
SmartApps: Application Centric Computing with STAPL
38
SmartApps: Application Centric Computing with STAPL Lawrence Rauchwerger http://parasol.tamu.edu/~rwerger Parasol Lab, Dept of Computer Science, Texas A&M N. Amato, B. Stroustrup, M. Adams
-
Upload
nayda-cobb -
Category
Documents
-
view
20 -
download
0
description
SmartApps: Application Centric Computing with STAPL. Lawrence Rauchwerger http://parasol.tamu.edu/~rwerger Parasol Lab, Dept of Computer Science, Texas A&M N. Amato, B. Stroustrup, M. Adams. STAPL Application. DataBase. Get Runtime Information. (Sample input, system information, etc.). - PowerPoint PPT Presentation
Transcript of SmartApps: Application Centric Computing with STAPL

SmartApps: Application Centric Computing with STAPL
Lawrence Rauchwergerhttp://parasol.tamu.edu/~rwerger
Parasol Lab, Dept of Computer Science, Texas A&M N. Amato, B. Stroustrup, M. Adams

SmartApps Architecture
Compiled code + runtime hooks
Static STAPL CompilerAugmented withruntime techniques
Predictor &Optimizer
STAPLSTAPL ApplicationApplication
advanced advanced stagesstages
development development stagestage
ToolboxToolbox
Get Runtime Information(Sample input, system information, etc.)
Execute Application
Continuously monitor performance and adaptas necessary
Predictor &Optimizer
Predictor &Evaluator
Adaptive Software
Runtime tuning (w/o recompile)
Compute Optimal Applicationand RTS + OS Configuration
Recompute Applicationand/or Reconfigure RTS + OS
Configurer
Predictor &Evaluator
Smart Application
Small adaptation (tuning)
Large adaptation(failure, phase change)
DataBase
Adaptive RTS+ OS

Outline
SmartApps Concept STAPL is vehicle we use to develop the
SmartApps Framework STAPL
– Overview– High Level Adaptivity in STAPL
Consistency Models FAST - Framework for Algorithm Selection & Tuning
– RTS– Compiler (Pivot)

STAPL: Standard Template Adaptive Parallel Library
STAPL: A library of parallel, generic constructs based on the C++ Standard Template Library (STL).
– Components for Program Development pAlgorithms, pContainers,
Views, pRange
– Portability and Optimization STAPL RTS and Adaptive
Remote Method Invocation (ARMI) Communication Library
Framework for Algorithm Selection and Tuning (FAST)

Applications Using STAPL
Particle Transport - TAXI Bioinformatics - Protein Folding Geophysics - Seismic Ray Tracing Aerospace - MHD
– Seq. “Ctran” code (7K LOC)– STL (1.2K LOC)– STAPL (1.3K LOC)

Outline
SmartApps Concept STAPL is vehicle we use to develop the
SmartApps Framework STAPL
– Overview– High Level Adaptivity in STAPL
Consistency Models FAST - Framework for Algorithm Selection & Tuning
– RTS– Compiler (Pivot)

Consistency Models
Processor Consistency (default and currently supported model)
– Accesses from a processor on another’s memory are sequential– Requires in-order processing of RMIs
Limited parallelism
Object Consistency (future)– Accesses to different objects can happen out of order– Uncovers fine-grained parallelism
Accesses to different objects are concurrent Potential gain in scalability
– Can be made default for specific computational phases
Mixed Consistency (future)– Use Object Consistency on select objects
Selection of objects fit for this model can be: Elective – the application can specify that an object’s state does not depend on
others’ states. Detected – if it is possible to assert the absence of such dependencies
– Use Processor Consistency on the rest

Algorithm SelectionProblem Description: Given multiple implementations of an abstract
operation with a specified execution environment and input data, choose one that maximizes performance
Our Objective: Create general framework for parallel algorithm selection– Applicable to any abstract operation: sorting, matrix multiplication, convex hull, …– Flexible specification of execution environment and input data parameters
Environment: #procs, memory interconnection, cache, thread management, OS policies Input data: data type, layout, size, other properties (e.g., sortedness of input)
– Generic modeling interface – interchange different approachesUse generic machine learning approaches
Our Strategy: FAST: Framework for Algorithms Selection & Tuning– Integrated approach within STAPL– Selection is transparent to end user– Library adaptively choose the best algorithm at run-time
from a library of implementation choices

