
Structured data meets unstructured data in Azure and Hadoop Parve and John...Structured data meets...
40
Structured data meets unstructured data in Azure and Hadoop Sameer Parve , Blesson John [email protected] [email protected] PFE – SQL Server/Analytics Platform System October 30 th 2014 1
Transcript of Structured data meets unstructured data in Azure and Hadoop Parve and John...Structured data meets...

Structured data meets unstructured data in Azure and Hadoop
Sameer Parve , Blesson John
PFE – SQL Server/Analytics Platform System
October 30th 2014
1
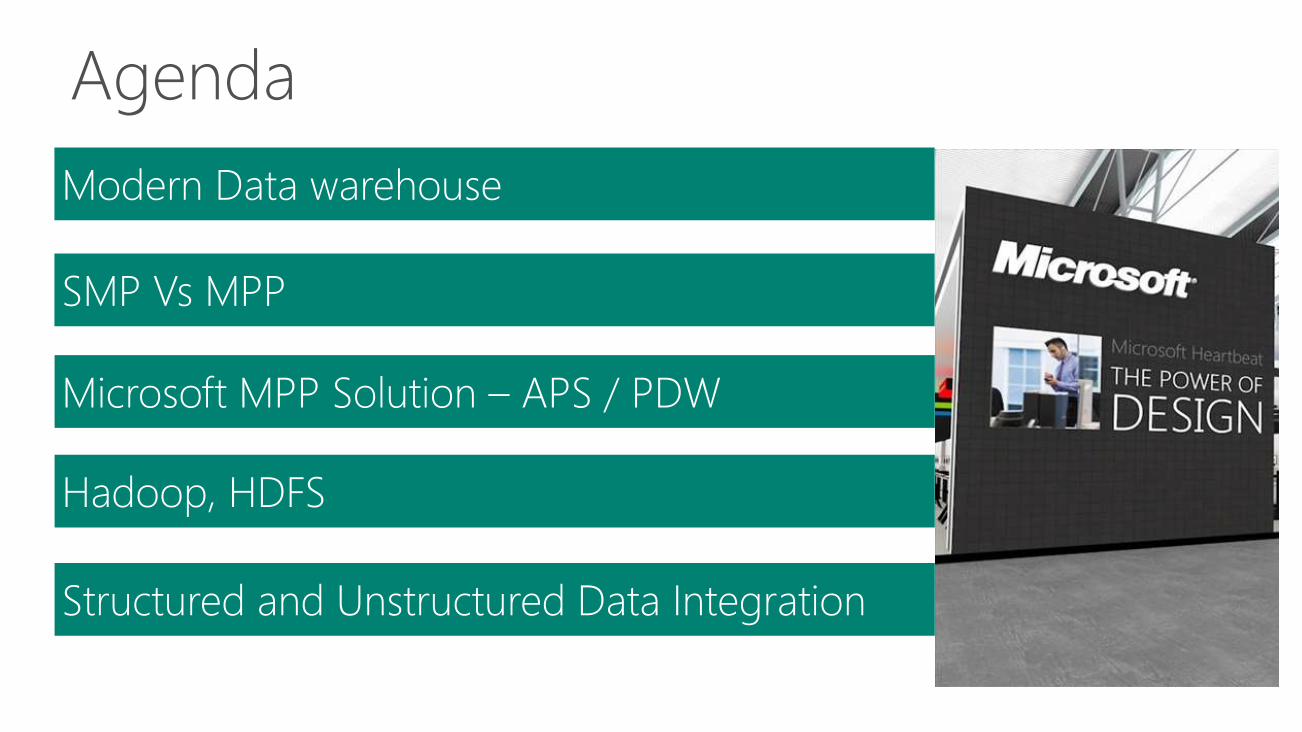
Agenda
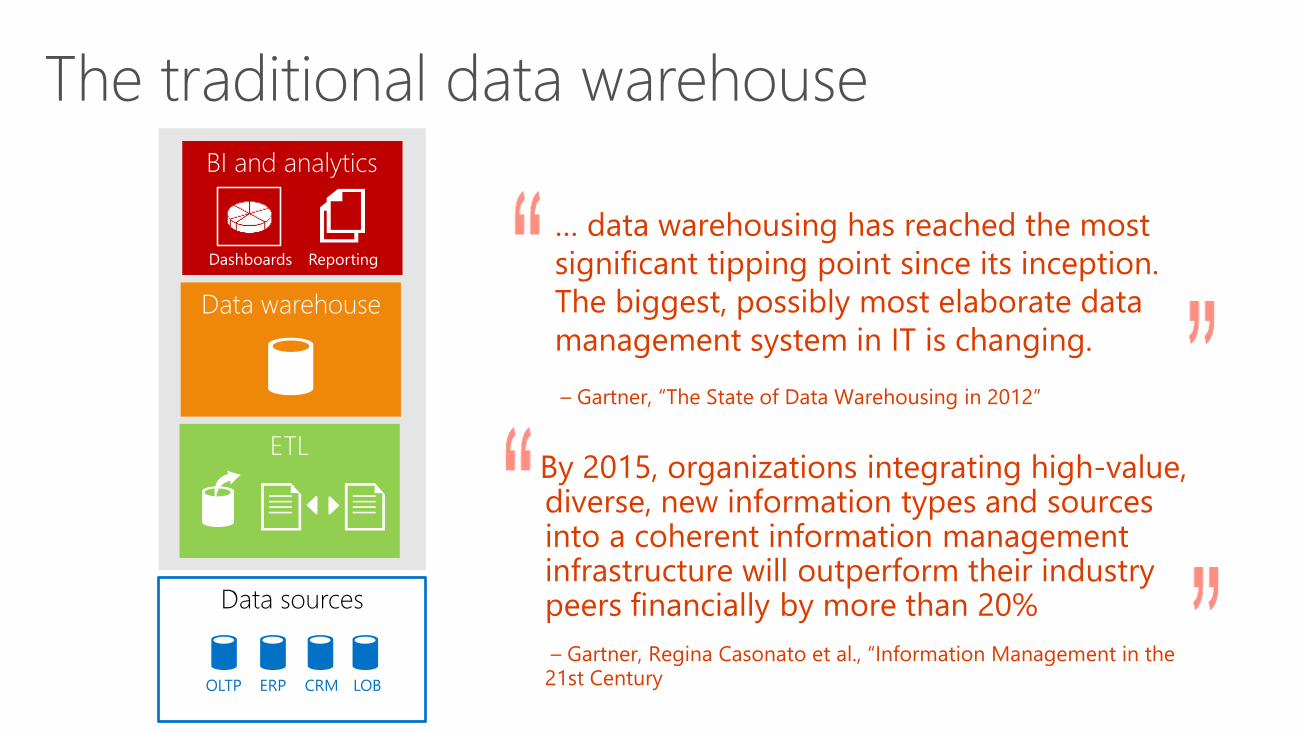
Data sources
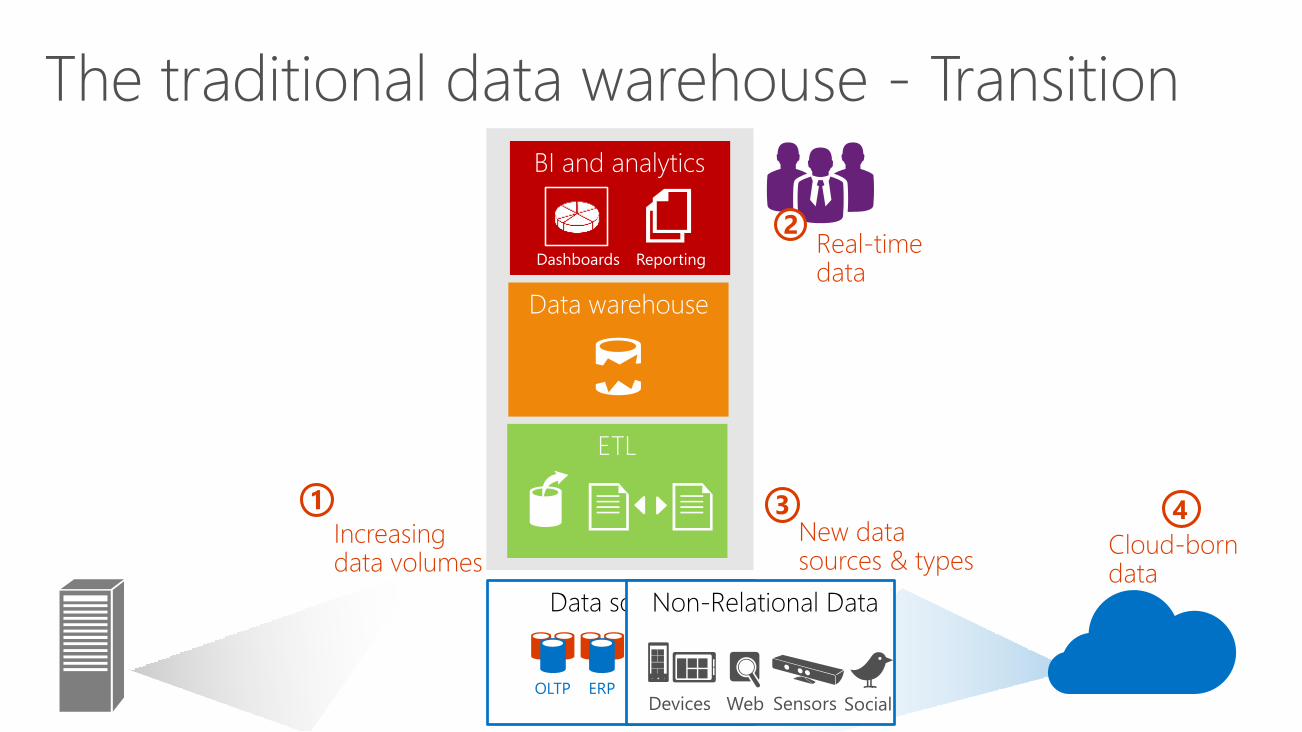
4
Data sourcesNon-Relational Data
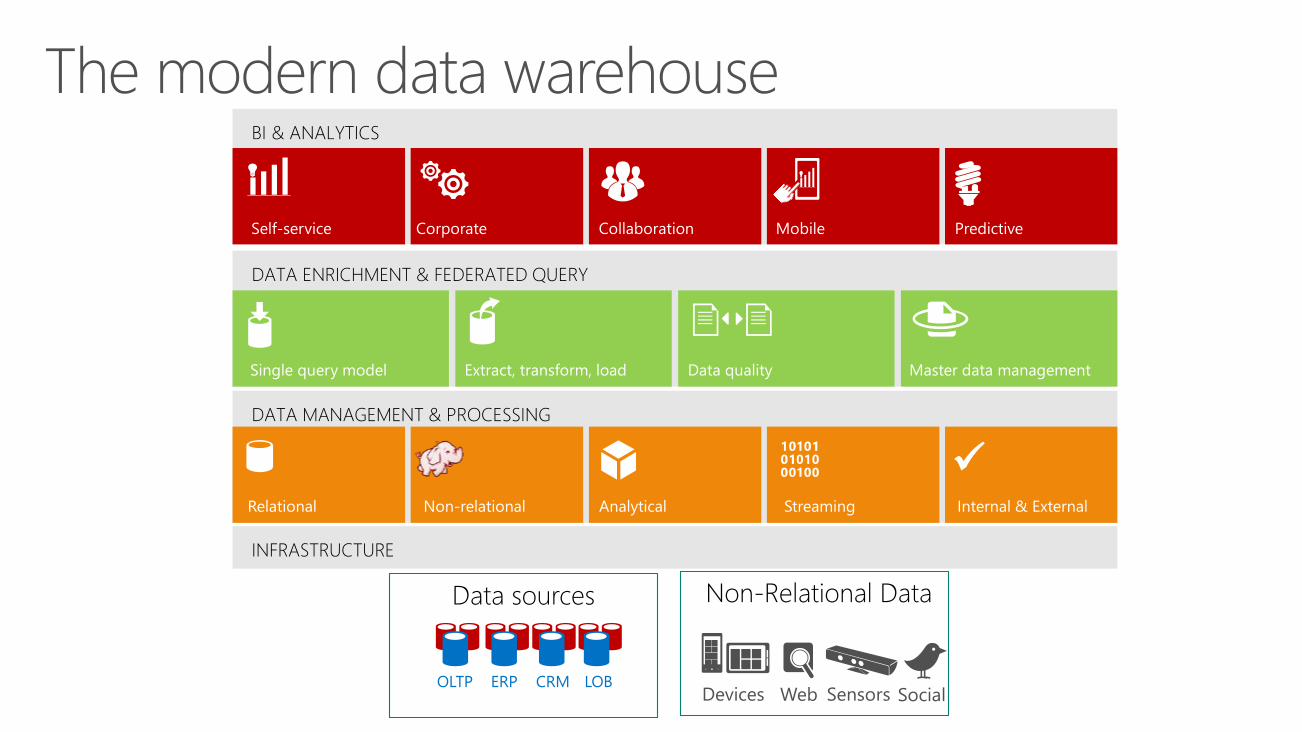
Data sources Non-Relational Data


