




![Radiometry and Reflectance: From Terminology Concepts to ...docs.fct.unesp.br/docentes/carto/enner/PPGCC...[18:16 27/2/2009 5270-Warner-Ch15.tex] Paper Size: a4 paper Job No: 5270](https://static.fdocuments.in/doc/165x107/607434d9c04595405c48cb35/radiometry-and-reiectance-from-terminology-concepts-to-docsfctunespbrdocentescartoennerppgcc.jpg)


Languages
Pages
Legal


Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 11
ELEC 5270/6270 Fall 2007ELEC 5270/6270 Fall 2007Low-Power Design of Electronic CircuitsLow-Power Design of Electronic Circuits
Power Aware MicroprocessorsPower Aware Microprocessors
Vishwani D. AgrawalVishwani D. AgrawalJames J. Danaher ProfessorJames J. Danaher Professor
Dept. of Electrical and Computer EngineeringDept. of Electrical and Computer EngineeringAuburn University, Auburn, AL 36849Auburn University, Auburn, AL 36849
[email protected]://www.eng.auburn.edu/~vagrawal/COURSE/E6270_Fall07/course.html

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 22
SIA Roadmap for Processors (1999)SIA Roadmap for Processors (1999)YearYear 19991999 20022002 20052005 20082008 20112011 20142014
Feature size (nm)Feature size (nm) 180180 130130 100100 7070 5050 3535
Logic transistors/cmLogic transistors/cm22 6.2M6.2M 18M18M 39M39M 84M84M 180M180M 390M390M
Clock (GHz)Clock (GHz) 1.251.25 2.12.1 3.53.5 6.06.0 10.010.0 16.916.9
Chip size (mmChip size (mm22)) 340340 430430 520520 620620 750750 900900
Power supply (V)Power supply (V) 1.81.8 1.51.5 1.21.2 0.90.9 0.60.6 0.50.5
High-perf. Power (W)High-perf. Power (W) 9090 130130 160160 170170 175175 183183
Source: http://www.semichips.org

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 33
Power Reduction in ProcessorsPower Reduction in Processors
Just about everything is used.Just about everything is used. Hardware methods:Hardware methods:
Voltage reduction for dynamic powerVoltage reduction for dynamic power Dual-threshold devices for leakage reductionDual-threshold devices for leakage reduction Clock gating, frequency reductionClock gating, frequency reduction Sleep modeSleep mode
Architecture:Architecture: Instruction setInstruction set hardware organizationhardware organization
Software methodsSoftware methods

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 44
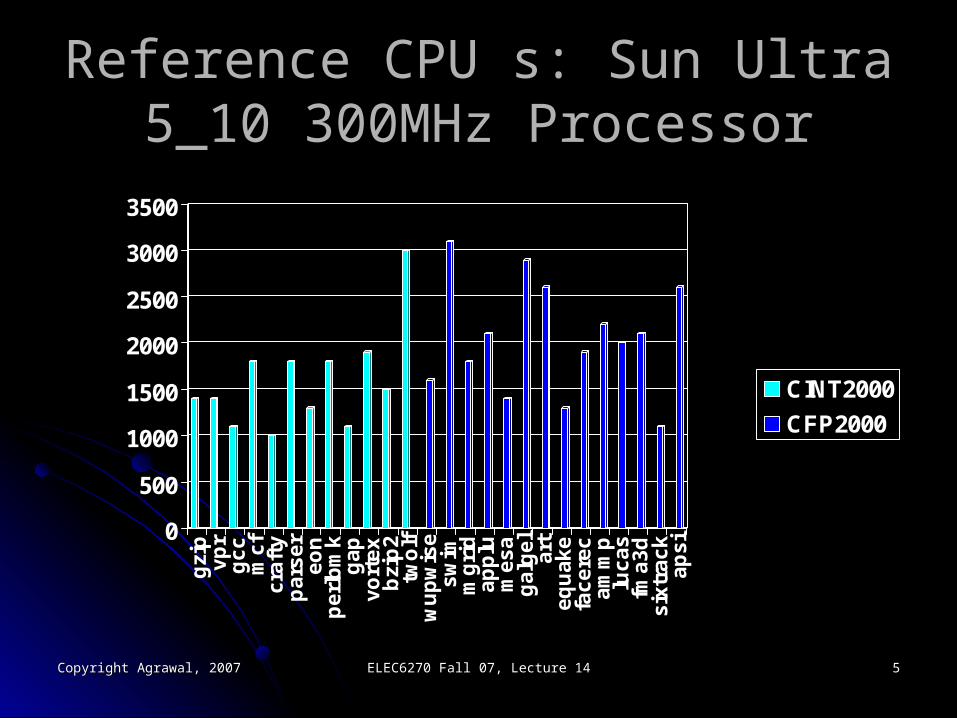
SPEC CPU2000 BenchmarksSPEC CPU2000 Benchmarks Twelve integer and 14 floating point programs, Twelve integer and 14 floating point programs,
CINT2000CINT2000 and and CFP2000CFP2000.. Each program run time is normalized to obtain a Each program run time is normalized to obtain a
SPEC ratioSPEC ratio with respect to the run time of with respect to the run time of Sun Sun Ultra 5_10 with a 300MHz processorUltra 5_10 with a 300MHz processor..
CINT2000CINT2000 and and CFP2000CFP2000 summary summary measurements are the geometric means of measurements are the geometric means of SPEC ratios.SPEC ratios.
LINPACK is numerically intensive floating point LINPACK is numerically intensive floating point linear system (Ax = b) program used for linear system (Ax = b) program used for benchmarking supercomputers.benchmarking supercomputers.
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 55
Reference CPU s: Sun Ultra 5_10 Reference CPU s: Sun Ultra 5_10 300MHz Processor300MHz Processor
0
500
1000
1500
2000
2500
3000
3500g
zip
vp
rg
cc
mc
fc
raft
yp
ars
er
eo
np
erl
bm
kg
ap
vo
rte
xb
zip
2tw
olf
wu
pw
ise
sw
imm
gri
da
pp
lum
es
ag
alg
el
art
eq
ua
ke
fac
ere
ca
mm
plu
ca
sfm
a3
ds
ixtr
ac
ka
ps
i
CINT2000
CFP2000
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 66
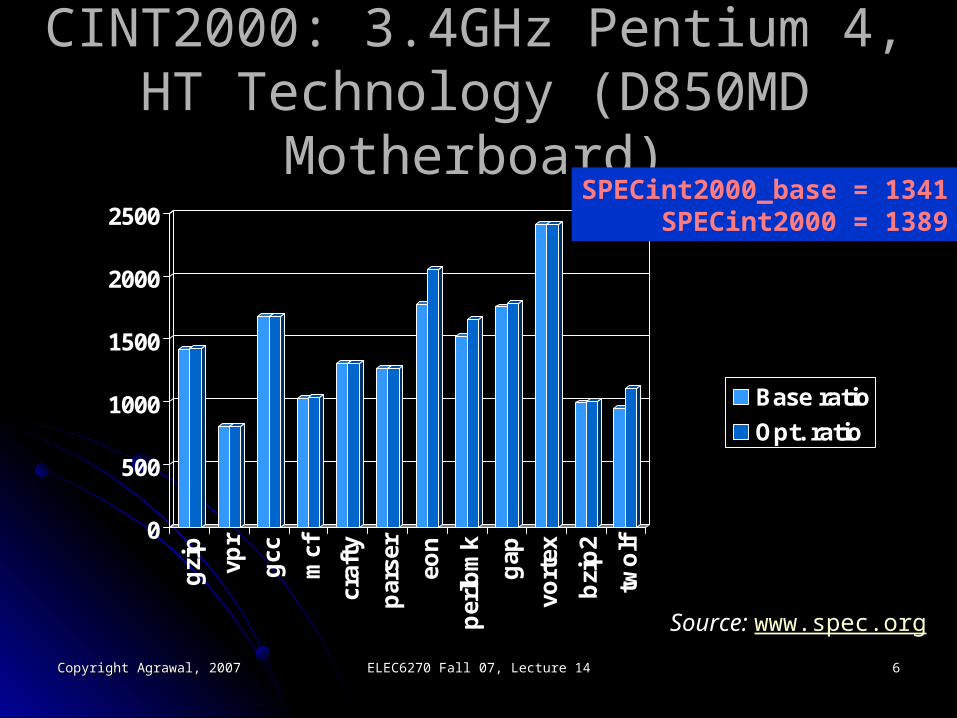
CINT2000: 3.4GHz Pentium 4, HT CINT2000: 3.4GHz Pentium 4, HT Technology (D850MD Motherboard)Technology (D850MD Motherboard)
0
500
1000
1500
2000
2500g
zip
vpr
gcc
mcf
craf
ty
par
ser
eon
per
lbm
k
gap
vort
ex
bzi
p2
two
lf
Base ratio
Opt. ratio
SPECint2000_base = 1341SPECint2000 = 1389
Source: www.spec.org

