
Study on Asian Script Entry and Display Formats · The Khmer script was chosen in this study of...
58
All Copyrights Reserved, CICC Study on Input and Output Method on Asian Scripts -Case Study of the Khmer script- (Extract) 1
Transcript of Study on Asian Script Entry and Display Formats · The Khmer script was chosen in this study of...

All Copyrights Reserved, CICC
Study on Input and Output Method on Asian Scripts
-Case Study of the Khmer script-
(Extract)
1

All Copyrights Reserved, CICC
This is an extract of the report of Study of Input and Output Method of Asian Script Project.
CICC planned this project and ordered to Ecellead Company in July 2002 and this report was
delivered to CICC on November 2002.
There are three objectives for this project.
1. To confirm the technology to compose complex syllable of Asian glyphs out from multiple
character codes.
2. To demonstrate the applicability of multiple input methods for the same character code
3. To find out if more coded elements are needed to handle Asian scripts properly.
Backgrounds:
1. Traditionally, character code are assigned for all necessary repertoire of the target script (such as
USASCII), however, this practice is not applied for syllabic characters of Asian scripts. Some of
the repertoires are expressed by a sequence of the character codes (no specific single code
assigned to the repertoire). Most of Asian countries faced a difficult time to understand how to
handle this new approach of encoding method.
2. As same as representation of a glyph for output such as display and printing, conventional input
method was also one to one correspondence type. One each key on a keyboard is assigned for one
each of corresponding character code. This practice required different keyboard for different
character code. Further more, there is a confusion of Asian countries for input method for the
sequence of codes that is described above. It is necessary to demonstrate that the keyboard
operation can be designed totally independent from character code (like Japanese input method).
3.Because of unique feature of Asian scripts, it is necessary to check if some of additional
functionality as a character code is needed or not.
Results:
Open Type Font like approach is applicable to output Asian script (under environment of glyph
description by a sequence of character codes.)
Japanese input like free input methods is also applicable as an input method for Asian scripts also.
Some kind of common rule to be agreed for WORDWRAPPING of Asian script that do not have a
SPACE between words.
2

All Copyrights Reserved, CICC
1. Outline of Study
1.1 Selection of Scripts to be Surveyed, Etc.
1.2 Survey Method
1.2.1 System
1.2.2 Schedule
2. What Is the Khmer script
2.1 Syllabic Characters
2.2 Characteristics of The Khmer script
3 Implementation of the Khmer Script Font
3.1 Review of Font Implementation Methods
3.2 Detailed Definition of Font Implementation
4. The Khmer script Input Methods
4.1 Current Local Entry Methods
4.2 Review of Entry Method Implementation Policies
5.Verification Program Development -Khmer Font Development
5.1 Outline of OpenType
5.1.1 Description of Main Open Type Tables
5.1.2 Substitution Tables
5.2 Khmer OpenType Font Specifications
5.2.1 Classification of Khmer Characters
5.2.2 Khmer OpenType Table Implementation Specifications
5.3 Font Development Procedure
5.3.1 Development Environment
5.3.2 Development Procedure
6. Verification Program Development
7. Pilot Tests
8. Information Obtained in This Survey and Discussion
8.1 Dealing with Complicated Character Structures
8.2 Handling of Diverse Character Codes for Same Script (Diversity of Display Methods)
8.3 Handling of Diverse Character Codes for Same Script (Diversity of Entry Methods)
8.4 Technical Conclusions
9. Future Tasks (Reference: For Realizing Results of This Survey)
3

All Copyrights Reserved, CICC
1. Outline of Study
1.1 Selection of Scripts to be Surveyed, Etc.
The aim of this study is to conduct survey and research on the input and output methods of
South Asian, South-East Asian, and Arabic scripts.
The Khmer script was chosen in this study of possible input and output methods because it has
the most complicated structure in the range of scripts considered for this study, and it combines
the characteristics of most of all other scripts. To deal with the diversity of this script, the
structure of ISO/IEC 10646 (also called UCS and Unicode, hereafter referred to as UCS)
developed basically for diverse variety of scripts was undertaken and basic tests and studies
were conducted using the UCS Khmer script.
Script Structure
Technically studied, South Asian, South-East Asian, and Arabic scripts are characterized by
syllable synthesis, presentation form, ligature, and accent/tone marks. The Khmer script posses
all the necessary and very complicated elements.
Indian scripts which include the Khmer script are called syllabic characters, and consist of
consonant characters and vowel characters (vowel symbols). When these two are combined,
they represent syllable units comprised of consonants and vowels. Hangul script is also a
clustered syllabic character, but the Indian script requires more complicated syllabification. The
Khmer script also has a unique feature called the foot (subscript character,). This is a type of
consonant sign. When two or three consonants coincide, the second and third consonants
become the subscript character, and change. If a support technique can be developed for the
Khmer script, that technique should be applicable for all Indian scripts.
Multi Character Compatible
UCS carries out encryption based on an architecture aimed at universally dealing with diverse
scripts. On the contrary, by establishing an appropriate output and input architecture for UCS
characters, the chances for dealing with diverse scripts will increase. In the midst of various
characters encoding of the Khmer script which was chosen for its script structure from the
above reasons, the Khmer script of UCS was chosen for experiments and research.
Verifications
Based on the need for verification of the validity of the results of the above survey to be carried
out by researchers who have knowledge of the script concerned, verification was carried out by
Japanese researchers involved in these scripts as well as by inviting native users of these scripts.
4

All Copyrights Reserved, CICC
In particular, as encoding in UCS aims at use for diverse scripts as mentioned earlier, native users
of the scripts would find a script odd on its own. This applies to Cambodia which also used the
Khmer script. There is strong opposition again UCS in the country (doubts about suitability). As
verification by these people should be the most accurate, the applicability of the development
results was tested with governmental organizations of Cambodia.
1.2 Survey Method
This survey was carried out by the following system and schedule.
1.2.1 System
Survey meetings were carried out by setting the working-level meeting members in Japan as
well as conducting field investigations in Cambodia. Collaborators were also invited from
Cambodia for pilot tests.
•
•
•
•
•
Working level meeting members
Makoto Minegishi, Tokyo University of Foreign Studies, Research Institute for the
Languages and Cultures of Asia and Africa
Tatsuo Kobayashi, President, Scholex Co., Ltd.
Takayuki K. Sato, Chief Researcher, CICC
Excellead Technology Co., Ltd.
Collaborators from Cambodia
National Information and Communication Authority CAMBODIA (hereafter NiDA)
SORSSAK PAN (Undersecretary of State)
HE, UNG Vuthy
CHEA Sok Huor
TOP Rithy
1.2.2 Schedule
This survey was conducted under the following schedule.
Survey and research period: June and August, 2002
Field investigation (July 15 to 18, 2002)
Survey of natural input methods to Cambodians, and technical surveys of
implementation methods
Development of verification programs: July to September 2002
Development of font and input (copy) programs
Pilot tests, survey report preparation period: August to October 2002
1st pilot test: August 23, 26, 27, 2002
5

All Copyrights Reserved, CICC
Participation of CHEA Sok Huor and TOP Rithy
2nd pilot test: September 25 and 26, 2002
Participation of HE, UNG Vuthy and CHEA Sok Huor
Survey report preparation
6

All Copyrights Reserved, CICC
2. What Is the Khmer script
2.1 Syllabic Characters
Indian scripts such as the Khmer script are called syllabic characters, and take syllables as the unit.
The characters are composed of consonant characters and vowel characters (vowel symbols to be
precise). By combining these two, syllable units composed of consonants and vowels can be
represented.
The syllabification of the various languages of South-East Asia is relatively complicated
compared to the Japanese language which is based on the open syllable of “consonant and vowel”.
The following syllables may be possible if Indian loanwords are included. C however represents a
consonant and V the vowel.
1. CV
2. CCV
3. CVC
4. CCVCC
5. ....
With South-East Asian scripts, such syllables are represented by adding vowel symbols to the top,
bottom, left, and right of the consonant/vowel. In other words, the Khmer script has more or less
the same syllabification as Korean Hangul script.
However, South-East Asian Indian syllabic characters have the following characteristics.
•
•
Horizontal writing from left to right. Not written vertically.
No space is left between words. Spaces are left between phrases and characters.
2.2 Characteristics of The Khmer script
*Note by CICC: This section describes a nature of Khmer script that includes all features of most
of other Asian scripts
The Khmer script is the oldest script of all existing South-East Asian scripts. It serves as the
original form of Burmese script, Thai script, and Laotian script. The Khmer script (Cambodian
script) is used for expressing the Khmer language (Cambodian language) as well as for expressing
Sanskrit and Pali languages in Cambodia and Thailand. It is said that the Khmer script was used in
the kingdom of King Ramkhamhaeng of the Sukhothai Dynasty who established the Thai script.
The Gold Scripture exhibited at the Wat Po Temple next to the Thai Palace is written in Pali using
the Khmer script. To Thai monks, the Khmer script is scripture.
7

All Copyrights Reserved, CICC
The shape of the Khmer script is decorative. Characteristically, it is decorated by waves above
characters.
The Khmer script is a type of syllable character made of consonant characters and vowel
characters. Letters can broadly be divided into two groups, mul characters and criana characters.
Mul characters can further be divided into mul characters and khama characters. Mul characters
means “round character, and is used in inscriptions, Buddhist text, titles and headings of printed
matter, public notices, signs, etc. and for purposes requiring decorative effects.
The criana character can further be divided into criana characters and jhara characters. criana
characters means “italic” and is used widely in general printed matter and daily reading and
writing. The jhara character means “upright character" and is the upright form of criana characters
in prints. Therefore, basically, the jhara character is the same as criana characters, and the
difference between the two lies in the difference in typeface. The differences between these four
typefaces lie in the difference between character designs and does not extend to the structure of
script.
The consonant characters of Cambodian language come in two types. One is the consonant/vowel
and the other is the consonant character called subscript character.
consonant/vowel can be written and read separately from other characters, while the subscript
character must always be written below the consonant/vowel. It cannot exist alone.
There are 33 types of consonant/vowel, and order of which follows the concept of sound
classification of India. Therefore plosive and nasal are arranged by place of articulation from near
to the throat to near to the lips (k, c, t, p (b)). They are also arranged in order from other
semivowel, liquids, and fricative.
Vowel symbols are always combined with consonant/vowel, and are not written alone. Vowel
symbols are written at a fixed position on the top, bottom, left, or right side of the
consonant/vowel or the combination of consonant/vowel and subscript character.
Other than the vowel sign, there is the independent vowel character that is not combined with
consonant/vowel. The independent vowel character expresses one syllable with one character.
This has been used for only a few terms, and with the simplification of the orthography in the
recent years, it is gradually being replaced by the combination of consonant/vowel and vowel
symbols.
In addition to this, there are the supplementary signs, numerals, punctuation marks added to
characters. Supplementary signs are signs added to syllables combining consonant characters and
vowel symbols. Numerals on the other hand are used for characteristic numbers and are common
to Thai and Cambodian. How numerals are represented is the same as Arabic numerals. In modern
times, Arabic numerals are also used. In addition, repetitive signs, numerals, and question marks
8

