
Traitement d'Images : Introduction et Filtrage...
86
Transcript of Traitement d'Images : Introduction et Filtrage...

Traitement d'Images :Introduction et Filtrage Spatial
Licence Pro - IUT Bordeaux I2004 /2005
Sylvie [email protected]

Table des matières
1 Introduction 31.1 Historique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Chaîne de manipulation d'images numériques . . . . . . . . . . . . . . 41.3 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.4 Image numérique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Vision 102.1 Lumière et vision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2 Description et fonctionnement de l'÷il . . . . . . . . . . . . . . . . . . 12
2.2.1 La cornée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2.2 La choroïde . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.2.3 L'iris et la pupille . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2.3.1 L'iris . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.2.3.2 La pupille . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2.4 Le cristallin . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.2.5 L'humeur aqueuse et le corps vitré . . . . . . . . . . . . . . . . 17
2.2.5.1 L'humeur aqueuse . . . . . . . . . . . . . . . . . . . . 172.2.5.2 Le corps vitré . . . . . . . . . . . . . . . . . . . . . . . 17
2.2.6 La rétine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.2.6.1 La macula et la fovéa . . . . . . . . . . . . . . . . . . 192.2.6.2 Les cônes et les bâtonnets . . . . . . . . . . . . . . . . 19
2.2.7 Transmission de l'information au cerveau . . . . . . . . . . . . . 202.2.7.1 Le nerf optique . . . . . . . . . . . . . . . . . . . . . . 202.2.7.2 Le cerveau . . . . . . . . . . . . . . . . . . . . . . . . 21
2.2.8 Défauts de vision . . . . . . . . . . . . . . . . . . . . . . . . . . 212.3 Mécanismes cognitifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.3.1 Illusions d'optiques ou quand le cerveau se trompe . . . . . . . . 222.3.2 Vision binoculaire . . . . . . . . . . . . . . . . . . . . . . . . . . 272.3.3 Complémentarité des hémisphères gauche et droit . . . . . . . . 29
3 Espaces de représentation des couleurs 313.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.2 Espaces additifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.3 Espaces soustractifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.4 Espaces intuitifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
1

4 Traitement d'images 414.1 Contexte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414.2 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 434.3 Transformations d'intensité classiques . . . . . . . . . . . . . . . . . . . 45
4.3.1 Transformation négative . . . . . . . . . . . . . . . . . . . . . . 454.3.2 Transformation logarithmique . . . . . . . . . . . . . . . . . . . 474.3.3 Transformation en puissance . . . . . . . . . . . . . . . . . . . . 474.3.4 Transformations linéaires par morceaux . . . . . . . . . . . . . . 50
4.3.4.1 Réhaussement de contraste . . . . . . . . . . . . . . . 504.3.4.2 Transformation d'une plage de niveaux de gris . . . . . 51
4.4 Manipulation d'histogrammes . . . . . . . . . . . . . . . . . . . . . . . 524.4.1 Egalisation d'histogramme . . . . . . . . . . . . . . . . . . . . . 544.4.2 Spéci�cation d'histogramme . . . . . . . . . . . . . . . . . . . . 58
4.5 Filtrage spatial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 624.5.1 Bases du �ltrage spatial . . . . . . . . . . . . . . . . . . . . . . 624.5.2 Filtres de lissage ou �ltres passe-bas . . . . . . . . . . . . . . . . 64
4.5.2.1 Filtres linéaires de lissage . . . . . . . . . . . . . . . . 654.5.2.2 Filtres non linéaires de lissage . . . . . . . . . . . . . . 67
4.5.3 Filtres de netteté ou �ltres passe-haut . . . . . . . . . . . . . . 684.5.3.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . 694.5.3.2 Dérivée seconde : utilisation du Laplacien . . . . . . . 714.5.3.3 Dérivée première : utilisation du Gradient . . . . . . . 76
4.5.4 Combinaisons de plusieurs �ltres . . . . . . . . . . . . . . . . . 79
2

Chapitre 1
Introduction
L'être humain dépend à 99% de sa vision pour récolter des informations sur lemonde qui l'entoure. L'importance de la vue dans notre vie quotidienne est telle qu'aumoindre défaut, on utilise des moyens arti�ciels pour la corriger (lunettes, lentilles).D'ailleurs, c'est un des seuls sens avec l'audition pour lequel ont été créées di�érentessortes de prothèses. Et le recours à ces outils est beaucoup plus systématique et rapidepour une perte d'acuité visuelle que lors de l'apparition de dé�ciences auditives.
Il est donc naturel que l'imagerie numérique ait pris une telle importance. Trèsgrossièrement, on peut dire que l'imagerie numérique est orientée vers deux principalesdirections. La première consiste à doter un ordinateur d'outils (matériels et logiciels)qui lui permettent de reproduire autant que possible les mécanismes (physiques etcognitifs) de la vision humaine. On parle de vision par ordinateur. La deuxième seconcentre sur la création par un ordinateur d'images, on parle souvent de scènes, quisuivant le type d'applications vont chercher soit à être réalistes ou du moins crédiblespour l'÷il humain, soit simplement exploitables en présentant de manière synthétiqueet expressive une information complexe. On regroupe généralement ces techniques sousle terme synthèse d'images.
Dans ce cours nous abordons quelques problématiques liées à la première approche.
1.1 HistoriqueLes journaux ont été les premiers utilisateurs d'images numériques. A l'époque, il
n'était même pas question d'ordinateurs. Il s'agissait de trouver des méthodes pourtransmettre le plus rapidement possible des photos d'un continent à un autre. Le sys-tème Bartlane mis au point par Harry G. Batholomew et Maynard D. McFarlane etdéveloppé en Grande Bretagne dans les années 1920 fut un des premiers procédés denumérisation et transmission d'images. L'information contenue dans l'image était audépart transcrite sur une carte perforée composée de 5 types de trous di�érents, d'oùdes images codées en 5 niveaux de gris. Ces images étaient ensuite transmises télé-graphiquement par câble sous-marin puis retraduites et imprimées à l'autre bout dela ligne. Cette technique permettait de transmettre des photos en moins de 3 heuresalors qu'une semaine était auparavant nécessaire. En 1925, de nouvelles améliorationsrendaient possible la transmission d'images en 15 niveaux de gris. Des exemples de telsimages sont visibles sur la �gure 1.1.
3

Fig. 1.1 � Images produites après transfert par le système Bartlane en 1921 et 1922 (5niveaux de gris) puis en 1929 (15 niveaux de gris)
Bien que ces images soient le résultat d'une sorte de processus de numérisation,elles ne rentrent pas dans le cadre de ce qu'on appelle classiquement les images numé-riques car leur fabrication n'a pas été réalisée à l'aide d'un ordinateur. L'histoire desimages numériques proprement dites est donc intimement liée à l'histoire et l'évolutiondes ordinateurs. Si les principes d'automatisation de calculs remontent à l'Antiquité(avec notamment l'Abacus, boulier utilisé à Babylone), et si de nombreuses machinesà calculer mécaniques ont été inventées au cours des siècles, la notion moderne d'ordi-nateur remonte aux années 1940. Elle repose sur deux concepts clés amenés par VonNeumann : une mémoire pour stocker les programmes et les données et la notion debranchements conditionnels. Cependant, il faudra attendre les années 1960 pour dis-poser de machines su�samment puissantes permettant de traiter informatiquementdes images. Le programme spatial de la NASA à l'époque a beaucoup contribué à lacréation et à l'évolution du traitement d'images par l'informatique. Il s'agissait d'êtrecapable d'améliorer et d'interpréter les images ramenées par les premières sondes spa-tiales (Ranger 7 et suivantes). La �n des années 1960 et le début des années 1970 voientensuite la naissance de l'imagerie médicale avec l'invention de la tomographie.
Depuis, l'utilisation d'images numériques s'est généralisée à de nombreux domaineset les progrès réalisés en informatique permettent de manipuler des images de plus enplus complexes.
1.2 Chaîne de manipulation d'images numériquesL'imagerie numérique possède un vaste champ d'applications qui demandent la mise
en ÷uvre de techniques variées. Elle peut être dé�nie comme l'ensemble des processusinformatiques qui produisent ou traitent une image.
Le dessin suivant (cf �gure 1.2) est une schématisation assez sommaire de ses di�é-rentes composantes.
Dans ce cours, nous nous focalisons principalement sur la partie traitement. Aupassage, on confond souvent traitement et analyse d'images qui sont deux étapes di�é-rentes. Le traitement vise à améliorer une image (contrastes, e�ets...) ou à lui associerun codage approprié (compression, transmission...), tandis que l'analyse cherche à luidonner un sens, à en extraire toutes les informations utiles (reconnaissance de formes,
4

Fig. 1.2 � schéma général des actions autour de l'image numérique
vision en robotique...). Le traitement est généralement une phase préalable à l'analyse.Pour vous donner une idée, voici le découpage classique d'un processus d'analyse
d'images :� Acquisition : scène réelle −→ image� Traitement : image −→ image (souvent en cascades)� Segmentation : image −→ image découpée en régions� Reconstruction : image/régions −→ modèles géométriques� Reconnaissance de formes : régions/modèles −→ objets identi�és
1.3 ApplicationsLes applications sont nombreuses et concernent des domaines très variés.On peut commencer par citer des applications industrielles et commerciales : sur-
veillance de chaînes de production, contrôle de pièces usinées, reverse engineering, lec-ture de code-barres, reconnaissance de caractères (e.g. code postal, chèques), vidéo-surveillance, identi�cation de visages, de plaques minéralogiques, reconnaissance degestes. . .
5

Fig. 1.3 � JPEG qualité max 14849 octets - qualité intermédiaire 5255 octets - qualitémin. 874 octets
Il existe aussi de nombreuses applications pour tout ce qui est multimédia : télé-vision, cinéma, marketing, jeux, réalité virtuelle· · · On peut notamment citer tout cequi est incrustation vidéo (sur fond bleu1), morphing (besoin d'une analyse préalablede l'image pour réaliser un morphisme �automatique�), réalité augmentée (combinai-son de réel et de virtuel : par exemple dans Jurassic Parc, le caméraman a �lmé despaysages et le spectateur y a vu en plus des dinosaures arti�ciellement ajoutés), visio-conférence. . . Les besoins liés au multimédia sont variés : compression, représentation,codage, transmission, indexation. . .. Il s'agit dans ces applications d'obtenir selon lecontexte le meilleur compromis qualité / compacité. D'où la dé�nition de standardsappropriés pour coder les images : JPEG, MPEG . . . (�gure 1.3).
L'imagerie numérique est de plus en plus intégré dans le domaine biomédical (cf�gure 1.4), que ce soit pour l'aide au diagnostic ou pour la réalisation de gestes assis-tés par ordinateur. Les contraintes sont alors la �abilité, la robustesse, la rapidité, leréalisme et l'utilisation de notions d'intelligence arti�cielle.
La robotique est aussi très friande d'images numériques (cf �gure 1.5), a�n de pou-voir doter les robots d'une �vision arti�cielle� à base d'analyse d'images, de �ltrage etde reconstruction. Les applications doivent être à la fois robuste et construite à partirde mécanismes d'intelligence arti�cielle.
1.4 Image numériqueUne image est un couple (S, I) où S est un ensemble structuré appelé support ou
domaine (en général une grille régulière) et I est une fonction qui associe à chaqueélément de S une quantité (e.g. une couleur).
Le support est en général une grille régulière qui est particulièrement adaptée ausupport d'a�chage, c'est à dire l'écran.
Un élément du support est appelé pixel pour picture element. Et à chaque pixel estassociée une quantité. Cette quantité est scalaire dans le cas des images en niveau degris. Elle est en général codée sur 8 bits soit un nombre entre 0 et 255 (photographie
1Les pros utilisent en général un fond bleu ou vert. Le bleu parce qu'il est éloigné des tons chairde la peau humaine. Le vert est utilisé surtout en vidéo car les capteurs CCD des caméras vidéo sontréputés plus sensibles au vert. Sur certains �lms, un fond rouge vif fut utilisé par exemple pour letournage de la maquette de l'avion du �lm Air Force One. La teinte doit être choisie en fonction descouleurs présentent sur les acteurs ou, sinon, vos acteurs vont se transformer en homme invisible ! Parexemple, si les acteurs portent des Jeans bleus, mieux vaut utiliser un fond vert.
6

Fig. 1.4 � Imagerie médicale
Fig. 1.5 � Robotique
7

noir et blanc, radiographie, IRM, microscope électronique). La quantité peut aussi êtrevectorielle. Dans le cas des images couleur par exemple, elle est codée avec 3 valeursentre 0 et 255, une valeur pour chaque composante de couleur (caméra CCD, photo-graphie couleur, images radars (vecteur de X composantes), microscopie confocale).
Une image numérique est ainsi généralement représentée par un tableau de pixels(souvent à 2 dimensions). Un pixel est alors caractérisé par ses coordonnées (x, y), engénéral entre 0 et Largeur-1 et 0 et Hauteur - 1. La quantité associée à ce pixel dansl'image I sera notée naturellement I(x, y).
Fig. 1.6 � Grille image
Une image numérique est caractérisée à la fois par sa résolution spatiale (largeuret hauteur en pixels) (cf Fig. 1.7), et sa résolution en nombre de �couleurs� possibles(cf Fig. 1.8). La qualité d'une image dépend bien évidemment fortement de ces deuxcaractéristiques.
8

(a) (b)
(c) (d)
Fig. 1.7 � 4 images avec di�érentes résolutions spatiales
(a) 256 couleurs (b) 4 couleurs
Fig. 1.8 � 2 images avec deux résolutions en nombre de couleurs di�érentes
9

Chapitre 2
Vision
La vision est l'ensemble des processus qui, à partir des informations sensorielles,aboutissent à une représentation mentale du monde extérieur. Trois types de phéno-mènes sont mis en jeu : optiques (÷il), chimiques et électriques (÷il et rétine) et cognitifs(cerveau).
La perception visuelle fait donc appel à la fois aux informations lumineuses pro-venant du monde extérieur, aux propriétés physico-chimiques de l'÷il, à des connais-sances a priori, à des règles de structuration d'images, au langage, au conditionnementculturel. . .
2.1 Lumière et visionUne ondre électromagnétique monochromatique est caractérisée par sa fréquence
qui détermine sa �couleur� et par son amplitude qui correspond à l'intensité lumineuse.Une lumière est une somme d'ondes monochromatiques caractérisée par l'amplitude dechacune de ses ondes.
On caractérise généralement les ondes électromagnétiques par leur longueur d'onde,λ, trajet parcouru par l'onde pendant une période, et leur fréquence, ν. Ces deux para-mètres sont liés par la formule λ = c/ν , où c est la célérité de l'onde électromagnétique,soit environ 300000 km.s−1, que l'on appelle aussi vitesse de la lumière dans le vide.L'ensemble des ondes électromagnétiques comprend les rayons gamma, X, ultraviolets,infrarouges, les ondes radios, etc, ainsi que le montre la �gure 2.1.
Les travaux de Max Planck et Albert Einstein sur la "lumière quantique" ont montréque la lumière avait une double nature : ondulatoire et corpusculaire. Autrement dit,l'énergie de la lumière est aussi en quelque sorte "granuleuse", ce "grain d'énergie" estappelé un photon. Il existe deux types d'objets :
� ceux qui produisent de la lumière, comme le soleil, les �ammes, les lampes à in-candescence, etc. Ceux-ci produisent souvent de la lumière par incandescence, lemouvement perpétuel d'agitation de la matière émettant des ondes électroma-gnétiques ;
� ceux qui ne sont visibles que s'ils sont éclairés (invisibles dans l'obscurité). Ilsabsorbent une partie de la lumière qu'ils reçoivent et di�usent la lumière nonabsorbée dans toutes les directions. Ce phénomène est appelé l'émission atomiqueou moléculaire.
10

Le système visuel humain ne peut détecter, dans le spectre de la lumière (�gure 2.1),que des longueurs d'ondes comprises entre environ 400 et 700 nanomètres. En dessousde ces limites on parle de l'ultra-violet, au dessus de l'infra-rouge. Notre système visuelperçoit cet intervalle de fréquences d'ondes lumineuses comme un arc-en-ciel de couleursvariant progressivement. On appelle cet intervalle de fréquences d'ondes lumineuses lespectre visible. Une lumière composée de toutes les longueurs d'onde du spectre visibleest une lumière blanche. La �gure 2.2 montre approximativement le spectre visible.
Fig. 2.1 � Spectre des ondes électromagnétiques
On peut se demander pourquoi on ne perçoit pas les rayonnements dans l'infrarougeet dans l'ultra-violet. En ce qui concerne les ultra-violets, c'est le cristallin qui n'estpas assez transparent pour les laisser passer. Les infra-rouges quant à eux atteignentbien la rétine mais aucun des photo-récepteurs n'est capable de traiter ces longueursd'ondes.
Fig. 2.2 � Spectre visible
La notion de couleur n'a pas d'existence propre dans le monde physique. En réalité,la couleur est le résultat d'une interaction complexe entre une lumière, un objet, et unobservateur1. Quand on parle de la couleur d'une onde électromagnétique, on parle dela couleur vue par un observateur dont la perception visuelle est normale sur un objetqui absorbe toutes les longueurs d'ondes sauf celle-là.
1Pour être tout à fait exact, il faudrait aussi tenir compte de l'environnement physique de ces troisparamètres
11

