
memoire stage stat ARC.pdf
86
UFR SCIENCES ET TECHNOLOGIES Département de Mathématiques 24 avenue des Landais 63171 Aubière Cedex RAPPORT DE STAGE DE MASTER 1 MASTER STATISTIQUES ET TRAITEMENT DES DONNEES Présenté par Thibault LEGRAIN Etude sur la qualité de vie des patients parkinsoniens Lieu du stage : Délégation à la Recherche Clinique et à l’Innovation Villa annexe IFSI CHU de Clermont-Ferrand 58 rue Montalembert 63003 Clermont-Ferrand Cedex Stage du 4 Avril au 31 Juillet 2011
Transcript of memoire stage stat ARC.pdf

UFR SCIENCES ET TECHNOLOGIES Département de Mathématiques 24 avenue des Landais 63171 Aubière Cedex
RAPPORT DE STAGE DE MASTER 1
MASTER STATISTIQUES ET TRAITEMENT DES DONNEES
Présenté par
Thibault LEGRAIN
Etude sur la qualité de vie des patients parkinsoniens
Lieu du stage : Délégation à la Recherche Clinique et à l’Innovation Villa annexe IFSI CHU de Clermont-Ferrand 58 rue Montalembert 63003 Clermont-Ferrand Cedex
Stage du 4 Avril au 31 Juillet 2011

1
Remerciements Tout d’abord, je tiens à remercier M. Patrick LACARIN et M. Nicolas SAVALE pour m’avoir accepté au sein de la Délégation à la Recherche Clinique et à l’Innovation du CHU de Clermont-Ferrand.
Je remercie tout particulièrement Bruno PEREIRA, mon maître de stage, pour sa gentillesse et pour toutes les connaissances en biostatistiques qu’il m’a apportées tout au long de mes quatre mois de stage. Merci encore pour tous vos conseils qui m’ont été précieux.
Un grand merci aussi à toute l’équipe de la DRCI pour leur convivialité, leur soutien et leur contribution à mon travail. Ce fût un réel plaisir de travailler à vos côtés chaque jour.
Enfin, je tiens également à remercier M. Laurent SERLET de m’avoir accepté au sein du Master STD, ainsi que tous les enseignants qui nous ont encadrés cette année.

2
SOMMAIRE
Remerciements ……………………………………………………………………………………………………………… 1
Sommaire ………………………………………………………………………………………………………………………. 2
Introduction ………………………………………………………………………………………………………………….. 4
I. Présentation de l’entreprise et de la recherche clinique ……………………………………………… 5
1.1 Le CHU …………………………………………………………………………………………………………. 5
1.2 La DRCI ………………………………………………………………………………………………………….. 6
1.3 Déroulement d’une étude clinique ………………………………………………………………. 8
II. Etape de planification : le calcul du NSN ……………………………………………………………………… 9
2.1 Explications générales du calcul du NSN : cas de la randomisation individuelle 9
2.2 Application à un essai clinique …………………………………………………………………….. 10
2.2.1 Calcul du NSN « à la main » pour le cas vertébroplastie versus corset 10
2.2.2 Calcul du NSN par le biais de 2 logiciels par le test de Student ………… 11
2.3 Cas particulier du calcul du NSN : la prise en compte des perdus de vue ……….. 12
2.4 Autre calcul du NSN sur le protocole HIFLOLUS ……………………………………………... 13
2.5 L’après calcul du NSN …………………………………………………………………………………….. 14
2.6 Calcul du NSN dans le cas d’une analyse en mesure répétées ………………………… 14
III. Analyse statistique sur la pdq-39 ………………………………………………………………………………. 17
3.1 Les échelles d’évaluations utiles pour le suivi de la maladie de Parkinson …….. 17
3.1.1 Les échelles fonctionnelles …………………………………………………………….. 17
3.1.2 Les échelles multidimensionnelles ………………………………………………… 18
3.1.3 L’échelle pdq-39 …………………………………………………………………………… 18
3.1.4 L’UPDRS ……………………………………………………………………………………….. 19
3.1.5 Les autres échelles : complément de l’UPDRS ………………………………. 20
3.2 Analyse descriptive sur la pdq-39 …………………………………………………………………. 21

3
3.2.1 Analyse sur les moyennes de l’évolution de la qualité de vie …………. 21
3.2.2 ACP par rapport aux différents temps …………………………………………… 26
IV- Analyse de la variance sur données longitudinales ………………………………………………….. 49
4.1 Les modèles mixtes et l’ANOVA ………………………………………………………………….. 49
4.1.1 Principe de l’ANOVA ………………………………………………………………………. 49
4.1.2 Principe des tests post-hoc ……………………………………………………………. 49
4.1.3 Principe des modèles mixtes …………………………………………………………. 50
4.1.4 Application ……………………………………………………………………………………. 51
4.2 ANOVA à mesures répétées …………………………………………………………………………. 59
V- Impact des données manquantes sur données longitudinales …………………………………… 69
5.1 Typologie ……………………………………………………………………………………………………... 70
5.1.1 Données MCAR …………………………………………………………………………….... 70
5.1.2 Données MAR ……………………………………………………………………………........ 70
5.1.3 Données MNAR ……………………………………………………………………………….. 71
5.1.4 Cas des données longitudinales ……………………………………………………….. 71
5.1.5 Quantité de données manquantes …………………………………………………… 72
5.2 Méthodes d’analyse en présence de données manquantes ………………………….. 72
5.2.1 Analyse des cas complets ………………………………………………………………… 73
5.2.2 Les techniques d’imputations simples ……………………………………………… 73
5.2.3 L’imputation multiple ………………………………………………………………………. 74
Conclusion ……………………………………………………………………………………………………………………… 77
Bibliographie ………………………………………………………………………………………………………………….. 78
Annexe 1 : questionnaire pdq-39 ……………………………………………………………………………………. 79
Annexe 2 : liste des abréviations ……………………………………………………………………………………. 83
Annexe 3 : programmes sous R ………………………………………………………………………………………. 84

4
INTRODUCTION
Etudiant en Master Statistique et Traitement des Données (STD) dans la continuité d’un
DEUG de Mathématiques et d’une Licence de Mathématiques Appliquées aux Sciences
Sociales (MASS) à l’Université Blaise Pascal de Clermont-Ferrand (63), j’ai effectué, dans le
cadre de ma formation, mon stage au sein de la DRCI (Délégation à la Recherche Clinique et
à l’Innovation) du CHU de Clermont-Ferrand. Ce stage de quatre mois a eu pour but
d’apprendre la méthodologie appliquée par un biostatisticien dans le déroulement d’essais
cliniques. Il fût à la fois informatique avec l’utilisation de logiciels statistiques (R, Sample Size
Calculator) mais également statistique avec l’utilisation de méthodes vues durant ma
formation ainsi que de nouvelles (modèles mixtes, modèle à mesures répétées, calcul du
NSN …).
Le cadre clinique de la majorité de mes analyses est celui de l’étude de la qualité de vie des
patients atteints de la maladie de Parkinson idiopathique (MPI). Cette maladie neurologique
chronique ne possède aucun traitement curatif, seuls des traitements médicamenteux
existent dont la L-DOPA qui est le traitement le plus actif. Ce traitement réduit notamment
le tremblement, l’akinésie et la rigidité, qui sont les trois symptômes les plus récurrents de la
maladie.
Le questionnaire sur la pdq-39 est l’outil principal utilisé dans la collecte d’information de
l’essai clinique. Il est tout d’abord rempli par les patients au temps pré-opératoire noté t=0,
avant la prise du traitement pour la première fois, puis est à nouveau rempli aux temps 12,
36 et 60 mois où les patients réitèrent la prise de L-DOPA. Afin de répondre à la question,
toute une série d’analyse sera effectuée pour définir si le patient se sent mieux, en général,
au bout d’un certain temps.

5
I- Présentation de l’entreprise et de la recherche clinique:
Dans cette partie, je vais vous présenter le rôle des hôpitaux dans le développement des
sciences médicales, avec une présentation plus détaillée sur la DRCI et sur le déroulement
d’une étude clinique.
1.1 Le CHU et les essais cliniques
Un centre hospitalier universitaire (CHU) est un hôpital lié à une université. L’hôpital peut
être un service de l’université ou peut être une entité distincte liée à l’université par une
convention. Le CHU permet ainsi la formation théorique et pratique des futurs
professionnels médicaux et personnels paramédicaux.
Depuis la loi Debré, les CHU ont une triple mission de soins, d’enseignement et de
recherche. La recherche clinique, recherche menée sur l’être humain dans le domaine de la
santé, est de plus en plus essentielle au progrès médical. Ces recherches contribuent à
l’amélioration de la qualité des soins car elles permettent de trouver de nouveaux moyens
pour mieux connaître ou traiter des maladies. Celles-ci ne sont réalisées qu’à plusieurs
conditions : tout d’abord, elles doivent être menées par des personnes compétentes pour
augmenter les connaissances médicales, elles doivent prendre toutes les mesures
nécessaires pour protéger les personnes qui se prêtent aux essais, et enfin les responsables
de ces recherches doivent avoir accompli toutes les obligations légales et réglementaires.
Les essais de recherche clinique se déroulent le plus souvent en quatre phases précédées
d’une phase pré-clinique :
- Etude de phase I : on intègre des volontaires sains afin d’évaluer l’action d’un
nouveau traitement (dosage, effets secondaires, etc).
- Etude de phase II : on étudie l’efficacité des traitements et le devenir des
médicaments dans l’organisme sur un nombre limité de malades ou de
volontaires sains. Cette phase permet de confirmer les résultats des tests de
phase I.
- Etude de phase III : on évalue l’efficacité des traitements par comparaison sur un
grand nombre de malades. Au terme de ces trois phases, une demande
d’autorisation de mise sur le marché peut être faite s’il s’agit d’un médicament.
- Etude de phase IV : le plus souvent après la commercialisation, elle permet
d’évaluer les effets indésirables rares et de mieux cibler les personnes pour qui le
traitement sera profitable.
La recherche au CHU de Clermont-Ferrand est gérée par la Délégation à la Recherche
Clinique et à l’Innovation, la DRCI.

6
1.2 La DRCI
Le développement de la recherche clinique constitue l’un des volets prioritaires de la
politique du CHU de Clermont-Ferrand. Cette stratégie s’appuie sur une structure principale :
la DRCI. La délégation à la Recherche Clinique et à l’Innovation de Clermont-Ferrand a été
créé en 1999 afin d’assurer le développement de la recherche biomédicale institutionnelle
en favorisant de nouvelles stratégies diagnostiques et thérapeutiques.
Les principales missions historiques de la DRCI sont d’inciter des équipes hospitalières à
l’émergence de projets, d’aider à la mise en forme de dossiers, de suivre la mise en œuvre
des projets selon les BPC (Bonnes Pratiques Cliniques), et de participer à l’évaluation finale
des résultats obtenus. A l’occasion du PHRC (Programme Hospitalier de Recherche Clinique)
et de l’AOI (Appel d’Offre Interne) du CHU, la DRCI intervient à différentes phases.
Lors de la présentation des dossiers, la DRCI exerce un rôle de soutien méthodologique et de
mise en relation entre les investigateurs et les équipes pour leur permettre de présenter un
projet possédant les meilleures qualités scientifiques et financières possibles.
Elle intervient, en second lieu, au moment de la sélection des projets. Dans le cadre du
PHRC, elle adresse au ministère tous les projets qui lui sont transmis en formulant un avis au
rapporteur qui le prendra en compte lors de la présentation du dossier au CNRC (Comité
National de la Recherche Clinique). Dans le cadre de l’AOI, elle affecte, sur la base d’avis
scientifiques, méthodologiques et financiers, les crédits mis à sa disposition par la Direction
Générale.
Pendant le déroulement du projet, elle se tient régulièrement informée du déroulement du
projet en liaison avec l’unité de recherche clinique et l’ARC (Attaché de Recherche Clinique).
Elle participe à l’évaluation et formule un avis sur les résultats obtenus et l’état des crédits
consommés.

