
Relational Database Design Concepts
51
Relational Database Design Concepts Session 2
Transcript of Relational Database Design Concepts

Relational Database Design Concepts Session 2

2
Table of Contents
Chapter 1: Developing Relational Database .................................................................. 5
Relational Database Fundamentals .............................................................................. 5
Traditional File-Based Approach ................................................................................ 5
Database Approach ................................................................................................... 5
Components of the DBMS Environment .................................................................... 5
Roles in the Database Environment ........................................................................... 6
Advantages and Disadvantages of DBMS ................................................................ 7
Database Development Methodology Overview ................................................... 8
Entity-Relationship Modeling .................................................................................... 10
Database Views ............................................................................................................ 16
Purpose of Views ........................................................................................................ 16
Updating Views .......................................................................................................... 16
Designing for security: Users, Privileges and Roles ...................................................... 17
About Users ................................................................................................................ 17
About Privileges ......................................................................................................... 17
About Roles ................................................................................................................ 17
Other Database Technologies (Graphical, ObjectOriented, NoSQL) ..................... 18
SQL / RDBMS / Relational databases ....................................................................... 18
Popular relational databases. .................................................................................. 18
NoSQL / Non-relational databases .......................................................................... 19
Activity ........................................................................................................................... 21
Chapter 2: Building a Logical Data Model ..................................................................... 22
What is Data Modelling? .............................................................................................. 22
Why use Data Model? ............................................................................................... 22
Types of Data Models ................................................................................................ 23
Conceptual Model .................................................................................................... 24
Logical Data Model .................................................................................................. 25
Physical Data Model ................................................................................................. 26
Advantages and Disadvantages of Data Model ................................................... 27
Normalization................................................................................................................. 28
Data Redundancy and Update Anomalies ............................................................ 29
Functional Dependencies ........................................................................................ 30
The Process of Normalization ....................................................................................... 31

3
First Normal Form (1NF) .............................................................................................. 32
Second Normal Form (2NF) ....................................................................................... 34
Third Normal Form (3NF) ............................................................................................ 34
Chapter 3: Populating the Database ............................................................................. 36
Data Definition Language ............................................................................................ 36
Create a Table ........................................................................................................... 36
Changing a Table Definition ..................................................................................... 36
Removing a Table...................................................................................................... 36
Granting Privileges to Other Users ............................................................................ 37
Revoking Privileges from Users .................................................................................. 37
Data Manipulation Language ..................................................................................... 37
Simple Queries ........................................................................................................... 37
Chapter 4: Basic SQL Queries .......................................................................................... 38
Definition and Manipulation......................................................................................... 38
Column Constraints ................................................................................................... 38
CREATE TABLE Statement .......................................................................................... 38
INSERT Statement ....................................................................................................... 39
ALTER TABLE Statement ............................................................................................. 39
DELETE Statement ...................................................................................................... 39
UPDATE Statement ..................................................................................................... 40
AND Operator ............................................................................................................ 40
SELECT Statement ...................................................................................................... 40
WHERE Clause ............................................................................................................ 41
AS Clause ................................................................................................................... 41
OR Operator .............................................................................................................. 41
% Wildcard ................................................................................................................. 42
_ Wildcard .................................................................................................................. 42
ORDER BY Clause ....................................................................................................... 42
LIKE Operator ............................................................................................................. 43
DISTINCT Clause ......................................................................................................... 43
BETWEEN Operator .................................................................................................... 43
LIMIT Clause ................................................................................................................ 44
NULL Values ................................................................................................................ 44
Chapter 5: Manipulating and Summarizing Results ....................................................... 45
Column References ...................................................................................................... 45
Aggregate Functions .................................................................................................... 45

4
SUM() Aggregate Function ....................................................................................... 45
MAX() Aggregate Function ...................................................................................... 46
COUNT() Aggregate Function .................................................................................. 46
GROUP BY Clause ...................................................................................................... 47
MIN() Aggregate Function ........................................................................................ 47
AVG() Aggregate Function ...................................................................................... 47
HAVING Clause .......................................................................................................... 48
ROUND() Function ..................................................................................................... 48
Chapter 6: Advanced Query Techniques ...................................................................... 49
Multiple Tables ............................................................................................................... 49
Outer Join ................................................................................................................... 49
WITH Clause ................................................................................................................ 49
UNION Clause ............................................................................................................ 50
CROSS JOIN Clause ................................................................................................... 50
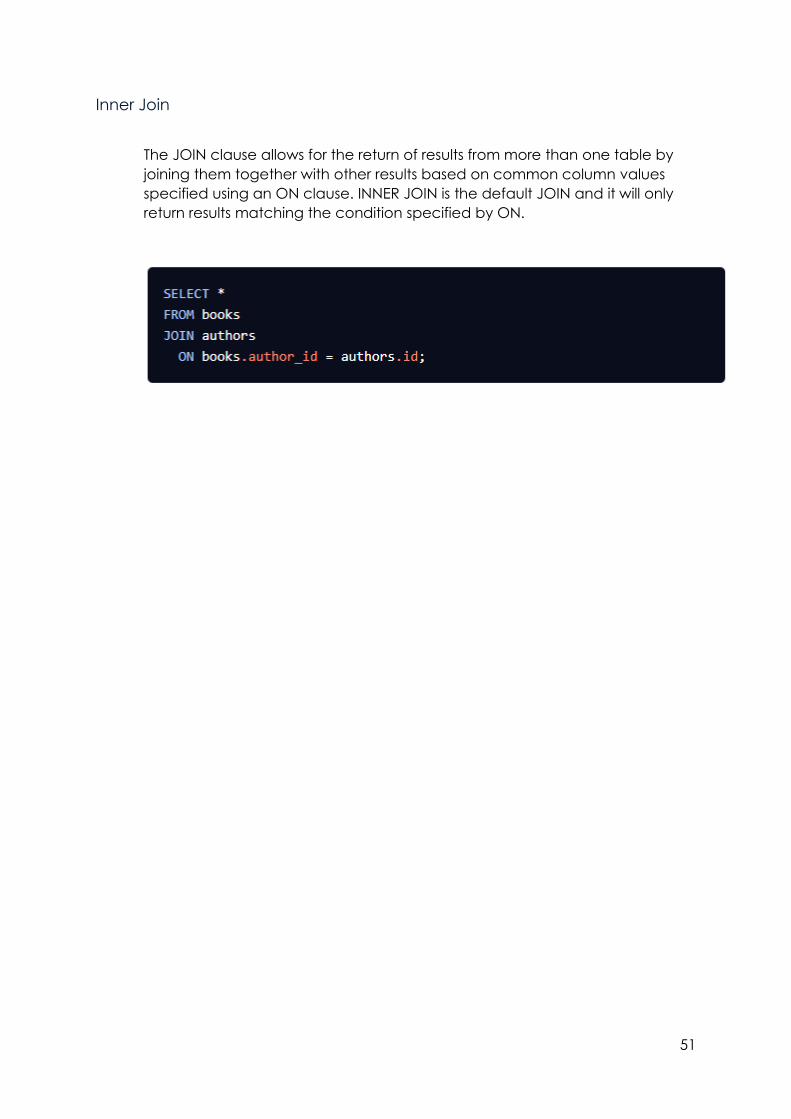
Inner Join .................................................................................................................... 51

5
Chapter 1: Developing Relational Database
Relational Database Fundamentals
Traditional File-Based Approach
File-Based System
A collection of application programs that perform services for the end-users
such as the production of reports. Each program defines and manages its
own data.
Limitations of the File-Based Approach
Separation and isolation of data.
Duplication of data.
Data dependence.
Incompatibility of files.
Fixed queries/proliferation of application programs.
Database Approach
Database
A shared collection of logically related data (and a description of this data),
designed to meet the information needs of an organization.
The Database Management System (DBMS)
A software system that enables users to define, create, and maintain the
database and provides controlled access to this database.
Data Definition Language (DDL)
The DDL allows users to specify the data types and structures, and the
constraints on the data to be stored in the database.
Data Manipulation Language (DML)
The DML allows users to insert, update, delete and retrieve data from the
database.
Components of the DBMS Environment
Hardware
The hardware can range from a single PC, to a single mainframe, to a
network of computers.

6
Software
The software component comprises the DBMS software itself and the
application programs, together with the operating system, including network
software if the DBMS is being used over a network.
Data
The database contains both the operational data and the meta-data, the
‘data about data’. The structure of the database is called schema, and
schema contains tables.
Procedures
Procedures refer to the instructions and rules that govern the design and use
of the database. The users of the system and the staff that manage the
database require documented procedures on how to use or run the system.
People
The users of the DBMS.
Roles in the Database Environment
Data and Database Administrators
Data Administrator (DA) is responsible for the management of the data
resource including database planning, development and maintenance of
standards, policies and procedures, and conceptual/logical database
design. The DA consults with and advises senior managers, ensuring that the
direction of the database development will ultimately support corporate
objectives.
Database Administrator (DBA) is responsible for the physical realization of the
database, including physical database design and implementation, security
and integrity control, maintenance of the operational system, and ensuring
satisfactory performance for the applications and users. The role of DBA is
more technically oriented than the role of DA, requiring detailed knowledge
of the target DBMS and the system environment.
Database Designers
Two types of designers: logical database designer and physical database
designer.
Logical database designer is concerned with identifying the data, the
relationships between the data, and the constraints on the data that is to be
stored in the database. The logical database designer must have a thorough
and complete understanding of the organization’s data and its business rules.

