
SAP HANA Training | SAP HANA Online Training | SAP HANA Course
Upload
sap-technologyCategory
view
828download
9
1© 2014 SAP AG or an SAP affiliate company. All rights reserved.
SAP HANA SPS 10 - What’s New? Enterprise Information Management
SAP HANA Product Management May, 2015
(Delta from SPS 09 to SPS 10)

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 2Public
Agenda
SAP HANA smart data integration
New Adapters
Writing to Virtual Tables
Web-Based .hdbflowgraph Editor
Remote Object Search
DDL Replication
Support for Multitenant Database Containers
Support for Extended Storage Tables (Dynamic Tiering)
Support for HANA smart data access remote sources
Logical Partitions
New Load Behaviors
Adapter SDK Enhancements

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 3Public
Agenda
SAP HANA smart data quality
Profiling – Metadata, Semantic and Frequency Distribution
Updated Cleanse Transform
New Match Transform
Side Effect Data – Match & Cleanse
Task Management

SAP HANA smart data
integration

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 5Public
New Adapters
ASEAdapter
Federation
Bulk extraction
Log Based Real Time Replication
HanaAdapter
Federation
Bulk extraction
Trigger Based Real Time Replication
TeradataAdapter
Federation
Bulk extraction
Trigger Based Real Time Replication

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 6Public
Writing to Virtual Tables
Provides the ability to write data to a virtual table in a remote source
In SPS9, virtual tables could be queried directly or used as a Data Source in a Flowgraph. In SPS10,
it’s also possible to have a Data Sink node (i.e. target) point to a virtual table from a remote source
configured using one the following adapters
ASEAdapter
FileAdapter
HanaAdapter
TeradataAdapter
DB2LogReaderAdapter
OracleLogReaderAdapter
MssqlLogReaderAdapter

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 7Public
New .hdbflowgraph editor
The HANA Web-Based Development Workbench has a
new .hdbflowgraph editor that allows you to model a
set of transformations applied to one or many data
sources
It provides the same capabilities already available in HANA
Studio in SPS09.
Batch and real time data movements with transformations
It also provides the following new capabilities
An updated Cleanse transform with content type detection and an
easy to follow configuration process
A new Match transform with content type detection and an easy
to follow configuration process

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 8Public
Remote Object Search
Allows you to search for remote objects (e.g. tables) in
a remote source
When invoking this functionality for the first time, you must
populate the dictionary (a HANA table) that will hold the
object name and descriptions.
This functionality can be invoked
By right-clicking on a remote source (Web Based Developer
Workbench – Catalog only)
When selecting objects for replication in the .hdbreptask editor
FileAdapter
HanaAdapter
TeradataAdapter
DB2LogReaderAdapter
OracleLogReaderAdapter
MssqlLogReaderAdapter
DB2ECCAdapter
OracleECCAdapter
MssqlECCAdapter
This functionality is supported for remote sources configured using the following adapters

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 9Public
DDL Replication
Data Definition Language(DDL) operations can be replicated just like insert, update and delete
operations
The following DDL operations are supported
ALTER TABLE ADD COLUMN
ALTER TABLE DROP COLUMN
DDL replication is possible when
The .hdbreptask is enabled for real time
The Table Level Replication setting is selected for the remote object
DDL replication is supported for remote sources configured using the following adapters
All tables
–DB2LogReaderAdapter
–OracleLogReaderAdapter
–MssqlLogReaderAdapter
Transparent tables only
–DB2ECCAdapter
–OracleECCAdapter
–MssqlECCAdapter