Ainsi, en plein jour, une tomate mûre paraît rouge à un observateur dont la visionest normale, parce que sa peau est telle qu'elle ne ré�échit que la composante rouge dela lumière qui l'éclaire. Comme tout objet, la tomate reçoit la lumière du soleil, plus oumoins �ltrée par les nuages, plus ou moins forte, mais qui reste malgré tout une lumièreblanche. Cette lumière est partiellement absorbée par la peau, et seule une partie seré�échit. C'est cette partie qui est perçue par l'÷il. Pour que la tomate semble rouge,c'est qu'elle a absorbée les autres couleurs composant la lumière blanche.
Si l'on plonge la tomate dans le noir, et qu'on l'éclaire avec un spot jaune oumagenta, le fruit semble toujours aussi rouge. En e�et, la lumière jaune est formée derouge et de vert, la lumière magenta de rouge et de bleu. La tomate absorbe tout saufle rouge : son apparence n'a donc pas changé. On note que la queue de la tomate -verte - apparaît noire sous un éclairage magenta, éclairage qui ne contient pas de vert.
Par contre, si l'on éclaire la tomate avec un spot vert ou bleu, elle semble noire.Pourquoi ? Parce que ni la lumière verte ni la lumière bleue ne contiennent de compo-sante rouge. La tomate absorbe donc toute la lumière qu'elle reçoit, et ne ré�échit plusrien : elle paraît noire.
Fig. 2.3 � Une tomate sous di�érents éclairages : lumières blanche puis magenta, jaune,verte et en�n bleue
Pour la même raison, les voitures bleues dans les tunnels éclairés en jaune-orangeparaîtront noires : ce n'est pas dû à la faible luminosité, mais bien au fait que la lumièrejaune est entièrement absorbée par le capot bleu.
D'autre part des lumières di�érentes, c'est à dire composées de longueurs d'ondesdi�érentes peuvent dans certaines conditions produire la même couleur. On parle alorsde couleurs métamères, c'est à dire des couleurs de même apparence mais produitespar des lumières de spectres di�érents (Figure 2.4).
2.2 Description et fonctionnement de l'÷ilL'÷il est un des organes les plus perfectionnés de notre corps. Son rôle consiste à
transformer les informations lumineuses provenant de l'environnement en in�ux ner-
12

(a) Di�érentes combinaisons de lon-gueurs d'ondes
(b) Couleur perçue
Fig. 2.4 � Couleurs métamères : réponse identique des capteurs à des lumières despectres di�érents
veux envoyés au cerveau et d'e�ectuer certains pré-traitements élémentaires sur lesinformations reçues. Son principe est proche de celui d'une caméra ré�exe très perfec-tionnée composée de 13 éléments. Pour mémoire, une caméra ré�exe est un appareil quicombine visée et prise de vue à travers le même objectif. La photo obtenue correspondexactement a ce qui a été vu dans le viseur.
L'÷il est une sphère d'environ 25 mm de diamètre. C'est un organe mobile contenudans une cavité appelée globe occulaire, qui lui empêche tout mouvement de translation(avant-arrière), mais qui lui permet la rotation grâce à des muscles permettant d'orien-ter le regard dans une in�nité de directions. C'est ce qu'on appelle le champ visuel, quipeut atteindre 200◦. La puissance de l'÷il est égale à 59 dioptries 2.
La cornée est une membrane transparente qui nous permet de voir. L'iris est le lediaphragme coloré. La pupille est un diaphragme qui laisse passer la lumière, elle peutne mesurer que 1 à 2 mm de diamètre en lumière intense pour atteindre 8 mm dansl'obscurité.
L'÷il est tapissé de 3 feuillets :� la sclérotique : c'est le blanc de l'÷il, elle est entourée d'une membrane très �neet transparente, appelée conjonctive,
� la choroïde : couche pleine de pigments qui constitue une chambre noire ; elle esttrès vascularisée,
� la rétine : tissu très important et très fragile, c'est un tissu sensoriel transformantle �ux lumineux en in�ux nerveux.
Derrière l'iris se trouve le cristallin. Il est entouré par les corps ciliaires auxquels
2la dioptrie est l'unité de puissance égale à l'inverse de la distance focale, exprimée en mètres
13

Fig. 2.5 � Coupe simpli�ée de l'÷il
Fig. 2.6 � Coupe encore plus simpli�ée de l'÷il
il est maintenu par la zonule de Zinn. Le cristallin est transparent et peut perdre satransparence, entre autres avec l'âge.
Entre le cristallin et le fond de l'÷il, on trouve le corps vitré qui est une massegélatineuse blanche transparente qui maintient la forme de l'÷il.
A l'avant de l'÷il on délimite 2 zones :� la chambre antérieure entre la cornée et l'iris. Elle est remplie par l'humeuraqueuse.
� la chambre postérieure entre l'iris et le cristallin.Les paupières répartissent les larmes par leur clignement. En�n, le nerf optique
fonctionne comme une courroie de transmission en direction du cerveau.
2.2.1 La cornée� Ensemble transparent� Objectif de l'÷il
14

Fig. 2.7 � Autre coupe de l'÷il (terminologie anglaise)
Fig. 2.8 � Cornée
La cornée est le prolongement le plus bombé de la sclérotique. La frontière sclérotique-cornée s'appelle le limbe. La cornée est très innervée donc très sensible. Elle est trans-parente et doit le rester pour assurer une bonne vision.
2.2.2 La choroïde� Couche pigmentée� Forme la chambre noire
Fig. 2.9 � Choroïde
La choroïde est une couche richement vascularisée qui assure la nutrition de l'iris etde la rétine. Elle est située entre la sclérotique et la rétine. Elle contient de nombreuxpigments colorés et forme donc un écran. Elle maintient l'intérieur de l'÷il en chambre
15

noire.
2.2.3 L'iris et la pupille2.2.3.1 L'iris
� Donne la couleur à l'oeil� Règle la dilatation de la pupille
Fig. 2.10 � Iris
C'est un diaphragme circulaire se réglant automatiquement suivant la quantité delumière reçue. Quand le diamètre est petit, la profondeur de champ augmente, et il ya moins d'aberrations : les rayons qui sont en trop sont éliminés par le diaphragme etl'image qui se forme sur la rétine est nette. La nuit, il n'y a pas beaucoup de lumière,la pupille se dilate, l'image qui se forme sur la rétine n'est plus nette : c'est la myopienocturne. L'iris est responsable de la couleur de l'oeil. La nutrition de l'iris est assuréepar l'humeur aqueuse dans laquelle elle baigne, et par quelques petites artérioles.
Les muscles qui sont responsables de la variation de diamètre de l'iris sont :� le dilatateur : contracte l'iris, c'est-à-dire dilate la pupille,� le sphincter : diminue le diamètre de la pupille.
2.2.3.2 La pupille� Trou circulaire au milieu de l'iris� Diaphragme de l'oeil� Taille variable en fonction de la lumière
Fig. 2.11 � Pupille
Son diamètre en lumière normale est de 3 à 6 mm. L'augmentation du diamètre dela pupille s'appelle : mydriase, et la diminution de ce diamètre s'appelle : myosis.
2.2.4 Le cristallin� Lentille transparente
16

� Objectif de l'oeil
Fig. 2.12 � Cristallin
Le cristallin est une lentille transparente biconvexe. Il est vascularisé. Sa courburepeut varier, entraînant une variation de sa puissance. On parle alors d'accommodation.Le cristallin se bombe, il augmente sa puissance. Le cristallin est enveloppé par unecapsule. Sur cette capsule sont �xés les �bres de la zonule de Zinn.
Les chi�res :� son indice n = 1,42� sa puissance est de 16 dioptries.Avec l'âge, il y a perte de l'élasticité du cristallin. C'est la presbytie. Le jaunissement
du cristallin, ou perte de transparence avec le temps provoque une opaci�cation. C'estla cataracte. Lorsque l'on a une cataracte, toutes les longueurs du visible ne sont pasvues : le bleu est très mal vu.
2.2.5 L'humeur aqueuse et le corps vitré2.2.5.1 L'humeur aqueuse
� Liquide transparent constamment renouvelé� Maintient la pression intra-oculaire
Fig. 2.13 � Humeur aqueuse
On parle de glaucome lorsque la pression de l'humeur aqueuse est trop importante.L'humeur aqueuse est composée essentiellement d'eau, mais aussi de vitamines C,
de glucose, d'acide lactique, de protéines. Elle se renouvelle en 2-3 heures. Son rôleest surtout nourricier, réparateur, régulateur de la pression intra-oculaire, ainsi que dumaintien de la forme de l'oeil.
2.2.5.2 Le corps vitré� Masse gélatineuse claire
17

� Capable d'amortir les chocs� 90% du volume de l'oeil
Fig. 2.14 � Corps Vitré
C'est un tissu conjonctif transparent. Il est entouré par une membrane. C'est unmatériau de remplissage. Il représente les 4/5 du volume de l'oeil. Il est ainsi le premierconstituant de l'oeil. Son rôle est d'assurer la rigidité du globe oculaire, et de mainte-nir la rétine en place bien collée contre le fond du globe oculaire. Sa structure le faitintervenir dans le maintien de la pression intra-oculaire et lui permet d'absorber lespressions auxquelles il est soumis sans altérer la fonction de l'oeil. Il est formé de 95%d'eau.
2.2.6 La rétine� Membrane nerveuse hypersensible� Tapisse le fond de l'oeil� C'est la pellicule� Est formée de 10 couches de cellules
Fig. 2.15 � Rétine
C'est un tissu sensible et fragile. C'est la membrane la plus interne. Elle a commeépaisseur 1/10 à 4/10 de mm. Elle est très vascularisée par un important réseau deveines et d'artères.
La rétine est une plaque hypersensible. Elle est parcourue de très nombreux petitsvaisseaux. Elle est composée de centaines de millions de cellules nerveuses : les côneset les bâtonnets. Le rôle de ces cellules est capital. Elles permettent de voir les détails,les lumières, les couleurs, les formes et les mouvements.
La lumière qui pénètre dans l'oeil doit traverser la rétine pour atteindre la couchesensible des cônes et des bâtonnets. Les cônes et les bâtonnets sont les cellules pho-toréceptrices. Ce sont ces cellules qui captent l'in�ux nerveux et le transmettent aucerveau pour le décoder et former une image.
18

On a beaucoup plus de bâtonnets (130 millions) que de cônes (6-7 millions). Lediamètre des cônes est beaucoup plus petit que celui des bâtonnets. Plus on s'éloignede la partie centrale, plus les cônes se font rares et plus leur diamètre augmente (�gure2.17).
En�n, au niveau de la rétine sont e�ectués des traitements élémentaires sur l'infor-mation reçue (moyennage spatial, amélioration de contraste).
2.2.6.1 La macula et la fovéa� Dépression située sur l'axe optique� Concentration de cônes� Permet la vision des détails en éclairage diurne
Fig. 2.16 � Macula
Dans la zone elliptique centrale se trouve le maximum de cônes. Cette zone permetdonc une vision très précise. Cette zone mesure 3 mm dans le grand axe et 2 mm dansle petit axe. Elle s'appelle la macula. La macula, tâche jaune, apparaît située au centredu pôle postérieur comme une �ne excavation.
La fovéa est une région de la rétine située dans la macula, près de l'axe optique del'oeil. Cette région est de la plus haute importance pour la vision. C'est elle qui donnela vision la plus précise, en éclairage diurne, c'est-à-dire pendant la journée. Quandnous �xons un objet, nous tournons les yeux de façon à aligner l'image sur cette partiede la rétine. La fovéa est la partie centrale de la macula. Elle mesure 1300 à 1500microns. Elle contient 400 000 cônes. Dans une vision encore plus centrale on trouvela fovéola. Elle mesure 300 à 400 microns de diamètre et contient 25 000 cônes. Plusau centre on trouve une zone ponctuelle qui s'appelle le bouquet de cônes centraux. Ilmesure 100 microns et contient 2500 cônes.
2.2.6.2 Les cônes et les bâtonnetsLes cônes ont besoin de plus de lumière que les bâtonnets pour être excités. Les
cônes réagiront plus en éclairage diurne qu'en éclairage nocturne. Les bâtonnets ontbesoin de beaucoup moins de lumière pour réagir, ils assurent la vision nocturne. Lavision par les cônes est appelée vision photopique et la vision par les bâtonnets visionscotopique.
19

Fig. 2.17 � Distribution des bâtonnets (rods) et des cônes (cones) sur la rétine
Il existe 3 sortes de cônes qui réagissent à des longueurs d'onde di�érentes : grossomodo bleu (450 nm), vert (540 nm), rouge (580 nm). Cette classi�cation n'est pas toutà fait exacte (�gure 2.18) et on préfère souvent parler de cônes S (small) ,M (medium),L(large) suivant les longueurs d'ondes auxquelles ils sont sensibles. Approximativement65% des cônes sont sensibles au rouge (L), 33% sont sensibles au vert (M) et seulement2% (S) sont sensibles au bleu. Cependant, ces derniers sont plus sensibles.
Fig. 2.18 � Représentation de la courbe de sensibilité spectrale des cônes : ceux-ci neréagissent pas à une seule longeur d'onde mais à un ensemble de longueurs d'ondes
Les cônes sont donc responsables de la vision des couleurs. Les bâtonnets ne parti-cipent pas à la vision des couleurs. La nuit seuls les bâtonnets fonctionnent, c'est pourcette raison que la nuit tous les chats sont gris !
2.2.7 Transmission de l'information au cerveau2.2.7.1 Le nerf optique
Le nerf optique transmet les informations au cerveau
20

Fig. 2.19 � Nerf Optique
Toutes les �bres optiques issues des cellules visuelles convergent vers un point précisde la rétine : la papille. Ce point ne contient donc pas de cellules visuelles mais seulementles �bres nerveuses. La papille est donc un point de l'oeil qui ne voit pas. On l'appelleaussi la tâche aveugle. En ce point débouche aussi le réseau veineux et artériel de larétine.
Les �bres optiques se rejoignent toutes là pour former un câble appelé le nerf op-tique. Il mesure 4 mm de diamètre et 5 cm de long.
Il y a un nerf optique par oeil, donc 2 nerfs optiques en tout.
2.2.7.2 Le cerveauCertaines aires sont spécialisées dans le traitement de l'information visuelle. La voie
visuelle se projette sur la partie occipitale du cortex. Pour cette raison, un choc violentsur l'arrière de la tête peut entraîner une perte de la vision.
Fig. 2.20 � L'image formée sur la rétine est à l'envers
L'image qui arrive sur la rétine est renversée (�gure 2.20). C'est le cerveau qui laremet à l'endroit.
2.2.8 Défauts de visionCertains problèmes de vision peuvent provenir de défauts du cristallin ou/et de la
cornée. Si l'÷il est trop convergent, l'image d'un objet va se former en avant de larétine, et la vision des objets lointains est altérée. On parle alors de myopie. Si aucontraire l'÷il n'est pas assez convergent alors l'image d'un objet va se former au-delàde la rétine. La vision de près devient di�cile et dans les cas les plus poussés la visionde loin est aussi détériorée. On parle alors d'hypermétropie (cf Fig. 2.21).
21

Fig. 2.21 � Défauts liés à la convergence de l'÷il
2.3 Mécanismes cognitifsDi�érentes zones du cerveau sont a�ectées à di�érentes fonctions. Et ces di�érentes
zones collaborent.L'image "physique" formée au fond de l'oeil, analysée point par point, puis trans-
mise au cerveau sous forme de messages codés est en principe la même pour tous.Ce sont les zones visuelles du cerveau qui analysent ces signaux et nous donnent unereprésentation de l'objet perçu.
Il s'agit d'un phénomène très complexe encore mal compris aujourd'hui.Les théories actuelles (Helmholtz) suggèrent que notre cerveau élabore des hypo-
thèses sur le monde extérieur et sélectionne la meilleure d'entre elles en fonction decritères qui lui sont propres. Il existe de nombreuses possibilités d'erreur qui peuventêtre dûes à diverses formes d'illusions d'optiques, à des images volontairement am-bigües, à des dé�ciences. . .
2.3.1 Illusions d'optiques ou quand le cerveau se trompeL'interprétation que fait le cerveau des images peut parfois être ambigüe. Ces "er-
reurs" d'interprétation sont des illusions d'optique, qui ne sont pas perçues de la mêmefaçon par chacun d'entre nous (nous n'avons pas tous le même "vécu", ni les mêmesimages en mémoire) . . .
Les illusions sont les témoins des mécanismes de la vision. Elles con�rment que notreperception du monde est assez éloignée de la photographie. En e�et, notre perceptionest le résultat :
� d'une stimulation des photorécepteurs rétiniens, qui peuvent subir des phéno-mènes de fatigue.
� et surtout d'une construction mentale, à partir des messages nerveux reçus, parfois
22

erronés. Le cerveau cherche à mettre du sens partout, même là où il n'y ena pas. Alors, il en fait trop, ampli�ant les contrastes, créant contours, couleurs,perspectives, reliefs, mouvements, en fonction de ce qu'il connaît. En e�et, malgréune organisation générale commune du cortex visuel, les apprentissages et levécu di�èrent d'une personne à l'autre, d'où une sensibilité variable à certainesillusions.
Quelques exemples d'illusions d'optique classiques se touvent dans les Figures 2.22,2.23, 2.24 et 2.25 :
Fig. 2.22 � Une impossibilité géométrique
23

(a) Mise en rela-tion de grandeur(Tichener) : lesdeux disques sontidentiques !
(b) E�ets d'angles(Zöllner) : leslignes obliquessont parallèles !
(c) Cette forme sembleavoir ses côtés incur-vés, pourtant c'est belet bien un carré
(d) La ligne verticalesemble plus longueet pourtant les deuxlignes sont physique-ment de la même lon-gueur
(e) Perspective : la verticalede droite semble plus grandeque la verticale de gauche
(f) Perspective (Ponzo) : icic'est la verticale de gauchequi semble plus grande quecelle de droite
Fig. 2.23 � Illusions géométriques
24

