

Leticia Gracia Medrano. [email protected] 30 … · 2012-07-29 · Area bajo la curva que...
67
Transcript of Leticia Gracia Medrano. [email protected] 30 … · 2012-07-29 · Area bajo la curva que...

La denición de Agresti y Franklin
Estadística es el arte y la ciencia de diseñar estudios y analizar losdatos que esos estudios generan. Su n último es traducir los datosen conocimiento y entendimiento del mundo que nos rodea. Enresumen Estadística es el arte y la ciencia de aprender de los datos.

La denición de Manzano Arrondo
La estadística es la ciencia que se ocupa del estudio de fenómenosde tipo genérico, normalmente complejos y enmarcados en ununiverso variable, mediante el empleo de modelos de reducción dela información y de análisis de validación de los resultados entérminos de la representatividad

Las humorísticas
I Se dice por ejemplo, que si una persona gana un millón y otranada, la estadística" establece que las dos han ganado mediomillón.
I La estadística dice: que si una persona pone la cabeza en lecongelador y los pies en el horno, su temperatura media serácorrecta.
I La estadística pronostica como un acierto el caso de unsoldado, que dispara sobre un blanco, una vez medio metro ala derecha y otra medio metro a la izquierda.
Cabe mencionar que en estos tres casos la media aritmética, estáafectada por una escasa representatividad.

Tipos de fenómenos
Una característica del humano es tratar de interpretar losfenómenos que lo rodean, aprender del mundo a partir de lo que seobserva y de su experiencia a lo largo del tiempo.A partir de estas experiencias uno aprende a hacer deduccionesútiles del mundo en que vive. No en balde el método cientíco tienecomo parte fundamental la observación.


Hay una gran variedad de fenómenos que quisiéramos describir,pero podemos empezar por clasicarlos como fenómenosdeterministas y fenómenos aleatorios.Un fenómeno determinista es aquel que, cuando se reproduce enlas mismas condiciones, podemos predecir con certeza cuál va a serel resultado, en otras palabras se rige bajo leyes causales. Este tipode fenómenos no son parte de nuestro estudio.Por otro lado, el fenómeno aleatorio es aquel que cada vez que serealiza, aun bajo condiciones idénticas (o casi), el resultado no seconoce con certeza, además el resultado sólo se sabe después derealizado el experimento.

Las herramientas con la que contamos para estudiar los fenómenos aleatorios son:
1. La probabilidad
I Grado de conanza o fundada apariencia de que algo suceda.I En los juegos o probabilidad clásica, es la razón entre el
número de casos favorables y el número de casos posibles.I y su formalización basada en planteamiento axiomático de
Kolmogorov en 1933.
2. La estadística.
I que es el estudio de los datos cuantitativos de la poblaciónI disciplina que utiliza grandes conjuntos de datos numéricos
para obtener inferencias basadas en el cálculo deprobabilidades.
I la estadística clásica o frecuentista se basa en la regularidadestadística, es decir que, al repetir un fenómeno aleatorio unnúmero grande de veces en condiciones constantes, lasproporciones en las que ocurren los posibles resultados sonmuy estables.
I la estadística subjetiva o Bayesiana que incorpora elconocimiento que tiene el individuo sobre el fenómenoaleatorio.

Concepto de medición y de variable
Para cuanticar o clasicar lo que percibimos de un fenómenoaleatorio necesitamos hacer mediciones u observaciones que nosayudarán a investigar una o varias características de interés sobre elfenómeno.Para un correcto manejo de nuestras mediciones, las observacionesdeben ser registradas tomando en cuenta su tipo, para poder saberque operaciones aritméticas podemos hacer con ellas.Como al medir un fenómeno aleatorio obtenemos diferentesregistros llamaremos variable al conjunto de posibles resultadosque podemos obtener.

De acuerdo a la característica que se desea estudiar, a los valoresque toma la variable, se tiene la siguiente clasicación:
Variables =
Categóricas
Ordinales
Nominales
Numéricas
Continuas
Discretas

CategóricaCuando el registro de la medición es un elemento de una categoría.
I Ordinales
Cuando el registro de la medición se expresa en grados deintensidad que tienen un orden, pero no se puede determinar elincremento entre los grados.Con variables de tipo ordinal podemos calcular: la moda, lamediana o los porcentiles de los datos.Ejemplo: Grados de satisfacción en un servicio Muy bueno,Bueno, Regular y Malo.
I Nominales
Cuando las categorías sólo se les da un nombre pero no tienen unorden entre ellas, deben ser mutuamente excluyentes (no hay unelemento que pertenezcan a dos o más categorías a la vez) yexhaustivas (todo elemento pertenece a una categoría). Podemoscalcular la(s) moda(s) y la frecuencia de ocurrencia en cada una delas categorías.Ejemplo: ¾Está de acuerdo con las obras de continuación delsegundo piso del Periférico? Sí No.

