
Praktikum - medicalbioinformatics.de · Image from MPI standard doc Broadcast, scatter, gather,...
18
1 Praktikum: Verteiltes Rechnen und Parallelprogrammierung „Introduction to MPI“ Agenda 1) Recap: MPI 2) 2. Übungszettel 3) Projektpräferenzen ? 4) Nächste Woche: 3. Übungszettel, Projektauswahl, Konzepte 5) Nächste Woche: 15:30 starten? MPI – Application Example
Transcript of Praktikum - medicalbioinformatics.de · Image from MPI standard doc Broadcast, scatter, gather,...

1
Praktikum:
Verteiltes Rechnen und Parallelprogrammierung
„Introduction to MPI“
Agenda
1) Recap: MPI
2) 2. Übungszettel
3) Projektpräferenzen ?
4) Nächste Woche: 3. Übungszettel, Projektauswahl, Konzepte
5) Nächste Woche: 15:30 starten?
MPI – Application Example
2
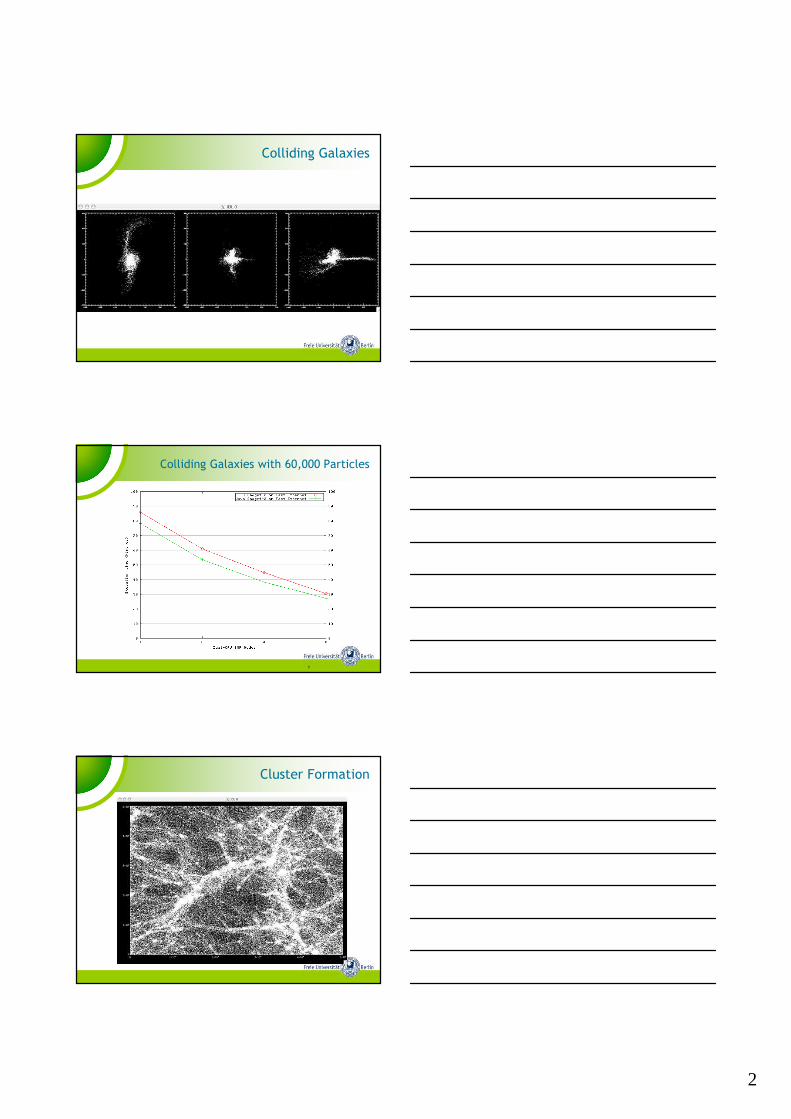
Colliding Galaxies
5
Colliding Galaxies with 60,000 Particles
Cluster Formation

3
7
Structure Formation with two million Particles
MPI Recap
Message-Passing Programming
Paradigm
• Each processor in a message-passing program runs a sub-program– written in a convential sequential language– all variables are private
– communicate via special subroutine calls
M
P
M
P
M
P
Memory
Processors
Interconnection Network

