
Taming Big Data!
57
Ian Foster Argonne National Laboratory and University of Chicago [email protected] ianfoster.org Taming Big Data!
-
Upload
ian-foster -
Category
Data & Analytics
-
view
813 -
download
1
Transcript of Taming Big Data!

Ian Foster
Argonne National Laboratory and University of Chicago
ianfoster.org
Taming Big Data!
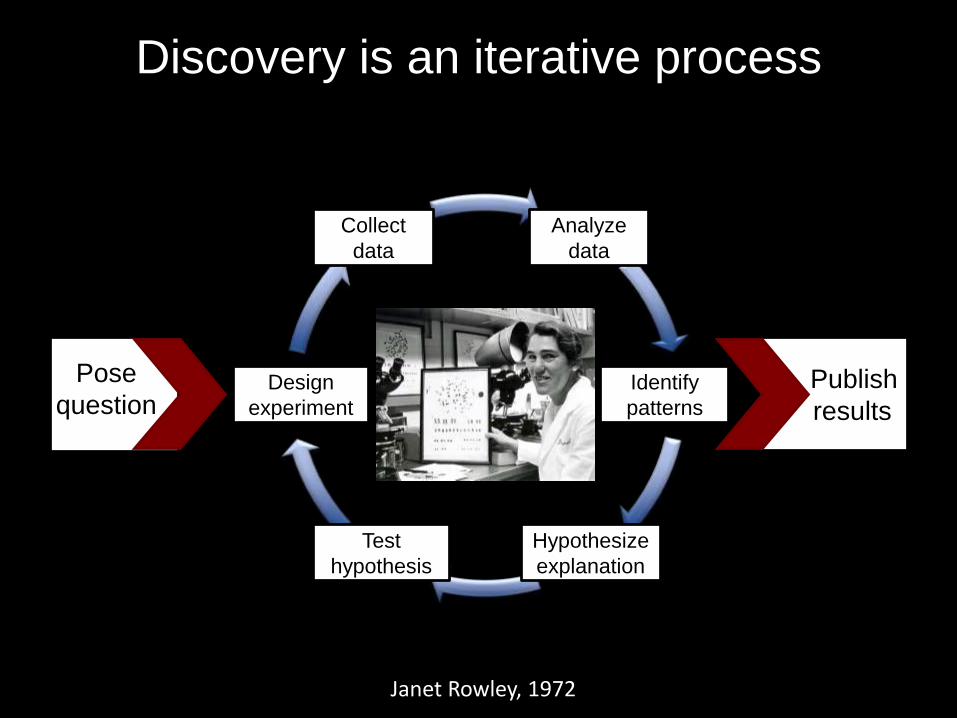
Publish
results
Collect
data
Design
experiment
Test
hypothesis
Hypothesize
explanation
Identify
patterns
Analyze
data
Discovery is an iterative process
Pose
question
Janet Rowley, 1972
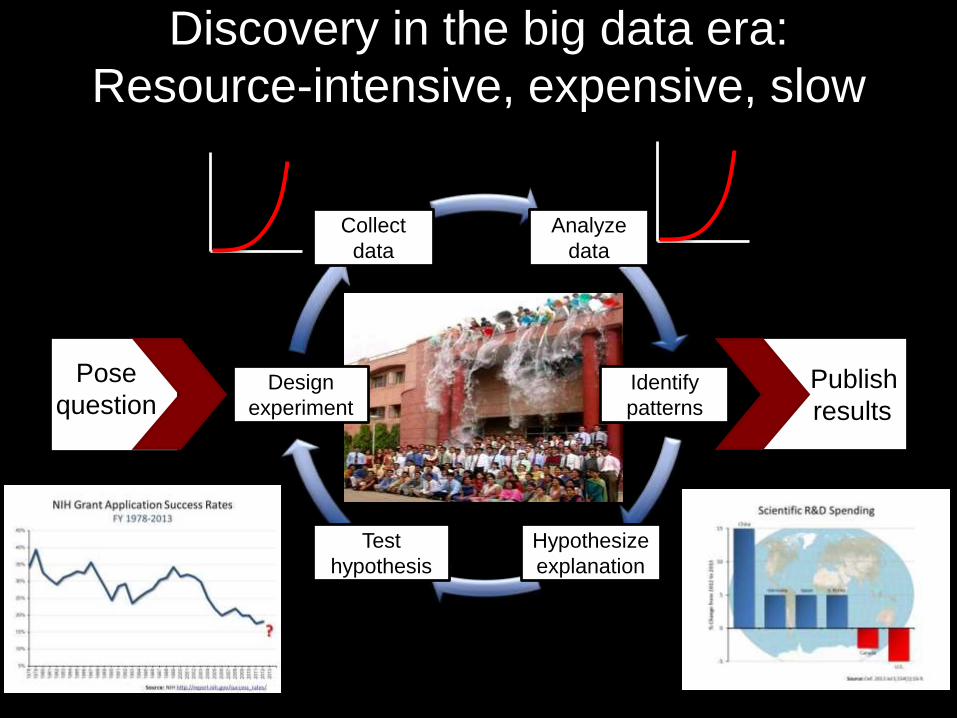
Publish
results
Collect
data
Design
experiment
Test
hypothesis
Hypothesize
explanation
Identify
patterns
Analyze
data
Discovery in the big data era:
Resource-intensive, expensive, slow
Pose
question

Three big data challenges
Channel massive flows
Automate management
Build discovery engines
4

Three big data challenges
Channel massive flows
Automate management
Build discovery engines
5

