
Neural Networks Chapter 7 Joost N. Kok Universiteit Leiden.
34
Neural Networks Chapter 7 Joost N. Kok Universiteit Leiden
-
Upload
pauline-chase -
Category
Documents
-
view
216 -
download
1
Transcript of Neural Networks Chapter 7 Joost N. Kok Universiteit Leiden.

Neural NetworksChapter 7
Joost N. Kok
Universiteit Leiden

Recurrent Networks
• Learning Time Sequences:– Sequence Recognition– Sequence Reproduction– Temporal Association

Recurrent Networks
• Tapped Delay Lines:– Keep several old values in a buffer

Recurrent Networks
• Drawbacks:– Length must be chosen in advance, leads to
large number of input units, large number of training patterns, etc.
• Replace fixed time delays by filters:
t
tdtxttGty )(),();(

Recurrent Networks
• Partially recurrent networks
Output Nodes
Hidden Nodes
Input Nodes Context Nodes

Recurrent Networks
• Jordan Network

Recurrent Networks
• Elman Network
Output Nodes
Hidden Nodes
Input Nodes Context Nodes
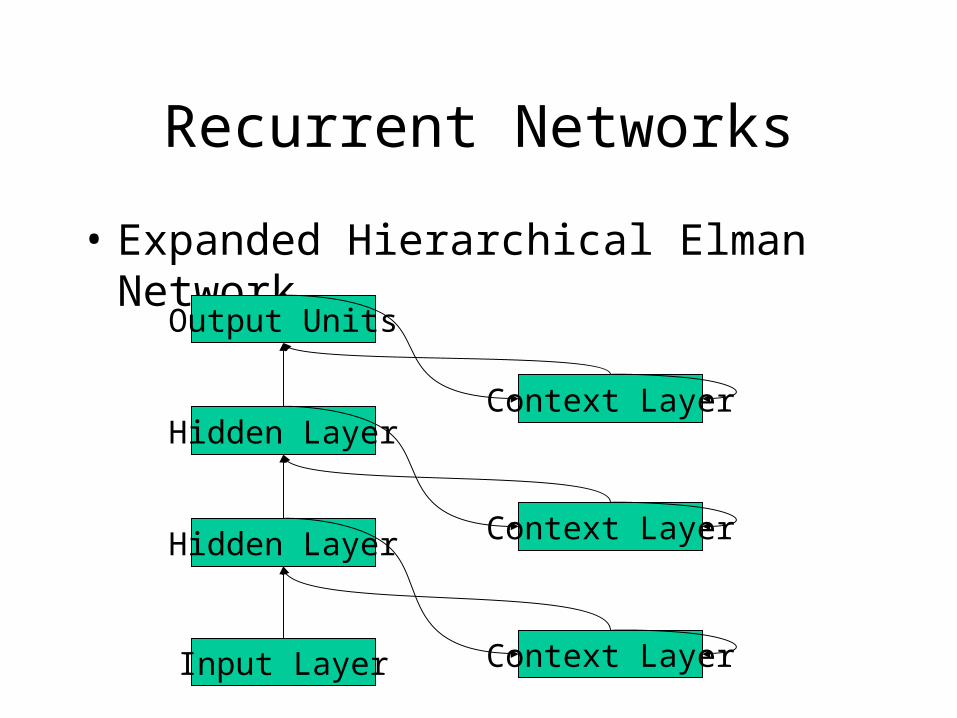
Recurrent Networks
• Expanded Hierarchical Elman Network
Input Layer
Hidden Layer
Hidden Layer
Output Units
Context Layer
Context Layer
Context Layer

Recurrent Networks
)1()1()()1( 2 tOtOtOtC iiii


Recurrent Networks
• Back-Propagation Through Time
jijijii ttVwgthgtV )()())(()1(

Reinforcement Learning
• Supervised learning with some feedback
• Reinforcement Learning Problems:– Class I: reinforcement signal is always the same
for given input-output pair– Class II: stochastic environment, fixed
probability for each input-output pair– Class III: reinforcement and input patterns
depend on past history of network output