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 77
Two Benchmark ResultsTwo Benchmark Results
Baseline: A uniform configuration not Baseline: A uniform configuration not optimized for specific program:optimized for specific program:
Same compiler with same settings and flags used Same compiler with same settings and flags used for all benchmarksfor all benchmarks
Other restrictionsOther restrictions
Peak: Run is optimized for obtaining the Peak: Run is optimized for obtaining the peak performance for each benchmark peak performance for each benchmark program.program.
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 88
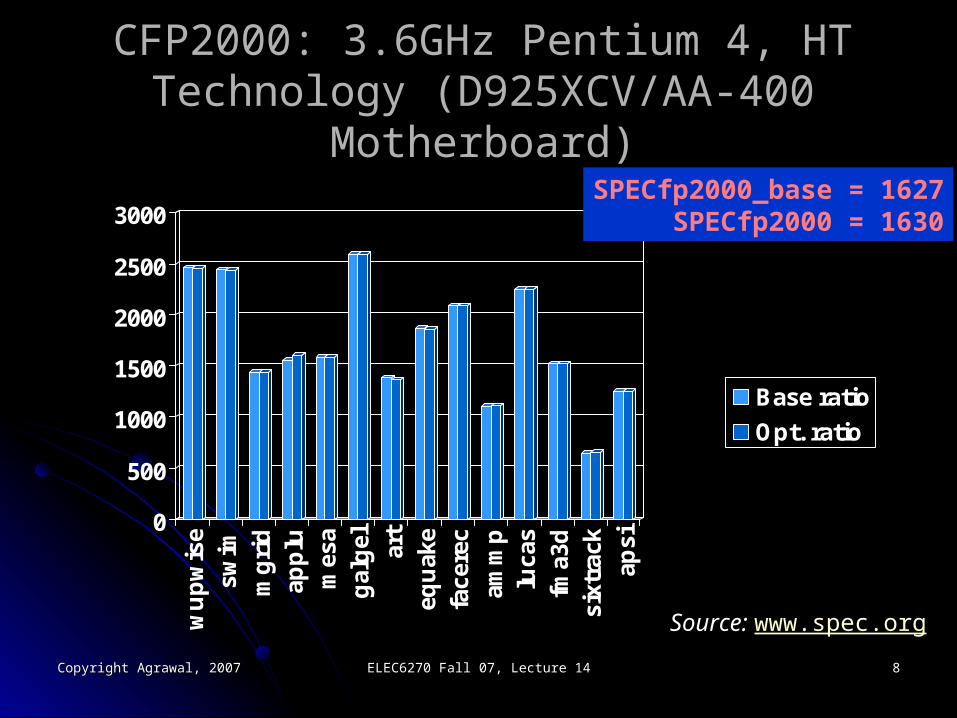
CFP2000: 3.6GHz Pentium 4, HT Technology CFP2000: 3.6GHz Pentium 4, HT Technology (D925XCV/AA-400 Motherboard)(D925XCV/AA-400 Motherboard)
0
500
1000
1500
2000
2500
3000w
up
wis
esw
im
mg
rid
app
lum
esa
gal
gel art
equ
ake
face
rec
amm
plu
cas
fma3
dsi
xtra
ck
apsi
Base ratio
Opt. ratio
SPECfp2000_base = 1627SPECfp2000 = 1630
Source: www.spec.org
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 99
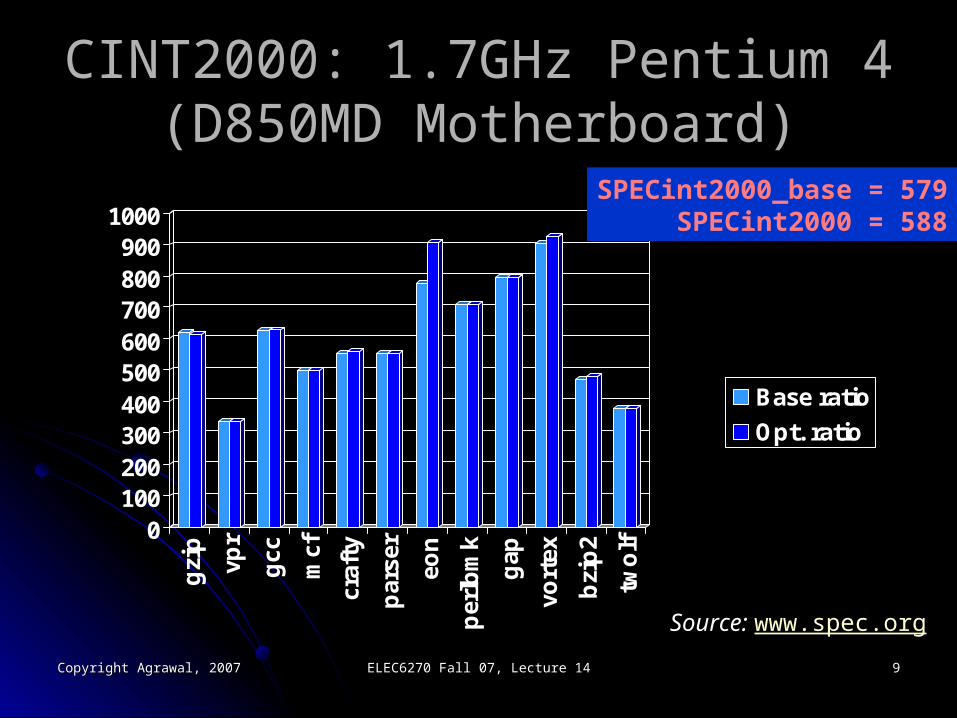
CINT2000: 1.7GHz Pentium 4CINT2000: 1.7GHz Pentium 4(D850MD Motherboard)(D850MD Motherboard)
0100200300400500600700800900
1000g
zip
vpr
gcc
mcf
craf
ty
par
ser
eon
per
lbm
k
gap
vort
ex
bzi
p2
two
lf
Base ratio
Opt. ratio
SPECint2000_base = 579SPECint2000 = 588
Source: www.spec.org
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 1010
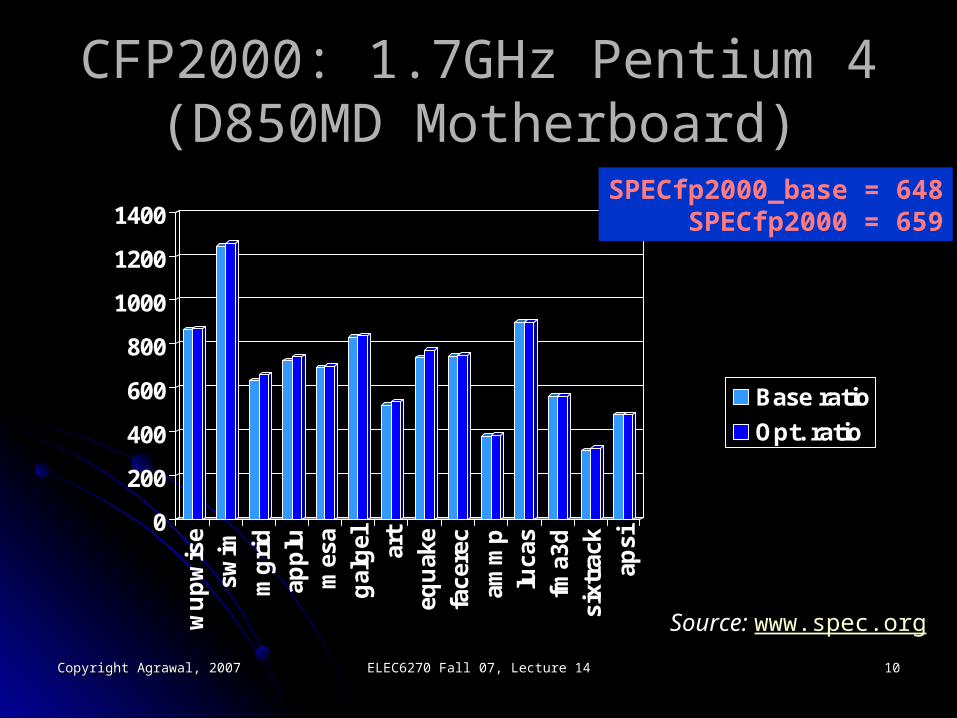
CFP2000: 1.7GHz Pentium 4 CFP2000: 1.7GHz Pentium 4 (D850MD Motherboard)(D850MD Motherboard)
0
200
400
600
800
1000
1200
1400w
up
wis
esw
im
mg
rid
app
lum
esa
gal
gel art
equ
ake
face
rec
amm
plu
cas
fma3
dsi
xtra
ck
apsi
Base ratio
Opt. ratio
SPECfp2000_base = 648SPECfp2000 = 659
Source: www.spec.org