Channel massive data flows
Data must move to be useful. We may optimize,
but we can never entirely eliminate distance.
• Sources: experimental facilities,
sensors, computations
• Sinks: analysis computers,
display systems
• Stores: impedance
matchers & time shifters
• Pipes: IO systems and
networks connect other elements
“We must think of data as a flowing river over time, not a static snapshot. Make copies, share, and do magic” – S. Madhavan
Store
Transfer is challenging at many levels
Speed and reliability
• GridFTP protocol
• Globus implementation
Scheduling and modeling
• SEAL and STEAL algorithms
• RAMSES project7
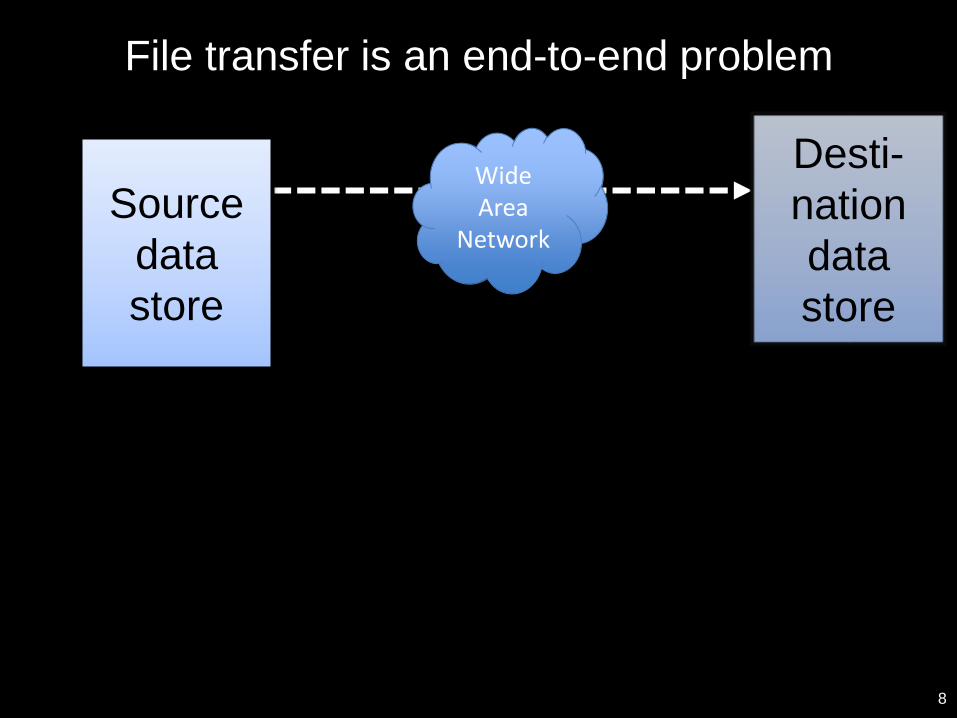
8
Source
data
store
Desti-
nation
data
store
Wide Area
Network
File transfer is an end-to-end problem
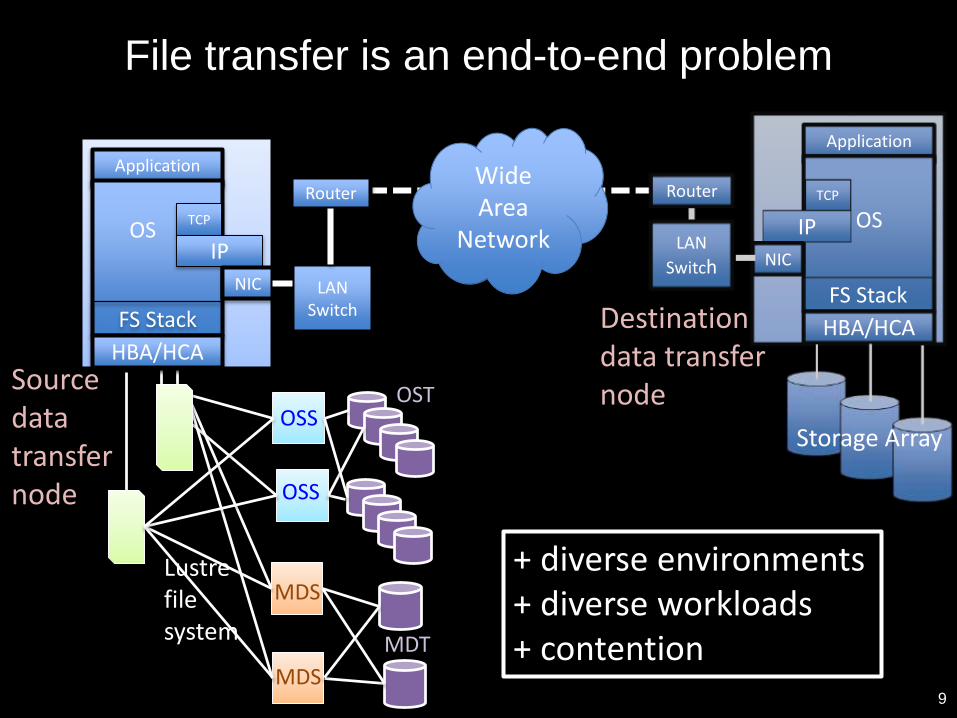
9
Application
OS
FS Stack
HBA/HCA
LANSwitch
Router
Source data transfer node
TCP
IP
NIC
Application
OS
FS Stack
HBA/HCA
LAN
Switch
Router TCP
IP
NIC
Storage Array
Wide Area
Network
OST
MDT
Lustre file system
Destination data transfer node
OSS
OSS
MDS
MDS
+ diverse environments+ diverse workloads+ contention
File transfer is an end-to-end problem
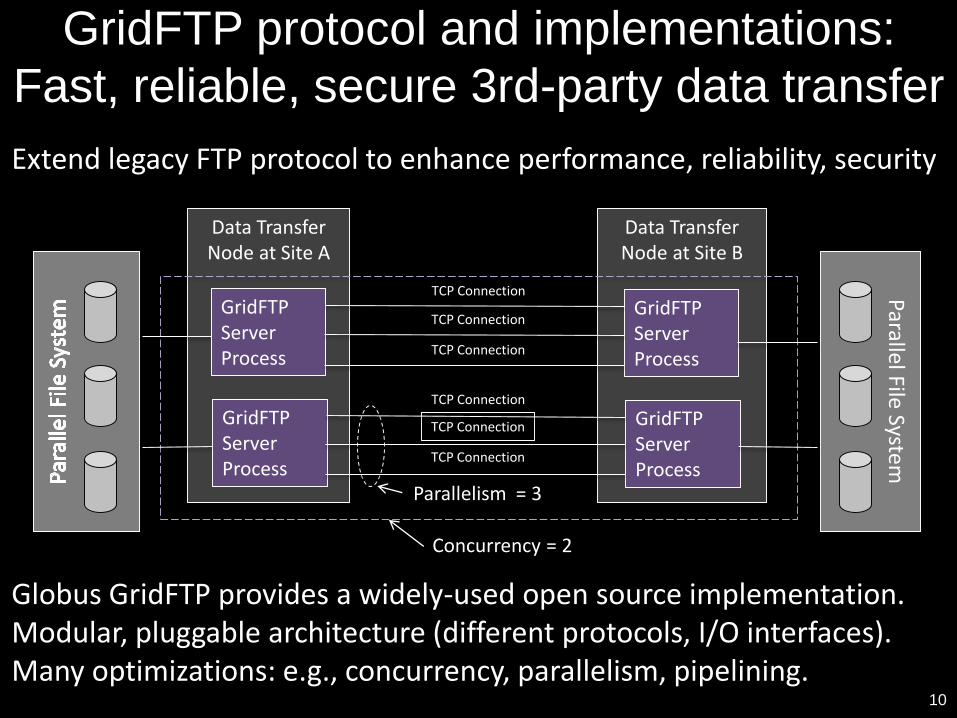
GridFTP protocol and implementations:
Fast, reliable, secure 3rd-party data transfer
10
Extend legacy FTP protocol to enhance performance, reliability, security
Globus GridFTP provides a widely-used open source implementation.Modular, pluggable architecture (different protocols, I/O interfaces).Many optimizations: e.g., concurrency, parallelism, pipelining.
Data Transfer Node at Site B
Data Transfer Node at Site A
Parallel File System
GridFTP Server Process
GridFTP Server Process
Parallelism = 3
Concurrency = 2
GridFTP Server Process
GridFTP Server Process
TCP Connection
TCP Connection
TCP Connection
TCP Connection
TCP Connection
TCP Connection
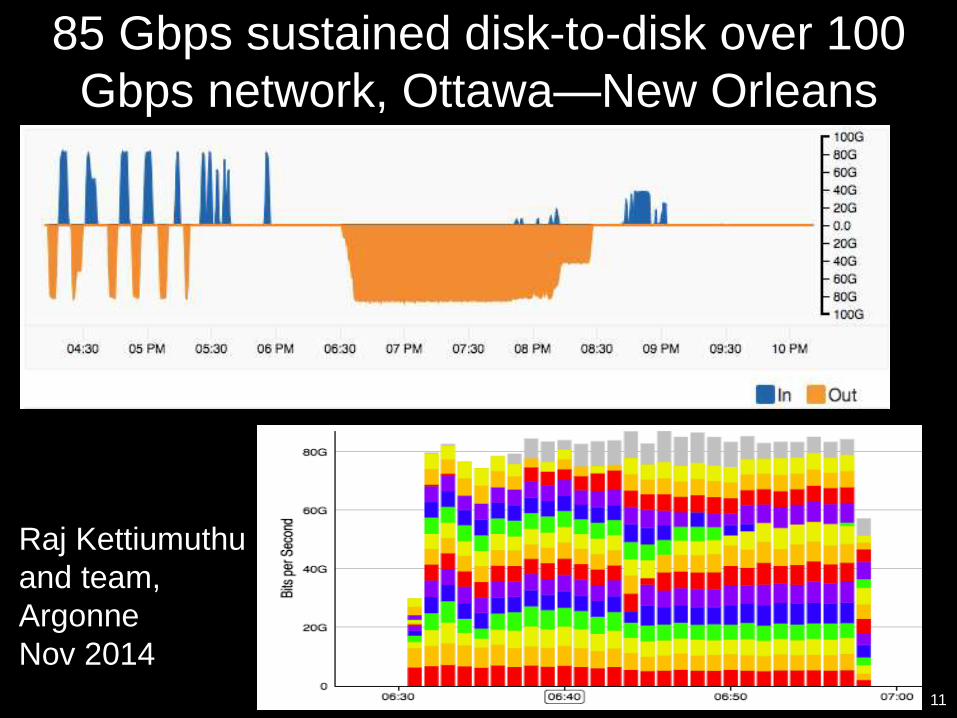
85 Gbps sustained disk-to-disk over 100
Gbps network, Ottawa—New Orleans
11
Raj Kettiumuthu
and team,
Argonne
Nov 2014