All Copyrights Reserved, CICC
are used in texts. Punctuation marks are used with small paragraphs consisting of several
sentences as the unit. This is a feature also seen in Thai.
The feature of the representation form of the Khmer script lies in the hierarchical structure where
the consonant characters are placed at the top and bottom in representation of multiple consonants.
The normal character serving as the base is called consonant alphabet while the character
changing to one arranged below are called subscript characters.
9

All Copyrights Reserved, CICC
3 Implementation of the Khmer Script Font
3.1 Review of Font Implementation Methods
By modifying the Khek Sangker font, the feasibility of implementing fonts which can be
implemented was verified, and the presence of problems with the existing standard in The Khmer
script was studied.
In implementing Font, it was basically agreed that the concept of Unicode 3.2 reflecting the
opinions pf Cambodia National Body would be taken in for the definition of character, based on
the concepts used in UCS. (Unicode 3.2 eliminates the subscript character, takes multiple coded
character codes as one code and give independent names and display formats to each).
In this project, approval was obtained from the Cambodia National Body that the 33 vowels, 35
consonants, 37 subscript characters, 18 other auxiliary signs, and ten numeral given as The Khmer
script in Unicode 3.2 can be taken as the Khmer script (symbols used in lunar calendar were
excluded).
However, gylphs not contained in Khek Sangker font were not newly created, but those currently
available were implemented where possible.
In the development of Khmer fonts, a major topic discussed was how to treat character code order
and rendering for expressing character code order and rendering for internal processing.
The agreements reached in the field studies in Cambodia can briefly be summarized as follows.
•
•
•
•
•
•
•
The character code order in internal processing shall basically be closest to the basic
pronunciation order.
*Note by CICC: ISO/IEC TR 14651 recommends a code value order free sorting. Using a
sort key. Thus this is not important issue.
By this, optimize the sorting and search processes
Adjustments with the output shall be carried out with the output engine or font.
After these agreements, information and opinions were exchanged with the person in charge of
implementing the Khmer script at Microsoft (hereafter referred to as MS) regarding OpenType
and Uniscribe, and common awareness was reached on the following points.
The mounting measures of Uniscribe by MS match the agreements and basic directions
of CICC and NiDA.
MS has the aim to reflect the intentions of native speakers faithfully and promptly in
Uniscribe.
Uniscribe shall perform the least required process for preventing loss of the uniqueness
of such language and entry to leave the freedom of Open Type Font where possible.
The Khmer main text font and heading font shall be dealt with the process for Open
Type Font.
10

All Copyrights Reserved, CICC
• MS shall provide technical information and support where possible for this project.
Based on the above agreement, this project carried out the development of font based on Uniscribe,
and adjustments with the MS method shall be made for the encoding and character layout for
internal processing.
Based on the above circumstances, it was decided that in this project, Open Type Font shall be
developed based on the technical information provided by Dr. Paul Nelson of MS.
*Note by CICC: Remember that one of the objectives is to confirm an applicability of Open-Type
like approach for Asian scripts.
For details on the coding undertaken by Uniscribe, visit the following URL.
Http://www.Microsoft.com/typography/otfntdev/khmerot/shaping.htm
3.2 Detailed Definition of Font Implementation
The Khek Sangker font was classified into the following based on the requests of the Cambodian
National Body, under the guidance of Professor Makoto Minegishi, Tokyo University of Foreign
Studies, Research Institute for the Languages and Cultures of Asia and Africa.
Define (1)Consonant, (2)Subscript Characters, (3)Various Signs, (4)Dependent Vowel symbols,
(5)Independent Vowels, (6)Various Signs, (7)Digits based on glyph variations and M width.
(hexadecimal representation).
Romanization is a form of entry method described later.
(1)Consonants
Consonant characters are divided into ten types; CA, CB, CC, CD, CE, CF, CG, CH, CI, and
CJ.
There are altogether 35 consonants. This time, as the two characters CC are not available as
font, 33 characters are implemented.
CA= (42, 44, 4E, 54, 68, 6E, 78) %%%% 7 characters.
In Romanization, /b, D, N, d, h, n, k’/.
The shape does not change.
CB={43, 64, 66, 70, 7A}%%% 5 characters.
In Romanization, /j, T, t’, p’, T’/.
The shape does not change.
However, as the top right is curved up slightly higher than CA, with certain font designs, the
11

All Copyrights Reserved, CICC
glyph positions of superior additional signs that follow SA, SB, SC, and SD, and superior
vowel symbols (DC) may be higher. In this implementation, due to restrictions of current
Khek Bros. font design, it is taken CB=CA because the glyph positions of CA and following
superior additional signs and superior vowel symbols are taken as not changing.
CC={67} %%% 1 character.
The /G/. form does not change in romanization.
However, because the top right is curved slightly higher than CA, the glyph positions of
superior additional signs that follow SA, SB, SC, and SD, and superior vowel symbols (DC)
are higher.
CC={76} %%% 1 character.
The /v/. form does not change in romanization.
However, because the top right is curved slightly higher than CA, the glyph positions of
superior additional signs that follow SA, SB, SC, and SD, and superior vowel symbols
(DC) are higher. In addition, only for Mul characters, these are joined with a superior
vowel sign. Due to restrictions of current Khek Bros. font design, as mul glyphs are
available for CD, CD is taken to be CC this time.
CE={72} %%% 1 character.
The /r/. shape does not change in romanization. (As mentioned later, note the subscript
character and glyph)
Due to the narrow character width as a consonant character, these protrude out from the left
when superior vowel characters and subscript characters are attached, and are unsightly. To
begin with, with /r/ glyph designs, it may be better to increase the character with (as done
with Thai characters) or prepare narrow glyphs for superior vowel symbols and subscript
characters for this character.
This time, CE is taken as CA.
CF={46, 47, 51, 58, 5A, 63, 6C, 6D, 71, 73, 79} %%% 11 characters.
The shape changes.
In Romanization, /d’, q, j’, g’, D’, c, l, m, c’, s, y/.
Except when part of the subscript character (JD) follows, these are joined to the right side of
right-side vowel symbols (DB) and left and right enclosed vowel symbols (DG). With
ISO/IEC 10646 (UCS or Unicode) [179D]/X/ and ISO/IEC 10646 (UCS or Unicode)
[179E]/S/, these characters are used only for Sanskrit, but with the Khek Bros. font, no glyph
12

All Copyrights Reserved, CICC
is available. If characters exist, there will be altogether 14 CFs.
CG={4B, 50, 6B, 74} %%% 4 characters
In Romanization, /g, b’, k. t/.
The shape does not change.
Except when part of the subscript character (JD) follows, these are joined to the right side of
right-side vowel symbols (DB) and left and right enclosed vowel symbols (DG). In addition,
only for the mul character, these are joined with superior vowel symbols. Due to restrictions
of current Khek Bros. font design, as mul glyphs are not available for CG, CG is taken as CF.
CH={4C} %%% 1 character.
In Romanization, /L/.
The shape does not change.
Except when part of the subscript character (JD) follows, this character is joined to the right
side of right-side vowel symbols (DB) and left and right enclosed vowel symbols (DG). In
addition, only for the mul character, it is joined to the right side of right-side vowel symbols
(DB) and left and right enclosed vowel symbols (DG). As the character is lower than the base
line (this character itself is a combination of a consonant and subscript character, and acts
that way), the glyph position of the inferior additional sign and inferior vowel sign is at the
bottom.
CI={6A} Non-glyph {56, D7} %%% 1 character.
In Romanization, /J/.
The shape changes.
This character is lower than the base line. It is a combination of the consonant character and
subscript character /<J/.
Therefore, when the subscript character follows, the consonant character itself changes to a
non-glyph {4A}. In particular, when the subscript character that follows is the same /J/, the
non-glyph {EF} of the subscript character /<J/ is attached to the bottom of {4A}. The glyph
positions of the non-glyph of inferior additional signs which follow SC, SD and inferior
vowel symbols (DD) become the following non-glyph.
CJ={62} Non-glyph {56, D7} %%% 1 character.
The shape changes.
In Romanization, /p/.
When joined with right-side vowel symbols and the right side of left-right enclosed vowel
13

All Copyrights Reserved, CICC
symbols, it becomes difficult to distinguish from the /h/ character. It therefore has a unique
joined non-glyph. {56} is joined with the right side vowel sign (DB) and right side of the left
and right enclosed vowel symbols (DG), {D7} is joined with the right side of the left and
right enclosed vowel symbols (DG). (Note: though glyphs with {4D}/M/ are required for the
top right of {56},but none is found)
(2)Joeung subscript character
Subscript characters are classified into six types; JA, JB, JC, JD, JE, and JF. There are
altogether 35 subscript characters. However, because two characters /X, S/ are not provided
as fonts, 33 characters were implemented.
Of these 33 characters, there are 31 types of typical glyphs of subscript characters. {C2}=/1/
and {C2}=/L/ and {91 or B6} =/T/ and {91 or B6}=/T/ glyphs are the same.
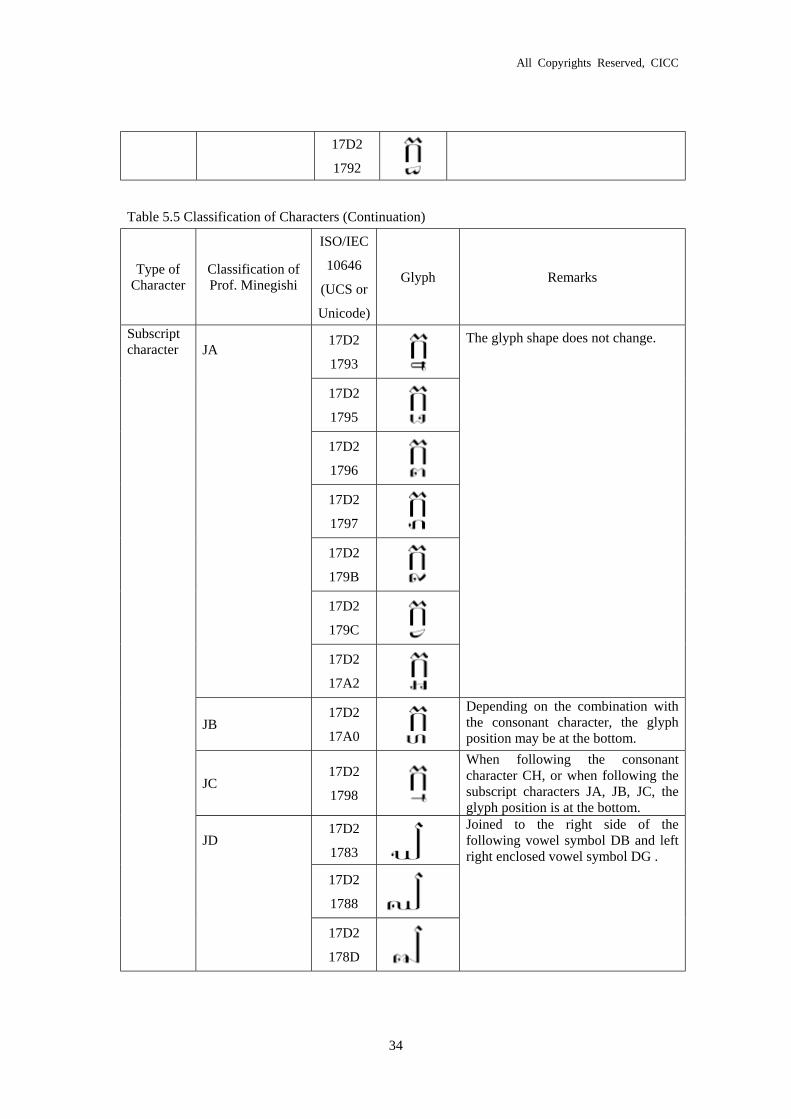
JA={82, 91, 91, A9, B5, B8, B9, BD, C2, C2, C3, C4, C5, CD, CF, D8, E6, EB, EC, ED,
F0, F5, FB, 7E} %%%% 25 characters.
In Romanization, /j, T, t, G, m, b’, p’, T’, I, L, v, t’, K’, c, C’, j, d, D, d’, q, g, b, N, k, n/.
The shape does not change.
With the Khek Bros font, {F5} and {FF} appear like the subscript characters of /b/, but the
differences are not clear. The ISO/IEC 10646 (UCS or Unicode) [17D2-179D] /X. are
characters used only for Sanskrit representation, but the glyph is not provided for Khek Bros.
font. If characters are provided, there will be altogether 25 Jas.
JB={FA} Non-glyph {F1} %%% 1 character
In Romanization, /h/.
The shape does not change, but it has a non-glyph positioned lower {F1}.
Example: Two examples /L, huG//dL, hiikrNO of following consonant character {4C} have
been confirmed.
JC={Glyph} %%%
Test-wise, the above JA {B5}/m/ does not change shape, but a lowered non-glyph similar to
{FA}/h/ is desired. The output environment follows /L/ like /h/ or follows other subscript
characters JA, JB, JD generally. In other words, this is limited to adding an exceptional
subscript character when other subscript characters are already present. For this aggregate, it
has been verified that there is one example of the continuous /lk, s, mii/ borrowed from
Sanskrit. Over the recent years, due to the increasing need to express names of not only the
French, English and Americans, but Russians, etc. as well, there should be a need to provide
14