7
Voici l’organigramme de la DRCI du CHU de Clermont-Ferrand :
Figure 1 : Organigramme de la DRCI
Mr Patrick LACARIN est chargé de la coordination administrative et financière de la
recherche, il est suppléé par Mr David BALAYSSAC, assistant de coordination innovation-STIC
(Soutien aux Techniques Innovantes et Coûteuses), et de Mme Lise LACLAUTRE, qui s’occupe
de l’assurance qualité vigilance. Mr Gérald GOUBY est chargé du pôle promotion CHU et du
suivi des études avec l’utilisation du logiciel SIGREC (Système Informatique de Gestion de la
Recherche et des Essais Cliniques). Mr Bruno PEREIRA est chargé de la méthodologie des
projets et du traitement des données pour permettre les publications scientifiques. Mme
Candide COUTURES et Mme Virginie PAQUET sont quant à elles chargées respectivement des
pôles Recherches Institutionnelles et Recherches Industrielles. Enfin, Mlle Marion
Directeur de la Recherche et de
l’Innovation
André SALAGNAC
(Directeur Général Adjoint CHU)
Adjoint des Cadres
Patrick LACARIN
ARC Technico-
réglementaire
Gérald GOUBY
Pharmacien
David BALAYSSAC
Pharmacien
Lise LACLAUTRE
Biostatisticien
Bruno PEREIRA
Adjoint administratif
Virginie PAQUET
Adjoint administratif
Candide COUTURES
Stagiaire en
management
Marion MATHONAT

8
MATHONAT s’est occupée d’organiser la 2nde Journée Nationale des Innovations
Hospitalières qui a eu lieu le vendredi 17 juin 2011 au CHU de Clermont-Ferrand.
1.3 Déroulement d’une étude clinique
Demande de l’étude
Rédaction du protocole
Elaboration du projet
Réalisation du cahier
d’observation
Plan de randomisation
Conception des dossiers et dépôt
auprès des organismes compétents
(AFSSAPS*, CPP*, …)
Mise en œuvre de l’étude
Si autorisation
AFSSAPS et avis
favorable du CPP
Collecte et traitement des
données
Rédaction du rapport
statistique
Publication dans les revues
de référence

9
II- Etape de planification : le calcul du NSN
L’utilisation d’une méthode préventive, diagnostique ou curative ne se conçoit que si cette
méthode a fait preuve de son efficacité. Pour cela, la phase de planification de tout essai,
épidémiologique ou clinique, reste une des étapes essentielle assurant sa crédibilité et sa
réussite. On peut toujours corriger une mauvaise analyse statistique si l’essai est de qualité
mais on ne peut jamais compenser la mauvaise qualité et le mauvais plan expérimental
d’une étude par quelque test statistique que ce soit. Aussi, afin d’éviter toute improvisation
ultérieure, il est essentiel de réfléchir à la mise en œuvre d’un essai avant toute inclusion.
Ce chapitre abordera la question essentielle du nombre de sujets nécessaires qui garantit à
une étude une puissance 1-β donnée afin de mettre en évidence une différence minimale Δ
entre plusieurs groupes expérimentaux. Pour notre part, nous nous concentrerons sur le cas
de deux groupes au plus.
2.1 Explications générales du calcul du NSN : cas de la randomisation
individuelle
Le calcul du NSN (Nombre de Sujets Nécessaires) est indispensable à la réalisation au
préalable de toute étude clinique. Un essai clinique aboutit à un objectif principal, et cet
objectif lui-même mène à un critère de jugement principal. Le calcul du nombre de sujets
nécessaires se fait sur ce critère de jugement en fonction des données de la littérature ou
des résultats préliminaires (étude pilote…). Les intérêts de ce calcul sont nombreux. Il
permet d’éviter de construire des essais peu puissants, c’est-à-dire dont la probabilité de
mettre en évidence une différence qui existe réellement est faible, et permet de déterminer
la faisabilité de l’étude (aspects financier et matériel). Il permet aussi et surtout de
supprimer les biais systématiques et d’augmenter les chances de vérifier les hypothèses à
l’origine de l’essai.
Pour réaliser ce calcul, un certain nombre d’informations est requis :
- Tout d’abord, il dépend du critère de jugement principal :
Quantitatif : comparaison de moyennes
Qualitatif : comparaison de pourcentages
Censuré : comparaison de courbes de survie,
- La taille de l’effet attendu, considérée comme cliniquement pertinente noté Δ :
par exemple dans le cas d’un critère quantitatif, cela correspond à la différence
des valeurs moyennes de deux traitements,
- La dispersion du critère principal de jugement : dans le cas quantitatif, c’est la
variance σ2,

10
- Le niveau de confiance que l’on souhaite accorder à la décision statistique : c’est
le risque de première espèce α (souvent établit à 5%), risque de conclure à une
différence entre les traitements qui n’existe pas,
- La puissance du test (1-β): c’est la probabilité de rejeter H0 alors que H0 est
fausse (probabilité de déceler une différence qui existe). Elle est souvent de
l’ordre de 80 ou 90%,
- La formulation des hypothèses : situation bilatérale, en général situation d’un
nouveau médicament versus traitement de référence (test de supériorité ou
d’infériorité), ou situation unilatérale, en général situation d’un nouveau
médicament versus placebo,
- Le type d’étude : cohorte, cas-témoin, etc.
Formule du NSN pour des variables quantitatives :
1) si test bilatéral : n= 2 (σ2/ Δ2)*(Z1-α/2+Z1-β)2
2) si test unilatéral : n= 2 (σ2/ Δ2)*(Z1-α+Z1-β)2
Ce calcul nous donne le nombre de sujets pour un seul groupe, il faut donc multiplier le
résultat par deux afin d’obtenir le nombre de patients nécessaires à l’étude.
2.2 Application à un essai clinique
Le nombre de sujets nécessaires doit figurer dans le protocole ainsi que les paramètres qui
ont servis à le calculer et les références bibliographiques qui ont servies à estimer ces
paramètres.
2.2.1 Calcul du NSN « à la main » pour le cas vertébroplastie versus
corset :
Description de l’étude : Cette étude vise à comparer l’efficacité de la vertébroplastie versus
corset orthopédique en comparant à 2 jours, 1 mois, 3 mois et 6 mois des critères cliniques,
radiologiques et médico-économiques : -> étude observationnelle dans le temps, étude
randomisée, faisant suite à la réalisation d’une étude pilote.
Critère de jugement principal : Efficacité clinique évaluée par une échelle d'handicap
fonctionnel (échelle EIFEL, traduction française de l'échelle de Roland Morris).
Critère quantitatif
Calcul du nombre de sujets nécessaire : L’objectif principal de cette étude réside dans
l’évaluation de la vertébroplastie sur l’efficacité clinique (mesurée par l’échelle d'handicap
fonctionnel EIFEL) à un mois dans le traitement des tassements vertébraux récents post-
traumatiques. Aussi, pour mettre en évidence une différence minimum du score moyen de

11
l'échelle EIFEL de 3 points avec un écart-type de 6.3 supposé identique dans les deux groupes
de randomisation, le nombre de sujets nécessaire est estimé à 110 sujets pour une erreur
de 5% et une puissance de 80%.
Test unilatéral : α=0.05 -> Z1-α=1.64, β=0.80 -> Z1-β=0.842, Δ=3, et σ=6.3
54.33 patients par groupes : soit 109 en tout.
Test bilatéral : seul changement Z1-α/2=1.96
69.25 patients par groupes soit 139 en tout.
Avec ce nombre de sujets, on a :
- 5 chances sur 100 de conclure que les traitements sont différents, alors qu’ils sont
identiques.
- 80 chances sur 100 de conclure que les traitements sont différents, alors que leur
différence moyenne d’efficacité est supérieure ou égale à 3.
2.2.2 Calcul du NSN par le biais de 2 logiciels par le test de Student :
Pour rappel, le test de Student permet de tester statistiquement l’hypothèse d’égalité de 2
moyennes.
Avec le logiciel R à l’aide du package ‘pwr’ :
Données : puissance=0.80, risque=0.05, taille effet= Δ/ σ=0.4762
Les commandes pnorm et qnorm permettent de retrouver les valeurs de Z associées à α et β.
Pour un test unilatéral :
Commande :
Résultats :

12
Pour un test bilatéral :
Commande :
Résultats :
Avec le logiciel Sample Size Calculator :
On remarque que l’on ne retrouve pas exactement les mêmes résultats suivant les logiciels
utilisés mais que l’on obtient des résultats à peu près cohérents.
2.3 Cas particulier du calcul du NSN : la prise en compte des perdus de vue
Qu’il s’agisse d’une précision ou d’une comparaison, il est important de prendre en compte
les pertes de vue au moment du calcul du NSN. Les perdus de vue sont les patients qui ne se
sont pas présentés aux visites de suivi. Si on note a le pourcentage de perdus de vues, le
calcul du NSN devient : (2*n)/(1-a).

13
Il peut aussi y avoir une prise en compte d’un cross-over (essai croisé) : chaque patient reçoit
un traitement A puis B ou inversement. Il est alors indispensable d’étudier simultanément
l’effet des traitements mais également l’ordre d’administration.
Exemple : Même étude clinique que précédemment.
Afin de tenir compte des patients perdus de vue (10%) et du cross-over possible (changement
de technique au dernier moment estimé à 12%), il conviendrait d’inclure 136 patients.
En comptant les perdus de vue, on obtient : 110/0.9=122 patients.
En tenant compte du cross-over, on a : 122+(122*0.12)=136 patients.
2.4 Autre calcul du NSN sur le protocole HIFLOLUS
Cette étude est une étude randomisée, faisant suite à la réalisation d’une étude pilote. Ainsi
les données dans la littérature manquent pour établir une différence attendue entre les
deux sous-groupes sur le critère principal. Dans l’étude pilote PULCO, nous avons pu
montrer que pour les patients extubés (ayant donc réussi le test de VS), le LUS moyen était
de 13 avec un écart-type de 3.
Considérant une perte d’aération d’un point (LUS passant de 13 à 14) entre l’échographie
faite juste avant extubation et l’échographie faite 4h plus tard chez des patients sous O2,
nous partons sur l’hypothèse d’une perte de 2 points à H24 pour le groupe O2 et sur
l’absence de perte d’aération sous OPTIFLOW® grâce à l’effet PEEP. Avec donc une moyenne
de 15 (groupe O2) versus 13 (groupe OPTIFLOW®), un écart type de 3, un risque de 1ère
espèce α à 0.05 et une puissance à 0.80, la calcul d’effectif est de 30 patients par groupe par
un test unilatéral. On a donc : Δ=2, σ=3, α=0.05, (1-β)=0.8
Résultat sous Sample Size Calculator :

14
Résultat sous R :
Pour obtenir des résultats corrects et fiables, on choisit de prendre 30 personnes par
échantillons afin d’être significatif au niveau des tests.
2.5 L’après calcul du NSN
A partir du moment où le nombre de personnes de chaque échantillon a été calculé, les
patients seront recrutés suivant les critères d’inclusion, de non-inclusion et d’exclusion
définis dans le protocole. Dès lors qu’ils sont recrutés, un Attaché de Recherche Clinique
(ARC) mandaté par le promoteur s’assurera de la bonne réalisation de l’étude, du recueil des
données générées par écrit, de leur documentation, enregistrement et rapport, en accord
avec les Procédures Opératoires Standards mises en application au sein du CHU de
Clermont-Ferrand et conformément aux Bonnes Pratiques Cliniques ainsi qu’aux dispositions
législatives et réglementaires en vigueur.
Aboutit à l’analyse des données
2.6 Calcul du NSN dans le cas d’une analyse en mesure répétées
L’utilisation d’études longitudinales où un sujet est suivi au cours de plusieurs visites dans le
temps est devenue de plus en plus fréquente en épidémiologie ; les techniques statistiques
associées à l’analyse de données corrélées s’étant elles-mêmes fortement développées.
Les sujets dans un même groupe ne peuvent pas être considérés comme indépendants l’un
de l’autre (deux observations émanant d’un même sujet seront rarement indépendantes) et
donc les calculs de la taille des échantillons doivent le prendre en compte. Dans ce cas, le
calcul du NSN nécessite de connaitre :
- Les moyennes pour chaque groupe et chaque temps
- L’écart-type global
- Les corrélations entre les mesures.

