Introduction to HPC at UCL · Introduction to HPC at UCL ... 76/104=73% mb-wes Westmere : 0/24=0%...
41
Institut de calcul intensif et de stockage de masse Introduction to HPC at UCL ● Technical reminders and available equipment • source code • compiling • optimized libraries: BLAS, LAPACK • OpenMP • MPI ● Job submission: SGE, Condor, SLURM ● CISM: working principles, management, access ● Machine room visit ● From algorithm to computer program: optimization and parallel code October 17th 2017 Damien François and Bernard Van Renterghem
Transcript of Introduction to HPC at UCL · Introduction to HPC at UCL ... 76/104=73% mb-wes Westmere : 0/24=0%...

Institut de calcul intensif et destockage de masse
Introduction to HPC at UCL
● Technical reminders and available equipment
• source code • compiling• optimized libraries: BLAS, LAPACK• OpenMP• MPI
● Job submission: SGE, Condor, SLURM
● CISM: working principles, management, access
● Machine room visit
● From algorithm to computer program: optimization and parallel code
October 17th 2017 Damien François and Bernard Van Renterghem

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Cache memory
program execution = information exchange between CPU and RAM memory (program instructions and data)
RAM slow + sequential set of instructions > cache memory: instructions and/or data read by entire blocks transferred from RAM to cache memory
Cache L1, L2, L3
Introduction to High Performance Computing at UCLOct. 17th 2017
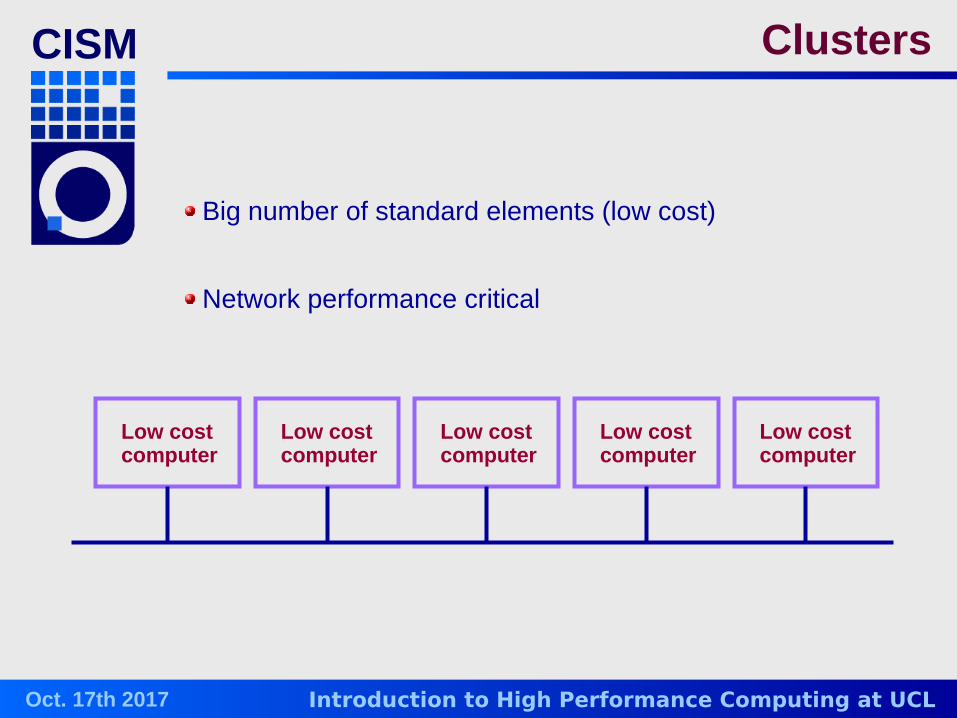
CISM Clusters
Big number of standard elements (low cost)
Network performance critical
Low cost computer
Low cost computer
Low cost computer
Low cost computer
Low cost computer

