
Some Recent Results in Secure Pseudorandom Number Generation Berry Schoenmakers Joint work with...
29
Some Recent Results in Secure Pseudorandom Number Generation Berry Schoenmakers Joint work with Andrey Sidorenko and (partly) with Reza Rezaeian Farashahi Coding & Crypto group TU Eindhoven 11th Workshop on Elliptic Curve Cryptography 2007 Dublin/September 6, 2007
-
date post
19-Dec-2015 -
Category
Documents
-
view
213 -
download
0
Transcript of Some Recent Results in Secure Pseudorandom Number Generation Berry Schoenmakers Joint work with...

Some Recent Results in Secure Pseudorandom Number GenerationBerry Schoenmakers
Joint work with Andrey Sidorenko and (partly) with Reza Rezaeian Farashahi
Coding & Crypto groupTU Eindhoven
11th Workshop on Elliptic Curve Cryptography 2007 Dublin/September 6, 2007

Plan 1. Revisiting a basic problem:
Random bits random numbers in a given interval.
2. Concrete security of provably secure PRGs Construction based on k-DDHI Cryptanalysis Dual Elliptic Curve Generator
3. New PRGs based on DDH “Practically” tight reduction to DDH Specific instances
QR(p): group of quadratic residues modulo p Gq: arbitrary subgroup of Zp
*
open problem: elliptic curve based one??

Random numbers in [0,B), 2n-1<B<2n
Given a source of (uniform) random bits.
Two folklore algorithms for generating x [0,B).
Alg.1: pick x {0,1}n, using n random bits, until x<B
Alg.2: pick x{0,1}n+k, using n+k random bits; output x mod B
Properties: Alg.1: perfectly uniform; but wastes up to n bits on average (worst
case B = 2n-1 + 1); Las Vegas algorithm Alg.2: statistical distance Δ<1/2k; wastes k bits exactly
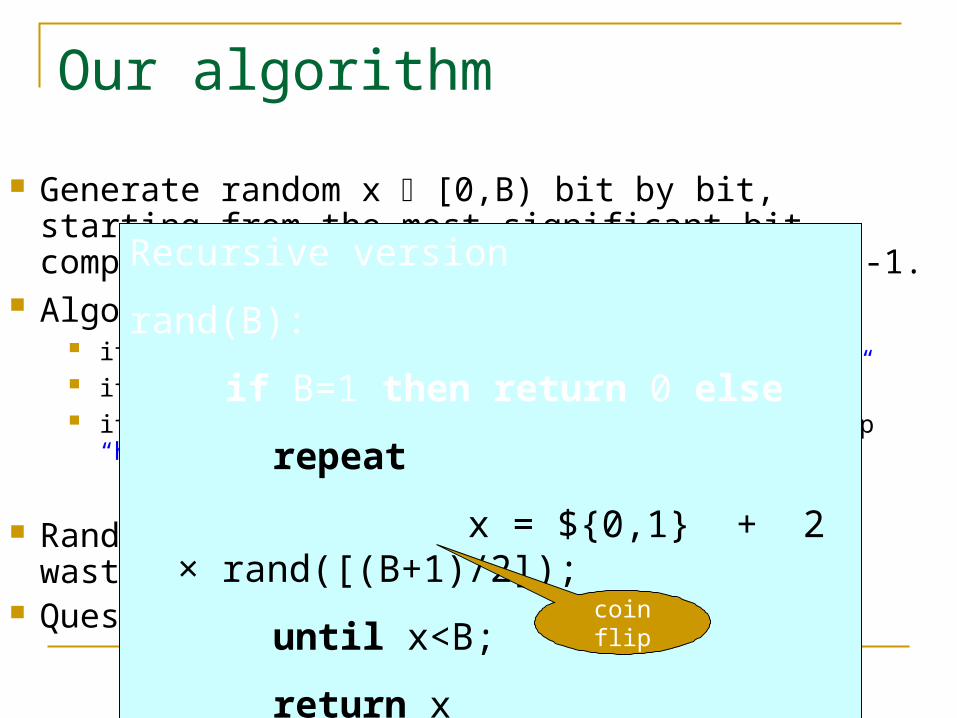
Our algorithm
Generate random x [0,B) bit by bit, starting from the most significant bit, comparing with most significant bits of B-1.
Algorithm: let xi be next random bit if xi > (B-1)i, start all over “too large” if xi = (B-1)i , continue with next bit “unsure” if xi < (B-1)i , complete x with random bits and stop “home free”
Randomness complexity: n bits plus some waste. Question: what’s the waste?
Recursive version
rand(B):
if B=1 then return 0 else
repeat
x = ${0,1} + 2 × rand([(B+1)/2]);
until x<B;
return xcoin flip