15
Ici, l’analyse de données est de type « doublement corrélée » c’est-à-dire qu’il y a corrélation
entre les mesures d’un même individu et corrélation entre les individus d’un même groupe.
Supposons la comparaison de deux groupes lors d’un essai où nous faisons v observations
sur chaque patient avant la randomisation au traitement et w observations après. Si l’effet
du traitement change au cours de la période d’observation post-randomisation, alors une
analyse efficace serait de calculer la moyenne d’observations avant et après la
randomisation. La pré-randomisation moyenne de chaque patient est alors considérée
comme une co-variable dans l’analyse de covariance des moyennes en post-randomisation.
Dans ce cas, on observe souvent que les observations faites au temps t sur un individu
particulier ont une corrélation ρ avec les observations faites au temps t’. Cette corrélation
est d’ailleurs souvent la même pour toutes les valeurs de t et t’, pour t ≠ t’. Ce type de
structure de corrélation est appelée « symétrie composée ». Des corrélations entre 0.6 et
0.75 sont généralement trouvées.
Si deux traitements sont comparés et que les observations proviennent d’une distribution
normale alors, avec l’effet de taille prévu entre eux indiqué par Ω, la taille type dans chaque
groupe de traitement pour un risque α en test bilatéral et une puissance 1-β est donnée par
la formule:
N= R*[[2(Z1-α/2+Z1-β)2/Ω2]+(Z21-α/2/4)]
où R désigne facteur de correction défini par :
R=[(1+(w-1)ρ)/w - (vρ/(1+(v-1)ρ))]
Dans le cas où il n’y a aucune pré-randomisation, c’est-à-dire v=0, on aura :
R=[(1+(w-1)ρ)/w]
Exemple : Cas de la post-randomisation en mesures répétées uniquement
Supposons que nous avons voulu concevoir une étude d’un traitement réduisant la tension
contre un contrôle de placebo dans lesquels nous n’avons aucune mesure de pré-
randomisation. On cherche alors le nombre de sujets nécessaires par groupes pour 1, 2 ou 3
évaluations de post-randomisation assumant une taille d’effet normalisée de 0.4, une
corrélation de 0.7, avec un risque de 5% et une puissance de 80%.
Ici, v=0, w=1, 2 et 3, ρ=0.7, Ω=0.4 et on a un test bilatéral avec risque de 5% et une puissance
de 80%. D’après la table fournie ci-après, on obtient comme facteur de correction R=1, 0.850
et 0.8 pour respectivement les valeurs en mesures répétées w=1, 2 et 3. Le nombre de sujets
nécessaires est alors de 100, 85 et 80 patients pour w=1, 2 et 3 mesures répétées.
Dans cet exemple, en augmentant le nombre de mesures de post-randomisation de 1 à 3 la
taille d’effectif nécessaire a été réduite de 20%. Ainsi, si le nombre de patient est limité, on

16
peut maintenir la puissance de l’étude en augmentant le nombre d’observations de
répétition par individus.
Dans l’exemple avec le logiciel on prend bien Ω=0.4=Dm/σ.

17
III- Analyse statistique sur la pdq-39
Dans cette partie, nous allons vous présenter tout d’abord les différentes échelles
d’évaluations utilisées sur les patients parkinsoniens avec notamment l’échelle pdq-39 qui
évalue la qualité de vie de ces mêmes patients. Après ces quelques explications, nous
passerons au côté statistique du sujet en réalisant une analyse descriptive de notre base de
données : d’une part une analyse sur les moyennes de chaque domaine du questionnaire et
d’autre part des ACP sur les quatre temps étudiés.
3.1 Les échelles d’évaluation utiles pour le suivi de la maladie de Parkinson
L’évaluation dans le cadre de la MPI (Maladie de Parkinson Idiopathique) est essentiellement
le fait d’échelles cliniques.
Ces échelles doivent répondre aux préoccupations du praticien. Elles visent une évaluation
objective de la sévérité, de la fluctuation, de la progression des symptômes cliniques ainsi
que leur retentissement sur la vie quotidienne, pour une maladie chronique et évolutive.
Elles ne sont pas indispensables au diagnostic et au suivi mais peuvent être utiles et même
nécessaires, lors de certaines décisions thérapeutiques notamment chirurgicales.
3.1.1 Les échelles fonctionnelles
Ce sont des échelles qui permettent de mesurer les conséquences de la MPI dans l’activité
de la vie quotidienne : échelles de la qualité de vie.
->PDQ-39 (Parkinson Disease Quotation) : teste 39 items sur 8 dimensions (mobilité,
activité de la vie quotidienne, bien être affectif, gène psychologique, soutien social, troubles
cognitifs, communication, inconfort physique). Elle a été déclinée dans une forme abrégée :
la PDQ-8 qui utilise les 8 items les plus représentatifs de la PDQ-39.
La PDQ-39 est fiable et validée. Sa cohérence avec l’UPDRS est élevée. Elle est spécifique de
la maladie et sensible aux changements.
->PDQL-37(Parkinson Disease Quality of Life). Elle teste 37 items, sur 4 dimensions
(symptôme parkinsoniens, symptômes systémiques, aspects sociaux et états émotionnels).
->ISAPD (Intermediate Scale for Assessment in Parkinson’s Disease) qui comprend 13
items.
->PIMS : (Parkinson Impact Scale) qui teste 10 aspects de la vie sociale.
->Schwab et England (établie en 1969) qui cote le handicap de 0 % (perturbations
maximales) à 100 %.

18
3.1.2 Les échelles multidimensionnellles
L’analyse de la bibliographie corrélée à l’analyse des experts soulignent que seules les
analyses multidimensionnelles permettent d’appréhender réellement la situation du
malade.
A ce titre, l’UPDRS (Unifed Parkinson Disease Rating Scale) résultat d’un atelier de travail de
1984 regroupant les principaux spécialistes mondiaux de la MPI, représente l’outil le mieux
validé. Cette échelle comporte 6 sections utilisables séparément :
I) État mental, comportemental et thymique (4 items) ;
II) Activité de la vie quotidienne en périodes ON et OFF (13 items) ;
III) Examen moteur en période ON et OFF (14 items) ;
IV) Complications du traitement (dyskinésies, fluctuations, problèmes digestifs et
dysautonomiques);
V) Stades de Hoehn et Yahr ;
VI) Échelle de Schwab et England.
L’UPDRS quantifie la progression de la maladie de Parkinson et l’efficacité du traitement.
3.1.3 L’échelle PDQ-39 :
C’est l’outil précieux pour l'optimisation de la prise en charge des patients parkinsoniens. Il
permet de mesurer la qualité de vie des patients parkinsoniens. Comme son nom l’indique,
elle comporte 39 items qui se répartissent de la manière suivante.
Mobilité : 10 items
Activité de la vie quotidienne : 6 items
Bien être affectif : 6 items
Gêne psychologique : 4 items
Soutien social : 3 items
Troubles cognitifs : 4 items
Communication : 3 items
Inconfort physique : 3 items
En fait, cette échelle comporte donc 19 items pour le domaine physique, 12 pour le domaine
mental, et 8 pour le domaine social.
Il existe 5 types de réponses possibles: jamais, rarement, parfois, souvent, et toujours ou
totalement incapable. Ces scores varient entre 0 et 100 pour chaque domaine. Plus le score

19
est élevé, moins la qualité de vie est bonne. L’interprétation des données du PDQ-39 se fait
grâce à un guide. Pour plus de détail sur le questionnaire, vous pouvez vous référer à
l’annexe 1 qui présente le questionnaire en question.
3.1.4 L’UPDRS
Dès le début et à tous les stades de la maladie, le patient peut être évalué. L’outil global le
plus utilisé et le mieux validé (grade A) est l’UPDRS. Elle a l’avantage :
d’être un prolongement de la clinique ;
d’être largement diffusée (en ambulatoire et en milieu hospitalier) ;
de permettre de suivre les patients dans les protocoles de recherche ;
de pouvoir être utilisée section par section séparément en fonction de l’état du
malade.
L’UPDRS comme toute échelle multidimensionnelle a ses limites ; l’évaluation de certaines
sections est trop succincte pour détailler certains profils de la maladie. Elle peut utilement
être complétée par les échelles neuropsychologiques, les échelles d’humeur, les échelles de
qualité de vie, les échelles de dyskinésie, les échelles de dysarthrie et les échelles de
déglutition.
Dans le cadre d’une MPI débutante, elle permet :
de quantifier une amélioration thérapeutique qui peut aussi participer au diagnostic
(section III) ;
de juger du retentissement sur la vie quotidienne (section II) ;
d’avoir une vision globale du malade (section V) ;
de juger de son état cognitif et thymique (section I) avant les choix médicamenteux.
Dans le suivi du patient, elle pourra être utilisée de façon partielle ou globale, en particulier
par sa section III, motrice.
Dans le cadre d’une MPI évoluée :
la section III est utilisée en période ON et en période OFF avec possibilité de test aigu à la L-
Dopa qui permet de connaître l’état basal du malade et sa réactivité à la L-Dopa par le calcul
du pourcentage d’amélioration, à l’acmé d’une dose supra-liminale donnée le matin à jeun.
Elle permet de connaître le délai et la durée d’action de cette dose ;

20
la section IV permet d’évaluer les dyskinésies et les fluctuations, quitte à la compléter par
des échelles plus spécifiques ;
la section I donne une image globale et peu précise des troubles cognitifs ;
la section II permet de juger du retentissement sur la vie quotidienne en période ON ou en
période OFF ;
la section VI apprécie le degré d’autonomie.
Ses intérêts : C’est une échelle connue, reconnue internationalement, validée, fiable avec
une très forte homogénéité qui présente une faible variabilité inter-observateurs.
C’est une échelle simple d’emploi, relativement rapide d’utilisation (moins de 30 minutes
pour un neurologue entraîné) et dont la fiabilité de cotation est améliorée par
l’entraînement. C’est une échelle multidimensionnelle applicable en période ON et OFF.
Ses limites : C’est une échelle un peu longue d’utilisation en pratique courante. Ses formules
abrégées qui ne sont pas validées, ne sont pas rentrées dans la pratique. Les dimensions
cognitive, comportementale et thymique sont abordées de façon trop succincte et
nécessitent le recours d’échelles plus spécifiques. La cotation des complications du
traitement par sa section IV est trop grossière et peut nécessiter l’adjonction d’un carnet
journalier d’évaluation horaire et/ou d’échelles plus spécifiques.
3.1.5 Les autres échelles : compléments de l’UPDRS
Echelle de Hoehn et Yahr (1967) pour l’évaluation globale :
Stades de Hoehn et Yahr (1967) :
Stade 0 : Pas de signes parkinsoniens
Stade I : Signes unilatéraux n’entraînant pas de handicap dans la vie quotidienne
Stade II : Signes à prédominance unilatérale entraînant un certain handicap
Stade III : Atteinte bilatérale avec une certaine instabilité posturale, malade autonome
Stade IV : Handicap sévère mais possibilité de marche, perte partielle de l’autonomie
Stade V : Malade en chaise roulante ou alité, n’est plus autonome.
L’échelle de Hamilton et l’échelle MADRS pour l’évaluation des troubles d’humeur
(dépression).

21
Échelle de dyskinésies et de fluctuations (Goetz, CAPIT, CAPSIT)
L’ETRS (Essential Tremor Rating Scale) pour l’évaluation du tremblement.
3.2 Analyse descriptive sur la pdq-39
On étudie les réponses du questionnaire sur la qualité de vie aux dates t=0, 12, 36 et 60
mois. Il faut savoir que plus le score est élevé moins la qualité de vie des patients
parkinsoniens est bonne. Voici une analyse descriptive des 8 domaines concernant la pdq-
39 réalisée sous le logiciel R avec la commande summary.
3.2.1 Analyse sur les moyennes de l’évolution de la qualité de vie
Domaine « activité de la vie quotidienne » :
En moyenne, on a la sensation que la qualité de l’activité de la vie quotidienne s’améliore
nettement sur cours terme, mais qu’elle revient à son point de départ à long terme.
6
8
10
12
0 20 40 60Visits
Evolution of pdq_adl

22
Domaine « bien être affectif » :
En moyenne, la qualité concernant le bien-être affectif s’améliore mais elle a tendance à
revenir à son point de départ.
Domaine « communication » :
6
7
8
9
10
0 20 40 60Visits
Evolution of pdq_bien_être

23
En moyenne, la qualité de vie du patient, concernant le domaine de la communication, se
détériore au fil du temps.
Domaine « gène psychologique » :
En moyenne, les patients ont beaucoup moins de gêne psychologique après la mise en place
du traitement. Le traitement à l’air efficace sur le cours terme.
3
4
5
6
0 20 40 60Visits
Evolution of pdq_com
3
4
5
6
7
8
0 20 40 60Visits
Evolution of pdq_gène_psy

24
Domaine « inconfort physique » :
En moyenne, le domaine de l’inconfort physique reste stable concernant la qualité de vie du
patient (au vue de l’échelle).
Domaine « mobilité » :
3.5
4
4.5
5
5.5
0 20 40 60Visits
Evolution of pdq_inconfort_phys

25
En moyenne, la mobilité des patients semble s’améliorer à court terme (12 mois) et a
tendance à s’aggraver sur du long terme (5 ans).
Domaine « soutien social » :
En moyenne, les patients se sentent mieux soutenus socialement sur du cours terme mais
ont l’air de se sentir légèrement délaissé à long terme.
12
14
16
18
20
22
0 20 40 60Visits
Evolution of pdq_mobilité
1
1.5
2
2.5
0 20 40 60Visits
Evolution of pdq_soutien_social

