Network Channel Estimation in Cooperative Wireless Networks
4
Network Channel Estimation in Cooperative Wireless Networks Ahmad Khoshnevis, and Ashutosh Sabharwal Dept. of Electrical and Computer Eng. Rice University Houston, TX 77005 E-mail: {farbod,ashu}@rice.edu Abstract — In distributed wireless networks, where nodes actively participate in helping com- munication for other nodes, they are typically unaware of their neighourhood and hence have to “estimate” it before sending any useful data. In this paper, we formalize the concept of node neighbourhood by introducing the notion of net- work channel, in which all nodes become part of a large channel. The notion of network channel is then used to study routing in decode and for- ward networks. To do the same, we introduce the concept of network coherence time, which de- notes the time for which the network topology re- mains approximately constant. The new concepts are used to study the tradeoffs between encoding rate of route discovery packets, number of discov- ered routes and accuracy of subsequent network channel estimation. Finally, we propose a simple adaptive algorithm for route selection using out- age capacity as the metric for route selection, and show that our algorithm outperforms the existing route selection based on the minimum hop count. I. Introduction Information theoretic analysis of wireless networks has highlighted the utility of node collaboration (e.g., [1, 2, 3]). Though the role of channel coding as a fun- damental construct is clear in the above cited analysis, the role of network protocols like routing and medium ac- cess remains unclear. In fact, it is not even clear if these protocols are fundamental constructs or not. If they are fundamental to the operation of wireless networks (and communication networks in general), then it is important to understand how they should be optimally designed. Motivated by these fundamental questions, in this paper we focus on routing in multi-hop wireless networks. 1 Our contributions in this paper are two-fold. First, we “reverse engineer” the reason why routing protocols are used in practical wireless networks. The main reason is that nodes are unaware of the presence of their desti- nation and their neighbourhood (and hence the channel probability law between different nodes). The above real- ization naturally leads to the concept of a network chan- nel between source and destination nodes. By treating the whole network of nodes as a channel, we show that routing protocols are simply network channel estimators, where the estimation is performed to find the channel probability law. Thus the objective of network channel estimation is different from conventional channel estima- tion, where the current channel realization is estimated to 1 Note that routing is used in both wired and wireless networks, but our work is directly applicable to only wireless networks. aid in reception. Finally, note that if there is no mobility in the system and the channel probability law between nodes does not change with time, network channel esti- mation is not an interesting problem. Since, without mo- bility, nodes can estimate the probability laws once and then use them forever at a vanishingly small asymptotic rate loss. Second, to demonstrate the utility of the network chan- nel formalism, we consider conventional minimum-hop routing (for decode and forward coding) and show it can be improved upon by no additional overhead. The main idea of the proposed improvement is simple, measure the loss probabilities of the routes before committing to one. The loss probabilities can be calculated by simply measur- ing the number of unacknowledged packets sent at rate R. Even with our elementary setup, several important tradeoffs and results appear. First, the rate at which route discovery packets are encoded impacts the number of discovered routes; lower encoding rates implies more routes can be potentially discovered. Second, if more routes are discovered, then the likelihood of both good and bad routes getting discovered increases, making the process of selecting the optimum routes harder. For our proposed network estimation based approach, it implies that longer estimation phase is needed for the case with more routes. Lastly, minimum hop-count route are sel- dom good and the transmitter is mostly better off select- ing a route at random. Throughout the paper, we study systems which first estimate the network channel probability law and then adapt their transmissions accordingly. Though this tech- nique is not shown to be capacity achieving in any sense, it should be noted that none of the known information- theoretic results apply to the problem of unknown net- work channels. Lack of knowledge about the exact chan- nel probability law is typically studied as the problem of compound channels, but that analysis is typically limited to systems where there is no feedback available to learn the probability law. Furthermore, as will become clear from the next section, network channel is markedly dif- ferent from the channels studied in compound channel capacity theorems. The network channel is not passive, i.e., it consists of other nodes which are equipped with both power and computational capabilities. The rest of the paper is organized as follows. In Sec- tion II, we introduce the concept of network channel via several examples. The main results are presented in Sec- tion III and we conclude in Section IV. II. Network is the Channel Consider a network N which has N nodes. Generi- cally, the nodes are considered to belong to one of the two classes. The first class, labelled as C, consists of
Transcript of Network Channel Estimation in Cooperative Wireless Networks

Network Channel Estimation in Cooperative Wireless Networks
Ahmad Khoshnevis, and Ashutosh SabharwalDept. of Electrical and Computer Eng.
