
Re-constructing High-Level Information for Language ... 2016...Re-constructing High-Level...
27
© 2016 IBM Corporation CGO 2016 Re-constructing High-Level Information for Language-specific Binary Re-optimization 1 Toshihiko Koju IBM Research - Tokyo Reid Copeland IBM Canada Motohiro Kawahito IBM Research - Tokyo Moriyoshi Ohara IBM Research - Tokyo
Transcript of Re-constructing High-Level Information for Language ... 2016...Re-constructing High-Level...

© 2016 IBM Corporation
CGO 2016
Re-constructing High-Level Information for Language-specific Binary Re-optimization
1
Toshihiko Koju IBM Research - Tokyo
Reid Copeland IBM Canada
Motohiro Kawahito IBM Research - Tokyo
Moriyoshi Ohara IBM Research - Tokyo

© 2016 IBM Corporation 2
Language-specific binary optimizer can achieve competitive performance relative to the state-of-the-art source compiler.
latest compiler
re-compiled binary
earlier compiler
binary optimizer
source code
original binary
optimized binary
Achieved +40.1% by our binary optimizer vs. +55.2% by the latest source compiler.
language-specific contextual info.
Summary

© 2016 IBM Corporation
Outline
! Motivation & Goal.
! Our Approach. – Four Major Optimizations.
! Performance Evaluation.
! Conclusions.
3

© 2016 IBM Corporation
Compilation Technologies are becoming Increasingly Important ! Recent processors are equipped with specialized HW units.
– e.g. SIMD, FPGA, GPU, DFP (Decimal Floating-Point)
! Re-compilation with the latest compilation technologies is typically required to exploit them.
4
downlevel processor
latest processor SIMD
FPGA
GPU
DFP
re-compiled application existing application latest
compiler
re-compilation
CPU generation
sing
le-th
read
pe
rf. o
f CP
U Specialized HW units complement
diminishing single-thread performance improvements.
w/o specialized HW units
with specialized HW units
© 2016 IBM Corporation
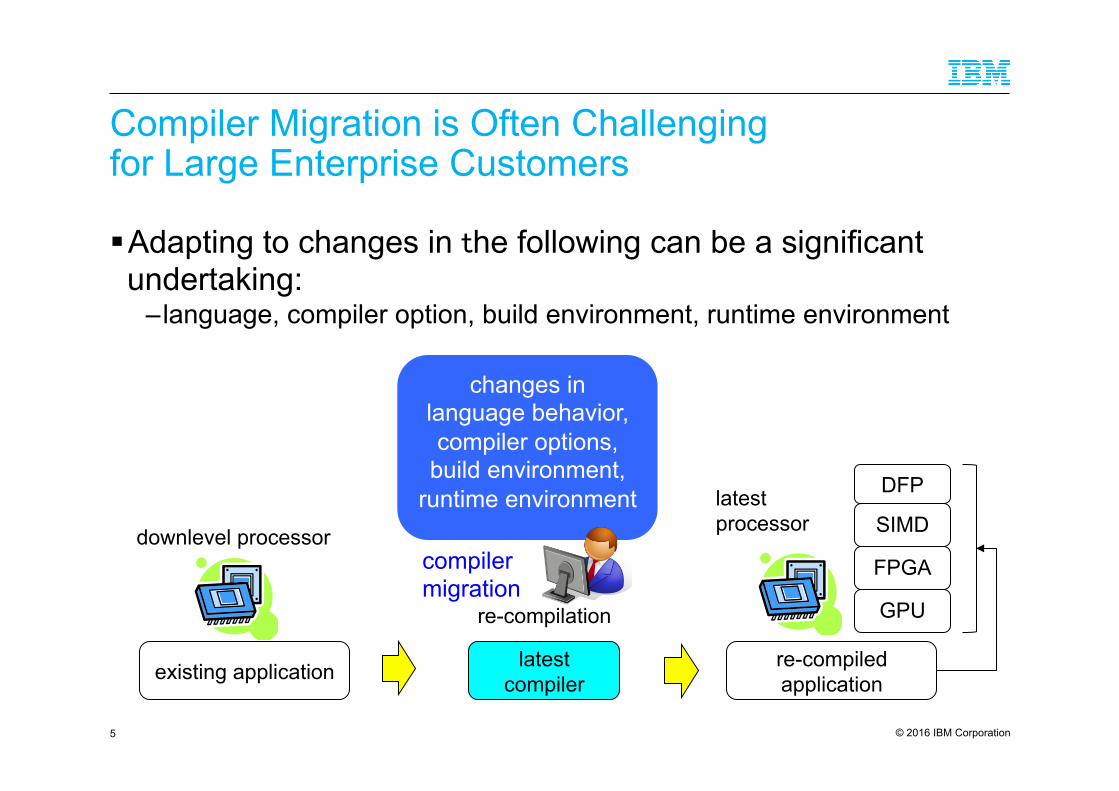
Compiler Migration is Often Challenging for Large Enterprise Customers
! Adapting to changes in the following can be a significant undertaking:
– language, compiler option, build environment, runtime environment
5
downlevel processor
latest processor SIMD
FPGA
GPU
DFP
re-compiled application existing application latest
compiler
re-compilation
changes in language behavior, compiler options,
build environment, runtime environment
compiler migration
© 2016 IBM Corporation
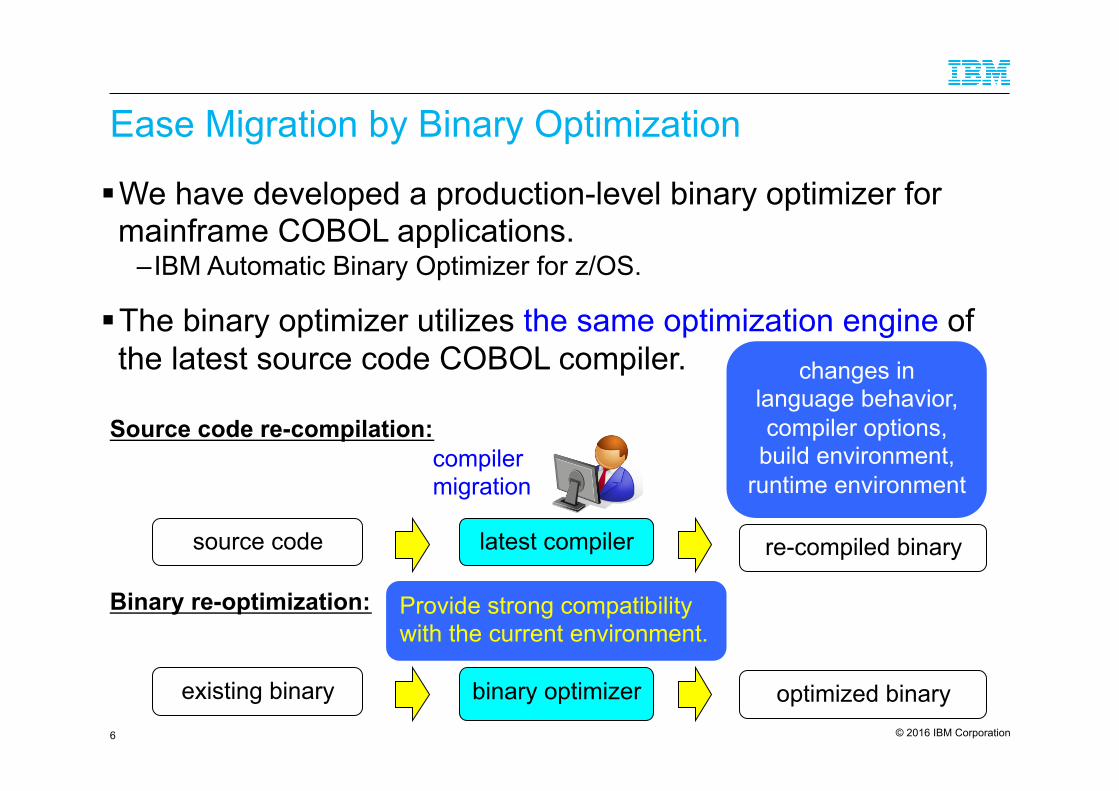
Ease Migration by Binary Optimization
! We have developed a production-level binary optimizer for mainframe COBOL applications.
– IBM Automatic Binary Optimizer for z/OS.
! The binary optimizer utilizes the same optimization engine of the latest source code COBOL compiler.
6
re-compiled binary latest compiler
optimized binary existing binary binary optimizer
Source code re-compilation:
Binary re-optimization: Provide strong compatibility with the current environment.
source code
compiler migration
changes in language behavior, compiler options,
build environment, runtime environment