Higgs discovery “only possible because of the extraordinary achievements of … grid computing”—Rolf Heuer, CERN DG
10s of PB, 100s of institutions, 1000s of scientists, 100Ks of CPUs, Bs of tasks
12
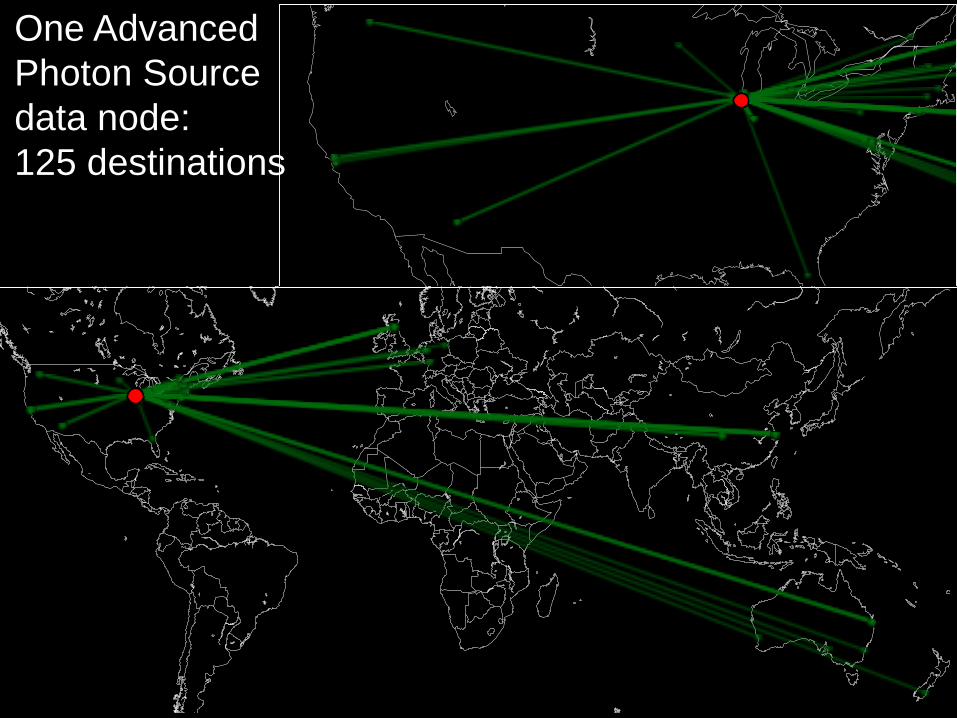
13
Endpoint aps#clutch has transfers to 125 other endpoints
Endpoint aps#clutch has transfers to 125 other endpoints
One Advanced
Photon Source
data node:
125 destinations
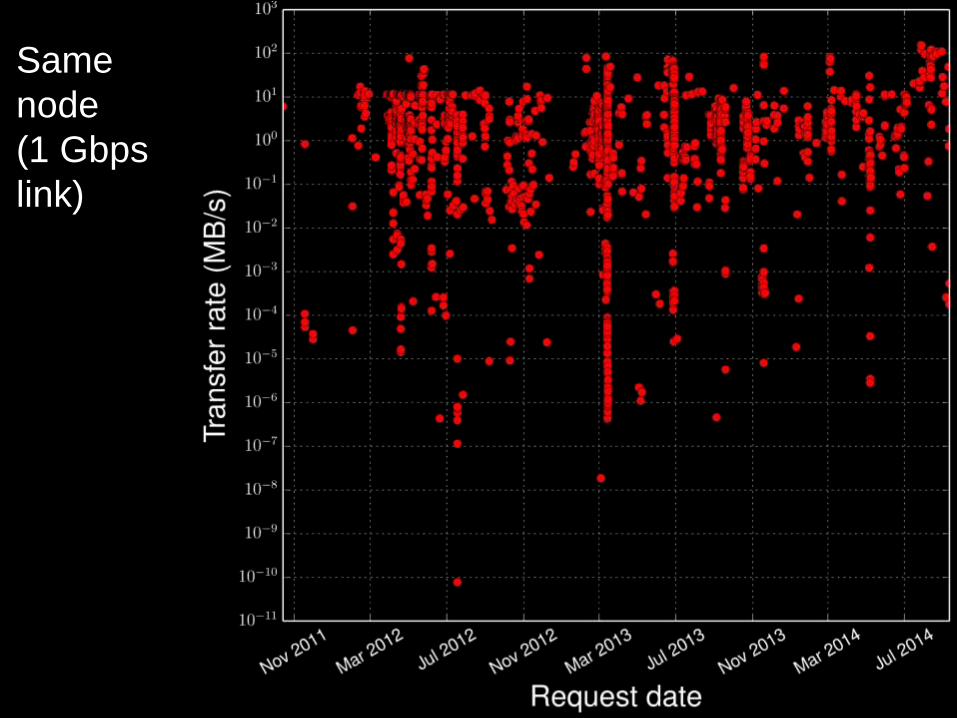
Same
node
(1 Gbps
link)
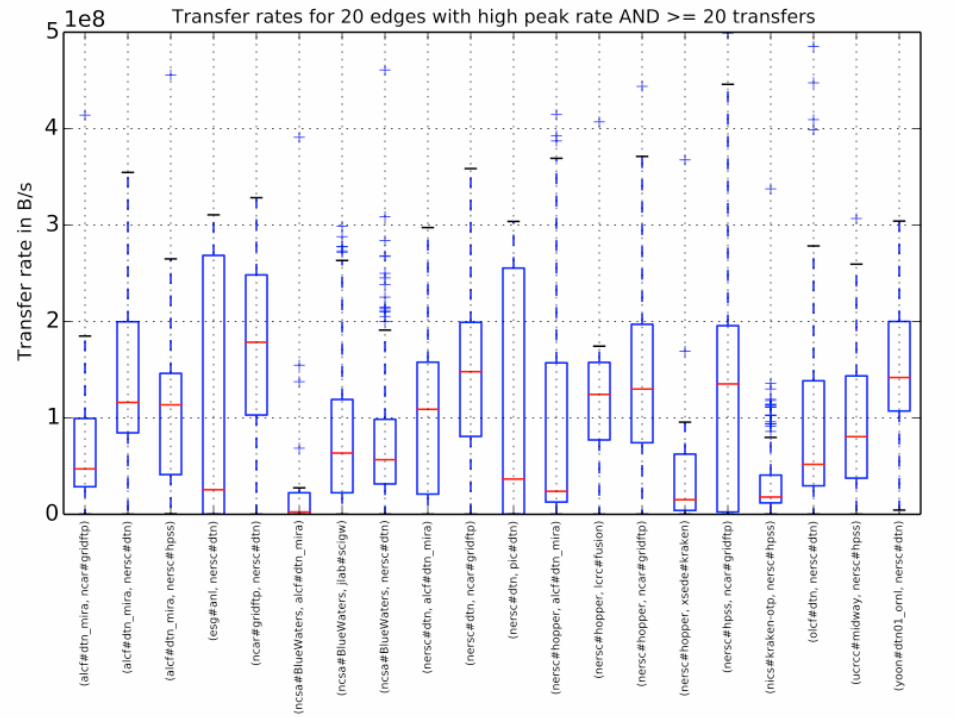
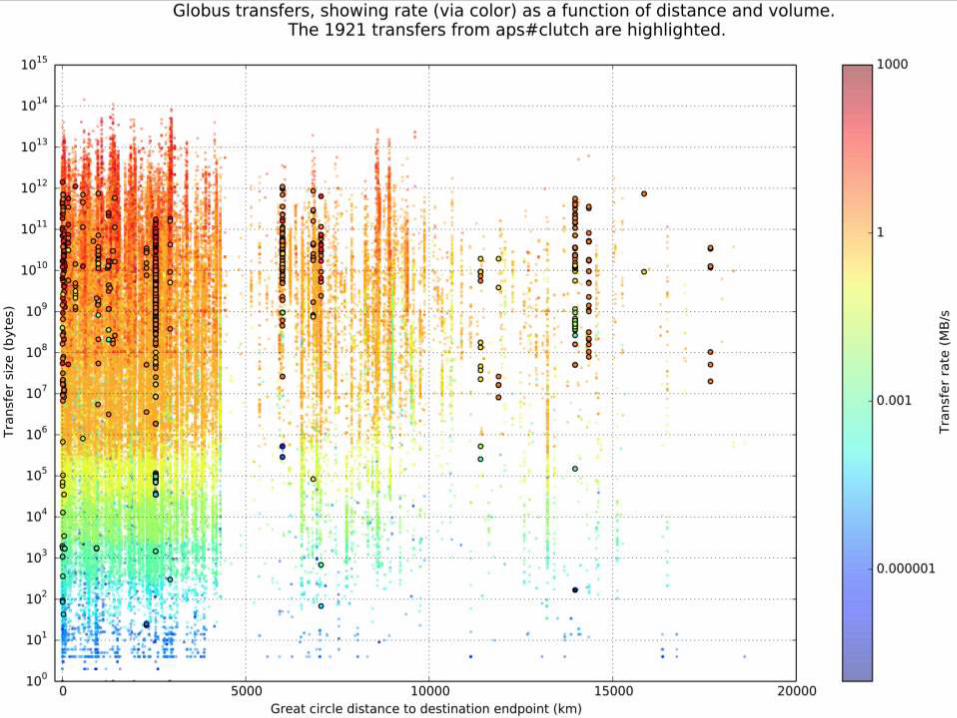
16
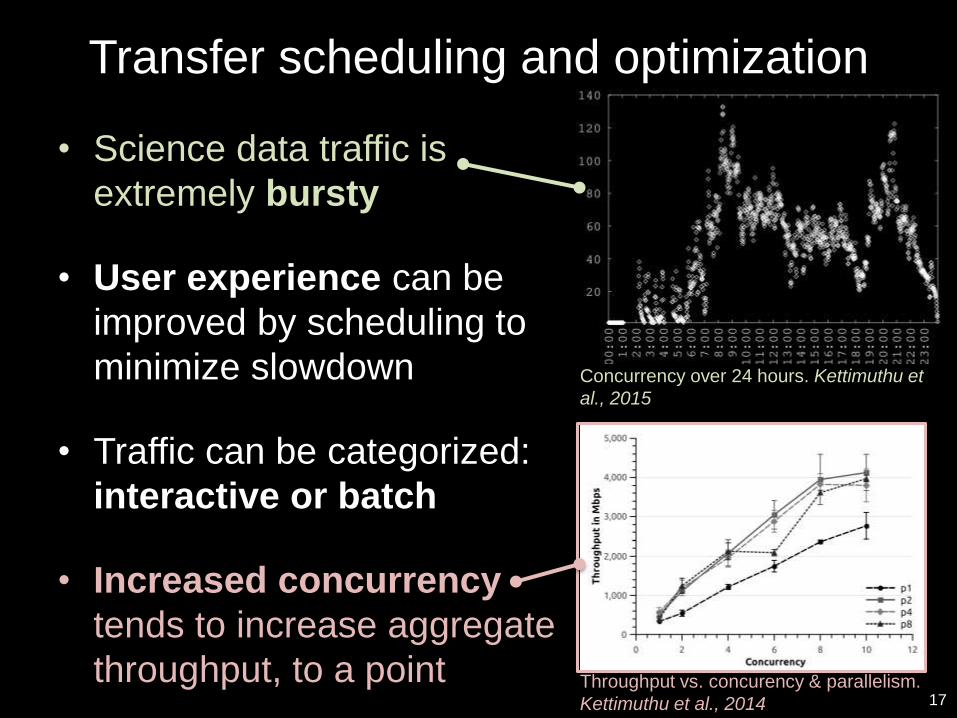
Transfer scheduling and optimization
• Science data traffic is
extremely bursty
• User experience can be
improved by scheduling to
minimize slowdown
• Traffic can be categorized:
interactive or batch
• Increased concurrency
tends to increase aggregate
throughput, to a point17
Concurrency over 24 hours. Kettimuthu et
al., 2015
Throughput vs. concurency & parallelism.
Kettimuthu et al., 2014
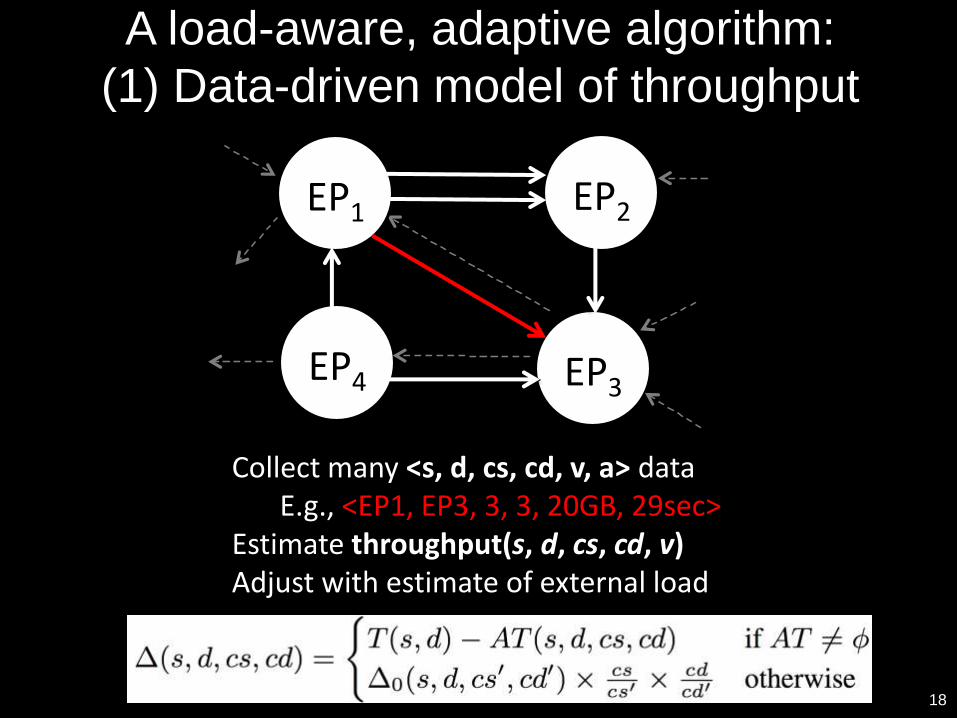
A load-aware, adaptive algorithm:
(1) Data-driven model of throughput
18
EP2
EP3EP4
EP1
Collect many <s, d, cs, cd, v, a> dataE.g., <EP1, EP3, 3, 3, 20GB, 29sec>
Estimate throughput(s, d, cs, cd, v) Adjust with estimate of external load

