
POMDPs: 5 Reward Shaping: 4 Intrinsic RL: 4 Function Approximation: 3.
25
• POMDPs: 5 • Reward Shaping: 4 • Intrinsic RL: 4 • Function Approximation: 3
-
Upload
tobias-palmer -
Category
Documents
-
view
217 -
download
0
Transcript of POMDPs: 5 Reward Shaping: 4 Intrinsic RL: 4 Function Approximation: 3.

• POMDPs: 5• Reward Shaping: 4• Intrinsic RL: 4• Function Approximation: 3

• https://www.youtube.com/watch?v=ek0FrCaogcs

Evaluation Metrics
• Asymptotic improvement• Jumpstart improvement• Speed improvement
– Total reward– Slope of line– Time to threshold

Task 2 from Scratch Task 2 with Transfer Task 1 + Task 2 withTransfer
Time
Target: no Transfer Target: with Transfer Target + Source: with Transfer
Two distinct scenarios:1. Target Time Metric: Successful if target task learning time reduced
Time to Threshold
2. Total Time Metric: Successful if total (source + target) time reduced
“Sunk Cost” is ignoredSource task(s) independently useful
Effectively utilize past knowledge
Only care about TargetSource Task(s) not usefulMinimize total training

K2
K3 T2
T1
K1
Both takers move towards player with ball
Goal: Maintain possession of ball
5 agents3 (stochastic) actions13 (noisy & continuous) state variables
Keeper with ball may hold ball or pass to either teammate
Keepaway [Stone, Sutton, and Kuhlmann 2005]
4 vs. 3:
7 agents4 actions19 state variables

Learning Keepaway• Sarsa update
– CMAC, RBF, and neural network approximation successful• Qπ(s,a): Predicted number of steps episode will last
– Reward = +1 for every timestep

’s Effect on CMACs
4 vs. 33 vs. 2
• For each weight in 4 vs. 3 function approximator:o Use inter-task mapping to find corresponding 3 vs. 2 weight

Keepaway Hand-coded χA
• Hold4v3 Hold3v2
• Pass14v3 Pass13v2
• Pass24v3 Pass23v2
• Pass34v3 Pass23v2
Actions in 4 vs. 3 have “similar” actions in 3 vs. 2

Value Function Transfer
ρ(QS (SS, AS)) = QT (ST, AT)
Action-Value function transferred
ρ is task-dependant: relies on inter-task mappings
ρ
Q not defined on ST and ATSource Task
Target Task
Environment
Agent
ActionT StateT RewardT
Environment
Agent
ActionS StateS RewardS
QS: SS×AS→ℜQT: ST×AT→ℜ

0 10 50 100 250 500 1000 3000 60000
5
10
15
20
25
30
35
Avg. 4 vs. 3 timeAvg. 3 vs. 2 time
# 3 vs. 2 Episodes
Sim
ulat
or H
ours
Value Function Transfer: Time to threshold in 4 vs. 3
Total Time
No Transfer
Target Task Time
}

• For similar target task, the transferred knowledge … [can] significantly improve its performance.
• But how do we define the similar task more specifically? – Same state-action space– similar objectives

– Is transfer beneficial for a given pair of tasks? • Avoid Negative Transfer?• Reduce total time metric?
Effects of Task Similarity
Transfer trivial Transfer impossible
Source identical to Target Source unrelated to Target

Example Transfer Domains• Series of mazes with different goals [Fernandez and Veloso, 2006]• Mazes with different structures [Konidaris and Barto, 2007]
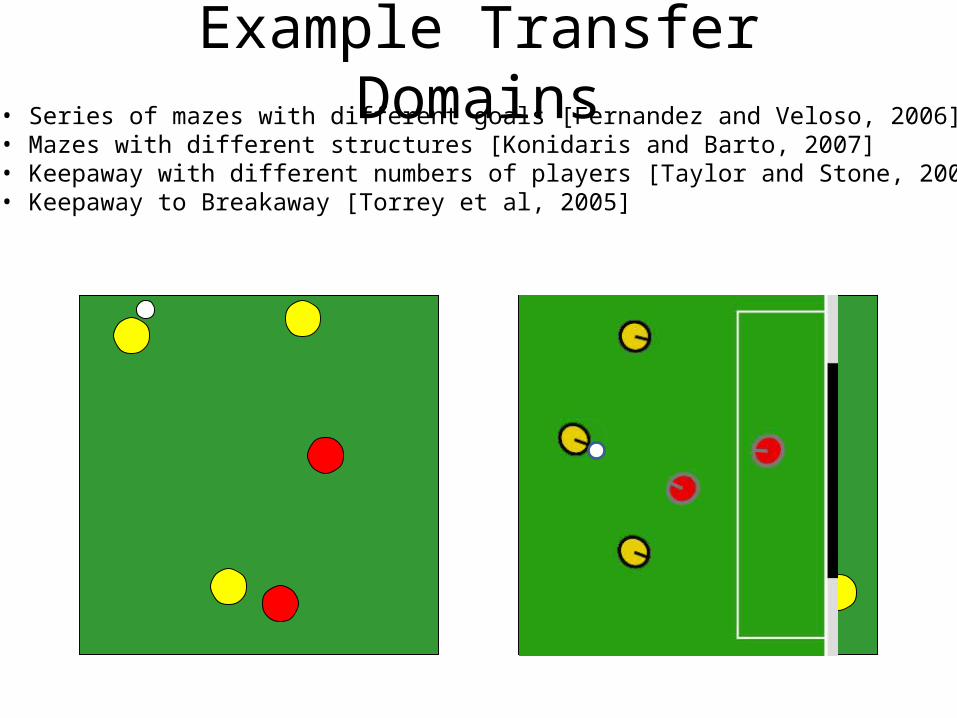
Example Transfer Domains• Series of mazes with different goals [Fernandez and Veloso, 2006]• Mazes with different structures [Konidaris and Barto, 2007]• Keepaway with different numbers of players [Taylor and Stone, 2005]• Keepaway to Breakaway [Torrey et al, 2005]

