
Tutorial-CloudComHadoop23.pdf
77
-
Upload
abhishek82 -
Category
Documents
-
view
3 -
download
1
Transcript of Tutorial-CloudComHadoop23.pdf

Hadoop 23 - dotNext
CloudCom 2012 – Taipei, Taiwan
December 5, 2012

- 2 -
About Me
• Principal Engg in the Yahoo! Grid Team since May 2008
• PhD from Rutgers University, NJ
– Specialization in Data Streaming, Grid, Autonomic Computing
• Worked on streaming data from live simulations executing in NERSC (CA), ORNL (TN) to Princeton Plasma Physics Lab (PPPL - NJ)
– Library introduce less then 5% overhead on computation
• PhD Thesis on In-Transit data processing for peta-scale simulation workflows
• Developed CorbaCoG kit for Globus
• Active contributor to Hadoop Apache, Pig, HCat and developer of Hadoop Vaidya

- 3 -
Agenda - (10:30am -12pm)
• Overview and Introduction
• HDFS Federation
• YARN
• Hadoop 23 User Impact

- 4 -
Hadoop Technology Stack at Yahoo!
• HDFS – Distributed File System
• Map/Reduce – Data Processing Paradigm
• HBase and HFile – columnar storage
• PIG – Data Processing Language
• HIVE – SQL like query processing language
• HCatalog – Table abstraction on top of big data allows interaction with Pig and Hive
• Oozie – Workflow Management System
4 4
HDFS
File Format (HFile)
HBase
Map Reduce
Hive PIG
HCatalog
Oozie

- 5 -
2004 Google
Map Reduce, BigTable
2010 Microsoft
Stream Insight
2011 Twitter Storm
2012 Berkeley Spark
2008 Hive
2005 Hadoop
Big Data
Low-Latency Analytic Processing
2006 PIG
2010 Google Percolator
2009 IBM Streams
2006 Google Dremel
2007 HBase
2009 Yahoo! S4
2012 Cloudera Impala
Evolution of Big Data Systems

- 6 -
Map & Reduce
• Primitives in Lisp (& Other functional languages) 1970s
• Google Paper 2004
– http://labs.google.com/papers/mapreduce.html

- 7 -
Output_List = Map (Input_List)
Square (1, 2, 3, 4, 5, 6, 7, 8, 9, 10) = (1, 4, 9, 16, 25, 36,49, 64, 81, 100)
Map

- 8 -
Output_Element = Reduce (Input_List)
Sum (1, 4, 9, 16, 25, 36,49, 64, 81, 100) = 385
Reduce

- 9 -
Parallelism
• Map is inherently parallel
– Each list element processed independently
• Reduce is inherently sequential
– Unless processing multiple lists
• Grouping to produce multiple lists

- 10 -
Apache Hadoop Version
• Stable Version: 0.20.205 (aka Hadoop 1.0)
– Stable release of Hadoop currently run at Yahoo!
• Latest Version: 0.23.4
– Being tested for certification in Yahoo!
– Hadoop version 2.0.2 in process of development in conjunction with Hortonworks

- 11 -
HDFS
• Data is organized into files and directories
• Files are divided into uniform sized blocks (default 64MB) and distributed across cluster nodes
• HDFS exposes block placement so that computation can be migrated to data

- 12 -
Hadoop 0.23 (dotNext) Highlights
• Major Hadoop release adopted by Yahoo! in over 2 years (after Hadoop 0.20 /Hadoop 1.0.2)
• Primary focus is scalability
– HDFS Federation – larger namespace & scalability
• Larger aggregated namespace
• Helps for better Grid consolidation
– YARN aka MRv2 – Job run reliability
• Agility & Evolution
• Hadoop 23 initial release does not target availability
• Addressed in future releases of Hadoop

- 13 -
Hadoop 23 Story at Yahoo!
• Extra effort is being taken to certify applications with Hadoop 23
• Sufficient time is provided for users to test their applications in Hadoop 23
• Users are encouraged to get accounts to test if their applications run on a sandbox cluster which has Hadoop 23 installed
• Roll Out Plan
– Q4-2012 through Q1 2013 Hadoop 23 will be installed in a phased manner on 50k nodes

