5
Elija:
* In 1666 a small bakery burned in the centre of London by
accident… …and from this place began a great fire that destroyed the
city.
1 2 3 4 5
Elija:
* Yesterday we were at school doing an exam. The teacher
told us to be silent… …but it talked a boy who complained about the exam
questions.
1 2 3 4 5
Elija:
* For a while, it seemed that nobody in the meeting was going
to say anything about the corruption in the British Government…
...However, there spoke a woman with a very strong Irish

172
accent.
1 2 3 4 5
Elija:
* Dictionaries often give an unusual definition of some words.
For example, think about the word “cool”. ... In my dictionary appears a very interesting definition for
this word.
1 2 3 4 5
Elija:
* I was at a funeral yesterday. Everybody got very emotional
… …because talked the wife of the man who had died.
1 2 3 4 5
Elija:
* The house was very dirty. All the windows were closed, the
rooms were dark.... …and from the kitchen came a horrible smell of burning
oil.
1 2 3 4 5
Elija:
* There was a basketball competition at school, but John

173
could not participate… …because played only the children who were 10 years old.
1 2 3 4 5
Elija:
* In 1789 France was a country with a lot of poor people who
were unhappy, … …so there began a new revolution called “The French
Revolution”.
1 2 3 4 5
Elija:
* My American friend, Paul, thinks that in Spain people are
very lazy and… …that it work only the people who are very ambitious.
1 2 3 4 5
Elija:
* Nowadays, it is very dangerous to walk alone at night in a
big city... ...because in those cities exist many dangerous criminals
who could kill you.
1 2 3 4 5
Elija:
*

174
Spain was not a democratic country for many years, but when democracy arrived…
…there appeared a great variety of new social problems.
1 2 3 4 5
Elija:
* After the Spanish civil war, the country was so poor that
there were no toys for children, so... …I think that it played only the children of people who
were rich.
1 2 3 4 5
Elija:
* In the conference several speakers talked about the
economic crisis. They all met later for dinner … …and spoke the president of the Economic Society of
America.
1 2 3 4 5
Elija:
* Some historians believe that 1940 is a very important year
… …because began a terrible war called the 'Second World
War'.
1 2 3 4 5
Elija:

175
* In the 1970’s AIDS was an unknown illness. At the end of the
1980’s it was better known... …but it came discrimination against people infected by the
illness.
1 2 3 4 5
Elija:
*A lot of university students have recently complained about the 'Bologna process', but...
...some experts say that exist some students who support it.
1 2 3 4 5
Elija:
* When I was at school, there was a special playing area, …
…but in this area played only the boys and girls who behaved well.
1 2 3 4 5
Elija:
* After several hours of discussion about work conditions,
everybody thought the meeting had finished... ...but it spoke a very angry man who started shouting.
1 2 3 4 5
Elija:

176
* Nowadays, people think that teachers do not work too
much, but the fact is that... ... there work only those teachers who are motivated.
1 2 3 4 5
Elija:
* Tourists are always interested in visiting the Houses of
Parliament in London … … because in that place talk the most important politicians
of the United Kingdom.
1 2 3 4 5
Elija:
* The economic crisis in the 1970’s affected the financial markets first. Then it affected a lot of companies and
business, … ... so there came a dramatic increase of 45% in
unemployment.
1 2 3 4 5
Elija:
* Malaria is one of the most common infectious diseases. In
the 1980s people were optimistic… …because it appeared a new medicine that was effective
against malaria.
1 2 3 4 5
Elija:

177
Por favor, si lo desea, escriba cualquier comentario u observación que desee hacer con respecto al cuestionario (dudas, opiniones, áreas problemáticas del cuestionario,
etc.)
Esta pregunta es opcional.
11.1.3 MAIN EXPERIMENTAL TESTS FOR L1 MACED-L2 ENG (IUSAJ)
IUSAJ
Pocituvani,
Ova istrazuvanje nareceno “IUSAJ” (Istrazuvanje za Usvojuvanje na Sintaksata na Angliskiot Jazik) go proucuva nacinot na koj govoritelite na makedonski jazik kako majcin jazik go
usvojuvaat angliskiot jazik. Ovaa studija e del od istrazuvackiot proekt OPOGRAM (Opcionalnost I Psevdo-Opcionalnost vo Gramatikite na Majcin I Nemajcin Jazik) na
Avtonomniot Univerzitet vo Madrid i Univerzitetot vo Granada (poveke informacii za ovoj proekt mozete da najdete ovde).
Ucestvoto vo ova studija e mnogu ednostavno. Istrazuvanjeto e anonimno, dostapno e
“online” i moze da ucestvuvaat samo govoriteli na makedonski jazik kako majcin jazik, koi ucat ili imaat poznavanje od angliski jazik (koe bilo nivo).
Ova testiranje se sostoi od dva dela:

178
1. PRASALNIK ZA USVOENO ZNAENJE. Prviot del e prasalnik koj se odnesuva na vaseto usvoeno znaenje od angliski jazik. Ednostavno, treba samo da odlucite koja recenica vi zvuci dobro a koja ne (ne obrnuvajte vnimanie na zborovite vo recenicata tuku samo na strukturata). Nema tocni ili netocni odgovori. Vazno e samo vaseto mislenje za strukturata
na recenicite.
2. TEST ZA ODREDUVANJE NA GRAMATICKO NIVO. Vtoriot test go odreduva vaseto poznavanje na gramatika na angliski jazik. Rezultatite se doverlivi, ke vi bidat dostapni
samo vas i ke gi dobiete vo sandaceto na vasata elektronska posta. Programata isto taka vi kazuva I koi delovi od angliskata gramatika mozete da gi podobrite.
Vo prodolzenie sledi prasalnikot za usvoeno znaenje.
There are 45 questions in this survey.
A Note On Privacy This survey is anonymous.
The record kept of your survey responses does not contain any identifying information about you unless a specific question in the survey has asked for this. If you have responded
to a survey that used an identifying token to allow you to access the survey, you can rest assured that the identifying token is not kept with your responses. It is managed in a
separate database, and will only be updated to indicate that you have (or haven't) completed this survey. There is no way of matching identification tokens with survey
responses in this survey.
IUSAJ UGR
You have completed 0% of this survey
0%
100%
PRASANJA ZA VASETO PRETHODNO IZUCUVANJE NA ANGLISKI JAZIK Ve molime odgovorete gi slednive prasanja povrzani so vaseto prethodno izucuvanje na angliski
jazik.
*Ve molime vnesete ja adresata na vasata elektronska posta na koja ke vi
bidat isprateni rezultatite od testot:

179
*Pol:
Женски
Машки
Vozrast (godini):
Onl nu bers ma be entered in this field
Vnesete broevi
Navedete go imeto na vasiot univerzitet ili uciliste (dokolku vo momentot ne studirate navedete “ne studiram”).
¿Kolku vreme imate uceno angliski jazik? (prosecno vo godini)
Only numbers may be entered in this field
Vnesete broevi
Dokolku imate prestojuvano vo nekoja zemja od anglisko govorno podracje navedete kade i kolku vreme.
(Dokolku nikogas ne ste prestojuvale, prodolzete na slednoto prasanje).
*Navedete go vasiot majcin jazik:
Choose one of the following answers
Makedonski
Drug jazik

180
Odberete edna od slednive opcii
*¿Koj e majciniot jazik na vasiot tatko? Choose one of the following answers
Makedonski
Drug jazik
Odberete edna od slednive opcii
*¿Koj e majciniot jazik na vasata majka?
Choose one of the following answers
Makedonski
Drug jazik
Odberete edna od slednive opcii
*¿Na koj jazik zboruvate doma? Choose one of the following answers
Makedonski
Drug jazik
Odberete edna od slednive opcii
*
Navedete go vaseto mislenje za vaseto nivo na poznavanje na angliskiot jazik:
Choose one of the following answers
Napredno visoko (C2)
Napredno nisko (C1)
181
Sredno visoko (B2)
Sredno nisko (B1)
Osnovno visoko (A2)
Osnovno nisko (A1)
Odberete edna od slednive opcii
IUSAJ UGR
You have completed 33% of this survey
0%
100%
INSTRUKCII
Na slednata stranica ke vidite redosled od recenici na angliski jazik.
Prviot del od recenicata se odnesuva na kontekstot. Vie treba da go ocenite vtoriot del.
Ocenuvanjeto e mnogu ednostavno: odberete 1 dokolku mislite deka strukturata na recenicata ne e dobra i 5 dokolku mislite deka strukturata e dobra. Mozete da odberete i sredni vrednosti, vo
zavisnot od vaseto mislenje za toa kolku dobro e sostavena recenicata (zaradi toa, ne obrnuvajte vnimanie na zborovite tuku samo na strukturata).
ZAPOMNETE: ova ne e test. Ne interesiraat site vasi odgovori i vasata prvicna reakcija na recenicite.
*
*Na primer:Slednata recenica vi pokazuva na koj nacin se ocenuvaat recenicite vo prasalnikot

182
Many students in Spain study only before the exam... ...because they like don't to study during the year.
1 2 3 4 5
Odberete:
Pomos: treba da ja ocenite slednava recenica "because they
like don't to study during the year" na skala od 1 do 5.
IUSAJ UGR
You have completed 66% of this survey
0%
100%
RECENICI NA ANGLISKI Ovde pocnuva testot. Ve molime ocenete gi slednive recenici:
* Nowadays, if you work as a policeman in Spain, you can easily
get into difficult situations, but... ... I think that it exist many more risky and dangerous jobs.
1 2 3 4 5
Odberete:
* In a very important meeting about the world crisis, the world
leaders were waiting for somebody to give a solution… …so there talked the president of the United States.

183
1 2 3 4 5
Odberete:
* Winter finishes around February or March and then the spring
begins because the birds start singing... …and appear the first flowers that grow in the gardens.
1 2 3 4 5
Odberete:
* The new building has a shopping centre and some offices. You
can find the shopping centre on the ground floor, … ... but on the top floor work the bosses of important
companies like Microsoft.
1 2 3 4 5
Odberete:
* In 2004 there were some terrible terrorist attacks in Madrid.
So, … … some politicians think that it began a new period in
Spanish history.
1 2 3 4 5
Odberete:
* The manager of Real Madrid decided that the football match
with Real Valladolid was not important…

184
…so there played only those football players who were very young.
1 2 3 4 5
Odberete:
* The Industrial Revolution was a period between the 18th and
the 19th century. Almost every aspect of human life was influenced …
...and came many important changes in the life of people.
1 2 3 4 5
Odberete:
* It was a very big conference about medicine. Most talks were
in rooms 1, 2 and 3, … … but in room 4 spoke a very important doctor from Oxford
University.
1 2 3 4 5
Odberete:
* Even though we live in a democratic country with plenty of
opportunities,... ... I believe that there exist unlucky people who are
extremely poor.
1 2 3 4 5
Odberete:

185
* The economic crisis is affecting everybody. A lot of workers
are unemployed. The result is… … that work only the people who have a stable job.
1 2 3 4 5
Odberete:
* In 1666 a small bakery burned in the centre of London by
accident… …and from this place began a great fire that destroyed the
city.
1 2 3 4 5
Odberete:
* Yesterday we were at school doing an exam. The teacher told
us to be silent… …but it talked a boy who complained about the exam
questions.
1 2 3 4 5
Odberete:
* For a while, it seemed that nobody in the meeting was going
to say anything about the corruption in the British Government…
...However, there spoke a woman with a very strong Irish accent.
1 2 3 4 5
Odberete:

186
* Dictionaries often give an unusual definition of some words.
For example, think about the word “cool”. ... In my dictionary appears a very interesting definition for
this word.
1 2 3 4 5
Odberete:
* I was at a funeral yesterday. Everybody got very emotional …
…because talked the wife of the man who had died.
1 2 3 4 5
Odberete:
* The house was very dirty. All the windows were closed, the
rooms were dark.... …and from the kitchen came a horrible smell of burning oil.
1 2 3 4 5
Odberete:
* There was a basketball competition at school, but John could
not participate… …because played only the children who were 10 years old.
1 2 3 4 5
Odberete:

187
* In 1789 France was a country with a lot of poor people who
were unhappy, … …so there began a new revolution called “The French
Revolution”.
1 2 3 4 5
Odberete:
* My American friend, Paul, thinks that in Spain people are very
lazy and… …that it work only the people who are very ambitious.
1 2 3 4 5
Odberete:
* Nowadays, it is very dangerous to walk alone at night in a big
city... ...because in those cities exist many dangerous criminals
who could kill you.
1 2 3 4 5
Odberete:
* Spain was not a democratic country for many years, but when
democracy arrived… …there appeared a great variety of new social problems.
1 2 3 4 5
Odberete:

188
* After the Spanish civil war, the country was so poor that there
were no toys for children, so... …I think that it played only the children of people who were
rich.
1 2 3 4 5
Odberete:
* In the conference several speakers talked about the economic
crisis. They all met later for dinner … …and spoke the president of the Economic Society of
America.
1 2 3 4 5
Odberete:
* Some historians believe that 1940 is a very important year …
…because began a terrible war called the 'Second World War'.
1 2 3 4 5
Odberete:
* In the 1970’s AIDS was an unknown illness. At the end of the
1980’s it was better known... …but it came discrimination against people infected by the
illness.
1 2 3 4 5
Odberete:

189
*A lot of university students have recently complained about the 'Bologna process', but...
...some experts say that exist some students who support it.
1 2 3 4 5
Odberete:
* When I was at school, there was a special playing area, …
…but in this area played only the boys and girls who behaved well.
1 2 3 4 5
Odberete:
* After several hours of discussion about work conditions,
everybody thought the meeting had finished... ...but it spoke a very angry man who started shouting.
1 2 3 4 5
Odberete:
* Nowadays, people think that teachers do not work too much,
but the fact is that... ... there work only those teachers who are motivated.
1 2 3 4 5
Odberete:

190
* Tourists are always interested in visiting the Houses of
Parliament in London … … because in that place talk the most important politicians of
the United Kingdom.
1 2 3 4 5
Odberete:
* The economic crisis in the 1970’s affected the financial markets first. Then it affected a lot of companies and
business, … ... so there came a dramatic increase of 45% in
unemployment.
1 2 3 4 5
Odberete:
* Malaria is one of the most common infectious diseases. In the
1980s people were optimistic… …because it appeared a new medicine that was effective
against malaria.
1 2 3 4 5
Odberete:
Ve molime, dokolku sakate, napisete nekakov komentar za prasalnikot (nejasnosti, mislenje, problematicni delovi i slicno)
Ova prasanje e izborno

191
11.1.4 RANDOMIZATION OF SENTENCES IN THE MAIN EXPERIMENTAL TEST
In order to avoid order-of-presentation effects, which are typical in experimental tests in
psychology and language acquisition research, the stimuli (sentences) presented to
participants in the main experimental test were randomized so as to minimize these
effects. We also intended to randomize the order of presentation for each participant,
but the software used (LimeSurvey) did not allow this.
ORDER OF DESIGN: ORDER OF PRESENTATION:
1 unac-exist-it 1
2 unac-exist-there 18
3 unac-exist-zero 7
4 unac-exist-pp 24
5 unac-appear-it 9
6 unac-appear-there 26
7 unac-appear-zero 15
8 unac-appear-pp 32
9 unac-begin-it 2
10 unac-begin-there 23
11 unac-begin-zero 12
12 unac-begin-pp 17
13 unac-come-it 30
14 unac-come-there 8
15 unac-come-zero 19
16 unac-come-pp 16
17 unerg-talk-it 27
18 unerg-talk-there 10
19 unerg-talk-zero 21
20 unerg-talk-pp 4
21 unerg-work-it 6
22 unerg-work-there 25
23 unerg-work-zero 31
24 unerg-work-pp 11
25 unerg-play-it 13
26 unerg-play-there 3
27 unerg-play-zero 28
28 unerg-play-pp 29
29 unerg-speak-it 22

192
30 unerg-speak-there 20
31 unerg-speak-zero 74
32 unerg-speak-pp 5
11.2 OPT (OXFORD PLACEMENT TEST)
The Oxford Placement Test was administered to both L1 Spa-L2 Eng and L1 Maced-
L2Eng learners in an online format.
Oxford Placement Test 1
Grammar Test PART 1
Look at these examples. The correct answer has been marked.
i. In warm climates people sitting outside in the sun. [INSERT SCAN OF
ANSWER SHEET]
a) like b) likes c) are liking
ii. If it is very hot, they sit the shade.
a) at b) in c) under
Now the test will begin. Mark the correct answers on the answer sheet.
1. Water at a temperature of 100ºC.
a) is to boil b) is boiling c) boils
2. In some countries very hot all the time.
a) there is b) is c) it is
3. In cold countries people wear thick clothes warm.
a) for keeping b) to keep c) for to keep
4. In England people are always talking about .
a) a weather b) the weather c) weather
5. In some places almost every day.
a) it rains b) there rains c) it raining
6. In deserts there isn‟t grass.
a) the b) some c) any

193
7. Places near the Equator have weather even in the cold season.
a) a warm b) the warm c) warm
8. In England time of year is usually from December to February.
a) coldest b) the coldest c) colder
9. people don‟t know what it‟s really like in other countries.
a) The most b) Most of c) Most
10. Very people can travel abroad.
a) less b) little c) few
11. Mohammed Ali his first world title fight in 1960.
a) has won b) won c) is winning
12. After he an Olympic gold medal he became a professional boxer.
a) had won b) have won c) was winning
13. His religious beliefs change his name when he became champion.
a) have made him b) made him to c) made him
14. If he lost his first fight with Sonny Liston, no one would have been surprised.
a) has b) would have c) had
15. He has travelled a lot as a boxer and as a world-famous personality.
a) both b) and c) or
16. He is very well known the world.
a) all in b) all over c) in all
17. Many people he was the greatest boxer of all time.
a) is believing b) are believing c) believe
18. To be the best the world is not easy.
a) from b) in c) of
19. Like any top sportsman Ali train very hard.
a) had to b) must c) should
20. Such is his fame that people always remember him as a champion.
a) would b) will c) did
21. The history of is a) aeroplane b) the aeroplane c) an aeroplane

194
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
short one. For many centuries men
to fly, but with
success. In the 19th century a few people
succeeded in balloons. But it wasn‟t until
the beginning of the century that anybody
able to fly in a machine
was heavier than air, in other words, in
we now call a „plane‟. The first people to achieve
„powered flight‟ were the Wright brothers. was
the machine which was the forerunner of the jumbo jets
that are common sight today.
They hardly have imagined that in 1969,
more than half a century later,
a man walking on the moon.
Already is taking the first steps towards the stars.
Space satellites have now existed around
half a century and we are dependent them for all
kinds of . Not only
being used for scientific research in
space, but also to see what kind of weather .
By 2008 there have been satellites in space for fifty
years and the „space superpowers‟ will be massive
space stations built. When these completed
it will be the first time astronauts will be
able to work in space in large numbers. all that,
in many ways the most remarkable flight all was
of the flying bicycle, which the world saw
on television, across the Channel from England to
France, with nothing a man to power it. As the
bicycle-flyer said, „It‟s the first time what hard work
it is to be a bird!‟
a) quite a
a) are trying
a) little
a) to fly
a) this
a) were
a) who
a) who
a) His
a) such
a) could
a) not much
a) will be
a) a man
a) since
a) from
a) informations
a) are they
a) is coming
a) would
a) having
a) will be
a) when
a) Apart
a) of
a) it
a) flying
a) apart
a) I realize
b) a quite
b) try
b) few
b) in flying
b) next
b) is
b) which
b) which
b) Their
b) such a
b) should
b) not many
b) had been
b) man
b) during
b) of
b) information
b) they are
b) comes
b) must
b) making
b) are
b) where
b) For
b) above
b) that
b) to fly
b) but
b) I‟ve realized
c) quite
c) had tried
c) a little
c) into flying
c) last
c) was
c) what
c) what
c) Theirs
c) so
c) couldn‟t
c) no much
c) would be
c) the man
c) for
c) on
c) an information
c) there are
c) coming
c) will
c) letting
c) will have been
c) that
c) Except
c) at
c) that one
c) fly
c) than
c) I am realizing
Grammar Test PART 2

195
51. Many teachers their students should learn a foreign language.
a) say to b) say c) tell
52. Learning a second language is not the same learning a first language.
a) as b) like c) than
53. It takes to learn any language.
a) long time b) long c) a long time
54. It is said that Chinese is perhaps the world‟s language to master.
a) harder b) hardest c) more hard
55. English is quite difficult because of all the exceptions have to be learnt.
a) who b) which c) what
56. You can learn the basic structures of a language quite quickly, but only if you an effort.
a) are wanting b) will to c) are willing to
57. A lot of people aren‟t used grammar in their own language.
a) to the study b) to study c) to studying
58. Many adult students of English wish they their language studies earlier.
a) would start b) would have started c) had started
59. In some countries students have to spend a lot of time working their own.
a) on b) by c) in
60. There aren‟t easy ways of learning a foreign language in your own country.
a) no b) any c) some
61. Some people try to improve their English by the BBC World Service.
a) hearing b) listening c) listening to
62. with a foreign family can be a good way to learn a language.
a) Live b) Life c) Living
63. It‟s no use to learn a language just by studying a dictionary.
a) to try b) trying c) in trying
64. Many students of English take tests.
a) would rather not b) would rather prefer not c) would rather not to
65. Some people think it‟s time we all a single international language.
a) learn b) should learn c) learnt

196
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
Charles Walker is a teacher at a comprehensive school in Norwich.
He the staff of the school in 1998
and there ever since.
Before to Norwich, he taught in Italy and in Wales, and
before that he a student at Cambridge University. So far
he in Norwich for as long as he was in Wales, but he likes
the city a lot and like to stay there for at least another two
years, or, he puts it, until his two children
grown up a bit. He met his wife, Kate, in 1992
while he abroad for a while,
and they got married in 1996. Their two children, Mark
and Susan, both born in Norwich.
The Walkers‟ boy, is five,
has just started at school, but sister
at home for another couple of years,
because she is nearly two years than him.
Charles and Kate Walker to live in the country,
but now that they have children, they into the city.
Charles wanted a house the
school get to work easily.
Unfortunately one the two of them really wanted was
too expensive, so they buy one a bit further away.
By the time the children to secondary school,
Charles and Kate hope will be in Norwich,
the Walkers living there for at least fifteen years.
They can‟t be sure if they ,
but if they , their friends won‟t be too surprised.
a) has joined
a) has been working
a) move
a) has been
a) isn‟t
a) should
a) how
a) have
a) was to live
a) are
a) who
a) his
a) shall stay
a) younger
a) are used
a) have moved
a) next
a) in order
a) the
a) must
a) go
a) that
a) will have been
a) stay
a) don‟t
b) joined
b) worked
b) to move
b) was
b) wasn‟t
b) would
b) which
b) will have
b) was living
b) were
b) which
b) their
b) stays
b) more young
b) use
b) move
b) near
b) for
b) a
b) should
b) will go
b) which
b) have been
b) do stay
b) didn‟t
c) joins
c) works
c) moving
c) was being
c) hasn‟t been
c) could
c) as
c) will be
c) had been living
c) have been
c) he
c) her
c) will be staying
c) the younger
c) used
c) moved
c) close
c) to
c) that
c) had to
c) will have gone
c) what
c) will be
c) will stay
c) won‟t
Look at the following examples of question tags in English. The correct form of the tag has been marked.
i. He‟s getting the 9.15 train, ?
a) isn‟t he b) hasn‟t he c) wasn‟t he
ii. She works in a library, ?