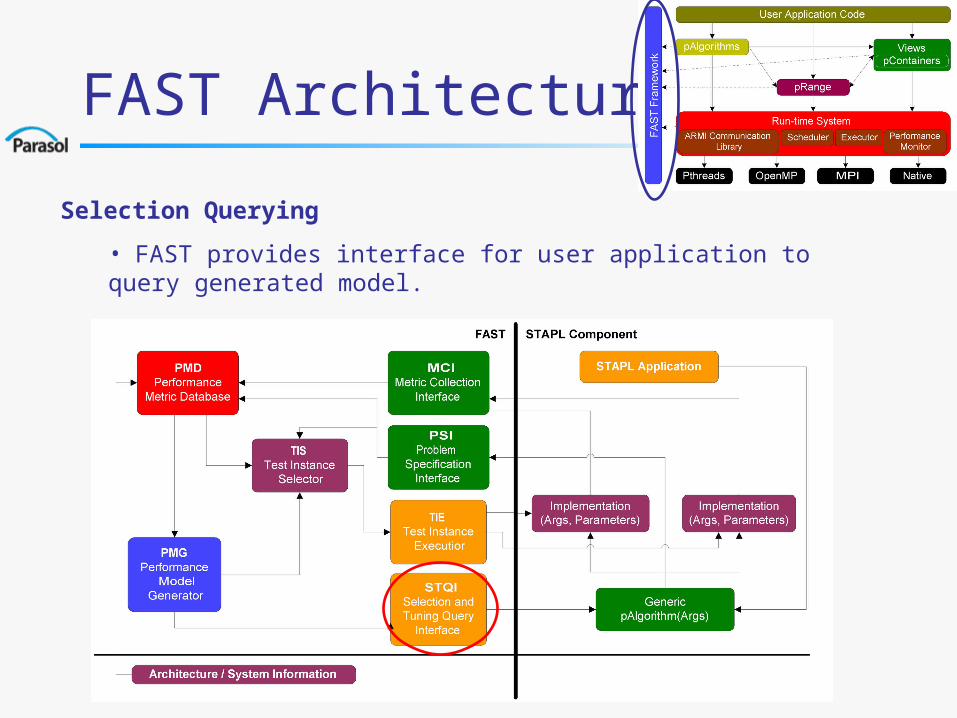
FAST Architecture

FAST Architecture
Problem Specification
• User specifies parameters that may affect performance (e.g., num processors, input size, algorithm specific) and ranges (e.g, input size=100M..200M).
• User supplies list of candidate implementations.

FAST Architecture
Metric Collection
• User provides method to collect data about an implementation execution (e.g., presortedness measure).

FAST Architecture
Instance Selection
• FAST selects instances to execute and use when making decision model.

FAST Architecture
Instance Execution
• FAST invokes user interface to execute test instances and collect metrics and timings.

FAST Architecture
Database Insertion
• FAST inserts results of training instances into database.

FAST Architecture
Model Generation
• FAST uses training instances to generate decision model.
FAST Architecture
Selection Querying
• FAST provides interface for user application to query generated model.

Parallel Sorting: Experimental Results
SGI Altix Selection Model
SGI Altix Validation Set (V1) – 100% Accuracy
No
rmal
ized
Exe
cuti
on
Tim
e
Radix
Sample
ColumnAdaptive
Nearly / Integer Rev / Integer Rand / Integer Nearly / Double Rand / Double
4 8 16 32 4 8 16 32 4 8 16 32 4 8 16 32 4 8 16 32Procs:|-------------------------------------------------------MaxElement = 120,000-------------------------------------------------------|
05
1015202530
N=120M
Adaptive Performance Penalty
Attributes for Selection Model–Processor Count–Data Type–Input Size –Max Value (impacts radix sort)
–Presortedness

Parallel Sorting - Altix Relative Performance (V2)
Model obtains 99.7% of the possible performance.
Next best algorithm (sample) provides only 90.4%.
0.2
0.4
0.6
0.8
1
2 4 8 16 32
Processors
Rel
ativ
e S
pee
du
p Sample
Column
Radix
Random
Adaptive
Best

FAST: Future Work Improve and refine algorithm selection framework
– Refine sampling for training input selection
– Algorithm developer specified models
– Online feedback/model refinement (incremental learning)
– Machine characterization & microbenchmarks
Expand employment in STAPL.– pContainers - locking strategies, data (re)distribution, consistency
model– pAlgorithms - more algorithms, parameter tuning– pRange - work granularity and scheduling policies– ARMI Runtime System - dynamic aggregation.

