
The xml
33
The XML .NET Document Object Model
-
Upload
raghu-nath -
Category
Education
-
view
79 -
download
3
Transcript of The xml

The XML NET Document Object Model
The structure of the XML Document Object Model (XML DOM) is a general
specification that is implemented using platform-specific features and components The
MSXML library provides a COM-based XML DOM implementation for the Microsoft
Win32 platform The SystemXml assembly provides a NET Framework-specific
implementation of the XML DOM centered on the XmlDocument class
The structure of the XML Document Object Model (XML DOM) is a general
specification that is implemented using platform-specific features and components The
MSXML library provides a COM-based XML DOM implementation for the Microsoft
Win32 platform The SystemXml assembly provides a NET Framework-specific
implementation of the XML DOM centered on the XmlDocument class
Although it is stored as flat text in a linear text file XML content is inherently
hierarchical Readers simply parse the text as it is read out of the input stream They
never cache read information and work in a stateless fashion As a result of this
arrangement you can neither edit nodes nor move backward The limited navigation
capabilities also prevent you from implementing node queries of any complexity The
XML DOM philosophy is quite different XML DOM loads all the XML content in memory
and exposes it through a suite of collections that overall offer a tree-based
representation of the original content In addition the supplied data structure is fully
searchable and editable
The XML DOM Programming InterfaceThe central element in the NET XML DOM implementation is the XmlDocument class
The XmlDocument class represents an XML document and makes it programmable by
exposing its nodes and attributes through ad hoc collections Lets consider a simple
XML document
ltMyDataSetgt
ltNorthwindEmployees count=3gt
ltEmployeegt
ltemployeeidgt1ltemployeeidgt
ltfirstnamegtNancyltfirstnamegt
ltlastnamegtDavolioltlastnamegt
ltEmployeegt
ltEmployeegt
ltemployeeidgt2ltemployeeidgt
ltfirstnamegtAndrewltfirstnamegt
ltlastnamegtFullerltlastnamegt
ltEmployeegt
ltemployeeidgt3ltemployeeidgt
ltfirstnamegtJanetltfirstnamegt
ltlastnamegtLeverlingltlastnamegt
ltEmployeegt
ltNorthwindEmployeesgt
ltMyDataSetgt
The XmlDocument class represents the entry point in the binary structure and the
central console that lets you move through nodes reading and writing contents Each
element in the original XML document is mapped to a particular NET Framework class
with its own set of properties and methods Each element can be reached from the
parent and can access all of its children and siblings Element-specific information such
as contents and attributes are available via properties
Any change you enter is applied immediately but only in memory The XmlDocument
class does provide an IO interface to load from and save to a variety of storage
media including disk files Subsequently all the changes to constituent elements of an
XML DOM tree are normally persisted all at once
The XmlDocument ClassWhen you need to load an XML document into memory for full-access processing you
start by creating a new instance of the XmlDocument class The class features two
public constructors one of which is the default parameterless constructor as shown
here
public XmlDocument()
public XmlDocument(XmlNameTable)
While initializing the XmlDocument class you can also specify an existing
XmlNameTable object to help the class work faster with attribute and node names and
optimize memory management Just as the XmlReader class does XmlDocument
builds its own name table incrementally while processing the document However
passing a precompiled name table can only speed up the overall execution The
following code snippet demonstrates how to load an XML document into a living
instance of the XmlDocument class
XmlDocument doc = new XmlDocument()
docLoad(fileName)
The Load method always work synchronously so when it returns the document has
been completely (and successfully we hope) mapped to memory and is ready for
further processing through the properties and methods exposed by the class As youll
see in a bit more detail later in this section the XmlDocument class uses an XML
reader internally to perform any read operation and to build the final tree structure for
the source document
The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

