
Http://parasol.tamu.edu SmartApps: Middleware for Adaptive Applications on Reconfigurable Platforms...
41
http://parasol.tamu.ed SmartApps: Middleware for Adaptive Applications on Reconfigurable Platforms Lawrence Rauchwerger http://parasol.tamu.edu/~rwerger/ Parasol Lab, Dept of Computer Science, Texas A&M
-
date post
22-Dec-2015 -
Category
Documents
-
view
215 -
download
2
Transcript of Http://parasol.tamu.edu SmartApps: Middleware for Adaptive Applications on Reconfigurable Platforms...

http://parasol.tamu.edu
SmartApps: Middleware for Adaptive
Applications on Reconfigurable Platforms
Lawrence Rauchwergerhttp://parasol.tamu.edu/~rwerger/
Parasol Lab, Dept of Computer Science, Texas A&M

Today: System Centric Computing
•Compilers are conservative
•OS offers generic services
•Architecture is generic
No Global Optimization
•No matching between Application/OS/HW
•intractable for the general case
WHAT’s MISSING ?
Classic avenues to performance:
•Parallel Algorithms
•Static Compiler Optimization
•OS support
•Good Architecture
Application
Compiler
HW
OS
System-Centric ComputingSystem-Centric Computing
Compiler(static)
Application(algorithm)
System(OS & Arch)
Execution
Development,Analysis &Optimization
Input Data

Our Approach: SmartAppsApplication Centric Computing
Application
Compiler
HW
OS
Application-Centric Computing
Compiler (static) +run-time techniques
Application(algorithm)
Run-time System:Execution, Analysis& Optimization
Development,Analysis &Optimization
Input DataArchitecture
(reconfigurable)
OS(modular)
Compiler(run-time)
SmartApp
Compiler + OS + Architecture + Data + Feedback
Application ControlInstance-specific optimization

SmartApps Architecture
Compiled code + runtime hooks
Static STAPL CompilerAugmented withruntime techniques
Predictor &Optimizer
STAPL ApplicationSTAPL Application
advanced advanced stagesstages
development development stagestage
ToolboxToolbox
Get Runtime Information(Sample input, system information, etc.)
Execute Application
Continuously monitor performance and adaptas necessary
Predictor &Optimizer
Predictor &Evaluator
Adaptive Software
Runtime tuning (w/o recompile)
Compute Optimal Applicationand RTS + OS Configuration
Recompute Applicationand/or Reconfigure RTS + OS
Configurer
Predictor &Evaluator
Smart Application
Small adaptation (tuning)
Large adaptation(failure, phase change)
DataBase
Adaptive RTS+ OS

Collaborative Effort:
STAPL (Amato – TAMU) STAPL Compiler (Stroustrup/Quinlan TAMU -
LLNL) , Cohen INRIA, France RTS – K42 Interface & Optimizations (Krieger IBM) Applications (Amato/Adams TAMU, Novak/Morel
LLNL/LANL) Validation on DOE extreme HW
BlueGene (PERCS?)(Moreira/Krieger) Texas A&M
Texas A&M (Parasol, NE) + IBM + LLNL + INRIA

SmartApps written in STAPL
STAPL (Standard Template Adaptive Parallel Library): – Collection of generic parallel algorithms,
distributed containers & run-time system (RTS)– Inter-operable with Sequential Programs– Extensible, Composable by end-user– Shared Object View: No explicit communication– Distributed Objects: no replication/coherence– High Productivity Environment

The STAPL Programming Environment
RTS + Communication Library (ARMI)
OpenMP/MPI/pthreads/native
pAlgorithms pContainers
User Code
pRange
Interface to OS (K42)

SmartApps Architecture
Compiled code + runtime hooks
Static STAPL CompilerAugmented withruntime techniques
Predictor &Optimizer
STAPLSTAPL ApplicationApplication
advanced advanced stagesstages
development development stagestage
ToolboxToolbox
Get Runtime Information(Sample input, system information, etc.)
Execute Application
Continuously monitor performance and adaptas necessary
Predictor &Optimizer
Predictor &Evaluator
Adaptive Software
Runtime tuning (w/o recompile)
Compute Optimal Applicationand RTS + OS Configuration
Recompute Applicationand/or Reconfigure RTS + OS
Configurer
Predictor &Evaluator
Smart Application
Small adaptation (tuning)
Large adaptation(failure, phase change)
DataBase
Adaptive RTS+ OS