4
Messages
• Messages are packets of data moving between sub-programs
• The message passing system has to be told the following information– Sending processor– Source location– Data type– Data length– Receiving processor(s)– Destination location– Destination size
Messages
• Access:– Each sub-program needs to be connected to a message
passing system
• Addressing:– Messages need to have addresses to be sent to
• Reception:– It is important that the receiving process is capable of
dealing with the messages it is sent
• A message passing system is similar to:– Post-office, Phone line, Fax, E-mail, etc
Point-to-Point Communication
• Simplest form of message passing• One process sends a message to another• Several variations on how sending a
message can interact with execution of the sub-program

5
Point-to-Point variations
• Synchronous Sends– provide information about the completion of the message– e.g. fax machines
• Asynchronous Sends– Only know when the message has left
– e.g. post cards
• Blocking operations– only return from the call when operation has completed
• Non-blocking operations– return straight away - can test/wait later for completion
Collective Communications
• Collective communication routines are higher level routines involving several processes at a time
• Can be built out of point-to-point communications• Barriers
– synchronise processes
• Broadcast– one-to-many communication
• Reduction operations– combine data from several processes to produce a single (usually)
result
Introduction
Hint: we are using mpjExpress because it can also be run in a multi-core environment.

6
16
Two Important Concepts
• Two fundamental concepts of parallel programming are: – Domain decomposition– Functional decomposition
17
Domain Decomposition
Image taken from https://computing.llnl.gov/tutorials/parallel_comp/
18
Functional Decomposition
Image taken from https://computing.llnl.gov/tutorials/parallel_comp/

7
Message Passing Interface (MPI)
• MPI is a standard (an interface or an API): – It defines a set of methods that are used by application developers to write their applications– MPI library implement these methods– MPI itself is not a library—it is a specification document that is followed!– MPI-1.2 is the most popular specification version
• Reasons for popularity:– Software and hardware vendors were involved– Significant contribution from academia– MPICH served as an early reference implementation – MPI compilers are simply wrappers to widely used C and Fortran compilers
• History: – The first draft specification was produced in 1993– MPI-2.0, introduced in 1999, adds many new features to MPI– Bindings available to C, C++, and Fortran
• MPI is a success story:– It is the mostly adopted programming paradigm of IBM Blue Gene systems
• At least two production-quality MPI libraries:– MPICH2 (http://www-unix.mcs.anl.gov/mpi/mpich2/)– OpenMPI (http://open-mpi.org)
• There’s even a Java library: – MPJ Express (http://mpj-express.org)
Message Passing Model
• Message passing model allows processors to communicate by passing messages: – Processors do not share memory
• Data transfer between processors required cooperative operations to be performed by each processor:– One processor sends the message while other receives the
message
21
node6
Allegro(cluster head node)
node1
node3
node2
node4
node5
node7
Distributed Memory Cluster

8
22
Minimal MPI Java Program
import mpi.*
class Hello {static public void main(String[] args) {
MPI.Init(args) ;
int myrank = MPI.COMM_WORLD.Rank() ;
if(myrank == 0) {char[] message = “Hello, there”.toCharArray() ;MPI.COMM_WORLD.Send(message, 0, message.length, MPI.CHAR, 1, 99) ;
}else {
char[] message = new char [20] ;MPI.COMM_WORLD.Recv(message, 0, 20, MPI.CHAR, 0, 99) ;
System.out.println(“received:” + new String(message) + “:”) ;}
MPI.Finalize() ;}
}
23
Steps involved in executing the “Hello World!” program
1. Let’s logon to the cluster head node
2. Write the Hello World program
3. Compile the program
4. Write the machines files
5. Start MPJ Express daemons
6. Execute the parallel program
7. Stop MPJ Express daemons
24
Step1: Logon to the head node

9
25
Step 2: Write the Hello World Program
26
Step 3: Compile the code
27
Step 4: Write the machines file

10
28
Step 5: Start MPJ Express daemons
29
Step 6: Execute the parallel program
aamir@barq:~/projects/mpj-user> mpjrun.sh -np 6 -headnodeip 10.3.20.120 -dport 11050 HelloWorld
..Hi from process <3> of total <6> Hi from process <1> of total <6> Hi from process <2> of total <6> Hi from process <4> of total <6> Hi from process <5> of total <6> Hi from process <0> of total <6> …
30
Step 7: Stop the MPJ Express daemons

11
31
COMM WORLD Communicator
import java.util.*;import mpi.*;
.. // Initialize MPI MPI.Init(args); // start up MPI
// Get total number of processes and ranksize = MPI.COMM_WORLD.Size(); rank = MPI.COMM_WORLD.Rank();
..
32
What is size?
• Total number of processes in a communicator:– The size of MPI.COMM_WORLD is 6
import java.util.*;import mpi.*;
..
// Get total number of processessize = MPI.COMM_WORLD.Size();
..
33
What is rank?
• The “unique” identify (id) of a process in a communicator:– Each of the six processes in MPI.COMM_WORLD has a distinct rank or id
import java.util.*;import mpi.*;
..
// Get total number of processesrank = MPI.COMM_WORLD.Rank();
..