Outline
SmartApps Concept STAPL is vehicle we use to develop the
SmartApps Framework STAPL
– Overview– High Level Adaptivity in STAPL
Consistency Models FAST - Framework for Algorithm Selection & Tuning
– RTS– Compiler (Pivot)

RTS – Current state
Application Specific Parameters
Smart Application
STAPL RTS
ARMI Executor
K42 User-Level
Dispatcher
Kernel Scheduler
(no custom scheduling, e.g. NPTL)Operating System
Memory ManagerAdvanced Advanced stagestage
Experimental Experimental stage: stage: multithreadingmultithreading
ARMI Executor
Comm. Thread
RMI Thread
Task Thread
Custom Custom schedulingscheduling
Kernel Kernel schedulingscheduling

ARMI – Current State
ARMI: Adaptive Remote Method Invocation– Abstraction of shared-memory and message passing
communication layer (MPI, pThreads, OpenMP, mixed, Converse).
– Programmer expresses fine-grain parallelism that ARMI adaptively coarsens to balance latency versus overhead.
– Support for sync, async, point-to-point and group communication.
– Automated (de)serialization of C++ classes.
ARMI can be as easy/natural as shared memory and as efficient as message passing.

ARMI Communication PrimitivesPoint to Point Communicationarmi_async - non-blocking: doesn’t wait for request arrival or completion.
armi_sync - blocking and non-blocking versions.
Collective Operationsarmi_broadcast, armi_reduce, etc.
can adaptively set groups for communication.
Synchronizationarmi_fence, armi_barrier - fence implements distributed termination algorithm
to ensure that all requests sent, received, and serviced.
armi_wait - blocks until at least at least one request is received and serviced.
armi_flush - empties local send buffer, pushing outstanding to remote destinations.

RTS Current Work - Multithreading
In ARMI Specialized communication thread dedicated the emission and
reception of messages– Reduces latency, in particular on SYNC requests
Specialized threads for the processing of RMIs – Uncovers additional parallelism (RMIs from different sources can
be executed concurrently)– Provides a suitable framework for future work on relaxing the consistency
model and on the speculative execution of RMIs
In the Executor Specialized threads for the execution of tasks
– Concurrently execute ready tasks from the DDG (when all dependencies are satisfied)

TAXI Experimental Results
uBGL - 1024 node, 2048 processor unclassified Blue Gene cluster at LLNL.
Results shown for two machine configurations.– Virtual Mode - two independent computation processes
per node.
– Coprocessor - one processor per node for computation and one for communication.

TAXI Results on uBGL
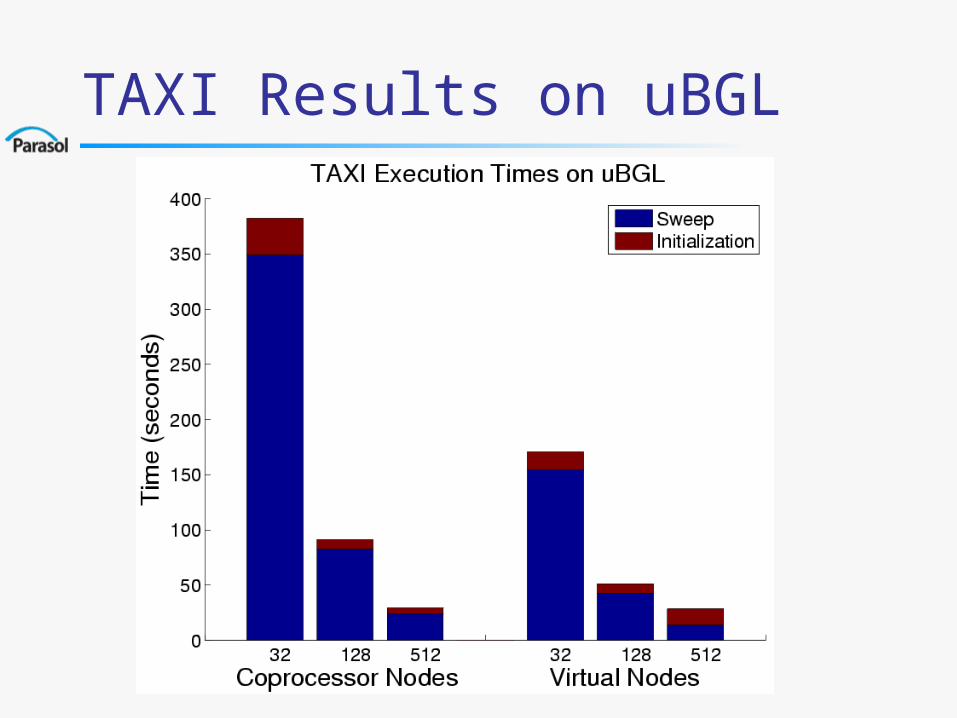
TAXI Results on uBGL