© 2016 IBM Corporation
Traditional Approach does not Work ! Naive translation from machine instructions to IR (intermediate Representation) degraded the performance.
– This is typically for binary translators based on general compiler engines.
7
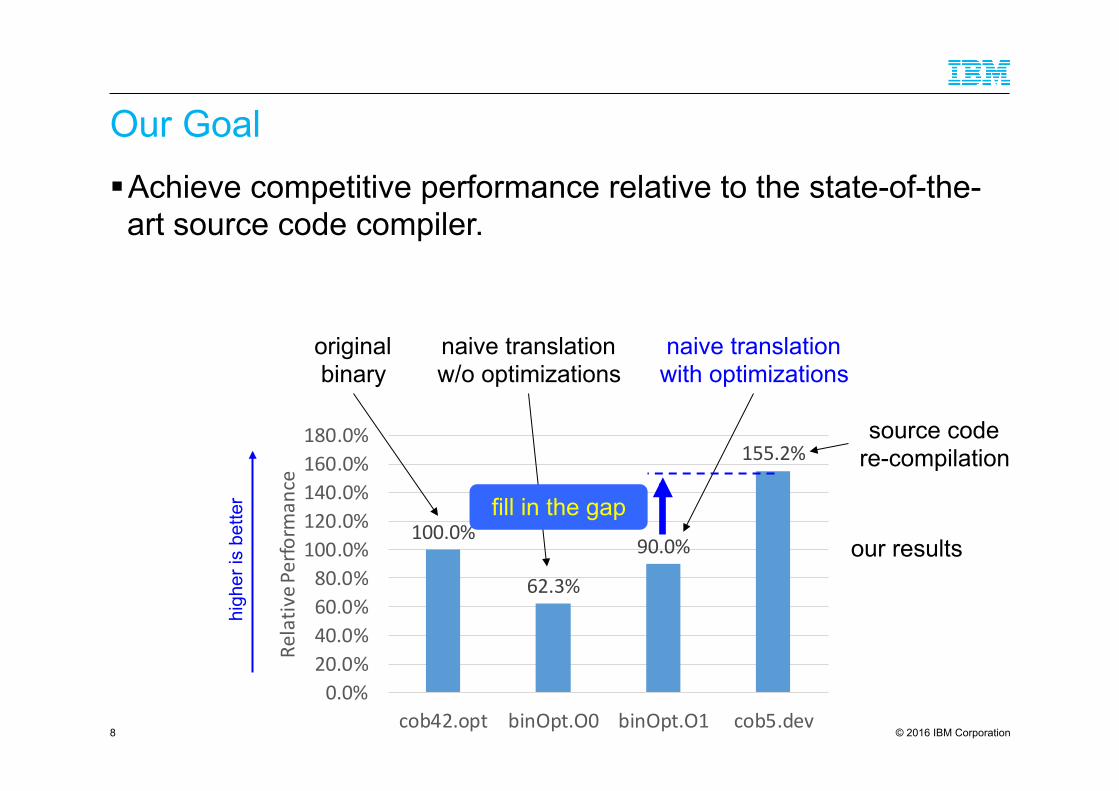
100.0%
62.3%
90.0%
155.2%
0.0%20.0%40.0%60.0%80.0%
100.0%120.0%140.0%160.0%180.0%
cob42.opt binOpt.O0 binOpt.O1 cob5.dev
Relativ
e Perform
ance
original binary
naive translation with optimizations
source code re-compilation
high
er is
bet
ter
naive translation w/o optimizations
© 2016 IBM Corporation
Our Goal ! Achieve competitive performance relative to the state-of-the-art source code compiler.
8
100.0%
62.3%
90.0%
155.2%
0.0%20.0%40.0%60.0%80.0%
100.0%120.0%140.0%160.0%180.0%
cob42.opt binOpt.O0 binOpt.O1 cob5.dev
Relativ
e Perform
ance
original binary
naive translation with optimizations
source code re-compilation
high
er is
bet
ter
naive translation w/o optimizations
our results
fill in the gap

