
Persistent RNNs: Stashing Recurrent Weights On-Chip
21
Persistent RNNs (stashing recurrent weights on-chip) Presenter: Gregory Diamos Silicon Valley AI Lab Baidu Jun 20, 2016 Presenter: Gregory Diamos Persistent RNNs
-
Upload
baidu-usa-research -
Category
Technology
-
view
163 -
download
2
Transcript of Persistent RNNs: Stashing Recurrent Weights On-Chip

Persistent RNNs(stashing recurrent weights on-chip)
Presenter: Gregory Diamos
Silicon Valley AI LabBaidu
Jun 20, 2016
Presenter: Gregory Diamos Persistent RNNs

Machine learning has benefited greatly from faster computer systems.
GPUs in particular, have delivered a step forward.
Presenter: Gregory Diamos Persistent RNNs

Imagine the problems that you could solve
with even faster systems.
Presenter: Gregory Diamos Persistent RNNs

HPC is an opportunity
10,000x
TitanX GPU
Fastest superco
mputer
Presenter: Gregory Diamos Persistent RNNs

Limits of data-parallelism
Presenter: Gregory Diamos Persistent RNNs

Hardware limits
wal
l-cl
ock
tim
e to
con
verg
ence
mini-batch size
inefficient hardware
Hardware becomes less efficient at small batch sizes.
Presenter: Gregory Diamos Persistent RNNs

Optimization limits
wal
l-cl
ock
tim
e to
con
verg
ence
mini-batch size
inefficient optimization
Optimization algorithms perform more work at large batch sizes.
Presenter: Gregory Diamos Persistent RNNs

Mini-batch limits
wal
l-cl
ock
tim
e to
con
verg
ence
mini-batch size
inefficient hardware inefficient optimization
These effects combine to limit the maximum number of GPUs.
Presenter: Gregory Diamos Persistent RNNs

Persistent RNNs
Open source CUDA implementation:
https://github.com/baidu-research/persistent-rnns
Presenter: Gregory Diamos Persistent RNNs

Persistent RNN Details
Presenter: Gregory Diamos Persistent RNNs

Persistent RNNs
weights
GEMM GEMM GEMM GEMM
Persistent RNN
weights
weights weights weights
data0 data1 data2 data3 data4
data0 data1 data2 data3 data4
RNNs built on GEMM routines reload the weights each timestep.
However, the weights are constant, and this is wasteful.
Presenter: Gregory Diamos Persistent RNNs

Cache weights in registers
weights
GPU thread
registers
datapath
Presenter: Gregory Diamos Persistent RNNs

A global barrier
data0 GPU data1 GPUbarrier
Presenter: Gregory Diamos Persistent RNNs

Experiments
Presenter: Gregory Diamos Persistent RNNs

Scaling to 128 GPUs
Presenter: Gregory Diamos Persistent RNNs
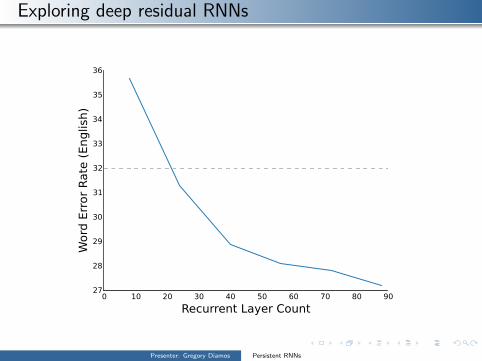
Exploring deep residual RNNs
Presenter: Gregory Diamos Persistent RNNs

Pascal and future
Future GPUs will enable bigger and faster RNN layers.
Presenter: Gregory Diamos Persistent RNNs

Three challenges
Presenter: Gregory Diamos Persistent RNNs

Close the gap with the fastest supercomputers.
Presenter: Gregory Diamos Persistent RNNs

Do not settle for inefficient algorithms.
Presenter: Gregory Diamos Persistent RNNs

Push performance to the edge of physical limits.
10 PetaFlops in 300 Watts.
150 ExaFlops in 25 MegaWatts.
Presenter: Gregory Diamos Persistent RNNs


