7
Physical database designer takes the logical data model and decides how it
is to be physically realized. This involves,
Mapping the logical data model into a set of tables and integrity constraints.
Selecting specific storage structures and access methods for the data to
achieve good performance for the database activities.
Designing any security measures required on the data.
Application Programmers
Once the database has been implemented, the application programs that
provides the required functionality for the end-users must be implemented.
This is the responsibility of the application programmers.
End-Users
The end-users are the ‘clients’ for the database – the database has been
designed and implemented and is being maintained to serve their
information needs.
Advantages and Disadvantages of DBMS
Advantages
Control of data redundancy Economy of scale
Data consistency Balance of conflicting requirements
More information from the same
amount of data
Improved data accessibility and
responsiveness
Sharing of data Increased productivity
Improved data integrity Improved maintenance through
data independence
Improved security Increased concurrency
Enforcement of standards Improved backups and recovery
sevices
Disadvantages
Complexity Size
Cost of DBMSs Additional hardware costs
Cost of conversion Performance
Higher impact of a failure
8
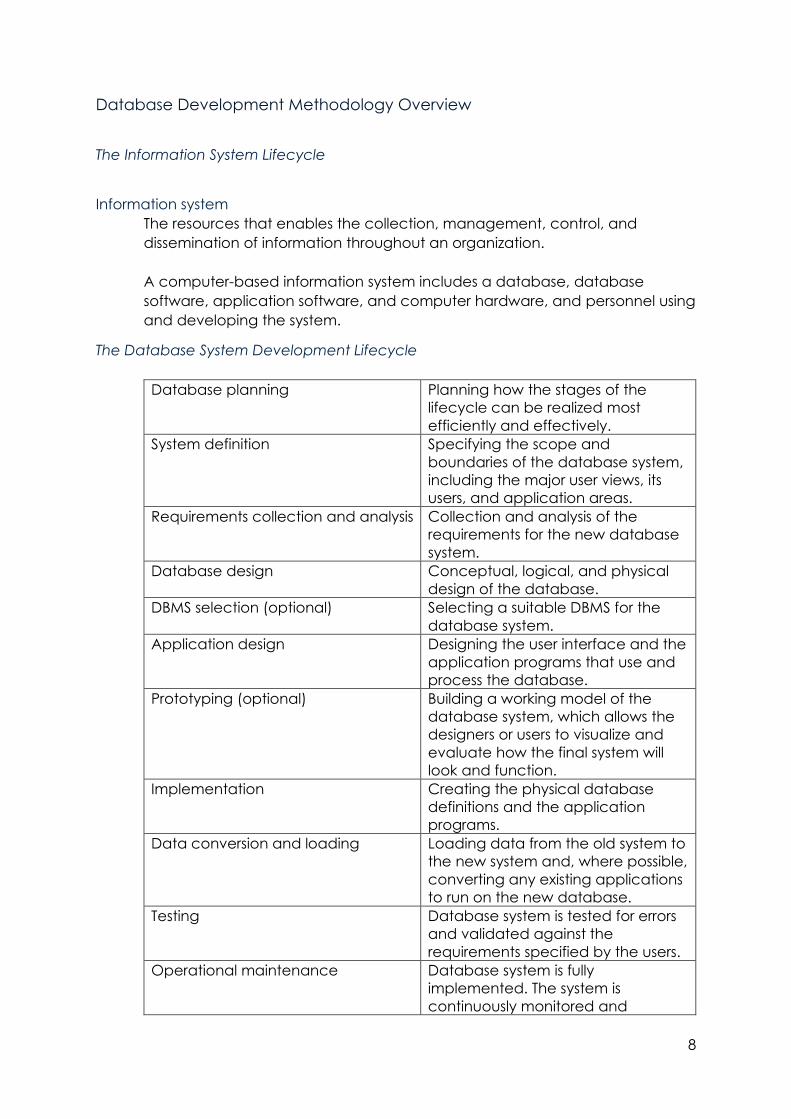
Database Development Methodology Overview
The Information System Lifecycle
Information system
The resources that enables the collection, management, control, and
dissemination of information throughout an organization.
A computer-based information system includes a database, database
software, application software, and computer hardware, and personnel using
and developing the system.
The Database System Development Lifecycle
Database planning Planning how the stages of the
lifecycle can be realized most
efficiently and effectively.
System definition Specifying the scope and
boundaries of the database system,
including the major user views, its
users, and application areas.
Requirements collection and analysis Collection and analysis of the
requirements for the new database
system.
Database design Conceptual, logical, and physical
design of the database.
DBMS selection (optional) Selecting a suitable DBMS for the
database system.
Application design Designing the user interface and the
application programs that use and
process the database.
Prototyping (optional) Building a working model of the
database system, which allows the
designers or users to visualize and
evaluate how the final system will
look and function.
Implementation Creating the physical database
definitions and the application
programs.
Data conversion and loading Loading data from the old system to
the new system and, where possible,
converting any existing applications
to run on the new database.
Testing Database system is tested for errors
and validated against the
requirements specified by the users.
Operational maintenance Database system is fully
implemented. The system is
continuously monitored and
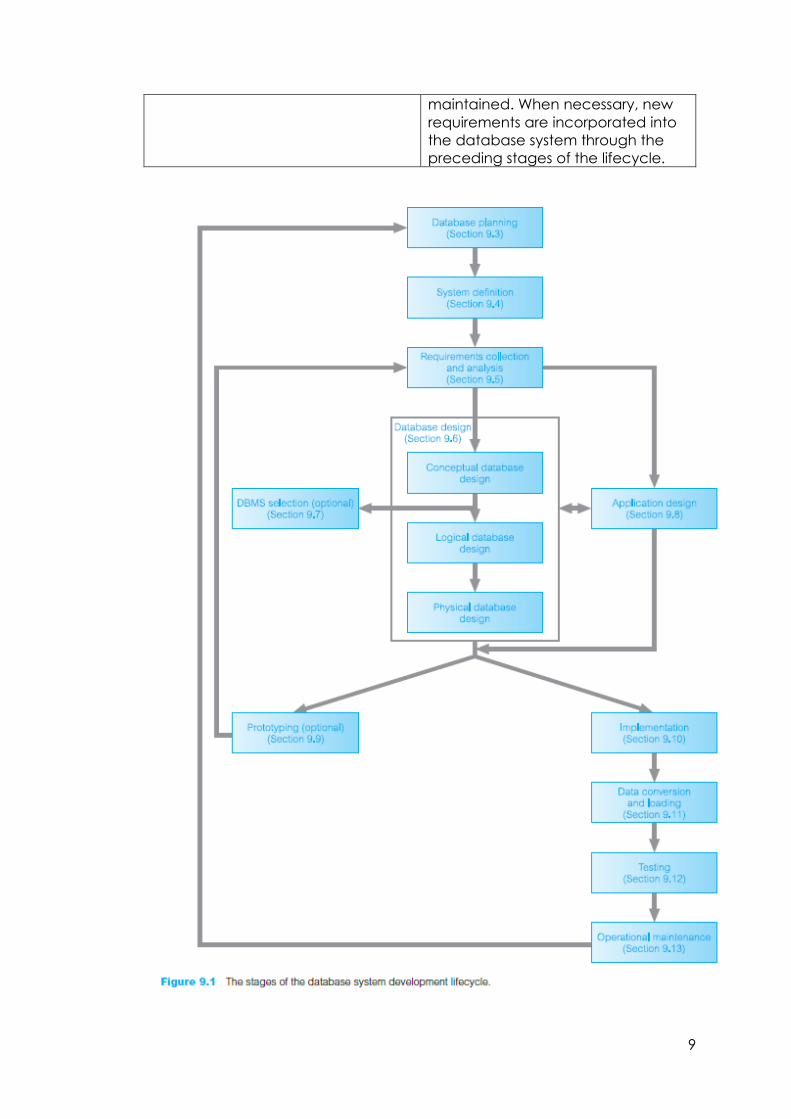
9
maintained. When necessary, new
requirements are incorporated into
the database system through the
preceding stages of the lifecycle.

10
Entity-Relationship Modeling
The basic concepts of the Entity-Relationship model include entity types,
relationship types, and attributes.
Entity Types
Entity Type
An object of concept that is identified by the enterprise as having an
independent existence.
Entity
An instance of an entity type that is uniquely identified.
Weak Entity Type
An entity type that is existence-dependent on some other entity type.
Strong Entity Type
An entity type that is not existence-dependent on some other entity type.
Attributes
Attribute
A property of an entity or a relationship type.
Attribute domain
A set of values that may be assigned to an attribute.
Simple Attribute
An attribute composed of a single component with an independent
existence.
Composite Attribute
An attribute composed of multiple components, each with an independent
existence.
Single-valued Attribute
An attribute that holds a single value for a single entity.
Multi-valued Attribute
An attribute that holds multiple values for a single entity.