Rice UniversityHouston, TX 77005
E-mail: {farbod,ashu}@rice.edu
Abstract — In distributed wireless networks,where nodes actively participate in helping com-munication for other nodes, they are typicallyunaware of their neighourhood and hence haveto “estimate” it before sending any useful data.In this paper, we formalize the concept of nodeneighbourhood by introducing the notion of net-work channel, in which all nodes become part ofa large channel. The notion of network channelis then used to study routing in decode and for-ward networks. To do the same, we introducethe concept of network coherence time, which de-notes the time for which the network topology re-mains approximately constant. The new conceptsare used to study the tradeoffs between encodingrate of route discovery packets, number of discov-ered routes and accuracy of subsequent networkchannel estimation. Finally, we propose a simpleadaptive algorithm for route selection using out-age capacity as the metric for route selection, andshow that our algorithm outperforms the existingroute selection based on the minimum hop count.
I. Introduction
Information theoretic analysis of wireless networkshas highlighted the utility of node collaboration (e.g.,[1, 2, 3]). Though the role of channel coding as a fun-damental construct is clear in the above cited analysis,the role of network protocols like routing and medium ac-cess remains unclear. In fact, it is not even clear if theseprotocols are fundamental constructs or not. If they arefundamental to the operation of wireless networks (andcommunication networks in general), then it is importantto understand how they should be optimally designed.Motivated by these fundamental questions, in this paperwe focus on routing in multi-hop wireless networks.1
Our contributions in this paper are two-fold. First,we “reverse engineer” the reason why routing protocolsare used in practical wireless networks. The main reasonis that nodes are unaware of the presence of their desti-nation and their neighbourhood (and hence the channelprobability law between different nodes). The above real-ization naturally leads to the concept of a network chan-nel between source and destination nodes. By treatingthe whole network of nodes as a channel, we show thatrouting protocols are simply network channel estimators,where the estimation is performed to find the channelprobability law. Thus the objective of network channelestimation is different from conventional channel estima-tion, where the current channel realization is estimated to
1Note that routing is used in both wired and wireless networks,but our work is directly applicable to only wireless networks.
aid in reception. Finally, note that if there is no mobilityin the system and the channel probability law betweennodes does not change with time, network channel esti-mation is not an interesting problem. Since, without mo-bility, nodes can estimate the probability laws once andthen use them forever at a vanishingly small asymptoticrate loss.
Second, to demonstrate the utility of the network chan-nel formalism, we consider conventional minimum-hoprouting (for decode and forward coding) and show it canbe improved upon by no additional overhead. The mainidea of the proposed improvement is simple, measure theloss probabilities of the routes before committing to one.The loss probabilities can be calculated by simply measur-ing the number of unacknowledged packets sent at rateR. Even with our elementary setup, several importanttradeoffs and results appear. First, the rate at whichroute discovery packets are encoded impacts the numberof discovered routes; lower encoding rates implies moreroutes can be potentially discovered. Second, if moreroutes are discovered, then the likelihood of both goodand bad routes getting discovered increases, making theprocess of selecting the optimum routes harder. For ourproposed network estimation based approach, it impliesthat longer estimation phase is needed for the case withmore routes. Lastly, minimum hop-count route are sel-dom good and the transmitter is mostly better off select-ing a route at random.
Throughout the paper, we study systems which firstestimate the network channel probability law and thenadapt their transmissions accordingly. Though this tech-nique is not shown to be capacity achieving in any sense,it should be noted that none of the known information-theoretic results apply to the problem of unknown net-work channels. Lack of knowledge about the exact chan-nel probability law is typically studied as the problem ofcompound channels, but that analysis is typically limitedto systems where there is no feedback available to learnthe probability law. Furthermore, as will become clearfrom the next section, network channel is markedly dif-ferent from the channels studied in compound channelcapacity theorems. The network channel is not passive,i.e., it consists of other nodes which are equipped withboth power and computational capabilities.
