
Symbolic and Machine Learning Methods for Patient...
29
Symbolic and Machine Learning Methods for Patient Discharge Summaries Encoding Julia Medori CENTAL (Centre for Natural Language Processing) Université catholique de Louvain (Belgium) Séminaire du Cental - 17/12/2010
-
Upload
phunghuong -
Category
Documents
-
view
213 -
download
0
Transcript of Symbolic and Machine Learning Methods for Patient...

Symbolic and Machine Learning
Methods for Patient Discharge
Summaries EncodingJulia Medori
CENTAL (Centre for Natural Language Processing)
Université catholique de Louvain (Belgium)
Séminaire du Cental - 17/12/2010

Overview
• Problem outline
• System structure
– Extraction
– Encoding
• Extraction module
• Encoding module
– Machine learning methods
• Experiments for features selection
• Results
– Symbolic methods description
• Method 1: Morphological Analysis (MA)
• Method 2: Extended lexical patterns (ELP)
• Methods combination
• Results
• Conclusions

Introduction
• Aim
Build a (semi-)automated system for ICD-9-CM encoding
• Collaboration CENTAL/Saint-Luc
– Université catholique de Louvain (Belgium)
• CENTAL : Centre for Natural Language Processing
• Saint-Luc hospital :
– team of 10 coders processes medical records :
Extraction of medical acts and diagnoses � ICD-9-CM codes
– 85,000 patient’s stays encoded each year.

Manual encoding

Data
• International Classification of Diseases -9th Revision-
Clinical Modification (ICD-9-CM)
– Hierarchy :
• first 3 digits -> general category : 1,135 categories
• Digits 4 and 5 -> specific diagnosis : 15,688 codes
• Example :
Code Label
001 Cholera
0010 Cholera due to Vibrio cholerae
0011 Cholera due to Vibrio cholerae el tor
0019 Cholera, unspecified

Objectives
• Design a coding help:
– a tool that will suggest the most likely codes to be
assigned to a patient’s medical record.
• Why not a fully automated system?
– Main source of information : Patient discharge
summary (PDS)
• PDS : letter, addressed to patient’s GP with no standard
structure
– 15-20% of the codes inferred from other sources
from patient’s medical record (often scanned
documents).
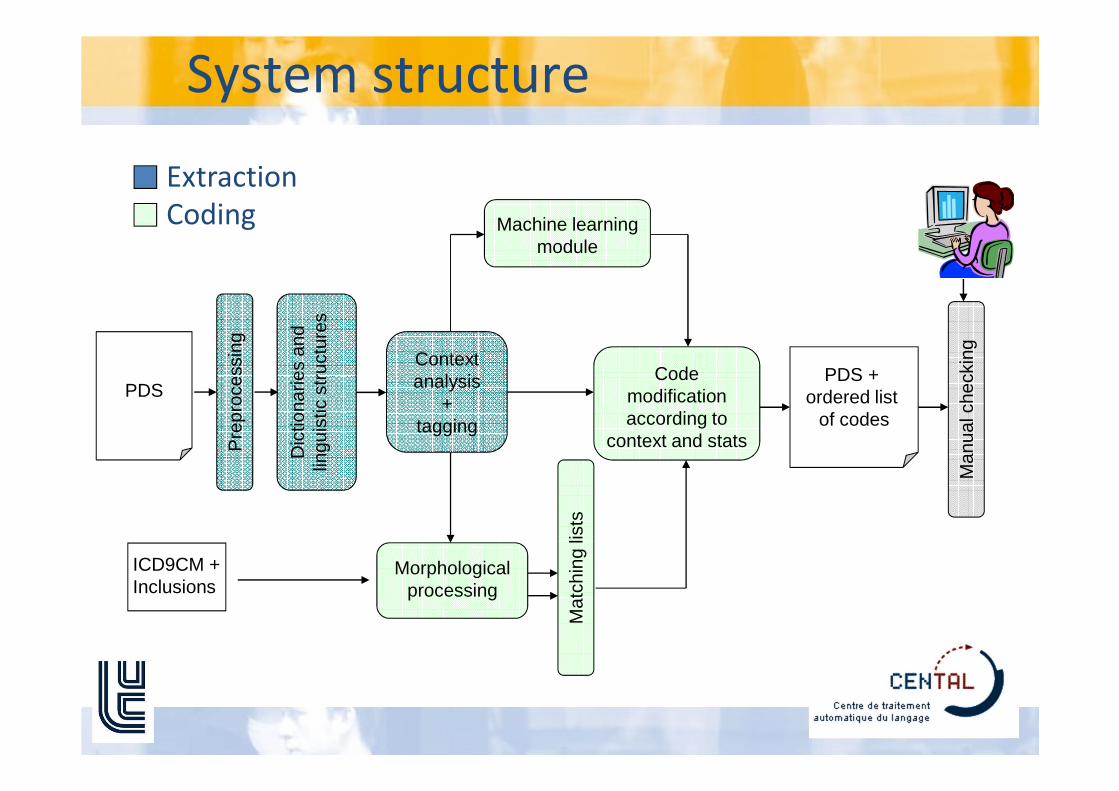
System structure
Pre
proc
essi
ng
Dic
tiona
ries
and
lingu
istic
str
uctu
res
Morphological processing
Context analysis
+ tagging
Mat
chin
g lis
ts
Code modification according to
context and stats
ICD9CM + Inclusions
PDSPDS +
ordered list of codes
Extraction
Coding
Man
ual c
heck
ing
Machine learning module