12
34
Single Program Multiple Data (SPMD) Model
import java.util.*;import mpi.*;
public class HelloWorld {
MPI.Init(args); // start up MPI
size = MPI.COMM_WORLD.Size(); rank = MPI.COMM_WORLD.Rank();
if (rank == 0) { System.out.println(“I am Process 0”);
} else if (rank == 1) {
System.out.println(“I am Process 1”); }
MPI.Finalize();}
35
Single Program Multiple Data (SPMD) Model
import java.util.*;import mpi.*;
public class HelloWorld {
MPI.Init(args); // start up MPI
size = MPI.COMM_WORLD.Size(); rank = MPI.COMM_WORLD.Rank();
if (rank%2 == 0) { System.out.println(“I am an even process”);
} else if (rank%2 == 1) {
System.out.println(“I am an odd process”); }
MPI.Finalize();}
36
Point to Point Communication
• The most fundamental facility provided by MPI• Basically “exchange messages between two processes”:
– One process (source) sends message– The other process (destination) receives message

13
37
Point to Point Communication
• It is possible to send message for each basic datatype:– Floats (MPI.FLOAT), Integers (MPI.INT), Doubles (MPI.DOUBLE)
…– Java Objects (MPI.OBJECT)
• Each message contains a “tag”—an identifier
38
Process 6
Process 0
Process 1
Process 3
Process 2
Process 4
Process 5
Process 7
message
Integers Process 4 Tag COMM_WORLD
Point to Point Communication
39
Blocking Send() and Recv() Methods
public void Send(Object buf, int offset, int count,Datatype datatype, int dest, int tag) throws MPIException
public Status Recv(Object buf, int offset, int count, Datatype datatype, int src, int tag) throws MPIException

14
40
Blocking and Non-blocking Point-to-Point Comm
• There are blocking and non-blocking version of send and receive methods
• Blocking versions: – A process calls Send() or Recv() , these methods return when
the message has been physically sent or received
• Non-blocking versions: – A process calls Isend() or Irecv() , these methods return
immediately
– The user can check the status of message by calling Test() or Wait()
• Non-blocking versions provide overlapping of computation and communication:– Asynchronous communication
41
Blocking vs. non-blocking
42
Non-blocking Point-to-Point Comm
public Request Isend(Object buf, int offset, int count, Datatype datatype, int dest, int tag) throws MPIException
public Request Irecv(Object buf, int offset, int count, Datatype datatype, int src, int tag) throws MPIException
public Status Wait() throws MPIException
public Status Test() throws MPIException
15
43
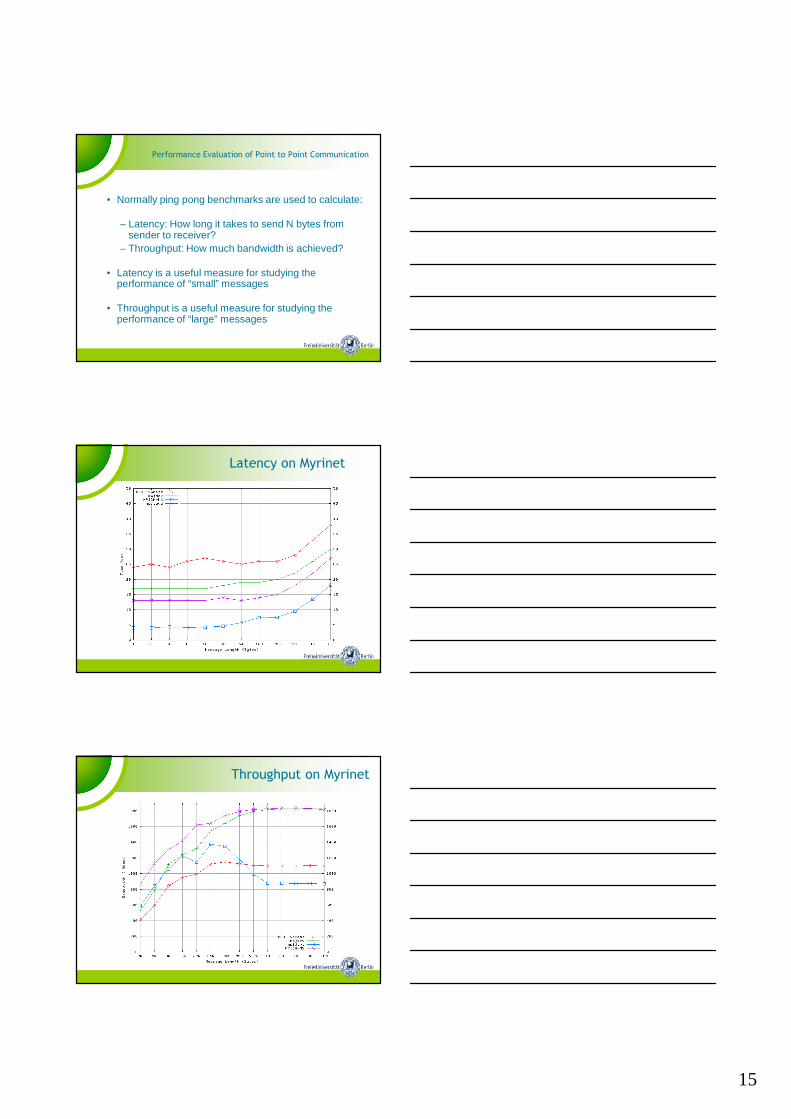
Performance Evaluation of Point to Point Communication
• Normally ping pong benchmarks are used to calculate:
– Latency: How long it takes to send N bytes from sender to receiver?
– Throughput: How much bandwidth is achieved?
• Latency is a useful measure for studying the performance of “small” messages
• Throughput is a useful measure for studying the performance of “large” messages
44
Latency on Myrinet
45
Throughput on Myrinet