26
Domaine « troubles cognitifs » :
En moyenne, les troubles cognitifs chez les patients sont moins présents sur le cours terme
et ont tendance à augmenter au fil du temps.
Plus généralement, en moyenne, la qualité de vie des patients semble s’améliorer juste
après l’application du traitement. Cependant, à long terme, elle semble plutôt se dégrader.
Cette conclusion n’est pas forcément exacte dans tous les cas car on raisonne sur des
moyennes, et les patients n’ont pas tous rempli les mêmes suivis aux mêmes temps :
certains ont été suivi pendant les 4 périodes, d’autres que sur 3, etc.
3.2.2 Analyse en Composantes Principales sur chaque temps
Toutes les ACP ont été réalisées sous le logiciel R en utilisant le package ‘ade4’
préalablement installé. Pour l’utiliser, il suffit d’écrire la commande suivante : library(ade4).
Elles sont réalisées sur les 8 variables quantitatives représentant les différents domaines du
questionnaire sur la pdq-39.
Pour chaque temps, l’ACP a été réalisée en plusieurs étapes. Tout d’abord, on fait une
analyse univariée des différentes variables à chaque temps (utilisation sous R de summary
et/ou boxplot) afin de voir s’il y a une dispersion des données. Si c’est le cas, on réalisera
3
3.5
4
4.5
5
0 20 40 60Visits
Evolution of pdq_troubles_cogn

27
alors une ACP centrée-réduite. La deuxième étape consiste à réaliser une analyse bivariée
des différentes variables afin de vérifier s’il y a de fortes corrélations entre celles-ci. La
troisième étape réside à faire un choix sur le nombre d’axes retenus qui peut se définir
suivant plusieurs critères. Le premier critère est la part d’inertie (où le seuil est fixé par nous-
même : souvent au moins 90%). Le second est le critère de Kaiser qui consiste à ne conserver
que les axes associés à des valeurs propres supérieures à 1. Il existe aussi un autre critère qui
est l’éboulis des valeurs propres : on cherche en fait un « coude » dans le graphe des valeurs
propres et on ne conserve les valeurs propres que jusqu’à ce « coude ». La quatrième étape
revient à étudier les variables en les représentant sur le ou les plans choisit à l’étape
précédente (cercle de corrélation). Dans l’étape suivante, on fait cette fois-ci une étude sur
les individus en les représentants à leurs tours dans ce fameux cercle afin de déceler certain
regroupement. La sixième étape consiste à juxtaposer les individus ainsi que les variables sur
le(s) plan(s) afin de trouver des liens. On peut enfin ajouter des variables supplémentaires à
cette analyse (dans notre étude cette variable sera les centres où les patients ont été
soignés).
ACP au temps t=0 :
1ère étape : Analyse univariée
On remarque qu’il y a une forte dispersion des données observées. Afin de rendre les
distances entre individus invariantes, on va effectuer une Analyse en Composantes
Principales centrées-réduites.
2nde étape : Analyse bivariée
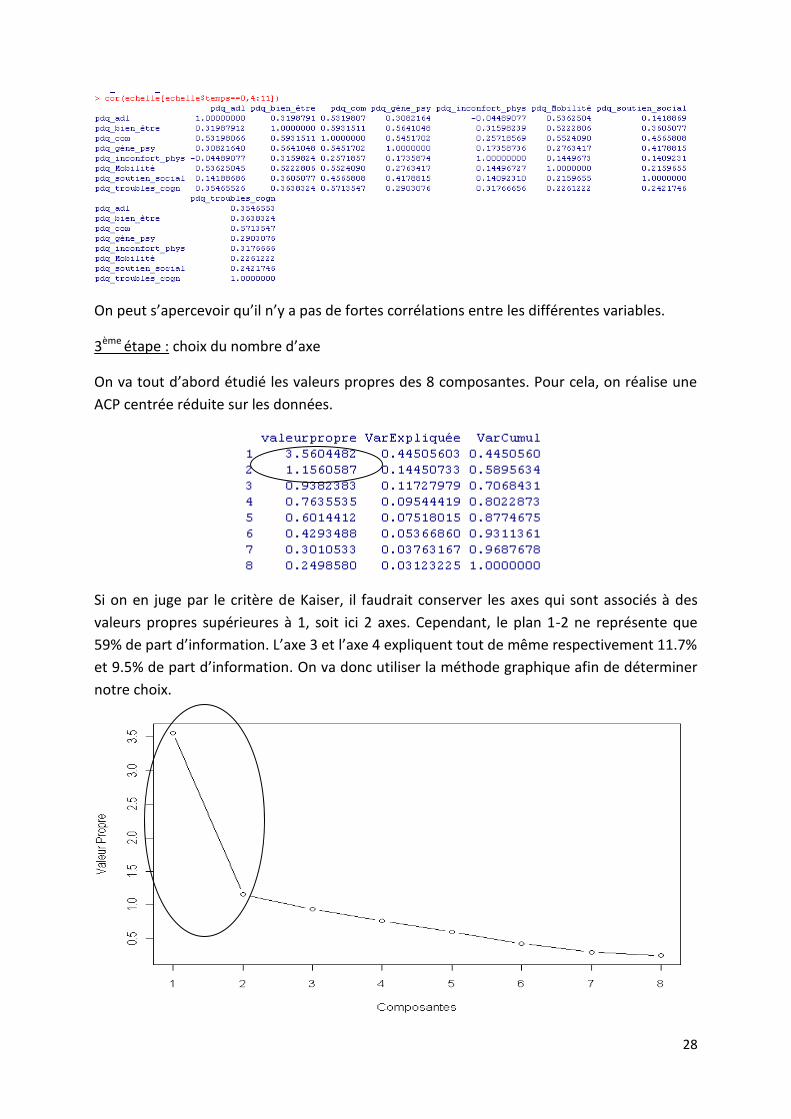
28
On peut s’apercevoir qu’il n’y a pas de fortes corrélations entre les différentes variables.
3ème étape : choix du nombre d’axe
On va tout d’abord étudié les valeurs propres des 8 composantes. Pour cela, on réalise une
ACP centrée réduite sur les données.
Si on en juge par le critère de Kaiser, il faudrait conserver les axes qui sont associés à des
valeurs propres supérieures à 1, soit ici 2 axes. Cependant, le plan 1-2 ne représente que
59% de part d’information. L’axe 3 et l’axe 4 expliquent tout de même respectivement 11.7%
et 9.5% de part d’information. On va donc utiliser la méthode graphique afin de déterminer
notre choix.

29
La méthode graphique amène aussi à conserver 2 axes au vu du coude présent entre les
composantes 2 et 3. On fait donc le choix de conserver 2 composantes principales.
4ème étape : étude des variables
Voici les coordonnées des variables représentées sur les différents axes : nous allons nous
intéresser uniquement aux deux premières colonnes qui correspondent aux deux axes
retenus.
On représente maintenant les variables sur le plan 1-2 :
La première composante est corrélée négativement avec les 8 variables initiales : plus la
qualité de vie est bonne chez le patient, plus elle sera négative sur la composante 1. Cette
composante est, de plus, fortement corrélée à la dimension communication.
La deuxième composante oppose le domaine de l’activité de la vie quotidienne au domaine
de l’inconfort physique.

30
5ème étape : Etude des individus
On calcule les coordonnées des individus sur les axes puis on représente les individus sur le
plan 1-2.
La composante 2 permet de distinguer 2 groupes d’individus particuliers. Il semble aussi que
certains individus se distinguent (le numéro 4 surtout).
6ème étape : juxtaposition individus-variables

31
7ème étape : Variable supplémentaire
On ne distingue pas les centres de Clermont-Ferrand et de Marseille. Il ne semble pas avoir
un lien entre le lieu du centre et la qualité de vie du patient.
ACP au temps t=12 :
1ère étape : Analyse univariée
Les variables sont à nouveau fortement dispersées, il faudra faire une ACP centrée-réduite.
2nde étape : Analyse bivariée

32
Il n’y a pas de forte corrélation entre les variables, les seules variables à peu près corrélées
concernent les domaines de la mobilité et de l’activité de la vie quotidienne.
3ème étape : choix du nombre d’axe
Par le critère de Kaiser il faudrait choisir 3 composantes. Cependant, elles ne
représenteraient que 65.8% d’information. On regarde alors le graphe des valeurs propres.
Part d’information
expliquée par 4 axes

33
Au vue du graphique et des éléments précédents, on considère que l’on va conserver 4 axes
(qui expliqueraient alors 75% de la part d’inertie).
4ème étape : étude des variables
Représentation des variables sur le plan 1-2 :
La première composante est corrélée négativement avec les 8 variables initiales : plus la
qualité de vie est bonne chez le patient, plus elle sera négative sur la composante 1.La
deuxième composante oppose le domaine de l’inconfort physique aux domaines de la
mobilité et de l’activité de la vie quotidienne.
Le domaine de l’inconfort physique est d’ailleurs mieux représenté sur la composante 2.
Représentation sur le plan 3-4 :

34
La composante 3 se caractérise par une forte corrélation négative avec le domaine du
soutien social.
5ème étape : étude des individus
On calcule les coordonnées des individus sur tous les axes puis on représente les individus
sur les plans 1-2 et 3-4.
Sur le plan 1-2 :

35
La composante 2 semble séparer les individus en 2 groupes. Certains individus semblent se
distinguer (112, 32, 80 et 2800).
Sur le plan 3-4 :
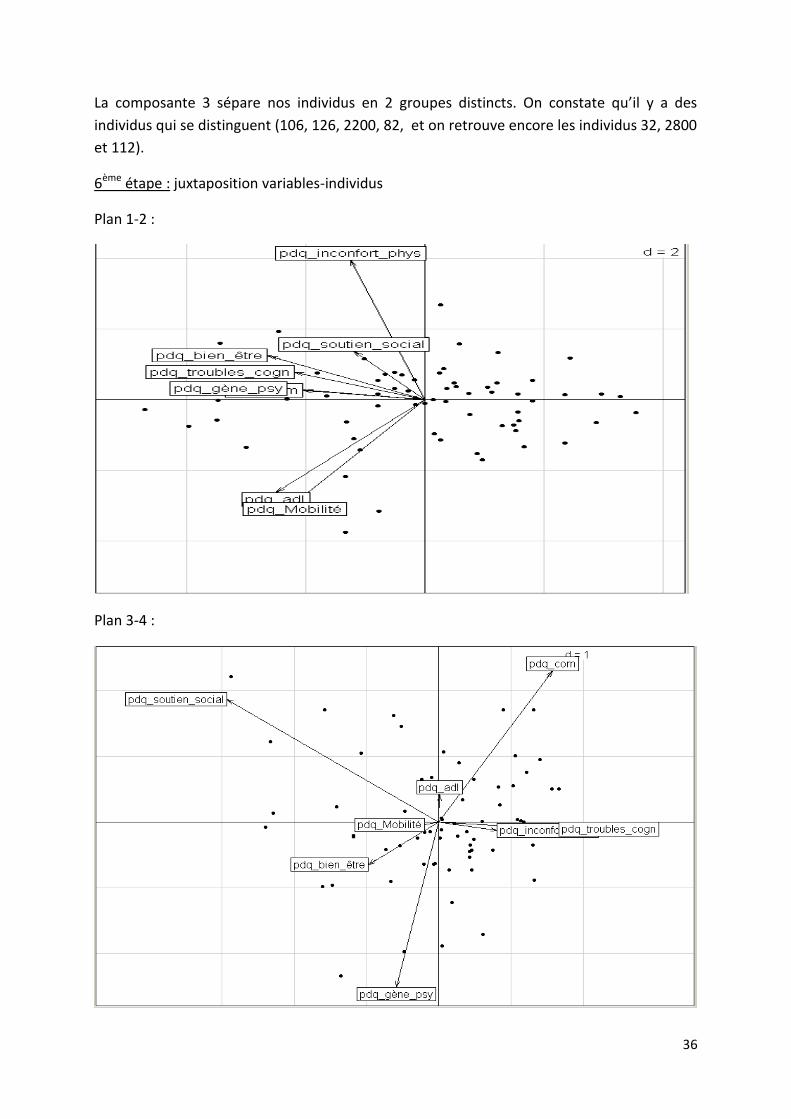
36
La composante 3 sépare nos individus en 2 groupes distincts. On constate qu’il y a des
individus qui se distinguent (106, 126, 2200, 82, et on retrouve encore les individus 32, 2800
et 112).
6ème étape : juxtaposition variables-individus
Plan 1-2 :
Plan 3-4 :

37
7ème étape : variable supplémentaire
Plan 1-2 :
Plan 3-4 :

38
On ne remarque toujours pas de différence significative entre les 2 centres.
ACP au temps t=36 :
1ère étape : analyse univariée
Les variables sont à nouveau fortement dispersées, il faudra faire une ACP centrée-réduite.
2nde étape : analyse bivariée
On ne constate pas de forte corrélation entre les variables.
3ème étape : choix du nombre d’axe
Par le critère de Kaiser il faudrait choisir 3 composantes.