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 1111
Energy SPEC BenchmarksEnergy SPEC Benchmarks
Energy efficiency mode: Besides the Energy efficiency mode: Besides the execution time, energy efficiency of SPEC execution time, energy efficiency of SPEC benchmark programs is also measured. benchmark programs is also measured. Energy efficiency of a benchmark program Energy efficiency of a benchmark program is given by:is given by:
1/(Execution 1/(Execution time)time)Energy efficiency Energy efficiency == ────────────────────────
joules joules consumedconsumed

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 1212
Energy EfficiencyEnergy Efficiency
Efficiency averaged on Efficiency averaged on nn benchmark programs: benchmark programs:
nnEfficiencyEfficiency == (( ΠΠ Efficiency Efficiencyii ))
1/1/nn
ii=1=1
where Efficiencywhere Efficiencyii is the efficiency for program is the efficiency for program ii..
Relative efficiency:Relative efficiency:
Efficiency of a computerEfficiency of a computerRelative efficiency = Relative efficiency = ──────────────────────────────────
Eff. of reference Eff. of reference computercomputer
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 1313
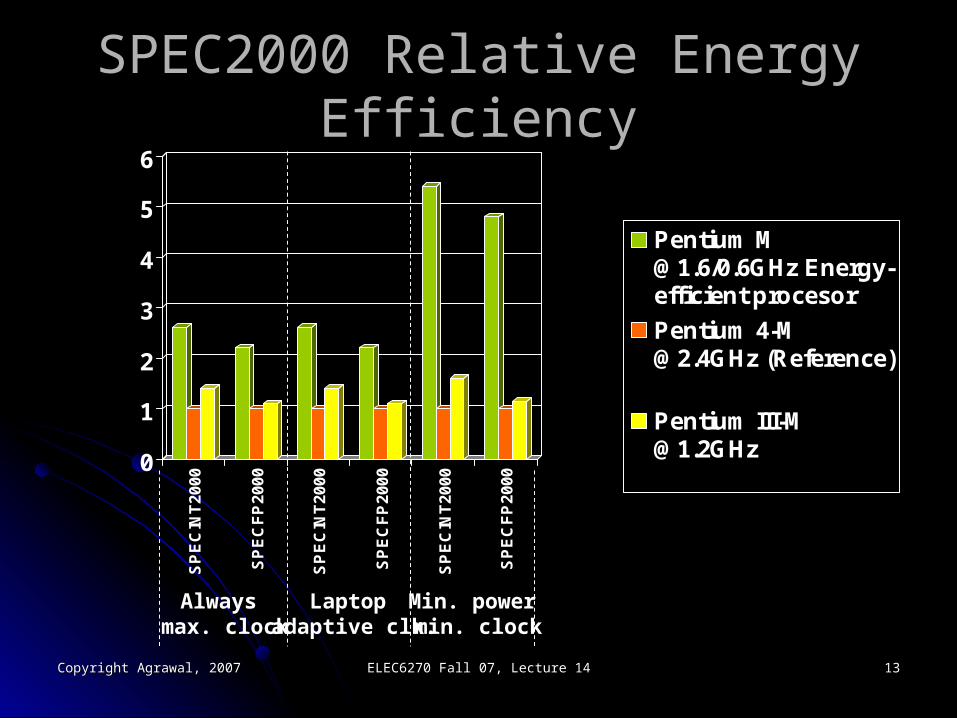
SPEC2000 Relative Energy EfficiencySPEC2000 Relative Energy Efficiency
0
1
2
3
4
5
6
SP
EC
INT
20
00
SP
EC
FP
20
00
SP
EC
INT
20
00
SP
EC
FP
20
00
SP
EC
INT
20
00
SP
EC
FP
20
00
Pentium [email protected]/0.6GHz Energy-efficient procesor
Pentium [email protected] (Reference)
Pentium [email protected]
Always max. clock
Laptop adaptive clk.
Min. power min. clock

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 1414
Voltage ScalingVoltage Scaling
Dynamic: Reduce voltage and frequency Dynamic: Reduce voltage and frequency during idle or low activity periods.during idle or low activity periods.
Static: Static: Clustered voltage scalingClustered voltage scalingLogicLogic on non-critical paths given lower voltage.on non-critical paths given lower voltage.47% power reduction with 10% area increase 47% power reduction with 10% area increase
reported.reported.M. Igarashi et al., “Clustered Voltage Scaling M. Igarashi et al., “Clustered Voltage Scaling
Techniques for Low-Power Design,” Techniques for Low-Power Design,” Proc. IEEE Proc. IEEE Symp. Low Power DesignSymp. Low Power Design, 1997., 1997.

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 1515
Processor UtilizationProcessor UtilizationThroughput = Operations / second
Th
rou
ghp
ut
Time
Compute-intensiveprocesses
Systemidle
Low throughput(background)
processes
Maximumthroughput

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 1616
Examples of ProcessesExamples of Processes
Compute-intensive: spreadsheet, spelling Compute-intensive: spreadsheet, spelling check, video decoding, scientific check, video decoding, scientific computing.computing.
Low throughput: data entry, screen Low throughput: data entry, screen updates, low bandwidth I/O data transfer.updates, low bandwidth I/O data transfer.
Idle: no computation, no expected output.Idle: no computation, no expected output.