All Copyrights Reserved, CICC
glyphs of the position of the second subscript character for all subscript characters. (In this
case, for JDs where the subscript character goes to the right side of the consonant character, it
is necessary to not only lower the position, but to provide a tall glyph as well).
JD={A7, B4, BA, CE, F3, F4} %%% 5 characters
In Romanization, /s, y, p, j’, D’, g’/.
The shape does not change.
These characters are joined to the right side of right-side vowel symbols (DB) and left and
right enclosed vowel symbols (DG). With ISO/IEC 10646 (UCS or Unicode) [1792-179E]/S/,
these characters are used only for Sanskrit, but with the Khek Bros. font, no glyph is
available. If characters exist, there will be altogether 14 CCs.
JE={A8} Non-glyph {E5} %%% 1 character.
In Romanization, /r/.
This is the only subscript character positioned on the left side of the consonant character.
(Hereafter, the reverse of the entry order is called Hindi Reverse.)
If following other subscript characters, it becomes a long non-glyph {E5}.
JF={C6} Non-glyph {EF} %%% 1 character.
In Romanization, /j/.
If same as the preceding consonant character /J/, /J/ becomes {4A}, and at the same time, the
subscript character /,J/ becomes the non-glyph {EF}.
(3)Various Signs Added Symbols
Added symbols are classified into four types, SA, SB, SC, SD.
SA={27, 26, 2A, E1, B1} 5(6) characters (Bantok, Samyoksanya, Ahsda, Robat, Kakabaat (,
Viriam)). Superior added symbol. Neither the position nor shape changes. However, for
Viriam (u-17D1) no glyph exists in Khek Bros.
SB={5F} Non-Glyph {5F->AD} 1 character (Toandakhiat)
Superior added symbol.
When the superior vowel sign DC follows, it changes to a tall non-glyph. With the Khek
Bros font, a combination non-gylph AD where 5F is follows by /i/. As this is originally used
in Sanskrit, it may be possible for a character in DC to be combined with /ii/.
SC={22} Non-Glyph {22->75, 22->AC} 1 character (Muusikatoan)
15

All Copyrights Reserved, CICC
Superior added symbol
When the upper vowel sign DC and DB {53} /aM follows, it changes to a non-glyph called
kbias-kraom.With the Khek Bros, the non-glyph has the same shape as the vowel sign.
Like /u/, when added to consonant character CI, and when subscript characters other than JE
follow, it becomes a low non-glyph AC.
(As the input, the Cambodian side requests that when Muusikatoan is key input, and the
vowel sign which follows is a superior vowel sign DC, it should automatically change to 75
or non-glyph of AC.)
SD={DF} {DF->75, DF-?AC} 1 Character (Triisap)
Superior added symbol
Like SC, when the upper vowel sign DC follows, it changes to a non-glyph called
kbias-kraom. Unlike SC, whether it changes or not is optional depending on the writer. There
are two ways of writing. (This can be confirmed in pages 1516 to 1522 on the addition of
superior vowel symbols of “h” in a Buddlish School dictionary.) The non-glyph has the same
shape as the vowel sign /u/ in Khek Bros. Like /u/, when added to consonant character CI and
subscript characters other than JE follow, it becomes a low non-glyph AC.
(When Triisap is entered, and the vowel sign which follows is a superior vowel sign DC,
there is a need to select the writing method to change to the 75 or AC non-glyph.)
(4)Dependent Vowel symbols
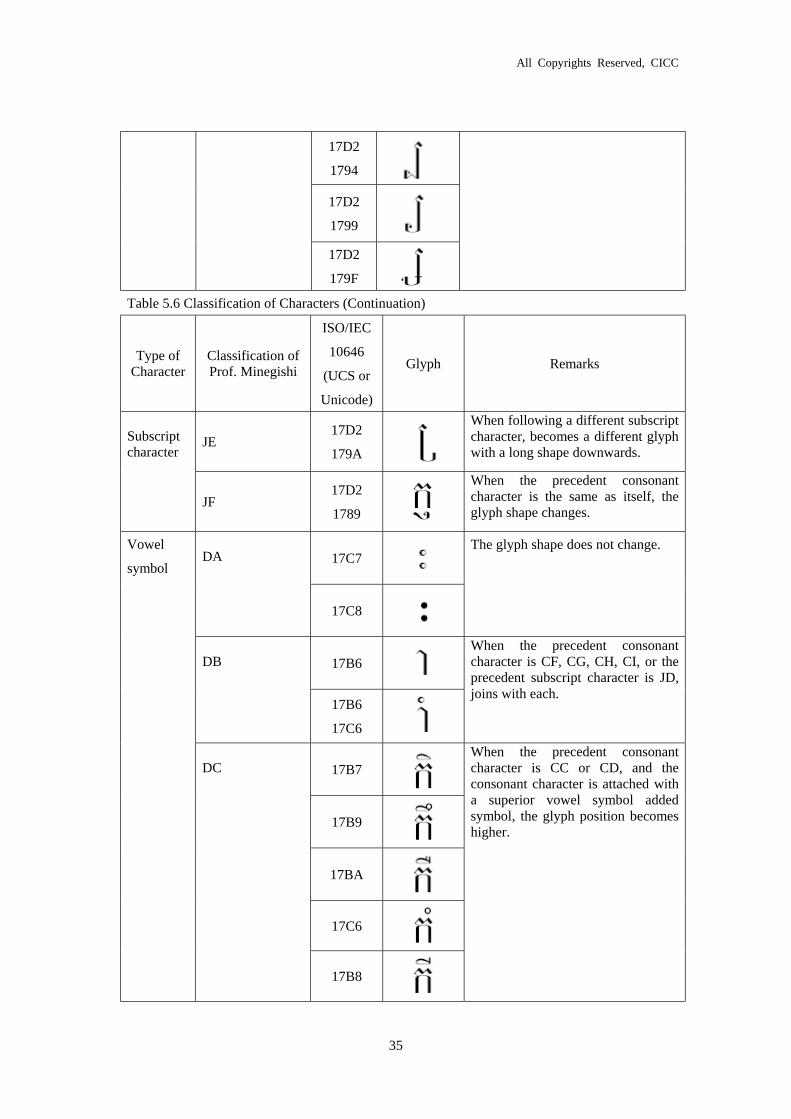
Vowel symbols are classified into nine types DA, DB, DC, DD, DE, DF, DG, DH, and DI.
(or 13 types when DJ, DK, DL, DM are added)
DA={4b, EE}%%% 2 Characters
Right side vowel sign. The shape does not change.
In Romanization, /H, Q/.
DB={61, 53} %%% 2 Characters.
Right side vowel sign.
In Romanization, /aa, aM/. When the preceding consonant characters are CF, CG, CH, CI, or
when the preceding subscript character is JD, these characters are joined to them. This time,
no joining glyph is provided. To join, a non-glyph is required.
DC={69, 49, 77, 57, 4D} Non-Glyph {69->5E, 49->E9, 77->B7, 57->E3, 4D->F7} %%% 5
Characters
16

All Copyrights Reserved, CICC
Superior vowel symbols.
In Romanization, /I, ii, w, ww, M/.
If the preceding consonant characters are CC, CD, or when no superior added symbol is
added to the consonant character, these characters become non-glyphs at high positions.
DD={75, 55, 59} Non-Glyph {75->AC, 55->E8, 59->E7} %%% 3 Characters
Inferior vowel symbols.
In Romanization, /u, uu, uo/.
If the preceding consonant characters are CH, CI, or when subscript characters other than JE
follow the consonant character, these characters become non-glyphs at low positions.
DE={4D+75} Non-Glyps {4D->F7, 75->AC}. %%% 1 Character.
Top, bottom enclosed vowel sign.
In Romanization, /uM/.
With current keyboards and fonts, this character is expressed by combining {4D}/M and
{75}/u/. Consequently, height is adjusted to that of {4D} and {75}. Consequently, when the
preceding consonant character is CC and CD, and a superior added symbol is added to the
consonant character, the top part {4D} becomes a non-glyph with a high position of {F7}.
When the preceding consonant character is CH and CI, and subscript characters other than JE
follow the consonant character, the bottom part {75} becomes a non-glyph {AC} with a low
position.
DF={45, 65, AB} %%% 3 Characters.
Left side vowel sign (Hindi Reverse).
In Romanization, /ee, e, ai/.
DG={65+61, 65+41} %%% 2 Characters.
Left right enclosed vowel sign.
In Romanization, /o, au/.
With current keyboards and fonts, these two characters are expressed by combining the left
side {65}/e/ and right parts {4F} and {6F}. The left part is placed on the left of the consonant
character by Hindi Reverse. When the preceding consonant character is CH, CI, and the
subscript characters other than JE follow the consonant character, the glyphs on the right side
become non-glyphs with long bottoms {AF} and {BF}.
DI={65+69} Non-Glyps {69->5E}. %%% 1 Character.
17

