
WBDB 2015 Performance Evaluation of Spark SQL using BigBench
29
Performance Evaluation of Spark SQL using BigBench Todor Ivanov and Max-Georg Beer Frankfurt Big Data Lab Goethe University Frankfurt am Main, Germany http://www.bigdata.uni-frankfurt.de/ 6th Workshop on Big Data Benchmarking 2015 June 16 th – 17 th , Toronto, Canada
Transcript of WBDB 2015 Performance Evaluation of Spark SQL using BigBench

Performance Evaluation of Spark SQL using BigBench
Todor Ivanov and Max-Georg Beer
Frankfurt Big Data LabGoethe University Frankfurt am Main, Germanyhttp://www.bigdata.uni-frankfurt.de/
6th Workshop on Big Data Benchmarking 2015June 16th – 17th, Toronto, Canada

Agenda
• Motivation & Research Objectives
• Towards BigBench on Spark– Our Experience with BigBench– Lessons Learned
• Data Scalability Experiments– Cluster Setup & Configuration– BigBench on MapReduce– BigBench on Spark SQL– Hive & Spark SQL Comparison
• Next Steps
6th Workshop on Big Data Benchmarking 2015 2

Motivation
• „Towards A Complete BigBench Implementation” by Tilmann Rabl @WBDB 2014– end-to-end, application-level, analytical big data benchmark– technology agnostic– based on TPC-DS– consists of 30 queries
• Implementation for the Hadoop Ecosystem– https://github.com/intel-hadoop/Big-Bench
What about implementing BigBench on Spark?
6th Workshop on Big Data Benchmarking 2015 3
BigBench Logical Data Schema

Research Objectives
• Understand and experiment with BigBench on MapReduce
• Implement & run BigBench on Spark
• Evaluate and compare both BigBench implementations
6th Workshop on Big Data Benchmarking 2015 4

Agenda
• Motivation & Research Objectives
• Towards BigBench on Spark– Our Experience with BigBench– Lessons Learned
• Data Scalability Experiments– Cluster Setup & Configuration– BigBench on MapReduce– BigBench on Spark SQL– Hive & Spark SQL Comparison
• Next Steps
6th Workshop on Big Data Benchmarking 2015 5

Towards BigBench on Spark
• Analyse the different query groups in BigBench
Evaluate the Data Scalability of the BigBench queries.
• The largest group consists of 14 pure HiveQL queries• Spark SQL supports the HiveQL syntax
Compare the performace of Hive and Spark SQL using the HiveQL queries.
6th Workshop on Big Data Benchmarking 2015 6
Query Types Queries Number of Queries
Pure HiveQL 6, 7, 9, 11, 12, 13, 14, 15, 16, 17, 21, 22, 23, 24 14
Java MapReduce with HiveQL 1, 2 2Python Streaming MR with HiveQL 3, 4, 8, 29, 30 5
Mahout (Java MR) with HiveQL 5, 20, 25, 26, 28 5OpenNLP (Java MR) with HiveQL 10, 18, 19, 27 4

Lessons Learned
Our BigBench on MapReduce experiments showed:
• The OpenNLP queries (Q19, Q10) scale best with the increase of the data size.• Q27 (OpenNLP) is not suitable for scalability comparison.• A subset of the Python Streaming (MR) queries (Q4, Q30, Q3) show the worst scaling
behavior.
Comparing Hive and Spark SQL we observed:
• A group of Spark SQL queries (Q7, Q16, Q21, Q22, Q23 and Q24) does not scale properly with the increase of the data size. Possible reason join optimization issues.
• For the stable HiveQL queries (Q6, Q9, Q11, Q12, Q13, Q14, Q15 and Q17) Spark SQL performs between 1.5x and 6.3x times faster than Hive.
6th Workshop on Big Data Benchmarking 2015 7

Our Experience with BigBench
• Validating the Spark SQL query results– Empty query results– Non-deterministic end results (OpenNLP and Mahout)– No reference results are available
• BigBench Setup: https://github.com/BigData-Lab-Frankfurt/Big-Bench-Setup
– Executing single or subset of queries– Gather execution times, row counts and sample values from result tables
6th Workshop on Big Data Benchmarking 2015 8
Query # Row CountSF 100
Row Count SF 300
Row Count SF 600
Row Count SF 1000 Sample Row
Q1 0 0 0 0
Q2 1288 1837 1812 1669 1415 41 1
Q3 131 426 887 1415 20 5809 1
Q4 73926146 233959972 468803001 795252823 0_1199 1
Q5 logRegResult.txtAUC = 0.50 confusion: [[0.0, 0.0], [1.0, 3129856.0]] entropy: [[-0.7, -
0.7], [-0.7, -0.7]]
… … …