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 1717
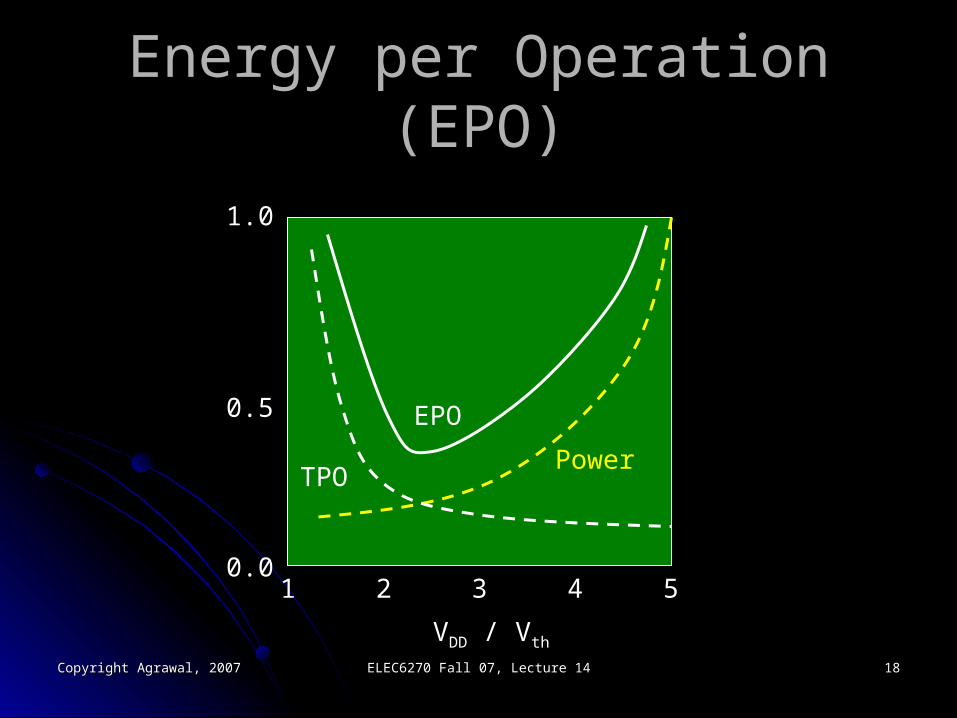
Effects of Voltage ReductionEffects of Voltage Reduction
Voltage reduction increases delay, Voltage reduction increases delay, decreases throughput:decreases throughput:
Slow reduction in throughput at firstSlow reduction in throughput at firstRapid reduction in throughput for VRapid reduction in throughput for VDD ≤ V≤ Vth
Time per operation (TPO) increasesTime per operation (TPO) increases
Voltage reduction continues to reduce Voltage reduction continues to reduce power consumption:power consumption:
Energy per operation (EPO) = Power × TPOEnergy per operation (EPO) = Power × TPO
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 1818
Energy per Operation (EPO)Energy per Operation (EPO)
VVDD / V / Vth
1 2 3 4 5
PowerTPO
EPO
1.0
0.5
0.0
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 1919
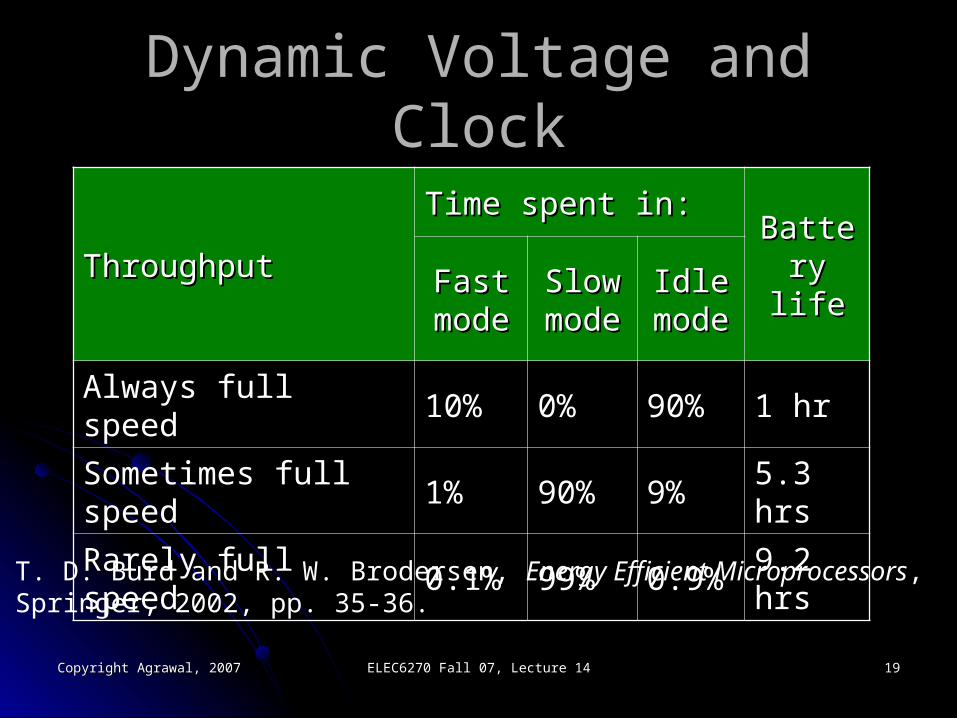
Dynamic Voltage and ClockDynamic Voltage and Clock
ThroughputThroughputTime spent in:Time spent in:
Battery Battery lifelifeFast Fast
modemodeSlow Slow modemode
Idle Idle modemode
Always full speedAlways full speed 10%10% 0%0% 90%90% 1 hr1 hr
Sometimes full speedSometimes full speed 1%1% 90%90% 9%9% 5.3 hrs5.3 hrs
Rarely full speedRarely full speed 0.1%0.1% 99%99% 0.9%0.9% 9.2 hrs9.2 hrs
T. D. Burd and R. W. Brodersen, Energy Efficient Microprocessors,Springer, 2002, pp. 35-36.
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 2020
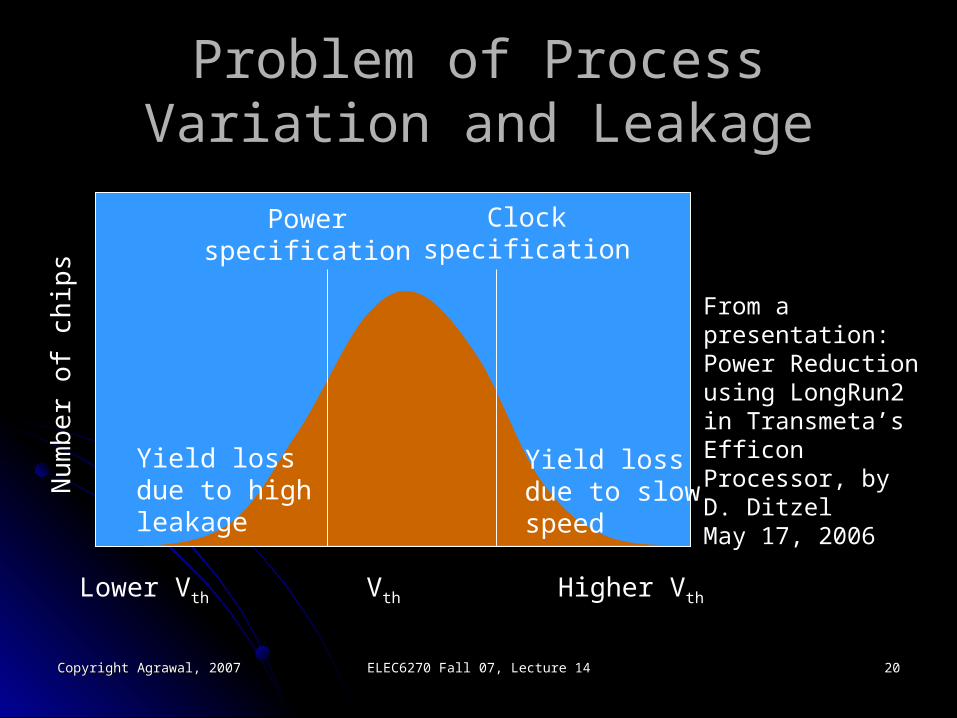
Problem of Process Variation and Problem of Process Variation and LeakageLeakage
Lower Vth Vth Higher Vth
Nu
mb
er
of c
hip
s
Powerspecification
Clockspecification
From a presentation:Power Reduction using LongRun2 in Transmeta’sEfficon Processor, by D. DitzelMay 17, 2006
Yield lossdue to highleakage
Yield lossdue to slowspeed