The structure of the XML Document Object Model (XML DOM) is a general
specification that is implemented using platform-specific features and components The
MSXML library provides a COM-based XML DOM implementation for the Microsoft
Win32 platform The SystemXml assembly provides a NET Framework-specific
implementation of the XML DOM centered on the XmlDocument class
The structure of the XML Document Object Model (XML DOM) is a general
specification that is implemented using platform-specific features and components The
MSXML library provides a COM-based XML DOM implementation for the Microsoft
Win32 platform The SystemXml assembly provides a NET Framework-specific
implementation of the XML DOM centered on the XmlDocument class
Although it is stored as flat text in a linear text file XML content is inherently
hierarchical Readers simply parse the text as it is read out of the input stream They
never cache read information and work in a stateless fashion As a result of this
arrangement you can neither edit nodes nor move backward The limited navigation
capabilities also prevent you from implementing node queries of any complexity The
XML DOM philosophy is quite different XML DOM loads all the XML content in memory
and exposes it through a suite of collections that overall offer a tree-based
representation of the original content In addition the supplied data structure is fully
searchable and editable
The XML DOM Programming InterfaceThe central element in the NET XML DOM implementation is the XmlDocument class
The XmlDocument class represents an XML document and makes it programmable by
exposing its nodes and attributes through ad hoc collections Lets consider a simple
XML document
ltMyDataSetgt
ltNorthwindEmployees count=3gt
ltEmployeegt
ltemployeeidgt1ltemployeeidgt
ltfirstnamegtNancyltfirstnamegt
ltlastnamegtDavolioltlastnamegt
ltEmployeegt
ltEmployeegt
ltemployeeidgt2ltemployeeidgt
ltfirstnamegtAndrewltfirstnamegt
ltlastnamegtFullerltlastnamegt
ltEmployeegt
ltemployeeidgt3ltemployeeidgt
ltfirstnamegtJanetltfirstnamegt
ltlastnamegtLeverlingltlastnamegt
ltEmployeegt
ltNorthwindEmployeesgt
ltMyDataSetgt
The XmlDocument class represents the entry point in the binary structure and the
central console that lets you move through nodes reading and writing contents Each
element in the original XML document is mapped to a particular NET Framework class
with its own set of properties and methods Each element can be reached from the
parent and can access all of its children and siblings Element-specific information such
as contents and attributes are available via properties
Any change you enter is applied immediately but only in memory The XmlDocument
class does provide an IO interface to load from and save to a variety of storage
media including disk files Subsequently all the changes to constituent elements of an
XML DOM tree are normally persisted all at once
The XmlDocument ClassWhen you need to load an XML document into memory for full-access processing you
start by creating a new instance of the XmlDocument class The class features two
public constructors one of which is the default parameterless constructor as shown
here
public XmlDocument()
public XmlDocument(XmlNameTable)
While initializing the XmlDocument class you can also specify an existing
XmlNameTable object to help the class work faster with attribute and node names and
optimize memory management Just as the XmlReader class does XmlDocument
builds its own name table incrementally while processing the document However
passing a precompiled name table can only speed up the overall execution The
following code snippet demonstrates how to load an XML document into a living
instance of the XmlDocument class
XmlDocument doc = new XmlDocument()
docLoad(fileName)
The Load method always work synchronously so when it returns the document has
been completely (and successfully we hope) mapped to memory and is ready for
further processing through the properties and methods exposed by the class As youll
see in a bit more detail later in this section the XmlDocument class uses an XML
reader internally to perform any read operation and to build the final tree structure for
the source document
The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

The structure of the XML Document Object Model (XML DOM) is a general
specification that is implemented using platform-specific features and components The
MSXML library provides a COM-based XML DOM implementation for the Microsoft
Win32 platform The SystemXml assembly provides a NET Framework-specific
implementation of the XML DOM centered on the XmlDocument class
Although it is stored as flat text in a linear text file XML content is inherently
hierarchical Readers simply parse the text as it is read out of the input stream They
never cache read information and work in a stateless fashion As a result of this
arrangement you can neither edit nodes nor move backward The limited navigation
capabilities also prevent you from implementing node queries of any complexity The
XML DOM philosophy is quite different XML DOM loads all the XML content in memory
and exposes it through a suite of collections that overall offer a tree-based
representation of the original content In addition the supplied data structure is fully
searchable and editable
The XML DOM Programming InterfaceThe central element in the NET XML DOM implementation is the XmlDocument class
The XmlDocument class represents an XML document and makes it programmable by
exposing its nodes and attributes through ad hoc collections Lets consider a simple
XML document
ltMyDataSetgt
ltNorthwindEmployees count=3gt
ltEmployeegt
ltemployeeidgt1ltemployeeidgt
ltfirstnamegtNancyltfirstnamegt
ltlastnamegtDavolioltlastnamegt
ltEmployeegt
ltEmployeegt
ltemployeeidgt2ltemployeeidgt
ltfirstnamegtAndrewltfirstnamegt
ltlastnamegtFullerltlastnamegt
ltEmployeegt
ltemployeeidgt3ltemployeeidgt
ltfirstnamegtJanetltfirstnamegt
ltlastnamegtLeverlingltlastnamegt
ltEmployeegt
ltNorthwindEmployeesgt
ltMyDataSetgt
The XmlDocument class represents the entry point in the binary structure and the
central console that lets you move through nodes reading and writing contents Each
element in the original XML document is mapped to a particular NET Framework class
with its own set of properties and methods Each element can be reached from the
parent and can access all of its children and siblings Element-specific information such
as contents and attributes are available via properties
Any change you enter is applied immediately but only in memory The XmlDocument
class does provide an IO interface to load from and save to a variety of storage
media including disk files Subsequently all the changes to constituent elements of an
XML DOM tree are normally persisted all at once
The XmlDocument ClassWhen you need to load an XML document into memory for full-access processing you
start by creating a new instance of the XmlDocument class The class features two
public constructors one of which is the default parameterless constructor as shown
here
public XmlDocument()
public XmlDocument(XmlNameTable)
While initializing the XmlDocument class you can also specify an existing
XmlNameTable object to help the class work faster with attribute and node names and
optimize memory management Just as the XmlReader class does XmlDocument
builds its own name table incrementally while processing the document However
passing a precompiled name table can only speed up the overall execution The
following code snippet demonstrates how to load an XML document into a living
instance of the XmlDocument class
XmlDocument doc = new XmlDocument()
docLoad(fileName)
The Load method always work synchronously so when it returns the document has
been completely (and successfully we hope) mapped to memory and is ready for
further processing through the properties and methods exposed by the class As youll
see in a bit more detail later in this section the XmlDocument class uses an XML
reader internally to perform any read operation and to build the final tree structure for
the source document
The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

