
Crawlers - Presentation 2 - April 20081 (Web) Crawlers Domain Presented by: Or Shoham Amit Yaniv Guy...
37
Crawlers - Presentation 2 - Apri Crawlers - Presentation 2 - Apri l 2008 l 2008 1 (Web) Crawlers (Web) Crawlers Domain Domain Presented by Presented by : : Or Shoham Or Shoham Amit Yaniv Amit Yaniv Guy Kroupp Guy Kroupp Saar Kohanovitch Saar Kohanovitch
-
Upload
sabina-kelly -
Category
Documents
-
view
224 -
download
1
Transcript of Crawlers - Presentation 2 - April 20081 (Web) Crawlers Domain Presented by: Or Shoham Amit Yaniv Guy...

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 11
(Web) Crawlers Domain(Web) Crawlers Domain
Presented byPresented by::
Or ShohamOr Shoham
Amit YanivAmit Yaniv
Guy KrouppGuy Kroupp
Saar KohanovitchSaar Kohanovitch

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 22
CrawlersCrawlers1. Crawlers: Background1. Crawlers: Background2. Unified Domain Model2. Unified Domain Model3. Individual Applications3. Individual Applications3.1 WebSphinx3.1 WebSphinx3.2 WebLech3.2 WebLech3.3. Grub3.3. Grub3.4 Aperture3.4 Aperture4. Summary and Conclusions 4. Summary and Conclusions

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 33
Crawlers – BackgroundCrawlers – Background
What is a crawler?What is a crawler? Collect information about internet pagesCollect information about internet pages Near-infinite amount of web pages, no directoryNear-infinite amount of web pages, no directory Use links contained within pages to find out about Use links contained within pages to find out about
new pages to visitnew pages to visit How do crawlers work?How do crawlers work?
Pick a starting page URL (seed)Pick a starting page URL (seed) Load starting page from internetLoad starting page from internet Find all links in page and enqueue themFind all links in page and enqueue them Get any desired information from pageGet any desired information from page LoopLoop

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 44
Crawlers – BackgroundCrawlers – Background
Rules which apply on the Domain:Rules which apply on the Domain: All crawlers have a URL FetcherAll crawlers have a URL Fetcher All crawlers have a Parser (Extractor)All crawlers have a Parser (Extractor) Crawlers are a Multi Threaded processesCrawlers are a Multi Threaded processes All crawlers have a Crawler ManagerAll crawlers have a Crawler Manager All crawlers have a Queue structureAll crawlers have a Queue structure
Strongly related to the search engine domainStrongly related to the search engine domain

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 55Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 55
Unified Domain Class Diagram *Common features
ExternalDB
ExternalDB
MergerMerger
DBDB
PageData
PageData
CrawlerHelper
CrawlerHelper
FilterFilter
*Added by code modeling
StorageManager
StorageManager
SpiderSpider
SpiderConfig
SpiderConfig
QueueQueue
ThreadThread
Extractor
Extractor
FetcherFetcher
RobotsRobots
Scheduler
Scheduler

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 66Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 66
Unified Domain Sequence DiagramUnified Domain Sequence Diagram
Pre-crawling phase:Pre-fetching phase:
Main loop Optional objects!
Fetching and extracting phase:
Optional object!
Post-processing phase:Finish crawling phase:
End of main loop

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 77
Unified Domain - ApplicationsUnified Domain - Applications
For the User Modeling group, the applications For the User Modeling group, the applications were the first chance to see things in practicewere the first chance to see things in practice
For the entire group, the applications provided a For the entire group, the applications provided a fresh view about the domain, which led to many fresh view about the domain, which led to many changes (Assignment 2)changes (Assignment 2)
With everyone viewing the applications in the With everyone viewing the applications in the domain context, most differences were domain context, most differences were explained as being application-specificexplained as being application-specific
Interesting experiment: Let new Code Modeling Interesting experiment: Let new Code Modeling group use applications as basis for domain?group use applications as basis for domain?

