Kohonen Self Organizing Maps
45
Artificial neural networks Kohonen Self Organising Maps (KSOM) (KSOM) K.Vijaya Lakshmi K.Vijaya Lakshmi
-
Upload
vijaya-lakshmi -
Category
Documents
-
view
76 -
download
0
Transcript of Kohonen Self Organizing Maps

Artificial neural networksKohonen Self Organising
Maps(KSOM)(KSOM)
K.Vijaya LakshmiK.Vijaya Lakshmi


The main property of a neural network is an The main property of a neural network is an ability to learn from its environment, and to ability to learn from its environment, and to improve its performance through learning. So improve its performance through learning. So far we have considered far we have considered supervisedsupervised oror active active learninglearning learning with an external “teacher” learning with an external “teacher” or a supervisor who presents a training set to the or a supervisor who presents a training set to the network. But another type of learning also network. But another type of learning also exists: exists: unsupervised learningunsupervised learning..
IntroductionIntroduction

In contrast to supervised learning, unsupervised or In contrast to supervised learning, unsupervised or self-organised learningself-organised learning does not require an does not require an external teacher. During the training session, the external teacher. During the training session, the neural network receives a number of different neural network receives a number of different input patterns, discovers significant features in input patterns, discovers significant features in these patterns and learns how to classify input data these patterns and learns how to classify input data into appropriate categories. Unsupervised into appropriate categories. Unsupervised learning tends to follow the neuro-biological learning tends to follow the neuro-biological organisation of the brain.organisation of the brain.
Unsupervised learning algorithms aim to learn Unsupervised learning algorithms aim to learn rapidly and can be used in real-time.rapidly and can be used in real-time.

In competitive learning, neurons compete among In competitive learning, neurons compete among themselves to be activated. themselves to be activated.
While in Hebbian learning, several output neurons While in Hebbian learning, several output neurons can be activated simultaneously, in competitive can be activated simultaneously, in competitive learning, only a single output neuron is active at learning, only a single output neuron is active at any time. any time.
The output neuron that wins the “competition” is The output neuron that wins the “competition” is called the called the winner-takes-allwinner-takes-all neuron. neuron.
Competitive learningCompetitive learning

The basic idea of competitive learning was The basic idea of competitive learning was introduced in the early 1970s. introduced in the early 1970s.
In the late 1980s, Teuvo Kohonen introduced a In the late 1980s, Teuvo Kohonen introduced a special class of artificial neural networks called special class of artificial neural networks called self-organising feature mapsself-organising feature maps. These maps are . These maps are based on competitive learning.based on competitive learning.

Our brain is dominated by the cerebral cortex, a Our brain is dominated by the cerebral cortex, a very complex structure of billions of neurons and very complex structure of billions of neurons and hundreds of billions of synapses. The cortex hundreds of billions of synapses. The cortex includes areas that are responsible for different includes areas that are responsible for different human activities (motor, visual, auditory, human activities (motor, visual, auditory, somatosensory, etc.), and associated with different somatosensory, etc.), and associated with different sensory inputs. We can say that each sensory sensory inputs. We can say that each sensory input is mapped into a corresponding area of the input is mapped into a corresponding area of the cerebral cortex. cerebral cortex. The cortex is a self-organising The cortex is a self-organising computational map in the human brain.computational map in the human brain.
What is a self-organising feature map?What is a self-organising feature map?

Feature-mapping Kohonen modelFeature-mapping Kohonen model
Input layer
Kohonen layer
(a)
Input layer
Kohonen layer
1 0(b)
0 1

The Kohonen model provides a topological The Kohonen model provides a topological mapping. It places a fixed number of input mapping. It places a fixed number of input patterns from the input layer into a higher-patterns from the input layer into a higher-dimensional output or Kohonen layer. dimensional output or Kohonen layer.
Training in the Kohonen network begins with the Training in the Kohonen network begins with the winner’s neighbourhood of a fairly large size. winner’s neighbourhood of a fairly large size. Then, as training proceeds, the neighbourhood size Then, as training proceeds, the neighbourhood size gradually decreases.gradually decreases.
The Kohonen networkThe Kohonen network
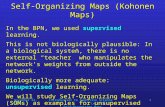
Architecture of the Kohonen NetworkArchitecture of the Kohonen Network
Inputlayer
O u
t p
u t
S i
g n
a l s
I n p
u t
S i
g n
a l s
x1
x2
Outputlayer
y1
y2
y3