Structure outline
• 2 steps :
– Extraction
• Develop an extraction system able to extract
information necessary to the encoding task :– Diagnoses, procedures, locations, dates, allergies, aggravating
factors, etc.
=> Reading help tool.
– Encoding
• Extracted information => codes
through a combination of statistical and symbolic
methods.

Extraction
• Develop specialized linguistic resources
– Specialized dictionaries
• Diagnoses and procedures <= ICD-9-CM + UMLS
• Medications
• Anatomy
– Linguistic structure description
• Diagnoses context (present, absent, probable, etc.)
• Allergies and smoking
• Dates
• Weight and height

Example of linguistic structure graph
Fracture de l’épaule =>
<MALINDET> Fracture de l’<ANAT>épaule</ANAT></MALINDET>

Extraction result

Structure outline
• 2 steps:
– Extraction
• Develop an extraction system able to extract
information necessary to the encoding task :
– Diagnoses, procedures, localisations, dates, allergies,
aggravating factors, etc.
=> Reading help tool.
– Encoding
• Extracted information => codes
through a combination of statistical and symbolic
methods.

Machine Learning
• Encoding = categorization problem
– Features = extracted phrases?
– Classes = codes
• Baseline method : Naive Bayes
– Tool: Weka
• Corpus :
– 13,635 PDS from Digestive Surgery
• 90% training set / 10% test set (1364 PDS)
• Average number of codes per PDS: 6.2
• Trained 1 classifier per code occurring>5 times in the corpus :
– 775 codes -> 775 classifiers
– Limitation: 5% rare codes
– attributes: kept only those co-occurring at least twice with the codes.
• Measures: Precision and recall according to the probability returned by the Naive Bayes test.

Experiments
• A series of experiments were conducted where attributes were variants of the extracted diagnoses and procedures after stemming.
• Variants implied: – Kept original word order or not.
• Ex: excisional biopsy bile duct
• Or bile biopsy duct excisional
– Included details like location, date, context.• Excisional biopsy
– Each word of the extracted phrases is a feature• Excisional
• Biopsy
• Bile
• Duct
– Words and morphemes (together) composing the extracted phrase• Bile biopsy excision excisional duct
– Words and morphemes (separately) composing the extracted phrase• Excisional biopsy bile duct
• Excision biopsy bile duct
– Values were 0 or 1 whether the attribute was in the text or not.
– Values were the frequency of the attribute in the text.

Results
Features Recall PrecisionAverage number of
suggested codes
Extracted phrases + details +
same word order + 0/1 as values 68,7 73,2 7,87
Extract phrases + details +
alphabetical order + 0/1 as
values59,1 75,7 6,49
Words and morphemes
(together) + details +
alphabetical order + 0/1 as
values
68,5 74,2 7,54
3 best results when thresholding the list of results where the probability
returned by Naive Bayes = 1

Discussion
• Limitations of the machine learning method:
– 5% rare codes – not enough data to build a
classifier for these codes
– Need for annotated data means that these
methods are unable to face changes in
classifications
⇒In these cases, we need to use symbolic methodsKevers Laurent et Medori Julia, Symbolic classification methods for patient
discharge summaries encoding into ICD, In: Advances in Natural Language
Processing, 7th International Conference on NLP, IceTAL 2010, Reykjavik,
August 16-18, 2010, Lecture Notes in Artificial Intelligence, 2010, p. 197-
208

