







Languages
Pages
Legal


Design Methodology for Customizable Design Methodology for Customizable Programmable ProcessorsProgrammable Processors
Berkeley – Finland Day, Oct. 18, 2002Berkeley – Finland Day, Oct. 18, 2002
Prof. Jarmo TakalaInstitute of Digital and Computer Systems
Tampere University of TechnologyTampere, Finland
Tel: +358 – 33115 3879; Email: [email protected]

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
OutlineOutline
MotivationTransport Triggered Architecture (TTA)Design Methodology for TTAsResearch at TUTConclusions

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
MotivationMotivation
Programmable processors often used in products using digital signal processing (DSP)Flexibility
Ease of verification
Traditionally DSP processor architectures have been developed based on average performance in several benchmark tasks (~100)User applications often contain only subset of total
benchmarks
Efficiency can be improved by customizing architecture according to given tasks

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
MotivationMotivationDSP applications are often hard realtime
constrainedexecution should be deterministicdynamic runtime behaviours should be avoided
Static scheduling lends itself to DSP
Current design complexities call for increase in designer productivity
High level languages should be used
DSP algorithms contain inherent parallelism
Instruction level parallelism (ILP) should be maximized

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
What is needed?What is needed?
Application driven design process with easy design space exploration
Replace hardware complexity by software complexityCompiler driven process
Use templated architectureFlexible
heterogeneous function units
Modularscalability
Orthogonalcompiler friendly

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
Choices for Architecture TemplateChoices for Architecture Template
FrontendFrontend
Application
sequential(superscalar)
dependence
(dataflow)
independence
(EPIC)
independence
(VLIW)
Compilation time(Software)
Determine DependenciesDetermine Dependencies
Determine IndependenciesDetermine Independencies
Bind Function UnitsBind Function Units
Determine DependenciesDetermine Dependencies
Determine IndependenciesDetermine Independencies
Bind Function UnitsBind Function Units
Bind Datapaths & ExecuteBind Datapaths & Execute
Run time(Hardware)
ILP Architectures

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
VLIW Gained Popularity in DSPVLIW Gained Popularity in DSP
Re
gis
ter
File
Inst
ruct
ion
Fet
ch
Inst
ruct
ion
Dec
ode
Dat
a M
emor
y
Inst
ruct
ion
Mem
ory
Byp
assi
ng
Net
wo
rkCPU
FU-1
FU-2
FU-3
FU-4
FU-5

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
Transport Triggered ArchitectureTransport Triggered Architecture
VLIW drawbacksBypass complexityRegister file complexityRegister file design restricts FU flexibilityOperation encoding format restricts FU flexibility
Reverse programming paradigm [H. Corporaal, 94]
data transport operation
Instruction set contains only a single instruction: move

