IO System CPU Performance: 60% per year I/O system performance limited by mechanical delays (disk...
33
IO System • CPU Performance: 60% per year • I/O system performance limited by mechanical delays (disk I/O) < 10% per year Amdahl's Law: system speed-up limited by the slowest part! Suppose we have a difference of 10% between CPU time and response time and suppose we speed up the CPU by a factor of 10, while neglecting I/O: We get a speedup of only 5 times! 5x Performance (or a loss of 50% of CPU potential) Suppose we speedup the CPU by a factor of 100, while neglecting I/O we get a speedup of only 10- times, 10x Performance (loosing 90% of CPU potential) A detailed numerical example given in class. I/O bottleneck: Diminishing value of faster CPUs The analogy is with a car: very fast engine will get nowhere if the movement of the wheels is too slow!
-
Upload
kristin-small -
Category
Documents
-
view
221 -
download
1
Transcript of IO System CPU Performance: 60% per year I/O system performance limited by mechanical delays (disk...

IO System• CPU Performance: 60% per year• I/O system performance limited by mechanical delays
(disk I/O)< 10% per year Amdahl's Law: system speed-up limited by the slowest part!Suppose we have a difference of 10% between CPU time and response
time and suppose we speed up the CPU by a factor of 10, while neglecting I/O:We get a speedup of only 5 times!5x Performance (or a loss of 50% of CPU potential)Suppose we speedup the CPU by a factor of 100, while neglecting I/Owe get a speedup of only 10- times, 10x Performance (loosing 90% of CPU potential)A detailed numerical example given in class.
I/O bottleneck: Diminishing value of faster CPUs
The analogy is with a car: very fast engine will get nowhere if the movement of the wheels is too slow!

Motivation: Who Cares About I/O?• Some people still maintain that I/O is really not important for the
overall performance. • The argument is that I/O Speed does not matter because the
CPU can always switch to another process if the running process requests an I/O operation. This argument is valid only in systems where the throughput is the measure of performance!
• If response time is a critical measure of performance then the argument is no more valid!
• Response time is critical in Personal computers (only a single user), in workstations since there is only one person (and often time one process) per CPU!
• Also the price of switching could be very high in terms of storage and switch time.

I/O Systems
Processor
Cache
Memory - I/O Bus
MainMemory
I/OController
Disk Disk
I/OController
I/OController
Graphics Network
interruptsinterrupts
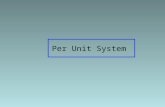
There are several ways of interfacing I/O devices to the CPUEither through the cache, the memory bus or through a separateI/O bus. In the figure this is a low-cost option the memory bus is
the I/O bus.
I/O Interface
Independent I/O Busconnected through the cache
CPU
Interface Interface
Peripheral Peripheral
Memory
memorybus
Seperate I/O instructions (in,out)
CPU
Interface Interface
Peripheral Peripheral
Memory
Lines distinguish between I/O and memory transferscommon memory
& I/O bus
VME busMultibus-IINubus
40 Mbytes/secoptimistically
10 MIP processorcompletelysaturates the bus!
Adv: less state-data problem
Disa: slow
See one more figure in class: bridge-based bus architecture
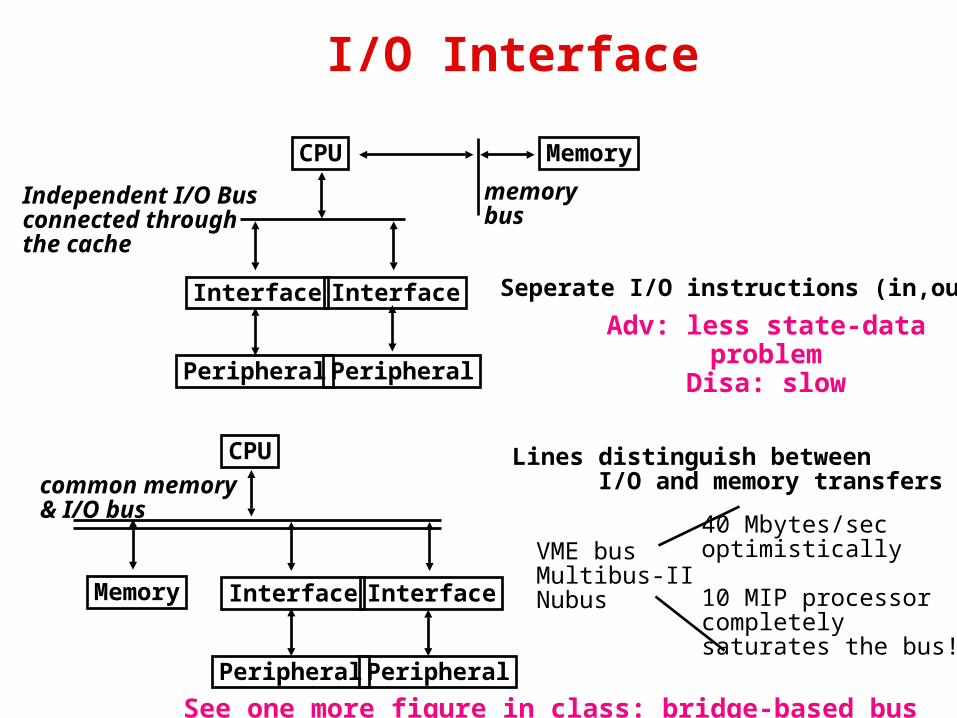
Technology Trends
Disk Capacity now doubles every 18 months; before1990 every 36 months
• Today: Processing Power Doubles Every 18 months
• Today: Memory Size Doubles Every 18 months(4X/3yr)
• Today: Disk Capacity Doubles Every 18 months
• Disk Positioning Rate (Seek + Rotate) Doubles Every Ten Years!
The I/OGAP
The I/OGAP