11
Derived Attribute
An attribute that represents a value that is derivable from the value of a
related attribute or set of attributes, not necessarily in the same entity.
Keys
Candidate Key
An attribute or set of attributes that uniquely identifies individual occurrences
of an entity type.
Primary Key
The candidate key selected to be the primary key.
Composite Key
A candidate key that consists of two or more attributes.
Foreign Key
An attribute, or set of attributes, within one relation that matches the
candidate key of some (possibly the same) relation.
Tuple
A tuple is a row of relation.
Relationship Types
Relationship type
A meaningful association among entity types.
Relationship
An association of entities where the association includes one entity from each
participating entity type.
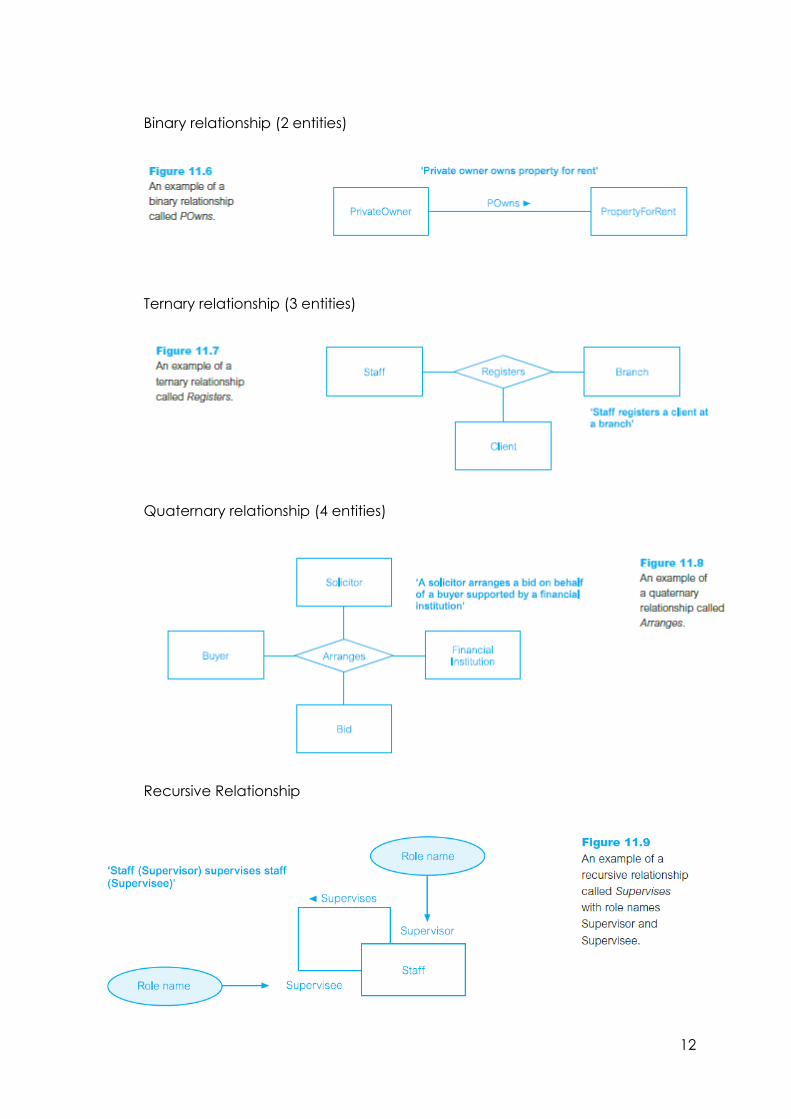
Degree of a relationship
The number of participating entities in a relationship.
Recursive Relationship
A relationship where the same entity participates more than once in different
roles.
12
Binary relationship (2 entities)
Ternary relationship (3 entities)
Quaternary relationship (4 entities)
Recursive Relationship
13
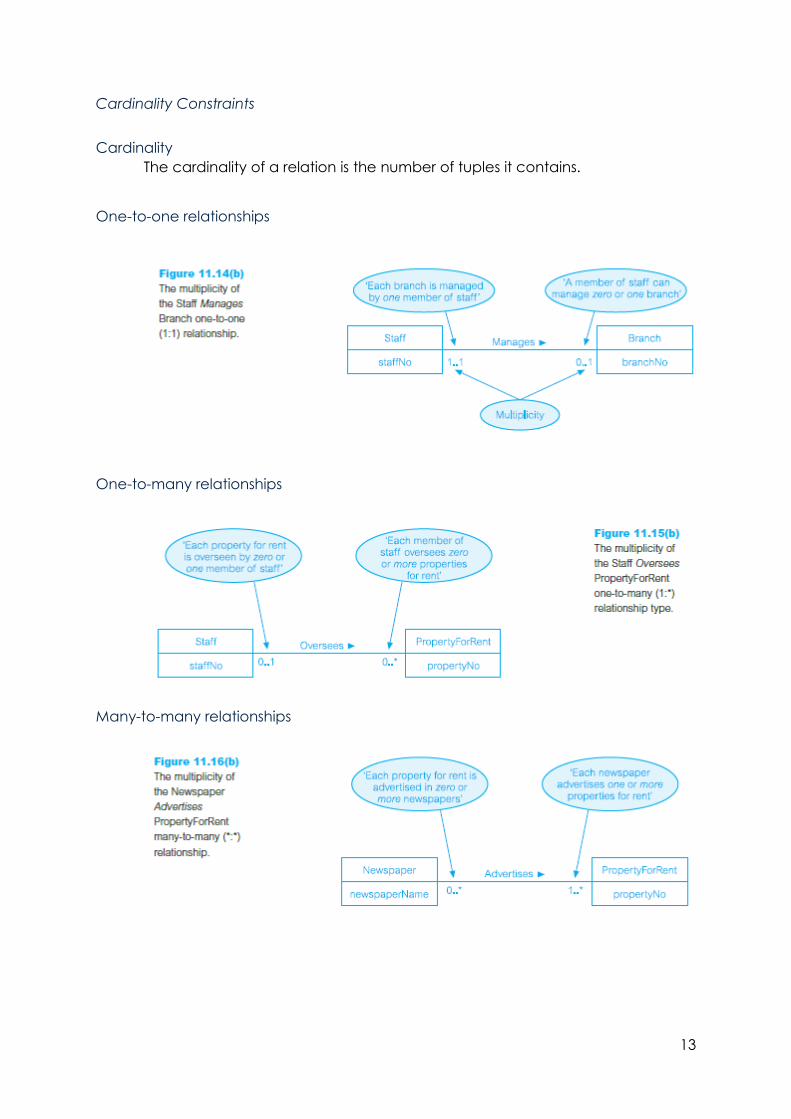
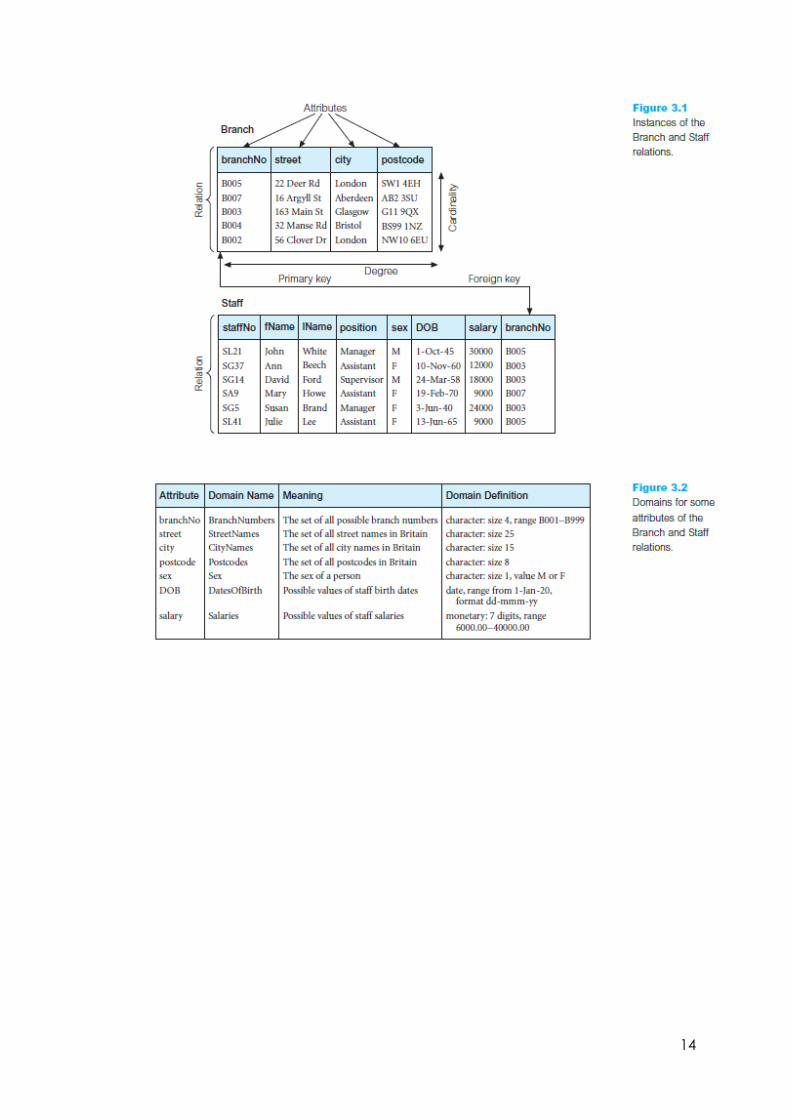
Cardinality Constraints
Cardinality
The cardinality of a relation is the number of tuples it contains.
One-to-one relationships
One-to-many relationships
Many-to-many relationships
14
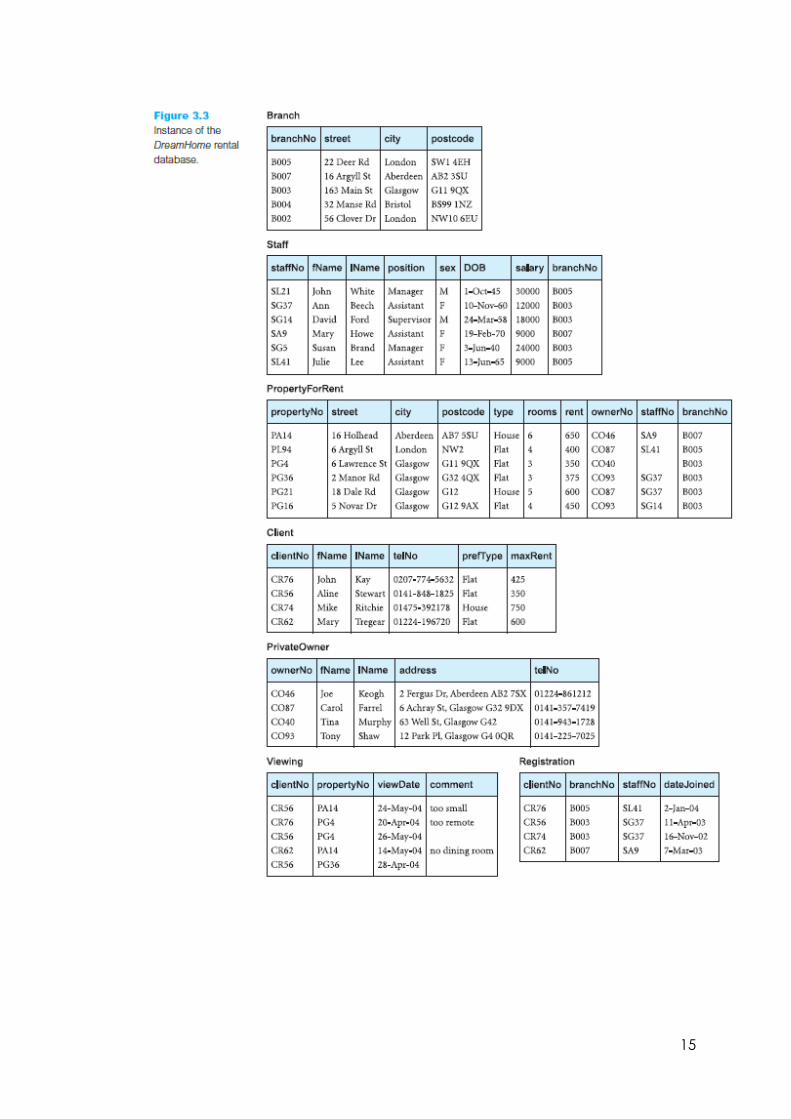
15

16
Database Views The dynamic result of one or more relational operations operating on the
base relations to produce another relation. A view is a virtual relation that
does not necessarily exist in the database but can be produced upon
request by a user, at the time of request.
Purpose of Views
• It provides a powerful and flexible security mechanism by hiding parts
of the database from certain users. Users are not aware of the
existence of any attributes or tuples that are missing from the view.
• It permits users to access data in a way that is customized to their
needs, so that the same data can be seen by different users in
different ways, at the same time.
• If can simplify complex operations on the base relations.
Updating Views
• Updates are allowed through a view defined using a simple query
involving a single base relation and containing either the primary key
of a candidate key of the base relation.
• Updates are not allowed through views involving multiple base
relations.
• Updates are not allowed through views involving aggregation or
grouping operations.

17
Designing for security: Users, Privileges and Roles Every application database has one or more users. When users connect to
the database, they log in with credentials that a superuser defines.
Database users should only have access to the database resources they
need to perform their tasks. To navigate these necessities, organization has
designated users, privileges, and roles.
About Users
Database users use the database in various ways, depending on their
privileges and roles. They generally fall into one of three groups:
• Superuser: This user is often the database administrator and is
automatically created when you create a new database. The
superuser can perform all database operations, including granting and
revoking privileges to other users and roles. The database superuser
does NOT have the same privileges as the Linux superuser (root).
• Object owner: This user can create a particular database object, such
as a table, schema, or view. By default, only an owner or superuser
can act on a database object.
• Everyone else: All non-superuser or object owners are PUBLIC users.
These users are granted the PUBLIC role. Object owners are considered
public users for objects they do not own.
About Privileges
Privileges are a type of permission that lets users perform an action on a
database object.
Privileges are granted to or revoked from users or roles.
Before application executes a statement, it checks to see if the requesting
user has the necessary privileges to perform the operation.
For example, to let a user create a table, the owner or superuser must grant
the user “create” privileges on the schema where the user wants to create
the table.
About Roles
A role is a collection of privileges, such as “administrator”. Superusers can
grant to or revoke from one or more roles. Use roles to make managing
permissions easier. Using roles avoids having to manually grant sets of
privileges user by user. For example, several users might be assigned the
“administrator” role.
You can also use roles to maintain consistency. For example, if you must grant
multiple privileges to users individually, you could forget to assign a role. Using
roles can help avoid this issue.
Superusers can grant or revoke privileges to or from the administrator role,
and all users who are granted the role will be affected by the change.

18
Other Database Technologies (Graphical, ObjectOriented, NoSQL)
Technically, there are two types of database systems: Relational DB and Non-
Relational DB.
SQL / RDBMS / Relational databases
Think of a relational database as a collection of tables, each with a schema
that represents the fixed attributes and data types that the items in the table
will have. RDBMS all provide functionality for reading, creating, updating, and
deleting data, typically by means of Structured Query Language (SQL)
statements.
The tables in a relational database have keys associated with them, which
are used to identify specific columns or rows of a table and facilitate faster
access to a particular table, row, or column of interest.
Popular relational databases.
• Oracle
• MySQL
• Microsoft SQL Server
• PostgreSQL
• DB2

19
NoSQL / Non-relational databases
NoSQL databases emerged as a popular alternative to relational databases
as web applications became increasingly complex. NoSQL/Non-relational
databases can take a variety of forms. However, the critical difference
between NoSQL and relational databases is that RDBMS schemas rigidly
define how all data inserted into the database must be typed and
composed, whereas NoSQL databases can be schema agnostic, allowing
unstructured and semi-structured data to be stored and manipulated.
Types
Key-Value Stores, such as Redis and Amazon DynamoDB, are extremely
simple database management systems that store only key-value pairs and
provide basic functionality for retrieving the value associated with a known
key.
The simplicity of key-value stores makes these database management
systems particularly well-suited to embedded databases, where the stored
data is not particularly complex and speed is of paramount importance.
Wide Column Stores, such as Cassandra, Scylla, and HBase, are schema-
agnostic systems that enable users to store data in column families or tables,
a single row of which can be thought of as a record — a multi-dimensional
key-value store.
These solutions are designed with the goal of scaling well enough to manage
petabytes of data across as many as thousands of commodity servers in a
massive, distributed system.
Although technically schema-free, wide column stores like Scylla and
Cassandra use an SQL variant called CQL for data definition and
manipulation, making them straightforward to those already familiar with
RDBMS.
Document Stores, including MongoDB and Couchbase, are schema-free
systems that store data in the form of JSON documents. Document stores are
similar to key-value or wide column stores, but the document name is the key
and the contents of the document, whatever they are, are the value.
In a document store, individual records do not require a uniform structure,
can contain many different value types, and can be nested. This flexibility
makes them particularly well-suited to manage semi-structured data across
distributed systems.
Graph Databases, such as Neo4J and Datastax Enterprise Graph, represent
data as a network of related nodes or objects in order to facilitate data
visualizations and graph analytics.