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
From VLIW to TTAFrom VLIW to TTA
Re
gis
ter
File
Byp
assi
ng
Net
wo
rkVLIW
Inst
ruct
ion
Fet
ch
Inst
ruct
ion
Dec
ode
Inst
ruct
ion
Mem
ory
FU-1
FU-2
FU-3
FU-4
FU-5
Dat
a M
emor
y
Inst
ruct
ion
Fet
ch
Inst
ruct
ion
Dec
ode
Byp
assi
ng
Net
wo
rk
FU-1
FU-2
FU-3
FU-4
FU-5
RegisterFileTTA
J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
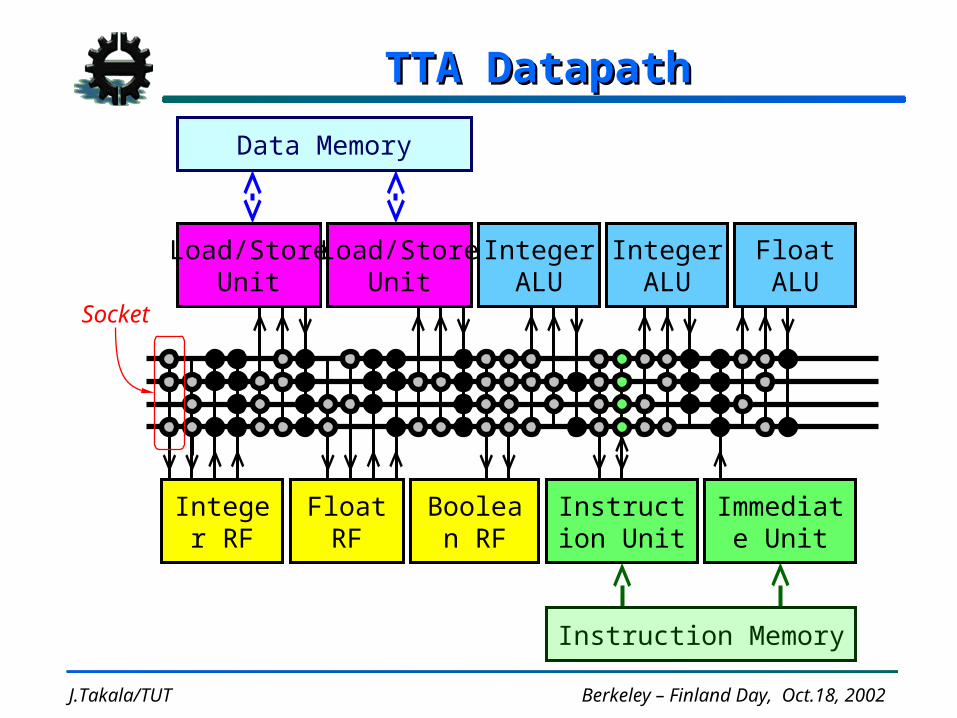
TTA DatapathTTA Datapath
IntegerALU
IntegerALU
FloatALU
Boolean RF
Float RF
Integer RF
Socket
Instruction Memory
Data Memory
Load/StoreUnit
Load/StoreUnit
Immediate Unit
Instruction Unit
J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
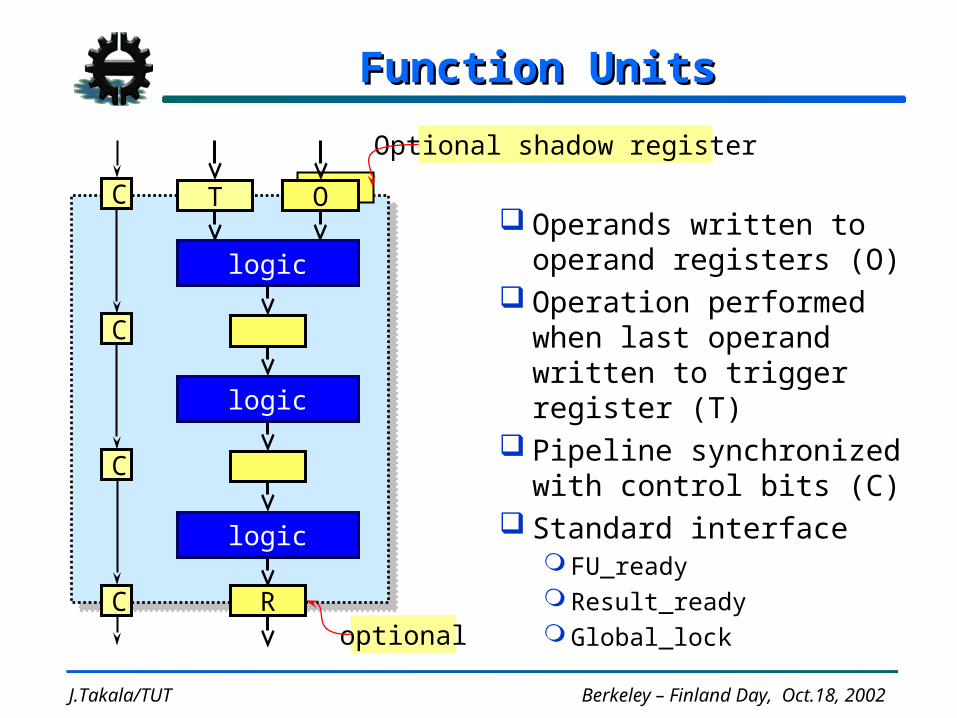
Function UnitsFunction Units
Operands written to operand registers (O)
Operation performed when last operand written to trigger register (T)
Pipeline synchronized with control bits (C)
Standard interface FU_ready Result_ready Global_lock
T
optional
Optional shadow register
O
logic
logic
R
logic
C
C
C
C

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
ILP ArchitecturesILP Architectures
FrontendFrontend
Application
sequential(superscalar)
dependence
(dataflow)
independence
(EPIC)
independence
(VLIW)
Compilation time
independence
(TTA)
Determine DependenciesDetermine Dependencies
Determine IndependenciesDetermine Independencies
Bind Function UnitsBind Function Units
Bind DatapathsBind Datapaths
ExecuteExecute
Determine DependenciesDetermine Dependencies
Determine IndependenciesDetermine Independencies
Bind Function UnitsBind Function Units
Bind DatapathsBind Datapaths
Run time