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 2121
Pipeline GatingPipeline Gating A pipeline processor uses speculative execution.A pipeline processor uses speculative execution.
Incorrect branch prediction results in pipeline stalls and Incorrect branch prediction results in pipeline stalls and wasted energy.wasted energy.
Idea: Stop fetching instructions if a branch Idea: Stop fetching instructions if a branch hazard is expected:hazard is expected:
If the count (M) of incorrect predictions exceeds a pre-If the count (M) of incorrect predictions exceeds a pre-specified number (N), then suspend fetching instruction for specified number (N), then suspend fetching instruction for some k cycles.some k cycles.
Ref.: S. Manne, A. Klauser and D. Grunwald, Ref.: S. Manne, A. Klauser and D. Grunwald, “Pipeline Gating: Speculation Control for Energy “Pipeline Gating: Speculation Control for Energy Reduction,” Reduction,” Proc. 25Proc. 25thth Annual International Annual International Symp. Computer ArchitectureSymp. Computer Architecture, June 1998., June 1998.

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 2222
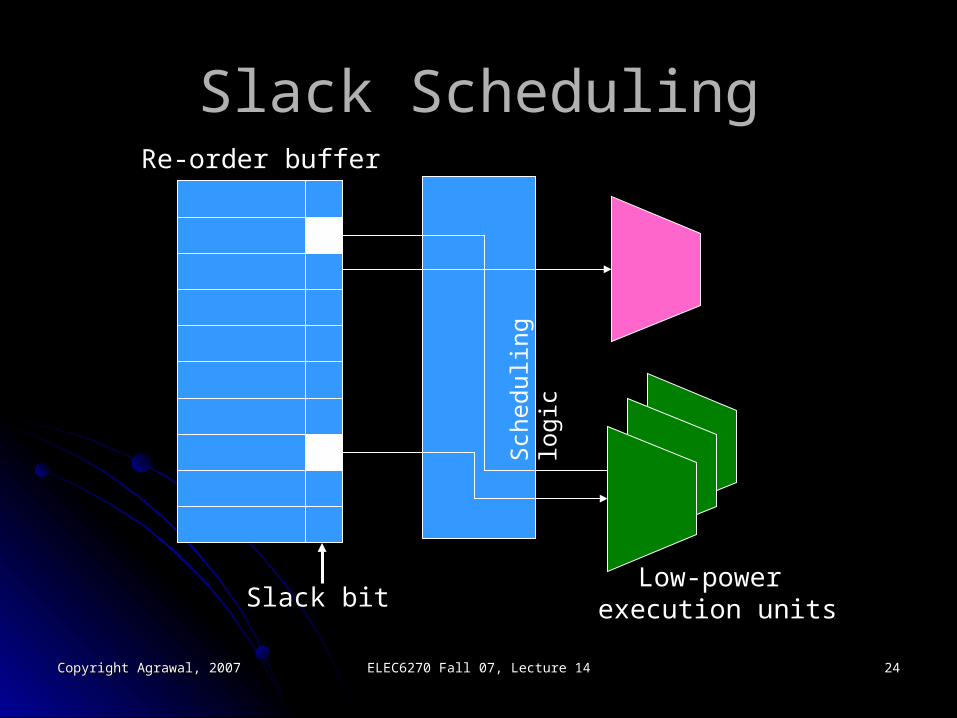
Slack SchedulingSlack Scheduling Application: Superscalar, out-of-order execution:Application: Superscalar, out-of-order execution:
An instruction is executed as soon as the required data and An instruction is executed as soon as the required data and resources become available.resources become available.
A commit unit reorders the results.A commit unit reorders the results.
Delay the completion of instructions whose result Delay the completion of instructions whose result is not immediately needed.is not immediately needed.
Example of RISC instructions:Example of RISC instructions: addadd r0, r1, r2;r0, r1, r2; (A)(A) sub r3, r4, r5;sub r3, r4, r5; (B)(B) and r9, x1, r9;and r9, x1, r9; (C)(C) or r5, r9, r10;or r5, r9, r10; (D)(D) xor r2, r10, r11;xor r2, r10, r11; (E)(E)
J. Casmira and D. Grunwald,“Dynamic Instruction SchedulingSlack,” Proc. ACM Kool ChipsWorkshop, Dec. 2000.