All Copyrights Reserved, CICC
Left top enclosed vowel sign.
In Romanization, /ae/.
With current keyboards and fonts, these two characters are expressed by combining the left
side {65}/e/ and right parts {4F} and {6F}. The left part is placed on the left of the consonant
character by Hindi Reverse. For the top part {69}, when the preceding consonant character is
CC, CD and added signs are added to the consonant character, this character becomes a
non-glyph with a high position {5E}.
(5)Independent Vowels
Independent vowels are used when vowels existing in Sanskrit or Parli are not accompanied
by the consonants at the head of the syllable. With the Khmer script, the head consonant of
the syllable {47/q/ is taken as the “zero consonant” in this case, and the orthography is
changed to one which does not use the independent vowel. Generations above middle-age
however tend to use this independent vowels.
{B2} In Romanization, /i/.
{F8} In Romanization, /ii/.
{F2} In Romanization, /RI/.
{C9} In Romanization, /RII/.
{AE} In Romanization, /LI/.
{BE} In Romanization, /LII/.
{D3} In Romanization, /u/.
{FC} In Romanization, /uu/.
{D2} In Romanization, /u, v/. These characters are exceptional, combining the non-glyphs
of vowel /u/ and syllable-marginal consonant /v/ which has no vowel corresponding to
Sanskrit (cannot be used alone currently.)
{E4} In Romanization, /e/.
{DE} In Romanization, /ai/.
{7B} In Romanization, /o/.
{5B}In Romanization, /o y/. Exceptional, combining the non-glyphs of vowel /o/ and
syllable-marginal consonant /y/ which has no vowel corresponding to Sanskrit (cannot be
used alone currently.)
(6)Various Signs
{2E} Punctuation u-17D4 (Khan)
{40} Repeated symbol u-17D7 (Lek Too)
18

All Copyrights Reserved, CICC
{B3} u-17D5 (Bariyoosan)
{D0} Quotation sign u-17D6 (Camnuc Pii Kuuh)
{DA} End sign u-17DA (koomuut)
{DB} Start sign u-17D9 (Phnaek Muan)
{DD} Currency sign u-17DB (Riel)
(7) Digits
{30} 0
{31} 1
{32} 2
{33} 3
{34} 4
{35} 5
{36} 6
{37} 7
{38} 8
{39} 9
19

All Copyrights Reserved, CICC
4. The Khmer script Input Methods
Along with the survey on the Khmer script fonts as described above, the Khmer script input
methods were surveyed and reviewed with the cooperation of Professor Makoto Minegishi, Tokyo
University of Foreign Studies, Research Institute for the Languages and Cultures of Asia and
Africa.
*Note by CICC: One of the objectives of this project is to demonstrate that the input method is
independent from character code. Many input method can be developed for the
same character code. In this project, two methods are developed for
demonstration purpose, but more input methods are able to be developed based
on different idea for the same code.
4.1 Current Local Entry Methods
8 bits single byte codes are assigned to current Khmer fonts to enable use of Khmer characters on
English systems. For this reason, the direct input method where the same keyboard as the English
system corresponds to codes (glyphs) one to one is used.
The Khek Bros fonts provided for this project correspond to the following keyboard layout.
he code assignment is as shown in Tables 5.1 to 5.3 by this layout and corresponding ASCII
ffers the following keyboard labels.
Figure 4.1 Khek Bros Keyboard
T
character string.
Khek Bros also o
20

All Copyrights Reserved, CICC
Figure 4.2 Khek Bros Keyboard Labels
ocal PC ships currently sell the following Khmer keyboard.
Figure 4.4 Key Assignment of Khmer Keyboard
he Cambodian National Body does not consider the Khek Bros and the several existing keyboard
L
Figure 4.3 Khmer Keyboard
T
layouts and proposes the following layout.
21

All Copyrights Reserved, CICC
22
Figure 4.5 Keyboard Layout Proposed by Cambodian National Body
The Cambodian National Body’s request lies especially in the Normal and Shift keys of the above
keyboard layout. Their request is laying out mainly subscript characters in the Shift Space and
Space area, with Space following Normal. In the bottom right area, Space is to follow Shift, and
the top right area is to be as shown.

All Copyrights Reserved, CICC
23
4.2 Review of Entry Method Implementation Policies
Currently, 8 bits single byte codes are assigned to enable use of the Khmer script to utilize
conventional English based systems. With ISO/IEC 10646 (UCS or Unicode), one glyph of the
Khmer script may consist of several character codes. This clearly means that to enable input of the
Khmer script, an input method for converting key input codes to Khmer characters assigned by
ISO/IEC 10646 (UCS or Unicode) according to some type of conversion rules is required.
Since there is a risk that the Cambodian side may lose sight of the fact that there exists multiple
technically general implementations by restricting input methods to one, the following two
methods were proposed, and the approval was obtained from the Cambodian National Body on
the policies.
• Transcription mode method from Latin alphabets (Roman letters)
by Professor Minegishi
• Direct code entry method based on existing keyboard layout
“Transcription mode method from Latin alphabets (Roman letters) by Professor Minegishi” can be
called the Khmer script transliteration mode and is an input method which takes up each Khmer
character whose pronunciation resembles Latin alphabets. For details, refer to the romanization in
“5.1.4 Detailed Definition of Font Implementation”.
“Direct code input method based on existing keyboard layout” is an input method based on the
key assignment proposed by the Cambodian National Body shown in Figure 5.8. This time
however, as the Cambodian National Body focused on such issues as the Space key conversion.
Regarding the potentials of the actual implementation, the following switching method was
therefore proposed in the sense to eliminate stereotypes, and approved.
Bottom left
Top right
Bottom right
Bottom top:
(NOTE: Sama as Figure 4.4 Keyboard Layout s Khmer Keyboard.)

All Copyrights Reserved, CICC
24
5.Verification Program Development -Khmer Font Development-
In this project, ISO/IEC 10646 (UCS or Unicode) compatible Khmer fonts were developed. The
OpenType font format which is the standard font format of general OSs such as Windows, MacOS,
and Solaris was adopted.
5.1 Outline of OpenType
The outline font is a general font format used with Windows and Mac operating systems,
operating systems employed extensively for personal computers. The outline font can mainly be
divided into the PostScript and TrueType. In 1996, the OpenType font format which combines the
two was released and is gradually becoming the standard format. In the future, font formats are
expected to centralize to this OpenType. The following outlines the OpenType font format, and
processing of Indian scripts using the OpenType font.
TrueType, the predecessor of the OpenType, is a font format established jointly by Apple
Computer and Microsoft. It is supported as standard by main operating systems such as Windows,
MacOS, Solaris, etc.
It can be used for both computer screen displays and printing.
With the TrueType font, tables for storing various information such as character outline, character
code mapping, and character design are defined. Fonts are constructed of the aggregate of such
table data. Character outline is expressed by two-dimensional B spline curves.
Microsoft has also established a font format called
the TrueType open as the extended format of
TrueType. With this format, new tables for
replacement of character glyphs, and adjustment of
character glyph positions are defined, which can
store high quality character layout information
inside the font. This character layout information
was originally available at the operating system
side (character layout processing system), but in the
relation between the character layout processing
system and font, it signifies that the role of the font
has become greater.
Head
Glyph Substitution
Character Glyph Image Data
Name
Font Design Information
(Other tables)
.
. .
Figure 5.1 TrueType Font
Structure

All Copyrights Reserved, CICC
25
OpenType is a format jointly developed by Microsoft and Adobe Systems. It can be called the
fusion of the TrueType and CID-Keyed font.
The font has the same structure as the table structure of TrueType. For the outline descriptive
method, the TrueType and Postscript CFF (Compact Font Format) font types can be used. There
are also more table types, and increased information which font venders must package.
The OpenType is supported as standard in Windows 2000/XP, Mac OS X, and Solaris.
By using the Adobe System Adobe Type Manager (ATM), it can be used in conventional
Windows OS and Mac OS.
5.1.1 Description of Main Open Type Tables
GSUB
The character glyph may be replaced by a different shape even if the same character code is given.
This table stores information for replacing the character glyph image with a different shape.
Replacement occurs in the following cases;
(a) Change of glyph depending on which position in the word the character is located such
as Arabic characters, etc.
(b) Change of glyph due to adjoining characters such as Indian characters
(c) Change of glyph due to language, one glyph is made up of more than two characters
(d) Layout of glyph changes in vertical writing
These are tables added in TrueType Open.
GPOS
Stores position control information when the layout position of character glyph differs according
to the combination with other character glyph.
Mort
Table with the same aim as GSUB. However the data structure and replacement algorithm differ.
The GSUB table is defined by Microsoft and is used as standard by Windows OS, while the mort
table us defined by Apple Computer, and is supported as standard by Mac OS.
cmap
Within the font, numbers called glyph IDs are given to each glyph. This table consists of data
describing the relation between character codes and glyph IDs (called mapping table). As this
relation can be described several times, different mapping such as shift JIS and ISO/IEC 10646
(UCS or Unicode) data can be provided.