SQL Server SMP
Microsoft MPP (APS/PDW)

SMP vs. MPP

Complete data
warehouse solution
Flexibility and choice Massive scalability
at a low cost
Microsoft data warehouse vision
Simplified data warehouse management
Make SQL Server the fastest and most affordable database for
customers of all sizes.

10
Appliance for high-end massively
parallel processing (MPP) data
warehousing
Ideal for high-scale or high-
performance data marts and
EDWs
Data warehouse appliance
(fully-integrated software and
hardware)
10s of TB – 6 PB
Infiniband
& Ethernet

MS Analytics Platform System (APS)
Pre-Built Hardware + Software Appliance
• Co-engineered with HP, Dell, and Quanta
• Pre-built Hardware
• Pre-installed Software
• Appliance installed in 1-2 days
• Support - Microsoft provides first call support
• Hardware partner provides onsite break/fix support
Plug and Play Built-in Best Practices
Save Time

Hardware architecture overview
One standard node type
2–8 core Intel processors
Doubled memory to 256 GB
Updating to the newest Infiniband (FDR – 56 GB/sec)
Moving from SAN to JBODs
Reducing costs significantly
Moving away from dependency on a handful of key SAN vendors
Using Windows Server 2012 technologies to achieve the same level of
reliability and robustness
Backup and Landing Zone (LZ) are now reference architectures and not
in the appliance
Customers can use their own hardware
Customers can use more than 1 BU or LZ for high availability
Scale unit concept
Base unit: Minimum configuration; populates rack with networking
Scale unit: Adds capacity by 2–3 compute nodes/related storage
Passive unit: Increases high availability (HA) capacity by adding more
spares
Host 2 (HST02)
Host 1 (HST01)
Host 3 (HSA01)
Host 4 (HSA02)
JBOD
IB and
Ethernet
Direct attached SAS

Virtual machine architecture overview
General details
All hosts run Windows Server 2012 Standard
All virtual machines run Windows Server 2012 Standard as a guest
operating system
All fabric and workload activity happens in Hyper-V virtual machines
Fabric virtual machines, MAD01, and CTL share one server
Lower overhead costs especially for small topologies
PDW Agent runs on all hosts and all virtual machines and collects
appliance health data on fabric and workload
DWConfig and Admin Console continue to exist
Minor extensions expose host-level information
Windows Storage Spaces handles mirroring and spares and enables
use of lower cost DAS (JBODs) rather than SAN
PDW workload details
SQL Server 2012 Enterprise Edition (PDW build) control node and
compute nodes for PDW workload
Storage details
More files per filegroup
Larger number of spindles in parallel
HST02
HST01
HSA01
HSA02
JBOD
IB and
Ethernet
Direct attached SAS
CTL MAD AD VMM
Compute 2
Compute 1
• Window Server 2012 Standard
• PDW engine
• DMS Manager
• SQL Server 2012 Enterprise Edition (PDW build)
• Shell databases just as in AU3+
• Window Server 2012 Standard
• DMS Core
• SQL Server 2012 Enterprise Edition (PDW build)