The rest of the paper is organized as follows. In Sec-tion II, we introduce the concept of network channel viaseveral examples. The main results are presented in Sec-tion III and we conclude in Section IV.
II. Network is the Channel
Consider a network N which has N nodes. Generi-cally, the nodes are considered to belong to one of thetwo classes. The first class, labelled as C, consists of

Communicating nodes which can take three roles: source,destination or a relay for other peer nodes. The class rep-resented by C consists of typical mobile nodes in a wire-less network. The other class, denoted by G, are Gate-way nodes, and act as gateways to the backbone networkfor all other nodes in class C. The number of nodes inclass C is denoted by nC and in class G by nG , such thatnC + nG = N or equivalently, C ∪ G = N .
The time-varying channel between any two nodes iand j is denoted by hij . The channel hij could repre-sent a multipath channel or a multiple antenna channel,and in general, belongs to the set of multidimensionaltime-varying impulse responses. The first order proba-bility distribution of hij is denoted by pt(hij). In typi-cal wireless channels, there are two time-scales of varia-tions. The probability distribution, pt(·) varies accord-ing to the slow time-scale, due to large-scale mobility.The fast time-scale changes in phase and amplitude ofthe channel, known as fading, cause short time-scale vari-ations. The set of all inter-node channels is denoted byH = {hij : i, j ∈ N , i 6= j}. Depending on the allowablecooperation and coding, only a subset of channels in Hmay be of interest.
Following three examples clarify the above definitions.
Example 1 (Cellular Network) A typical cellu-lar network is shown in Figure 1(a). In this case,all mobile nodes m1, m2, . . . belong to the set C andthe base-stations belong to the set G. If all com-munication happens directly between base-stationsand mobiles, then the set of channels of interest isHc = {hij : i ∈ G & j ∈ C OR i ∈ C & j ∈ G} ⊂ H; theset of channels of interest are depicted in Figure 1(b).
Figure 1: Cellular Network.
Example 2 (Ad hoc Network) An ad hoc network isa collection of nodes with no central infrastructure, shownin Figure 2(a). In this case, all nodes in the networkbelong to the set C and set G is empty. Variations of adhoc networks exist which may have asymmetric node roles(some nodes act as only relays) and/or some nodes act asgateways to outside world. In ad hoc networks, Ha = H,i.e., all channels between nodes are of interest, as shownin Figure 2(b).
Example 3 (Cellular with ad hoc Extension)Consider the network in Figure 3(a), where nodes ina cellular network also act as relays for other peernodes [4, 5, 6, 7]. In this case, the set of C and G aredefined similar to Example 1, but the network channel isricher than that in a cellular network. Since nodes can
Figure 2: Ad hoc Network.
cooperate in relaying or forwarding other users informa-tion, He = {hij : i ∈ C & j ∈ N \ {i} OR i ∈ G & j ∈ C}.That is all channels between different mobiles are ofinterest, but the channels between different base-stationsare not of interest.
Figure 3: Ad hoc extension to cellular network.
III. Main Results
In this section, we review the concept of outage ca-pacity, introduce network channel estimation and thenpropose a simple method of estimating outage capacitywith no additional overhead to current protocols.
A Outage Capacity
The quality of any route is measured using its outagecapacity defined as
Ck(R) = (1− αk(R))R, (1)
where R is the rate of packet transmission and αk is theprobability of outage of route k under consideration. Letroute k constitute of g hops and the outage probabilityof each hop be given by αk,i, for i = 1, . . . , g. Then αk
can be calculated as
αk(R) = 1−g∏
i=1
(1− αk,i(R)) (2)
The outage probability for each hop, αk,i is defined as theprobability that the instantaneous mutual information isless than the desired rate R,
αk,i(R) = Probθ (I(X; Y |θ) < R) . (3)
The parameter θ denotes the state of system and changesin each transmission. For example, if there is no otherconcurrent transmission in the system which interferesthe current transmission, then θ = h, the current chan-nel state. If there is an interfering transmission, thenθ refers to a multidimensional parameter which includesadditional information about the interference.