Algorithm Adaptivity
Problem: Parallel algorithms highly sensitive to:– Architecture – number of processors, memory
interconnection, cache, available resources, etc– Environment – thread management, memory
allocation, operating system policies, etc– Data Characteristics – input type, layout, etc
Solution: adaptively choose the best algorithm from a library of options at run-time

Adaptive Framework
Overview of Approach
GivenMultiple implementation choices for the same high level algorithm.
STAPL installationAnalyze each pAlgorithm’s performance on system and create a selection model.
Program executionGather parameters, query model, and use predicted algorithm.
Installation Benchmarks
Architecture &Environment
AlgorithmPerformance
Model
UserCode Parallel Algorithm Choices
Data Characteristics
Run-Time Tests
Selected Algorithm
Data Repository
STAPL
Adaptive Executable

Results – Current Status
Investigated three operations– Parallel Reductions – Parallel Sorting– Parallel Matrix Multiplication
Several Platforms– 128 processor SGI Altix– 1152 nodes, dual processor Xeon Cluster– 68 nodes, 16 way IBM SMP Cluster– HP V Class 16 way SMP– Origin 2000

Adaptive Reduction Selection Framework
Static Setup Phase Dynamic Adaptive Phase
Synthetic experiments
Modelderivation
Algo. selection code Select algo.
Selected algo.
Optimizing compiler
Application
Characteristics changed?
Adaptive executable

Reductions: Frequent OperationsReduction : update operation via associative and commutative
operators : x = x expr
FOR i = 1 to M sum = sum + B[i]
DOALL i = 1 to M p = get_pid() s[p] = s[p] + B[i]sum = s[1]+s[2]+…+s[#proc]
Irregular Reduction : updates of array elements through indirection.
FOR i = 1 to M A[ X[i] ] = A[ X[i] ] + B[i]
Final
Partial acc.
• Bottleneck for optimization.
• Many parallellization transformations (algorithms) were proposed andnone of them always delivers the best performance.

Parallel Reduction Algorithms
Replicated Buffer :simple but won’t scale when data access pattern is sparse.
Replicated Buffer with Links [ICS02] reduced communication.
Selective Privatization: [ICS02] reduced communication and memory consumption.
Local Write [Han & Tseng] :zero communication, extra work.

Comparison of Parallel Reduction Algorithms
Programs Description # Inputs
Data size
IRREG Kernel, CFD 4 — 2M
NBF Kernel, GRAMOS 4 — 1M
MOLDYN Synthetic, M.D. 4 — 100K
Charmm Kernel, M.D. 3 — 600K
SPARK 98 Sparse sym. MVM 2 — 30K
SPICE 2G6 Circuit Simulation 4 — 189K
FMA3D 3D FE solver for solids
1 175K
Total 22 7K — 2M
Experimental setup

Performance Comparison (HP, P=8)
0
0.2
0.4
0.6
0.8
1C
=10
0
C=
50
C=
5
C=
1
C=
2
C=
5
C=
50
C=
200
C=
96
C=
34
C=
7
C=
1.5
C=
18
C=
9
C=
4.5
N=
21k
N=
90k
N=
180k
N=
99k
N=
90k
N=
34k
C=
0.5
Irreg Nbf Moldyn Charmm Spark98 Spice Fma3d
Application - Input
No
rmal
ized
Sp
eed
up
s
RepBufs RepLink SelPriv LocalWrite
Observations: • Overall, SelPriv is overall the best performed algorithm (13/22).
• No single algorithm works well for all the cases.
0
0.2
0.4
0.6
0.8
1
C=
100
C=
50
C=
5
C=
1
C=
18
C=
9
C=
4.5
Irreg Charmm
Application - Input
No
rma
lize
d S
pe
ed
up
s
RepBufs RepLink SelPriv LocalWrite