© 2016 IBM Corporation
Outline
! Motivation & Goal.
! Our Approach. – Four Major Optimizations.
! Performance Evaluation.
! Conclusions.
9
© 2016 IBM Corporation
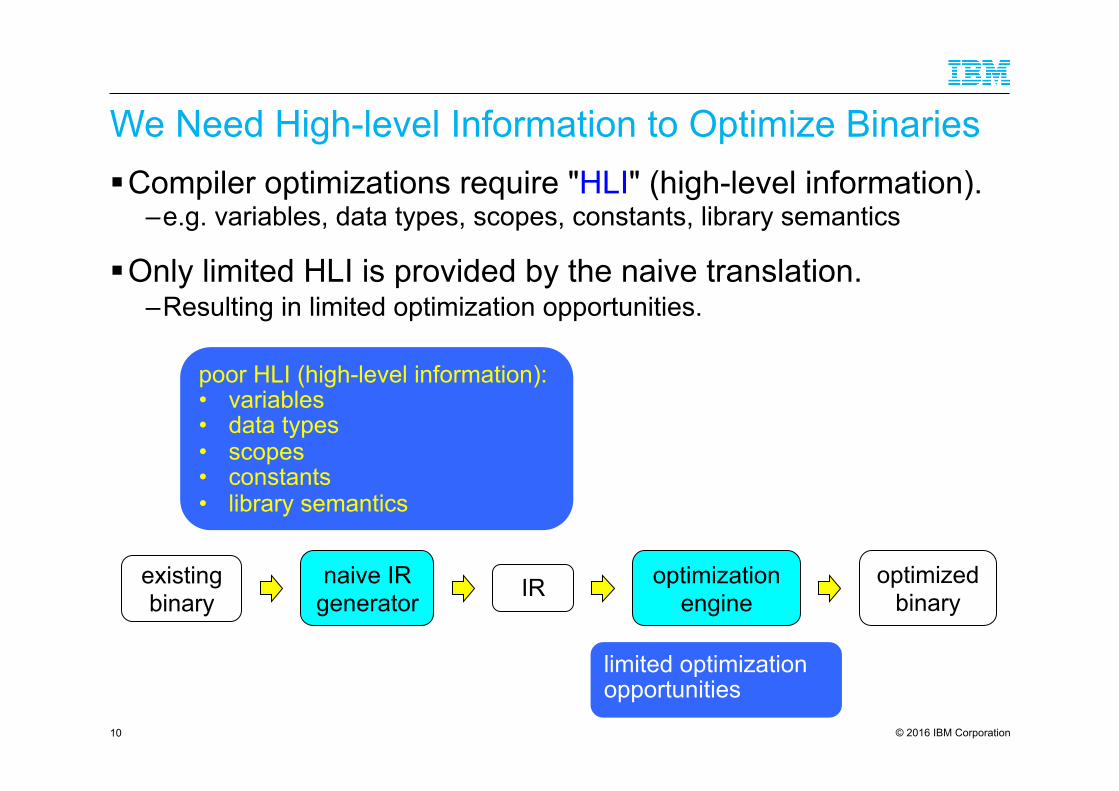
We Need High-level Information to Optimize Binaries ! Compiler optimizations require "HLI" (high-level information).
– e.g. variables, data types, scopes, constants, library semantics
! Only limited HLI is provided by the naive translation. – Resulting in limited optimization opportunities.
10
limited optimization opportunities
existing binary IR
poor HLI (high-level information): • variables • data types • scopes • constants • library semantics
optimized binary
optimization engine
naive IR generator
© 2016 IBM Corporation
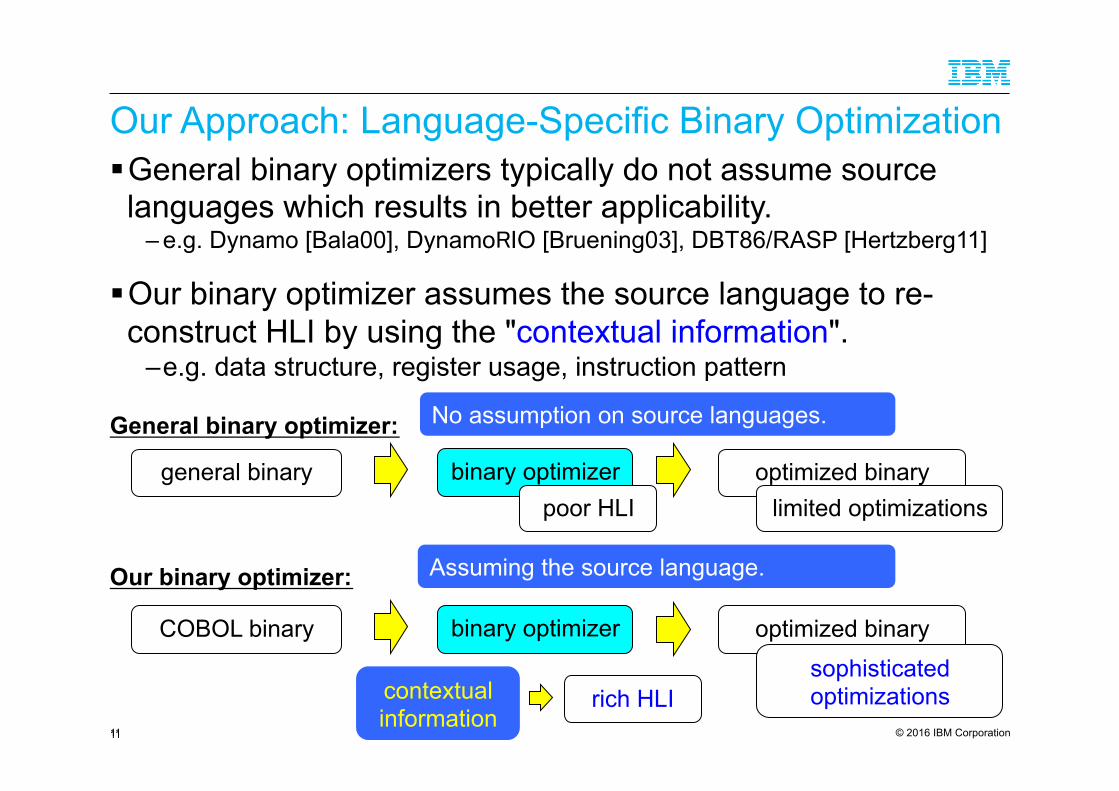
Our Approach: Language-Specific Binary Optimization ! General binary optimizers typically do not assume source languages which results in better applicability.
– e.g. Dynamo [Bala00], DynamoRIO [Bruening03], DBT86/RASP [Hertzberg11]
! Our binary optimizer assumes the source language to re-construct HLI by using the "contextual information".
– e.g. data structure, register usage, instruction pattern
11 11
optimized binary general binary binary optimizer
General binary optimizer: No assumption on source languages.
optimized binary COBOL binary binary optimizer
Our binary optimizer: Assuming the source language.
sophisticated optimizations
limited optimizations poor HLI
contextual information
rich HLI