Agenda
• Motivation & Research Objectives
• Towards BigBench on Spark– Our Experience with BigBench– Lessons Learned
• Data Scalability Experiments– Cluster Setup & Configuration– BigBench on MapReduce– BigBench on Spark SQL– Hive & Spark SQL Comparison
• Next Steps
6th Workshop on Big Data Benchmarking 2015 9

Cluster Setup
• Operating System: Ubuntu Server 14.04.1. LTS• Cloudera’s Hadoop Distribution - CDH 5.2• Replication Factor of 2 (only 3 worker nodes)• Hive version 0.13.1• Spark version 1.4.0-SNAPSHOT (March 27th 2015)• BigBench & Scripts (https://github.com/BigData-Lab-Frankfurt/Big-Bench-Setup)
• 3 test repetitions• Performance Analysis Tool (PAT) (https://github.com/intel-hadoop/PAT)
6th Workshop on Big Data Benchmarking 2015 10
Setup Description SummaryTotal Nodes: 4 x Dell PowerEdge T420
Total Processors/ Cores/Threads:
5 CPUs/ 30 Cores/ 60 Threads
Total Memory: 4x 32GB = 128 GB
Total Number of Disks:13 x 1TB,SATA, 3.5 in, 7.2K
RPM, 64MB CacheTotal Storage Capacity: 13 TB
Network: 1 GBit Ehternet

Cluster Configuration
• Optimizing cluster performance can be very time-consuming process.• Following the best practices published by Sandy Ryza (Cloudera):
– “How-to: Tune Your Apache Spark Jobs”, http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/
6th Workshop on Big Data Benchmarking 2015 11
Component Parameter Configuration Values
YARN yarn.nodemanager.resource.memory-mb 31GB yarn.scheduler.maximum-allocation-mb 31GB yarn.nodemanager.resource.cpu-vcores 11
Spark
master yarn num-executors 9 executor-cores 3
executor-memory 9GB
spark.serializer org.apache.spark. serializer.KryoSerializer
MapReduce
mapreduce.map.java.opts.max.heap 2GB mapreduce.reduce.java.opts.max.heap 2GB
mapreduce.map.memory.mb 3GB mapreduce.reduce.memory.mb 3GB
Hive hive.auto.convert.join (Q9 only) true Client Java Heap Size 2GB

Agenda
• Motivation & Research Objectives
• Towards BigBench on Spark– Our Experience with BigBench– Lessons Learned
• Data Scalability Experiments– Cluster Setup & Configuration
– BigBench on MapReduce– BigBench on Spark SQL– Hive & Spark SQL Comparison
• Next Steps
6th Workshop on Big Data Benchmarking 2015 12

BigBench on MapReduce
• Tested Scale Factors: 100 GB, 300 GB, 600 GB and 1TB • Times normalized with respect to 100GB SF as baseline.
• Longer normalized times indicate slower execution with the increase of the data size.
• Shorter normalized times indicate better scalability with the increase of the data size.
6th Workshop on Big Data Benchmarking 2015 13
0123456789
10111213
Nor
mal
ized
Tim
e
Normalized BigBench Times with respect to baseline 100GB Scale Factor 300GB 600GB1TB Linear 300GBLinear 600GB Linear 1TB

BigBench on MapReduce – worst scalability
• Tested Scale Factors: 100 GB, 300 GB, 600 GB and 1TB • Times normalized with respect to 100GB SF as baseline.
• Group A: Q4, Q30, Q3 (Python Streaming) and Q5 (Mahout) show the worst scalingbehavior.
6th Workshop on Big Data Benchmarking 2015 14
-202468
101214
Nor
mal
ized
Tim
e
Normalized BigBench + MapReduce Times with respect to baseline 100GB SF300GB 600GB1TB Linear 300GBLinear 600GB Linear 1TB