(a) Estimations relatives(Muller-Lyer) : les lignesne paraissent pas être dela même taille
(b) Estimations relatives(Poggendor�) : le segmentoblique inférieur est dansl'axe de l'oblique de droite
(c) Couleur : les deux car-rés semblent ne pas êtrede la même couleur
(d) Couleur (Her-mann) : des pointsgris semblent appa-raître entre les car-rés noirs
(e) Illusion subjective(Kanizsa) : nous voyonsun triangle qui n'existepas
(f) Les lignes du damiersont parallèles !
Fig. 2.24 � Illusions géométriques
25

(a) Un saxo ou un vi-sage ?
(b) Un visage dejeune femme ou degrand-mère ?
(c) Un visage dejeune femme, degrand-mère oud'homme ?
(d) Quel animal se cache danscette image ?
Fig. 2.25 � Illusions artistiques
26

Le langage joue aussi un grand rôle dans notre perception des images. Ainsi dansl'exemple de la �gure 2.26-a, notre cerveau corrige automatiquement la faute commisetandis que dans la �gure 2.26-b, le langage et la vue sont en contradiction. D'ailleursdans ce dernier cas, une expérience simple consiste à faire lire à quelqu'un deux pagescouvertes de noms de couleurs : sur la première chaque nom de couleur est écrit avecl'encre correspondant à cette couleur, dans la deuxième le nom de la couleur est écritavec une encre de couleur di�érente. La majorité des personnes testées lit plus lentementla deuxième page que la première à cause de ce hiatus entre le langage et la vue.
(a) Le langage �corrige� la faute
vertbleurougevertbleu
(b) Le langage et la vue sont en contradic-tion
Fig. 2.26 � In�uence du langage sur la vision
2.3.2 Vision binoculaireDans un autre ordre d'idée, les images produites par nos deux yeux sont di�érentes
l'une de l'autre parce que nos deux yeux sont séparés de quelques centimètres. Ladisparité binoculaire causée par cette séparation fournit un e�et de profondeur puissantappelé stéréoscopie ou vision stéréo (�gure 2.27).
Fig. 2.27 � Vision binoculaire : nos deux yeux ne perçoivent pas la même image
Notre cerveau fusionne les deux images séparées en une seule interprétée commeétant 3D. Pour être en mesure de pouvoir réaliser cette opération, le cerveau doitprocéder à une analyse très complexe d'une quantité d'informations considérable. Lessystèmes informatiques actuels de traitements d'images ne permettent généralementpas une telle analyse en temps réel.
Il était couramment admis autrefois (à tort) que le cerveau gauche traitait l'imageperçue par l'÷il droit tandis que le cerveau droit analysait l'image perçue par l'÷il
27

gauche. Si tel était le cas, nous n'aurions aucune perception des reliefs puisque celle-ci est fondée sur la comparaison des images fournies par chaque ÷il. Il a depuis étémontré que le cerveau gauche traite l'information fournie par les deux yeux concernantle champ visuel droit et que le cerveau droit s'occupe du champ visuel gauche (�gure2.28).
Fig. 2.28 � Vision binoculaire : le champ visuel droit est analysé par l'hémisphèregauche et vice versa
La visualisation des distances et donc l'impression 3D proviennent simplement de lacomparaison des images en fonction de l' angle de vergence (ou angle de convergence).En e�et, la connnaissance de l'angle de vergence permet de corréler sans ambiguïté lespoints des deux images (�gure 2.29).
Les lunettes stéréoscopiques sont un dispositif qui permettent de voir une image2D en 3D : les lunettes rouges et vertes en sont une sorte. Une image est dessinée enrouge sur le papier (ou l'écran) et l'autre image, légèrement décalée, est dessinée envert. Lorsque vous mettez les lunettes, votre oeil "rouge" peut uniquement voir l'imageverte et vice-versa. Ainsi, chaque oeil voit la même image mais légèrement décalée, cequi constitue le fondement de la stéréovision ! Les lunettes rouges et vertes agissentcomme des �ltres (�gure 2.30).
28

Fig. 2.29 � Vision binoculaire : l'angle de vergence θ dépend de la distance du pointregardé par rapport à l'observateur, plus le point est loin, plus l'angle est petit
Fig. 2.30 � Utilisation de lunettes polarisées
2.3.3 Complémentarité des hémisphères gauche et droitEn�n, la complémentarité des hémisphères gauche et droit du cerveau intervient
aussi au niveau de la vision des détailsEn e�et, la collaboration entre les deux hémisphères gauche et droit n'intervient
pas seulement dans la vision stéréoscopique mais aussi dans notre faculté à observer lesdétails d'une image ou à en avoir une vue d'ensemble. Des expériences ont montré quel'hémisphère gauche fournit une vue d'ensemble tandis que l'hémisphère droit analyseles détails (�gure 2.31).
29

(a) lettres ditesde Navon : imagesdans lesquellesune grande lettreest réalisée à par-tir de plusieurspetites lettres
(b) activité cérébrale liée à la lecture deces lettres : le cerveau représenté à gauchecorrespond à quelqu'un qui voit les pe-tites lettres, le cerveau de droite à quel-qu'un qui voit la grande lettre
Fig. 2.31 � Vision d'ensemble et vision des détails
(a) Original
(b) Hémisphère droit endom-magé
(c) Hémisphère gauche endom-magé
30

Chapitre 3
Espaces de représentation des couleurs
A�n de pouvoir manipuler correctement des couleurs et d'échanger des informationsconcernant celles-ci, il est nécessaire de disposer de moyens permettant de les catégoriseret de les choisir. Ainsi, il n'est pas rare d'avoir à choisir la couleur d'un produit avantmême que celui-ci ne soit fabriqué. Dans ce cas, une palette de couleurs nous estprésentée, dans laquelle nous choisissons la couleur convenant le mieux à notre envieou notre besoin. La plupart du temps, le produit (véhicule, bâtiment, ...) possède unecouleur qui correspond à celle que l'on a choisie.
En informatique, de la même façon, il est essentiel de disposer d'un moyen de choisirune couleur parmi toutes celles utilisables. Or la gamme de couleur possible est trèsvaste et la chaîne de traitements de l'image passe par di�érents périphériques : parexemple un numériseur (scanner), puis un logiciel de retouche d'image et en�n uneimprimante. Il est donc nécessaire de pouvoir représenter �ablement la couleur a�n des'assurer de la cohérence entre ces di�érents périphériques.
On appelle ainsi espace de couleurs la représentation mathématique d'un ensemblede couleurs. Il en existe plusieurs, parmi lesquels les plus connus sont :
� Le codage RGB (Rouge, Vert, Bleu, en anglais RGB, Red, Green, Blue),� Le codage TSL (Teinte, Saturation, Luminance, en anglais HSL, Hue, Saturation,Luminance),
� Le codage CMYK,� Le codage CIE,� Le codage YUV,� Le codage YIQLe spectre de couleurs qu'un périphérique d'a�chage permet d'a�cher est appelé
gamut ou espace colorimétrique. Les couleurs n'appartenant pas au gamut sont appeléescouleurs hors-gamme.
Nous présentons tout d'abord quelques généralités sur les couleurs puis détaillonsquelques espaces de couleurs paticulièrement importants.
3.1 GénéralitésTrois caractéristiques sont généralement utilisées pour décrire la qualité d'une source
lumineuse : sa radiance, sa luminance, et sa clarté. La radiance est la quantité totaled'énergie qui part de la source lumineuse et est généralement mesurée en Watts (W ).
31

La luminance, donnée en lumens (lm) correspond à la quantité d'énergie reçue par l'ob-servateur. Ces deux valeurs sont généralement di�érentes. Ainsi, une source de lumièredont les longueurs d'ondes se situent dans l'infra-rouge, peut tout à fait posséder uneénergie (radiance) signi�cative, tandis qu'un observateur ne la percevra pas ou à peine :sa luminance sera proche de 0. La clarté en�n est une donnée subjective, impossible àmesurer en pratique, elle représente l'intensité de la lumière, qui correspond à sa partieachromatique, autrement dit à son niveau de gris.
Comme nous l'avons vu au chapitre précédent des lumières de spectres di�érentspeuvent provoquer une même réponse de nos cellules visuelles (Figure 2.4 page 13). Età vrai dire une réaction donnée de ces cellules peut être provoquée par un nombre in�nide spectres di�érents. Cette observation laisse penser qu'un petit nombre de spectresindépendants peuvent être combinés a�n de produire toutes les couleurs discernablespar un ÷il humain.
D'autre part, notre vision des couleurs dépend de trois types de photo-récepteurs(trois types de cônes). Il est donc naturel de tenter de représenter les couleurs parcomposition de trois variables.
Il existe pour cela plusieurs approches qui débouchent sur la création de nombreuxespaces de couleurs. On peut principalement distinguer l'approche additive, l' approchesoustractive et l' approche intuitive. Les deux premières sont parfois imposées par lesupport sur lequel on veut visualiser l'image.
Le modèle additif (resp. soustractif) est fondé sur 3 couleurs dites primaires tellesque toutes les autres couleurs que l'on veut créer peuvent être obtenue par addition(resp. soustraction) de quantités plus ou moins grandes de ces 3 couleurs. Une couleurappartenant à un ensemble de trois couleurs primaires pour l'addition (resp. la sous-traction) ne peut pas être obtenue par addition (resp. soustraction) des deux autres.
Le modèle additif le plus connu est celui dont les 3 couleurs primaires sont le rouge,le vert et le bleu ou modèle RGB. Le modèle soustractif le plus employé a commecouleurs primaires le cyan, le magenta, et le jaune ou modèle CMY .
On appelle couleurs secondaires, les 3 couleurs qui résultent d'un mélange de deuxcouleurs primaires. Les couleurs secondaires du modèle RGB sont le cyan (vert + bleu),le magenta (rouge + bleu) et le jaune (vert + rouge). Symétriquement les couleurssecondaires du modèle CMY sont le rouge (magenta + jaune), le vert (cyan + jaune)et le bleu (cyan + magenta) (Figure 3.1).
L'÷il humain, un écran d'ordinateur ou de télévision utilisent la méthode addi-tive pour reproduire une couleur, tandis que la peinture, la teinture et les procédésd'imprimeries se servent de la méthode soustractive.
Ces deux méthodes conduisent à distinguer la notion de couleurs primaires de lalumière de celle de couleurs primaires de pigments. Dans ce dernier cas, en e�et, unecouleur est dite primaire si elle absorbe une couleur primaire de la lumière et ré�échitles deux autres (Figure 3.2). Un matériau coloré absorbe ainsi une partie du spectre.L'obtention d'une couleur est obtenue par superposition de �ltres ou mélange de pig-ments.
Un exemple de synthèse additive, est constitué par un écran muni d'un tube catho-dique. Trois canons à électrons produisent respectivement une lumière rouge, verte etbleue qui s'additionnent pour former les couleurs à l'écran.
Les espaces intuitifs de couleurs se fondent quant à eux sur des paramètres plus
32

(d) Exemple d'un modèle additif (e) Exemple d'un modèle sous-tractif
Fig. 3.1 � Modèles RGB et CMY
(a) Un pigment magenta absorbele vert et ré�met le bleu et lerouge
(b) Le pigment cyan absorberouge, le pigment magenta, levert, seul le bleu est renvoyé
(c) Le pigment jaune absorbe lebleu, le pigment bleu, le rougeet le pigment magenta, le vert,toute les longueurs d'ondes sontabsorbées
Fig. 3.2 � Principe de la synthèse soustractive
33

visuels. Les trois caractéristiques qui permettent généralement de di�érencier des cou-leurs sont la clarté (brightness), la teinte (hue) et la saturation ou pureté. La clartéreprésente, comme dit précédemment, la quantité de lumière achromatique contenuedans la couleur, autrement dit son niveau de gris. La teinte correspond à la longueurd'onde dominante de la couleur. En�n, la saturation rend compte de la quantité blancajoutée à la teinte. Ainsi rose (rouge + blanc) et lavande (violet + blanc) sont-elles descouleurs moins saturées que rouge ou violet.
(a) Clarté (noir, di�érents gris . . .)
(b) Teinte (jaune, vert, bleu. . .)
(c) Saturation (rose pâle, rouge car-min. . .)
3.2 Espaces additifsL'espace RGB est certainement l'espace le plus utilisé. Cet attachement à ce sys-
tème de primaires s'explique principalement par la dépendance aux matériels (cartesd'acquisition, cartes vidéos, caméras, écrans) qui e�ectuent leurs échanges d'informa-tions uniquement en utilisant des triplets (R,G,B).
Cependant, il faut noter que ce système dépend de la dé�nition des trois primairesR, G, B et du blanc. Et il existe en fait di�érents systèmes RGB. Parmi ces di�érentssystèmes on peut citer ceux utilisés par les trois principaux standards de la télévision.Celui dédié à la télévision américaine répondant à la norme NTSC (National TelevisionStandards Committee) utilise les primaires dé�nies par la FCC (Federal Communica-tions Commission). Ceux employés par la télévision européenne sont fondés soit surla norme PAL (Phase Alternation by Line) adoptée par l'UER (Union Européenne deRadio-télévision), soit sur la norme française SECAM (SEquentiel Couleur A Mémoire).En plus de ces normes qui n'utilisent pas le même blanc de référence, les moniteursrépondent à leur tour aux normes des constructeurs. On peut aussi citer le systèmede primaires appelé visu couleur introduit par la CIE (Commission Internationale del'Eclairage) spécialement pour les moniteurs CRT (Cathod Ray Tube).
34

Finalement, le seul espace qu'il serait légitime d'appeler RGB est sans doute celuiintroduit par la CIE en 1931 où les longueurs d'ondes associées aux primaires sont lessuivantes :
Rouge Vert Bleu700 nm 546.1 nm 435.8 nm
Le modèle RGB est fondé sur un système de coordonnées cartésiennes. Le sous-espace de couleurs intéressant est celui formé par le cube de la �gure 3.2-a dont 3coins correspondent aux couleurs primaires R, G et B et les 3 autres coins aux cou-leurs secondaires C, M , Y . Dans cette représentation normalisée, les valeurs des troiscomposantes de chaque couleur sont comprises entre 0 et 1.
(d) Représentation shématique du cube decouleurs RGB. Les points le long de la dia-gonale principale ont des valeurs de gris,du noir au point origine au blanc au point(1, 1, 1)
(e) cube de couleursRGB (24-bits : 8 bitspar primaire → ' 16millions de couleurs)
Fig. 3.3 � Cube de couleurs RGB
Les modèles utilisés en télévision pour représenter les couleurs sont des variantes del'espace RGB qui doivent répondre aux besoins spéci�ques de ce média. Ces modèlespossèdent eux-aussi 3 composantes qui sont obtenues par combinaison linéaire descomposantes R, G et B. L'une de ces trois composantes représente la luminance qui serautilisée seule pour les téléviseurs noir et blanc. Les deux autres composantes dé�nissentla chromaticité autrement dit la couleur proprement dite.
Les modèles les plus utilisés sont l'espace Y IQ (pour le standard NTSC), l'espaceY UV (pour le standard allemand PAL), l'espace Y CrCb (dédié au codage d'imagespour la télévision numérique) et l'espace Y DrDb (pour le standard SECAM). Cedernier est nettement moins utilisé. Vous trouverez ci-dessous, à titre d'information,les matrices de transformations permettant de passer d'un espace RGB à un des troispremiers espaces cités :
35

Fig. 3.4 � Reconstruction des couleurs à partir des composantes rouge, verte, et bleue
YIQ
=
0.299 0.587 0.1140.596 −0.274 −0.3220.212 −0.523 0.311
∗ R
GB
Y
UV
=
0.299 0.587 0.114−0.147 −0.289 0.4370.615 −0.515 −0.100
∗ R
GB
Y
Cr
Cb
=
0.299 0.587 0.114−0.169 −0.331 −0.5000.500 0.419 −0.081
∗ R
GB
Attention dans les standards Y IQ, Y UV (et Y DrDb) les composantes R,G,B à
partir desquelles sont construites les matrices de transformations sont les composantesR, G et B propres aux di�érents standards. L'espace Y CrCb en revanche n'imposeaucune règle sur la dé�nition de ces primaires, ce modèle fait intégralement partie dustandard JPEG2000.
Tous ces modèles construits à partir du modèle RGB partagent un même défaut :ils ne sont pas capables de synthétiser toutes les couleurs. On voit sur la �gure 3.4 quepour construire des couleurs dont la longueur d'onde est comprise entre un peu plusde 400 et un peu plus de 500 nm, il faut soustraire du rouge au lieu d'en ajouter !
Pour pallier ce problème, la CIE a créé un autre modèle de couleurs appelé XY Z.Les trois composantes X, Y et Z peuvent être vues comme des primaires virtuelles. Ellesont été choisies de sorte que toute couleur puisse être construite de manière purementadditive à partir d'elles (cf �gure 3.5). Dans ce modèle, la composante Y correspondelle-aussi à la luminance de la couleur, tandis que X et Z dé�nissent sa chromaticité.Di�érentes matrices de passage ont été construites pour passer d'un système RGB ausystème XY Z, elles sont, bien entendu, dépendantes du choix des primaires R, G etB.
Ce modèle 3D est di�cile à manipuler, on utilise souvent un de ses dérivés, quipermet d'obtenir un diagramme de chromaticité 2D. On considère en e�et les troisvariables x, y et z dé�nies par :
36