20
A node or object in a graph database contains free-form data that is
connected by relationships and grouped according to labels. Graph-
Oriented Database Management Systems (DBMS) software is designed with
an emphasis on illustrating connections between data points.
As a result, graph databases are typically used when analysis of the
relationships between heterogeneous data points is the end goal of the
system, such as in fraud prevention, advanced enterprise operations, or
Facebook’s original friends graph.
Search Engines, such as Elasticsearch, Splunk, and Solr, store data using
schema-free JSON documents. They are similar to document stores, but with
a greater emphasis on making your unstructured or semi-structured data
easily accessible via text-based searches with strings of varying complexity.

21
Activity
• Transforming to Physical Design
• Migrating entities to tables, selecting primary keys, defining columns,
enforcing relationships with foreign keys, enforcing business rules, NOT NULL,
UNIQUE and Check Constraints, assigning DEFAULT values, DELETE and UPDATE
rules

22
Chapter 2: Building a Logical Data Model
What is Data Modelling?
Data modelling (data modelling) is the process of creating a data model for
the data to be stored in a Database.
This data model is a conceptual representation of Data objects, the
associations between different data objects and the rules.
Data modelling helps in the visual representation of data and enforces
business rules, regulatory compliances, and government policies on the data.
Data Models ensure consistency in naming conventions, default values,
semantics, security while ensuring quality of the data.
Data model emphasizes on what data is needed and how it should be
organized instead of what operations need to be performed on the data.
Data Model is like architect's building plan which helps to build a conceptual
model and set the relationship between data items.
The two types of Data Models techniques are
1. Entity Relationship (ER) Model
2. Unified Modelling Language (UML)
Why use Data Model?
The primary goal of using data model are:
• Ensures that all data objects required by the database are accurately
represented. Omission of data will lead to creation of faulty reports
and produce incorrect results.
• A data model helps design the database at the conceptual, physical
and logical levels.
• Data Model structure helps to define the relational tables, primary and
foreign keys and stored procedures.
• It provides a clear picture of the base data and can be used by
database developers to create a physical database.
• It is also helpful to identify missing and redundant data.
• Though the initial creation of data model is labor and time consuming,
in the long run, it makes your IT infrastructure upgrade and
maintenance cheaper and faster.
23
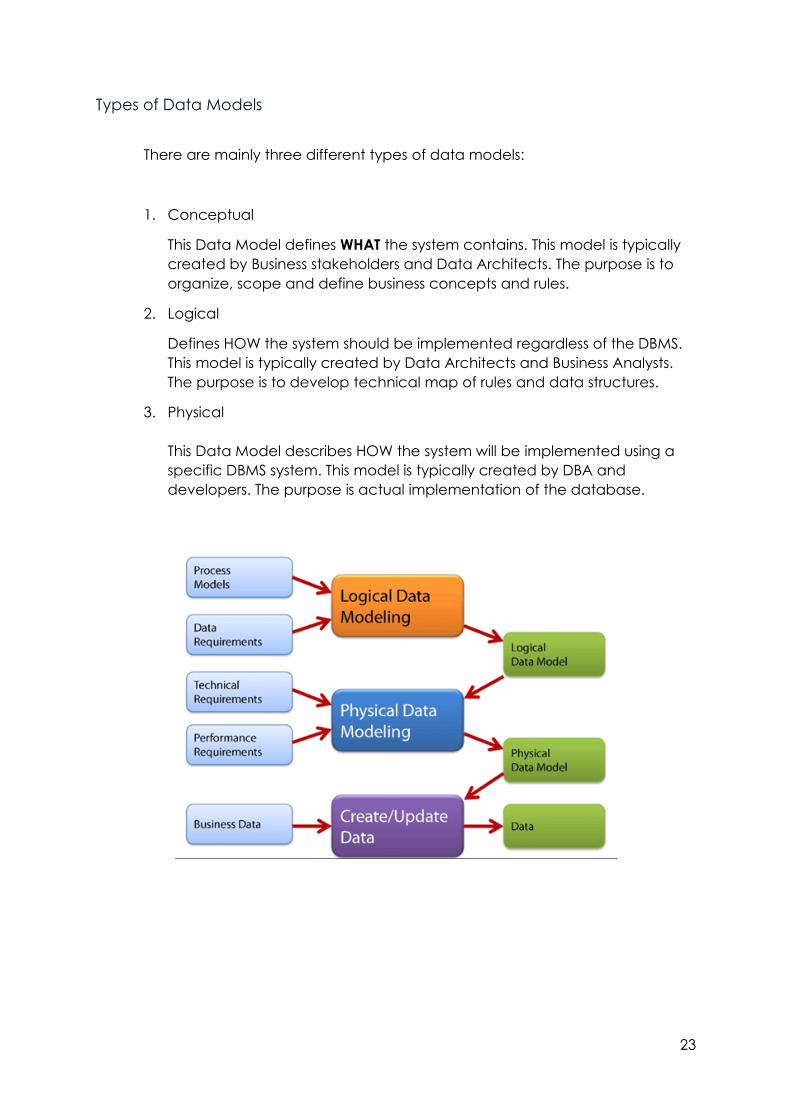
Types of Data Models
There are mainly three different types of data models:
1. Conceptual
This Data Model defines WHAT the system contains. This model is typically
created by Business stakeholders and Data Architects. The purpose is to
organize, scope and define business concepts and rules.
2. Logical
Defines HOW the system should be implemented regardless of the DBMS.
This model is typically created by Data Architects and Business Analysts.
The purpose is to develop technical map of rules and data structures.
3. Physical
This Data Model describes HOW the system will be implemented using a
specific DBMS system. This model is typically created by DBA and
developers. The purpose is actual implementation of the database.

24
Conceptual Model
The main aim of this model is to establish the entities, their attributes, and their
relationships. In this Data modelling level, there is hardly any detail available
of the actual Database structure.
The 3 basic tenants of Data Model are
Entity: A real-world thing.
Attribute: Characteristics or properties of an entity.
Relationship: Dependency or association between two entities.
For example:
• Customer and Product are two entities. Customer number and name
are attributes of the Customer entity
• Product name and price are attributes of product entity
• Sale is the relationship between the customer and product
Characteristics of a conceptual model
• Offers Organisation-wide coverage of the business concepts.
• This type of Data Models is designed and developed for a business
audience.
• The conceptual model is developed independently of hardware
specifications like data storage capacity, location or software
specifications like DBMS vendor and technology. The focus is to
represent data as a user will see it in the "real world."
Conceptual data models known as Domain models create a common
vocabulary for all stakeholders by establishing basic concepts and scope.

25
Logical Data Model
Logical data models add further information to the conceptual model
elements. It defines the structure of the data elements and set the
relationships between them.
The advantage of the Logical data model is to provide a foundation to form
the base for the Physical model. However, the modelling structure remains
generic.
At this Data Modelling level, no primary or secondary key is defined. At this
Data modelling level, you need to verify and adjust the connector details
that were set earlier for relationships.
Characteristics of a logical data model
• Describes data needs for a single project but could integrate with
other logical data models based on the scope of the project.
• Designed and developed independently from the DBMS.
• Data attributes will have datatypes with exact precisions and length.
• Normalization processes to the model is applied typically till 3NF.

26
Physical Data Model
A Physical Data Model describes the database specific implementation of
the data model. It offers an abstraction of the database and helps generate
schema. This is because of the richness of meta-data offered by a Physical
Data Model.
This type of Data model also helps to visualize database structure. It helps to
model database columns keys, constraints, indexes, triggers, and other
RDBMS features.
Characteristics of a physical data model
• The physical data model describes data need for a single project or
application though it may be integrated with other physical data
models based on project scope.
• Data Model contains relationships between tables that which
addresses cardinality and nullability of the relationships.
• Developed for a specific version of a DBMS, location, data storage or
technology to be used in the project.
• Columns should have exact datatypes, lengths assigned and default
values.
• Primary and Foreign keys, views, indexes, access profiles, and
authorizations, etc. are defined.

27
Advantages and Disadvantages of Data Model
Advantages
• The main goal of a designing data model is to make certain that data
objects offered by the functional team are represented accurately.
• The data model should be detailed enough to be used for building the
physical database.
• The information in the data model can be used for defining the
relationship between tables, primary and foreign keys, and stored
procedures.
• Data Model helps business to communicate the within and across
organizations.
• Data model helps to documents data mappings in ETL process
• Help to recognize correct sources of data to populate the model
Disadvantages
• To develop Data Model, one should know physical data stored
characteristics.
• This is a navigational system produces complex application
development, management. Thus, it requires a knowledge of the
biographical truth.
• Even smaller change made in structure require modification in the
entire application.
• There is no set data manipulation language in DBMS.