All Copyrights Reserved, CICC
26
Glph
Table for storing the shapes of TrueType font character outlines.
CFF
Table for storing the shapes of PostScript font character outlines.
Name
Table for storing font names, family names, and copyright indications, etc.
OS/2
Table for describing information on font design characteristics and character sets stored in fonts.
Used by Windows operating system, OS/2.
5.1.2 Substitution Tables
With Indian scripts like Devanagari, the shape of character glyphs and layout position change
intricately according to the combination of other characters. With OpenType, character
substitution and character layout position information can be stored to enable appropriate
processing of Indian scripts on computers. Some main examples are the GSUB and GPOS tables.
GSUB (Glyph Substitution Table)
The GSUB table stores character glyph substitution information. It is classified by function (this
classification is called feature) for the substitution information, and defined with four-character
tags. This feature is related to specific writing systems and languages. Substitution by one or
multisubscript character glyph index numbers defined in cmap and substitution from index
numbers after glyph substitution can be defined. The GSUB table supports the following six types
of substitution methods.
• Substitution of one glyp with another glyph(single substitution). This is used when
the glyph changes according to the character position as in Arabic, or when glyphs for
vertical writing as in Japanese are required.
Figure 5.2 Example of Single Substitution

All Copyrights Reserved, CICC
• One character is substituted to more than two glyphs (multi substitution).
• Character are the same, but substituted to several different glyphs (alternate
substitution). For example, subscript character glyphs with different designs are
provided for selection by the user.
• Substitution of several charactes with totally different glyph(s) (ligature substitution).
An example is character substitution by consonant clustering in Indian scripts.
• Substitution of
substitution). G
(b)classification
(c)defining aggr
• Substitution usi
Extension of co
GPOS (Glyph Positioning T
The GPOS table stored info
layouts. Like GSUB, this ta
and languages.
The layout position of certa
other character glyphs. For
tone mark to alphabets are
same character, the diacritica
with the next glyph, and is a
Figure 5.3 Example of Multi Substitution
Figure 5.4 Example of Alternate Substitution
Figure 5.5 Example of Ligature Substitution27
one or more glyph patterns by one or more glyphs (contextual
lyph patterns consist of (a) taking glyph strings as patterns,
of glyphs into classes, and taking the class strings as patterns,
egates of glyphs, and taking the aggregate strings as patterns.
ng multiple contextual substitution (chaining contextual substitution).
ntextual substitution.
able)
rmation for minutely controlling layout positions of glyphs in text
ble is classified by function, and related to specific character systems
in character glyphs may change according to the combination with
example, In Vietnamese, character systems adding diacritical marks,
used. When the diacritical mark and tone marks are attached to the
l mark shifts to an upper position. In the Arabic Urdu, the glyph joins
rranged downwards in the direction from right to left. Such character

All Copyrights Reserved, CICC
28
systems require not only the writing direction in character layout processing, but also
two-dimensional glyph position control.
The drawing of this verse was excerpted from
http://www.Microsoft.com/typography/otspec/default.htm.
Figure 5.6 Example of Mark Position in Vietnamese
Figure 5.7 Example of Urdu

All Copyrights Reserved, CICC
29
5.2 Khmer OpenType Font Specifications
This section describes the implementation specifications of OpenType font First the character
categories for implementation are described, followed by the implementation specifications and
development methods of each table of Open Type.
The development of the Unicode Khmer OpenType was based on the 1byte Khmer font Khek
Sangker of Khek Brothers. The format of this font is the TrueType. It is converted to the
OpenType font by adding the required table.
5.2.1 Classification of Khmer Characters
Khmer characters consist of consonant characters, subscript characters (consonant signs),
independent vowel characters, vowel symbols, added symbols, and Khmer numerals. Of this, the
consonant characters serve as the base of characters, and arranged around it are the subscript
character, vowel sign, and added symbol on the top, bottom, left, and right. In some cases,
multiple subscript characters may come under one consonant character. The glyph shape or glyph
position change according to the combination with consonant characters or combination with
other subscript characters, vowel symbols, added symbols, etc. With certain consonant characters,
the glyph shape may change. Independent vowel symbols and Khmer numerals compose
characters independently.
As characters can be classified according to the changes in glyph shape and glyph position, Khmer
font was implemented referring to this classification. The classification of characters conforms to
the classification method of Professor Makoto Minegishi, Tokyo University of Foreign Studies,
Research Institute for the Languages and Cultures of Asia and Africa.

All Copyrights Reserved, CICC
30
Table 5.1 Classification of Characters
Type of Character
Classification of Prof. Minegishi
ISO/IEC
10646
(UCS or
Unicode)
Glyph Remarks
1781
178C
178E
1791
1793
1796
CA
17A0
The glyph shape does not change.
1787
178A
178B
1790
CB
1795
Depending on the font design, the glyph position of the following superior added symbols SA, SB, SD and superior vowel symbol DC may be at the top.
Consonant character
CC 1784
The glyph position of the following superior added symbols SA, SB, SD and superior vowel symbol DC is at the top.

All Copyrights Reserved, CICC
31
Table 5.2 Classification of Characters (Continuation)
Type of Character
Classification of Prof. Minegishi
ISO/IEC
10646
(UCS or
Unicode)
Glyph Remarks
CD 179C
The glyph position of the following superior added symbols SA, SB, SD and superior vowel symbol DC is at the top. In addition, only for the mul character, it is joined with a superior vowel symbol.
CE 179A
The glyph shape does not change, but a narrow glyph should ideally be provided for the superior vowel symbol and subscript character combined with.
1783
1785
1786
1788
178D
1792
1798
1799
179B
179F
Consonant character
CF
17A2
Except when part of the subscript character (JD) follows, this is joined to the right side vowel symbol (DB) and right side of the left right enclosed vowel symbol (DG).

All Copyrights Reserved, CICC
32
Table 5.3 Classification of Characters (Continuation)
Type of Character
Classification of Prof. Minegishi
ISO/IEC
10646
(UCS or
Unicode)
Glyph Remarks
1780
1782
178F
Consonant character
CG
1797
Except when part of the subscript character (JD) follows, this is joined to the right side vowel symbol (DB) and right side of the left right enclosed vowel symbol (DG). In addition, only for the mul character, it is joined with a superior vowel symbol.
CH 17A1
Except when part of the subscript character (JD) follows, this is joined to the right side vowel symbol (DB) and right side of the left right enclosed vowel symbol (DG). The glyph position of the following inferior added symbol and inferior vowel symbol is at the bottom.
CI 1789
When the subscript character follows, the glyph shape changes. Particularly, if the following subscript character is the same consonant, the glyph shape of this subscript character changes. The glyph position of a different glyph of the following inferior added symbols SC and SD and inferior vowel symbol (DD) is at the bottom.
CJ 1794
Joined to the right side vowel symbol and right side of the left right enclosed vowel symbol to become a different glyph shape.

All Copyrights Reserved, CICC
33
Table 5.4 Classification of Characters (Continuation)
Type of Character
Classification of Prof. Minegishi
ISO/IEC
10646
(UCS or
Unicode)
Glyph Remarks
17D2
1780 17D2
1781 17D2
1782 17D2
1784 17D2
1785 17D2
1786 17D2
1787 17D2
178A 17D2
178B
17D2
178C
17D2
178E 17D2
178F 17D2
1790
Subscript character
JA
17D2
1791
The glyph shape does not change.
All Copyrights Reserved, CICC
34
17D2
1792
Table 5.5 Classification of Characters (Continuation)
Type of Character
Classification of Prof. Minegishi
ISO/IEC
10646
(UCS or
Unicode)
Glyph Remarks
17D2
1793
17D2
1795
17D2
1796
17D2
1797
17D2
179B 17D2
179C
JA
17D2
17A2
The glyph shape does not change.
JB 17D2
17A0
Depending on the combination with the consonant character, the glyph position may be at the bottom.
JC 17D2
1798
When following the consonant character CH, or when following the subscript characters JA, JB, JC, the glyph position is at the bottom.
17D2
1783 17D2
1788
Subscript character
JD
17D2
178D
Joined to the right side of the following vowel symbol DB and left right enclosed vowel symbol DG .
All Copyrights Reserved, CICC
35
17D2
1794
17D2
1799
17D2
179F
Table 5.6 Classification of Characters (Continuation)
Type of Character
Classification of Prof. Minegishi
ISO/IEC
10646
(UCS or
Unicode)
Glyph Remarks
JE 17D2
179A
When following a different subscript character, becomes a different glyph with a long shape downwards.
Subscript character
JF 17D2
1789
When the precedent consonant character is the same as itself, the glyph shape changes.
17C7
DA
17C8
The glyph shape does not change.
17B6
DB
17B6
17C6
When the precedent consonant character is CF, CG, CH, CI, or the precedent subscript character is JD, joins with each.
17B7
17B9
17BA
17C6
Vowel
symbol
DC
17B8
When the precedent consonant character is CC or CD, and the consonant character is attached with a superior vowel symbol added symbol, the glyph position becomes higher.

All Copyrights Reserved, CICC
36
17BC
17BD
DD
17BB
When the precedent consonant character is CH or CI, and the consonant character is followed by a subscript character other than JE, the glyph position becomes lower.
Table 5.7 Classification of Characters (Continuation)
Type of Character
Classification of Prof. Minegishi
ISO/IEC
10646
(UCS or
Unicode)
Glyph Remarks
DE 17BB
17C6
When the precedent consonant character is CC or CD, and the consonant character is attached with a superior vowel symbol added symbol, the top glyph position becomes higher.
17C1
17C2
DF
17C3
When the precedent consonant character is CH or CI, and the consonant character is followed by a subscript character other than JE, the bottom glyph position becomes lower.
17C4
DG
17C5
The right side joins when the precedent consonant character is CF, CG, CH, CI or the precedent subscript character is JD.
17BF
Vowel symbol
DH
17C0
When the precedent consonant character is CH or CI, and the consonant character is followed by a subscript character other than JE, it changes to a glyph shape with the right side long downwards.
All Copyrights Reserved, CICC
37
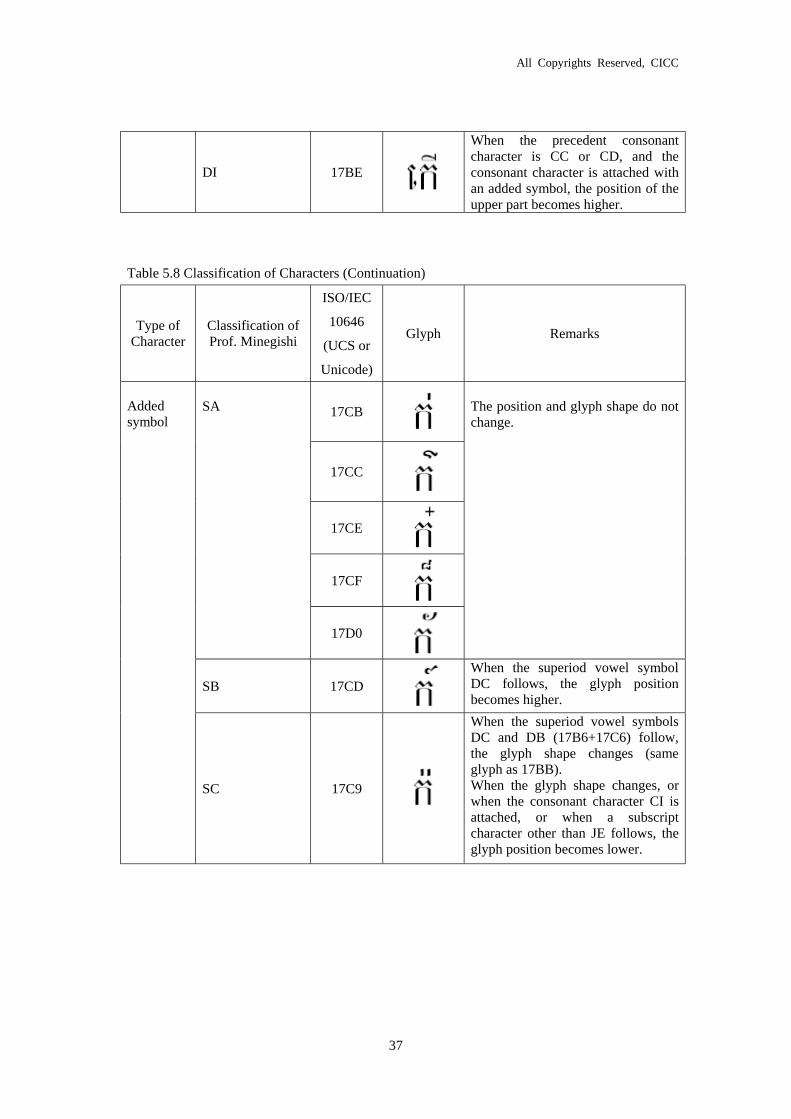
DI 17BE
When the precedent consonant character is CC or CD, and the consonant character is attached with an added symbol, the position of the upper part becomes higher.
Table 5.8 Classification of Characters (Continuation)
Type of Character
Classification of Prof. Minegishi
ISO/IEC
10646
(UCS or
Unicode)
Glyph Remarks
17CB
17CC
17CE
17CF
SA
17D0
The position and glyph shape do not change.
SB 17CD
When the superiod vowel symbol DC follows, the glyph position becomes higher.
Added symbol
SC 17C9
When the superiod vowel symbols DC and DB (17B6+17C6) follow, the glyph shape changes (same glyph as 17BB). When the glyph shape changes, or when the consonant character CI is attached, or when a subscript character other than JE follows, the glyph position becomes lower.