© 2016 IBM Corporation
Re-construction of the Key HLI
12
machine instructions
EFA (Effective Address)
constant value
original operation
location
data type
scope
aliasing
abstract interpretation: • data structure • register usage
inspection of literal pool: • EFA • data structure
liveness analysis: • location • data structure
Variable
use-define analysis: • EFA • data structure
inspection of usage: • location • instruction pattern
generation of aliasing information: • location • scope
determination of routine: • EFA • data structure
runtime routine
analyze parameter: • semantics of routine • parameter information
inspection of instruction pattern: • variable • instruction pattern
© 2016 IBM Corporation
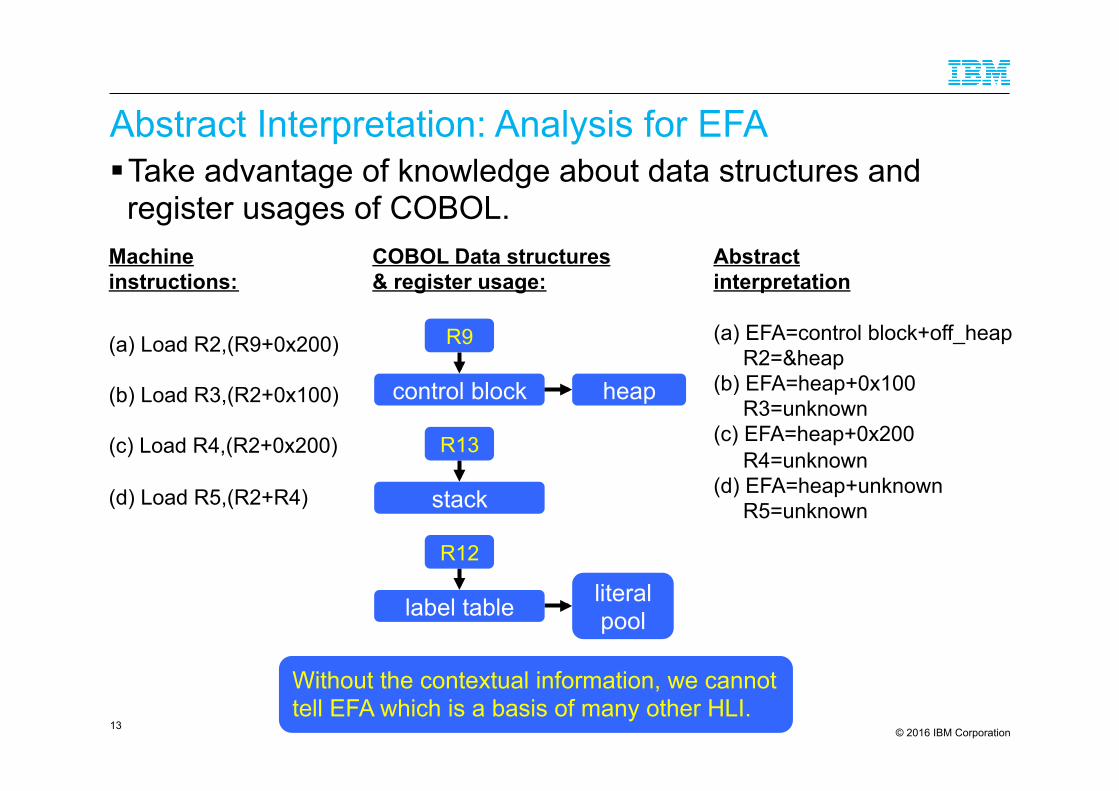
Abstract Interpretation: Analysis for EFA ! Take advantage of knowledge about data structures and register usages of COBOL.
COBOL Data structures & register usage:
Machine instructions:
Abstract interpretation
(a) Load R2,(R9+0x200) (b) Load R3,(R2+0x100) (c) Load R4,(R2+0x200) (d) Load R5,(R2+R4)
(a) EFA=control block+off_heap R2=&heap (b) EFA=heap+0x100 R3=unknown (c) EFA=heap+0x200 R4=unknown (d) EFA=heap+unknown R5=unknown
Without the contextual information, we cannot tell EFA which is a basis of many other HLI.
13
control block heap
R9
R13
stack
label table literal pool
R12