28
Normalization
Normalization is a database design technique, which begins by examining
the relationships (called functional dependencies) between attributes.
Attributes describe some property of the data or of the relationships between
the data that is important to the enterprise.
Normalization uses a series of tests (described as normal forms) to help identify
the optimal grouping for these attributes to ultimately identify a set of suitable
relations that supports the data requirements of the enterprise.
The Purpose of Normalization
The purpose of normalization is to identify a suitable set of relations that
support the data requirement of an enterprise. The characteristics of a
suitable set of relations include the following:
• The minimal number of attributes necessary to support the data
requirements of the enterprise.
• Attributes with a close logical relationship are found in the same
relation.
• Minimal redundancy with each attribute represented only once with
the important exception of attributes that form all or part of foreign
keys, which are essential for the joining of related relations.
The benefits of using a database that has a suitable set of relations is that the
database will be easier for the user to access and maintain the data and
take up minimal storage space on the computer.
29
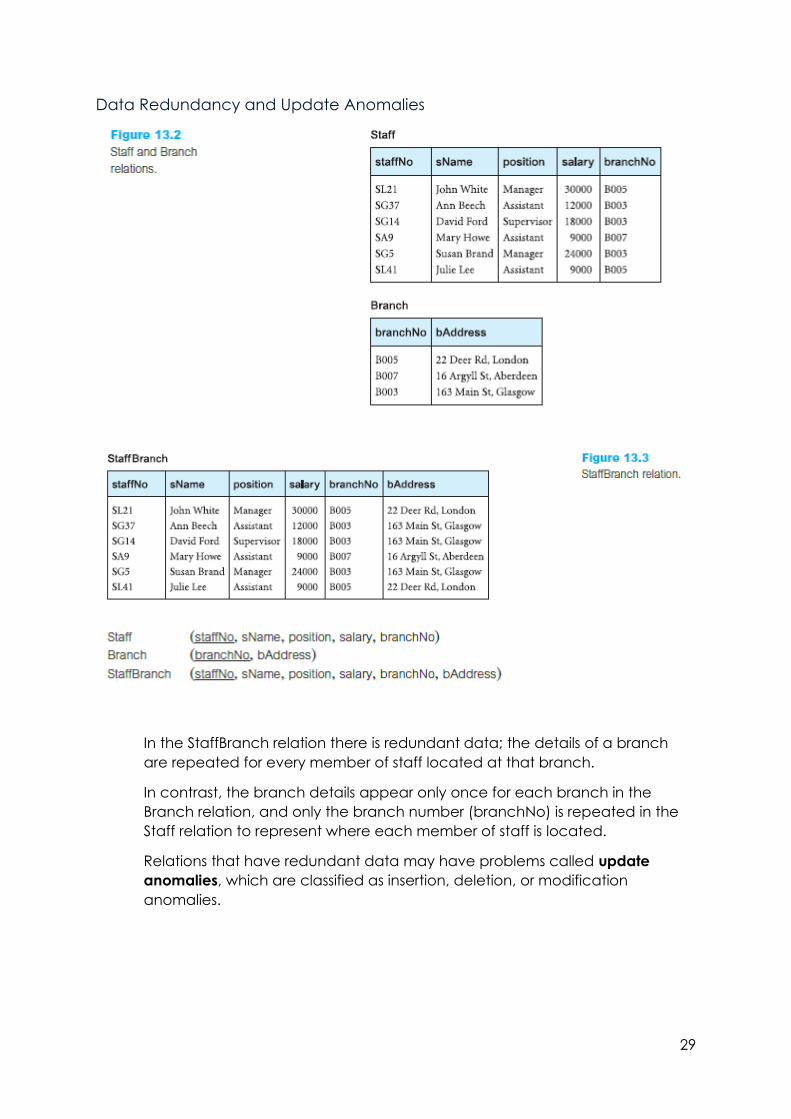
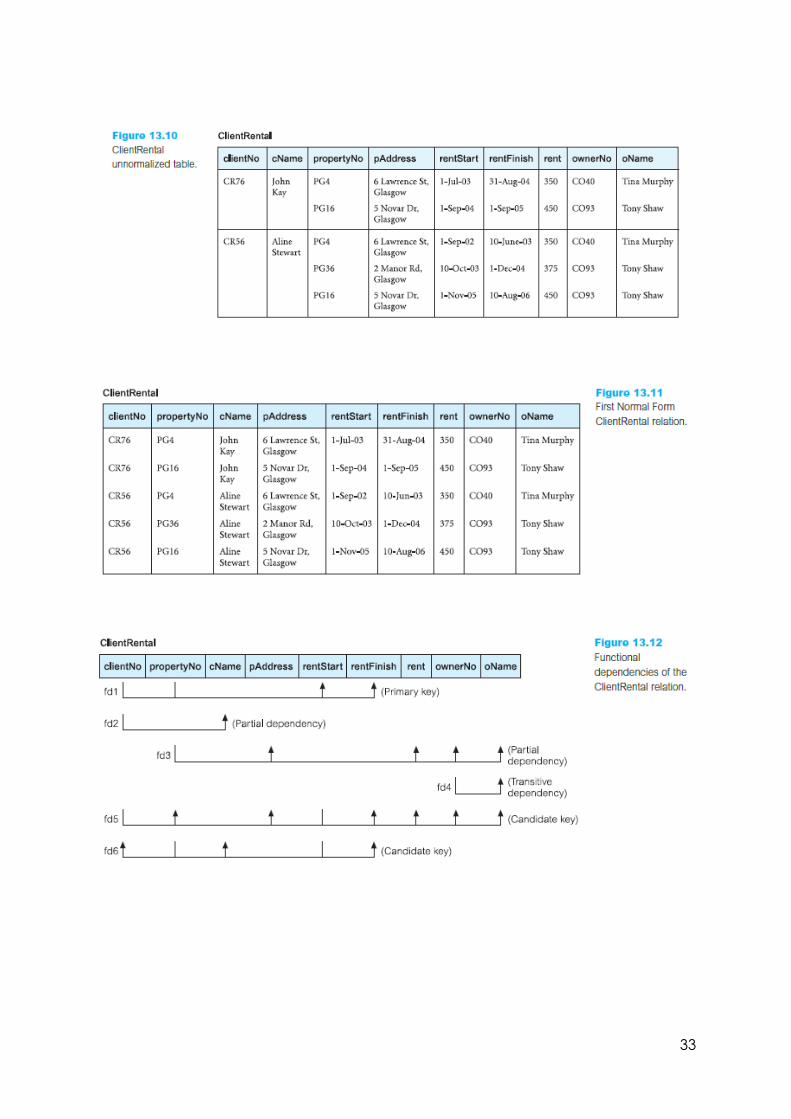
Data Redundancy and Update Anomalies
In the StaffBranch relation there is redundant data; the details of a branch
are repeated for every member of staff located at that branch.
In contrast, the branch details appear only once for each branch in the
Branch relation, and only the branch number (branchNo) is repeated in the
Staff relation to represent where each member of staff is located.
Relations that have redundant data may have problems called update
anomalies, which are classified as insertion, deletion, or modification
anomalies.
30
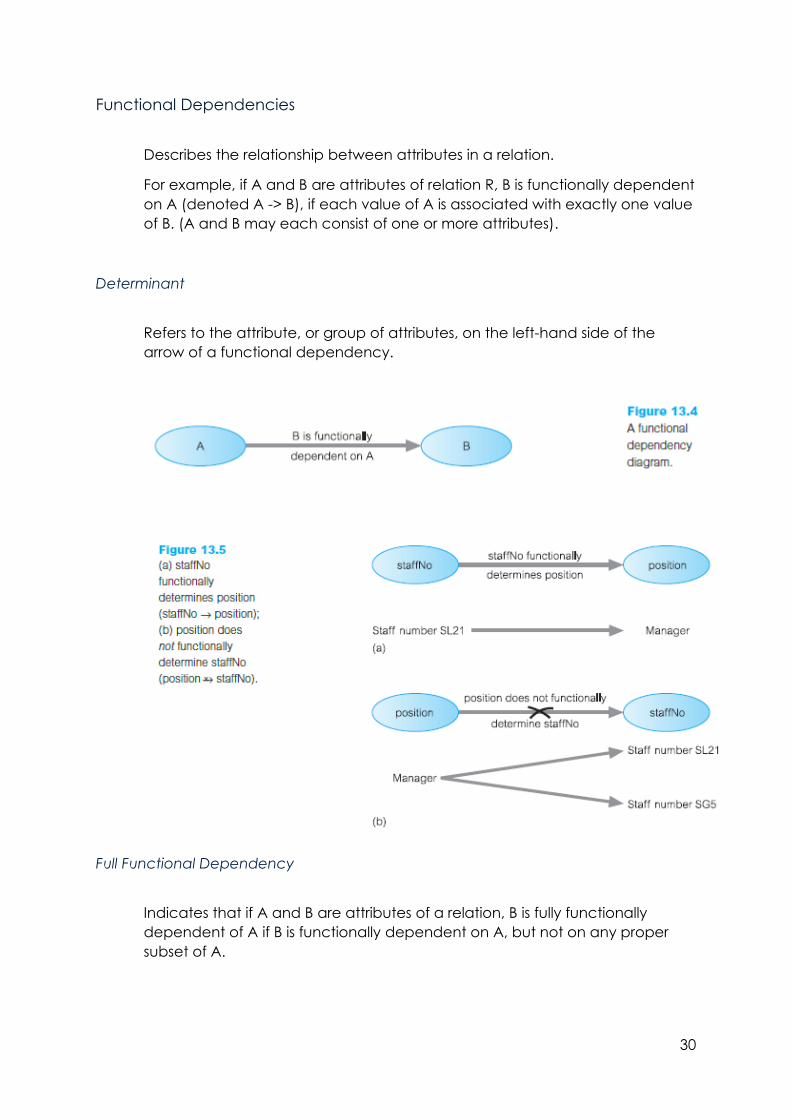
Functional Dependencies
Describes the relationship between attributes in a relation.
For example, if A and B are attributes of relation R, B is functionally dependent
on A (denoted A -> B), if each value of A is associated with exactly one value
of B. (A and B may each consist of one or more attributes).
Determinant
Refers to the attribute, or group of attributes, on the left-hand side of the
arrow of a functional dependency.
Full Functional Dependency
Indicates that if A and B are attributes of a relation, B is fully functionally
dependent of A if B is functionally dependent on A, but not on any proper
subset of A.
31
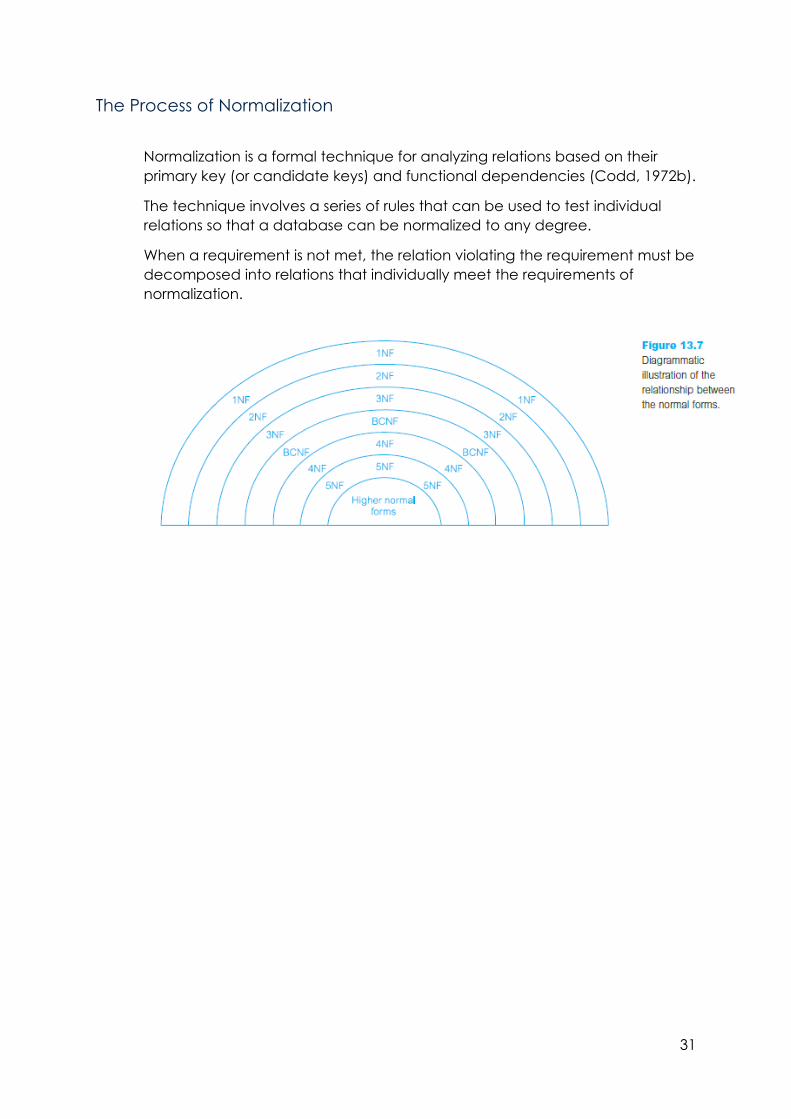
The Process of Normalization
Normalization is a formal technique for analyzing relations based on their
primary key (or candidate keys) and functional dependencies (Codd, 1972b).
The technique involves a series of rules that can be used to test individual
relations so that a database can be normalized to any degree.
When a requirement is not met, the relation violating the requirement must be
decomposed into relations that individually meet the requirements of
normalization.
32
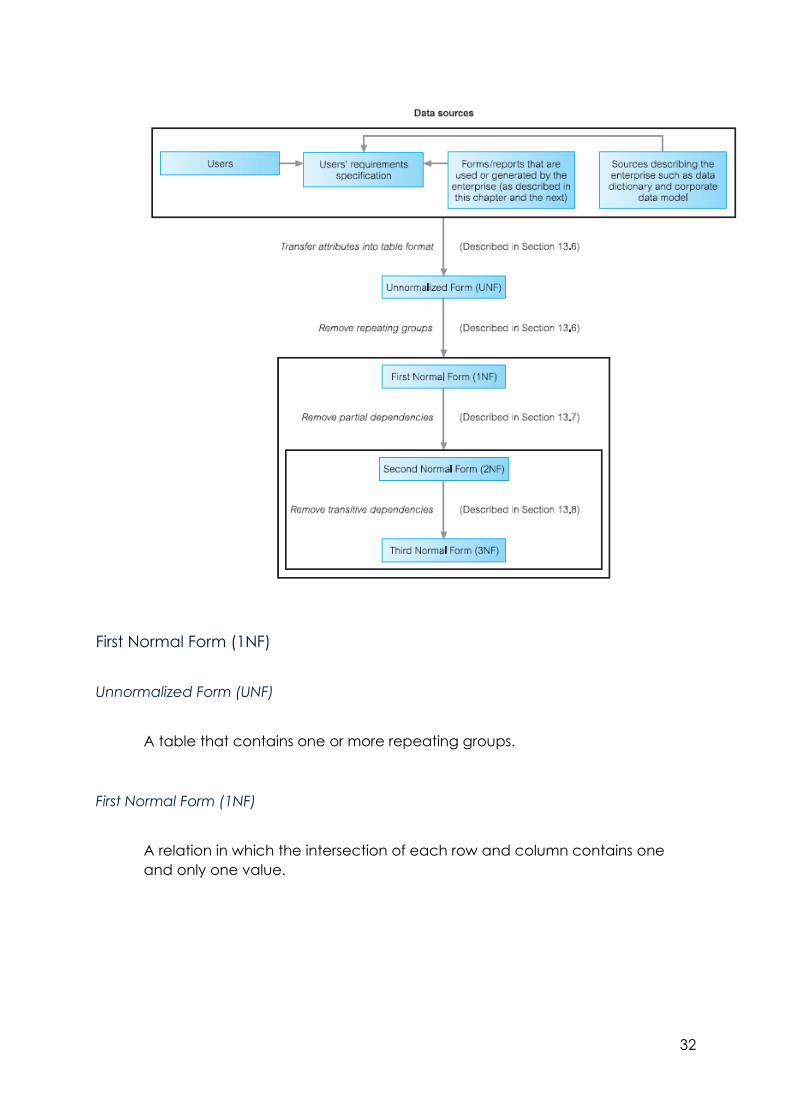
First Normal Form (1NF)
Unnormalized Form (UNF)
A table that contains one or more repeating groups.
First Normal Form (1NF)
A relation in which the intersection of each row and column contains one
and only one value.
33
34
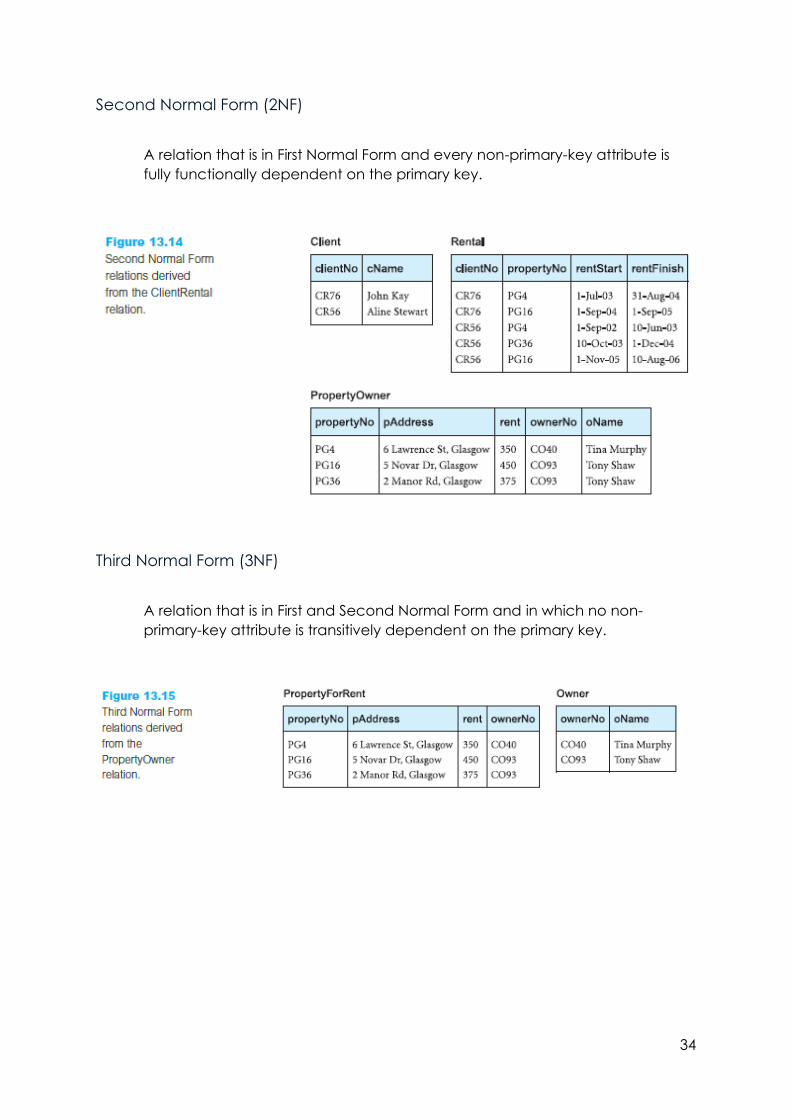
Second Normal Form (2NF)
A relation that is in First Normal Form and every non-primary-key attribute is
fully functionally dependent on the primary key.
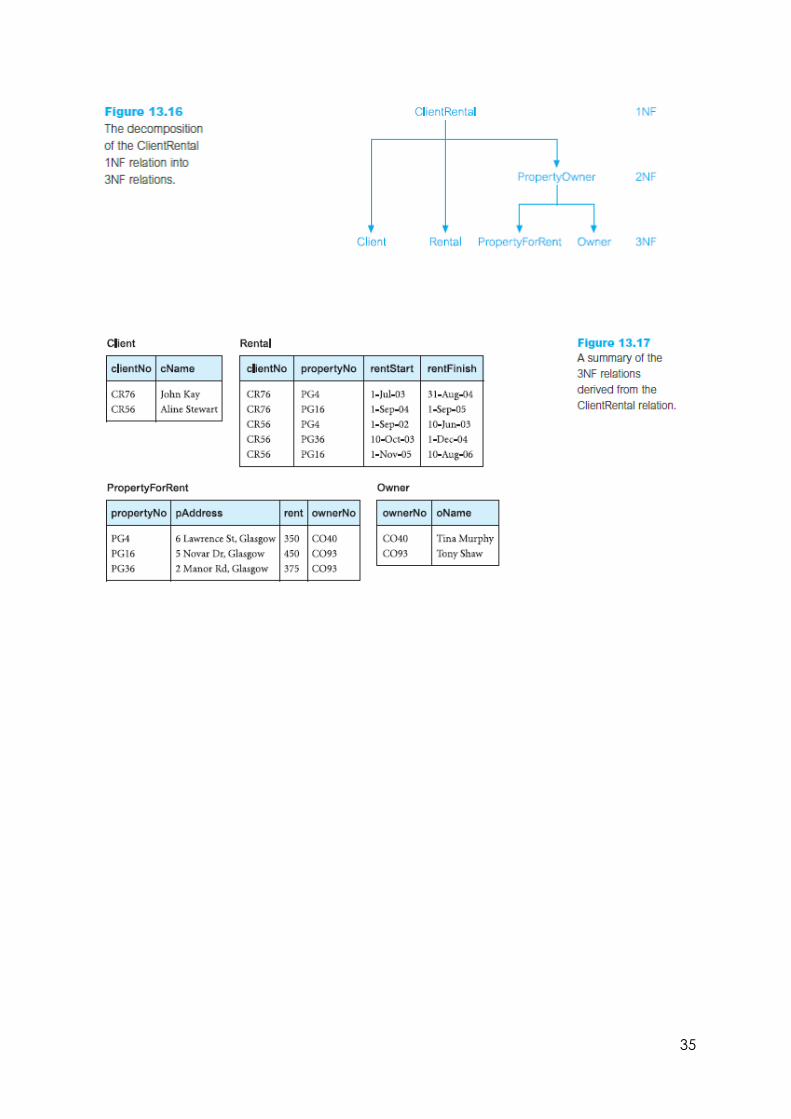
Third Normal Form (3NF)
A relation that is in First and Second Normal Form and in which no non-
primary-key attribute is transitively dependent on the primary key.
35