197
a) isn‟t she b) doesn‟t she c) doesn‟t he [INSERT SCAN OF ANSWER
SHEET]
iii. Tom didn‟t tell you, ?
a) hasn‟t he b) didn‟t he c) did he
iv. Someone‟s forgotten to switch off the gas, ?
a) didn‟t one b) didn‟t they c) haven‟t they
Now, on the answer sheet, mark the correct question tag in the following 10 items:
91. John‟s coming to see you, ?
a) hasn‟t he b) wasn‟t he c) isn‟t he
92. It‟s been a long time since you‟ve seen him, ?
a) hasn‟t it b) isn‟t it c) haven‟t you
93. He‟s due to arrive tomorrow, ?
a) won‟t he b) isn‟t he c) will he
94. He won‟t be getting in till about 10.30, ?
a) isn‟t he b) is he c) will he
95. You met him while you were on holiday, ?
a) didn‟t you b) weren‟t you c) haven‟t you
96. I think I‟m expected to pick him up, ?
a) aren‟t I b) don‟t I c) are you
97. No doubt you‟d rather he stayed in England now, ?
a) didn‟t you b) wouldn‟t you c) shouldn‟t you
98. Nobody else has been told he‟s coming, ?
a) is he b) has he c) have they
99. We‟d better not stay up too late tonight, ?
a) didn‟t we b) have we c) had we
100. I suppose it‟s time we called it a day, ?
a) didn‟t we b) isn‟t it c) don‟t
11.3 PILOT STUDY ON MACEDONIAN NATIVES‟ INTUITIONS ON
UNACCUSATIVITY

198
In the following sections we list the pilot study used to test Macedonian native
speakers‟ sensitivity to SV/VS distribution with unaccusatives and unergatives, as
described in section 2.2.3.3.2, page 72. This is followed by the raw data.
11.3.1 PILOT STUDY ON MACEDONIAN NATIVES: THE TEST
We will include the test instructions and stimuli followed by their English translation.
Understandably, the online version of test contained only the Macedonian stimuli and
can be accessed at the following link:
https://spreadsheets.google.com/spreadsheet/gform?key=tiJgNC795kZwR8bjk5GieA#e
dit
Збороред во македонски реченици
Word order in Macedonian sentences
ИНСТРУКЦИИ : Почитувани,
Ова е краток експеримент кој истражува кој збороред им
звучи поприродно на говорителите на Македонски јазик како
мајчин јазик. Подолу има 16 реченици за кои ни треба вашето
мислење. Треба да ги прочитате речениците и да одберете
еден од двата дадени одговори без да мислите кој одговор е
точен. Двете опции се точни но нам ни треба вашето мислење
кој одговор ви звучи ПОПРИРОДНО. Пред да започнете со
прашалникот Ве молиме впишете ја Вашата емаил адреса и
податоци за возраст. По завршувањето на тестот само
кликнете на копчето SUBMIT и ние автоматски ке ги добиеме
вашите одговори.
Ви благодариме на времето одвоено за овој експеримент.
INSTRUCTIONS: Dear participants
This is a short experiment studying which word order sounds
more natural to native speakers of Macedonian. We have
listed 16 sentences below and we need your opinion about
them. Please read the sentences and choose one of the two

199
given answers without thinking which one is correct. Both
answers are correct but we need your opinion on which one
of them sounds more NATURAL. Before you start doing the
questionnaire please write your email address and age
information in the designated space. After you finish the
test click on the SUBMIT button and we will automatically
receive your answers.
Thank you for your time.
1. neutral context – unaccusatives / COME
Вчера на факултетот имаше предавања по граматика. Ти
присуствуваше, но Ана неможеше да дојде. Таа ти се јави
денес и те праша: “Што се случи вчера на предавањата?” Ти
ќе одговориш:
1) Нов професор дојде (SV)
2) Дојде нов професор (VS)
Yesterday there were lectures on grammar at the faculty.
You attended the lectures but Ana was not able to come. She
called you today and asked: “What happened yesterday at the
lectures”? You reply:
1) A new professor came (SV)
2) Came a new professor (VS)
2. presentational context – unaccusatives / EXIST
Гледаш документарец за некои натприродни суштества во
Трансилванија. Доаѓа твојата сестра и прашува: “Постои ли
нешто чудно во Трансилванија?“ Ти одговараш:

200
1) вампири постојат (SV)
2) постојат вампири (VS)
You are watching a documentary about supernatural creatures
in Transilvania. Your sister comes and asks: “Does anything
weird exist in Transilvania?” You answer:
1) vampires exist (SV)
2) exist vampires (VS)
3. presentational context – unergatives / WORK
На гости доаѓа твојата пријателка Сања која забележува дека
твојата градина е многу убаво средена и прашува: Кој
работеше во градинава? Ти одговараш:
1) Една сосетка работеше (SV)
2) Работеше еден сосетка (VS)
Your friend Sanya comes to visit you and she makes a
comment about your beautifully arranged garden by asking:
Who worked in the garden? You answer:
1) A neighbor worked (SV)
2) Worked a neighbor (VS)
4. neutral context – unaccusatives / BEGIN
Гледаш вести со семејството и почнувате загрижено да
разговарате за некоја вест која штотуку ја слушнавте. Доаѓа
твојата мајка и прашува: “Што се случи“? Ти одговараш:
1) почна војна (VS)
2) војна почна (SV)

201
You are watching the news with your family and you start
talking worriedly about some news you have just heard.
Your mother enters and asks: “ What happened?” You answer:
1) began a war (VS)
2) a war began (SV)
5. presentational context – unergatives / PLAY
Твојата ќерка доаѓа дома од училиште и веднаш забележува
дека некој си играл со нејзината омилена кукла додека таа
не била дома. Веднаш прашува: “Кој си играше со куклата“?
Ти одговараш:
1) едно девојче си играше (SV)
2) си играше едно девојче (VS)
Your daughter comes back from school and notices that
someone has been playing with her favourite doll while she
was not at home. She asks immediately: “Who played with the
doll”? You answer:
1) a girl played (SV)
2) played a girl (VS)
6. neutral context – unaccusatives / APPEAR
Гледаш хорор филм со Весна и заѕвонува нејзиниот телефон.
Таа излегуваш од собата и се враќа по завршувањето на
разговорот. Во меѓувреме испушти еден дел од филмот и
прашува: “Што се случи“? Ти одговараш:
1) се појави дух (VS)
2) дух се појави (SV)
You are watching a horror film with Vesna when her
telephone rings. She goes out of the room and she comes

202
back after she has finished the conversation. She missed
one part of the film and asks: “What happened”? You answer:
1) appeared a ghost (VS)
2) a ghost appeared (SV)
7. neutral context– unergatives / SPEAK
Вчера разговараше со твојата пријателка Марта и и кажа
дека ќе одиш на некоја прес-конференција. Се видовте денес
и таа те праша: “ Што се случи вчера на прес-
конференцијата?“ Ти одговараш:
1) една поп-ѕвезда зборуваше (SV)
2) зборуваше една поп-ѕвезда (VS)
You talked to your friend Marta yesterday and you told her
you were going to go at a press conference. Today you saw
her and she asked: “ What happened at the press
conference?” You answer:
1) a pop-star spoke (SV)
2) spoke a pop-star (VS)
8. presentational context – unaccusatives / COME
Ти си на забава со твојата пријателка Тања. Таа оди да си
земе пијачка и во меѓувреме на забавата доаѓа некој
непознат човек. Тања се враќа, забележува дека некој дошол
и прашува: “Кој дојде“? Ти одговараш:
1) еден човек дојде (SV)
2) дојде еден човек (VS)
You are at a party with your friend Tanya. She goes to get
a drink and in the meantime there comes an unknown man.

203
Tanya returns, notices that someone has come and asks: “Who
came”? You answer:
1) a man came (SV)
2) came a man (VS)
9. neutral context – unaccusatives / EXIST
Твојата пријателка сака да знае што е актуелно во
политичката состојба во Македонија и те прашува: “Што се
случува во политиката во Македонија?“. Ти одговараш:
1) корупција постои (SV)
2) постои корупција (VS)
Your friend would like to know something more about the
political situation in Macedonia and she asks: “What is
happening in Macedonian politics?”. You reply:
1) corruption exists (SV)
2) exists corruption (VS)
10. neutral context – unergatives / CRY
Синоќа те разбуди едно дете кое почна да плаче на улицата и
после тоа неможеше да заспиеш. Ова утро пријателката го
забележува твоето ненаспано лице и прашува: “ Што се
случи“? Ти одговараш:
1) плачеше едно дете (SV)
2) едно дете плачеше (VS)
Last night you were awaken by a child who started crying in
the street and you could sleep afterwards. This morning
your friend notices your sleepy face and asks:” What
happened”? You answer:

204
1) a child cried (SV)
2) cried a child (VS)
11. neutral context – unergatives / WORK
Гледаш репортажа за тешкиот живот во Индија. Доаѓа твојата
мајка и прашува: “ Што се случува во фабриките во Индија?“
Ти одговараш:
1) деца работат (SV)
2) работат деца (VS)
You are watching a reportage about the difficult life
conditions in India. Your mother comes and asks: “What is
happening in the factories in India?” You answer:
1) children work (SV)
2) work children (VS)
12. presentational context – unaccusatives /
APPEAR
Додека разговарате со пријателката некој ѕвони на вратата.
Одиш да отвориш и се враќаш со изненаден израз на лицето.
Пријателката прашува: Кој се појави на вратата? Ти
одговараш:
1) еден просјак се појави (SV)
2) се појави еден просјак (VS)
While you are talking with your friend someone rings the
bell. You go to open the door and you come back with a
surprised look on your face. Your friend asks: “ Who
appeared at the door”? You answer:
1) a beggar appeared (SV)

205
2) appeared a beggar (VS)
13. neutral context – unergatives / PLAY
Твојата мајка доаѓа дома без да знае дека претходно сте
имале гости кои имаат мало дете. Гледа доста работи
оставени на подот и прашува: “Што се случи“?Ти одговараш:
1) едно дете си играше (SV)
2) си играше едно дете (VS)
Your mother comes home without knowing that previously you
had guests who have a small child. She sees a lot of things
left on the floor and she asks : “What happened”? You
answer:
1) A child played (SV)
2) played a child (VS)
14. presentational context – unergatives / SPEAK
Твојот колега Марко неможеше да присуствува на состанокот
за финансиската состојба на фирмата и те прашува: “Кој
зборуваше на состанокот?“ Ти одговараш:
1) еден економист зборуваше (SV)
2) зборуваше еден економист (VS)
Your colleague Marko was not able to attend the meeting
about the financial situation of the company and he asks.
“Who spoke at the meeting?” You answer:
1) an economist spoke (SV)
2) spoke an economist (VS)
15. presentational context – unaccusatives / BEGIN

206
На една домашна забава забележуваш како повеќето од
присутните момци седнуваат пред телевизорот. Ана го
збаележува истото и те прашува: “Што мислиш дека почна на
телевизија“? Ти одговараш:
1) натпревар почна (SV)
2) почна натпревар (VS)
At a home party you notice how most of the present men
suddenly sit in front of the TV. Ana notices the same thing
and asks you: “What do you think began on the TV”? You
answer:
1) a match began (SV)
2) began a match (VS)
16. presentational context – unergatives / CRY
Одиш на кино да изгледаш некој филм. При крај на филмот
една жена која седи близу до тебе почна да плаче. По
завршувањето на филмот ја среќаваш Ана која исто така го
гледала филмот и слушнала како некој плаче. Таа прашува: “
Кој плачеше “? Ти одговараш:
1) плачеше една жена (VS)
2) една жена плачеше (SV)
You go to the cinema to watch a film. Towards the end of
the film a woman who sits close to you starts to cry. After
the end of the film you meet Ana who also watched the film
and heard someone crying. She asks: “ Who cried”? You
answer:
1) cried a woman (VS)
2) a woman cried (SV)

207
ДОКОЛКУ ИМАТЕ НЕКОЈ КОМЕНТАР ЗА ТЕСТОТ ВЕ МОЛИМЕ ВПИШЕТЕ ГО
ВО ПРАЗНИТЕ МЕСТА ПОДОЛУ.
ВИ БЛАГОДАРИМЕ ЗА УЧЕСТВОТО.
IF YOU HAVE ANY COMMENT ABOUT THE TEST PLEASE WRITE IT IN
THE EMPTY SPACE BELOW.
THANK YOU FOR PARTICIPATING.
11.3.2 PILOT STUDY ON MACEDONIAN NATIVES: RAW DATA
This first chart (overleaf) shows the results for the analysis on four verbs per condition.