RTS – The Next GenerationApplication Specific Parameters
Virtualization LayerProvides a unified view of the RTS services
Smart Application
STAPL RTS implementation
ARMI
Communicator
Executor
Smart User-Level
Scheduler
K42 User-Level
Dispatcher
Kernel Scheduler
(no custom scheduling, e.g. NPTL)
Other RTS
(E.g., Converse, Marcel …)
Unsupported System
Best Affinity
Supported System
Memory Manager
M:N
Threading Model
1:1
Scheduler Virtualizatio
n
Synchronization
Server
(fence, distributed locks …)

RTS Virtualization
Another level of portability– Allow porting the Smart Application to another runtime system– Achieving the best possible affinity between RTS and OS
If another RTS is better for a specific system, use it!
– Abstract the complexity of supporting a heterogeneous group of heterogeneous systems
Avoid the special-case implementation paradigm– Providing support for multiple architectures is costly
In time and maintenance In performance (a system supported as a special case will invariably
present poorer performance than the principal targets).
– Why emulate the wheel ?

RTS Threading Models
1:1 threading model : (1 user-level thread mapped onto 1 kernel thread) – Default kernel scheduling – Heavy kernel threads
M:N threading model : (M user-level threads mapped onto N kernel threads) – Customized scheduling
Enables scheduler-based optimizations (e.g. priority scheduling, better support for relaxing the consistency model …)
– Light user-level threads Smaller threading cost
Can match N with the number of available hardware threads : no kernel-thread swapping, no preemption, no kernel over-scheduling …
User-level thread scheduling requires no kernel trap Perfect and free load balancing within the node
User-level threads are cooperatively scheduled on the available kernel threads (they migrate freely).

RTS Executor
Customized task scheduling– Executor maintains a ready queue (all tasks for which dependencies
are satisfied in the DDG)– Order tasks from the ready queue based on a scheduling policy (e.g.
round robin, static block or interleaved block scheduling, dynamic scheduling …)
– The RTS decides the policy, but the user can also specify it himself
– Policies can differ for every pRange
Customized load balancing– Implement load balancing strategies (e.g. work stealing)– Allow the user to choose the strategy– K42 : generate a customized work migration manager

RTS Synchronization Efficient implementation of synchronization primitives is crucial
– One of the main performance bottlenecks in parallel computing– Common scalability limitation
Fence– Efficient implementation using a novel Distributed Termination
Detection algorithmGlobal Distributed Locks
– Symmetrical implementation to avoid contention– Support for logically recursive locks (required by the compositional
SmartApps framework)
Group-based synchronization– Allows efficient usage of ad-hoc computation groups– Semantic equivalent of the global primitives– Scalability requirement for large-scale systems

Outline
SmartApps Concept STAPL is vehicle we use to develop the
SmartApps Framework STAPL
– Overview– High Level Adaptivity in STAPL
Consistency Models FAST - Framework for Algorithm Selection & Tuning
– RTS– Compiler (Pivot)

The Pivot: Static Analysis of C++ Applications (lead: Bjarne Stroustrup)
Compiler
IPR
XPR
Tool 2
Tool 1
C++ source Object code
C++ source
IDL
Tool 4
“information”
Tool 3
Specialized representation(e.g. flow graph)
CompilerCompiler

Context for the Pivot Semantically Enhanced Library (Language)
– Enhanced notation through libraries– Restrict semantics through tools
And take advantage of that semantics
C++
DomainSpecific Library
SemanticRestriction
s
Bell Labs Proverbs• Library design is language design• Language design is library design

Context for the Pivot
Provide the advantages of specialized languages– Without introducing new “special purpose” languages– Without supporting special-purpose language tool chains– Avoiding the 99.?% language death rate
Provide general support for the SELL idea– Not just a specialized tool per application/library– The Pivot fits here
C++
DomainSpecific Library
SemanticRestriction
s

Current and future work
Complete infrastructure– Complete EDG and GCC interfaces– Represent headers (modularity) directly– Complete type representation in XPR
Initial applications– Style analysis
including type safety and security
– Analysis and transformation of STAPL programs
Build alliances Currently: compiles Firefox Inserts measurement & control for SmartApps

Conclusion
STAPL is a good platform for developing SmartApps– used on several large-scale, complex applications – We plan to release a version soon to friendly
users Intel TBB – The simple STAPL for multicoresUniversity research into commercial product More info at http://parasol.tamu.edu/


