Storage Technology Drivers
• Driven by the prevailing computing paradigm– 1950s: migration from batch to on-line processing
– 1990s: migration to ubiquitous computing
» computers in phones, books, cars, video cameras, …
» nationwide fiber optical network with wireless tails
• Effects on storage industry:– Embedded storage
» smaller, cheaper, more reliable, lower power
– Data utilities
» high capacity, hierarchically managed storage
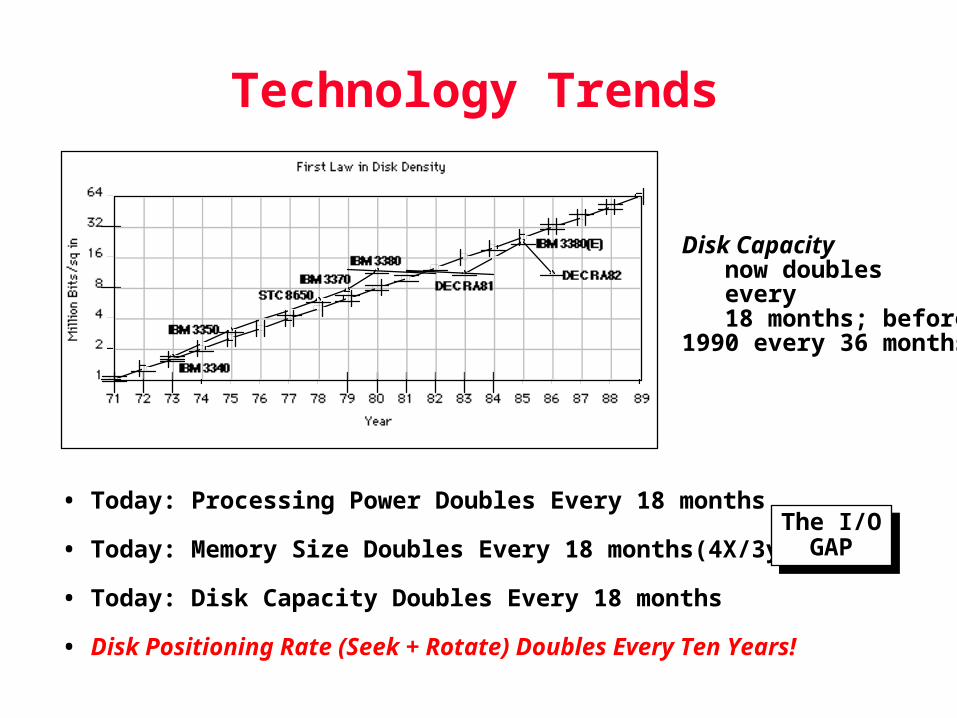
Disk Device Terminology
Purpose:1: Long-term non-volatile storage
2: Large, inexpensive, slow level in the memory hierarchy3. A collection of platters rotating on a spindle at a certain
RPM (3600 - 7200)Each platter is a metal disk covered with a magnetic
recording material on both sides.Reading and writing involves mechanical movement
seeking and rotating, to be explained next.