- 14 -
HADOOP 23 FEATURES HDFS FEDERATION

- 15 -
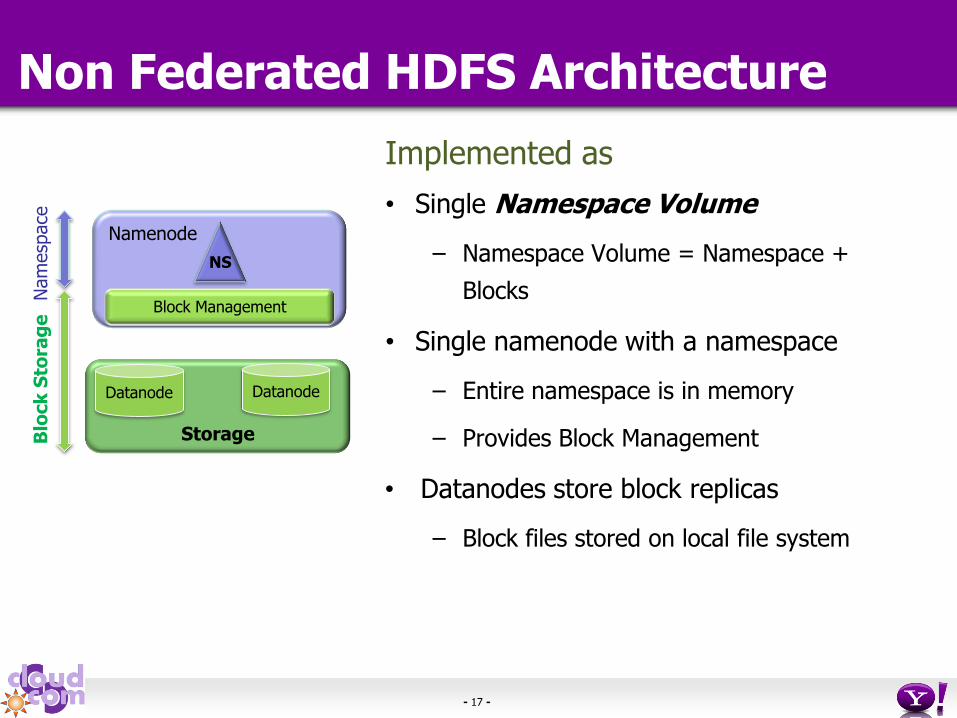
Non Federated HDFS Architecture

- 16 -
Non Federated HDFS Architecture
Two main layers
• Namespace
– Consists of dirs, files and blocks
– Supports create, delete, modify and list files
or dirs operations
• Block Storage
– Block Management
• Datanode cluster membership
• Supports create/delete/modify/get block
location operations
• Manages replication and replica placement
– Storage - provides read and write access to
blocks
Blo
ck
Sto
rag
e
Nam
esp
ace
Namenode
Block Management
NS
Storage
Datanode Datanode …
- 17 -
Non Federated HDFS Architecture
Implemented as
• Single Namespace Volume
– Namespace Volume = Namespace +
Blocks
• Single namenode with a namespace
– Entire namespace is in memory
– Provides Block Management
• Datanodes store block replicas
– Block files stored on local file system
Blo
ck
Sto
rag
e
Nam
esp
ace
Namenode
Block Management
NS
Storage
Datanode Datanode
NS

- 18 -
Limitation - Single Namespace
• Scalability
– Storage scales horizontally - namespace doesn’t
– Limited number of files, dirs and blocks
• 250 million files and blocks at 64GB Namenode heap size
• Performance
– File system operations throughput limited by a single node
• 120K read ops/sec and 6000 write ops/sec
• Poor Isolation
– All the tenants share a single namespace
• Separate volume for tenants is not possible
– Lacks separate namespace for different categories of applications
• Experimental apps can affect production apps
• Example - HBase could use its own namespace
• Isolation is problem, even in a small cluster