Define transfer priority:
Schedule transfers if neither source nor destination
is saturated, using model to decide concurrency
If source or destination is saturated, interrupt active
transfer(s) to service waiting requests, if in so doing
can reduce overall average slowdown
19
A load-aware, adaptive algorithm:
(2) Concurrency-constrained scheduling
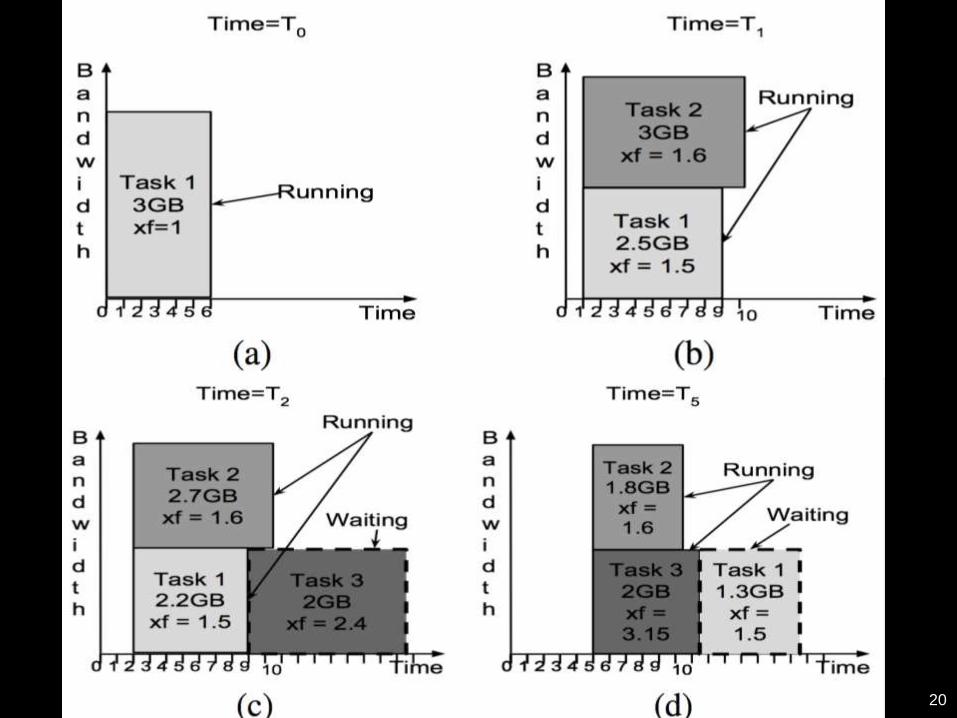
20
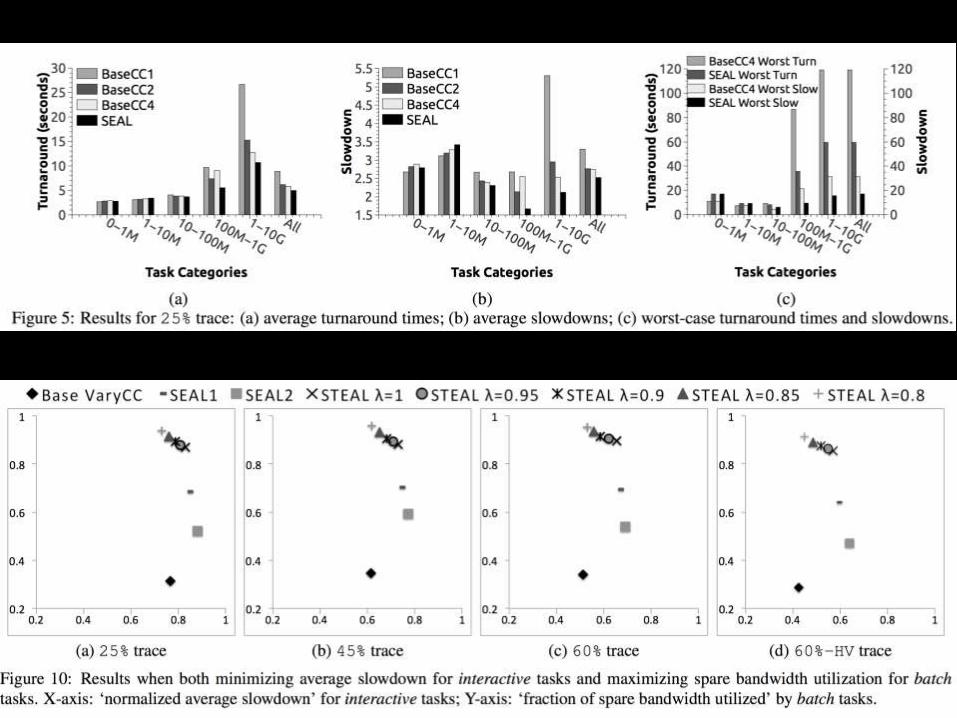
21