Group A: Analysis of Q4 (Python) & Q5 (Mahout)
Scale Factor: 1TB Q4 (Python Streaming) Q5 (Mahout)
Average Runtime (minutes): 929 minutes 273 minutes
Avg. CPU Utilization %:
48.82 (User %); 3.31 (System %);4.98 (IOwait%)
51.50 (User %);3.37 (System %);3.65 (IOwait%)
Avg. Memory Utilization %: 95.99 % 91.85 %
6th Workshop on Big Data Benchmarking 2015 15
• Q4 is memory bound with 96% utilization and around 5% IOwaits, which means that theCPU is waiting for outstanding disk I/O requests.
• Q5 is memory bound with around 92% utilization. The Mahout execution takes only 18minutes before the query end and utilizes very few resources.
0
50
100
019
0338
1457
3176
5095
5411
464
1338
115
300
1720
419
115
2103
122
950
2485
426
765
2868
130
600
3250
434
415
3633
138
250
4015
442
065
4398
145
900
4780
449
715
5163
153
550
5545
4CPU
Util
izat
ion
%
Time (sec)
Q4 (Python)
IOwait % User % System %
0
50
100
064
012
7519
1425
5131
9038
2544
6451
0157
4063
7570
1476
5282
9089
2595
6410
202
1084
011
475
1211
412
752
1339
014
025
1466
415
302
1594
016
575
CPU
Util
izat
ion
%
Time (sec)
Q5 (Mahout)
IOwait % User % System %
Starts the Mahout execution.
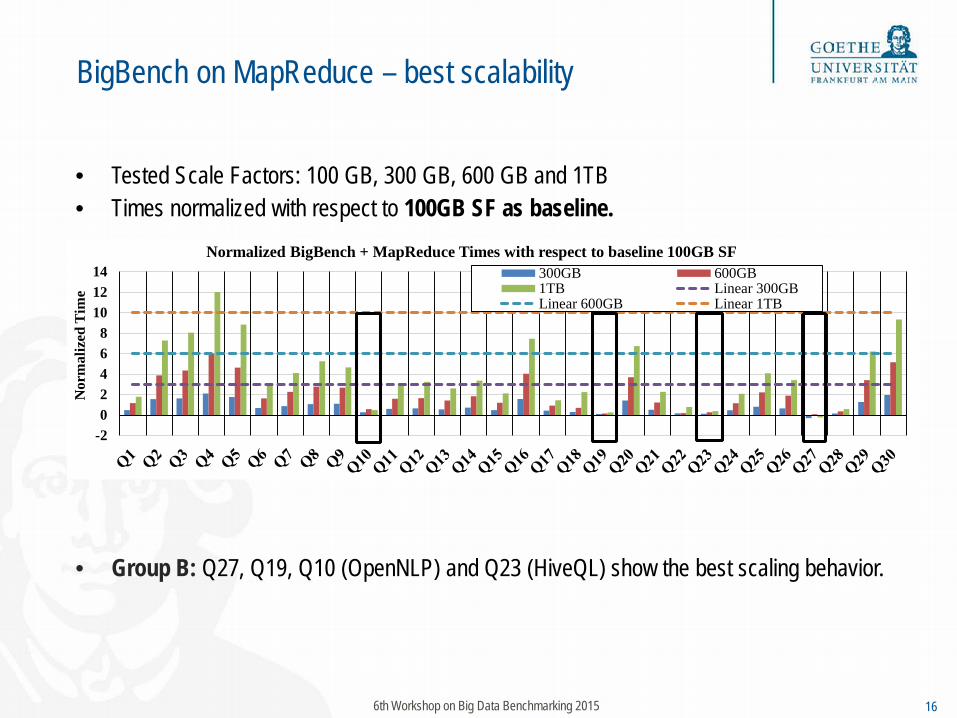
BigBench on MapReduce – best scalability
• Tested Scale Factors: 100 GB, 300 GB, 600 GB and 1TB • Times normalized with respect to 100GB SF as baseline.
• Group B: Q27, Q19, Q10 (OpenNLP) and Q23 (HiveQL) show the best scaling behavior.
6th Workshop on Big Data Benchmarking 2015 16
-202468
101214
Nor
mal
ized
Tim
e
Normalized BigBench + MapReduce Times with respect to baseline 100GB SF300GB 600GB1TB Linear 300GBLinear 600GB Linear 1TB

Group B: Analysis of Q27 (OpenNLP)
• Q27 keeps the system underutilized and outputs non-deterministic values.
6th Workshop on Big Data Benchmarking 2015 17
Scale Factor: 1TB Q27 (OpenNLP)Input Data size/ Number of Tables: 2GB / 1 Tables
Average Runtime (minutes): 0.7 minutes
Avg. CPU Utilization %:
10.03 (User %);1.94 (System %); 1.29 (IOwait%)
Avg. Memory Utilization %: 27.19 %
Scale Factor 100GB 300GB 600GB 1TBNumber of rows in
result table 1 0 3 0
Times (minutes) 0.91 0.63 0.98 0.70
020406080
100
0 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48 51 54 57 60 63 66 69 72 75 78 84
CPU
Util
izat
ion
%
Time (sec)IOwait % User % System %
0
20
40
60
80
100
2 5 8 11 14 17 20 23 26 29 32 35 38 41 44 47 50 53 56 59 62 65 68 71 74 77 82Mem
ory
Util
izat
ion
%
Time (sec)