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 10Public
Support for Multitenant Database Containers
HANA EIM can be used to replicate or transform data in a HANA system with Multitenant
Database Containers
Each container
Has its own dpserver
Must be configured individually
– Register the Data Provisioning Agent(s)
– Register the Data Provisioning Adapter(s)
– Create Remote Sources
Support for Multitenant Database Containers was introduced in HANA SPS09 revision 95
© 2015 SAP SE or an SAP affiliate company. All rights reserved. 11Public
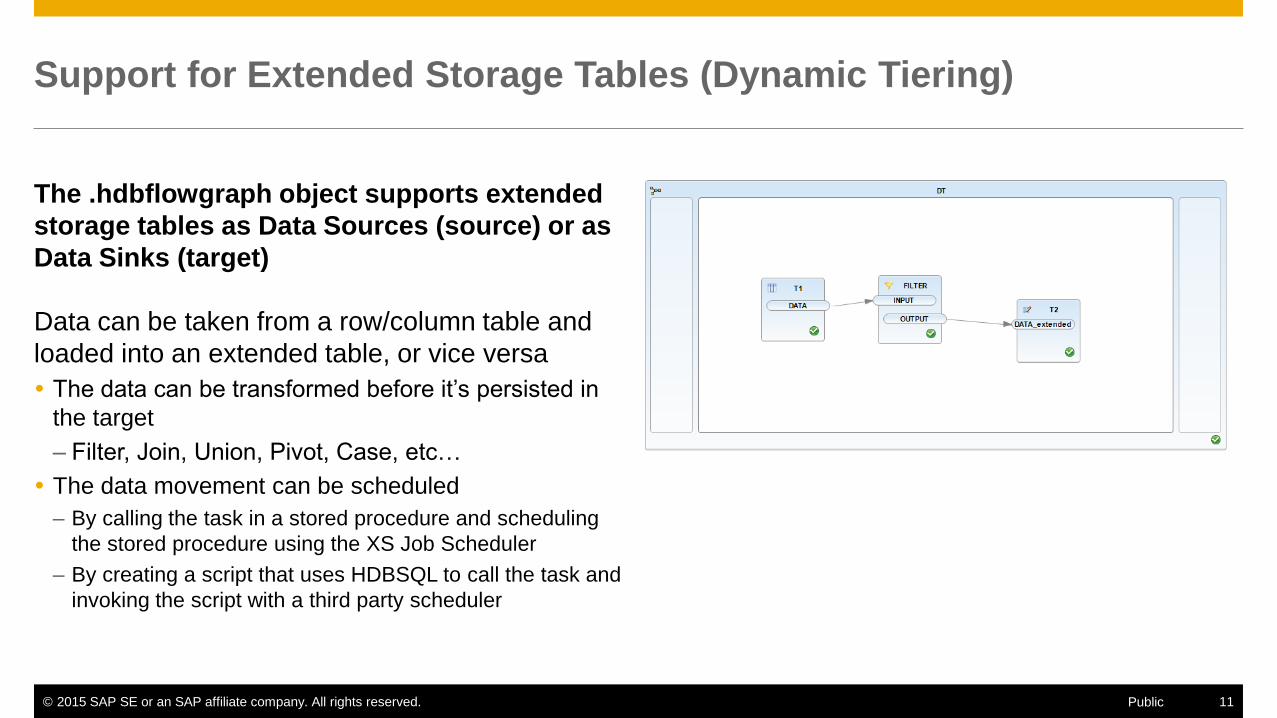
Support for Extended Storage Tables (Dynamic Tiering)
The .hdbflowgraph object supports extended
storage tables as Data Sources (source) or as
Data Sinks (target)
Data can be taken from a row/column table and
loaded into an extended table, or vice versa
The data can be transformed before it’s persisted in
the target
– Filter, Join, Union, Pivot, Case, etc…
The data movement can be scheduled
– By calling the task in a stored procedure and scheduling
the stored procedure using the XS Job Scheduler
– By creating a script that uses HDBSQL to call the task and
invoking the script with a third party scheduler

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 12Public
Support for HANA smart data access remote sources
Remote sources created using HANA smart data access adapters are now displayed in the
.hdbreptask editor of the HANA Web-Based Development Workbench
When configuring a remote source, HANA smart data access adapters always have indexserver as the
Source Location.
Initial Load Only
– smart data access adapters don’t have real time change data capture capabilities so this configuration option
will be selected and disabled

