Topical Web Crawlers: Evaluating Adaptive...
38
Topical Web Crawlers: Evaluating Adaptive Algorithms FILIPPO MENCZER Indiana University GAUTAM PANT University of Utah and PADMINI SRINIVASAN University of Iowa Topical crawlers are increasingly seen as a way to address the scalability limitations of universal search engines, by distributing the crawling process across users, queries, or even client comput- ers. The context available to such crawlers can guide the navigation of links with the goal of efficiently locating highly relevant target pages. We developed a framework to fairly evaluate top- ical crawling algorithms under a number of performance metrics. Such a framework is employed here to evaluate different algorithms that have proven highly competitive among those proposed in the literature and in our own previous research. In particular we focus on the tradeoff be- tween exploration and exploitation of the cues available to a crawler, and on adaptive crawlers that use machine learning techniques to guide their search. We find that the best performance is achieved by a novel combination of explorative and exploitative bias, and introduce an evolution- ary crawler that surpasses the performance of the best non-adaptive crawler after sufficiently long crawls. We also analyze the computational complexity of the various crawlers and discuss how performance and complexity scale with available resources. Evolutionary crawlers achieve high efficiency and scalability by distributing the work across concurrent agents, resulting in the best performance/cost ratio. Categories and Subject Descriptors: H.3.3 [Information Storage and Retrieval]: Information Search and Retrieval—search process; H.3.4 [Information Storage and Retrieval]: Systems and Software—distributed systems ; information networks ; performance evaluation (efficiency and effectiveness); I.2.8 [Artificial Intelligence]: Problem Solving, Control Methods, and Search— graph and tree search strategies ; heuristic methods; I.2.11 [Artificial Intelligence]: Distributed Artificial Intelligence—intelligent agents ; multiagent systems General Terms: Performance, Measurement, Algorithms, Design Additional Key Words and Phrases: Topical crawlers, evaluation, efficiency, exploration, exploita- tion, evolution, reinforcement learning This work was funded in part by NSF CAREER grant no. IIS-0133124/0348940 to FM. Current authors’ addresses: F. Menczer, School of Informatics and Department of Computer Science, Indiana University, Bloomington, IN 47408, [email protected]; G. Pant, School of Accounting and Information Systems, The University of Utah, Salt Lake City, UT 84112, [email protected]; P. Srinivasan, School of Library and Information Science, The Univer- sity of Iowa, Iowa City, IA 52242, [email protected]. Permission to make digital/hard copy of all or part of this material without fee for personal or classroom use provided that the copies are not made or distributed for profit or commercial advantage, the ACM copyright/server notice, the title of the publication, and its date appear, and notice is given that copying is by permission of the ACM, Inc. To copy otherwise, to republish, to post on servers, or to redistribute to lists requires prior specific permission and/or a fee. c 2004 ACM 1529-3785/2004/0700-0001 $5.00 ACM Transactions on Internet Technology, Vol. V, No. N, August 2004, Pages 1–38.
Transcript of Topical Web Crawlers: Evaluating Adaptive...

Topical Web Crawlers:Evaluating Adaptive Algorithms
FILIPPO MENCZER
Indiana University
GAUTAM PANT
University of Utah
and
PADMINI SRINIVASAN
University of Iowa
Topical crawlers are increasingly seen as a way to address the scalability limitations of universal
search engines, by distributing the crawling process across users, queries, or even client comput-
ers. The context available to such crawlers can guide the navigation of links with the goal ofefficiently locating highly relevant target pages. We developed a framework to fairly evaluate top-
ical crawling algorithms under a number of performance metrics. Such a framework is employed
here to evaluate different algorithms that have proven highly competitive among those proposedin the literature and in our own previous research. In particular we focus on the tradeoff be-
tween exploration and exploitation of the cues available to a crawler, and on adaptive crawlers
that use machine learning techniques to guide their search. We find that the best performance isachieved by a novel combination of explorative and exploitative bias, and introduce an evolution-
ary crawler that surpasses the performance of the best non-adaptive crawler after sufficiently longcrawls. We also analyze the computational complexity of the various crawlers and discuss how
performance and complexity scale with available resources. Evolutionary crawlers achieve high
efficiency and scalability by distributing the work across concurrent agents, resulting in the bestperformance/cost ratio.
Categories and Subject Descriptors: H.3.3 [Information Storage and Retrieval]: InformationSearch and Retrieval—search process; H.3.4 [Information Storage and Retrieval]: Systems
and Software—distributed systems; information networks; performance evaluation (efficiency and
effectiveness); I.2.8 [Artificial Intelligence]: Problem Solving, Control Methods, and Search—graph and tree search strategies; heuristic methods; I.2.11 [Artificial Intelligence]: Distributed
Artificial Intelligence—intelligent agents; multiagent systems
General Terms: Performance, Measurement, Algorithms, Design
Additional Key Words and Phrases: Topical crawlers, evaluation, efficiency, exploration, exploita-
tion, evolution, reinforcement learning
This work was funded in part by NSF CAREER grant no. IIS-0133124/0348940 to FM.Current authors’ addresses: F. Menczer, School of Informatics and Department of Computer
Science, Indiana University, Bloomington, IN 47408, [email protected]; G. Pant, School ofAccounting and Information Systems, The University of Utah, Salt Lake City, UT 84112,
[email protected]; P. Srinivasan, School of Library and Information Science, The Univer-sity of Iowa, Iowa City, IA 52242, [email protected] to make digital/hard copy of all or part of this material without fee for personalor classroom use provided that the copies are not made or distributed for profit or commercial
advantage, the ACM copyright/server notice, the title of the publication, and its date appear, andnotice is given that copying is by permission of the ACM, Inc. To copy otherwise, to republish,
to post on servers, or to redistribute to lists requires prior specific permission and/or a fee.c© 2004 ACM 1529-3785/2004/0700-0001 $5.00
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004, Pages 1–38.

2 · Filippo Menczer et al.
1. INTRODUCTION
Searching the Web is a difficult task. A lot of machine learning work is being appliedto one part of this task, namely ranking indexed pages by their estimated relevancewith respect to user queries. This is a crucial task because it heavily influences theperceived effectiveness of a search engine. Users often look at only a few top hits,making the precision achieved by the ranking algorithm of paramount importance.Early search engines ranked pages principally based on their lexical similarity tothe query. The key strategy was to devise the best weighting algorithm to representWeb pages and queries in a vector space, such that closeness in such a space wouldbe correlated with semantic relevance.
More recently the structure of hypertext links has been recognized as a powerfulnew source of evidence for Web semantics. Many machine learning techniques havebeen employed for link analysis, so that a page’s linkage to other pages, togetherwith its content, could be used to estimate its relevance [Kleinberg and Lawrence2001]. The best known example of such link analysis is the PageRank algorithmsuccessfully employed by the Google search engine [Brin and Page 1998]. Othermachine learning techniques to extract meaning from link topology have been basedon identifying hub and authority pages via eigenvalue analysis [Kleinberg 1999] andon other graph-theoretical approaches [Gibson et al. 1998; Flake et al. 2002; Kumaret al. 1999]. While purely link-based methods have been found to be effective insome cases [Flake et al. 2002], link analysis is most often combined with lexicalpre/post-filtering [Brin and Page 1998; Kleinberg 1999].
However, all this research only addresses half of the problem. No matter howsophisticated the ranking algorithm we build, the results can only be as good asthe pages indexed by the search engine — a page cannot be retrieved if it has notbeen indexed. This brings us to the other aspect of Web searching, namely crawlingthe Web in search of pages to be indexed. The visible Web with its estimated sizebetween 4 and 10 billion “static” pages as of this writing [Cyveillance 2000] offersa challenging information retrieval problem. This estimate is more than double the2 billion pages that the largest search engine, Google, reports to be “searching.”In fact the coverage of the Web by search engines has not improved much over thepast few years [Lawrence and Giles 1998; 1999]. Even with increasing hardwareand bandwidth resources at their disposal, search engines cannot keep up withthe growth of the Web. The retrieval challenge is further compounded by thefact that Web pages also change frequently [Wills and Mikhailov 1999; Cho andGarcia-Molina 2000; Brewington and Cybenko 2000]. For example Cho and Garcia-Molina [2000] in their daily crawl of 720,000 pages for a period of about 4 months,found that it takes only about 50 days for 50% of the Web to change. They alsofound that the rate of change varies across domains. For example it takes only11 days in the .com domain versus 4 months in the .gov domain for the sameextent of change. Thus despite the valiant attempts of search engines to indexthe whole Web, it is expected that the subspace eluding indexing will continue togrow. Hence the solution offered by search engines, i.e., the capacity to answerany query from any user is recognized as being limited. It therefore comes as nosurprise that the development of topical crawler algorithms has received significantattention in recent years [Aggarwal et al. 2001; Chakrabarti et al. 1999; Cho et al.ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 3
1998; Hersovici et al. 1998; Menczer and Belew 2000; Menczer et al. 2001; Menczer2003].
Topical crawlers (also known as focused crawlers) respond to the particular infor-mation needs expressed by topical queries or interest profiles. These could be theneeds of an individual user (query time or online crawlers) or those of a commu-nity with shared interests (topical or vertical search engines and portals). Topicalcrawlers support decentralizing the crawling process, which is a more scalable ap-proach [O’Meara and Patel 2001; Pant et al. 2003]. An additional benefit is thatsuch crawlers can be driven by a rich context (topics, queries, user profiles) withinwhich to interpret pages and select the links to be visited.
Starting with the early breadth first [Pinkerton 1994] and depth first [De Bra andPost 1994] crawlers defining the beginnings of research on crawlers, we now see avariety of algorithms. There is Shark Search [Hersovici et al. 1998], a more aggres-sive variant of De Bra’s Fish Search [1994]. There are crawlers whose decisions relyheavily on link based criteria [Cho et al. 1998; Diligenti et al. 2000]. Diligenti et al.[2000], for example, use backlinks based context graphs to estimate the likelihoodof a page leading to a relevant page, even if the source page itself is not relevant.Others exploit lexical and conceptual knowledge. For example Chakrabarti et al.[1999] use a hierarchical topic classifier to select links for crawling. Still othersemphasize contextual knowledge [Aggarwal et al. 2001; Menczer and Belew 2000;Najork and Wiener 2001] for the topic including that received via relevance feed-back. For example Aggarwal et al. [2001] learn a statistical model of the featuresappropriate for a topic while crawling. In previous work by one of the authors,Menczer and Belew [2000] show that in well-organized portions of the Web, effec-tive crawling strategies can be learned and evolved by agents using neural networksand evolutionary algorithms.
The present highly creative phase regarding the design of topical crawlers isaccompanied by research on the evaluation of such crawlers, a complex problem inand of itself. For example a challenge specific to Web crawlers is that the magnitudeof retrieval results limits the availability of user based relevance judgments. Inprevious research we have started to explore several alternative approaches both forassessing the quality of Web pages as well as for summarizing crawler performance[Menczer et al. 2001]. In a companion paper [Srinivasan et al. 2004] we expandsuch a methodology by describing in detail a framework developed for the fairevaluation of topical crawlers. Performance analysis is based on both quality andon the use of space resources. We formalize a class of crawling tasks of increasingdifficulty, propose a number of evaluation metrics based on various available sourcesof relevance evidence, analyze the time complexity and scalability of a number ofcrawling algorithms proposed in the literature, and study the relationship betweenthe performance of various crawlers and various topic characteristics.
Our goal in this paper is to examine the algorithmic aspects of topical crawlers.We have implemented within our evaluation framework a group of crawling algo-rithms that are representative of the dominant varieties published in the literature.Based on the evaluation of such crawlers in a particular task, we have designed andimplemented two new classes of crawling algorithms that currently stand as the bestperforming crawlers for the task considered. These proposed crawler classes allow
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