Group B: Analysis of Q18 (OpenNLP)
• Q18 is memory bound with around 90% utilization and high CPU usage of 56%.
6th Workshop on Big Data Benchmarking 2015 18
Scale Factor: 1TB Q18 (OpenNLP)Input Data size/ Number of Tables: 71GB / 3 Tables
Average Runtime (minutes): 28 minutes
Avg. CPU Utilization %:
55.99 (User %); 2.04 (System %);0.31 (IOwait%)
Avg. Memory Utilization %: 90.22 %
020406080
100
0 50 96 144
190
236
284
330
376
424
470
516
564
610
656
704
750
796
844
890
936
984
1030
1076
1124
1170
1216
1264
1310
1356
1404
1450
1496
1544
1590
1636
1684C
PU U
tiliz
atio
in%
Time (sec)IOwait % User % System %
020406080
100
5 55 101
149
195
241
289
335
381
429
475
521
569
615
661
709
755
801
849
895
941
989
1035
1081
1129
1175
1221
1269
1315
1361
1409
1455
1501
1549
1595
1641
1689M
emor
y U
tiliz
atio
n %
Time (sec)

Agenda
• Motivation & Research Objectives
• Towards BigBench on Spark– Our Experience with BigBench– Lessons Learned
• Data Scalability Experiments– Cluster Setup & Configuration– BigBench on MapReduce
– BigBench on Spark SQL– Hive & Spark SQL Comparison
• Next Steps
6th Workshop on Big Data Benchmarking 2015 19

BigBench on Spark SQL – worst scalability
• Test the group of 14 pure HiveQL queries.• Tested Scale Factors: 100 GB, 300 GB, 600 GB and 1TB • Times normalized with respect to 100GB SF as baseline.
• Group A: Q24, Q21, Q16 and Q7 achieve the worst data scalability behavior.• Possible reason for Group A behavior is reported in SPARK-2211 (Join Optimization).
6th Workshop on Big Data Benchmarking 2015 20
0369
1215182124
Nor
mal
ized
Tim
e
Normalized BigBench + Spark SQL Times with respect to baseline 100GB SF
300GB 600GB1TB Linear 300GBLinear 600GB Linear 1TB

BigBench on Spark SQL – best scalability
• Test the group of 14 pure HiveQL queries.• Tested Scale Factors: 100 GB, 300 GB, 600 GB and 1TB • Times normalized with respect to 100GB SF as baseline.
• Group B: Q15, Q11,Q9 and Q14 achieve the best data scalability behavior.
6th Workshop on Big Data Benchmarking 2015 21
0369
1215182124
Nor
mal
ized
Tim
e
Normalized BigBench + Spark SQL Times with respect to baseline 100GB SF 300GB 600GB1TB Linear 300GBLinear 600GB Linear 1TB

Agenda
• Motivation & Research Objectives
• Towards BigBench on Spark– Our Experience with BigBench– Lessons Learned
• Data Scalability Experiments– Cluster Setup & Configuration– BigBench on MapReduce– BigBench on Spark SQL
– Hive & Spark SQL Comparison
• Next Steps
6th Workshop on Big Data Benchmarking 2015 22

Hive & Spark SQL Comparison (1)
• Calculate the Hive to Spark SQL ratio (%): ((HiveTime * 100) / SparkTime) - 100)
• Group 1: Q7, Q16, Q21, Q22, Q23 and Q24 drastically increase their Spark SQL execution time for the larger data sets.
• Complex Join issues described in SPARK-2211(https://issues.apache.org/jira/browse/SPARK-2211 ).
6th Workshop on Big Data Benchmarking 2015 23
Q6 Q7 Q9 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q21 Q22 Q23 Q24100GB 150 257 152 148 259 245 156 46 70 387 71 -55 9 44300GB 204 180 284 234 279 262 251 89 88 398 -35 -68 -24 -54600GB 246 37 398 344 279 263 328 132 25 402 -62 -78 -55 -761TB 279 13 528 443 295 278 389 170 12 423 -69 -76 -64 -81
-100-50
050
100150200250300350400450500
Tim
eR
atio
(%)
Hive to Spark SQL Query Time Ratio (%) defined as ((HiveTime*100)/SparkTime)-100)

