
Reinforcement Learning - LMU Münchendeckert/light-and-matter/teaching/... · Christian Hanauer...
42
Reinforcement Learning Christian Hanauer 5 July 2017 Advanced Topics in Machine Learning, LMU
Transcript of Reinforcement Learning - LMU Münchendeckert/light-and-matter/teaching/... · Christian Hanauer...

Reinforcement Learning
Christian Hanauer
5 July 2017Advanced Topics in Machine Learning, LMU

The Reinforcement Learning Problem
Reinforcement Learning (RL)
RL is the study of learning in a scenario where an agent actively interactswith the environment to achieve a certain goal.
Christian Hanauer Reinforcement Learning 2 / 42

The Reinforcement Learning Problem
RL is characterized by:
No supervisor
Delayed rewards
Exploration versus exploitation dilemma
Uncertainty about environment
Reward Hypothesis
All goals can be described by the maximisation of the expected cumulativereward.
→ determine optimal policy π∗ (best course of actions)Can you think of a counterexample?
Christian Hanauer Reinforcement Learning 3 / 42
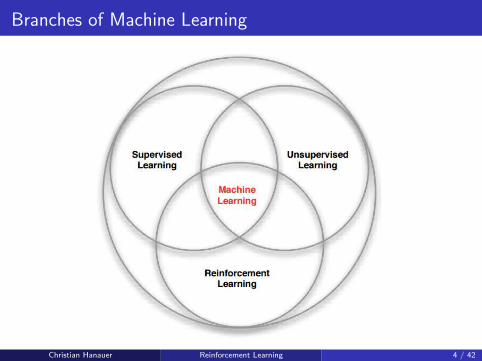
Branches of Machine Learning
Christian Hanauer Reinforcement Learning 4 / 42

Applications of Reinforcement Learning
Christian Hanauer Reinforcement Learning 5 / 42

Outline
1 Introduction
2 Markov Decision ProcessesMarkov Decision ProcessesValue FunctionsBellman Equation
3 Model Free Reinforcement LearningGeneralized Policy IterationMonte Carlo MethodsTemporal-Difference Learning
4 Function ApproximationMotivationPrediction ObjectiveMethods
5 Summary
Christian Hanauer Reinforcement Learning 6 / 42

Markov Property
“The future is independent of the past given the present”
Definition
A state St is Markov if and only if
Pr[St+1|St ] = Pr[St+1|S1, ...,St ]
Definition
A Markov Process (or Markov Chain) is a tuple 〈S,P〉, where
S is a countable non-empty set of states
P is a state transition probability matrix withPss′ = Pr[St+1 = s ′|St = s]
Christian Hanauer Reinforcement Learning 7 / 42

Markov Decision Process
Definition
A Markov Decision Process (MDP) is a tuple 〈S,A,P,R, γ〉, where
S is a countable non-empty set of states
A is a countable non-empty set of actions
P is a state transition probability matrix withPass′ = Pr[St+1 = s ′|St = s,At = a]
R is a reward function Ras = E[Rt+1|St = s,At = a]
γ is a discount factor with γ ∈ [0, 1]
Task of learning agent in MDP:Determine the action to take at each state, the so called policy π : S → A
Christian Hanauer Reinforcement Learning 8 / 42
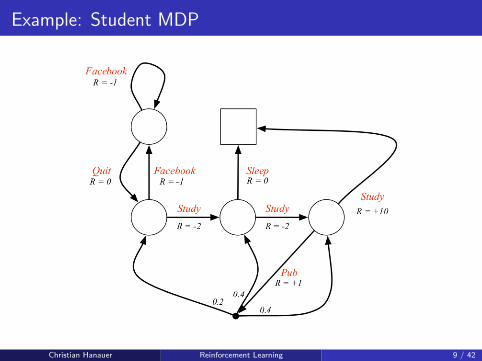
Example: Student MDP
Christian Hanauer Reinforcement Learning 9 / 42

Goals and Rewards
What quantity do we want to maximize?
Definition
The return Gt is the total discounted sum of rewards from time-step t:
Gt = Rt+1 + γRt+2 + ... =∞∑k=0
γkRt+k+1
The reward Rt is a scalar feedback signal
γ ∈ [0, 1] determines the amount we take into account future rewards
Mathematically convenientRepresent uncertainty of the futureHuman behaviour shows preference for immediate rewards
Christian Hanauer Reinforcement Learning 10 / 42