208
EM
AIL
neu
tral_
un
ac_co
me
neu
tral_
un
accu
sati
ves_b
eg
in
neu
tral_
un
accu
sati
ves_ap
pear
neu
tral_
un
accu
sati
ve_exis
t
neu
tral_
un
erg
ati
ves_sp
eak
neu
tral_
un
erg
ati
ves_cry
neu
tral_
un
erg
ati
ves_w
ork
neu
tral_
un
erg
ati
ves_p
lay
pre
sen
tati
on
al_
un
accu
sati
ves_co
me
pre
sen
tati
on
al_
un
accu
sati
ves_b
eg
in
pre
sen
tati
on
al_
un
accu
sati
ves_ap
pear
pre
sen
tati
on
al_
un
accu
sati
ves_exis
t
pre
sen
tati
on
al_
un
erg
ati
ves_sp
eak
pre
sen
tati
on
al_
un
erg
ati
ve_cry
pre
sen
tati
on
al_
un
erg
ati
ves_w
ork
pre
sen
tati
on
al_
un
erg
ati
ve_p
lay
CO
MM
EN
T
Возраст
neu
tral_
un
ac
neu
tral_
un
erg
pre
sen
tati
on
al_
un
ac
pre
sen
tati
on
al_
un
erg
neu
tral_
un
ac(%
)
neu
tral_
un
erg
(%)
pre
sen
tati
on
al_
un
ac(%
)
pre
sen
tati
on
al_
un
erg
(%)
7/13/2011 20:45:41 [email protected] VS VS VS VS VS SV SV VS VS VS VS SV SV VS SV SV 25
7/13/2011 20:46:02
nikola.mladenovski@yahoo.
com VS VS SV VS SV VS VS SV VS VS VS SV SV SV SV SV 19
7/14/2011 14:08:49 [email protected] VS VS VS VS SV VS VS VS VS VS VS VS VS SV VS VS
последната реченица,
имаш испуштено буква 29
7/14/2011 15:02:21 [email protected] VS VS VS VS VS SV SV SV SV VS SV VS SV SV SV SV 24
7/14/2011 15:42:11 [email protected] VS VS VS VS VS SV VS SV VS VS VS VS VS VS SV SV 29
7/14/2011 15:49:59 [email protected] VS VS VS VS VS SV SV SV VS VS VS VS VS VS SV SV 27
7/14/2011 16:11:00 [email protected] SV VS SV SV SV VS VS SV SV VS VS VS SV SV SV SV
46
go
7/14/2011 16:24:00 [email protected] VS VS VS VS VS SV VS SV VS VS VS VS VS VS VS VS 24
7/14/2011 16:50:12 [email protected] VS VS VS VS VS VS VS VS VS VS VS SV SV SV SV SV 34
7/14/2011 16:55:07
sasodimitrovski1982@yahoo
.com VS VS VS VS VS VS VS SV SV SV SV SV VS SV SV SV 29
7/14/2011 17:15:47 [email protected] VS VS VS VS VS SV SV SV SV SV VS SV SV SV SV VS 29
7/14/2011 17:36:30 [email protected] VS VS VS VS VS VS VS VS VS VS VS VS VS SV VS VS 26
7/14/2011 17:40:19 VS VS VS VS VS VS VS VS VS VS VS VS VS SV VS VS 28
7/14/2011 17:54:56 [email protected] VS VS VS VS VS VS VS VS VS VS VS VS VS VS SV VS 29
7/14/2011 17:55:14 [email protected] VS VS VS VS VS VS VS VS VS VS VS VS VS VS SV VS 29
7/14/2011 17:57:28 [email protected] VS VS SV VS VS VS SV VS VS VS SV SV VS SV VS VS 29
7/14/2011 17:59:41 [email protected] VS VS VS VS VS SV SV SV VS SV VS SV SV SV SV SV 26
7/14/2011 18:06:01
om VS VS VS VS VS SV SV SV SV VS SV VS SV SV VS VS 25
7/14/2011 18:15:59 [email protected] VS VS VS VS VS SV VS VS VS VS VS VS VS SV VS VS 29
7/14/2011 18:25:35 [email protected] VS VS VS VS VS VS VS VS SV SV SV VS SV SV SV SV 19
7/14/2011 18:29:42 [email protected] VS SV VS SV VS SV VS VS SV SV SV SV SV SV SV SV 28
7/14/2011 18:31:55 [email protected] VS VS SV SV VS SV SV VS VS VS SV SV VS SV SV VS 28
7/14/2011 18:42:34 [email protected] VS VS VS VS VS SV SV SV VS VS VS VS VS VS VS VS 10
7/14/2011 18:43:08
vasko_boskov2006@yahoo.
com SV VS VS VS SV VS VS VS VS VS SV VS SV SV VS VS 19
7/14/2011 19:19:53 [email protected] VS VS VS VS VS VS VS VS VS VS VS VS VS VS SV VS
28
go
7/14/2011 20:04:15 [email protected] VS VS VS VS VS VS VS SV VS VS VS VS VS VS SV VS 22
7/14/2011 20:05:16 [email protected] VS VS VS VS SV SV VS SV VS VS VS VS SV SV SV SV 30
7/14/2011 20:14:34 [email protected] VS VS SV VS VS SV VS SV SV VS SV VS SV SV SV SV 18
7/14/2011 20:45:18 [email protected] VS VS VS VS VS SV VS SV VS VS VS SV SV SV SV SV Fala 28
7/14/2011 21:02:06
om VS VS VS VS VS VS SV VS VS VS VS VS VS SV SV VS 22
7/14/2011 21:06:19
m VS SV SV SV VS VS SV SV SV SV SV SV VS SV SV SV 29
7/14/2011 21:11:44
aleksandardimov10@yahoo.
com VS VS VS VS VS VS SV VS VS VS VS VS VS VS VS VS 21
7/14/2011 21:14:25 [email protected] VS VS VS SV VS VS VS VS SV SV VS VS SV VS SV SV 21
7/14/2011 21:17:11 [email protected] VS VS SV VS VS VS SV VS VS VS SV VS SV SV SV VS 21
7/14/2011 22:01:57
om VS SV VS VS VS VS SV VS VS SV SV VS SV SV SV SV 22
7/14/2011 22:13:18
aleksandra_filipova@hotmail
.com VS VS VS VS VS VS VS VS VS VS SV VS VS SV SV VS 18
7/14/2011 22:26:21 [email protected] SV VS SV SV SV VS SV SV SV SV SV SV SV VS SV SV 35
7/14/2011 22:28:44 [email protected] VS VS VS VS VS VS VS VS VS VS VS VS VS VS SV SV
Голем дел од
прашањата ги користам
и двата одговори во 27
7/14/2011 23:52:29 [email protected] VS VS VS VS VS VS VS SV VS VS VS VS VS SV VS VS 37
7/15/2011 5:01:23
biljana_katmeroska@yahoo.
com VS VS VS VS VS SV SV VS VS VS SV VS VS SV VS SV 25
7/15/2011 9:35:55 SV SV SV SV SV SV SV SV SV SV SV SV SV SV SV SV
7/15/2011 10:43:14 [email protected] VS VS SV VS VS SV SV SV VS VS VS VS SV SV SV SV 31
7/15/2011 12:15:59 [email protected] VS VS VS VS SV SV VS VS SV VS SV VS SV SV SV SV
7/15/2011 12:24:48 [email protected] VS SV SV VS VS VS SV VS SV VS VS VS VS SV SV SV 28
7/15/2011 12:31:42 [email protected] VS VS VS VS VS SV SV SV VS VS VS VS VS SV SV VS
29
go
di
ni
7/15/2011 14:29:48 [email protected] VS VS VS VS VS VS SV VS SV SV SV VS SV SV SV SV 24
7/15/2011 14:53:19
om VS VS SV VS VS SV VS VS VS VS VS VS VS VS VS VS 25
7/15/2011 15:12:28 VS VS VS VS VS VS VS VS SV VS SV VS VS VS SV SV
7/17/2011 8:40:50
m VS VS VS VS VS VS SV SV SV SV SV SV VS SV VS VS 17
7/18/2011 13:08:16
mk VS VS VS VS SV SV SV VS VS VS SV VS SV SV SV SV 29
7/18/2011 13:29:17
m VS VS VS VS VS SV SV VS VS VS SV SV VS SV VS VS 29
7/18/2011 13:32:44
gordana.ciplakovska@pumpi
.com.mk VS VS VS VS VS SV VS VS VS VS VS VS VS SV VS SV 27
7/18/2011 14:23:26 [email protected] VS VS VS VS SV SV SV SV SV VS SV VS SV VS SV SV 31
7/18/2011 18:21:42 [email protected] VS VS SV VS VS VS VS VS SV VS SV SV VS SV SV SV 23
7/18/2011 18:29:07 [email protected] SV SV SV VS SV SV SV SV SV SV SV SV SV SV SV SV
7/18/2011 18:58:11 [email protected] VS VS VS VS VS VS VS VS VS VS VS VS VS SV VS VS 20
7/18/2011 18:59:12 [email protected] VS VS VS VS VS VS VS VS VS VS VS VS VS VS VS SV 29
7/18/2011 19:41:29 [email protected] VS VS VS VS VS VS VS SV SV VS SV VS VS SV VS SV 30
7/18/2011 21:29:49 [email protected] VS VS VS VS VS VS SV SV SV SV VS VS SV SV SV SV 29
7/18/2011 23:51:18 [email protected] VS VS VS VS VS VS SV VS SV SV SV VS SV SV SV SV 22
7/19/2011 1:27:41 SV VS VS VS VS VS VS VS VS VS VS VS VS SV VS VS
7/20/2011 0:21:43 [email protected] VS VS VS SV VS SV VS VS VS SV VS VS VS SV SV SV 29
SV 6 6 14 8 11 27 28 26 23 16 27 17 27 45 42 36 34 92 83 150 13,7 37,1 33 60
VS 56 56 48 54 51 35 34 36 39 46 35 45 35 17 20 26 214 156 165 98 86,3 62,9 67 40
This second chart shows the results of the version on three verbs per condition.
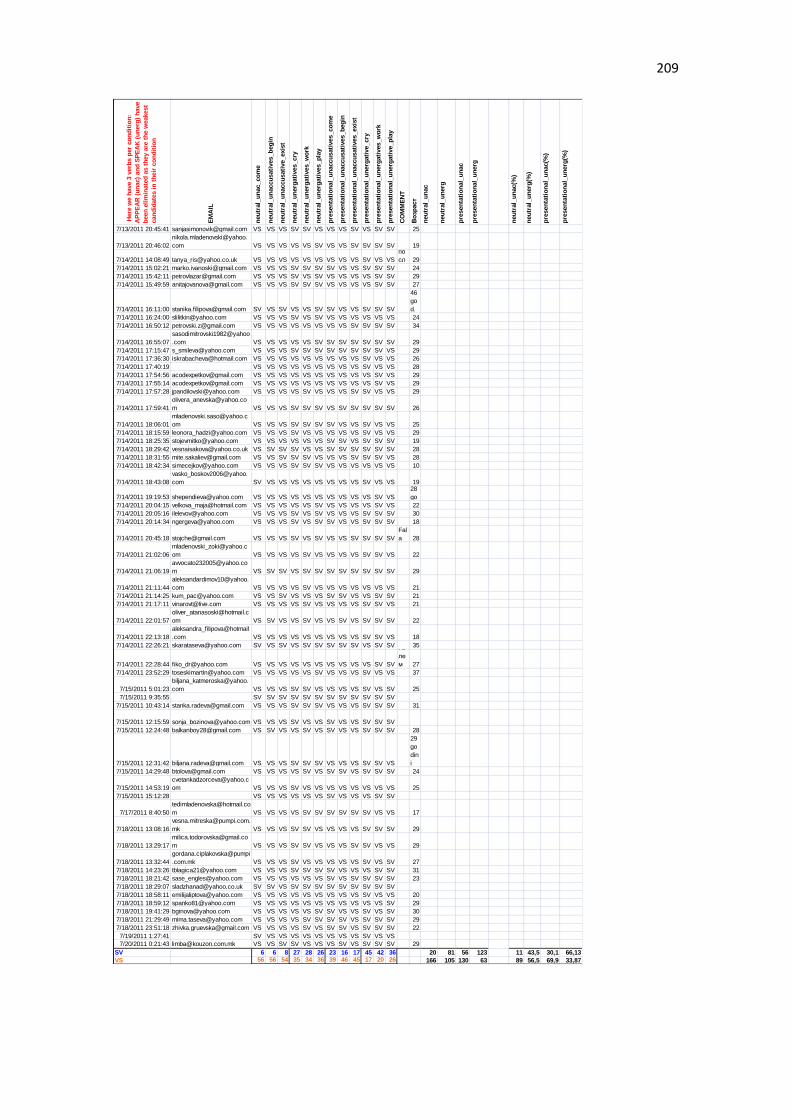
209
Here
we h
ave 3
verb
s p
er
co
nd
itio
n:
AP
PE
AR
(u
nac)
an
d S
PE
AK
(u
nerg
) h
ave
been
eli
min
ate
d a
s t
hey a
re t
he w
eakest
can
did
ate
s i
n t
heir
co
nd
itio
n
EM
AIL
neu
tral_
un
ac_co
me
neu
tral_
un
accu
sati
ves_b
eg
in
neu
tral_
un
accu
sati
ve_exis
t
neu
tral_
un
erg
ati
ves_cry
neu
tral_
un
erg
ati
ves_w
ork
neu
tral_
un
erg
ati
ves_p
lay
pre
sen
tati
on
al_
un
accu
sati
ves_co
me
pre
sen
tati
on
al_
un
accu
sati
ves_b
eg
in
pre
sen
tati
on
al_
un
accu
sati
ves_exis
t
pre
sen
tati
on
al_
un
erg
ati
ve_cry
pre
sen
tati
on
al_
un
erg
ati
ves_w
ork
pre
sen
tati
on
al_
un
erg
ati
ve_p
lay
CO
MM
EN
T
Возраст
neu
tral_
un
ac
neu
tral_
un
erg
pre
sen
tati
on
al_
un
ac
pre
sen
tati
on
al_
un
erg
neu
tral_
un
ac(%
)
neu
tral_
un
erg
(%)
pre
sen
tati
on
al_
un
ac(%
)
pre
sen
tati
on
al_
un
erg
(%)
7/13/2011 20:45:41 [email protected] VS VS VS SV SV VS VS VS SV VS SV SV 25
7/13/2011 20:46:02
nikola.mladenovski@yahoo.
com VS VS VS VS VS SV VS VS SV SV SV SV 19
7/14/2011 14:08:49 [email protected] VS VS VS VS VS VS VS VS VS SV VS VS
по
сл 29
7/14/2011 15:02:21 [email protected] VS VS VS SV SV SV SV VS VS SV SV SV 24
7/14/2011 15:42:11 [email protected] VS VS VS SV VS SV VS VS VS VS SV SV 29
7/14/2011 15:49:59 [email protected] VS VS VS SV SV SV VS VS VS VS SV SV 27
7/14/2011 16:11:00 [email protected] SV VS SV VS VS SV SV VS VS SV SV SV
46
go
d.
7/14/2011 16:24:00 [email protected] VS VS VS SV VS SV VS VS VS VS VS VS 24
7/14/2011 16:50:12 [email protected] VS VS VS VS VS VS VS VS SV SV SV SV 34
7/14/2011 16:55:07
sasodimitrovski1982@yahoo
.com VS VS VS VS VS SV SV SV SV SV SV SV 29
7/14/2011 17:15:47 [email protected] VS VS VS SV SV SV SV SV SV SV SV VS 29
7/14/2011 17:36:30 [email protected] VS VS VS VS VS VS VS VS VS SV VS VS 26
7/14/2011 17:40:19 VS VS VS VS VS VS VS VS VS SV VS VS 28
7/14/2011 17:54:56 [email protected] VS VS VS VS VS VS VS VS VS VS SV VS 29
7/14/2011 17:55:14 [email protected] VS VS VS VS VS VS VS VS VS VS SV VS 29
7/14/2011 17:57:28 [email protected] VS VS VS VS SV VS VS VS SV SV VS VS 29
7/14/2011 17:59:41
m VS VS VS SV SV SV VS SV SV SV SV SV 26
7/14/2011 18:06:01
om VS VS VS SV SV SV SV VS VS SV VS VS 25
7/14/2011 18:15:59 [email protected] VS VS VS SV VS VS VS VS VS SV VS VS 29
7/14/2011 18:25:35 [email protected] VS VS VS VS VS VS SV SV VS SV SV SV 19
7/14/2011 18:29:42 [email protected] VS SV SV SV VS VS SV SV SV SV SV SV 28
7/14/2011 18:31:55 [email protected] VS VS SV SV SV VS VS VS SV SV SV VS 28
7/14/2011 18:42:34 [email protected] VS VS VS SV SV SV VS VS VS VS VS VS 10
7/14/2011 18:43:08
vasko_boskov2006@yahoo.
com SV VS VS VS VS VS VS VS VS SV VS VS 19
7/14/2011 19:19:53 [email protected] VS VS VS VS VS VS VS VS VS VS SV VS
28
go
7/14/2011 20:04:15 [email protected] VS VS VS VS VS SV VS VS VS VS SV VS 22
7/14/2011 20:05:16 [email protected] VS VS VS SV VS SV VS VS VS SV SV SV 30
7/14/2011 20:14:34 [email protected] VS VS VS SV VS SV SV VS VS SV SV SV 18
7/14/2011 20:45:18 [email protected] VS VS VS SV VS SV VS VS SV SV SV SV
Fal
a 28
7/14/2011 21:02:06
om VS VS VS VS SV VS VS VS VS SV SV VS 22
7/14/2011 21:06:19
m VS SV SV VS SV SV SV SV SV SV SV SV 29
7/14/2011 21:11:44
aleksandardimov10@yahoo.
com VS VS VS VS SV VS VS VS VS VS VS VS 21
7/14/2011 21:14:25 [email protected] VS VS SV VS VS VS SV SV VS VS SV SV 21
7/14/2011 21:17:11 [email protected] VS VS VS VS SV VS VS VS VS SV SV VS 21
7/14/2011 22:01:57
om VS SV VS VS SV VS VS SV VS SV SV SV 22
7/14/2011 22:13:18
aleksandra_filipova@hotmail
.com VS VS VS VS VS VS VS VS VS SV SV VS 18
7/14/2011 22:26:21 [email protected] SV VS SV VS SV SV SV SV SV VS SV SV 35
7/14/2011 22:28:44 [email protected] VS VS VS VS VS VS VS VS VS VS SV SV
Го
ле
м 27
7/14/2011 23:52:29 [email protected] VS VS VS VS VS SV VS VS VS SV VS VS 37
7/15/2011 5:01:23
biljana_katmeroska@yahoo.
com VS VS VS SV SV VS VS VS VS SV VS SV 25
7/15/2011 9:35:55 SV SV SV SV SV SV SV SV SV SV SV SV
7/15/2011 10:43:14 [email protected] VS VS VS SV SV SV VS VS VS SV SV SV 31
7/15/2011 12:15:59 [email protected] VS VS VS SV VS VS SV VS VS SV SV SV
7/15/2011 12:24:48 [email protected] VS SV VS VS SV VS SV VS VS SV SV SV 28
7/15/2011 12:31:42 [email protected] VS VS VS SV SV SV VS VS VS SV SV VS
29
go
din
i
7/15/2011 14:29:48 [email protected] VS VS VS VS SV VS SV SV VS SV SV SV 24
7/15/2011 14:53:19
om VS VS VS SV VS VS VS VS VS VS VS VS 25
7/15/2011 15:12:28 VS VS VS VS VS VS SV VS VS VS SV SV
7/17/2011 8:40:50
m VS VS VS VS SV SV SV SV SV SV VS VS 17
7/18/2011 13:08:16
mk VS VS VS SV SV VS VS VS VS SV SV SV 29
7/18/2011 13:29:17
m VS VS VS SV SV VS VS VS SV SV VS VS 29
7/18/2011 13:32:44
gordana.ciplakovska@pumpi
.com.mk VS VS VS SV VS VS VS VS VS SV VS SV 27
7/18/2011 14:23:26 [email protected] VS VS VS SV SV SV SV VS VS VS SV SV 31
7/18/2011 18:21:42 [email protected] VS VS VS VS VS VS SV VS SV SV SV SV 23
7/18/2011 18:29:07 [email protected] SV SV VS SV SV SV SV SV SV SV SV SV
7/18/2011 18:58:11 [email protected] VS VS VS VS VS VS VS VS VS SV VS VS 20
7/18/2011 18:59:12 [email protected] VS VS VS VS VS VS VS VS VS VS VS SV 29
7/18/2011 19:41:29 [email protected] VS VS VS VS VS SV SV VS VS SV VS SV 30
7/18/2011 21:29:49 [email protected] VS VS VS VS SV SV SV SV VS SV SV SV 29
7/18/2011 23:51:18 [email protected] VS VS VS VS SV VS SV SV VS SV SV SV 22
7/19/2011 1:27:41 SV VS VS VS VS VS VS VS VS SV VS VS
7/20/2011 0:21:43 [email protected] VS VS SV SV VS VS VS SV VS SV SV SV 29
SV 6 6 8 27 28 26 23 16 17 45 42 36 20 81 56 123 11 43,5 30,1 66,13
VS 56 56 54 35 34 36 39 46 45 17 20 26 166 105 130 63 89 56,5 69,9 33,87
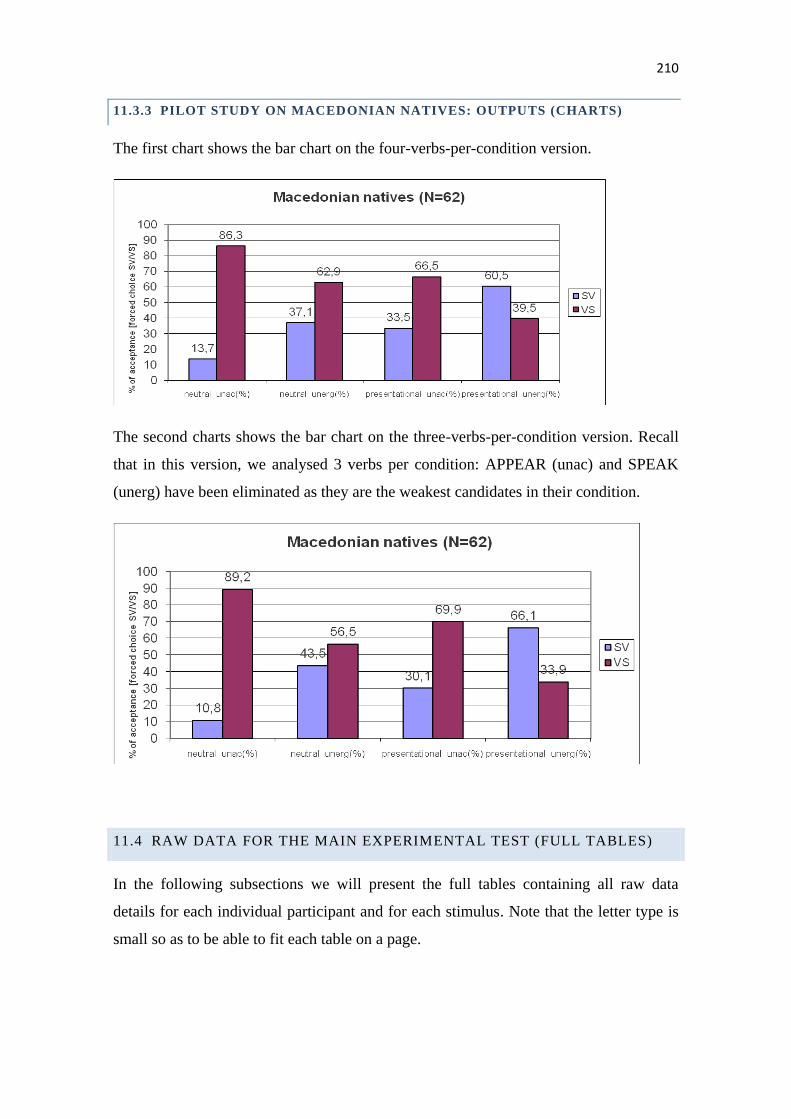
210
11.3.3 PILOT STUDY ON MACEDONIAN NATIVES: OUTPUTS (CHARTS)
The first chart shows the bar chart on the four-verbs-per-condition version.
The second charts shows the bar chart on the three-verbs-per-condition version. Recall
that in this version, we analysed 3 verbs per condition: APPEAR (unac) and SPEAK
(unerg) have been eliminated as they are the weakest candidates in their condition.
11.4 RAW DATA FOR THE MAIN EXPERIMENTAL TEST (FULL TABLES)
In the following subsections we will present the full tables containing all raw data
details for each individual participant and for each stimulus. Note that the letter type is
small so as to be able to fit each table on a page.