SOM ArchitectureSOM Architecture• Two layers of neuronsTwo layers of neurons• Input layerInput layer• Output map layerOutput map layer• Each output neuron is connected to each Each output neuron is connected to each
input neuroninput neurono Fully connected networkFully connected network
• Output map usually has two dimensionsOutput map usually has two dimensionso one and three dimensions also usedone and three dimensions also used
• Neurons in output map can be laid out in Neurons in output map can be laid out in different patternsdifferent patternso rectangularrectangularo HexagonalHexagonal

SOM ArchitectureSOM Architecture• SOMs are competitive networksSOMs are competitive networks• Neurons in the network compete with each Neurons in the network compete with each
otherother• Other kinds of competitive network existOther kinds of competitive network exist
o e.g. ARTe.g. ART

SOM AlgorithmSOM Algorithm• Each output neuron is connected to each neuron in the Each output neuron is connected to each neuron in the
input layerinput layer• Therefore, each output neuron has an incoming connection Therefore, each output neuron has an incoming connection
weight vectorweight vector• Dimensionality of this vector is the same as the Dimensionality of this vector is the same as the
dimensionality of the input vectordimensionality of the input vector• Since the dimensionality of these vectors is the same, we Since the dimensionality of these vectors is the same, we
can measure the Euclidean distance between themcan measure the Euclidean distance between them
• Winning node is that with the least distance Winning node is that with the least distance o i.e. the lowest value of i.e. the lowest value of DD
• Outputs from a SOM are binaryOutputs from a SOM are binary• A node is either the winner, or it is notA node is either the winner, or it is not• Only one node can winOnly one node can win

SOM TrainingSOM Training
• Based on rewarding the winning nodeBased on rewarding the winning node• This is a form of competitive learningThis is a form of competitive learning• Winners weights are adjusted to be closer to Winners weights are adjusted to be closer to
the input vectorthe input vector• Why not equal?Why not equal?
o We want the output map to learn regions, not We want the output map to learn regions, not examplesexamples

SOM TrainingSOM Training
• Based on rewarding the winning nodeBased on rewarding the winning node• This is a form of competitive learningThis is a form of competitive learning• Winners weights are adjusted to be closer to Winners weights are adjusted to be closer to
the input vectorthe input vector• Why not equal?Why not equal?
o We want the output map to learn regions, not We want the output map to learn regions, not examplesexamples

SOM TrainingSOM Training
• An important concept in SOM training is that An important concept in SOM training is that of the “Neighbourhood”of the “Neighbourhood”
• The output map neurons that adjoin the The output map neurons that adjoin the winnerwinner
• Neighbourhood size describes how far out Neighbourhood size describes how far out from the winner the neighbours can befrom the winner the neighbours can be
• Neighbours weights are also modifiedNeighbours weights are also modified

NeighbourhoodNeighbourhood

SOM TrainingSOM Training
• Number of neighbours is effected by the Number of neighbours is effected by the shape of the mapshape of the mapo rectangular gridsrectangular grids
4 neighbours4 neighbourso hexagonal gridshexagonal grids
6 neighbours6 neighbours• Neighbourhood size and learning rate is Neighbourhood size and learning rate is
reduced gradually during trainingreduced gradually during training

SOM TrainingSOM Training
• Overall effect of trainingOverall effect of trainingo groups, or “clusters” form in output mapgroups, or “clusters” form in output mapo clusters represent spatially nearby regions in input clusters represent spatially nearby regions in input
spacespaceo since dimensionality of the output map is less than since dimensionality of the output map is less than
the dimensionality of the input spacethe dimensionality of the input space vector quantisationvector quantisation