Devices: Magnetic Disks
Sector: the smallest unit that can be read/written
Track
Cylinder
HeadPlatter
• Purpose:– Long-term, nonvolatile storage
– Large, inexpensive, slow level in the storage hierarchy
• Characteristics:• Seek Time (~8 ms avg)
» positional latency (track)
• rotational latency (sector within track)
• Transfer rate
– About a sector per ms (5-15 MB/s) (in Blocks)
• Queuing Delay: time waiting for the disk to become free
• Controller time
• Capacity– Gigabytes
– Quadruples every 3 years
7200 RPM = 120 RPS => 8 ms per rev ave rot. latency = 4 ms
128 sectors per track => 0.25 ms per sector1 KB per sector => 16 MB / s
Response time = Queue + Controller + Seek + Rot + Xfer
Service timeLe’st see some numbers page
490
Le’st see some numbers page
490
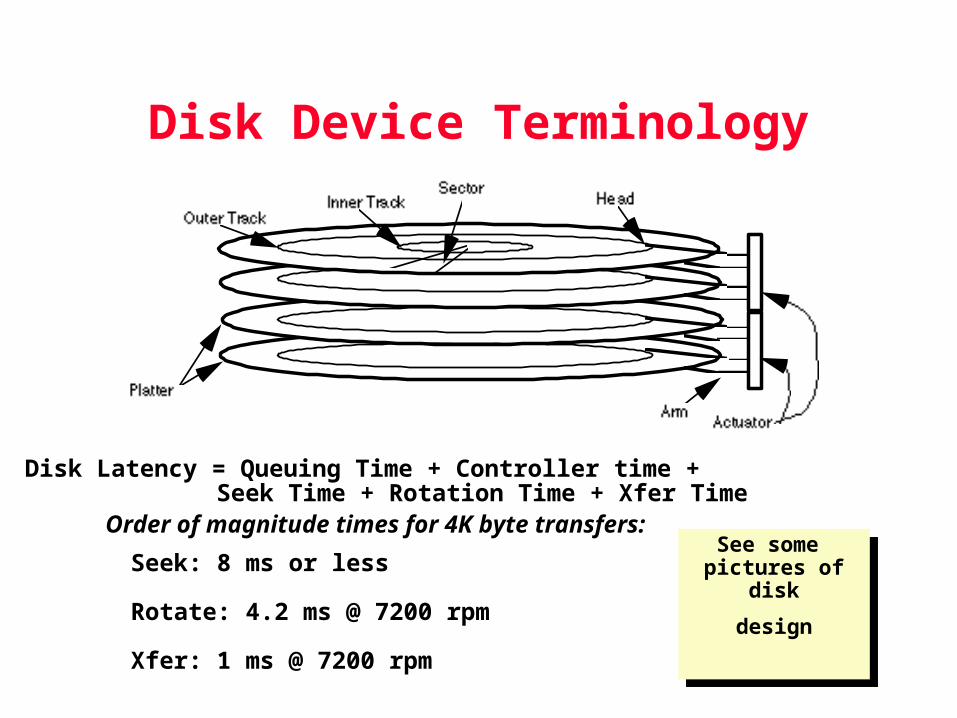
Disk Device Terminology
Disk Latency = Queuing Time + Controller time +Seek Time + Rotation Time + Xfer Time
Order of magnitude times for 4K byte transfers:
Seek: 8 ms or less
Rotate: 4.2 ms @ 7200 rpm
Xfer: 1 ms @ 7200 rpm
See some pictures of disk
design
See some pictures of disk
design

Disk Time Example
• Disk Parameters:– Transfer size is 8K bytes
– Advertised average seek is 12 ms
– Disk spins at 7200 RPM
– Transfer rate is 4 MB/sec
• Controller overhead is 2 ms
• Assume that disk is idle so no queuing delay
• What is Average Disk Access Time for a Sector?– Ave seek + ave rot delay + transfer time + controller overhead
– 12 ms + 0.5/(7200 RPM/60) + 8 KB/4 MB/s + 2 ms
– 12 + 4.15 + 2 + 2 = 20 ms.