39
Au vue du graphique, on se permet de choisir 4 composantes principales, expliquant ainsi
près de 80% de l’information.
4ème étape : étude des variables
Représentation des variables sur le plan 1-2 :

40
La première composante est corrélée négativement avec les 8 variables initiales et
fortement avec toutes sauf pour le domaine du soutien social qui lui est mieux représenté
sur l’axe 2.
Représentation sur le plan 3-4 :
On remarque que les variables ne sont pas très bien représentées sur les axes 3 et 4.
5ème étape : étude des individus
Sur le plan 1-2 :

41
On ne distingue de groupes distincts, cependant certains individus se distinguent (1200, 600,
89, 84).
Sur le plan 3-4 :
La composante 3 semble séparer les individus en 2 groupes. Quelques individus se
distinguent (60, 129, 55, 800, 81, 37 et encore 1200).
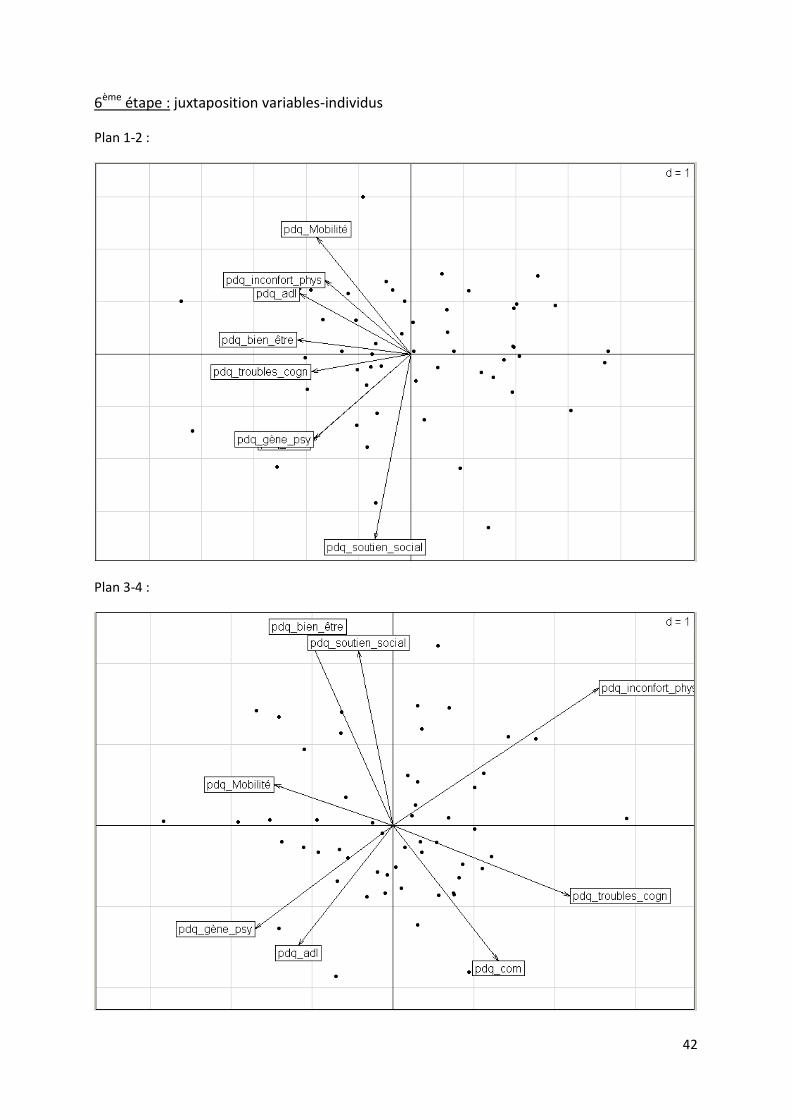
42
6ème étape : juxtaposition variables-individus
Plan 1-2 :
Plan 3-4 :

43
7ème étape : variable supplémentaire
Plan 1-2 :
Plan 3-4 :

44
Il n’y a toujours pas de différence significative entre les 2 centres.
ACP au temps t=60 :
1ère étape : analyse univariée
2nde étape : analyse bivariée
On remarque une forte corrélation entre le domaine de la mobilité et le domaine de
l’activité de la vie quotidienne.
3ème étape : choix du nombre d’axe
Par le critère de Kaiser, il faudrait choisir 2 axes. Cependant, ils ne contiennent que 56% de
l’information.
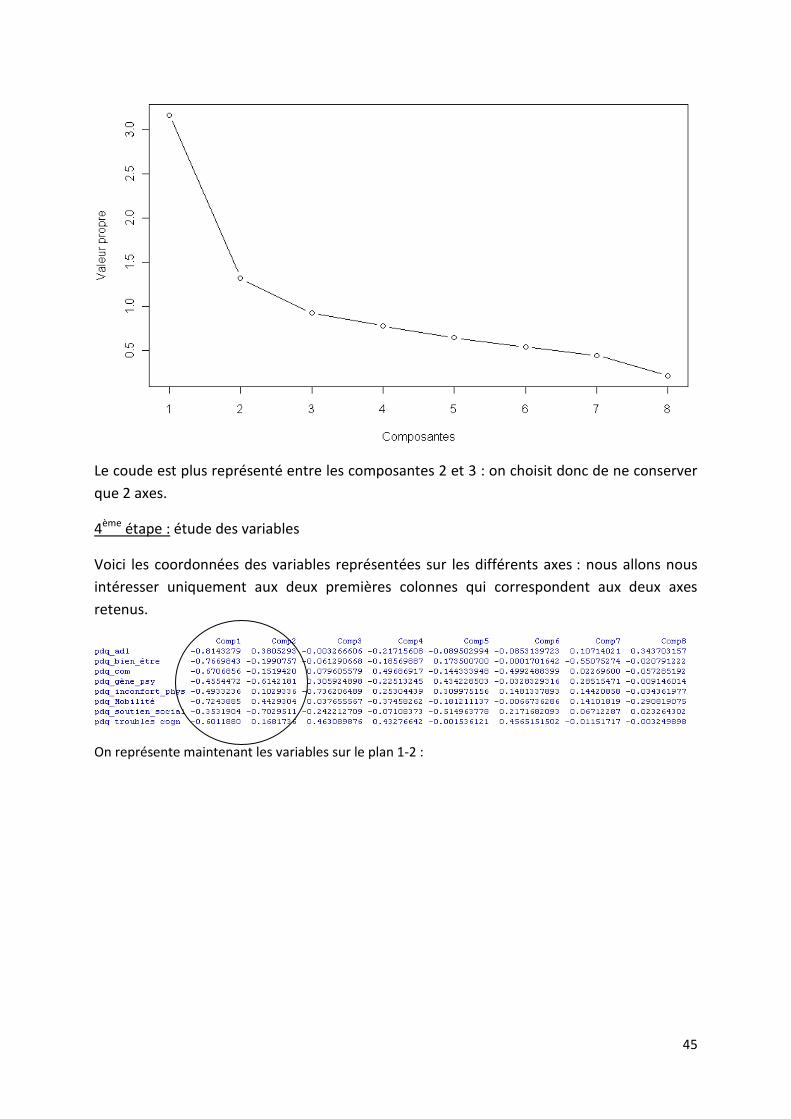
45
Le coude est plus représenté entre les composantes 2 et 3 : on choisit donc de ne conserver
que 2 axes.
4ème étape : étude des variables
Voici les coordonnées des variables représentées sur les différents axes : nous allons nous
intéresser uniquement aux deux premières colonnes qui correspondent aux deux axes
retenus.
On représente maintenant les variables sur le plan 1-2 :

46
Les domaines de la mobilité, de l’activité de la vie quotidienne et du bien-être sont
fortement corrélés, négativement, à la composante 1.
Les domaines du soutien social et de la gêne psychologique sont eux fortement corrélés,
négativement, à la composante 2.
5ème étape : étude des individus

47
La composante 2 semble séparer les individus en 2 groupes. Il semble aussi que certain
individus se distinguent (73, 1700, 129, 11000 et 16).
6ème étape : juxtaposition variables-individus

48
7ème étape : variable supplémentaire
Les centres n’influent pas sur la qualité de vie.
Cependant, on remarque qu’il y a un problème de variance intra-individuelle sur des
données longitudinales : utilisation des modèles à mesures répétées et/ou modèles mixtes.
Effet temps Effet individu
Pour analyser des données corrélées (longitudinales ou clusterisées), le recours à des
modèles dits mixtes est de plus en plus fréquent. En effet, ce type de modèles, parfaitement
adapté pour analyser ce type de données corrélées, permet via l’introduction d’effets
aléatoires de modéliser, en quelques sortes, la non indépendance des données entre les
différentes mesures d’un même individu au cours du temps.

49
IV- Analyse de la variance sur données longitudinales
Dans cette partie nous expliquerons les principes généraux de l’analyse de variance, de
l’utilisation ensuite des tests post-hoc, nous expliquerons à quoi correspond les modèles
mixtes, et enfin nous appliquerons ces principes à notre étude.
4.1 Les modèles mixtes et l’ANOVA
4.1.1 Principe de l’ANOVA
Les analyses de variances, dites aussi ANOVA, sont des techniques permettant de savoir si
une ou plusieurs variables dépendantes, appelées aussi variables à expliquer, sont en
relation avec une ou plusieurs variables dites indépendantes. Le nom de ce test s’explique
par sa façon de procéder : on décompose la variance totale de l’échantillon en deux
variances partielles, la variance inter-classes et la variance résiduelle, et on compare ces
deux variances. L’analyse de la variance peut être vue aussi comme une comparaison
multiple de moyennes.
Pour réaliser ce test, il faut vérifier des hypothèses assez restrictives. Tout d’abord, il faut
vérifier la normalité des distributions. Pour vérifier cette hypothèse, on peut par exemple
effectuer un test de Shapiro-Smirnov, un test de Shapiro-Wilks ou bien un diagramme
quantile-quantile (qq-plot). Ensuite, l’autre hypothèse à vérifier est l’homogénéité des
variances. Pour cette deuxième, on peut utiliser un test de Bartlett ou un test de Levene.
Cependant l’ANOVA n’est qu’un test global. En effet, si l’hypothèse nulle H0 est rejetée au
seuil α, c’est-à-dire si l’hypothèse d’égalité des moyennes est rejetée, le test ne fournit pas
d’analyse des raisons de ce sujet.
4.1.2 Principe des tests post-hoc
Si l’ANOVA est significative, on sait dès lors que les moyennes des groupes ne sont pas
toutes identiques. Le problème est que l’on sait que la variabilité des moyennes des groupes
par rapport à la variabilité des individus est trop importante pour que ce résultat puisse être
attribué au hasard, il faut donc chercher à savoir quels groupes diffèrent de tels groupes.
On pourrait comparer les groupes deux à deux avec un t-test de Student. Mais cela poserait
un problème d’inflation du risque α (=probabilité de fausse alarme) que l’on notera α*. Le
risque α* correspond à la probabilité d’obtenir au moins une fausse alarme après N
comparaisons au seuil de signification α, alors que H0 est vraie. Ce risque suit donc une loi
binomiale cumulative et on a donc α*=1-(1-α)N.