All tasks are drawn from the same domaino Task: An MDPo Domain: Setting for semantically similar tasks
oWhat about Cross-Domain Transfer?o Source task could be much simplero Show that source and target can be less similar
Example Transfer Domains• Series of mazes with different goals [Fernandez and Veloso, 2006]• Mazes with different structures [Konidaris and Barto, 2007]• Keepaway with different numbers of players [Taylor and Stone, 2005]• Keepaway to Breakaway [Torrey et al, 2005]

Source Task: Ringworld
RingworldGoal: avoid being tagged
2 agents3 actions7 state variablesFully ObservableDiscrete State Space (Q-table with ~8,100 s,a pairs)Stochastic Actions
Opponent moves directly towards player
Player may stay or run towards a pre-defined location
K2
K3 T2
T1
K1
3 vs. 2 KeepawayGoal: Maintain possession of ball
5 agents3 actions13 state variablesPartially ObservableContinuous State SpaceStochastic Actions

Rule Transfer Overview
1. Learn a policy (π : S → A) in the source task– TD, Policy Search, Model-Based, etc.
2. Learn a decision list, Dsource, summarizing π
3. Translate (Dsource) → Dtarget (applies to target task)– State variables and actions can differ in two tasks
4. Use Dtarget to learn a policy in target task
Allows for different learning methods and function approximators in source and target tasks
Learn π Learn DsourceTranslate (Dsource)
→ Dtarget Use Dtarget

Rule Transfer DetailsLearn π Learn Dsource
Translate (Dsource) → Dtarget
Use Dtarget
Environment
Agent
Action State Reward
Source Task
• In this work we use Sarsao Q : S × A → Return
• Other learning methods possible

Rule Transfer DetailsLearn π Learn Dsource
Translate (Dsource) → Dtarget
Use Dtarget
• Use learned policy to record S, A pairs• Use JRip (RIPPER in Weka) to learn a decision list
Environment
Agent
Action State RewardAction State
State Action
… …
• IF s1 < 4 and s2 > 5 → a1
• ELSEIF s1 < 3 → a2
• ELSEIF s3 > 7 → a1
• …

Rule Transfer DetailsLearn π Learn Dsource
Translate (Dsource) → Dtarget
Use Dtarget
• Inter-task Mappings• χx: starget→ssource
– Given state variable in target task (some x from s = x1, x2, … xn)
– Return corresponding state variable in source task
• χA: atarget→asource
– Similar, but for actions
rule rule’translate
χ A
χ x

Rule Transfer DetailsLearn π Learn Dsource
Translate (Dsource) → Dtarget
Use Dtarget
K2
K3 T2
T1
K1
Stay Hold BallRunNear Pass to K2
RunFar Pass to K3
dist(Player, Opponent) dist(K1,T1)… …
χx
χA
IF dist(Player, Opponent) > 4 → Stay
IF dist(K1,T1) > 4 → Hold Ball

Rule Transfer DetailsLearn π Learn Dsource
Translate (Dsource) → Dtarget
Use Dtarget
• Many possible ways to use Dtarget
o Value Bonuso Extra Actiono Extra Variable
• Assuming TD learner in target tasko Should generalize to other learning methods
Evaluate agent’s 3 actions in state s = s1, s2
Q(s1, s2, a1) = 5Q(s1, s2, a2) = 3Q(s1, s2, a3) = 4
Dtarget(s) = a2
+ 8
Evaluate agent’s 3 actions in state s = s1, s2
Q(s1, s2, a1) = 5Q(s1, s2, a2) = 3Q(s1, s2, a3) = 4Q(s1, s2, a4) = 7 (take action a2)
Evaluate agent’s 3 actions in state s = s1, s2
Q(s1, s2, s3, a1) = 5Q(s1, s2, s3, a2) = 3Q(s1, s2, s3, a3) = 4
Evaluate agent’s 3 actions in state s = s1, s2
Q(s1, s2, a2, a1) = 5Q(s1, s2, a2, a2) = 9Q(s1, s2, a2, a3) = 4
(shaping)(initially force agent to select)(initially force agent to select)

Comparison of Rule Transfer Methods
Without Transfer Only Follow Rules
Rules from 5 hours of training
Extra VariableExtra ActionValue Bonus

Inter-domain Transfer: Averaged Results
Training Time (simulator hours)
Epis
ode
Dur
ation
(sim
ulat
or s
econ
ds)
Ringworld: 20,000 episodes (~1 minute wall clock time)
Success: Four types of transfer improvement!

Future Work
• Theoretical Guarantees / Bounds• Avoiding Negative Transfer• Curriculum Learning• Autonomously selecting inter-task mappings• Leverage supervised learning techniques• Simulation to Physical Robots• Humans?
![Correction and reassessment of intrinsic viscosity and the … · 2007. 11. 21. · the [rl] is reduced dramatically. For n-alkanes smaller than octane, the [rl] becomes negative](https://static.fdocuments.in/doc/165x107/6103ca5fb0266e2bd873dab6/correction-and-reassessment-of-intrinsic-viscosity-and-the-2007-11-21-the-rl.jpg)

