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 2323
Slack Scheduling ExampleSlack Scheduling Example
Slack schedulingSlack scheduling
AABB CC
DD
EE
Standard schedulingStandard scheduling
AA BB CC
DD
EE
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 2424
Slack SchedulingSlack Scheduling
Slack bitLow-power
execution units
Re-order buffer
Sch
edul
ing
logi
c
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 2525
Clock DistributionClock Distribution
clock

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 2626
Clock PowerClock Power
Pclk = CLVDD2f + CLVDD
2f / λ + CLVDD2f / λ2 + . . .
stages – 1 1= CLVDD
2f Σ ─ n = 0 λn
where CL = total load capacitance
λ = constant fanout at each stage in distributionnetwork
Clock consumes about 40% of total processor power.

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 2727
Clock Network ExamplesClock Network ExamplesAlpha 21064Alpha 21064 Alpha 21164Alpha 21164 Alpha 21264Alpha 21264
TechnologyTechnology 0.750.75μμ CMOS CMOS 0.50.5μμ CMOS CMOS 0.350.35μμ CMOS CMOS
Frequency (MHz)Frequency (MHz) 200200 300300 600600
Total capacitanceTotal capacitance 12.5nF12.5nFClock gating Clock gating used. Total used. Total power 80 -power 80 -
110W110W
Clock loadClock load 3.25nF3.25nF 3.75nF3.75nF
Clock powerClock power 40%40% 40% (20W)40% (20W)
Max. clock skewMax. clock skew 200ps (<10%)200ps (<10%) 90ps90ps
D. W. Bailey and B. J. Benschneider, “Clocking Design and Analysis for a 600-MHz Alpha Microprocessor,” IEEE J. Solid-State Circuits, vol. 33, no. 11, pp. 1627-1633, Nov. 1998.