Seamlessly add capacity – PDW/HDI
Smallest to largest
• Start small with a warehouse capacity of several terabytes
• Add capacity up to 6 PB
53 TB 6 PB
Add
capacity
Add
capacity
Largest warehouse
PB
Start small and grow

PDW table geometries• Replicated: A table structure that exists as a full copy within each PDW node
CREATE TABLE <TableName>
(
<Column Names and Types>
)
WITH (DISTRIBUTION = REPLICATE)
• Distributed: A table structure that is hashed and distributed as evenly as possible across all
PDW nodes on the appliance
CREATE TABLE <TableName>
(
<Column Names and Types>
)
WITH (DISTRIBUTION = HASH(<One Column Name>))

Date Dim
Date Dim ID
Calendar Year
Calendar Qtr
Calendar Mo
Calendar Day
Store Dim
Store Dim ID
Store Name
Store Mgr
Store Size
Item Dim
Prod Dim ID
Prod Category
Prod Sub Cat
Prod Desc
Sales Fact
Date Dim ID
Store Dim ID
Prod Dim ID
Mktg Camp Id
Qty Sold
Dollars Sold
Promo Dim
Mktg Camp ID
Camp Name
Camp Mgr
Camp Start
Camp End
ID
DD
SD
ID
PD
SF
2
DD
SD
ID
PD
SF
3
DD
SD
ID
PD
SF
4
DD
SD PD
SF
1
SMP system Compute nodes
PDW table geometries
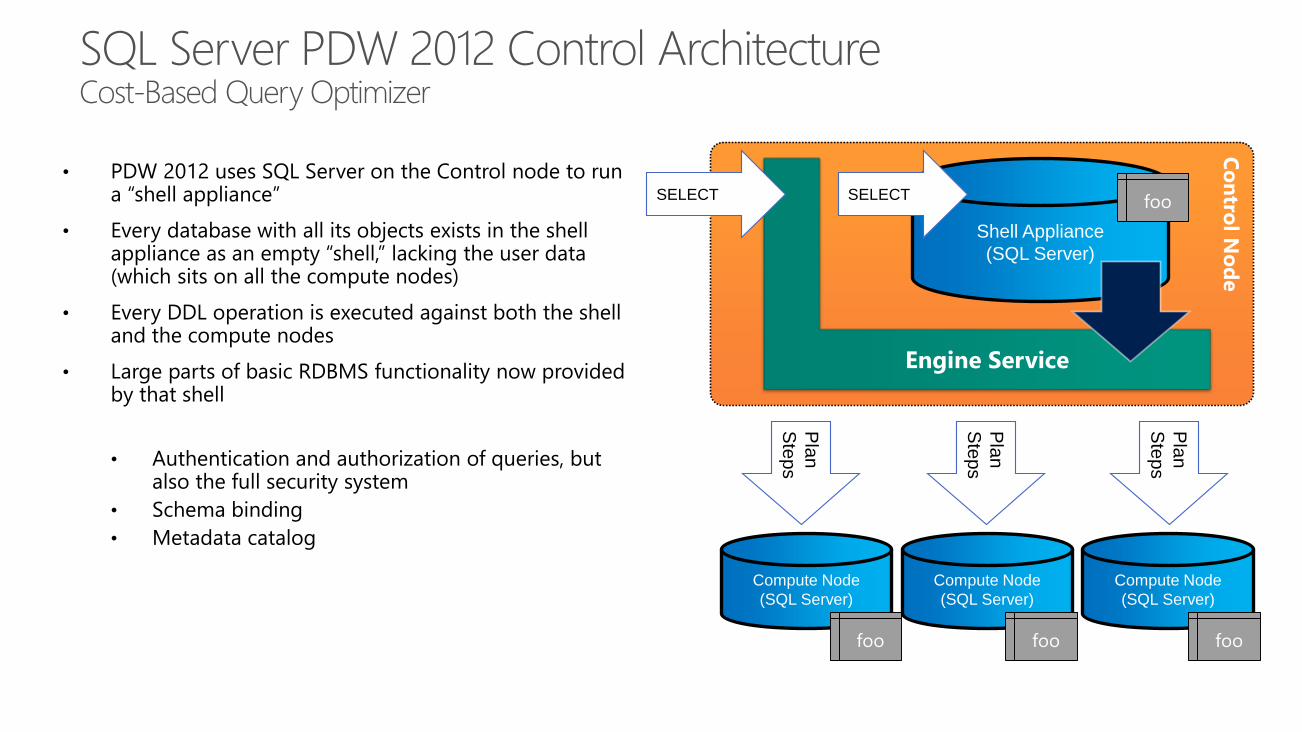
SQL Server PDW 2012 Control Architecture Cost-Based Query Optimizer
Shell Appliance
(SQL Server)
Engine Service
Pla
n
Ste
ps
Pla
n
Ste
ps
Pla
n
Ste
ps
Compute Node
(SQL Server)
Compute Node
(SQL Server)
Compute Node
(SQL Server)
Co
ntro
l No
de
SELECTSELECT
foo foofoo
foo
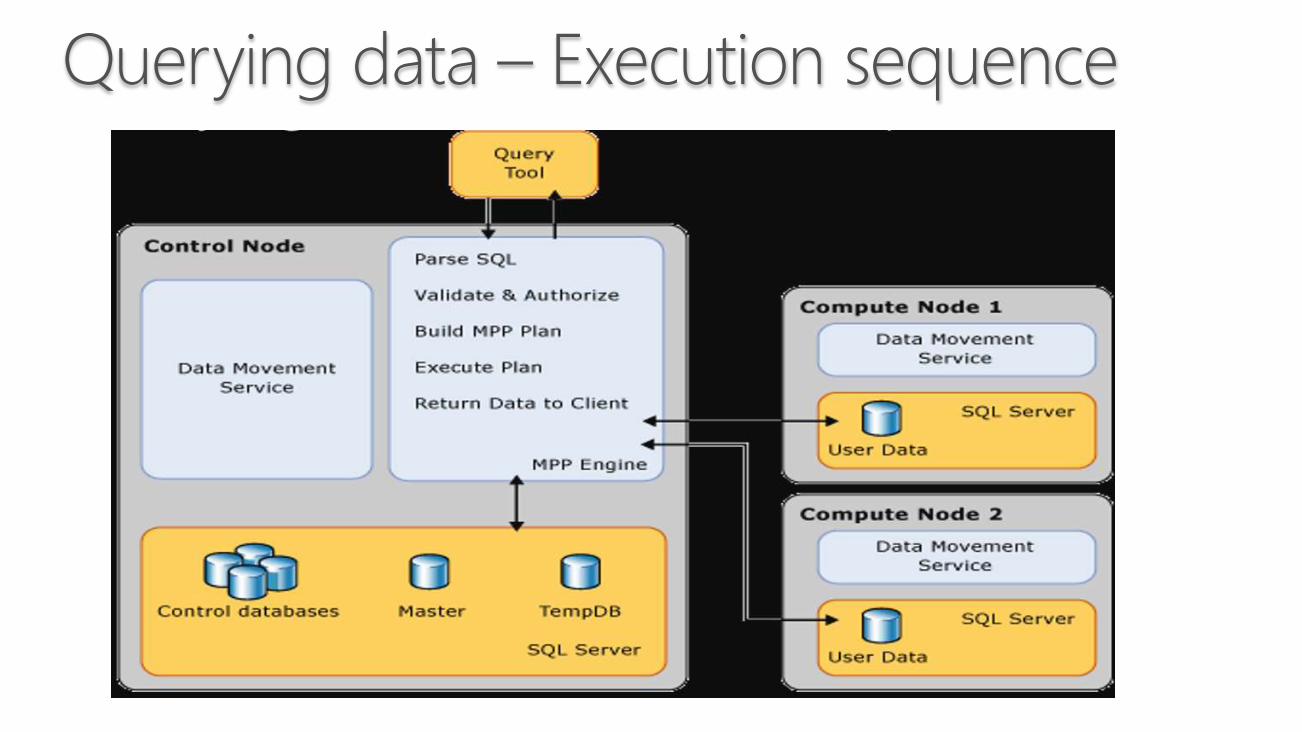
Querying data – Execution sequence