- 19 -
Limitation – Tight coupling
• Namespace and Block Management are distinct services
– Tightly coupled due to co-location
– Scaling block management independent of namespace is simpler
– Simplifies Namespace and scaling it
• Block Storage could be a generic service
– Namespace is one of the
applications to use the service
– Other services can be built directly
on Block Storage
• HBase
• Foreign namespaces
19
Blo
ck
Sto
rag
e
Nam
esp
ace
Namenode
Block Management
NS
Storage
Datanode Datanode
NS

- 20 -
HDFS Federation
• It is an administrative/operational feature for better managing resources
• Multiple independent Namenodes and Namespace Volumes in a cluster
› Namespace Volume = Namespace + Block Pool
• Block Storage as generic storage service
› Set of blocks for a Namespace Volume is called a Block Pool
› DNs store blocks for all the Namespace Volumes – no partitioning
Datanode 1 Datanode 2 Datanode m ... ... ...
NS1
Foreign NS n
... ...
NS k
Block Pools
Pool n Pool k Pool 1
NN-1 NN-k NN-n
Common Storage
Blo
ck S
tora
ge
Nam
esp
ace

- 21 -
Managing Namespaces
• Federation has multiple namespaces – Don’t you need a single global namespace? – Key is to share the data and the names used
to access the data
• A global namespace is one way to do that
• Client-side mount table is another way to share. – Shared mount-table => “global” shared view
– Personalized mount-table => per-application view
• Share the data that matter by mounting it
• Client-side implementation of mount tables – No single point of failure
– No hotspot for root and top level directories
home project
NS1 NS3 NS2
NS4
tmp
/ Client-side mount-table
data

- 22 -
viewfs:// schema instead of hdfs:// schema
• With striped HDFS, user's applications were forced to use explicit URL of the source strip to read the data
• Federation hides all that detail. User sees only one single Virtual storage:
– The viewfs: URI schema can be used as the default file system replacing the hdfs schema

- 23 -
Client-Side Mount Table and VIEWFS
• Client-Side Mount Table is a type of file name indirection analogous to mount points in a conventional file system
– Indirection table available to the client application
• "client-side" is truly client side as HDFS client library is involved
– Namenodes are not part of the implementation.
• Data can be moved from one namespace to another without requiring changes in user applications
– An appropriate Client Side Mount Table should be provided

- 24 -
Client-Side Mount Table and VIEWFS
• The mount table is specified in a config file, like all other Hadoop configurations, core-site.xml
• The Client Side Mount Table definitions will by supplied by the Operations team
• 0.20.XXX
<property>
<name>fs.default.name</name>
<value>hdfs://NameNode:port/</value>
</property>
• 0.23
<property>
<name>fs.default.name</name>
<value>viewfs://ClusterName/</value>
</property>

- 25 -
Client-Side Mount Table Example
• mountTable.xml has a definition of the mount table called "KrRd" for the cluster MyCluster.
• MyCluster is a federation of the three name spaces managed by the three Namenodes “nn1" “nn2" and “nn3"
– /user and /tmp managed by “nn1”.
– /projects/foo managed by “nn2“
– /projects/bar managed by “nn3"

- 26 -
Client-Side Mount Table XML Example <configuration>
<property>
<name>fs.viewfs.mounttable.KrRd.link./user</name>
<value> hdfs://nn1/user </value>
</property>
<property>
<name>fs.viewfs.mounttable.KrRd.link./tmp</name>
<value> hdfs://nn1/tmp </value>
</property>
<property>
<name>fs.viewfs.mounttable.KrRd.link./projects/foo</name>
<value> hdfs://nn2/projects/foo </value>
</property>
<property>
<name>fs.viewfs.mounttable.KrRd.link./projects/bar</name>
<value> hdfs://nn3/projects/bar</value>
</property>
</configuration>

- 27 -
HDFS Federation - Wire Compatibility
• Wire Backward Compatibility
– Hadoop 23 is NOT RPC wire compatible with prior version’s of Hadoop (0.20.X)
– Client must be updated to use the same version of Hadoop client library as installed on the server
– Application must be recompiled with new version of HDFS library
• API compatible

- 28 -
HDFS Federation: Append Functionality
• Append Functionality
– HDFS Federation has full support of append functionality along with flush.
– The hflush call by the writing client, ensures that all previously written bytes are visible to all new reading clients.