Gagan Agarwal1* Prasanna Balaprakash2 Ian Foster2* Raj Kettimuthu2
Sven Leyffer2 Vitali Morozov2 Todd Munson2 Nagi Rao3*
Saday Sadayappan1 Brad Settlemyer3 Brian Tierney4* Don Towsley5*
Venkat Vishwanath2 Yao Zhang2
1 Ohio State University 2 Argonne National Laboratory 3 Oak Ridge National Laboratory 4 ESnet 5 UMass Amherst (* Co-PIs)
Advanced Scientific Computing Research
Program manager: Rich Carlson♦︎
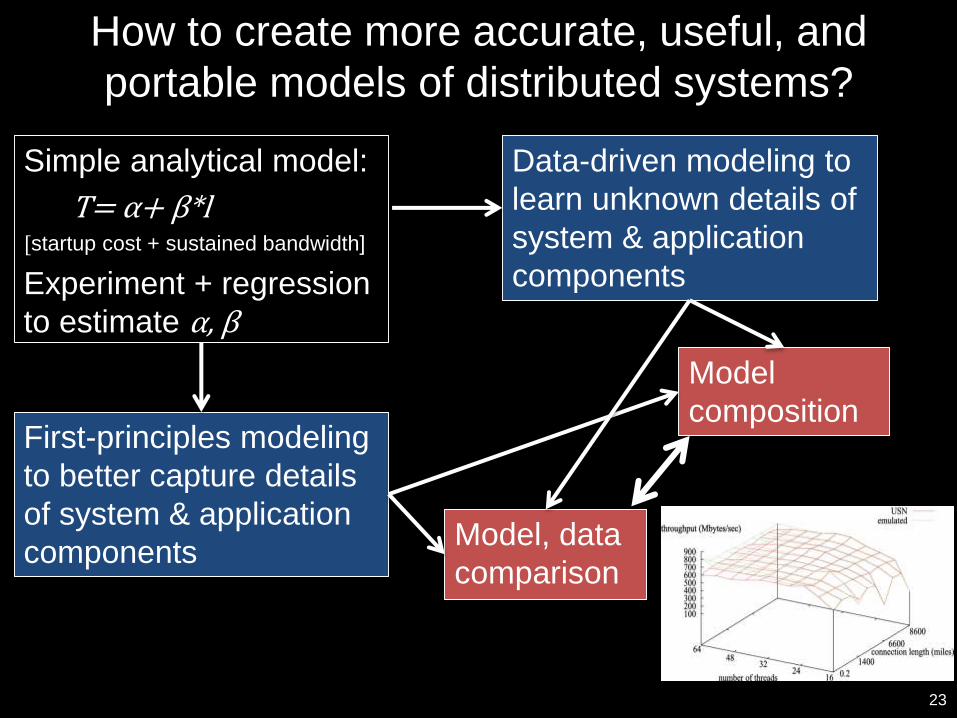
How to create more accurate, useful, and
portable models of distributed systems?
Simple analytical model:
T= α+ β*l[startup cost + sustained bandwidth]
Experiment + regression
to estimate α, β
23
First-principles modeling
to better capture details
of system & application
components
Data-driven modeling to
learn unknown details of
system & application
components
Model
composition
Model, data
comparison

Differential regression for combining
data from different sources
Example of use: Predict performance on connection length L
not realizable on physical infrastructure
E.g., IB-RDMA or HTCP throughput on 900-mile connection
1) Make multiple measurements of performance on path lengths d:
– Ms(d): OPNET simulation
– ME(d): ANUE-emulated path
– MU(di): Real network (USN)
2) Compute measurement regressions on d: ṀA(.), A∈{S, E, U}
3) Compute differential regressions: ∆ṀA,B(.) = ṀA(.) - ṀB(.), A, B∈{S, E, U}
4) Apply differential regression to obtain estimates, C∈{S, E}
𝓜U(d) = MC(d) - ∆ṀC,U(d)
simulated/emulated measurements point regression estimate

Source LAN
profile
WAN
profileDestination LAN
profile
Configuration for
host and edge
devices
Configuration
for WAN
devices
Configuration for
host and edge
devices
composition
operations
End-to-end profile composition

Three big data challenges
Channel massive flows
Automate management
Build discovery engines
26

Registry
Staging Store
IngestStore
AnalysisStore
Community Store
Archive Mirror
IngestStore
AnalysisStore
Community Store
Archive Mirror
Registry
Quota
exceeded
!
Expired
credentials
!
Network
failed. Retry.
!
Permission
denied
!
It should be trivial to Collect, Move, Sync, Share, Analyze,
Annotate, Publish, Search, Backup, & Archive BIG DATA
… but in reality it’s often very challenging

One researcher’s perspective
on data management challenges
28
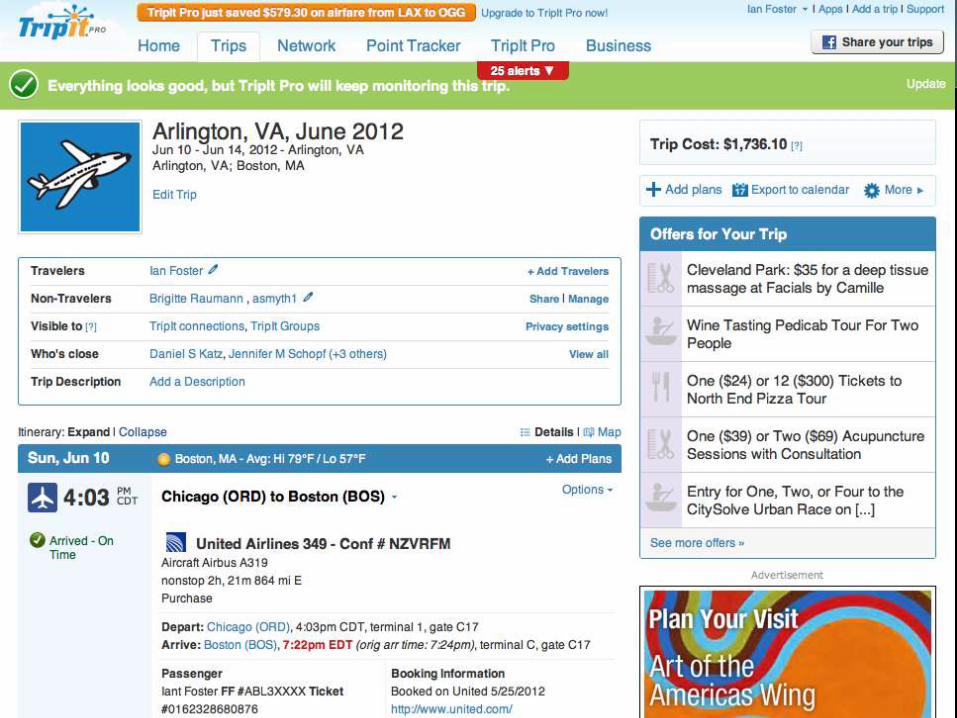
29

Tripit exemplifies process automation
Me
Book flights
Book hotel
Record flights
Suggest hotel
Record hotel
Get weather
Prepare maps
Share info
Monitor prices
Monitor flight
Other services
How the “business cloud” works
Platform
services
Database, analytics, application, deployment, workflow, queuing Auto-scaling, Domain Name Service, content distributionElastic MapReduce, streaming data analyticsEmail, messaging, transcoding. Many more.
Infrastructure
services
Computing, storage, networking
Elastic capacity
Multiple availability zones