4 · Filippo Menczer et al.
us to focus on two crucial machine learning issues that have not been previouslystudied in the domain of Web crawling strategies: (i) the role of exploration versusexploitation, and (ii) the role of adaptation (learning and evolutionary algorithms)versus static approaches. Overall, our intention is to obtain a more complete andreliable picture of the relative advantages and disadvantages of various crawlingstrategies than what can be drawn from the current literature.
In Section 2 we summarize the aspects of our evaluation framework that arerelevant to this study. This includes our system architecture, a formalization ofthe crawling task, a description of the dataset used, and the evaluation metricsemployed for assessing both effectiveness and efficiency of the crawlers. Section 3outlines a number of crawling algorithms proposed in the literature, on which suf-ficient information is available to allow for our own implementation, and comparestheir performance with respect to their effectiveness and efficiency. The scalabilityof the algorithms is also analyzed by varying the resource constraints of the crawlers.A class of best-first crawling algorithms and a class of shark-search algorithms areintroduced in Section 4 and used to study the tradeoff between exploration andexploitation. The issue of adaptation is discussed in Section 5, using a multi-agentclass of crawling algorithms in which individuals can learn to estimate links byreinforcement based on local link and lexical cues, while the population can evolveto bias the exploration process toward areas of the Web that appear promising. InSection 6 we analyze the robustness of our results in the face of longer crawls, andfinally Section 7 discusses our findings and concludes the paper with ideas aboutfurther research.
2. EVALUATION FRAMEWORK
In order to empirically study the algorithmic issues outlined above, we need to firstillustrate the evaluation framework that we will use in our experiments. Here wefocus on just the aspects of the framework that are relevant to the analyses in thispaper. For a more complete treatment the reader is referred to a companion paper[Srinivasan et al. 2004].
2.1 System Architecture
Figure 1 illustrates the architecture of the crawler evaluation framework. The sys-tem is designed so that all the logic about any specific crawling algorithm is encap-sulated in a crawler module which can be easily plugged into the system through astandard interface. All crawling modules share public data structures and utilitiesto optimize efficiency without affecting the fairness of any evaluations. Examples ofcommon facilities include a cache, an HTTP interface for the Web, a simple HTMLparser, a stemmer [Porter 1980], benchmarking and reporting routines. The sys-tem is implemented in Perl with Berkeley embedded databases for storing persistentdata as well as data structures shared across concurrent processes.
Each tested crawler can visit up to MAX PAGES pages per topic, starting from aseed set. We use a timeout of 10 seconds for Web downloads. Large pages arechopped so that we retrieve only the first 10 KB. The only protocol allowed isHTTP GET (with redirection), and we also filter out all but pages with text/htmlcontent. Stale links yielding HTTP error codes are removed as they are found; onlygood links are used in the analysis.ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 5
Concurrent Crawler Logic Concurrent Crawler Logic
Frontier& Private
Data
Frontier& Private
Data
FetcherLexical Analyzer
HTML ParserURL Utils HTTP
URL Mapping& Cache
DatabasesWeb
HTTP
Benchmarking& History Data
Offline Analysis
Topics
Main KeywordsSeed URLs
DescriptionsTarget URLs
Fig. 1. Architecture of crawler evaluation framework.
2.2 Resource Constraints
Crawlers consume resources: network bandwidth to download pages, memory tomaintain private data structures in support of their algorithms, CPU to evaluateand select URLs, and disk storage to store the (stemmed) text and links of fetchedpages as well as other persistent data. Obviously the more complex the selectionalgorithm, the greater the use of such resources. In order to allow for a fair com-parison of diverse crawling algorithms, we take two measures:
(1) We track the CPU time taken by each crawler for each page and each topic,ignoring the time taken by the fetch module, which is common to all the crawlers.We do this since it is impossible to control for network traffic and congestion, andwe want to benchmark only the crawler-specific operations. The monitored CPUtime will be used to compare the complexity of the crawling algorithms.
(2) We limit the memory available to each crawler by constraining the size ofits buffer. This buffer is used by a crawler to temporarily store link data, typicallya frontier of pages whose links have not been explored. Each crawler is allowedto track a maximum of MAX BUFFER links. If the buffer becomes full, the crawlermust decide which links are to be substituted as new ones are added. The valueof the MAX BUFFER parameter will be varied between 28 and 211 to gauge how the
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

6 · Filippo Menczer et al.
d=1d=0(Targets)
d=D(Seeds)
d=D-1
Fig. 2. Generalized crawl task. A seed page and its path to a target are shown in gray.
performance of the crawling algorithms scales with their memory resources. Notethat we set the size of the buffer to such small values because we are particularlyinterested in analyzing crawler performance in the most demanding circumstances,i.e., when memory is very scarce. This would be realistic, for example, if a crawlerwas deployed as an applet [Pant and Menczer 2002].
2.3 Crawl Task
What should be the starting URLs, i.e., the seed set for a crawler? In the discussionthat follows, we use the word targets to represent a known subset of relevant pages.If we identify a target set for any given topic, we would like our crawlers to reachthese target pages, and/or pages similar to the targets, from whatever seed pagesare used to begin the crawl.
Figure 2 illustrates a generalized crawl task. Seed pages are chosen so as toguarantee that from each seed there exist at least one path to some target page,within a distance of at most D links. In practice we identify the seed pages by firstconsidering the inlinks of each target page. Submitting a link: query to a searchengine1 yields up to 20 URLs of pages linking to a page. We then repeat this foreach of these first-neighbors, and so on for D steps. Hence, if we had 10 targets tostart with, we would end up with a maximum of 10× 20D unique URLs. A subsetof 10 seed URLs is then picked at random from this set. Note that this proceduredoes not guarantee a path from the seed set to every target.
Such a generalized crawl task formalizes a class of problems whose difficulty
1At the time of the experiments described here we used http://google.yahoo.com, which al-lowed us to comply with the Robot Exclusion Standard. Currently we use the Google Web API
(http://www.google.com/apis/).
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 7
intuitively increases with D. For D = 0, the seeds coincide with the targets so thatthe crawlers start from pages that are assumed to be relevant. This task mimics the“query by example” search mode where the user provides the crawler with a fewsample relevant pages. As an alternative strategy these seeds may also be obtainedfrom a Web search engine. The idea is to see if the crawlers are able to find otherrelevant pages for the topic. This is the approach used in most crawler evaluationresearch to date (see e.g. Ben-Shaul et al. [1999], Chakrabarti et al. [1999], Diligentiet al. [2000]).
An assumption implicit in the D = 0 crawl task is that pages that are relevanttend to be neighbors of each other. Thus the objective of the crawler is to stayfocused, i.e., to remain within the neighborhood in which relevant documents havebeen identified. However, the seeds obviously cannot be used to evaluate the per-formance of a crawler.2 Typical applications of the D = 0 crawl task are query-timesearch agents that use results of a search engine as starting points to provide a userwith recent and personalized results [Pant and Menczer 2002]. Such a task mayalso be a part of Web mining or competitive intelligence applications, e.g., a searchstarting from competitors’ home pages [Pant and Menczer 2003].
For D > 0, crawl seeds are different from the target pages. So in this case there islittle prior information available to the crawlers about the relevant pages when thecrawl begins. The idea is to see if the crawlers are able to find the targets, and/orother relevant pages. The D > 0 crawl task involves seeking relevant pages whilestarting the crawl from links that are a few links away from some known relevantpages.
With a few exceptions, D > 0 crawl tasks are rarely considered in the literaturealthough they allow to model problems of varying difficulty. A D > 0 problemis also realistic since quite commonly users are unable to specify known relevantURLs. The effort by Aggarwal et al. [2001] is somewhat related to this task in thatthe authors start the crawl from general points such as Amazon.com. Although Choet al. [1998] start their crawls at a general point, i.e., the Stanford Web site, topicshave rather primitive roles in their research as no target set is identified.
We believe that it is important to understand crawlers within task contexts cor-responding to more than a single D value, i.e., with varying degrees of difficultysince they serve different yet valid search modes. For the purposes of this paper welimit our analyses to one difficult task, D = 3. Note that given the large averagefanout of Web pages, this problem is a bit like looking for a needle in a haystack.To illustrate this point, observe that a breadth-first crawler would have a chancein `−D to visit a target from a seed assuming an average fanout of ` links. Startingfrom 10 seeds and visiting 1,000 pages, ` ≈ 10 and D = 3 would imply an expectedupper bound of around 10% on the recall of target pages.
2.4 Topics and Targets Dataset
In order to evaluate crawler algorithms, we need topics and some correspondingrelevant targets. One could theoretically generate topics and target sets using fre-quent queries from search engines and user assessments. However this approach
2A variant of this task would be to use only part of the target set as seed set and evaluate the
crawler’s capability to locate the rest [Pant and Menczer 2003].
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

8 · Filippo Menczer et al.
would make it very expensive to obtain a large number of topics and target sets,and very cumbersome to keep such a dataset up to date over time given the dy-namic nature of the Web. Fortunately this data is already available from Webdirectories updated by human editors. While in our past research we have usedYahoo!3 due to its popularity [Menczer et al. 2001], in our current work we use theOpen Directory Project4 (ODP) because (i) it has less of a commercial bias, (ii) itis an “open resource,” and (iii) it is maintained by a very large and diverse numberof volunteer editors.
We collected topics by running randomized breadth-first crawls starting fromeach of the main categories on the Open Directory site. These crawls identify ODP“leaves,” i.e., pages that have no children category nodes. Leaves with five or moreexternal links are then used to derive topics. A topic is represented by three typesof information derived from the corresponding leaf page. First, the words in theODP hierarchy form the topic’s keywords. Second, the external links form thetopic’s targets. Third, we concatenate the text descriptions and anchor text of thetarget URLs (written by ODP human editors) to form a topic’s description. Thedifference between a topic’s keywords and its description is that we give the formerto the crawlers, as models of (short) query-like topics; and we use the latter, whichis a much more detailed representation of the topic, to gauge the relevance of thecrawled pages in our post-hoc analysis. Table I shows a few sample topics. Theexperiments described in this paper use 50 such topics.
2.5 Performance Metrics
In previous research we explored several alternative methodologies for evaluatingcrawlers [Menczer 2003; Menczer et al. 2001]. These include methods for assessingpage relevance using linear classifiers, and using similarity computations. We alsoexplored different methods for summarizing crawler performance such as plottingthe mean similarity of retrieved pages to topic descriptions over time and computingthe average fraction of retrieved pages that were assessed as being “relevant” bythe classifiers (at the end of the crawl). Based upon our previous experience, in acompanion paper we discuss in detail a number of measures that we have selected asthe minimal set needed to provide a well rounded assessment of crawler performance[Srinivasan et al. 2004]. In particular we propose to assess both recall and precision,using target and lexical criteria for page relevance. This leads to a set of 4 ·D ·Gperformance metrics, where D is the task difficulty parameter and G is a topicgenerality parameter.5 Each performance metric can be plotted as a function ofcrawling time to yield a dynamic perspective. In addition we assess the efficiencyof the crawling algorithms — an aspect that was not previously considered in theliterature.
In this paper we employ only two of the performance metrics proposed in Srini-vasan et al. [2004], focusing on the effect of different machine learning techniqueson the performance of crawling algorithms over time. This view is especially ap-propriate when studying issues such as greediness and adaptation, whose effects are
3http://dir.yahoo.com4http://dmoz.org5Considering only ODP leaf topics, as in this paper, is a special case corresponding to G = 0.
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 9
Table I. A few sample ODP topics. The descriptions are truncated for space limitations.
Keywords Description Targets
ComputersSoftwareWorkflowConsulting
Document Management andWorkflow Consulting - EID hasbeen providing document man-agement and workflow consult-ing for over years and is heav-ily involved in establishing in-dustry standards Our servicesrange from feasibility stud-ies to implementation manage-ment; Fast Guard SoftwareServices - Specialized softwaresales and consulting for NT andExchange networks email di-rectory synchronization work-flow document managementNT print management Internetmanagement Wang and Banyanmigration Eastman SoftwareWMX SP; FormSoft Group -Provides enterprise workflowconsulting web application de-velopment and training to cor-porate and government enti-ties; [...]
http://www.eid-inc.com/http://www.fastguard.com/http://www.formsoftgroup.com/http://www.gain.ch/http://www.iicon.co.uk/http://www.mondas.com/index.htmhttp://www.pdfsolutions.co.uk/
SocietyActivismConsumer
Bad Business Bureau - Rip offReport is the nationwide con-sumer reporting web site to en-ter complaints about compa-nies and individuals who areripping people off; ConsumerSoundoff - Consumer advocatewho offers a free service tohelp reconcile consumer dis-putes and problems with busi-nesses; Foundation for Tax-payer and Consumer Rights - Anationally recognized Califor-nia based non profit consumereducation and advocacy orga-nization Deals in insurance re-form healthcare reform billingerrors and other issues; [...]
http://www.badbusinessbureau.com/http://soundoff1.tripod.com/http://www.consumerwatchdog.org/http://members.tripod.com/~birchmore1/muzak/http://www.ourrylandhomes.com/http://www.ripoffrevenge.com/http://www.konsumentsamverkan.se/english/...http://www.ucan.org/http://www.nocards.org/
SportsLumberjack
Always Wanted to Be a Lum-barjack - To grow up and sur-vive in Hayward WI a fewthings to learn; American Bir-ling Association - Created topromote log rolling boom run-ning and river rafting it isthe best source of informationfor lumberjack water sports;American Lumberjack Associa-tion - A group of sportsmen andwomen dedicated to furtheringupgrading and standardizingtimbersports; Lumber Jack JillFestival - Festival held in AvocaNew York; Lumberjack Days- Held in July on the beau-tiful St Croix River; Lumber-jack Entertainment And Tim-bersports Guide - Informationon lumberjack contests showsworld records and competitionequipment; [...]
http://www.subway.com/subpages/namap/usa/lumber/http://www.logrolling.org/http://www.americanlumberjacks.com/http://www.westny.com/logfest.htmhttp://www.lumberjackdays.com/http://www.starinfo.com/ljguide/lumberjack.htmlhttp://www.lumberjackworldchampionships.com/http://www.canadian-sportfishing.com/...http://www.starinfo.com/woodsmen/http://www.orofino.com/Lumberjack.htmhttp://lumberjacksports.com/http://www.stihlusa.com/timbersports.htmlhttp://www.usaxemen.com/http://www.hotsaw.com/
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