Group 1: Analysis of Q7 (HiveQL)
Scale Factor: 1TB Hive Spark SQLAverage Runtime (minutes):
46 minutes 41 minutes
Avg. CPU Utilization %:
56.97 (User %);3.89 (System %);0.40 (IOwait %)
16.65 (User %);2.62 (System %);21.28 (IOwait %)
Avg. Memory Utilization %: 94.33 % 93.78 %
6th Workshop on Big Data Benchmarking 2015 24
• Q7 is only 13% slower on Hive compared to Spark SQL.
• Spark SQL spends around 21% (IOwait) of the CPU time on waiting for outstanding disk I/Orequests in Q7 utilizes efficiently only around 17% of the CPU.
0
50
100
0 256 511 766 1021 1276 1531 1786 2041 2296 2551 2806CPU
Util
izat
ion
%
Time (sec)
Q7 Hive
IOwait % User % System %
0
50
100
0 256 511 766 1021 1276 1531 1787 2042 2297 2595
CPU
Util
izat
ion
%
Time (sec)
Q7 Spark SQL
IOwait % User % System %

Hive & Spark SQL Comparison (2)
• Group 2: Q12,Q13 and Q17 show modest performance improvement with the increase of the data size.
6th Workshop on Big Data Benchmarking 2015 25
Q6 Q7 Q9 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q21 Q22 Q23 Q24100GB 150 257 152 148 259 245 156 46 70 387 71 -55 9 44300GB 204 180 284 234 279 262 251 89 88 398 -35 -68 -24 -54600GB 246 37 398 344 279 263 328 132 25 402 -62 -78 -55 -761TB 279 13 528 443 295 278 389 170 12 423 -69 -76 -64 -81
-100-50
050
100150200250300350400450500
Tim
eR
atio
(%)
Hive to Spark SQL Query Time Ratio (%) defined as ((HiveTime*100)/SparkTime)-100)

Hive & Spark SQL Comparison (3)
• Group 3: Q6, Q9, Q11, Q14 and Q15 perform between 46% and 528% faster on Spark SQL than on Hive.
6th Workshop on Big Data Benchmarking 2015 26
Q6 Q7 Q9 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q21 Q22 Q23 Q24100GB 150 257 152 148 259 245 156 46 70 387 71 -55 9 44300GB 204 180 284 234 279 262 251 89 88 398 -35 -68 -24 -54600GB 246 37 398 344 279 263 328 132 25 402 -62 -78 -55 -761TB 279 13 528 443 295 278 389 170 12 423 -69 -76 -64 -81
-100-50
050
100150200250300350400450500
Tim
eR
atio
(%)
Hive to Spark SQL Query Time Ratio (%) defined as ((HiveTime*100)/SparkTime)-100)

Group 3: Analysis of Q9 (HiveQL)
• Spark SQL is 6 times faster than Hive.
• Hive utilizes on average 60% CPU and 78% memory, whereas Spark SQL consumes on average 28% CPU and 61% memory.
6th Workshop on Big Data Benchmarking 2015 27
Scale Factor: 1TB Hive Spark SQL
Average Runtime (minutes): 18 minutes 3 minutes
Avg. CPU Utilization %:
60.34 (User %);3.44 (System %);0.38 (IOwait %)
27.87 (User %);2.22 (System %);4.09 (IOwait %)
Avg. Memory Utilization %: 78.87 % 61.27 %
0
50
100
0 30 59 88 117
146
175
204
233
262
291
320
349
378
407
436
465
494
523
552
581
610
639
668
697
726
755
784
813
842
871
900
929
958
987
1016
1045
1074
1103
CPU
Util
izat
ion
%
Time (sec)
Q9 Hive
IOwait % User % System %
0
50
100
0 7 13 19 25 31 37 43 49 55 61 67 73 79 85 91 97 103
109
115
121
127
133
139
145
151
157
163
169
175
181
187
193C
PU U
tiliz
atio
n %
Time (sec)
Q9 Spark SQL
IOwait % User % System %