Numéricas
Cuando los registros son valores numéricos
I Discretas
son las variables que toman un número nito o numerable devalores.Ejemplo: Número de hijos en un matrimonio, número de accidentes.
I Continuas
Toman cualquier valor numérico entero, fraccionario o irracional.La precisión del registro dependerá del instrumento de medición.Ejemplo: la estatura de una persona tomada al azar.

Variables aleatorias
Las variables aleatorias (v.a.) serán nuestros modelos que nosserviran para representar la regularidad estadística. Y lasdenotaremos letras mayúsculas X , Y , W , etc.Una v.a.´s es una función que sirve para cuanticar los resultadosde modo que se asigne un número real a cada uno de los resultadosposibles del experimento.Por ejemplo, en el experimento de lanzar una moneda, losresultados posibles son Ω = águila, sol, entonces podemos denirla v.a. X como
X =
1 si cae águila
0 si cae sol.

Existen v.a. continuas y discretas, pero para cada variable aleatorianosotros podemos asignarle una función de densidad, denotada f (·)con las siguientes propiedades:
I f (x) ≥ 0, y
I
∑∀x∈Ω
f (x) = 1 cuando la v.a. es discreta
∞−∞ f (x)dx = 1 cuando la v.a. es continua.
Area bajo la curva que determina f (x)En el estudio de la regularidad estadística con variables categóricaso bien con variables numéricas con muchos valores (y se establecenclases o intervalos), la suma de las frecuencias relativas oproporciones siempre es uno (el 100%).

Distribución Normal
La función de densidad normal o Gaussiana1 destaca entre lasdistribuciones de tipo continuo, ya que es un modelo que se adecúaa una gran cantidad de situaciones en el mundo real, y porque sumanejo matemático es más sencillo en muchas técnicas deinferencia.Denición
Diremos que una v.a. X se distribuye normal con media µ y
varianza σ2, denotado por X ∼ N(µ, σ2), si su función de
densidad es:
fX (x) =1
σ√2π
exp
−(x − µ)2
2σ2
, para −∞ < x <∞
donde , µ = E (X ), −∞ < µ <∞, Var (X ) = σ2 y σ2 > 0.
1En honor al matemático Johann Carl Friedrich Gauss 1777 1855.

Observaciones
1. A(µ, σ2
)se les conoce como los parámetros de la función de
densidad.
2. µ coincide con la media, σ2 coincide con la varianza de la v.a.y√σ2 = σ se le conoce como la desviación estándar.
3. Cada par de valores µ y σ2 determinan una función dedensidad distinta
4. La función de densidad es simétrica alrededor del parámetro µ .
5. La media, la moda y la mediana coinciden en µ.
6. Si hacemos que µ = 0 y σ2 = 1 entonces
fX (x) =1√2π
exp
−x
2
2
, para −∞ < x <∞
que se conoce como la función de distribución normal
estándar. Este miembro de la familia de normales es muyimportante porque a partir de ella se pueden calcular lasprobabilidades de cualquier miembro de la familia.

−4 −2 0 2 4
0.0
0.2
0.4
0.6
0.8
x
µ = 0 σ2 = 1 2
σ2 = 1µ = 0
µ = 0 σ2 = 2

A partir de cualquier v.a. X ∼ N(µX , σ2
X ) con σ2X > 0, podemosllevarla a una v.a. normal estándar haciendo la siguientetransformación
Z =X − µXσX
,
a este proceso se le llama estandarización o estandarizar la v.a.X .Con el n de ejemplicar lo antes dicho, supongamos que tenemosdos números reales jos a y b tales que a ≤ b; entonces si queremossacar la probabilidad de que la v.a. X tome alguno de los valoresen el intervalo [a, b] esto lo calculamos de la siguiente forma:
P (a ≤ X ≤ b) = P (a − µX ≤ X − µX ≤ b − µX )
= P(a − µXσX
≤ X − µXσX
≤ b − µXσX
)= P
(a − µXσX
≤ Z ≤ b − µXσX
).

En resumen calcular la probabilidad del evento a ≤ X ≤ b, es
equivalente a el eventoa − µXσX
≤ Z ≤ b − µXσX
, donde
Z ∼ N (0, 1).Recordemos que para calcular probabilidades en el caso de v.a.´scontinuas es necesario calcular el área bajo la curva que determina lafunción de densidad f (x), es decir
P (a ≤ X ≤ b) = P (X ≤ b)− P (X ≤ a) = F (b)− F (a) = b
af (x)dx ,
donde F (·) es la función de distribución. En general no es fácil calcular elárea bajo la curva determinada por la función de densidad normalestándar f (z). Por fortuna existen tablas de la función de distribuciónF (z) = P (Z ≤ z) para la normal estándar. Estas tablas están integradade las siguiente forma: a) la primera columna tiene valores de la variableZ de -3.6 a 3.62 b) el primer renglón permiten obtener valores más nosde la variable aleatoria hasta centésimos, y c) el resto de la tabla contienelas probabilidades de que la v.a. Z , es decir, P (Z ≤ z).
2Para ver la tabla completa ver el apéndice