Querying data – MPP engine
• The MPP engine is designed for high-performance
queries against large data sets
• Understanding the query architecture and execution
steps of the PDW is key to writing good queries
• Control node orchestrates the entire set of operations
across all nodes to satisfy a query
• Avoid queries that create hot spots and excessive data
redistribution

20
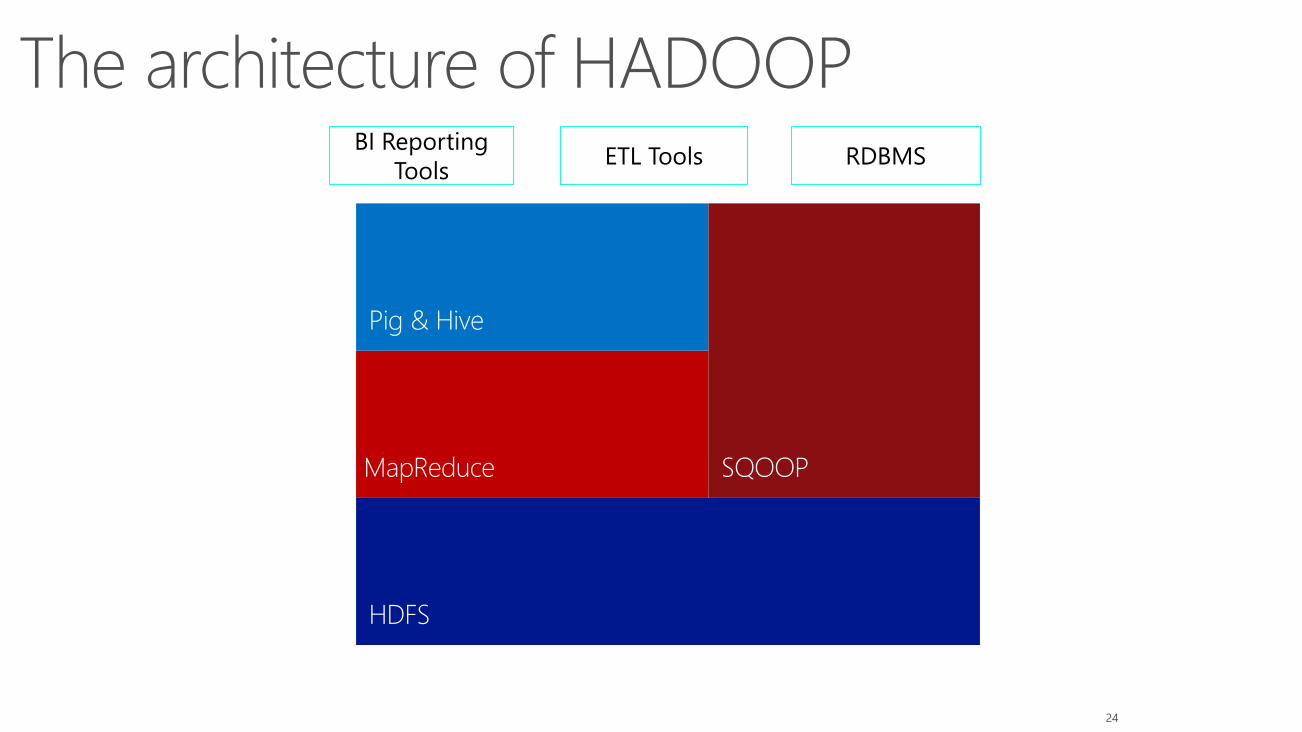
What is HADOOP?
• Solution that allows commodity computers to store data and
process them in parallel fashion.
• Resilience/fault tolerance is not provided by the use of
Hardware such as RAID but by the use of cluster.