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 88
WebSphinxWebSphinx
WebSphinx: WebSphinx: WebWebsite-site-SSpecific pecific PProcessors rocessors for for HHTML TML ININformation eformation eXXtraction (2002)traction (2002)
The WebSphinx class library provides The WebSphinx class library provides support for writing web crawlers in Javasupport for writing web crawlers in Java
Designation: Small-scope crawls for Designation: Small-scope crawls for mirroring, offline viewing, hyperlink trees mirroring, offline viewing, hyperlink trees
Extensible to saving information about Extensible to saving information about page elementspage elements

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 99
WebSphinxWebSphinx
Hyperlink Tree

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 1010
WebSphinxWebSphinx
Extractor
Extractor
Scheduler
Scheduler
Settings
Settings
LinkLink
Spider, Queue
Spider, Queue
(Configuration)
(Configuration)
Fetcher,
Fetcher,
PageData,
PageData,
StorageManager
StorageManager
Mirror
Mirror
ElementElement
ThreadThread
RobotsRobots
FiltersFilters
Mirror: A collection of files (Pages) intended to provide a perfect copy of another website
Element: Web pages are composed of many elements (<element></element>). Elements can be nested (For example, <body> will have many child elements)
Link: A link is a type of element, usually <A HREF=“”></A>, which points to a specific page or file. Storing information about each link relative to our seeds can help us analyze results

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 1111
WebSphinxWebSphinx

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 1212
Web LechWeb Lech
Web Lech allows you to "spider" a website Web Lech allows you to "spider" a website and to recursively download all the pages and to recursively download all the pages on it.on it.

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 1313
Web LechWeb Lech
Web Lech is a fully featured web site Web Lech is a fully featured web site download/mirror tool in Java, which download/mirror tool in Java, which supports :supports :
download websites download websites emulate standard web-browser behavior emulate standard web-browser behavior
Web Lech is multithreaded and Web Lech is multithreaded and willwill feature a GUI console. feature a GUI console.

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 1414
Web LechWeb Lech Open Source MIT License means it's totally free and you Open Source MIT License means it's totally free and you
can do what you want with it can do what you want with it Pure Java code means you can run it on any Java-Pure Java code means you can run it on any Java-
enabled computer enabled computer Multi-threaded operation for downloading lots of files at Multi-threaded operation for downloading lots of files at
once once Supports basic HTTP authentication for accessing Supports basic HTTP authentication for accessing
password-protected sites password-protected sites HTTP referrer support maintains link information HTTP referrer support maintains link information
between pages (needed to Spider some websites) between pages (needed to Spider some websites)

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 1515
Web LechWeb Lech Lots of configuration options: Lots of configuration options:
Depth-first or breadth-first traversal of the site Depth-first or breadth-first traversal of the site Candidate URL filtering, so you can stick to one web Candidate URL filtering, so you can stick to one web
server, one directory, or just Spider the whole web server, one directory, or just Spider the whole web Configurable caching of downloaded files allows restart Configurable caching of downloaded files allows restart
without needing to download everything again without needing to download everything again URL prioritization, so you can get interesting files first URL prioritization, so you can get interesting files first
and leave boring files till last (or ignore them and leave boring files till last (or ignore them completely) completely)
Check pointing so you can snapshot spider state in the Check pointing so you can snapshot spider state in the middle of a run and restart without lots of processing. middle of a run and restart without lots of processing.

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 1616
Class Diagram

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 1717
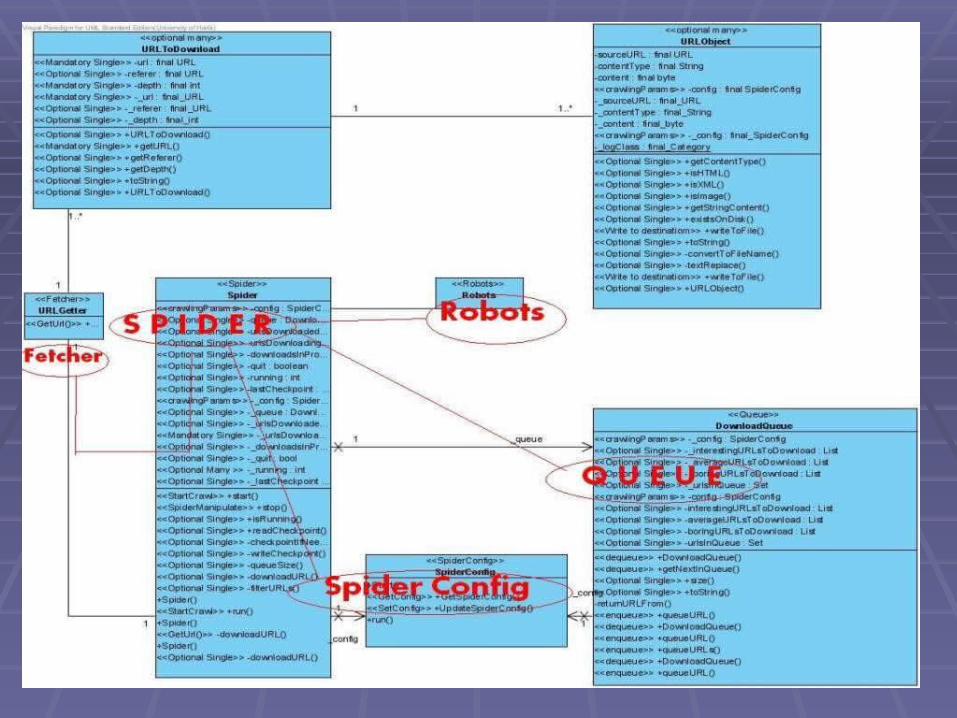
Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 1818