Por ejemplo, si deseamos calcular P (Z ≤ 1.48), buscamos en la primeracolumna el número 1.4 y en la primera hilera el número 0.08. El númeroubicado en la intersección de la hilera con el número 1.4 y la columnaencabezada por 0.08 es la probabilidad buscada, es decir:
P (Z ≤ 1.48) = 0.93056

Ejemplo. Sea una v.a. Z ∼ N(0, 1). Deseamos encotrarP (Z ≤ 2.33) y P (Z ≥ 2.33). La primera probabilidad correspondeal área sombreada en la siguiente gura
−3 −2 −1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
xv
yv
y puede obtenerse directamente de la tabla. Por lo tanto,P (Z ≤ 2.33) = 0.9901. La segunda probabilidad pedidacorresponde al área que no está sombreada en la gura. Puesto queel área total bajo la curva es uno, entoncesP (Z ≥ 2.33) = 1− 0.9901 = 0.0099.

Distribución χ2 o de Pearson
Una v.a. χ2(se lee, ji cuadrada) se genera a partir de la suma devariables aleatorias independientes normales con media cero yvarianza uno. Es decir, si Z1,Z2, . . . ,Zk ∼ N (0, 1) y sonindependientes entonces si denimos la nueva v.a. W como
W = Z 2
1 + · · ·+ Z 2
k ,
entonces diremos W se distribuye como una ji cuadrada con k
grados de libertad, y lo denotaremos como W ∼ χ2k .

Observaciones
1. El número de términos en la suma son los grados de libertad.
2. Se puede probar que la esperanza de W es k , es decir queE (W ) = k , y
3. la varianza de W es 2k , es decir Var (W ) = 2k .
A continuacion algunas funciones de densidad W ∼ χ2k , paradistintas k´s.

Distribución t de StudentSi Z ∼ N(0, 1) y W ∼ χ2k donde Z y W son independiente. Sientonces la v.a. denida por la transformación
Y =Z√Wk
,
diremos que Y se distribuye t de Student con k grados de
libertad, y lo denotaremos por Y ∼ tk .Observaciones
I Los grados de libertad de tk son los mismos grados de la χ2
que la genera.I Esta función de distribución es parecida a la normal centrada
en ceroI en el sentido de que también es simétrica alrededor del cero,I pero la tk se diferencía de la normal en que tiene colas más
pesadas.I Cuando los grados de libertad k tienden a innito, entonces tk
tiende a una N (0, 1), y lo podemos escribir comotk −→ N (0, 1) cuando k →∞.

−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
t(1)
t(5)
t(50)t(50)

Distribución F de Snedecor
Si u y v son números enteros positivos y denimos las siguentesv.a.´s como V ∼ χ2u y W ∼ χ2v donde V y W son independiente.Entonces la v.a. denida por la transformación
K =V/d1W/d2
,
se dice que K se distribuye F de Snedecor con u y v grados de
libertad, y lo denotaremos por K ∼ Fu,v .Observaciones
I Los grados de libertad u y v de la Fu,v los determinan losgrados de la χ2 en el numerador y en el denominadorrespectivemete.
I Si K ∼ Fu,v entonces1
K=K−1 ∼ Fv ,u.
A continuación se ilustran alguna funciones de densidad Fu,v para
distintas u′s y v ′s :

0 2 4 6 8
0.0
0.2
0.4
0.6
0.8
x
F(1,1)
F(1,5)
F(1,5)
F(100,1)

La Distribución de la Media Muestral XMedia y varianza de la media muestral.
Sea X1,X2, ...,Xn una muestra aleatoria de una función dedistribución de probabilidades fX (x), con media µX y varianza σ2X .La media y la varianza de la media muestral X son:
E(X ) = µX = µX
Var(X ) = σ2X
=σ2Xn
Si la muestra se toma sin reemplazo de una población nita detamaño N, la expresión anterior debe modicarse como sigue:
σ2X
=
(N − n
N − 1
)σ2Xn
Los resultados que se presentan son para la media de variablesaleatorias , es decir, para la media de lo que llamamos una muestraaleatoria, y no volveremos a ocuparnos del muestreo sin reemplazo.

Teorema Central del Límite
Sea X1,X2, ...,Xn una muestra aleatoria de una función deprobabilidades fX (x), con media µX y varianza σ2X . SeaX = 1
n(X1 + X2 + ...+ Xn) la media aritmética de las variables
aleatorias que integran la muestra. Para un tamaño de muestra (n)grande, la distribución de la variable aleatoria X es
aproximadamente normal con media µX y varianza σ2X/n. Ensímbolos esto se escribe:
X ∼N(µX ,
σ2Xn
)donde el símbolo ∼ debe leerse se distribuye aproximadamente.Si se estandariza la variable aleatoria X , tenemos:
X − µXσX√n
=
√n(X − µX )
σX∼ N(0, 1).