21
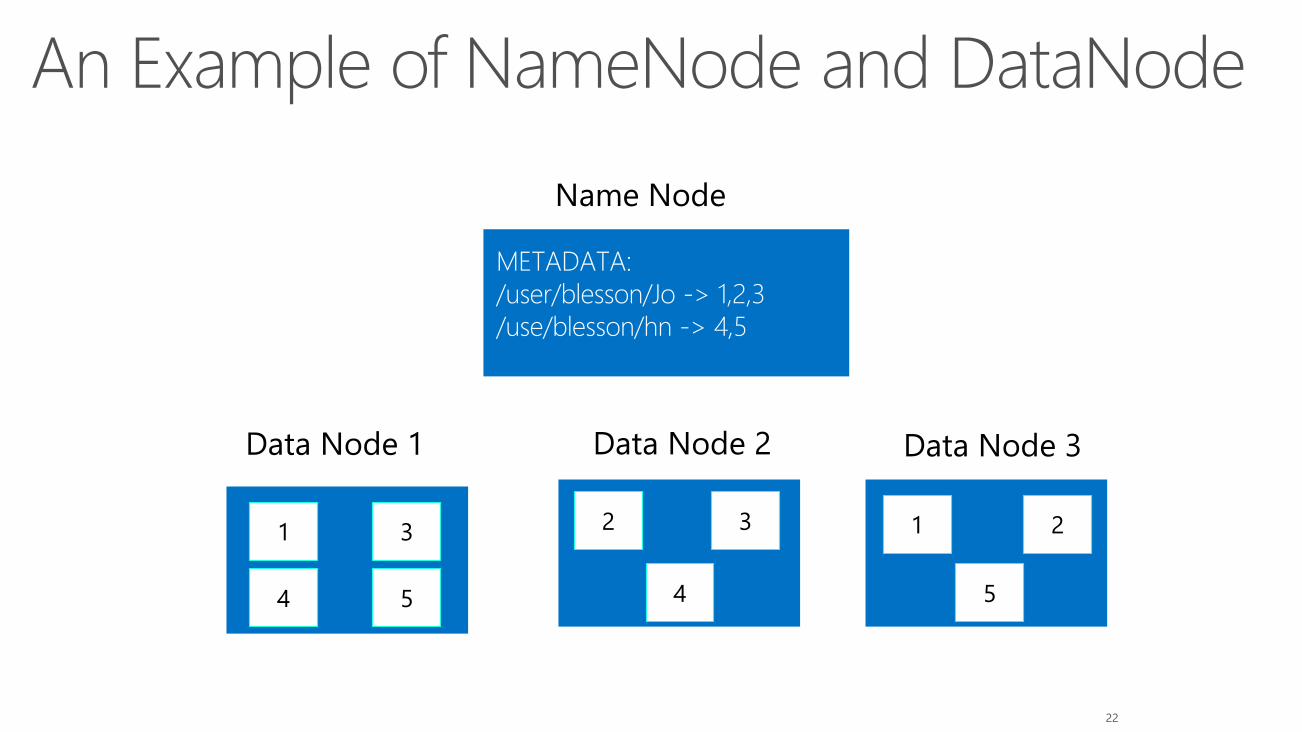
Types of Nodes on HDFS
•NameNode – One per cluster-responsible for providing
metadata information about the blocks within the
filesystem,tracking replication and managing filesystem
namespace.
•Backup Node – Acts as the backup of NameNode
•DataNodes – Responsible for storage of file blocks and
contains the data requested by the client.
22
An Example of NameNode and DataNode
31
4 5
2 3
4
1 2
5

23
Other tasks on HADOOP cluster
•Job Tracker – Responsible for submitting client application
request to task tracker on nodes that contain the data to be
processed. It also monitors the task tracker using heart beats
and reschedules the task on another task tracker in case of a
failure. One per cluster.
•Task Tracker – Responsible for performing map, reduce and
shuffle operation on data. One per Node.
24
The architecture of HADOOPBI Reporting
ToolsRDBMSETL Tools

25
MapReduce•MapReduce is a framework that allows user to write
applications that take advantage of the fault tolerance
provided by HADOOP.
•MapReduce programs transform lists of input data elements
into lists of output data elements. This is done twice once
using map method and then using reduce method.
•We do not alter the initial input data. The initial input is
transformed and the transformed output becomes the input
for the reducer function.