211
11.4.1 RAW DATA FOR ENGLISH NATIVES
809
Y2011-0
7-2
0 1
8:5
3:3
12011-0
7-2
0 1
8:4
3:0
9129.1
00.1
85.2
02
Fem
en
ino3
2E
ng
lish
12
11
33
12
34
13
12
31
41
21
33
11
11
12
11
23
12
41
31
31
33
21
31
32
41
11
21
11
31
11
21
21
32,3
1,4
1,8
3,0
1,3
3,3
1,0
1,3
1,0
2,5
0,9
1,8
3,3
811
Y2011-0
7-2
0 2
0:5
9:0
42011-0
7-2
0 2
0:5
2:5
394.1
73.1
19.2
43
Fem
en
ino3
4E
ng
lish
11
22
53
22
44
15
13
51
51
41
55
13
11
34
12
45
1H
i C
ris!!
Very
hap
py t
o h
elp
wit
h y
ou
r stu
dy.
Ho
pe a
ll is
well.
S
usie
x1
43
51
52
53
41
51
52
51
21
41
21
51
21
41
33
43,3
2,3
1,5
4,5
25
1,0
2,3
1,5
4,3
1,0
2,3
6,0
812
Y2011-0
7-2
0 2
1:1
8:4
92011-0
7-2
0 2
1:1
1:4
346.2
22.2
08.1
45
Mascu
lino5
9E
ng
lish
22
33
43
24
44
34
13
31
52
41
23
12
22
33
12
24
32
43
23
33
33
42
42
44
51
31
21
23
41
22
31
32
43,2
2,2
2,5
3,8
33,5
1,0
2,5
2,0
3,3
1,0
1,3
1,8
813
Y2011-0
7-2
0 2
1:4
4:4
12011-0
7-2
0 2
1:3
6:1
986.1
35.1
76.1
0F
em
en
ino4
9E
ng
lish
32
13
42
23
43
33
23
32
53
33
23
23
31
32
22
33
32
33
23
33
32
33
31
33
52
12
33
23
42
23
22
33
42,8
2,6
23,0
33,3
2,3
2,0
2,8
3,3
0,3
1,0
1,3
814
Y2011-0
7-2
0 2
2:4
5:0
22011-0
7-2
0 2
2:3
9:3
9188.2
3.1
85.1
11
Mascu
lino3
1E
ng
lish
51
11
21
11
44
15
13
21
51
41
55
11
11
12
11
11
11
41
51
51
21
41
51
11
51
11
11
11
21
11
21
31
42,4
1,4
13,5
14,3
1,0
1,5
1,0
2,3
1,0
2,0
5,8
816
Y2011-0
7-2
1 0
1:0
8:2
62011-0
7-2
1 0
1:0
2:1
8190.1
48.1
70.1
96
Mascu
lino2
2E
ng
lish
11
12
13
21
32
14
12
31
51
41
24
11
11
25
11
15
11
22
21
42
33
41
41
51
51
11
11
11
11
21
51
21
32,6
1,5
1,5
3,8
1,5
3,5
1,0
1,5
1,0
2,5
1,1
2,3
4,3
817
Y2011-0
7-2
1 0
1:1
9:0
32011-0
7-2
1 0
1:0
9:5
175.4
5.9
.38
Fem
en
ino2
2E
ng
lish
11
11
23
31
41
14
12
11
51
31
24
11
11
13
11
11
1In
th
e d
irecti
on
s,
it m
ay b
e b
ett
er
to in
form
us t
hat
we a
re t
o ju
dg
e t
he s
eco
nd
half o
f th
e s
en
ten
ce o
r th
e last
ph
rase o
r ad
d s
pace b
etw
een
th
e g
iven
an
d t
he ju
dg
ed
sen
ten
ce.
So
me o
f th
e s
en
ten
ces w
ere
hard
to
read
an
yw
ay b
ecau
se t
he g
ram
mar
was in
co
rrect,
wh
ich
is t
he p
oin
t o
f th
e a
ssig
nm
en
t, s
o b
y m
akin
g t
he d
irecti
on
s a
s c
lear
an
d d
irect
as p
ossib
le is b
est.
T
han
k y
ou
.1
11
21
41
13
31
41
11
51
11
11
11
21
31
31
21
41,9
1,6
1,5
2,3
13
1,0
1,8
1,0
2,5
0,4
0,5
2,8
818
Y2011-0
7-2
1 0
2:1
7:1
32011-0
7-2
1 0
2:1
4:1
176.2
6.2
33.1
17
Fem
en
ino2
9E
ng
lish
54
54
43
33
33
43
33
33
34
44
34
43
43
33
35
44
44
33
34
44
33
44
33
43
33
53
44
54
44
34
33
33
33,4
3,6
3,5
3,8
3,5
33,5
4,0
3,5
3,5
-0,2
-0,3
-0,3
819
Y2011-0
7-2
1 0
3:4
5:0
22011-0
7-2
1 0
3:3
6:4
899.1
59.2
12.6
7M
ascu
lino4
3E
ng
lish
12
14
35
14
43
15
15
44
52
41
24
13
23
24
12
44
52
32
25
44
45
42
53
44
51
14
41
21
31
12
41
53
43,6
2,4
3,8
3,8
34
1,0
2,3
2,5
3,8
1,3
1,5
1,0
820
Y2011-0
7-2
1 0
5:4
0:3
42011-0
7-2
1 0
5:1
3:0
697.1
02.1
97.4
4F
em
en
ino6
1E
ng
lish
33
21
23
35
35
24
33
43
43
43
55
34
33
33
33
33
33
53
53
51
43
43
43
35
43
23
33
32
23
33
33
34
33,6
2,9
34,3
34,3
3,0
2,8
3,0
2,8
0,8
1,5
2,5
822
Y2011-0
7-2
1 0
7:5
3:3
22011-0
7-2
1 0
7:3
9:2
3203.2
21.2
50.1
75
Mascu
lino2
8E
ng
lish
11
13
25
43
34
24
34
43
53
43
44
23
44
44
33
45
4I th
ink t
his
was v
ery
in
tresti
ng
becau
se i h
ave n
ever
had
to
ju
dg
e g
ram
mer.
1
44
44
43
45
44
44
53
53
13
43
32
22
43
43
43
33,9
2,9
3,5
4,3
3,5
4,3
2,8
3,0
2,8
3,3
0,9
1,3
1,5
823
Y2011-0
7-2
1 1
0:5
6:3
32011-0
7-2
1 1
0:4
7:2
9109.9
.114.2
36
Mascu
lino5
8E
ng
lish
11
11
44
11
45
15
11
31
51
51
25
11
21
13
11
34
11
51
21
51
34
52
51
41
51
11
31
11
41
11
31
11
42,9
1,6
1,8
4,8
1,3
3,8
1,0
1,0
1,0
3,5
1,3
3,8
5,5
824
Y2011-0
7-2
1 1
1:3
1:4
02011-0
7-2
1 1
1:2
6:5
5192.8
7.7
9.5
1F
em
en
ino4
2E
ng
lish
11
11
51
11
54
15
13
51
51
51
45
11
11
11
11
15
11
41
41
51
51
51
51
51
51
11
11
11
51
11
11
31
52,9
1,6
14,8
14,8
1,0
1,5
1,0
3,0
1,3
3,3
7,5
827
Y2011-0
7-2
1 1
6:2
6:3
72011-0
7-2
1 1
6:2
1:0
0188.8
4.5
1.6
6M
ascu
lino4
7E
ng
lish
31
11
11
11
12
13
12
11
31
21
23
11
11
22
11
22
11
22
21
31
11
21
31
21
31
11
21
11
11
11
21
21
11,7
1,2
12,3
1,3
2,3
1,0
1,3
1,0
1,5
0,5
1,0
2,3
828
Y2011-0
7-2
1 1
7:2
1:5
02011-0
7-2
1 1
7:1
3:2
997.1
00.1
49.5
4M
ascu
lino2
5E
ng
lish
12
24
45
33
13
14
22
22
53
22
32
23
32
44
24
24
32
34
33
24
25
23
42
43
52
22
22
41
42
33
42
23
13,2
2,4
32,8
3,5
3,5
2,0
2,8
2,3
2,8
0,8
0,0
-0,3
830
Y2011-0
7-2
1 2
2:2
5:4
92011-0
7-2
1 2
1:5
9:5
986.1
1.3
3.2
6M
ascu
lino3
6E
ng
lish
21
11
43
21
44
25
14
42
52
31
55
11
21
24
11
53
2It
wo
uld
be u
sefu
l to
have a
su
mm
ary
of
wh
at
the 1
to
5 o
pti
on
s m
ean
ag
ain
on
th
e q
uesti
on
s p
ag
e.
Th
e f
irst
pag
e o
n t
he q
uesti
on
air
e h
as s
en
ten
ces in
Sp
an
ish
(even
th
ou
gh
En
glis
h w
as s
ele
cte
d).
14
25
25
14
33
25
13
15
11
25
11
24
12
24
14
14
2,9
2,3
1,8
3,8
1,5
4,8
1,0
2,0
1,8
4,3
0,7
1,8
5,3
831
Y2011-0
7-2
2 0
0:1
2:5
52011-0
7-2
2 0
0:0
2:0
1129.1
00.1
99.2
16
Fem
en
ino3
7E
ng
lish
51
11
42
33
55
14
13
51
51
41
55
11
22
15
11
34
11
51
51
51
52
42
42
43
51
11
31
11
41
31
51
31
53,1
2,1
1,5
4,5
1,8
4,8
1,0
2,0
1,0
4,3
1,1
2,5
6,0
833
Y2011-0
7-2
2 1
5:2
8:0
32011-0
7-2
2 1
5:1
8:3
281.1
51.1
19.8
4F
em
en
ino5
1E
ng
lish
51
11
12
11
24
15
14
11
51
51
43
11
11
13
11
11
11
41
41
31
12
51
51
11
51
11
11
11
11
11
31
41
22,3
1,4
1,3
3,3
13,8
1,0
1,8
1,0
1,8
0,9
1,5
4,8
834
Y2011-0
7-2
2 1
5:4
3:5
02011-0
7-2
2 1
5:3
7:1
376.6
9.5
6.1
79
Fem
en
ino2
7E
ng
lish
11
11
55
15
55
15
11
11
51
51
51
11
11
11
11
11
11
51
51
11
15
51
51
15
51
11
11
11
51
11
11
11
52,8
1,5
23,0
24
1,0
1,0
1,0
3,0
1,3
2,0
3,0
835
Y2011-0
7-2
2 1
8:1
9:1
02011-0
7-2
2 1
8:0
2:3
882.1
25.1
61.4
7M
ascu
lino2
1E
ng
lish
21
11
14
12
42
14
11
31
51
31
12
11
11
12
11
14
31
21
13
21
34
31
41
42
51
11
11
11
11
11
21
11
42,4
1,3
2,3
2,8
1,3
3,3
1,0
1,0
1,0
2,0
1,1
1,8
2,5
836
Y2011-0
7-2
2 2
1:4
1:3
22011-0
7-2
2 2
1:2
8:2
4184.7
7.1
62.2
01
Fem
en
ino3
4E
ng
lish
23
45
45
45
54
25
24
54
53
52
45
25
32
45
23
45
43
44
44
55
55
53
52
55
52
44
42
32
42
43
52
45
54,3
3,4
3,5
4,8
4,3
4,8
2,0
3,8
3,5
4,5
0,9
1,0
1,8
837
Y2011-0
7-2
3 1
5:0
5:3
62011-0
7-2
3 1
4:5
7:3
592.9
.54.1
0M
ascu
lino4
0E
ng
lish
32
22
34
23
44
33
12
32
24
32
22
42
31
12
22
23
32
41
23
22
34
33
31
33
21
22
22
23
34
24
22
22
42,6
2,4
2,5
3,0
2,3
2,5
2,3
2,0
2,8
2,8
0,1
1,0
0,8
838
Y2011-0
7-2
3 2
1:2
3:4
12011-0
7-2
3 2
1:1
6:0
797.1
00.1
43.2
21
Mascu
lino3
1E
ng
lish
11
11
43
43
55
24
12
41
41
21
25
11
11
34
12
42
41
53
24
51
43
21
41
23
41
11
41
22
41
41
41
21
52,8
2,2
2,3
3,5
23,5
1,0
2,3
1,3
4,3
0,6
1,3
2,8
840
Y2011-0
7-2
5 2
3:0
4:1
02011-0
7-2
5 2
2:4
9:2
682.7
.214.2
15
Fem
en
ino4
3E
ng
lish
31
21
22
13
33
14
12
32
52
21
44
13
22
33
11
23
2I th
ink t
hat
mo
st
of
the issu
es h
ere
were
to
do
wit
h t
en
ses a
nd
ph
rasin
g.
So
me m
ean
ing
was lo
st
du
e t
o s
pelli
ng
err
or.
1
33
42
41
32
22
42
33
51
22
21
11
21
12
31
23
32,8
1,8
1,8
3,0
2,3
41,0
1,5
2,0
2,5
1,0
1,5
3,0
En
g1,5
3,6
2,1
3,3
2,3
3,8
1,9
3,1
3,1
3,6
1,9
4,2
1,6
3,3
2,5
4,6
1,4
1,6
1,7
2,5
1,5
1,8
1,6
3,1
1,5
2,0
1,8
3,1
1,4
2,7
2,0
3,6
En
g2,9
2,1
En
g2,1
3,6
2,1
3,8
En
g1,4
2,0
1,8
3,1
En
g0,8
En
g1,6
En
g3,1
212
11.4.2 RAW DATA FOR L1 SPA – L2 ENG LEARNERS
307/1
74
Y2010-1
1-1
5 1
8:1
1:3
82010-1
1-1
5 1
7:5
1:5
685.6
1.1
0.6
7lu
pi_
dm
x@
ho
tmail.c
om
Fem
en
ino
19
Un
ivers
idad
de G
ran
ad
a6
Read
ing
15 d
ias
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
24
14
25
42
52
15
45
54
54
52
55
54
45
44
25
55
556
a2
42
45
55
45
55
45
55
25
41
45
25
12
54
44
25
45
4,4
3,6
4,8
4,3
3,5
53,3
3,8
3,3
4,0
0,8
0,5
1,0
24/3
06
Y2010-1
1-1
8 1
1:4
8:3
62010-1
1-1
8 1
1:3
4:3
480.5
8.2
05.4
1ern
esto
992@
gm
ail.c
om
Mascu
lin
o23
Un
ivers
idad
de G
ran
ad
a5
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
13
25
54
44
52
44
25
44
53
33
55
45
44
34
42
43
456
a2
32
35
45
54
43
44
43
45
22
44
32
45
44
34
45
55
3,9
3,8
3,8
3,3
44,5
3,3
3,3
4,0
4,5
0,1
0,0
0,0
10/3
45
Y2010-1
1-1
8 2
0:0
5:4
32010-1
1-1
8 1
9:4
6:3
980.3
1.3
7.8
0jo
se13-1
@h
otm
ail.c
om
Mascu
lin
o19
escu
ela
un
ivers
itari
a m
ag
iste
rio
safa
ub
ed
a12
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Pri
ncip
ian
te a
lto
(A
2)
51
15
51
15
55
55
15
55
55
11
55
15
51
15
55
51
556
a2
15
15
55
55
11
55
11
55
11
55
15
55
11
55
55
55
3,5
3,8
23,0
45
2,0
3,0
5,0
5,0
-0,3
0,0
2,0
106/5
5Y
2010-1
1-1
4 1
1:5
4:5
82010-1
1-1
4 1
1:4
2:2
095.6
2.2
6.1
46
mu
rara
ro@
ho
tmail.c
om
Mascu
lin
o28
facu
ltad
filo
so
fia y
letr
as G
ran
ad
a5
Rein
o u
nid
o 4
meses
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
11
11
55
54
15
45
15
51
51
51
55
11
25
54
25
45
557
a2
15
55
55
15
55
25
55
45
11
14
15
45
15
14
25
11
4,3
2,6
45,0
35
1,3
4,0
1,8
3,5
1,6
1,0
3,0
34/7
8Y
2010-1
1-1
4 1
7:1
9:4
72010-1
1-1
4 1
6:5
2:2
679.1
46.6
4.1
77
bele
ncilla
.dilo
cu
@g
mail.c
om
Fem
en
ino
24
Un
ivers
idad
Filo
so
fía y
Letr
as d
e G
ran
ad
a5
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
15
14
43
15
15
12
41
51
22
54
25
54
55
21
43
457
a2
15
55
44
54
42
55
43
35
11
14
21
11
24
15
22
51
4,0
2,1
3,3
3,5
4,5
4,8
1,8
2,0
2,0
2,8
1,9
1,5
0,5
334/2
84
Y2010-1
1-1
7 1
8:4
0:5
62010-1
1-1
7 1
8:2
7:5
681.3
3.1
2.2
28
josem
t.ic
@g
mail.c
omM
ascu
lin
o20
UG
R0E
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Pri
ncip
ian
te a
lto
(A
2)
13
15
55
14
51
54
12
54
42
45
54
35
55
54
42
54
558
a2
31
55
54
55
54
54
54
44
11
45
52
55
31
24
42
55
4,3
3,4
4,5
3,3
4,8
4,5
3,3
1,5
4,0
4,8
0,9
1,8
-1,5
98/1
68
Y2010-1
1-1
5 1
6:5
5:2
42010-1
1-1
5 1
6:4
8:0
9150.2
14.3
6.9
an
gele
s.c
hen
oa@
ho
tmail.c
om
Fem
en
ino
23
UN
IVE
RS
IDA
D D
E G
RA
NA
DA
8R
EIN
O U
NID
O 9
ME
SE
SE
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
11
11
15
15
15
11
15
51
51
51
55
15
55
41
11
51
559
a2
15
45
55
15
55
51
51
55
11
15
11
11
11
11
15
51
3,9
1,8
44,0
3,8
41,0
2,0
2,0
2,0
2,2
2,0
0,3
143/4
05
Y2010-1
1-1
9 2
1:5
2:3
72010-1
1-1
9 2
1:2
4:2
187.2
18.1
90.1
04
po
et_
dre
am
er_
SJ@
ho
tmail.c
om
Fem
en
ino
21
Un
ivers
idad
Au
tón
om
a
14
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
43
12
25
15
33
42
25
53
52
33
34
41
22
53
22
43
558
a2
33
53
54
25
53
22
23
55
21
34
32
42
41
23
25
13
3,6
2,6
3,8
3,3
3,5
3,8
2,8
2,3
2,5
3,0
0,9
1,0
-0,3
198/4
67
Y2010-1
1-2
2 0
9:3
7:3
22010-1
1-2
2 0
9:1
8:4
283.5
9.2
00.8
5K
EV
INA
L34@
GM
AIL
.CO
MF
em
en
ino
32
U.J
aén
6E
EU
U,
UK
, M
alt
a,
Pu
ert
o R
ico
, E
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
11
15
35
22
53
34
42
51
43
41
15
54
52
51
43
55
454
a2
13
51
45
55
54
54
25
24
41
15
13
33
52
31
42
45
3,8
2,9
34,3
4,3
3,5
3,5
2,0
2,8
3,5
0,8
2,3
0,5
45/6
81
Y2010-1
2-0
7 2
3:3
8:3
32010-1
2-0
7 2
3:2
7:4
9201.1
02.1
8.1
60
mari
_m
ulo
r@h
otm
ail.c
om
Fem
en
ino2
2n
ing
un
o5E
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
13
35
21
11
11
11
51
51
11
51
11
15
55
11
11
159
a2
11
55
11
35
51
11
51
15
11
11
11
13
12
15
11
11
2,6
1,4
31,0
2,5
41,0
1,3
1,0
2,5
1,2
-0,3
-0,5
122/7
15
Y2010-1
2-1
5 1
2:5
9:0
52010-1
2-1
5 1
2:5
0:5
362.3
2.1
71.2
5axis
s23@
ho
tmail.c
omM
ascu
lin
o26
Un
ivers
idad
de G
ran
ad
a15
Ing
late
rra,
1 m
es
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
12
34
45
25
45
45
34
53
52
52
45
34
54
53
11
44
455
a2
25
54
45
45
55
55
44
55
33
34
21
44
32
23
14
44
4,5
2,9
3,8
4,8
4,8
4,8
2,3
2,5
3,3
3,8
1,6
2,3
1,0
255/7
88
Y2011-0
1-1
5 1
8:2
7:1
12011-0
1-1
5 1
7:5
3:3
095.1
20.1
94.8
2ale
xb
leed
ing
@h
otm
ail.c
om
Fem
en
ino
21
Un
ivers
idad
de V
allad
olid
13
Wo
rth
ing
(In
gla
terr
a)
21 d
ías
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
11
12
12
22
12
32
52
22
21
52
53
43
23
12
42
456
a2
12
25
42
15
22
42
32
22
31
24
12
11
51
23
12
32
2,6
2,1
2,5
2,0
2,3
3,5
2,5
1,5
2,0
2,5
0,4
0,5
0,8
131/7
78
Y2011-0
1-1
0 2
0:1
6:5
32011-0
1-1
0 1
9:0
0:3
1157.8
8.2
31.3
6ra
ul.m
ora
l@u
va.e
sM
ascu
lin
o33
nin
gu
no
4E
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Pri
ncip
ian
te a
lto
(A
2)
12
31
41
54
24
41
12
22
21
21
23
24
41
42
11
23
254
a2
24
42
23
12
12
41
13
42
13
22
11
44
25
12
12
42
2,4
2,3
1,5
3,0
3,3
1,8
1,3
2,8
2,8
2,5
0,1
0,3
0,0
273/2
82
Y2010-1
1-1
7 1
8:0
2:0
42010-1
1-1
7 1
7:4
5:2
080.2
6.1
62.1
33
no
e.v
alv
erd
e@
ho
tmail.c
om
Fem
en
ino
21
Au
ton
om
a d
e M
ad
rid
13
Esta
do
s U
nid
os 3
sem
an
as
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
12
12
55
42
55
33
14
22
55
51
24
21
25
53
31
24
559
a2
25
52
54
22
55
23
54
25
11
22
11
35
24
53
34
15
3,6
2,7
4,3
4,5
2,8
31,8
2,5
2,8
3,8
0,9
2,0
0,5
A2
1,9
3,4
4,1
4,1
4,1
4,1
3,1
4,4
4,1
3,4
3,8
3,4
3,6
3,1
3,4
4,4
1,9
1,4
2,4
3,9
1,8
2,3
2,9
3,3
2,8
2,6
2,4
3,4
2,4
3,5
3,4
3,2
A2
3,7
2,7
A2
3,4
3,5
3,6
4,1
A2
2,2
2,4
2,8
3,4
A2
0,9
A2
1,1
A2
0,5
257/1
89
Y2010-1
1-1
5 2
1:1
7:4
52010-1
1-1
5 2
1:0
0:0
7217.2
16.6
3.1
40
mari
selo
14@
ho
tmail.
co
mF
em
en
ino
22
ET
SIIT
15
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
11
25
11
51
14
25
21
51
51
51
54
13
14
55
13
13
560
b1
14
55
54
55
15
15
43
15
22
11
13
21
15
15
11
31
3,7
1,9
2,8
4,0
35
1,3
2,8
1,8
2,0
1,8
1,3
3,3
76/3
47
Y2010-1
1-1
8 2
0:0
2:5
72010-1
1-1
8 1
9:5
2:4
580.3
0.1
3.8
jarr
icu
@co
rreo
.ug
r.es
Mascu
lino
23
Gra
nad
a6
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
14
34
55
35
25
25
13
32
53
52
34
23
35
24
21
23
561
b1
45
23
54
43
55
35
53
55
13
22
21
25
23
34
23
32
4,1
2,5
4,8
4,3
3,5
41,8
2,5
2,5
3,3
1,6
1,8
0,0
102/2
60
Y2010-1
1-1
7 0
0:2
7:0
12010-1
1-1
6 2
3:4
4:3
684.7
7.1
40.1
59
mig
uel_
a_m
igu
el@
ho
tmail.
co
mM
ascu
lino
29
UA
M19
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
12
12
24
33
33
34
23
12
32
31
23
31
22
54
33
33
4L
os e
xp
leti
vo
s n
o lo
s d
om
ino
, th
e s
ub
ject
req
uir
em
en
t co
n t
here
no
lo
veo
mu
y c
laro
, la
mayo
ría d
e las f
rases m
e s
uen
an
bie
n la p
rim
era
part
e p
ero
la s
eg
un
da m
e r
ech
ina u
n p
oco
. 62
b1
23
52
43
21
43
24
23
33
21
23
13
32
33
24
33
13
2,9
2,4
33,0
32,5
2,3
2,5
2,0
3,0
0,4
0,5
-0,5
176/1
7Y
2010-1
1-1
3 1
7:0
9:5
72010-1
1-1
3 1
6:4
4:2
188.2
4.8
5.1
0m
ari
_fe
rex@
ho
tmail.
co
mF
em
en
ino
23
Gra
nad
a10
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
52
41
51
15
14
41
11
11
54
22
21
15
21
23
14
564
b1
15
22
52
21
15
14
54
11
45
11
43
14
25
11
21
11
2,6
2,3
34,0
1,5
23,0
3,5
1,0
1,8
0,3
0,5
1,5
304/6
3Y
2010-1
1-1
4 1
2:3
5:1
72010-1
1-1
4 1
2:2
3:5
585.4
9.1
10.1
65
rric
hu
@h
otm
ail.
co
mF
em
en
ino
25
Un
ivers
idad
Au
tón
om
a d
e M
ad
rid
13
Ed
imb
urg
o (
Esco
cia
) 10 m
eses
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
13
11
14
12
24
15
11
21
31
12
22
21
14
44
11
43
5U
n t
est
larg
o,
y m
uch
as p
reg
un
tas c
on
err
ore
s d
el m
ism
o t
ipo
.67
b1
34
42
52
12
41
15
43
23
11
14
21
11
21
14
11
12
2,9
1,6
42,5
23
1,5
1,0
1,0
2,8
1,3
1,5
-0,5
250/4
34
Y2010-1
1-2
0 1
9:3
9:4
52010-1
1-2
0 1
9:2
3:4
979.1
47.4
2.1
71
pili
8a_@
ho
tmail.
co
mFem
en
ino
21
Un
ivers
idad
de G
ran
ad
a13
2 s
em
an
as e
n D
ub
lín (
Irla
nd
a),
2 m
eses e
n L
yth
am
(L
iverp
oo
l-U
K),
9 m
eses e
n G
alw
ay (
IRL
)E
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
11
33
15
44
32
12
44
54
51
51
54
23
55
55
12
45
567
b1
12
55
54
35
55
52
55
45
43
44
12
11
24
15
14
33
4,1
2,7
44,0
4,3
4,3
2,0
3,3
2,3
3,3
1,4
0,8
0,0
231/5
30
Y2010-1
1-2
4 1
3:4
4:1
52010-1
1-2
4 1
3:2
1:3
995.6
2.2
52.1
65
jelo
_47@
ho
tmail.
co
mFem
en
ino
21
Gra
nad
a8
Irla
nd
a,
3 s
em
an
as
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
15
15
45
15
11
13
51
45
52
52
55
55
55
54
21
51
563
b1
51
55
55
54
55
53
51
55
51
55
21
14
51
24
21
51
4,3
2,8
53,0
54,3
3,5
1,0
3,3
3,5
1,5
2,0
-2,8
184/6
44
Y2010-1
2-0
2 1
9:2
0:2
62010-1
2-0
2 1
9:0
5:4
8148.2
15.3
8.3
9d
oxi_
yeti
@h
otm
ail.
co
mF
em
en
ino2
4U
NIV
ER
SID
AD
AU
TÓ
NO
MA
DE
L E
ST
AD
O D
E M
ÉX
ICO
7N
O N
UN
CA
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
15
35
35
45
25
14
55
51
51
55
15
51
55
45
55
5N
o e
nte
nd
í alg
un
as o
racio
nes.
62
b1
15
55
55
55
55
55
15
55
11
55
15
23
13
15
44
54
4,5
3,1
35,0
55
1,8
3,3
3,3
4,3
1,4
1,8
2,0
151/3
4Y
2010-1
1-2
4 1
8:0
4:1
82010-1
1-2
4 1
7:5
8:1
788.8
.158.9
7118591677A
Fem
en
ino1
8U
niv
ers
idad
Au
tón
om
a d
e M
ad
rid
10
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
14
44
53
24
35
24
54
51
22
34
55
31
12
54
42
34
463
b1
45
55
45
45
33
14
24
42
54
13
42
25
32
24
44
13
3,8
3,1
3,3
4,3
3,5
44,0
3,0
1,5
3,8
0,7
1,3
1,5
97/4
3Y
2010-1
2-0
7 1
9:2
4:3
62010-1
2-0
7 1
9:1
8:4
188.1
.12.1
72
2716221
Mascu
lino2
0U
AM
15
Rein
o U
nid
o-
3 s
em
an
as
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
15
24
55
15
45
34
41
45
34
55
33
45
54
51
32
54
365
b1
55
53
33
44
55
54
44
53
42
55
52
35
41
41
31
54
4,2
3,4
4,3
4,3
4,8
3,5
4,0
1,5
4,3
3,8
0,8
2,8
-1,3
B1
2,7
3,9
4,3
3,7
4,6
3,7
3,5
3,5
3,8
4,2
2,9
4,1
3,7
3,5
3,5
3,7
2,9
2,3
2,7
3,3
2,3
2,3
1,8
3,1
2,5
2,8
1,8
3,7
2,3
2,3
2,8
2,4
B1
3,7
2,6
B1
3,7
3,8
3,6
3,8
B1
2,5
2,4
2,3
3,1
B1
1,1
B1
1,4
B1
0,3
186/2
5Y
2010-1
1-1
3 2
0:1
9:3
82010-1
1-1
3 2
0:0
4:4
095.1
9.1
45.2
46
xin
xiy
an
a@
ho
tmail.c
om
Fem
en
ino
23
Un
ivers
idad
de G
ran
ad
a14
Uk (
9m
eses)
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
21
35
33
41
25
24
54
53
31
55
12
53
54
14
54
568
b2
11
55
55
15
53
55
34
35
22
45
14
23
13
34
14
24
3,8
2,8
3,5
3,3
3,5
51,3
3,3
2,8
4,0
1,0
0,0
1,3
175/1
44
Y2010-1
1-1
5 1
3:0
2:5
32010-1
1-1
5 1
2:4
1:1
1213.1
44.3
6.9
5n
fern
an
dez-s
an
ch
ez@
ad
if.e
sF
em
en
ino
27
Nin
gu
no
17
Esta
do
s U
nid
os,
un
mes
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
11
32
55
14
51
15
54
51
32
51
45
11
44
34
21
12
568
b2
11
34
55
25
55
45
42
43
53
11
11
15
11
24
24
15
3,6
2,4
3,8
3,3
3,3
4,3
2,3
2,3
1,3
3,8
1,3
1,0
0,5
152/2
26
Y2010-1
1-1
6 1
8:0
9:2
42010-1
1-1
6 1
7:5
9:2
6213.3
7.1
17.3
3alv
aro
.zu
marr
ag
a@
gm
ail.c
om
Mascu
lin
o24
cseu
la s
alle
14
ing
late
rra 2
meses e
eu
u 2
meses
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
12
23
11
15
55
12
41
51
11
51
45
12
51
51
31
53
568
b2
25
54
55
35
15
52
13
51
42
15
11
11
11
11
31
25
3,6
1,9
2,3
4,5
4,5
32,3
1,3
1,3
3,0
1,6
3,3
0,8
173/2
3Y
2010-1
1-1
3 1
9:3
8:0
02010-1
1-1
3 1
9:1
8:4
0217.2
16.6
3.9
4b
ran
co
_se_p
art
e@
ho
tmail.c
om
Mascu
lin
o25
Un
ivers
idad
de G
ran
ad
a4
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
12
25
14
11
11
31
21
21
11
21
32
15
31
31
12
5E
l err
or
qu
e m
as s
e r
ep
ite c
reo
qu
e e
s e
l d
e e
str
uctu
ra s
intá
cti
ca,
el o
rden
en
de las o
racio
nes d
e in
dic
ati
vo
en
in
glé
s d
eb
en
ten
er
la e
str
uctu
ra S
VO
. L
ueg
o h
ay c
on
str
uccio
nes c
on
"th
ere
" +
un
verb
o q
ue n
o e
s "
to b
e",
y c
reo
qu
e e
s in
co
rrecto
au
nq
ue n
o e
sto
y s
eg
uro
al 100%
. S
alu
do
s.
69
b2
11
32
51
22
51
11
52
42
31
11
11
12
31
11
31
21
2,4
1,5
41,3
2,5
1,8
2,5
1,0
1,3
1,3
0,9
0,3
-3,5
19/1
16
Y2010-1
1-1
5 0
0:5
6:2
22010-1
1-1
5 0
0:0
6:1
295.1
8.1
48.4
3b
elu
zo
n@
co
rreo
.ug
r.es
Fem
en
ino
21
Un
ivers
idad
de G
ran
ad
a14
Irla
nd
a,
9 m
eses;
Rein
o U
nid
o,
2 s
em
an
as;
Malt
a,
3 s
em
an
as
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
11
21
15
21
11
14
11
41
21
21
31
11
11
11
11
12
470
b2
11
13
41
14
52
14
12
12
12
11
11
11
12
11
11
11
2,1
1,1
2,8
1,5
13,3
1,0
1,5
1,0
1,0
1,0
0,0
1,0
280/2
07
Y2010-1
1-1
6 1
2:4
2:1
32010-1
1-1
6 1
2:3
2:4
588.1
3.2
.247
lin
gle
z@
ho
tmail.c
omM
ascu
lin
o26
UA
M15
Ing
late
rra,
cin
co
día
s.
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
15
54
32
55
12
11
42
21
11
42
12
32
32
11
21
172
b2
15
34
12
54
41
32
21
22
11
22
11
15
13
12
11
25
2,6
1,9
22,3
3,3
31,0
1,5
1,5
3,5
0,8
0,8
0,0
63
/104
Y2010-1
1-1
4 2
2:0
2:4
22010-1
1-1
4 2
1:3
9:1
183.5
0.4
5.2
36
marg
uit
uri
@h
otm
ail.c
om
Fem
en
ino
28
UA
M16
Irla
nd
a:
1 a
ño
. U
K:
1 s
em
an
aE
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o a
lto
(C
2)
12
21
32
22
42
24
12
42
42
41
23
12
32
12
11
12
2M
e p
are
ce q
ue la m
ayo
r p
art
e d
e las f
rases t
en
ían
un
a e
str
uctu
ra g
ram
ati
cal m
ás p
rop
ia d
el caste
llan
o q
ue d
el in
glé
s:
la c
olo
cació
n d
e lo
s v
erb
os e
n la f
rase n
o e
ra c
orr
ecta
. N
o h
e t
en
ido
mu
y c
lara
la in
ten
sid
ad
de la v
alo
ració
n (
he d
ud
ad
o e
ntr
e m
arc
ar
1 ó
2,
4 ó
5),
pu
es a
med
ida q
ue h
e id
o c
on
testa
nd
o las p
reg
un
tas,
he m
od
ific
ad
o la p
erc
ep
ció
n d
e la in
ten
sid
ad
de c
orr
ecció
n o
in
co
rrecció
n d
e las f
rases.
73
b2
22
12
23
14
24
34
22
24
12
21
11
23
12
22
12
24
2,5
1,8
22,8
1,8
3,5
1,0
1,8
2,0
2,5
0,7
1,0
2,5
247/1
67
Y2010-1
1-1
5 1
7:0
5:5
62010-1
1-1
5 1
6:4
3:3
579.1
46.2
36.1
24
gig
an
te5@
ho
tmail.c
om
Mascu
lin
o22
Un
ivers
idad
de G
ran
ad
a12
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
12
12
32
33
45
14
44
51
31
42
53
23
22
53
21
43
2H
ay u
n p
rob
lem
a c
on
el cu
esti
on
ari
o:
le p
on
em
os p
un
tuacio
n d
el 1 a
l 5 p
ero
sin
em
barg
o lo
s m
ati
ces q
ue n
os e
mp
uja
n a
po
ner
un
a n
ota
u o
tra n
o s
e t
ien
en
en
cu
en
ta.
En
mi o
pin
ion
, la
pu
ntu
acio
n n
o e
s s
uficie
nte
para
valo
rar
co
n p
recis
ion
nu
estr
o n
ivel d
el in
gle
s,
pu
esto
qu
e e
so
s m
ati
ces d
e lo
s q
ue h
ab
lo s
e o
bvia
n.
73
b2
25
55
23
25
24
24
23
33
41
14
21
13
23
13
24
34
3,3
2,4
23,8
34,3
2,5
2,3
1,5
3,5
0,8
1,5
3,0
51/3
05
Y2010-1
1-1
8 1
1:4
2:3
12010-1
1-1
8 1
1:1
6:2
583.3
6.1
26.1
04
merc
on
fer@
yah
oo
.esFem
en
ino
46
nin
gu
no
35
ing
late
rra,
1 a
ño
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
45
35
52
55
15
15
31
53
52
55
32
25
33
25
51
573
b2
15
35
55
53
55
25
51
25
14
15
25
13
35
33
25
25
3,9
3,1
44,0
34,5
2,0
4,8
1,8
4,0
0,8
-0,8
1,5
303/4
82
Y2010-1
1-2
2 1
6:0
7:3
22010-1
1-2
2 1
5:4
8:2
584.7
6.1
63.5
2kh
ryssy@
ho
tmail.c
omFem
en
ino
23
UG
R5E
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
12
23
55
55
53
15
25
42
52
53
54
33
43
55
32
43
574
b2
23
55
54
34
55
45
33
55
22
24
32
15
35
25
35
35
4,1
3,3
3,8
3,8
4,3
4,8
2,8
3,5
2,0
4,8
0,9
0,3
0,5
293/2
6Y
2010-1
1-1
7 2
1:1
4:2
52010-1
1-1
7 2
1:0
4:0
682.1
58.8
0.2
53
5290036
Fem
en
ino
18
Un
ivers
idad
Au
tón
om
a d
e M
ad
rid
12
Rein
o U
nid
o,
1 m
es
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
23
11
31
21
15
12
43
43
21
53
32
44
45
21
44
2¿
me p
od
ría d
ecir
cu
án
to o
en
qu
é m
ed
ida h
e f
allad
o?
71
b2
11
45
23
34
12
45
44
14
12
34
11
11
33
35
22
22
3,0
2,3
22,5
34,5
1,8
2,0
2,3
3,0
0,8
0,5
2,0
263/4
55
Y2010-1
1-2
1 1
6:4
1:2
42010-1
1-2
1 1
6:2
0:0
987.2
22.2
23.6
0su
nh
a_sea@
ho
tmail.c
om
Fem
en
ino
21
Un
ivers
idad
de V
allad
olid
10
Un
ited
Kin
gd
om
, 1 m
es
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
15
15
11
41
15
11
51
51
11
51
41
15
11
51
11
569
b2
11
15
51
55
51
15
51
15
11
11
11
11
41
11
51
14
3,0
1,6
41,0
25
2,8
1,0
1,0
1,8
1,4
0,0
0,0
275/6
33
Y2010-1
2-0
1 1
7:1
6:0
62010-1
2-0
1 1
7:0
2:3
685.6
0.6
6.9
8b
ch
oza@
fun
dacio
nsafa
.es
Fem
en
ino2
7N
ING
UN
O3
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io b
ajo
(B
1)
12
23
14
22
14
12
22
21
21
11
25
22
12
22
12
22
2E
s d
ific
il v
alo
rar
qu
é f
allo
es m
ás im
po
rtan
te q
ue o
tro
...
74
b2
24
22
25
32
41
12
22
22
22
12
12
11
22
12
12
21
2,4
1,6
2,5
3,0
22
1,5
2,0
1,3
1,5
0,8
1,0
0,5
178/6
54
Y2010-1
2-0
3 0
7:0
0:2
42010-1
2-0
3 0
6:4
7:5
1187.1
93.1
38.1
nad
iam
la@
yah
oo
.co
m.m
xF
em
en
ino2
7U
niv
ers
idad
Au
ton
om
a d
el E
do
. d
e M
éxic
o6
Ing
late
rra 3
sem
an
as
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
11
11
11
15
12
11
51
51
21
51
11
15
52
11
11
574
b2
15
55
51
15
12
12
51
15
11
11
11
11
11
12
11
11
2,9
1,1
32,3
24,3
1,0
1,0
1,0
1,3
1,8
1,3
1,5
14/7
64
Y2011-0
1-0
8 0
3:2
9:1
22011-0
1-0
8 0
3:0
4:3
6189.1
36.1
84.8
3ly
tzi0
981@
ho
tmail.c
om
Fem
en
ino
29
nin
gu
no
7in
gla
terr
a 1
5 d
ias
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o a
lto
(C
2)
11
24
53
25
13
14
21
53
41
41
54
21
21
13
23
43
569
b2
13
15
54
45
34
24
13
54
22
34
13
15
22
13
21
11
3,4
2,1
2,5
3,5
34,5
1,8
2,0
1,5
3,3
1,3
1,5
2,5
B2
1,3
2,9
3,1
4,1
3,9
3,2
2,7
4,1
3,5
3,0
2,6
3,7
3,0
2,3
2,7
3,5
2,1
1,9
1,7
2,7
1,3
1,7
1,1
2,7
1,9
2,3
1,6
2,6
2,0
2,3
1,8
3,2
B2
3,1
2,1
B2
2,9
2,8
2,8
3,8
B2
1,8
2,1
1,6
2,8
B2
1,0
B2
0,8
B2
0,9
272/3
69
Y2010-1
1-1
9 1
0:1
5:2
82010-1
1-1
9 1
0:0
1:5
689.1
28.1
71.1
7sh
irka05@
ho
tmail.
co
mF
em
en
ino
25
Un
ivers
idad
Au
tón
om
a d
e M
ad
rid
19
Ing
late
rra -
8 m
eses (
4 v
era
no
s)
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
11
11
11
14
11
11
11
11
51
15
31
13
11
21
14
5H
e e
mp
ezad
o e
l te
st
vie
nd
o q
ue t
od
as las o
racio
nes e
sta
ban
mal d
eb
ido
al su
jeto
, p
ero
lu
eg
o m
e h
a p
are
cid
o q
ue a
lgu
nas s
i q
ue s
on
gra
mati
calm
en
te c
orr
ecta
s,
y m
e h
a d
esp
ert
ad
o d
ud
as s
ob
re e
ste
tip
o d
e o
racio
nes q
ue a
ho
ra t
en
go
qu
e r
ep
asar
po
rqu
e n
o m
e a
cu
erd
o b
ien
!!81
c1
14
11
55
11
15
11
34
11
11
11
11
11
31
11
21
11
2,3
1,2
2,5
4,5
11
1,8
1,0
1,0
1,0
1,1
3,5
2,0
91/9
Y2010-1
1-1
3 1
6:0
7:1
42010-1
1-1
3 1
5:5
2:3
074.1
79.1
01.1
75
josem
an
uelr
od
rig
uezm
ora
@g
mail.
co
mM
ascu
lino
29
Un
ivers
idad
Pab
lo d
e O
lavid
e13
Ing
late
rra (
1 m
es);
Irl
an
da (
1 m
es);
EE
UU
(1 m
es)
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
11
11
51
15
15
15
11
51
51
15
11
15
51
11
55
582
c1
15
51
55
11
15
15
55
15
11
15
11
11
15
11
15
11
3,3
1,8
35,0
23
1,0
3,0
1,0
2,0
1,5
2,0
3,0
39/5
7Y
2010-1
1-1
4 1
2:0
2:4
52010-1
1-1
4 1
1:4
7:3
589.1
41.3
4.1
80
luis
felip
e.f
uen
tes@
estu
dia
nte
.uam
.es
Mascu
lino
20
Un
ivers
idad
Au
tón
om
a d
e M
ad
rid
13
Rein
o U
nid
o (
7 s
em
an
as)
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
12
11
51
11
11
15
11
11
51
15
11
11
11
14
15
182
c1
11
11
15
21
15
11
15
11
11
11
14
11
15
11
15
11
1,8
1,7
14,0
1,3
11,0
3,8
1,0
1,0
0,1
0,3
2,8
37/1
34
Y2010-1
1-1
5 1
1:3
7:3
72010-1
1-1
5 1
1:3
1:1
1217.2
16.8
4.7
5cri
sti
na.g
cia
.v@
gm
ail.
co
mF
em
en
ino
25
Un
ivers
idad
de G
ran
ad
a16
Rein
o U
nid
o,
9 m
eses
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
12
34
43
43
14
13
12
41
31
32
13
44
34
32
44
284
c1
13
33
22
21
43
44
44
34
11
24
12
13
14
14
33
34
2,9
2,4
2,8
3,0
33
1,5
2,5
1,8
3,8
0,6
0,5
0,3
7/4
53
Y2010-1
1-2
1 1
6:3
0:0
02010-1
1-2
1 1
6:1
4:2
081.1
72.2
9.2
3m
iri_
du
ru_2@
ho
tmail.
co
mF
em
en
ino
22
Un
ivers
idad
de V
alla
do
lid15
Ing
late
rra (
2 m
eses),
Esco
cia
(9 m
eses)
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
11
11
11
12
11
12
11
11
21
12
11
11
11
11
12
184
c1
12
11
12
11
12
11
12
11
11
11
11
11
11
11
12
11
1,3
1,1
12,0
11
1,0
1,3
1,0
1,0
0,2
0,8
1,0
265/1
1Y
2010-1
1-1
4 2
1:3
1:3
82010-1
1-1
4 2
1:2
5:3
782.1
58.1
0.1
651133084J
Fem
en
ino
18
Un
ivers
idad
Au
tón
om
a d
e M
ad
rid
12
Ing
late
rra:
1 m
es
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
12
34
35
25
35
24
15
32
52
42
24
23
33
51
42
25
379
c1
25
52
34
43
54
34
35
55
13
22
22
23
22
21
45
33
3,9
2,4
3,3
4,5
4,3
3,5
2,3
3,0
2,3
2,3
1,4
1,5
0,5
270/5
07
Y2010-1
1-2
3 1
4:2
1:1
72010-1
1-2
3 1
4:0
5:0
083.5
0.1
01.2
04
ireri
es@
yah
oo
.es
Fem
en
ino
29
Un
ivers
idad
La S
alle
23
Ing
late
rra (
2 a
ño
s)
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
13
14
53
12
21
12
11
51
21
21
51
11
12
32
11
11
476
c1
31
35
41
45
32
12
21
22
11
11
11
15
11
12
11
12
2,6
1,4
31,3
2,5
3,5
1,0
1,0
1,0
2,5
1,2
0,3
-0,8
28/5
18
Y2010-1
1-2
3 2
0:2
9:4
12010-1
1-2
3 2
0:1
3:0
687.2
22.1
54.5
2la
uri
ta91_m
dc@
ho
tmail.
co
mF
em
en
ino
18
facu
ltad
de f
iloso
fia y
letr
as v
alla
do
lid11
Irla
nd
a 2
1 d
ias
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
12
11
41
12
52
11
14
31
51
32
33
11
24
23
11
23
577
c1
22
23
53
13
13
21
43
25
11
12
21
14
11
13
14
15
2,6
1,9
32,8
1,8
31,3
1,8
1,0
3,5
0,8
1,0
1,0
214/5
23
Y2010-1
1-2
3 2
2:5
0:2
62010-1
1-2
3 2
2:4
0:1
679.1
53.2
07.8
1ag
uad
ob
ele
n@
ho
tmail.
co
mF
em
en
ino
27
Filo
so
fía y
Letr
as,
Valla
do
lid17
Lo
nd
res 4
dia
s,
Ed
imb
urg
o m
es y
med
ioE
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
51
55
51
55
15
55
11
51
55
15
51
15
15
55
55
580
c1
15
11
55
11
55
15
55
15
55
15
55
15
55
15
55
15
3,3
4,0
45,0
13
5,0
5,0
1,0
5,0
-0,8
0,0
3,0
113/6
00
Y2010-1
1-2
8 2
1:1
4:3
72010-1
1-2
8 2
0:5
5:4
888.2
2.2
33.1
37
rflg
lr@
gm
ail.
co
mM
ascu
lino
30
nin
gu
no
15
Rein
o U
nid
o 1
mes,
Irla
nd
a 1
mes
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
12
45
13
22
25
11
22
23
11
52
13
15
13
11
21
180
c1
12
15
12
22
51
15
51
32
11
22
11
24
11
33
11
32
2,4
1,8
31,5
1,8
3,5
1,0
1,0
2,5
2,8
0,6
0,5
0,3
253/5
88
Y2010-1
1-2
7 1
8:1
4:2
02010-1
1-2
7 1
8:0
3:2
687.2
23.2
16.7
6b
elg
ara
th_89@
ho
tmail.
co
mM
ascu
lino
21
Un
ivers
idad
Au
tón
om
a d
e M
ad
rid
10
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
43
42
43
52
15
32
44
52
21
44
23
23
35
22
53
383
c1
12
34
34
34
22
25
33
35
34
45
12
14
24
25
22
35
3,1
3,1
2,3
2,8
2,8
4,5
2,0
3,0
2,5
4,8
0,0
-0,3
2,3
326/7
61
Y2011-0
1-0
7 2
0:0
7:4
72011-0
1-0
7 2
0:0
0:0
584.1
25.1
07.8
0m
issb
an
do
n@
live.c
om
Fem
en
ino
27
UV
A5E
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol y o
tra(s
) le
ng
ua(s
)In
term
ed
io a
lto
(B
2)
12
24
23
23
33
14
12
43
51
31
32
11
13
32
22
32
476
c1
23
33
42
44
33
14
32
35
12
33
12
12
12
12
22
13
3,1
1,8
32,5
2,8
41,3
2,0
1,5
2,5
1,3
0,5
0,8
246/3
04
Y2010-1
1-1
8 1
1:2
3:5
62010-1
1-1
8 1
1:1
0:0
785.5
7.2
46.1
03
el_
san
ch
ez_10@
ho
tmail.
co
mM
ascu
lino
21
Un
ivers
idad
de V
alla
do
lid12
Esta
do
s U
nid
os (
2 m
eses),
In
gla
terr
a (
2 m
eses),
Esco
cia
(9 m
eses)
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
11
15
21
42
15
13
11
51
51
21
11
12
23
12
21
184
c1
12
22
11
11
55
15
21
15
11
12
12
11
12
13
13
14
2,3
1,6
2,3
2,3
1,3
3,3
1,0
2,0
1,0
2,5
0,6
0,3
2,0
C1
1,4
2,8
2,4
2,5
3,1
3,2
2,1
2,2
2,8
3,5
1,5
3,3
3,2
3,2
2,1
3,5
1,5
1,8
1,6
2,6
1,5
1,9
1,2
2,7
1,6
2,6
1,3
2,5
1,9
3,0
1,6
2,8
C1
2,7
2,0
C1
2,6
3,2
22,9
C1
1,6
2,3
1,4
2,7
C1
0,7
C1
0,8
C1
1,4
244/2
04
Y2010-1
1-1
6 0
0:4
3:5
72010-1
1-1
6 0
0:3
0:0
180.3
8.1
35.2
42
azu
rera
inb
ow
@h
otm
ail.
co
mM
ascu
lino
22
Un
ivers
idad
de G
ran
ad
a12
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Inte
rmed
io a
lto
(B
2)
11
31
15
32
55
15
25
51
51
51
52
13
33
42
41
14
587
c2
15
45
52
15
55
35
34
25
23
11
11
11
13
12
45
35
3,8
2,2
3,5
4,0
2,5
52,0
3,0
1,5
2,3
1,6
1,0
3,0
80/2
2Y
2010-1
1-1
3 1
9:2
1:3
82010-1
1-1
3 1
9:0
9:0
790.1
68.1
58.8
7o
bim
bc@
ho
tmail.
co
mFem
en
ino
25
Un
ivers
idad
de G
ran
ad
a13
Ing
late
rra,
un
añ
oE
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o a
lto
(C
2)
12
12
12
22
24
23
13
31
33
41
22
33
32
32
34
35
388
c2
24
32
32
23
24
33
25
23
11
13
14
21
32
32
33
32
2,8
2,2
2,3
3,8
2,5
2,8
2,0
2,5
2,3
2,0
0,6
1,3
1,8
243/4
5Y
2010-1
1-1
4 0
0:2
2:5
92010-1
1-1
4 0
0:1
3:2
083.5
9.2
07.1
12
am
an
dam
ola
s@
co
rreo
.ug
r.es
Fem
en
ino
18
Un
ivers
idad
de G
ran
ad
a12
Rein
o U
nid
o,
2 s
em
an
as
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
21
12
11
22
14
13
11
41
41
23
11
11
14
11
14
1O
pin
o q
ue s
e h
a r
ep
eti
do
excesiv
am
en
te u
n m
ism
o t
ipo
de e
rro
r. E
l te
st
se a
larg
a c
on
pre
gu
nta
s q
ue t
ien
den
a s
er
igu
ale
s las u
nas a
las o
tras,
y d
ud
o q
ue e
sto
ap
ort
e n
uevo
s d
ato
s.
96
c2
12
12
13
11
24
14
14
14
12
11
11
11
11
14
13
12
2,1
1,4
1,3
3,3
12,8
1,0
1,8
1,0
2,0
0,6
1,5
3,8
343/4
14
Y2010-1
1-2
0 1
1:3
3:3
22010-1
1-2
0 1
1:2
5:5
781.3
9.7
3.2
45
batt
osai1
868@
ho
tmail.
co
mM
ascu
lino
25
Un
ivers
idad
de V
alla
do
lid6
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
52
25
41
22
11
14
31