Analysis of randomness complexity 1st computing the exact probability distribution and
then the expected value is cumbersome We determine expected value E directly! Example: S = Σi=0..∞ ri:
S = Σi=0..∞ ri = 1 + Σi=0..∞ ri+1 =1+r S, so S = 1/(1-r)
Example: T = Σi=0..∞ i ri: T = Σi=0..∞ (1+i) ri+1 = r S + r T, so T = r/(1-r)2
By conditioning on the right event, this leads to: E = n + 2n/B Σi=2..n i(1-(B-1)n-i)/2i < n + 3 So, waste is bounded by a small constant! Averaged over all B, waste is approx. 1.1 random bits

Knuth-Yao 1976
Minimize randomness complexity Average wasted random bits for x [0,B):
0.58 random bits on average, over all B < 1 random bits for worst case B
Actually, any probability distribution can be generated from random bits, with average waste < 2 bits (beyond entropy).

Knuth-Yao B=5
$ $ $ $ $
…
0
1
2
3
4
0
1
2
3
4

Context of secure multiparty computation In context of secure multiparty computation:
Generating “encrypted” random bits is expensive. But, also comparing “encrypted” bits, arithmetic
with “encrypted” bits, etc.
Our algorithm strikes a better balance than Knuth-Yao’s minimal waste algorithm (depending on the setting) cheaper to make our algorithm oblivious
“Data independent execution paths”

Pseudorandom Generator (PRG)
n truly random bits (seed)
M bits that “look random” (pseudorandom sequence)
Pseudorandom generator:
deterministic algorithm
10001010111001110101111010111101
1001101011011001010111101011110110101111101100010011101000101110101011101011000
Preferably M>>n and a fast PRG Focus on provably secure PRGs
PRG is called provably secure if “breaking” the PRG is as hard as solving a presumably hard problem

Provably secure PRGs
Distinguisher: running time at mostT
Truly random sequence of the same length
OR
Pseudorandom sequence for a truly random seed
“I think that you gave me a pseudorandom sequence”
If probability of successful guess < ½ (1+ ε) the PRG is (T, ε)-secure

Provably secure PRGs (cont.)
(T, ε)-distinguisher for a PRG: {0, 1}n → {0, 1}M (T', ε')-solver for a hard
problem with security parameter n (e.g., DL problem in n-bit finite field)
If T'/ε' ≈ T/ε, reduction is called tight If T'/ε' >> T/ε, reduction is called not tight
If the reduction is tight, a desired security level can be achieved for a relatively low value of security parameter n (seed length)
reduction

Formal Security of PRGs (Yao 1982) Un uniform distribution on {0, 1}n
UM uniform distribution on {0, 1}M
Pseudorandom generator PRG: {0,1}n → {0, 1}M
Distinguisher D: {0,1}M → {0, 1}
PRG is called (T, ε)-secure if for all T-time D
| Pr[D(PRG(Un)) = 1] – Pr[D(UM) = 1] | < ε

Typical PRG
seed state1 state2 statei…
output1 output2 outputi
…
State should remain secret, given all outputs !