Value Functions
Definition
The state-value function vπ(s) of an MDP is the expected return startingfrom state s and then following policy π
vπ(s) = Eπ[Gt |St = s]
Definition
The action-value function qπ(s, a) of an MDP is the expected returnstarting from state s, taking action a and then following policy π
qπ(s, a) = Eπ[Gt |St = s,At = a]
Ordering over policies:
π ≥ π′ if vπ(s) ≥ vπ′(s) ∀ s
Christian Hanauer Reinforcement Learning 11 / 42

Evaluating the Value Function
How can we determine the value function vπ(s)?
Idea: Decompose vπ(s) into immediate and future reward
vπ(s) = Eπ[Gt |St = s]
= Eπ[Rt+1 + γRt+2 + γ2Rt+3 + ...|St = s]
= Eπ[Rt+1 + γ(Rt+2 + γRt+3 + ...)|St = s]
= Eπ[Rt+1 + γGt+1|St = s]
= Eπ[Rt+1 + γvπ(St+1)|St = s] (Bellman Expectation Equation for vπ)
Can be solved directly (matrix equation) or iteratively (DynamicProgramming)
Christian Hanauer Reinforcement Learning 12 / 42

Optimizing the Value Function
How can we find an optimal policy π?
(i) The optimal action-value function q∗ is given by
q∗ = maxπ
qπ(s, a)
(ii) Use the Bellman Expectation Equation for qπ
qπ(s, a) = Eπ[Rt+1 + γqπ(St+1,At+1)|St = s,At = a]
(iii) The optimal qπ is described by the Bellman Optimality Equation
q∗(s, a) = Eπ[Rt+1 + γmaxπ
qπ(St+1,At+1)|St = s,At = a]
For any MDP: an optimal policy π∗ always exists
Christian Hanauer Reinforcement Learning 13 / 42
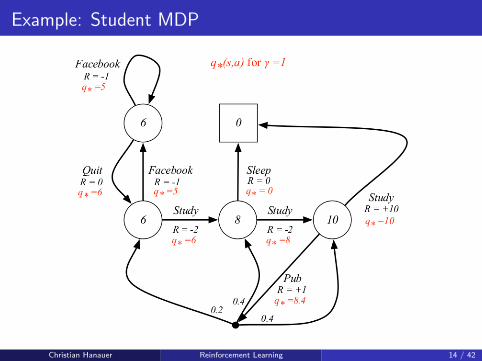
Example: Student MDP
Christian Hanauer Reinforcement Learning 14 / 42

1 Introduction
2 Markov Decision ProcessesMarkov Decision ProcessesValue FunctionsBellman Equation
3 Model Free Reinforcement LearningGeneralized Policy IterationMonte Carlo MethodsTemporal-Difference Learning
4 Function ApproximationMotivationPrediction ObjectiveMethods
5 Summary
Christian Hanauer Reinforcement Learning 15 / 42

Generalized Policy Iteration
How do we learn an optimal policy π∗?
Policy evaluation: Monte Carlo, TD(0)...Policy improvement: Greedy policy improvement...
Christian Hanauer Reinforcement Learning 16 / 42

Policy Improvement Theorem
Theorem
Let π and π′ be any pair of policies such that for all s qπ(s, π′(s)) ≥ vπ(s).Then the policy π′ must be as good as, or better than π:
vπ′(s) ≥ vπ(s)
Proof:
vπ(s) ≤ qπ(s, π′(s)) = Eπ′ [Rt+1 + γvπ(St+1)|St = s]
≤ Eπ′ [Rt+1 + γqπ(St+1, π′(St+1))|St = s]
≤ Eπ′ [Rt+1 + γRt+2 + γ2qπ(St+2, π′(St+2))|St = s]
≤ Eπ′ [Rt+1 + γRt+2 + ...|St = s]
= vπ′(s)
Christian Hanauer Reinforcement Learning 17 / 42

Monte Carlo Methods
Overview:
MC methods learn from episodes of experience
MC methods are model-free
Update of V (St) after end of episode
Basic idea: sample sequences of MDP
How do we evaluate a policy using Monte Carlo Methods?
The value function is given by
vπ(s) = Eπ[Gt |St = s]
MC policy evaluation uses the empirical mean return toestimate vπ(s)
V (St)← V (St) + α(Gt − V (St))
Christian Hanauer Reinforcement Learning 18 / 42

Remark: Incremental Mean
We will compute the mean µk of the sequence x1,x2,... incrementally:
µk =1
k
k∑j=1
xj
=1
k
xk +k−1∑j=1
xj
=
1
k(xk + (k − 1)µk−1)
= µk−1 +1
k(xk − µk−1)
Christian Hanauer Reinforcement Learning 19 / 42