Associative Reward-Penalty
• Stochastic Output Units • Reinforcement Signal• Target
• Error
1iS
1r
1
1
rifS
rifS
i
ii
iii S

Associative Reward Penalty
• Learning Rule
)(1][
)(1][
penaltyrifVSS
rewardrifVSSw
jii
jiiij

Models and Critics
Environment

Reinforcement Comparison
EnvironmentCritic

Reinforcement Learning
• Reinforcement-Learning Model– Agent receives input I which is some indication
of current state s of environment– Then the agent chooses an action a – The action changes the state of the environment
and the value is communicated through a scalar reinforcement signal r

Reinforcement Learning
• Environment: You are in state 65. You have four possible actions.
• Agent: I’ll take action 2.• Environment: You received a reinforcement of 7 units.
You are now in state 15. You have two possible actions.• Agent: I’ll take action 1.• Environment: You received a reinforcement of -4 units.
You are now in state 12. You have two possible actions.• Agent: I’ll take action 2.• …

Reinforcement Learning
• Environment is non-deterministic: – same action in same state may result in
different states and different reinforcements
• The environment is stationary:– Probabilities of making state transitions or
receiving specific reinforcement signals do not change over time

Reinforcement Learning
• Two types of learning:– Model-free learning– Model based learning
• Typical application areas:– Robots– Mazes– Games– …

Reinforcement Learning
• Paper: A short introduction to Reinforcement Learning (Stephan ten Hagen and Ben Krose)

Reinforcement Learning
• Environment is a Markov Decision Proces
}|Pr{ 1 aassssP kkkass
)(,, sAaSss

Reinforcement Learning
• Optimize interaction with environment
• Optimize action selection mechanism
• Temporal Credit Assignment Problem
• Policy: action selection mechanism
• Value function:
1
1 }|{)(N
kiki
ki ssrEsV

Reinforcement Learning
• Optimal Value function based on optimal policy:
)(max)()(** sVsVsV

Reinforcement Learning
• Policy Evaluation: approximate value function for given policy
• Policy Iteration: start with arbitrary policy and improve
}|)({:)( 111 sssVrEsV kklkl
))((:)( )()(1 sVRPsV l
sss
s
sssl

Reinforcement Learning
• Improve Policy:
))((maxarg:)( sVRPs mass
s
ass
a

Reinforcement Learning
• Value Iteration: combine policy evaluation and policy improvement steps:
))((maxarg:)(1 sVRPs lass
s
ass
al
))((max:)(1 sVRPsV lass
s
ass
al

Reinforcement Learning
• Monte Carlo: use if and are not known
• Given a policy, several complete iterations are performed
• Exploration/Exploitation Dilemma– Extract Information– Optimize Interaction
assP
assR

Reinforcement Learning
• Temporal Difference (TD) Learning– During interaction, part of the update can be calculated– Information from previous interactions is used
))()(()()( 111 ttttttttt sVsVrsVsV
ttt sssVsV if)()(1

Reinforcement Learning
• TD() learning: discount factor : the longer ago the state was visited, the less it will be effected by the present update
)())()(()()( 111 sesVsVrsVsV tttttttt
t
kss
ktt kse
1,)()(
otherwise0
1,
kss
ssk

Reinforcement Learning
• Q-learning: combine actor and critic:
1
1 }|{),(N
kikki
ki aassrEasQ
s
ass
ass sVRPasQ ))((),(

Reinforcement Learning
• Use temporal difference learning
),(),(if),(),(1 tttt asasasQasQ
)),(),(max(),(),( 111 ttttta
ttttttt asQasQrasQasQ

Reinforcement Learning
• Q() learning:
),(1 asQt
)()),(),(max(),( 11 seasQasQrasQ tttttta
tt

Reinforcement Learning
• Feedforward Neural Networks are used when state/action spaces are large for of estimates of V(s) and Q(s,a).


