- 29 -
HDFS Federation - Sticky Bits
• Sticky Bits for Directories
– Directories (not files) have sticky-bits.
– A file in a sticky directory may only be removed or renamed by:
– a user if the user has write permission for the directory and the
– user is the owner of the file, or
– the owner of the directory, or
– the super-user.

- 30 -
HDFS Federation - FileContext
• File Context:
– New API for access to HDFS features.
– Replacement for the existing File System interface.
– FileContext is intended for application developers.
– FileSystem is intended for Service Provider

- 31 -
HDFS Federation - Symbolic Links
• Symbolic links allow the redirection of a filename to full URI
• Symbolic links may cross file systems
• No requirement for the target to exist when the link is created
• Symbolic links are available only via the File Context interface.

- 32 -
HDFS Federation - Hadoop ARchive (HAR)
• har://scheme-hostname:port/archivepath/fileinarchive
• If no scheme is provided it assumes the underlying filesystem
– har:///archivepath/fileinarchive
• Naming scheme with viewfs
– har:///viewfs://cluster-name/foo/bar
– har:///foo/bar , if the default file system is viewfs:
– har:///hdfs://name-server/a/b/foo/bar

- 33 -
HDFS Federation - MapReduce
• Hadoop framework transparently handles initialization of delegation token for all the Namenodes in the current Federated HDFS
• User job requires to access external HDFS
– Set mapreduce.job.hdfs-servers with a comma separated list of the Namenodes

- 34 -
YET ANOTHER RESOURCE NEGOTIATOR (YARN) NEXT GENERATION OF HADOOP MAP-REDUCE

- 35 -
Hadoop MapReduce Today
• JobTracker
– Manages cluster resources and job scheduling
• TaskTracker
– Per-node agent
– Manage tasks

- 36 -
Current Limitations of the Job Tracker
• Scalability
– Maximum Cluster size – 4,000 nodes
– Maximum concurrent tasks – 40,000
• Single point of failure
– Failure kills all queued and running jobs
– Jobs need to be re-submitted by users
• Restart is very tricky due to complex state
• Hard partition of resources into map and reduce slots

- 37 -
Current Limitations of the Job Tracker
• Lacks support for alternate paradigms
– Iterative applications implemented using MapReduce are 10x slower.
– Example: K-Means, PageRank
• Lack of wire-compatible protocols
– Client and cluster must be of same version
– Applications and workflows cannot migrate to different clusters

- 38 -
Design Theme for YARN
• Reliability
• Availability
• Scalability - Clusters of 6,000-10,000 machines
– Each machine with 16 cores, 48G/96G RAM, 24TB/36TB disks
– 100,000 concurrent tasks
– 10,000 concurrent jobs
• Wire Compatibility
• Agility & Evolution – Ability for customers to control upgrades to the grid software stack.

- 39 -
Design Methodology
• Split up the two major functions of JobTracker
– Cluster resource management
– Application life-cycle management
• MapReduce becomes user-land library

- 40 -
Architecture

- 41 -
Architecture

- 42 -
Architecture

- 43 -
Architecture of YARN
• Resource Manager
– Global resource scheduler
– Hierarchical queues
• Node Manager
– Per-machine agent
– Manages the life-cycle of container
– Container resource monitoring
• Application Master
– Per-application
– Manages application scheduling and task execution

- 44 -
Improvements vis-à-vis current Job Tracker
• Scalability
– Application life-cycle management is very expensive
– Partition resource management and application life-cycle management
– Application management is distributed
– Hardware trends - Currently run clusters of 4,000 machines
• 6,000 2012 machines > 12,000 2009 machines
• <16+ cores, 48/96G, 24TB> v/s <8 cores, 16G, 4TB>

- 45 -
Improvements vis-à-vis current Job Tracker
• Availability
– Resource Manager
• No single point of failure – availability via ZooKeeper
– Targeted in Future release of Hadoop 23
• Application Masters are restarted automatically on RM restart
• Applications continue to progress with existing resources during restart, new resources aren’t allocated
– Application Master
• Optional failover via application-specific checkpoint
• MapReduce applications pick up where they left off