Relative Cost of Storage Technology—Late 1995/Early 1996
Magnetic Disks5.25” 9.1 GB $2129 $0.23/MB
$1985 $0.22/MB
3.5” 4.3 GB $1199 $0.27/MB$999 $0.23/MB
2.5” 514 MB $299 $0.58/MB1.1 GB $345 $0.33/MB
Optical Disks5.25” 4.6 GB $1695+199 $0.41/MB
$1499+189 $0.39/MB
PCMCIA CardsStatic RAM 4.0 MB $700 $175/MB
Flash RAM 40.0 MB $1300 $32/MB
175 MB $3600 $20.50/MB

Processor Interface Issues
• An interface answers the following questions for us:
• 1) how is a user I/O request transformed into a device command and communicated to the device?
• 2) how is data actually transferred to or from a memory location?
• 3) what is the role of the operating system in this?
• The OS is important since the I/O system is shared by multiple programs using the CPU. This sharing needs to be implemented in a fair way. The CPU can not do that, it is busy executing programs.

Processor Interface Issues
• Processor interface– Interrupts
– Memory mapped I/O
• I/O Control Structures– Polling
– Interrupts
– DMA
– I/O Controllers
– I/O Processors
• Capacity, Access Time, Bandwidth
• Interconnections– Busses

A Need for an I/O Interface• One may wonder why we don’t connect peripherals
directly to the system bus. Reasons for not doing that:
• There are a wide variety of peripherals with various methods of operation. It would be very impractical to incorporate the necessary logic within the processor to control each device.
• The data transfer rate of the peripheral is much slower than that of the memory or the processor. Thus it is impractical to use a high-speed system bus to communicate directly with a peripheral.
• Peripherals often use different data formats and word lengths than the computer to which they are attached.
• Next question is how to connect the I/O interface that may be attached to an I/O bus to the CPU?

Example of an Interface• Interface to system bus
• data registers
• control/status registers
• I/O logic used for decoding commands from the processor such as read, write, scan, address recognition, status reporting etc.
• External device interface (data, status, control)
• function of the interface:– control and timing
– processor communication
– device communication
– data buffering
– error correction
• Next how does the CPU address an I/O device to send or receive data?
See figures in class.See figures in class.
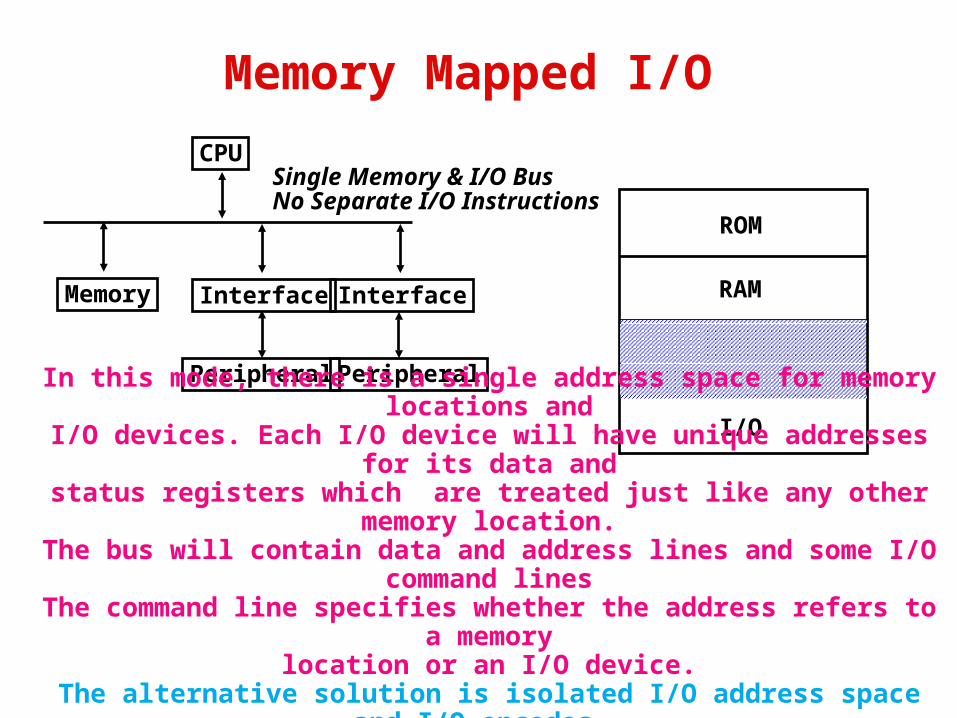
Memory Mapped I/O
Single Memory & I/O Bus No Separate I/O Instructions
CPU
Interface Interface
Peripheral Peripheral
Memory
ROM
RAM
I/O
In this mode, there is a single address space for memory locations andI/O devices. Each I/O device will have unique addresses for its data andstatus registers which are treated just like any other memory location.
The bus will contain data and address lines and some I/O command lines
The command line specifies whether the address refers to a memorylocation or an I/O device.
The alternative solution is isolated I/O address space and I/O opcodes. In this case I/O ports are only accessible by special I/O instructions.