El Teorema Central del Límite establece que para un tamaño demuestra grande la distribución de X es aproximadamente normal:
1. independientemente de que la v.a. X 3 de la cual se estámuestreando,
2. el teorema funciona aún si la distribución es discreta,
3. sea simétrica o asimétrica la forma de la densidad de fX (x)
4. la expresión tamaño de muestra grande es ambigüa, por lotanto el tamaño de muestra para el cual la aproximación esbuena depende de la forma de fX (x).
3Siempre y cuanto tenga hasta segundo momento nito.

Ejemplo
La función de probabilidades de una varible aleatoria X es:
X -4 -3 -2 0 1 2 3
P (X = x) 0.3 0.1 0.1 0.1 0.2 0.1 0.1
Como podemos ver la densidad de X no se parece a unadistribución Normal. Con objeto de ver la rapidez con que ladistribución de medias se aproxima a una Normal, se tomaron 100muestras aleatorias de tamaño 2 de fX (x) y se calculó la mediaaritmética para cada una de las 100 muestras.
−4 −3 −2 −1 0 1 2 3
0.10
0.15
0.20
0.25
0.30
x
prob
abili
dad

muestra[, 4]
Fre
quen
cy
−4 −3 −2 −1 0 1 2
05
1015
El anterior histograma correspondiente los pormedios las muestrasaleatorias de tamaño dos. A pesar de que el histograma no tieneuna gran similitud con una distribución normal, notemos que esmás simétrica que fX (x). No perdamos de vista que cada muestraes de tamaño 2.

El siguiente histograma es el que se obtuvo al obtener 100 muestrasaleatorias tamaño 10 de la misma fX (x), y notamos un parecidomayor a la normal con tan solo una muestra de tamaño 10.
rowMeans(muestra)
Fre
quen
cy
−3 −2 −1 0 1
02
46
810

Calidad en los datosInspección visual. Para detectar si hay datos fuera de los rangosestablecidos, conocer el máximo y mínimo de cada variable.Vericar que las codicaciones sean consistentes en toda la base.Distribución de frecuencias de las variables de mayor interés, verdistribución de la muestra.Grácas de dispersión. Identicar grupos u observacionesdiscrepantes.Vericar métodos de recolección de los datos para detectarposibles fuentes de sesgo.Observaciones faltantes. Tratar de rastrearlas, ir a registrosoriginales, razones de su omisión. Denir que se hará con estasobservaciones, se puede usar algún valor de reemplazo o imputacióno seleccionar cuáles si se desechan. Los valores faltantes generansesgo este tema es de suma importanciaCuidado con el número de dígitos a usar, puede perderse precisión oal revés desperdiciar espacio.Tener control sobre los estándares de medición.Un grupo de datos de poca calidad no merece un análisis muydetallado.

Observaciones Discrepantes
Estas observaciones también son conocidas como aberrantes,discordantes, contaminantes,sorprendentes, en inglés OUTLIER.Puede denírseles de varias formas, una de ellas es decir que es unaobservación que se encuentra a una distancia ANORMAL de lasdemás, y entonces hay que denir lo que es una distanciaNORMAL, es decir la observación se encuentra fuera de la nube dedatos.Estas observaciones pueden distorsionar la información, tambiénpueden ser una señal de que el modelo de distribución de los datosNO es el adecuado, o reejar el haber encontrado una situaciónsorprendente o peculiar. Si la observación causa un impacto en elobservador se le llama generalmente discrepante.

Una observación contaminante será cualquiera que nocorresponda a la distribución supuesta, y ésta puede no serpercibida por el observador.Estas observaciones afectan fuertemente al estimador X de lamedia µ, y consecuentemente a los estimadores de Var(X ), de lasde Cov(X ,Y ) y de Corr(X ,Y ).En análisis de regresión interesa identicar a las observacionesinuyentes, que son aquellas que al omitirlas del análisis losvalores de las β's varían mucho.Detectar estas observaciones puede ser una tarea bastantecomplicada, sobre todo cuando se tienen datos altamentemultivariados.En el caso univariado se les puede detectar muy fácilmente a travésde grácos boxplot o también al vericar si la media de los datosdiere mucho de la mediana.

Datos FaltantesDatos faltantes completamente al azar
Pueden ser muy variadas las razones por las que existan valoresfaltantes. Ya sea porque las condiciones climáticas, de seguridad opolíticas no permiten recoger la información, porque ese día losinstrumentos se descomponen, por que no se encontró a la personau objeto de la encuesta, aquí se puede pensar que la información seperdió completamente al azar (MCAR por su siglas en inglés). Esdecir cuando la probabilidad de que Xi sea no observada no estárelacionada con el valor mismo de xi o con el de cualquier otravariable.Por ejemplo si las personas con un nivel de ingresos alto tienden ano contestar por miedo a ser sujetos secuestrables, entonces esaobservación no se perdió completamente al azar.MCAR corresponde a pensar que ese dato se perdió con la mismaprobabilidad que cualquier otro dato. Si la persona no respondeacerca de sus ingresos, de la misma manera que no responde acuántos hijos tiene, entonces se considera MCAR. En este caso losparámetros pueden estimarse sin sesgo.