41
51
15
12
14
11
13
24
592
c2
12
11
55
23
55
11
44
14
15
12
13
12
14
11
14
22
2,8
2,0
3,8
4,0
1,3
2,3
1,0
4,0
1,3
1,8
0,8
0,0
1,3
200/4
12
Y2010-1
1-2
0 0
9:2
3:4
82010-1
1-2
0 0
9:1
6:4
588.3
1.2
37.1
88
isab
el.p
ere
z@
cch
s.c
sic
.es
Fem
en
ino
37
cch
s-c
sice
e u
u d
os m
eses
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
12
11
11
15
15
11
51
51
51
15
11
11
41
11
34
186
c2
15
41
15
25
15
15
14
15
11
13
11
11
11
11
11
11
2,9
1,1
14,8
24
1,0
1,0
1,0
1,5
1,8
3,8
5,8
328/7
6Y
2010-1
1-1
4 1
6:4
7:5
32010-1
1-1
4 1
6:2
5:3
487.2
35.8
8.5
7sere
ste
ban
@h
otm
ail.
co
mM
ascu
lino
28
Un
ivers
idad
de G
ran
ad
a7
Ing
late
rra:
Liv
erp
oo
l 9 m
eses,
Oxfo
rd 2
ag
no
sE
sp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o a
lto
(C
2)
11
14
33
22
35
34
45
42
52
51
55
32
22
54
22
45
3Á
reas p
rob
lem
áti
cas:
Dete
rmin
ar
el g
rad
o d
e g
ram
ati
calid
ad
de las o
racio
nes m
e h
a r
esu
ltad
o m
uy d
ifíc
il p
ues d
esco
no
zco
el cri
teri
o,
otr
o q
ue n
o s
ea W
ord
Ord
er.
El re
gis
tro
no
se s
i h
ab
ía q
ue in
dic
arl
o c
om
o in
ap
rop
iad
o o
no
(it
becam
e e
ven
sti
lted
at
tim
es w
here
it
wasn
't t
hat
necessary
). A
lso
, b
y b
ein
g a
ware
of
the f
act
that
the t
est
is g
eare
d t
ow
ard
a S
pan
ish
au
dic
en
ce y
ou
th
en
beco
me t
oo
self-a
ware
wh
en
an
sw
eri
ng
qu
esti
on
s n
ot
really
th
inkin
g in
En
glis
h a
ny m
ore
. 96
c2
15
55
35
44
35
24
25
25
41
24
12
33
32
24
25
23
3,8
2,7
2,3
5,0
3,3
4,5
2,5
2,5
2,3
3,5
1,1
2,5
4,0
236/5
54
Y2010-1
1-2
5 1
1:0
5:3
62010-1
1-2
5 1
0:5
7:5
787.2
17.1
21.2
43
mart
aflo
resvic
en
te@
ho
tmail.
co
mF
em
en
ino
21
EU
La S
alle
7E
sp
añ
ol
Otr
a len
gu
aE
sp
añ
ol
Esp
añ
ol y o
tra(s
) le
ng
ua(s
)P
rin
cip
ian
te b
ajo
(A
1)
51
35
11
51
21
51
14
15
43
15
11
33
13
11
53
11
186
c2
11
11
11
51
11
11
31
14
13
51
53
51
35
31
54
32
1,6
3,1
1,5
1,0
21,8
3,5
3,8
4,0
1,3
-1,6
-2,8
-0,8
209/6
04
Y2010-1
1-2
9 1
2:3
7:4
82010-1
1-2
9 1
2:2
4:0
788.1
1.5
5.6
7n
linn
itt@
gm
ail.
co
mM
ascu
lino
28
SA
FA
Ub
ed
a25
Ing
late
rra,
2 m
eses
Esp
añ
ol
Ing
lés
Esp
añ
ol
Esp
añ
ol y o
tra(s
) le
ng
ua(s
)A
van
zad
o a
lto
(C
2)
23
23
33
23
43
34
33
53
53
42
53
24
32
32
33
23
489
c2
33
35
43
35
34
34
23
35
32
32
23
33
22
32
33
44
3,5
2,8
33,3
34,8
2,5
2,5
3,3
2,8
0,8
0,8
2,0
276/6
76
Y2010-1
2-0
7 1
7:1
1:3
12010-1
2-0
7 1
6:5
6:3
3189.2
47.4
.34
dels
ea23@
yah
oo
.co
m.m
xF
em
en
ino3
1fa
cu
ltad
de L
en
gu
as U
niv
ers
idad
Au
tón
om
a d
e M
12
Can
ad
á,
un
mes
Esp
añ
ol
Otr
a len
gu
aO
tra len
gu
aE
sp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
51
11
31
11
11
14
11
31
11
13
11
14
11
12
15
186
c2
11
11
13
11
11
11
45
13
15
11
12
11
13
11
14
11
1,7
1,6
1,8
2,5
11,5
1,0
3,5
1,0
1,0
0,1
-1,0
1,3
322/6
77
Y2010-1
2-0
7 1
9:1
8:0
82010-1
2-0
7 1
9:0
3:4
5189.2
47.2
08.6
5aco
sta
man
uel1
2@
ho
tmail.
co
mM
ascu
lino2
9U
niv
ers
idad
Au
ton
om
a d
el E
sta
do
de M
éxic
o12
Esta
do
s U
nid
os 1
añ
o 3
meses
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
41
11
41
11
15
15
11
21
51
15
11
11
11
11
15
190
c2
11
11
15
11
15
15
15
12
14
11
11
11
14
11
15
11
2,1
1,6
14,0
12,3
1,0
3,5
1,0
1,0
0,4
0,5
4,3
157/7
70
Y2011-0
1-0
8 1
7:3
8:0
32011-0
1-0
8 1
7:2
5:4
583.3
5.8
4.6
zm
en
dik
ute
@w
an
ad
oo
.es
Fem
en
ino
34
nin
gu
no
10
UK
1 m
es,
Irla
nd
a 1
mes,
Irla
nd
a 4
meses
Esp
añ
ol
Otr
a len
gu
aE
sp
añ
ol
Esp
añ
ol y o
tra(s
) le
ng
ua(s
)A
van
zad
o a
lto
(C
2)
11
11
11
11
22
12
11
21
31
21
11
11
11
11
11
12
1M
e e
s d
ifíc
il p
un
tuar
las f
rases q
ue c
reo
in
co
rrecta
s e
n u
na e
scala
del 1 a
l 5 p
orq
ue p
ien
so
qu
e o
so
n c
orr
ecta
s o
in
co
rrecta
s.
96
c2
12
11
11
12
12
12
12
13
11
11
11
11
11
11
11
12
1,4
1,1
11,8
12
1,0
1,0
1,0
1,3
0,4
0,8
1,8
327/7
56
Y2011-0
1-0
7 1
3:4
8:1
32011-0
1-0
7 1
3:3
5:0
983.6
1.2
42.2
18
du
blit
ati
va@
ho
tmail.
co
mF
em
en
ino
24
Un
ivers
idad
de S
ala
man
ca
15
Rein
o U
nid
o (
1 m
es)
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol y o
tra(s
) le
ng
ua(s
)In
term
ed
io b
ajo
(B
1)
11
11
51
53
55
15
11
11
51
51
15
11
15
55
15
53
594
c2
15
51
55
11
15
15
53
35
11
15
15
15
15
15
11
15
3,3
2,5
34,5
2,5
31,0
3,0
1,0
5,0
0,8
1,5
2,0
112/8
01
Y2011-0
1-2
4 1
7:2
7:1
82011-0
1-2
4 1
7:1
5:1
590.1
65.5
6.6
1elis
ab
arb
a@
co
rreo
.ug
r.es
Fem
en
ino
27
Un
ivers
idad
de G
ran
ad
a15
Rein
o u
nid
o (
Ing
late
rra,
3 m
eses,
Gale
s 9
meses ,
Irl
an
da d
el N
ort
e 9
meses)
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Esp
añ
ol
Avan
zad
o b
ajo
(C
1)
11
11
11
11
13
11
11
21
21
11
22
11
12
31
11
12
185
c2
13
32
12
12
11
11
22
12
11
11
11
11
11
11
11
11
1,6
1,0
1,3
2,0
1,5
1,8
1,0
1,0
1,0
1,0
0,6
1,0
1,0
C2
1,2
3,0
2,5
2,2
2,5
3,2
1,9
2,6
2,1
3,6
1,5
3,2
2,4
3,6
1,5
3,8
1,5
2,3
1,5
2,0
1,4
2,2
1,7
1,7
1,5
2,6
1,5
2,0
1,9
3,1
1,8
2,4
C2
2,6
1,9
C2
23,4
1,9
2,9
C2
1,6
2,5
1,7
2,0
C2
0,6
C2
0,8
C2
2,4
213
11.4.3 RAW DATA FOR L1 MACED – L2 ENGLISH LEARNERS
10/3
45
Y2011-0
1-3
0 0
2:4
7:3
32011-0
1-3
0 0
2:3
0:2
779.1
25.1
91.4
8nik
ola
.mla
denovs
ki@
yahoo.c
om
Masculin
o19
Sv.
Kir
il i M
eto
dij
- S
kopje
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
15
24
45
34
23
15
15
41
41
51
42
11
33
32
14
14
353
A2
53
34
32
44
55
35
34
44
12
11
14
14
13
12
15
12
3,8
1,9
43,5
3,5
4,3
1,0
3,5
1,0
2,3
1,9
0,0
0,3
24/3
06
Y2011-0
2-0
4 1
2:1
9:3
22011-0
2-0
4 1
2:0
3:5
577.2
9.1
87.8
zafiro
vanto
nie
@yahoo.c
om
Masculin
o22
FE
IT S
kopje
4M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
22
45
55
32
23
42
21
51
53
52
45
32
55
42
14
55
553
A2
23
44
55
55
55
52
55
25
24
15
24
45
33
32
11
22
4,2
2,8
4,3
4,5
44
2,0
3,0
2,5
3,5
1,4
1,5
0,3
34/7
8Y
2011-0
2-0
4 1
2:5
1:5
32011-0
2-0
4 1
2:4
1:2
193.1
06.1
48.4
0m
ari
na.tra
jkovi
c@
hotm
ail.
com
Fem
enin
o24
ne s
tudir
am
10
Macedonia
nO
traM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
11
31
42
53
55
42
25
54
52
55
45
55
55
44
15
55
556
A2
15
44
55
15
25
52
55
35
23
45
55
44
55
24
15
55
3,9
4,0
3,3
5,0
3,3
43,3
4,5
3,8
4,5
-0,1
0,5
2,5
45/6
81
Y2011-0
2-0
4 1
4:5
7:3
12011-0
2-0
4 1
3:3
1:3
689.2
05.4
7.4
3jo
sifovs
kid
ane@
aol.deM
asculin
o21
Fon U
niv
erz
itet-
Ekonom
ski nauki
13
Anglij
a-
10 d
ena
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado b
ajo
(C
1)
13
41
55
51
55
11
55
55
51
51
51
55
11
55
55
15
559
A2
35
55
51
15
55
11
15
15
54
51
15
15
55
15
55
55
3,4
3,9
3,5
4,0
24
4,0
4,8
3,0
4,0
-0,6
-0,8
2,5
98/1
68
Y2011-0
2-0
4 2
2:2
4:1
52011-0
2-0
4 2
2:1
6:3
895.8
6.6
.215
a_m
eshkova
@yahoo.c
om
Fem
enin
o24
UC
TM
8M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
13
22
33
24
54
54
25
54
45
52
55
54
55
33
43
53
558
A2
34
35
55
25
35
54
53
44
22
45
23
53
52
53
45
45
4,1
3,7
44,3
3,5
4,5
3,3
3,0
4,5
4,0
0,4
1,3
1,3
106/5
5Y
2011-0
2-0
5 1
1:1
1:0
52011-0
2-0
5 1
0:5
6:5
495.8
6.1
2.6
7avv
ocato
232005@
yahoo.c
om
Fem
enin
o28
ne s
tudir
am
10
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
15
11
52
13
31
51
15
51
53
41
24
11
14
43
55
15
458
A2
51
42
44
15
24
11
45
35
11
11
15
55
11
33
55
13
3,2
2,6
3,8
3,5
2,3
3,3
2,0
3,0
2,5
3,0
0,6
0,5
0,8
122/7
15
Y2011-0
2-0
7 1
7:0
9:5
72011-0
2-0
7 1
6:5
5:4
8213.1
35.1
68.1
95
km
urg
oski@
gm
ail.
comM
asculin
o25
ne s
tudir
am
9U
SA
2 g
od A
vstr
alij
a 3
meseci N
ov
Zela
nd 3
meseci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
13
23
25
52
31
55
42
53
53
54
53
25
55
55
33
54
555
A2
31
55
53
35
55
55
54
25
42
35
43
52
25
35
32
53
4,1
3,5
4,5
3,3
3,8
53,3
3,0
4,0
3,8
0,6
0,3
0,0
131/7
78
Y2011-0
2-0
8 1
6:0
2:3
72011-0
2-0
8 1
5:4
6:5
879.1
26.2
01.8
3la
lkovv
@yahoo.c
om
Masculin
o30
Univ
erz
itet K
iril
i M
eto
dij
8London,
3 m
eseci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
21
14
54
15
45
45
12
55
55
51
55
15
15
15
51
25
553
A2
15
15
55
45
45
15
55
55
11
52
11
45
11
55
52
54
4,1
3,0
3,8
5,0
2,8
52,0
1,3
4,8
4,0
1,1
3,8
3,5
143/4
05
Y2011-0
2-1
4 0
1:1
1:4
92011-0
2-1
4 0
0:5
9:2
477.2
8.7
6.2
3kik
i4ka_sm
ale
y@
hotm
ail.
com
Fem
enin
o21
univ
erz
itet sv.
kir
il i m
eto
dij
6M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado b
ajo
(C
1)
11
12
11
22
22
21
11
31
21
31
33
11
31
23
22
21
359
A2
12
23
33
23
13
31
11
22
11
12
12
21
12
13
21
12
2,1
1,5
1,5
2,3
2,3
2,3
1,3
1,5
1,3
2,0
0,6
0,8
0,8
198/4
67
Y2011-0
2-1
7 2
2:4
5:1
32011-0
2-1
7 2
2:2
5:4
878.1
57.4
.115
em
ilija
pavl
ova
@yahoo.c
om
Fem
enin
o29
"Sv.
Kir
il i M
eto
dij"
-"Justinija
n I
"-S
kopje
10
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
11
15
21
52
55
12
12
51
11
51
55
11
31
54
15
35
157
A2
15
55
15
55
15
32
15
21
11
13
15
12
15
14
12
15
3,3
2,2
15,0
3,8
3,3
1,0
3,3
1,0
3,5
1,1
1,8
3,5
255/7
88
Y2011-0
3-0
1 0
0:0
2:4
22011-0
2-2
8 2
3:5
4:1
378.1
57.0
.89
anic
a5petr
ova
@yahoo.c
om
Fem
enin
o21
Univ
erz
itet S
v.K
iril
i M
eto
dij
10
US
AM
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
23
42
43
45
45
34
22
42
52
33
55
22
34
53
24
34
558
A2
35
55
55
24
33
34
44
55
24
23
34
34
24
23
22
24
4,1
2,9
3,8
4,3
3,8
4,5
2,3
3,5
2,3
3,5
1,2
0,8
1,3
273/2
82
Y2011-0
3-0
5 2
1:5
3:5
62011-0
3-0
5 2
1:4
1:2
677.2
9.6
0.1
88
keti_kejt@
hotm
ail.
comF
em
enin
o21
ne s
tudir
am
0M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
bajo
(B
1)
15
54
55
55
15
55
15
55
55
51
55
11
55
55
15
55
559
A2
55
55
55
45
55
55
55
55
15
55
15
55
15
55
15
11
4,9
3,5
55,0
4,8
51,0
5,0
4,0
4,0
1,4
0,0
0,3
307/1
74
Y2011-0
4-0
4 1
3:3
1:1
52011-0
4-0
4 1
3:1
2:3
595.1
80.1
70.1
79
em
ilija
_ja
neva
@yahoo.c
om
Fem
enin
o22
Farm
acevt
ski F
akulte
t-S
kopje
62 m
eseci-
U.S
.A.
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
14
42
55
55
55
54
25
53
51
54
55
14
55
55
25
55
3S
meta
m d
eka n
acin
ot za o
cenuva
nje
na p
ravi
lnosta
na r
ecenic
ite e
neja
sen t.e
. ili
recenic
ata
e tocna ili
ne e
.Isto
taka s
meta
m d
eka z
a d
a m
ozete
da g
o o
cenite p
oznava
nje
to n
a a
nglis
kio
t ja
zik
kaj m
akedonskata
popula
cija
,ne tre
ba s
am
o d
a s
e o
gra
nic
uva
te n
a k
onstr
ukcija
ta n
a r
ecenic
ata
tuku i n
z n
ejz
inata
gra
maticka tocnost.S
e n
adeva
m d
eka b
are
m m
alk
u v
i pom
ognav.
So s
reka..
.:)
56
A2
45
55
35
25
55
54
55
55
24
35
45
55
15
15
25
45
4,6
3,8
4,3
5,0
4,3
4,8
2,3
4,8
3,3
5,0
0,8
0,3
1,3
334/2
84
Y2011-0
6-2
8 2
0:5
2:2
82011-0
6-2
8 2
0:3
1:4
762.1
62.2
09.6
8jo
kis
om
Masculin
o25
ne s
tudir
am
8/
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
14
23
52
44
15
53
23
51
51
34
45
22
55
42
34
25
455
A2
45
44
45
35
23
53
55
45
22
12
44
55
24
12
33
21
4,1
2,7
3,8
4,5
44,3
2,8
3,3
2,3
2,5
1,4
1,3
1,0
A2
2,9
3,9
3,9
4,4
4,1
4,1
2,8
4,7
3,4
4,5
3,6
3,1
3,9
4,4
3,4
4,4
1,9
2,6
2,6
3,2
2,2
3,9
3,6
3,9
2,2
3,6
2,4
3,6
2,6
3,4
2,8
3,4
A2
3,8
3,0
A2
3,6
4,2
3,4
4,1
A2
2,2
3,4
2,9
3,5
A2
0,8
A2
0,8
A2
1,4
76/3
47
Y2011-0
2-0
4 1
7:1
3:4
22011-0
2-0
4 1
7:0
3:3
789.2
05.3
9.1
84
trajk
ovs
ki_
tk@
yahoo.c
om
Masculin
o22
FE
IT7
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
13
31
34
25
23
45
33
53
52
44
45
32
55
45
32
35
561
B1
33
44
55
15
44
55
55
55
33
33
42
43
32
25
33
22
4,3
2,9
4,3
4,3
3,8
4,8
3,3
2,5
2,8
3,3
1,3
1,8
1,0
97/4
3Y
2011-0
2-0
4 2
2:1
4:5
42011-0
2-0
4 2
2:0
1:5
992.5
3.1
4.1
88
fcw
izard
@gm
ail.
com
Masculin
o20
Fakulte
t za turi
zam
i u
gostite
lstv
o4
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
bajo
(B
1)
12
14
55
13
42
25
13
41
53
52
53
12
55
45
11
52
467
B1
22
45
43
44
55
55
52
35
11
15
21
25
11
35
13
24
3,9
2,4
43,0
44,8
1,3
1,5
2,0
4,8
1,6
1,5
-0,3
102/2
60
Y2011-0
2-0
4 2
3:4
9:2
12011-0
2-0
4 2
3:4
0:2
289.2
05.3
6.2
53
bunte
_b@
yahoo.c
om
Masculin
o28
ne s
tudir
am
8M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
11
55
15
51
35
55
15
51
55
51
55
15
55
55
15
55
564
B1
15
55
55
55
55
55
55
15
15
15
15
51
15
55
15
53
4,5
3,4
45,0
45
1,0
5,0
4,0
3,5
1,1
0,0
2,0
151/3
4Y
2011-0
2-1
5 2
2:1
2:0
82011-0
2-1
5 2
2:0
1:1
595.8
6.5
0.2
29
anasta
sija
olu
mceva
@yahoo.c
o.u
kF
em
enin
oM
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
11
33
53
51
15
13
13
11
11
51
55
15
15
51
55
13
563
B1
15
55
55
31
35
13
53
11
13
11
15
15
15
11
53
51
3,3
2,5
3,5
4,5
2,5
2,5
2,0
4,0
2,0
2,0
0,8
0,5
1,0
176/1
7Y
2011-0
2-1
7 0
0:1
5:3
42011-0
2-1
6 2
3:5
3:4
578.1
57.4
.115
zhiv
ka.g
ruevs
ka@
gm
ail.
com
Fem
enin
o22
Univ
erz
itet S
v. K
iril
i M
eto
dij
10
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
bajo
(B
1)
13
44
42
21
53
23
13
45
44
52
25
23
43
52
55
54
564
B1
33
52
55
44
25
43
34
14
14
55
25
24
22
42
53
35
3,6
3,4
3,3
4,3
3,5
3,3
2,5
3,5
3,5
4,0
0,2
0,8
0,8
184/6
44
Y2011-0
2-1
7 0
9:0
1:2
92011-0
2-1
7 0
1:3
7:5
977.2
46.8
7.2
4m
ishela
86@
yahoo.c
omFem
enin
o24
Univ
ers
ité d
'Avi
gnon
8M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado b
ajo
(C
1)
11
32
42
33
35
34
14
51
41
51
45
22
25
34
34
45
561
B1
15
34
55
25
25
24
55
34
13
14
14
34
23
14
34
23
3,8
2,7
3,3
5,0
2,5
4,3
1,8
3,5
1,8
3,8
1,1
1,5
3,5
231/5
30
Y2011-0
2-2
6 1
2:4
0:2
02011-0
2-2
6 1
2:1
1:3
162.1
62.1
64.1
13
anitceto
_d@
yahoo.c
omFem
enin
o21
Univ
erz
itet G
oce D
elc
ev
11
Massachusets
, U
SA
, 4 m
eseci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
24
54
44
25
55
24
23
52
53
53
55
25
45
43
44
33
5S
meta
m d
eka tre
base p
od s
ekoe p
rasanje
da d
adem
e p
rim
er
kako s
meta
m d
eka tre
ba d
a izgle
da r
ecenic
ata
. M
i bese m
nogu tesko d
a g
i ocenam
. 63
B1
45
45
55
45
45
44
53
55
25
23
34
24
22
33
43
55
4,5
3,3
4,5
4,5
4,3
4,8
2,8
3,5
3,0
3,8
1,3
1,0
0,5
250/4
34
Y2011-0
2-2
8 0
1:1
0:4
82011-0
2-2
8 0
0:5
7:4
792.5
3.5
7.4
3vi
kce77kr@
yahoo.c
omFem
enin
o21
Univ
irzitet K
iril
i M
eth
odi, E
konom
ski F
akult
8U
SA
, tr
i pati p
o 4
meseci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
12
12
55
22
55
55
11
31
33
52
52
41
54
55
14
55
567
B1
25
55
52
23
55
55
45
23
11
15
24
55
42
35
11
15
3,9
2,9
44,3
3,5
42,0
2,0
2,5
5,0
1,1
2,3
0,8
257/1
89
Y2011-0
3-0
1 1
3:3
6:0
12011-0
3-0
1 1
3:1
7:2
792.5
3.4
8.2
38
sanja
_ta
sevs
ka1988@
yahoo.c
om
Fem
enin
o22
Sv
,,K
iril
i M
eto
dij"
-S
kopje
8A
nglij
a (
2 p
ati p
o 3
nedeli)
i U
SA
(3 m
eseci)
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
11
23
22
52
35
34
34
52
23
44
54
44
44
54
44
44
361
B1
15
55
34
35
24
44
44
22
32
24
44
32
45
34
44
43
3,6
3,4
2,5
4,3
3,5
43,8
3,8
3,0
3,3
0,1
0,5
2,3
304/6
3Y
2011-0
4-0
1 1
9:4
2:4
72011-0
4-0
1 1
9:3
1:4
179.1
25.2
49.8
1la
zaro
va.v
@gm
ail.
comF
em
enin
o26
Sv.
Kir
il i M
eto
dij
12
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nP
rincip
iante
alto
(A
2)
32
11
52
11
31
11
11
51
51
31
22
12
21
11
11
11
561
B1
21
12
52
15
23
21
11
15
11
11
11
15
11
11
11
23
2,2
1,4
2,5
1,8
1,3
3,3
1,0
1,0
1,3
2,5
0,8
0,8
1,3
B1
2,0
3,9
4,1
4,2
4,7
4,1
2,9
4,2
3,4
4,6
3,7
3,9
4,2
3,7
2,4
3,9
1,5
2,8
1,8
3,6
2,1
3,5
2,8
3,8
2,1
2,8
2,6
3,5
2,8
3,0
3,1
3,4
B1
3,7
2,8
B1
3,6
4,1
3,3
4,1
B1
2,1
3,0
2,6
3,6
B1
0,9
B1
1,1
B1
1,3
14/7
64
Y2011-0
2-0
3 1
5:3
6:0
52011-0
2-0
3 1
5:0
9:0
277.2
8.1
07.8
1ve
sna.m
itresk
a@
pum
pi.com
.mk
Fem
enin
o29
ne s
tudir
am
9A
nlij
a-e
den m
ese
cM
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanza
do b
ajo
(C
1)
11
11
32
41
25
35
11
51
51
31
12
11
14
25
12
45
569
B2
15
21
52
15
23
15
45
15
11
14
12
33
14
15
11
12
3,0
2,0
33,8
1,3
41,0
2,0
1,5
3,5
1,0
1,8
3,5
19/1
16
Y2011-0
2-0
3 2
2:4
3:3
12011-0
2-0
3 2
2:3
1:5
189.2
05.2
2.1
85
kris
.petr
ova
@yahoo.c
om
Fem
enin
o21
Sv.
Kir
il i M
eto
dij
Sko
pje
11
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanza
do b
ajo
(C
1)
11
35
55
55
55
55
14
55
54
51
55
14
24
55
32
55
471
B2
15
55
45
55
55
25
45
55
13
55
12
55
15
45
34
45
4,4
3,6
3,5
5,0
4,3
51,5
3,5
4,5
5,0
0,8
1,5
2,3
51/3
05
Y2011-0
2-0
4 1
4:2
0:0
32011-0
2-0
4 1
4:0
9:0
977.2
8.9
7.6
0eftim
ovs
ka_nata
sa@
yahoo.c
om
Fem
enin
o31
ne s
tudir
am
10
US
A-
1 m
onth
, U
K-1
month
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanza
do a
lto (
C2)
11
11
11
51
15
11
11
11
11
51
55
11
11
15
15
55
172
B2
15
15
15
11
15
11
15
11
11
15
15
11
15
15
11
11
2,3
2,0
15,0
12
1,0
3,0
1,0
3,0
0,3
2,0
5,0
63/1
04
Y2011-0
2-0
4 1
5:3
7:4
92011-0
2-0
4 1
5:2
0:0
777.2
8.1
54.2
45
dafina@
kouzo
n.c
om
.mk
Fem
enin
o30
ne s
tudir
am
12
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanza
do a
lto (
C2)
12
13
35
21
55
24
12
51
52
32
55
25
45
45
22
35
571
B2
25
45
55
35
53
44
55
15
11
13
22
23
22
25
22
55
4,1
2,5
4,3
4,5
34,8
1,8
1,8
2,5
4,0
1,6
2,8
2,0
152/2
26
Y2011-0
2-1
6 1
2:3
1:0
02011-0
2-1
6 1
2:1
7:1
877.2
8.1
05.1
27
mark
o@
kouzo
n.c
om
.mk
Masc
ulin
o24
Euro
pean U
niv
ers
ity20
US
A-4
m, M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanza
do a
lto (
C2)
11
15
55
13
55
15
15
52
52
52
55
24
25
35
24
15
570
B2
15
35
55
55
55
25
55
35
11
21
24
15
21
25
25
45
4,3
2,7
45,0
3,3
51,8
2,8
2,3
4,0
1,6
2,3
2,8
173/2
3Y
2011-0
2-1
6 2
3:1
7:2
92011-0
2-1
6 2
3:0
8:1
689.2
05.3
3.1
9ka
teri
na_m
akr
esk
a@
hotm
ail.
com
Fem
enin
o25
Evr
opsk
i U
niv
erz
itet -
magis
ters
ki s
tudii
10
Anglij
a 3
nedeli
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanza
do a
lto (
C2)
11
13
45
24
55
54
34
51
52
32
53
23
33
45
35
53
569
B2
15
45
53
35
53
34
33
45
31
15
25
54
22
25
34
35
3,8
3,3
3,5
3,5
3,5
4,8
2,5
3,0
2,8
4,8
0,6
0,5
1,3
175/1
44
Y2011-0
2-1
6 2
3:3
5:4
62011-0
2-1
6 2
3:2
6:5
0187.1
05.1
3.2
00
cve
tanka
_gj@
yahoo.c
om
Fem
enin
o30
ne s
tudir
am
2M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
12
31
24
44
55
35
24
42
53
52
45
14
54
35
21
55
568
B2
25
34
55
14
45
55
45
45
23
25
21
32
14
35
24
45
4,1
3,0
3,8
5,0
3,3
4,5
1,8
3,0
3,0
4,3
1,1
2,0
2,5
178/6
54
Y2011-0
2-1
7 0
0:4
3:2
22011-0
2-1
7 0
0:0
5:0
977.2
9.2
09.1
88
cukn
eva
vesn
a@
yahoo.c
om
Fem
enin
o27
Sv.
Kir
il i M
eto
dij
Sko
pje
12
Anglij
a 5
mese
ci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanza
do b
ajo
(C
1)
11
11
53
32
55
15
11
31
31
51
35
11
31
24
11
32
570
B2
15
23
55
13
35
35
12
23
11
13
11
15
13
14
11
15
3,1
1,9
2,5
4,3
23,5
1,0
1,5
1,0
4,3
1,1
2,8
3,3
186/2
5Y
2011-0
2-1
7 0
3:5
6:3
52011-0
2-1
7 0
3:4
4:4
495.1
80.1
55.6
1m
agde_petk
ovi
c@
hotm
ail.
com
Fem
enin
o25
uki
m m
ake
donija
15
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
11
14
55
31
14
15
11
51
41
45
55
14
35
14
41
43
568
B2
14
15
55
45
54
35
53
14
11
14
51
15
13
14
41
41
3,8
2,4
44,0
2,3
4,8
2,8
1,5
1,8
3,5
1,4
2,5
2,5
247/1
67
Y2011-0
2-2
7 1
8:1
4:2
82011-0
2-2
7 1
8:0
6:2
677.2
9.1
50.7
3sa
sedim
kov@
hotm
ail.
com
Masc
ulin
o23
ne s
tudir
am
10
Flo
rida 2
mese
ci, V
irgin
ia 4
mese
ci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanza
do a
lto (
C2)
11
23
35
24
34
43
12
51
11
21
14
11
11
12
11
43
374
B2
14
11
34
35
52
13
13
41
12
14
11
43
12
12
12
13
2,6
1,9
2,5
3,3
2,3
2,5
1,0
1,8
1,8
3,0
0,8
1,5
1,0
263/4
55
Y2011-0
3-0
2 1
1:0
4:4
12011-0
3-0
2 1
0:5
1:5
579.9
9.5
6.6
6dra
gana_m
itova
@yahoo.c
om
Fem
enin
o21
Univ
erz
iet G
oce D
elc
ev
11
US
A -
4 m
ese
ci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanza
do a
lto (
C2)
31
13
42
45
53
25
23
54
53
52
45
33
55
55
23
43
468
B2
13
54
45
35
25
55
53
55
21
44
23
24
34
35
23
35
4,1
3,1
34,0
4,5
4,8
2,3
2,8
3,0
4,5
0,9
1,3
1,3
275/6
33
Y2011-0
3-0
6 2
2:5
0:3
02011-0
3-0
6 2
2:3
6:1
779.1
25.2
38.2
14
e_st
oja
novs
ka@
hotm
ail.
com
Fem
enin
o27
ne s
tudir
am
6M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
11
12
55
32
12
14
12
51
22
41
11
11
11
11
12
15
169
B2
12
11
11
25
54
14
15
22
11
11
12
15
13
21
12
11
2,4
1,6
23,0
1,5
31,0
2,0
1,3
2,0
0,8
1,0
2,5
280/2
07
Y2011-0
3-0
9 1
4:1
7:2
12011-0
3-0
9 1
4:0
5:0
077.2
9.1
51.4
7off
ice@
slogain
tern
atio
nal.c
om
Masc
ulin
o26
Ne s
tudir
am
8M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanza
do b
ajo
(C
1)
43
34
45
45
55
55
24
54
52
52
54
33
54
35
33
35
472
B2
35
35
44
45
55
55
45
55
23
43
23
54
34
25
34
35
4,5
3,4
44,8
4,3
52,5
3,5
3,5
4,3
1,1
1,3
1,5
293/2
6Y
2011-0
3-1
2 2
2:0
1:4
82011-0
3-1
2 2
1:4
1:5
289.2
05.2
0.1
41
dija
na_va
landovo
@hotm
ail.
com
Fem
enin
o17
ne s
tudir
am
6M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
14
35
54
51
55
44
35
55
44
45
52
54
53
55
44
54
570
B2
45
55
52
55
44
54
34
14
33
55
54
45
55
45
45
45
4,1
4,4
43,8
44,5
4,3
4,3
4,3
5,0
-0,4
-0,5
0,3
303/4
82
Y2011-0
3-2
9 0
1:5
2:5
22011-0
3-2
9 0
1:4
5:1
195.1
80.2
13.2
35
radm
ila_11@
yahoo.c
om
Fem
enin
o23
Univ
ers
ity o
f S
ts.
Cyri
l and M
eth
odiu
s14
US
A 1
year
Macedonia
nO
traM
acedonia
nM
acedonia
nA
vanza
do a
lto (
C2)
11
53
34
21
45
11
13
14
11
51
15
12
51
11
15
13
172
B2
15
11
15
31
45
51
13
11
15
41
15
13
12
11
13
24
2,4
2,3
1,8
4,5
2,5
11,0
3,8
2,0
2,3
0,2
0,8
1,3
B2
1,5
4,5
2,7
3,7
3,9
4,1
2,9
4,3
4,0
4,2
3,1
4,1
3,1
4,1
2,7
3,7
1,5
1,9
2,3
3,5
1,9
2,7
2,6
3,8
1,7
3,3
2,0
4,1
2,1
2,8
2,7
3,8
B2
3,5
2,7
B2
3,1
4,2
2,9
3,9
B2
1,8
2,7
2,4
3,8
B2
0,9
B2
1,6
B2
2,2
7/4
53
Y2011-0
1-2
9 1
2:0
0:5
42011-0
1-2
9 1
1:3
6:3
095.8
6.8
.227
sanja
sim
onovi
k@
gm
ail.
com
Faculty
of
Philo
logy
10
US
A 4
month
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
12
21
23
22
23
23
24
42
22
32
33
22
22
23
23
33
384
C1
23
23
33
14
33
23
23
22
22
23
23
22
22
23
24
22
2,6
2,3
2,5
3,0
1,8
32,0
2,8
2,0
2,5
0,3
0,3
1,8
28/5
18
Y2011-0
2-0
4 1
2:1
7:4
72011-0
2-0
4 1
2:1
0:5
295.8
6.8
.73
ngerg
eva
@yahoo.c
omF
em
enin
o18
SO
U 'D
obri
Daskalo
v'9
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado b
ajo
(C
1)
11
15
21
44
51
15
11
51
51
11
51
11
11
15
11
11
177
C1
11
15
11
55
11
15
11
45
11
11
11
12
14
15
11
15
2,4
1,8
11,0
2,8
51,0
1,8
1,0
3,3
0,7
-0,8
2,3
37/1
34
Y2011-0
2-0
4 1
3:2
3:5
02011-0
2-0
4 1
2:5
7:5
289.2
05.3
5.1
29
d.todoro
vska@
yahoo.c
om
Fem
enin
o24
Faculty
of
Philo
logy "
Bla
ze K
oneski"
- S
kopje
12
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
11
23
55
44
54
54
34
54
51
51
54
24
41
55
22
55
5I
thin
k that th
e p
roble
m in these s
ente
nces in g
enera
l is
the u
se o
f "i
t",
"there
" and "
pla
cin
g the v
erb
at th
e b
egin
nin
g o
f th
e s
ente
nce inste
ad a
t th
e e
nd".
83
C1
14
55
54
35
55
44
15
45
32
45
12
55
24
15
24
45
4,1
3,4
34,5
44,8
2,0
3,0
3,5
5,0
0,7
1,5
2,3
39/5
7Y
2011-0
2-0
4 1
3:2
3:1
92011-0
2-0
4 1
3:1
1:3
992.5
3.3
6.2
54
dark
oo_i@
yahoo.c
om
ne s
tudir
am
8M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
11
11
12
21
54
24
13
32
53
52
44
13
42
35
21
54
5m
alk
u n
eja
sen,inaku v
o r
ed
83
C1
14
34
54
13
25
44
24
15
11
25
21
21
12
35
23
35
3,3
2,4
2,5
4,3
2,3
41,5
1,8
2,5
4,0
0,8
2,5
3,5
91/9
Y2011-0
2-0
4 1
9:3
8:4
02011-0
2-0
4 1
9:2
9:0
477.2
9.4
3.3
9i.dala
s@
hotm
ail.
com
Masculin
o31
ne s
tudir
am
0U
SA
, 1 g
odin
aM
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nIn
term
edio
alto
(B
2)
21
12
23
34
52
24
21
31
31
41
42
12
22
32
22
23
382
C1
12
34
32
23
34
24
23
43
21
12
12
22
13
12
21
25
2,8
1,9
2,3
2,8
2,8
3,5
1,5
1,8
1,5
2,8
0,9
1,0
1,3
113/6
00
Y2011-0
2-0
6 0
4:5
2:0
12011-0
2-0
6 0
4:3
9:5
278.1
57.6
.10
igor_
spasovs
ki@
hotm
ail.
com
Masculin
o29
Univ
erz
itet S
v. K
iril
i M
eto
di
20
SA
D-
1 m
esec
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
32
44
52
22
53
24
25
52
33
43
24
33
43
24
34
43
478
C1
23
22
44
45
24
44
33
23
24
24
34
25
32
34
35
35
3,2
3,4
2,8
3,5
33,5
2,8
3,8
2,5
4,5
-0,2
-0,3
1,3
214/5
23
Y2011-0
2-2
1 2
1:0
4:2
22011-0
2-2
1 2
0:5
2:5
878.1
57.4
.115
tanja
.dim
itro
vska@
yahoo.c
om
Fem
enin
o26
ne s
tudir
am
16
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado b
ajo
(C
1)
11
15
55
51
55
45
45
55
44
55
55
55
52
55
54
55
580
C1
15
55
55
55
55
55
25
14
41
55
54
45
55
45
55
55
4,3
4,5
3,3
5,0
44,8
4,8
3,8
4,5
5,0
-0,3
1,3
2,5
246/3
04
Y2011-0
2-2
7 1
6:4
8:0
22011-0
2-2
7 1
6:3
8:0
589.2
05.5
7.1
13
jord
evs
tefa
n@
yahoo.c
om
Masculin
o21
""S
s.
Cyri
l and M
eth
odiu
s"
12
US
A 7
meseci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
51
21
55
15
51
15
15
11
51
51
11
11
11
15
11
15
184
C1
11
11
11
11
55
15
15
55
12
11
11
15
11
15
15
15
2,5
2,1
23,0
23
1,0
2,3
1,0
4,0
0,4
0,8
2,0
253/5
88
Y2011-0
2-2
8 2
3:4
8:5
12011-0
2-2
8 2
3:2
0:1
392.5
3.3
0.1
71
mark
ovs
ki.vi
kto
om
Masculin
o21
Evr
opski U
niv
erz
itet na R
epublik
a M
akedonija
10
Nov
Zela
nd,
5 g
odin
iM
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
11
11
13
11
31
13
15
41
54
41
42
11
34
35
31
55
282
C1
11
34
22
14
34
33
45
15
11
15
11
11
11
45
35
13
2,9
2,2
2,5
3,0
24
1,5
2,0
1,8
3,5
0,7
1,0
2,5
326/7
61
Y2011-0
6-2
4 2
0:1
6:1
52011-0
6-2
4 2
0:1
4:1
077.2
9.2
53.9
6nata
shapetr
evs
ka@
gm
ail.
com
Fem
enin
o27
mashin
ski fa
kulte
t11
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
32
23
22
32
33
32
23
32
33
32
33
23
42
33
23
33
277
C1
23
33
23
33
23
42
23
23
22
23
23
32
23
33
23
33
2,7
2,6
23,0
32,8
2,0
2,8
2,8
2,8
0,1
0,3
0,8
265/1
1Y
2011-0
3-0
2 1
7:0
4:1
12011-0
3-0
2 1
6:5
5:4
077.2
9.1
13.1
71
sera
fim
ovs
ka.jana@
gm
ail.
com
Fem
enin
o13
o.u
. m
irce a
cev
5M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado b
ajo
(C
1)
22
22
22
22
32
22
22
22
22
52
55
22
22
25
22
22
290%
od r
ecenic
ite d
obija
2 b
idejk
i bea g
ram
aticki nelo
gic
ni.
78
C1
22
25
25
22
25
22
22
22
22
22
22
22
22
25
22
23
2,6
2,3
23,5
22,8
2,0
2,0
2,0
3,0
0,3
1,5
2,3
270/5
07
Y2011-0
3-0
3 2
3:3
4:1
92011-0
3-0
3 2
3:1
5:4
589.2
05.2
0.1
41
limbam
k@
gm
ail.
com
Fem
enin
o29
ne s
tudir
am
12
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
11
24
24
53
45
44
14
52
43
41
34
12
31
44
21
24
4O
dgovo
rite
odnosno o
cenuva
nje
to o
d 1
do 5
e m
n g
enera
lno.
80
C1
15
43
44
45
44
34
14
34
12
22
11
42
15
34
24
24
3,6
2,5
2,5
4,3
3,5
41,3
3,0
2,8
3,0
1,1
1,3
2,3
272/3
69
Y2011-0
3-0
4 1
5:4
1:3
02011-0
3-0
4 1
4:5
6:3
579.1
25.1
91.2
31
despin
apoposka@
rocketm
ail.
com
Fem
enin
o25
12
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
11
11
15
11
15
13
15
11
11
51
15
14
15
11
25
15
579
C1
15
11
55
11
55
13
55
11
11
11
15
11
11
11
25
41
2,9
1,8
45,0
11,5
1,3
3,0
1,8
1,0
1,1
2,0
1,5
C1
1,3
3,0
2,7
3,5
3,2
3,3
2,5
3,5
3,2
4,1
2,8
3,7
2,2
3,7
2,5
3,6
1,8
1,7
2,0
3,0
1,8
2,3
2,3
2,7
1,8
2,7
2,2
4,0
2,2
3,6
2,5
3,9
C1
3,0
2,5
C1
2,5
3,5
2,6
3,6
C1
1,9
2,6
2,3
3,4
C1
0,5
C1
0,9
C1
2,0
80/2
2Y
2011-0
2-0
4 1
7:5
3:3
22011-0
2-0
4 1
7:3
8:2
992.5
3.3
6.2
54
kik
ica_del@
yahoo.c
omFem
enin
o25
ne s
tudir
am
12
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
33
44
53
54
45
34
23
33
33
42
34
24
42
43
33
34
486
C2
35
43
44
43
34
44
24
43
24
33
23
35
25
33
33
44
3,6
3,3
34,3
43,3
2,3
3,8
3,3
3,8
0,4
0,5
0,5
112/8
01
Y2011-0
2-0
6 0
0:2
7:1
32011-0
2-0
6 0
0:1
6:1
179.1
25.1
89.1
42
em
a_m
ak@
yahoo.c
omFem
enin
o26
Ne s
tudir
am
8A
nglij
a 4
godin
iM
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
11
11
54
13
54
31
11
11
51
11
45
11
11
21
11
15
186
C2
14
24
15
11
41
11
15
35
11
11
11
35
11
11
11
15
2,5
1,6
1,8
3,8
1,8
2,8
1,0
1,0
1,5
3,0
0,9
2,8
3,0
157/7
70
Y2011-0
2-1
6 1
5:2
9:1
32011-0
2-1
6 1
5:1
4:5
877.2
9.1
33.1
64
jasjo
vanova
@yahoo.c
o.u
kF
em
enin
o31
ne s
tudir
am
12
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
13
52
51
13
55
14
13
21
41
31
44
11
11
45
11
45
1D
ali
navi
stina tre
ba s
am
o d
a s
e z
em
a v
o p
redvi
d r
edosle
dot na z
boro
vite
vo r
ecenic
ata
ili
i pra
viln
ata
, odnosno n
epra
viln
ata
upotr
eba n
a o
dre
deni zboro
vi i u
potr
eba n
a d
rugi zboro
vi n
am
esto
niv
?92
C2
35
44
14
22
13
14
15
34
15
14
11
15
11
15
13
15
2,9
2,3
1,5
4,3
2,5
3,5
1,0
2,5
1,0
4,8
0,6
1,8
3,8
200/4
12
Y2011-0
2-1
8 0
9:4
3:1
72011-0
2-1
8 0
9:3
5:2
362.1
62.1
21.1
94
nik
olo
vskam
eri
@gm
ail.
com
Fem
enin
o33
Univ
erz
itet S
v.K
iril
i M
eto
di
12
Anglij
a,
3 m
eseci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
12
51
52
11
53
14
14
32
42
42
55
22
21
45
23
55
286
C2
23
45
25
13
24
24
15
14
15
25
23
15
21
25
24
25
3,0
2,9
1,8
4,3
24
1,8
3,3
1,8
5,0
0,1
1,0
4,5
209/6
04
Y2011-0
2-2
0 2
0:4
5:3
02011-0
2-2
0 2
0:2
5:5
278.1
57.4
.115
sasodim
itro
vski1
982@
yahoo.c
om
Masculin
o28
Univ
erz
itet S
v. K
iril
i M
eto
dij
12
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
11
31
55
41
53
15
12
21
41
41
24
22
11
14
11
22
188
C2
13
12
14
12
54
15
12
14
13
12
11
15
24
14
12
25
2,4
2,3
23,3
13,3
1,3
2,5
1,3
4,0
0,1
0,8
3,5
236/5
54
Y2011-0
2-2
6 2
2:3
4:2
02011-0
2-2
6 2
2:2
4:3
379.1
25.2
48.1
13
mis
s_m
ari
ja@
yahoo.c
om
Fem
enin
o22
ne s
tudir
am
12
US
A -
7 m
eseci; C
anada -
3 m
eseci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado b
ajo
(C
1)
44
24
42
34
54
23
13
42
42
52
44
24
33
45
34
54
586
C2
44
44
54
44
25
33
34
44
12
25
24
24
23
25
33
45
3,8
3,1
3,5
4,3
3,8
3,8
2,0
3,0
2,5
4,8
0,8
1,3
0,8
243/4
5Y
2011-0
2-2
7 1
5:0
4:5
12011-0
2-2
7 1
4:5
1:4
077.2
8.5
.65
babid
aholm
s@
yahoo.c
om
Fem
enin
o14
Peta
r P
op A
rsov
7M
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado b
ajo
(C
1)
12
35
53
35
53
35
13
52
53
21
53
11
11
25
11
45
194
C2
23
25
13
55
32
15
15
55
13
24
11
35
13
35
13
15
3,3
2,6
1,8
3,3
3,3
51,0
2,5
2,3
4,8
0,7
0,8
3,3
244/2
04
Y2011-0
2-2
7 1
6:0
8:0
92011-0
2-2
7 1
5:5
1:3
977.2
8.2
18.2
45
ivj0
00555@
gm
ail.
comM
asculin
o22
Kir
il i M
eto
dij
Skopje
91 g
odin
a U
SA
i U
K z
aedno
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado b
ajo
(C
1)
12
22
43
23
52
24
13
33
53
42
44
23
42
25
24
54
3?? ?
?????? ?
???? ?
????? ?
? ?
? ?
???? ?
???????? ?
? ?
?????? ?
?????????.
???????? ?
? ?
??? ?
?? ?
? ?
? ?
???? ?
? ?
???? ?
??????? ?
???????..
...
86
C2
22
24
34
23
34
44
24
35
12
35
24
24
22
35
23
35
3,2
3,0
2,5
3,5
2,8
41,8
2,8
2,8
4,8
0,2
0,8
2,3
276/6
76
Y2011-0
3-0
8 1
8:3
5:3
22011-0
3-0
8 1
8:2
5:3
977.2
8.1
1.1
43
bra
nkic
aiv
anova
@gm
ail.
com
Fem
enin
o31
ne s
tudir
am
12
Am
eri
ka-6
meseci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado b
ajo
(C
1)
21
13
33
33
25
44
34
31
53
53
45
32
32
44
34
35
385
C2
15
44
35
33
35
34
25
35
31
13
34
43
33
34
34
22
3,6
2,9
2,3
5,0
3,3
43,0
3,0
2,5
3,0
0,8
2,0
3,5
322/6
77
Y2011-0
6-2
4 1
4:0
4:4
22011-0
6-2
4 1
4:0
0:0
995.8
6.2
2.1
3ta
tjana@
trave
o.c
om
.mk
Fem
enin
o29
ne s
tudir
am
10
uk 3
meseci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
51
12
12
11
22
12
11
21
21
21
12
11
11
12
11
12
191
C2
12
11
12
22
22
12
12
12
11
11
11
11
11
12
11
12
1,6
1,1
1,3
2,0
1,3
1,8
1,0
1,0
1,0
1,5
0,4
1,0
1,3
327/7
56
Y2011-0
6-2
5 2
1:0
1:4
62011-0
6-2
5 2
0:5
4:5
377.2
9.2
53.9
6m
ilena.c
vetk
ova
@yahoo.c
om
Fem
enin
o24
Filo
zofs
ki fa
kulte
t12
Am
eri
ka ,
5 m
eseci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado b
ajo
(C
1)
22
22
23
32
23
32
23
32
32
32
22
23
22
22
22
22
295
C2
23
22
22
23
33
22
22
23
22
22
22
32
23
22
23
32
2,3
2,3
2,3
2,5
22,5
2,0
2,5
2,5
2,0
0,1
0,0
0,8
328/7
6Y
2011-0
6-2
5 2
2:5
1:3
02011-0
6-2
5 2
2:3
6:1
746.2
17.6
9.1
67
sonja
georg
ieva
@yahoo.c
om
Fem
enin
o28
ne s
tudir
am
8E
ngla
nd 5
month
sM
acedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
11
41
13
31
55
25
15
21
52
51
55
33
54
33
35
14
495
C2
15
35
45
12
35
55
44
15
14
11
15
21
33
23
35
35
3,6
2,7
34,8
2,5
4,3
2,0
4,3
2,0
2,5
0,9
0,5
3,5
343/4
14
Y2011-0
7-0
9 0
1:4
6:2
12011-0
7-0
9 0
1:2
4:5
192.5
3.3
3.5
2iv
_oko@
yahoo.c
om
Masculin
o25
Prv
Pri
vate
n U
niv
erz
itet -
FO
N13
Am
eri
ka,
4 m
eseci
Macedonia
nM
acedonia
nM
acedonia
nM
acedonia
nA
vanzado a
lto (
C2)
42
32
25
13
45
23
13
41
11
42
45
21
13
41
14
15
288
C2
25
44
25
24
54
13
35
31
13
11
24
22
21
11
13
14
3,3
1,9
34,8
2,5
31,5
2,8
1,3
2,0
1,4
2,0
2,3
C2
1,9
3,8
2,8
3,6
2,3
4,0
2,3
2,8
3,0
3,5
2,2
3,5
1,8
4,0
2,6
3,8
1,3
2,8
1,6
2,8
1,6
2,6
2,2
3,6
1,8
2,4
1,9
3,5
1,8
2,9
2,2
4,2
C2
3,0
2,5
C2
2,3
3,8
2,5
3,5
C2
1,7
2,7
2,0
3,5
C2
0,6
C2
1,2
C2
2,5