10 · Filippo Menczer et al.
likely to vary in the course of the crawl. The dynamic measures provide a temporalcharacterization of the crawl strategy, by considering the pages fetched while thecrawl is in progress.
The first metric is the simple recall level based on the target pages:
ρ(i) =|S(i) ∩ T |
|T |(1)
where S(i) is the set of pages crawled by crawler i and T is the target set. Thismeasure allows us to determine how well a crawler can locate a few highly relevantpages. However, there may well be many other relevant pages that are not specifiedin the target set. To assess a crawler’s capability to locate these other relevantpages, we have to estimate the relevance of any crawled page. We do so using thelexical similarity between a page and the topic description. Recall that the crawlersdo not have any knowledge of topic descriptions, and that these descriptions aremanually compiled by human experts as they describe relevant sites. Thereforepages similar to these descriptions have a good likelihood to be closely relatedto the topic. Rather than inducing a binary relevance assessment by guessing anarbitrary similarity threshold, in the second metric we measure the mean similaritybetween the topic description and the set of pages crawled:
σ(i) =
∑p∈S(i) cos(p, V )
|S(i)|(2)
where V is the vector representing the topic description and
cos(p, V ) =
∑k∈p∩V wpkwV k√(∑
k∈p w2pk
) (∑k∈V w2
V k
) (3)
is the standard cosine similarity function. Here wdk is the TF-IDF weight of term kin d where inverse document frequency is computed from the crawl set
⋃i S(i) once
MAX PAGES pages have been visited by each crawler. Both recall ρ and mean simi-larity σ can be plotted against the number of pages crawled to obtain a trajectoryover time that displays the dynamic behavior of the crawl.
3. CRAWLING ALGORITHMS
Crawlers exploit the Web’s hyperlinked structure to retrieve new pages by traversinglinks from previously retrieved ones. As pages are fetched, their outward links maybe added to a list of unvisited pages, which is referred to as the crawl frontier. Akey challenge during the progress of a topical crawl is to identify the next mostappropriate link to follow from the frontier.
The algorithm to select the next link for traversal is necessarily tied to the goalsof the crawler. A crawler that aims to index the Web as comprehensively as pos-sible will make different kinds of decisions than one aiming to collect pages fromuniversity Web sites or one looking for pages about movie reviews. For the firstcrawl order may not be important, the second may consider the syntax of the URLto limit retrieved pages to the .edu domain, while the third may use similarity withsome source page to guide link selection. Even crawlers serving the same goal mayadopt different crawl strategies.ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 11
FIFO queue
Webpage
Links
Fig. 3. A Breadth-First crawler.
Breadth-First (starting_urls) {
foreach link (starting_urls) {
enqueue(frontier, link);
}
while (visited < MAX_PAGES) {
link := dequeue_link(frontier);
doc := fetch(link);
enqueue(frontier, extract_links(doc));
if (#frontier > MAX_BUFFER) {
dequeue_last_links(frontier);
}
}
}
Fig. 4. Pseudocode of the Breadth-First algorithm.
3.1 Crawler Descriptions
In this section we describe and evaluate five different crawling algorithms thatwe have implemented within our evaluation framework: Breadth-First, Best-First,PageRank, Shark-Search, and InfoSpiders. Our selection is intended to be a broadrepresentation of the crawler algorithms reported in the literature, with an ob-vious bias toward those that we have been able to reimplement. One of thesealgorithms, InfoSpiders, derives from our own prior and current research [Menczer1997; Menczer and Belew 1998; 2000; Menczer and Monge 1999]. In Section 4 wewill generalize two of these algorithms (Best-First and Shark-Search) through aparameterization of their greediness level.
3.1.1 Breadth-First. A Breadth-First crawler is the simplest strategy for crawl-ing. This algorithm was explored as early as 1994 in the WebCrawler [Pinkerton1994] as well as in more recent research [Cho et al. 1998; Najork and Wiener 2001].It uses the frontier as a FIFO queue, crawling links in the order in which they areencountered. Note that when the frontier is full, the crawler can add only one linkfrom a crawled page. The Breadth-First crawler is illustrated in Figure 3 and thealgorithm is shown in Figure 4. Breadth-First is used here as a baseline crawler;since it does not use any knowledge about the topic, we expect its performance toprovide a lower bound for any of the more sophisticated algorithms.
3.1.2 Best-First. Best-First crawlers have been studied by Cho et al. [1998] andHersovici et al. [1998]. The basic idea is that given a frontier of links, the best linkaccording to some estimation criterion is selected for crawling. Different Best-First
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

12 · Filippo Menczer et al.
Fig. 5. A Best-First crawler.
Priority queue
Webpage
Links
Link estimator
BFS (topic, starting_urls) {
foreach link (starting_urls) {
enqueue(frontier, link, 1);
}
while (visited < MAX_PAGES) {
link := dequeue_top_link(frontier);
doc := fetch(link);
score := sim(topic, doc);
enqueue(frontier, extract_links(doc), score);
if (#frontier > MAX_BUFFER) {
dequeue_bottom_links(frontier);
}
}
}
Fig. 6. Best-First-Search algorithm.
strategies of increasing complexity and (potentially) effectiveness could be designedon the bases of increasingly sophisticated link estimation criteria. In our “naive”implementation, the link selection process is guided by simply computing the lexicalsimilarity between the topic’s keywords and the source page for the link. Thus thesimilarity between a page p and the topic keywords is used to estimate the relevanceof the pages pointed by p. The URL with the best estimate is then selected forcrawling. Cosine similarity is used by the crawler and the links with minimumsimilarity score are removed from the frontier if necessary in order to not exceedthe limit size MAX BUFFER. Figure 5 illustrates a Best-First crawler, while Figure 6offers a simplified pseudocode of the Best-First-Search (BFS) algorithm. The sim()function returns the cosine similarity between topic and page:
sim(q, p) =
∑k∈q∩p fkqfkp√(∑
k∈p f2kp
) (∑k∈q f2
kq
) (4)
where q is the topic, p is the fetched page, and fkd is the frequency of term k in d.Preliminary experiments in a D = 0 task have shown that BFS is a competitive
crawler [Menczer et al. 2001], therefore here we want to assess how it comparesACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 13
PageRank (topic, starting_urls, frequency) {
foreach link (starting_urls) {
enqueue(frontier, link);
}
while (visited < MAX_PAGES) {
if (multiplies(visited, frequency)) {
recompute_scores_PR;
}
link := dequeue_top_link(frontier);
doc := fetch(link);
score_sim := sim(topic, doc);
enqueue(buffered_pages, doc, score_sim);
if (#buffered_pages >= MAX_BUFFER) {
dequeue_bottom_links(buffered_pages);
}
merge(frontier, extract_links(doc), score_PR);
if (#frontier > MAX_BUFFER) {
dequeue_bottom_links(frontier);
}
}
}
Fig. 7. Pseudocode of the PageRank crawler.
with other algorithms in a more challenging crawling task.
3.1.3 PageRank. PageRank was proposed by Brin and Page [1998] as a possiblemodel of user surfing behavior. The PageRank of a page represents the probabilitythat a random surfer (one who follows links randomly from page to page) will beon that page at any given time. A page’s score depends recursively upon the scoresof the pages that point to it. Source pages distribute their PageRank across all oftheir outlinks. Formally:
PR(p) = (1− γ) + γ∑
{d∈in(p)}
PR(d)|out(d)|
(5)
where p is the page being scored, in(p) is the set of pages pointing to p, out(d) is theset of links out of d, and the constant γ < 1 is a damping factor that represents theprobability that the random surfer requests another random page. As originallyproposed PageRank was intended to be used in combination with content basedcriteria to rank retrieved sets of documents [Brin and Page 1998]. This is in facthow PageRank is used in the Google search engine. More recently PageRank hasbeen used to guide crawlers [Cho et al. 1998] and to assess page quality [Henzingeret al. 1999].
In previous work we evaluated a crawler based on PageRank [Menczer et al. 2001].We used an efficient algorithm to calculate PageRank [Haveliwala 1999]. Even so,as one can see from Equation 5, PageRank requires a recursive calculation untilconvergence, and thus its computation can be a very resource intensive process. Inthe ideal situation we would recalculate PageRanks every time a URL needs to beselected from the frontier. Instead, to improve efficiency, we recomputed PageRanksonly at regular intervals.
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