36
Chapter 3: Populating the Database
Data Definition Language
The SQL Data Definition Language (DDL) allows database objects such as
schemas, domains, tables, views, and indexes to be created and destroyed.
The main SQL data definition language statements are:
CREATE SCHEMA DROP SCHEMA
CREATE DOMAIN ALTER DOMAIN DROP DOMAIN
CREATE TABLE ALTER TABLE DROP TABLE
CREATE VIEW DROP VIEW
Create a Table
Changing a Table Definition
Removing a Table

37
Granting Privileges to Other Users
Revoking Privileges from Users
Data Manipulation Language
This section looks at the SQL DML statements, namely:
• SELECT – to query data in the database
• INSERT – to insert data into a database
• UPDATE – to update data in a table
• DELETE – to delete data from a table
Simple Queries

38
Chapter 4: Basic SQL Queries
Definition and Manipulation
Column Constraints
Column constraints are the rules applied to the values of individual columns:
• PRIMARY KEY constraint can be used to uniquely identify the row.
• UNIQUE columns have a different value for every row.
• NOT NULL columns must have a value.
• DEFAULT assigns a default value for the column when no value is
specified.
There can be only one PRIMARY KEY column per table and multiple UNIQUE
columns.
CREATE TABLE Statement
The CREATE TABLE statement creates a new table in a database. It allows one
to specify the name of the table and the name of each column in the table.

39
INSERT Statement
The INSERT INTO statement is used to add a new record (row) to a table.
It has two forms as shown:
• Insert into columns in order.
• Insert into columns by name.
ALTER TABLE Statement
The ALTER TABLE statement is used to modify the columns of an existing table.
When combined with the ADD COLUMN clause, it is used to add a new
column.
DELETE Statement
The DELETE statement is used to delete records (rows) in a table. The WHERE
clause specifies which record or records that should be deleted. If the WHERE
clause is omitted, all records will be deleted.