214
11.5 CHARTS FOR THE MAIN EXPERIMENT (CHART OUTPUTS)
In this section we will present all the bar charts and the trend charts from the raw
results. A selection of these charts has been used in the Results chapter in this
dissertation. Charts will be presented according to L1: L1 Spa-L2 Eng and L1 Maced-
L2 Eng. The English natives are shown in each learner chart.
11.5.1 CHARTS FOR THE MAIN EXPERIMENT: L1 SPA – L2 ENG LEARNERS
215
11.5.2 CHARTS FOR THE MAIN EXPERIMENT: L1 MACED – L2 ENGLISH
LEARNERS
11.6 EMAIL: INVITATION TO PARTICIPATE
In this appendix we will list the emails that were sent to all speakers inviting them to
participate in the main online experiment: SAES for the English natives, EASI for the
Spanish natives and IUSAJ for the Macedonian natives.

216
11.6.1 PARTICIPATE IN SAES (INVITATION FOR ENGLISH NATIVES)
-------- Original Message --------
Subject: Study on the Acquisition of English Syntax (SAES)
-- online participation
Date: Wed, 20 Jul 2011 18:16:13 +0200
To: [deleted list of recipients]
Dear friends and colleagues:
I have a little favour to ask you. We're conducting a pilot
study on how Spanish speakers learn English grammar. For
technical reasons, we need a group of English native
speakers to participate in the study.
If you are not a native speaker of English, please forward
this email to natives who might be interested in
participating.
If you are a native speaker of English I would be very
grateful if you could spend a few minutes to complete the
online questionnaire. It is very simple: you just have to
judge whether you like some English sentences or not.
Please, forward this message to other English native
speakers who could be interested. Thank you!
LINK:
http://test.ugr.es/limesurvey/index.php?sid=83934&lang=en