The lateral connections are used to create a The lateral connections are used to create a competition between neurons. The neuron with the competition between neurons. The neuron with the largest activation level among all neurons in the largest activation level among all neurons in the output layer becomes the winner. This neuron is output layer becomes the winner. This neuron is the only neuron that produces an output signal. the only neuron that produces an output signal. The activity of all other neurons is suppressed in The activity of all other neurons is suppressed in the competition.the competition.
The lateral feedback connections produce The lateral feedback connections produce excitatory or inhibitory effects, depending on the excitatory or inhibitory effects, depending on the distance from the winning neuron. This is distance from the winning neuron. This is achieved by the use of a achieved by the use of a Mexican hat functionMexican hat function which describes synaptic weights between neurons which describes synaptic weights between neurons in the Kohonen layer.in the Kohonen layer.

The Mexican hat function of lateral connectionThe Mexican hat function of lateral connection
Connectionstrength
Distance
Excitatoryeffect
Inhibitoryeffect
Inhibitoryeffect
0
1

In the Kohonen network, a neuron learns by In the Kohonen network, a neuron learns by shifting its weights from inactive connections to shifting its weights from inactive connections to active ones. Only the winning neuron and its active ones. Only the winning neuron and its neighbourhood are allowed to learn. If a neuron neighbourhood are allowed to learn. If a neuron does not respond to a given input pattern, then does not respond to a given input pattern, then learning cannot occur in that particular neuron.learning cannot occur in that particular neuron.
The The competitive learning rulecompetitive learning rule defines the change defines the change wwijij applied to synaptic weight applied to synaptic weight wwijij as as
where where xxii is the input signal and is the input signal and is the is the learning learning raterate parameter. parameter.
ncompetitio theloses neuron if ,0
ncompetitio the winsneuron if ),(
j
jwxw iji
ij

The overall effect of the competitive learning rule The overall effect of the competitive learning rule resides in moving the synaptic weight vector resides in moving the synaptic weight vector WWjj of of the winning neuron the winning neuron jj towards the input pattern towards the input pattern XX. . The matching criterion is equivalent to the The matching criterion is equivalent to the minimum minimum Euclidean distanceEuclidean distance between vectors. between vectors.
The Euclidean distance between a pair of The Euclidean distance between a pair of nn-by-1 -by-1 vectors vectors XX and and WWjj is defined by is defined by
where where xxii and and wwijij are the are the iith elements of the vectors th elements of the vectors XX and and WWjj, respectively., respectively.
2/1
1
2)(
n
iijij wxd WX

To identify the winning neuron, To identify the winning neuron, jjXX, that best , that best matches the input vector matches the input vector XX, we may apply the , we may apply the following condition:following condition:
where where mm is the number of neurons in the Kohonen is the number of neurons in the Kohonen layer.layer.
,jj
minj WXX

Suppose, for instance, that the 2-dimensional input Suppose, for instance, that the 2-dimensional input vector vector XX is presented to the three-neuron Kohonen is presented to the three-neuron Kohonen network,network,
The initial weight vectors, The initial weight vectors, WWjj, are given by, are given by
12.052.0
X

We find the winning (best-matching) neuron We find the winning (best-matching) neuron jjXX using the minimum-distance Euclidean criterion:using the minimum-distance Euclidean criterion:
Neuron 3 is the winner and its weight vector Neuron 3 is the winner and its weight vector WW33 is is updated according to the competitive learning rule. updated according to the competitive learning rule.

The updated weight vector The updated weight vector WW33 at iteration ( at iteration (pp + 1) + 1) is determined as:is determined as:
The weight vector The weight vector WW33 of the wining neuron 3 of the wining neuron 3 becomes closer to the input vector becomes closer to the input vector XX with each with each iteration.iteration.
20.044.0
01.00.01
21.043.0
)()()1( 333 ppp WWW

Step 1Step 1:: InitialisationInitialisation.. Set initial synaptic weights to small random Set initial synaptic weights to small random values, say in an interval [0, 1], and assign a small values, say in an interval [0, 1], and assign a small positive value to the learning rate parameter positive value to the learning rate parameter ..
Competitive Learning AlgorithmCompetitive Learning Algorithm

