
On the convergence of SDDP and related algorithms
32
On the convergence of SDDP and related algorithms Speaker: Ziming Guan Supervisor: A. B. Philpott Sponsor: Fonterra New Zealand
description
On the convergence of SDDP and related algorithms. Speaker: Ziming Guan Supervisor: A. B. Philpott Sponsor: Fonterra New Zealand. Motivation. Pereira and Pinto, Multi-Stage Stochastic Optimization Applied to Energy Planning, Mathematical Programming, 52, pp. 359-375, 1991. Summary. - PowerPoint PPT Presentation
Transcript of On the convergence of SDDP and related algorithms

On the convergence of SDDP and related algorithms
Speaker: Ziming Guan
Supervisor: A. B. Philpott
Sponsor: Fonterra New Zealand

Motivation
• Pereira and Pinto, Multi-Stage Stochastic Optimization Applied to Energy Planning, Mathematical Programming, 52, pp. 359-375, 1991.

Summary
• Description of problem class
• SDDP and its related algorithm
• Theoretical convergence
• Implementation issues

Properties for random quantities
• Random quantities appear only on the right-hand side of the linear constraints in each stage.
• The set of random outcomes is discrete and finite.
• Random quantities in different stages are independent.
• Can accommodate PARMA process for RHS uncertainty.
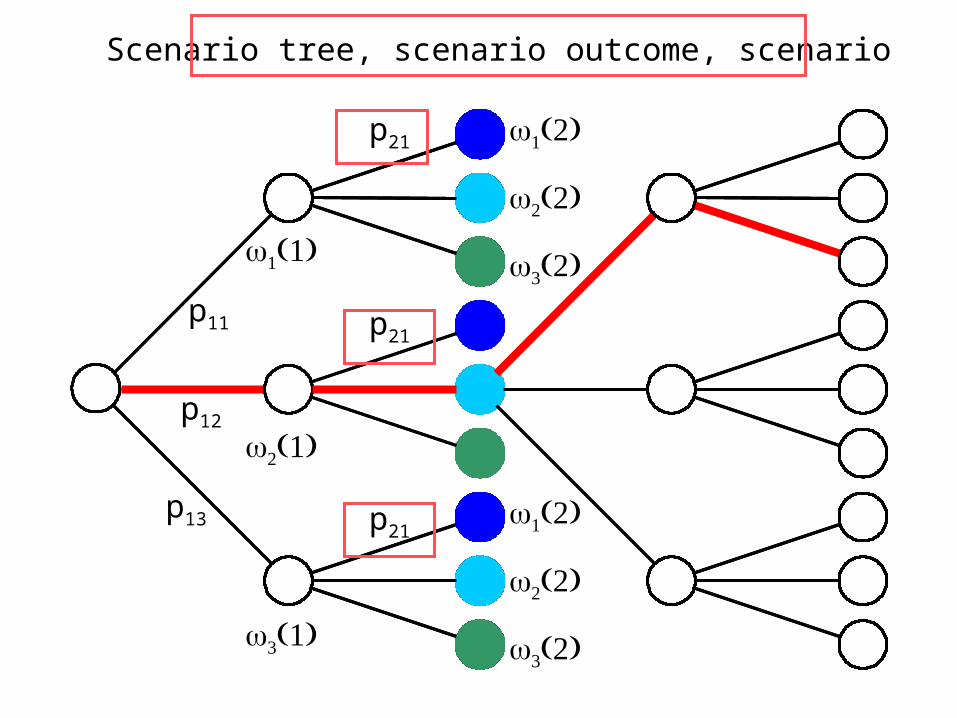
p12
p11
p13
p21
p21
p21
Scenario tree, scenario outcome, scenario

Hydro-thermal scheduling

Stage problem

Cuts
Θ(t+1)
Reservoir storage, x(t+1)

Stochastic Dual Dynamic Programming
• [Pereira and Pinto, 1991]
• Initialization: Sample some scenarios and fix them through the course of the algorithm.
• Forward pass: For stage t=1,…,T, solve the stage t problem for each scenario.
• Calculate the lower bound and upper bound.• If not converge,
– Backward pass: For stage t=T-1,…,1, for the stage t problem in each scenario, solve all stage t+1 problems to calculate a cut for stage t problems.
– Back to Forward pass.

p11
p13
p12

p11
p13
p12

p11
p13
p12

Dynamic Outer Approximation Sampling Algorithm
No upper bound calculation until algorithm is terminated.

p11
p13
p12

p11
p13
p12

p11
p13
p12

• We have a convergence proof for DOASA.
• This can be used to understand the convergence behaviour of SDDP.

Sampling properties of DOASA
• Forward Pass Sampling Property (FPSP):
Each scenario is traversed infinitely many times with probability 1 in the forward pass.

How do we guarantee this?
Either • Independently sample a single outcome in each stage
with a positive probability for each scenario outcome in the forward pass.
• Repeat an exhaustive enumeration of each scenario in the forward pass.

Convergence Theorem
• Under FPSP, DOASA converges with probability 1 to an optimal solution to the stage 1 problem in a finite number of iterations.

Sampling in cut calculation
• Sample some stage problems.
• Keep a list of dual solutions, search the best one for the stage problem that are not sampled.
• Backward Pass Sampling Property (BPSP):
In any stage, each scenario outcome is visited infinitely many times with probability 1 in the backward pass.

Convergence Theorem
• Under FPSP and BPSP, the algorithm converges with probability 1 to an optimal solution to the stage 1 problem in a finite number of iterations.

Corollaries
• If every outcome is used in cut calculation we only need FPSP.
• We can bias sampling as long as FPSP is satisfied. (Note estimation of upper bound needs unbiased scenarios.)

Resampling
• SDDP does not resample the forward pass. It creates N scenarios of inflows at the start.
• FPSP is NOT satisfied.
• SDDP will terminate with probability 1.
• Cuts give a lower bound, but policy need not be optimal.

Dry
Dry
Dry
Wet
Wet
Wet
Always Dry, when at convergence...

Negative inflows
• SDDP uses PARMA model for inflows.
• Negative inflows might result – not physically possible.
• Some implementations adjust random outcomes to make inflow non-negative – this destroys stage-wise independence.
• Cut sharing is no longer valid.
• Log-normal inflows not valid for convexity reasons.

Convexity matters in backward pass
• Transmission losses can make stage problem not convex if free disposal is not allowed.
• Unit commitment integer effects are not convex.

Convergence expectation
• We run DOASA on a problem at Fonterra NZ.
• Maximum size for convergence = 12 stages x 24 states.
• In revenue management application, 8 states, 5000 stages converge, 20 states, 5000 stages does not.
• Convergence is problem dependent.

Case study: NZ model
S
N
demand
demand TPO
HAW
MAN

Computational results: NZ model
• 9 reservoirs• 52 weekly stages• 30 inflow outcomes per stage • Model written in AMPL/CPLEX
• Takes 100 iterations and 2 hours on a standard Windows PC to converge

2005-2006 policy simulated with historical inflow sequences
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 10 20 30 40 50
1995
1996
1997
1998
1999
2000
2001
2002
2003
2004

END


