REAL A[N], pA[N,P]INTEGER X[2,M]
DOALL i = 1, M C1 = func1() C2 = func2() pA[X[1,i], p] += C1 pA[X[2,i], p] += C2
DOALL i = 1, N A[i] += pA[ i, 1:P ]
Memory Reference Model
Number of distinct reduction elements in one iteration.It affects the iteration replication ratio of Local Write.
Mobility
N Number of shared data elements
Other workworkreduction of Time
workreduction -non of Time
Instrument light-weight timer (~ 100 clock cycles) in few iterations.
N
MConnectivity (M: # iterations, N: # shared data elements)

Model (cont.)
Usage of Replicated Buffer - Irreg
0 1 2 3 4 5 6 7 8 9
Processor IDs
Ran
ge
of
Su
bsc
rip
ts
Usage of Replicated Buffer - Nbf
0 1 2 3 4 5 6 7 8 9
Processor IDs
Ran
ge
of
Su
bsc
rip
ts
Usage of Replicated Buffer - Moldyn
0 1 2 3 4 5 6 7 8 9
Processor IDs
Ran
ge
of
Su
bsc
rip
ts
Memory access patterns of Replicated Buffer
# Clusters = # Clusters of the touched elements in replicated array
How efficient are the regional usages ?
31 2 94 5 6 7 8
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
1 2 3 4 5
Sparsity = How efficient is the usage ?# touched elements in replicated arrays
Size of replicated arrays

Setup Phase — Model Generation
Setup phase – off-line
Speedup = F(Parameters)
Parameterized Synthetic
Reduction Loops
SyntheticParameter
ValuesFactorial experiment
Model Generation
ExperimentalSpeedupsExperimental execution
General linear modelfor each algorithm

Synthetic Experiments
double data[1:N]FOR j = 1, N * CON FOR i = 1, OTH Non-reduction work expr[i] = (memory read scalar ops) FOR i = 1, MOB k = index[i,j] data[k] += expr[i]
index[*] Sparsity, #Cluster
Parameters Selected values
N (data size)
8196 — 4,194,304
Connectivity 0.2 — 128
Mobility 2 — 8
Other Work 1 — 8
Sparsity 0.02 — 0.99
# Clusters 1, 4, 20~
Total cases
~800
Synthetic Reduction Loop Experimental Parameters

Model Generation
C: connectivityN: the size of reduction arrayM: mobilityO: non-reduction-work/reduction-workS: sparsity of replicated arrayL: # clusters
3)1( LSOMNC
Regression Models
• Match parameters with speedup of a scheme
• From a general linear modelwe sequentially select terms
– Final models contain ~30 terms.
Other method: Decision Tree Classification

Q1: Can the prediction models select the right algorithm for a given loop execution instance ?
Evaluation
HP V-Class, P=8
IBM Regatta, P=16
Total loop-input cases 22 21
Algorithm speedup of model-based recommendation
Algorithm speedup of oracle's recommendationEffectiveness =
Q2: How far from the best possible performance using ourprediction models ?
Average effectiveness 98% 98.8%
Correctly predicted cases 18 19

Evaluation (cont.)
Speedup of algorithm chosen by alternative selection method
Speedup of algorithm recommended by our modelsRelative-speedup =
Alternative Selection Methods• RepBuf: always use Replicated Buffer• Random: randomly select algorithms (average used)• Default: use SelPriv on HP and LocalWr on IBM
Q3: performance improvement using our prediction models ?
0.2
0.4
0.6
0.8
1
HP V-Class, P=8 IBM Regatta, P=16
Average relative-
speedups
RepBuf Random Default Models

Adaptive Reductions
FOR (t = 1:steps) DO FOR (i = 1:M) DO access x[ index[i] ]
Static Irregular Reduction
FOR (t = 1:steps) DO IF (adapt(t)) THEN update index[*] FOR (i = 1:M) DO access x[ index[i] ]
Adaptive Irregular Reduction
Phase behavior
• Reusability = # steps in a phase
• Estimate phase-wise speedups by modeling the overheads of the setup phases of SelPriv and LocalWr.