Although it is stored as flat text in a linear text file XML content is inherently
hierarchical Readers simply parse the text as it is read out of the input stream They
never cache read information and work in a stateless fashion As a result of this
arrangement you can neither edit nodes nor move backward The limited navigation
capabilities also prevent you from implementing node queries of any complexity The
XML DOM philosophy is quite different XML DOM loads all the XML content in memory
and exposes it through a suite of collections that overall offer a tree-based
representation of the original content In addition the supplied data structure is fully
searchable and editable
The XML DOM Programming InterfaceThe central element in the NET XML DOM implementation is the XmlDocument class
The XmlDocument class represents an XML document and makes it programmable by
exposing its nodes and attributes through ad hoc collections Lets consider a simple
XML document
ltMyDataSetgt
ltNorthwindEmployees count=3gt
ltEmployeegt
ltemployeeidgt1ltemployeeidgt
ltfirstnamegtNancyltfirstnamegt
ltlastnamegtDavolioltlastnamegt
ltEmployeegt
ltEmployeegt
ltemployeeidgt2ltemployeeidgt
ltfirstnamegtAndrewltfirstnamegt
ltlastnamegtFullerltlastnamegt
ltEmployeegt
ltemployeeidgt3ltemployeeidgt
ltfirstnamegtJanetltfirstnamegt
ltlastnamegtLeverlingltlastnamegt
ltEmployeegt
ltNorthwindEmployeesgt
ltMyDataSetgt
The XmlDocument class represents the entry point in the binary structure and the
central console that lets you move through nodes reading and writing contents Each
element in the original XML document is mapped to a particular NET Framework class
with its own set of properties and methods Each element can be reached from the
parent and can access all of its children and siblings Element-specific information such
as contents and attributes are available via properties
Any change you enter is applied immediately but only in memory The XmlDocument
class does provide an IO interface to load from and save to a variety of storage
media including disk files Subsequently all the changes to constituent elements of an
XML DOM tree are normally persisted all at once
The XmlDocument ClassWhen you need to load an XML document into memory for full-access processing you
start by creating a new instance of the XmlDocument class The class features two
public constructors one of which is the default parameterless constructor as shown
here
public XmlDocument()
public XmlDocument(XmlNameTable)
While initializing the XmlDocument class you can also specify an existing
XmlNameTable object to help the class work faster with attribute and node names and
optimize memory management Just as the XmlReader class does XmlDocument
builds its own name table incrementally while processing the document However
passing a precompiled name table can only speed up the overall execution The
following code snippet demonstrates how to load an XML document into a living
instance of the XmlDocument class
XmlDocument doc = new XmlDocument()
docLoad(fileName)
The Load method always work synchronously so when it returns the document has
been completely (and successfully we hope) mapped to memory and is ready for
further processing through the properties and methods exposed by the class As youll
see in a bit more detail later in this section the XmlDocument class uses an XML
reader internally to perform any read operation and to build the final tree structure for
the source document
The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