- 46 -
Improvements vis-à-vis current Job Tracker
• Wire Compatibility
– Protocols are wire-compatible
– Old clients can talk to new servers
– Rolling upgrades

- 47 -
Improvements vis-à-vis current Job Tracker
• Innovation and Agility
– MapReduce now becomes a user-land library
– Multiple versions of MapReduce (& ecosystems) can run in the same cluster
• Faster deployment cycles for improvements
– Customers upgrade MapReduce versions on their schedule
– Users can run customized versions of MapReduce
• HOP (Hadoop Online Prototype)
– modified version of Hadoop MapReduce that allows data to be pipelined between tasks and between jobs

- 48 -
Improvements vis-à-vis current Job Tracker
• Utilization
– Generic resource model
• Memory (in 23 the rest are for future releases)
• CPU
• Disk b/w
• Network b/w
– Remove fixed partition of map and reduce slots

- 49 -
Improvements vis-à-vis current Job Tracker
• Support for programming paradigms other than MapReduce
– MPI : Work already in progress
– Master-Worker
– Machine Learning
– Iterative processing
– Enabled by allowing use of paradigm-specific Application Master
– Run all on the same Hadoop cluster

- 50 -
Performance Improvements
• Small Job Optimizations
– Runs all tasks of Small job (i.e. job with up to 3/4 tasks) entirely in Application Master's JVM
• Reduces JVM startup time and also eliminates inter-node and inter-process data transfer during the shuffle phase.
– Transparent to the user
• Several Other improvements
– Speculation: Less aggressive
– Overhauled Shuffling algorithm yielding 30% improvement.

- 51 -
• Scalable
– Largest YARN cluster in the world built at Yahoo! running on (Hadoop 0.23.4), with no scalability issues so far
– Ran tests to validate that YARN should scale to 10,000 nodes.
• Surprisingly Stable
• Web Services
• Better Utilization of Resources at Yahoo!
– No fixed partitioning between Map and Reduce Tasks
– Latency from resource available to resource re-assigned is far better than 1.x in big clusters
Experiences of YARN – High Points

- 52 -
• HDFS
– Read (Throughput 5.37% higher)
• MapReduce
– Sort (Runtime 4.59% smaller, Throughput 3.98% higher)
– Shuffle (Shuffle Time 13.25% smaller)
– Gridmix (Runtime 5.29% smaller)
– Small Jobs – Uber AM (Word Count 3.5x faster, 27.7x fewer resources)
Performance (0.23.3 vs. 1.0.2)

- 53 -
• MPI (www.open-mpi.org nightly snapshot)
• Machine Learning (Spark)
• Real-time Streaming (S4 and Storm)
• Graph Processing (GIRAPH-13)
YARN Synergy with new Compute Paradigms

- 54 -
• Oozie on YARN can have potential deadlocks (MAPREDUCE-4304)
– UberAM can mitigate this
• Some UI scalability issues (YARN-151, MAPREDUCE-4720)
– Some pages download very large tables and paginate in JavaScript
• Minor incompatibilities in the distributed cache
• No generic history server (MAPREDUCE-3061)
• AM failures hard to debug (MAPREDUCE-4428, MAPREDUCE-3688)
The Not So Good

- 55 -
HADOOP 23 IMPACT ON END USERS

- 56 -
Hadoop 23 Compatibility – Command Line
• Users should depend on environment variables: – $HADOOP_COMMON_HOME
– $HADOOP_MAPRED_HOME
– $HADOOP_HDFS_HOME
• hadoop command to execute mapred or hdfs sub-
commands has been deprecated
– Old usage (will work) – hadoop queue –showacls
– hadoop fs -ls
– hadoop mapred job -kill <job_id>
– New Usage – mapred queue -showacls
– hdfs dfs –ls <path>
– mapred job -kill <job_id>

- 57 -
Hadoop 23 Compatibility – Map Reduce
• An application that is using a version of Hadoop 20 will not work in Hadoop 0.23
• Hadoop 0.23 version is API compatible with Hadoop 0.20
– But not binary compatible
• Hadoop Java programs will not require any code change, However users have to recompile with Hadoop 0.23
– If code change is required, please let us know.
• Streaming applications should work without modifications
• Hadoop Pipes (using C/C++ interface) application will require a re-compilation with new libraries

- 58 -
Hadoop 23 Compatibility - Pipes
• Although not deprecated, no future enhancements are planned.
– Potential of being deprecated in future
• As of now, it should work as expected.
– Recompilation with new Hadoop library is required.
• Recommended use of Hadoop Streaming for any new development.