© 2016 IBM Corporation
Four Major Optimizations
! There are four significant optimizations which are newly introduced to the latest source code compiler.
1. Type Reduction of Decimal Type. 2. Strength Reduction of Edited Moves. 3. Skipping Truncations of Binary Numbers. 4. Inlining Efficient Version of Routines.
14 14
100.0%
62.3%
90.0%
155.2%
0.0%20.0%40.0%60.0%80.0%
100.0%120.0%140.0%160.0%180.0%
cob42.opt binOpt.O0 binOpt.O1 cob5.dev
Relativ
e Perform
ance
original binary
naive translation with optimizations
source code re-compilation
high
er is
bet
ter
naive translation w/o optimizations
four optimizations

© 2016 IBM Corporation
Optimization 1: Type Reduction of Decimal Type (1/2) ! Convert decimal types to decimal floating-point (DFP) types.
– Computation on decimal type: memory-to-memory – Computation on DFP type: register-to-register
15
zoned decimal type " 0xF8F7
Representation of integer number 87: binary integer type " 87
Business applications perform a lot of decimal computations.
Original instruction: ZonedToPacked (R13+272, 5 bytes), (R2+0, 8 bytes) ByteOR (R13+276), 0xf ZonedToPacked (R13+280, 5 bytes), (R2+8, 8 bytes) ByteOR (R13+284),0xf PackedAdd (R13+272, 5bytes), (R13+280, 5 bytes) PackedToZoned (R2+0, 8 bytes), (R13+272, 5 bytes)
Simple Example:
packed decimal type " 0x087F
HLI about variables is necessary to enable the type reduction.
COBOL: ZonedDecimal A, B; A = A + B

© 2016 IBM Corporation
EFA information
Optimization 1: Type Reduction of Decimal Type (2/2)
16
Original instruction: ZonedToPacked (R13+272, 5 bytes), (R2+0, 8 bytes) ByteOR (R13+276), 0xf ZonedToPacked (R13+280, 5 bytes), (R2+8, 8 bytes) ByteOR (R13+284),0xf PackedAdd (R13+272, 5bytes), (R13+280, 5 bytes) PackedToZoned (R2+0, 8 bytes), (R13+272, 5 bytes)
Use-Def Analysis: *D=DEF, U=Use ZonedToPacked ByteOR ZonedToPacked ByteOR PackedAdd PackedToZoned
D U UD
D U
U UD U D
UD
use-def analysis
liveness analysis ZonedToPacked TMP1, A PackedSetSign TMP1, plus ZonedToPacked TMP2, B PackedSetSign TMP2, plus PackedAdd TMP1, TMP2 PackedToZoned TMP1, A
Optimized instruction: ZonedToDFP FPR1,*(A) ZonedToDFP FPR2,*(B) DFPAdd FPR1,FPR2 DFPToZoned FPR1,*(A)
Type Reduction
Re-constructed HLI about variables
TMP1 TMP2 A B Variables:

© 2016 IBM Corporation
Optimization 2: Strength Reduction of Edited Moves
! Generate a specialized instruction sequence for a string format operation in COBOL.
17
Simple Example: COBOL: * FOO: string of the format 9999. MOVE 123 TO FOO. " FOO=0123
Original instruction: EDIT control-bytes,numeric
EDIT is a millicode instruction which interprets each byte of the control-bytes.
Re-construct HLI about the original operation from control-bytes.
Optimized instruction: ConvToZoned TMP, numeric CopyZoned FOO, TMP

© 2016 IBM Corporation
Optimization 3: Skipping Truncations of Binary Numbers ! Generate guard code to skip unnecessary truncation of binary integer numbers.
18
Simple Example: COBOL: * FOO: binary number with 4 digits. FOO=FOO+1000.
Original code: TMP=FOO+1000 FOO=TMP%10000
Divide instruction is unconditionally executed to suppress overflows.
Optimized code: TMP=FOO+1000 if abs(TMP) >= 10000
TMP=TMP%10000 FOO=TMP
Re-construct HLI about the original operation: • Quot is not in use. • Dividend is a constant of Pow10.
Overflow is rare.

© 2016 IBM Corporation
Optimization 4: Inlining Efficient Version of Routines
! Replace a runtime routine with the equivalent code which exploits a more efficient algorithm and newer instructions.
19
Simple Example: COBOL: * FOO, BAR: large packed decimal numbers (e.g. 18 digits). FOO=FOO/BAR
Original instruction: CALL LargeDivide
Runtime path length is more than 100 instructions.
Optimized instruction: PackedToDFP FPR1,FOO PackedToDFP FPR2,BAR DFPDivide FPR1,FPR2 DFPRound FPR1 DFPToPacked FPR1,FOO
Re-construct HLI about the original operation: • Semantics of the runtime routine. • Parameter information.
Exploit new DFP instructions.