40
UPDATE Statement
The UPDATE statement is used to edit records (rows) in a table. It includes a
SET clause that indicates the column to edit and a WHERE clause for
specifying the record(s).
AND Operator
The AND operator allows multiple conditions to be combined. Records must
match both conditions that are joined by AND to be included in the result set.
The given query will match any car that is blue and made after 2014.
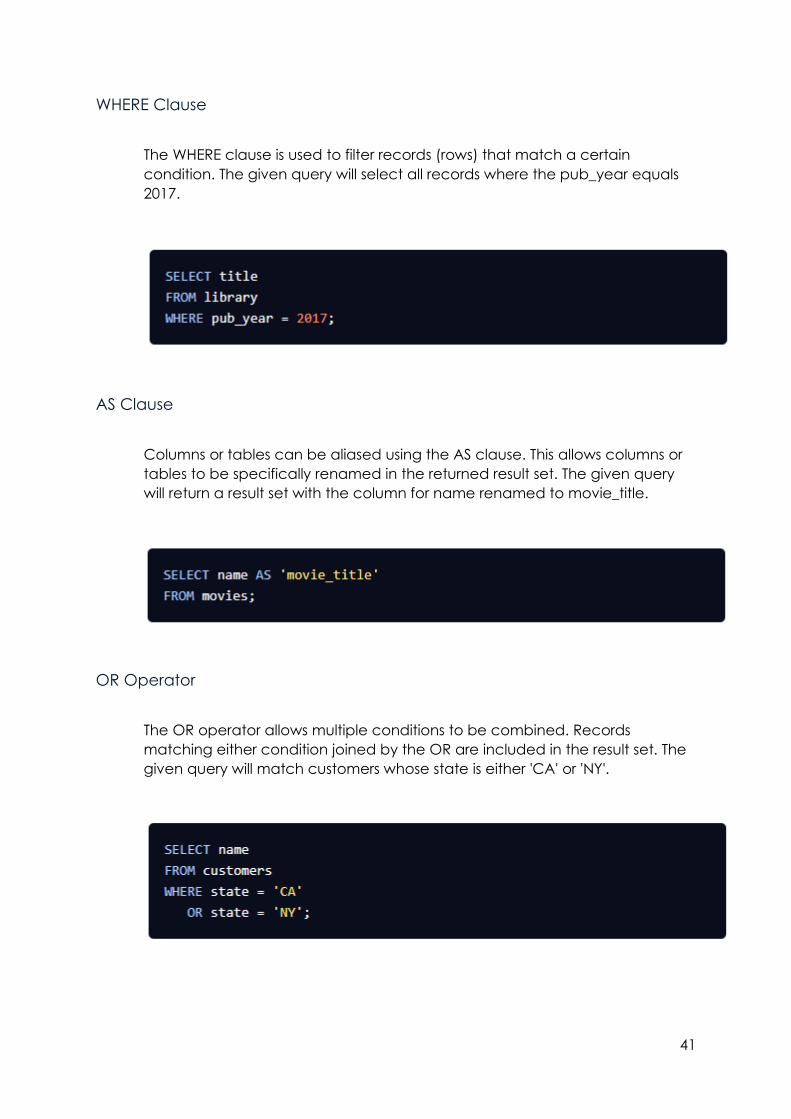
SELECT Statement
The SELECT * statement returns all columns from the provided table in the
result set. The given query will fetch all columns and records (rows) from the
movies table.
41
WHERE Clause
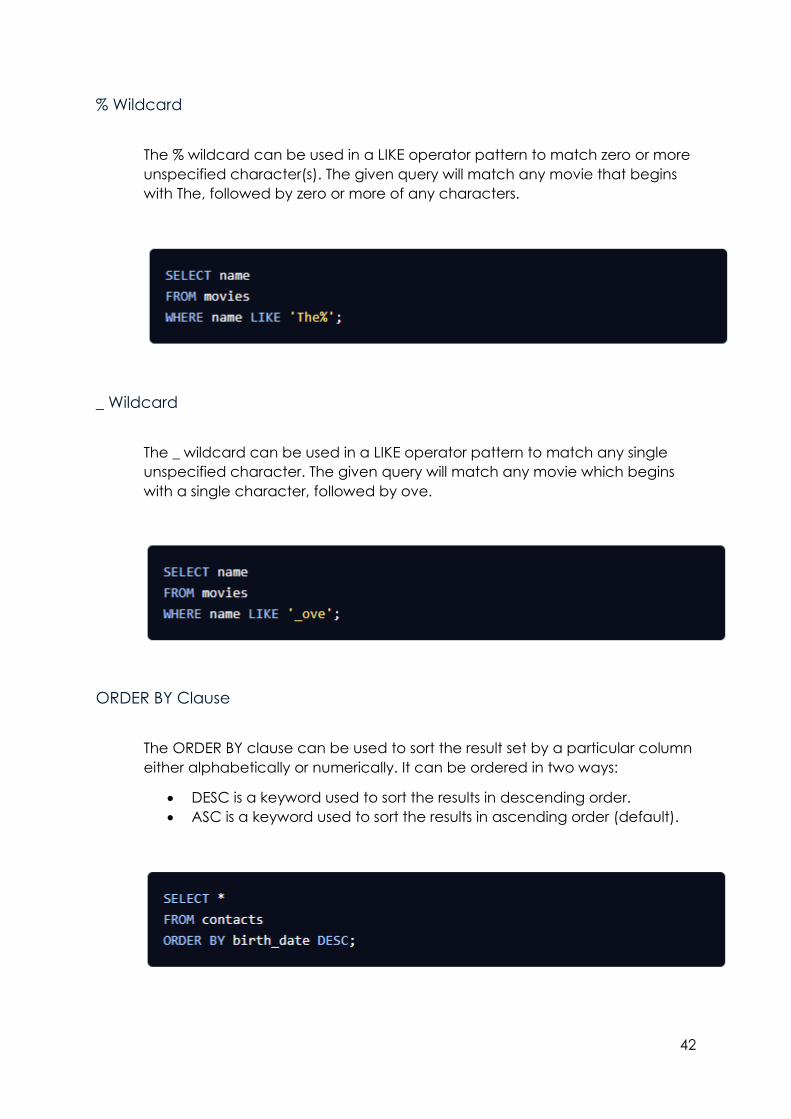
The WHERE clause is used to filter records (rows) that match a certain
condition. The given query will select all records where the pub_year equals
2017.
AS Clause
Columns or tables can be aliased using the AS clause. This allows columns or
tables to be specifically renamed in the returned result set. The given query
will return a result set with the column for name renamed to movie_title.
OR Operator
The OR operator allows multiple conditions to be combined. Records
matching either condition joined by the OR are included in the result set. The
given query will match customers whose state is either 'CA' or 'NY'.
42
% Wildcard
The % wildcard can be used in a LIKE operator pattern to match zero or more
unspecified character(s). The given query will match any movie that begins
with The, followed by zero or more of any characters.
_ Wildcard
The _ wildcard can be used in a LIKE operator pattern to match any single
unspecified character. The given query will match any movie which begins
with a single character, followed by ove.
ORDER BY Clause
The ORDER BY clause can be used to sort the result set by a particular column
either alphabetically or numerically. It can be ordered in two ways:
• DESC is a keyword used to sort the results in descending order.
• ASC is a keyword used to sort the results in ascending order (default).

43
LIKE Operator
The LIKE operator can be used inside of a WHERE clause to match a specified
pattern. The given query will match any movie that begins with Star in its title.
DISTINCT Clause
Unique values of a column can be selected using a DISTINCT query. For a
table contact_details having five rows in which the city column contains
Chicago, Madison, Boston, Madison, and Denver, the given query would
return:
• Chicago
• Madison
• Boston
• Denver
BETWEEN Operator
The BETWEEN operator can be used to filter by a range of values. The range of
values can be text, numbers, or date data. The given query will match any
movie made between the years 1980 and 1990, inclusive.

44
LIMIT Clause
The LIMIT clause is used to narrow, or limit, a result set to the specified number
of rows. The given query will limit the result set to 5 rows.
NULL Values
Column values can be NULL, or have no value. These records can be
matched (or not matched) using the IS NULL and IS NOT NULL operators in
combination with the WHERE clause. The given query will match all addresses
where the address has a value or is not NULL.