The XML DOM Programming InterfaceThe central element in the NET XML DOM implementation is the XmlDocument class
The XmlDocument class represents an XML document and makes it programmable by
exposing its nodes and attributes through ad hoc collections Lets consider a simple
XML document
ltMyDataSetgt
ltNorthwindEmployees count=3gt
ltEmployeegt
ltemployeeidgt1ltemployeeidgt
ltfirstnamegtNancyltfirstnamegt
ltlastnamegtDavolioltlastnamegt
ltEmployeegt
ltEmployeegt
ltemployeeidgt2ltemployeeidgt
ltfirstnamegtAndrewltfirstnamegt
ltlastnamegtFullerltlastnamegt
ltEmployeegt
ltemployeeidgt3ltemployeeidgt
ltfirstnamegtJanetltfirstnamegt
ltlastnamegtLeverlingltlastnamegt
ltEmployeegt
ltNorthwindEmployeesgt
ltMyDataSetgt
The XmlDocument class represents the entry point in the binary structure and the
central console that lets you move through nodes reading and writing contents Each
element in the original XML document is mapped to a particular NET Framework class
with its own set of properties and methods Each element can be reached from the
parent and can access all of its children and siblings Element-specific information such
as contents and attributes are available via properties
Any change you enter is applied immediately but only in memory The XmlDocument
class does provide an IO interface to load from and save to a variety of storage
media including disk files Subsequently all the changes to constituent elements of an
XML DOM tree are normally persisted all at once
The XmlDocument ClassWhen you need to load an XML document into memory for full-access processing you
start by creating a new instance of the XmlDocument class The class features two
public constructors one of which is the default parameterless constructor as shown
here
public XmlDocument()
public XmlDocument(XmlNameTable)
While initializing the XmlDocument class you can also specify an existing
XmlNameTable object to help the class work faster with attribute and node names and
optimize memory management Just as the XmlReader class does XmlDocument
builds its own name table incrementally while processing the document However
passing a precompiled name table can only speed up the overall execution The
following code snippet demonstrates how to load an XML document into a living
instance of the XmlDocument class
XmlDocument doc = new XmlDocument()
docLoad(fileName)
The Load method always work synchronously so when it returns the document has
been completely (and successfully we hope) mapped to memory and is ready for
further processing through the properties and methods exposed by the class As youll
see in a bit more detail later in this section the XmlDocument class uses an XML
reader internally to perform any read operation and to build the final tree structure for
the source document
The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new
ltMyDataSetgt
ltNorthwindEmployees count=3gt
ltEmployeegt
ltemployeeidgt1ltemployeeidgt
ltfirstnamegtNancyltfirstnamegt
ltlastnamegtDavolioltlastnamegt
ltEmployeegt
ltEmployeegt
ltemployeeidgt2ltemployeeidgt
ltfirstnamegtAndrewltfirstnamegt
ltlastnamegtFullerltlastnamegt
ltEmployeegt
ltemployeeidgt3ltemployeeidgt
ltfirstnamegtJanetltfirstnamegt
ltlastnamegtLeverlingltlastnamegt
ltEmployeegt
ltNorthwindEmployeesgt
ltMyDataSetgt
The XmlDocument class represents the entry point in the binary structure and the
central console that lets you move through nodes reading and writing contents Each
element in the original XML document is mapped to a particular NET Framework class
with its own set of properties and methods Each element can be reached from the
parent and can access all of its children and siblings Element-specific information such
as contents and attributes are available via properties
Any change you enter is applied immediately but only in memory The XmlDocument
class does provide an IO interface to load from and save to a variety of storage
media including disk files Subsequently all the changes to constituent elements of an
XML DOM tree are normally persisted all at once
The XmlDocument ClassWhen you need to load an XML document into memory for full-access processing you
start by creating a new instance of the XmlDocument class The class features two
public constructors one of which is the default parameterless constructor as shown
here
public XmlDocument()
public XmlDocument(XmlNameTable)
While initializing the XmlDocument class you can also specify an existing
XmlNameTable object to help the class work faster with attribute and node names and
optimize memory management Just as the XmlReader class does XmlDocument
builds its own name table incrementally while processing the document However
passing a precompiled name table can only speed up the overall execution The
following code snippet demonstrates how to load an XML document into a living
instance of the XmlDocument class
XmlDocument doc = new XmlDocument()
docLoad(fileName)
The Load method always work synchronously so when it returns the document has
been completely (and successfully we hope) mapped to memory and is ready for
further processing through the properties and methods exposed by the class As youll
see in a bit more detail later in this section the XmlDocument class uses an XML
reader internally to perform any read operation and to build the final tree structure for
the source document
The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new
ltemployeeidgt3ltemployeeidgt
ltfirstnamegtJanetltfirstnamegt
ltlastnamegtLeverlingltlastnamegt
ltEmployeegt
ltNorthwindEmployeesgt
ltMyDataSetgt
The XmlDocument class represents the entry point in the binary structure and the
central console that lets you move through nodes reading and writing contents Each
element in the original XML document is mapped to a particular NET Framework class
with its own set of properties and methods Each element can be reached from the
parent and can access all of its children and siblings Element-specific information such
as contents and attributes are available via properties
Any change you enter is applied immediately but only in memory The XmlDocument
class does provide an IO interface to load from and save to a variety of storage
media including disk files Subsequently all the changes to constituent elements of an
XML DOM tree are normally persisted all at once
The XmlDocument ClassWhen you need to load an XML document into memory for full-access processing you
start by creating a new instance of the XmlDocument class The class features two
public constructors one of which is the default parameterless constructor as shown
here
public XmlDocument()
public XmlDocument(XmlNameTable)
While initializing the XmlDocument class you can also specify an existing
XmlNameTable object to help the class work faster with attribute and node names and
optimize memory management Just as the XmlReader class does XmlDocument
builds its own name table incrementally while processing the document However
passing a precompiled name table can only speed up the overall execution The
following code snippet demonstrates how to load an XML document into a living
instance of the XmlDocument class
XmlDocument doc = new XmlDocument()
docLoad(fileName)
The Load method always work synchronously so when it returns the document has
been completely (and successfully we hope) mapped to memory and is ready for
further processing through the properties and methods exposed by the class As youll
see in a bit more detail later in this section the XmlDocument class uses an XML
reader internally to perform any read operation and to build the final tree structure for
the source document
The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new
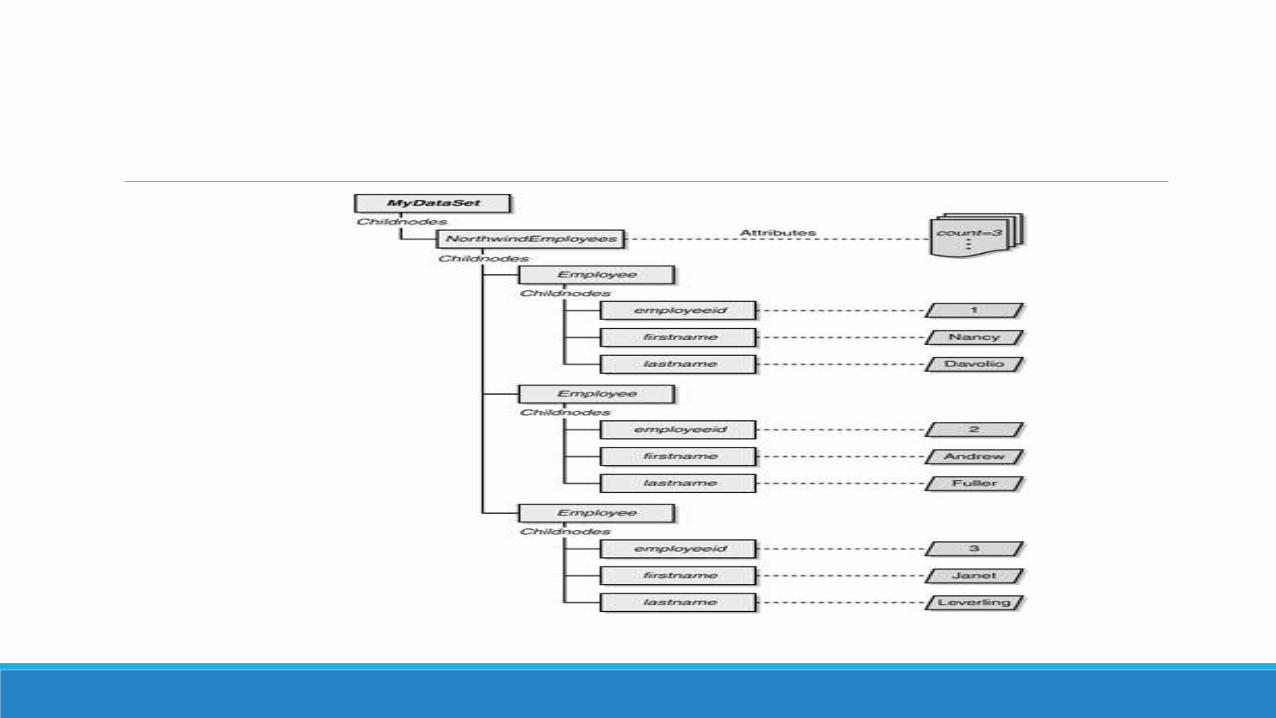
The XmlDocument class represents the entry point in the binary structure and the
central console that lets you move through nodes reading and writing contents Each
element in the original XML document is mapped to a particular NET Framework class
with its own set of properties and methods Each element can be reached from the
parent and can access all of its children and siblings Element-specific information such
as contents and attributes are available via properties
Any change you enter is applied immediately but only in memory The XmlDocument
class does provide an IO interface to load from and save to a variety of storage
media including disk files Subsequently all the changes to constituent elements of an
XML DOM tree are normally persisted all at once
The XmlDocument ClassWhen you need to load an XML document into memory for full-access processing you
start by creating a new instance of the XmlDocument class The class features two
public constructors one of which is the default parameterless constructor as shown
here
public XmlDocument()
public XmlDocument(XmlNameTable)
While initializing the XmlDocument class you can also specify an existing
XmlNameTable object to help the class work faster with attribute and node names and
optimize memory management Just as the XmlReader class does XmlDocument
builds its own name table incrementally while processing the document However
passing a precompiled name table can only speed up the overall execution The
following code snippet demonstrates how to load an XML document into a living
instance of the XmlDocument class
XmlDocument doc = new XmlDocument()
docLoad(fileName)
The Load method always work synchronously so when it returns the document has
been completely (and successfully we hope) mapped to memory and is ready for
further processing through the properties and methods exposed by the class As youll
see in a bit more detail later in this section the XmlDocument class uses an XML
reader internally to perform any read operation and to build the final tree structure for
the source document
The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