Fig. 3.5 � Reconstruction des couleurs à partir des composantes virtuelles x, y et z.
x =X
X + Y + Z
y =Y
X + Y + Z
z =Z
X + Y + Z
On note que pour un tel modèle x + y + z = 1. La connaissance de x et y impliquedonc la connaissance de z. Le diagramme correspondant, autrement dit, représentantles couleurs en fonction de x et y se trouve �gure 3.6-a. Un tel diagramme est notam-ment utilisé pour représenter la gamme de couleurs ou gamut visualisable par diverspériphériques (cf Fig. 3.6-b).
Le diagramme représente sur la périphérie les couleurs pures, c'est-à-dire les rayon-nements monochromatiques correspondant aux couleurs du spectre (couleurs de l'arcen ciel), repérées par leur longueur d'onde. La ligne fermant le diagramme (donc fer-mant les deux extrémités du spectre visible) se nomme la droite des pourpres, car ellecorrespond à la couleur pourpre, composée des deux rayonnements monochromatiquesbleu (420 nm) et rouge (680 nm).
On représente généralement le gamut d'un dispositif d'a�chage en traçant dans lediagramme chromatique un polygone renfermant toutes les couleurs qu'il est capablede produire.
Toutefois ce mode de représentation purement mathématique ne tient pas comptedes facteurs physiologiques de perception de la couleur par l'oeil humain, ce qui résulteen un diagramme de chromaticité laissant par exemple une place beaucoup trop largeaux couleurs vertes.
En 1976, a�n de pallier ces lacunes, la CIE développe le modèle colorimétriqueLa∗b∗ (aussi connu sous le nom de CIELab), dans lequel une couleur est repérée partrois valeurs :
� L, la luminance, exprimée en pourcentage (0 pour le noir à 100 pour le blanc)� a et b deux gammes de couleur allant respectivement du vert au rouge et du bleuau jaune avec des valeurs allant de -120 à +120.
37

Le mode Lab couvre ainsi l'intégralité du spectre visible par l'oeil humain et lereprésente de manière uniforme. Il permet donc de décrire l'ensemble des couleursvisibles indépendamment de toute technologie graphique. De cette façon il comprendla totalité des couleurs RGB et CMY K, c'est la raison pour laquelle des logiciels telsque PhotoShop utilisent ce mode pour passer d'un modèle de représentation à un autre.
Il s'agit d'un mode très utilisé dans l'industrie, mais peu retenu dans la plupart deslogiciels étant donné qu'il est di�cile à manipuler.
Les modèles de la CIE ne sont pas intuitifs, toutefois le fait de les utiliser garantitqu'une couleur créée selon ces modèles sera vue de la même façon par tous !
(a) Diagramme de chromaticité (b) Exemples de �gamut� de moniteurscouleur (triangle) et d'imprimantes (ré-gion irrégulière)
(c) Toute combinaison d'une couleur aet d'une couleur b se trouve sur le seg-ment ab
(d) lien avec la teinte, la saturation etla clarté
Fig. 3.6 � Diagramme de chromaticité et ses utilisations
38

3.3 Espaces soustractifsDans le cas de la synthèse soustractive, un mélange en quantité égale de magenta,
cyan et jaune produit théoriquement du noir. En pratique, les systèmes d'impressionsont incapables de produire un noit correct par ce procédé. On rajoute donc généra-lement une quatrième couleur au modèle CMY à savoir le noir. Ce modèle est alorsappelé CMY K. Le K représente aussi bien le �k� dans le mot black que la premièrelettre du mot key black. Ce modèle est particulièrement utilisé en imprimerie, on parlede quadrichromie.
3.4 Espaces intuitifsLes modèles HSL, HSB (Brightness), HSV (Value), HSI (Intensity), HCI
(Chroma),. . . bien que dérivés de l'espace RGB proposent une approche plus natu-relle de la couleur en faisant intervenir des critères psycho-physiologiques. La teintecaractérise la couleur elle même (en général d'après sa position dans le disque chroma-tique), la saturation est une comparaison entre la couleur choisie et la même couleurpure, la luminosité est la contenance relative de noir et de blanc. Avec ce système, il estpossible de décrire assez facilement une chemise verte délavée à la tombée de la nuit.Chaque modèle propose ses propres échelles de nombres (angles en degrés, pourcen-tages, échelles de 0 à 100) et sa propre dé�nition de la saturation et de la luminosité (ilen résulte quelques di�cultés d'interprétation quand on ignore à partir de quel modèleles données ont été produites).
Les espaces intuitifs sont donc fondés sur les notions précédemment dé�nies declarté, saturation, et teinte. Un tel espace est associé à un objet 3D dont la hauteurmesure la clarté. Di�érents types d'objets permettent de représenter de tels espaces :cône, cylindre, double-cône, tétraèdre, cône hexagonal. . . (cf exemples �gure 3.7-a). Lesplans de coupe perpendiculaires à la hauteur permettent de visualiser les informationsde saturation et de teinte à clarté �xée. Suivant les modèles, ces plans peuvent avoir laforme de disques, de triangle, d'hexagones. . . La teinte et la saturation correspondentaux coordonnées polaires, angle et distance, d'un repère centré sur le barycentre de lacoupe de l'objet 3D (cf �gure 3.7-b).
39

(a) Exemples de deux modèles intuitifs
(b) Mesure de la teinte et de la saturation
Fig. 3.7 � Modèles intuitifs
40

Chapitre 4
Traitement d'images
Le traitement d'une image consiste à l'amélioration de cette image en vue d'uneapplication spéci�que. Ce mot spéci�que est important car ce qu'on entend par imageaméliorée dépend fortement de l'utilisation que l'on veut en faire. Ainsi, par exemple,une méthode reconnue pour traiter des images construites à partir de rayons X ne serapas la meilleure approche pour manipuler des images de Mars transmises par une sondespatiale.
Les approches de traitements d'images peuvent être classées dans deux catégories :les méthodes spatiales et les méthodes fréquentielles. Les méthodes spatiales agissentsur le domaine spatial de l'image, autrement dit le plan image (généralement la grillede pixels). Les méthodes fréquentielles modi�ent le domaine fréquentiel de l'image enintervenant sur sa transformée de Fourier. Cette deuxième approche sera abordée dansun autre module. Il existe en�n des méthodes qui combinent les deux approches. Nousnous concentrons ici sur les méthodes spatiales.
4.1 ContexteIl n'existe pas de théorie générale sur l'amélioration des images. Quand une image
est traitée pour être interprétée visuellement, l'observateur de l'image est le juge �nal desa qualité. Mais l'évaluation visuelle est par nature hautement subjective et ne permetpas de fournir des outils de comparaisons objectifs de l'e�cacité relative des algorithmesutilisés. Lorsque le traitement d'images est le premier pas d'une application de visionpar ordinateur, il est alors possible de comparer plus facilement les algorithmes utilisés.Ainsi, par exemple, lorsque l'on souhaite écrire une application de reconnaissance decaractères, on dira que le meilleur traitement est celui qui permet à la machine dereconnaître le mieux les caractères.
La �gure 4.1 montre où intervient le traitement d'images dans la chaîne d'analyseet de visualisation d'images. Cette chaîne comporte 3 étapes :
� Acquisition : construction d'une image à partir de capteurs (camera CCD, radar,interférométrie, spectroscopie, IRM, scanner,. . .)
� Traitement : modi�cations spatiales ou fréquentielles de l'image (dynamique, �l-trage, rehaussement, e�ets spéciaux, compression,. . .)
� Analyse : extraction des di�érents objets contenus dans l'image par segmentation(approche régions, approche contours).
41

Fig. 4.1 � Chaîne d'analyse d'images
Les traitements peuvent intervenir au niveau de l'amélioration et de la retouched'images. L'appréciation de l'e�cacité de tels algorithmes est subjective et laissée auxsoins de l'observateur �nal de l'image. L'amélioration d'une image peut être réaliséepar réhaussement des contrastes, éliminination des bruits ou artefacts, réalisation d'unlissage ou au contraire mise en valeur des détails de l'image. Les retouches peuventconduire à déformer l'image, à obtenir des e�ets artistiques. Elles peuvent aussi inter-venir au niveau du design (changement de couleur, d'ambiance, de textures).
(a) image avant déconvolution (b) image après déconvolution
Fig. 4.2 � Déconvolution (microscopie confocale)
Les traitements réalisés peuvent aussi être préalables à des applications plus com-plexes d'analyse automatique. Certains traitements sont par exemple particulièrementutilisés dans les domaines de la productique, de la robotique et de l'imagerie satellite. Ils'agit entre autres des méthodes fondées sur la colorimétrie qui permettent par exemplede repérer des zones nuageuses. D'autres techniques sont mises en ÷uvre pour détecterdes mouvements dans une séquence d'images. D'autres traitements sont plus adaptésà la visualisation et à la mesure d'informations. Ainsi de fausses couleurs peuvent-ellesêtre utilisées pour mettre en évidence certaines zones de l'image, par exemple pourdistinguer des zones de productions agricoles dans une image satellite (cf Fig. 4.3).
42

(a) Vue du satellite SPOT (b) Types de cultures
Fig. 4.3 � Une image du satellite SPOT avant et après l'utilisation de fausses couleurs
4.2 GénéralitésLe terme domaine spatial fait référence comme dit précédemment à l'ensemble des
pixels composant une image. Etant donnée une image (S, I), on dé�nit sa dynamiquede la manière suivante :
La dynamique de l'image I est le nombre d'occurrences de chaque couleur possible.Dans le cas particulier des images en niveaux de gris, il existe 256 valeurs de couleur
possibles entre 0 et 255.Les méthodes spatiales consistent à modi�er la dynamique d'une image et pour
cela, modi�ent directement les valeurs de ses pixels. Les pixels d'une image construitesur une grille sont repérés par leur coordonnées x et y. Les opérations modi�ant ladynamique d'une image sont alors mathématiquement traduites par l'équation :
g(x, y) = T [f(x, y)] (4.1)
où f(x, y) et g(x, y) représentent respectivement l'image de départ et l'image d'arri-vée. T symbolise l'opération réalisée sur l'image. Elle est dé�nie sur un certain voisinagedu pixel (x, y). Dans certains cas, T peut être dé�nie comme une opération sur unesérie d'images. Elle peut par exemple réaliser l'addition pixel par pixel d'une série deN images (réduction de bruit).
Certaines opérations spatiales ne prennent en compte que la valeur du pixel qu'ellesveulent modi�er. D'autres réalisent cette modi�cation en fonction des valeurs d'unensemble prédé�ni de pixels voisins du pixel à changer.
Autrement dit, réaliser une opération spatiale nécessite de dé�nir un voisinage au-tour d'un pixel. Le voisinage le plus couramment utilisé est un voisinage carré ourectangulaire centré sur le pixel (cf Fig. 4.4). L'opération T modi�e alors la valeurdu pixel en fonction du voisinage choisi. D'autres types de voisinages par exemple undisque peuvent être utilisés mais les voisinages carré et rectangulaire sont préférés carils sont plus faciles à implémenter.
Le cas particulier où une opération ne tient compte que du pixel à modi�er consiste
43

Fig. 4.4 � Exemple d'un 3× 3 voisinage d'un point (x, y) dans une image
simplement à considérer le voisinage 1 × 1 réduit au pixel lui-même. Dans ce derniercas, g dépend seulement de la valeur de f en (x, y). T est alors appelée fonction detransformation de niveau de gris (ou d'intensité), et s'écrit :
s = T (r) (4.2)
où s et r représentent respectivement le niveau de gris du pixel (x, y) de l'imaged'arrivée et de l'image de départ.
Par exemple, si T (r) correspond à la fonction de la �gure 4.5 (gauche), l'opérationaura pour e�et de produire une image avec un plus grand contraste. En e�et, elle rendplus sombre l'ensemble de pixels dont la valeur dans l'image originale était inférieure àm, et éclaircit ceux dont la valeur était supérieure à m. Cette technique, connue sousle nom de rehaussement de contraste (contrast stretching), compresse les valeurs despixels de l'image initiale inférieures à une valeur donnée vers une gamme de couleursréduite et sombre de l'image d'arrivée. L'e�et opposé a lieu pour les valeurs de pixelssupérieures à m. Cettre transformation compresse en e�et aussi les valeurs des pixelsde l'image initiale supérieures à une valeur donnée vers une gamme de couleur réduiteet décalée vers le blanc. Le cas limite d'une telle opération est la binarisation de l'image(cf partie droite de la �gure 4.5). On parle alors de seuillage (ou thresholding).
Un certain nombre d'opérations simples mais très utiles peuvent être formuléescomme des applications de transformation d'intensité. Comme ces techniques ne dé-pendent que de la valeur du pixel de l'image initiale à modi�er, on parle de traitementponctuel (ou point processing).
Considérer des voisinages plus grands permet cependant une bien meilleure �exibi-lité. L'approche générale consiste à considérer une fonction manipulant les valeurs despixels dans un voisinage prédé�ni du pixel à modi�er. L'une des principales méthodespour formuler ce type d'approche utilise la notion de masques (appelés aussi �ltres, fe-nêtres, noyaux . . .). Un masque est tout simplement un petit tableau 2D (souvent 3 × 3comme sur la �gure 4.4) centré sur le pixel considéré. Chacune de ses cases contient une
44

Fig. 4.5 � Fonctions de transformations d'intensité augmentant le contraste
valeur et l'opération de transformation consiste à remplacer la valeur du pixel (x, y) parle barycentre de l'ensemble des valeurs des pixels impliqués dans le masque, pondéréespar les coe�cients du masque. Les valeurs des coe�cients du masque dépendent bienentendu de la nature de l'opération à e�ectuer sur l'image. Ce type de techniques estappelé �ltrage par masques (ou mask �ltering).
4.3 Transformations d'intensité classiquesCe sont les transformations qui peuvent s'écrire s = T (r) avec r et s représentant
respectivement l'intensité d'un pixel dans l'image initiale et l'intensité d'un pixel dansl'image d'arrivée. Comme on travaille sur des espaces discrets, les fonctions T sontgénéralement représentées par des tables de correspondances contenant 256 entrées.Tous les pixels de l'image initiale possédant un niveau de gris donné rk auront dansl'image résultante le même niveau de gris : sk = T (rk). Si une image comporte Lniveaux de gris, la transformation T sera représentée par la table de correspondancessuivante :
s0 s1 s2 · · · · · · sL−1
r0 r1 r2 · · · · · · rL−1
La �gure 4.3 rassemble quelques transformations classiques. Elles sont principale-ment de trois sortes : linéaires (transformations identité et négative), logarithmiques(transformations log et log inverse), et puissances (transformation puissance neme etracine neme).
4.3.1 Transformation négativeLa transformation négative (parfois aussi appelée transformation d'inversion) qui
s'applique sur une image en niveaux de gris dont les valeurs appartiennent à un inter-valle [0, L− 1] est donnée par l'expression :
45

Fig. 4.6 � Transformations en intensité classiques
s = L− 1− r (4.3)
Cette opération consiste à produire l'équivalent du négatif d'une photographie.Elle est particulièrement utile lorsqu'il s'agit de mettre en valeur des détails blancsou gris inclus dans des régions sombres, surtout quand ces dernières ont des taillesprédominantes dans l'image. Un exemple est donné dans la �gure 4.3.1. Pour cettemammographie, il est plus facile d'analyser la lésion dans le négatif de l'image quedans l'image originale.
Fig. 4.7 � Mammographie : à gauche, l'image originale, à droite son négatif
46

4.3.2 Transformation logarithmiqueUn autre type de transformation est obtenu par l'utilisation de la fonction log et
de son inverse. Sa forme générale est la suivante :
s = clog(1 + r) (4.4)
où c est une constante et où r est le niveau de gris de l'image initiale (supérieurou égale à 0). La forme de la fonction log sur la �gure 4.3 montre qu'un intervalleétroit de valeurs sombres de l'image initiale est envoyé sur un intervalle plus large del'image d'arrivée, tandis qu'il compresse un large intervalle de valeurs claires de l'imagede départ dans un intervalle étroit de l'image d'arrivée. Cette transformation introduitdonc plus de nuances dans les parties sombres de l'image et en supprime dans les partiesclaires.
Les transformations qui suivent une loi de puissance réalisent le même type detransformations si ce n'est qu'elles sont en général plus souples. Les transformationsen logarithme sont plus particulièrement utilisés sur des images où les intervalles devaleurs sont les plus importants. Un exemple est donné sur la �gure 4.3.2. Ces imagesreprésentent un même spectre de Fourier, dont les valeurs sont comprises entre 0 et 1.5∗106. Sur la première image, les valeurs du spectre ont été linéairement transformées enniveaux de gris, tandis que sur la deuxième la transformation a été réalisée à l'aide d'unefonction logarithme. La transformation log a permis de réduire l'intervalle [0, 1.5∗106]en l'intervalle [0, 6.2] plus facilement représentable.
Fig. 4.8 � Spectre de Fourier converti linéairement en niveaux de gris (à gauche) etconverti en niveaux de gris à l'aide d'une fonction log avec c = 1
4.3.3 Transformation en puissanceLes transformations en puissance ont quant à elles la forme suivante :
s = crγ (4.5)
où c et γ sont des constantes positives. Dans certains cas, une telle transformationpeut s'écrire sous la forme s = c(r + ε)γ pour tenir compte d'un o�set, ce qui permet
47

d'avoir une sortie mesurable lorsque l'entrée est nulle. Généralement l'o�set est éliminépar calibration. C'est pourquoi on n'en tient la plupart du temps pas compte.
Une famille de courbes correspondant à di�érentes transformations puissance pourplusieurs valeurs de γ se trouve �gure 4.9.
Fig. 4.9 � Représentation des équations s = crγ pour di�érentes valeurs de γ (et pourc = 1)
Les transformations puissance pour lesquelles γ est inférieur à 1 ont le même com-portement que la fonction log. Cependant, contrairement aux transformations log, ilsu�t de jouer sur le paramètre γ pour avoir accès à toute une famille de transforma-tions. D'autre part, comme on pouvait s'en douter, les transformations pour lesquellesγ est supérieur à 1 ont exactement l'e�et inverse de celles dont le γ est inférieur à 1.En�n, le cas particulier, c = γ = 1 est équivalent à la fonction identité.
Une grande variété de périphériques de capture, d'impression ou d'a�chage d'imagesrépondent à une loi de puissance. Par convention, l'exposant de cette loi est appelégamma (d'où sa représentation par le symbole γ). Le procédé utilisé pour corriger laréponse en puissance est appelé correction gamma. Ainsi, un écran muni d'un tube ca-thodique (CRT ) utilise une loi de réponse intensité/voltage qui est une loi de puissancedont le coe�cient est généralement compris entre 1.8 et 2.5. Un exemple est donné surla �gure 4.10. L'image originale apparaît plus sombre sur le moniteur qui répond àune loi de puissance de coe�cient 2.5, la correction gamma consiste tout simplement àcompenser la loi de puissance du moniteur, autrement dit à pré-traiter l'image en luifaisant subir la transformation en puissance inverse : s = r1/2.5 = r0.4.
La correction gamma est nécessaire pour a�cher correctement une image sur unécran. Sans un tel prétraitement les images peuvent paraître blanchies ou le plus sou-vent trop sombres. La di�culté principale repose sur la diversité des lois de puis-
48