- 59 -
Hadoop 23 Compatibility - Ecosystems
• Applications relying on default setup of Oozie, Pig and Hive should continue to work.
• Pig and Hive scripts should continue to work as expected
• Pig and Hive UDFs written in Java/Python should continue to function as expected
– Recompilation of Java UDF’s against Hadoop 23 is required
- 60 -
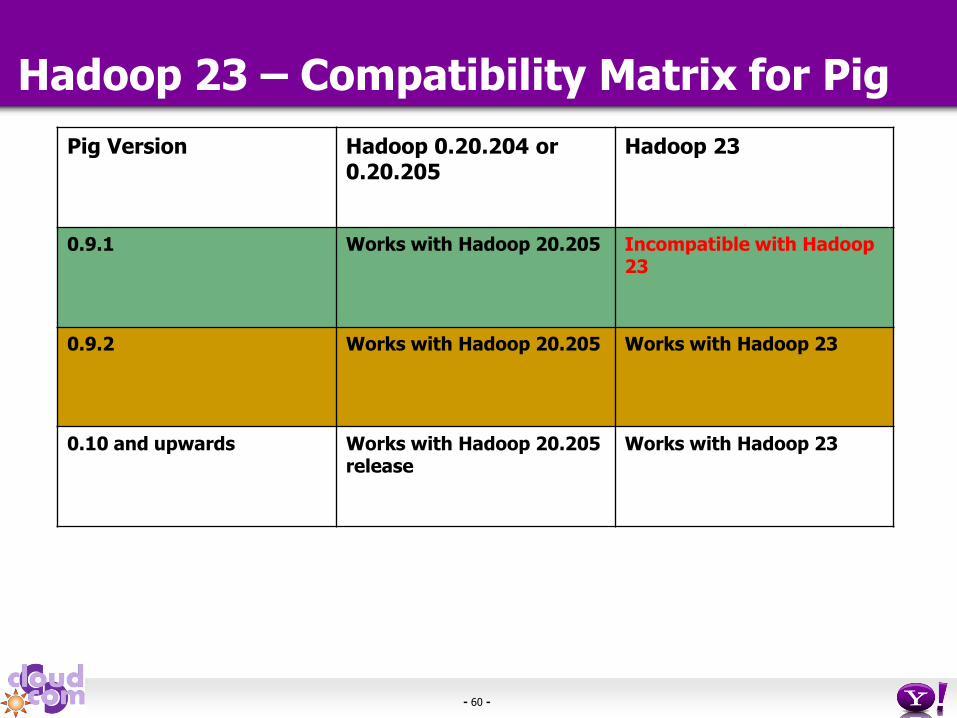
Hadoop 23 – Compatibility Matrix for Pig
Pig Version Hadoop 0.20.204 or 0.20.205
Hadoop 23
0.9.1 Works with Hadoop 20.205 Incompatible with Hadoop 23
0.9.2 Works with Hadoop 20.205 Works with Hadoop 23
0.10 and upwards Works with Hadoop 20.205 release
Works with Hadoop 23