Logical Partitions

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 14Public
Logical Partitions
Provides the ability to expedite the extraction of data from a remote source
By creating multiple logical partitions, the system will execute parallel queries on a virtual table, each
extracting a subset of the entire dataset
Is available in the Partitions tab of the .hdbreptask editor and in the Partitions tab of the Data Source
node of the .hdbflowgraph editor
One or more named partitions can be created
– Partitions are used to create filter criteria to select subsets of data
A hidden partition will be created to extract all records that don’t meet the filter criteria of all named
partitions
Partitions can only be created for one column in the table
Partitions are only allowed on non-null columns
Recommendation – Select a column with an index in the remote source for even better performance
© 2015 SAP SE or an SAP affiliate company. All rights reserved. 15Public
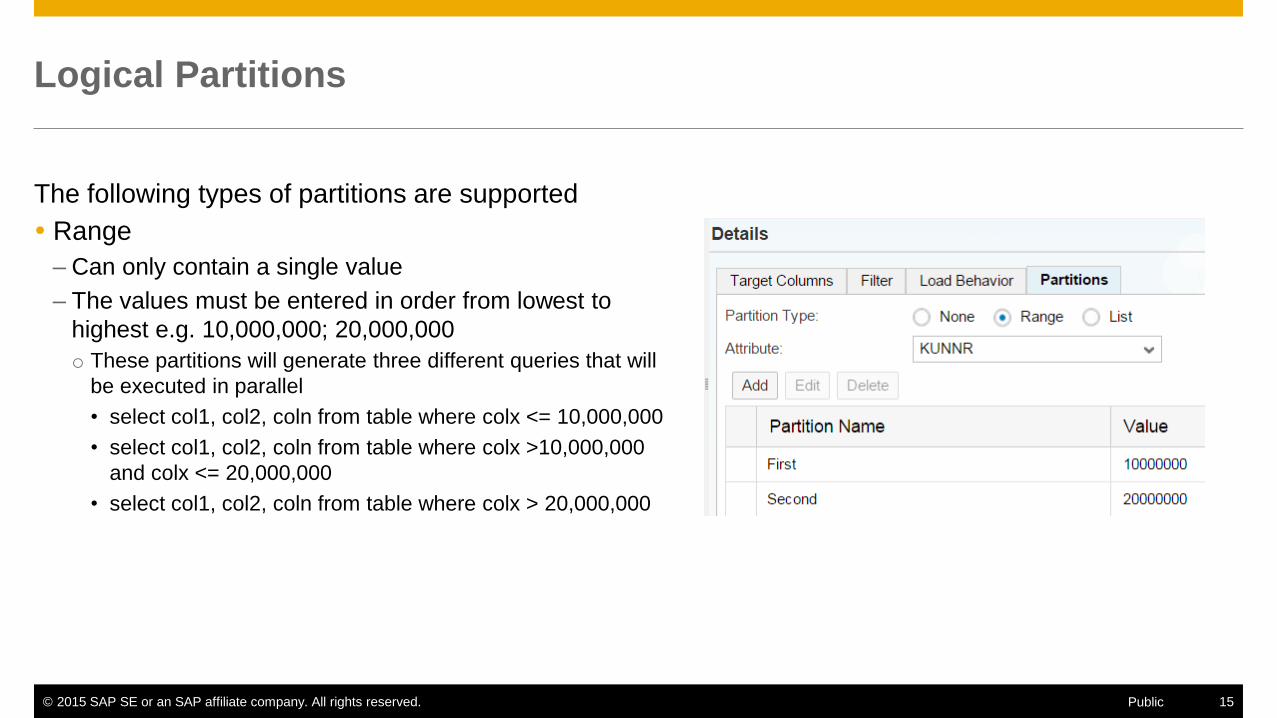
Logical Partitions
The following types of partitions are supported
Range
– Can only contain a single value
– The values must be entered in order from lowest to
highest e.g. 10,000,000; 20,000,000
o These partitions will generate three different queries that will
be executed in parallel
• select col1, col2, coln from table where colx <= 10,000,000
• select col1, col2, coln from table where colx >10,000,000
and colx <= 20,000,000
• select col1, col2, coln from table where colx > 20,000,000

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 16Public
Logical Partitions
The following types of partitions are supported
List
– Each named partition can contain a single value
o Canada – ‘CA’
o United States – ‘US’
o Germany – ‘DE’
– Each named partition can contain multiple comma
delimited values
o North America – ‘CA’, ‘US’, ‘MX’
o Europe – ‘DE’, ‘FR’, ‘GB’, ‘IT’, ‘ES’

New Load Behaviors

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 18Public
Replicate, Replicate with logical delete
Allows you to change the behavior of the real time replication functionality
When selecting a table for real time replication, you can choose one of the following load behaviors
Replicate (default value)
– Applies insert, update and delete operations to the target table in HANA.
Replicate with logical delete
– Applies insert and update operations and converts delete operations to update operations
– Creates two new columns in the target table
o The incoming database operation (I, U or D)
o The timestamp of the transaction applied to the target table in HANA
– Produces rows that can be used by consuming applications like SAP Business Warehouse and SAP Data
Services to identify which records changed and when. This is especially useful when the remote source
doesn’t provide a way for SAP BW or SAP DS to identify changed records directly.