Process automation for science
Run experiment
Collect data
Move data
Check data
Annotate data
Share data
Find similar data
Link to literature
Analyze data
Publish data
Automate
and
outsource:
the
Discovery
cloud
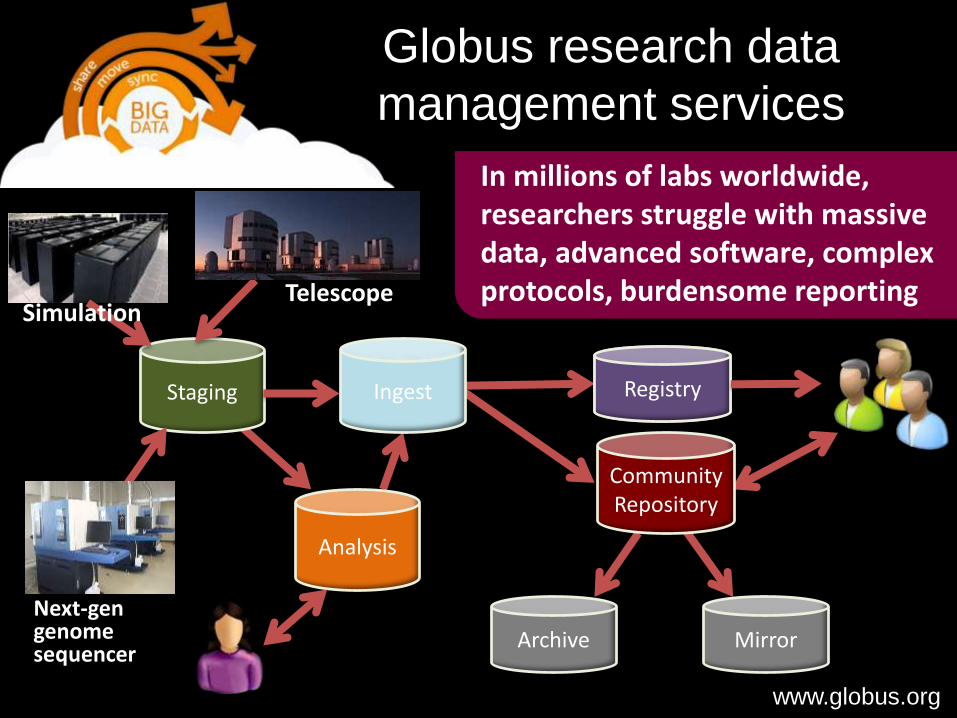
Analysis
Staging Ingest
Community Repository
Archive Mirror
Registry
Next-gen genomesequencer
Telescope
In millions of labs worldwide, researchers struggle with massive data, advanced software, complex protocols, burdensome reporting
Globus research data
management services
www.globus.org
Simulation
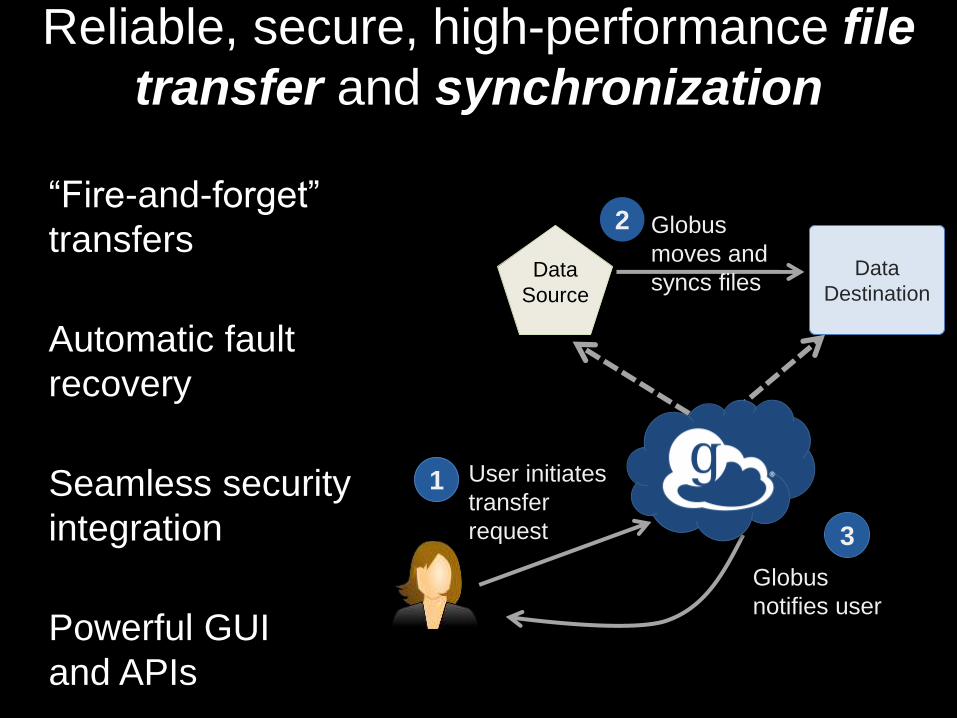
Reliable, secure, high-performance file
transfer and synchronization
“Fire-and-forget”
transfers
Automatic fault
recovery
Seamless security
integration
Powerful GUI
and APIs
Data
Source
Data
Destination
User initiates
transfer
request
1
Globus
moves and
syncs files
2
Globus
notifies user
3
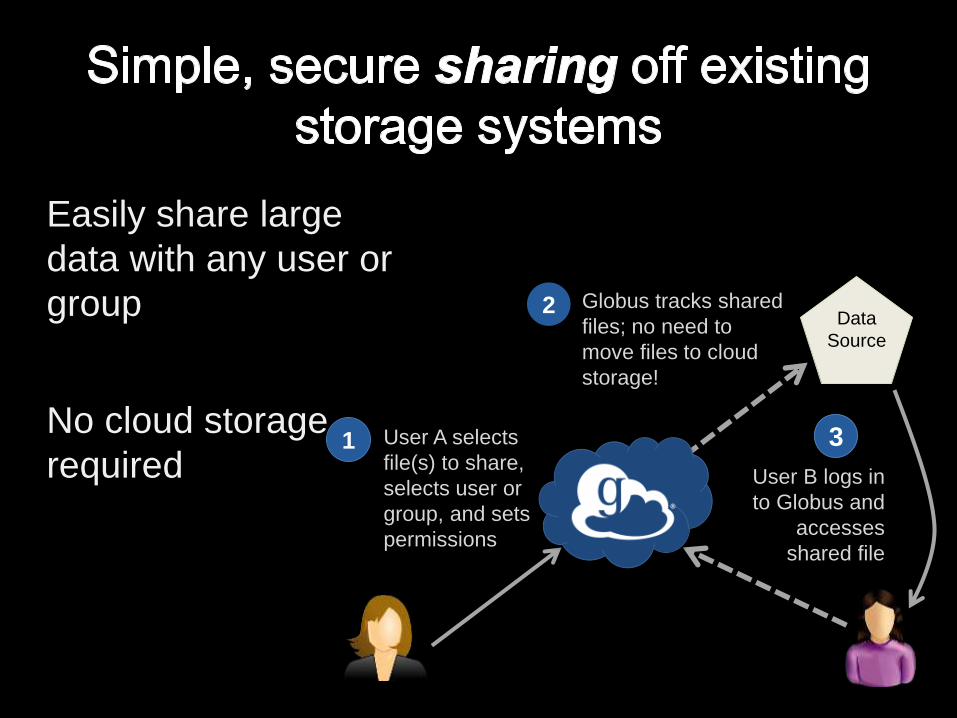
Data
Source
User A selects
file(s) to share,
selects user or
group, and sets
permissions
1
Globus tracks shared
files; no need to
move files to cloud
storage!
2
User B logs in
to Globus and
accesses
shared file
3
Easily share large
data with any user or
group
No cloud storage
required

Extreme ease of use
• InCommon, Oauth, OpenID, X.509, …
• Credential management
• Group definition and management
• Transfer management and optimization
• Reliability via transfer retries
• Web interface, REST API, command line
• One-click “Globus Connect Personal” install
• 5-minute Globus Connect Server install
37

38
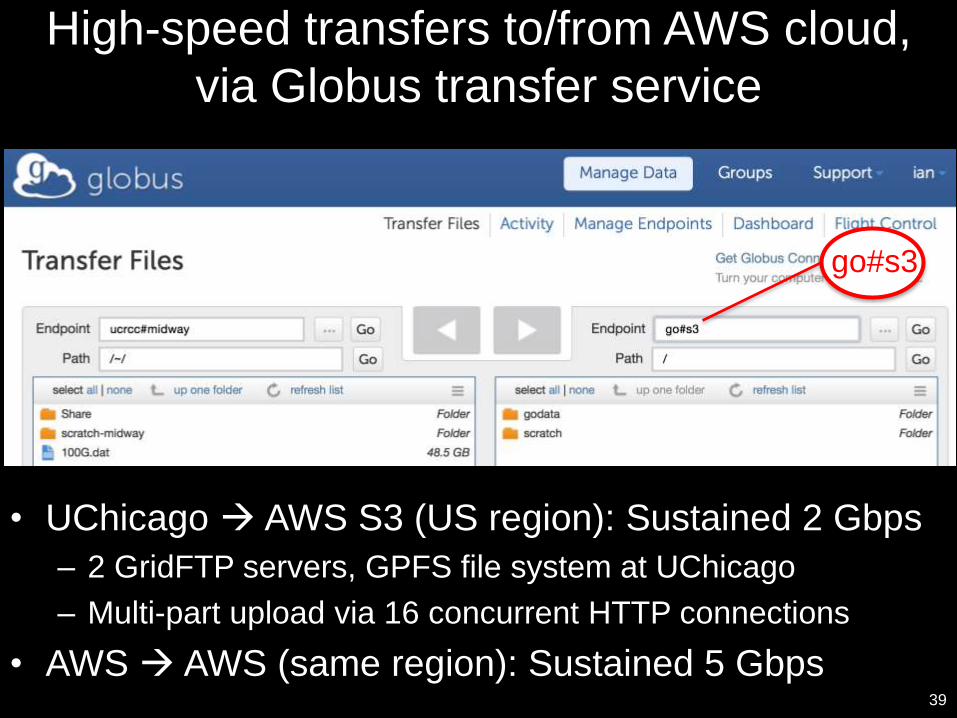
High-speed transfers to/from AWS cloud,
via Globus transfer service
• UChicago AWS S3 (US region): Sustained 2 Gbps
– 2 GridFTP servers, GPFS file system at UChicago
– Multi-part upload via 16 concurrent HTTP connections
• AWS AWS (same region): Sustained 5 Gbps39
go#s3