Blum-Micali PRG (1984)
Based on DL-problem in Zp*
Provably secure
Outputs just 1 bit per modular exponentiation
Let n = log2p. If this PRG is not (T, ε)-secure, then DL problem can be solved in time T' = 64 n3 (M/ε)4 T with success probability ε' = ½
T'/ε' >> T/ε, so reduction is not tight
seed x ←R Zp* x ← gx
output [x < p/2]
x ← gx
output [x < p/2]
…

Blum-Micali PRG (cont.) Blum-Micali PRG is (T, ε)-secure if
128 n3 (M/ε)4 T < TDL(Zp*)
For M = 220, T/ε = 280, this PRG is (T, ε)-secure if n > 61000
Large seed length n implies poor efficiency due to far from tight reduction
We propose a PRG with a much better security reduction based on the DDH assumption (stronger than DL assumption) output of n bits (instead of 1 bit) per iteration
polynomial in n
subexponential in n

Universal hash function used as extractor Good results But assumption k-DDHI less standard k-DDHI: distinguish
k-DDHI based PRG
a ←R Zq
s0← gy ←R {0,1}l
s1 ← s0a …
outputextract(s1,y)
s2 ← s1a
outputextract(s2,y)
kaaa gggg ,...,,,2/1
kaar gggg ,...,,,2

Proposed by Barker and Kelsey in a NIST draft standard [BK05]
For prime p = 2256 + 2224 + 2192 + 296+1, let E(Fp) be an elliptic curve such that #E(Fp) is prime. Let P, Q ←R E(Fp)
Sequence siQ is indistinguishable from sequence of uniformly random points under DDH assumption and x-logarithm assumption [Brown 2006]
However, random bits are extracted from random points improperly so the PRG is insecure
Dual Elliptic Curve PRG
seed s0 ←R Fp s1 ← x(s0P) …
outputlsb240(x(s1Q))
s2 ← x(s1P)
outputlsb240(x(s2Q))

Distinguishing attack
Point siQ is mapped to block lsb240(x(siQ))
Blocks b ←R {0, 1}240 have on average 216 preimages
Blocks lsb240(x(R)) with R ←R E(Fp) have on average more than 216 preimages
For each block bi count the number of points P s.t. bi = lsb240(x(P)) If average number of preimages is above 216, decide that the sequence
is pseudorandom; Otherwise, decide that the sequence is “truly random”
…outputlsb240(x(s1Q))
outputlsb240(x(s2Q))
block b1
outputlsb240(x(siQ)) …
block biblock b2

Detailed analysis
We tested 330 outputs of Dual Elliptic Curve PRG each output consisted of 4000 output blocks
Running time of the attack is about 3 hours on a 3GHz Linux machine with 1Gb of memory
number of preimages
frequency
Fits normal distributionN(65537.0, 255.6)
216 = 65536
Note the shift by
+1

Decisional Diffie-Hellman (DDH) problem G=<g> is a multiplicative group of prime order q
Algorithm A solves the DDH problem in G with advantage ε iff for a random triple (a, b, r)
| Pr(A(g, ga, gb, gab) = 1) – Pr(A(g, ga, gb, gr) = 1) | ≥ ε
For concrete analysis: DDH problem is assumed to be as hard as the DL problem

DDH generator (intuition) Let a ← Zq be a fixed integer Consider Doubleg,a(b) = (gb, gab) [NR97]
for b ←R Zq the output is pseudorandom under DDH “doubles” the input
Is Double a pseudorandom generator? No! It produces pseudorandom group elements
rather than pseudorandom bits Converting group elements into bits is a non-trivial
problem Double cannot be iterated to produce as much
randomness as required by the application

DDH generator (construction) rank is a bijection mapping elements of group G to numbers in Zq
rank: G → Zq
More generally, allow additional input/output number in Z l:
rank: G × Zl → Zq × Zl Public parameters for DDH generator: x, y ←R G
Outputs log2 q bits per step Seed length log2 q + 2 log2 l
seed s ←R Zq,rx, ry ←R Zl
…(s, rx) ← rank(xs, rx)
(z, ry) ← rank(ys, ry)output z
(s, rx) ← rank(xs, rx)
(z, ry) ← rank(ys, ry)output z