50
En effet, si on prend l’exemple traité ci-après, on réalise une expérience sur k=4 temps. On
peut alors effectuer (k(k-1)/2)=6 comparaisons de moyennes deux à deux. L’erreur globale
devient :
α*=1-(1-0.05)6 =0.265
Soit 26.5 % de chance d’obtenir au moins un résultat significatif faux et non pas 5% !!
Afin de protéger α* d’une inflation, on utilise des tests post-hoc, également appelés tests de
comparaison multiple, qui ajustent α* au moyen de corrections différentes. Ces
comparaisons post-hoc permettent de traiter le rôle du hasard dans le choix des moyennes à
comparer. Il existe plusieurs tests dont certains sont plus puissants que les autres. Nous ne
parlerons dans notre rapport que du test de Bonferroni et du test HSD de Tukey.
Le test HSD (Honest Significant Differences) de Tukey correspond aux méthodes exactes du
contrôle de l’erreur globale : α*=0.05. Le test de Bonferroni est plus un test conservatif
c’est-à-dire que α*<0.05. Dans la suite de notre rapport, nous utiliserons plus
particulièrement le test HSD de Tukey.
4.1.3 Principe des modèles mixtes
Au cours d'une expérience, différents facteurs peuvent être soupçonnés d’affecter les
résultats de l'expérience donc les valeurs de la variable observée. On peut catégoriser ces
facteurs de la sorte :
- Facteurs à effets fixes : facteurs ayant un nombre fini de niveaux qui sont
entièrement représentés. Ils sont retrouvés dans tous les types de modèles.
- Facteurs à effets aléatoires : facteurs dont le nombre des niveaux peut être infini
et les données disponibles ne représentent alors qu’un échantillonnage des
niveaux de chaque facteur.
Comme son nom l’indique, ce modèle associe des effets mixtes, c’est-à-dire qu’il associe des
effets fixes et des effets aléatoires (au moins un de chaque pour les modèles mixtes). Dans
ce modèle, la variable expliquée (variable dépendante) est toujours par définition une
variable aléatoire, mais ce n’est pas elle qui constitue un effet aléatoire.
Quand les niveaux d’une variable sont fixés a priori, on dit que cette variable est contrôlée et
elle constitue alors un effet fixe. Les effets aléatoires quant à eux dépendent de l’échantillon
et déterminent la structure des corrélations. Une fois modélisée la covariance des effets
aléatoires, les résidus sont indépendants.
Le modèle mixte peut être considéré mathématiquement comme une extension du modèle
linéaire auquel on ajoute des effets aléatoires (dû aux individus) qui ne sont pas observés

51
directement (contrairement aux effets fixes). Il permet d’obtenir des estimations des effets
aléatoires et des trajectoires individuelles. L’estimation des paramètres est alors réalisée par
les méthodes ML (Maximum de Vraisemblance), REML (Maximum de Vraisemblance
Restreinte) ou encore GEE (Equations d’Estimation Généralisées). Pour une variable à
expliquer Y, le modèle s’écrit :
Y= X.β + Z.b +ε
où X est une matrice n x p (covariables), β est le vecteur des coefficients des effets fixes (à
estimer), b est le vecteur des coefficients des effets aléatoires, Z est la matrice d’incidence
de taille n x q, et ε est l’erreur résiduelle.
Dans l’exemple qui suit, le facteur « temps » est un effet fixe, les individus et le temps sont
des effets aléatoires (on peut considérer un effet fixe comme un effet aléatoire). Les
analyses de variances sont effectuées sous le logiciel R à l’aide du package ‘lme4’.
4.1.4 Application
Dans ce jeu de données, on étudie l’évolution des 8 domaines de la qualité de vie (réponses
au questionnaire pdq-39) sur 4 temps : temps pré-opératoire t=0, 12, 36 et 60 mois. On a
donc affaire à des données répétées et longitudinales (corrélées). Afin d’analyser ces
données, nous utiliserons donc les modèles mixtes.
Domaine « activité de la vie quotidienne :
Modèle mixte avec prise en compte des effets aléatoires sujet et temps :
L’interprétation des résultats se fait par rapport au temps initial (temps 0). On choisit un
seuil α de 5% pour tous les tests. Ici, on remarque que les données aux instants 12 et 36
mois sont significativement plus faibles qu’aux données initiales : en effet, on a un effet
significatif car ρ<0.0001 (valeur de Pr(>|t|)), et les valeurs des données sont plus faibles car
on a des paramètres (estimate) négatifs (-3.905135 et -2.637830 pour les temps respectifs
12 et 36 mois).

52
ANOVA suivie d’un test post-hoc :
On observe donc un effet significatif du paramètre « temps », c’est-à-dire que l’on rejette
l’hypothèse « les moyennes de qualité de vie sur les 4 temps sont égales ». On peut alors
effectuer un test de comparaison multiple : le test de Tukey-Kramer (= test HSD de Tukey).
Les différences significatives correspondent aux données qui sont entourées en bleu : ici,
entre les temps 0 et 12, entre les temps 0 et 36, entre les temps 12 et 36 et entre les temps
36 et 60.
Domaine « bien être affectif » :
Modèle mixte avec prise en compte des effets aléatoires sujet et temps :
Ici, on remarque qu’il y a une différence significative (plus faible) des données aux temps 12
et 36 par rapport aux données initiales. Pas de différence significative au temps 60 mois.

53
ANOVA suivie d’un test post-hoc :
On remarque qu’il y a un effet significatif du paramètre « temps ». On peut donc faire un
test de comparaison multiple : test de Tukey-Kramer.
On constate une différence significative de qualité de vie dans le domaine « bien-être
affectif » entre les temps 0 et 12, 0 et 36 ainsi qu’entre les temps 12 et 60.
Au vue de la valeur de la p-value entre les temps 12 et 36 qui est proche de 1, on en déduit
qu’il y a une stabilisation entre ces temps de la qualité de vie. De même, on peut en déduire
que la qualité de vie au temps 60 est à peu près la même qu’au temps pré-opératoire.
Domaine « communication » :
Modèle mixte avec prise en compte des effets aléatoires sujet et temps :
On remarque que les données aux temps 36 et 60 sont significativement plus fortes que les
données au temps 0. Pas de différence significative pour le temps 12 par rapport au temps
pré-opératoire.

54
ANOVA suivie d’un test post-hoc :
Il y a un effet significatif du facteur « temps », on applique alors un test post-hoc.
On remarque donc une différence significative entre les temps 0 et 60, ainsi qu’entre les
temps 12 et 60. On peut aussi constater qu’il y a une stabilisation entre les temps 0 et 12.
Domaine « gène psychologique » :
Modèle mixte avec prise en compte des effets aléatoires sujet et temps :
On remarque que les données aux temps 12, 36 et 60 sont significativement inférieures aux
données pré-opératoires.

55
ANOVA suivie d’un test post-hoc :
On observe un effet significatif du facteur « temps », d’où l’intérêt des comparaisons
multiples.
On constate qu’il y a une différence significative entre les temps 12, 36 et 60 mois et le
temps pré-opératoire. On remarque aussi qu’il y a une stabilisation entre les temps 12 et 36,
ainsi qu’entre 36 et 60.
Domaine « inconfort physique » :
Modèle mixte avec prise en compte des effets aléatoires sujet et temps :
On remarque que les données au temps 12 sont significativement plus faibles que les
données initiales. Pas d’effet significatif aux temps 36 et 60.

56
ANOVA suivie d’un test post-hoc :
Effet significatif du facteur « temps », on fait un test de comparaison multiple.
On constate qu’il y a une différence significative entre les temps 0 et 12. On remarque une
stabilisation entre les temps 12 et 36 mois.
Domaine « mobilité » :
Modèle mixte avec prise en compte des effets aléatoires sujet et temps :
On remarque que les données au temps 12 sont significativement plus faibles à celles du
temps initial. Pas de différence significative pour les temps 36 et 60.

57
ANOVA suivie d’un test post-hoc :
Effet significatif du facteur « temps », d’où l’intérêt des comparaisons multiples.
On remarque une différence significative entre les temps 0 et 12, 12 et 60, ainsi qu’entre les
temps 36 et 60. On constate aussi un retour aux données pré-opérationnel pour le temps 60.
Domaine « soutien social » :
Modèle mixte avec prise en compte des effets aléatoires sujet et temps :
Pas d’effet significatif du paramètre au cours du temps.
ANOVA suivie d’un test post-hoc :

58
Pas d’effet significatif du facteur « temps », il n’est donc pas nécessaire de tester les
comparaisons multiples.
Domaine « troubles cognitifs » :
Modèle mixte avec prise en compte des effets aléatoires sujet et temps :
Pas d’évolution significative du paramètre au cours du temps.
ANOVA suivie d’un test post-hoc :
Pas d’effet significatif du paramètre « temps ».

59
4.2 ANOVA à mesures répétées
Une ANOVA simple ne règle pas le problème des données répétées. Dans ce cas particulier
de l’ANOVA à mesures répétées, l’hypothèse d’indépendance des observations n’est plus
vérifiée puisque les mesures sont prises dans le temps sur les mêmes individus. Les données
sont donc corrélées. Le but de ce type d’analyse est de tester l’hypothèse de significativité
du temps, car en général on suppose que la variance intra-sujet est strictement positive.
Domaine activité de la vie quotidienne :
Les variances ont l’air d’être homogènes, on va le vérifier avec le test de bartlett.
On accepte l’hypothèse nulle c’est–à-dire que les variances sont égales.
Test de la normalité : méthode graphique du qq-plot/droite de Henry :

60
Anova :
La sortie montre que le facteur temps a pour source adjointe l’interaction sujet: temps, et
que son effet est significatif. On peut donc effectuer des tests post-hoc.
Les différences significatives sont entourées en vert pour tous les tests post-hoc.
Domaine bien être affectif :

61
On accepte H0 : Variances égales
Test de la normalité des résidus :
ANOVA :
La sortie montre que le facteur temps a pour source adjointe l’interaction sujet: temps, et
que son effet est significatif. On peut donc effectuer des tests post-hoc.
Domaine communication :

62
Test d’homogénéité des variances :
Egalité des variances
Test de la normalité des résidus :
ANOVA :
La sortie montre que le facteur temps a pour source adjointe l’interaction sujet :temps, et
que son effet est significatif. On peut donc effectuer des tests post-hoc.

63
Domaine gène psychologique :
Test d’homogénéité des variances :
Egalité des variances
Test de la normalité :
ANOVA :
La sortie montre que le facteur temps a pour source adjointe l’interaction sujet: temps, et
que son effet est significatif. On peut donc effectuer des tests post-hoc.

64
Domaine inconfort physique :
Test d’homogénéité des variances :
Egalité des variances
Test de la normalité des résidus :
ANOVA :

65
La sortie montre que le facteur temps a pour source adjointe l’interaction sujet: temps, et
que son effet est significatif. On peut donc effectuer des tests post-hoc.
Domaine mobilité :
Test d’homogénéité des variances :
Egalité des variances
Test de normalité des résidus :

66
ANOVA :
La sortie montre que le facteur temps a pour source adjointe l’interaction sujet: temps, et
que son effet est significatif. On peut donc effectuer des tests post-hoc.
Domaine soutien social :
Test d’homogénéité des variances :
Variances égales

67
Test sur la normalité résiduelle :
ANOVA :
Pas d’effet significatif
Domaine troubles cognitifs :
Test sur l’homogénéité des variances :
Egalité des variances
Test sur la normalité des résidus :

68
ANOVA :
La sortie montre que le facteur temps a pour source adjointe l’interaction sujet: temps, et
que son effet est significatif. On peut donc effectuer des tests post-hoc.

69
V- Impact des données manquantes sur données
longitudinales
Malgré tous les soins apportés à la préparation et au déroulement d’une enquête, les
observations incomplètes sont de plus en plus fréquentes en épidémiologie comme dans
bien d’autres domaines. Lors d’une étude clinique, on est confronté à deux types/structures
de données manquantes :
- de sortie d’étude : quand le sujet ne participe pas à une évaluation
(visites, questionnaire), les évaluations suivantes sont manquantes. Par
exemple, cela peut être dû à un traitement inefficace, une mauvaise
tolérance, ou que le patient est perdu de vue. Dans ce cas, on a des
valeurs manquantes monotones.
? ? ?
? ?
?
Structure monotone
- données manquantes intermittentes : quand un sujet ne peut ou ne veut
pas participer à une évaluation mais les évaluations suivantes sont
effectuées. Cela peut être dû à une visite oubliée, à cause d’une maladie,
une mesure invalide, etc. Dans ce cas, on a une structure des données
non-monotone.
?
?
?
? ?
?
?
?
Structure non-monotone

70
Lors d’études cliniques, les deux structures sont combinées, cela revient à une structure
non-monotone.
Les épidémiologistes ont l’habitude des raisonnements statistiques et ils sont conscients
qu’un recueil d’information incomplet risque d’affecter la précision et l’exactitude de leurs
calculs. D’où une certaine prise de conscience récente de l’intérêt d’étudier les données
manquantes.
5.1 Typologie
Voici la typologie des processus d’observation incomplète proposée par Little et Rubin, qui
comporte trois catégories (appelée aussi mécanisme des données manquantes).
5.1.1 MCAR (Missing Completely At Random)
On parle de données manquant complétement aléatoirement ou complétement au hasard
(MCAR) lorsque la probabilité qu’une observation soit incomplète est une constante :
autrement dit, la probabilité qu’une donnée soit manquante ne dépend ni des valeurs
observées ni des valeurs manquantes. En termes mathématiques, cela s’écrit :
P(r|xobs,xmiss)=P(r) où r représente la réponse.
Par exemple, lorsqu’une mesure est trop coûteuse, on ne procède à la mesure que sur un
sous-échantillon. Dans ce cas, les données complètes constituent un sous-échantillon
représentatif de l’échantillon initial : aucun biais. La conséquence immédiate de ce type de
données est une perte de précision (puissance).
5.1.2 MAR (Missing At Random)
On parle de données manquant aléatoirement ou au hasard (MAR) lorsque la probabilité
qu’une observation soit incomplète ne dépend que de valeurs observées (mais pas de
valeurs manquantes). En termes mathématiques, cela s’écrit :
P(r|xobs,xmiss)=P(r|xobs)
Par exemple, les personnes âgées refusent de donner leur revenu. La conséquence de ce
type de données est une perte de puissance de l’analyse. Il n’y a aucun biais avec des
méthodes statistiques appropriées.