217
11.6.2 PARTICIPATE IN EASI (INVITATION FOR L1 SPANISH-L2 ENGLISH
LEANERS)
-------- Original Message --------
Subject: PARTICIPE EN "EASI" (Estudio sobre la Adquisición
de la Sintaxis del Inglés)
Date: 12 Feb 14:45:41 +0100
PARTICIPE EN "EASI" (Estudio sobre la Adquisición de la
Sintaxis del Inglés)
¿QUÉ ES "EASI"? "Easi" un proyecto de investigación de
la Universidad de Granada y la Universidad Autónoma de
Madrid en el que estamos estudiando cómo los hablantes
nativos de español aprenden inglés.
¿CÓMO PARTICIPO? Participar en el estudio es muy
sencillo. El estudio está disponible "online" y usted
simplemente tendrá que decidir si unas oraciones le suenan
mejor que otras. Puede participar cualquier hablante de
español que sepa (o esté aprendiendo) inglés, de cualquier
nivel.
¿QUÉ OBTENGO POR PARTICIPAR? Una vez concluida la
prueba de nivel, usted podrá conocer GRATUITAMENTE su nivel
gramatical en inglés (A1, A2, B1, etc). Además, el programa
le indicará especificamtamente qué aspectos gramaticales
puede usted mejorar. Finalmente, le enviaremos un