Objective
• Automatic encoding of PDS according to
categories (first 3 digits)
• Use of symbolic methods
– No need for annotated data
– Can assign rare codes (27% used 5 times or less)
• Principle :
– Make use of the nomenclature
– Enrich it with other resources in French from
UMLS (Unified Medical Language System)

Corpus
• 19,692 patient discharge summaries (PDS) in
French
• General Internal Medicine
• 150,116 codes (137,336 categories)
• 6,029 distinct codes (895 categories)
• Average = 7.6 codes/document (7 categories)

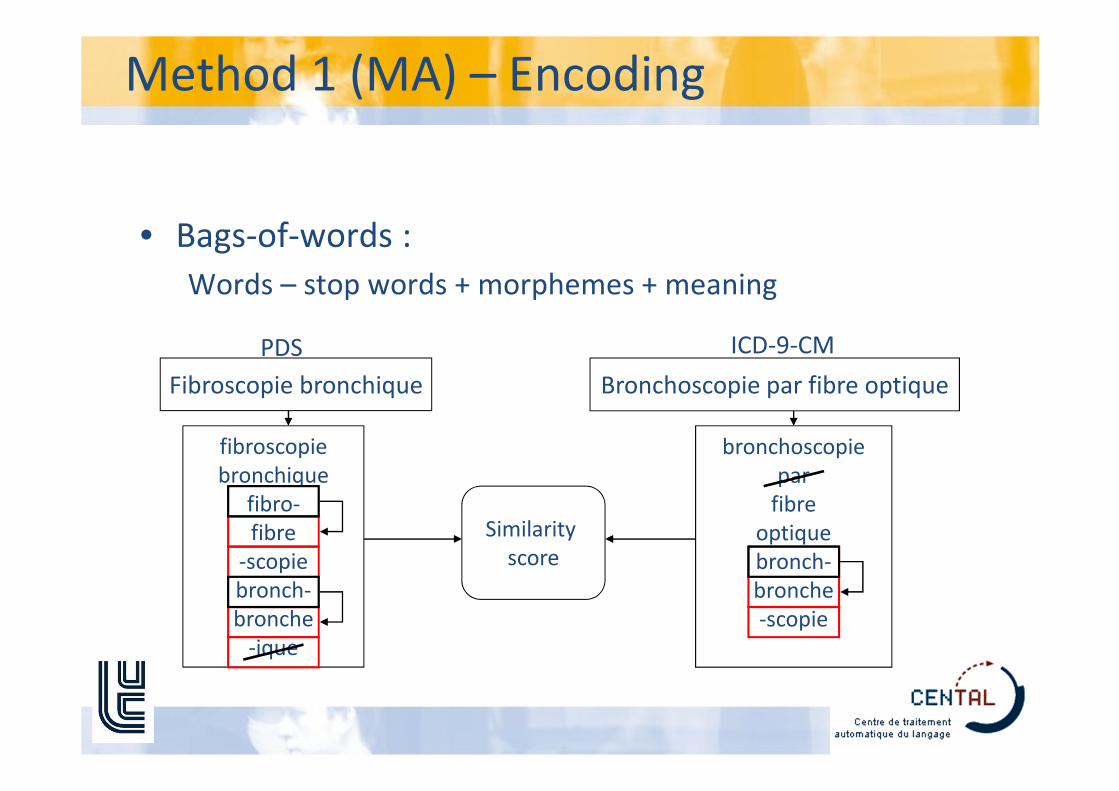
Method 1 (MA) – General Principle
• Based on the rich morphology of medical
language
– Ex. Bronchoscopy:
Fibroscopie bronchique = bronchoscopie par fibre optique
• 2 steps process :
– Extract phrases or terms describing diagnoses or
procedures to be encoded
– Encoding : match these terms to the right code.
fibroscopie
bronchique
fibro-
fibre
-scopie
bronch-
bronche
-ique
bronchoscopie
par
fibre
optique
bronch-
bronche
-scopie
• Bags-of-words :
Words – stop words + morphemes + meaning
Fibroscopie bronchique Bronchoscopie par fibre optique
PDS ICD-9-CM
Similarity
score
Method 1 (MA) – Encoding