14 · Filippo Menczer et al.
Shark (topic, starting_urls) {
foreach link (starting_urls) {
set_depth(link, d);
enqueue(frontier, link);
}
while (visited < MAX_PAGES) {
link := dequeue_top_link(frontier);
doc := fetch(link);
doc_score := sim(topic, doc);
if (depth(link) > 0) {
foreach outlink (extract_links(doc)) {
score = (1-r) * neighborhood_score(outlink)
+ r * inherited_score(outlink);
if (doc_score > 0) {
set_depth(outlink, d);
} else {
set_depth(outlink, depth(link) - 1);
}
enqueue(frontier, outlink, score);
}
if (#frontier > MAX_BUFFER) {
dequeue_bottom_link(frontier);
}
}
}
}
Fig. 8. Pseudocode of the Shark-Search crawler.
The PageRank crawler can be seen as a variant of Best-First, with a different linkevaluation function (see Figure 5). The algorithm is illustrated in Figure 7. Thesim() function returns the cosine similarity between a topic’s keywords and a pageas measured according to Equation 4, and the PageRank is computed according toEquation 5. Note that the PageRank algorithm has to maintain a data structure ofvisited pages in addition to the frontier, in order to compute PageRank. This buffercan contain at most MAX BUFFER pages. We assume pages with 0 out-degree (suchas the URLs in the frontier) to be implicitly linked to every page in the buffer, asrequired for the PageRank algorithm to converge. We use γ = 0.8 and the thresholdfor convergence is set at 0.01.
3.1.4 Shark-Search. Shark-Search [Hersovici et al. 1998] is a more aggressiveversion of Fish-Search [De Bra and Post 1994]. In Fish-Search, the crawlers searchmore extensively in areas of the Web in which relevant pages have been found. Atthe same time, the algorithm discontinues searches in regions that do not yieldrelevant pages. Shark-Search offers two main improvements over Fish-Search. Ituses a continuous valued function for measuring relevance as opposed to the binaryrelevance function in Fish-Search. In addition, Shark-Search has a more refinednotion of potential scores for the links in the crawl frontier. The potential score oflinks is influenced by anchor text, text surrounding the links, and inherited scorefrom ancestors (pages pointing to the page containing the links).
The Shark-Search crawler can be seen as a variant of Best-First, with a moresophisticated link evaluation function (see Figure 5). Figure 8 shows the pseudocodeACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 15
Local priorityqueue
Webpage
Links
Adaptive linkestimator
Fig. 9. A population of InfoSpiders.
of the Shark-Search algorithm. The parameters d and r represent respectivelythe maximum depth and the relative importance of inherited versus neighborhoodscores. In our implementation we set d = 3 and r = 0.1. This closely follows thedetails given by Hersovici et al. [1998].
3.1.5 InfoSpiders. In InfoSpiders [Menczer 1997; Menczer and Belew 1998; 2000;Menczer and Monge 1999], an adaptive population of agents search for pages rel-evant to the topic using evolving query vectors and neural nets to decide whichlinks to follow. The idea is illustrated in Figure 9. This evolutionary approachuses a fitness measure based on similarity as a local selection criterion. The origi-nal algorithm (see, e.g., Menczer and Belew [2000]) was previously simplified andimplemented as a crawler module [Menczer et al. 2001]. This crawler was outper-formed by BFS due to its extreme local behavior and the absence of any memory— once a link was followed the agent could only visit pages linked from the newpage. Since then we have made a number of improvements to the original algorithmwhile retaining its capability to learn link estimates via neural nets and focus itssearch toward more promising areas by selective reproduction. The resulting novelalgorithm is schematically described in the pseudocode of Figure 10.
InfoSpiders agents are independent from each other and crawl in parallel. Theadaptive representation of each agent consists of a list of keywords (initialized withthe topic keywords) and a neural net used to evaluate new links. Each input unitof the neural net receives a count of the frequency with which the keyword occursin the vicinity of each link to be traversed, weighted to give more importanceto keywords occurring near the link (and maximum in the anchor text). Thereis a single output unit. One of the simplifications that we have retained in thisimplementation is that the neural networks do not have hidden layers, thereforeconsisting of simple perceptrons. What this implies is that although a neural net’soutput unit computes a nonlinear sigmoidal function of the input frequencies, theneural network can only learn linear separations of the input space. However we feel
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

16 · Filippo Menczer et al.
IS (topic, starting_urls) {
agent.topic := topic;
agent.energy := 0;
agent.fsize := MAX_BUFFER;
agent.frontier := starting_urls;
insert(agent, population);
while (visited < MAX_PAGES) {
foreach parallel agent (population) {
link := pick_and_dequeue(agent.frontier);
doc := fetch(link);
newenergy = sim(agent.topic, doc);
agent.energy += newenergy;
learn_to_predict(agent.nnet, newenergy);
foreach outlink (extract_links(doc)) {
score = ALPHA * newenergy +
(1 - ALPHA) * agent.nnet(doc, outlink);
enqueue(agent.frontier, outlink, score);
}
if (#agent.frontier > agent.fsize) {
dequeue_bottom_links(agent.frontier);
}
delta := newenergy - sim(topic, agent.doc);
if (boltzmann(delta)) {
agent.doc := doc;
}
if (agent.energy > THETA and pop_size < MAX_POP_SIZE) {
child.topic := expand(agent.topic, agent.doc);
(child.energy, agent.energy) := (0, 0);
(child.fsize, agent.fsize) := half(agent.fsize);
(child.frontier, agent.frontier) := split(agent.frontier);
child.nnet := extend(agent.nnet, child.topic)
insert(child, population);
}
}
}
}
Fig. 10. Pseudocode of the InfoSpiders algorithm. In the actual implementation, each agentexecutes as a concurrent process.
that this is a powerful enough representation to internalize the levels of correlationbetween relevance and the distributions of keywords around links. The outputof the neural net is used as a numerical quality estimate for each link consideredas input. These estimates are then combined with estimates based on the cosinesimilarity (Equation 4) between the agent’s keyword vector and the page containingthe links. A parameter α, 0 ≤ α ≤ 1 regulates the relative importance given to theestimates based on the neural net versus the parent page. Based on the combinedscore, the agent uses a stochastic selector to pick one of the links with probability
Pr(λ) =eβµ(λ)∑
λ′∈φ eβµ(λ′)(6)
where λ is a link from the agent’s local frontier φ and µ(λ) is its combined score.The β parameter regulates the greediness of the link selector. In the experimentsACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 17
described in this paper we use α = 0.5 and β = 5.After a new page has been fetched, the agent receives energy in proportion to the
similarity between its keyword vector and the new page (Equation 4). The agent’sneural net can be trained to improve the link estimates by predicting the similarityof the new page, given the inputs from the page that contained the link leading toit. We use one epoch of standard error back-propagation [Rumelhart et al. 1986]with a learning rate 0.5. Such a simple reinforcement learning technique providesInfoSpiders with the unique capability to adapt the link-following behavior in thecourse of a crawl by associating relevance estimates with particular patterns of key-word frequencies around links. While InfoSpiders was the first crawling algorithmto use reinforcement learning [Menczer 1997], others have considerably expandedon this idea [Rennie and McCallum 1999; McCallum et al. 1999; O’Meara and Patel2001].
An agent moves to the newly selected page only if the boltzmann() functionreturns a true condition (cf. Figure 10). This is determined stochastically basedon the probability
Pr(δ) =1
1 + e−δ/T(7)
where δ is the difference between the similarity of the new and current page to theagent’s keyword vector and T = 0.1 is a temperature parameter.
An agent’s energy level is used to determine whether or not an agent shouldreproduce after visiting a page. An agent reproduces when the energy level passesthe constant threshold THETA=2. At reproduction, the offspring receives half of theparent’s link frontier. The offspring’s keyword vector is also mutated (expanded)by adding the term that is most frequent in the parent’s current document. Sucha mutation provides InfoSpiders with the unique capability to adapt the searchstrategy based on new clues captured from promising pages, while reproductionitself allows the population to bias the search toward areas (agents) that lead togood pages.
There can be at most MAX POP SIZE=8 agents, maintaining a distributed frontierwhose total size does not exceed MAX BUFFER. The behavior of individual agents isstill based on localized link estimates and keyword expansion, however unlike in theoriginal algorithm, each agent retains a more global representation of the searchspace in its frontier.
Others have explored the use of evolutionary algorithms for Web search problems.For example a genetic algorithm has been applied to evolve populations of keywordsand logic operators, used to collect and recommend pages to the user [Moukas andZacharia 1997; Nick and Themis 2001]. In such systems the learning process issustained by meta-search engines and guided by relevance feedback from the user,while in this paper we are interested in agents that can actually crawl the Web andlearn from unsupervised interactions with the environment.
3.2 Experimental Results
We now outline the results of a number of crawls carried out to evaluate and com-pare performance, efficiency and scalability for the crawling algorithms describedin Section 3.1.
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

18 · Filippo Menczer et al.
Fig. 11. Average similarity to
topic descriptions by PageRankand Best-First crawlers on a
D = 0 task. The data (fromMenczer et al. [2001]) is based
on 53 topics.
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.2
0.22
0 200 400 600 800 1000
aver
age
sim
ilarit
ypages crawled
MAX_BUFFER=200PR
BFS
Unless otherwise stated, the results in this and the following sections are basedthe D = 3 crawling task and the MAX PAGES parameter is set to 1,000. These settingscorrespond to a particularly difficult task in which the relevant pages are far awayand the crawler can only visit a very small number of pages — possibly while theuser awaits [Pant and Menczer 2002]. As discussed in Section 2.3 this challengingtask is akin to searching for needles in a haystack, making it an interesting testproblem on which to evaluate the various crawlers.
Also unless otherwise stated, the results in this and the following sections arebased on averages across 50 topics. Throughout the paper, error bars in plotscorrespond to ±1 standard error, i.e. standard deviation of the mean across topics.We interpret non-overlapping error bars as a statistically significant difference atthe 68% confidence level assuming normal noise.
3.2.1 Dynamic Performance. In our prior experiments the PageRank crawlerwas found not to be competitive (worse than Breadth-First) due to its minimalexploitation of the topic context and its resource limitations [Menczer et al. 2001].The PageRank metric is designed as a global measure and its values are of littleuse when computed over a small set of pages. To illustrate, Figure 11 plots averagesimilarity to topic descriptions in a D = 0 crawl, i.e., starting from target pages.Given the poor performance of PageRank under the performance measures andtasks we use here, we will not further report on this crawling algorithm in theremainder of this paper.
The performance of the other four crawlers — Breadth-First, Best-First, Shark-Search and InfoSpiders — is compared in Figure 12. We ran four variations of eachcrawling algorithm for values of MAX BUFFER between 28 = 256 and 211 = 2, 048.6
Recall and similarity yield qualitatively consistent results. As expected Breadth-First performs poorly and thus constitutes a baseline. Surprisingly, Shark-Searchdoes not perform significantly better than Breadth-First except for one case, thesimilarity metric for MAX BUFFER=256. Our intuition for the poor performance ofShark-Search is that this algorithm may not be sufficiently explorative (see Sec-tion 4). Best-First and InfoSpiders significantly outperform the other two crawlers
6Error bars are a bit larger for MAX BUFFER=2,048 because the averages are based on only 28 topics
due to time constraints.
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 19
0
0.1
0.2
0.3
0.4
0.5
0.6
0 200 400 600 800 1000
aver
age
reca
ll
�
pages crawled
MAX_BUFFER=256Shark
BreadthFirstIS
BFS
0.08
0.09
0.1
0.11
0.12
0.13
0.14
0 200 400 600 800 1000
aver
age
sim
ilarit
y
pages crawled
MAX_BUFFER=256Shark
BreadthFirstIS
BFS
0
0.1
0.2
0.3
0.4
0.5
0.6
0 200 400 600 800 1000
aver
age
reca
ll
�
pages crawled
MAX_BUFFER=512Shark
BreadthFirstIS
BFS
0.08
0.09
0.1
0.11
0.12
0.13
0.14
0 200 400 600 800 1000
aver
age
sim
ilarit
y
pages crawled
MAX_BUFFER=512Shark
BreadthFirstIS
BFS
0
0.1
0.2
0.3
0.4
0.5
0.6
0 200 400 600 800 1000
aver
age
reca
ll
�
pages crawled
MAX_BUFFER=1024Shark
BreadthFirstIS
BFS
0.08
0.09
0.1
0.11
0.12
0.13
0.14
0 200 400 600 800 1000
aver
age
sim
ilarit
y
pages crawled
MAX_BUFFER=1024Shark
BreadthFirstIS
BFS
0
0.1
0.2
0.3
0.4
0.5
0.6
0 200 400 600 800 1000
aver
age
reca
ll
�
pages crawled
MAX_BUFFER=2048Shark
BreadthFirstIS
BFS
0.08
0.09
0.1
0.11
0.12
0.13
0.14
0 200 400 600 800 1000
aver
age
sim
ilarit
y
pages crawled
MAX_BUFFER=2048Shark
BreadthFirstIS
BFS
Fig. 12. Average target recall (left) and similarity to topic descriptions (right) by the Breadth-First, Best-First, Shark-Search and InfoSpiders crawlers on the D = 3 task. The plots in each row
correspond to a different value of MAX BUFFER between 256 and 2, 048.
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