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 19Public
Preserve all
Preserve all
– Applies insert operations and converts update and delete operations to insert operations, resulting in a history
table containing all changes that occur over time
– Creates three new columns in the target table and adds them to the primary key
o The incoming database operation (I, U or D)
o The timestamp of the transaction applied to the target table in HANA
o The sequence number of the operations within a transaction
• Is necessary to ensure uniqueness because a single transaction can contain multiple update operations on the same
record
– Produces rows that can be used by consuming applications like SAP Business Warehouse and SAP Data
Services to identify which records changed and when. This is especially useful when the remote source
doesn’t provide a way for SAP BW or SAP DS to identify changed records directly.
– Produces rows that can be used for historical reporting

Adapter SDK Enhancements

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 21Public
UPSERT
The Adapter SDK provides new operations that can enable the creation of new custom HANA
EIM adapters or enhance the capabilities of existing custom adapters
In addition to the Insert, Before Image (Update), After Image (Update) and Delete operations that were
introduced in the initial version of the HANA EIM SDK in SPS9, the following row types are now
available.
RowType.UPSERT
– Inserts or Updates the record
– The primary key columns of the target table are used to check for the existence of the record, not the primary
key columns of the source table
– Performs an update if the record exists in the target table
– Performs an insert if the record doesn’t in the target table

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 22Public
EXTERMINATE
RowType.EXTERMINATE
– Deletes records based on the primary key from the incoming source record
– Only the primary key fields are used, all others may be null
– If these records are sent to a table via remote subscription with a filter, the filter will not be applied
– If these records are sent to a task, it will only be provided to the Table Comparison transform for processing
and to the table writer to perform the delete.
Please note that the RowType.DELETE requires the entire record as it exists in the target table in
order to perform the delete so using RowType.EXTERMINATE might be a preferable option.

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 23Public
REPLACE
The following row types are used together in order to replace an existing set of rows from a target table
with a new set of incoming rows.
For example, an existing sales order is changed where some items are added, others are removed and others
have their quantities changed. When a remote source can’t provide the details of the change but instead
provides the end result, the following row types must be used.
RowType.BEGIN_REPLACE_SET
– A row that indicates that a set of rows to be replaced will be provided immediately after this row

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 24Public
REPLACE
RowType.TRUNCATE_REPLACE_TARGET
– A row that identifies all records to be removed
o the column values in the row are used to identify the records to be deleted e.g. order_id = ‘010203’ will delete all order
detail records for this order
o The columns which have values can be primary key columns
o The columns which have values can be non-primary key columns but those columns must be non-null
o LOB columns can’t be used
– If all the values in the row are null, the entire table will be truncated
RowType.REPLACE
– A new row to be inserted
– Is optional. If no replace rows are provided, then rows will be deleted and not replaced.
RowType.END_REPLACE_SET
– Indicates that all rows to be replaced were provided

SAP HANA smart data quality

ProfilingMetadata, Semantic and Frequency Distribution

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 27Public
Semantic Profiling
Semantic profiling shows the character semantics and byte semantics of existing data and
assigns a content type to each column specified
This process relies on reviewing the existing data to determine and uncover anomalies in the
databases. Such a profile is useful in finding areas where the content of the existing system is not what
we would have expected it to be because of irregularities in the data.
Semantic profiling stored procedure:
PROCEDURE _SYS_TASK.PROFILE_SEMANTIC (
IN schema_name NVARCHAR(256),
IN object_name NVARCHAR(256),
IN profile_sample TINYINT,
IN columns _SYS_TASK.PROFILE_SEMANTIC_COLUMNS,
OUT result _SYS_TASK.PROFILE_SEMANTIC_RESULT
)