A diferencia de los datos MCAR, donde la probabilidad de noobservar a Xi no depende del valor mismo de xi o de otrasvariables. En este caso esa probabilidad no dependerá de xi luegode controlar o condicionar con otra variable.
Por ejemplo, una persona con depresión puede ser que tienda más ano contestar acerca de su ingreso, la gente con depresión a su vezen general tiene menos ingresos, entonces lo que ocurre es que sihay un tasa alta de no respuesta entre las personas con depresión,la media real puede ser menor que la calculada con los datosexistentes, es decir sin tomar en cuenta a los datos faltantes. Ahorasi entre las personas con depresión la probabilidad de no contestaracerca de su ingreso no está relacionada con su nivel de ingreso,entonces los datos se consideran faltantes al azar, (MAR). EstoNo signica que estos faltantes no produzcan sesgo y que se
pueda uno olvidar del problema.

Cuando no son MCAR ni MAR entonces se dice que son datosfaltantes no al azar (MNAR).Ejemplo: Si se estudia una cierta enfermedad y las persona quepadecen esa enfermedad son las que tienen una mayor probabilidada no contestar a si la padecen, entonces los datos son faltantes noal azar, MNAR. Claramente el estimador de la proporción quepadece esa enfermedad será menor que la proporción que seobtendría con los datos completos. Lo mismo ocurre en el caso delas personas con menor ingreso son las que tienden a no contestarsu nivel de ingreso. Esta falta de datos no al azar es un problema,la única manera de obtener un estimador insesgadoReferencia bibliográca:http://www.uvm.edu/~dhowell/StatPages/More_Stu/Missing_Data/Missing.html

Tratamiento de datos faltantesOmisión total
Si los datos son MCAR las estimaciones obtenidas serán insesgadassi no son MCAR serán sesgadas, hay que tener en cuenta que estapérdida de datos genera pérdida de potencia en las pruebas.

Por ejemplo en el cálculo de las correlaciones se usan lasobservaciones disponibles, pero entonces cada estimación estásoportada por diferentes bases de datos. Puede ser el caso que sellegue a una matriz de correlaciones estimada NO denida positiva.No hay que olvidar que hay que analizar a las observaciones NA ytratar de ver si se comportan (en ciertas variables ) como lapoblación total o si dieren.Otra cosa importante es considerar qué es lo que se tiene perdido.La situación de perder variables explicativas es diferente a perdervariables respuesta.

Hot Deck
sustituir el caso por alguno semejante (de dónde sacamos a alguiensemejante si ya acabó la encuesta, tener la providencia de guardarun montoncito extra para la sustitución?).Imputación Simple
I Sustituir los valores faltantes por la media (el estimador demáxima verosimilitud), pero eso tiene consecuencias sobre laestimación de la varianza, porque siempre estaremossustituyendo con el mismo valor.
I se puede sustituir usando una regresión, pero el problema siguesiendo que se sustituye por una media ( esta vez condicionada)SPSS permite sumar una variación aleatoria, se subsana enalgo este tipo de problema.
I Se puede usar el Algoritmo EM. En regresión si se conocieranlos NA, estimar los parámetros del modelo sería fácil, y si seconocieran los parámetros del modelo de los datos seríasencillo hacer predicciones insesgadas de las observacionesfaltantes. Este algoritmo es iterativo y va haciendo ambascosas: con los datos existentes se estiman los parámetros delmodelo de los datos, enseguida con estos parámetros se hacenestimaciones de los datos faltantes, y de nuevo se re-estimanlos parámetros con las datos ya completados. Schafer (1997)hizo un programa NORM disponible en:http://www.stat.psu.edu/~jls/misoftwa.html, SPSS tiene unprocedimiento que hace imputación utilizando EM.