All Copyrights Reserved, CICC
38
SD 17CA
When the superior vowel symbol DC follows, the glyph shape changes (same glyp as 17BB). When the glyph shape changes, or when the consonant character CI is attached, or when a subscript character other than JE follows, the glyph position becomes lower.
*The glyph shape of the subscript characters, vowel symbols, and added symbols in the tables are
shown combined with consonant character U+1780.

All Copyrights Reserved, CICC
39
5.2.2 Khmer OpenType Table Implementation Specifications
The following describe is the specifications of the OpenType table related to Khmer font.
The implementation of the GSUB and GPOS tables conform to the Khmer OpenType font
specifications defined by Microsoft.
(1)cmap table
A mapping table based on the use of fonts in the Windows environment has been added.
Table 5.9 Mapping table
Data Value Description of Value
Platform ID 3 Table referred to by Microsoft OS
Encoding ID 1 ISO/IEC 10646 (UCS or Unicode) mapping
Format 4 Microsoft standard mapping table format
Glyphs were also mapped for the following character codes. With fonts before OpenType
(TrueType Open to be precise), there was a need to assign different character codes if the
glyph shape or position were different even for the same character. With OpenType, as it is
possible to output different glyphs or change the glyph position with the same character code,
basically one character code is assigned to one character. Consequently, the Khmer
OpenType font consists of many glyphs for which character codes cannot be assigned.
*Khek Sangker consists of fonts missing from character sets defined by ISO/IEC 10646
(UCS or Unicode).
Table 5.10 Glyphs Mapping Character Codes
Character Code Corresponding Glyph
U+0020 Space
U+0030~0039 0-9
U+1780~U+17E9 Khmer Character
*The left superior vowel symbol and left right attached vowel symbol are divided into two as
glyphs (with consonant characters in between), but exist as one as a character code. With the
OpenType mapping, the upper or right side glyph and character codes are related by mapping
tables.

All Copyrights Reserved, CICC
40
(2)Name Table
Though information of 1byte TrueType font name table serving as the base can be used,
information is rewritten for changing the font name.
The information stored in the name table is constructed of sets of Platform ID,
Platform-specific Encoding ID, Language ID, Name ID, and String.
Table 5.11 Setting of name Tables
(Platform ID, Platform-specific Encoding ID Settings 1)
Data Value Description
Platform ID 1 Mac
Platform-specific encoding ID 0 Roman
Language ID 0 English
(Platform ID, Platform-specific Encoding ID Settings 2)
Data Value Description
Platform ID 1 Mac
Platform-specific encoding ID 0 Roman
Language ID 0 English
(Name ID, String Settings for Above Two Sets of Platform ID, Platform-specific Encoding ID)
Name ID String
0(Copyright notice) Copyright 1994-99 by Khek
Brothers. All rights reserved.
Designed by Kantol Khek.
1(Font Family name) Khek Sangker Test
(Font Subfamily name) Regular
3(Unique font identifier) Khek Sangker Test
4(Full font name) Khek Sangker Test
5(Version string) 0.01
6(Postscript name) KhekSangkerTest
(3)OS/2 Table
The following information is rewritten using the OS/2 information of the 1byte TrueType
font serving as the base.
With the OpenType specifications, the OS/2 table version is 2. But in this project, version 1
was mounted.

All Copyrights Reserved, CICC
41
Table 5.12 OS/2 Table Rewritten Areas and Values
Data Value Description
ulUnicodeRange1 0x00000001 Accommodated character set
ulUnicodeRange2 0 Accommodated character set
ulUnicodeRange3 0x00010000 Accommodated character set
ulUnicodeRange4 0 Accommodated character set
UsLastCharIndex 0x17E9 Final character code
ulCodePageRange1 0x00000001 Specify code page
ulCodePageRange2 0 Specify code page
(4)GSUB Table
Microsoft defines the following features for substitution of glyphs implemented for the
Khmer OpenType font.
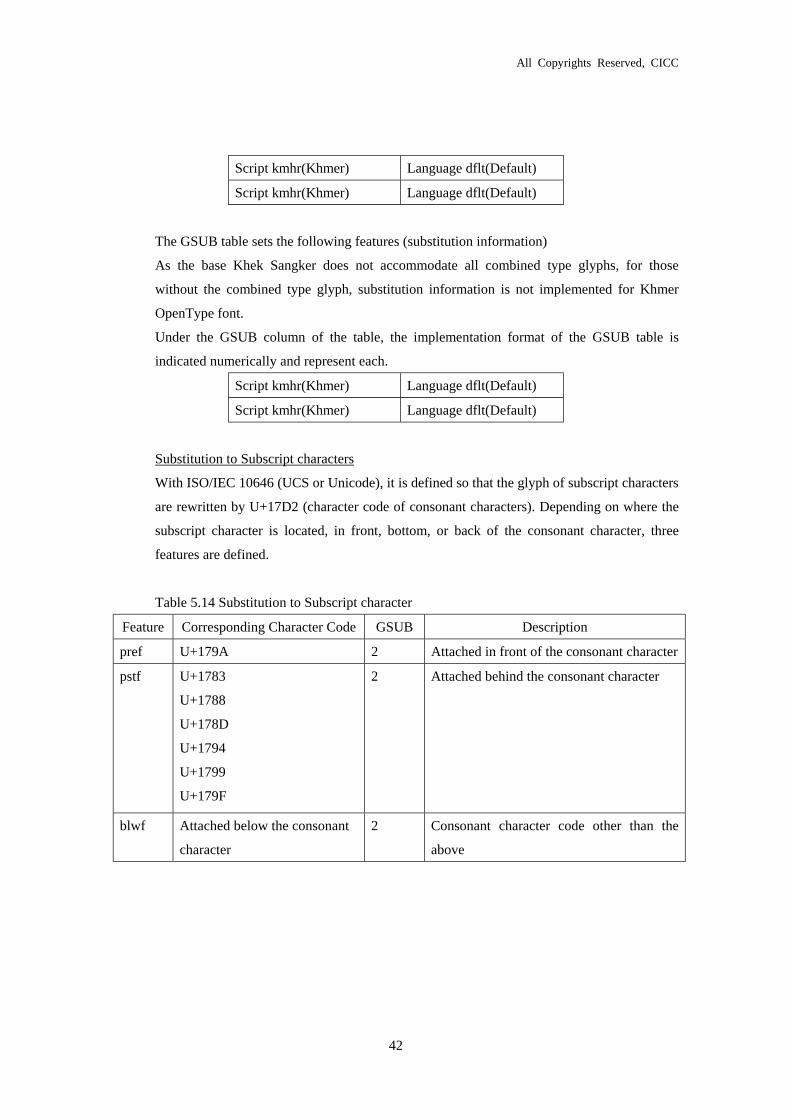
Table 5.13 Substitution Features Related to the Khmer script Defined by Microsoft
The GSUB and GPOS tables relate the scripts (character system) and language using the
features implemented in this table.
With the Khmer OpenType font, they are related with feature.
Feature Description
pref Information on substitution to subscript character attached to front of consonant character
blwf Information on substitution to subscript character attached to bottom of consonant character
abvf Information on substitution to symbol attached to top of consonant character
pstf Information on substitution to subscript character attached to back of consonant character
pres Information on substitution to different glyph of subscript character attached in front.
Applied to substitution of glyph when arranged with attached subscript character.
blws Information on substitution to different glyph of subscript character attached to the bottom.
abvs Information on substitution to different glyph of superior symbol.
Applied to the substitution of one glyph by joining two superior symbols
psts Information on substitution to different glyph of subscript character attached to the back.
Applied to the substitution of glyph when one consonant character is arranged with an
inferior subscript character.
clig Applied to the substitution of glyph when consonant characters and vowel symbols are
joined.
All Copyrights Reserved, CICC
42
Script kmhr(Khmer) Language dflt(Default)
Script kmhr(Khmer) Language dflt(Default)
The GSUB table sets the following features (substitution information)
As the base Khek Sangker does not accommodate all combined type glyphs, for those
without the combined type glyph, substitution information is not implemented for Khmer
OpenType font.
Under the GSUB column of the table, the implementation format of the GSUB table is
indicated numerically and represent each.
Script kmhr(Khmer) Language dflt(Default)
Script kmhr(Khmer) Language dflt(Default)
Substitution to Subscript characters
With ISO/IEC 10646 (UCS or Unicode), it is defined so that the glyph of subscript characters
are rewritten by U+17D2 (character code of consonant characters). Depending on where the
subscript character is located, in front, bottom, or back of the consonant character, three
features are defined.
Table 5.14 Substitution to Subscript character
Feature Corresponding Character Code GSUB Description
pref U+179A 2 Attached in front of the consonant character
pstf U+1783
U+1788
U+178D
U+1794
U+1799
U+179F
2 Attached behind the consonant character
blwf Attached below the consonant
character
2 Consonant character code other than the
above

All Copyrights Reserved, CICC
43
Different Glyphs of Consonant Characters
Table 5.15 Different Glyphs of Consonant Characters
Feature Character
Code
Character
Classification
Before
Substitution
After
Substitution GSUB Description
blws U+1789 CI
1 The glyph shape
changes when
subscript character
is attached
clig U+1794 CJ
2 Becomes a
different glyph
shape when joined
with right side
vowel symbol and
right side of the left
right enclosed
vowel symbol.

All Copyrights Reserved, CICC
44
Different Glyphs of Subscript characters
Table 5.15 Different Glyphs of Subscript characters
Feature Character
Code
Character
Classification
Before
Substitution
After
Substitution GSUB Description
pres U+17D2
U+179A
JE
2 When following
different subscript
characters,
becomes a different
glyph with a long
bottom.
U+17BF DH
psts
U+17C0 DH
2 When the
precedent
consonant
character is CH or
CI, and subscript
characters other
than JE follow the
consonant
character, becomes
a glyph shape with
a long right side
downwards.
pres U+17D2
U+1789
JF
+<JF>
1 When the
precedent
consonant
character is the
same as itself, the
glyph shape
changes.