26
The Mapper Function
1 4 52 3 41 2 5
1(1)
2 (1)
4 (1)
4 (1)
5 (1)
5(1)
3(1)
1(1)
2 (1)
27
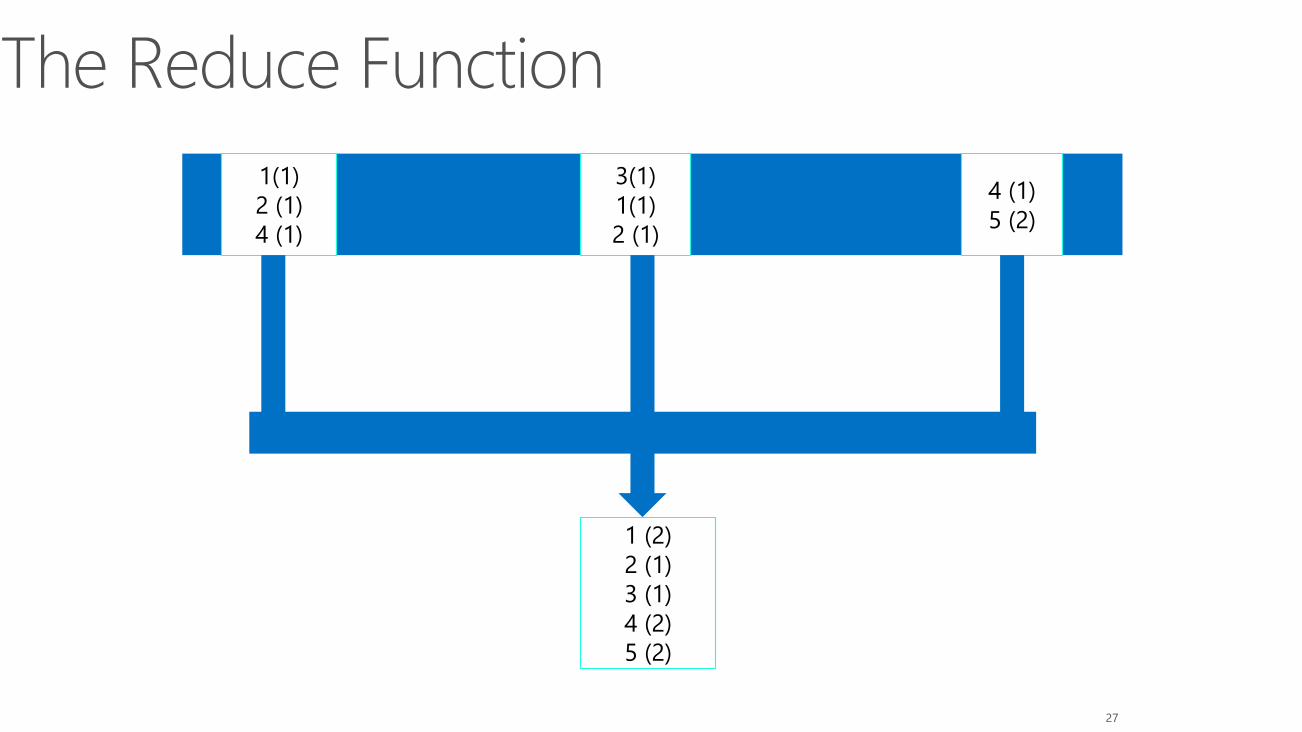
The Reduce Function
1(1)
2 (1)
4 (1)
4 (1)
5 (2)
3(1)
1(1)
2 (1)
1 (2)
2 (1)
3 (1)
4 (2)
5 (2)

28
Pseudo Code for the MapReduce Jobmapper (Inputfilename, filedata):
for each number in filedata:
emit (number, 1)
reducer (number, values):
sum = 0
for each value in values:
sum = sum + value
emit (number, sum)

Sqoop – Load/Unload Utility
SQL Server
SQL Server SQL Server
…
SQL Server
Hadoop Cluster
29
Sqoop