When there are no interfering users (θ = h), then fora Rayleigh block faded channel, the probability of outageis given by
αk,i(R) = Prob
(|hi|2 <
2R − 1
SNRi
)= 1− e−γ , where γ =
2R − 1
SNRi
. (4)
The factor SNRi is the average received SNR at the re-ceiving node of the ith hop.
αk(R) = 1−g∏
i=1
(1− αk,i(R))
= 1− e−∑g
i=1 γi . (5)
B Network Channel Estimation
In practice, the source node is not unaware of the net-work channel, i.e., the network topology and the proba-bility law governing the channel between any two nodesis unknown. Almost all of information-theoretic analysiswhich proposes to use advanced collaborative coding toachieve higher end-to-end throughput assumes that theseprobability laws and the network topology are knownapriori [1, 2, 8]. Since the network channel is unknown,either it has to be estimated before the source can deter-mine at what rates it can reliably send the data, or it canuse an estimation-free method, much like in compoundchannel problems [9]. Note that compound channel ca-pacity analysis consists of methods which do not aim atestimating the channel distribution and using feedback atthe transmitter. Thus, with the availability of feedback,it is not immediately clear which transmission strategiesare optimal over the network channel.
Routing algorithms perform two tasks. First, they de-termine if the destination node is available or not.2 Sec-ond, they provide an estimate of the network topologyand the inter-node distributions. Below we present threeresults, which show the tradeoff involved in probability ofdiscovering a route, number of routes and the probabilityof finding the capacity optimal route.Route Discovery: Consider that the route discovery isperformed by using packets encoded at rate R′. Thenroute k is discovered with probability 1 − αk(R′). Now,it is straightforward to show the following result.
Fact 1 For any two routes x and y (with possibly unequalnumber of hops),
αx(R) < αy(R) ⇐⇒ αx(R′) < αy(R′),
for any value of R and R′ if αx and αy are given byEquation (5).
The above statement implies that routes with higher out-age capacity are more likely to be discovered, indepen-dent of the rate used to encode the route discovery pack-ets. Note that αk(R) decreases monotonically as R is de-creased. Thus smaller is R′ (the rate for route discovery
2In a usual information theoretic setup, destination node isassumed to be ready to receive the data. Destination discoveryis in essence a binary hypothesis test performed by the wholenetwork to determine the presence of the destination node.
packets), the higher is the chance that the route(s) withmaximum outage capacity Ck will be discovered. Butreducing R′ means that more routes will be discoveredand more network time will be consumed since smallerR′ implies longer packets.
Number of discovered routes: The choice of rate R′ de-termines the number of discovered routes. As R′ reducesthe outage probability for all routes reduces, thus increas-ing their chances of being discovered. Discovering routesat smaller R′ not only increases the chances of findingthe outage optimal route but also poor routes. Thus,with more discovered routes, the choice of finding theoptimal route becomes more challenging, as will becomeclear from the following results.
C Route Selection
By the end of route discovery procedure, the transmitteris provided with a set U = {ri}i∈A, where A is a finiteindexing set of routes ri, i ∈ A, from source node todestination node. In the next step, source node selects aroute, r ∈ U , for sending its data to the destination node.
In current systems there are variety of criteria, suchas minimum hop-count, minimum end-to-end delay, orhighest end-to-end throughput, used for route selection.However since the route discovery is performed by a singletransmission, the transmitter has only a single sample ofthe network channel. Hence network channel estimationbased on one measurement is by design very inaccurate.For example, in [10], it is shown that minimum hop countroute is not always throughput optimal or outage capacityoptimal, and finding the optimal routes requires manynetwork channel measurements.