All Copyrights Reserved, CICC
45
Different Glyphs of Vowel Symbols
Table 5.15 Different Glyphs of Vowel Symbols
Feature Character
Code
Character
Classification
Before
Substitution
After
Substitution GSUB Description
U+17BF DH
psts
U+17C0 DH
2 When the precedent
consonant character
is CH or CI, and
subscript characters
other than JE follow
the consonant
character, becomes a
glyph shape with a
long right side
downwards.
Different Glyphs of Added Symbols
Table 5.15 Different Glyphs of Added Symbols
Feature Character
Code
Character
Classification
Before
Substitution
After
Substitution GSUB Description
clig U+17C9 SC
1 When the superior
vowel symbol DC and
DB (17B6+17C6)
follow, the glyph
shape changes (same
glyph as 17BB).
clig U+17CA SD
1 When the superior
vowel symbol DC
follows, the glyph
shape changes (same
glyph as 17BB).
All Copyrights Reserved, CICC
46
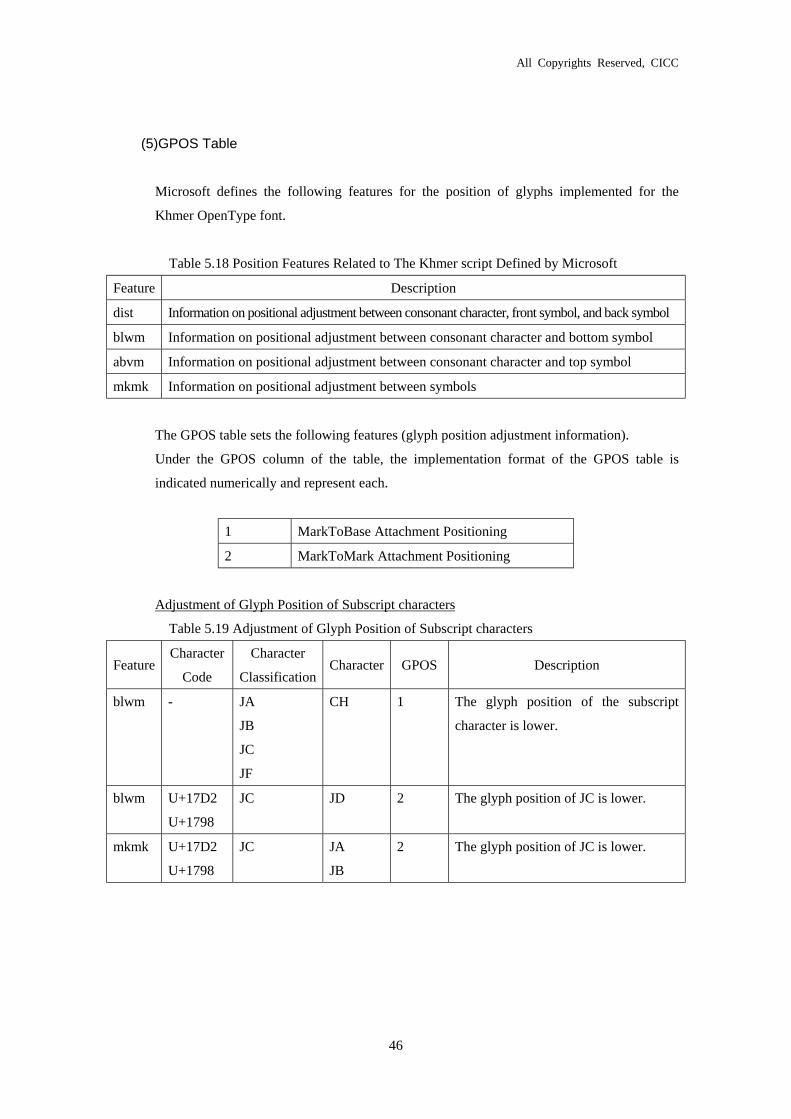
(5)GPOS Table
Microsoft defines the following features for the position of glyphs implemented for the
Khmer OpenType font.
Table 5.18 Position Features Related to The Khmer script Defined by Microsoft
The GPOS table sets the following features (glyph position adjustment information).
Under the GPOS column of the table, the implementation format of the GPOS table is
indicated numerically and represent each.
1 MarkToBase Attachment Positioning
2 MarkToMark Attachment Positioning
Adjustment of Glyph Position of Subscript characters
Table 5.19 Adjustment of Glyph Position of Subscript characters
Feature Character
Code
Character
Classification Character GPOS Description
blwm - JA
JB
JC
JF
CH 1 The glyph position of the subscript
character is lower.
blwm U+17D2
U+1798
JC JD 2 The glyph position of JC is lower.
mkmk U+17D2
U+1798
JC JA
JB
2 The glyph position of JC is lower.
Feature Description
dist Information on positional adjustment between consonant character, front symbol, and back symbol
blwm Information on positional adjustment between consonant character and bottom symbol
abvm Information on positional adjustment between consonant character and top symbol
mkmk Information on positional adjustment between symbols

All Copyrights Reserved, CICC
47
Adjustment of Glyph Position of Vowel Symbols
Table 5.20 Adjustment of Glyph Position of Vowel Symbols
Feature Character
Code
Character
Classification Character GPOS Description
blwm - DD
DE
CH 1 The glyph position of the inferior vowel
symbol (or bottom of vowel symbol) is
lower.
blwm - DD
DE
CI 1 The glyph position of the inferior vowel
symbol (or bottom of vowel symbol) is
lower.
blwm - DD
DE
JD 2 The glyph position of the inferior vowel
symbol (or bottom of vowel symbol) is
lower.
abvm - DC CC
CD
1 The glyph position of the superior vowel
symbol is higher.
mkmk - DD
DE
JA
JB
JC
JF
2 The glyph position of the inferior vowel
symbol (or bottom of vowel symbol) is
lower.
mkmk - DC SD 2 The glyph position of the superior vowel
symbol is higher.
All Copyrights Reserved, CICC
48
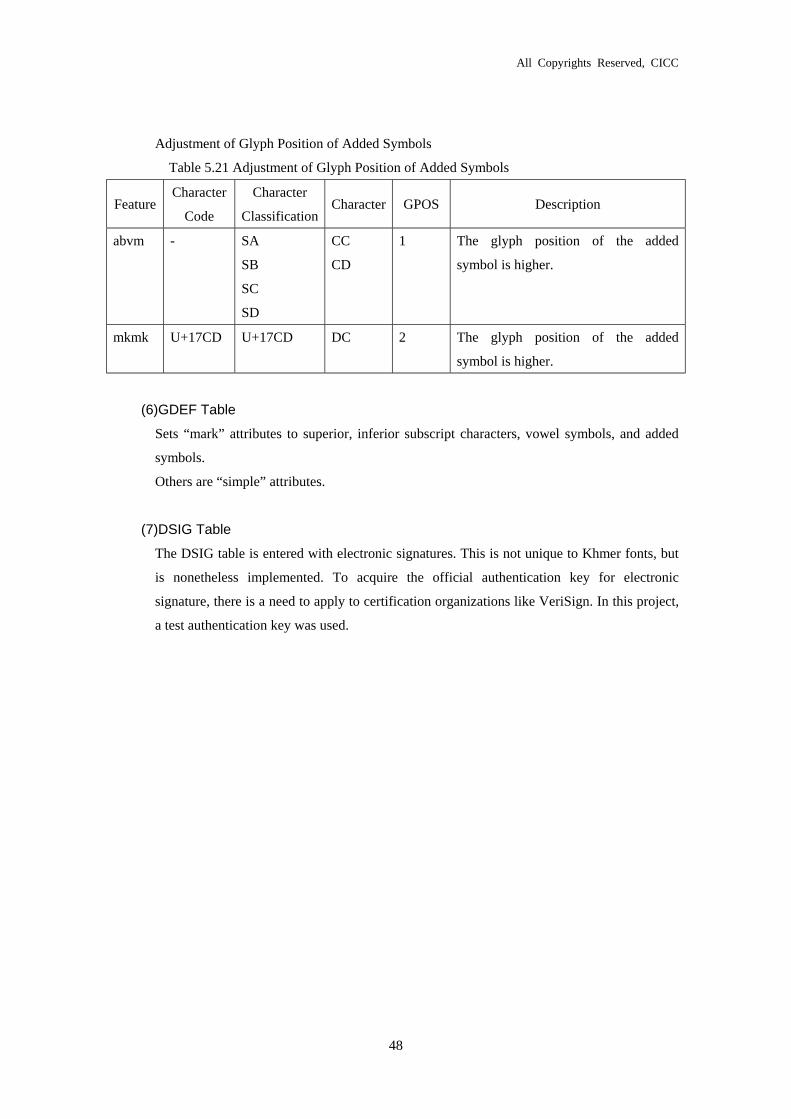
Adjustment of Glyph Position of Added Symbols
Table 5.21 Adjustment of Glyph Position of Added Symbols
(6)GDEF Table
Sets “mark” attributes to superior, inferior subscript characters, vowel symbols, and added
symbols.
Others are “simple” attributes.
(7)DSIG Table
The DSIG table is entered with electronic signatures. This is not unique to Khmer fonts, but
is nonetheless implemented. To acquire the official authentication key for electronic
signature, there is a need to apply to certification organizations like VeriSign. In this project,
a test authentication key was used.
Feature Character
Code
Character
Classification Character GPOS Description
abvm - SA
SB
SC
SD
CC
CD
1 The glyph position of the added
symbol is higher.
mkmk U+17CD U+17CD DC 2 The glyph position of the added
symbol is higher.