20 · Filippo Menczer et al.
by the end of the crawls, except for the similarity metric in the MAX BUFFER=2048case, where InfoSpiders suffers a large initial loss from which it has not fully recov-ered after 1,000 pages.
While Best-First displays an advantage over InfoSpiders in the early stage of thecrawls, by the time 1,000 pages are crawled the difference is no longer significant inmost cases (with the exception of recall for MAX BUFFER=2048). These plots seemto suggest that in the initial stages of the crawls BFS is helped by its greedinesswhile InfoSpiders pays a penalty for its adaptability — the neural networks arenot trained, the evolutionary bias has not yet had a chance to kick in, and thestochastic selector makes some locally suboptimal choices. However those featuresprove more useful in the later stages of the crawl. For example the similarity totopic descriptions seems to hold steady or improve slightly for InfoSpiders in 3 ofthe 4 graphs while all the other crawlers show a downward trend after 200 pages.
3.2.2 Scalability. Figure 12 shows that performance is affected by the valueof the MAX BUFFER parameter. Note that even when MAX BUFFER > MAX PAGES,performance can be affected by frontier size because the number of links encounteredby a crawler is typically much larger than the number of pages visited. But whilethe limited buffer size forces any crawler to remove many links from its frontier,which links are eliminated depends on the crawler algorithm. To better assess howthe various crawling algorithms scale with the space (memory) resources available tothem, Figure 13 plots performance (target recall and similarity to topic descriptionsat 1,000 pages) versus MAX BUFFER.
Breadth-First, Shark-Search and Best-First do not appear to be affected by thefrontier size, with one exception; similarity to topic descriptions increases signif-icantly for Breadth-First when MAX BUFFER goes from 256 to 512. This indicatesthat the limitation of space resources will hurt a crawling algorithm more if it can-not prioritize over its links, due to the higher risk of throwing away good links. ForInfoSpiders, performance seems to decrease with increasing frontier size. We willdiscuss this effect in Section 7.
3.2.3 Efficiency. Let us now analyze the time complexity of the various crawlingalgorithms. We focus on CPU time, since all crawlers are equally subject to noisynetwork I/O delays. We also exclude the CPU time taken by common utilityfunctions shared by all crawlers (cf. Section 2.1).
While we have made an effort to employ appropriate data structures and algo-rithms, naturally we can only evaluate the efficiency of our own implementationsof the crawlers. Consider for example the data structure used to implement thefrontier priority queue in the Best-First algorithm. The basic operations of insert-ing and removing links from the queue are most efficiently supported by a heap,yielding O(log(MAX BUFFER)) complexity. However it is also necessary to checkif a newly extracted URL is already in the frontier; this has linear complexityin a heap, and must be done for each link in a newly crawled page. Alterna-tively, using an associative array or hash table, this checking operation is cheap(O(1)) but inserting and removing links requires an expensive sorting operation(O(MAX BUFFER · log(MAX BUFFER))) once per page crawled. The asymptotic com-plexity of priority queue operations per crawled page is O(L · MAX BUFFER) for theACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 21
0
0.1
0.2
0.3
0.4
0.5
0.6
256 512 1024 2048
aver
age
reca
ll
�
MAX_BUFFER
SharkBreadthFirst
BFSIS
0.08
0.09
0.1
0.11
0.12
0.13
0.14
256 512 1024 2048
aver
age
sim
ilarit
y
MAX_BUFFER
SharkBreadthFirst
BFSIS
Fig. 13. Scalability of aver-
age target recall (top) and ofsimilarity to topic descriptions
(bottom) with MAX BUFFER by
the Breadth-First, Best-First,Shark-Search and InfoSpiders
crawlers.
heap and O(L+MAX BUFFER · log(MAX BUFFER)) for the hash, where L is the averagenumber of links per page. Figure 14 plots the actual costs for L = 7, which isan accurate estimate for the Web [Kumar et al. 2000]. The plot shows that whilein the range of MAX BUFFER used in our experiments the two data structures yieldvery similar efficiency, the hash is preferable for improved crawlers described inSection 4. For this reason we use an associative array to store the link frontier, notonly in Best-First but in the other crawlers as well. Even so, further optimizationmay be possible for some of the crawlers and therefore we cannot claim that ourefficiency analysis will necessarily apply to other implementations.
Another caveat is that the actual time taken by any algorithm is irrelevant sinceit depends largely on the load and hardware configuration of the machine(s) usedto run the crawls — even the crawling experiments described in this paper wererun on a large number of machines with widely different hardware configurationsand changing loads. To obtain a measure of time complexity that can be useful tocompare the efficiency of the crawlers, we introduce a relative cost c of crawler ias the ratio between the time taken by i to visit p pages and the mean cumulativetime taken by a set of crawlers to visit MAX PAGES pages:
cp(i) =tp(i) · |C|∑
i′∈C tMAX PAGES(i′)(8)
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

22 · Filippo Menczer et al.
Fig. 14. Asymptotic complex-
ity of priority queue operationsin crawlers using heap and hash
data structures. Higher L val-
ues (L > 7) and/or smallerMAX BUFFER values make the
comparison more favorable forthe hash, and vice-versa. The
BFS256 line corresponds to an
algorithm described in Section 4,where the hash is sorted only
once every 256 pages crawled.
100
1000
10000
256 512 1024 2048
asym
ptot
ic q
ueue
cos
t per
pag
eMAX_BUFFER
BFS heapBFS hash
BFS256 hash
where C is a set of crawlers and i ∈ C. The relative cost metric is robust with re-spect to crawling different topics from different machines, as long as all the crawlersrun a single topic from the same machine.
Another useful metric would be one that combines the two sources of evidencefor performance with efficiency. To this end let us define a performance/cost metricP as the ratio between performance and relative cost of a crawler i, where theformer is given by the product of mean target recall and mean similarity to topicdescriptions after p pages:
Pp(i) =〈ρp(i)〉Q · 〈σp(i)〉Q
〈cp(i)〉Q(9)
where Q is the set of topics.Figure 15 plots both c1000 and P1000 versus MAX BUFFER for the four crawlers.
Shark-Search is the most expensive crawler and Breadth-First, as expected, is themost efficient. Breadth-First becomes more efficient for larger frontier size since ithas to trim its frontier less frequently. Best-First has intermediate complexity. Itbecomes less efficient with increasing frontier size because there are more links tocompare. What is most surprising, InfoSpiders is almost as efficient as Breadth-First, with the two time complexities converging for MAX BUFFER=2,048. We discussthe decreasing complexity of InfoSpiders with increasing frontier size in Section 5.
The performance/cost ratio plot in Figure 15 yields InfoSpiders as the winnerowing to its good performance and excellent efficiency. There is also a clear positivetrend with increasing frontier size. Best-First pays a price for its complexity and issurpassed by Breadth-First for all but the smallest frontier size. Poor performanceand inefficiency place Shark-Search in the last position. Clearly these results arestrongly dependent upon the time complexity of the algorithms and their usefulnesswill depend on the particular application of the crawlers.
4. EXPLORATION VERSUS EXPLOITATION
In this section we raise the issue of exploration versus exploitation as a definingcharacteristic of a Web crawler. This issue is a universal one in machine learningand artificial intelligence, since it presents itself in any task where search is guidedby quality estimations. Under some regularity assumption, a measure of quality atACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 23
0
0.5
1
1.5
2
2.5
3
256 512 1024 2048
rela
tive
cost
MAX_BUFFER
SharkBreadthFirst
BFSIS
0
0.05
0.1
0.15
0.2
0.25
256 512 1024 2048
perf
orm
ance
/cos
t
�
MAX_BUFFER
SharkBreadthFirst
BFSIS
Fig. 15. Scalability of timecomplexity (top) and perfor-
mance/cost ratio (bottom) with
MAX BUFFER by the Breadth-
First, Best-First, Shark-Search
and InfoSpiders crawlers.
one point in the search space provides some information on the quality of nearbypoints. A greedy algorithm can then exploit this information by concentrating thesearch in the vicinity of the most promising points. However, this strategy canlead to missing other equally good or even better points, for two reasons: first, theestimates may be noisy; and second, the search space may have local optima thattrap the algorithm and keep it from locating global optima. In other words, it maybe necessary to visit some “bad” points in order to arrive at the best ones. At theother extreme, algorithms that completely disregard quality estimates and continueto explore in a uniform or random fashion do not risk getting stuck at local optima,but they do not use the available information to bias the search and thus may spendmost of their time exploring suboptimal areas. A balance between exploitation andexploration of clues is obviously called for in heuristic search algorithms, but theoptimal compromise point is unknown unless the topology of the search space iswell understood — which is typically not the case for interesting search spaces.
Topical crawlers fit into this picture very well if one views the Web as the searchspace, with pages as points and neighborhoods as defined by hyperlinks. A crawlermust decide which pages to visit based on the cues provided by links from nearbypages. If one assumes that a relevant page has a higher probability to be near otherrelevant pages than to any random page, then quality estimate of pages providecues that can be exploited to bias the search process. However, given the short
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

24 · Filippo Menczer et al.
BFS_N (topic, starting_urls, N) {
foreach link (starting_urls) {
enqueue(frontier, link);
}
while (visited < MAX_PAGES) {
links_to_crawl := dequeue_top_links(frontier, N);
foreach link (randomize(links_to_crawl)) {
doc := fetch(link);
score := sim(topic, doc);
merge(frontier, extract_links(doc), score);
if (#frontier > MAX_BUFFER) {
dequeue_bottom_links(frontier);
}
}
}
}
Fig. 16. Pseudocode of BFSN crawlers. BFS1 (N = 1) corresponds to the algorithm in Figure 6.
range of relevance clues across the Web graph [Menczer 2004], a very relevant pagemight be only a few links behind an apparently irrelevant one. Balancing theexploitation of quality estimate information with exploration of suboptimal pagesmay be crucial for the performance of topical crawlers, something that we want toconfirm empirically here.
4.1 Crawler Descriptions
In this section we describe generalized versions of the Best-First [Pant et al. 2002]and Shark-Search crawlers, designed to tune the greediness level of these crawlersand thus study the tradeoff between exploitation and exploration that is appropriatein a crawling application.
4.1.1 Generalized Best-First. Best-First was described in Section 3.1.3. BFSNis a generalization of BFS in that at each iteration a batch of top N links to crawlare selected. After completing the crawl of N pages the crawler decides on the nextbatch of N and so on. Figure 16 offers a simplified pseudocode of the BFSN class.
BFSN offers an ideal context for our study. The parameter N controls the greedybehavior of the crawler. Increasing N results in crawlers with greater emphasis onexploration and consequently a reduced emphasis on exploitation. Decreasing Nreverses this; selecting a smaller set of links is more exploitative of the evidenceavailable regarding the potential merits of the links. In our experiments we testfive BFSN crawlers by setting N to 1, 16, 64, 128 and 256. Note that increasingN also results in increased efficiency because the frontier only needs to be sortedevery N pages (cf. Figure 14).
4.1.2 Generalized Shark-Search. Shark-Search was described in Section 3.1.4.Figure 17 shows the pseudocode of our SharkN class of crawlers, which generalizesthe “standard” Shark algorithm in the same way that BFSN extends BFS. At eachiteration a batch of top N links to crawl are selected. After completing the crawlof N pages the crawler decides on the next batch of N and so on. Thus SharkNcan be made more exploitative or explorative by varying N just as for Best-First.ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 25
Shark_N (topic, starting_urls, N) {
foreach link (starting_urls) {
set_depth(link, d);
enqueue(frontier, link);
}
while (visited < MAX_PAGES) {
links_to_crawl := dequeue_top_links(frontier, N);
foreach link (randomize(links_to_crawl)) {
doc := fetch(link);
doc_score := sim(topic, doc);
if (depth(link) > 0) {
foreach outlink (extract_links(doc)) {
score = (1-r) * neighborhood_score(outlink)
+ r * inherited_score(outlink);
if (doc_score > 0) {
set_depth(outlink, d);
} else {
set_depth(outlink, depth(link) - 1);
}
enqueue(frontier, outlink, score);
}
if (#frontier > MAX_BUFFER) {
dequeue_bottom_links(frontier);
}
}
}
}
}
Fig. 17. Pseudocode of SharkN crawlers. Shark1 (N = 1) corresponds to the algorithm in
Figure 8.
4.1.3 Greediness in Other Crawlers. Any crawler algorithm can be made moreexplorative or exploitative by regulating the amount of noise in its link estimates.In the case of PageRank, the frequency with which PageRank calculations areredone is key to its greediness level; the more frequent the calculations, the moreexploitative the crawler.
In InfoSpiders we can regulate greediness by changing the value of β, the inverse-temperature parameter used in the stochastic selector (Equation 6). We increase βto get greater exploitation and decrease it for greater exploration, with the extremecase β = 0 generating a uniform probability distribution over the frontier.
4.2 Experimental Results
Here we focus on the BFSN and SharkN classes of crawlers whose behavior is themost straightforward to interpret in terms of the exploration parameter N . Theresults in this section summarize and extend preliminary experiments [Pant et al.2002] showing that for BFSN crawlers, N = 256 yields the best performance undera number of measures, for 20 ≤ N ≤ 28.
4.2.1 Dynamic Performance. The dynamic results are summarized in Figure 18.The parameter MAX BUFFER is set to 256 links. For readability, we are only plottingthe performance of a selected subset of the BFSN crawlers (N = 1 and N =
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