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
TTA Characteristics: HWTTA Characteristics: HW
ModularCan be constructed with standard building blocks
Very flexible and scalableFU functionality can be arbitrarySupports user defined Special Function Units (SFU)
Lower complexityReduction on # register portsReduced bypass complexityReduction in bypass connectivityReduced register pressureTrivial decoding (implies long instructions)

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
TTA Characteristics: SWTTA Characteristics: SW
Traditional operation-triggered instruction:
Transport-triggered instruction:
Reminds dataflow and time-stationary coding
mul r1,r2,r3;
r1mul.o; r2mul.t; mul.rr3;
r1mul.o, r2mul.t; mul.rr3;
or

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
TTA Design ToolsTTA Design Tools
Design tools based on TTA architecture template have been developed at Delft University of Technology (DUT), Delft, the NetherlandsMOVE project lead by Prof. Henk CorporaalFully parametric C/C++ Compiler
buses, connections, function units, register files, etc.
Design space explorerProcessor generator

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
Sequential Simulator
Sequential Simulator
Code Generation TrajectoryCode Generation Trajectory
I/O
Parallel Code
GCC or SUIF
Profiling Data
Parallel SimulatorParallel
Simulator
Compiler BackendCompiler Backend
Sequential Code
Application (C/C++)Ar
chite
ctur
e De
scrip
tion Compiler
FrontendCompiler Frontend
I/O
(MOVE Project at DUT)

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
TTA Specific OptimizationsTTA Specific OptimizationsTTA allows extra scheduling optimizationsE.g., software bypassing
Bypassing can eliminate the need of RF access
However, more difficult to schedule !
Example: r1 → add.o, r2 → add.t;add.r → r3;r3 → sub.o, r4 → sub.tsub.r → r5;
Translates to: r1 → add.o, r2 → add.t;add.r → sub.o, r4 → sub.t;sub.r → r5;

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
ResourceOptimization
ConnectivityOptimization
Design Space ExplorationDesign Space Exploration
Application(C/C++)
Application(C/C++)
Map&ScheduleMap&Schedule
FrontendFrontend
FU modelsCost Functions
FU modelsCost Functions
SimulatorSimulator
Resources(Mach)
Resources(Mach)
Map&ScheduleMap&Schedule
Design Point
SimulatorSimulator
Design Points
Select ResourcesSelect Resources
Reduce ConnectionsReduce Connections
(MOVE Project at DUT)

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
Exploration: Resourse OptimizationExploration: Resourse Optimization
Pareto curve represents the lowest bound of found architecture configurations
Selected architecture for further optimization
(MOVE Project at DUT)
IRUIRU
ALU ALU
IU
LSU
IU
LSU
IU
LSU

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
ExpExplloration: oration: CConnectivity onnectivity OptimizationOptimization(MOVE Project at DUT)
Reduced connections decrease bus delay
Critical connections have been removed
IRUIRU
ALU ALU
IU
LSU
IU
LSU
IU
LSU

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
Topics to be InvestigatedTopics to be Investigated Poor code density
good target for code compression techniques apriori information of application, thus instruction propabilities known
Estimations Power estimation Fast estimations with sufficient accuracy
Flexibity, reuse Applications may change, thus additional resources need to assigned
although not needed by the original application Tool-assisted special function unit generation
Analysis support Model creation support Characterization support
Parameterized processor generator Interconnections, control, etc. maybe realized in several ways depending on
the target Low-power optimizations
Clustered TTAs Interprocessor communication schemes
These topics considered in FlexDSP Project at TUT

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
Code Compression
Code Compression
New Design EnvironmentNew Design Environment
Functionality(C/C++)
Functionality(C/C++)
OperationAnalysis
OperationAnalysis
Parametric CompilerParametric Compiler Parametric Processor Generator
Parametric Processor Generator
ParallelObject Code
HDLCode
FrontendFrontend
Design SpaceExploration
Design SpaceExploration
FU models(C, HDL)
Cost Functions (area, power,
speed)
FU models(C, HDL)
Cost Functions (area, power,
speed)ResourceConstraints
ResourceConstraints
TTA Processor
SFU GenerationSFU Generation
Target of FlexDSP Project at TUT

J.Takala/TUT Berkeley – Finland Day, Oct.18, 2002
ConclusionsConclusions Design methodologies allowing processor
customization will improve efficiency in certain application areas, e.g., multimedia, telecom
TTA is a promising candidate for architectural template for customized processors In particular, support for custom function units allows
powerful tailoring Results of MOVE project at DUT have already proven
the concept Parameterized compiler allows tool-assisted design space
exploration Still more research needed on
Hardware implementations Enhanced compiler strategies
Top Related