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 28Public
Metadata Profiling
Metadata profiling looks at column names, lengths and types as well as the location of the table
to determine its contents
The metadata can then be used to discover problems such as illegal values, misspelling, missing
values, varying value representation, and duplicates
Metadata profiling stored procedure:
PROCEDURE _SYS_TASK.PROFILE_METADATA (
IN schema_name NVARCHAR(256),
IN object_name NVARCHAR(256),
IN columns _SYS_TASK.PROFILE_METADATA_COLUMNS,
OUT result _SYS_TASK.PROFILE_METADATA_RESULT
)

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 29Public
Frequency Distribution Profiling
Distribution profiling allows you to create profiles of patterns, words and fields in existing data
For example, you could perform distribution profiling on single columns of data individually to get an
understanding of frequency distribution of different values, type, and use of each column
Contains pattern, word and field profiling
Frequency distribution stored procedure:
CREATE PROCEDURE _SYS_TASK.PROFILE_METADATA (
IN schema_name NVARCHAR(256),
IN object_name NVARCHAR(256),
IN columns _SYS_TASK.PROFILE_METADATA_COLUMNS,
OUT result _SYS_TASK.PROFILE_METADATA_RESULT
)

CleanseHANA Web-Based Development Workbench – .hdbflowgraph editor

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 31Public
Cleanse Configuration
A wizard will guide users through the process of
creating a cleanse configuration. Cleanse rules will
be suggested based upon semantic profiling results
The following cleanse components are supported
Person, Firm, Address, Phone, Email and Title

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 32Public
Content Types
Content types describe data within each column and
are grouped together to form cleanse components.
The cleanse components determine the cleanse rules
that can be used.
The semantic profiling results can be reviewed and
modified if needed
To change the content type if the results were ambiguous
To fine-tune the results in order to affect the mapping of columns
to the cleanse components
There are over 20 pre-defined content types that can be assigned
to any column

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 33Public
Cleanse Components
Cleanse components are the entities defined that will be
mapped into the cleanse operation
Cleanse components can be composed of
1-N number of input columns depending upon type
– Address and Person will usually have more than 1 input column
associated with them
Data from one input source
© 2015 SAP SE or an SAP affiliate company. All rights reserved. 34Public
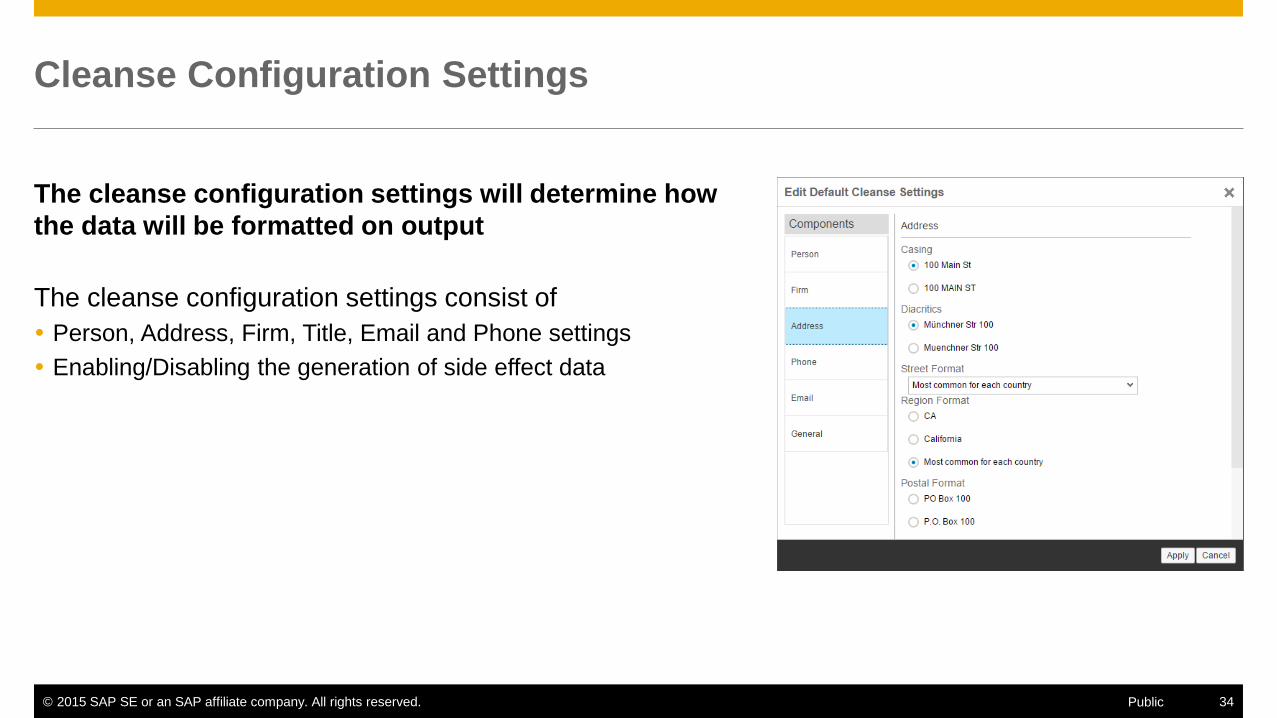
Cleanse Configuration Settings
The cleanse configuration settings will determine how
the data will be formatted on output
The cleanse configuration settings consist of
Person, Address, Firm, Title, Email and Phone settings
Enabling/Disabling the generation of side effect data