On-policy first-visit MC control
On-policy first-visit MC control
Initialize ∀ s ∈ S, a ∈ AQ(s, a) arbitraryReturns(s, a) empty listπ(a|s) an arbitrary policy
Repeat:
(a) Generate an episode {S1,A1,R2, ...ST} using π
(b) For each pair s, a in the episode:
G ← return following the first occurrence of s, aAppend G to Returns(s, a)Q(s, a)← average(Returns(s, a))
(c) For each s in the episode:
Update policy π epsilon greedily
Christian Hanauer Reinforcement Learning 20 / 42

Remarks
Which door do you want toopen?
You get an reward R = 1
Which door do you want toopen?
Are you sure you have chosenthe right door?
Christian Hanauer Reinforcement Learning 21 / 42

Temporal-Difference Learning
Overview:
TD methods learn from episodes of experience
TD methods are model-free
Update of V (St) after each time step
Basic idea: update a guess towards a guess
How do we evaluate a policy using TD methods?
MC: Update the value V (St) towards actual return Gt
V (St)← V (St) + α(Gt − V (St))
TD: Update the value V (St) towards estimated return
V (St)← V (St) + α(Rt+1 + γV (St+1)− V (St))
Christian Hanauer Reinforcement Learning 22 / 42

Example: Driving Home
State Elapsed Time Predicted Predicted(min) Time to Go Total Time
leaving office 0 30 30reach car, raining 5 35 40exiting highway 20 15 35
behind truck 30 10 40entering home street 40 3 43
arriving home 43 0 43
Christian Hanauer Reinforcement Learning 23 / 42

Example: Driving Home
Christian Hanauer Reinforcement Learning 24 / 42

Q-learning: Off-Policy TD Control
Q-learning
Initialize Q(s, a) ∀s ∈ S, a ∈ A arbitrarilyRepeat (for each episode):
Initialize SRepeat (for each step of episode):
Choose A from S using policy πTake action A, observe R,S ′
Q(S ,A)← Q(S ,A) + α[R + γmaxa
Q(S ′, a)− Q(S ,A)]
S ← S ′
until S is terminal
Q-learning: Update of Q independent of the policy (off-policy)
Sarsa: Update of Q depends on the policy’s action (on-policy)
Christian Hanauer Reinforcement Learning 25 / 42

Example: Student MDP
Christian Hanauer Reinforcement Learning 26 / 42

MC vs. TD
Monte Carlo Methods:
Slow convergence
Markov property not exploited
Update at the end of an episode
TD methods:
Fast convergence
Markov property exploited
Update after every time step
TD(λ) methods:
Use weighted n-step returns as update target
Christian Hanauer Reinforcement Learning 27 / 42

Example: Cliff Walking
Christian Hanauer Reinforcement Learning 28 / 42

Overview
Full Backup (DP) Sample Backup (TD)
Bellman ExpectationEquation for vπ(s)
Iterative Policy Evalu-ation
TD Learning
Bellman ExpectationEquation for qπ(s, a)
Q-Policy Iteration Sarsa
Bellman OptimalityEquation for q∗(s, a)
Q-Value Iteration Q-Learning
Christian Hanauer Reinforcement Learning 29 / 42
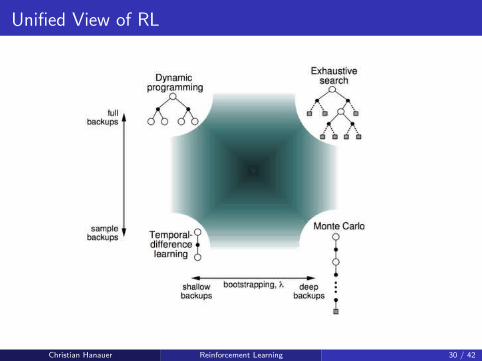
Unified View of RL
Christian Hanauer Reinforcement Learning 30 / 42

1 Introduction
2 Markov Decision ProcessesMarkov Decision ProcessesValue FunctionsBellman Equation
3 Model Free Reinforcement LearningGeneralized Policy IterationMonte Carlo MethodsTemporal-Difference Learning
4 Function ApproximationMotivationPrediction ObjectiveMethods
5 Summary
Christian Hanauer Reinforcement Learning 31 / 42

Motivation
Why do we need value function approximation?
Situation:
Value function represented by lookup table V (s)Go: 10170 states
Problem with large MDPs:
Large set of states/actions to store in memorySlow exploration of states/actions
Solution for large MDPs:
Estimate value function with function approximators
v(s,w) ≈ vπ(s)
Generalize from known to unknown states
Christian Hanauer Reinforcement Learning 32 / 42