All Copyrights Reserved, CICC
49
5.3 Font Development Procedure
5.3.1 Development Environment
The following shows the Khmer OpenType font development hardware and software
environment of this project.
Table 5.22 Development Environment
Hardware Intel architecture machine
Software OS: Windows XP Professional
Uniscribe (dll 1.453.3665.0)
Development Tools • Cygwin (Unix compatible environment)
(Acquired from: http://cygwin.com/)
• gcc 2.95.3-5
(C compiler)
(Acquired from: Cgywin installation)
• VOLT 1.1b
(OpenType Layout Table compilation tool)
(Acquired from:
http://www.microsoft.com/typography/developers/volt/default.htm)
• dsig (Signature generation tool)
(Acquired from:
http://www.microsoft.com/typography/developers/dsig/default.htm)

All Copyrights Reserved, CICC
5.3.2 Development Procedure
The following shows the development procedure of the Khmer OpenType font.
(1)Deletion
The Platfo
cmap table
The unique
delcmap is
The using
(2)Modificat
The origin
mkname is
The using
The name
Deletion of cmap table Modification of name table Modification of OS/2 table
Addition of DSIG table Addition of GSUB, GPOS,
GDEF tables Addition of cmap tables
delcmap
mkname
<Platfor
Figure 6.8 Development Procedure of Khmer OpenType Font
50
of cmap Table
rm ID=3 Encoding ID=1 mapping table is deleted from the original TrueType font
.
tool delcmap developed was used for the deletion.
command based, and the development language is C.
method is:
ion of name Table
al TrueType font name table is rewritten using the unique tool mkname.
command based, and the development language is C.
method is:
table information file stores items set in the name table in text format.
<Font name> <Mapping table index number>
<Font name> <Name table information file>
m ID> <Platform-specific encoding ID> <Language ID> <name ID> <String>

All Copyrights Reserved, CICC
The following shows a specific example.
*Items are divided by tab.
(3)Modification of OS/2 Table
The original TrueType font OS/2 table is rewritten using the unique tool mkos2.
Rewriting is done only for modified parts.
mkos2 is command based, and the development language is C.
The using method is:
T
T
*
1 0 0 1 Khek Sangker Test
1 0 0 2 Regular
1 0 0 3 Khek Sangker Test
mkos2 <Font name> <OS/2 table information file>he os/2 table information file stores items and values set in the OS/2 table in text format.
<Item 1><Value 1>
<Item 2><Value 2>
….
51
he following shows a specific example.
Items are divided by tab.
ulUnicodeRange1 0x00000001 % bit0
ulUnicodeRange2 0
ulUnicodeRange3 0x00010000 % bit80
ulUnicodeRange4 0
usLastCharIndex 0x17E9
ulCodePageRange1 0x00000001 % bit0
ulCodePageRange2 0

All Copyrights Reserved, CICC
52
(4)Addition of cmap Table
The original TrueType font cmap table is added with ISO/IEC 10646 (UCS or Unicode)
compatible mapping table of Platform ID=3 Encoding ID=1.
The unique tool mkcmap4 developed was used for the addition.
mkcmap4 is the base of the command generating the format 4 mapping table, and the
development language is C.
The using method is:
The cmap table information file stores items and values set in the mapping table in text
format.
(5)Addition of GSUB, GPOS, GDEF Tables
The GSUB, GPOS, GDEF tables were implemented using the VOLT (Visual OpenType
Layout Tool) provided by Microsoft. This is a GUI based tool. The tables can be
implemented while visually checking the changes in the glyph shape and position.
*VOLT independently rewrites the cmap table. But some original cmap table information
may be lost. The lost information must be set again using VOLT.
(6)Addition of DSIG Table
The DSIG table was implemented using dsig (signature generation tool provided by
Microsoft. This is a command base.
mkcmap4 <Font name> <cmap table information file>
<segment count>
<endCount 1>
<endCoount 2>
…
<startCount 1>
<startCount 2>
….
<character code1> <glyph index 1>
<character code2> <glyph index 2>
…

All Copyrights Reserved, CICC
53
6. Verification Program Development -Development of Input (Transcription) Programs-
An input (transcription) program was developed as a method for inputting the Khmer script.
The following points were taken into consideration in the development of the program.
• Development in general OS environment
• Natural input method based on intentions of native speakers
• Flexible architecture not limited by technical constraints of specific input methods
The following input method was developed based on the above conditions.
• TCL program running on the Windows Im interface
• Input shall be a free keyboard sequence
• Simple logics can be incorporated
• Outputs corresponding to multiple entries are encoded character strings of UCS
• Has multiple modes which can be switched freely (actually four modes).
The above IM was implemented with two modes based the instructions from Professor Minegishi
and exisiting keyboard layouts obtained in field studies.
• Transcription mode method from Latin alphabets by Professor Minegishi’s method.
• Direct encode input method based on existing keyboard layout.

All Copyrights Reserved, CICC
54
7. Pilot Tests Over the following two occasions, guests from NiDA (Under Secretary of State: Mr. SORASAK
PAN) were invited for user verification by native speakers at the Tokyo University of Foreign
Studies, Research Institute for the Languages and Cultures of Asia and Africa.
• 1st time; August 23, 26, 27, 2002
Participated by CHEA Sok Huor and TOP Rithy
• 2nd time: September 25 and 26, 2002
Participated by HE. UNG Vuthy and CHEA Sok Huor
The results confirmed that the basic functions are satisfactory.
At this point, there are no marked elements that are insufficient as encoded characters.
However, it was found that auxiliary function characters are required for end-of-line processing.
(when at the end-of-the-line, function which clearly prompts starting a new line and function
which clearly stops starting a new line).
In addition, there exists ambiguous combinations of whether to perform a ligature process and it
was clarified that functional elements to inhibit ligature processing in the display of one syllable
are essential.
Examples of such auxiliary function characters are ZWJ (zero width joiner;U+200C) and ZWNJ
(zero width non-joiner;U+200D), ZWSP (zero width space; U+200B) used by Microsoft for trial
implementations.
*Note by CICC: The third objective of this project is to identify needs this kind of additional
functutions.
To prevent confusion in future implementations, it should be necessary to disclose the handling of
these function characters in the Khmer script based on the agreement between related
organizations such as Cambodian National Body, ISO/IEC JTC1, Unicode Technical Committee,
etc.

All Copyrights Reserved, CICC
55
8. Information Obtained in This Survey and Discussion As a result of this survey, the following were implemented for UCS the Khmer script;
(1)All glyph images required for display were implemented, character code strings and relation of
glyphs for display were described by methods such as tables, and it was clarified that the method
for displaying the glyphs of required characters can be put to practical application.
(2)The input results are not used as direct data for various character input methods, and data
strings are made according to conversion programs and reference tables. It was verified that data
strings can be made from the same character codes regardless of the input method, without using
the input results as direct data.
(3)Even the Cambodian agency who had doubts regarding the UCS method in the beginning about
the output and input by this method confirmed the practicability of this method.
Reference information:
The Laos Governmental Science and Technology Environment Agency IT center has also
confirmed the potentials of extending the Laotian characters.
8.1 Dealing with Complicated Character Structures
With conventional character output methods, the structure of multiple characters was defined by
the fixed relation between the attributes of letter shapes for output and character codes. Due to the
need to deal with each character structure by script and character code, this serves as the
bottleneck of corresponding language. With the method verified here, required letter shapes for
output were prepared for all results for this complicated structure, and the relation with character
codes is displayed by separately describing character codes and output a glyph images. The
experiment results show that all rendering requirements can be fulfilled such as fine tuning of
mutual position of each element, minute changes and synthesis of glyphsbylcharacter codes
sythesis, addition of accent/tone marks, etc., adjustment of letter shapes and change in output
golyph according to mutual positional relations within character code strings. (presentation form).
With this method, basically all the required items are prepared, and by defining the relation, the
technology should be applicable to all scripts in the regions studied, and reviews on letter shape
changes of independent, beginning of words, in words, and at the end of words of Arabic
characters.
Furthermore, this method should be applicable to European and American accented characters and
synthesized characters (presentation forms) and should be usable gerenerally.

All Copyrights Reserved, CICC
56
8.2 Handling of Diverse Character Codes for Same Script (Diversity of Display Methods)
This survey was conducted centering around the implementation of UCS character codes.
However, character codes actually used are not limited to UCS. On the contrary, character
codes other than UCS are used extensively, and the diversity is complicating the handling of
character codes.
Though character codes are described as being diverse, eventually only one is displayed. The
difference lies only in the diversity of the methods involved. With the method used to confirm
the effectiveness of the results of this survey, all the items required for output eventually were
prepared, and the relation with separate character codes is described logically. For this reason,
by changing only the description of the relation, it may be possible to output diverse character
codes as intended by eliminating character processing unique to character codes which may
lose the interchangeability of output letter shape development by character code which takes up
the most time and efforts and data processing processes.
8.3 Handling of Diverse Character Codes for Same Script (Diversity of Entry Methods)
For the input of character codes, due to the need for character input methods matching the logical
character of character codes, there is a need to design inputs by character codes for the same
language and same script.
With the methods verified for their usefulness in this survey, diverse character codes of the same
script can be inputted using the same input method.
8.4 Technical Conclusions
The output and input methods verified in this survey were confirmed to be applicable to
South-East Asian languages for which implementation has been slow, and recommendable as
methods useful for diversifying character codes of targeted languages.

All Copyrights Reserved, CICC
57
9. Future Tasks (Reference: For Realizing Results of This Survey) The implementation of UCS characters with international consistency by each Asian country is a
common theme.
Based on the knowledge obtained in this survey, information such as the recommended processes,
precautions, project expenses, etc. for implementing the scripts of each Asian country in the future
are provided as reference in the aim to contribute to the establishment of plans for dealing with
diverse languages.
This survey and research and prototype development project successfully achieved the foal of the
survey and research on the technical development on expandability of Arabic and South and
South-East Asian scripts.
The potentials of technical development for expanding security were successfully clarified by
technically clarifying multi-lingual implementation and verifying the effectiveness of current
international standards (ISO/IEC 10646 UCS).
However, from the viewpoint of the infrastructure for further promoting information provision
and exchange by digitalization and multi-language, in order to realize a practical environment for
outputting and inputting the Khmer scripts using UCS, more diverse support is evidently
necessary. Likewise, the same trends are seen for the other Arabic and South and South-East
Asian scripts, and similar support is indispensable.
With regard to the Khmer script which was taken up in this project, based on the fact that the
development process of UCS was not participated by native speakers and governmental
representatives of the country concerned, the Cambodian National Body (NiDA), which had just
been set up by the good interests and support of volunteers from non-governmental organizations
from several countries including Japan, requested revision of the UCS standards to ISO/IEC
JTC1/SC2. During this process, various proposals on encoding methods, system implementations,
font developments were carried out by groups involved in the development of UCS The Khmer
script, good will non-governmental organization volunteer groups, and IT venders in Cambodia,
however no consideration was given to consistency, sustainability, and succession whatsoever
between these groups.
As a result, problems reviewed for individual proposals and implementations, criticisms of groups
against those proposals and implementations were not accumulated as knowhow. If a proposal or
implementation failed to receive support from the market or National Body, other proposals and
implementations would start all over again from scratch, thus lacking the process of learning from
failure whatsoever.

All Copyrights Reserved, CICC
58
Based on such a background, future development support and technical transfer should require
sustainable and progressive processes taking into consideration collaboration with the Cambodian
National Body, international consistency, marketability, etc.
From this perspective, it should be necessary to undertake projects for establish more practical
input/output environments in a sustainable and progressive manner based on the results of this
survey and prototype development project.
---end----




![A study of ancient Khmer ephemerides - arXiv · A study of ancient Khmer ephemerides 2 of these methods of computation.3 Following the works of Billard [4] and Mercier [5], we tried](https://static.fdocuments.in/doc/165x107/5ad574247f8b9a48398d9973/a-study-of-ancient-khmer-ephemerides-arxiv-study-of-ancient-khmer-ephemerides.jpg)