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 35Public
Cleanse Configuration Output
A set of best practice output fields will be automatically
selected for the user based upon the semantic profiling
results
Users can perform the following related to output field
selection
Adjust the output fields based upon the visual representation
Select from a list of suggested actions
Manually customize the output fields from a list of fields for each
cleanse component
Full control of the entire output schema from the cleanse operation
is possible

MatchHANA Web-Based Development Workbench – .hdbflowgraph editor

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 37Public
Match Configuration
A wizard will guide users through the process of
creating a match configuration. Match policies will
be suggested based upon semantic profiling results
The following match components are supported
Person, Firm, Address, Phone, Email, Date and Custom
Components are used to define match policies
The following policies are supported and can be used in
combination with each other
Person, Firm, Address, Phone, Email, Date and Custom

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 38Public
Content Types
Content types describe the data in each column and
are grouped together to form match components
For each source, the semantic profiling results for each
content type can be chosen or ignored for matching
View cleansed components
View uncleansed columns (input data)
Address and Person components contain multiple content
types
Person may contain First Name and Last Name and other
combinations
Address may contain Country, Address Line, City, Region and
Postcode

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 39Public
Match Components
Match components are used individually or in
combination with each other to form match policies
Match components can be composed of
Multiple input columns from semantic profiling results defined
by content types
– Each match component can be user defined
Multiple input columns from a cleanse operation defined
from the MATCH_STD_* columns
If a cleanse operation does not precede the match
operation, then the MATCH_STD_* fields will be generated

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 40Public
Adding Custom Match Components
Custom match components can be added to a
configuration to be used to create a custom match
policy
A custom match component is defined:
By providing a name for the match component
By selecting the column associated with the match component
– On a source-by-source basis when multiple sources are
being used
Custom match components can be used in match policies:
When performing exact-based matching
When performing fuzzy-based matching
– Only when combined with Phone, Email or Address