45
Chapter 5: Manipulating and Summarizing Results
Column References
The GROUP BY and ORDER BY clauses can reference the selected columns by
number in which they appear in the SELECT statement. The example query will
count the number of movies per rating, and will:
• GROUP BY column 2 (rating)
• ORDER BY column 1 (total_movies)
Aggregate Functions
SUM() Aggregate Function
The SUM() aggregate function takes the name of a column as an argument
and returns the sum of all the value in that column.
46
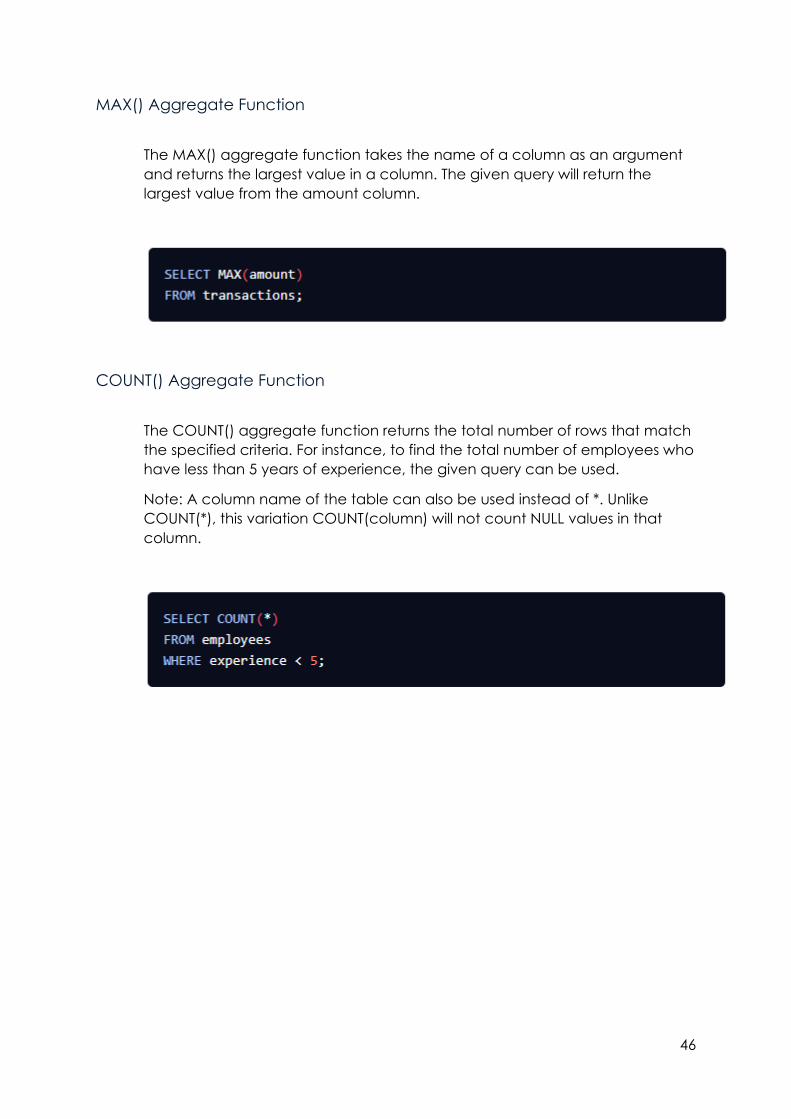
MAX() Aggregate Function
The MAX() aggregate function takes the name of a column as an argument
and returns the largest value in a column. The given query will return the
largest value from the amount column.
COUNT() Aggregate Function
The COUNT() aggregate function returns the total number of rows that match
the specified criteria. For instance, to find the total number of employees who
have less than 5 years of experience, the given query can be used.
Note: A column name of the table can also be used instead of *. Unlike
COUNT(*), this variation COUNT(column) will not count NULL values in that
column.
47
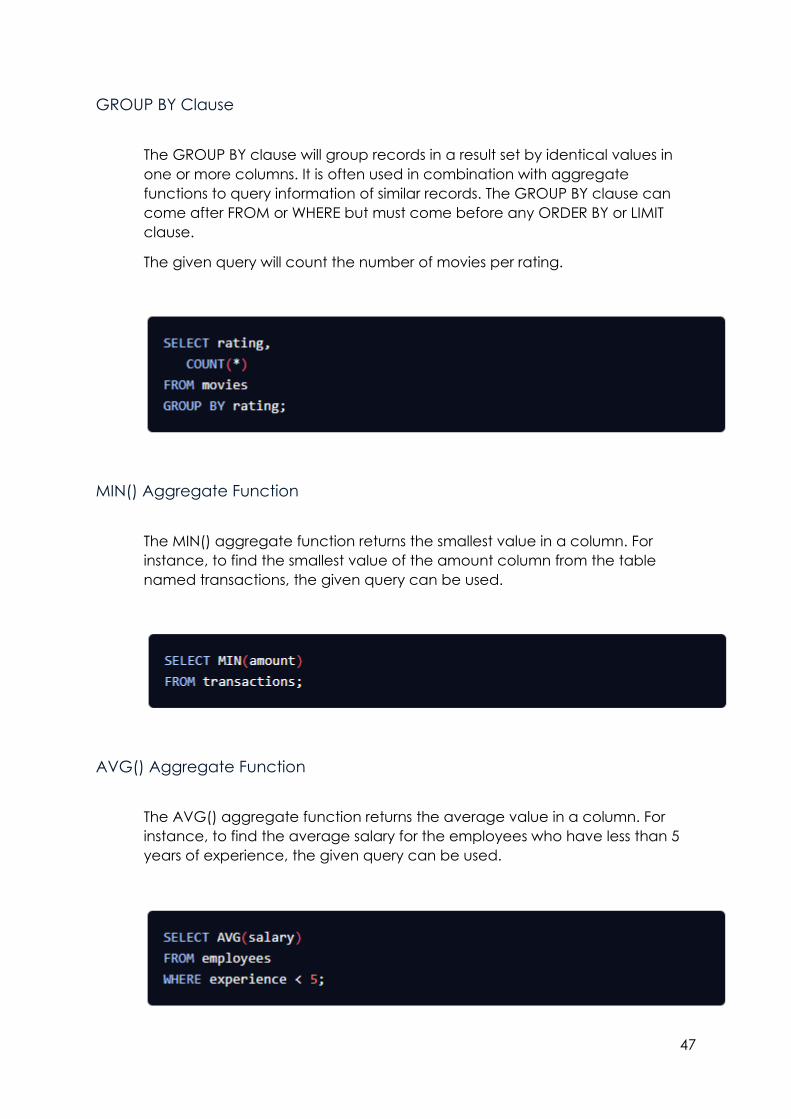
GROUP BY Clause
The GROUP BY clause will group records in a result set by identical values in
one or more columns. It is often used in combination with aggregate
functions to query information of similar records. The GROUP BY clause can
come after FROM or WHERE but must come before any ORDER BY or LIMIT
clause.
The given query will count the number of movies per rating.
MIN() Aggregate Function
The MIN() aggregate function returns the smallest value in a column. For
instance, to find the smallest value of the amount column from the table
named transactions, the given query can be used.
AVG() Aggregate Function
The AVG() aggregate function returns the average value in a column. For
instance, to find the average salary for the employees who have less than 5
years of experience, the given query can be used.

48
HAVING Clause
The HAVING clause is used to further filter the result set groups provided by the
GROUP BY clause. HAVING is often used with aggregate functions to filter the
result set groups based on an aggregate property. The given query will select
only the records (rows) from only years where more than 5 movies were
released per year.
ROUND() Function
The ROUND() function will round a number value to a specified number of
places. It takes two arguments: a number, and a number of decimal places.
It can be combined with other aggregate functions, as shown in the given
query. This query will calculate the average rating of movies from 2015,
rounding to 2 decimal places.
49
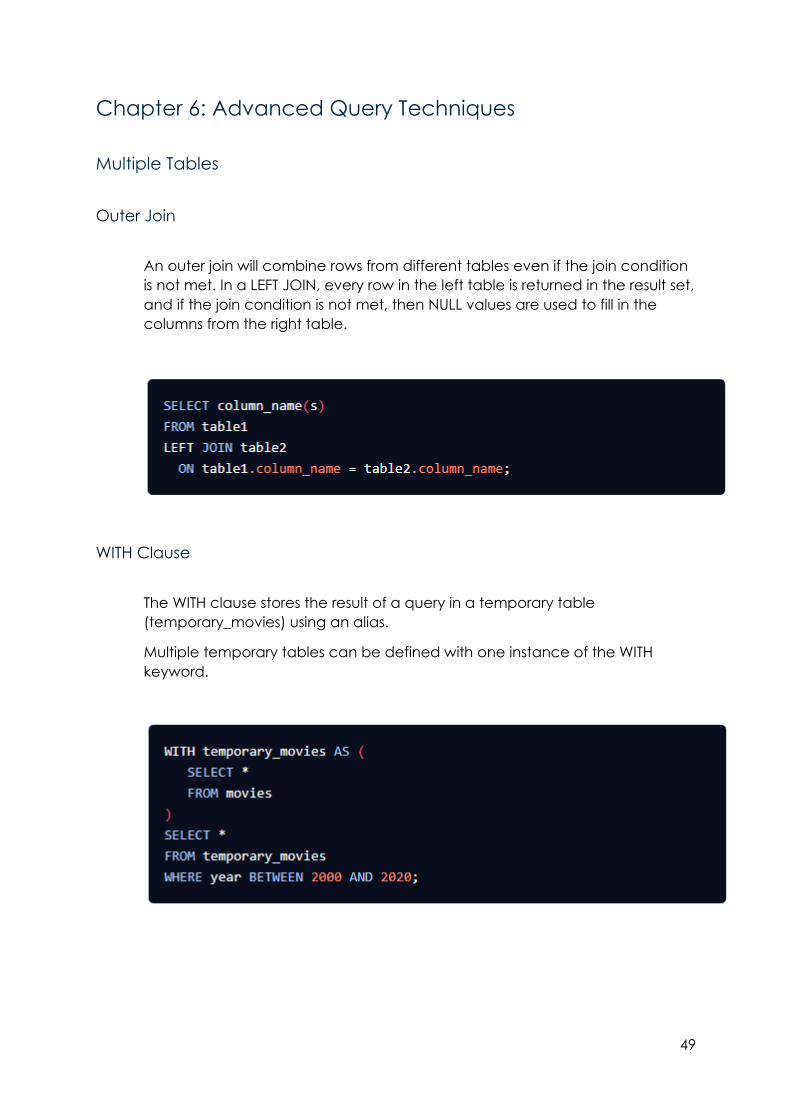
Chapter 6: Advanced Query Techniques
Multiple Tables
Outer Join
An outer join will combine rows from different tables even if the join condition
is not met. In a LEFT JOIN, every row in the left table is returned in the result set,
and if the join condition is not met, then NULL values are used to fill in the
columns from the right table.
WITH Clause
The WITH clause stores the result of a query in a temporary table
(temporary_movies) using an alias.
Multiple temporary tables can be defined with one instance of the WITH
keyword.
50
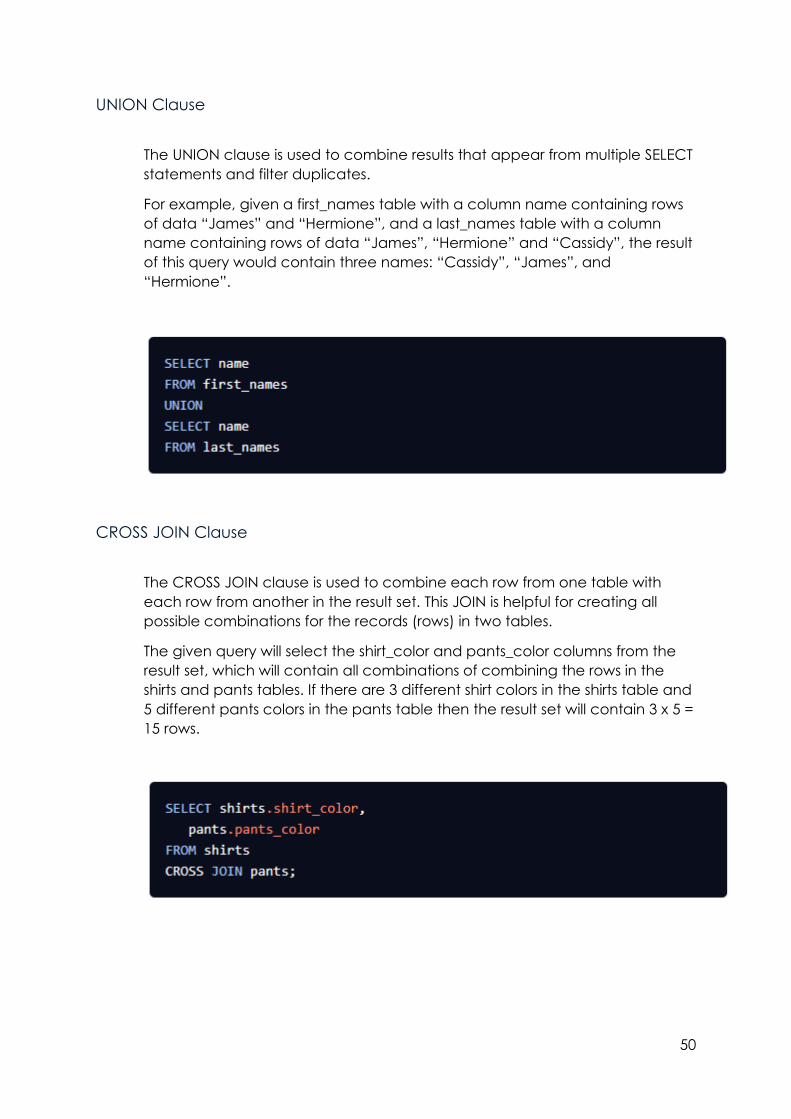
UNION Clause
The UNION clause is used to combine results that appear from multiple SELECT
statements and filter duplicates.
For example, given a first_names table with a column name containing rows
of data “James” and “Hermione”, and a last_names table with a column
name containing rows of data “James”, “Hermione” and “Cassidy”, the result
of this query would contain three names: “Cassidy”, “James”, and
“Hermione”.
CROSS JOIN Clause
The CROSS JOIN clause is used to combine each row from one table with
each row from another in the result set. This JOIN is helpful for creating all
possible combinations for the records (rows) in two tables.
The given query will select the shirt_color and pants_color columns from the
result set, which will contain all combinations of combining the rows in the
shirts and pants tables. If there are 3 different shirt colors in the shirts table and
5 different pants colors in the pants table then the result set will contain 3 x 5 =
15 rows.
51
Inner Join
The JOIN clause allows for the return of results from more than one table by
joining them together with other results based on common column values
specified using an ON clause. INNER JOIN is the default JOIN and it will only
return results matching the condition specified by ON.


