Step 2Step 2:: Activation and Similarity MatchingActivation and Similarity Matching.. Activate the Kohonen network by applying the Activate the Kohonen network by applying the input vector input vector XX, and find the winner-takes-all (best , and find the winner-takes-all (best matching) neuron matching) neuron jjXX at iteration at iteration pp, using the , using the minimum-distance Euclidean criterionminimum-distance Euclidean criterion
where where nn is the number of neurons in the input is the number of neurons in the input layer, and layer, and mm is the number of neurons in the is the number of neurons in the Kohonen layer.Kohonen layer.
,)()()(2/1
1
2][
n
iijij
jpwxpminpj WXX

Step 3Step 3:: LearningLearning.. Update the synaptic weightsUpdate the synaptic weights
where where wwijij((pp) is the weight correction at iteration ) is the weight correction at iteration pp..
The weight correction is determined by the The weight correction is determined by the competitive learning rule:competitive learning rule:
where where is the is the learning ratelearning rate parameter, and parameter, and jj((pp) is ) is the neighbourhood function centred around the the neighbourhood function centred around the winner-takes-all neuron winner-takes-all neuron jjXX at iteration at iteration pp..
)()()1( pwpwpw ijijij
)( ,0
)( , )( )(
][pj
pjpwxpw
j
jijiij

Step 4Step 4:: IterationIteration.. Increase iteration Increase iteration pp by one, go back to Step 2 and by one, go back to Step 2 and continue until the minimum-distance Euclidean continue until the minimum-distance Euclidean criterion is satisfied, or no noticeable changes criterion is satisfied, or no noticeable changes occur in the feature map.occur in the feature map.

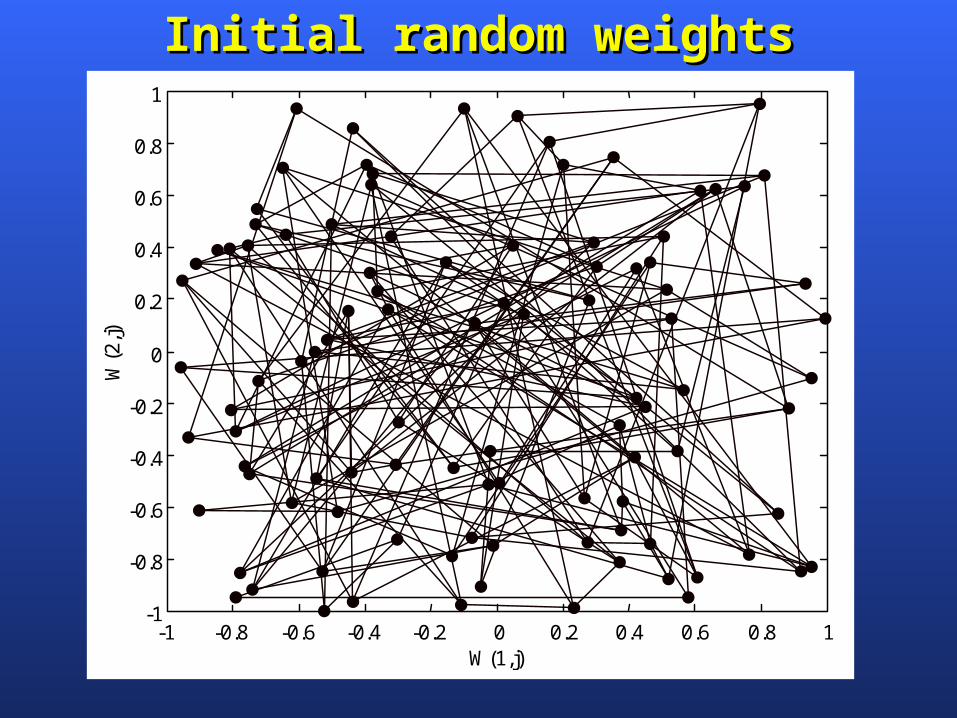
To illustrate competitive learning, consider the To illustrate competitive learning, consider the Kohonen network with 100 neurons arranged in the Kohonen network with 100 neurons arranged in the form of a two-dimensional lattice with 10 rows and form of a two-dimensional lattice with 10 rows and 10 columns. The network is required to classify 10 columns. The network is required to classify two-dimensional input vectors two-dimensional input vectors each neuron in the each neuron in the network should respond only to the input vectors network should respond only to the input vectors occurring in its region.occurring in its region.
The network is trained with 1000 two-dimensional The network is trained with 1000 two-dimensional input vectors generated randomly in a square region input vectors generated randomly in a square region in the interval between –1 and +1. The learning rate in the interval between –1 and +1. The learning rate parameter parameter is equal to 0.1. is equal to 0.1.
Competitive learning in the Kohonen networkCompetitive learning in the Kohonen network
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1W(1,j)
-1-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1W
(2,j)
Initial random weightsInitial random weights

