










EE324 DISTRIBUTED SYSTEMS FALL 2015 MapReduce. Overview 2 MapReduce.
Upload
myron-carrCategory
view
219download
1
LOGO
www.nordridesign.com
Introduction to MapReduce
Overview of ReStore�
Implementation Details�
Experiments�
Outline

LOGO
www.nordridesign.com
Introduction to MapReduceMapReduce and its
implementations such as Hadoop are common in Facebook, Yahoo, and Google as well as smaller companies
Use high-level query languages such as Pig to express their complex analysis tasks.
Translate queries into workflows of MapReduce jobs, output is stored in the distributed file system

LOGO
www.nordridesign.com
Introduction to MapReduceHigh-level language translate an
query into physical operators(Join, Select)
Embed all physical operators into mapper and reducer stages
Compiler generates code for each MapReduce job and passes it to the MapReduce system
ReStore extends this dataflow to reuse the output of physical operators

LOGO
www.nordridesign.com
Overview ReStoreReStore improves the
performance of workflows by storing the intermediate results and reusing them
Enable queries submitted at different times to share results
Built on top of dataflow language processors

LOGO
www.nordridesign.com
Overview ReStoreReuse job outputs previously
storedStore the outputs of executed
jobs for future reuseCreate more reuse opportunities
by storing the outputs of sub-jobs Selects the outputs of jobs toRewrites a MapReduce job and
submits it to the MapReduce system to be executed.

LOGO
www.nordridesign.com
Types of Result ReuseIf all dependant jobs of Join are
stored in the system, Ttotal (Join) = ET(Jobn)
Parts of the query execution plan are stored in the system

LOGO
www.nordridesign.com
ReStore System ArchitectureInput is a workflow of MapReduce
jobs generated by a dataflow system
Outputs are: ◦A modified MapReduce workflow that
exploits prior executed jobs stored by ReStore
◦A new set of job outputs to store in the distributed file system.

LOGO
www.nordridesign.com
ReStore System ArchitectureRepository to manage the stored
MapReduce job outputs:◦The physical query execution plan of
the MapReduce job (Input, output, operators)
◦The filename of the output in the distributed file system,
◦Statistics about the MapReduce job and the frequency of use of this output by different workflows. (size of input and output, execution time)

LOGO
www.nordridesign.com
Plan Matcher and RewritereGoal is to find physical plans in
the repository that can be used to rewrite the input workflow
Before a job is matched against the repository, all other jobs that it depends on have to be matched and rewritten to use the job outputs stored in the repository

LOGO
www.nordridesign.com
Plan Matcher and RewritereThe flow:
◦Scan sequentially through the physical plans in the repository
◦Rewrite it to use the matched physical plan in the repository
◦After rewriting, a new sequential scan through the repository is started
◦If a scan does not find any matches, ReStore proceeds to matching the next MapReduce job in the workflow

LOGO
www.nordridesign.com
Plan Matcher and RewritereTwo operators are equivalent if:
◦Their inputs are pipelined from operators that are equivalent or from thesame data sets
◦They perform functions that produce the same output data

LOGO
www.nordridesign.com
Plan Matcher and RewritereReStore uses the first match that
it finds in the repositoryRules to order the physical plans
in the repository◦Plan A is preferred to plan B if all the
operators in plan B have equivalent operators in plan A
◦The ratio between the size of the input data and output data and the execution time of the MapReduce job

LOGO
www.nordridesign.com
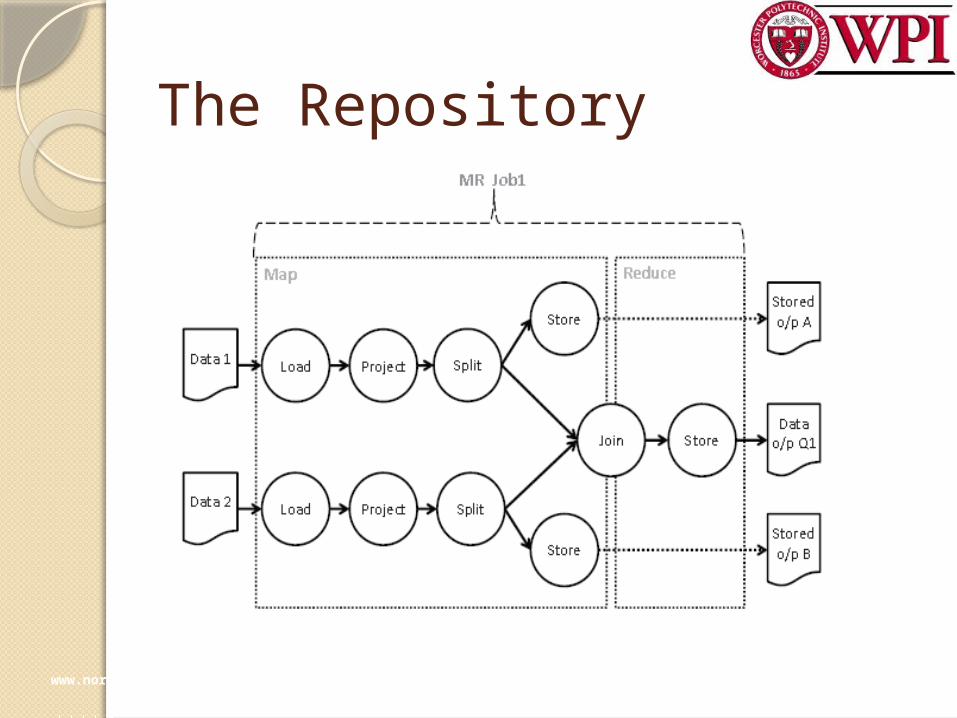
The RepositoryCan we treat all possible sub-jobs
as candidates? NO!!!◦Require a substantial amount of
storage the overhead of storing all◦The intermediate data would
considerably slow down the execution of the input MapReduce job

LOGO
www.nordridesign.com
The RepositoryTwo heuristics for choosing
candidate sub-jobs:◦Conservative Heuristic: Use the
outputs of operators that are known to reduce their input size (Project, Filter)
◦Aggressive Heuristic: Use the outputs of operators that are known to be expensive (Project,Filter, Join, Group)

LOGO
www.nordridesign.com
The RepositoryRules to keep a candidate job in
the repository:◦The size of its output data is smaller
than the size of its input data◦There will be a reduction in
execution time for workflows reusing this job

LOGO
www.nordridesign.com
The RepositoryRules to evict a candidate job in
the repository:◦Evict a job from the repository if it
has not been reused within a window of time
◦Evict a job from the repository if one or more of its inputs is deleted or modified


