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 1919
Sequence Diagram

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 2020

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 2121
Common Features

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 2222
Common Features

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 2323
Unique Features

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 2424
Grub CrawlerGrub Crawler
A Little bit about NASA’s SETIA Little bit about NASA’s SETI
What are distributed Crawlers?What are distributed Crawlers?
Why distributed Crawlers?Why distributed Crawlers?
Pros & Cons of distributed CrawlersPros & Cons of distributed Crawlers
Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 2525
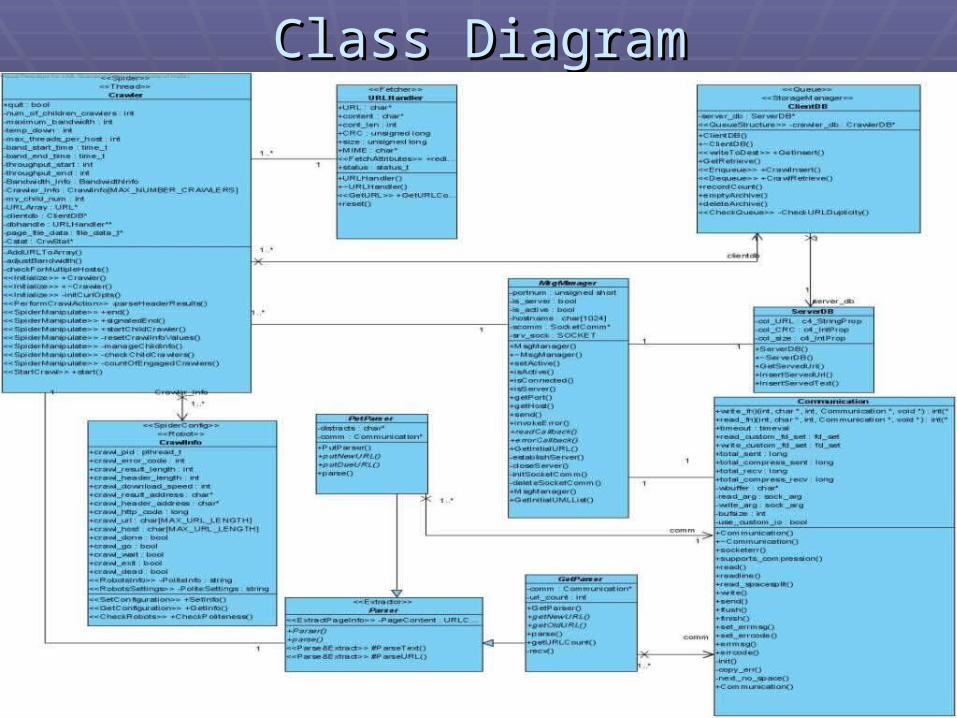
Class DiagramClass Diagram

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 2626
Class Diagram (2)Class Diagram (2)
Spider & ThreadSpider & Thread Config & RobotConfig & Robot

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 2727
Class Diagram (3)Class Diagram (3)
FetcherFetcher
ExtractorExtractor
Queue & Storage Queue & Storage ManagerManager

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 2828
Sequence DiagramSequence Diagram

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 2929
Sequence DiagramSequence Diagram

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 3030
Use CaseUse Case

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 3131
ApertureAperture
Developing Year: 2005Developing Year: 2005 Designation: crawling and indexingDesignation: crawling and indexing Crawl different information systemsCrawl different information systems Many common file formatsMany common file formats Flexible architectureFlexible architecture Main process phases:Main process phases:
Fetch information from a chosen sourceFetch information from a chosen source Identify source type (MIME protocol)Identify source type (MIME protocol) Full-text and metadata extractionFull-text and metadata extraction Store and index informationStore and index information

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 3232Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 3232
Aperture Web DemoAperture Web Demo•Go to: http://www.dfki.unikl.de/ApertureWebProject/