Security of the DDH generator DDH generator produces pseudorandom numbers in Zq
if q 2n then it produces pseudorandom bits directly for arbitrary q, additional effort needed to convert numbers
into bits (from integers in [0,q) to bits)
Theorem. Assume that 0< (2n – q)/2n < δ. Then (T, ε)-distinguisher for the DDH generator implies a
(T, nε/M – δ)-solver for the DDH problem in G
Proof is based on a hybrid argument Hybrids Hj = (u1,u2,…,uj-1,output1,…,outputk-j+1) A given 4-tuple (x,y,X,Y) is DDH tuple iff output ~ Hj

PRG1: instance based on QR(p) Safe prime p = 2q + 1, with q prime
G = QR(p), |G| = q Consider the following bijection (Chevassut et al. 2005; Cramer-
Shoup 2003, and … ?):
rank: QR(p) Zq with rank(x) = min(x, p-x)
Public parameters x, y ←R G
Extracts n bits per iteration (2 modular exponentiations)
seed s ←R Zq …s ← rank(xs)
output rank(ys)
s ← rank(xs)
output rank(ys)

PRG1 (cont.) What seed length, n, guarantees security?
recall that for Blum-Micali PRG n > 61000
PRG1 is (T, ε)-secure if 2MT/nε < TDL(QRp)
For M = 220, T/ε = 280, PRG1 is (T, ε)-secure if… n > 1600
The seed length n is short because the reduction is (almost) tight PRG1 is much more efficient than Blum-Micali PRG PRG1 based on a stronger assumption (the DDH
assumption) Limitation: works only for specific subgroup of Zp
*

PRG2: instance based on any subgroup G is a (prime) order q subgroup of Zp
*, p – 1 = ql
t is an element of Zp* of order l, so tl = 1
Let rank: G × Zl → Zq × Zl be the following bijection:
rank(x, r) = (x tr mod q, x tr div q)
seed s ←R Zq,rx, ry ←R Zl
…(s, rx) ← rank(xs, rx)
(z, ry) ← rank(ys, ry)output z
(s, rx) ← rank(xs, rx)
(zi, ry) ← rank(ys, ry)output z

PRG by Jiang (2006)
seed (A0,A1) ←R Zq× Zq
…A2 ← grank(A0)rank(A1)
output rank(grank(A2))
A3 ← grank(A1)rank(A2)
output rank(grank(A3))
Also, standard DDH assumption
Speed of the two generators is the same Seed of our generator is twice as short as for Jiang’s generator
For most applications, the length of the seed is a critical issue Our generator can be used with any prime order group such that
the elements of the group can be “efficiently ranked” Jiang’s generator is designed for a specific subgroup of Zp
* for safe primes p

Conclusions DDH based PRGs
Showed a general constructions of PRGs based on DDH assumption Specific instances of our DDH-based PRG are presented
subgroup of quadratic residues modulo prime p – seed length |p| Jiang’s generator is an alternative in this case
arbitrary order q subgroup of Zp* -- seed length 2|p| -|q|
Open problem: how to use an elliptic curve group? would result in considerably shorter seeds maybe use Kaliski’s map from points on an elliptic curve
(over Fq) and its quadratic twist to Z2q
Revisiting problems related to conversion/extraction of random bits, random numbers, random group elements, all in the context of secure multiparty computation leads to new approaches and solutions.

Author’s address
Berry Schoenmakers
Coding and Crypto groupDept. of Mathematics and Computer Science
Technical University of Eindhoven P.O. Box 513
5600 MB EindhovenNetherlands
[email protected]://www.win.tue.nl/~berry/














![products arXiv:1111.6038v2 [q-fin.CP] 13 Feb 2012 · Kolodko and Schoenmakers (2004) and Schoenmakers (2005)). In a Wiener en-vironment, Belomestny et. al. (2009) providesa fast generic](https://static.fdocuments.in/doc/165x107/6044437b5dabfd7ffe20ee3f/products-arxiv11116038v2-q-fincp-13-feb-2012-kolodko-and-schoenmakers-2004.jpg)