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 41Public
Match Policies
Match policies are used to determine how matches
are identified within a single source, or across
multiple sources of data
Policies can be created by:
Selecting one or more components
A match policy must contain one of the following
components:
Address
Phone
Date
Custom
© 2015 SAP SE or an SAP affiliate company. All rights reserved. 42Public
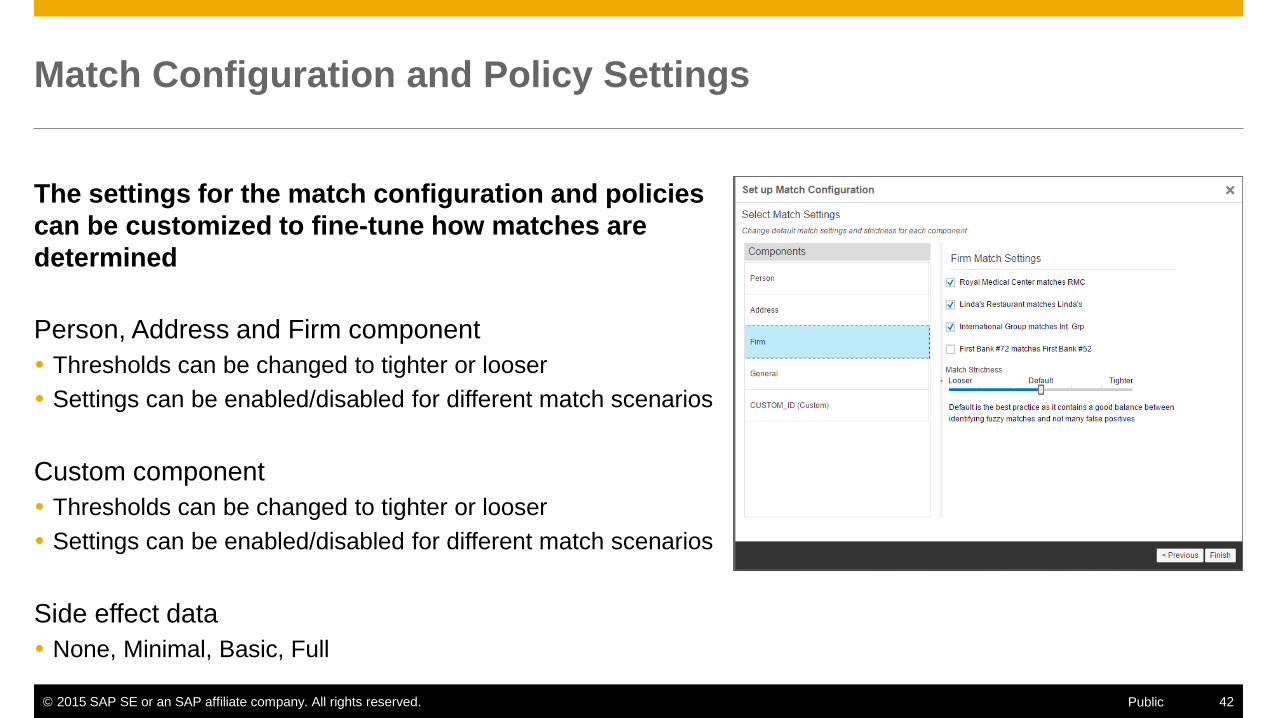
Match Configuration and Policy Settings
The settings for the match configuration and policies
can be customized to fine-tune how matches are
determined
Person, Address and Firm component
Thresholds can be changed to tighter or looser
Settings can be enabled/disabled for different match scenarios
Custom component
Thresholds can be changed to tighter or looser
Settings can be enabled/disabled for different match scenarios
Side effect data
None, Minimal, Basic, Full

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 43Public
Multi-source Matching
The match operation supports finding duplicates
within sources of data and across sources of data
This can be configured by
Directly mapping each data source to the match operation
Leveraging the union operation to combine the multiple
sources intoa common data model
– A column specifying the source is required here
Source settings
Define a constant source ID
Get a source ID from a column
Remove source from determining duplicates within it

Side Effect DataMatch & Cleanse

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 45Public
Side Effect Data Overview
Side effect data is generated by the cleanse and match operations and provides insight and
clarity into the impact and results of each operation. This provides the framework to easily
develop capabilities to create custom review and remediation tools for Data Quality in HANA
Side effect cleanse/match configuration options:
None
– Side effect data is not generated
Minimal
– Generates only the statistic tables that contain summary information about the operation stored in the _SYS_TASK schema
Basic
– Generates the statistic tables that contain summary and detailed information about the operation
Full
– Generates everything in basic along with a copy of the input data prior to the operation. The copy of the input data is stored
in the user’s schema

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 46Public
Side Effect Data for Match
Match side effect data will provide summary and detailed information related to the match
operation along with details specific to each match found on a group or record level
Match side effect tables consist of (in schema _SYS_TASK):
MATCH_STATISTICS
– Provides a summary of a specified match operation including match groups, matches found, unique records, number of
match groups to review, the comparisons performed and number of decisions made
MATCH_SOURCE_STATISTICS
– Provides a summary of input sources and the data when doing multi-source matching
MATCH_GROUP_INFO
– Provides detailed information of a specified match group within a match operation including how many records are in the
match group, review/conflict flags and how many sources of data the match group contains
MATCH_RECORD_INFO
– Provides the relationship information on a record-by-record basis for each match group within a match operation
MATCH_TRACING
– Provides very detailed information on a record-by-record basis as to how and why the match was made along with the score