Imputación múltiple
Se generan valores para hacer la imputación basados en los datosexistentes. Suponiendo que se estimay usando x , pero estaimputación se hace varias veces, es decir tendremos variosconjuntos de datos completados. Para hacer esto se usan métodosconocidos Markov Chain Monte Carlo.El programa NORM en la parte llamada data augmentation lo hace.SAS tiene dos procedimientos MI y MIANALYZE.Schafer, J.L. & Olsden, M. K.. (1998). Multiple imputation for
multivariate missing-data problems: A data analyst's perspective.
Multivariate Behavioral Research, 33, 545-571.
En R esta el paquete MICE, material con referencia en: VanBuuren, S., Groothuis-Oudshoorn, K. (2011) MICE: Multivariate
Imputation by Chained Equations in R. Journal of Statistical
Software.
http://www.stefvanbuuren.nl/publications/MICEinR-Draft.pdf

Grácas datos univariados
I gráca de barras y de pie son solo para datos categóricos,debe haber espacios entre las barras.
I histograma debe tenerse cuidado con los anchos de barras ycon los puntos que se consideran en el eje de las x.
I boxplot permite rápidamente ver observaciones discrepantes.
I q-qplot permite ver si dos muestras provienen de la mismadistribución.
I tallo y hoja, una versión de los histogramas pero permite verlos datos tal cual.

Grácos de Pie y Dot Chart
El uso de grácos circulares o pasteles es bastante común entrepersonas no profesionales en estadstica y lamentablemente se hatrivializado tanto que si en muchas de las situaciones donde se usanse suprimieran se ahorraran muchas hojas de papel.Los grácos de puntos son elegantemente simples y permitenumerosas variaciones. La única razón por la cual no se han vueltopopulares es que los programas de hojas electrónicas no loselaboren presionando una tecla.

> pie(pie.sales) # default colours > pie(pie.sales, col = c("purple", "violetred1", "green3", + "cornsilk", "cyan", "white"))
> dotchart(pie.sales)

Gráco de Barras
> barplot(VADeaths)
> barplot(VADeaths, beside = TRUE, + col = c("lightblue", "mistyrose", "lightcyan", + "lavender", "cornsilk"), + legend = rownames(VADeaths), ylim = c(0, 100)) > title(main = "Death Rates in Virginia", font.main = 4)

Gráco de Tallo y Hoja
Este gráco fue propuesto por Tukey (1977) y a pesar de no ser ungráco para presentación denitiva se utiliza a la vez que el analistarecoge la información ve la distribución de los mismos. Estosgrácos son fáciles de realizar a mano y se usan como una formarápida y no pulida de mirar los datos. Qué nos muestra?1. El centro de la distribución2. La forma general de la distribuciónSimétrica si las porciones a cada lado del centro son imágenesespejos de las otras.Sesgada a la izquierda Si la cola izquierda (los valores menores) esmucho más larga que los de la derecha (los valores mayores)Sesgada a la derecha opuesto a la sesgada a la izquierda.3. Desviaciones marcadas de la forma global de la distribución.Outliers Observaciones individuales que caen muy por fuera delpatrón general de los datos.gaps Huecos en la distribución

> stem(islands) The decimal point is 3 digit(s) to the right of the | 0 | 00000000000000000000000000000111111222338 2 | 07 4 | 5 6 | 8 8 | 4 10 | 5 12 | 14 | 16 | 0 > stem(log10(islands)) The decimal point is at the | 1 | 1111112222233444 1 | 5555556666667899999 2 | 3344 2 | 59 3 | 3 | 5678 4 | 012
> as.data.frame(islands) islands Africa 11506 Antarctica 5500 Asia 16988 Australia 2968 Axel Heiberg 16 Baffin 184 Banks 23 Borneo 280 Britain 84 Celebes 73 Celon 25 Cuba 43 Devon 21 Ellesmere 82 Europe 3745 Greenland 840 Hainan 13 Hispaniola 30 Hokkaido 30 Honshu 89 Iceland 40 Ireland 33 Java 49 Kyushu 14 Luzon 42 Madagascar 227 Melville 16 Mindanao 36
Moluccas 29 New Britain 15 New Guinea 306 New Zealand (N) 44 New Zealand (S) 58 Newfoundland 43 North America 9390 Novaya Zemlya 32 Prince of Wales 13 Sakhalin 29 South America 6795 Southampton 16 Spitsbergen 15 Sumatra 183 Taiwan 14 Tasmania 26 Tierra del Fuego 19 Timor 13 Vancouver 12 Victoria 82

Histograma
El histograma es el gráco estadístico por excelencia. El histogramade un conjunto de datos es un gráco de barras que representan lasfrecuencias con que aparecen las mediciones agrupadas en ciertosrangos o intervalos. Para uno construir un histograma se debedividir la recta real en intervalos o clases (algunos recomiendan quesean de igual longitud) y luego contar cuantas observaciones caenen cada intervalo.formula de Sturges para determinar el numero de barras.Regla de Sturges: k = 1 + log2(n)Scott (1992), basado en la distribuci´on normal recomienda elsiguiente número de barras para el histograma Regla deScott:k = (2n)1/3
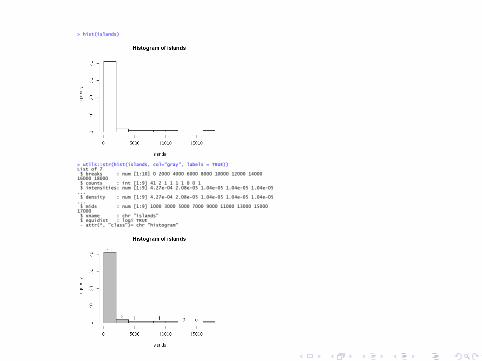
> hist(islands)
> utils::str(hist(islands, col="gray", labels = TRUE)) List of 7 $ breaks : num [1:10] 0 2000 4000 6000 8000 10000 12000 14000 16000 18000 $ counts : int [1:9] 41 2 1 1 1 1 0 0 1 $ intensities: num [1:9] 4.27e-04 2.08e-05 1.04e-05 1.04e-05 1.04e-05 ... $ density : num [1:9] 4.27e-04 2.08e-05 1.04e-05 1.04e-05 1.04e-05 ... $ mids : num [1:9] 1000 3000 5000 7000 9000 11000 13000 15000 17000 $ xname : chr "islands" $ equidist : logi TRUE - attr(*, "class")= chr "histogram"