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Symmetric multi-processors

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM
Equipment: servers

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Equipment: servers
CISM servers
● Manneback● With CP3 working nodes● « exotic » or « interactive » machines
UCL CECI servers
● Hmem● Lemaitre2
CECI servers
● Vega ULB● Hercules UNamur● Dragon1 Umons● Nic4 ULiege

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Equipment: clusters
● Charles Manneback (1894-1975) Georges Lemaitre's friend
● Made of several different generations of hardware● Har , Neh, Westmere,SandyB, IvyB, Haswell,...● Opteron● GPU Tesla● Mic Xeon Phi
●Cp3 partition 125 nodes, 2424 core●Zoe partition 26 nodes, 416 core●Def partition 102, 1280 core
● Installed compilers: GCC, Intel, PGI
● OS: GNU/Linux Centos 6
● Batch system: SLURM
Manneback

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Equipment: clusters
Manneback
Welcome to | |
__ `__ \ _` | __ \ __ \ _ \ __ \ _` | __| | / | | | ( | | | | | __/ | | ( | ( < _| _| _| \__,_| _| _| _| _| \___| _.__/ \__,_| \___| _|\_\
Charles Manneback Lemaitre fellow cluster
(GNU/Linux CentOS 6.9) front-end: 2x8Core E5-2650@2GHz/64GB RAM
contact, support : [email protected]
Use the following commands to adjust your environment:'module avail' - show available modules'module add <module>' - adds a module to your environment for this session'module initadd <module>' - configure module to be loaded at every login

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM
Equipment: clusters
Sumitting jobs with SLURM: http://www.cism.ucl.ac.be/faq~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ http://www.uclouvain.be/cism http://www.ceci-hpc.be~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
[root@manneback ~]# sloadMBack : 3262/4128=79% mb-har Harpertown : 238/632=37% mb-opt Opteron : 1086/1248=87% mb-neh Nehalem : 76/104=73% mb-wes Westmere : 0/24=0% mb-sab SandyBridge: 583/704=82% mb-ivy IvyBridge : 895/896=99% mb-has Haswell(p zoe): 384/416=92%

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM
# sinfo NODELIST NODES PARTI CPUS MEMORY FEATURES GRES mb-har[121-123,125-130] 9 Def* 8 13869+ Harpertown,Xeon,X5460 localscratch:340mb-har[124,131-140] 11 Def* 8 13930+ Harpertown,Xeon,X5460 localscratch:20mb-har[001-009,011-014] 13 Def* 8 15947 Harpertown,Xeon,L5420 localscratch:166mb-har102 1 Def* 8 32108 Harpertown,Xeon,L5420 localscratch:146 mb-neh070 1 Def* 8 24019 Nehalem,Xeon,X5550 localscratch:814,gpu:TeslaC1060/M1060:2 mb-sab040 1 Def* 16 64398 SandyBridge,Xeon,E5-2660 localscratch:458,gpu:TeslaM2090:2,mic:5110P:1
[...]

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Equipment: exotic machines
Other peculiar machines● Lm9 : interactive matlab, TermoCalc, R,
2 6 core [email protected] GHz, 144 GB RAM
● Mb-neh070): dual quad [email protected] (85 Gflops) + ( 2x) Tesla M1060 = 240 GPU core, 624 SP Gflops, 77 DP Gflops GPU.
● Mb-sab040 : dual octa [email protected] +(2x) Tesla M2090 = 512 GPU core, 1332 SP Gflops, 666 DP Gflops GPU + Xeon Phi 61 [email protected] 1011 DP Gflops
● SCMS-SAS 3&4 : for SAS, STATA, R,...2*16 core 8192 Gflops 128GB RAM Xeon [email protected]
● LmPp001-003 : lemaitre2 PostProcessing Nvidia Quadro 4000 = 256 GPU core, 486 SP Gflops, 243 DP Gflops GPU.