71
5.1.3 MNAR (Missing Not At Random)
On parle de données manquant non aléatoirement ou ne manquant pas au hasard (données
manquantes informatives) lorsque la probabilité qu’une observation soit incomplète dépend
de valeurs non observées, autrement dit la probabilité qu’une donnée soit manquante
dépend des valeurs manquantes. En termes mathématiques cela s’écrit :
P(r|xobs,xmiss)=P(r|xmiss)
Par exemple, les personnes avec un revenu important refusent de le dévoiler. Les
conséquences sont une perte de puissance ainsi que la présence de biais, ce qui demande un
besoin de recourir à une analyse de sensibilité.
5.1.4 Cas des données longitudinales
On a toujours trois catégories de données pour des données longitudinales. Premier cas, le
patient s’est présenté à toutes les visites, les données sont donc complètes. Deuxième cas,
on a des valeurs manquantes intermittentes, le patient ne s’est pas rendu à un certain
nombre de visite. Enfin dernier cas, on a des valeurs manquantes monotones, le patient est
perdu de vue (c’est-à-dire ne vient plus à partir d’une certaine date).
Cependant, on peut alors se demander comment déterminer à quel type de données
manquantes on a affaire ? Il est impossible de savoir à partir des données si les observations
manquantes sont MCAR, MAR ou MNAR.
Plusieurs analyses statistiques de données avec des valeurs manquantes font l’hypothèse
que les données manquent de manière complétement aléatoire (MCAR). Il n’existe que très
peu de test de cette hypothèse. Little et Rubin proposent un test statistique global de cette
hypothèse. A ce jour, ce test est uniquement implanté dans le module Missing Value
Analysis (MVA) du logiciel SPSS. Il faut remarquer que l’hypothèse testée (MCAR) est plus
forte que l’hypothèse MAR (l’hypothèse MCAR est un cas particulier de l’hypothèse MAR
donc plus restreint). Le test proposé par Little et Rubin est asymptotiquement valable sous
les hypothèses de normalité.
Par la suite, ils ont présenté un concept pour comprendre la distinction entre les données
MAR et MNAR. Ce concept est celui de « l’ignorabilité ». Le mécanisme MAR est dit
ignorable alors que MNAR est non ignorable. Aucune procédure, à ce jour, ne peut
définitivement distinguer ces deux types de données manquantes c’est-à-dire si le
mécanisme est ignorable ou non. L’identification du mécanisme des données manquantes
est une tâche fortement influencée par la nature des données. Dans les études à plan
longitudinal-expérimental, le schéma intermittent peut être généralement considéré comme
ignorable si la proportion de données manquantes est faible.

72
5.1.5 Quantité de données manquantes
Toute analyse de données commence généralement par une analyse descriptive des
variables. Le méthodologue décrit les variables, leurs distributions, leurs significations. Il en
va de même pour les données qui devaient être récoltées et qui ne l’ont pas été. La
description des données manquantes constitue un point de départ pour évaluer l’impact que
ces dernières peuvent avoir. Cette description permettra aussi de juger de la validité des
résultats.
La quantité de données manquantes peut être définie de différentes manières. On peut se
référer aux individus, aux variables ou à l’échantillon complet. Dans le premier cas, la
proportion d’individus avec données complètes correspond à la division du nombre
d’individus avec données complètes par le nombre total d’individus. Dans le second cas, la
proportion de variables avec données complètes correspond à la division du nombre de
variables avec données complètes par le nombre total de variables. Enfin, si on veut se
référer à l’échantillon complet, on calcule alors la proportion d’observations manquantes,
qui correspond à la division du nombre d’observations manquantes sur le nombre total
d’observations effectuées. On peut aussi calculer la proportion moyenne de variables
manquantes en calculant le ratio proportion d’observations manquantes sur proportion
d’individus avec des données manquantes.
Il existe de nombreuses proportions basées sur ces différentes statistiques. Ces proportions
fournissent une estimation de la densité des données manquantes au niveau des individus
ou au niveau des variables. Elles permettront ainsi de définir en partie le mécanisme des
données manquantes.
Voici le pourcentage de valeurs manquantes sur les différents domaines de la pdq-39 :
Domaines
adl
Bien-être
Communication
Gène psychologique
Inconfort physique
Mobilité
Soutien social
Troubles cognitifs
% données manquantes
9.81 12.66 11.08 10.76 9.49 8.86 10.44 10.13
Dans toute cette base de données, on rencontre en tout 246 variables manquantes sur
316*8=2528 données soit 9.73% de données manquantes.
5.2 Méthodes d’analyses en présence de données manquantes
Les méthodes statistiques relatives aux données manquantes sont extrêmement
nombreuses. Nous ne présenterons ici que les méthodes ayant un certain intérêt.

73
5.2.1 Analyse des cas complets :
Cette technique est une des plus simples qui puisse être envisagée. Il s’agit d’analyser
uniquement les observations sans données manquantes c’est-à-dire dans le cas de notre
étude conserver uniquement les patients qui ont des mesures complètes. C’est l’analyse qui
est faite par défaut par la plupart des logiciels statistiques standards. Cette méthode est
adaptée si les données sont MCAR ou si les données sont MAR en cas d’ajustement sur les
variables qui prédisent le manque de données. Elle est peu efficiente car beaucoup
d’observations peuvent « disparaitre ». Cependant, elle devient raisonnable si les individus
avec des données manquantes sont en faible proportion (moins de 5%).
Individu
V1 V2 V3
1 120 120 25
2 189 ? 65
3 ? 134 75
4 142 156 45
5 ? 125 98
6 113 153 47
Dans cet exemple, on ne conserve donc que 3 lignes sur 6 soit 50% des données sur les
individus. Beaucoup trop d’informations ont été supprimées : la méthode ne paraît pas
appropriée.
Les conséquences de ce type de méthode sont la perte de précision et la présence de biais
importants. La solution serait de compléter les informations manquantes par « imputation »
mais pas n’importe comment!
5.2.2 Les techniques d’imputations simples
L’imputation regroupe les méthodes utilisées pour remplacer les données manquantes.
L’imputation simple consiste à remplacer chaque valeur manquante par une unique
prédiction obtenue à partir des autres observations. Il existe à ce jour une multitude de
techniques développées à cet effet :
- Imputation par la moyenne : on remplace les valeurs manquantes par la
moyenne des valeurs observées sur la variable. Cette méthode donne des
estimations non biaisées si les données sont MCAR. Dans le cadre d’une
analyse de variance, elle est souvent utilisée. Cette méthode résout les
problèmes de biais mais conduit tout de même à sous-estimer les
variances.

74
- Hot deck : les valeurs manquantes sont remplacées par des valeurs
observées chez un individu ayant les mêmes caractéristiques. Cette
méthode est utilisable sous l’hypothèse que les données sont MAR, elle
implique une sous-estimation de la variance et un biais possible.
Sujet V1 V2 V3 V4
1 4 1 2 3
2 5 4 2 5
3 3 4 2 ? ->5
- Imputation par modèle de régression : La variable est modélisée par un
modèle de régression (à partir des données observées), et la prédiction du
modèle remplace la donnée manquante. Cette méthode préserve les
relations entre les variables, néanmoins elle surestime les corrélations
entre les variables.
- LOCF (Last Observation Carried Forward) : Pour des données
longitudinales, la valeur manquante est remplacée par la dernière valeur
disponible. Cette méthode fait donc l’hypothèse que le profil de réponse
du patient est constant au cours du temps, ce qui parait peu réaliste.
5.2.3 L’imputation multiple
La technique de l’imputation multiple a été développée en particulier par Rubin (1987) afin
de remédier à certains problèmes de l’imputation simple comme la sous-estimation des
variances.
Cette méthode consiste à créer plusieurs valeurs possibles pour une même valeur
manquante. Les buts sont nombreux. Tout d’abord, le but est de refléter correctement
l’incertitude des données manquantes, ensuite de préserver les aspects importants des
distributions et enfin de préserver les relations importantes entre les variables. Cette
méthode n’a, en aucun cas, pour but de prédire les données manquantes avec la plus grande
précision ou de décrire les données de la meilleure façon possible.
L’approche est basée sur une méthode de simulation pour analyser les données
incomplètes. Cette méthode se fait en trois étapes. La première consiste à remplacer toutes
les valeurs par N>1 valeurs tirées d’une distribution appropriée (valeurs simulées). On
obtient ainsi N bases de données avec des valeurs observées et imputées. Ensuite, ces N
bases de données complétées sont analysées indépendamment en utilisant une méthode
standard. Enfin, on combine les résultats des analyses afin de refléter la variabilité
supplémentaire due aux données manquantes (« pooling »). On obtient ainsi des
estimateurs uniques pour chacune des données manquantes.

75
1ere étape : Imputations
1 2 … N
Il faut savoir que, plus le nombre N d’imputations est grand, plus les estimateurs seront
précis. Pour avoir de bons résultats, Rubin préconise entre trois et cinq imputations
seulement.
Schéma représentatif des étapes de l’imputation multiple :
1 2 3
1
2 NA
3 NA
4
5 NA
6 NA
Ces trois étapes sont réalisables sous SAS. La première se réalise avec la procédure MI
(Multiple Imputation), la seconde se réalise avec une procédure classique (reg, logistic, etc),
et enfin la dernière est réalisable avec la procédure MIANALYSE.
Je vais vous montrer un petit exemple de la procédure MI de SAS sur la base de données
incomplètes qui comprend 79 patients suivis sur 4 temps. En voici un petit extrait :
N bases de données
complètes
N analyses des
données
complètes
:
3ème étape
Combinaison des résultats :
« pooling »
2ème étape

76
On remarque ici sur la 2nde ligne que le patient no 500 n’a répondu qu’aux questions portant
sur la mobilité et l’inconfort physique, ses autres sont donc manquantes. On va alors
appliquer la procédure MI de SAS afin d’obtenir des bases de données complètes.
On réalise avec cette procédure 3 bases de données complètes dont le début de la première
est :

77
CONCLUSION
Mon stage de fin d’année au sein de la DRCI du CHU de Clermont-Ferrand a été enrichissant
aussi bien sur le plan professionnel que sur le plan humain. J’ai eu le plaisir d’intégrer une
équipe conviviale qui m'a énormément apportée en termes de connaissances aussi bien sur
le plan médical que sur le plan statistique.
Durant ce stage, j’ai pu découvrir de nouvelles méthodes d’analyses statistiques ainsi que de
nouvelles méthodologies applicables dans le milieu médical. J’ai aussi découvert comment se
déroule un essai clinique avec toutes ses contraintes administratives et ces multiples étapes.
Mon maître de stage m’a apporté de nombreuses connaissances et m’a rapidement donné la
responsabilité de réaliser mes propres analyses en m’aiguillant au fil du temps. Il m’a montré
le rôle et les différentes fonctions du biostatisticien durant un essai clinique. J’ai pu donc
appliquer et approfondir mes connaissances acquises lors de ma formation. J’ai notamment,
grâce aux analyses effectuées avec le logiciel R, amélioré énormément la maitrise de cet
outil, qui n’était pas le logiciel que je maitrisais et utilisais le plus auparavant.
Pour conclure, j’ai donc eu l’opportunité d’apprendre, durant ces quatre mois, le métier de
biostatisticien. Il resterait à approfondir le travail sur les données manquantes dans les
modèles longitudinaux. Je garde en tout cas une bonne expérience de ce stage.