> hist(sqrt(islands), breaks = 12, col="lightblue", border="pink")

Boxplot o Caja de Tukey
Realizado por Tukey (1977). Es un gráco simple, ya que se realizabásicamente con cinco números.Permite comparar diversos conjuntos de datos simultáneamente.Este gráco contiene un rectángulo, usualmente orientado con elsistema de coordenadas tal que el eje vertical tiene la misma escaladel conjunto de datos. La parte superior y la inferior del rectángulocoinciden con el tercer cuartil y el primer cuartil de los datos. Estacaja se divide con una linea horizontal a nivel de la mediana. Sedene un paso como 1.5 veces el rango intercuartil, y una lineavertical (un bigote) se extiende desde la mitad de la parte superiorde la caja hasta la mayor observación de los datos si se encuentrandentro de un paso. Igual se hace en la parte inferior de la caja Lasobservaciones que caigan más allá de estas líneas son dibujadasindividualmente. La denición de los cuartiles puede variar y otrasdeniciones de el paso son planteadas por otros autores.

La localización esta representada en la linea que corta la caja yrepresenta la mediana (que esta dentro de la caja), la dispersiónesta dada por la altura de la caja, como por la distancia entre losextremos de los bigotes. El sesgo se observa en la desviación queexista entre la linea de la mediana con relación al centro de la caja,y también la relación entre las longitudes de los bigotes. Las colasse pueden apreciar por la longitud de los bigotes con relación a laaltura de la caja, y también por las observaciones que se marcanexplícitamente.

> boxplot(decrease ~ treatment, data = OrchardSprays, col = "bisque")
> boxplot(decrease ~ treatment, data = OrchardSprays, + log = "y", col = "bisque")

¾Qué es un cuantil?Son puntos tomados a intervalos regulares de la funciónacumulativa de distribución de una variable aleatoria. Dividir alconjunto de los datos ordenados en q conjuntos del mismo tamaño,es el objetivo de los q-cuantiles. Los cuantiles son las fronterasentre los conjuntos.Cuantiles más comunesEl 2-cuantil, parte en dos partes iguales y es la mediana.Los 3-cuantiles o terciles,Los 4-cuantiles o cuartiles,los 10-cuantiles o deciles,los 100-cuantiles o porcentiles.El k-ésimo q cuantil satisface lo siguiente:Pr(X < x) ≤ k/q. y Pr(X ≤ x) ≥ k/qPara un conjunto tamaño Npuede calcularse como Ip = N ∗ (k/q), si es un entero se elige laobservación que ocupe esa posición ordenada y ¾si no es unentero???, se redondea, o se toma una cierta interpolación entre lasdos observaciones.

QQplot
Sirve para determinar si dos conjuntos de datos provienen depoblaciones con la misma distribución.Se gracan los cuantiles del primer conjunto contra los cuantiles delsegundo conjunto. Se dibuja también una recta de 45 grados dependiente(es decir y = x). Si las observaciones provienen de lamisma distribución, caerán aproximadamente sobre la recta. Entremás se separan de la recta, más alejadas serán sus distribuciones.Si caen sobre una recta con pendiente de 45 grados pero condistinta ordenada al origen, tendrán un traslado en el parámetro delocalización, si varía la pendiente variará en la desviación estándar.Los conjuntos pueden ser de distinto tamaño( se hacencorresponder los cuantiles del conjunto más grande con los valoresordenados del más pequeño, y los cuantiles intermedios seinterpolan).Una gráca de probabilidad es semejante a una qqplot solo quese sustituyen al segundo conjunto de datos por los cuantiles de ladistribución teórica a probar.