Globus transfer & sharing; identity & group
management, data discovery & publication
25,000 users, 75 PB and 3B files transferred, 8,000 endpoints
Globus endpoints

Identity, group, profile
management services
…
Sharing service
Transfer service
Globus Toolkit
Glo
bu
s C
on
ne
ct
X

Identity, group, profile
management services
Sharing service
Transfer service
Globus Toolkit
Glo
bu
s C
on
ne
ct
Publication and discovery
X
43
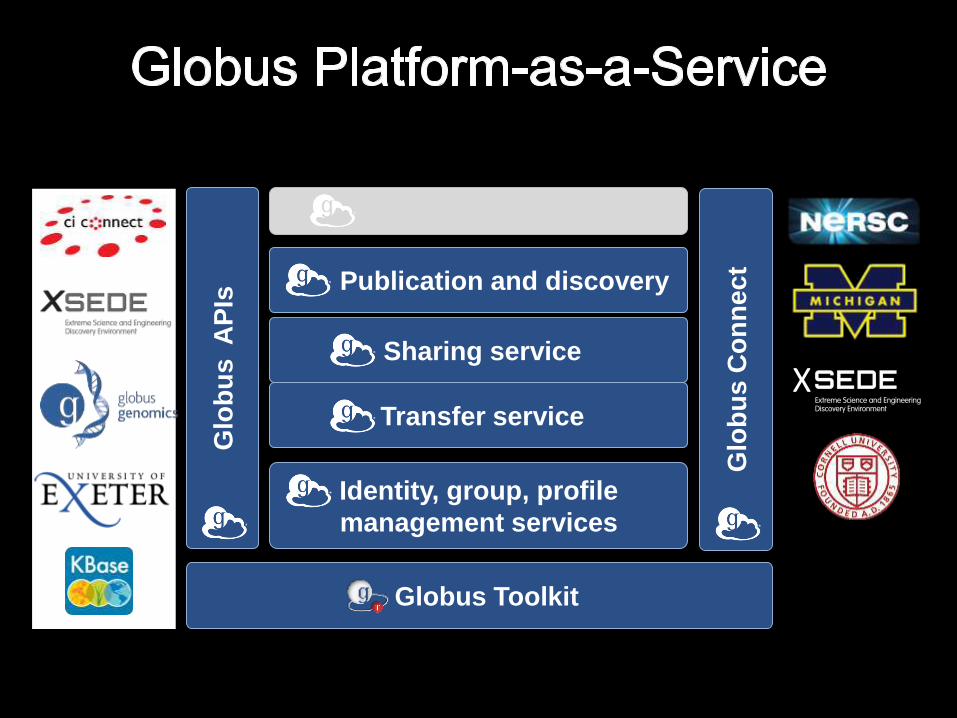
Identity, group, profile
management services
Sharing service
Transfer service
Globus Toolkit
Glo
bu
s A
PIs
Glo
bu
s C
on
ne
ct
Publication and discovery
X

The Globus Galaxies platform:
Science as a service
Globus
Galaxies
platform
Tool and workflow execution,
publication, discovery, sharing;
identity management; data
management; task scheduling
Infra-
structure
services
EC2, EBS, S3, SNS,
Spot, Route 53,
Cloud Formation
Emattermaterials
scienceFACE-IT
PDACS

Three big data challenges
Channel massive flows
Automate management
Build discovery engines
46
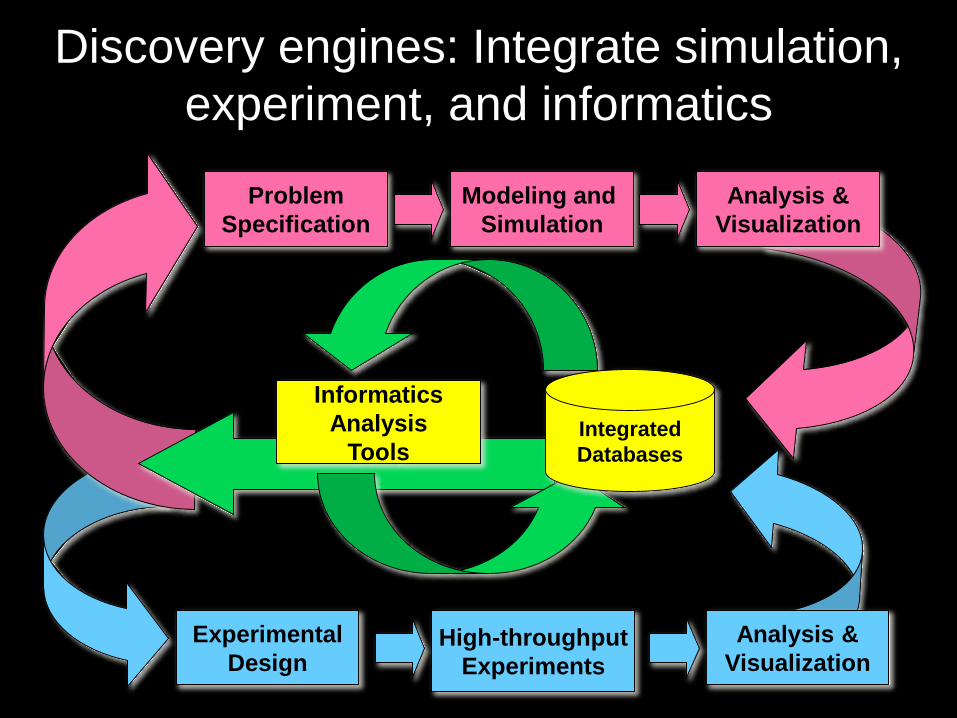
Discovery engines: Integrate simulation,
experiment, and informatics
Informatics
Analysis
Tools
High-throughput
Experiments
Problem
Specification
Modeling and
Simulation
Analysis &
Visualization
Experimental
Design
Analysis &
Visualization
Integrated
Databases
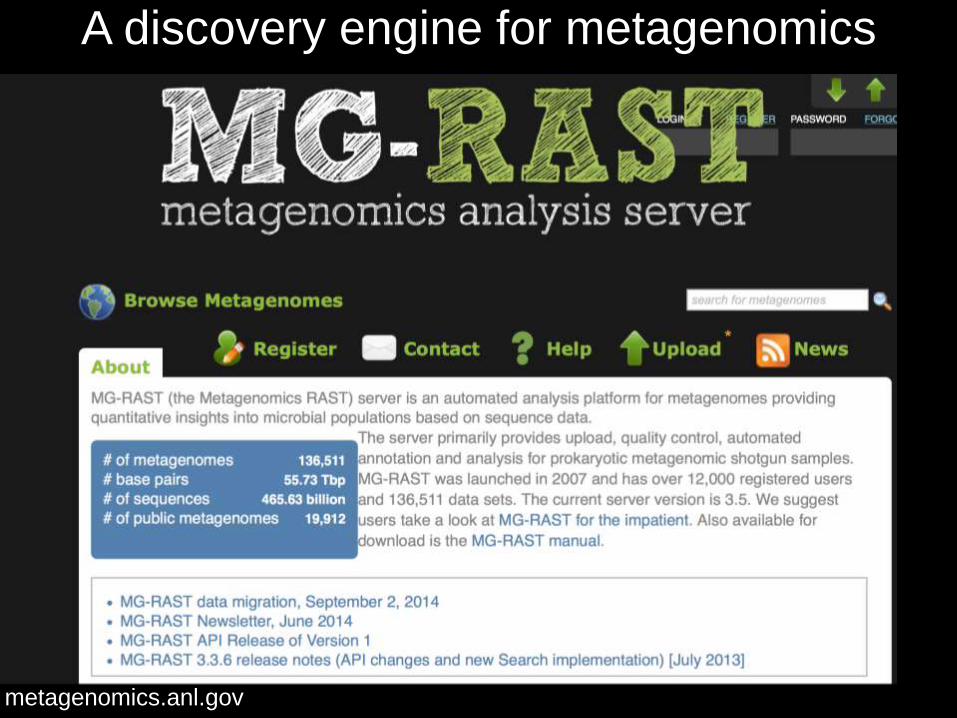
metagenomics.anl.gov
A discovery engine for metagenomics