Method 1 (MA) – Results
Recall Precision F-measure Nb.
classes
Best Recall 46.13 14.70 21.10 20
Best F-
measure
34.52 27.34 28.00 8.6

Method 2 (ELP) – General principle
� Developed by L. Kevers as designed for the Stratego
project on parliamentary documents.
• Symbolic method with less manual work
� Use existing « terminological » resources
– ICD-9-CM + UMLS
� Two steps process
1. Automatic transformation of existing terminological
resources into an extraction resource (only once)
2. Use extraction resource on documents for terms
extraction and classification (for each document)

Method 2 (ELP) – build extraction resource (1)
� For each ICD-9-CM term (= a class), the automatic processing
implies :
� Gather synonyms (UMLS)
« dengue »
→ « dengues », « dengue fever », « infection by the dengue virus »
� Parse complex compound expressions
« Infectious and parasitic diseases » → « Infectious disease »
→ « Parasitic disease »
� Transform initial term into Extended Lexical Pattern (ELP)
- Stopwords : → « infection <TOKEN> dengue virus »
- Stemming : → « infect <TOKEN> dengue virus »
- Allow insertions : → « infect <I> <TOKEN> <I> dengue <I> virus »
� Add negative contexts patterns
� Build the main transducer for text annotation

Method 2 (ELP) – Transducer & output
Zona [[053]]extremement douloureux [[729]]
gastroscopie [[Z44]]acide [[E96]]
anemie normochrome normocytaire [[285]]sequellaires apicales droite (tuberculose [[137]]
intestin grele [[Z45]]tuberculose [[V12]]
oesophagite moderee aspecifique [[947]]infection a mycobacterie [[031]]
fond de oeil [[Z16]]pas de [[-]] atteinte du nerf [[957]]
zona [[053]]hyperthyroidie [[242]]
goitre [[706]]goitre [[240]]
• Transducer for class '061'
• Output of main transducer for a document

Method 2 (ELP) – Class assignment (2)
� For a text to classify, analyse the main transducer
output
� When negative contexts, the phrase is skipped
� Each recognized phrase has one (or more) related
code
� Compute a weight for each phrase based on
– Frequency
– Is a multi word expression (frequency*2), or not
� Compute a weight for each code by summing up the
weights obtained for the phrases
� Result : ordered list of codes (possibly threshold it)

Method 2 (ELP) – Results
Recall Precision F-measure Nb of
classes
Best Recall 52.74 20.69 27.37 19.6
Best F-
measure
37.97 30.30 29.43 9.8

Combination of methods 1 & 2
• Merge the lists from method 1 & 2
1. Threshold(M.1 union M.2)
2. Threshold(M.1 inter M.2)
3. Threshold(M.1) union Threshold(M.2)
4. Threshold(M.1) inter Threshold(M.2)
• The weight for each method can be balanced
– Example: 0.4*M.1 union 0.6* M.2

Evaluation of symbolic methods combination
Recall
(R)
Precision
(P)
F-measure
(F1)
Nb.
classes
Threshold α/1-α
Mix1 : Threshold(Method1 union Method2)
Best R 60.21 13.20 20.86 30.5 No Any
Best F1 37.13 33.12 31.64 8.1 Yes 0.3/0.7
Mix2 : Threshold(Method1 inter Method2)
Best R 38.66 29.28 30.52 9.1 No Any
Best F1 34.73 34.55 31.50 7 Yes 0.3/0.7
Mix3 : Threshold(Method1) union Threshold(Method2)
Best F1 43.28 20.59 27.90 14.7 Yes N/A
Mix4 : Threshold(Method1) inter Threshold(Method2)
Best F1 24.07 37.95 29.46 4.4 Yes N/A

Conclusions
• Results have to be put into perspective:
– Inter-annotator agreement ~70%
– 15 to 20% cannot be inferred from PDS
– Machine learning methods performed well.
– Symbolic methods:
• MA method based on extraction module : 66% of useful information is extracted.
• ELP method performs better when built from short unambiguous phrases. ICD-9-CM code descriptions are more complex.
• Future work :
– Give more weight to information contained in important parts of the PDS (introduction, conclusion…)
– Evaluate the actual help given to human coders
– Combine with learning algorithms


