Fig. 4.10 � Réponse d'un moniteur avant et après correction gamma. La loi de réponseintensité/voltage du moniteur est une loi de puissance de coe�cients c = 1 et γ = 2.5.La correction gamma est apportée par l'utilisation de la loi s = r1+2.5
sances utilisées par les di�érents moniteurs. Reproduire des couleurs demande aussides connaissances sur la correction gamma, car modi�er la valeur de gamma ne changepas seulement l'intensité mais aussi les quantités relatives de rouge, vert et bleu. Laplupart des ordinateurs sont dotés de systèmes de correction gamma partiels. Cepen-dant, lorsque l'on veut di�user une image sur un site internet par exemple, il peut êtrejudicieux de la prétraiter avec une correction gamma, pour une valeur de gamma dansla moyenne des valeurs courramment utilisées par les moniteurs.
Outre la correction gamma, ces lois de transformations en puissance sont réguliè-rement utilisées pour manipuler le contraste des images. Un exemple se trouve �gure4.3.3 qui montre une image originale d'une irm et trois images obtenues par troistransformations en puissance avec des γ di�érents. L'image originale est très sombreet l'utilisation d'une loi de puissance permet d'augmenter la palette de niveaux de grisutilisée (autrement dit on diminue le contraste). On note que plus la valeur de gammadécroît, plus les détails deviennent visibles. Cependant pour la plus petite valeur de γ(0.3), l'image commence à avoir un aspect délavé. Cette valeur est la limite en dessousde laquelle le contraste est réduit de manière inacceptable.
La �gure 4.3.3 est un exemple de problème inverse. L'image originale a une ap-parence délavée qui indique qu'une compression des niveaux de gris, autrement ditune augmentation du contraste, est souhaitable. Ce type d'opérations peut être réaliséen utilisant des gammas supérieurs à 1. Des résultats corrects sont obtenus avec ungamma égal à 3.0 et 4.0, l'image correspondant à cette dernière valeur semble meilleur
49

Fig. 4.11 � Image par résonance magnétique (IRM) d'une fracture de la colonne ver-tébrale : en haut à gauche, image originale, de gauche à droite et de haut en bas,transformations en puissance avec c = 1 et un γ respectivement égal à 0.6, 0.4 et 0.3
car elle possède un plus grand contraste. La dernière valeur 5.0 fournit une image dontcertaines régions sont trop noires ce qui conduit à la disparition de détails.
4.3.4 Transformations linéaires par morceauxUne approche complémentaire aux trois méthodes précédemment envisagées consiste
à considérer des transformations linéaires par morceaux.
4.3.4.1 Réhaussement de contrasteUne des transformations linéaires par morceaux les plus simples est une opération
de rehaussement de contraste (cf un exemple sur la �gure 4.13). Un trop faible contrastepeut être le fait d'un éclairage faible, de la dynamique trop réduite d'un capteur (parexemple un capteur ne pouvant produire que des images en 5 niveaux de gris). . .
L'idée d'une telle transformation consiste à augmenter la dynamique des niveauxde gris de l'image manipulée. La fonction dessinée sur la �gure 4.13 possède 2 points decontrôle (r1, s1) et (r2, s2) dont les positions caractérisent la transformation. Lorsquer1 = s1 et r2 = s2, la fonction est linéaire et ne produit aucun changement sur lesniveaux de gris. Si r1 = r2, s1 = 0 et s2 = L− 1, on retrouve une fonction de seuillagequi réalise la binarisation de l'image. Tous les pixels de l'image originale dont la valeurest inférieure à r1 = r2 deviennent noirs dans l'image de destination tandis que tousles pixels dont la valeur est supérieure à r1 = r2 deviennent blancs.
De manière générale, pour de telles fonctions, r1 ≤ r2 et s1 ≤ s2 ce qui garantit la
50

Fig. 4.12 � Vue aérienne : en haut à gauche, image originale, de gauche à droite et dehaut en bas, transformations en puissance avec c = 1 et un γ respectivement égal à3.0, 4.0 et 5.0
croissance de la fonction, et préserve ainsi l'ordre des niveaux de gris. Cette conditionempêche l'apparition d'artefacts d'intensité dans l'image résultante.
Le réhaussement de contraste de l'image en haut à droite de la �gure 4.13 quiapparaît en bas à gauche, a été réalisée avec la transformation dé�nie par (r1, s1) =(rmin, 0) et (r2, s2) = (rmax, L− 1) avec rmin et rmax respectivement le plus petit et leplus grand niveaux de gris de l'image originale. Cette transformation permet de tirerpartie de toute la palette de niveaux de gris représentable. En bas à droite apparaît lerésultat de la binarisation de l'image pour laquelle r1 = r2 = m, m étant la valeur deniveau de gris moyenne de l'image.
4.3.4.2 Transformation d'une plage de niveaux de grisDe nombreuses opérations nécessitent d'éclairer un intervalle donné de niveaux de
gris. Dans le cas des images satellites par exemple, on peut souhaiter améliorer laperception des étendues d'eau. De tels traitements sont aussi couramment utilisés pourles images obtenues à partir de rayons X. Il existe plusieurs manières d'obtenir detels résultats. La plupart sont des variations des deux approches suivantes (cf Fig.4.14). La première consiste à a�cher un niveau de gris clair pour toutes les valeurs del'image initiale comprises dans la plage souhaitée, et à a�cher un niveau de gris sombrepour toutes les autres. Une telle transformation produit une image binaire. La secondeapproche éclaircit aussi la plage de niveaux de gris considérée mais laisse intacts lesautres niveaux de gris.
51

Fig. 4.13 � Rehaussement de contraste d'une image de pollen obtenue par microscopeélectronique : de gauche à droite et de haut en bas, représentation de la transforma-tion, image originale avec un faible contraste, résultat d'un rehaussement de contraste,résultat d'un seuillage ou binarisation de l'image
4.4 Manipulation d'histogrammesL'histogramme associé à une image en niveaux de gris ([0, L− 1]) est une fonction
discrète h(rk) = nk, où rk, k ∈ [0, L− 1], est le keme niveau de gris et nk le nombre depixels de l'image dont le niveau de gris est rk. Un histogramme normalisé est donné parla fonction p(rk) = nk/n où n est le nombre total de pixels de l'image. Grosso modo,p(rk) représente la probabilité de trouver un pixel de niveau de gris rk dans l'image.On note que la somme des p(rk) pour les k de 0 à L− 1 est égale à 1.
L'histogramme d'une image en L niveaux de gris peut être mémorisé par un tableaupossédant L cases.
Considérons par exemple la petite image ci-dessous qui possède 8 niveaux de gris :
0 0 0 1 22 3 0 1 13 3 5 0 17 6 7 1 27 7 7 0 05 6 0 0 0
Son histogramme peut être représenté par :
10 5 3 3 0 2 2 50 1 2 3 4 5 6 7
52

Fig. 4.14 � Transformation d'une plage de niveaux de gris. En haut à gauche, unetransformation qui éclaircit les niveaux de gris appartenant à la plage [A, B], a�ecte àtous les autres niveaux de gris une valeur donnée (sombre) et produit ainsi une imagebinaire. En haut à droite, une transformation qui éclaircit les niveaux de gris de laplage [A, B] sans modi�er les autres. En bas de gauche à droite, une image et le résulatde sa transformation par la première transformation
où la case i du tableau contient le nombre de pixels dont la couleur est le ieme niveaude gris
Pour manipuler l'histogramme normalisé, il su�t de diviser le nombre présent danschaque case par 30 (qui est le nombre total de pixels de l'image).
Les histogrammes sont à la base de nombreuses transformations spatiales sur lesimages. L'information qu'ils fournissent peut être utilisée à la fois pour améliorer uneimage, mais aussi pour réaliser de la segmentation, de la compression. . .. En outre, ilssont simples à calculer et sont particulièrement adaptés aux traitements d'images entemps réel.
Di�érents exemples d'images accompagnées de leur histogramme normalisé corres-pondant peuvent être vus sur la �gure 4.15. On note que l'histogramme associé à uneimage sombre est plus dense dans les valeurs basses de niveaux de gris. De la mêmemanière, l'histogramme d'une image claire est concentré vers les valeurs hautes (claires)de niveaux de gris. Les valeurs d'un histogramme de faible contraste sont concentréesdans un petit intervalle de niveaux de gris centré autour d'une valeur médiane tandisqu'elles sont réparties quasiment uniformément dans tout l'intervalle des niveaux degris pour une image à fort contraste. Ce dernier type d'images contient une grande va-riété de niveaux de gris et permet donc d'atteindre un niveau élevé de détails. On verrapar la suite qu'il est tout à fait possible de réaliser une transformation sur une image,simplement à partir de son histogramme pour obtenir une image de grand contraste.
53

Fig. 4.15 � 4 types classiques d'images. De haut en bas : image sombre (sous-exposée),claire (sur-exposée), avec un faible contraste, et avec un fort contraste
4.4.1 Egalisation d'histogrammeOn se concentre sur les transformations de la forme :
sk = T (rk), pour rk ∈ [0, L− 1] (4.6)
telles que T soit une application monotone croissante, avec en outre T (rk) ∈ [0, L−1].
Le fait que T soit une application et non simplement une fonction garantit que toutrk a une seule image par T , ce qui garantit l'existence d'une transformation inverse(rien ne garantit cependant que cette transformation inverse est elle-aussi une applica-tion, en e�et, si T n'est pas injective, T−1 ne sera pas une application). La propriété decroissance monotone de F préserve l'ordre des niveaux de gris dans l'image �nale. La
54

dernière condition garantit en�n que les intervalles de niveaux de gris utilisés sont iden-tiques dans les images initiale et �nale. Parfois on normalise rk et sk en les dé�nissantcomme des valeurs entre 0 et 1.
Un exemple d'une transformation T valide (avec des niveaux de gris normalisés) estdonnée �gure 4.16
Fig. 4.16 � Une transformation de niveaux de gris qui est une application monotonecroissante
Egaliser un histogramme revient à obtenir un histogramme avec une distributionuniforme, autrement dit tel que la fonction histogramme h soit constante.
L'opération utilisée se comprend mieux sur ce qu'on appelle l'histogramme cu-mulé d'une image.
L'histogramme cumulé associé à une image en niveaux de gris ([0, L − 1]) est unefonction discrète c(rk) =
∑i=ki=0 ni où, comme précédemment, rk, k ∈ [0, L − 1], est le
keme niveau de gris et nk le nombre de pixels de l'image dont le niveau de gris est rk. Siun histogramme est uniforme, son histogramme cumulé peut être représenté par unedroite.
On veut associer à tout niveau de gris rk de l'image initiale un niveau de grissk de l'image d'arrivée. La transformation T est croissante, donc le nombre de pixelsdont la valeur est inférieure ou égale à rk dans l'image initiale est égal au nombre depixels dont la valeur est inférieure ou égale à sk dans l'image d'arrivée. On connaît parl'histogramme cumulé de l'image initiale le nombre de pixels dont la valeur est inférieureà rk, on le note
∑i=ki=0 nk. L'histogramme cumulé de l'image d'arrivée correspond donc
à celui de la �gure 4.18. On peut en déduire aisément la valeur de sk :
sk
L− 1=
∑i=ki=0 ni
n(4.7)
avec n le nombre total de pixels de l'image et ni le nombre de pixels posséndant leieme niveau de gris. Autrement dit :
sk =i=k∑i=0
ni
n∗ (L− 1) (4.8)
Cette transformation T peut comme précédemment être représentée par une tablede correspondances :
n0
n∗ (L− 1) (n0
n+ n1
n) ∗ (L− 1) (n0
n+ n1
n+ n2
n) ∗ (L− 1) · · · · · · ∑i=L−1
i=0ni
n∗ (L− 1)
r0 r1 r2 · · · · · · rL−1
55
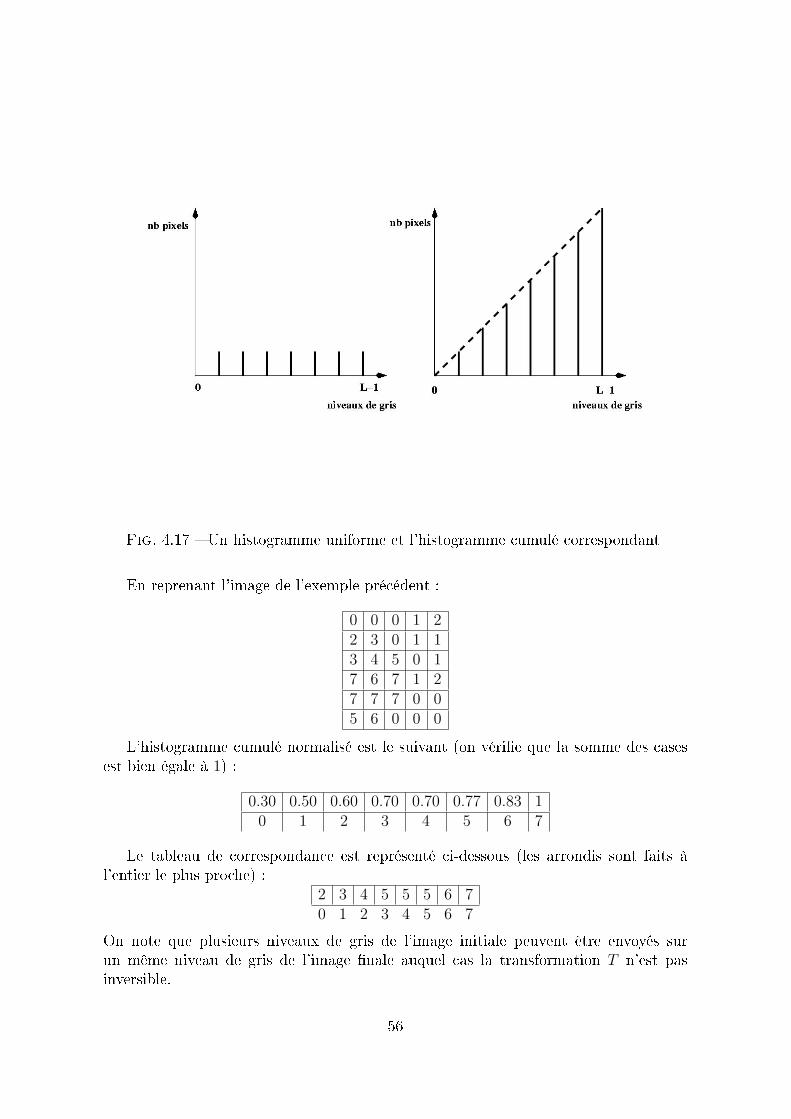
Fig. 4.17 � Un histogramme uniforme et l'histogramme cumulé correspondant
En reprenant l'image de l'exemple précédent :
0 0 0 1 22 3 0 1 13 4 5 0 17 6 7 1 27 7 7 0 05 6 0 0 0
L'histogramme cumulé normalisé est le suivant (on véri�e que la somme des casesest bien égale à 1) :
0.30 0.50 0.60 0.70 0.70 0.77 0.83 10 1 2 3 4 5 6 7
Le tableau de correspondance est représenté ci-dessous (les arrondis sont faits àl'entier le plus proche) :
2 3 4 5 5 5 6 70 1 2 3 4 5 6 7
On note que plusieurs niveaux de gris de l'image initiale peuvent être envoyés surun même niveau de gris de l'image �nale auquel cas la transformation T n'est pasinversible.
56

L'obtention de la formule de l'égalisation d'histogramme se fait généralement enayant recours aux probabilités. A titre d'information, voici comment elle est calculéepar ce biais là :
Les niveaux de gris (normalisés) d'une image peuvent être vus comme des variablesaléatoires comprises dans l'intervalle [0, 1]. L'un des descripteurs fondamentaux de tellesvariables est la fonction de densité de probabilité (PDF : Probability Density Function).On appelle respectivement pr(r) et ps(s) les fonctions de densité de probabilité de r(niveau de gris de l'image initiale) et s (niveau de gris de l'image �nale). Un résultatbasique de la théorie élémentaire des probabilités indique que si pr et T sont connusalors ps est donné par la formule suivante :
ps(s) = pr(r)
∣∣∣∣∣dr
ds
∣∣∣∣∣ (4.9)
La transformation suivante est très importante en traitement d'images :
s = T (r) =∫ r
0pr(w)dw (4.10)
La partie droite de cette équation représente en e�et la fonction de distributioncumulée (CDF : Cumulative Distribution Funcion) de la variable aléatoire r.
De l'expression de cette transformation, on peut déduire :
ds
dr
= pr(r) (4.11)
L'équation 4.9 devient alors :
ps(s) = pr(r)
∣∣∣∣∣dr
ds
∣∣∣∣∣ (4.12)
= 1 pour s ∈ [0, 1] (4.13)
Cette transformation T conduit ainsi à une image dont la fonction de densité deprobabilité est uniforme, autrement dit à une image dont les niveaux de gris sontuniformément répartis. La transformation T n'est autre que celle qui permet d'obtenirune égalisation d'histogramme. Pour obtenir la formulation discrète, il su�t de serappeler que la probabilité d'occurence du niveau de gris rk dans l'image initiale estdonné par pr(rk) = nk/n. La discrétisation de la formule 4.10 donne alors l'expressiondiscrète de sk, pour tout k dans l'intervalle [0, L− 1] :
sk = T (rk) =i=k∑i=0
ni/n (4.14)
Cette expression est bien entendu la même que celle donnée précédemment (équa-tion 4.8).
57