© 2016 IBM Corporation
Outline
! Motivation & Goal.
! Our Approach. – Four Major Optimizations.
! Performance Evaluation.
! Conclusions.
20
© 2016 IBM Corporation
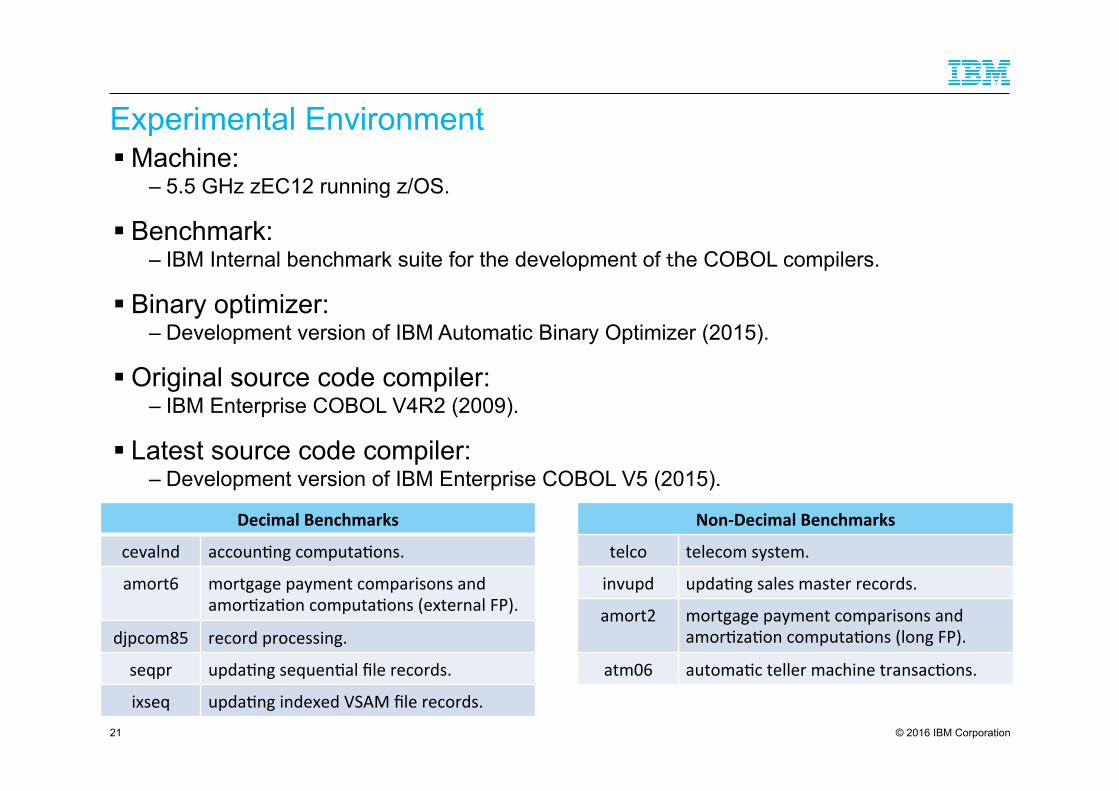
Experimental Environment ! Machine:
– 5.5 GHz zEC12 running z/OS.
! Benchmark: – IBM Internal benchmark suite for the development of the COBOL compilers.
! Binary optimizer: – Development version of IBM Automatic Binary Optimizer (2015).
! Original source code compiler: – IBM Enterprise COBOL V4R2 (2009).
! Latest source code compiler: – Development version of IBM Enterprise COBOL V5 (2015).
21
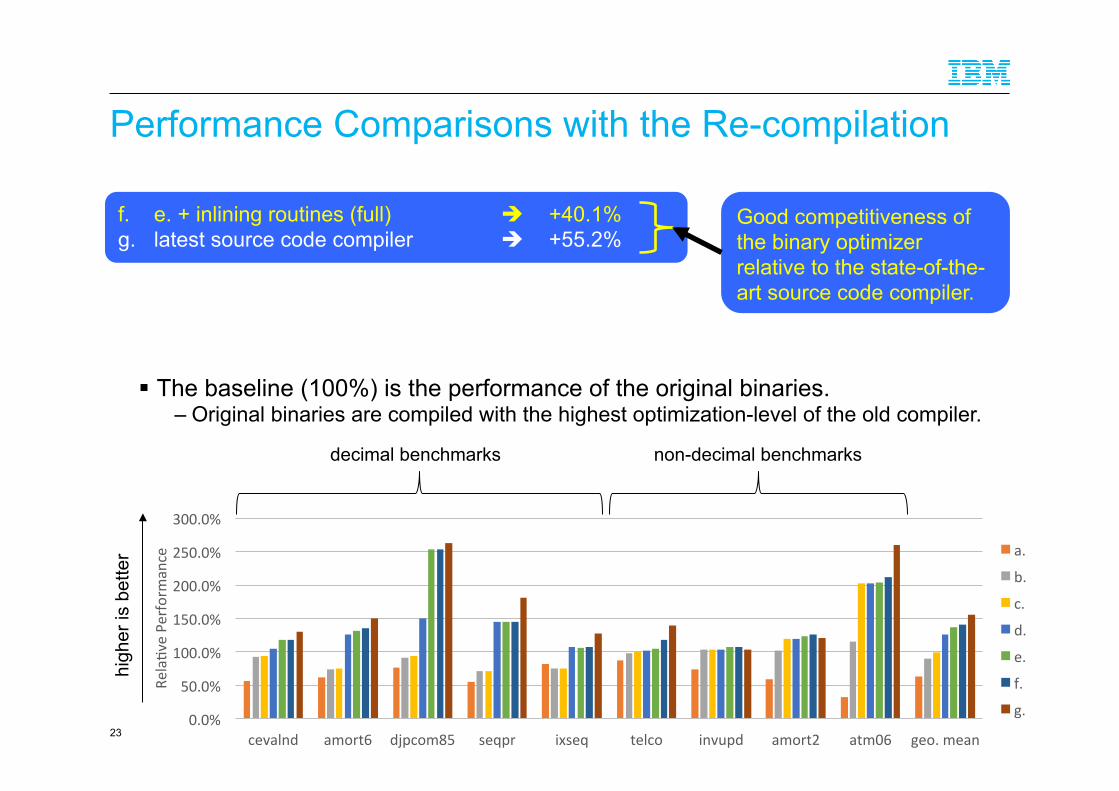
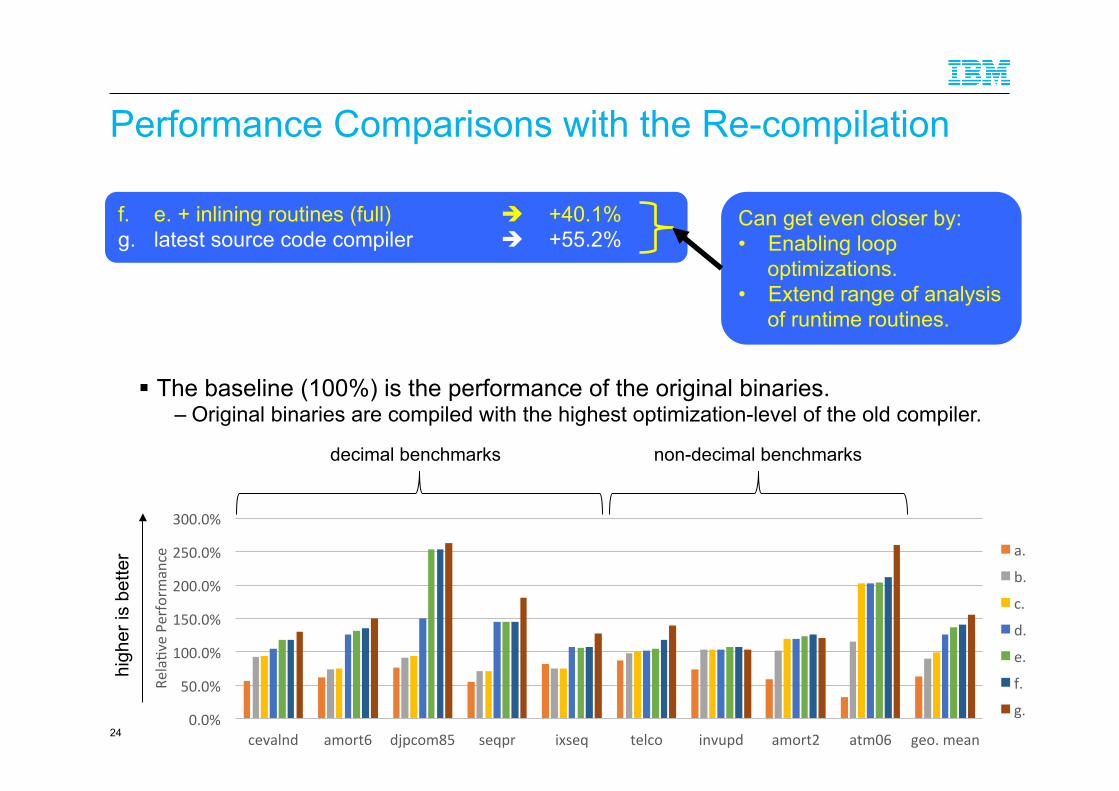
Decimal Benchmarks
cevalnd accoun*ng computa*ons.
amort6 mortgage payment comparisons and amor*za*on computa*ons (external FP).
djpcom85 record processing.
seqpr upda*ng sequen*al file records.
ixseq upda*ng indexed VSAM file records.
Non-‐Decimal Benchmarks
telco telecom system.
invupd upda*ng sales master records.
amort2 mortgage payment comparisons and amor*za*on computa*ons (long FP).
atm06 automa*c teller machine transac*ons.
© 2016 IBM Corporation 0.0%$
50.0%$
100.0%$
150.0%$
200.0%$
250.0%$
300.0%$
cevalnd$ amort6$ djpcom85$ seqpr$ ixseq$ telco$ invupd$ amort2$ atm06$ geo.$mean$
Rela?ve$Pe
rformance$ a.$
b.$
c.$
d.$
e.$
f.$
g.$
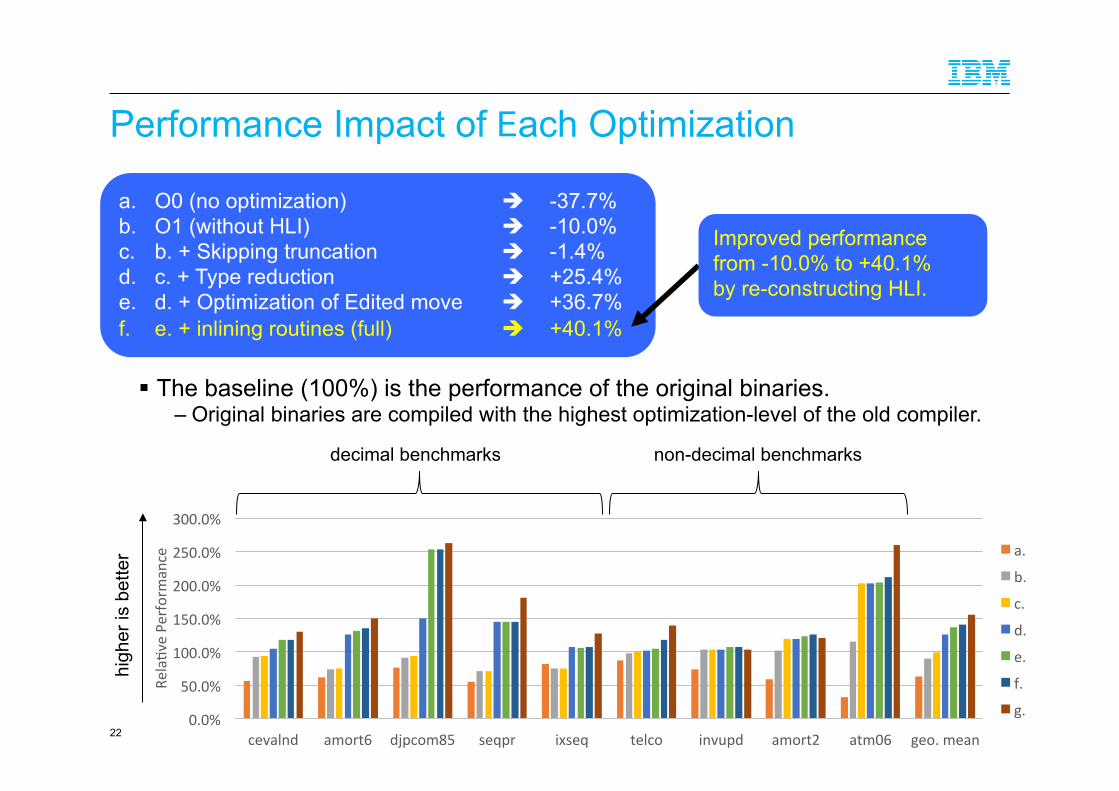
Performance Impact of Each Optimization
22
a. O0 (no optimization) " -37.7% b. O1 (without HLI) " -10.0% c. b. + Skipping truncation " -1.4% d. c. + Type reduction " +25.4% e. d. + Optimization of Edited move " +36.7% f. e. + inlining routines (full) " +40.1%