218
certificado de participación sellado por la Universidad
Autónoma de Madrid.
PARA PARTICIPAR, vaya al siguiente enlace:
http://test.ugr.es/limesurvey/index.php?sid=68427&lang=es
11.6.3 PARTICIPATE IN IUSAJ (INVITATION FOR L1 MACEDONIAN-L2
ENGLISH LEANERS)
-------- Original Message --------
Asunto: Doznajte go vaseto nivo na angliski jazik i
ucestvuvajte vo istrazuvanjeto IUSAJ
Desde: [email protected]
Fecha: 2011.02.24 10:07 pm
Prioridad: Normal
DALI SAKATE DA GO DOZNAETE VASETO NIVO NA POZNAVANJE NA
GRAMATIKA NA
ANGLISKIOT JAZIK
ZEMETE UCESTVO VO ISTRAZUVANJETO IUSAJ (Istrazuvanje za
Usvojuvanje na
Sintaksata na Angliskiot Jazik)
** ¿”STO E IUSAJ”
IUSAJ (Istrazuvanje za Usvojuvanje na Sintaksata na
Angliskiot Jazik) e
istrazuvacki proekt na Univerzitetot vo Granada i
Avtonomniot Univerzitet
vo Madrid koj proucuva kako govoritelite na makedonski
jazik go usvojuvaat
angliskiot jazik.
** ¿KAKO DA UCESTVUVAM?
Ucestvoto e mnogu ednostavno. Istrazuvanjeto e dostapno
“onlajn” i vie
samo treba da odlucite koja recenica vi zvuci dobro a koja
ne. Moze da

219
ucestvuvaat samo govoriteli na makedonski jazik kako majcin
jazik koi ucat
ili imaat poznavanje od angliski jazik (bilo koe nivo).
ZABELESKA:ZA DA BIDAT VALIDNI VASITE REZULTATI TREBA DA GI
RESITE DVATA
TESTA I NA SEKOJ TEST DA JA VPISETE ISTATA EMAIL ADRESA.
** ¿STO DOBIVAM SO MOETO UCESTVO? Po zavrsuvanjeto na
testot za
odreduvanje na nivo na angliskiot jazik ke dobiete
informacija za vaseto
nivo na angliski jazik (A1, A2, B1 itn.) Dopolnitelno,
programata
vi ukazuva koi gramaticki aspekti mozete da gi podobrite.
Otkoga ke gi dobieme vasite rezultati ke vi ispratime na
email elektronski
sertifikat za ucestvo.
** ZA DA UCESTVUVATE prodolzete na sledniov link:
http://test.ugr.es/limesurvey/index.php?sid=46846&lang=mk
Dopolnitelno, dokolku mozete slobdno prepratete go ovoj
email na vasi
poznajnici koi smetate deka bi sakale da go doznaat nivnoto
nivo na
poznavanje na angliskiot jazik.
Vi blagodaram ucestvoto vo ova istrazuvanje koe e del od
mojot magisterski
trud
So pocit,
Aleksandra Simonovikj
11.7 EMAIL: SEE YOUR RESULTS
In this section we will present the email that was sent to learners stating how they could
check their OPT results after participating in the online test. Obviosly, there is no such
email that was sent to English natives, since they did not participate in the placement
test.

220
11.7.1 EMAIL SENT TO L1 SPA-L2 ENG LEARNERS: SEE YOUR RESULTS
This email was only sent to Macedonian group due to the fact that sometimes the
system would not show the OPT results immediately after the test was completed. The
system worked properly for the Spanish participants hence there was not need to send
this email.
11.7.2 EMAIL SENT TO L1 MACED-L2 ENG LEARNERS: SEE YOUR RESULTS
Asunto: IUSAJ rezultati
Desde: [email protected]
Fecha: 2011.03.02 3:01 pm
Prioridad: Normal
Pocituvan,
Dokolku ne gi dobivte rezultatite od testiranjeto za IUSAJ
(Istrazuvanje za Usvojuvanje na Sintaksata na Angliskiot
Jazik) vi go prakam linkot na koj ke mozete da gi vidite
vasite rezultati od QPT (Quick
Placement Test) za odreduvanje na nivo na gramatika na
angliskiot jazik.
http://www.wagsoft.com/cgi-bin/showDiagnostics-
gr.cgi?i.dalas%40hotmail.com
Vi blagodaram,
So pocit,
11.8 EMAIL: PLEASE COMPLETE THE OPT
In this section we will list the emails that were sent to participants who took the first
part of the main test (SAES/EASI/IUSAJ) but did not participate in the second part (i.e.,
the Oxford Placement Test, OPT). This email was used to nudge them so that they did
not forget to participate in the OPT.

221
11.8.1 EMAIL SENT TO L1 SPA-L2 ENG LEARNERS: PLEASE COMPLETE THE
OPT
-------- Original Message --------
Subject: Estudio "EASI" **** falta el Oxford Placement
Test
Date: Mon, 29 Nov 2010 18:39:18 +0100
From: Cristóbal Lozano <[email protected]>
Estimado/a participante:
Hemos recibido tus datos del estudio "EASI" (Estudio sobre
la Adquisición de la Sintaxis del Inglés) y agradecemos
enormemente tu participación.
Para que tus datos sean válidos, hemos de recibir el test
de nivel (Oxford Placement Test). Al completar el test, el
software te proporcionará tu nivel de inglés (A1, A2, B1,
B2, C1, C2). Además, también se te indicará los áreas
gramaticales que has de mejorar. Finalmente, te enviaremos
también un certificado de participación impreso, firmado y
sellado por la Universidad Autónoma de Madrid, para hacer
constar que has participado en "EASI".
Para hacer el Oxford Placement Test:
http://www.wagsoft.com/OPT/OPT-gr.html
Nota: es imprescindible que introduzcas el mismo email que
introdujiste para EASI. Así, podremos enviarte los
resultados.

222
11.8.2 EMAIL SENT TO L1 MACED-L2 ENG LEARNERS: PLEASE COMPLETE
THE OPT
Asunto: Ve molime resete go testot za odreduvanje na
nivo (OPT)
Desde: [email protected]
Fecha: 2011.06.24 1:49 pm
Prioridad: Normal
Pocituvani,
Ve molime resete go testot za odreduvanje na nivo na
angliskiot jazik za
da go doznaete vasiot stepen na poznavanje na angliskiot
jazik i za da
mozeme da gi procesirame vasite rezultati za istrazuvanjeto
“IUSAJ”
(Istrazuvanje za Usvojuvanje na Sintaksata na Angliskiot
Jazik)i da vi
ispraime sertifikat za ucestvo.
ZABELESKA: neophodno e da ja navedete istata e-mail adresa
koja veke ja
napisavte vo vovedniot del na prasalnikot “IUSAJ” za da
mozeme de gi
odredime vasite rezultati.
Za da pocnete so resavanje na Oksford testot za odreduvanje
na
gramaticko nivo kliknete ovde:
http://www.wagsoft.com/OPT/OPT-gr.html
Vi blagodarime
11.9 CERTIFICATE OF PARTICIPATION
In this appendix we will list the email that was sent to learners asking them whether
they would like to receive a certificate of participation, plus the actual certificate of
participation that was sent to all those speakers that successfully completed both the

223
online experiment on unaccusatives (SAES/EASI/IUSAJ) and the Oxford Placement
Test.
11.9.1 CERTIFICATE OF PARTICIPATION FOR L1 SPA-L2 ENG LEARNERS
-------- Original Message --------
Subject: Estudio "EASI" --- certificado de participación
Date: Mon, 15 Nov 2010 19:27:06 +0100
From: Cristóbal Lozano <[email protected]>
Estimado/a participante:
Gracias por haber participado recientemente en el estudio
"EASI" (Estudio sobre la Adquisición de la Sintaxis del
Inglés).
Si así lo deseas, podrás recibir un certificado de
participación impreso y sellado por la Universidad Autónoma
de Madrid.
Si estás interesado, responde a este email y envía los
siguientes datos:
Email (el que proporcionaste al hacer el test)
Nombre y apellidos
Dirección postal a donde remitir el certificado impreso
Gracias.
Cristóbal Lozano (Universidad de Granada)
Si deseas conocer más sobre nuestros proyectos de
investigación: http://www.uam.es/woslac

224
Amaya Mendikoetxea Pelayo,
CERTIFICA
Que [NOMBRE Y APELLIDOS] ha participado el [FECHA] en el estudio
online “EASI” (Estudio sobre la Adquisición de la Sintaxis del Inglés), que se
enmarca dentro el proyecto de investigación OPOGRAM (Opcionalidad y
pseudo-opcionalidad en las gramáticas nativas y no nativas: FFI2008-
01584/FILO), dirigido desde la Universidad Autónoma de Madrid en el
seno del grupo de investigación WOSLAC (www.uam.es/woslac) .
Para lo cual firmo este documento en Madrid a [FECHA].
Fdo: Dra. Amaya Mendikoetxea Pelayo
Departamento de Filología Inglesa (UAM)
Directora del proyecto de investigación
http://www.uam.es/woslac

225
11.9.2 CERTIFICATE OF PARTICIPATION FOR L1 MACED-L2 ENG LEARNERS
Asunto: Blagodarnica za ucestvo vo IUSAJ (Istrazuvanje
za Usvojuvanje na Sintaksata na Angliskiot
Jazik)
Desde: [email protected]
Fecha: 2011.04.17 8:45 pm
Prioridad: Normal
Pocituvana,
Vi ja prakam prikacena blagodarnicata za ucestvo vo IUSAJ
(Istrazuvanje za
Usvojuvanje na Sintaksata na Angliskiot Jazik).
So pocit,
Aleksandra Simonovikj

226
БЛАГОДАРНИЦА ЗА УЧЕСТВО
вп
Истражуваоетп за Усвпјуваое на Синтаксата на Англискипт Јазик
Ппчитуван учеснику, Ви благпдариме за вашетп учествп и за времетп кпе гп пдвпивте за истражуваоетп ИУСАЈ (Истражуваое за Усвпјуваое на Синтаксата на Англискипт Јазик). Вашите ппдатпци, кпи се дел пд истражуваое за усвпјуваое на втпр јазик спрпведенп пд Автпнпмнипт Универзитет вп Мадрид и Универзитетпт вп Гранада, Шпанија, се чувани сп дпверливпст и ќе бидат упптребени за истражувачки цели.
Вашипт придпнес кпн пвпј прпект е пд пгрпмнп значеое. Благпдарение на дпбрпвплнптп учествп на луде какп вас, веќе гп
имаме првичнипт брпј на ппдатпци пптребни за пва истражуваое.
Дпкплку сакате да дпзнаете ппвеќе инфпрмации за истражувачкипт прпект ппсетете ја веб страницата
http://www.uam.es/ woslac.
Сп ппчит,
Александра Симпнпвиќ
Студент на ппстдиплпмски студии пп применета лингвистика
на Универзитетпт вп Гранада, Шпанија
ппд ментпрствп на
Прпф. Кристпбал Лпзанп Prof. Cristóbal Lozano
Предавач пп применета лингвистика Lecturer in applied linguistics Оддел за англистика Department of English Studies
Универзитет вп Гранада, Шпанија Universidad de Granada (Spain)
Top Related