Fig. 4.18 � Calcul de la valeur de sk
4.4.2 Spéci�cation d'histogrammeObtenir un histogramme uniforme n'est pas toujours la meilleure solution (cf Fig.
4.20), en particulier si l'histogramme initial est très concentré. Dans de tels cas, l'éga-lisation d'histogramme peut faire apparaître des bords et des régions erronés, ou aug-menter le bruit de l'image. Il est alors parfois intéressant d'utiliser une autre approchequi consiste à déterminer à l'avance la forme de l'histogramme que l'on souhaite obte-nir. On va donc réaliser une transformation T sur une image de sorte que l'histogrammede l'image transformée soit conforme à un histogramme de référence. La distribution deréférence peut être obtenue soit à partir d'une image, soit à partir d'une région d'uneimage. Ce type de transformation est particulièrement utile lorsqu'on veut comparerdes photos prises au même endroit mais à des moments de la journée di�érents et doncavec des luminosités di�érentes ou lorsqu'on veut �mosaïquer� des images adjacentes
58

Fig. 4.19 � Gauche : images de la �gure 4.15 ; Milieu : résultat de l'égalisation del'image ; Droite : histogrammes correspondants
prises à des moments di�érents.La méthode de spéci�cation d'histogramme revient à appliquer à l'image initiale
une transformation d'égalisation, et à appliquer à l'image résultant l'inverse de la trans-formation d'égalisation de l'image de référence. L'histogramme de l'image résultanteet de l'image de référence seront généralement légèrement di�érents. Mais les aspectsvisuels des deux images seront semblables.
Ce mécanisme est assez intuitif. En e�et, lorsqu'on réalise un processus d'égalisationd'histogramme sur une image donnée, on trouvera (aux erreurs d'arrondis près) toujoursle même résultat quelles que soient les transformations d'intensité que l'on ait pu faireprécédemment.
Autrement dit l'égalisation de l'image d'entrée ou de l'image de sortie du processusde spéci�cation donnera le même résultat, autrement dit la même image égalisée.
Le processus est décrit par la �gure 4.21.Pour pouvoir réaliser une telle opération, il est nécessaire que l'inverse de la trans-
formation d'égalisation de l'image de référence soit une application, autrement dit quela transformation d'égalisation soit monotone strictement croissante.Lorsque ce n'estpas le cas (la plupart du temps), on est obligé de réaliser des approximations (au plusprès).
L'algorithme de spéci�cation d'histogramme est le suivant :
1. Egaliser l'image d'entrée pour obtenir une image avec des niveaux de gris uni-formes, grâce à l'équation 4.8 :
59

(a) image initiale (b) histogramme de l'image initiale
(c) image égalisée
Fig. 4.20 � L'égalisation d'histogramme de cette image ne donne pas un résultat sa-tisfaisant
Fig. 4.21 � Processus de spéci�cation d'histogramme
sk = T (rk) =i=k∑i=0
ni
n∗ (L− 1)
2. Construire le tableau de correspondances relatif à l'égalisation d'histogramme del'image de référence
vk = G(zk) =i=k∑i=0
n′i
n′ ∗ (L− 1)
3. En déduire le tableau de correspondance zk/rk en réalisant au besoin les approxi-mations nécessaires
60

z = G−1(v = s) = G−1[T (r)]
Voici un exemple de spéci�cation d'histogramme. On considère une image en 8niveaux de gris possédant l'histogramme et l'histogramme cumulé ci-dessous :
Histogramme 790 1023 850 656 329 245 122 81HistogrammeCumulé
0.19 0.25 0.21 0.16 0.08 0.06 0.03 0.02
r0 r1 r2 r3 r4 r5 r6 r7
0 1 2 3 4 5 6 7
Ci-dessous l'histogramme normalisé désiré :
HistogrammeNormalisé
0.00 0.00 0.00 0.15 0.20 0.30 0.20 0.15
z0 z1 z2 z3 z4 z5 z6 z7
0 1 2 3 4 5 6 7
Le calcul de l'égalisation d'histogramme donne le tableau de correspondance suivant(à vous de véri�er !) sk = T (rk) :
niveau de gris 1 3 5 6 6 7 7 7r0 r1 r2 r3 r4 r5 r6 r7
On note au passage que certains niveaux de gris ne sont pas présents dans l'imageégalisée (0,2 et 4). L'histogramme associé aux sk est donné ci-dessous :
0 790 0 1023 0 850 985 448s0 s1 s2 s3 s4 s5 s6 s7
0 1 2 3 4 5 6 7
On calcule maintenant vk = G(zk). Le tableau de correspondance obtenu est donnéci-dessous. Comme on aura besoin de la transformation inverse,
niveau de gris 0 0 0 1 2 5 6 7z0 z1 z2 z3 z4 z5 z6 z7
Là encore plusieurs niveaux de gris de l'image initiale n'existent pas dans l'imaged'arrivée, et l'application G n'est pas inversible. On ne sait par exemple pas quelle estl'image par G−1 du niveau de gris 0. Cela peut aussi bien être z0, z1, ou z2. Le tableauci-dessous résume les informations que l'on possède sur G−1.
? z3 z4 ? ? z5 z6 z7
0 1 2 3 4 5 6 7
On compose maintenant les transformations z = H(r) = G−1[T (r)]. Lorsqu'il existeune ambiguité sur la valeur on choisit le niveau de gris inférieur le plus proche.
61

r → s s → z r → zr0 = 0 → 1 s0 = 0 →? r0 = 0 → 3r1 = 1 → 3 s1 = 1 → 3 r1 = 1 →?4r2 = 2 → 5 s2 = 2 → 4 r2 = 2 → 5r3 = 3 → 6 s3 = 3 →? r3 = 3 → 6r4 = 4 → 6 s4 = 4 →? r4 = 4 → 6r5 = 5 → 7 s5 = 5 → 5 r5 = 5 → 7r6 = 6 → 7 s6 = 6 → 6 r6 = 6 → 7r7 = 7 → 7 s7 = 7 → 7 r7 = 7 → 7
4.5 Filtrage spatial
4.5.1 Bases du �ltrage spatialComme dit précédemment, certaines opérations de transformations utilisent les in-
formations contenues dans le voisinage d'un point ainsi que des données supplémen-taires stockées dans un tableau de la taille du voisinage, parfois aussi considéré commeune sous-image et indi�éremment nommé masque, �ltre, noyau, modèle ou fenêtre (aveccependant une préférence pour les trois premiers termes). Les valeurs de ce masque sontappelées ses coe�cients.
Le principe général du �ltrage se fonde sur l'utilisation de transformées de Fourieremployées dans le domaine fréquentiel qui sera abordé dans un autre module. Le �ltragespatial (appelé ainsi pour le di�érencier du �ltrage fréquentiel) consiste tout simplementen la traduction dans le domaine spatial des notions de �ltrages dé�nies dans le domainefréquentiel. Autrement dit, il met en ÷uvre des techniques fondées sur la manipulationdirecte des pixels d'une image. Le concept de �ltrage spatial est illustré par la �gure4.22. Ce procédé consiste tout simplement à déplacer le masque de pixel en pixel a�nde parcourir toute l'image. La réponse au �ltre est calculée en chaque point de l'imageen utilisant une relation prédé�nie. Dans le cas d'un masque linéaire, par exemple, laréponse est donnée par la somme des valeurs des pixels du voisinage, chacune de cesvaleurs étant pondérée par le coe�cient du masque lui correspondant. Autrement dit,la réponse R en un point (x, y) de l'image dé�nie par f(x, y) �ltrée par le masque 3×3de la �gure 4.22 est donnée par :
R = w(−1,−1)f(x− 1, y − 1) + w(−1, 0)f(x− 1, y) + w(−1, 1)f(x− 1, y + 1)
+w(0,−1)f(x, y − 1) + w(0, 0)f(x, y) + w(0, 1)f(x, y + 1)
+w(1,−1)f(x + 1, y − 1) + w(1, 0)f(x + 1, y) + w(1, 1)f(x + 1, y + 1)
Il s'agit bien de la somme des produits de chaque pixel du voisinage par le coe�cientdu masque placé au-dessus de lui. D'autre part, le masque est centré sur le point (x, y)(le coe�cient de la valeur au pixel (x, y) est w(0, 0)).
Par la suite, on considérera des masques de taille m × n, m ≥ 3 et n ≥ 3. Onsupposera que m et n sont impairs, autrement dit qu'il existe deux entiers positifs a etb tels que m = 2a + 1 et n = 2b + 1, ce qui permet de centrer le masque sur le pixeldont on veut modi�er la valeur.
62

Le �ltrage linéaire d'une image par un masque de taille m×n est donné par l'équa-tion :
s=a∑s=−a
t=b∑t=−b
w(s, t)f(x + s, y + t) (4.15)
qui, pour donner un �ltrage complet de l'image, doit être appliquée sur tous sespixels.
Fig. 4.22 � Illustration du mécanisme de �ltrage spatial. La partie agrandie montre unmasque 3× 3 et la portion de l'image juste sous ce masque
Ce procédé est similaire à la méthode de convolution utilisée dans le domaine fré-quentiel. On dit alors souvent par analogie que le �ltrage spatial est réalisé parconvolutiond'un masque avec une image. On parle aussi de masques de convolution ou de noyaude convolution.
Pour simpli�er les notations, on note aussi parfois la réponse R de la convolutiond'une image par un masque de taille m× n :
R = w1z1 + w2z2 + · · ·+ wmnzmn =i=mn∑i=1
wizi (4.16)
où les w sont les coe�cients du masque (cf exemple de masque 3× 3 Fig. 4.23) etles z les valeurs des pixels du voisinage.
Les �ltres spatiaux non linéaires s'appliquent eux aussi sur un voisinage mais la ré-ponse à un tel �ltrage n'est pas donnée par une somme pondérée. Un exemple classique
63

Fig. 4.23 � Représentation simpli�ée d'un masque 3× 3
de �ltre non linéaire est le �ltre médian qui remplace la valeur d'un pixel par la valeurmédiane des pixels qui l'entourent.
L'utilisation de ces masques amènent à se poser la question de la gestion des bordsd'une image. En e�et, un problème survient dès lors que le centre du masque est posésur un pixel situé vers le bord de l'image et tel qu'une partie du masque ne repose plussur l'image. Considérons par exemple un masque de taille n × n. Si le centre d'un telmasque est positionné sur un pixel situé à une distance du bord de l'image inférieureà (n− 1)/2 pixels, alors au moins une ligne ou une colonne du masque ne repose plussur l'image. Il existe di�érentes manières de traiter ces cas. Lorsque l'application nenécessite pas de conserver la taille de l'image intacte, on considère que le résultat du�ltrage est la sous-image maximale sur laquelle on a pu e�ectuer le �ltrage. Autrementdit, dans le cas d'un �ltre m × n, et d'une image originale de taille M × N , l'image�ltrée sera de taille (M−m−1)×(N−n−1) puisqu'on n'aura pas pu traiter (m−1)/2pixels à gauche et à droite de l'image et (n− 1)/2 pixels en haut et en bas de l'image.L'avantage de cette méthode est que l'ensemble des pixels aura été traité avec le mêmemasque et en utilisant les données de l'image initiale. Cependant, certaines applicationsrequièrent que l'image �nale possède la même taille que l'image initiale. Une solutionpossible consiste alors à n'appliquer à un pixel que la partie du masque centré surlui qui recouvre e�ectivement l'image. Cette méthode implique que tous les pixels del'image ne seront pas traités avec le masque entier. Une autre méthode consiste àrajouter des pixels �virtuels� sur les bords de l'image, dans certains cas, il peut s'agirde colonnes et de lignes de 0s, dans d'autres de recopies de colonnes et de lignes del'image. Ces colonnes et ces lignes ne sont bien entendu prises en compte que pour lescalculs et n'apparaissent pas dans l'image �nale. Plus le masque est grand plus cettedernière méthode est susceptible de provoquer des erreurs ou des e�ets non désirés surles bords. En fait, la seule solution pour avoir un �ltrage exact consiste à accepter ladiminution de la taille �nale de l'image.
4.5.2 Filtres de lissage ou �ltres passe-basLes �ltres de lissage sont principalement utilisés pour rajouter du �ou dans une
image et pour réduire certains types de bruits. Rendre une image plus �oue revienten quelque sorte à enlever certains détails. Cette technique est souvent utilisée commepré-traitement, lorsque l'on veut extraire les formes générales présentes dans une image.Elle est aussi utilisée pour gommer des trous �ns dans des lignes ou des courbes. Laréduction de bruit peut être réalisée à l'aide de �ltres de lissage linéaires mais aussi
64

non-linéaires.
4.5.2.1 Filtres linéaires de lissageLa réponse de tels �ltres est tout simplement une moyenne pondérée des valeurs des
pixels du voisinage. La pondération dépend du masque utilisé. Ces masques sont ainsiparfois appelés �ltres moyenneurs, ou encore �ltres passe-bas, ce dernier nom étant enrelation avec leur équivalent dans le domaine fréquentiel.
Deux exemples de tels �ltres se trouvent sur la �gure 4.5.2.1.
Fig. 4.24 � Deux masques moyenneurs classiques
L'idée sous-jacente à un tel �ltre est assez simple : en remplaçant un pixel parune moyenne calculée à partir de son voisinage, on va faire disparaître des transitionsbrutales d'intensité dans l'image. Or les bruits aléatoires sont typiquement caractériséspar des transitions brutales d'intensité, ce qui rend cette technique particulièrementappropriée pour l'élimination de tels bruits. Cependant, les contours des objets, lesbords se trouvant dans une image sont aussi catactérisés par de fortes variations lo-cales en intensité. L'application d'un �ltre moyenneur tend donc à faire disparaître oudu moins à atténuer ces caractéristiques de l'image, ce qui peut produire un e�et de�ou non souhaité. En�n, cette technique peut contribuer à réduire le nombre de fauxcontours pouvant apparaître dans une image qui n'est pas représentée avec une paletteassez large de niveaux de gris.
Lz �ltre moyenneur le plus simple est associé au premier masque de la �gure 4.5.2.1.La réponse à un tel �ltrage se traduit par :
R =1
9
i=9∑i=1
zi (4.17)
Il s'agit tout simplement de la moyenne des valeurs de 9 pixels appartenant auvoisinage 3 × 3 du pixel considéré. On remarque que les coe�cients du masque sont1 et non 1
9. Il est en e�et moins coûteux de réaliser en chaque pixel une opération
d'addition et de diviser toutes les valeurs des pixels de l'image par 9 une fois quel'image a été entièrement �ltrée. 9 est le facteur de normalisation du masque 3×3 donttous les coe�cients sont égaux à 1. Un masque de taille m×n rempli de 1 sera associéà un facteur de normalisation égal à m × n. Un tel masque moyenneur dont tous lescoe�cients sont égaux est parfois appelé un box �lter.
Le second masque de la �gure 4.5.2.1 est un peu plus intéressant, il revient à calculerune moyenne pondérée des valeurs des pixels du voisinage. Autrement dit, il attribue
65

à certains pixels du voisinage un poids et donc une importance plus grande dans lecalcul de la moyenne. Il existe di�érents masques proposant le recours à une moyennepondérée. Le choix de la pondération de chaque pixel peut être motivée par di�érentesraisons. La pondération est, dans ce cas précis, fonction de la distance de ce pixel avecle pixel sur lequel est centré le masque. Son principe repose sur l'idée que plus unpixel est géométriquement proche d'un autre, plus leurs valeurs ont de chance d'êtreproches. Ainsi les pixels proches auront un poids plus grands que les pixels lointains.Cette technique vise à diminuer l'e�et de �ou et à éviter un trop grand lissage. Diversmasques avec des coe�cients di�érents mettent en pratique cette technique. Un avan-tage supplémentaire du masque représenté �gure 4.5.2.1 repose sur le fait que la sommede ses coe�cients est égale à 16, caractéristique pratique pour les ordinateurs puisqu'ils'agit d'une puissance de 2. D'autre part, vue la taille du masque 3 × 3, tout masquedont les coe�cients respectent une loi de pondération inversement proportionnelle à ladistance avec le pixel central réalise quasiment le même �ltrage sur une image donnée.La taille du masque est en e�et trop faible pour que les di�érences de coe�cients aientun impact sur l'apparence globale de l'image.
L'expression générale de l'application d'un tel �ltre de dimension m× n, avec m =2a + 1 et n = 2b + 1 à une image f(x, y) est donnée par :
g(x, y) =
∑s=as=−a
∑s=bs=−b w(s, t)f(x + s, y + t)∑s=as=−a
∑s=bs=−b w(s, t)
(4.18)
Le dénominateur est simplement la somme des coe�cients du masque. Il s'agit doncd'une constante que l'on calcule une fois pour toute. Comme précédemment, ce facteurn'est appliqué aux pixels de l'image qu'une fois que le processus de �ltrage est terminé.
Les e�ets d'un �ltre de lissage apparaissent sur la �gure 4.25. Lorsque le masque estde taille 3×3, on note un léger e�et de �ou sur la totalité de l'image mais on remarqueque les détails qui étaient approximativement de la taille du �ltre dans l'image dedépart ont été bien plus modi�és que les autres parties de l'image (par exemple, lesdeux petits carrés, la plus petite lettre �a� et le bruit qui possède un grain �n). Le bruitest moins prononcé et le contour des caractères a un aspect plus lisse. Pour le masquede taille 5 × 5, l'e�et est globalement identique même si le �ou est plus accentué. Lemasque 9× 9 augmente encore signi�cativement le �ou et un des disques les plus clairsse confond presque avec le fond, ce qui illustre l'e�et de mélange ou de dilution decouleurs que peut provoquer un �ltre de lissage sur une zone de l'image dont la couleurest assez proche de celle de son voisinage. On note aussi un lissage plus signi�catif desrectangles bruités. Les �ltrages avec les masques 15×15 et 35×35 sont extrêmes comptetenus de la taille des objets de l'image. Ces �ltres excessifs sont utilisés lorsque l'onsouhaite éliminer des petits objets de l'image. Ainsi dans l'image �ltrée par le masque35×35, trois petits carrés, deux des cercles et les rectangles bruités se sont fondus dansle fond de l'image. On remarque aussi le cadre noir de plus en plus accentué autour del'image, il provient de l'utilisation de pixels virtuels noirs (0) permettant d'appliquerle masque sur tous les pixels de l'image.
Les propriétés de dilution de niveaux de gris des �ltres moyenneurs sont notammentutilisés pour l'analyse d'images spatiales lorsque l'on veut juste avoir une représentationbrute des objets étudiés. Ils permettent en e�et la dilution des détails dans le fond del'image. Un exemple est donné �gure 4.26. La taille du masque est choisie en fonction
66