The XmlDocument ClassWhen you need to load an XML document into memory for full-access processing you
start by creating a new instance of the XmlDocument class The class features two
public constructors one of which is the default parameterless constructor as shown
here
public XmlDocument()
public XmlDocument(XmlNameTable)
While initializing the XmlDocument class you can also specify an existing
XmlNameTable object to help the class work faster with attribute and node names and
optimize memory management Just as the XmlReader class does XmlDocument
builds its own name table incrementally while processing the document However
passing a precompiled name table can only speed up the overall execution The
following code snippet demonstrates how to load an XML document into a living
instance of the XmlDocument class
XmlDocument doc = new XmlDocument()
docLoad(fileName)
The Load method always work synchronously so when it returns the document has
been completely (and successfully we hope) mapped to memory and is ready for
further processing through the properties and methods exposed by the class As youll
see in a bit more detail later in this section the XmlDocument class uses an XML
reader internally to perform any read operation and to build the final tree structure for
the source document
The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

While initializing the XmlDocument class you can also specify an existing
XmlNameTable object to help the class work faster with attribute and node names and
optimize memory management Just as the XmlReader class does XmlDocument
builds its own name table incrementally while processing the document However
passing a precompiled name table can only speed up the overall execution The
following code snippet demonstrates how to load an XML document into a living
instance of the XmlDocument class
XmlDocument doc = new XmlDocument()
docLoad(fileName)
The Load method always work synchronously so when it returns the document has
been completely (and successfully we hope) mapped to memory and is ready for
further processing through the properties and methods exposed by the class As youll
see in a bit more detail later in this section the XmlDocument class uses an XML
reader internally to perform any read operation and to build the final tree structure for
the source document
The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

The Load method always work synchronously so when it returns the document has
been completely (and successfully we hope) mapped to memory and is ready for
further processing through the properties and methods exposed by the class As youll
see in a bit more detail later in this section the XmlDocument class uses an XML
reader internally to perform any read operation and to build the final tree structure for
the source document
The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

The XmlDocument ImplementationThe Implementation property of the XmlDocument class defines the operating context
for the document object Implementation returns an instance of the XmlImplementation
class which provides methods for performing operations that are independent of any
particular instance of the DOM
In the base implementation of the XmlImplementation class the list of operations that
various instances of XmlDocument classes can share is relatively short These
operations include creating new documents testing for supported features and more
important sharing the same name table
The XmlImplementation class is not sealed so you could try to define a custom
implementation object and use that to create new XmlDocument objects with some
nonstandard settings (for example PreserveWhitespace set to true by default) The
following code snippet shows how to create two documents from the same
implementation
XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