26 · Filippo Menczer et al.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 200 400 600 800 1000
aver
age
reca
ll
�
pages crawled
MAX_BUFFER=256BFS256
BFS
0.09
0.1
0.11
0.12
0.13
0.14
0 200 400 600 800 1000
aver
age
sim
ilarit
y
pages crawled
MAX_BUFFER=256BFS256
BFS
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 200 400 600 800 1000
aver
age
reca
ll
�
pages crawled
MAX_BUFFER=256Shark
Shark256
0.09
0.1
0.11
0.12
0.13
0.14
0 200 400 600 800 1000
aver
age
sim
ilarit
y
pages crawled
MAX_BUFFER=256Shark
Shark256
Fig. 18. Average target recall (left) and similarity to topic descriptions (right) by representatives
of the BFSN (top) and SharkN (bottom) crawling algorithms, for N = 1 and N = 256.
256). The behavior of the remaining crawlers (BFS16, BFS64 and BFS128) can beextrapolated between the curves corresponding to BFS1 and BFS256. The sameholds for SharkN crawlers.
In the case of SharkN , it is clear that exploration helps. However the performanceof SharkN crawlers in general is significantly worse than that of BFSN crawlersafter the first 250 pages. Generalized Best-First also paints a more interestingpicture. We observe that the more exploratory algorithm, BFS256, seems to bearan initial penalty for exploration but recovers in the long run; after about 500 pagesBFS256 catches up, and in the case of recall BFS256 eventually surpasses BFS1.These results are consistent with the observations from the previous section — thegreediness of BFS1 helps early on but hinders performance in the longer run. It isalso noteworthy that pure (blind) exploration alone is not sufficient to achieve thebest performance. If it were, Breadth-First would be the winner, however Figure 12shows that Breadth-First is outperformed by BFS. We conclude that a successfulcrawling strategy must employ a combination of explorative and exploitative bias,as is generally the case in any interesting search problem with local optima.
Incidentally, inspection of Figures 12 and 18 reveals that the best overall per-formance after 1,000 pages crawled in the D = 3 task is achieved by BFS256 withMAX BUFFER=256 links.
4.2.2 Scalability. Figure 19 plots the performance of BFS1 and BFS256 at 1,000pages versus frontier size, for MAX BUFFER between 256 and 1,024. No significanttrends are observed; BFSN seems to be unaffected by the frontier size in this range.ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 27
0
0.1
0.2
0.3
0.4
0.5
0.6
256 512 1024
aver
age
reca
ll
�
MAX_BUFFER
BFSBFS256
0.08
0.09
0.1
0.11
0.12
0.13
0.14
256 512 1024
aver
age
sim
ilarit
y
MAX_BUFFER
BFSBFS256
Fig. 19. Scalability of average
target recall (top) and of simi-larity to topic descriptions (bot-
tom) with MAX BUFFER by repre-
sentatives of the BFSN crawl-ing algorithms, for N = 1 and
N = 256.
5. ADAPTIVE CRAWLERS
The Web is a very heterogeneous space. The value of its link and lexical cuesvaries greatly depending on the purpose of pages. For example, a researcher’shomepage might carefully link to pages of colleagues who do related work, while acommercial site might carefully avoid any pointers to the competition. In fact wehave shown that pages in the .edu domain tend to link to lexically similar pageswith a significantly higher likelihood than pages in the .com domain [Menczer 2004].
One question that arises from this observation, for topical crawlers, is whethercrawling algorithms should take advantage of adaptive techniques to change theirbehavior based on their experiential context — if I am looking for “rock climbing”pages and the term “rock” has often misled me into following links about musicrather than sports, it might be wise to give more importance to the term “climbing”than to “rock” in the future. In our previous research we have shown that this typeof spatial and temporal context can be exploited by individual and population-basedadaptive crawling algorithms [Menczer and Belew 2000], but those experimentswere limited to relatively small and well-organized portions of the Web such as theEncyclopaedia Britannica Online.7
7http://www.eb.com
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

28 · Filippo Menczer et al.
5.1 Crawler Description
In this section we study whether the noisy Web “at large” provides crawlers withsignals that can be internalized to improve crawling performance in the course of acrawl. Such signals would have to be reliable enough to help, rather than hinder anagent’s capability to focus its search. The InfoSpiders crawling algorithm describedin Section 3.1.5 was designed principally to explore this question, therefore thereare a number of adaptive mechanisms built into InfoSpiders.
At the individual level, an agent’s neural network weights can be adjusted byreinforcement so that an agent may learn to predict the value of links. In theexample above, the weight from the unit associated with the term “climbing” shouldbe made larger relative to the weight associated with the term “rock.” This wouldhappen if an agent followed some links highly rated by the neural net because oftheir proximity with “rock,” only to find that the pages pointed by those links hada small similarity with the topic “rock climbing.” The algorithm uses the errorin similarity prediction as a reinforcement signal to train the neural network intomaking more accurate link evaluations. To study the effect of individual learning oncrawling performance, we consider variations of the InfoSpiders algorithm in whichlearning is disabled and all neural networks are frozen at their initial configurations,with identical weights.
At the population level, there are two adaptive mechanisms in InfoSpiders.Through selective reproduction, the search is biased to favor the portions of theWeb that appear more promising. If an agent encounters several pages with highsimilarity to its topic keywords, that may be an indication that its frontier containshigher quality links than other agents. Agents can locally internalize this informa-tion by creating offspring when their energy surpasses the reproduction threshold.This in practice doubles the frequency with which the links of the parent agent aregoing to be jointly explored by the parent and offspring agents. Since for fairnessthe collective frontier of the population as a whole must be maintained within theMAX BUFFER boundary, at reproduction the local frontier (and its size) is split be-tween parent and offspring. This implies a cost for such an adaptive bias; as thecrawling algorithm becomes more distributed, local link estimates will be based onsmaller frontiers and thus more subject to local fluctuations. The MAX POP SIZEparameter determines the maximum degree of distributedness of the algorithm.We explore values of 8 and 1 here to study the tradeoff in performance between adistributed crawling strategy with evolutionary bias and a centralized one.
The second adaptive mechanism stemming from InfoSpiders’ evolutionary bias isa selective expansion of the topic keywords. At reproduction, the offspring agentpicks up a new term from the page where the parent is currently “situated.” Recallthat each agent maintains a biased random walk through the pages it visits, so thatwith high probability its “current location” is a page with high similarity to itstopic keywords (cf. Figure 10 and Equation 7). The offspring thus can potentiallyimprove on its crawling performance by internalizing a new lexical feature thatappears positively correlated with relevance estimates. The risk, of course, is toadd noise by paying attention to a term that in reality is not a good indicator ofrelevance. Selective expansion of topic keywords is disabled when the MAX POP SIZEparameter is set to 1.ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 29
5.2 Experimental Results
Here we compare four variations of InfoSpiders crawlers — with and without rein-forcement learning enabled at the individual level, and with and without evolutionenabled at the population level. Values between 256 and 2,048 are again exploredfor the MAX BUFFER parameter.
5.2.1 Dynamic Performance. Figure 20 shows the dynamic performance plotsof the four InfoSpiders variations. Few differences are significant but we can stillobserve some general trends. When the frontier is small (MAX BUFFER=256) bothevolution and learning seem to hinder target recall. The problem with evolutionis understandable since with a small frontier, each agent has a very small set oflinks to work with and thus the risk to make poor decisions increases with thedecentralization of the link selection process. Evolution does not seem to hinder(nor help) similarity to topic descriptions; there are probably more pages similar tothe target descriptions than targets, so missing a target does not necessarily implymissing other possibly relevant pages.
The negative impact of learning on performance for small frontier is less clearand deserves further analysis. Figure 21 plots the errors made by an InfoSpidersagent (MAX POP SIZE=1) in estimating the similarity of the pages pointed by thelinks that are actually followed. The plot shows both the error of the neural net(used for training) and the error of the actual estimates used to pick the links,obtained by combining the neural net output with the similarity of the parentpage (cf. Section 3.1.5). While the actual estimates do improve over time, theneural net’s errors are subject to significant noise, with a sharp initial decreasefollowed by an increase after 100-300 pages, followed by a slower decrease. Thisdata shows that the heterogeneity of the Web can lead an agent astray, especiallyafter a few hundred pages. The negative effect of learning can thus be interpretedby considering the risk that spawned agents may not see enough pages to learn aneffective representation.
When the frontier is large (cf. Figure 20, MAX BUFFER=2,048) there is a reversalfor similarity to topic descriptions; the dominant factor seems to be evolution whilelearning does not appear to have an effect. The fact that evolution helps here can beexplain by considering that a large frontier allows each agent to retain an adequatenumber (2, 048/8 = 256) of links to pick from. Thus decentralizing the search isless risky and the crawler can take advantage of the positive effects of evolution,namely biasing the search toward promising areas and selective keyword expansion.
Incidentally, inspection of Figures 12, 18 and 20 reveals that InfoSpiders (with noevolution and no learning) competes head-to-head with BFS256 for the best overallperformance after 1,000 pages crawled in the D = 3 task with MAX BUFFER=256links. While we are pleased to have introduced the two best-performing crawlers, wefind it somewhat disappointing that the adaptive capabilities of InfoSpiders appearto do more harm than good in these short crawls with very limited resources.
5.2.2 Scalability. The plots in Figure 22 show that performance in all of the In-foSpiders variants does not scale very well with the frontier size. Again this negativetrend will be discussed in Section 7. However, few of the differences between per-formance of variants (at 1,000 pages) are significant. As was observed in Figure 20,
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