30
APS and Hadoop Integration

HDFS Bridge in Polybase
DMSSQL Server DMS SQL Server
HDFS Hadoop
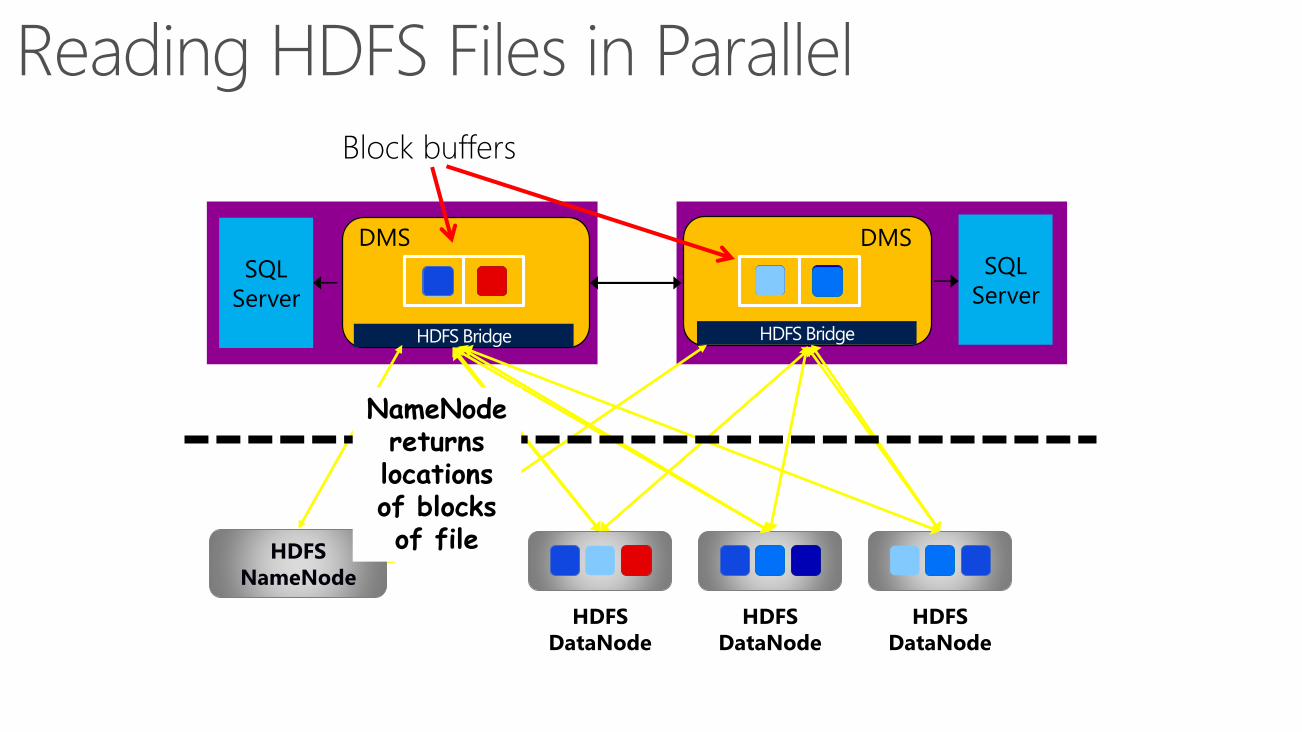
Cluster1. DMS is present on all compute and has been extended to have HDFS Bridge.
2. HDFS Bridge hides complexity of HDFS. The DMS components are reused for type conversions.
3. All HDFS file types (text, sequence, RCFiles) supported through the use of appropriate RecordReaders by the HDFS Bridge. The JAVA class used is InputFormat.
HDFSHDFS
31
PDW Node PDW Node
SQL
Server
DMSSQL
Server
DMS
Reading HDFS Files in Parallel
32
HDFS
NameNode
HDFS
DataNode
HDFS
DataNode
HDFS
DataNode
Block buffers
NameNodereturns locations of blocks of file

33
External Table Command•There are two different ways to import data from HDFS to
PDW
I. CREATE EXTERNAL TABLE
II.CREATE TABLE AS SELECT (CTAS)
•There is only one way to export data from PDW to HDFS
I. CREATE EXTERNAL TABLE AS SELECT
•Finally, the DROP EXTERNAL TABLE command

34
Example of CREATE EXTERNAL TABLE - TempCREATE EXTERNAL TABLE ClickStream
(
url varchar(50),
event_date date,
user_IP varchar(50) )
WITH
(
LOCATION = 'hdfs://10.192.63.147:5000/tpch1GB/ClickStream.txt‘
,FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
, DATE_FORMAT = ꞌMM/dd/yyyyꞌ )
) ;

35
Example of CREATE TABLE AS SELECT –
PART 1 – Persistent--Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt
(
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH
(
LOCATION = 'hdfs://MyHadoop:5000/tpch1GB/ClickStream.txt‘
,FORMAT_OPTIONS ( FIELD_TERMINATOR = '|') ) ;

36
Example of CREATE TABLE AS SELECT –
PART 2 –Persistent--Use your own processes to create the Hadoop text-delimited files on the
-- Hadoop Cluster.
--Use CREATE TABLE AS SELECT to import the Hadoop data into a new
--SQL Server PDW table called ClickStreamPDW
CREATE TABLE ClickStreamPDW
WITH
(
CLUSTERED COLUMNSTORE INDEX
,DISTRIBUTION = HASH (user_IP)
)
AS
SELECT *
FROM ClickStreamExt ;

37
Example of CREATE EXTERNAL TABLE AS
SELECT (Export)
USE AdventureWorksPDW2012;
CREATE EXTERNAL TABLE hdfsCustomer
WITH
(
LOCATION = 'hdfs://10.192.63.147:5000/files/Customer
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
)
AS SELECT * FROM dimCustomer;

38
The DROP EXTERNAL TABLE
--Drop an external table from PDW. This does not delete the external data.
DROP EXTERNAL TABLE [ database_name . [ dbo ] . | dbo . ]table_name [;]
EXAMPLE:-
DROP EXTERNAL TABLE ClickStream;




