Moldyn
The performance of algorithms does not change much dynamically
→ artificially specified the Reuseability of phases.
Relative Speedups (HP V-class, P=8)
0
0.2
0.4
0.6
0.8
1
1.2
23328 55296 108000 186624 186624#molecules
RepBuf SelPriv LocalWr DynaSel
Time steps
Adaptation phases
Large phases
Small phases

PP2D in FEATFLOW
• PP2D (17K lines) nonlinear coupled equations solver using multi-grid methods.
• Irregular reduction loop in GUPWD subroutine ~ 11% of program execution time.
• The distributed input has 4 grids, with the largest one having ~100K nodes
• Loop invoked with 4 (fixed) distinct memory access patterns in an interleaved manner.
• Algorithm selection module is wrapped around each invocation of the loop
• Selection for each grid is reused for later instances.
Instrumentation
The program (real application)

PP2D in FEATFLOW (cont.)Relative Speedups (HP V-class, P=8)
0
0.2
0.4
0.6
0.8
1
1.2
Total Lev=5 Lev=4 Lev=3 Lev=2
RepBuf SelPriv LocalWr DynaSel
Relative Speedups (IBM Regatta, P=16)
0
0.2
0.4
0.6
0.8
1
1.2
Total Lev=5 Lev=4 Lev=3 Lev=2
RepBuf SelPriv LocalWr DynaSel
Notes:• RepBuf, SelPriv, LocalWr correspond to applying fixed algorithm for all grids.• DynaSel dynamic selects once for each grid and reuses the decisions.• Relative Speedups are normalized to the best of the fixed algorithms.
Result: our framework• Introduces negligible overhead (HP system).• Can further improve performance (IBM system).

SmartApps Architecture
Compiled code + runtime hooks
Static STAPL CompilerAugmented withruntime techniques
Predictor &Optimizer
STAPLSTAPL ApplicationApplication
advanced advanced stagesstages
development development stagestage
ToolboxToolbox
Get Runtime Information(Sample input, system information, etc.)
Execute Application
Continuously monitor performance and adaptas necessary
Predictor &Optimizer
Predictor &Evaluator
Adaptive Software
Runtime tuning (w/o recompile)
Compute Optimal Applicationand RTS + OS Configuration
Recompute Applicationand/or Reconfigure RTS + OS
Configurer
Predictor &Evaluator
Smart Application
Small adaptation (tuning)
Large adaptation(failure, phase change)
DataBase
Adaptive RTS+ OS

RTS needs to provide (among others): Communication library (ARMI) Thread management Application specific Scheduling
– based on Data Dependence Graph (DDG)– based on application specifics policies– thread to processor mapping
Memory management Applications – OS bi-directional Interface
Adaptive Apps Adaptive RTS Adaptive OS

Optimizing Communication (ARMI)
Adaptive RTS Adaptive Communication (ARMI)
Minimize Applications Exec Time using application specific info. :
– Use parallelism to hide latency (MT…)– Reduce Critical Path Lengths of apps.– Selectively use asynch./synch
communication

K42 User-Level Scheduler
RMI service request threads may be created on:– local dispatcher and migrated to the dispatcher of
the remote thread– dispatcher of the remote thread
New scheduling logic in the user-level dispatcher – Currently only FIFO ReadyQueue implementation
is supported– Implementing different priority-based scheduling
policies

SmartApps RTS Scheduler
Integrating Application scheduling with K42
K42 Kernel
Kernel LevelDispatchers – Scheduled by the kernel
User-level Dispatchers
User-level Threads Scheduled by K42 user-level scheduler
User Level

Priority-based Communication Scheduling
Based on type of request – SYNC or ASYNC
SYNC RMI - A new high priority thread is created
ASYNC RMI – A new thread is created
SYNC RMI
– New thread is scheduled to RUN immediately ASYNC RMI
– New thread is not scheduled to RUN until the current thread yields voluntarily

Priority-based Communication Scheduling
Based on application specified priorities Discrete Ordinates Particle Transport
Computation (developed in STAPL):
One sweep Eight simultaneous sweeps

Dependence Graph
Numbers are cellset indices Colors indicate processors
angle-set A angle-set B angle-set C1
2 5
3 6
4 7
8
10 13
18 2112 15
14 1711
9
22 2516 19
26 2920 23
3024 27
28 31
32
4
3 8
2 7
1 6
5
11 16
19 249 14
15 2010
12
23 2813 18
27 3217 22
3121 26
25 30
29
32
31 28
30 27
29 26
25
23 20
15 1221 18
19 1622
24
11 817 14
7 413 10
39 6
5 2
1
29
30 25
31 26
32 27
28
22 17
14 924 19
18 1323
21
10 520 15
6 116 11
212 7
8 3
4
angle-set D