decimal benchmarks non-decimal benchmarks
high
er is
bet
ter
Improved performance from -10.0% to +40.1% by re-constructing HLI.
! The baseline (100%) is the performance of the original binaries. – Original binaries are compiled with the highest optimization-level of the old compiler.
© 2016 IBM Corporation 0.0%$
50.0%$
100.0%$
150.0%$
200.0%$
250.0%$
300.0%$
cevalnd$ amort6$ djpcom85$ seqpr$ ixseq$ telco$ invupd$ amort2$ atm06$ geo.$mean$
Rela?ve$Pe
rformance$ a.$
b.$
c.$
d.$
e.$
f.$
g.$
Performance Comparisons with the Re-compilation
23
f. e. + inlining routines (full) " +40.1% g. latest source code compiler " +55.2%
decimal benchmarks non-decimal benchmarks
high
er is
bet
ter
! The baseline (100%) is the performance of the original binaries. – Original binaries are compiled with the highest optimization-level of the old compiler.
Good competitiveness of the binary optimizer relative to the state-of-the-art source code compiler.
© 2016 IBM Corporation
Can get even closer by: • Enabling loop
optimizations. • Extend range of analysis
of runtime routines.
0.0%$
50.0%$
100.0%$
150.0%$
200.0%$
250.0%$
300.0%$
cevalnd$ amort6$ djpcom85$ seqpr$ ixseq$ telco$ invupd$ amort2$ atm06$ geo.$mean$
Rela?ve$Pe
rformance$ a.$
b.$
c.$
d.$
e.$
f.$
g.$
Performance Comparisons with the Re-compilation
24
f. e. + inlining routines (full) " +40.1% g. latest source code compiler " +55.2%
decimal benchmarks non-decimal benchmarks
high
er is
bet
ter
! The baseline (100%) is the performance of the original binaries. – Original binaries are compiled with the highest optimization-level of the old compiler.