Note that to estimate outage of any route requiresknowing the cummulative exponent in Equation (5),which can only be obtained by repeated measuremensof instantaneous SNRs on each of the links. But sucha procedure is not feasible in a real network. If the in-stantaneous SNR on any hop is low for a transmission,then that packet is lost and then the receiver possiblygets no feedback on the actual channel during that trans-mission. Thus, instead of directly measuring the averageSNR in Equation (5), we propose to measure the packetloss or equivalently outages αk(R) directly by measuringthe number of missing ACK packets.
Definition: Network coherence time, Tc, is defined asthe time during which the topology of the network is notaffected significantly by the mobility of nodes. Networkcoherence time is measured in packets and not in symbols.
Let Tc be the network coherence time, Ttr � Tc bethe channel estimation time, and U be the set of discov-ered routes. We divide Tc into two portions, i.e., chan-nel estimation phase, lasting Ttr packet durations, andtransmission period, lasting Ttx packet durations. There-fore Tc = Ttr + Ttx. During the estimation phase, Ttr,source node multiplexes through all the available routesfor sending the data. Receipt of acknowledgment of atransmission using a route, r ∈ U , can be seen as a onebit of feedback that gives the source node informationabout the reliability of that route. At the end of theestimation phase, the source node calculates the outageassociated with each route by simply dividing the num-
ber of losses by the total number of packets sent on eachroute. Network channel estimation phase provides moresamples of network channel for the source node, allowingit to estimate outage capacities of each route.
As one can notice, the decision made by the sourcenode is highly dependent on the number of samples ofnetwork channel, ns. Let |U| be the number of discoveredroutes. Then ns = Ttr/|U|. If length of the estimationphase is fixed, then ns depends on the number of discov-ered routes. Higher ns means fewer measurements perroute, which in turn leads to poorer accuracy estimatefor each of the routes. Hence there is a trade-off betweenthe number of discovered routes (which depends on therate of discovery R′) and the accuracy in finding outageoptimal route.
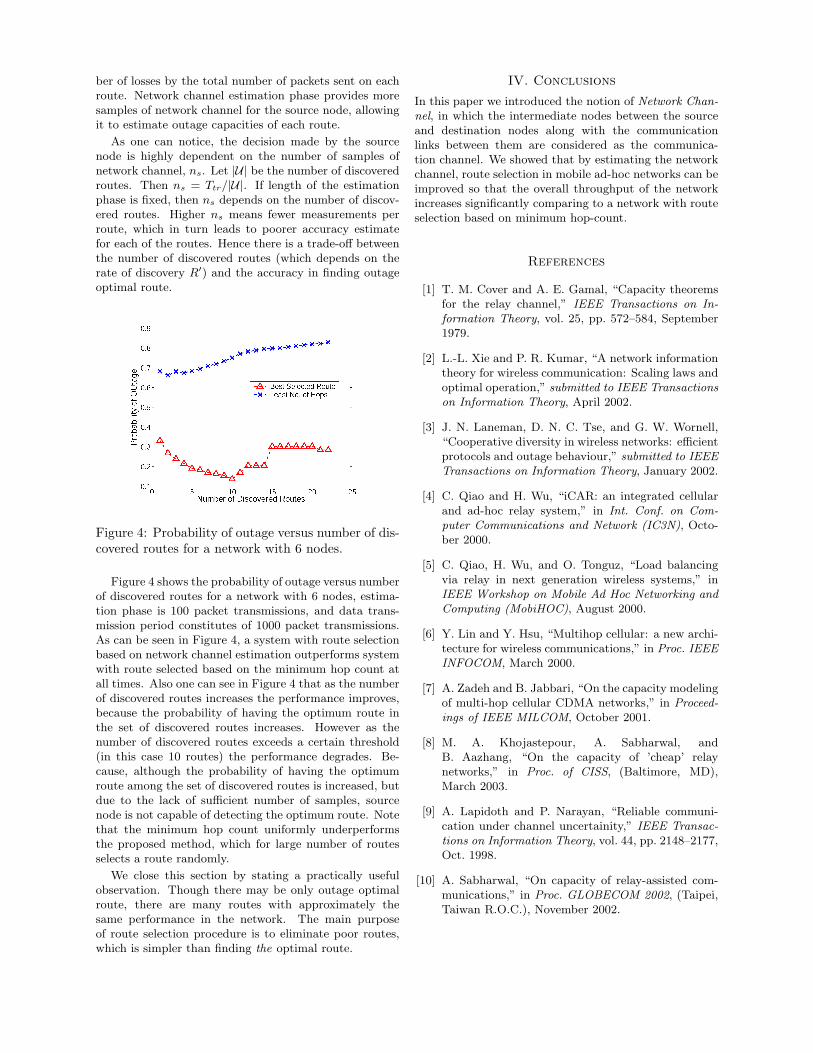
Figure 4: Probability of outage versus number of dis-covered routes for a network with 6 nodes.