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 47Public
Match Side Effect Data – Table Relationships
The match side effect data is stored in a relational data model
The data in the tables in stored in order of level of detail provided
from summary information in MATCH_STATISTICS to detailed
match record information in MATCH_TRACING.
All data can be queried essentially using TASK_EXECUTION_ID,
GROUP_ID and ROW_ID
TASK_EXECUTIONS
MATCH_STATISTICS MATCH_SOURCE_STATI
STICS
MATCH_GROUP_INFO
MATCH_RECORD_INFO
MATCH_TRACING

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 48Public
Side Effect Data for Cleanse
Cleanse side effect data will provide summary and detailed information related to the cleanse
operation along with details specific to how the data (entities and components) was changed
Cleanse side effect tables consist of (in schema _SYS_TASK):
CLEANSE_STATISTICS
– Provides a summary of a specified cleanse operation including number of valid, suspect, blank and high significant changes
on an entity-by-entity basis. An entity is equivalent to a cleanse component (Address, Person, Firm, Phone, etc.)
CLEANSE_ADDRESS_RECORD_INFO
– Provides a summary of the address cleansing results of a specific operation including assignment level, assignment type
and assignment information code (V/I/C) for each row in the input data
CLEANSE_CHANGE_INFO
– Provides detailed information on a row-by-row, entity-by-entity and component-by-component basis that explains the
significance of the change and the type of change. This makes cleanse a complete white box with transparency
CLEANSE_INFO_CODES
– Provides detailed information on a row-by-row and entity-by-entity basis that defines exactly the issue with the data that
caused the entity to not validate during the cleansing operation

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 49Public
Cleanse Side Effect Data – Table Relationships
The cleanse side effect data is stored in a relational data model
The data in the tables in stored in order of level of detail provided
from summary information in CLEANSE_STATISTICS to detailed
cleanse information in CLEANSE_CHANGE_INFO.
All data can be queried essentially using TASK_EXECUTION_ID,
ENTITY_ID and ROW_ID
ENTITY_ID can be looked up using data found in the
TASK_LOCALIZATION using the LOC_ID column
TASK_EXECUTIONS
CLEANSE_STATISTICS CLEANSE_ADDRESS_R
ECORD_INFO
CLEANSE_CHANGE_INF
O
TASK_LOCALIZATION

Task Management

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 51Public
Task Management
Tasks can now be stopped before execution completes using a new SQL statement
CANCEL TASK <TASK_EXECUTION_ID> [WAIT <TIME_IN_SECONDS>]
The cancel task command can be used:
Within a SQL console
Within a stored procedure
Retrieve the TASK_EXECUTION_ID by:
Obtaining the last task execution ID
– SELECT session_context('TASK_EXECUTION_ID') FROM dummy;
Viewing the monitoring information
– SELECT * FROM M_TASKS WHERE TASK_EXECUTION_ID = CAST(session_context('TASK_EXECUTION_ID') AS
BIGINT);

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 52Public
Disclaimer
This presentation outlines our general product direction and should not be relied on in making
a purchase decision. This presentation is not subject to your license agreement or any other
agreement with SAP.
SAP has no obligation to pursue any course of business outlined in this presentation or to
develop or release any functionality mentioned in this presentation. This presentation and
SAP’s strategy and possible future developments are subject to change and may be changed
by SAP at any time for any reason without notice.
This document is provided without a warranty of any kind, either express or implied, including
but not limited to, the implied warranties of merchantability, fitness for a particular purpose, or
non-infringement. SAP assumes no responsibility for errors or omissions in this document,
except if such damages were caused by SAP intentionally or grossly negligent.

© 2015 SAP SE or an SAP affiliate company. All rights reserved. 53Public
Additional Resources
SAP HANA EIM documentation on SAP Help Portal
– http://help.sap.com/hana_options_eim
SAP HANA Academy on YouTube – What’s new with SAP HANA SPS10 playlist
– https://www.youtube.com/playlist?list=PLkzo92owKnVxweu0HK_3QjCfHiMn0jIcA

© 2015 SAP SE or an SAP affiliate company. All rights reserved.
Thank you
Contact information
Richard LeBlanc | Ken Beutler
SAP HANA EIM Product Management


