© 2016 IBM Corporation
Outline
! Motivation & Goal.
! Our Approach. – Four Major Optimizations.
! Performance Evaluation.
! Conclusions.
25
© 2016 IBM Corporation 26
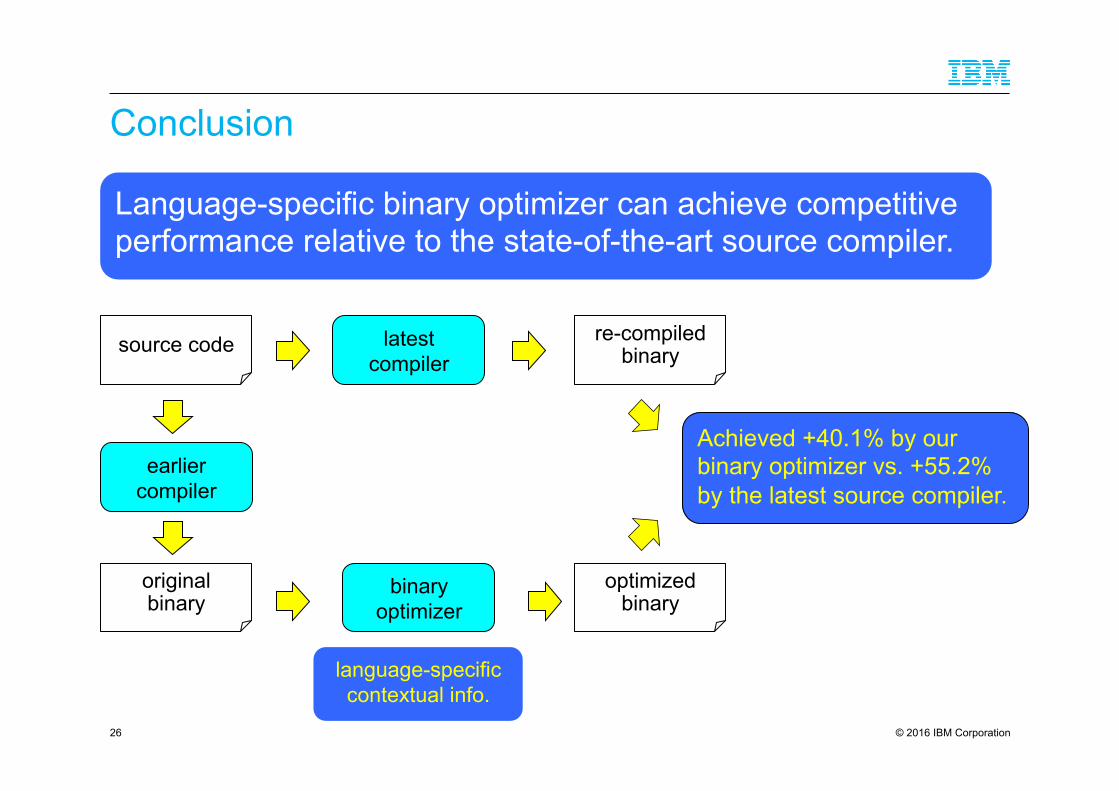
Language-specific binary optimizer can achieve competitive performance relative to the state-of-the-art source compiler.
latest compiler
re-compiled binary
earlier compiler
binary optimizer
source code
original binary
optimized binary
Achieved +40.1% by our binary optimizer vs. +55.2% by the latest source compiler.
language-specific contextual info.
Conclusion

© 2016 IBM Corporation
Questions?
27










![thesis: [re]constructing Belle Isle](https://static.fdocuments.in/doc/165x107/568c4d751a28ab4916a4062d/thesis-reconstructing-belle-isle.jpg)