> x1<-rnorm(100,5,1) > z<-rnorm(100) > x2<-rnorm(100,0,5) > z<-rnorm(100) > x2<-rnorm(110,0,5) > par(mfrow=c(1,2)) > qqplot(z,x1,main="N(5,1) Q-Q Plot")### variando la media > abline(0,1) > abline(5,1,col=2) > qqplot(z,x2,main="N(0,5) Q-Q Plot")#### variando la desviacion estandar > abline(0,1) > abline(0,5,col=2)

x <- rt(100, df=3)
# normal fit
qqnorm(x); qqline(x)
> x<-rchisq(20,3) > qqnorm(x); qqline(x)

Grácas datos multivariados
I Estrellas. Convienen cuando no se tienen muchos atributos,pues con más de 10 o 12 aristas las confundimos en su forma.
I Caritas, debidas a Chernov, dado que el ojo humano esta muyentrenado para reconocer rostros humanos. A cada elementode la cara: pelo, ancho cara, largo nariz, tamaño de ojos se leasocia una característica.

> stars(longley)
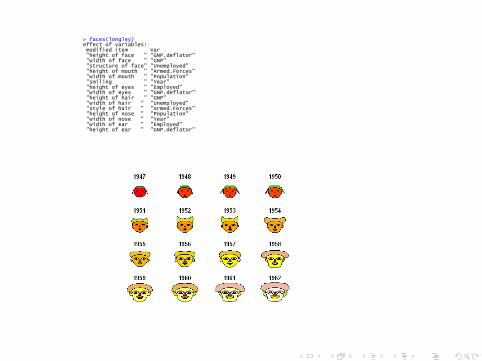
> faces(longley) effect of variables: modified item Var "height of face " "GNP.deflator" "width of face " "GNP" "structure of face" "Unemployed" "height of mouth " "Armed.Forces" "width of mouth " "Population" "smiling " "Year" "height of eyes " "Employed" "width of eyes " "GNP.deflator" "height of hair " "GNP" "width of hair " "Unemployed" "style of hair " "Armed.Forces" "height of nose " "Population" "width of nose " "Year" "width of ear " "Employed" "height of ear " "GNP.deflator"

Curvas de Andrews
A cada individuo se le asigna una curva de la siguiente manera:t ∈ [−π, π] Si p es impar
fi (t) =Xi1√2
+ Xi2 sin(t) + Xi3 cos(t) + . . .+ Xip cos((p − 1)
2t)
Si p es par
fi (t) =Xi1√2
+ Xi2 sin(t) + Xi3 cos(t) + . . .+ Xip sin(p
2t)
Estas tres grácas no son únicas, pues según ordenemos lasvariables darán origen a estrellas, curvas o caras distintas.
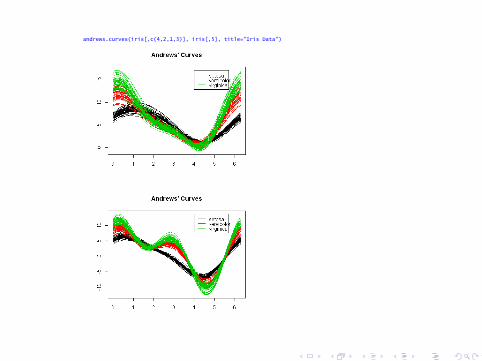
andrews.curves(iris[,c(4,2,1,3)], iris[,5], title="Iris Data")

BagplotParecida a un boxplot pero en dos dimensiones.
> cardata Weight Disp. [1,] 2560 97 [2,] 2345 114 [3,] 1845 81 [4,] 2260 91 [5,] 2440 113 [6,] 2285 97 [7,] 2275 97 [8,] 2350 98 [9,] 2295 109 [10,] 1900 73
…
[59,] 3185 146 [60,] 3690 146 > bagplot(cardata,factor=3,show.baghull=TRUE, + show.loophull=TRUE,precision=1,dkmethod=2) > title("car data Chambers/Hastie 1992")

Gráca de paralelasSe usan sobre todo cuando hay varias mediciones para un soloindividuo.
parallel(~iris[,1:4],col=as.numeric(iris$Species),main="Parallelplot IRIS")

Gráco series de tiempo múltiples
> USeconomic log(M1) log(GNP) rs rl 1954 Q1 6.111246 7.249073 0.010800000 0.02613333 1954 Q2 6.115892 7.245084 0.008133333 0.02523333 1954 Q3 6.129268 7.257003 0.008700000 0.02490000 1954 Q4 6.141177 7.271565 0.010366667 0.02566667 1955 Q1 6.151881 7.292746 0.012600000 0.02746667 1955 Q2 6.159307 7.303641 0.015133333 0.02816667 1955 Q3 6.162472 7.316880 0.018633333 0.02926667 1955 Q4 6.161840 7.325610 0.023466667 0.02890000 1956 Q1 6.164157 7.323633 0.023800000 0.02886667
…
1987 Q1 6.448731 8.236606 0.055333333 0.07636667 1987 Q2 6.453310 8.248791 0.057333333 0.08576667 1987 Q3 6.445879 8.259795 0.060333333 0.09083333 1987 Q4 6.446513 8.274612 0.060033333 0.09240000


