- 61 -
Hadoop 23 Compatibility - Pig
• Pig versions 0.9.2 and future releases will be fully supported on Hadoop 0.23
• No Changes in Pig script if it uses relative paths in HDFS
• Changes in pig script is required if HDFS absolute path (hdfs:// ) is used
– HDFS Federation part of Hadoop 23 requires the usage of viewfs:// (HDFS discussion to follow)
– Change hdfs:// schema to use viewfs:// schema
• Java UDF’s must be re-compiled with Pig 0.9.2 jar
– Ensures if user is using incompatible or deprecated APIs
– Code change might not be required for most cases
- 62 -
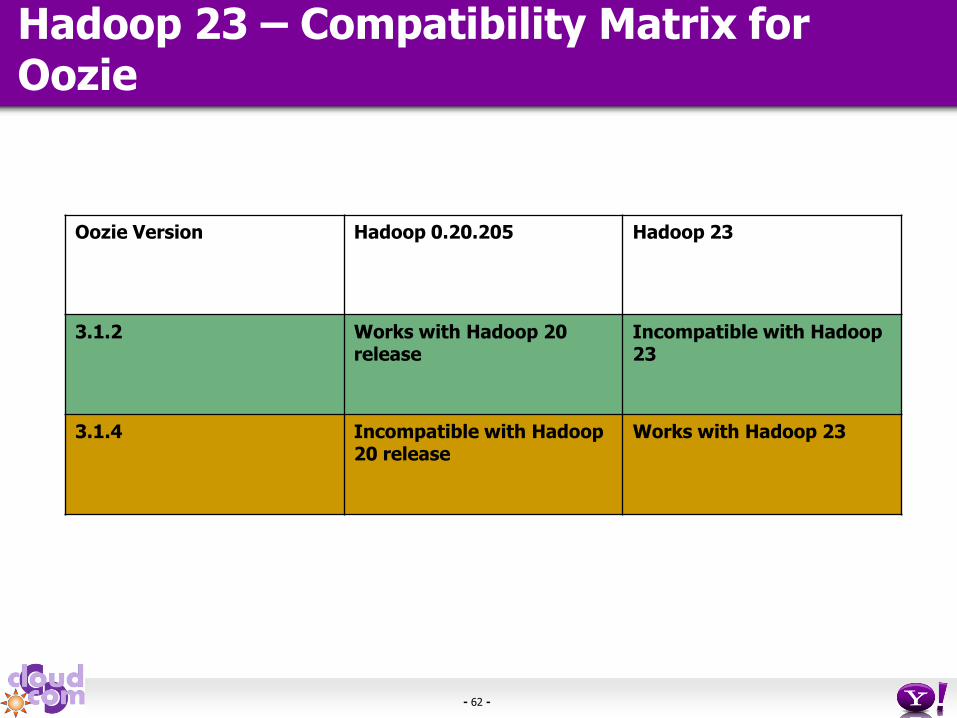
Hadoop 23 – Compatibility Matrix for Oozie
Oozie Version Hadoop 0.20.205 Hadoop 23
3.1.2 Works with Hadoop 20 release
Incompatible with Hadoop 23
3.1.4 Incompatible with Hadoop 20 release
Works with Hadoop 23

- 63 -
• Oozie 3.1.4 and later versions compatible with Hadoop 23
• Existing user workflow and coordinator definition (XML) should continue to work as expected
• No need to redeploy the Oozie coordinator jobs
• Users will need to update workflow definition to use viewfs:// instead of hdfs:// schema
– Due to HDFS Federation (discussion to follow)
– If HDFS is updated to have multi-volume (i.e. Federated) and there is a need to relocate the data
Hadoop 23 Compatibility - Oozie

- 64 -
Hadoop 23 Compatibility – Oozie Actions
• All Java actions must be recompiled with Hadoop 23 libraries
• “distcp” action or “Java” action invoking distcp requires Hadoop 23 compatible distcp jar
• Users responsibility to package Hadoop 23 compatible jars with their workflow definition
– Pig 0.9.2 jar needs to be packaged for Pig action to function in Hadoop 23

- 65 -
Hadoop 23 - Oozie Challenges
• Learning curve for maven builds
– Build iterations, local maven staging repo staleness
• Queue configurations, container allocations require revisiting the design
• Many iterations of Hadoop 23 deployment
– Overhead to test Oozie compatibility with new release
• Initial deployment of YARN did not have a view of the Application Master (AM) logs
– Manual ssh to AM for debugging launcher jobs

- 66 -
• Hive version 0.8.1 and upwards are fully supported
• Hive SQL/scripts should continue to work without any modification
• Java UDF’s in Hive must be re-compiled with Hadoop 23 compatible hive.jar
– Ensures if user is using incompatible or deprecated APIs
Hadoop 23 Compatibility - Hive