Figure 4 shows the probability of outage versus numberof discovered routes for a network with 6 nodes, estima-tion phase is 100 packet transmissions, and data trans-mission period constitutes of 1000 packet transmissions.As can be seen in Figure 4, a system with route selectionbased on network channel estimation outperforms systemwith route selected based on the minimum hop count atall times. Also one can see in Figure 4 that as the numberof discovered routes increases the performance improves,because the probability of having the optimum route inthe set of discovered routes increases. However as thenumber of discovered routes exceeds a certain threshold(in this case 10 routes) the performance degrades. Be-cause, although the probability of having the optimumroute among the set of discovered routes is increased, butdue to the lack of sufficient number of samples, sourcenode is not capable of detecting the optimum route. Notethat the minimum hop count uniformly underperformsthe proposed method, which for large number of routesselects a route randomly.
We close this section by stating a practically usefulobservation. Though there may be only outage optimalroute, there are many routes with approximately thesame performance in the network. The main purposeof route selection procedure is to eliminate poor routes,which is simpler than finding the optimal route.
IV. Conclusions
In this paper we introduced the notion of Network Chan-nel, in which the intermediate nodes between the sourceand destination nodes along with the communicationlinks between them are considered as the communica-tion channel. We showed that by estimating the networkchannel, route selection in mobile ad-hoc networks can beimproved so that the overall throughput of the networkincreases significantly comparing to a network with routeselection based on minimum hop-count.
References
[1] T. M. Cover and A. E. Gamal, “Capacity theoremsfor the relay channel,” IEEE Transactions on In-formation Theory, vol. 25, pp. 572–584, September1979.
[2] L.-L. Xie and P. R. Kumar, “A network informationtheory for wireless communication: Scaling laws andoptimal operation,” submitted to IEEE Transactionson Information Theory, April 2002.
[3] J. N. Laneman, D. N. C. Tse, and G. W. Wornell,“Cooperative diversity in wireless networks: efficientprotocols and outage behaviour,” submitted to IEEETransactions on Information Theory, January 2002.
[4] C. Qiao and H. Wu, “iCAR: an integrated cellularand ad-hoc relay system,” in Int. Conf. on Com-puter Communications and Network (IC3N), Octo-ber 2000.
[5] C. Qiao, H. Wu, and O. Tonguz, “Load balancingvia relay in next generation wireless systems,” inIEEE Workshop on Mobile Ad Hoc Networking andComputing (MobiHOC), August 2000.
[6] Y. Lin and Y. Hsu, “Multihop cellular: a new archi-tecture for wireless communications,” in Proc. IEEEINFOCOM, March 2000.
[7] A. Zadeh and B. Jabbari, “On the capacity modelingof multi-hop cellular CDMA networks,” in Proceed-ings of IEEE MILCOM, October 2001.
[8] M. A. Khojastepour, A. Sabharwal, andB. Aazhang, “On the capacity of ’cheap’ relaynetworks,” in Proc. of CISS, (Baltimore, MD),March 2003.
[9] A. Lapidoth and P. Narayan, “Reliable communi-cation under channel uncertainity,” IEEE Transac-tions on Information Theory, vol. 44, pp. 2148–2177,Oct. 1998.
[10] A. Sabharwal, “On capacity of relay-assisted com-munications,” in Proc. GLOBECOM 2002, (Taipei,Taiwan R.O.C.), November 2002.

