XmlImplementation imp = new XmlImplementation()
XmlDocument doc1 = impCreateDocument()
XmlDocument doc2 = impCreateDocument()
The following code shows how XmlImplementation could work with a custom
implementation object
MyImplementation imp = new MyImplementation()
XmlDocument doc = impCreateDocument()
As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

As you can see the XmlDocument class has a lot of methods that create and return instances of node objects In the NET Framework all the objects that represent a node type (Comment Element Attribute and so on) do not have any publicly usable constructors For this reason you must resort to the corresponding method
How can the XmlDocument class create and return instances of other node objects if no public constructor for them is available The trick is that node classes mark their
constructors with the internal modifier (Friend in Microsoft Visual Basic) The internal keyword restricts the default visibility of a type method or property to the boundaries of the assembly The internal keyword works on top of other modifiers like public and
protected XmlDocument and other node classes are all defined in the SystemXml assembly which ensures the effective working of factory methods The following pseudocode shows the internal architecture of a factory method
public virtual XmlXXX CreateXXX( params )
return new XmlXXX ( params )
The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

The XmlNodeChangedEventArgs structure contains the event data The structure has
four interesting fields
1048707 Action Contains a value indicating what type of change is occurring on
the node Allowable values listed in the XmlNodeChangedAction
enumeration type are Insert Remove and Change
1048707 NewParent Returns an XmlNode object representing the new parent of
the node once the operation is complete The property will be set to null
if the node is being removed If the node is an attribute the property
returns the node to which the attribute refers
1048707 Node Returns an XmlNode object that denotes the node that is being
added removed or changed Cant be set to null
1048707 OldParent Returns an XmlNode object representing the parent of the
node before the operation began Returns null if the node has no
parentmdashfor example when you add a new node
Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

Graphical representation of the hierarchy of node classes and theirrelationships in the NET Framework
Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

Both XmlLinkedNode and XmlCharacterData are abstract classes that provide basic
functionality for more specialized types of nodes Linked nodes are nodes that you
might find as constituent elements of an XML document just linked to a preceding or a
following node Character data nodes on the other hand are nodes that contain and
manipulate only text
The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

The collection of child nodes is implemented as a linked list The ChildNodes property
returns an internal object of type XmlChildNodes (The object is not documented but
you can easily verify this claim by simply checking the type of the object that
ChildNodes returns) You dont need to use this object directly however Suffice to say
that it merely represents a concrete implementation of the XmlNodeList class whose
methods are for the most part marked as abstract In particular XmlChildNodes
implements the Item and Count properties and the GetEnumerator method
XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

XmlChildNodes is not a true collection and does not cache any information When you
access the Count property for example it scrolls the entire list counting the number of
nodes on the fly When you ask for a particular node through the Item property the list
is scanned from the beginning until a matching node is found To move through the list
the XmlChildNodes class relies on the nodes NextSibling method But which class
actually implements the NextSibling method Both NextSibling and PreviousSibling are
defined in the XmlLinkedNode base class
The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

The XmlLinkedNode classs NextSibling method lets applications navigatethrough the children of each node
Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

Working with XML Documents
To be fully accessible an XML document must be entirely loaded in memory and its
nodes and attributes mapped to relative objects derived from the XmlNode class The
process that builds the XML DOM triggers when you call the Load method You can use
a variety of sources to indicate the XML document to work on including disk files and
URLs and also streams and text readers
Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

Loading XML DocumentsLoading XML Documents
The Load method always transforms the data source into an XmlTextReader object and
passes it down to an internal loader object as shown here
public virtual void Load(Stream)
public virtual void Load(string)
public virtual void Load(TextReader)
public virtual void Load(XmlReader)
The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

The loading process of an XmlDocumentobject
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new
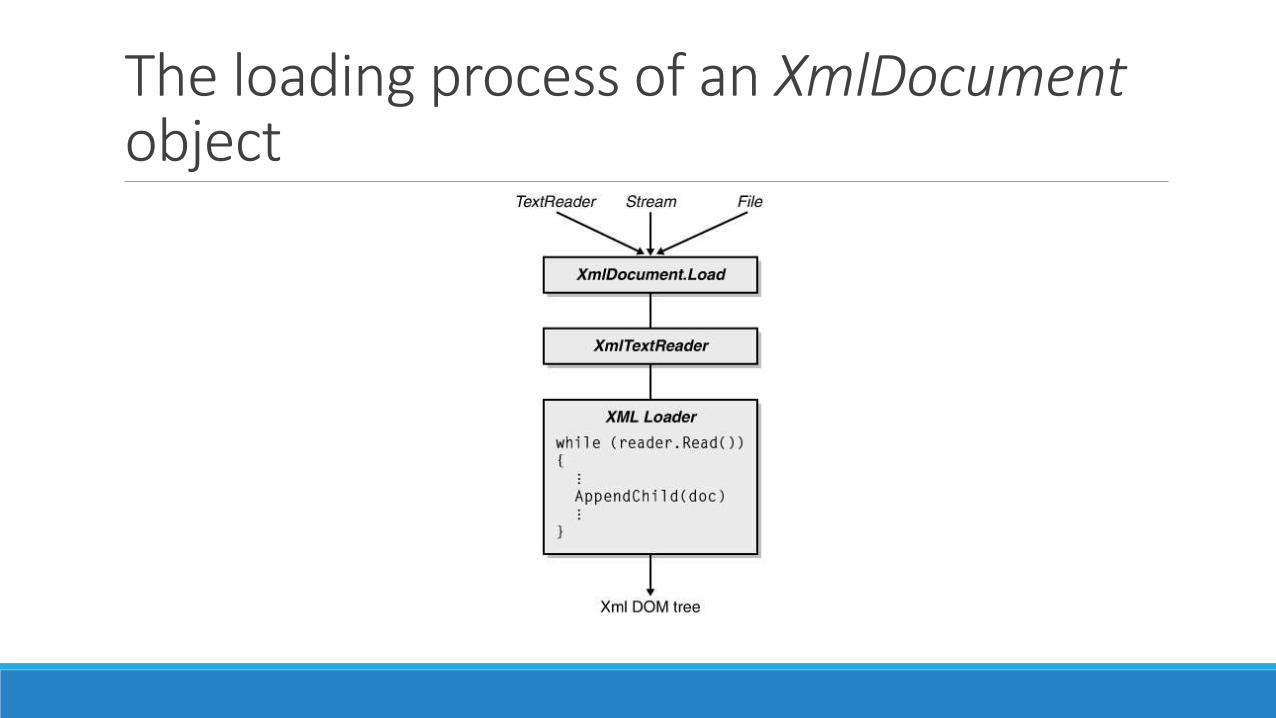
Well-Formedness and ValidationThe XML document loader checks only input data for well-formedness If parsing errors
are found an XmlException exception is thrown and the resulting XmlDocument object
remains empty To load a document and validate it against a DTD or a schema file you
must use the Load methods overload which accepts an XmlReader object You pass
the Load method a properly initialized instance of the XmlValidatingReader class as
shown in the following code and proceed as usual
XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

