
Progress in Chinese EBMT for LingWear Ying Zhang (Joy) Language Technologies Institue Carnegie...
33
Progress in Chinese EBMT for LingWear Ying Zhang (Joy) Language Technologies Institue Carnegie Mellon University Email: joy@ cs . cmu . edu Sep 08, 2000
-
date post
20-Dec-2015 -
Category
Documents
-
view
213 -
download
0
Transcript of Progress in Chinese EBMT for LingWear Ying Zhang (Joy) Language Technologies Institue Carnegie...

Progress in Chinese EBMTfor LingWear
Ying Zhang (Joy)
Language Technologies Institue
Carnegie Mellon University
Email: [email protected]
Sep 08, 2000

IntroductionLingwear
Multi-engine Machine Translation
EBMTcorpus
Chinese EBMTSegmentationRe-ordering

Tasks in Project1. Data Collection
Corpus Glossary
2. Data Preprocess Convert code Segmentation for Chinese Bracketing English Align bilingual corpus

Task in Project (Cont.)
3. Indexing glossary
4. Building dictionary
5. Building corpus
6. Creating statistical dictionary

Data Collection (Corpus)
Hong Kong bilingual legal code collected by LDC ( the Linguistics Data Consortium )
24 Chinese files in Big5; 24 English files *a small portion of English is not the correspondent translation of Chinese source
Average size: 1.5 M Bytes/file for English
1.0 M Bytes/file for Chinese, 10,000 lines each, >400,000
Chinese characters Total corpus:
37.8 M Byte English23 M Byte Chinese

Data Collection (Corpus) Cont.
Each paragraph in the corpus is a line.
Id tag (<s id= XXX>) added by LDC
There are English definitions for legal terms

Data Collection (Corpus) Cont.
<s id=1> To consolidate and amend the law relating to the construction, application and interpretation of laws, to make general provisions with regard thereto, to define terms and expressions used in laws and public documents, to make general provision with regard to public officers, public contracts and civil and criminal proceedings and for purposes and for matters incidental thereto or connected therewith.
<s id=2> [31 December 1966] L.N. 88 of 1966<s id=3> PART I<s id=4> SHORT TITLE AND APPLICATION<s id=5> This Ordinance may be cited as the Interpretation and General Clauses
Ordinance.<s id=6> Remarks:<s id=7> Amendments retroactively made - see 26 of 1998 s. 2<s id=8> (1) Save where the contrary intention appears either from this Ordinance
or from the context of any other Ordinance or instrument, the provisions of this Ordinance shall apply to this Ordinance and to any other Ordinance in force, whether such other Ordinance came or comes into operation before or after the commencement of this Ordinance, and to any instrument made or issued under or by virtue of any such Ordinance.

Data Collection (Corpus) Cont.
GlossaryFrom LDC Chinese-English dictionary
Seems to be a combination of several printed dictionary
Punctuation Dictionary (by Joy)Definition from corpus

Data Preprocess
Convert code Coding System:
There are two main coding schemes for Chinese:
Big5 (Hong Kong, Taiwan, Southeastern Aisa)
GB2312, GBK (Mainland China) Tool
NJStar Universal converter Problems
HKSCS (Hong Kong Supplementary Character Set)

Data Preprocess (Cont.)
Segmentation for ChineseWhy does Chinese need to be segmented?
Because Chinese is written without any space between words, word segmentation is a particular important issue for Chinese language processing.
e.g.
( c ) things attached to land or permanentlyfastened to anything attached to land ;

Data Preprocess (Cont.)Segmenter
LDC SegmenterBased on the word frequency dictionary, using Dynamic programming to find the path which has the highest multiple of word probability, the next word is selected from the longest phrase.
Errors: Miss-segmentation: There are no such word in freq.
Dict, so segmenter just segment every character.
Incorrect-segmentation:

Data Preprocess (Cont.)
Miss-segmentation is much more than incorrect-segmentation
e.g. From a sample with 6960 words, LDC Segmenter miss-segmented 57 words(100 cases, 1.43%), incorrect-segmented 9 words(10 cases, 0.143%).
The reason for this is because of the dictionary used by the segmenter does not have entries for words in legal domain.

Segmenter ImprovementLonger chunks are better for EBMT
Improve Chinese segmenter by extracting ‘words’ from corpus and added them to the dictionary of segmenter
To find out corresponding translation for segmented Chinese ‘words’, English corpus need to be ‘bracketed’ for phrases

Example of Improvement

Basic Ideas
Searching patterns appeared in corpus as candidates for words
Refine patterns and create words

Challenges
Memory concerns If all patterns are kept in memory until the end of the
scan process, there will be explosive requirement of memory
Length of patterns to be searched (how about the word with 7 characters?)
Whether a pattern is a ‘word’ Distinguish patterns that are not words Construct longer words from patterns
Performance---Speed

Solutions
Memory concerns “Sliding-window”: dump the patterns to file dynamically Scan only patterns with length 2,3,4 (2,3,4,5 for English)
Whether a pattern is a ‘word’ Using mutual information to decide whether a pattern is a
word Merging shorter patterns to longer “word” if shorter
patterns have the same appearing times and appear in the same range.