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 2828
Power Reduction ExamplePower Reduction Example Alpha 21064: 200MHz @ 3.45V, power dissipation =Alpha 21064: 200MHz @ 3.45V, power dissipation = 26W Reduce voltage to 1.5V, power (5.3x) =Reduce voltage to 1.5V, power (5.3x) = 4.9W Eliminate FP, power (3x) =Eliminate FP, power (3x) = 1.6W Scale 0.75→0.35Scale 0.75→0.35μμ, power (2x) =, power (2x) = 0.8W Reduce clock load, power (1.3x) =Reduce clock load, power (1.3x) = 0.6W Reduce frequency 200→160MHz, power (1.25x) =Reduce frequency 200→160MHz, power (1.25x) = 0.5W
J. Montanaro J. Montanaro et alet al., “A 160-MHz, 32-b, 0.5-W CMOS RISC ., “A 160-MHz, 32-b, 0.5-W CMOS RISC Microprocessor,” Microprocessor,” IEEE J. Solid-State CircuitsIEEE J. Solid-State Circuits, vol. 31, no. , vol. 31, no. 11, pp. 1703-1714, Nov. 1996.11, pp. 1703-1714, Nov. 1996.
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 2929
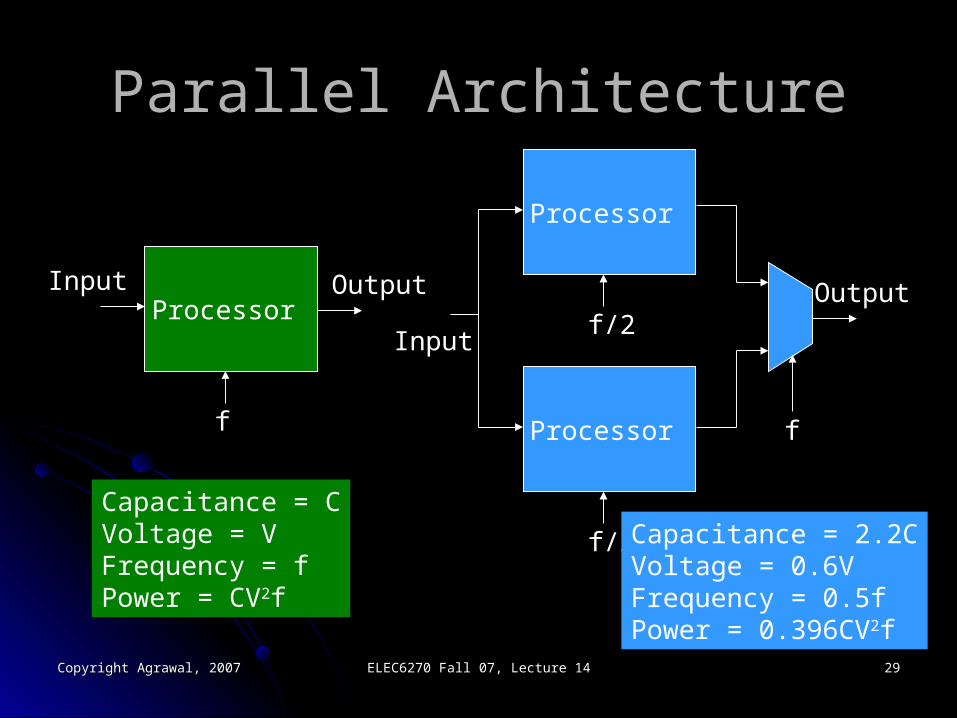
Parallel ArchitectureParallel Architecture
Processor
f
Processor
f/2
Processor
f/2
f
Input Output
Input
Output
Capacitance = CVoltage = VFrequency = fPower = CV2f
Capacitance = 2.2CVoltage = 0.6VFrequency = 0.5fPower = 0.396CV2f
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 3030
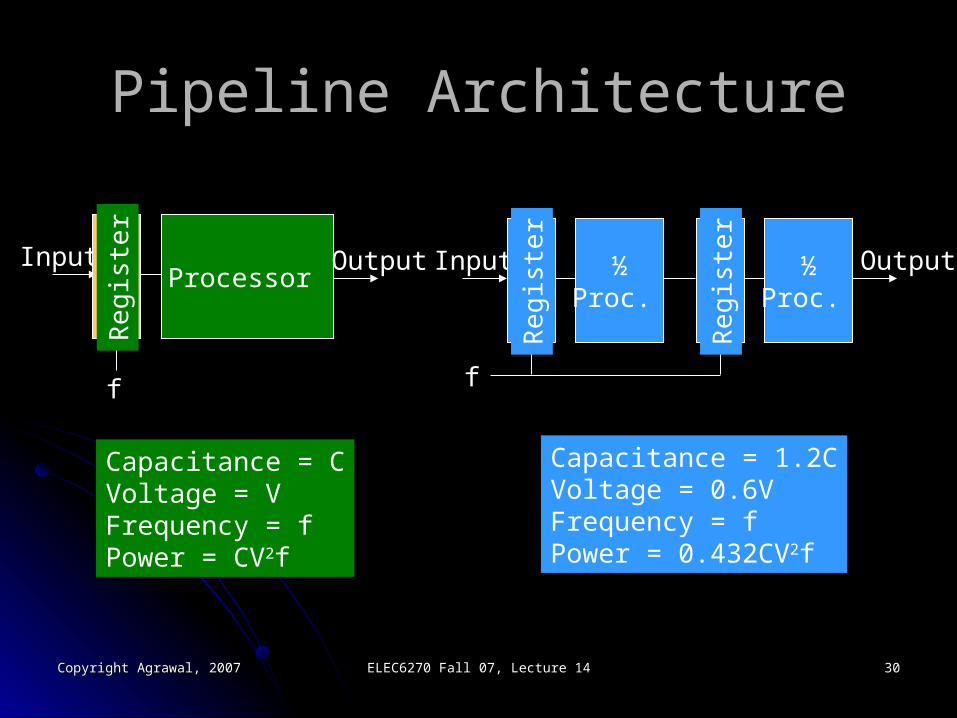