Fig. 4.25 � En haut à gauche, image originale 500 × 500 pixels, de haut en bas dedroite à gauche résultats d'un lissage par des masques moyenneurs carrés de taillesrespectives 3, 5, 9, 15, 35
de la taille des objets que l'on souhaite voir disparaître dans le fond. Un tel �ltrage esttypiquement utilisé comme pré-traitement d'une opération de binarisation. Ainsi, surla �gure 4.26, l'image du milieu est le résultat d'un �ltrage par un masque 15 × 15.Certains détails se sont fondus dans le fond, d'autres ont vu leur intensité diminuer etsont éliminés par un seuillage approprié dont le résultat apparaît sur l'image de droite.Si on compare cette dernière image avec l'image originale, on constate que les objetsconservés correspondent bien aux objets les plus brillants.
4.5.2.2 Filtres non linéaires de lissageLes réponses de tels �ltres, appelés �ltres statistiques (ou order-statistics �lers) sont
fondées sur un classement des valeurs des pixels présents dans un certain voisinage d'unpixel. Celles-ci sont rangées par ordre croissant et une règle d'élection est déterminéequi permet de choisir une valeur parmi elles qui remplacera la valeur du pixel central.
Les �ltres statistiques les plus utilisés sont les �ltres médians pour lesquels la règled'élection consiste à choisir la valeur médiane des valeurs présentes dans le voisinage(valeur du pixel central comprise). Ces �ltres sont populaires car ils donnent de bonsrésultats quand il s'agit de réduire des bruits impulsifs, appelés aussi bruits poivre et selà cause de l'apparence qu'ils donnent aux images (impression de points noirs et blancssuperposés à l'image). La valeur médiane ξ d'un ensemble de valeurs est telle que la
67

Fig. 4.26 � A gauche, image produite par le télescope Hubble, au milieu résultat d'un�ltrage par masque moyenneur 15× 15, à droite résultat d'un seuillage ou binarisationréalisée sur l'image �ltrée
moitié des valeurs du voisinage est inférieure ou égale à ξ, et que la moitié des valeurs estsupérieure ou égale à ξ. Pour réaliser un �ltrage médian, on classe d'abord les valeursdes pixels du voisinage du pixel à modi�er par ordre croissant, on détermine ensuite lavaleur médiane, et on remplace la valeur du pixel par cette valeur médiane. Lorsque le�ltre est exécuté sur un voisinage 3× 3, la valeur médiane est la 5eme valeur de la listeordonnée. Pour un masque 9×9, il s'agit de la 13eme valeur. Considérons, par exemple,un voisinage dont les valeurs sont (10, 20, 20, 20, 15, 20, 20, 25, 100). Le rangement desvaleurs par ordre croissant fournit la liste (10, 15, 20, 20, 20, 20, 20, 25, 100), ce qui donneune valeur médiane de 20. Ainsi la principale fonction d'un �ltre médian est de forcer despoints de niveaux de gris di�érents à ressembler plus à leurs voisins. Ainsi, des portionsde l'image qui sont foncées ou claires par rapport à leur voisinage et dont la surfaceest inférieure à n2/2, sont éliminées par application d'un �ltre médian n×n. �Eliminé�signi�e ici positionné au niveau de gris médian des voisins. De larges ensembles depixels sont bien moins a�ectés.
D'autres �ltres statistiques classiques sont le �ltre maximal et le �ltre minimalpour lesquels la valeur choisie est respectivement la plus grande et la plus petite del'ensemble des valeurs des voisins. Le premier est utilisé pour éclaircir les pixels del'image, le second pour les obscurcir.
On peut comparer l'e�et d'un �ltre moyenneur et d'un �ltre médian sur une imagecorrompue par un bruit poivre et sel. Il apparaît, comme sur la �gure 4.5.2.2, quele premier est moins e�cace que le second. En e�et, même si le bruit est atténuépar le �ltre moyenneur, le prix à payer est un e�et de �ou sur l'ensemble de l'image.L'utilisation du �ltre médian élimine plus de bruit tout en conservant la netteté del'image.
4.5.3 Filtres de netteté ou �ltres passe-hautCes �ltres permettent principalement d'accentuer des détails �ns de l'image, et
d'améliorer des détails qui sont devenus �ous suite à une erreur ou à des caractéristiquesnaturelles du processus d'acquisition employé.
De tels �ltres interviennent dans des domaines variés, aussi bien dans l'électronique(représentation de circuits intégrés), dans l'imagerie médicale, que dans le guidage
68

Fig. 4.27 � A gauche une image par rayons X représentant un circuit électroniquecorrompue par un bruit de type poivre et sel, au milieu l'image sur laquelle a étéappliqué un �ltre moyenneur, à droite le résultat de l'application d'un �ltre médian
automatique de systèmes militaires. . .Nous avons vu précédemment que le lissage d'une image peut être accompli dans
le domaine spatial par le calcul de moyennes de valeurs de pixels dans un voisinage.Comme la notion de moyenne est fortement liée à celle d'intégration, on peut supposer(à raison) que l'amélioration de la netteté d'une image peut être réalisée par dérivation.
Il s'agit donc de dé�nir des opérateurs discrets de dérivation. Il existe plusieursmanières d'aborder ce problème. Cette étude est l'objet de cette section.
La force d'un opérateur de dérivation est proportionnelle au degré de discontinuitéde l'image au point où la transformation est appliquée. Ainsi, de tels opérateurs mettenten valeurs les bords et autres discontinuités (comme du bruit) et uniformisent les zonesdont les niveaux de gris sont proches.
4.5.3.1 GénéralitésDans la suite, nous considérerons des �ltres qui se fondent sur des dérivées du pre-
mier et du second ordre. Avant de décrire précisément ces �ltres, nous présentons iciles propriétés essentielles de ces dérivées. Pour simpli�er, nous nous concentrons surdes dérivées dans une direction. On s'intéresse en particulier au comportement de cesdérivées dans des zones de niveau de gris constant (segments plats ou �at segments),sur les amorces et les �ns de discontinuités (step and ramp discontinuities), et le longdes rampes de niveaux de gris (gray-level ramp). De telles discontinuités peuvent êtreutilisées pour modéliser des point, lignes et arêtes bruités d'une image. Le comporte-ment de ces dérivés pendant les transitions entre ces caractéristiques de l'image mériteaussi d'être étudié.
Les dérivées d'une fonction discrète s'expriment en terme de di�érences. Il existeplusieurs manières de dé�nir ces di�érences. On impose généralement cependant quetoute dé�nition d'une dérivée première véri�e les 3 conditions suivantes :
1. elle doit être égale à 0 sur tous les segments plats,
2. elle doit être di�érente de 0 à l'amorce et à la �n des discontinuités,
3. elle doit être di�érente de 0 le long d'un changement linéaire de niveau de gris.
De manière équivalente, toute dé�nition d'une dérivée seconde doit véri�er les 3conditions suivantes :
69

1. elle doit être égale à 0 sur tous les segments plats
2. elle doit être di�érente de 0 à l'amorce et à la �n des discontinuités,
3. elle doit être égale à 0 le long d'un changement linéaire de niveau de gris.
Puisque l'on manipule des quantités discrètes dont les valeurs sont �nies, l'écartmaximum possible entre deux niveaux de gris est lui aussi �ni, et la distance la pluscourte sur laquelle un tel changement est possible est elle-aussi �nie (2 pixels adjacents).
Une dé�nition basique d'une dérivée du premier ordre d'une fonction de dimension1, f(x) est donnée par :
∂f
∂x= f(x + 1)− f(x) (4.19)
On utilise la notation de dérivée partielle pour pouvoir garder la même notationlorsqu'on manipulera des fonctions de deux variables f(x, y).
De la même manière, une dérivée du second ordre est décrite par :
∂2f
∂2x= f(x + 1) + f(x− 1)− 2f(x) (4.20)
Il est aisé de montrer que ces deux formules véri�ent respectivement les conditionsdésirées pour les dérivées premières et secondes.
Un exemple est donné �gure 4.5.3.1. Il s'agit d'une image simple qui contient dif-férents objets solides, une ligne et un seul point bruité. A droite de l'image, se trouvele pro�l de niveaux de gris 1D de la ligne horizontale passant par le centre de l'image(et contenant le point bruité). Une version simpli�ée de ce pro�l apparaît en dessous,qui contient juste un nombre su�sant de niveaux de gris (8) pour pouvoir analyser lesdérivées premières et secondes autours des di�érentes zones d'intérêt de l'image. Dansce diagramme simpli�é, la transition linéaire se fait sur 4 pixels, le point bruité occupe1 pixel, la ligne possède une largeur de 3 pixels et le saut de niveau de gris se situeentre deux pixels adjacents.
On peut regarder les propriétés des dérivées première et seconde en observant lepro�l de gauche à droite. On remarque d'abord que la dérivée première est non nullesur toute la transition linéaire tandis que la dérivée seconde n'est non nulle qu'auxextrémités de la transition. Comme les bords dans une image ressemblent à ce type detransition, on peut conclure que les dérivées premières produisent des bords épais etles dérivées secondes des bords �ns. On rencontre ensuite le point bruité. Ici la réponseau point et autour du point est plus forte pour la dérivée seconde. En e�et, un �ltre dusecond ordre est plus e�cace qu'un �ltre du premier ordre pour améliorer les variationsnettes. On peut donc attendre d'un �ltre du second ordre qu'il améliore beaucoup plusdes détails �ns (y compris du bruit) qu'un �ltre du premier ordre. La ligne mince estelle aussi un détail �n et on constate la même di�érence de comportement de la dérivéepremière et de la dérivée seconde que précédemment. Si l'intensité maximale de la ligneavait été plus élevée, la réponse de la dérivée seconde aurait été encore plus forte. En�n,dans ce cas, les dérivées première et seconde réagissent pareillement face au saut deniveau de gris (step). Dans la plupart des cas cependant, quand la transition ne se faitpas à partir de 0 la dérivée seconde est plus faible. On note aussi que la dérivée secondea une transition du positif vers le négatif.
70

Fig. 4.28 � en haut à gauche : une image simple - à droite : le pro�l 1D de niveau degris le long de la ligne horizontale traversant l'image en son centre (et passant par lepoint bruité blanc) - en bas : pro�l simpli�é (ramené en 8 niveaux de gris)
Pour résumer, lorsque l'on compare les réponses des dérivées premières et secondes,on peut formuler les observations suivantes :
1. Les dérivées du premier ordre produisent généralement des bords plus épaiss dansune image,
2. les dérivées du second ordre ont une réponse plus forte face à des détails �nscomme des lignes minces et des points isolés
3. les dérivées du premier ordre ont une réponse plus forte à un saut de niveau degris
4. les dérivées du second ordre produisent une double réponse devant les sauts deniveau de gris.
Dans beaucoup d'applications, la dérivée seconde est plus utilisée que la dérivéepremière pour sa capacité à mettre en valeur des détails �ns.
4.5.3.2 Dérivée seconde : utilisation du LaplacienL'approche choisie ici consiste à utiliser une méthode liée aux dérivées secondes
pour améliorer une image. Il s'agit de trouver une formulation discrète d'une dérivéedu second ordre et de construire un masque à partir de cette formulation. On s'intéresseici aux �ltres isotropiques, autrement dit aux �ltres dont la réponse ne dépend pas de
71

la direction des discontinuités de l'image sur laquelle est appliquée le �ltre. En d'autrestermes, ces �ltres sont invariants par rotation : appliquer une rotation à une image puisun tel �ltre ou appliquer d'abord le �ltre et ensuite e�ectuer une rotation de l'imageproduit le même résultat.
Il a été montré que l'opérateur de dérivation seconde le plus simple est le Laplacien.Pour une image dé�nie par f(x, y), cet opérateur est dé�ni par :
∇2f =∂2f
∂x2+
∂2f
∂y2(4.21)
Cet opérateur est noté ∇2 chez les anglophones et plutôt ∆ chez les francophones.Les dérivés étant linéaires, cet opérateur est lui aussi linéaire. Pour pouvoir l'utiliseren imagerie, il est nécessaire de donner une version discrète de cet opérateur. Il existedi�érentes manières de dé�nir un Laplacien discret en utilisant les voisinages. Quelleque soit la dé�nition, elle doit cependant véri�er les critères dé�nis précédemment.La dé�nition proposée ici est certainement la plus utilisée. L'expression de l'opérateurprend bien entendu en compte le fait que les fonctions images sont des fonctions dedeux variables.
∂2f
∂x2= f(x + 1, y) + f(x− 1, y)− 2f(x, y) (4.22)
∂2f
∂y2= f(x, y + 1) + f(x, y − 1)− 2f(x, y) (4.23)
On en déduit immédiatement l'expression discrète du Laplacien :
∇2f = f(x + 1, y) + f(x− 1, y) + f(x, y + 1) + f(x, y − 1)− 4f(x, y) (4.24)
Cette équation peut être implémentée en utilisant le masque en haut à gauche dela �gure 4.29, qui donne des résultats isotropes pour des rotations dont l'angle est unmultiple de 90◦.
Il est possible d'incorporer dans la dé�nition du Laplacien les directions diagonalesen rajoutant deux termes additionnels pour chaque diagonale. La forme de chacun deces termes est similaire à celle de l'équation 4.22 ou de l'équation 4.23, si ce n'est que lescoordonnées sont prises selon les diagonales. Comme chaque terme diagonal contient un−2f(x, y), le total soustrait se monte maintenant à 8f(x, y). Le masque correspondantà cette version du Laplacien apparaît en haut à droite de la �gure 4.29. Ce masqueprocure des résultats isotropes pour des rotations dont l'angle est un multiple de 45◦.Les deux autres masques de la �gure 4.29 sont aussi utilisés en pratique. Ils sont fondéssur une dé�nition du Laplacien qui est la version négative de celle donnée ici.
Comme le Laplacien est un opérateur de dérivation, son utilisation met en valeurles discontinuités dans les niveaux de gris d'une image et occulte les régions dont lesniveaux de gris varient lentement. Ainsi, des images traitées par cet opérateur auronttendance à montrer des arêtes et autres discontinuités dans des tons de gris, superposéesà un fond très sombre dans lequel on ne distingue qu'elles. Il est cependant possiblede récupérer les objets présents dans le fond sans perdre l'e�et de netteté obtenu.Il su�t tout simplement pour cela de superposer l'image initiale et l'image obtenue
72

Fig. 4.29 � Di�érents masques utilisés pour implémenter le Laplacien
après passage du Laplacien. La superposition se fait par addition lorsque la valeur aucentre du masque utilisé pour le Laplacien est positive, et par soustraction dans le cascontraire.
g(x, y) =
f(x, y) − ∇2f(x, y) lorsque le coe�cient central du
masque est négatiff(x, y) + ∇2f(x, y) lorsque le coe�cient central du
masque est positif
(4.25)
Un exemple d'une telle opération est donné �gure 4.30.L'opération décrite par l'équation 4.25 peut être implémentée à l'aide d'un seul
masque, déduit de l'équation suivante obtenue en remplaçant dans 4.25 ∇2f par lapartie droite de l'équation 4.24
g(x, y) = 5f(x, y)− [f(x + 1, y) + f(x− 1, y) + f(x, y + 1) + f(x, y − 1)]
Le masque correspondant est représenté dans la �gure 4.31. De manière similaire,on peut construire la transformation qui tient compte des valeurs diagonales (le masquecorrespondant apparaît aussi sur la �gure 4.31)
Un procédé couramment utilisé dans l'édition pour améliorer la netteté de l'imageconsiste à soustraire une version �oue de l'image de l'image elle-même. Ce procédé deréduction de bruit, connu en anglais sous le nom de unsharp masking s'exprime de lamanière suivante :
fs(x, y) = f(x, y)− f(x, y) (4.26)
où fs(x, y) représente l'image améliorée, et où f(x, y) est une version �oue de f(x, y).Une généralisation de ce procédé est appelé high-boost �ltering. Une image transforméepar ce �ltre est dé�nie par
73

Fig. 4.30 � De gauche à droite et de haut en bas : Image du pôle nord de la lune, image�ltrée par un Laplacien, même image mais avec un changement d'échelle des niveaux degris, image améliorée par superposition du résultat du �ltrage par Laplacien à l'imageoriginale
fhb(x, y) = Af(x, y)− f(x, y) (4.27)
où fhb est l'image résultante, A ≥ 1 et comme précédemment f est une version �ouede f(x, y). Cette équation peut s'écrire :
fhb(x, y) = (A− 1)f(x, y) + f(x, y)− f(x, y) (4.28)
En utilisant l'équation 4.26, elle devient :
fhb(x, y) = (A− 1)f(x, y) + fs(x, y) (4.29)
L'équation 4.29 peut en fait s'appliquer en général et n'impose pas la manière donton obtient l'image nette. Si l'on décide d'utiliser le Laplacien, alors on peut obtenirfs(x, y) par l'équation 4.25 et l'équation 4.29 devient :
fhb(x, y) =
Af(x, y) − ∇2f(x, y) lorsque le coe�cient central du
masque est négatifAf(x, y) + ∇2f(x, y) lorsque le coe�cient central du
masque est positif
(4.30)
74