30 · Filippo Menczer et al.
0
0.1
0.2
0.3
0.4
0.5
0.6
0 200 400 600 800 1000
aver
age
reca
ll
�
pages crawled
MAX_BUFFER=256IS no evolution, no learning
IS no evolution, learningIS evolution, no learning
IS evolution, learning
0.095
0.1
0.105
0.11
0.115
0.12
0.125
0.13
0.135
0.14
0 200 400 600 800 1000
aver
age
sim
ilarit
y
pages crawled
MAX_BUFFER=256IS no evolution, no learning
IS no evolution, learningIS evolution, no learning
IS evolution, learning
0
0.1
0.2
0.3
0.4
0.5
0.6
0 200 400 600 800 1000
aver
age
reca
ll
�
pages crawled
MAX_BUFFER=512IS no evolution, no learning
IS no evolution, learningIS evolution, no learning
IS evolution, learning
0.095
0.1
0.105
0.11
0.115
0.12
0.125
0.13
0.135
0.14
0 200 400 600 800 1000
aver
age
sim
ilarit
y
pages crawled
MAX_BUFFER=512IS no evolution, no learning
IS no evolution, learningIS evolution, no learning
IS evolution, learning
0
0.1
0.2
0.3
0.4
0.5
0.6
0 200 400 600 800 1000
aver
age
reca
ll
�
pages crawled
MAX_BUFFER=1024IS no evolution, no learning
IS no evolution, learningIS evolution, no learning
IS evolution, learning
0.095
0.1
0.105
0.11
0.115
0.12
0.125
0.13
0.135
0.14
0 200 400 600 800 1000
aver
age
sim
ilarit
y
pages crawled
MAX_BUFFER=1024IS no evolution, no learning
IS no evolution, learningIS evolution, no learning
IS evolution, learning
0
0.1
0.2
0.3
0.4
0.5
0.6
0 200 400 600 800 1000
aver
age
reca
ll
�
pages crawled
MAX_BUFFER=2048IS no evolution, no learning
IS no evolution, learningIS evolution, no learning
IS evolution, learning
0.095
0.1
0.105
0.11
0.115
0.12
0.125
0.13
0.135
0.14
0 200 400 600 800 1000
aver
age
sim
ilarit
y
pages crawled
MAX_BUFFER=2048IS no evolution, no learning
IS no evolution, learningIS evolution, no learning
IS evolution, learning
Fig. 20. Average target recall (left) and similarity to topic descriptions (right) by the four variants
of InfoSpiders crawlers. The plots in each row correspond to a different value of MAX BUFFER.
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 31
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0 100 200 300 400 500 600 700 800 900
mea
n sq
uare
d er
ror
pages crawled
MAX_BUFFER=256alpha-averaged estimate
neural net estimate
Fig. 21. Link estimate error of
a single InfoSpiders agent, aver-aged across 8 topics.
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
0.6
256 512 1024 2048
aver
age
reca
ll
�
MAX_BUFFER
IS no evolution, no learningIS no evolution, learningIS evolution, no learning
IS evolution, learning
0.095
0.1
0.105
0.11
0.115
0.12
0.125
0.13
256 512 1024 2048
aver
age
sim
ilarit
y
MAX_BUFFER
IS no evolution, no learningIS no evolution, learningIS evolution, no learning
IS evolution, learning
Fig. 22. Scalability of aver-
age target recall (top) and ofsimilarity to topic descriptions
(bottom) with MAX BUFFER by
the four variants of InfoSpiderscrawlers.
the largest spread is observed for small frontier size (MAX BUFFER=256), where bothlearning and evolution hinder target recall, and learning hinders similarity to topicdescriptions as well.
5.2.3 Efficiency. The complexity plot in Figure 23 reveals some interesting re-sults. As expected, learning increases the complexity of the crawler since it requiresextra time to train the neural nets. But evolution decreases the complexity, and
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.
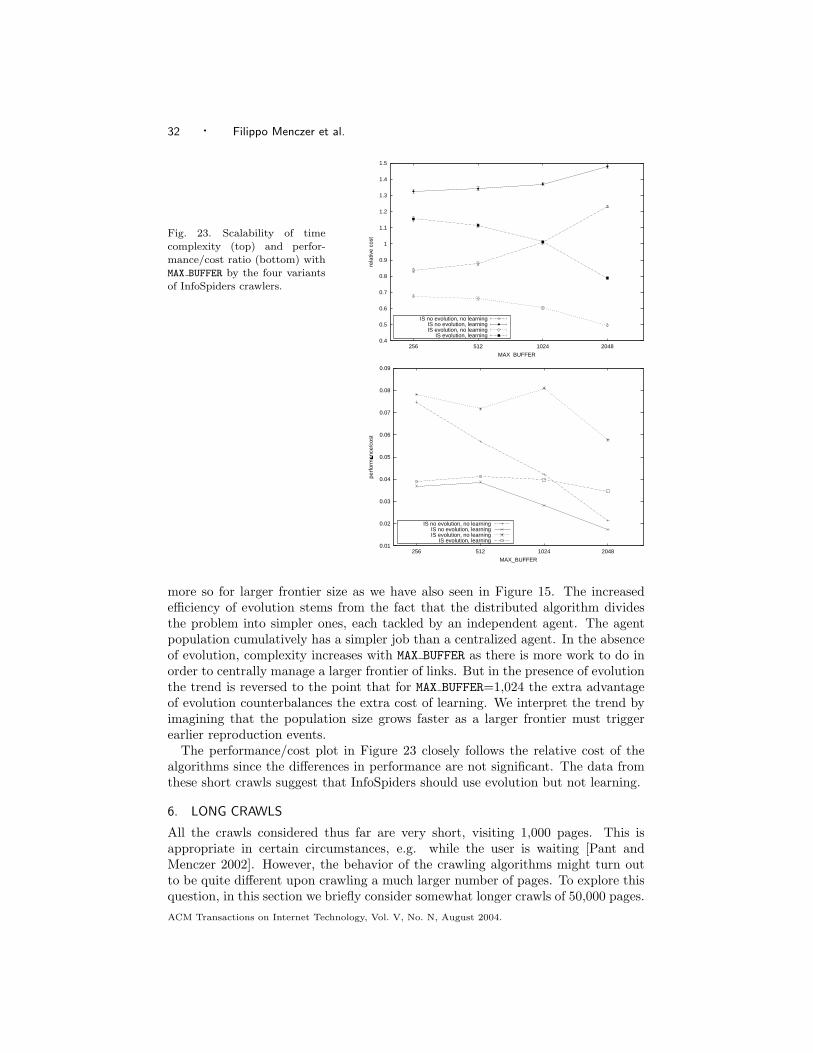
32 · Filippo Menczer et al.
Fig. 23. Scalability of time
complexity (top) and perfor-mance/cost ratio (bottom) with
MAX BUFFER by the four variantsof InfoSpiders crawlers.
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
1.5
256 512 1024 2048
rela
tive
cost
MAX_BUFFER
IS no evolution, no learningIS no evolution, learningIS evolution, no learning
IS evolution, learning
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
256 512 1024 2048
perf
orm
ance
/cos
t
�
MAX_BUFFER
IS no evolution, no learningIS no evolution, learningIS evolution, no learning
IS evolution, learning
more so for larger frontier size as we have also seen in Figure 15. The increasedefficiency of evolution stems from the fact that the distributed algorithm dividesthe problem into simpler ones, each tackled by an independent agent. The agentpopulation cumulatively has a simpler job than a centralized agent. In the absenceof evolution, complexity increases with MAX BUFFER as there is more work to do inorder to centrally manage a larger frontier of links. But in the presence of evolutionthe trend is reversed to the point that for MAX BUFFER=1,024 the extra advantageof evolution counterbalances the extra cost of learning. We interpret the trend byimagining that the population size grows faster as a larger frontier must triggerearlier reproduction events.
The performance/cost plot in Figure 23 closely follows the relative cost of thealgorithms since the differences in performance are not significant. The data fromthese short crawls suggest that InfoSpiders should use evolution but not learning.
6. LONG CRAWLS
All the crawls considered thus far are very short, visiting 1,000 pages. This isappropriate in certain circumstances, e.g. while the user is waiting [Pant andMenczer 2002]. However, the behavior of the crawling algorithms might turn outto be quite different upon crawling a much larger number of pages. To explore thisquestion, in this section we briefly consider somewhat longer crawls of 50,000 pages.ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 33
6.1 Crawler Descriptions
We select a few representative crawlers among those described in this paper tosee if their relative performance qualitatively changes as more pages are crawled.The naive BFS256 crawler is an obvious candidate because it displays one of thebest performances. InfoSpiders without learning is also a strong performer in shortcrawls, however we are more interested in studying whether learning might turnout to be helpful in the longer run so we select the “normal” InfoSpiders with bothevolution and learning. Finally, Breadth-First is selected as usual to provide abaseline. Note that in the theoretical limit for very long crawls (MAX PAGES →∞)one might expect all crawlers to converge (σ → 0 and hopefully ρ → 1). Thequestion is how fast this happens for each crawler. The best crawler is the one suchthat σ converges slowest and ρ converges to the highest level. Breadth-First is ahelpful baseline because it provides a lower bound for σ.
6.2 Experimental Results
We ran 50,000-page crawls for BFS256, InfoSpiders and Breadth-First for 10 topics,with MAX BUFFER=2,048 links. Note that the number of topics is limited by the timerequired to run these longer crawls.
Figure 24 shows the dynamic performance of the three crawlers in the longercrawls. The error bars can be quite large owing to the small number of topics. Asexpected, Breadth-First is significantly outperformed by both BFS256 and InfoS-piders for both target recall and similarity to topic descriptions.
For target recall BFS256 initially beats InfoSpiders (consistently with the resultsfrom shorter crawls), but eventually after 7,500 pages InfoSpiders surpasses BFS256,with the difference becoming significant after 20,000 pages. Note that all the threecrawlers seem to have converged after about 20,000 pages, therefore we do notexpect to learn much more from running even longer crawls. The final recall levelof almost 70% of the targets achieved by InfoSpiders seems like a pretty good resultconsidering the difficulty of the D = 3 task.
For similarity to topic descriptions the differences between BFS256 and InfoSpi-ders are not significant, however the trends paint a very similar picture. BFS256performs better than InfoSpiders in the early phase of the crawl, while InfoSpiderseventually catches up by staying more focused. These results suggest that while theadaptive mechanisms of InfoSpiders may not be helpful (or may even be harmful)in very short crawls, they confer a winning advantage after the agents have hada chance to internalize important features about the environment. Such featuresallow the agents to discover relevant pages long after static crawlers have lost theirfocus.
7. CONCLUDING REMARKS
We believe that the crawling algorithms discussed in this paper are a good sampleof the current state of the art. Of course there are many other algorithms that arenot considered here due to timeliness, insufficient information available, or our ownignorance. Even for the most sophisticated crawlers described in the literature it isimpossible to gauge their effectiveness in isolation, without fair comparative studiesusing well defined common tasks, performance measures, and equal resources. It is
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

