Microarrays for transcription factor binding location analysis (chIP-chip)
22
Microarrays for transcription factor binding location analysis (chIP-chip) and the “Active Modules” approach
description
Microarrays for transcription factor binding location analysis (chIP-chip). and the “Active Modules” approach. Protein-DNA interactions: ChIP-chip. Lee et al., Science 2002. Simon et al., Cell 2001. ChIP-chip Microarray Data. Differentially represented intergenic regions - PowerPoint PPT Presentation
Transcript of Microarrays for transcription factor binding location analysis (chIP-chip)

Microarrays for transcription factor binding location analysis
(chIP-chip)
and the “Active Modules” approach

Protein-DNA interactions: ChIP-chip
Simon et al., Cell 2001Lee et al., Science 2002

ChIP-chip Microarray Data
Differentially represented
intergenic regionsprovides evidencefor protein-DNA
interaction

Network representation of TF-DNA interactions

Dynamic role of transcription factors
Harbison C, Gordon B, et al. Nature 2004

Mapping transcription factor binding sites
Harbison C, Gordon B, et al. Nature 2004

Integrating gene Expression Data with Interaction Networks

Need computational tools able to distill pathways of interest from large molecular interaction databases
Data Integration

List of Genes Implicated in an Experiment
• What do we make of such a result?
Jelinsky S & Samson LD,Proc. Natl. Acad. Sci. USAVol. 96, pp. 1486–1491,1999

KEGGhttp://www.genome.jp/kegg/

Activated Metabolic Pathways

Types of Information to Integrate
• Data that determine the network (nodes and edges)
– protein-protein– protein-DNA, etc…
• Data that determine the state of the system– mRNA expression data– Protein modifications– Protein levels– Growth phenotype– Dynamics over time

Network Perturbations
• Environmental: – Growth conditions– Drugs– Toxins
• Genetic: – Gene knockouts– Mutations– Disease states

Finding “Active” Sub-graphs
Active Modules

Finding “Active” Modules/Pathways in a Large Network is Hard
• Finding the highest scoring subnetwork is NP hard, so we use heuristic search algorithms to identify a collection of high-scoring subnetworks (local optima)
• Simulated annealing and/or greedy search starting from an initial subnetwork “seed”
• Considerations: Local topology, sub-network score significance (is score higher than would be expected at random?), multiple states (conditions)

Activated Sub-graphs
Ideker T, Ozier O, Schwikowski B, Siegel AF. Discovering regulatory and signaling circuits in molecular interaction networks.Bioinformatics. 2002;18 Suppl 1:S233-40.

Scoring a Sub-graph
Ideker T, Ozier O, Schwikowski B, Siegel AF. Discovering regulatory and signaling circuits in molecular interaction networks. Bioinformatics. 2002;18 Suppl 1:S233-40.

Significance Assessment of Active Module
Ideker T, Ozier O, Schwikowski B, Siegel AF. Discovering regulatory and signalling circuits in molecular interaction networks. Bioinformatics. 2002;18 Suppl 1:S233-40.
Score distributions for the 1st - 5th best scoring modules before (blue) and after (red) randomizing Z-scores (“states”). Randomization disrupts correlation between gene expression and network location.

Network Regions of Differential Expression After Gene Deletions
Ideker, Ozier, Schwikowski, Siegel. Bioinformatics (2002)

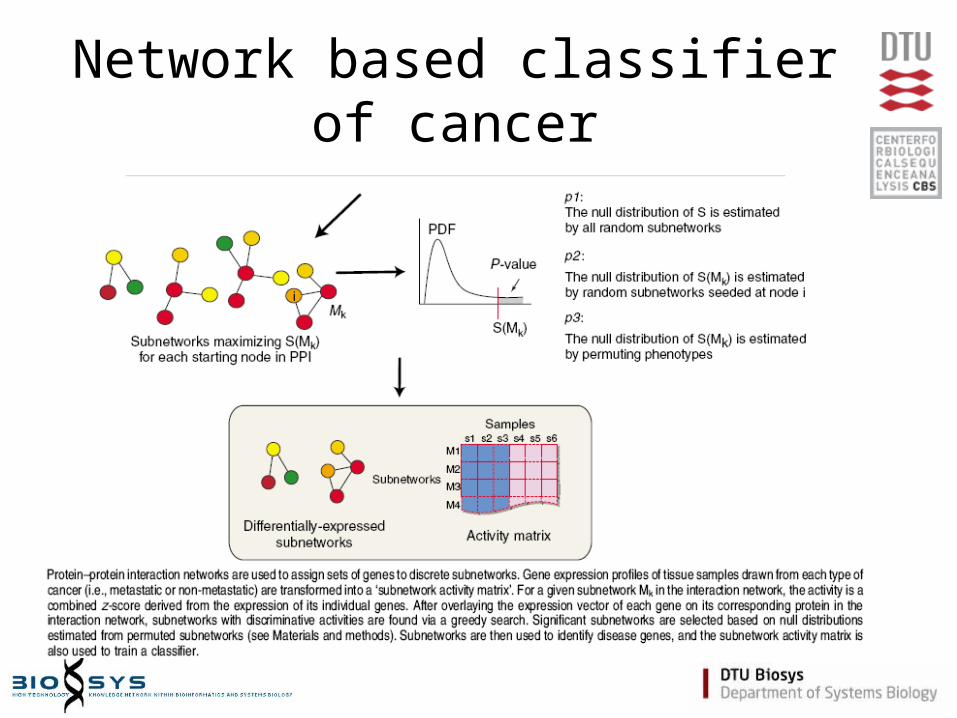
Network based classifier of cancer