XmlTextReader _coreReader
XmlValidatingReader reader
_coreReader = new XmlTextReader(xmlFile)
reader = new XmlValidatingReader(_coreReader)
docLoad(reader)
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new
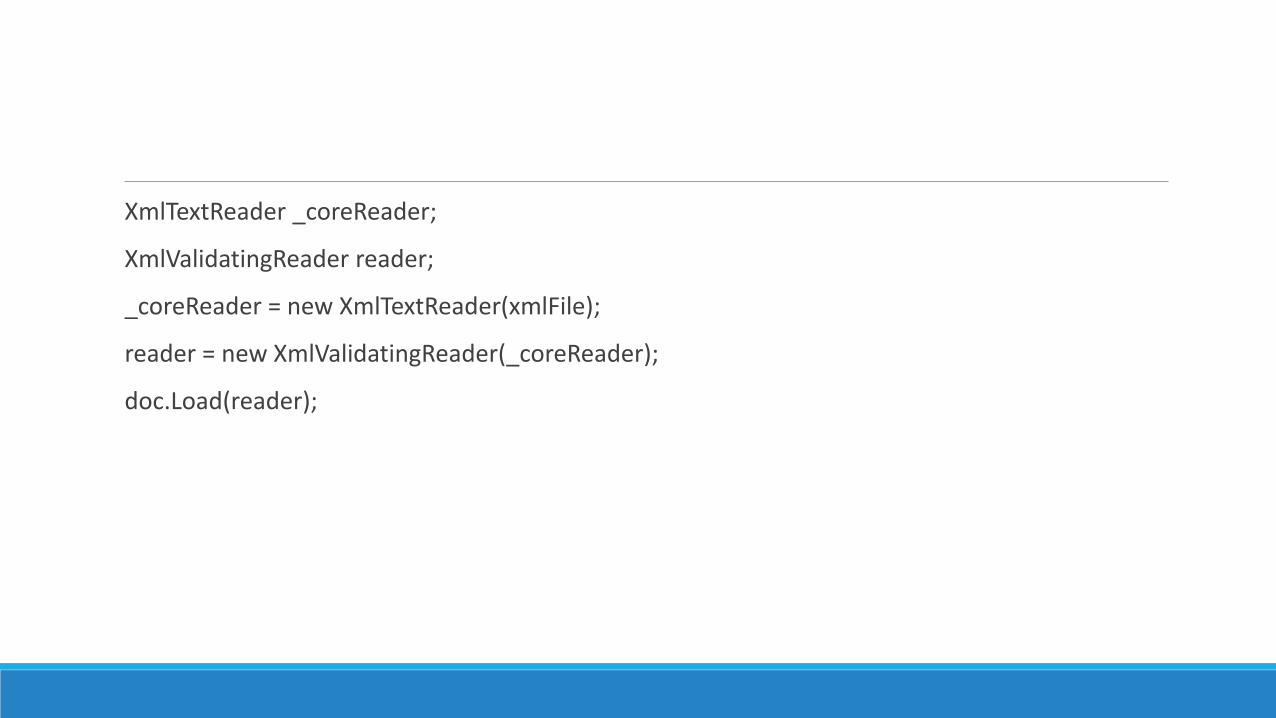
Loading from a String
The XML DOM programming interface also provides you with a method to build a DOM
from a well-formed XML string The method is LoadXml and is shown here
public virtual void LoadXml(string xml)
This method neither supports validation nor preserves white spaces Any contextspecific
information you might need (DTD entities namespaces) must necessarily be
embedded in the string to be taken into account
Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