34 · Filippo Menczer et al.
Fig. 24. Average target recall
(top) and similarity to topic de-scriptions (bottom) by BFS256,
InfoSpiders and Breadth-Firstover ten 50,000 page crawls.
0
0.2
0.4
0.6
0.8
1
0 10000 20000 30000 40000 50000
aver
age
reca
ll
�
pages crawled
MAX_BUFFER=2048BreadthFirst
ISBFS256
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0 10000 20000 30000 40000 50000
aver
age
sim
ilarit
y
pages crawled
MAX_BUFFER=2048BreadthFirst
ISBFS256
our hope that by describing the state of the art in topical crawlers within a unifiedevaluation framework, one can foster further studies that will lead to improvedcrawling algorithms and ultimately better search tools for the public at large.
Let us conclude by summarizing the main contributions of this paper, discussingour results, and outlining some directions for future work.
7.1 Summary
The major contributions of the present work are summarized as follows:
— Two novel crawling algorithms, BFS256 and InfoSpiders, have been intro-duced by generalizing or improving on previous algorithms. Based on our evalua-tion metrics, and to the best of our knowledge, these crawlers are currently the bestperformers at difficult crawling tasks such as the one in which seed URLs are D = 3links away from known relevant targets. Recall levels above 60% are achieved byInfoSpiders after around 10,000 pages.
— A number of crawlers from the literature have been reimplemented and eval-uated under fair conditions. Their relative effectiveness has been shown to beconsistent across different performance metrics and space (memory) resources.
— The naive Best-First algorithm has been shown to be an effective crawler,especially in the short run. For very short crawls it is best to be greedy; this is aACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 35
lesson that should be incorporated into algorithms for query time (online) crawlerssuch as MySpiders8 [Pant and Menczer 2002].
— We have shown consistently that exploration leads to better coverage of highlyrelevant pages, in spite of a possible penalty during the early stage of the crawl. Thissuggests that exploration allows to tradeoff short term gains for longer term andpotentially larger gains. However, we also found that a blind exploration leads topoor results, demonstrating that a mix of exploration and exploitation is necessaryfor good overall performance.
— Our study of adaptive crawlers has demonstrated that machine learning tech-niques making use of local information alone can confer a significant advantage inperformance after sufficiently long crawls. However, while InfoSpiders is a verycompetitive crawler in general, we have shown that reinforcement learning does notprovide for a sufficiently strong advantage in predicting the value of links to offsetthe increased cost and the risk of additional mistakes during the initial trainingphase.
— We have analyzed the time complexity of crawlers and found that distributedalgorithms such as InfoSpiders can be extremely efficient and scalable, improvingfor large amounts of available resources to the point of being no more expensivethat a blind algorithm such as Breadth-First. InfoSpiders thus achieves the bestperformance/cost ratio. Greedy algorithms such as Best-First, on the other hand,require a large amount of time to sort through candidate links and are less scalable.
7.2 Discussion
We find it somewhat disappointing that adaptation does not yield a greater advan-tage in performance, and that reinforcement learning in particular seems to hinderperformance in short crawls. Clearly the Web is a very noisy environment and mis-takes can be costly for tasks such as D = 3. It would be interesting to repeat theexperiment with adaptive crawlers on simpler tasks such as D = 0, 1, 2. Anotherfactor to consider is that there are several parameters in InfoSpiders, which havebeen tuned preliminarily but not extensively and not in the D = 3 task. Tuningsome of those parameters, for example the learning rate for training the neural netsor the greediness parameter β, might prove beneficial.
We observed InfoSpiders becoming more efficient for large frontier sizes, buttheir performance parallelly worsening. This phenomenon deserves further study.Our current theory is that a larger frontier may lead to earlier reproduction, thusexplaining the gain in efficiency. Such early reproduction might be seen as a sortof “premature bias,” or suboptimal exploitation of early evidence that leads tomissing other good pages later. In this sense a better understanding of optimalreproduction frequencies should be obtained by further tuning the reproductionthreshold parameter (THETA). Of course one must also consider that the simplegrowth of the frontier implies an inherent increase in noise with which crawlersmay have a hard time coping.
The present analysis is based on a small number of evaluation metrics selected forthe particular task discussed in this paper. Many other measures could of course
8http://myspiders.informatics.indiana.edu/
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

36 · Filippo Menczer et al.
be used. Furthermore, all the analyses in this paper are based on averages acrosstopics. Much can be learned by taking a different approach, namely studyingdiverse characteristics of each topic and then observing whether certain topicalfeatures are associated with particularly good (or poor) performance by any givencrawler. These are issues that we discuss in a companion paper focusing on theevaluation aspects of crawlers [Srinivasan et al. 2004].
In this study we have devoted significant resources to obtain statistically signif-icant results when possible by analyzing data across many topics. This, togetherwith the large number of experiments and crawlers, and given obvious limitations inhardware, bandwidth and time, severely constrained the length of the crawls thatcould be carried out. Longer crawls are of course always desirable, especially whenconsidering applications such as in support of topical portals [Pant et al. 2003].However it must be stressed that it takes many topics (or at least random repli-cates) to obtain reliable results and that such reliability is key to understandingthe behavior of topical crawlers in such a complex environment as the Web.
ACKNOWLEDGMENTS
We are grateful to Soumen Chakrabarti, Steve Lawrence, Rik Belew, Nick Streetand Dave Eichmann for helpful comments since the early stages of this project,to several anonymous reviewers for constructive criticism and suggestions, and toAlberto Segre and Dave Eichmann for computing support.
REFERENCES
Aggarwal, C., Al-Garawi, F., and Yu, P. 2001. Intelligent crawling on the World Wide Webwith arbitrary predicates. In Proc. 10th International World Wide Web Conference. 96–105.
Ben-Shaul, I. et al. 1999. Adding support for dynamic and focused search with Fetuccino.
Computer Networks 31, 11–16, 1653–1665.
Brewington, B. E. and Cybenko, G. 2000. How dynamic is the Web? In Proc. 9th InternationalWorld-Wide Web Conference.
Brin, S. and Page, L. 1998. The anatomy of a large-scale hypertextual Web search engine.
Computer Networks 30, 1–7, 107–117.
Chakrabarti, S., van den Berg, M., and Dom, B. 1999. Focused crawling: A new approach to
topic-specific Web resource discovery. Computer Networks 31, 11–16, 1623–1640.
Cho, J. and Garcia-Molina, H. 2000. The evolution of the Web and implications for an incre-mental crawler. In Proceedings of the 26th International Conference on Very Large Databases(VLDB).
Cho, J., Garcia-Molina, H., and Page, L. 1998. Efficient crawling through URL ordering.Computer Networks 30, 1–7, 161–172.
Cyveillance. 2000. Sizing the internet. White paper. http://www.cyveillance.com/.
De Bra, P. and Post, R. 1994. Information retrieval in the World Wide Web: Making client-based searching feasible. In Proc. 1st International World Wide Web Conference (Geneva).
Diligenti, M., Coetzee, F., Lawrence, S., Giles, C. L., and Gori, M. 2000. Focused crawling
using context graphs. In Proc. 26th International Conference on Very Large Databases (VLDB
2000). Cairo, Egypt, 527–534.
Flake, G., Lawrence, S., Giles, C., and Coetzee, F. 2002. Self-organization of the Web and
identification of communities. IEEE Computer 35, 3, 66–71.
Gibson, D., Kleinberg, J., and Raghavan, P. 1998. Inferring Web communities from linktopology. In Proc. 9th ACM Conference on Hypertext and Hypermedia. 225–234.
Haveliwala, T. 1999. Efficient computation of pagerank. Tech. rep., Stanford Database Group.
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

Topical Web Crawlers · 37
Henzinger, M., Heydon, A., Mitzenmacher, M., and Najork, M. 1999. Measuring search
engine quality using random walks on the Web. In Proc. 8th International World Wide WebConference (Toronto). 213–225.
Hersovici, M., Jacovi, M., Maarek, Y. S., Pelleg, D., Shtalhaim, M., and Ur, S. 1998.
The shark-search algorithm — An application: Tailored Web site mapping. In Proc. 7th Intl.World-Wide Web Conference.
Kleinberg, J. 1999. Authoritative sources in a hyperlinked environment. Journal of the
ACM 46, 5, 604–632.
Kleinberg, J. and Lawrence, S. 2001. The structure of the Web. Science 294, 5548, 1849–1850.
Kumar, S., Raghavan, P., Rajagopalan, S., Sivakumar, D., Tomkins, A., and Upfal, E. 2000.
Stochastic models for the Web graph. In Proc. 41st Annual IEEE Symposium on Foundationsof Computer Science. IEEE Computer Society Press, Silver Spring, MD, 57–65.
Kumar, S., Raghavan, P., Rajagopalan, S., and Tomkins, A. 1999. Trawling the Web for
emerging cyber-communities. Computer Networks 31, 11–16, 1481–1493.
Lawrence, S. and Giles, C. 1998. Searching the World Wide Web. Science 280, 98–100.
Lawrence, S. and Giles, C. 1999. Accessibility of information on the Web. Nature 400, 107–109.
McCallum, A., Nigam, K., Rennie, J., and Seymore, K. 1999. A machine learning approach tobuilding domain-specific search engines. In Proc. 16th International Joint Conf. on Artificial
Intelligence. Morgan Kaufmann, San Francisco, CA, 662–667.
Menczer, F. 1997. ARACHNID: Adaptive Retrieval Agents Choosing Heuristic Neighborhoodsfor Information Discovery. In Proc. 14th International Conference on Machine Learning. Mor-
gan Kaufmann, San Francisco, CA, 227–235.
Menczer, F. 2003. Complementing search engines with online Web mining agents. DecisionSupport Systems 35, 2, 195–212.
Menczer, F. 2004. Lexical and semantic clustering by Web links. Journal of the American
Society for Information Science and Technology. Forthcoming.
Menczer, F. and Belew, R. 1998. Adaptive information agents in distributed textual envi-
ronments. In Proc. 2nd International Conference on Autonomous Agents. Minneapolis, MN,
157–164.
Menczer, F. and Belew, R. 2000. Adaptive retrieval agents: Internalizing local context and
scaling up to the Web. Machine Learning 39, 2–3, 203–242.
Menczer, F. and Monge, A. 1999. Scalable Web search by adaptive online agents: An InfoS-piders case study. In Intelligent Information Agents: Agent-Based Information Discovery and
Management on the Internet, M. Klusch, Ed. Springer, Berlin, 323–347.
Menczer, F., Pant, G., Ruiz, M., and Srinivasan, P. 2001. Evaluating topic-driven Webcrawlers. In Proc. 24th Annual Intl. ACM SIGIR Conf. on Research and Development in
Information Retrieval, D. H. Kraft, W. B. Croft, D. J. Harper, and J. Zobel, Eds. ACM Press,
New York, NY, 241–249.
Moukas, A. and Zacharia, G. 1997. Evolving a multi-agent information filtering solution in
Amalthaea. In Proc. 1st International Conference on Autonomous Agents.
Najork, M. and Wiener, J. L. 2001. Breadth-first search crawling yields high-quality pages. InProc. 10th International World Wide Web Conference.
Nick, Z. and Themis, P. 2001. Web search using a genetic algorithm. IEEE Internet Comput-
ing 5, 2, 18–26.
O’Meara, T. and Patel, A. 2001. A topic-specific Web robot model based on restless bandits.IEEE Internet Computing 5, 2, 27–35.
Pant, G., Bradshaw, S., and Menczer, F. 2003. Search engine - crawler symbiosis. In Proc.7th European Conference on Research and Advanced Technology for Digital Libraries (ECDL),T. Koch and I. Solvberg, Eds. Lecture Notes in Computer Science, Vol. 2769. Springer Verlag,
Berlin.
Pant, G. and Menczer, F. 2002. MySpiders: Evolve your own intelligent Web crawlers. Au-
tonomous Agents and Multi-Agent Systems 5, 2, 221–229.
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.

38 · Filippo Menczer et al.
Pant, G. and Menczer, F. 2003. Topical crawling for business intelligence. In Proc. 7th European
Conference on Research and Advanced Technology for Digital Libraries (ECDL), T. Koch andI. Solvberg, Eds. Lecture Notes in Computer Science, Vol. 2769. Berlin.
Pant, G., Srinivasan, P., and Menczer, F. 2002. Exploration versus exploitation in topic driven
crawlers. In Proc. WWW-02 Workshop on Web Dynamics.
Pinkerton, B. 1994. Finding what people want: Experiences with the WebCrawler. In Proc. 2ndInternational World Wide Web Conference (Chicago).
Porter, M. 1980. An algorithm for suffix stripping. Program 14, 3, 130–137.
Rennie, J. and McCallum, A. 1999. Using reinforcement learning to spider the Web efficiently.
In Proc. 16th International Conf. on Machine Learning. Morgan Kaufmann, San Francisco,CA, 335–343.
Rumelhart, D., Hinton, G., and Williams, R. 1986. Learning internal representations by error
propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cogni-
tion, D. Rumelhart and J. McClelland, Eds. Vol. 1. Bradford Books (MIT Press), Cambridge,MA, Chapter 8, 318–362.
Srinivasan, P., Pant, G., and Menczer, F. 2004. A general evaluation framework for topical
crawlers. Information Retrieval . Forthcoming.
Wills, C. and Mikhailov, M. 1999. Towards a better understanding of Web resources andserver responses for improved caching. In Proc. 8th International World Wide Web Conference
(Toronto).
Received May 2002; revised December 2002; accepted February 2003
ACM Transactions on Internet Technology, Vol. V, No. N, August 2004.