Pipeline ArchitecturePipeline Architecture
Processor
f
Input Output
Re
gis
ter
½Proc.
f
Input Output
Re
gis
ter
½Proc.
Re
gis
ter
Capacitance = CVoltage = VFrequency = fPower = CV2f
Capacitance = 1.2CVoltage = 0.6VFrequency = fPower = 0.432CV2f
Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 3131
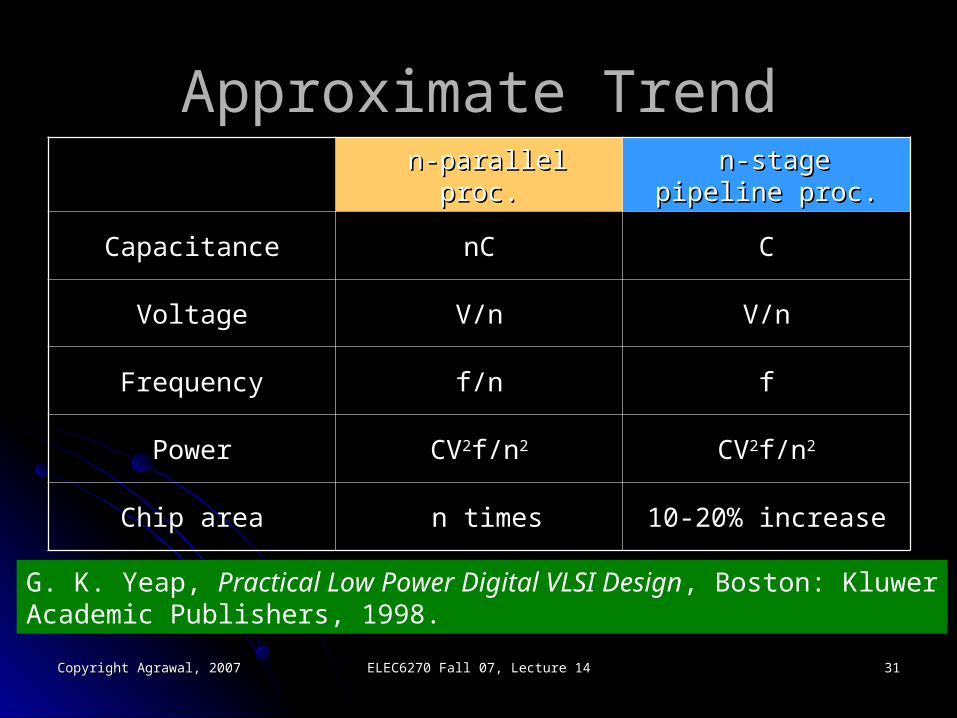
Approximate TrendApproximate Trend n-parallel proc.n-parallel proc. n-stage pipeline proc.n-stage pipeline proc.
CapacitanceCapacitance nCnC CC
VoltageVoltage V/nV/n V/nV/n
FrequencyFrequency f/nf/n ff
PowerPower CVCV22f/nf/n22 CVCV22f/nf/n22
Chip areaChip area n timesn times 10-20% increase10-20% increase
G. K. Yeap, Practical Low Power Digital VLSI Design, Boston: KluwerAcademic Publishers, 1998.

Copyright Agrawal, 2007Copyright Agrawal, 2007 ELEC6270 Fall 07, Lecture 14ELEC6270 Fall 07, Lecture 14 3232
For More on MicroprocessorsFor More on Microprocessors
T. D. Burd and R. W. Brodersen, Energy T. D. Burd and R. W. Brodersen, Energy Efficient Microprocessor Design, Springer, Efficient Microprocessor Design, Springer, 2002.2002.
R. Graybill and R. Melhem, R. Graybill and R. Melhem, Power Aware Power Aware ComputingComputing, New York: Plenum Publishers, , New York: Plenum Publishers, 2002.2002.
Top Related