kbase.us
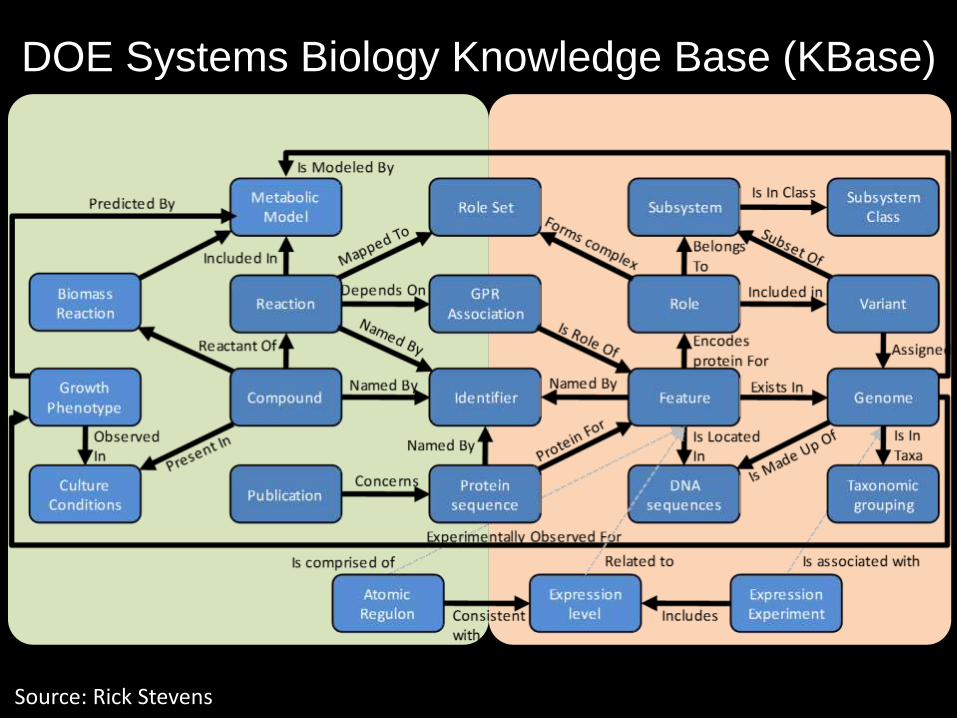
DOE Systems Biology Knowledge Base (KBase)
Source: Rick Stevens

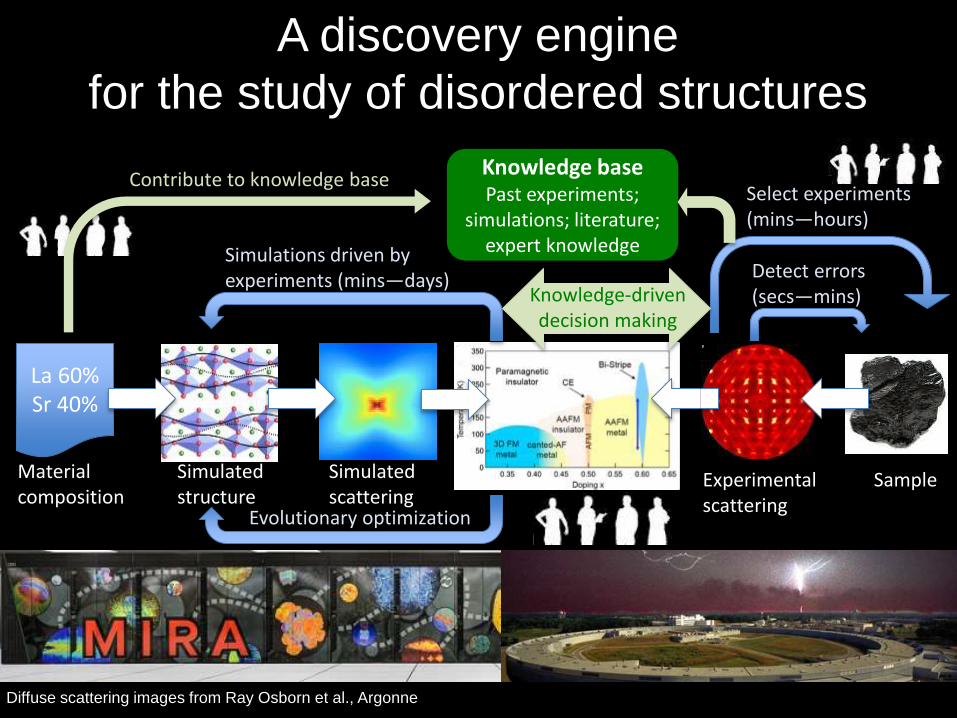
A discovery engine
for the study of disordered structures
Diffuse scattering images from Ray Osborn et al., Argonne
SampleExperimentalscattering
Material composition
Simulated structure
Simulatedscattering
La 60%Sr 40%
Detect errors (secs—mins)
Knowledge basePast experiments;
simulations; literature; expert knowledge
Select experiments (mins—hours)
Contribute to knowledge base
Simulations driven by experiments (mins—days)
Knowledge-drivendecision making
Evolutionary optimization
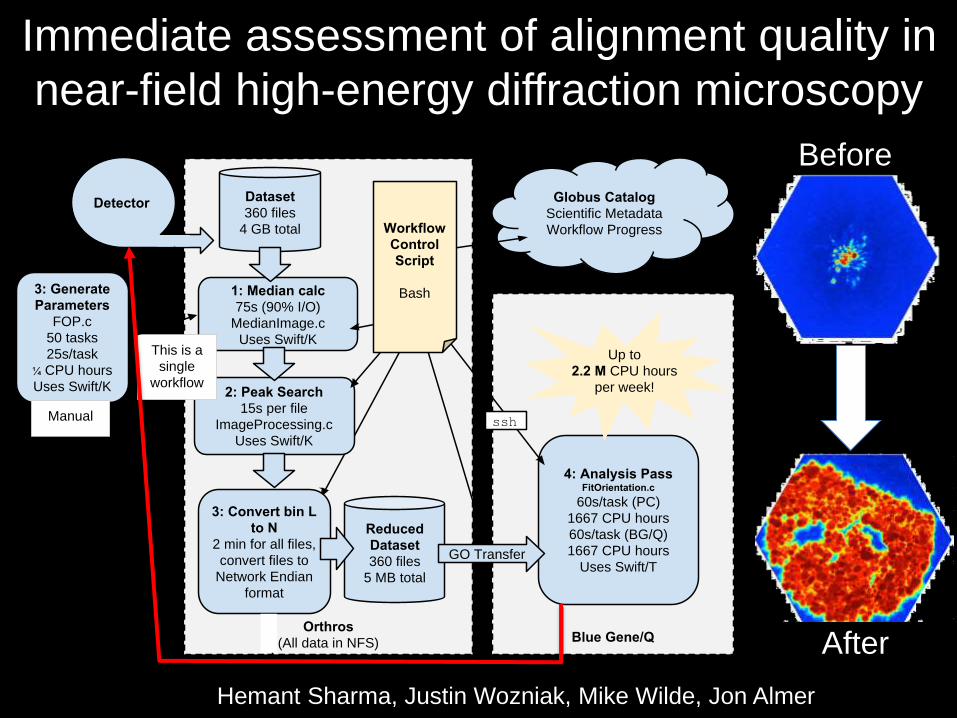
Immediate assessment of alignment quality in
near-field high-energy diffraction microscopy
53
Blue Gene/QOrthros
(All data in NFS)
3: Generate
Parameters
FOP.c
50 tasks
25s/task
¼ CPU hours
Uses Swift/K
Dataset
360 files
4 GB total
1: Median calc
75s (90% I/O)
MedianImage.c
Uses Swift/K
2: Peak Search
15s per file
ImageProcessing.c
Uses Swift/K
Reduced
Dataset
360 files
5 MB total
feedback to experiment
Detector
4: Analysis PassFitOrientation.c
60s/task (PC)
1667 CPU hours
60s/task (BG/Q)
1667 CPU hours
Uses Swift/TGO Transfer
Up to
2.2 M CPU hours
per week!
ssh
Globus Catalog
Scientific Metadata
Workflow ProgressWorkflow
Control
Script
Bash
Manual
This is a
single
workflow
3: Convert bin L
to N
2 min for all files,
convert files to
Network Endian
format
Before
After
Hemant Sharma, Justin Wozniak, Mike Wilde, Jon Almer

Integrate data movement, management, workflow,
and computation to accelerate data-driven
applications
New data, computational capabilities, and
methods create opportunities and challenges
Integrate statistics/machine learning to assess
many models and calibrate them against `all'
relevant data
New computer facilities enable on-demand
computing and high-speed analysis of large
quantities of data

Three big data challenges
Channel massive flows– New protocols and
management algorithms
Automate management– The Discovery Cloud
Build discovery engines– MG-RAST, kBase, Materials
56

U.S. DEPARTMENT OF
ENERGY
57

58


