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Equipment CECI Clusters
● 16 Dell PowerEdge R815 + 1 HP + 3 Ttec
● 17x48 core AMD Opteron 6174(Magny-Cours) @2.2GHz
+ 3x8 core AMD Opteron 8222 @3GHz (24h partition)
● 2: 512, 7:256, 8:128, 3:128 GB RAM
● /scratch 3.2TB or 1.7TB
● Infiniband 40Gb/s
● SLURM batch queuing system
=
● Tot: 840 core, 4128 TB RAM, 31 TB /scratch, 11TB /home, 7468 GFlops
Hmem ( www.ceci-hpc.be )

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM
● 112 HP DL380 with 2x6 core [email protected] 48GB RAM
● /scratch lustreFS 120TB, /tmp 325GB
● Infiniband 40Gb/s
● SLURM batch queuing system
=
● Tot: 1344 core, 5.25 TB RAM, 120 TB /scratch, 30TB /home, 13.6 TFlops
Lemaitre2 ( www.ceci-hpc.be )
Equipment CECI Clusters

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM
ULB+Unamur,+UMons+UCL+ULiège = CECI
Equipment CECI Clusters
See www.ceci-hpc.be/clusters.html

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM
Manneback (2012)
1400 CPUs
Manneback (2012)
1400 CPUs
HMEM (2011)
816 CPUs
HMEM (2011)
816 CPUs
Lemaitre2 (2012)
1380 CPUs
Lemaitre2 (2012)
1380 CPUs
Vega (2013)
2752 CPUs
Vega (2013)
2752 CPUs
Dragon1 (2013)
416 CPUs
Dragon1 (2013)
416 CPUs
Hercules (2013)
896 CPUs
Hercules (2013)
896 CPUs
Nic4 (2014)
2048 CPUs
Nic4 (2014)
2048 CPUs
~ 8300 CPUs
(2010)
Zenobe (2014)13536 CPUs
Zenobe (2014)13536 CPUs
(2012)

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM
280 M/mois = 4.7 MhCPU~ 533 ans/CPU

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM CECI Distributed Filesystem

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM CECI Distributed Filesystem
Belnet10 Gbps
UCL
ULg
HPC
Solution core design
(2014)HPC

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM To reduce computing time…
… improve your code
● choice of algorithm ● source code● optimized compiling● optimized libraries
… use parallel computation
● OpenMP (mostly on SMP machines) ● MPI

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Source code
• Algorithm choice: volume of calculation increases with n, n x n,…? Stability ?
● indirect addressing expensive (pointers) ● fetching order of array elements (for optimal use of cache memory)● loop efficiency (get all uneccessary bits and pieces out of them)
• Programming language: FORTRAN, C, C++,…?
• Coding practise

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Compiling
• The compiler…
• Optimization options: -01, -02, -03
• Different qualities of compilers !!
● translates an instruction list written in a high level language into a machine readable (binary) file [= the object file]
e. g. ifc –c myprog.f90 generates object file myprog.o● link binary object files to produce an executable file
e. g. ifc –o myprog module1.o libmath.a myprog.o generates the executable file (= program) myprog

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Optimized libraries: BLAS
Basic Linear Algebra Subroutines
● set of optimized subroutines to handle vector x vector, matrix x vector, matrix x matrix operations (for real and complex numbers, single or double precision)
● the subrouines are optimized for a specific machine CPU/OS
● See http://www.netlig.org/blas● Example…

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Optimized libraries: BLAS
● compiling from BLAS source: ifc –o mvm sgemv.f mvm.f
● compiling with pre-compiled BLAS library (optimized for Intel CPU):
ifc –o mvm mvm.f sblasd13d.a
real*8 matlxc(nl, nc)real*8 vectc(nc), result(nl)
call random_number(matlxc)call random_number(vectc)
do i=1,nl result(i)=0.0 do j=1,nc result(i)=result(i)+matlxc(i,j)*vectc(j) end doend do
call SGEMV('N',nl,nc,1.0d0,matlxc,nl,vectc,1,0.d0,result,1)