Benefits of Memory-Mapped I/O
• Data Transfer to and from the Processor is standardized.
• The number of connections to the processor chip or board are reduced.
• With the increasing number of address bits (32, 64) etc. there is sufficient extra room to apportion some of the memory space to I/O.

I/O Addressing
• In both cases (memory-mapped, isolated I/O), each I/O device has registers for status (busy, ready, idle, etc.), and control information.
• The CPU sets flags to determine the operation the I/O device will perform, either through load/store instructions in memory-mapped, or through special I/O instructions for the isolated I/O.
• The next question is how is this interaction done?

Programmed I/O (Polling)
CPU
IOC
device
Memory
2. busy wait loop
The problem with this method is that the processor has towait for a long time for the I/O module of concern to be readyfor either reception or transmission of data. The processor
while waiting must repeatedly interrogate the module.
See diagram in class first and example next.
See diagram in class first and example next.
1. The CPUperiodically
checks status bits to see if there is I/Ooperation.
3. The CPU endsup doing all
the work! 4.Not an efficient way to use the CPU
unless the deviceis very fast!

Polling
• 1. CPU interrogates the I/O module to check status of the attached device.
• 2. The I/O module returns device status• 3. If the device is operational and ready to
transmit, the CPU requests the transfer of data, by means of a command to the I/O module.
• 4. The I/O module obtains a unit of data from the external device
• 5. The data are transferred from the I/O module to the processor.

Overhead of Polling• Three different devices: mouse, floppy disk, hard
disk.• Assume the polling operation (transferring to the
polling routine, accessing the device, and restarting the user program) takes 400 CCs.
• Processor is 500-MHz.• Mouse must be polled 30 times/second.• Floppy disk transfers data to the processor in 16-
bits units and has a data rate of 50 KB/sec. No data can be missed.
• Hard disk transfers data in 16-byte (four-word) chunks and can transfer at 4 MB/sec. Again no data can be missed.
• Devices always busy.

Overhead of Polling• Mouse:
• clock cycles per second for polling: 30 X 400 = 12,000 Cycles per second.
• Fraction of the processor clock cycles consumed:
• 12,000/500 X 106 = 0.002%
• Polling is good for the mouse in this computer. It does not degrade the performance significantly.
• Floppy disk:
• the rate at which we must poll is: 50 KB/s divided by 2 bytes per polling access, we get:
• 25K polling accesses per second.
• Cycles per second for polling: 25k X 400 = 10 X 106
• Fraction of processor clock cycles consumed:
• 10 X 106 / 500 X 106 = 2 %, could be tolerable.

Overhead of Polling• Hard disk:
• polling rate is 250 K times per second (why?)
• (4 MB per second/ 16 bytes per transfer) = 250 K (a quarter of a mega).
• cycles per second for polling: 250 K X 400
• fraction of processor consumed: 100 Mega. /500 MHz = 20%.
• One-fifth of the processor is used just for polling the disk. This is clearly not acceptable.
• Alternative solution to polling is interrupt-driven I/O next!

Interrupt Driven Data TransferCPU
IOC
device
Memory
addsubandornop
readstore...rti
memory
userprogram(1) I/O
interrupt
(2) save PC
(3) interruptservice addr
interruptserviceroutine(4)User program progress only halted during
actual transfer
to deal with different I/O devices, interrupt mechanisms have several levels of priority. These priorities indicate the order in which the processor should process the interrupts. Interrupt algorithm given in class.Interrupt algorithm given in class.