- 67 -
Hadoop 23 – Hive Challenges
• Deprecation of code in MiniMRCluster that fetches the stack trace from the JobTracker “no longer” works
– Extra amount of time in debugging and rewriting test cases
• Incompatibility of HDFS commands between Hadoop 1.0.2 and 0.23
– -rmr vs. -rm -r
– mkdir vs. mkdir –p
– Results in fixing tests in new ways or inventing workarounds so that they run in both Hadoop 1.0.2 and Hadoop 0.23
• As Hive uses MapRed API’s; more work required for certification
– Would be good to move to MapReduce API’s (for example: Pig)

- 68 -
• HCat 0.4 and upwards version will be certified to work with Hadoop 23
Hadoop 23 Compatibility - HCat

- 69 -
Hadoop 23 New Features – User Logs in User Dir
• User logs (stdout/stderr/syslog from the job) go into “/user/” HDFS dir and are subject to quotas
– User logs have potential to fill up user HDFS quota
• User has to periodically clean up
– Previously in Hadoop 20 were stored on task tracker machines
• Deleted after a fixed interval
• Storing of User logs fails if
– User quota on HDFS maxed out
• Application Master logs (counters, start time, #maps, #reducers)
– Stored on the system directories
– Cleaned up on a periodic basis

- 70 -
Hadoop 23 Compatibility - Job History API Log Format
• History API & Log format are changed
– Affects all applications and tools that directly use Hadoop History API
– Stored as Avro serialization in JSon format
• Applications and tools are recommended to use Rumen
– Data extraction and analysis tool for Map-Reduce
– https://issues.apache.org/jira/secure/attachment/12450044/rumen.pdf

- 71 -
Hadoop 23 Queue Changes
• Hadoop 23 has support for Hierarchical Queues
• Container Queues contain other Leaf/Job Queues
• Jobs are submitted to Leaf queues
• Higher level of controls to the administrators
• Better scheduling of jobs with competing resources within the container queues
• Queues (as before) can steal resources beyond their capacity subject to their Max-Capacity setting

- 72 -
Hadoop 23 Compatibility - Web-UI
• Different Look and Feel to Web UI
– Customizable by the user
• Any user applications/tools depending on Web UI screen-scrapping to extract data will fail
– Users should depend on the web services API instead

- 73 -
Resource Manager

- 74 -
32 bits 64 bit JDK for Hadoop 23?
• Only 32 bit JDK is certified for Hadoop 23
• 64 bit JDK would be bundled but not certified
– 64 bit support postponed to post Hadoop 23 deployment

- 75 -
Hadoop 23 Operations and Services
• Grid Operations at Yahoo! transitioned Hadoop 1.0.2 Namenode to Hadoop 23 smoothly
– No data was lost
• Matched the container configurations on Hadoop 23 clusters with the old Map Reduce slots
– Map Reduce slots were configured based on memory hence transition was smooth
• Scheduling, planning and migration of Hadoop 1.0.2 applications to Hadoop 23 for about 100+ customers was a major task for solutions
– Many issues were caught in the last minute needed emergency fixes (globbing, pig.jar packaging, change in mkdir command )
– Hadoop 0.23.4 build planned

- 76 -
Acknowledgements
• YARN – Robert Evans, Thomas Graves, Jason Lowe
• Pig - Rohini Paliniswamy
• Hive and HCatalog – Chris Drome
• Oozie – Mona Chitnis and Mohammad Islam
• Services and Operations – Rajiv Chittajallu and Kimsukh Kundu

- 77 -
References
• 0.23 Documentation
– http://people.apache.org/~acmurthy/hadoop-0.23/
• 0.23 Release Notes
– http://people.apache.org/~acmurthy/hadoop-0.23/hadoop-project-dist/hadoop-common/releasenotes.html
• YARN Documentation
– http://people.apache.org/~acmurthy/hadoop-0.23/hadoop-yarn/hadoop-yarn-site/YARN.html
• HDFS Federation Documentation
– http://people.apache.org/~acmurthy/hadoop-0.23/hadoop-yarn/hadoop-yarn-site/Federation.html


