78
Bibliographie
Ouvrage :
Gaël Millot. ‘’Comprendre et réaliser les tests statistiques à l’aide de R’’. Editions De Boeck,
avril 2009.
David Machin, Michael J.Campbell, Say Beng Tan and Sze Huey Tan. “Sample size tables for
clinical studies”. Third edition. Edition Wiley-Blackwell, 2009.
G. Molenberghs, M. G. Kenward. “Missing data in clinical studies”. Vol 1, 524 pages, edition
Willey, 2007.
Article :
Roderick J. A. Little. ‘’A test of missing completely at random for multivariate data with
missing values’’. Journal of the American statistical association, vol 83, no 404, p 1198-1202,
december 1988.
Site internet:
Encyclopédie Wikipedia: http://fr.wikipedia.org/wiki
Site institutionnel du CHU: http://www.chu-clermontferrand.fr
Langage R : http://www.biostat.envt.fr/spip/IMG/pdf/Une_introduction_au_langage_R.pdf
Questionnaire pdq-39 : http://www.em-consulte.com/article/50904
http://www.has-sante.fr
Modèles mixtes sous R: http://zoonek2.free.fr/UNIX/48_R_2004/17.html

79
Annexe 1 : Questionnaire sur la pdq-39
Questionnaire à remplir par le patient
Date : |__|__| |__|__| |__|__| Jour Mois Année
PDQ 39 (1/4)
A cause de votre maladie de Parkinson, combien de fois avez-vous vécu l’une des situations
suivantes, au cours du MOIS PRÉCÉDENT ?
Veuillez cocher une case pour chaque réponse
Jamais
Rarement
Parfois
Souvent
Toujours
ou
totalement
incapable
1. Avez-vous eu des difficultés dans la pratique
de vos loisirs ?
2. Avez-vous eu des difficultés à vous occuper de
votre maison, par exemple : bricolage,
ménage, cuisine ?
3. Avez-vous eu des difficultés à porter des sacs
de provisions ?
4. Avez-vous eu des problèmes pour faire 1 km à
pied ?
5. Avez-vous eu des problèmes pour faire 100 m
à pied ?
6. Avez-vous eu des problèmes à vous déplacer
chez vous, aussi aisément que vous l’auriez
souhaité ?
7. Avez-vous eu des difficultés à vous déplacer
dans les lieux publics ?
8. Avez-vous eu besoin de quelqu’un pour vous
accompagner lors de vos sorties ?
9. Avez-vous eu peur ou vous êtes-vous senti(e)
inquiet(e) à l’idée de tomber en public ?
Veuillez vérifier que vous avez coché une case pour chaque question avant de passer à la page suivante.

80
PDQ 39 (2/4)
Veuillez cocher une case pour chaque réponse Jamais
Rarement
Parfois
Souvent
Toujours
ou
totalement
incapable
10. Avez-vous été confiné(e) chez vous plus que
vous ne l’auriez souhaité ?
11. Avez-vous eu des difficultés pour vous laver ?
12. Avez-vous eu des difficultés pour vous
habiller ?
13. Avez-vous eu des problèmes pour boutonner
vos vêtements ou pour lacer vos chaussures ?
14. Avez-vous eu des problèmes pour écrire
lisiblement ?
15. Avez-vous eu des difficultés pour couper la
nourriture ?
16. Avez-vous eu des difficultés pour tenir un
verre sans le renverser ?
17.Vous êtes-vous senti(e) déprimé(e) ?
18. Vous êtes-vous senti(e) isolé(e) et seul(e) ?
19. Vous êtes-vous senti(e) au bord des larmes
ou avez-vous pleuré ?
20. Avez-vous ressenti de la colère ou de
l’amertume ?
21. Vous êtes-vous senti(e) anxieux(se) ?
22. Vous êtes-vous senti(e) inquiet(e) pour votre
avenir ?
Veuillez vérifier que vous avez coché une case pour chaque question avant de passer à la page suivante

81
PDQ 39 (3/4)
Veuillez cocher une case pour chaque réponse Jamais
Rarement
Parfois
Souvent
Toujours
ou
totalement
incapable
23. Avez-vous ressenti le besoin de dissimuler
aux autres votre maladie de Parkinson ?
24. Avez-vous évité des situations où vous deviez
manger ou boire en public ?
25. Vous êtes-vous senti(e) gêné(e) en public à
cause de votre maladie de Parkinson ?
26. Vous êtes-vous senti(e) inquiet(e) des
réactions des autres à votre égard ?
27. Avez-vous eu des problèmes dans vos
relations avec vos proches ?
28. Avez-vous manqué du soutien, dont vous
aviez besoin, de la part de votre époux(se) ou
conjoint(e) ?
29. Avez-vous manqué du soutien dont vous
aviez besoin, de la part de votre famille ou de
vos amis proches ?
30. Vous êtes-vous endormi(e) dans la journée
de façon inattendue ?
31. Avez-vous eu des problèmes de
concentration, par exemple en lisant ou en
regardant la télévision ?
32. Avez-vous senti que votre mémoire était
mauvaise ?
33. Avez-vous fait de mauvais rêves, ou eu des
hallucinations ?
34. Avez-vous eu des difficultés pour parler ?
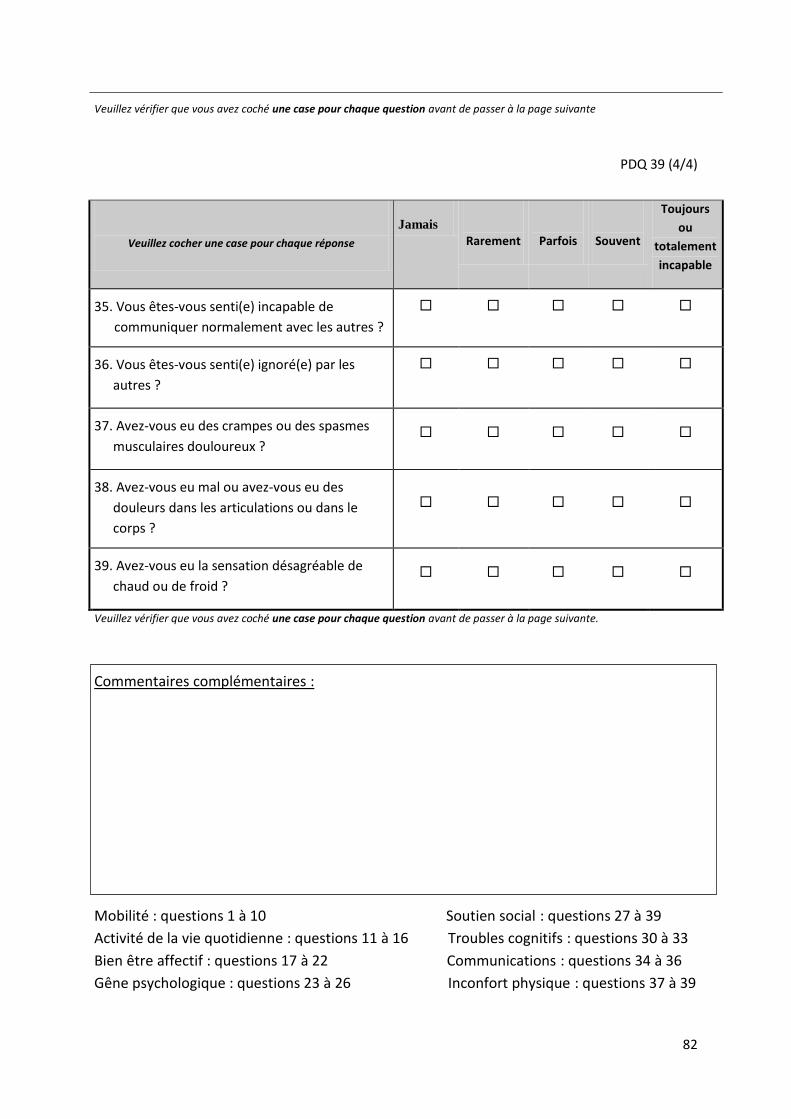
82
Veuillez vérifier que vous avez coché une case pour chaque question avant de passer à la page suivante
PDQ 39 (4/4)
Veuillez cocher une case pour chaque réponse Jamais
Rarement
Parfois
Souvent
Toujours
ou
totalement
incapable
35. Vous êtes-vous senti(e) incapable de
communiquer normalement avec les autres ?
36. Vous êtes-vous senti(e) ignoré(e) par les
autres ?
37. Avez-vous eu des crampes ou des spasmes
musculaires douloureux ?
38. Avez-vous eu mal ou avez-vous eu des
douleurs dans les articulations ou dans le
corps ?
39. Avez-vous eu la sensation désagréable de
chaud ou de froid ?
Veuillez vérifier que vous avez coché une case pour chaque question avant de passer à la page suivante.
Commentaires complémentaires :
Mobilité : questions 1 à 10 Soutien social : questions 27 à 39
Activité de la vie quotidienne : questions 11 à 16 Troubles cognitifs : questions 30 à 33
Bien être affectif : questions 17 à 22 Communications : questions 34 à 36
Gêne psychologique : questions 23 à 26 Inconfort physique : questions 37 à 39

83
Annexe 2 : Liste des abréviations
ACP : Analyse en Composantes Principales
AFSSAPS : Agence Française de Sécurité Sanitaire des Produits de Santé : établissement
public dont la mission principale est d’évaluer les risques sanitaires présentés par les
médicaments et plus généralement tous les produits de santé destinés à l’homme.
AOI : Appel d’Offre Interne
ARC : Attaché de Recherche Clinique
BPC : Bonnes Pratiques Cliniques : ensemble de disposition à mettre en place pour garantir
la qualité d’un essai tant dans sa conduite que lors du recueil des résultats. Leurs
applications assurent les droits et la sécurité des personnes participantes ainsi que la
confidentialité des informations.
CNRC : Comité National de Recherche Clinique
CPP : Comité de Protection des Personnes : comité dont le rôle est de vérifier, avant la mise
en œuvre d’un projet de recherche, que celui-ci obéit aux grandes règles de l’éthique et que
toutes les mesures sont prises pour protéger au mieux les personnes qui y participeront,
cette participation ne pouvant être que volontaire et librement consentie après qu’une
information claire leur ait été donnée.
HSD: Honest Significant Differences
LOCF: Last Observation Carried Forward
MAR: Missing At Random
MCAR: Missing Completely At Random
MNAR : Missing Not At Random
MPI : Maladie de Parkinson Idiopathique
NSN : Nombre de Sujets Nécessaires
PDQ : Parkinson Disease Quotation
PHRC : Programme Hospitalier de Recherche Clinique
UPDRS: Unifed Parkinson Disease Rating Scale

84
Annexe 3: Programmes sous R
Importation des données:
On importe les données dans une table que l’on nomme a. La commande Header permet de
spécifier si la première ligne de données correspond aux noms des variables.
Analyse descriptive :
On fait une analyse descriptive sur les 8 variables de la pdq-39. Cet exemple est réalisé pour
le domaine « activité de la vie quotidienne » (adl), pour les autres variables il suffit de
remplacer adl par les noms des autres domaines inscris dans la table a.
Tout d’abord, on charge la librairie Hmisc. Celle-ci permet avec la commande summary de
produire des tableaux de statistiques descriptives ressemblant à ceux de SAS. Je crée ensuite
une fonction g qui permettra d’incorporer dans mon tableau des statistiques plus élaborées
(quantile, médiane, écart-type). Enfin, j’affiche les statistiques demandées de chaque
domaine en fonction du temps.
On veut ensuite afficher le graphe de l’évolution des moyennes des variables en fonction du
temps. Pour cela, on récupère uniquement les moyennes de la variable sur chaque temps
avec la première ligne de commande. On crée ensuite le vecteur temps sur la seconde ligne
de commande, et enfin on affiche le graphe avec l’option plot.
ACP sur chaque temps :
L’exemple ici sera effectué sur le temps t=0, il suffit donc pour les autres analyses de
remplacer le temps 0 par 12, 36 et 60. Afin de réaliser cette analyse multidimensionnelle, il
faut au préalable installer et charger le package ade4.
4 : 11 correspond aux 8 colonnes des 8 variables de la pdq-39
Ici, on réalise les deux premières étapes de l’ACP, on effectue tout d’abord une analyse
univariée en réalisant les boîtes à moustaches de toutes les variables, puis une analyse

85
bivariée en affichant la matrice des corrélations des variables. Par la suite, on exécute la
troisième étape de l’ACP : le choix du nombre d’axes.
On réalise une ACP centrée-réduite des données de la table a sur la première ligne de
commande. La seconde ligne correspond au calcul de la part de variance expliquée par
chaque axe. La troisième ligne crée un data frame qui affiche les valeurs propres de chaque
composantes, la variance expliquée et la variance cumulée. Enfin, on affiche le graphe des
valeurs propres sur la dernière ligne.
La première ligne correspond à la représentation des variables sur le plan 1-2 (acp$co
correspond aux coordonnées des variables). La seconde représente cette fois les individus
sur ce même plan (acp$li correspond aux coordonnées des individus). La troisième ligne de
commande représente à la fois les individus et les variables sur le plan 1-2. Enfin, la dernière
ligne correspond à la représentation des individus groupés par centre.
Anova sur chaque domaine :
Ici, l’exemple est présenté pour le domaine activité de la vie quotidienne.
Modèle mixte avec effet fixe le temps et 2 effets aléatoire temps et sujet (patients).
Anova :
Test post-hoc de Tukey :


