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Optimized libraries: BLAS
Performance comparison of Intel and PGI FORTRAN compilers, for self-made code, BLAS code and pre-compiled optimized libraries (matrix 10,000 x 5,000)
Compiler Subroutine Options Mflpos
Intel (ifc) DO loop - O0 11
- O3 11
BLAS source - O0 42
O3 115
BLAS compiled - O0 120
O3 120
PGI (pgf90) DO loop - O0 11
- O3 11
BLAS source - O0 48
- O3 57
BLAS compiled -O0 116
-O3 119

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Optimized libraries: LAPACK
• Linear Algebra Subroutines:
● linear equation system Ax=b● least square: min ||Ax-b||²● eigen value: Ax=x, AX=Bx● for real or complex, single or double precision● includes all utility routines (LU factoring, Cholesky,…)
• Based on BLAS (don't depend on hardware, always optimized)
• See http://www.netlib.org/lapack

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM OpenMP
• Open Memory Parallelism: standard language (compiler directives, functions, environment variables) for shared memory architectures (OpenMP 2.0)
• Principle: compiler directives > parallelism details are left to the compiler > fast implementation
!OMP PARALLEL DO
modèle fork and join…
DO I=1,1000 a(i)=b(i)*c(i)END DO…

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM MPI environment
• MPI = Message Passing Interface (2.0)
• Principle: the program has full control over data exchange between nodes while distributing work and managing communication between nodes
• Widely used standard for clusters (but also exists for SMP boxes)
…REAL a(100) …C Process 0 sends, process 1 receives: if( myrank.eq.0 ) then call MPI_SEND(a,100,MPI_REAL,1,17,MPI_COMM_WORLD,ierr) else if ( myrank.eq.1 ) then call MPI_RECV(a,100,MPI_REAL,0,17,MPI_COMM_WORLD,status,ierr) endif …

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Job submission
• Goal: one single task per CPU
• Principle: the user hands his program over to an automatic job management system, specifying his requirements (memory, architecture, number of cpus,…). When the requested resources become available, the job is dispatched and starts running.
• Slurm Workload Manager
● sbatch● sinfo● scancel

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Job submission
• Submission script examples…
• To submit your job: sbatch myscript

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM CISM: research environment
ELEN
TERM
SC
TOPO
ELIENAPS
RDGN
RECI
BSMA
IMAP
MOST
MEMA
BIB
COMU
LICR
ELEN
INGI
INMA
ELIC
INFM
CP3
FACM
NAPS
LOCI
GERU
PAMO
LSM
ECON
RSPO

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM CISM
• Equipment and support available for any UCL (and CECI) member
• Equipments are acquired through projects
• Goals: joining forces to acquire and manage more powerful equipments
• Institut de Calcul Intensif et de Stockage de Masse:
● management committee composed of representatives of user's entities: debates and decides on strategies; chairman elected for four years
● offices in Mercator; machine rooms in Pythagore and Marc de Hemptinne
● daily management by technical computer team, under leadership of CISM Director (elected for four years)

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM CISM management team
Thomas KeutgenDirecteur CISM
Olivier MattelaerGestionnaire système &Support utilisateur
Bernard Van RenterghemGestionnaire système &
support utilisateur
Damien FrançoisGestionnaire système &
support utilisateur

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Environmental challenges

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Environmental challenges
• two 60 KW water chillers
Aquarium
• water cooling (rack based)

Introduction to High Performance Computing at UCLOct. 17th 2017
CISM Environmental challenges
• total hosting capacity 120 KW
• electrical redundancy and 200 KVA UPS protection
• 5 m3 buffer tank• redundant
pumps, electrical feed through independent UPS
Aquarium

Introduction to High Performance Computing at UCLOct. 17th 2017
CISMDCIII Data Center 3

Introduction to High Performance Computing at UCLOct. 17th 2017
CISMDCIII Data Center 3

Introduction to High Performance Computing at UCLOct. 17th 2017
CISMDCIII Data Center 3

Introduction to High Performance Computing at UCLOct. 17th 2017
CISMDCIII Data Center 3