Overhead of Interrupt-driven I/O
• Suppose we have same hard disk and processor as before.
• The overhead for each transfer including the interrupt is 500 clock cycles.
• Let’s find the fraction of the processor consumed if the hard disk is only transferring data 5% of the time.
• The interrupt rate when the disk is busy is the same as the polling rate, hence :
• Cycles per second for disk = 250K X500
• 125 X 106 cycles per second. (see previous example for this).

Overhead of Interrupt-driven I/O
• Fraction of the processor consumed during a transfer: 125 x 106 / 500 X 106 = 25%
• assuming that the disk is only transferring data at 5% of the time,
• Fraction of the processor consumed is 25% X5 % = 1.25%
• so the absence of overhead when the I/O device is not actually transferring is the major advantage of interrupt-driven interface versus polling.
• Interrupt-driven I/O relieves the CPU from having to wait for every I/O event. However, if we use this method and the disk is transferring it still costs 25%.

Direct Memory Access Controllers
• A solution to that is the DMA:a mechanism for off-loading the processor and having the device controller transfer data directly to or from memory without involving the processor.
• The interrupt mechanism is still used by the I/O device to communicate with the processor but only on completion of an I/O transfer.
• DMA is implemented with a specialized controller that transfers data between an I/O device and the memory independent of the processor.

Direct Memory Access Controllers
• Step 1: CPU sets up the DMA by supplying the identity of the device, the operation to perform, the memory address, and the number of bytes to transfer.
• Step2: DMA starts operation and arbitrates for the bus, and transfers the data.
• Step3: Once DMA transfer is complete, the controller interrupts the processor.
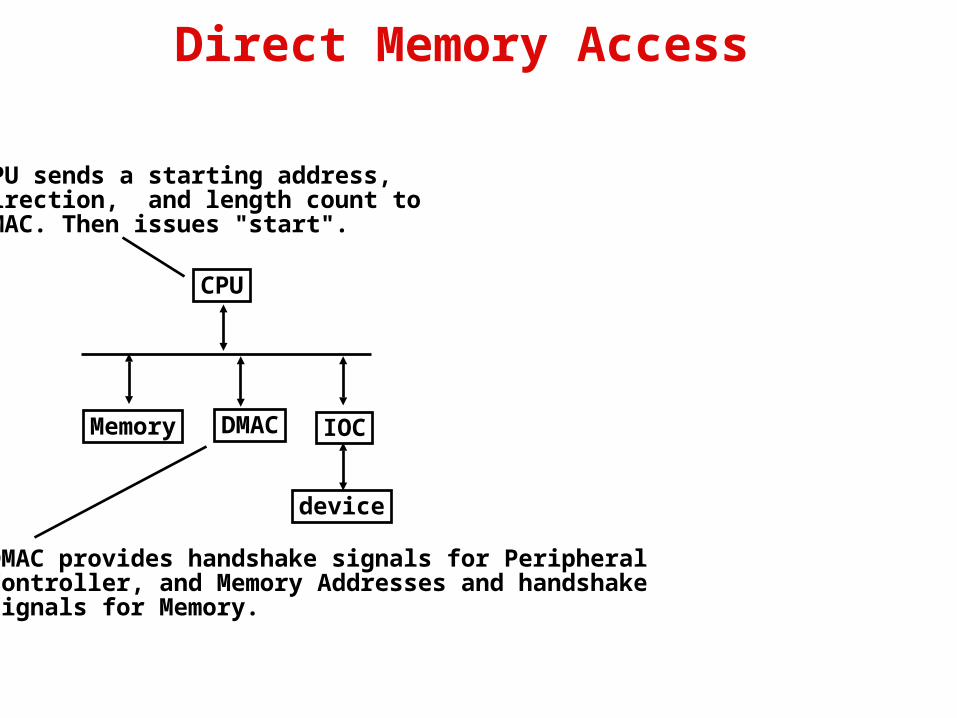
Direct Memory Access
CPU
IOC
device
Memory DMAC
CPU sends a starting address, direction, and length count to DMAC. Then issues "start".
DMAC provides handshake signals for PeripheralController, and Memory Addresses and handshakesignals for Memory.