Initial State
Ordinary Thread
RMI Thread
Dispatcher
Physical Processor
In the Initial State,
each dispatcher has a thread in RUN state
P1 P2 P3
RMI Request Trace
Initial State
Ordinary Thread
RMI Thread
Dispatcher
Physical Processor
RMI
Request
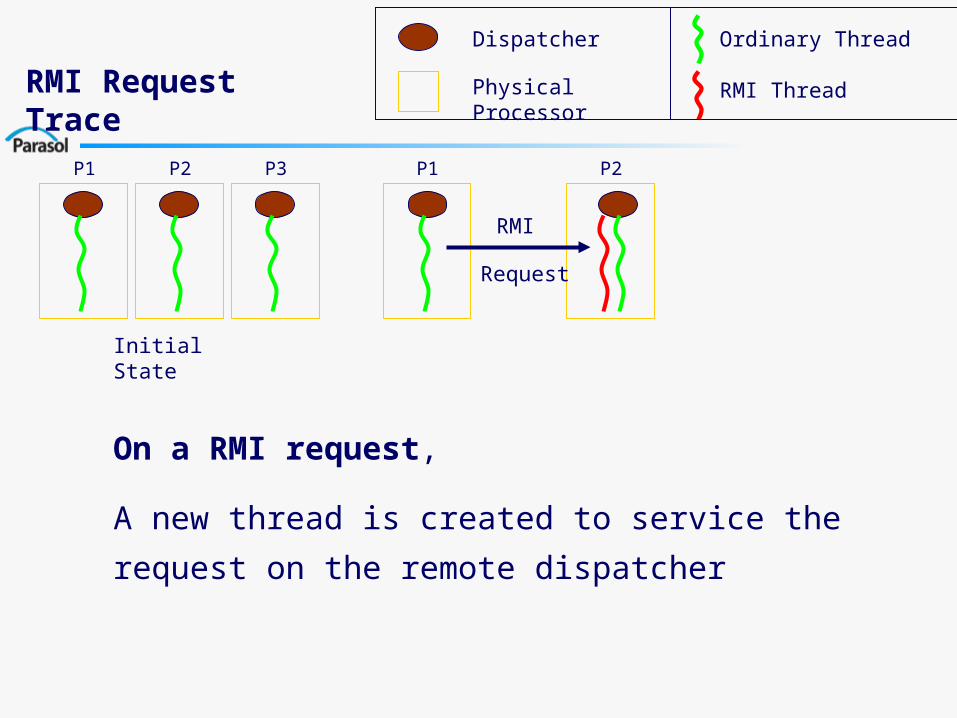
On a RMI request,
A new thread is created to service the request on the
remote dispatcher
P1 P1P2 P3 P2
RMI Request Trace

Initial State
Ordinary Thread
RMI Thread
Dispatcher
Physical Processor
RMI
Request
For SYNC RMI requests,
- Current running thread is moved to READY state
- The new thread is scheduled to RUN
P1 P1P2 P3 P2
RMI Request Trace

Initial State
Ordinary Thread
RMI Thread
Dispatcher
Physical Processor
RMI
Request
For ASYNC RMI requests,
The new thread is not scheduled to RUN until the current thread voluntarily yields
P1 P1P2 P3 P2
RMI Request Trace

Initial State
Ordinary Thread
RMI Thread
Dispatcher
Physical Processor
RMI
Request
RMI
Request
On multiple pending requests,
The scheduling logic prescribed by the application would be enforced to order the service of RMI requests
P1 P1P2 P3 P2 P3
RMI Request Trace

Memory Consistency Issues
Switching between threads to service RMI requests may result in memory consistency issues
Checkpoints need to be defined for stopping the execution of thread to service RMI requests
– e.g. completion of a method may be a checkpoint for servicing pending RMI requests
![WELCOME [parasol.tamu.edu]amato/Courses/engr181/... · Honors Program Coordinator and Associate Professor tsvetkov@tamu.edu Marna Stepan Undergraduate Program ... (SNL) • First-of-a-kind](https://static.fdocuments.in/doc/165x107/5ed3f11c00e59e5d421cbc8c/welcome-amatocoursesengr181-honors-program-coordinator-and-associate.jpg)

