Prediction Objective
Prediction Objective: Minimize the squared error J(w)
J(w) =∑s∈S
[vπ(s)− v(s,w)]2
Adjust w in direction of the negative gradient:
∆w = α [vπ(St)− v(St ,w)] ∇v(St ,w)
Christian Hanauer Reinforcement Learning 33 / 42

Methods
Incremental MethodsSubstitute a target for vπMC: Use return as target
∆w = α [Gt − v(St ,w)] ∇v(St ,w)
TD: Use estimated return as target
∆w = α [Rt+1 + γv(St ,w)− v(St ,w)] ∇v(St ,w)
Batch MethodsSample state and value from experience
〈s, vπ〉 ∼ D
Apply stochastic gradient descent update
∆w = α [vπ − v(St ,w)] ∇v(St ,w)
Experience replay: decorrelates samples
Christian Hanauer Reinforcement Learning 34 / 42

Summary
RL: Study of learning of an agent in interaction with environment
Markov Decision Processes: Divide task into prediction and control
Model-Free RL
Monte Carlo MethodsTemporal-Difference Learning MethodsTD(λ)
Large MDPs: function approximation
Outlook:
Policy Gradient Methods
Model based RL
...
Christian Hanauer Reinforcement Learning 35 / 42

RL Agent Classification
Christian Hanauer Reinforcement Learning 36 / 42
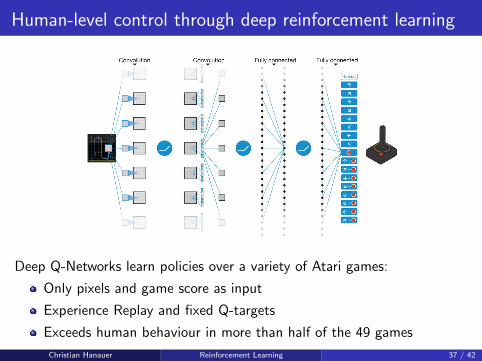
Human-level control through deep reinforcement learning
Deep Q-Networks learn policies over a variety of Atari games:
Only pixels and game score as input
Experience Replay and fixed Q-targets
Exceeds human behaviour in more than half of the 49 games
Christian Hanauer Reinforcement Learning 37 / 42

Thank you for your attention!
Christian Hanauer Reinforcement Learning 38 / 42

Questions
The only stupid question is the one you were afraid to askbut never did. (Rich Sutton)
Christian Hanauer Reinforcement Learning 39 / 42

Resources I
Mnih, Volodymyr et. al. (2015)Human-level control through deep reinforcement learning.Nature, 518, 529-533.
Mohri, Mehryar, Rostamizadeh, Afshin and Talwalkar, AmeetFoundations of Machine Learning. Adaptive Computation andMachine LearningMIT Press. Cambridge, Massachusetts, 2012
Sutton, Richard S. and Barto, Andrew G.Reinforcement Learning. An Introduciton (Draft)MIT Press. Cambridge, Massachusetts, 2016
Christian Hanauer Reinforcement Learning 40 / 42

Resources II
Szepesvari, CsabaAlgorithms for Reinforcement Learning. Draft of the lecture pubishedin the Synthesis Lectures on ARtificial Intelligence and machineLearningMorgan & Claypool Publishers. Cambridge, Massachusetts, 2013
A painless Q-learning tutorial (4.7.2017)http://mnemstudio.org/path-finding-q-learning-tutorial.htm
List of resources on Reinforcement Learning (4.7.2017)https://github.com/aikorea/awesome-rl
OpenAI Gym (4.7.2017)https://gym.openai.com/
Christian Hanauer Reinforcement Learning 41 / 42

Resources III
Repository with code, exercises and solutions for popularReinforcement Learning algorithms (4.7.2017)https://github.com/dennybritz/reinforcement-learning
Teaching Your Computer To Play Super Mario Bros (4.7.2017)http://www.ehrenbrav.com/2016/08/teaching-your-computer-to-play-super-mario-bros-a-fork-of-the-google-deepmind-atari-machine-learning-project/
University College London course on Reinforcement Learning(4.7.2017)http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html
Christian Hanauer Reinforcement Learning 42 / 42






![Reinforcement Learning [0.3in] Lecture Notes on Deep Learning · episode An agent operates in an environment in order to maximize its rewards during each episode. By episode, we mean](https://static.fdocuments.in/doc/165x107/5eac1e797302812d066c3c4c/reinforcement-learning-03in-lecture-notes-on-deep-learning-episode-an-agent-operates.jpg)