Network after 100 iterationsNetwork after 100 iterations
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1W(1,j)
-1-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1W
(2,j)

Network after 1000 iterationsNetwork after 1000 iterations
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1W(1,j)
-1-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1W
(2,j)

Network after 10,000 iterationsNetwork after 10,000 iterations
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1W(1,j)
-1-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1W
(2,j)

Kohonens: The Basic IdeaKohonens: The Basic Idea Make a two dimensional array, or map, and Make a two dimensional array, or map, and
randomize it.randomize it. Present training data to the map and let the cells Present training data to the map and let the cells
on the map compete to win in some way. on the map compete to win in some way. Euclidean distance is usually used.Euclidean distance is usually used.
Stimulate the winner and some friends in the Stimulate the winner and some friends in the “neighborhood”.“neighborhood”.
Do this a bunch of times.Do this a bunch of times. The result is a 2 dimensional “weight” map.The result is a 2 dimensional “weight” map.

““Competitive Learning”Competitive Learning”
There are two types of competitive learning: hard and soft.
Hard competitive learning is essentially a “winner-take-all” scenario. The winning neuron is the only one which receives any training response.
(Closer to most supervised learning models?)

““Competitive Learning”Competitive Learning” Soft competitive learning is essentially a “share with your neighbors” scenario.
• This is actually closer to the real cortical sheet model.• This is obviously what the KSOM and other unsupervised connectionist methods use.

Feature Vector PresentationFeature Vector Presentation

Update StrategyUpdate Strategy

A Trained KSOMA Trained KSOM

Applications: GeneralApplications: General Oil and Gas exploration.Oil and Gas exploration. Satellite image analysis.Satellite image analysis. Data mining.Data mining. Document OrganizationDocument Organization Stock price prediction (Zorin, 2003).Stock price prediction (Zorin, 2003). Technique analysis in football and other sports (Barlett, Technique analysis in football and other sports (Barlett,
2004).2004). Spatial reasoning in GIS applicationsSpatial reasoning in GIS applications As a pre-clustering engine for other ANN architecturesAs a pre-clustering engine for other ANN architectures Over 3000 journal-documented applications, last count.Over 3000 journal-documented applications, last count.

Next time….Next time….
Satellite Image Analysis(Questions?)

ConclusionConclusion
• Kohonen SOMs are competitive networksKohonen SOMs are competitive networks• SOMs learn via an unsupervised algorithmSOMs learn via an unsupervised algorithm• SOM training is based on forming clustersSOM training is based on forming clusters• SOMs perform vector quantisationSOMs perform vector quantisation






![Gene Expressionusers.cis.fiu.edu/~giri/teach/Bioinf/S05/Lecx5.pdf · Self-Organizing Maps [Kohonen] • Kind of neural network. • Clusters data and find complex relationships between](https://static.fdocuments.in/doc/165x107/5e9790617bbc2528081219d3/gene-giriteachbioinfs05lecx5pdf-self-organizing-maps-kohonen-a-kind-of.jpg)


![Implementation of Kohonen Network in Behavioral Control of ... · Kohonen network A SOM ( Self Organizing Maps ) neural network [10], also known as a Kohonen fea- ture map, is a self-learning](https://static.fdocuments.in/doc/165x107/5be3b86f09d3f219598bbaf6/implementation-of-kohonen-network-in-behavioral-control-of-kohonen-network.jpg)