Overheard of I/O using DMA
• Suppose same processor and hard disk as before.
• Assume that the initial setup of a DMA transfer takes 1000 clock cycles for the processor, and assume the handling of the interrupt at DMA completion requires 500 clock cycles for the processor.
• Hard disk has transfer rate of 4MB/sec.
• Average transfer from disk is 8KB.
• Disk is transferring 100%.
• What fraction of the 500MHz processor is consumed?

Overheard of I/O using DMA
• Each DMA transfer takes: 8 KB / 4MB/sec = 0.002 sec.
• If the disk is constantly transferring, it requires:
• 1000 + 500 cycles/transfer / 0.002 second per transfer = 750,000 clock cycles/second
• processor is 500MHz, fraction of processor consumed: 750,000 / 500 X106 = 0.2%.
• Of course the disk is not always transferring and this number will be even lower.
• To further relieve the processor from I/O, the I/O controller could be made more intelligent. Such a controller is often called and I/O processor. This processor executes I/O programs already stored.
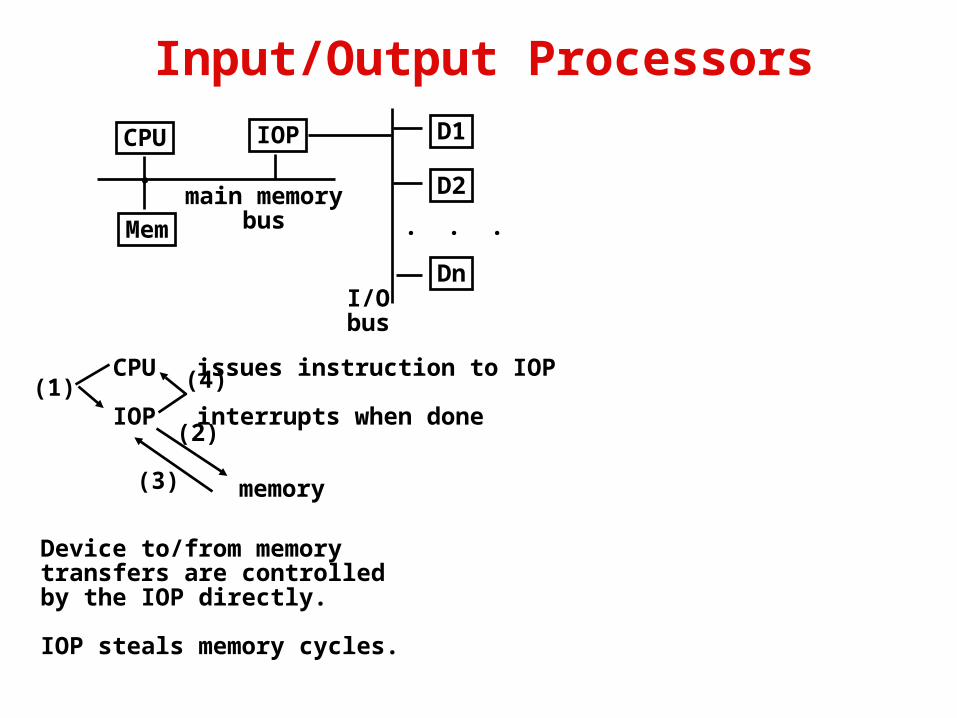
Input/Output Processors
CPU IOP
Mem
D1
D2
Dn
. . .main memory
bus
I/Obus
CPU
IOP
issues instruction to IOP
interrupts when done(1)
memory
(2)
(3)
(4)
Device to/from memorytransfers are controlledby the IOP directly.
IOP steals memory cycles.

Summary• Disk industry growing rapidly, improves:
– bandwidth 40%/yr ,
– areal density 60%/year, $/MB faster?
• queue + controller + seek + rotate + transfer
• Advertised average seek time benchmark much greater than average seek time in practice
• Response time vs. Bandwidth tradeoffs
• Value of faster response time:– 0.7sec off response saves 4.9 sec and 2.0 sec (70%) total time per
transaction => greater productivity
– everyone gets more done with faster response, but novice with fast response = expert with slow
• Processor Interface: today peripheral processors, DMA, I/O bus, interrupts