Assumptions used in sliding-window 1
Assumption1:Localization: One word appears more frequently
in a certain region, rather than distributed evenly among the whole corpus

Assumptions used in sliding-window 2Assumption2: If there will be another pattern appear, it
should appear in a range related to the average distance of appeared patterns
ExpectationRange = 30 * averageDistance

Sliding-windowFor every 50 clauses{
check patterns if it can be dumped}
Check_patterns_if_it’s_a_would_be_word{if(isAWordFinal($_[0], $thisWord)){
recycleMem; return 0;}else{
if($distance==0){ #appear only in once clause nowif($scanRange<$rangeLimit){ return 1;}else{ recycleMem;}
}else{ if($notAppearRange>(($appearRange/
$times)*$niceRate)){recycleMem; return 0;
}else{ return 1; }
}}}

Refine Patterns for Words
Step1: Add info. for the same pattern (because of sliding window)
Step2: Choose longest pattern among patterns have the same info (appearing times and range)e.g. ab 7 390
abc 7 390
abcd 7 390
Choose ‘abcd’ and give up ‘ab’, ‘abc’

Refine Patterns for Words (cont.)
Step3: Split words according to “mutual info”
e.g. For word like Abc, the “mutual info” is
)*)'(')'('
*)'('
(log2
TotalCharbcfreq
TotalCharAfreqTotalChar
Abcfreq

Refine Patterns for Words (cont.)Step4: Construct longer words.
As only patterns of length 2,3,4 are extracted, longer words need to be constructed based on pattern with 4 characters.
Step5: Adding the words to the segmenter’s dictionary
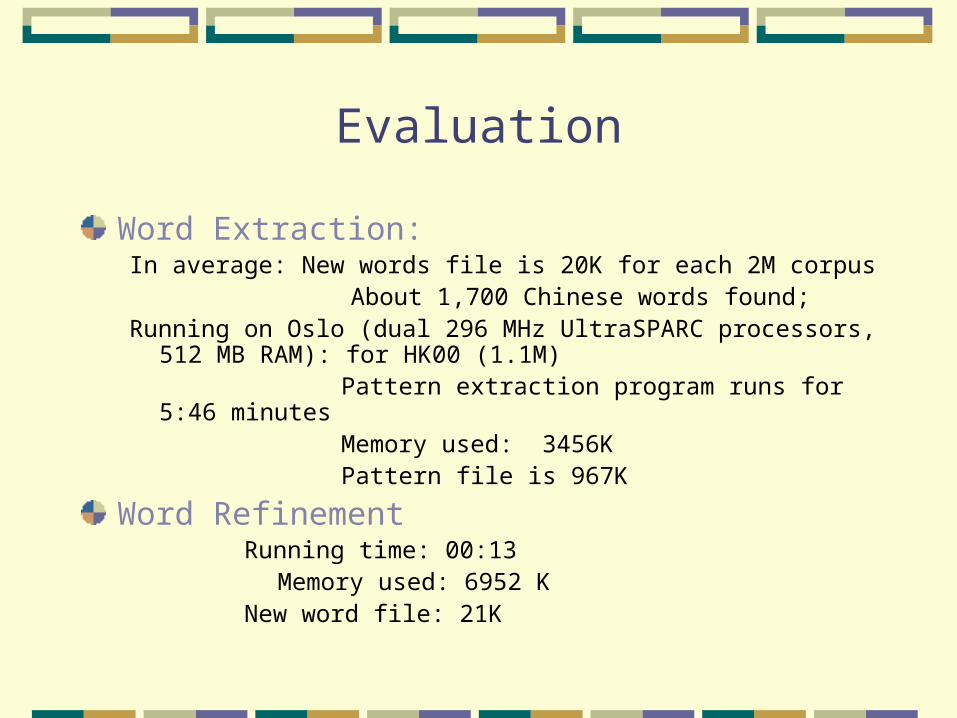
Evaluation
Word Extraction:In average: New words file is 20K for each 2M corpus
About 1,700 Chinese words found;Running on Oslo (dual 296 MHz UltraSPARC processors, 512 MB
RAM): for HK00 (1.1M) Pattern extraction program runs for 5:46 minutes Memory used: 3456K Pattern file is 967K
Word Refinement Running time: 00:13
Memory used: 6952 K New word file: 21K

Evaluation (cont.)
Evaluated on HK00 (first 5 pages)
Total Chinese characters: 2172
Original Segmenter:
miss-segmentation: 120 cases (5.5%)
incorrect-segmentation: 5 cases (0.23%)
Improved Segmenter:
miss-segmentation: 38 cases (1.75%)
incorrect-segmentation: 7 cases (0.32%)

Bracketer for EnglishUsing the same algorithm for Chinese.
English is easier than Chinese (esp. for refinement) Using underscore to concatenating English words to form
phrase
e.g.joint_creditors
joint_estate
journalistic_material
judge_by
judge_of
judgment_creditor
judgment_debtorjudgment_debtors

Creating aligned bilingual corpusAfter the segmentation of Chinese and bracketing of English:

Creating Statistical Dict.
Ralf’s program can generate a statistical bilingual dictionary for words based on the bilingual corpus.With bracketed English corpus, this program can generate bilingual dictionary for phrase now.
In this dictionary, there are 13695 entries are generated for English phrase bracketed, the other 7680 entries are for words or phrases from LDC dictionary

Conclusion
By improving Chinese segmenter and English bracketer, the quality of EBMT system has been improved.

Problems and future work
As there is no deep analysis of the semantic info on words, some of the words generated are not real words: e.g.
Adjust the parameters of Chinese segmenter and English bracketer, so that they can find more coherent patterns.

Problems for EBMT
Purify the glossary and add preference information to word entries;
Improved Chinese segmenter and English bracketer need to be augmented to provide more accurate segmentations;
Re-ordering translation in English;
Modify the language model for better translation

Thank you!
Questions and comments?

Enjoy your weekend


