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 3333Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 3333
Aperture Class Diagram
Aperture offers a crawler for each data source.
Our domain focus on web !crawling
Aperture offers many extractors which are able to extract data and metadata from files,email,sites,calendars etc.
CrawlReport
CrawlReport
MimeMime
DataObject
DataObject
RDFContainer
RDFContainer
StorageManager
StorageManager
SpiderSpider
, ,
SpiderConfig,
SpiderConfig,
QueueQueue
ThreadThread,,Scheduler
Scheduler
,,RobotsRobots
FetcherFetcher
, ,
CrawlerHelper
CrawlerHelper
DBDB
CrawlerHelper
CrawlerHelper
Extractor
Extractor
CrawlerCrawler
TypesTypes
Extractor
Extractor
TypesTypes
Classes name:DataObjectRDFContainerAperture’s unique!
Roll: Represnet a source object after fetching it. Object includes source data and metadata in a RDF format.
Class name :MimeAperture’s unique!
Roll: Identify source type in order to choose the correct extractor.
Interface name:CrawlReportAperture’s unique!
Roll: Help crawler to keep necessary information about crawling changing status, fails and successes
Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 3434Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 3434
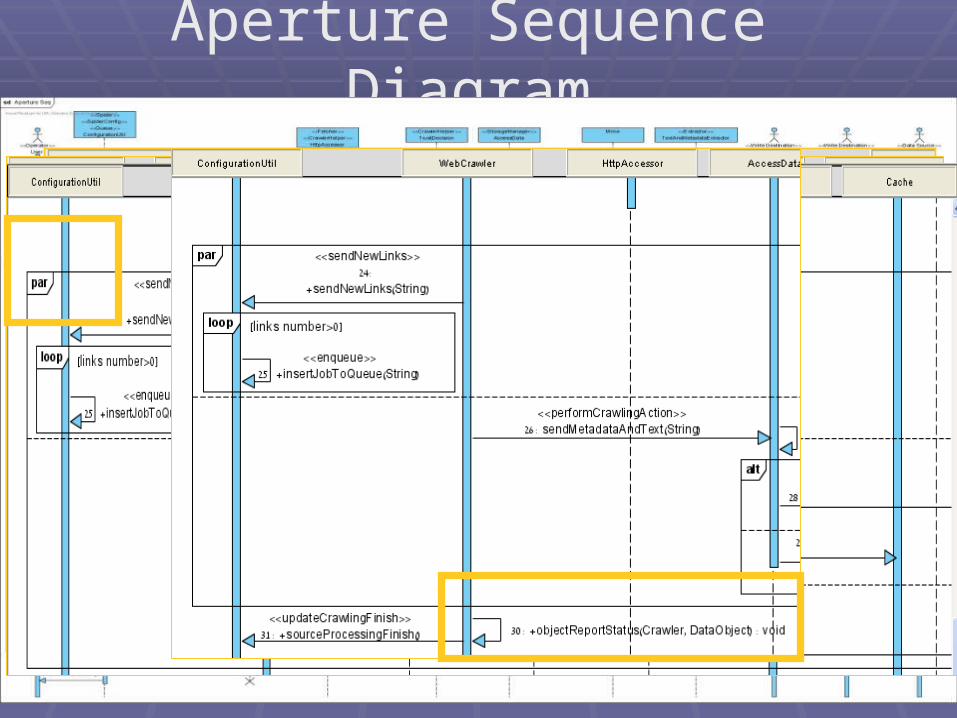
Aperture Sequence Diagram

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 3535
Summary - ADOMSummary - ADOM
ADOM was helpful in establishing domain ADOM was helpful in establishing domain requirementsrequirements
With better understanding of ADOM, abstraction With better understanding of ADOM, abstraction became easier – level of abstraction was became easier – level of abstraction was improved (increased) with each assignmentimproved (increased) with each assignment
Using XOR and OR limitations on relations Using XOR and OR limitations on relations helpful in creating domain class diagramhelpful in creating domain class diagram
Difficult not to get carried away with “It’s Difficult not to get carried away with “It’s optional, no harm in adding it” decisionsoptional, no harm in adding it” decisions

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 3636
Summary – Domain ModelingSummary – Domain Modeling
Difficulty in modeling functional entities – Difficulty in modeling functional entities – functions are often contained within functions are often contained within another classanother class
Difficult to model when many optional Difficult to model when many optional entities exist, some of which heavily entities exist, some of which heavily impact class relations and sequencesimpact class relations and sequences
Vast difference in application scaleVast difference in application scale Next time, we’ll pick a different domain…Next time, we’ll pick a different domain…

Crawlers - Presentation 2 - April 2008Crawlers - Presentation 2 - April 2008 3737
CrawlersCrawlers
Thank youThank you Any questions?Any questions?


