Fig. 4.31 � de gauche à droite et de haut en bas : 2 masques Laplacien composites,image obtenue avec un microscope électronique, image résultant du �ltrage par lepremier masque, image résultant du �ltrage pas le second masque. On note que l'imagede droite est plus nette que celle de gauche.
Ce type de �ltrage peut alors être implémenté en une passe en utilisant un des deuxmasques de la �gure 4.32.
Fig. 4.32 � Masques permettant d'implémenter un �ltre de type high-boost avec A ≥ 1
Un �ltrage high-boost est généralement utilisé lorsque l'image en entrée est plussombre que souhaité. En faisant varier le coe�cient A (boost coe�cient), il est possibled'obtenir une hausse globale des niveaux de gris de l'image, ce qui permet d'obtenirune image plus claire. Un exemple d'une telle utilisation est donné dans la �gure 4.33.
75

Fig. 4.33 � de gauche à droite et de haut en bas : image sombre, image résultant del'application du masque à droite de la �gure 4.32 avec A = 0, pareil mais avec A = 1,puis avec A = 1.7
4.5.3.3 Dérivée première : utilisation du GradientLes opérations utilisant les dérivées premières se fondent sur l'utilisation de la norme
du gradient. Etant donnée une fonction de deux variables : f(x, y), le gradient de f aupoint de coordonnées (x, y) est dé�ni comme le vecteur 2D :
∇~f =
Gx
Gy
=
∂f∂x
∂f∂y
(4.31)
La norme de ce vecteur est donnée par
∇f =[G2
x + G2y
] 12
=[(
∂f∂x
)2+
(∂f∂y
)2] 1
2(4.32)
Les composantes du gradient sont des opérateurs linéaires mais la norme ne l'estévidemment pas (élévation au carré et racine carrée). D'un autre côté, les dérivéespartielles ne sont pas invariantes par rotation (donc pas isotropes) mais la norme duvecteur gradient l'est. Même si ce n'est pas correct, l'expression �norme du gradient�est souvent abrégée en gradient.
Calculer la norme du gradient en tout point d'une image n'est pas une opération
76

simple. On préfère souvent réaliser l'approximation suivante :
∇f ' |Gx|+ |Gy| (4.33)
Cette équation est plus simple à calculer et préserve les changements relatifs deniveaux de gris. Cependant la propriété d'isotropie est perdue dans la plupart des cas.Mais si les dé�nitions discrètes proposées par la suite ne garantissent pas une isotropiegénérale, elles proposent cependant une isotropie pour certaines valeurs d'angles derotation : les multiples de 90◦.
Fig. 4.34 � Une région 3×3 d'une image et les masques utilisés pour calculer la normedu gradient
Comme précédemment, on dé�nit une approximation discrète des équations précé-dentes qui vont servir à construire des masques appropriés. Pour simpli�er l'écrituredes formules, on utilise la notation de la �gure 4.34. Par exemple, le centre z5 représentef(x, y), z1 dénote f(x − 1, y − 1). Les approximations les plus simples d'une dérivéede premier ordre véri�ant les conditions évoquées plus haut sont Gx = (z8 − z5) etGy = (z6 − z5). Deux autres dé�nitions ont été proposées par Roberts en utilisant desdi�érences croisées.
Gx = (z9 − z5)andGy = (z8 − z6) (4.34)
On en déduit la valeur de la norme et celle de son approximation.
∇f = [(z9 − z5)2 + (z8 − z6)
2]12 (4.35)
∇f ' |z9 − z5|+ |z8 − z6| (4.36)
77

Ces équations peuvent être implémentées par les masques 2 × 2 de la �gure 4.34(Roberts cross-gradient operators). Les masques de taille paires sont di�ciles à implé-menter. Le plus petit �ltre 3× 3 utilise une autre approximation :
∇f ' |(z7 + 2z8 + Z9)− (z1 + 2z2 + z3)|+ |(z3 + 2z6 + z9)− (z1 + 2z4 + z7)| (4.37)
La di�érence entre la première et la dernière ligne du masque 3 × 3 réalise uneapproximation de la dérivée dans la direction de x, celle entre la première et la dernièrecolonne réalise une approximation de la dérivée dans la direction y. Ces deux opérateurssont appelés opérateurs de Sobel. L'idée derrière l'utilisation d'un poids de 2 permetd'obtenir une sorte de lissage en accordant plus d'importance au point central. Lasomme des coe�cients du masque est 0, autrement dit la valeur de la dérivée est biennulle sur une zone de niveau de gris constant.
Une généralisation de ce �ltre est donné par les masques :
mj =
1 0 −1c 0 −c1 0 −1
mi =
1 c 10 0 0−1 −c −1
Les masques de Sobel correspondent au cas c = 2. Lorsque c = 1, on parle des
masques de Prewitt.Ces masques ont une propriété particulièrement intéressante : ils sont séparables.
Autrement dit, ils correspondent à la composition de deux convolutions. Par exemple,mj représente la réponse impulsionnelle d'un �ltre séparable comprenant un lissagedans la direction verticale à l'aide du noyau hLi
= t[1, c, 1] et une dérivation suivant ladirection horizontale à l'aide du noyau hDj
= [1, 0,−1]. Autrement dit :
mj = hLihDj
(4.38)
et de même
mi = hDihLj
(4.39)
Ainsi le produit de convolution du masque mj et de l'image f(x, y) devient :
s=a∑s=−a
hLi(s)
t=b∑t=−b
hDj(t)f(x + s, y + t) (4.40)
Cette formulation est plus intéressante du point de vue de la complexité des calculs.En e�et, la formulation classique donnée par l'équation 4.15 page 63 implique (2a +1)(2b+1) multiplications tandis que l'équation 4.40 n'en demande que (2a+1)+(2b+1).Ainsi, dès lors qu'un �ltre est séparable, il est algorithmiquement souhaitable d'en tenircompte pour réaliser le �ltrage.
Le gradient est couramment utilisé dans tout ce qui concerne l'inspection indus-trielle, autrement dit il peut aider à la détection des défauts ou le plus souvent êtreun pré-traitement préalable à une inspection automatique. La �gure 4.35 montre unelentille de contact, illuminé de sorte à mettre ses défauts en valeurs, comme les deuxdéfauts apparaissant sur le bord à 4 et 5 heure. L'image de droite a été obtenue grâce
78

à l'utilisation de deux masques de Sobel. Les défauts sont aussi visibles dans cetteimage avec l'avantage supplémentaire que les niveaux de gris ont été supprimés faci-litant ainsi la tâche à une inspection automatique. La faculté de mettre en valeur despetites discontinuités dans une image presque uniformément grise est une autre qualitéimportante du gradient.
Fig. 4.35 � Image optique d'une lentille de contact (on remarque des défauts sur lebord autour de 4 et 5 heure ) - gradient de Sobel de l'image
4.5.4 Combinaisons de plusieurs �ltresLa plupart du temps, l'amélioration d'une image implique l'application successive
de plusieurs �ltres. Les images ci-dessous (Figs 4.5.4,4.37) illustrent ce propos.
79

Fig. 4.36 � De haut en bas et de gauche à droite : (a) Image de face et de dos d'unsquelette (b) Laplacien de l'image (avec un changement d'échelle des niveaux de grispour l'a�chage) (c) Image plus nette par ajout des deux précédentes (d) Filtre de Sobelde la première image
80

Fig. 4.37 � De haut en bas et de gauche à droite : (e) Sobel lissé par un masquemoyenneur 5 × 5 (f) Produit de (e) et (c) (g) Image plus nette : (a)+(f) (h) Loi detransformation en puissance sur (g)
81

Table des �gures
1.1 Images produites après transfert par le système Bartlane en 1921 et 1922(5 niveaux de gris) puis en 1929 (15 niveaux de gris) . . . . . . . . . . 4
1.2 schéma général des actions autour de l'image numérique . . . . . . . . 51.3 JPEG qualité max 14849 octets - qualité intermédiaire 5255 octets -
qualité min. 874 octets . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.4 Imagerie médicale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.5 Robotique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.6 Grille image . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.7 4 images avec di�érentes résolutions spatiales . . . . . . . . . . . . . . . 91.8 2 images avec deux résolutions en nombre de couleurs di�érentes . . . . 9
2.1 Spectre des ondes électromagnétiques . . . . . . . . . . . . . . . . . . . 112.2 Spectre visible . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.3 Une tomate sous di�érents éclairages : lumières blanche puis magenta,
jaune, verte et en�n bleue . . . . . . . . . . . . . . . . . . . . . . . . . 122.4 Couleurs métamères : réponse identique des capteurs à des lumières de
spectres di�érents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.5 Coupe simpli�ée de l'÷il . . . . . . . . . . . . . . . . . . . . . . . . . . 142.6 Coupe encore plus simpli�ée de l'÷il . . . . . . . . . . . . . . . . . . . 142.7 Autre coupe de l'÷il (terminologie anglaise) . . . . . . . . . . . . . . . 152.8 Cornée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.9 Choroïde . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.10 Iris . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.11 Pupille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.12 Cristallin . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.13 Humeur aqueuse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.14 Corps Vitré . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.15 Rétine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.16 Macula . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.17 Distribution des bâtonnets (rods) et des cônes (cones) sur la rétine . . . 202.18 Représentation de la courbe de sensibilité spectrale des cônes : ceux-
ci ne réagissent pas à une seule longeur d'onde mais à un ensemble delongueurs d'ondes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.19 Nerf Optique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.20 L'image formée sur la rétine est à l'envers . . . . . . . . . . . . . . . . 212.21 Défauts liés à la convergence de l'÷il . . . . . . . . . . . . . . . . . . . 222.22 Une impossibilité géométrique . . . . . . . . . . . . . . . . . . . . . . . 23
82

2.23 Illusions géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.24 Illusions géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.25 Illusions artistiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.26 In�uence du langage sur la vision . . . . . . . . . . . . . . . . . . . . . 272.27 Vision binoculaire : nos deux yeux ne perçoivent pas la même image . . 272.28 Vision binoculaire : le champ visuel droit est analysé par l'hémisphère
gauche et vice versa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.29 Vision binoculaire : l'angle de vergence θ dépend de la distance du point
regardé par rapport à l'observateur, plus le point est loin, plus l'angleest petit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.30 Utilisation de lunettes polarisées . . . . . . . . . . . . . . . . . . . . . . 292.31 Vision d'ensemble et vision des détails . . . . . . . . . . . . . . . . . . 30
3.1 Modèles RGB et CMY . . . . . . . . . . . . . . . . . . . . . . . . . . 333.2 Principe de la synthèse soustractive . . . . . . . . . . . . . . . . . . . . 333.3 Cube de couleurs RGB . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.4 Reconstruction des couleurs à partir des composantes rouge, verte, et
bleue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363.5 Reconstruction des couleurs à partir des composantes virtuelles x, y et z. 373.6 Diagramme de chromaticité et ses utilisations . . . . . . . . . . . . . . 383.7 Modèles intuitifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.1 Chaîne d'analyse d'images . . . . . . . . . . . . . . . . . . . . . . . . . 424.2 Déconvolution (microscopie confocale) . . . . . . . . . . . . . . . . . . 424.3 Une image du satellite SPOT avant et après l'utilisation de fausses couleurs 434.4 Exemple d'un 3× 3 voisinage d'un point (x, y) dans une image . . . . . 444.5 Fonctions de transformations d'intensité augmentant le contraste . . . . 454.6 Transformations en intensité classiques . . . . . . . . . . . . . . . . . . 464.7 Mammographie : à gauche, l'image originale, à droite son négatif . . . . 464.8 Spectre de Fourier converti linéairement en niveaux de gris (à gauche)
et converti en niveaux de gris à l'aide d'une fonction log avec c = 1 . . 474.9 Représentation des équations s = crγ pour di�érentes valeurs de γ (et
pour c = 1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484.10 Réponse d'un moniteur avant et après correction gamma. La loi de ré-
ponse intensité/voltage du moniteur est une loi de puissance de coe�-cients c = 1 et γ = 2.5. La correction gamma est apportée par l'utilisa-tion de la loi s = r1+2.5 . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.11 Image par résonance magnétique (IRM) d'une fracture de la colonne ver-tébrale : en haut à gauche, image originale, de gauche à droite et de hauten bas, transformations en puissance avec c = 1 et un γ respectivementégal à 0.6, 0.4 et 0.3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.12 Vue aérienne : en haut à gauche, image originale, de gauche à droiteet de haut en bas, transformations en puissance avec c = 1 et un γrespectivement égal à 3.0, 4.0 et 5.0 . . . . . . . . . . . . . . . . . . . . 51
83

4.13 Rehaussement de contraste d'une image de pollen obtenue par micro-scope électronique : de gauche à droite et de haut en bas, représentationde la transformation, image originale avec un faible contraste, résultatd'un rehaussement de contraste, résultat d'un seuillage ou binarisationde l'image . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.14 Transformation d'une plage de niveaux de gris. En haut à gauche, unetransformation qui éclaircit les niveaux de gris appartenant à la plage[A, B], a�ecte à tous les autres niveaux de gris une valeur donnée (sombre)et produit ainsi une image binaire. En haut à droite, une transformationqui éclaircit les niveaux de gris de la plage [A, B] sans modi�er les autres.En bas de gauche à droite, une image et le résulat de sa transformationpar la première transformation . . . . . . . . . . . . . . . . . . . . . . 53
4.15 4 types classiques d'images. De haut en bas : image sombre (sous-exposée), claire (sur-exposée), avec un faible contraste, et avec un fortcontraste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.16 Une transformation de niveaux de gris qui est une application monotonecroissante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.17 Un histogramme uniforme et l'histogramme cumulé correspondant . . 564.18 Calcul de la valeur de sk . . . . . . . . . . . . . . . . . . . . . . . . . . 584.19 Gauche : images de la �gure 4.15 ; Milieu : résultat de l'égalisation de
l'image ; Droite : histogrammes correspondants . . . . . . . . . . . . . . 594.20 L'égalisation d'histogramme de cette image ne donne pas un résultat
satisfaisant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 604.21 Processus de spéci�cation d'histogramme . . . . . . . . . . . . . . . . . 604.22 Illustration du mécanisme de �ltrage spatial. La partie agrandie montre
un masque 3× 3 et la portion de l'image juste sous ce masque . . . . . 634.23 Représentation simpli�ée d'un masque 3× 3 . . . . . . . . . . . . . . . 644.24 Deux masques moyenneurs classiques . . . . . . . . . . . . . . . . . . . 654.25 En haut à gauche, image originale 500 × 500 pixels, de haut en bas de
droite à gauche résultats d'un lissage par des masques moyenneurs carrésde tailles respectives 3, 5, 9, 15, 35 . . . . . . . . . . . . . . . . . . . . . 67
4.26 A gauche, image produite par le télescope Hubble, au milieu résultatd'un �ltrage par masque moyenneur 15 × 15, à droite résultat d'unseuillage ou binarisation réalisée sur l'image �ltrée . . . . . . . . . . . . 68
4.27 A gauche une image par rayons X représentant un circuit électroniquecorrompue par un bruit de type poivre et sel, au milieu l'image surlaquelle a été appliqué un �ltre moyenneur, à droite le résultat de l'ap-plication d'un �ltre médian . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.28 en haut à gauche : une image simple - à droite : le pro�l 1D de niveaude gris le long de la ligne horizontale traversant l'image en son centre(et passant par le point bruité blanc) - en bas : pro�l simpli�é (ramenéen 8 niveaux de gris) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4.29 Di�érents masques utilisés pour implémenter le Laplacien . . . . . . . . 73
84

4.30 De gauche à droite et de haut en bas : Image du pôle nord de la lune,image �ltrée par un Laplacien, même image mais avec un changementd'échelle des niveaux de gris, image améliorée par superposition du ré-sultat du �ltrage par Laplacien à l'image originale . . . . . . . . . . . . 74
4.31 de gauche à droite et de haut en bas : 2 masques Laplacien composites,image obtenue avec un microscope électronique, image résultant du �l-trage par le premier masque, image résultant du �ltrage pas le secondmasque. On note que l'image de droite est plus nette que celle de gauche. 75
4.32 Masques permettant d'implémenter un �ltre de type high-boost avec A ≥ 1 754.33 de gauche à droite et de haut en bas : image sombre, image résultant
de l'application du masque à droite de la �gure 4.32 avec A = 0, pareilmais avec A = 1, puis avec A = 1.7 . . . . . . . . . . . . . . . . . . . . 76
4.34 Une région 3 × 3 d'une image et les masques utilisés pour calculer lanorme du gradient . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.35 Image optique d'une lentille de contact (on remarque des défauts sur lebord autour de 4 et 5 heure ) - gradient de Sobel de l'image . . . . . . 79
4.36 De haut en bas et de gauche à droite : (a) Image de face et de dos d'unsquelette (b) Laplacien de l'image (avec un changement d'échelle desniveaux de gris pour l'a�chage) (c) Image plus nette par ajout des deuxprécédentes (d) Filtre de Sobel de la première image . . . . . . . . . . . 80
4.37 De haut en bas et de gauche à droite : (e) Sobel lissé par un masquemoyenneur 5× 5 (f) Produit de (e) et (c) (g) Image plus nette : (a)+(f)(h) Loi de transformation en puissance sur (g) . . . . . . . . . . . . . . 81
85


