Next Steps
6th Workshop on Big Data Benchmarking 2015 28
Hive (MR) Spark SQLSF 100GB 300GB 600GB 1TB 100GB 300GB 600GB 1TB
Time min. min. Δ (%) min. Δ (%) min. Δ (%) min. min. Δ (%) min. Δ (%) min. Δ (%)
Q1 3.75 5.52 47.20 8.11 116.27 10.48 179.47Q2 8.23 21.07 156.01 40.11 387.36 68.12 727.70Q3 9.99 26.32 163.46 53.45 435.04 90.55 806.41Q4 71.37 221.32 210.10 501.97 603.33 928.68 1201.22Q5 27.70 76.56 176.39 155.68 462.02 272.53 883.86Q6 6.36 10.69 68.08 16.73 163.05 25.42 299.69 2.54 3.52 38.58 4.83 90.16 6.70 163.78Q7 9.07 16.92 86.55 29.51 225.36 46.33 410.80 2.54 6.04 137.80 21.47 745.28 41.07 1516.93Q8 8.59 17.74 106.52 32.46 277.88 53.67 524.80Q9 3.13 6.56 109.58 11.50 267.41 17.72 466.13 1.24 1.71 37.90 2.31 86.29 2.82 127.42
Q10 15.44 19.67 27.40 24.29 57.32 22.92 48.45Q11 2.88 4.61 60.07 7.46 159.03 11.24 290.28 1.16 1.38 18.97 1.68 44.83 2.07 78.45Q12 7.04 11.60 64.77 18.67 165.20 29.86 324.15 1.96 3.06 56.12 4.92 151.02 7.56 285.71Q13 8.38 13.00 55.13 20.23 141.41 30.18 260.14 2.43 3.59 47.74 5.57 129.22 7.98 228.40Q14 3.17 5.48 72.87 8.99 183.60 13.84 336.59 1.24 1.56 25.81 2.10 69.35 2.83 128.23Q15 2.04 3.01 47.55 4.47 119.12 6.37 212.25 1.40 1.59 13.57 1.93 37.86 2.36 68.57Q16 5.78 14.83 156.57 29.13 403.98 48.85 745.16 3.41 7.88 131.09 23.32 583.87 43.65 1180.06Q17 7.60 10.91 43.55 14.60 92.11 18.57 144.34 1.56 2.19 40.38 2.91 86.54 3.55 127.56Q18 8.53 11.02 29.19 14.44 69.28 27.60 223.56Q19 6.56 7.22 10.06 7.58 15.55 8.18 24.70Q20 8.38 20.29 142.12 39.32 369.21 64.83 673.63Q21 4.58 6.89 50.44 10.22 123.14 14.92 225.76 2.68 10.64 297.01 27.18 914.18 48.08 1694.03Q22 16.64 19.43 16.77 19.82 19.11 29.84 79.33 36.66 60.69 65.55 88.92 142.55 122.68 234.64Q23 18.20 20.51 12.69 23.22 27.58 25.16 38.24 16.68 27.02 61.99 52.11 212.41 69.01 313.73Q24 4.79 7.02 46.56 10.30 115.03 14.75 207.93 3.33 15.27 358.56 42.19 1166.97 77.05 2213.81Q25 6.23 11.21 79.94 19.99 220.87 31.65 408.03Q26 5.19 8.57 65.13 15.08 190.56 22.92 341.62Q27 0.91 0.63 -30.77 0.98 7.69 0.70 -23.08Q28 18.36 21.24 15.69 24.77 34.91 28.87 57.24Q29 5.17 11.73 126.89 22.78 340.62 37.21 619.73Q30 19.48 57.68 196.10 119.86 515.30 201.20 932.85
Next Steps
Next Steps
Next Steps
Legend:
The 4 best scaling queriesThe 4 worst scaling queries

Acknowledgments
• Fields Institute – Research in Mathematical Sciences
• SPEC Research Big Data Working Group
• Tilmann Rabl (Univesity of Toronto/Bankmark UG)
• John Poelman (IBM)
• Yi Yao Joshua & Bhaskar Gowda (Intel)
• Marten Rosselli, Karsten Tolle, Roberto V. Zicari & Raik Niemann (Frankfurt Big Data Lab)
6th Workshop on Big Data Benchmarking 2015 29



![Adding Velocity to BigBench - TU Berlindbtest.dima.tu-berlin.de/media/DBTEST.io_Presentations/dbtest_ivanov_18-06.pdfAdding Velocity to BigBench [Work-in-Progress] Todor Ivanov ...](https://static.fdocuments.in/doc/165x107/5ed369e9c2fb686a33539481/adding-velocity-to-bigbench-tu-adding-velocity-to-bigbench-work-in-progress.jpg)