16
46
Collective communications
• Provided as a convenience for application developers:– Save significant development time– Efficient algorithms may be used – Stable (tested)
• Built on top of point-to-point communications• These operations include:
– Broadcast, Barrier, Reduce, Allreduce, Alltoall, Scatter, Scan, Allscatter
– Versions that allows displacements between the data
47
Image from MPI standard doc
Broadcast, scatter, gather, allgather, alltoall
48
Broadcast, scatter, gather, allgather, alltoall
public void Bcast(Object buf, int offset, int count,Datatype type, int root) throws MPIException
public void Scatter(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype,Object recvbuf, int recvoffset, int recvcount, Datatype recvtype,int root) throws MPIException
public void Gather(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype,Object recvbuf, int recvoffset, int recvcount, Datatype recvtype,int root) throws MPIException
public void Allgather(Object sendbuf, int sendoffset int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype)
throws MPIException
public void Alltoall(Object sendbuf, int sendoffset, int sendcount, Datatype sendtype, Object recvbuf, int recvoffset, int recvcount, Datatype recvtype)
throws MPIException

17
49
Reduce collective operations
1
2
3
4
5
15
1
2
3
4
5
15
15
15
15
15
reduce
allreduce
Processes
Data� MPI.PROD� MPI.SUM� MPI.MIN� MPI.MAX� MPI.LAND� MPI.BAND� MPI.LOR� MPI.BOR� MPI.LXOR� MPI.BXOR� MPI.MINLOC� MPI.MAXLOC
Processes
50
Reduce collective operations
public void Reduce(Object sendbuf, int sendoffset,Object recvbuf, int recvoffset, int count,Datatype datatype, Op op, int root)
throws MPIException
public void Allreduce(Object sendbuf, int sendoffset,Object recvbuf, int recvoffset, int count,
Datatype datatype, Op op) throws MPIException
51
Collective Communication Performance

18
52
MPJ Design
MPJ point to point communications (Base level)
mpjdev (MPJ Device level)
MPJ collective Communications (High level)
Hardware (NIC, Memory etc)
MPJ API
JNI Java NIO
Java Virtual Machine (JVM)
JNI
Native MPIgmdev
ThreadsAPI
smpdev
xdev
niodev
53
Summary
• MPJ Express is a Java messaging system that can be used to write parallel applications: – MPJ/Ibis and mpiJava are other similar software
• MPJ Express provides point-to-point communication methods like Send() and Recv(): – Blocking and non-blocking versions
• Collective communications is also supported


