Loading Documents Asynchronously
The NET Framework implementation of the XML DOM does not provide for
asynchronous loading The Load method in fact always work synchronously and does
not pass the control back to the caller until completed As you might guess this can
become a serious problem when you have huge files to process and a rich user
interface
In similar situationsmdashthat is when you are writing a Windows Forms rich clientmdashusing
threads can be the most effective solution You transfer to a worker thread the burden
of loading the XML document and update the user interface when the thread returns as
shown here
Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

Extracting XML DOM Subtrees
You normally build the XML DOM by loading the entire XML document into memory
However the XmlDocument class also provides the means to extract only a portion of
the document and return it as an XML DOM subtree The key method to achieve this
result is ReadNode shown here
public virtual XmlNode ReadNode(XmlReader reader)
The ReadNode method begins to read from the current position of the given reader and
doesnt stop until the end tag of the current node is reached The reader is then left
immediately after the end tag For the method to work the reader must be positioned
on an element or an attribute node
ReadNode returns an XmlNode object that contains the subtree representing
everything that has been read including attributes ReadNode is different from
ChildNodes in that it recursively processes children at any level and does not stop at
the first level of siblings
Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

Updating Text and Markup
Once an XML document is loaded in memory you can enter all the needed changes by
simply accessing the property of interest and modifying the underlying value For
example to change the value of an attribute you proceed as follows
Retrieve a particular node and update an attribute
XmlNode n = rootSelectSingleNode(days)
nAttributes[module] = 1
Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new

Detecting Changes
Callers are notified of any changes that affect nodes through events You can set event
handlers at any time and even prior to loading the document as shown here
XmlDocument doc = new XmlDocument()
docNodeInserted += new XmlNodeChangedEventHandler(Changed)
docLoad(fileName)
If you use the preceding code you will get events for each insertion during the building
of the XML DOM The following code illustrates a minimal event handler
void Changed(object sender XmlNodeChangedEventArgs e)
ConsoleWriteLine(eActionToString())
Note that by design XML DOM events give you a chance to intervene before and after a
node is added removed or updated
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new
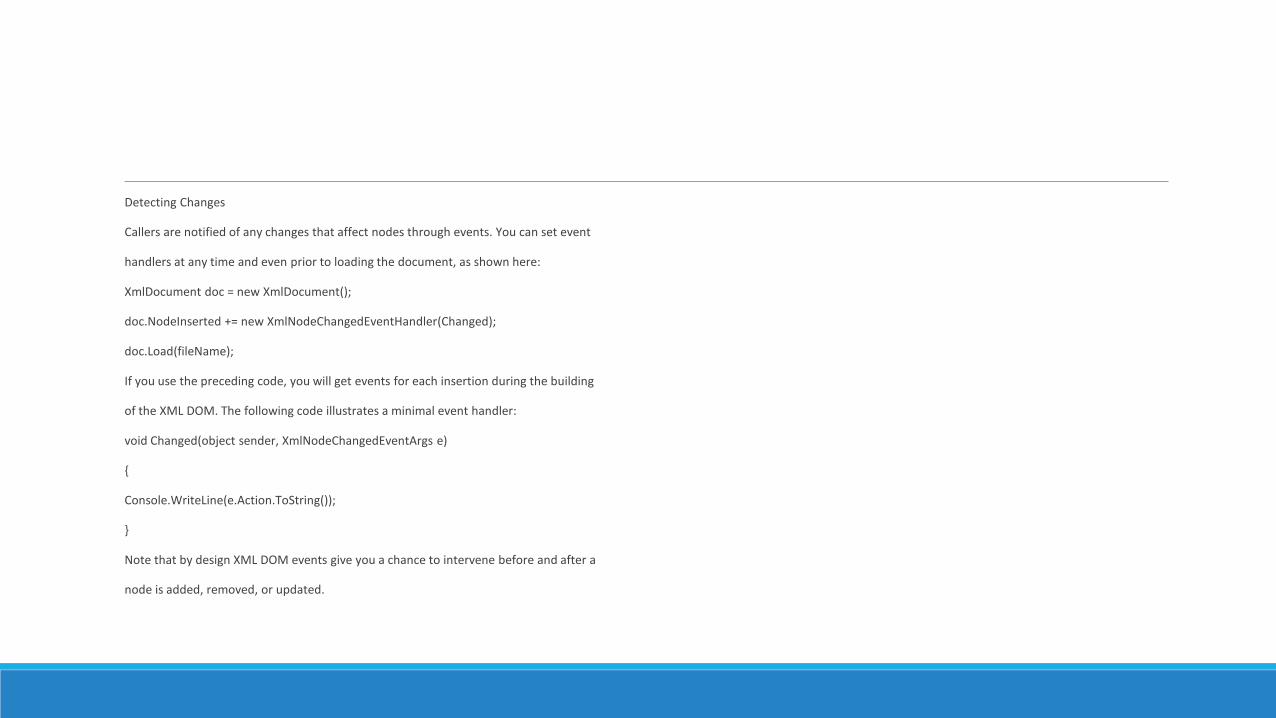
Creating XML DocumentsIf your primary goal is analyzing the contents of an XML document you will probably
find the XML DOM parsing model much more effective than readers in spite of the
larger memory footprint and set-up time it requires A document loaded through XML
DOM can be modified extended shrunk and more important searched The same
cant be done with XML readers XML readers follow a different design center But what
are the advantages of creating XML documents using XML DOM
To create an XML document using the XML DOM API you must first create the
document in memory and then call the Save method or one of its overloads This
system gives you great flexibility because no changes you make are set in stone until
you save the document In general however using the XML DOM API to create a new



















